
Open Innovation Web-Based Platform for Evaluation of Water Quality Based on Big Data Analysis




Abstract
:1. Introduction
2. Background and Related Work
2.1. Background
2.2. Related Works
- The existence of complex mathematical calculations;
- Equal treatment to the old data and new data;
- Difficult prediction due to overlap of multiple variables.
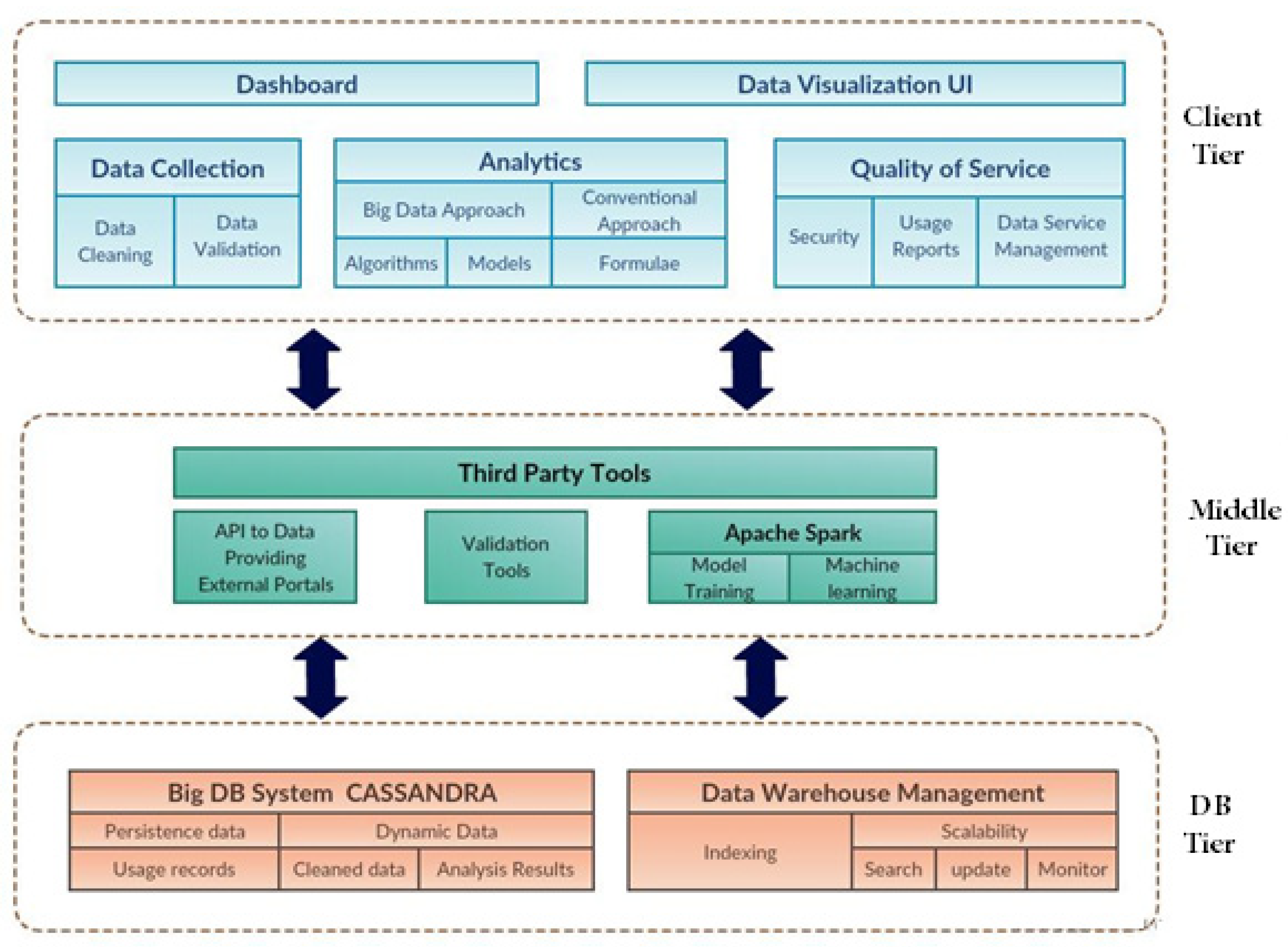
3. System Analysis and Design
3.1. System Overview
- Data Collection: The application can automatically collect data from the configured data source. A configured panel is provided to the system manager to set how to collect data.
- Data Extraction: The application can extract the corresponding data according to the purpose of analysis. For example, it can extract the data by region, year, and water quality parameters, etc.
- Data Analysis: The application uses different methods to analyze data. Some traditional methods and big data methods are implemented here, which are provided to the users. Moreover, data analysis can be done from different perspectives, such as water region, time period, and overall water data.
- Data Visualization: The analysis results should be shown in a friendly way to the users. The data visualization module provides an easy way to show the results and help users better understand the results. For example, if there are some certain points in the area that lead to heavy pollution, they are shown in the map by highlights or a special color.
- Comparing Different Models: In this application, different models or algorithms are used to evaluate the water quality. Different models would give different analysis results with different accuracy; hence, the application will provide a comparison of these different models.
- Prediction: This is an additional feature of the application. The application provides prediction results on the tendency or future result based on the current water quality.
- Finding Causes: The application can help the users to find the cause of the anomalies in the data and the source of pollution.
3.2. System Infrastructure
3.3. Class Diagram
- User: User class keeps track of all the users’ login and logout details. A user can extract data and get the analysis results;
- Collect Sensor Data: User extracts data using this class. Desired request of data is first looked up in the big data database Cassandra using search and reference keys. If not found, third-party APIs are used to extract the data from the data sources. Data is then cleansed using validation tools and stored in the database for further use;
- Conventional Analysis: User can perform conventional analysis using this class. This provides various formulae to perform the analysis;
- Big Data Analysis: To see the results of big data analysis, this class is invoked. This provides different models such as the analysis model and predictive model, using a variety of algorithms to perform analysis;
- Data Visualization: This class provides various libraries to draw different charts on the basis of what chart type the user wants to use for analysis;
- Spark: Big Data Analysis class uses the third-party tool, Spark. Any functionality and programming associated with the tool Spark are maintained and written in class “Spark;”
- Admin: Admin class is made for admin-specific functionalities. An admin can add different models, diagnose the applications, modify functionalities related to database and see the user analytics reports;
- Usage Report: User analytics reports are maintained in this class. This class uses the service database made for the application and stores the regular user activities. This class is mainly accessed by admin to track the activities of the application and user;
- Validation Record: When data are collected, the raw data are cleansed, and only clean data are kept in the database. The records of the cleaning are kept using this class. It records the results of how much data was missing and truncated from the raw data. This class is useful to find the quality of the data source. For example, for a particular database, 99% of the data is always truncated due to garbage values or missing data, then the admin could decide whether to use that data source in the future or not;
- Data Service Management: This class provides database-specific activities. All the database operations such as select, update, insert and delete are handled by this class. The application consists of two databases. One is for storing data and the other is for analytics. Both of these databases are maintained in this class.
3.4. System Data and Database Design
3.4.1. Big Data Warehouse Database Design
3.4.2. Relation Database Design
4. Analytics Module—Water Quality Assess Modeling
4.1. Conventional Model
4.2. Big Data Modeling and Analysis
4.2.1. K-Means Clustering
- Place K point into the space represented by the objects that are being clustered. These points represent initial group centroids;
- Assign each object to the group that has the closest centroids;
- When all objects have been assigned, recalculate the positions of the K centroids;
- Repeat steps 2 and 3 until the centroids no longer move. This produces a separation of the objects into groups from which the metric to be minimized can be calculated.
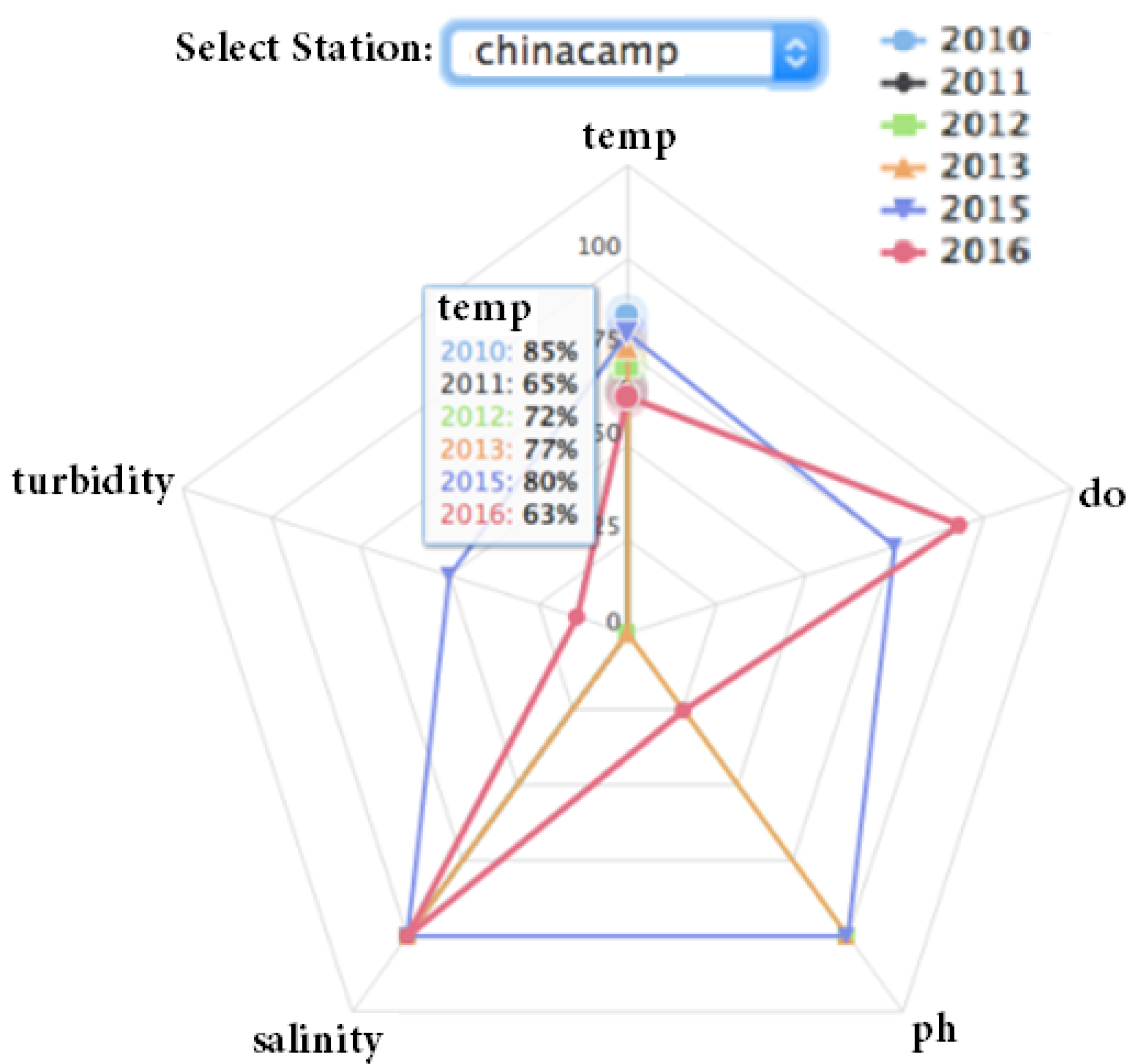
4.2.2. Calculation of Overall Water Quality Using Spider Index
- Mean of Parameter Quality: calculate the average of all the quality parameters to find the overall quality parameter, assuming all the parameters affect water quality equally. The larger the average, the better the quality.
- Area of Polygon: the area of polygon could be calculated to find the overall quality. A bigger area means better quality.
5. The Application of Platform
5.1. Data Collection
Data Sources
5.2. Data Extraction and Validation
Data Extraction
5.3. Data Validation
5.4. Data Storage
5.5. Data Presentation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Diersing, N.; Nancy, F. Water Quality: Frequently Asked Questions; Florida National Marine Sanctuary: Key West, FL, USA, 2009. [Google Scholar]
- Abbasi, T.; Abbasi, S.A. Water Quality Indices; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- He, T.; Lu, Y.; Cui, Y.; Luo, Y.; Wang, M.; Meng, W.; Zhang, K.; Zhao, F. Detecting gradual and abrupt changes in water quality time series in response to regional payment programs for watershed services in an agricultural area. J. Hydrol. 2015, 525, 457–471. [Google Scholar] [CrossRef]
- Lobato, T.C.; Hauser-Davis, R.A.; Oliveira, T.F.; Silveira, A.M.; Silva, H.A.N.; Tavares, M.R.M.; Saraiva, A.C.F. Construction of a novel water quality index and quality indicator for reservoir water quality evaluation: A case study in the Amazon region. J. Hydrol. 2015, 522, 674–683. [Google Scholar] [CrossRef]
- Newton, A.; Mudge, S.M. Lagoon-sea exchanges, nutrient dynamics and water quality management of the Ria Formosa (Por-tugal). Estuar. Coast. Shelf Sci. 2005, 62, 405–414. [Google Scholar] [CrossRef]
- Newton, A.; Mudge, S.M. Temperature and salinity regimes in a shallow, mesotidal lagoon, the Ria Formosa, Portugal. Estuar. Coast. Shelf Sci. 2003, 57, 73–85. [Google Scholar] [CrossRef] [Green Version]
- Lattemann, S.; Höpner, T. Environmental impact and impact assessment of seawater desalination. Desalination 2008, 220, 1–15. [Google Scholar] [CrossRef]
- Alizadeh, M.J.; Kavianpour M, R. Development of wavelet-ANN models to predict water quality parameters in Hilo Bay, Pacific Ocean. Mar. Pollut. Bull. 2015, 98, 171–178. [Google Scholar] [CrossRef] [PubMed]
- Lima, E.; Legey, L.F.L. Water Quality Restoration in Rio de Janeiro: From a Piecemeal to a Systems Approach. J. Environ. Dev. 2010, 19, 375–396. [Google Scholar] [CrossRef]
- Shrestha, S.; Kazama, F. Assessment of surface water quality using multivariate statistical techniques: A case study of the Fuji river basin, Japan. Environ. Model. Softw. 2007, 22, 464–475. [Google Scholar] [CrossRef]
- Sridhar, R.; Thangaradjou, T.; Kumar, S.S.; Kannan, L. Water quality and phytoplankton characteristics in the Palk Bay, southeast coast of India. J. Environ. Biol. 2006, 27, 561–566. [Google Scholar] [PubMed]
- Vega, M.; Pardo, R.; Barrado, E.; Debán, L. Assessment of seasonal and polluting effects on the quality of river water by exploratory data analysis. Water Res. 1998, 32, 3581–3592. [Google Scholar] [CrossRef]
- Coskun, H.G.; Tanik, A.; Alganci, U.; Cigizoglu, H.K. Determination of environmental quality of a drinking water reservoir by remote sensing, GIS and regression analysis. Water Air Soil Pollut. 2008, 194, 275–285. [Google Scholar] [CrossRef]
- Beck, M.W.; Hagy, J.D., III. Adaptation of a Weighted Regression Approach to Evaluate Water Quality Trends in an Estuary. Environ. Modeling Assess. 2015, 20, 637–655. [Google Scholar] [CrossRef]
- Chenini, I.; Khemiri, S. Evaluation of ground water quality using multiple linear regression and structural equation modeling. Int. J. Environ. Sci. Technol. 2009, 6, 509–519. [Google Scholar] [CrossRef] [Green Version]
- Modaresi, F.; Araghinejad, S. A Comparative Assessment of Support Vector Machines, Probabilistic Neural Networks, and K-Nearest Neighbor Algorithms for Water Quality Classification. Water Resour. Manag. 2014, 28, 4095–4111. [Google Scholar] [CrossRef]
- Areerachakul, S.; Sanguansintukul, S. Clustering Analysis of Water Quality for Canals in Bangkok, Thailand; International Conference on Computational Science and Its Applications; Springer: Berlin/Heidelberg, Germany, 2010; pp. 215–227. [Google Scholar]
- Aryafar, A.; Gholami, R.; Rooki, R.; Ardejani, F.D. Heavy metal pollution assessment using support vector machine in the Shur River, Sarcheshmeh copper mine, Iran. Environ. Earth Sci. 2012, 67, 1191–1199. [Google Scholar] [CrossRef]
- Liu, M.; Lu, J. Support vector machine―an alternative to artificial neuron network for water quality forecasting in an agricultural nonpoint source polluted river? Environ. Sci. Pollut. Res. 2014, 21, 11036–11053. [Google Scholar] [CrossRef] [PubMed]
- Noori, R.; Karbassi, A.; Ashrafi, K.; Ardestani, M.; Mehrdadi, N.; Bidhendi, G.-R.N. Active and online prediction of BOD5 in river systems using reduced-order support vector machine. Environ. Earth Sci. 2011, 67, 141–149. [Google Scholar] [CrossRef]
- Kaur, M.; Das, S.K.; Sarma, K. Water quality assessment of Tal Chhapar Wildlife Sanctuary using water quality index (CCME WQI). Acta Ecol. Sin. 2021. [Google Scholar] [CrossRef]
- Masoud, A.M.; Ali, M.H. Coupled multivariate statistical analysis and WQI approaches for groundwater quality assessment in Wadi El-Assiuty downstream area, Eastern Desert, Egypt. J. Afr. Earth Sci. 2020, 172, 103982. [Google Scholar] [CrossRef]
- Dolly, G.; Vincent, P.; Sonam, S.; Madhav, V. Big Data Based Water Quality Evaluation for San Francisco Bay Based on COAST Data. A Project Report Presented to The Faculty of the Computer Engineering Department. Master’s Thesis, San Jose State University, San Jose, CA, USA.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Water Quality Index | Water Usage |
|---|---|
| Brown (NSF-WQI) | General |
| Nemerow and sumitomos index (US Environmental Protection Agency) | Human, indirect, remote contact use |
| Prati’s index | General |
| DEininger and landwehr’s | Public Water Supply (PWS) |
| McDuffie and Haney’s | River pollution index |
| Dinius’ water quality index | Impact of pollution control efforts |
| O’Connor’s Indices | Fish and Wildlife (FAWL) and PWS |
| Walski And Parker’s index | recreation water (swimming and fishing) |
| Stoner’s index | PWS and irrigation water |
| Paper ID | Purposes | Model/Methods | Parameters/Metrics | Data Source |
|---|---|---|---|---|
| [5] | Evaluate coastal waters for ecological and recreational value | EEA 2001 | NH4+, NO2− and NO3− | Historical data |
| [6] | Water deterioration in southern Portugal | Evaporation and salinity model | temperature and salinity | Data stations |
| [7] | Seawater desalination capacities | Environmental Impact Assessment (EIA) | Temperature, Density and Salinity | World Health Organization |
| [8] | Predict ocean water quality in Hilo Bay | Artificial neural network | Chlorophyll, Dissolved Oxygen, Salinity, Turbidity and Temperature | Data station in Hilo Bay |
| [9] | Analyze water quality restoration in Guanabara Bay | Eutrophication models | Chlorophyll, phosphorous, nitrogen, BOD, DC, and PC | Japan International Cooperation Agency |
| [10] | Eutrophication and degradation of coastal waters | WASP Model | Salinity, Dissolved Oxygen, Nitrogen, Ammonia, Organic Nitrogen, Phosphorus | |
| [11] | Analyze water quality of Chesapeake Bay | Hydrodynamic model | Dissolved Oxygen, Nitrite, Ammonia, Chlorophyll, Total phosphate | Chesapeake Bay |
| [12] | Evaluate pollution effects on river water quality | Sampling and Cluster | Iron, Flow rate, hardness, bicarbonate, potassium, magnesium | Water sample |
| Paper ID | Purpose | Algorithms |
|---|---|---|
| [13] | Determine the environmental quality of a drinking water reservoir by remote sensing | multiple Regression Analysis |
| [14] | Evaluate water quality trends in an estuary | Weighted regression |
| [15] | Evaluate groundwater quality | Multiple linear regression |
| [16] | Water quality classification | Machine leaning algorithms |
| [17] | Evaluate water quality of canals in Bangkok | K-means |
| [18] | Heavy metal pollution assessment in the Shur River | Support Vector Machine |
| [19] | Water quality forecasting in an agricultural nonpoint source polluted river | Support Vector Machine |
| [20] | Prediction of BOD5 in river systems | Support Vector Machine |
| CCME Index Value | Water Quality |
|---|---|
| 95–100 | Excellent |
| 80–94 | Good |
| 60–79 | Fair |
| 45–59 | Marginal |
| 0–44 | Poor |
| CeNCOOS | Gallinas Creek | Dumbarton | San Mateo | Pier 17/Fort Point | Alcatraz | China Camp |
|---|---|---|---|---|---|---|
| USGS | 13, 12.5, 11 | 36, 29.5, 30, 32 | 27, 24 | 21, 20 | 18 | 15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, X.; Shen, H.; Hu, H.; Gao, J. Open Innovation Web-Based Platform for Evaluation of Water Quality Based on Big Data Analysis. Sustainability 2022, 14, 8811. https://doi.org/10.3390/su14148811
Han X, Shen H, Hu H, Gao J. Open Innovation Web-Based Platform for Evaluation of Water Quality Based on Big Data Analysis. Sustainability. 2022; 14(14):8811. https://doi.org/10.3390/su14148811
Chicago/Turabian StyleHan, Xiaofang, Hong Shen, Hongqing Hu, and Jerry Gao. 2022. "Open Innovation Web-Based Platform for Evaluation of Water Quality Based on Big Data Analysis" Sustainability 14, no. 14: 8811. https://doi.org/10.3390/su14148811
APA StyleHan, X., Shen, H., Hu, H., & Gao, J. (2022). Open Innovation Web-Based Platform for Evaluation of Water Quality Based on Big Data Analysis. Sustainability, 14(14), 8811. https://doi.org/10.3390/su14148811