
Satisfaction with the Pedestrian Environment and Its Relationship to Neighborhood Satisfaction in Seoul, South Korea


Abstract
:1. Introduction
2. Literature Review
3. Materials and Methods
3.1. Data
3.2. Variables
3.2.1. Dependent Variable
3.2.2. Independent Variables of Interest
3.2.3. Control Variables
3.3. Analysis Methods
3.3.1. Proportional Odds Logistic Regression
3.3.2. Gradient Boosting Decision Tree Regressor
4. Results
4.1. Proportional Odds Logistic Regression
4.2. Gradient Boosting Decision Tree Regressor
4.2.1. Feature Importance
4.2.2. Partial Dependence
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Campbell, A.; Converse, P.E.; Rodgers, W.L. The Quality of American Life: Perceptions, Evaluations, and Satisfactions; Russell Sage Foundation: New York, NY, USA, 1976; ISBN 978-1-61044-103-2. [Google Scholar]
- Diener, E.; Chan, M.Y. Happy People Live Longer: Subjective Well-Being Contributes to Health and Longevity. Appl. Psychol. Health Well Being 2011, 3, 1–43. [Google Scholar] [CrossRef]
- Kushlev, K.; Drummond, D.M.; Diener, E. Subjective Well-Being and Health Behaviors in 2.5 Million Americans. Appl. Psychol. Health Well Being 2020, 12, 166–187. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Wu, X.; Yuan, Y. Examining Built Environmental Correlates of Neighborhood Satisfaction: A Focus on Analysis Approaches. J. Plan. Lit. 2018, 33, 419–432. [Google Scholar] [CrossRef]
- Marans, R.W.; Stimson, R.J. Investigating Quality of Urban Life: Theory, Methods, and Empirical Research; Springer Science & Business Media: New York, NY, USA, 2011; ISBN 978-94-007-1742-8. [Google Scholar]
- Yin, R.; Miao, X.; Geng, Z.; Sun, Y. Assessment of Residential Satisfaction and Influence Mechanism—A Case Study of Jinan City. J. Bus. Adm. Res. 2018, 7, 9. [Google Scholar] [CrossRef] [Green Version]
- Anton, C.E.; Lawrence, C. Home Is Where the Heart Is: The Effect of Place of Residence on Place Attachment and Community Participation. J. Environ. Psychol. 2014, 40, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Putnam, R.D. Bowling Alone: America’s Declining Social Capital. In Culture and Politics: A Reader; Crothers, L., Lockhart, C., Eds.; Palgrave Macmillan US: New York, NY, USA, 2000; pp. 223–234. ISBN 978-1-349-62965-7. [Google Scholar]
- Yang, Y. A Tale of Two Cities: Physical Form and Neighborhood Satisfaction in Metropolitan Portland and Charlotte. J. Am. Plan. Assoc. 2008, 74, 307–323. [Google Scholar] [CrossRef]
- Lee, S.-W.; Ellis, C.D.; Kweon, B.-S.; Hong, S.-K. Relationship between Landscape Structure and Neighborhood Satisfaction in Urbanized Areas. Landsc. Urban Plan. 2008, 85, 60–70. [Google Scholar] [CrossRef]
- Hamersma, M.; Tillema, T.; Sussman, J.; Arts, J. Residential Satisfaction Close to Highways: The Impact of Accessibility, Nuisances and Highway Adjustment Projects. Transp. Res. Part A Policy Pract. 2014, 59, 106–121. [Google Scholar] [CrossRef] [Green Version]
- Lee, B.A.; Guest, A.M. Determinants of Neighborhood Satisfaction: A Metropolitan-Level Analysis. Sociol. Q. 1983, 24, 287–303. [Google Scholar] [CrossRef]
- Mouratidis, K. Neighborhood Characteristics, Neighborhood Satisfaction, and Well-Being: The Links with Neighborhood Deprivation. Land Use Policy 2020, 99, 104886. [Google Scholar] [CrossRef]
- Kim, J.W.; Lim, U. The Effect of Part-time Work on the Satisfaction of Personal Life—Using Seoul Survey. J. Korean Reg. Sci. Assoc. 2019, 35, 59–71. [Google Scholar] [CrossRef]
- Seoul Metropolitan Government. The 2021 Seoul Urban Policy Indicator Survey Final Report; Seoul Metropolitan Government: Seul, Korea, 2021. Available online: https://data.seoul.go.kr/dataList/OA-15564/F/1/datasetView.do (accessed on 30 June 2022).
- Subramanian, S.; Jones, V.; Duncan, C. Multilevel Methods for Public Health Research. In Neighborhoods and Health; Oxford University Press: Oxford, UK, 2003; ISBN 978-0-19-974792-4. [Google Scholar]
- McCullagh, P. Regression Models for Ordinal Data. J. R. Stat. Soc. Ser. B 1980, 42, 109–127. [Google Scholar] [CrossRef]
- Fagerland, M.W.; Hosmer, D.W. A Goodness-of-Fit Test for the Proportional Odds Regression Model. Stat. Med. 2013, 32, 2235–2249. [Google Scholar] [CrossRef] [PubMed]
- McNulty, K. Handbook of Regression Modeling in People Analytics: With Examples in R and Python; CRC Press: Boca Raton, FL, USA, 2021; ISBN 978-1-00-319415-6. [Google Scholar]
- Brant, R. Assessing Proportionality in the Proportional Odds Model for Ordinal Logistic Regression. Biometrics 1990, 46, 1171–1178. [Google Scholar] [CrossRef] [PubMed]
- Hillel, T.; Bierlaire, M.; Elshafie, M.Z.E.B.; Jin, Y. A Systematic Review of Machine Learning Classification Methodologies for Modelling Passenger Mode Choice. J. Choice Model. 2021, 38, 100221. [Google Scholar] [CrossRef]
- Lee, S. Transportation Mode Choice Behavior in the Era of Autonomous Vehicles: The Application of Discrete Choice Modeling and Machine Learning. Ph.D. Thesis, Portland State University, Portland, OR, USA, 2022. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: Boca Raton, FL, USA, 2017; ISBN 978-1-315-13947-0. [Google Scholar]
- Bi, Q.; Goodman, K.E.; Kaminsky, J.; Lessler, J. What Is Machine Learning? A Primer for the Epidemiologist. Am. J. Epidemiol. 2019, 188, 2222–2239. [Google Scholar] [CrossRef]
- Azmi, S.S.; Baliga, S. An Overview of Boosting Decision Tree Algorithms Utilizing AdaBoost and XGBoost Boosting Strategies. Int. Res. J. Eng. Technol. 2020, 7, 5. [Google Scholar]
- Zhang, T.; He, W.; Zheng, H.; Cui, Y.; Song, H.; Fu, S. Satellite-Based Ground PM2.5 Estimation Using a Gradient Boosting Decision Tree. Chemosphere 2021, 268, 128801. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Shi, X.; Huang, R.; Qiu, X.; Chen, C. Feasibility of Stochastic Gradient Boosting Approach for Predicting Rockburst Damage in Burst-Prone Mines. Trans. Nonferrous Met. Soc. China 2016, 26, 1938–1945. [Google Scholar] [CrossRef]
- Nassif, A.B. Short Term Power Demand Prediction Using Stochastic Gradient Boosting. In Proceedings of the 2016 5th International Conference on Electronic Devices, Systems and Applications (ICEDSA), Ras Al Khaimah, United Arab Emirates, 6–8 December 2016; pp. 1–4. [Google Scholar]
- Wu, T.; Zhang, W.; Jiao, X.; Guo, W.; Hamoud, Y.A. Comparison of Five Boosting-Based Models for Estimating Daily Reference Evapotranspiration with Limited Meteorological Variables. PLoS ONE 2020, 15, e0235324. [Google Scholar] [CrossRef] [PubMed]
- Lee, S. Exploring Associations between Multimodality and Built Environment Characteristics in the U.S. Sustainability 2022, 14, 6629. [Google Scholar] [CrossRef]
- van Cranenburgh, S.; Wang, S.; Vij, A.; Pereira, F.; Walker, J. Choice Modelling in the Age of Machine Learning—Discussion Paper. J. Choice Model. 2022, 42, 100340. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.-L.; Zeileis, A.; Hothorn, T. Bias in Random Forest Variable Importance Measures: Illustrations, Sources and a Solution. BMC Bioinform. 2007, 8, 25. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Apley, D.W.; Zhu, J. Visualizing the Effects of Predictor Variables in Black Box Supervised Learning Models. J. R. Stat. Soc. Ser. B 2020, 82, 1059–1086. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation Importance: A Corrected Feature Importance Measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [PubMed]
- Huang, N.; Lu, G.; Xu, D. A Permutation Importance-Based Feature Selection Method for Short-Term Electricity Load Forecasting Using Random Forest. Energies 2016, 9, 767. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.-H. Ensemble Methods: Foundations and Algorithms, 1st ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2012; ISBN 978-1-4398-3003-1. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2016; ISBN 978-0-387-84857-0. [Google Scholar]
- Lee, D.; Mulrow, J.; Haboucha, C.J.; Derrible, S.; Shiftan, Y. Attitudes on Autonomous Vehicle Adoption Using Interpretable Gradient Boosting Machine. Transp. Res. Rec. 2019, 2673, 865–878. [Google Scholar] [CrossRef]
- Molnar, C.; Freiesleben, T.; König, G.; Casalicchio, G.; Wright, M.N.; Bischl, B. Relating the Partial Dependence Plot and Permutation Feature Importance to the Data Generating Process. arXiv 2019, arXiv:2109.01433. [Google Scholar]
- Friedman, J.H. Multivariate Adaptive Regression Splines. Ann. Stat. 1991, 19, 1–67. [Google Scholar] [CrossRef]
- Guo, Z.; Loo, B.P.Y. Pedestrian Environment and Route Choice: Evidence from New York City and Hong Kong. J. Transp. Geogr. 2013, 28, 124–136. [Google Scholar] [CrossRef]
- The Seoul Research Data Service Transportation Mode Choice Patterns. Available online: https://data.si.re.kr/data/ (accessed on 13 July 2022).
- Kang, C.-D. The S + 5Ds: Spatial Access to Pedestrian Environments and Walking in Seoul, Korea. Cities 2018, 77, 130–141. [Google Scholar] [CrossRef]
- Lee, S.; Han, M.; Rhee, K.; Bae, B. Identification of Factors Affecting Pedestrian Satisfaction toward Land Use and Street Type. Sustainability 2021, 13, 10725. [Google Scholar] [CrossRef]
- Lee, J.; Kim, D.; Park, J. A Machine Learning and Computer Vision Study of the Environmental Characteristics of Streetscapes That Affect Pedestrian Satisfaction. Sustainability 2022, 14, 5730. [Google Scholar] [CrossRef]
- Kim, S.; Park, S.; Lee, J.S. Meso- or Micro-Scale? Environmental Factors Influencing Pedestrian Satisfaction. Transp. Res. Part D Transp. Environ. 2014, 30, 10–20. [Google Scholar] [CrossRef]
- Prescott, M.; Miller, W.C.; Borisoff, J.; Tan, P.; Garside, N.; Feick, R.; Mortenson, W.B. An Exploration of the Navigational Behaviours of People Who Use Wheeled Mobility Devices in Unfamiliar Pedestrian Environments. J. Transp. Health 2021, 20, 100975. [Google Scholar] [CrossRef]
- Lanza, K.; Burford, K.; Ganzar, L.A. Who Travels Where: Behavior of Pedestrians and Micromobility Users on Transportation Infrastructure. J. Transp. Geogr. 2022, 98, 103269. [Google Scholar] [CrossRef]



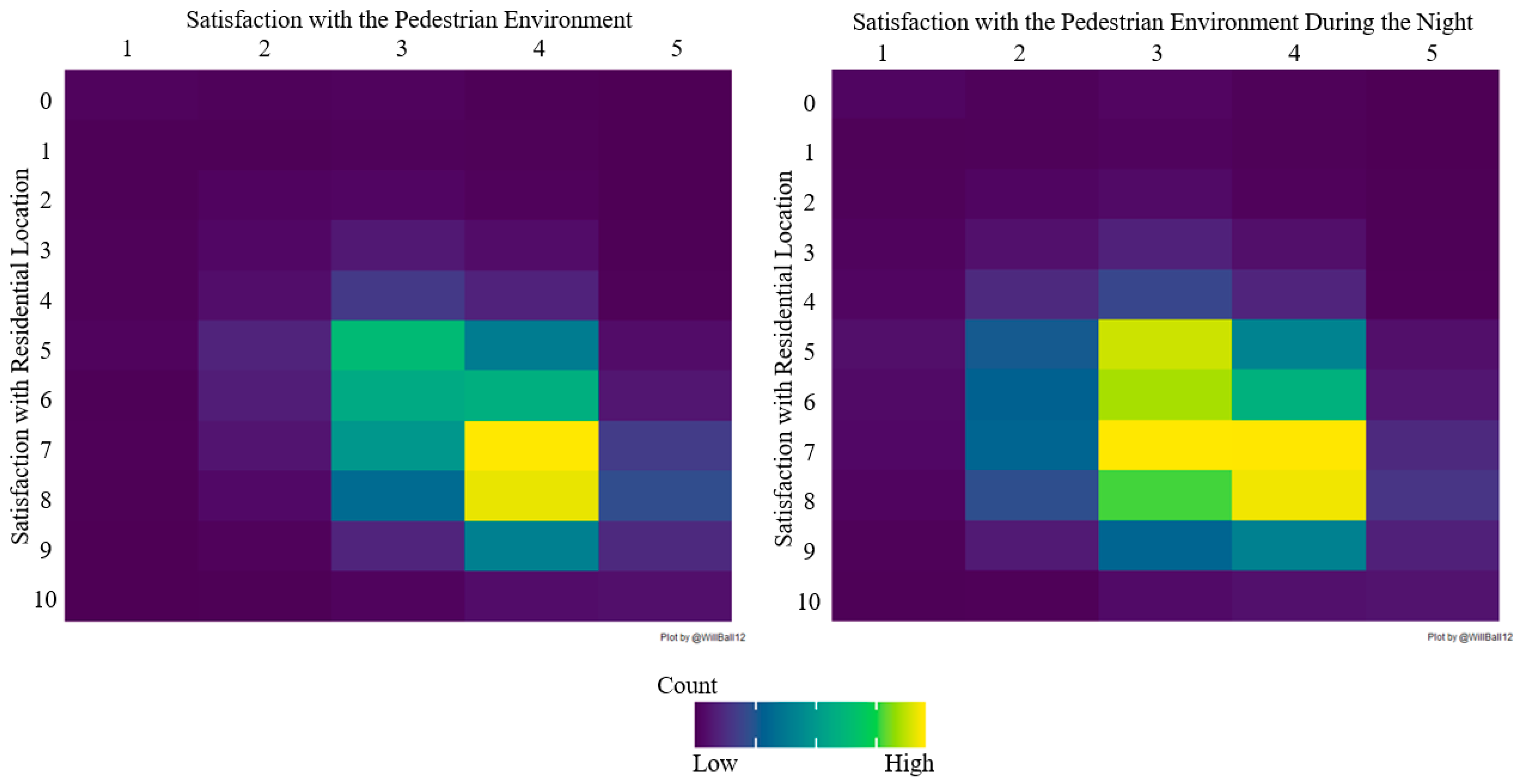{kind=link}
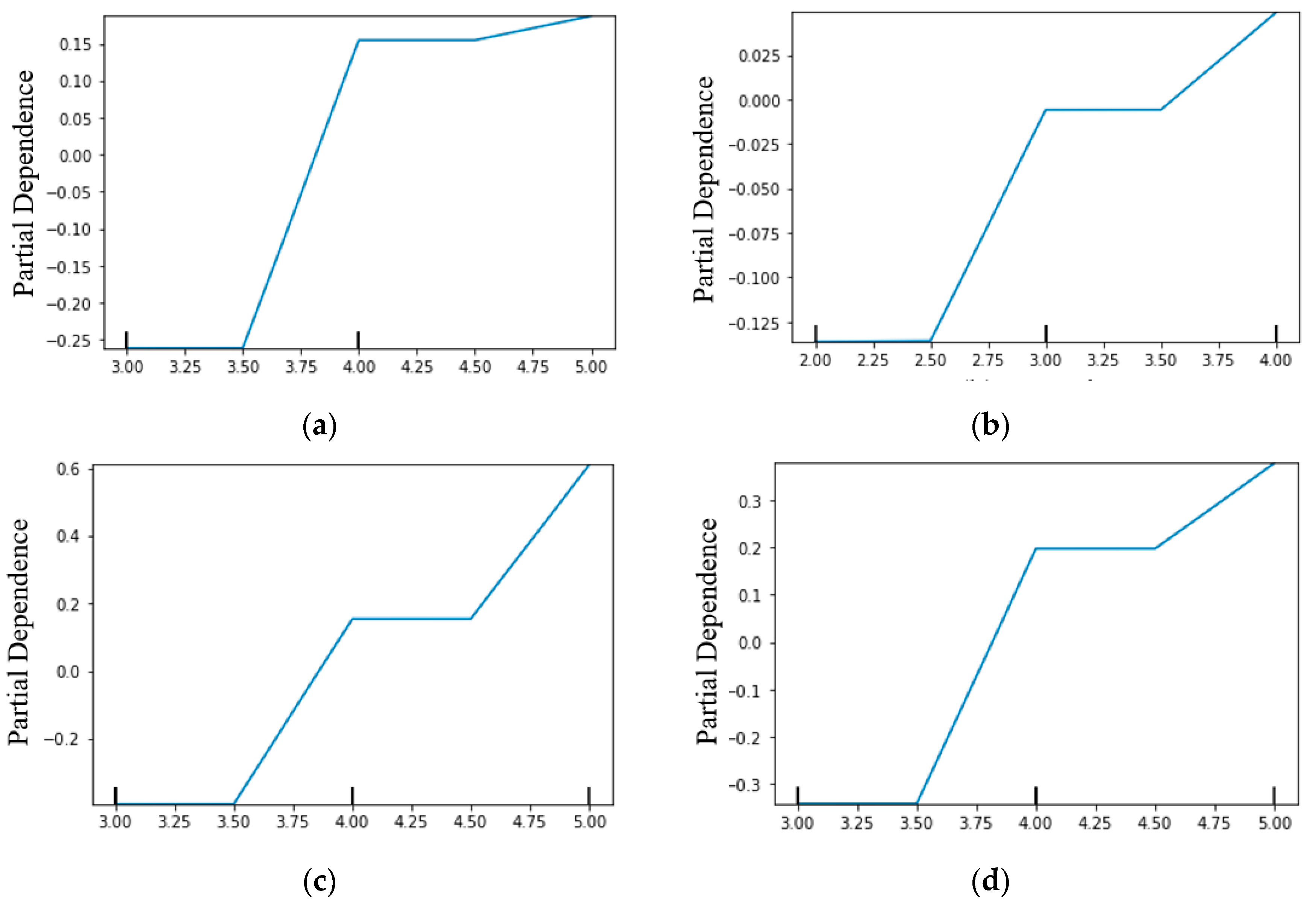{kind=link}
| Features | Study Sample | Population in Seoul | ||||
|---|---|---|---|---|---|---|
| Unweighted | Weighted | |||||
| Count | % | Count | % | Count | % | |
| Gender | ||||||
| Male | 14,380 | 71.90% | 13,294 | 66.47% | 2,132,468 | 57.45% |
| Female | 5620 | 28.10% | 6706 | 33.53% | 1,579,268 | 42.55% |
| Age | ||||||
| Under 29 | 1089 | 5.45% | 1372 | 6.86% | 210,249 | 5.66% |
| 30~39 | 4316 | 21.58% | 4230 | 21.15% | 417,970 | 11.26% |
| 40~49 | 5089 | 25.45% | 4453 | 22.27% | 428,783 | 11.55% |
| 50~59 | 4288 | 21.44% | 3858 | 19.29% | 618,204 | 16.66% |
| Over 60 | 5218 | 26.09% | 6087 | 30.44% | 2,036,530 | 54.87% |
| Homeownership | ||||||
| Own | 10,695 | 53.48% | 8418 | 42.09% | 1,730,671 | 43.46% |
| Rent | 9305 | 46.53% | 11,582 | 57.91% | 2,251,619 | 56.54% |
| Education Attainment | ||||||
| Under middle school | 1194 | 5.97% | 2641 | 13.21% | Unknown | |
| High school | 4846 | 24.23% | 5602 | 28.01% | Unknown | |
| College or Bachelor’s | 12,561 | 62.81% | 9627 | 48.14% | Unknown | |
| Graduate School | 1399 | 7.00% | 2130 | 10.65% | Unknown | |
| Household Income | ||||||
| Less than KRW 2,000,000 | 2228 | 11.14% | 3550 | 17.75% | Unknown | |
| KRW 2,000,000~KRW 4,000,000 | 6243 | 31.22% | 6701 | 33.51% | Unknown | |
| KRW 4,000,000~KRW 6,000,000 | 5945 | 29.73% | 5014 | 25.07% | Unknown | |
| KRW 6,000,000~KRW 8,000,000 | 3178 | 15.89% | 2555 | 12.78% | Unknown | |
| Over KRW 8,000,000 | 2406 | 12.03% | 2180 | 10.90% | Unknown | |
| Name | Description | Mean | S.D. |
|---|---|---|---|
| Dependent variable | |||
| st_neigh | The degree to which study participants were satisfied with the neighborhood in which they lived (10-point satisfaction Likert scale: 0. Very dissatisfied; 10. Very satisfied) | 6.55 | 1.75 |
| Independent variables | |||
| Satisfaction-related Factors | |||
| st_ped | Satisfaction with the pedestrian environment in the neighborhood in which they lived (5-point satisfaction Likert scale: 1. Very dissatisfied; 5. Very satisfied) | 3.59 | 0.80 |
| st_ped_n | Satisfaction with the pedestrian environment during the night in the neighborhood in which they lived (5-point satisfaction Likert scale: 1. Very dissatisfied; 5. Very satisfied) | 3.27 | 0.87 |
| st_econ | Satisfaction with the economic environment in the neighborhood in which they lived (5-point satisfaction Likert scale: 1. Very dissatisfied; 5. Very satisfied) | 3.28 | 0.90 |
| st_soci | Satisfaction with the social environment in the neighborhood in which they lived (5-point satisfaction Likert scale: 1. Very dissatisfied; 5. Very satisfied)) | 3.44 | 0.82 |
| st_educ | Satisfaction with the educational environment in the neighborhood in which they lived (5-point satisfaction Likert scale: 1. Very dissatisfied; 5. Very satisfied) | 3.31 | 0.81 |
| st_home | Satisfaction with a home where the respondent lives (5-point satisfaction Likert scale: 1. Very dissatisfied; 5. Very satisfied) | 3.46 | 0.92 |
| st_infra | Satisfaction with infrastructures in the neighborhood in which they lived (5-point satisfaction Likert scale: 1. Very dissatisfied; 5. Very satisfied) | 3.63 | 0.82 |
| Socio-demographic characteristics | |||
| male | 1 if the respondent is male, 0 otherwise | 0.47 | 0.49 |
| married | 1 if the respondent is married, 0 otherwise | 0.61 | 0.48 |
| job_pro | 1 if the respondent has a professional job, 0 otherwise | 0.13 | 0.34 |
| job_white | 1 if the respondent has a white-color job, 0 otherwise | 0.36 | 0.48 |
| job_blue | 1 if the respondent has a blue-color job, 0 otherwise | 0.17 | 0.38 |
| disab | 1 if the respondent has a disability, 0 otherwise | 0.02 | 0.13 |
| age | The age of the respondent (1. 10~19; 2. 20~29; 3. 30~39; 4. 40~49; 5. 50~59; 6. more than 60) | 4.10 | 1.44 |
| edu | The education attainment of the respondent (1. less than high school; 2. High school; 3. College or bachelors’ degree; 4. Graduate school) | 2.66 | 0.68 |
| hh_inc | The household income of the respondent (1. less than KRW 1,000,000; 2. KRW 1,000,000~KRW 2,000,000; 3. KRW 2,000,000~KRW 3,000,000; 4. KRW 3,000,000~KRW 4,000,000; 5. KRW 4,000,000~KRW 5,000,000; 6. KRW 5,000,000~KRW 6,000,000; 7. KRW 6,000,000~KRW 7,000,000; 8. KRW 7,000,000~KRW 8,000,000; 9. KRW 8,000,000~KRW 9,000,000; 10. more than KRW 9,000,000) | 6.61 | 2.22 |
| own | 1 if the respondent owns a home, 0 otherwise | 0.60 | 0.49 |
| apt | 1 if the respondent lives in an apartment, 0 otherwise | 0.46 | 0.49 |
| sfr | 1 if the respondent lives in a single-family home, 0 otherwise | 0.23 | 0.42 |
| resi_dt | 1 if the respondent lives in a downtown area, 0 otherwise | 0.08 | 0.27 |
| resi_en | 1 if the respondent lives in the east-northern area of Seoul, 0 otherwise | 0.32 | 0.46 |
| resi_wn | 1 if the respondent lives in the west-northern area of Seoul, 0 otherwise | 0.12 | 0.32 |
| resi_ws | 1 if the respondent lives in the west-southern area of Seoul, 0 otherwise | 0.29 | 0.45 |
| hl_seoul | The number of years for residing in Seoul | 31.1 | 15.8 |
| hl_gu | The number of years for residing in a Gu (an administrative level in South Korea) inside Seoul | 14.9 | 12.0 |
| Algorithms | Brief Description |
|---|---|
| LR | LR deals with linear functions of the input features on the outcome target. LR usually serves as a baseline regressor in machine learning. |
| SVM | SVM finds a separating linear decision boundary called hyperplane (optimal decision surface) that maximizes the distance between data points [23]. |
| DT | DT is used to predict a classification outcome by splitting training data based on the splitter for input features [24]. DT runs a sequential and hierarchical decision based on features. |
| RF | RF fits the same underlying algorithm to each bootstrapped copy of the original training data and then creates a final prediction by averaging the predictions from the different copies [25]. |
| ADA | Boosting trains multiple models with subsets of data in a sequential fashion. ADA begins by assigning equal initial weights to all training data for weak learning training and then adjusts the weight distribution based on the results of the prediction [26]. |
| GBDT | GBDT is a decision tree approach that is iterative. Its weak learners have strong dependencies between one another and are trained through progressive iterations based on the residuals. The ultimate result is calculated by adding up the results of all weak learners [27]. |
| SGBDT | SGBDT is a hybrid algorithm that takes advantage of bagging and boosting techniques to improve prediction accuracy [28]. Using the term "stochastic" means that a random percentage of training data points will be used for each iteration rather than using all of the data for training [29]. |
| CGBDT | CGBDT introduces modified target-based statistics that allow for the utilization of the entire dataset for training while avoiding the possibility of overfitting by performing random permutations [30]. |
| XGBDT | XGBDT is an upgraded version of the GBDT. It obtains the residual by using second-order Taylor expansion on the cost function and incorporates a regularization term to regulate the complexity of the model simultaneously [30]. |
| Model | Negative Mean Absolute Error | R Squared | Explained Variance | |||
|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | |
| LR | −0.919 | 0.026 | 0.247 | 0.012 | 0.248 | 0.012 |
| SVM | −0.898 | 0.028 | 0.104 | 0.047 | 0.111 | 0.048 |
| DT | −0.909 | 0.031 | 0.246 | 0.019 | 0.247 | 0.020 |
| RF | −0.857 | 0.026 | 0.319 | 0.013 | 0.321 | 0.013 |
| ADA | −0.902 | 0.030 | 0.266 | 0.016 | 0.268 | 0.017 |
| GBDT | −0.847 | 0.022 | 0.342 | 0.009 | 0.343 | 0.009 |
| SGBDT | −0.868 | 0.023 | 0.309 | 0.011 | 0.310 | 0.011 |
| CGBDT | −0.853 | 0.017 | 0.325 | 0.016 | 0.326 | 0.016 |
| XGBDT | −0.853 | 0.022 | 0.327 | 0.017 | 0.328 | 0.017 |
| Variables | Value | Std. Err | T-Value | p-Value | Odds Ratio |
|---|---|---|---|---|---|
| st_ped (reference: 1. very dissatisfied) | |||||
| 2. dissatisfied | 0.068 | 0.312 | 0.219 | 0.827 | 1.071 |
| 3. neutral | 0.068 | 0.307 | 0.222 | 0.825 | 1.070 |
| 4. satisfied | 0.565 | 0.307 | 1.839 | 0.066 | 1.759 |
| 5. very satisfied | 0.614 | 0.309 | 1.984 | 0.047 | 1.847 |
| st_ped_n (reference: 1. very dissatisfied) | |||||
| 2. dissatisfied | 0.516 | 0.097 | 5.304 | 0.000 | 1.675 |
| 3. neutral | 0.594 | 0.095 | 6.250 | 0.000 | 1.812 |
| 4. satisfied | 0.685 | 0.096 | 7.123 | 0.000 | 1.983 |
| 5. very satisfied | 0.693 | 0.113 | 6.126 | 0.000 | 1.999 |
| st_econ (reference: 1. very dissatisfied) | |||||
| 2. dissatisfied | 0.020 | 0.081 | 0.251 | 0.802 | 1.021 |
| 3. neutral | 0.086 | 0.079 | 1.084 | 0.278 | 1.089 |
| 4. satisfied | 0.006 | 0.081 | 0.075 | 0.940 | 1.006 |
| 5. very satisfied | −0.040 | 0.094 | −0.427 | 0.669 | 0.960 |
| st_soci (reference: 1. very dissatisfied) | |||||
| 2. dissatisfied | 0.016 | 0.124 | 0.132 | 0.895 | 1.016 |
| 3. neutral | 0.044 | 0.123 | 0.360 | 0.719 | 1.045 |
| 4. satisfied | 0.059 | 0.124 | 0.475 | 0.635 | 1.061 |
| 5. very satisfied | −0.014 | 0.133 | −0.108 | 0.914 | 0.986 |
| st_educ (reference: 1. very dissatisfied) | |||||
| 2. dissatisfied | 0.085 | 0.110 | 0.770 | 0.441 | 1.089 |
| 3. neutral | 0.106 | 0.108 | 0.978 | 0.328 | 1.112 |
| 4. satisfied | 0.065 | 0.111 | 0.587 | 0.557 | 1.067 |
| 5. very satisfied | 0.024 | 0.123 | 0.193 | 0.847 | 1.024 |
| st_home (reference: 1. very dissatisfied) | |||||
| 2. dissatisfied | 0.668 | 0.389 | 1.717 | 0.086 | 1.951 |
| 3. neutral | 1.423 | 0.384 | 3.703 | 0.000 | 4.150 |
| 4. satisfied | 2.078 | 0.385 | 5.403 | 0.000 | 7.991 |
| 5. very satisfied | 2.958 | 0.387 | 7.642 | 0.000 | 19.265 |
| st_infra (reference: 1. very dissatisfied) | |||||
| 2. dissatisfied | 2.709 | 0.765 | 3.541 | 0.000 | 15.016 |
| 3. neutral | 2.126 | 0.762 | 2.790 | 0.005 | 8.383 |
| 4. satisfied | 2.848 | 0.762 | 3.736 | 0.000 | 17.260 |
| 5. very satisfied | 3.206 | 0.763 | 4.200 | 0.000 | 24.692 |
| male (ref: 0. no) | −0.077 | 0.028 | −2.798 | 0.005 | 0.926 |
| married (ref: 0. no) | 0.137 | 0.035 | 3.956 | 0.000 | 1.147 |
| age (reference: 1. 10~19) | |||||
| 2. 20~29 | −0.050 | 0.085 | −0.593 | 0.553 | 0.951 |
| 3. 30~39 | −0.182 | 0.088 | −2.069 | 0.039 | 0.834 |
| 4. 40~49 | −0.262 | 0.090 | −2.921 | 0.003 | 0.770 |
| 5. 50~59 | −0.417 | 0.088 | −4.726 | 0.000 | 0.659 |
| 6. over 60 | −0.390 | 0.088 | −4.417 | 0.000 | 0.677 |
| edu (reference: 1. less than high school) | |||||
| 2. high school | 0.356 | 0.055 | 6.488 | 0.000 | 1.428 |
| 3. college or bachelor | 0.376 | 0.061 | 6.121 | 0.000 | 1.456 |
| 4. graduate school | 0.591 | 0.156 | 3.789 | 0.000 | 1.806 |
| hh_inc (reference: 1. less than KRW 1,000,000) | |||||
| 2. KRW 1,000,000~KRW 2,000,000 | 0.600 | 0.359 | 1.670 | 0.095 | 1.823 |
| 3. KRW 2,000,000~KRW 3,000,000 | 0.711 | 0.350 | 2.029 | 0.043 | 2.036 |
| 4. KRW 3,000,000~KRW 4,000,000 | 1.077 | 0.349 | 3.083 | 0.002 | 2.936 |
| 5. KRW 4,000,000~KRW 5,000,000 | 1.106 | 0.349 | 3.165 | 0.002 | 3.022 |
| 6. KRW 5,000,000~KRW 6,000,000 | 0.903 | 0.350 | 2.580 | 0.010 | 2.467 |
| 7. KRW 6,000,000~KRW 7,000,000 | 1.015 | 0.350 | 2.901 | 0.004 | 2.760 |
| 8. KRW 7,000,000~KRW 8,000,000 | 1.289 | 0.351 | 3.677 | 0.000 | 3.629 |
| 9. KRW 8,000,000~KRW 9,000,000 | 1.304 | 0.352 | 3.703 | 0.000 | 3.685 |
| 10. over KRW 9,000,000 | 1.436 | 0.352 | 4.080 | 0.000 | 4.203 |
| OWN_HOME (ref: 0. no) | 0.144 | 0.029 | 4.928 | 0.000 | 1.155 |
| APT (ref: 0. no) | −0.076 | 0.030 | −2.529 | 0.011 | 0.926 |
| SFR (ref: 0. no) | 0.067 | 0.035 | 1.898 | 0.058 | 1.069 |
| resi_dt (ref: 0. no) | −0.345 | 0.054 | −6.396 | 0.000 | 0.709 |
| resi_en (ref: 0. no) | −0.118 | 0.039 | −2.988 | 0.003 | 0.889 |
| resi_wn (ref: 0. no) | −0.035 | 0.048 | −0.741 | 0.459 | 0.965 |
| resi_ws (ref: 0. no) | −0.453 | 0.040 | −11.437 | 0.000 | 0.636 |
| job_pro (ref: 0. no) | 0.016 | 0.058 | 0.284 | 0.777 | 1.016 |
| job_white (ref: 0. no) | 0.077 | 0.038 | 2.046 | 0.041 | 1.080 |
| job_blue (ref: 0. no) | −0.049 | 0.039 | −1.253 | 0.210 | 0.952 |
| disab (ref: 0. no) | −0.432 | 0.118 | −3.651 | 0.000 | 0.649 |
| hl_seoul | 0.006 | 0.001 | 5.351 | 0.000 | 1.006 |
| hl_gu | −0.003 | 0.001 | −1.885 | 0.059 | 0.997 |
| Intercept | |||||
| 0|1 | −1.908 | 0.927 | −2.057 | 0.040 | |
| 1|2 | −0.982 | 0.876 | −1.121 | 0.262 | |
| 2|3 | 0.241 | 0.864 | 0.279 | 0.781 | |
| 3|4 | 1.830 | 0.863 | 2.119 | 0.034 | |
| 4|5 | 3.405 | 0.865 | 3.937 | 0.000 | |
| 5|6 | 4.826 | 0.865 | 5.576 | 0.000 | |
| 6|7 | 6.091 | 0.866 | 7.035 | 0.000 | |
| 7|8 | 7.448 | 0.866 | 8.600 | 0.000 | |
| 8|9 | 9.219 | 0.866 | 10.642 | 0.000 | |
| 9|10 | 12.353 | 0.870 | 14.196 | 0.000 | |
| Model Statistics | |||||
| Observations | 20,000 | ||||
| McFadden | 0.079 | ||||
| CoxSnell Score | 0.235 | ||||
| Nagelkerke Score | 0.243 | ||||
| AIC | 62,889.630 | ||||
| Variables | Impurity-Based Feature Importance | Permutation-Based Feature Importance | ||
|---|---|---|---|---|
| Magnitude | Rank | Magnitude | Rank | |
| st_ped | 0.068 | 5 | 0.103 | 3 |
| st_ped_n | 0.048 | 7 | 0.057 | 6 |
| st_econ | 0.035 | 9 | 0.003 | 20 |
| st_soci | 0.033 | 10 | 0.002 | 22 |
| st_educ | 0.032 | 11 | 0.000 | 26 |
| st_home | 0.156 | 1 | 0.299 | 1 |
| st_infra | 0.110 | 2 | 0.178 | 2 |
| male | 0.016 | 17 | 0.001 | 24 |
| married | 0.015 | 18 | 0.007 | 17 |
| job_pro | 0.010 | 24 | 0.001 | 24 |
| job_white | 0.013 | 21 | 0.008 | 15 |
| job_blue | 0.013 | 21 | 0.006 | 18 |
| disab | 0.004 | 26 | 0.002 | 22 |
| age | 0.044 | 8 | 0.029 | 10 |
| edu | 0.023 | 12 | 0.009 | 14 |
| hh_inc | 0.064 | 6 | 0.064 | 4 |
| OWN_HOME | 0.018 | 14 | 0.012 | 13 |
| APT | 0.018 | 14 | 0.005 | 19 |
| SFR | 0.015 | 18 | 0.008 | 15 |
| resi_dt | 0.007 | 25 | 0.003 | 20 |
| resi_en | 0.017 | 16 | 0.030 | 9 |
| resi_wn | 0.012 | 23 | 0.024 | 11 |
| resi_ws | 0.020 | 13 | 0.044 | 7 |
| resi_es | 0.014 | 20 | 0.016 | 12 |
| hl_seoul | 0.103 | 3 | 0.031 | 8 |
| hl_gu | 0.093 | 4 | 0.061 | 5 |
| 1996 | 2002 | 2006 | 2010 | |||||
|---|---|---|---|---|---|---|---|---|
| Active transportation | 4,389,859 | 13.64% | 5,230,690 | 14.98% | 6,110,389 | 16.38% | 6,499,084 | 17.26% |
| Vehicle | 6,829,224 | 21.22% | 7,982,832 | 22.87% | 8,188,781 | 21.95% | 7,501,988 | 19.92% |
| Taxi | 2,901,178 | 9.01% | 2,194,799 | 6.29% | 1,959,612 | 5.25% | 2,236,058 | 5.94% |
| Bus | 8,357,730 | 25.96% | 7,705,001 | 22.07% | 8,616,326 | 23.10% | 8,745,685 | 23.23% |
| Transit | 8,182,634 | 25.42% | 10,284,673 | 29.46% | 10,839,341 | 29.05% | 11,289,362 | 29.98% |
| Others | 1,528,794 | 4.75% | 1,512,971 | 4.33% | 1,592,022 | 4.27% | 1,382,479 | 3.67% |
| Total | 32,189,419 | 100.00% | 34,910,966 | 100.00% | 37,306,471 | 100.00% | 37,654,656 | 100.00% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S. Satisfaction with the Pedestrian Environment and Its Relationship to Neighborhood Satisfaction in Seoul, South Korea. Sustainability 2022, 14, 9343. https://doi.org/10.3390/su14159343
Lee S. Satisfaction with the Pedestrian Environment and Its Relationship to Neighborhood Satisfaction in Seoul, South Korea. Sustainability. 2022; 14(15):9343. https://doi.org/10.3390/su14159343
Chicago/Turabian StyleLee, Sangwan. 2022. "Satisfaction with the Pedestrian Environment and Its Relationship to Neighborhood Satisfaction in Seoul, South Korea" Sustainability 14, no. 15: 9343. https://doi.org/10.3390/su14159343
APA StyleLee, S. (2022). Satisfaction with the Pedestrian Environment and Its Relationship to Neighborhood Satisfaction in Seoul, South Korea. Sustainability, 14(15), 9343. https://doi.org/10.3390/su14159343