1. Introduction
Highway facilities are a significant transportation mode for passengers and goods. For instance, the United States has one of the most sophisticated highway networks, spanning 1.3 million miles. Highway utilization has progressively augmented over the years with the development in connectivity between counties within the state. More than 343,600 thousand daily vehicle miles traveled in 2019 compared with 296,263 thousand miles in 2014 [
1].
It is indispensable for highway project contract parties to ensure timely construction within the constricted accomplishment period. Unfortunately, though, construction activities regularly interfere with traffic disturbances from detours and lane closings. Although the US transportation department and the other involved parties seem to distinguish that traffic interferences are inevitable in construction projects, their influences on project delivery can still be controlled and minimalized.
Thus, the
are considered reasonable reimbursement for the project owner to ensure the tangible damages that probably will be demanded through legalized arrangements for construction completion beyond the contractual project duration. In addition, many aspects (i.e., environment, public mobility, economy, access, and safety) are affected by the transportation project’s duration [
2]. However, the planning stage for estimating the construction time and all relevant development stages had not received sufficient attention [
3]. Using linear regression modeling, a study has offered a proposed model to handle this issue with three features to estimate the highway project duration [
4]. Moreover, planar flow-based variational auto-encoder prediction model has been proposed to decrease the data bias and overfitting [
5]. In the same vine,
technique was applied to enhance the driving evaluation and risk prediction, by selecting the most important related features [
6].
Claims management is a critical need for construction project success [
7], especially in large and complex projects (i.e., megaprojects) [
8,
9]. Therefore, claim management performance criteria have been proposed to enhance the claiming management process positively. In addition, interviews have been conducted to enhance the efficiency of claims management. As a result, there is an urgent need to monitor the additional cost confirmed by project agents and
issues [
10].
is considered a significant feature in managing material procurement and storage [
11].
Contract parties specify a pre-evaluated quantity of damage documented within the contract itself. Such measures are critical to comprise a contractual procedure instigated to recover these additional expenditures from the contractor as an alternative to actual damages [
12,
13]. The concurrent delay caused by subcontractors themselves or between the main contractor and other subcontractors was discussed. How to logically distribute these damages between contractors and sub-contractors in terms of liability [
14]. Alternatives to the financing process were addressed in the construction project to effectively reduce financing expenditures and avert
using the cash flow prediction model [
15]. Project delay can lead to an increase in the overall project cost due to the
[
16,
17].
A comprehensive analysis of policies and laws was undertaken by considering several relevant aspects (i.e.,
, conflict resolution, time extension issues, change orders, and circumstance site conditions) to compare the
federal acquisition regulation (and the Saudi public works contract from an international contracting perspective. This study provides the literature with integrated insight to properly understand and reduce potential risks once large contractors engage with international contracts [
18]. A comprehensive survey and targeted interviews were conducted considering the
effect for the investigation of all possible alternative highway contracting using Department of Transportation
data [
19]. Twenty-three private–public partnerships were examined for all potential conflicts of interest regarding public sector authority and franchisor empowerment in United States highway projects. The study shows various techniques have been applied to observe concessionaire behavior rather than empowering them in the public-private partnership [
20].
In general, the
can be thought of as accurate delay compensation fees that must be paid to the owner [
21,
22]. The
that can be afforded by insurance companies in terms of predictable loss have been estimated using a case study. However, the estimated error in determining the
was significantly high when applying this estimate to other cases where they had just established their model by adopting only one case study. Thus, this is not adequate for inclusive use [
23]. For example, the I-95 express lanes project, the
consequence has been illustrated using (VDOT 2012); The government has the authority to levy USD 5000 in
for each day that the officially declared final decision for project completion is not released [
24].
Highway construction projects normally face delays in its delivery. Such wasted time significantly affects the projects’ sustainability. As it has ripple impacts on the main project objective functions (i.e., time, quality, safety, cost, and combined ). In such cases, having an accurate prediction is vital for decision makers, where prospective conflicts amongst stakeholders can be avoided. Thus, a comprehensive model that considers all compelling circumstances and constraints is critically required to adapt with the construction project dynamic situations (i.e., generic prediction model). In the related model available in the literature, the actual damage is estimated, which may be much greater or less than the liquidated amount written in the relevant contract clause. To this end, few papers have investigated the prediction. However, to the best of the authors’ knowledge, a limited number of ML-based prediction models are available in the literature. Such investigations have not provided a well-defined and described analysis of the forecasting process, where only a few influential attributes were considered, and preliminary prediction tools were employed. Accordingly, the need to estimate the actual liquidated amount has become a critical issue that must be addressed in construction projects.
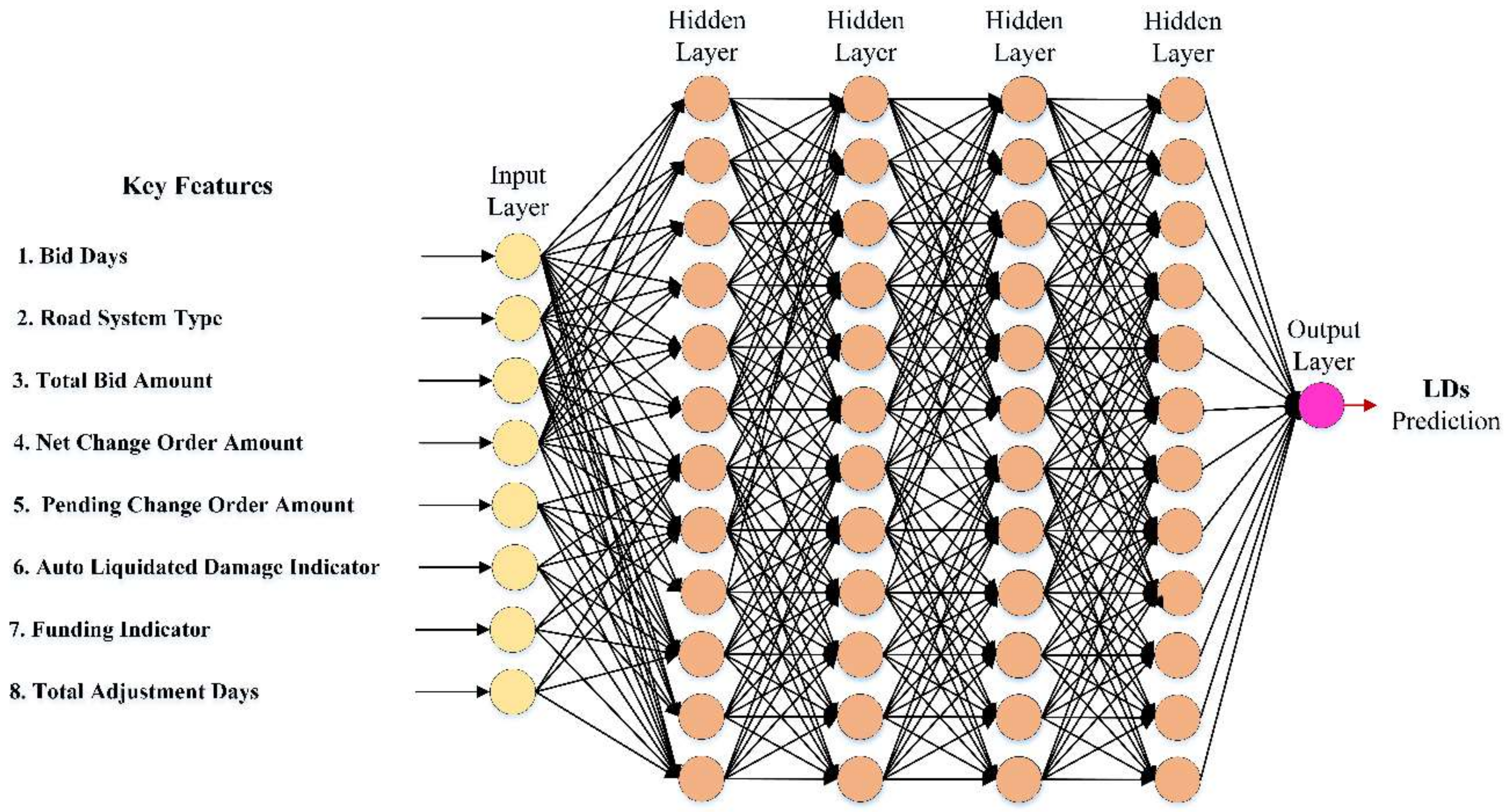
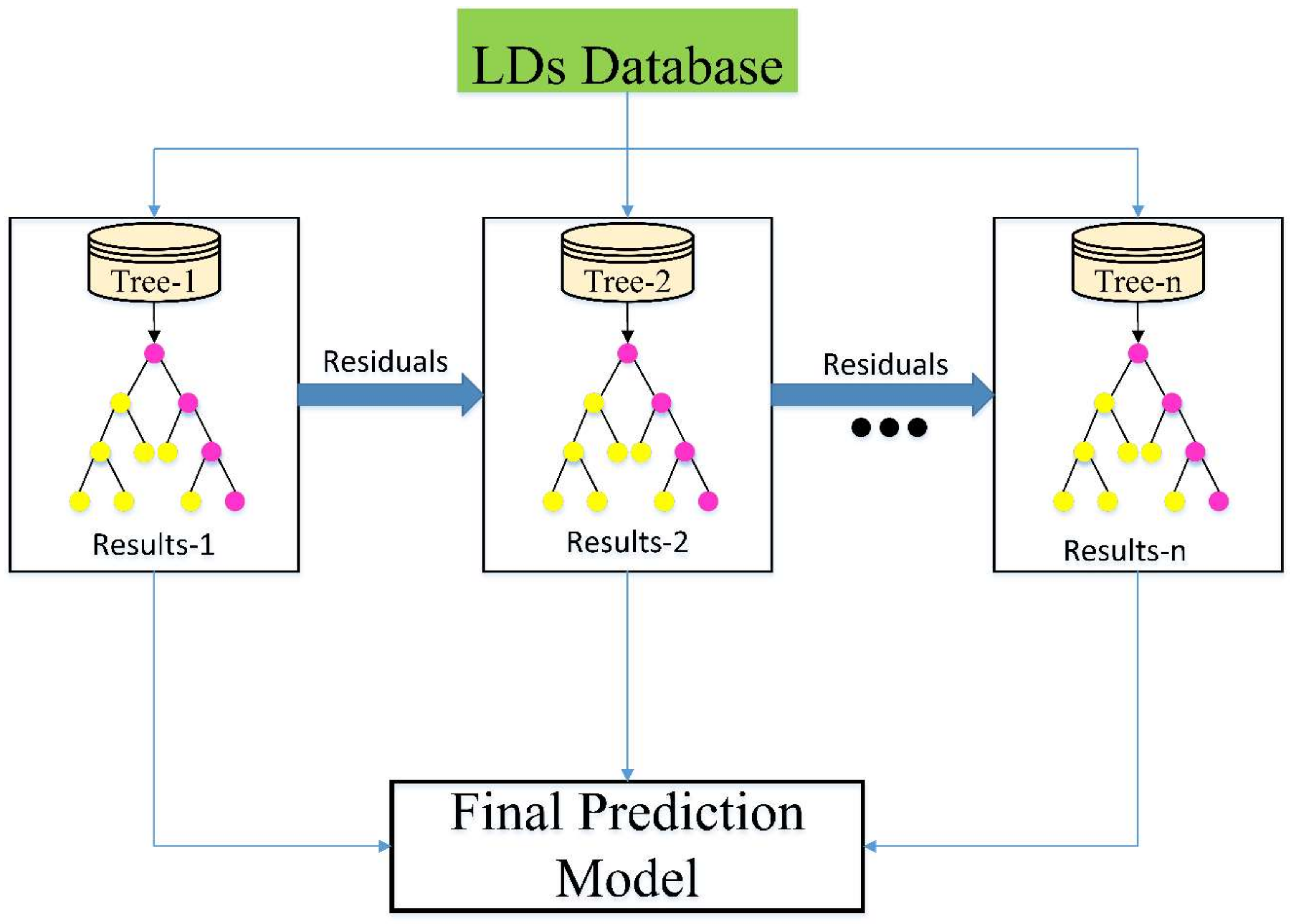
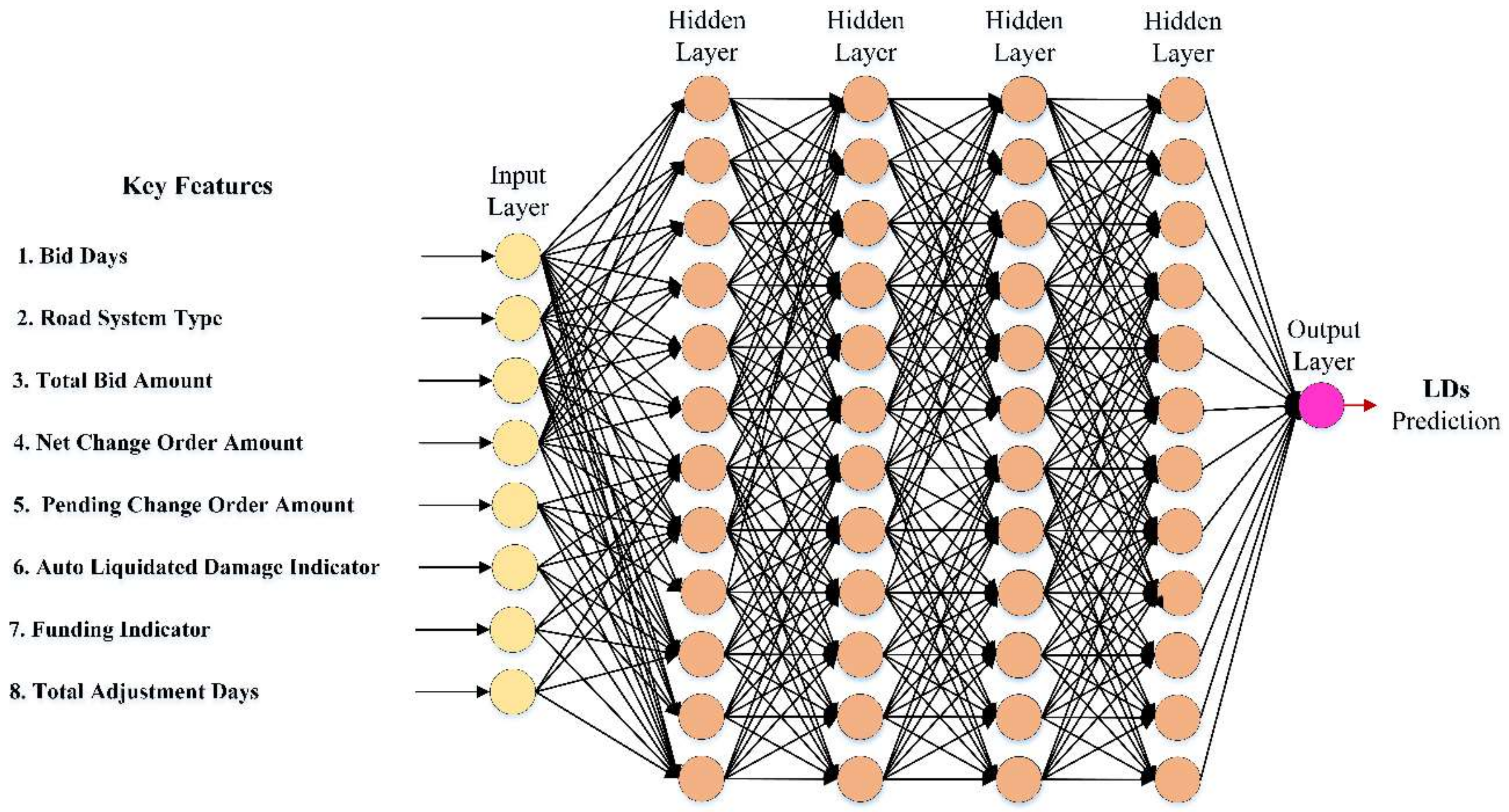
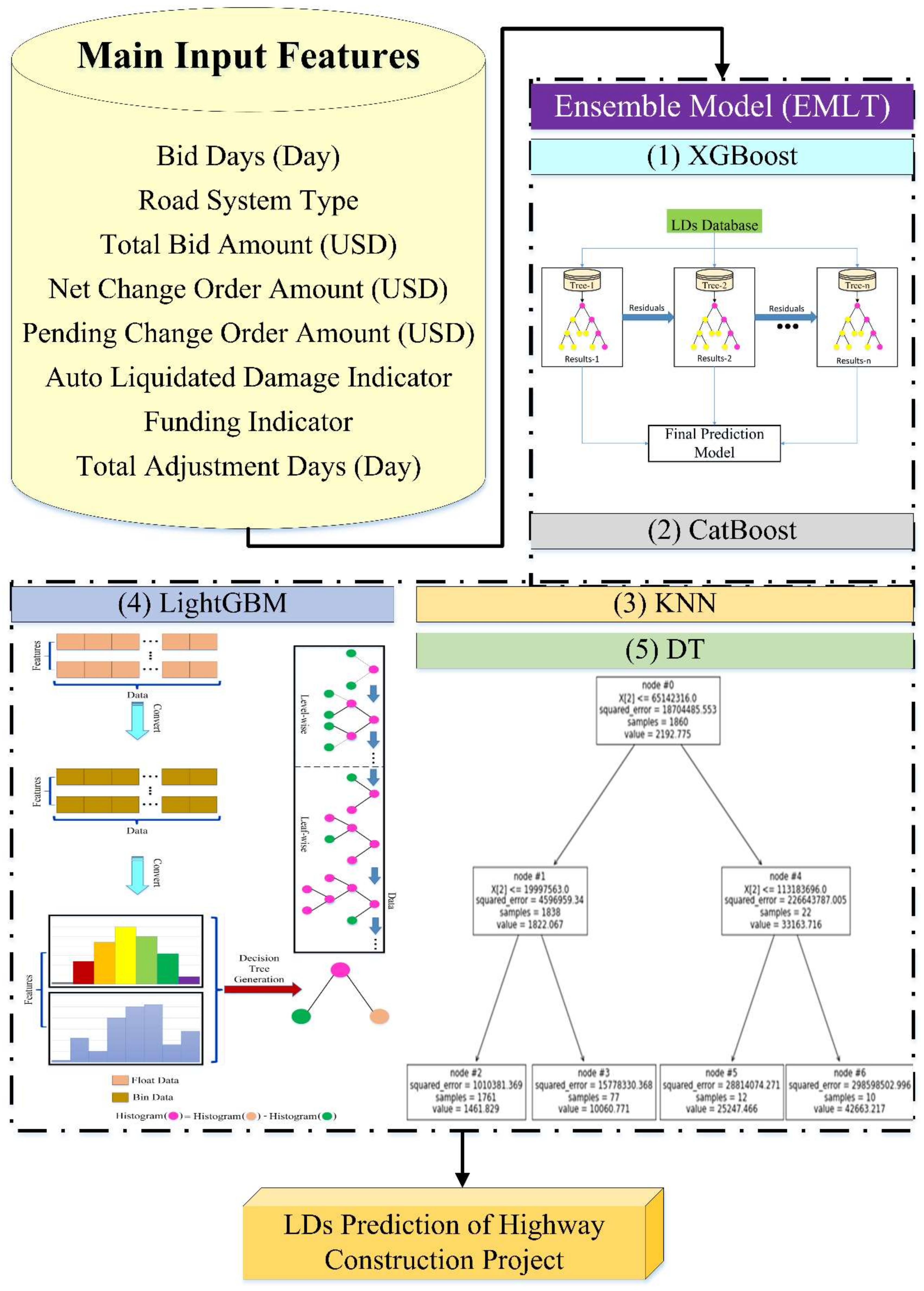
The current study creates a combined ML-based forecasting models for the prediction of . Datasets developed during a 15-year data gathering procedure for hundreds of highway building projects collected on their contractual were used for training and testing. According to the recent research available within the literature and using up-to-date pre- and post-processing techniques, the most influential attributes that affect the prediction were chosen and defined. These factors are the net change order amount, bid days, total bid amount, road system type, auto liquidated damage indicator, pending change order amount, total adjustment days, and funding indicator. Using a complex assembled model and being generic, while considering all influential factors provide the proposed model with a step forward in the prediction arena. Moreover, the current study findings can be incorporated into broader ongoing research to offer a decision support tool for modernizing the estimation strategies worldwide.
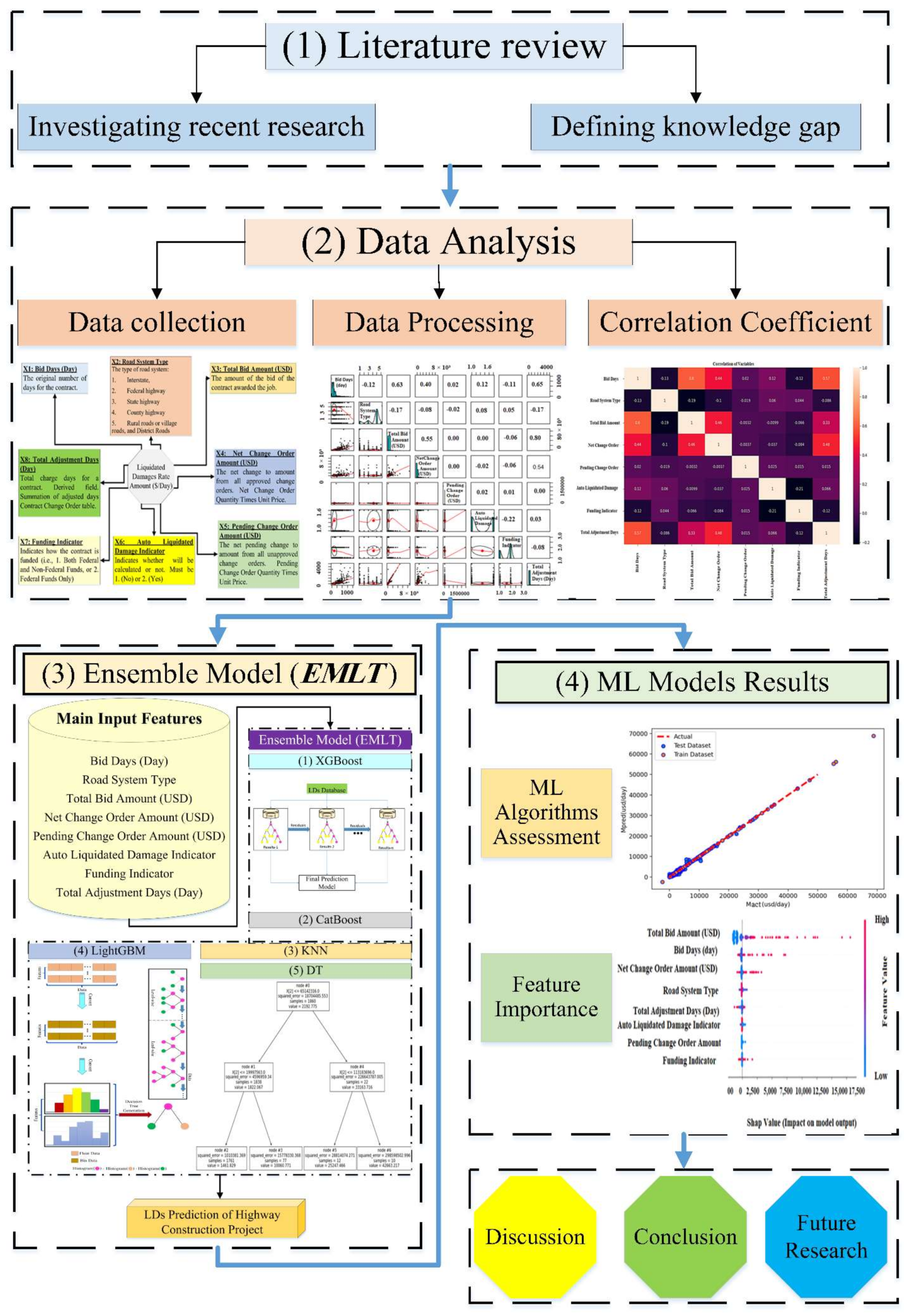
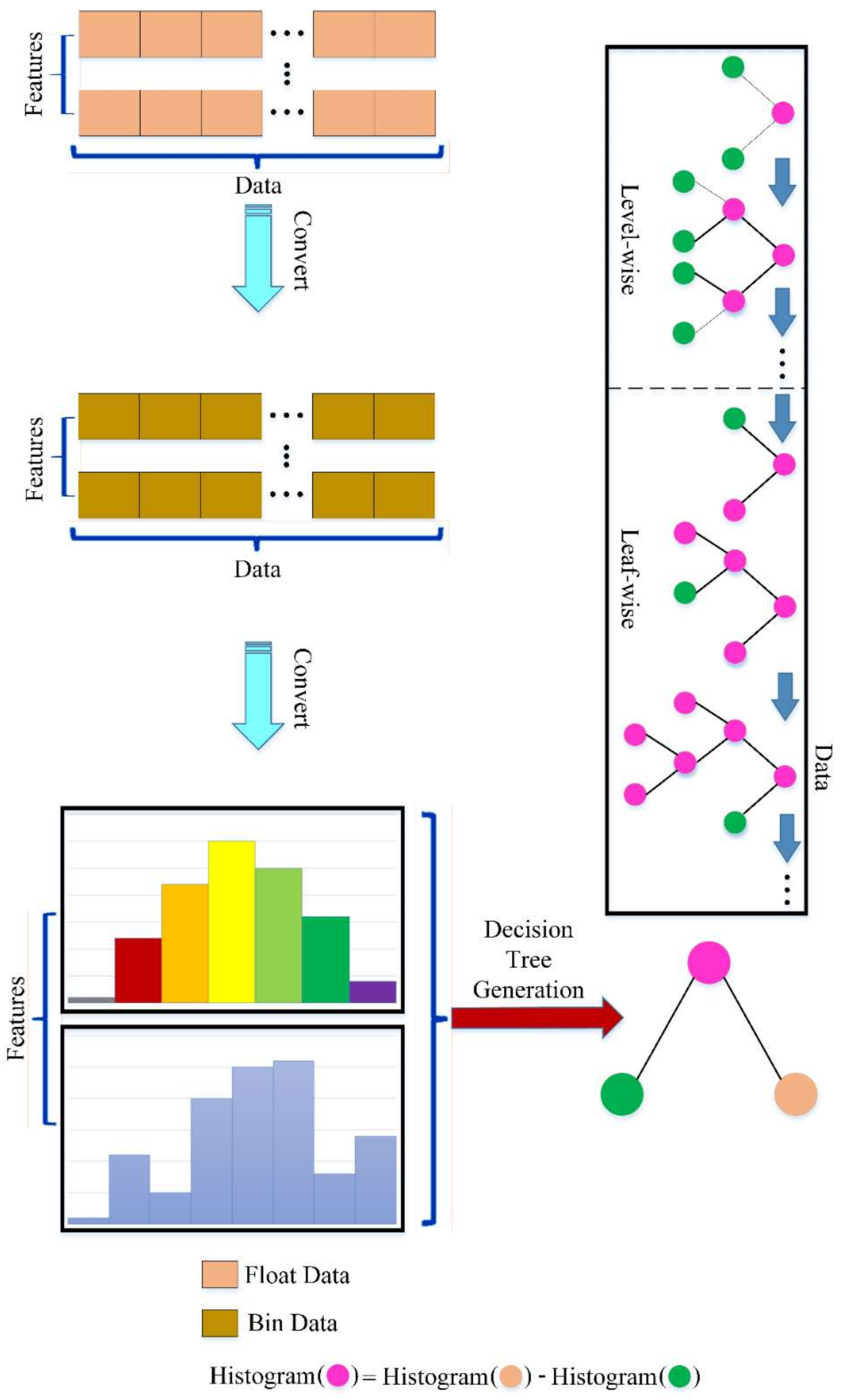
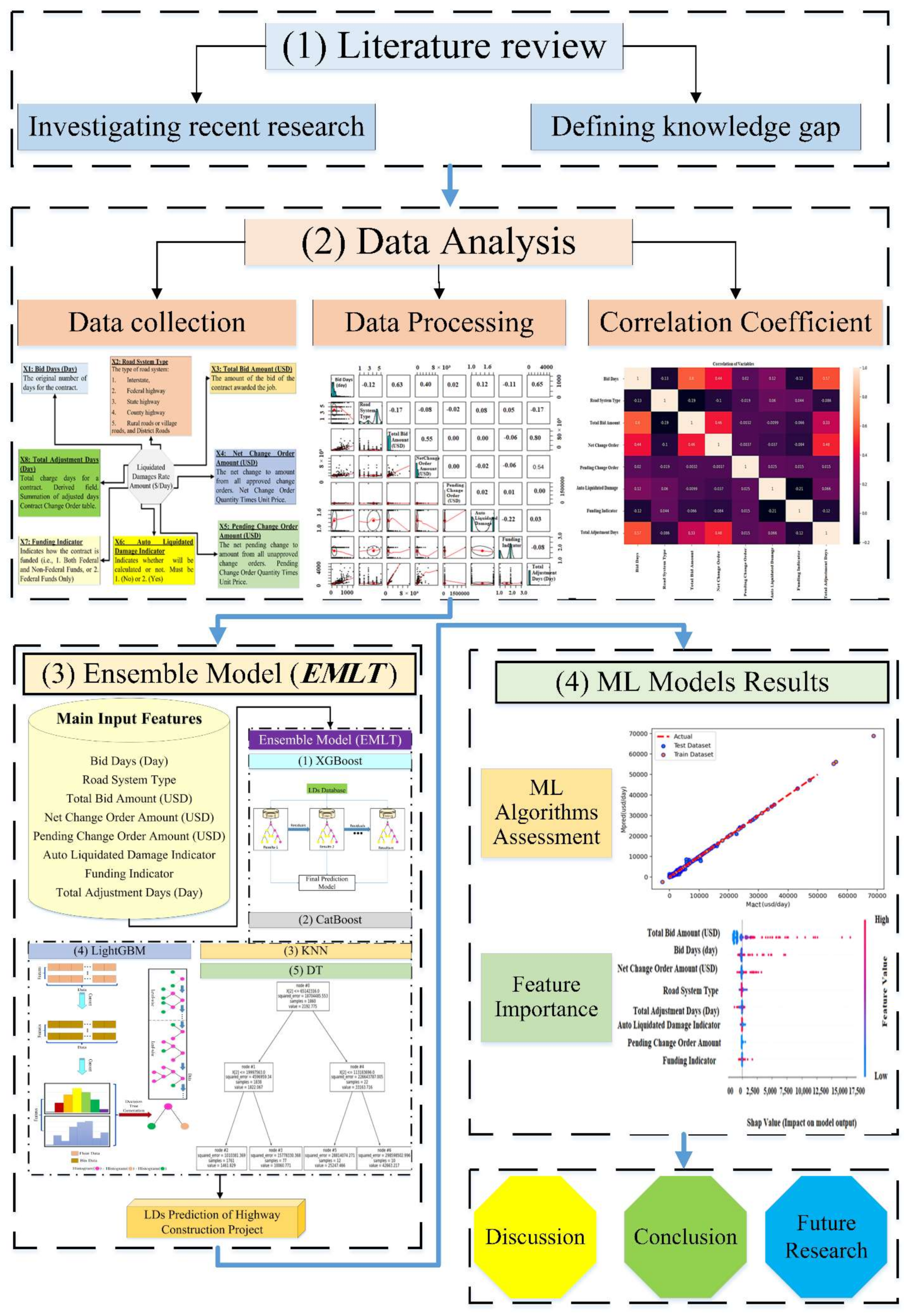
2. Prediction Methodology
The current research paper is structured as follows. First, the latest research efforts related to
prediction and ML-based forecasting models related to the literature are comprehensively illustrated. Then, the data collection, processing phases, and critical attributes considered in
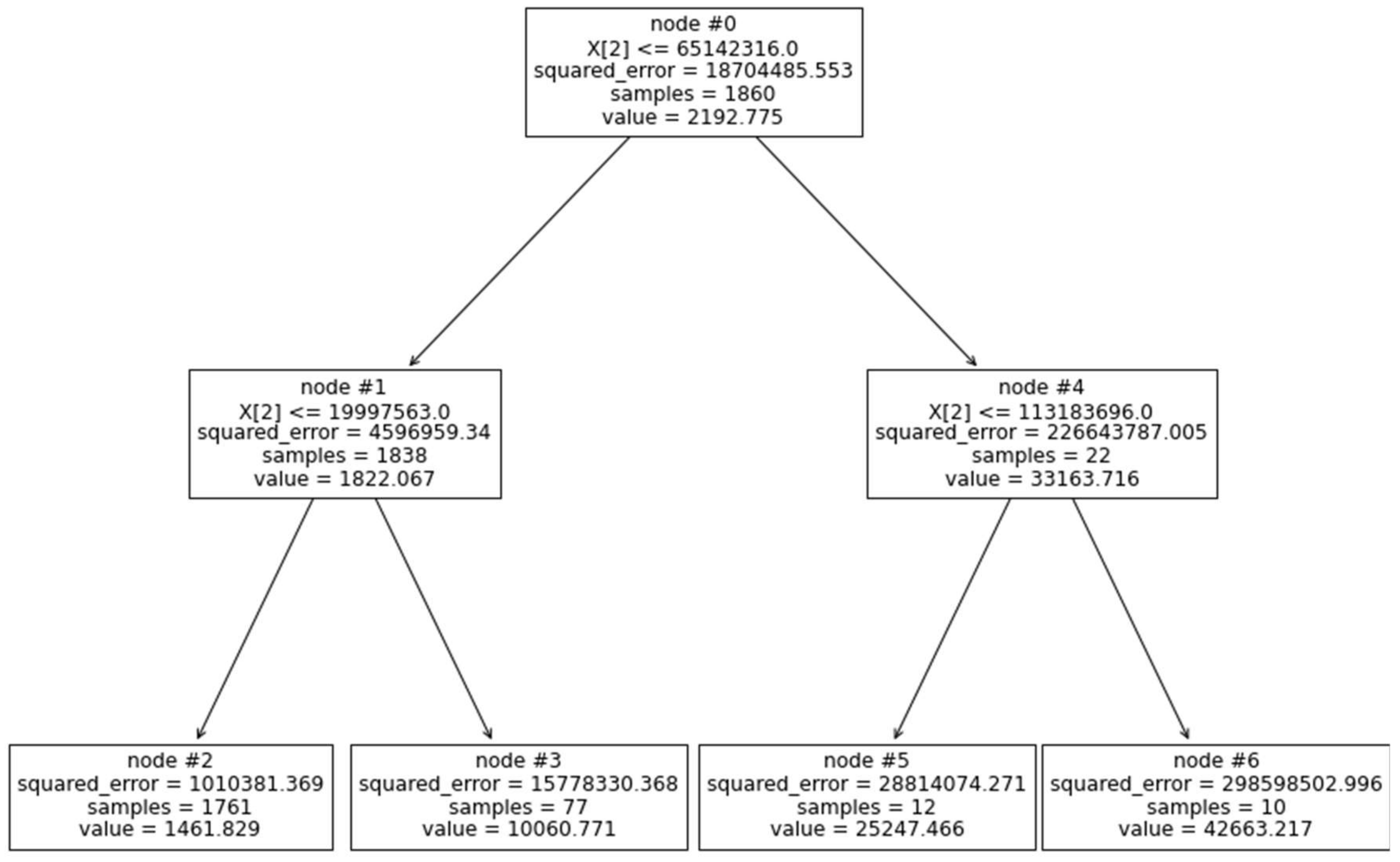
predictions were illustrated. In addition, the research methodology is presented, where various utilized ML techniques (i.e., XGBoost, CatBoost, kNN, LightGBM, ANN, DT) are explained and then combined. After that, various modeling results are presented and thoroughly discussed, where prediction accuracy is evaluated and compared using several performance indecencies (i.e.,
,
,
,
). These evaluation metrics were computed to assess the proposed models’ efficiency and validity. The coefficient of determination
embodies the precision of the forecast. Thus, for
R2 closer to one, additional forecast precision is acquired. The
, the
, and the
are standard measures to assess the prediction accuracy with continuous dependent attributes, where they offer awareness about the forecast’s potential errors. Finally, the research conclusion along with future research recommendations are listed. The developed prediction models showed high accuracy with distinguished capabilities for
forecasting the highway projects. Results are anticipated to play a vital role in eradicating possible struggles amongst contract parties, particularly when decision-makers tackle different complications and challenges in assessing the actual
. For more illustrations, the methodology flowchart was carried out in
Figure 1.
3. Data Processing and Analysis
3.1. Data Collection and Features Selection
The data were collected between 2006 and 2021 from the in Florida, US. Where the is a vital component for tracking the relevant dataset and the specific features of highway construction projects. For the analysis process to be more appropriate, the data was imported into Excel. The data appear to be a promising clue that gives a proper visualization to which is considered a critical factor that undergoes the project’s stakeholders to tense. The gathered data was related to the major categories of the road systems such as federal highway, interstate, county highway, state highway, rural roads, district roads, and village roads.
The gathered data provides a clue to visualize the projects’ variables and their description. Data collection transformation took about 10 months to ensure that the accumulated datasets were appropriate and representative of the models’ technique. The study factors of were represented by the main attributes needed to improve the usefulness and efficiency of the developed model.
Feature selection is used to identify the most important inputs or attributes that will affect model prediction. This strategy is necessary for the success of the study, and it is an important aspect of ML to assure the creation of highly linked features [
25,
26]. Feature selection reduces the number of input variables to those that are deemed to be most essential to the accuracy of the prediction model. The most influential elements have been picked to launch the
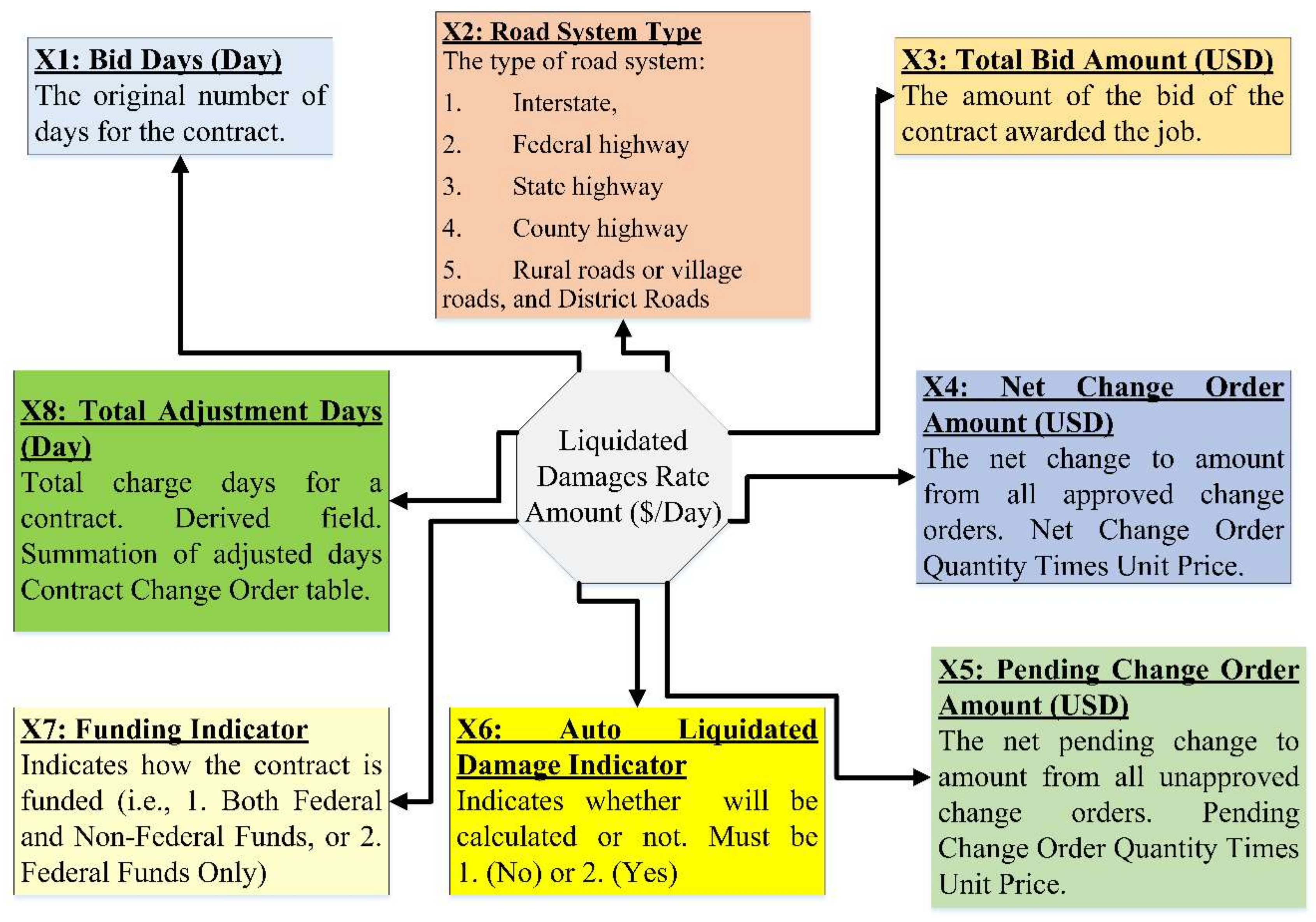
prediction models based on common information, the available literature, DOT requirements, and construction project professionals. The crucial factors were considered (i.e., net change order amount, bid days, total bid amount, road system type, auto liquidated damage indicator, pending change order amount, total adjustment days, and funding indicator).
are determined by several interconnected elements that have a latent influence on their value. Thus, during the prediction process itself, the feature importance is estimated and the models’ priorities from a factor selection point of view are updated accordingly. To consider the integral integrated relationship form algorithms, all LD properties must be fully identified to enable appropriate collection. To match the model input or enhance analytical precision, any features demand a transformation step. The model gets more generic and simpler by utilizing fewer functions, boosting its accuracy. Some associated features have been picked to begin the
prediction model based on common information, the available literature, and professionals in building projects. Furthermore, a wrapper approach (backward elimination) selected the relevant feature by using its performance as an assessment criterion. Where an iterative procedure is used to reduce the model’s lowest performing features until the total accuracy of the model reaches an acceptable range [
27]. The
p-value is the performance parameter utilized in this study to evaluate feature performance, and features with a
p-value of 0.05 or less are deleted. These variables play a significant role in the estimation process of
of road projects.
Figure 2 shows the description of the eight influential dependents (
to
) and one independent feature (
).
3.2. Data Pre-Processing
Pre-processing the data is a crucial step for managing the data before using algorithm. This step is required due to the need for data suitable for techniques. The data-selection process leads to choosing a key parameter for estimation.
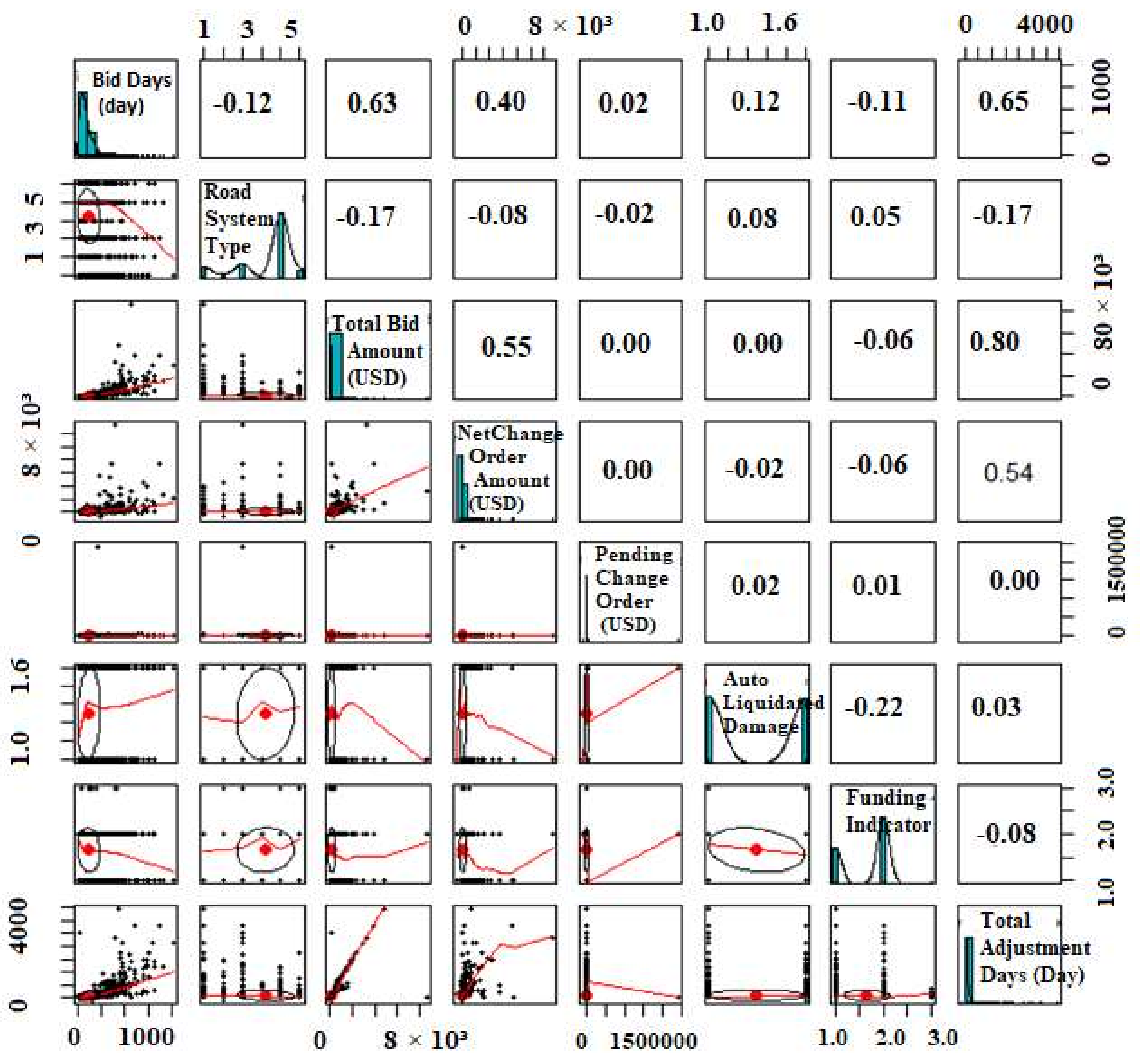
Thus,
Table 1 shows the numerical and independent features’ statistical measurements for the real collected data. Moreover, the scatterplot matrix for the full features is illustrated in
Figure 3.
To enhance the model stability, data pre-preparation should be conducted. Several measures are needed for this process, such as data noise, normalization, outlier cleaning, standardization, conversion, and usual assortment. For pre-processing the datasets, the outliers must be excluded firstly, which is since outliers could reduce the efficiency of the model when using techniques. Additionally, in this process, data normalization is highly required. Moreover, data filtering is conducted by employing an interquartile range to detect the extreme and outlier values. Boxplots, for example, have been chosen as a graphical method for eliminating the outliers. The “Null” indicator concept was employed for missing value representation and elimination. Consequently, a little quantity of missing data necessitated pre-processing (i.e., 8.9% of the initial database). The average and median values of pertinent attributes were used to replace the missing data points. The previously stated phases within the pre-processing step have a positive impact of the dataset readiness for the ML-based prediction phase.
After that, the transformation (from categorical feature into numerical feature) process will ensure convergence and a smooth modeling system. One-Hot Encoding is used to execute the transition [
28]. Despite this, label encoding is straightforward, but algorithms can misread numeric values, since they include a hierarchical class. This ordering problem is handled through another popular alternative strategy known as ‘One-Hot Encoding’. Each category value is translated into a new column and assigned a 1 or 0 (notation for true/false) value to the column in this method. For example, the property feature categories can be encoded into numerical values, such as 100, 010, and 001 for road system type, auto liquidated damage indicator, and financing indication, respectively.
Table 2 shows how to use the One-Hot Encoding to turn the categorial property attribute into a number attribute. As a result, the entire database is converted only to contain the numerical values for all attributes.
3.3. Correlation Coefficients (CC)
The (
) is used to boost the relationship between two variables by providing a linear relationship between two variables.
is applied to calculate a numerical degree of the linear relationship between two variables
as shown in Equation (1).
where
,
can be calculated, as shown in Equations (2)–(4), respectively.
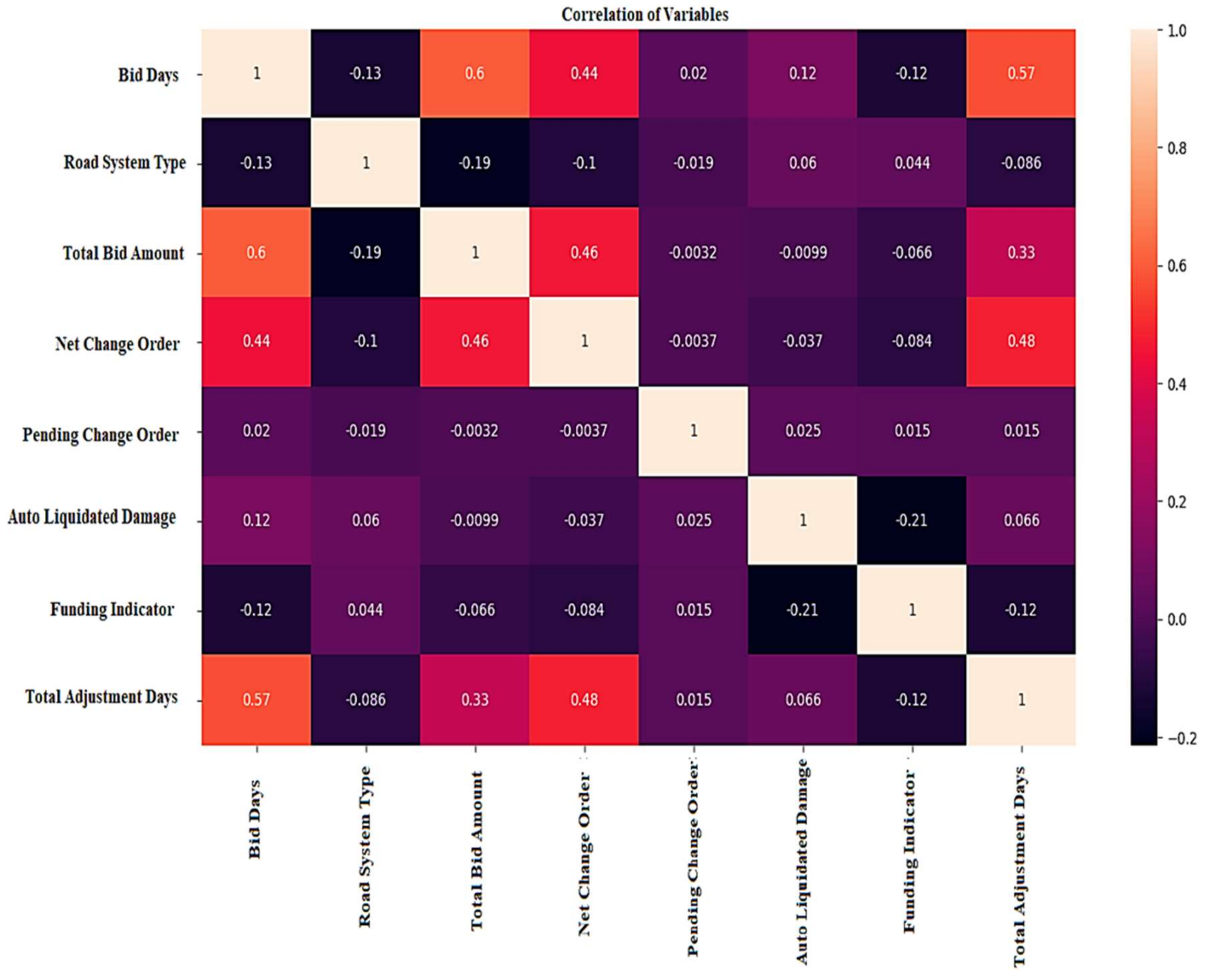
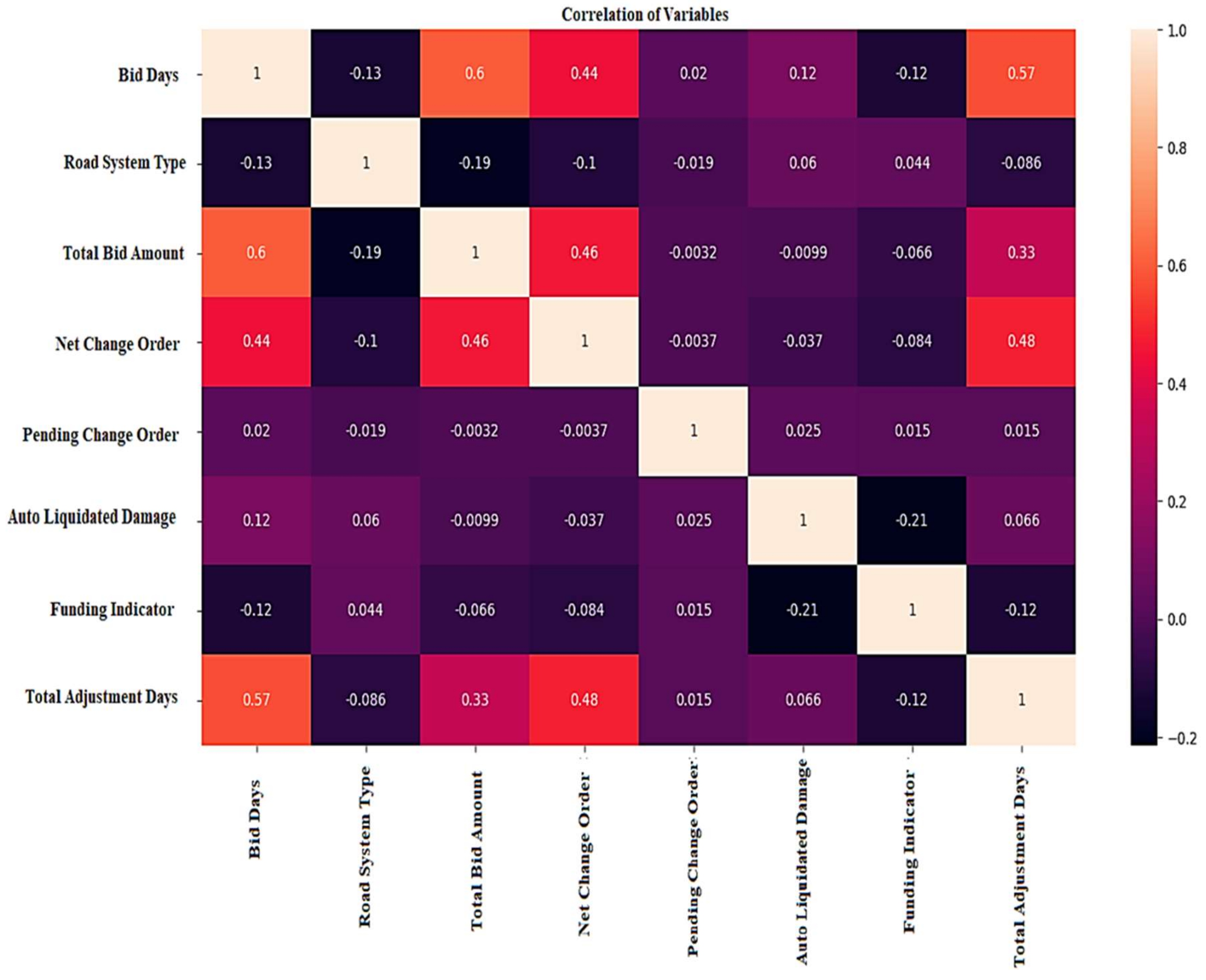
The set of the input and output of the proposed model can be represented by for ). In terms of Equation (1), the results will be three cases: (1) if , which means no linear correlation between input and output , (2) , which means a sturdy linear relationship between those variables, and (3) , which means a sturdy reverse linear relationship between those variables. Thus, it is spirited to illustrate the relationship between features and assign the pairs with high positive or negative correlations. Hence, features are being defined as the Pearson coefficient into expressions; correlation rates close to one are robust and explicit correlations between the two attributes. Otherwise, the correlation values near appear robust yet are the inverse correlation between the two features. For example, the total bid amount and bid days features have a correlation value of , indicating that the bid days increase as the total bid amount increases. This positive correlation means a higher value.
Conversely, total bid amount and road system type features have a correlation estimate of
, demonstrating the opposite impact on each other. Yet, both factors have a positive impact on the
value. Such an illustration represents the importance of generating a heatmap that shows the interconnected relation amongst the considered attributes.
Figure 4 shows the correlation between the different features.
5. Result and Discussion
The assessment metric was used to examine the adequacy of the suggested model. It is vital to assess the efficacy and prognostic capacity of the developed model after evaluating the primary model assumptions. As indicated in
Table 3, four statistical indices (
,
,
, R
2) were used to analyze the efficacy of the developed model quantitatively. If the R
2 value approaches one, and the
,
, and
values approach zero, the model’s accuracy and performance will improve.
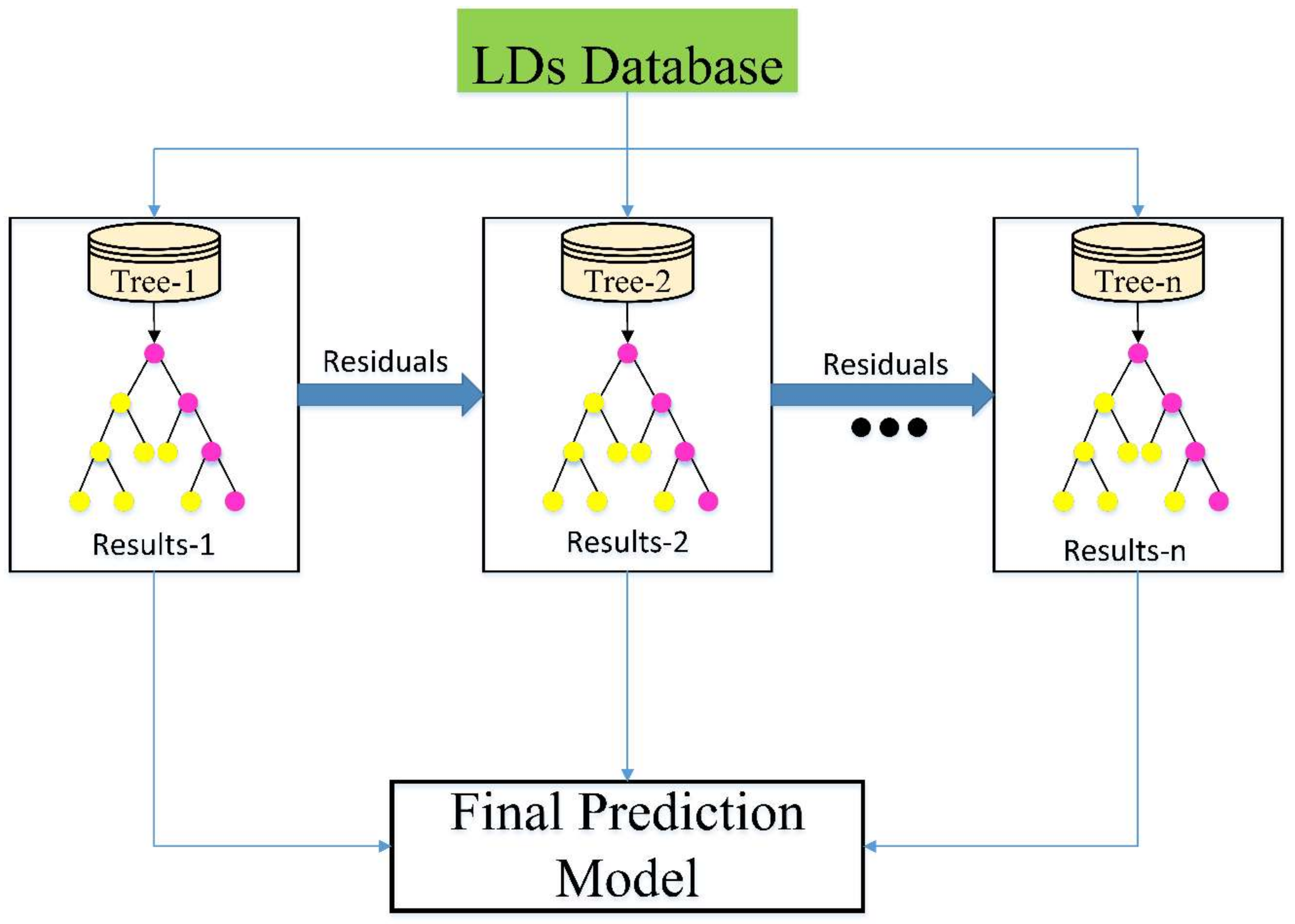
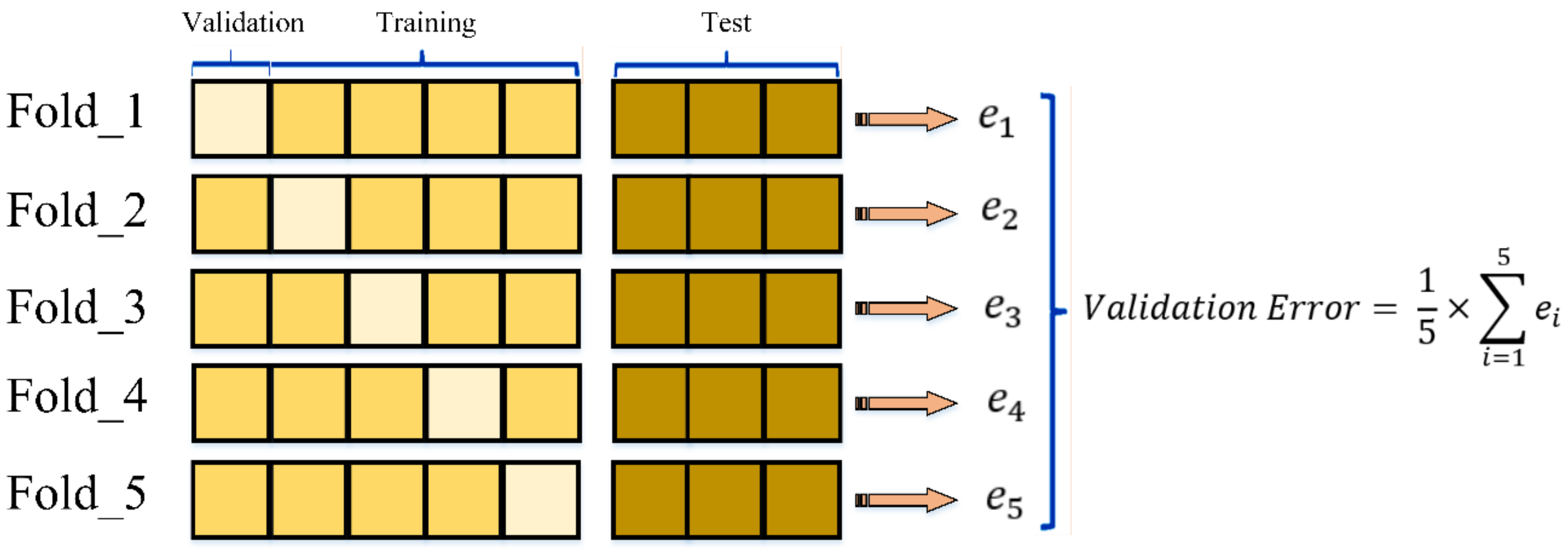
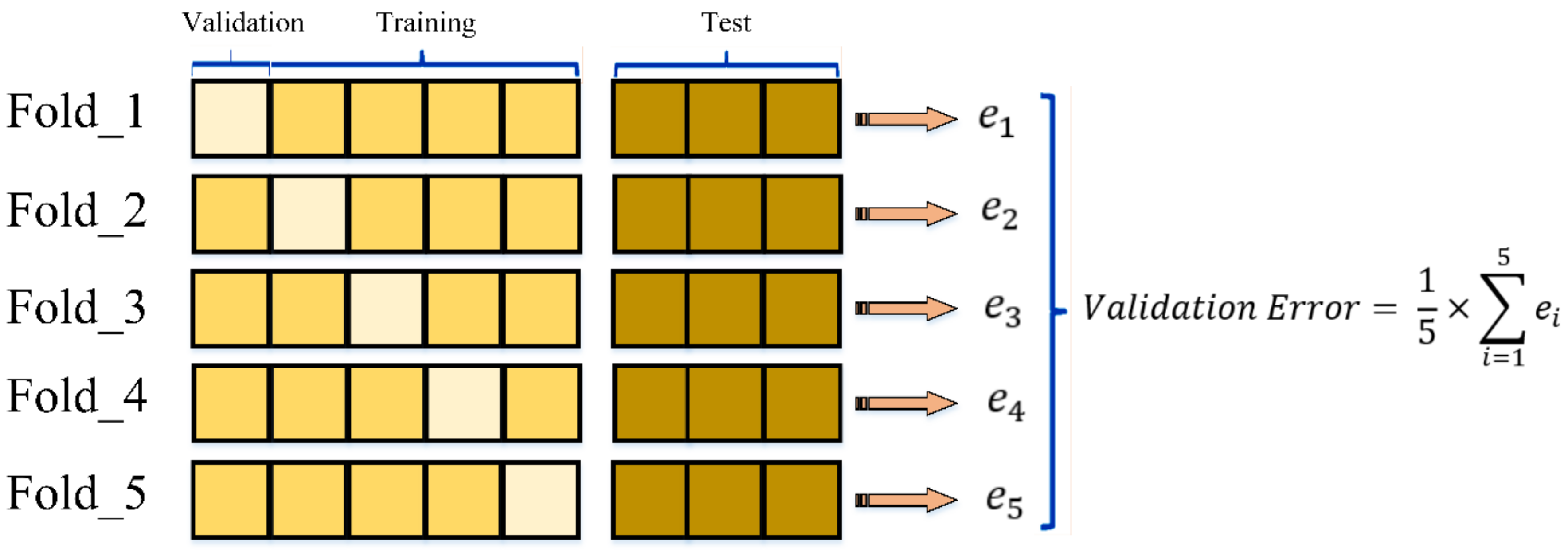
The training procedure on the
dataset was carried out using
k-fold cross-validations to assess the ensembled models’ efficacy.
Table 4 demonstrates a group of nonoverlapping and random partitioned folds, utilized as datasets for the training purposes of
k = 3,
k = 5, and
k = 7, along with their related performance assessment measures. Thus, five-fold cross-validation had the greatest prediction accuracy.
Figure 10 depicts the current model’s five-fold cross-validation results. It worth mentioning, as indicated in
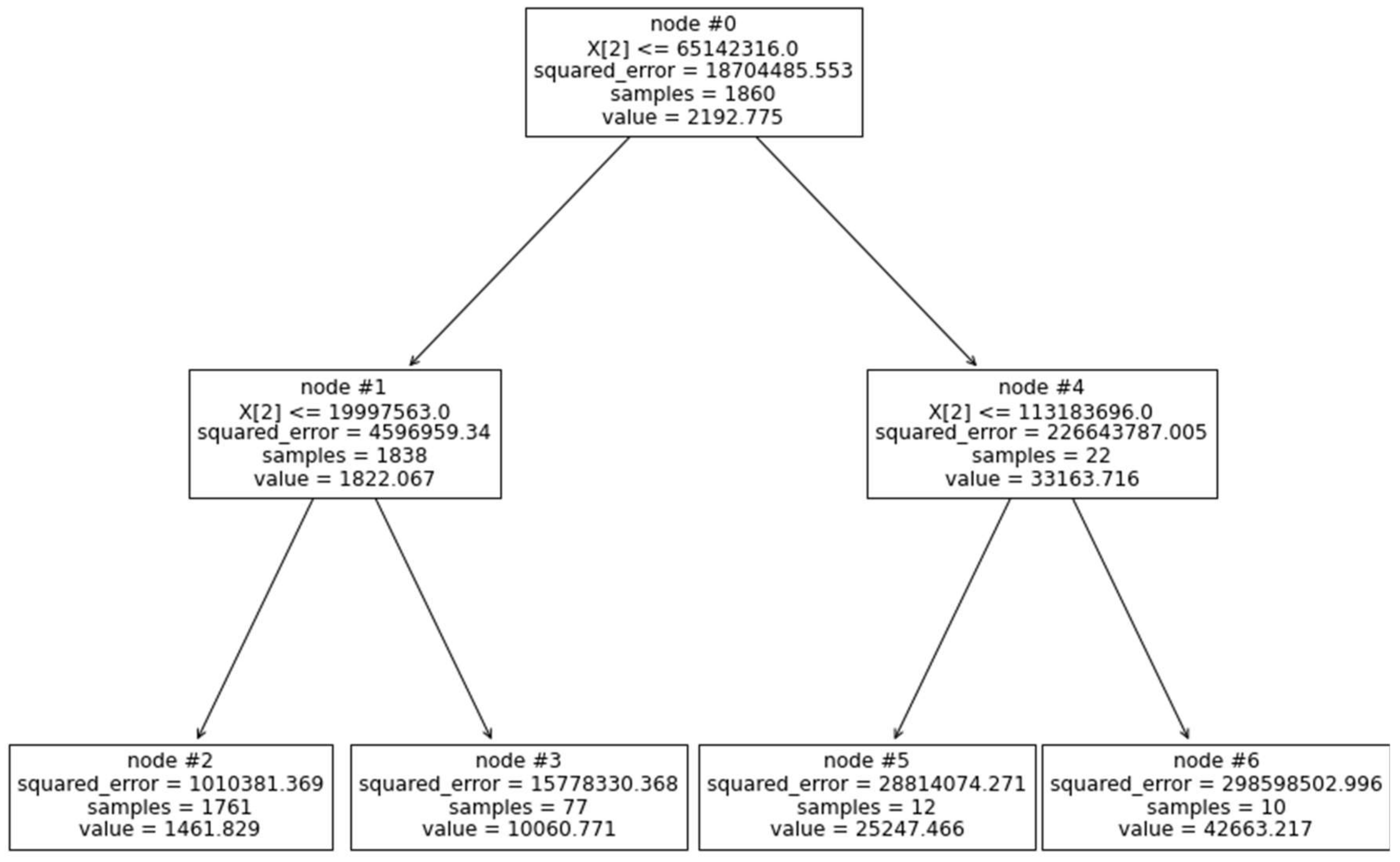
Table 4, the
model was eliminated from the assembly process because of its low accuracy.
Table 5 shows how the proposed ML algorithms utilized in this work must adjust their hyperparameters to determine the needed time to train the dataset. Herein, such hyperparameters are to be changed based on the actual dataset. The order in which these hyperparameters were optimized was dictated by their reciprocal interaction and the relevance of their effect on the ML model. The
was also the quickest model, taking
s, whereas the
took
s. As a result, the
was around 0.5 min quicker than the EMLT. Even though, the
was slower than the
it has provided a superior prediction accuracy.
5.1. ML Models of Prediction Results
This paper intends to comprehensively compare the efficacy of the state-of-the-art algorithms (i.e., , , , ,) with to predict the . Various evaluation metrics (i.e., , , , ) checked the model’s comparisons to investigate the prediction capability of the developed models.
The previously described performance measures are calculated and given in
Table 6 for the entire model.
Table 6 shows that the
model outperforms the single models in predictive performance (i.e.,
,
,
,
,
,
). The
and
models fared similarly on the training dataset, while the
model achieved better performance on the test dataset, as shown in
Table 6. The
model performed the worst on the training and test sets alike, with the lowest coefficient of determination (68.9% and 59.5% on the training and test sets, respectively) and the highest in the rest of the metrics, such as
(7.65 and 8.46 on the training and test datasets, respectively), as shown in
Table 6. The
model outperformed all other developed models on the training and test phases alike, as seen by the performing measures in
Table 6. The arithmetical metrics for the
developed model is 95.3% (
), 1.01 (
), 1.13 (
), and 4.1% (
) on the test dataset, as itemized in
Table 6. The coefficient of determination numeric value for the
,
,
,
,
, and
models was 84.4%, 86.4%, 87.2%, 78.2%, 59.5%, and 87.7%, respectively, matched to
value of 95.3% for the
model developed on the test dataset, as described in
Table 6.
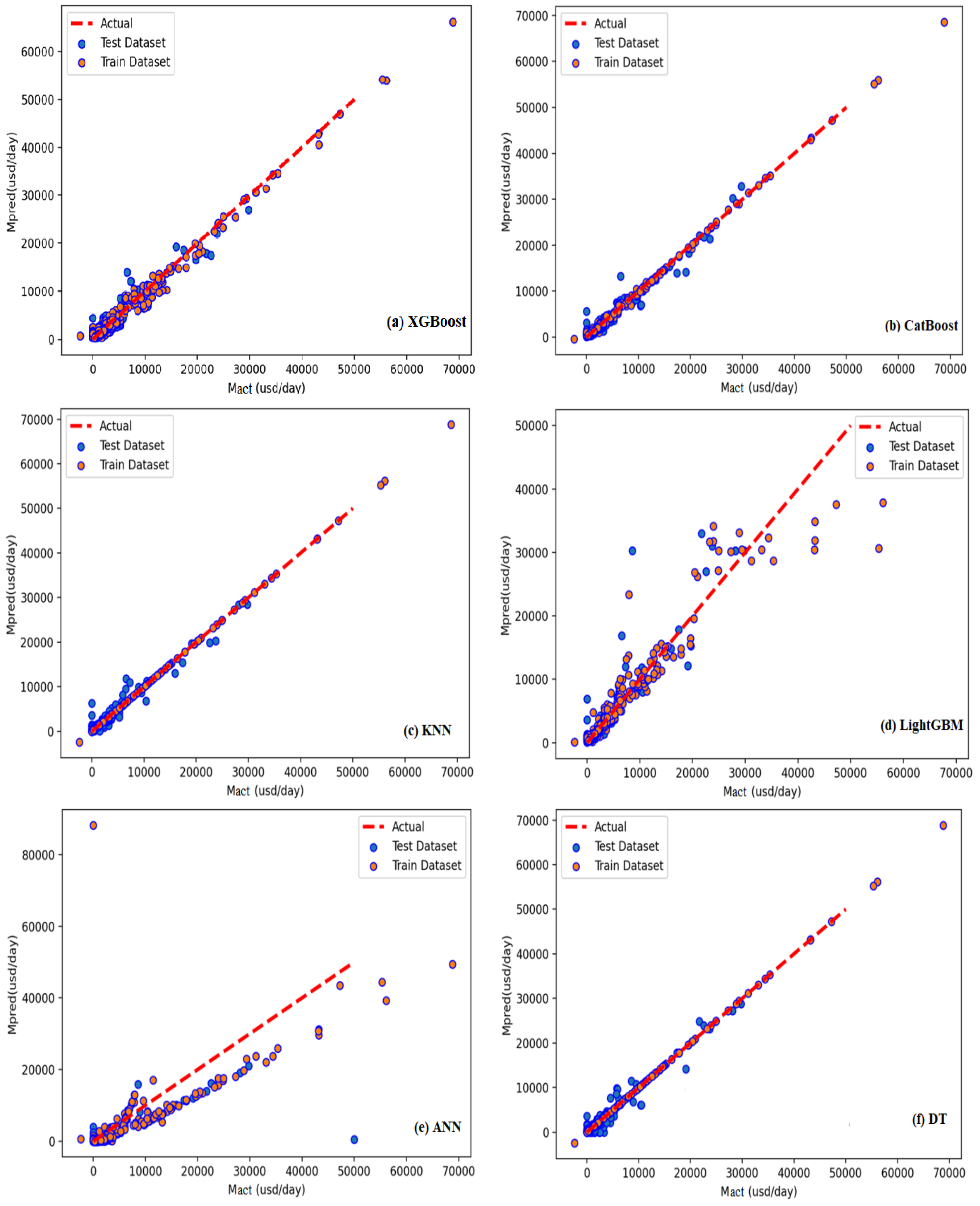
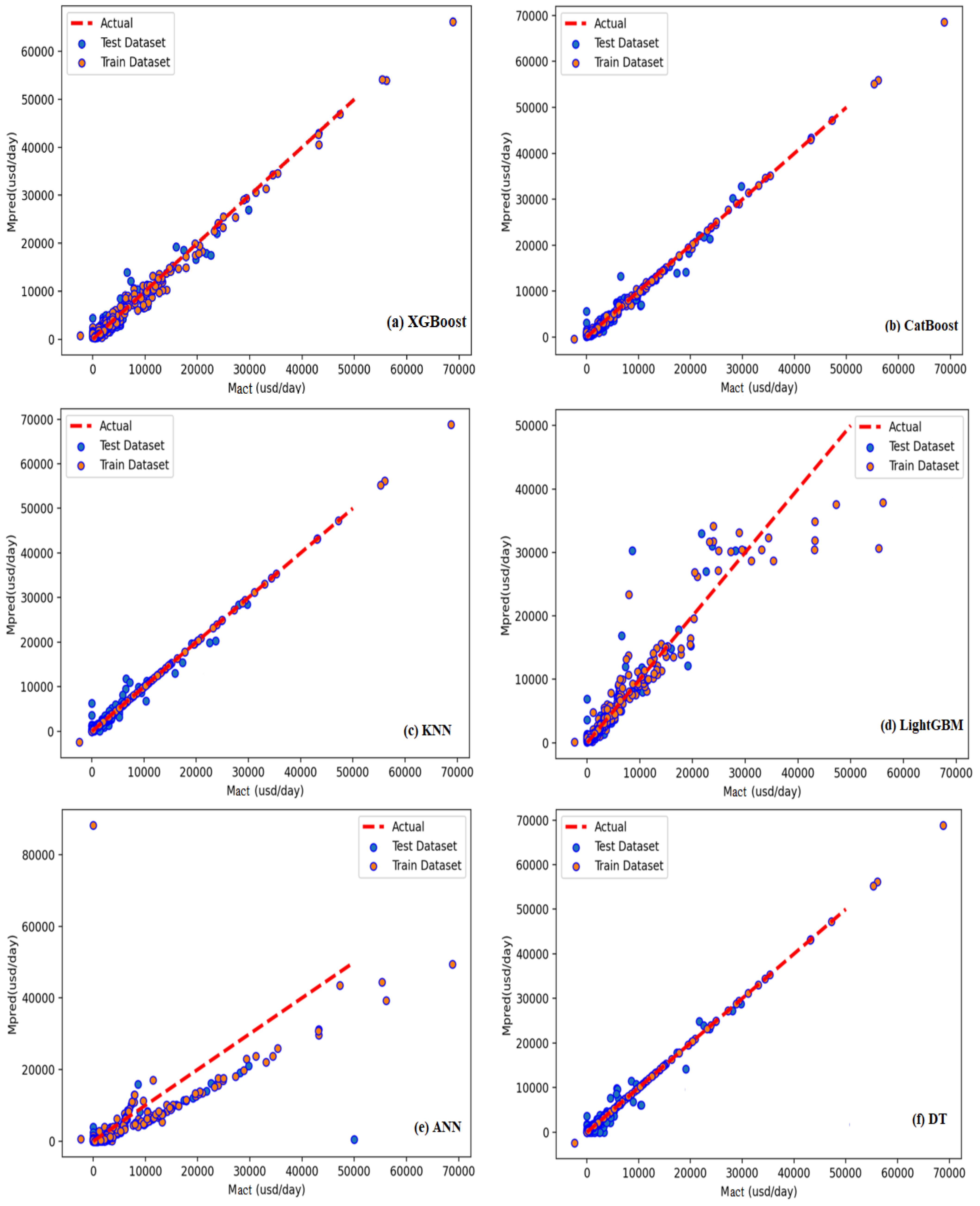
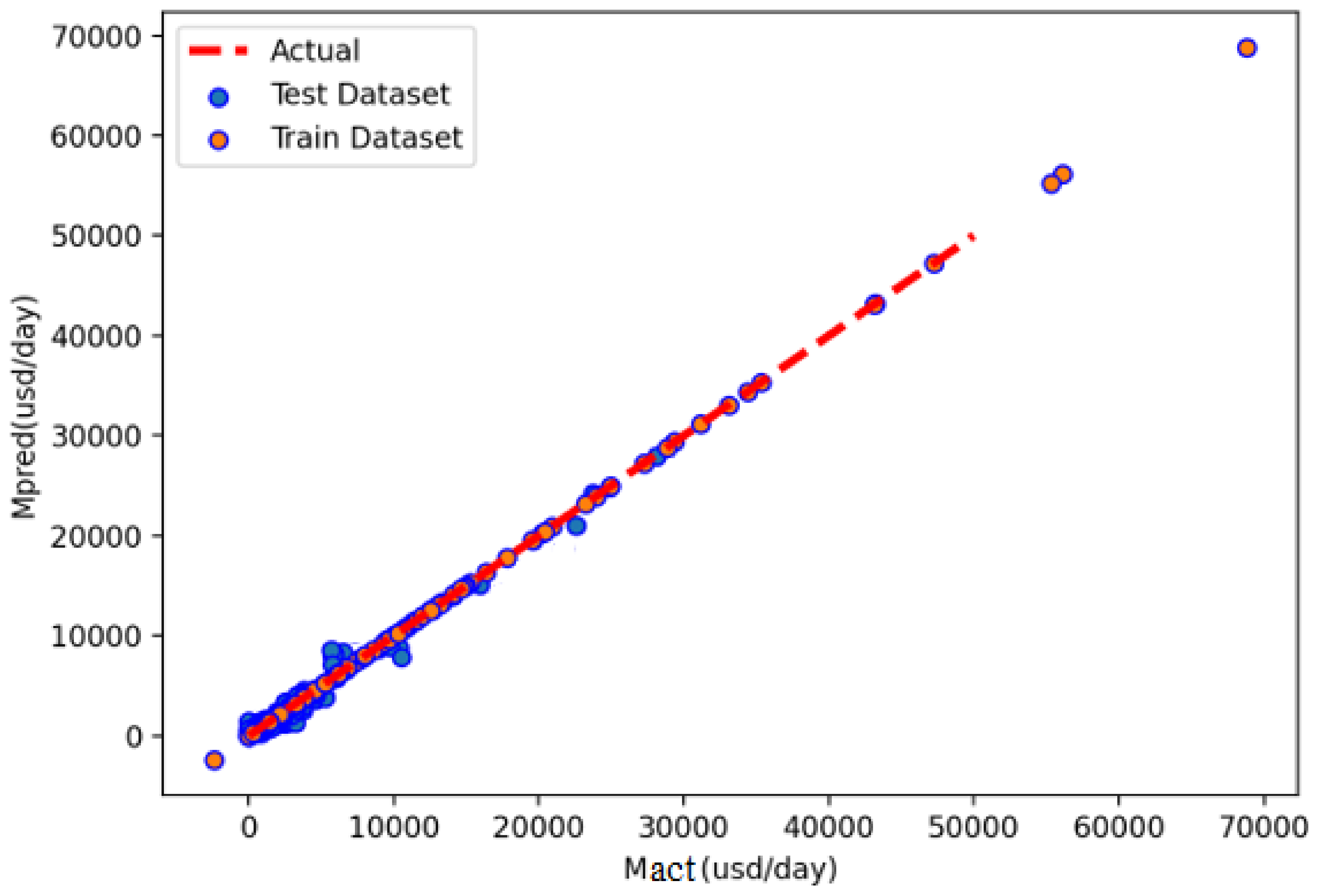
Figure 11a–f and
Figure 12 provide scatter plots for anticipated (
) against actual (
)
values, using single
and ensemble
models’
, respectively. Overall, the created
models (
,
,
,
,
) demonstrated a 97.5%correlation between
’ actual and projected values during the testing phase. Among the single models,
had the lowest prognostic performance in the training and test sets, while
had the highest.
However, the
model requires improvement because its
R2 in the testing procedure for
s prediction was 87.7%. As shown in
Figure 12, the predicted value of the testing and training processes is tightly centered on the 45-degree diagonal line, which displays a complete matching among the predicted and corresponding actual values in the testing and training datasets. Furthermore, as shown in
Table 6, the proposed ensemble model
resulted in a significant correlation between the predicted and actual, as indicated by the coefficient of determination, R
2 95.3%, in both phases (i.e., testing and training). As a result of this discovery, the suggested ensemble model
successfully forecasts the
, as shown in
Figure 12.
5.2. Feature’s Importance Analysis
We do feature significance analysis based on the
after developing the
model with the eight features to predict
.
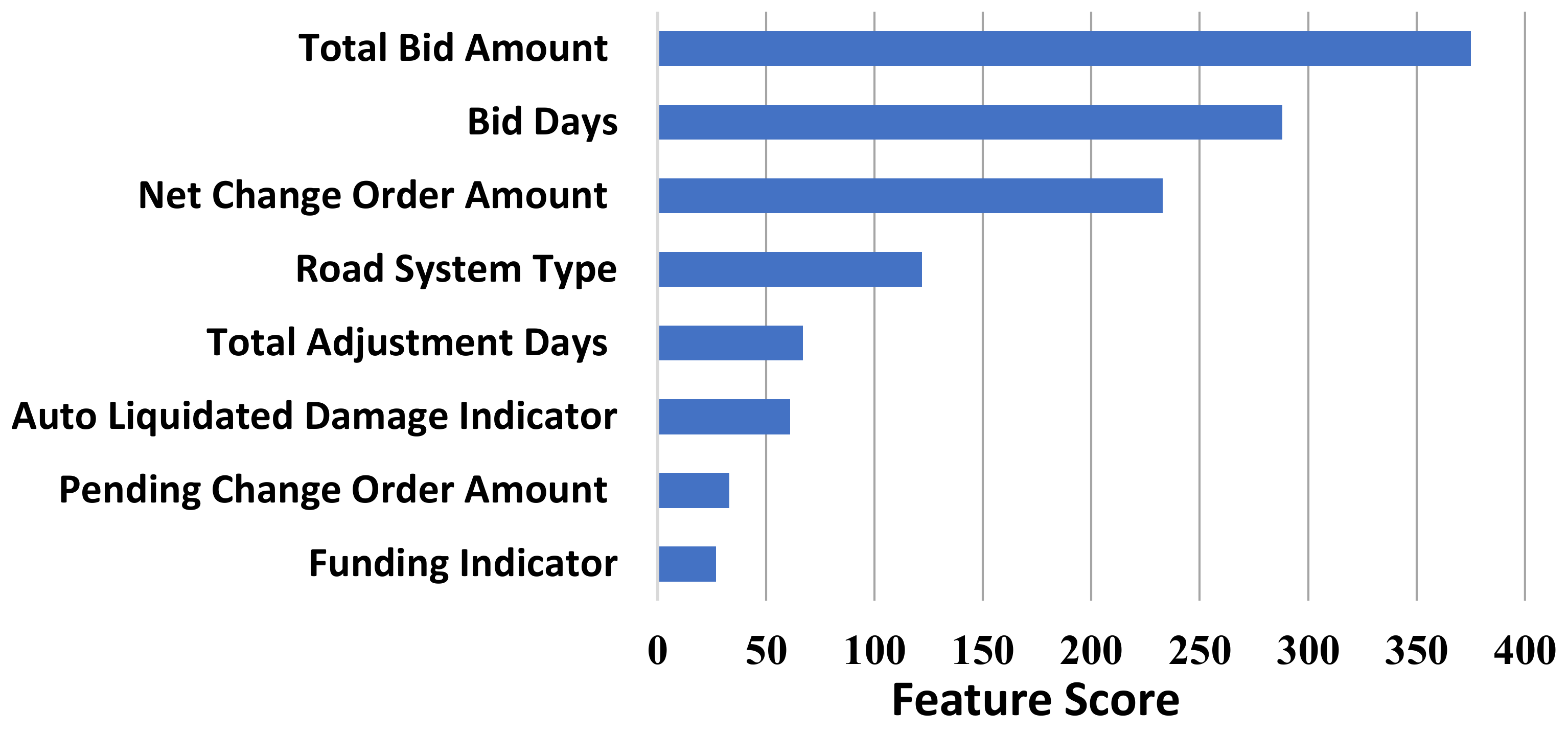
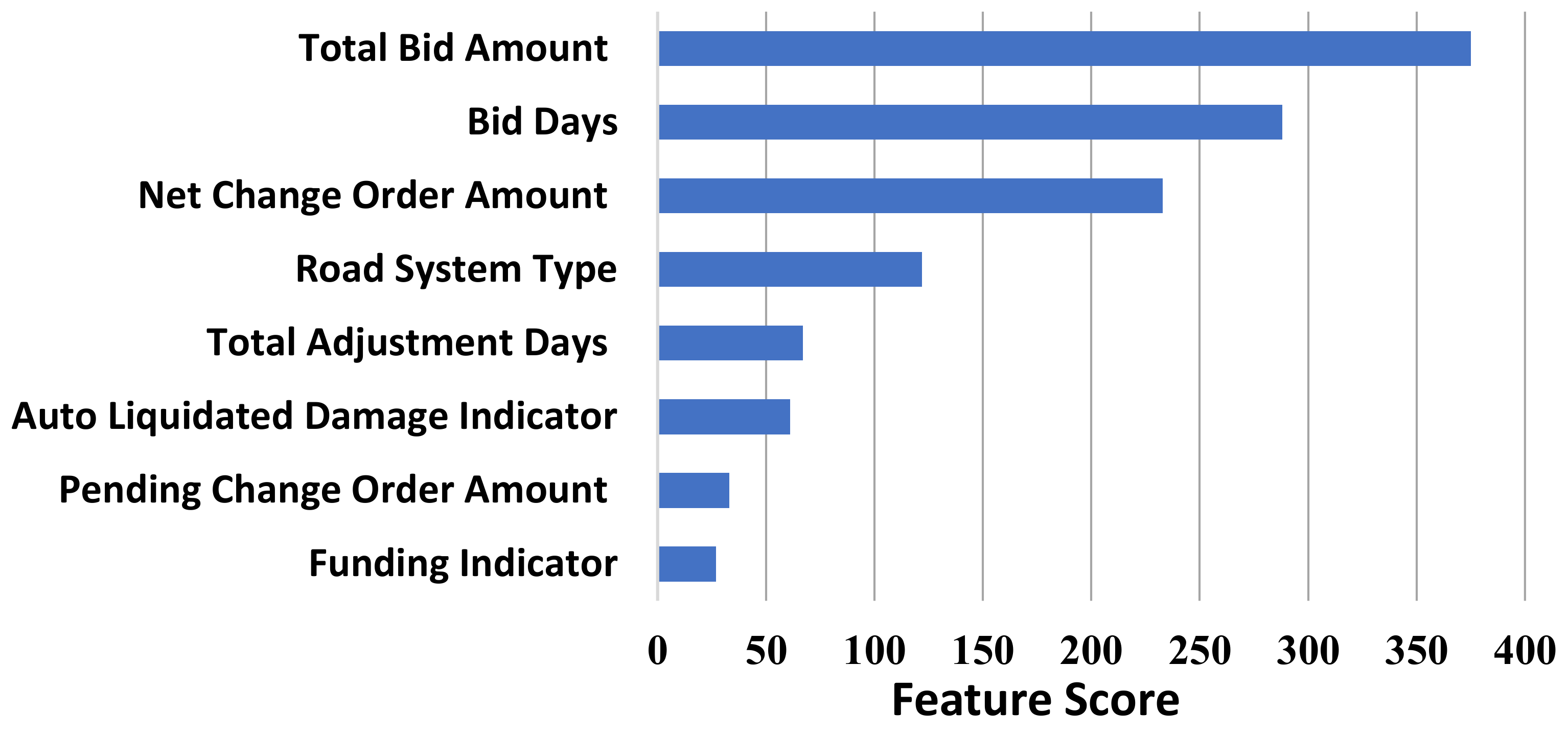
Figure 13 depicts these traits in descending order of significance. In this part, we take the feature significance analysis a step further. The contribution of each feature to increasing the prediction performance of the overall model is referred to as feature significance. It can intuitively reflect the relevance of features and observe which characteristics significantly affect the final model, but it is hard to determine how the feature and the final forecast are related.
The total bid amount, bid days, and net change order amount are the three most significant factors, as shown in
Figure 13. In contrast, the pending change order amount and financing indication are the least relevant parameters for predicting
using the suggested
model.
Figure 13 does not reveal whether these characteristics have positive or negative correlations with
or whether they have other more complicated associations.
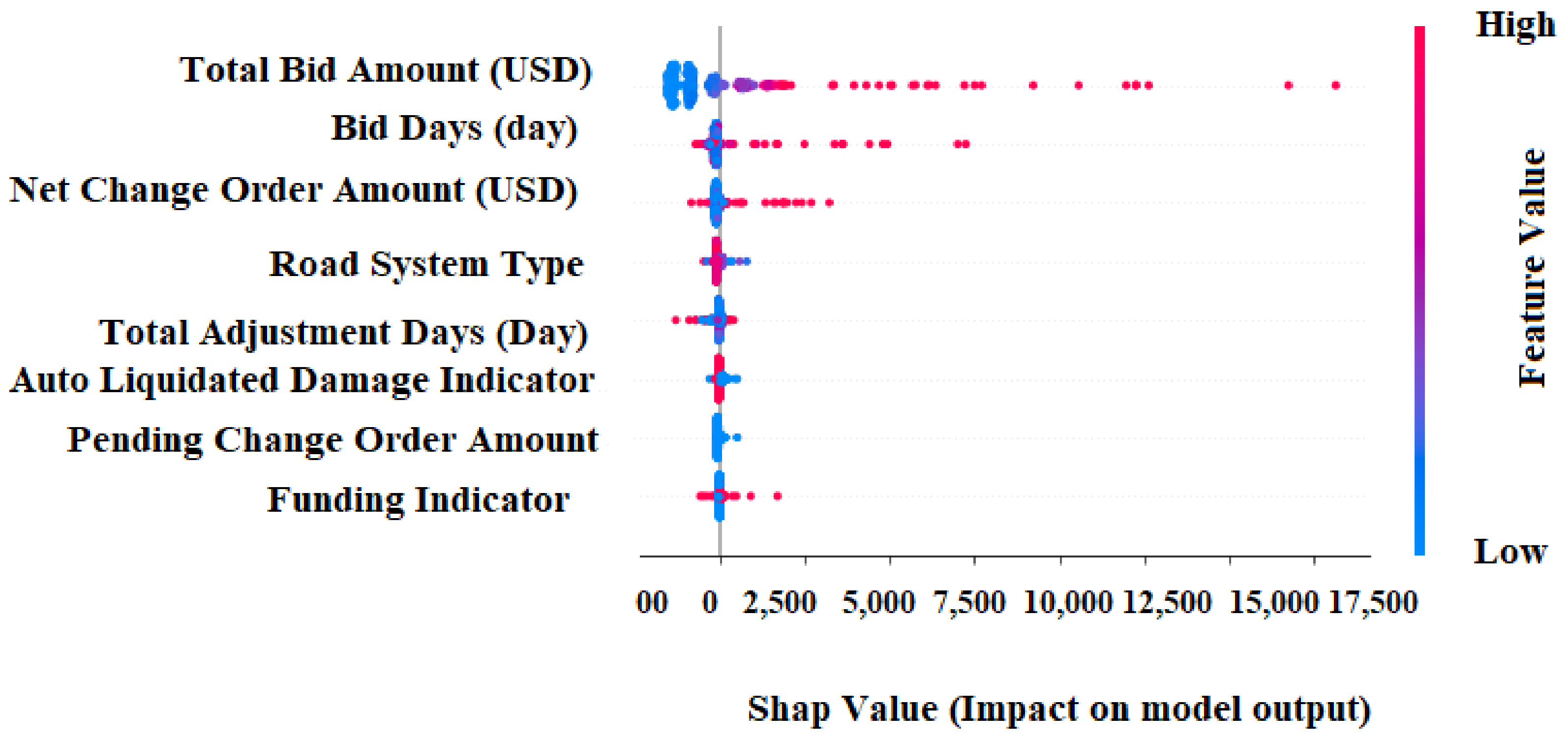
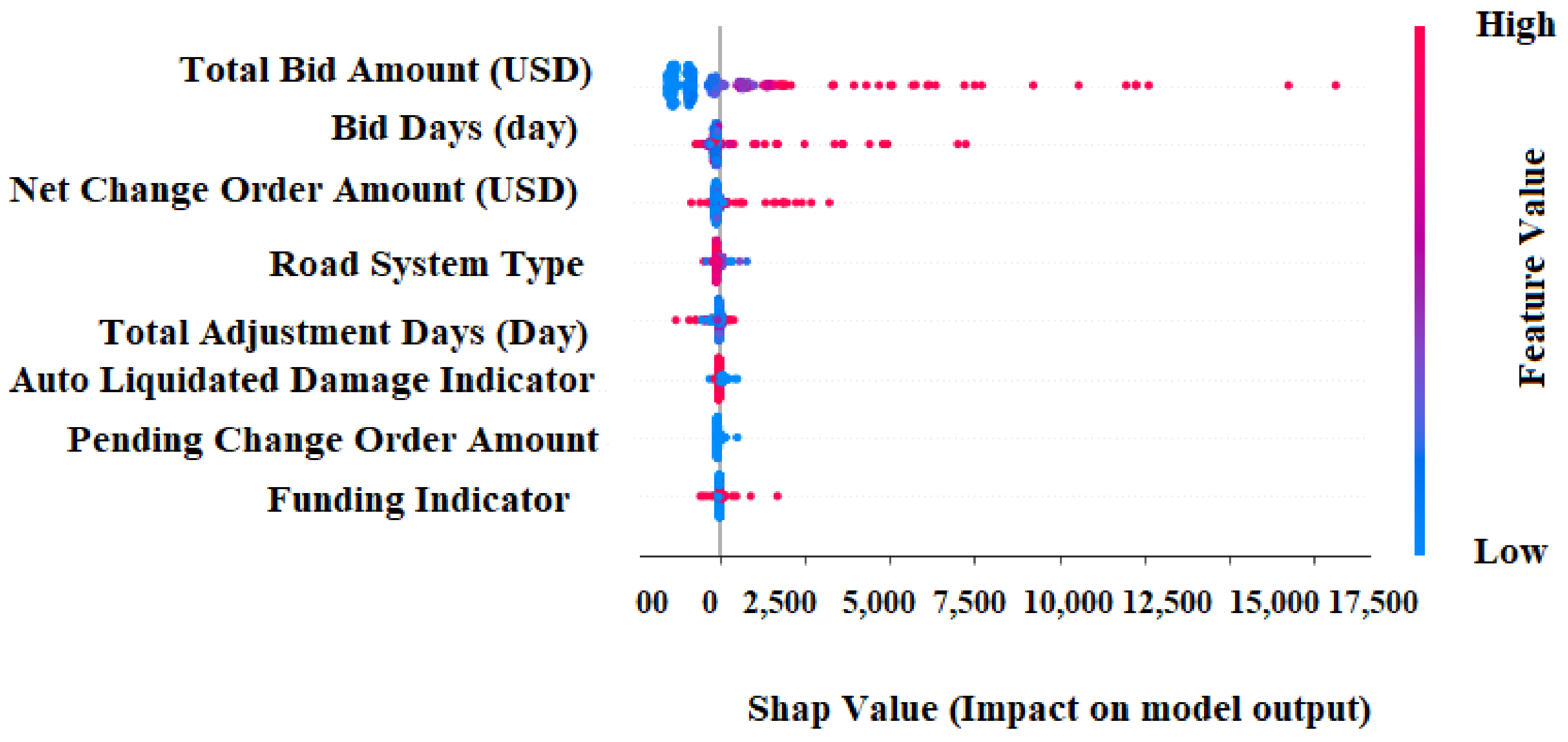
Figure 14 depicts the distribution of Shapley values for every attribute throughout the whole dataset.
Each point in this diagram signifies a Shapley value for an attribute and a unique reflection in the dataset. Each dot on the
x-axis indicates a Shapley value for each factor, indicating the effect of each component on the
, while the
y-axis lists the factors in order of significance. The higher the value of the feature is, the redder the color, and the lower the value of the feature is, the bluer the color. We can see from
Figure 14 that the total bid amount is an essential aspect, and it is largely positively connected with
.
Bid days, net change order amount, and financing indicators are also good predictors of , so raising the values of these variables can improve prediction. Pending change order quantity and road system type are inversely connected with, and the lower the values of these characteristics are, the better the model’s prediction. Other characteristics do not affect .
During the -year study period, the departments of transportation all over the have collected around distinct highway construction projects, with eight early specified characteristics to construct a model with a flexible concept to deal with all the types of factors that might arise in the future. Furthermore, the suggested model may be constructed with new road forms that must be handled. Eight road system data variables were employed as predictor factors for highway development projects to generate hybrid machine learning models to forecast the associated liquidated damages.
The modeling prediction results are intended to contribute to developing a comprehensive long-term framework, for estimating the presently enacted highway code requirements and prosecution processes enlightened by the findings of this study. As a result, the proposed model gives the scientific capability for the decision-maker to evaluate these conflicts in such a setting. Furthermore, they would be given sufficient information regarding the disagreement.
This disagreement was identified as a critical obstacle that needs to be solved to finish a motorway project. Contractors aim to reduce their expenditures due to late task execution by keeping the owner responsible as the principal cause of late delivery/task execution. However, the expected income might change at any time. Whereas, if the contractors are not entirely aware of the expenditures and time compensation, the business may go bankrupt due to
. According to contract law, the time required to finish a highway project must already be established. Therefore, contractors would be held accountable for such a delay. This approach was created to assist decision-makers in dealing with any
difficulties that significantly impede project progress. Thus, it is imperative to develop technological and research-based tools (e.g., machine and deep learning, optimization, and decision support tools) that can be practically used to pave the road towards creating comprehensive guidelines and policies to minimize the financial claims in the construction industry and foster the automation in the construction management arena [
35,
36,
37,
38,
39,
40,
41,
42,
43,
44,
45,
46].
6. Conclusions
The current study proposed six modified 𝑀𝐿 models for forecasting 𝐿𝐷𝑠, while a hybrid model was developed via a systematic combination of the crated individual models adopted with the model. The obtained results from each individual ML model can be classified as satisfactory, i.e., the EMLT had an accuracy of 0.997, compared to the DT, kNN, CatBoost, XGBoost, and LightGBM, with an accuracy of 0.989, 0.988, 0.986, 0.975, and 0.873, respectively. However, to reach maximum prediction accuracy, it was found that the developed model’s fusion is vital to enhance the forecasting results. According to the analysis results, the most critical eight independent indicators for forecasting are road system type, bid days, finance indicator, total bid amount, net change order amount, auto liquidated damage indicator, total adjustment days, and pending change order amount. Nevertheless, the four most significant attributes were the overall bid amount, bid days, net change order amount, and type of road system.
Since are often calculated as a percentage of the entire venture expense, the impact of the total bid amount may be explained. As a result, the are likely to rise as the entire project cost rises. In addition, the circumstance clarifies the impact of bid days that venture length has a significant impact on , since projects with extended periods have higher costs. Additionally, the amount of the net change order plays a vital role in determining the . Thus, the net change order amount has a positive relationship with the . This can be explained by the fact that contractors gain high revenues from the projects’ change orders, without considering their impact of the project timeline. Thus, more change orders are expected to cause extensive delays that are associated with high values of the . Ultimately, the impact of the type of road system may be clarified by the fact that the highway system represents an essential part in establishing the regulations and guidelines that the organization that supports the project implements. Furthermore, federal requirements must ensue when the venture is a federal or interstate road, whereas state standards must be observed for state and county roads. On the other hand, the total adjustment days might not be utilized to forecast since some of these modifications are the consequences of change orders according to the owner’s specifications, and developers are not held accountable for delays caused by the owner’s specifications. Consequently, the outcomes of such requests are very uncertain. Moreover, the auto liquidated damage indicator, funding indicator, and pending change order amount have minimal impact of the prediction process.
A rudimentary model improved the prediction in numerous situations. With better prediction performance matrices, the developed model had outperformed each individually created model. Using the same comparison criteria, the descending order of the developed models’ accuracy is , , , , , , and , respectively.
The proposed hybrid prediction model (i.e., ) will most likely benefit decision-makers by predicting . The managerial impact of the developed model is expected to pave the way towards broader long-term context for assessing the available enacted highway construction code requirements and prosecution processes informed by the conclusions of the current research. Consequently, the developed model provides the systematic capacity for decision and policymakers to assess these inconsistencies in such cases.
As a future research recommendation, data collection and recording procedures might be improved, as exact and comprehensive data are vital to forecasting correctly. In addition, more holistic prediction modeling might be conducted according to further advanced algorithms, after being fused with technological tools (e.g., Building Information Modeling (), Digital Twin, Internet of Things (), and Blockchain) which might be utilized to automatically forecast the liquidated damages for various types of construction projects.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}