
Intelligent Identification of the Line-Transformer Relationship in Distribution Networks Based on GAN Processing Unbalanced Data


Abstract
:1. Introduction
2. Methodology
2.1. Technical Route
2.2. Intelligent Identification of the Line-Transformer Relationship in Distribution Networks Based on GAN Processing Unbalanced Data
2.2.1. Feature Extraction
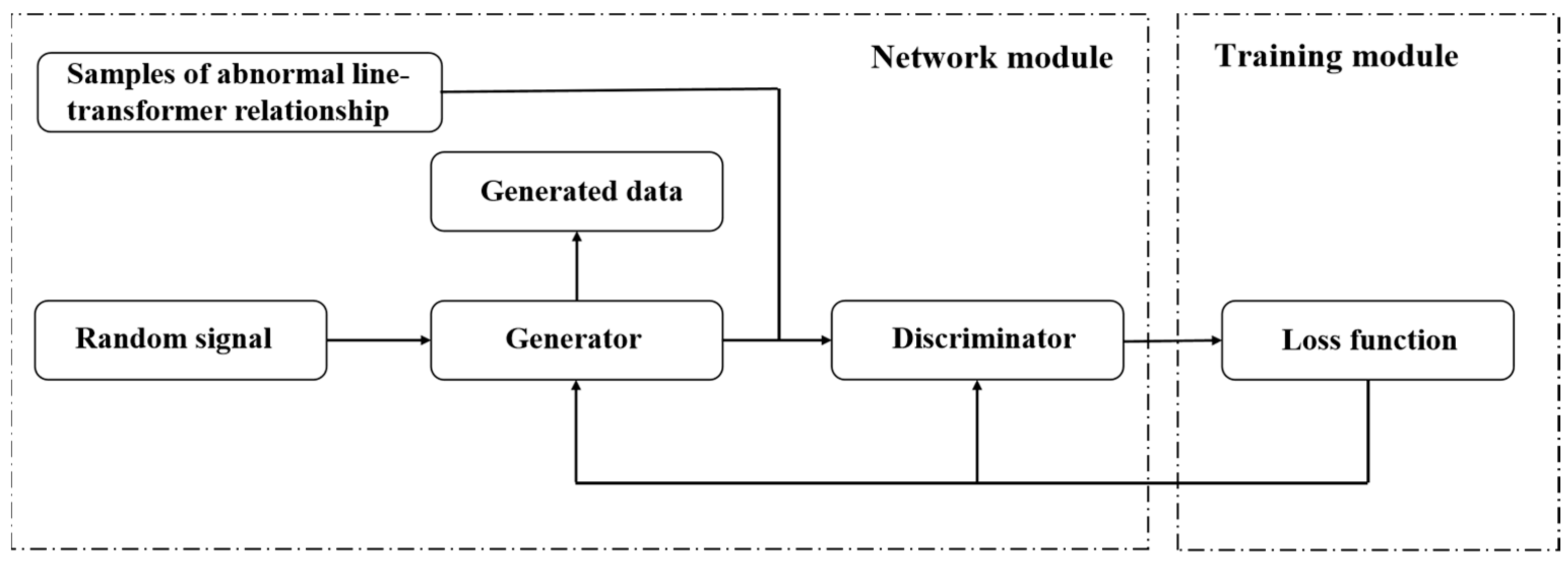
2.2.2. The GAN-Based Model for Generating Samples of Abnormal Line-Transformer Relationship
2.2.3. Support Vector Machine
3. Experimental Results and Analysis
3.1. Data Description
3.2. Data Preprocessing
3.3. Feature Extraction
3.4. Generating Samples of Abnormal Line-Transformer Relationship Based on GAN
3.5. Build the Classifier Model
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gao, C. Research on the Application of Monitoring Technology Based on the Influencing Factors of Line Loss in the Power Consumption Area in the Power Consumption Information Collection System. In Proceedings of the 2022 IEEE International Conference on Electrical Engineering, Big Data and Algorithms (EEBDA), Changchun, China, 25–27 February 2022; pp. 132–136. [Google Scholar] [CrossRef]
- Chen, B.; Xiang, K.; Yang, L.; Su, Q.; Huang, D.; Huang, T. Theoretical Line Loss Calculation of Distribution Network Based on the Integrated Electricity and Line Loss Management System. In Proceedings of the 2018 China International Conference on Electricity Distribution (CICED), Tianjin, China, 17–19 September 2018; pp. 2531–2535. [Google Scholar] [CrossRef]
- Li, S.; Gao, S.; Wu, J.; Xie, D.; Xi, G.; Zhao, Y.; Zuo, Z.; Huang, H.; Qi, L. Research on Topology Identification of Distribution Network Under the Background of Big Data. In Proceedings of the 2020 IEEE 4th Conference on Energy Internet and Energy System Integration (EI2), Wuhan, China, 30 October–1 November 2020; pp. 4294–4297. [Google Scholar] [CrossRef]
- Lai, X.; Cao, M.; Liu, S.; Sun, C. Low-voltage distribution network topology identification method based on characteristic current. In Proceedings of the 2021 6th Asia Conference on Power and Electrical Engineering (ACPEE), Chongqing, China, 8–11 April 2021; pp. 1233–1238. [Google Scholar] [CrossRef]
- Zhao, G.; Chu, J.; Deng, L.; Pan, K. Research on Line-transformer-user Topological Anomaly Recognition Model Based on Multi-source Data Mining. In Proceedings of the 2020 5th Asia Conference on Power and Electrical Engineering (ACPEE), Chengdu, China, 4–7 June 2020; pp. 192–196. [Google Scholar] [CrossRef]
- Gao, Q.; Han, B.; Huang, X.; Zhang, P.; Liu, J.; Ge, L. Verification method of topological relationship of low voltage distribution equipment based on KNN and Pearson correlation coefficient. In Proceedings of the 2021 International Conference on Power System Technology (POWERCON), Haikou, China, 8–9 December 2021; pp. 127–132. [Google Scholar] [CrossRef]
- Bing, L.; Lou, B.; Li, C.; Deng, J.; Zhu, L.; Yang, C.; Chen, W. Low-voltage distribution network topology verification method based on Revised Pearson correlation coefficient. J. Phys. Conf. Ser. 2020, 1633, 012084. [Google Scholar]
- Li, J.; Wu, D.; Jin, W.; Chu, Z.; Liu, S.; Ma, J.; Lin, Z.; Yang, L. Identification of distribution network topology parameters based on multidimensional operation data. Energy Rep. 2021, 7 (Suppl. 1), 304–311. [Google Scholar] [CrossRef]
- Ganguly, S.; Samajpati, D. Distributed Generation Allocation on Radial Distribution Networks Under Uncertainties of Load and Generation Using Genetic Algorithm. IEEE Trans. Sustain. Energy 2015, 6, 688–697. [Google Scholar] [CrossRef]
- Liu, B.; Wang, D.; Li, Y.; Qiao, L.; Chen, S. Topology identification method of distribution network based on branch active power. J. Phys. Conf. Ser. 2021, 2108, 012062. [Google Scholar] [CrossRef]
- Dong, Y.; Li, X.; Zhang, L.; Yang, J. Automatic Identification of Low Voltage Distribution Network Topology Based on HPLC. J. Phys. Conf. Ser. 2021, 1881, 022023. [Google Scholar] [CrossRef]
- Wang, L.; Han, M.; Li, X.; Zhang, N.; Cheng, H. Review of Classification Methods on Unbalanced Data Sets. IEEE Access 2021, 9, 64606–64628. [Google Scholar] [CrossRef]
- Yi, H.; Jiang, Q.; Yan, X.; Wang, B. Imbalanced Classification Based on Minority Clustering Synthetic Minority Oversampling Technique with Wind Turbine Fault Detection Application. IEEE Trans. Ind. Inform. 2021, 17, 5867–5875. [Google Scholar] [CrossRef]
- Arumugam, G. Handling Class Imbalance in Multiclass Datasets by using a Neighborhood based Adaptive Heterogeneous Oversampling Ensemble Classifier. In Proceedings of the 2022 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), Erode, India, 7–9 April 2022; pp. 1498–1501. [Google Scholar] [CrossRef]
- Janet, B.; Joshua, A.K.R.; Didugu, P.S.G. Credit Card Fraud Detection with Unbalanced Real and Synthetic dataset using Machine Learning models. In Proceedings of the 2022 International Conference on Electronic Systems and Intelligent Computing (ICESIC), Chennai, India, 22–23 April 2022; pp. 73–78. [Google Scholar] [CrossRef]
- Xiong, H. Unbalanced Data Set Classification Based on Convolutional Neural Network. In Proceedings of the 2021 International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 24–26 September 2021; pp. 186–190. [Google Scholar] [CrossRef]
- Rathore, S.S.; Chouhan, S.S.; Jain, D.K.; Vachhani, A.G. Generative Oversampling Methods for Handling Imbalanced Data in Software Fault Prediction. IEEE Trans. Reliab. 2022, 71, 747–762. [Google Scholar] [CrossRef]
- Rosadi, D.; Arisanty, D.; Andriyani, W.; Peiris, S.; Agustina, D.; Dowe, D.; Fang, Z. Improving Machine Learning Prediction of Peatlands Fire Occurrence for Unbalanced Data Using SMOTE Approach. In Proceedings of the 2021 International Conference on Data Science, Artificial Intelligence, and Business Analytics (DATABIA), Medan, Indonesia, 11–12 November 2021; pp. 160–163. [Google Scholar] [CrossRef]
- Ileberi, E.; Sun, Y.; Wang, Z. Performance Evaluation of Machine Learning Methods for Credit Card Fraud Detection Using SMOTE and AdaBoost. IEEE Access 2021, 9, 165286–165294. [Google Scholar] [CrossRef]
- Dharmasaputro, A.A.; Fauzan, N.M.; Kallista, M.; Wibawa, I.P.D.; Kusuma, P.D. Handling Missing and Imbalanced Data to Improve Generalization Performance of Machine Learning Classifier. In Proceedings of the 2021 International Seminar on Machine Learning, Optimization, and Data Science (ISMODE), Jakarta, Indonesia, 29–30 January 2022; pp. 140–145. [Google Scholar] [CrossRef]
- Lu, Y.-W.; Liu, K.-L.; Hsu, C.-Y. Conditional Generative Adversarial Network for Defect Classification with Class Imbalance. In Proceedings of the 2019 IEEE International Conference on Smart Manufacturing, Industrial & Logistics Engineering (SMILE), Hangzhou, China, 20–21 April 2019; pp. 146–149. [Google Scholar] [CrossRef]
- Alnujaim, I.; Oh, D.; Kim, Y. Generative Adversarial Networks to Augment Micro-Doppler Signatures for the Classification of Human Activity. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 9459–9461. [Google Scholar] [CrossRef]
- Liu, Z.; Tong, M.; Liu, X.; Du, Z.; Chen, W. Research on Extended Image Data Set Based on Deep Convolution Generative Adversarial Network. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 47–50. [Google Scholar] [CrossRef]
- Ayanoglu, E.; Davaslioglu, K.; Sagduyu, Y.E. Machine Learning in NextG Networks via Generative Adversarial Networks. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 480–501. [Google Scholar] [CrossRef]
- Jiang, T.; Xie, W.; Li, Y.; Du, Q. Discriminative Semi-Supervised Generative Adversarial Network for Hyperspectral Anomaly Detection. In Proceedings of the IGARSS 2020–2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2420–2423. [Google Scholar] [CrossRef]
- Bhagwani, H.; Agarwal, S.; Kodipalli, A.; Martis, R.J. Targeting class imbalance problem using GAN. In Proceedings of the 2021 5th International Conference on Electrical, Electronics, Communication, Computer Technologies and Optimization Techniques (ICEECCOT), Mysuru, India, 10–11 December 2021; pp. 318–322. [Google Scholar] [CrossRef]
- Kalita, D.J.; Singh, S. SVM Hyper-parameters optimization using quantized multi-PSO in dynamic environment. Soft Comput. 2020, 24, 1225–1241. [Google Scholar] [CrossRef]
- Willsch, D.; Willsch, M.; De Raedt, H.; Michielsen, K. Support vector machines on the D-Wave quantum annealer. Comput. Phys. Commun. 2019, 248, 107006. [Google Scholar] [CrossRef]
- Altayef, E.; Anayi, F.; Packianather, M.; Benmahamed, Y.; Kherif, O. Detection and Classification of Lamination Faults in a 15 kVA Three-Phase Transformer Core Using SVM, KNN and DT Algorithms. IEEE Access 2022, 10, 50925–50932. [Google Scholar] [CrossRef]
- Ali, O.M.A.; Kareem, S.W.; Mohammed, A.S. Evaluation of Electrocardiogram Signals Classification Using CNN, SVM, and LSTM Algorithm: A review. In Proceedings of the 2022 8th International Engineering Conference on Sustainable Technology and Development (IEC), Erbil, Iraq, 23–24 February 2022; pp. 185–191. [Google Scholar] [CrossRef]
- Lee, C.Y.; Yang, M.R.; Chang, L.Y.; Lee, Z.J. A hybrid algorithm applied to classify unbalanced data. In Proceedings of the 6th International Conference on Networked Computing and Advanced Information Management, Seoul, Korea, 16–18 August 2010; pp. 618–621. [Google Scholar]
- Mingyue, F.; Zao, F.; Xiaodong, W.; Jun, M. A Pipeline Blockage Identification Model Learning from Unbalanced Datasets Based on Random Forest. In Proceedings of the 2021 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 696–701. [Google Scholar] [CrossRef]
- Pereira, J.; Saraiva, F. A Comparative Analysis of Unbalanced Data Handling Techniques for Machine Learning Algorithms to Electricity Theft Detection. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Lv, Y.; Lin, L.; Liu, J.; Guo, H.; Tong, C. Research on Imbalanced Data Classification Based on Classroom-Like Generative Adversarial Networks. Neural Comput. 2022, 34, 1045–1073. [Google Scholar] [CrossRef] [PubMed]
- Branco, P.; Torgo, L.; Ribeiro, R.P. Relevance-Based Evaluation Metrics for Multi-Class Imbalanced Domains; Springer International Publishing: Cham, Switzerland, 2017; pp. 698–710. [Google Scholar]
- Ziherl, P.; Kamien, R.D. Maximizing Entropy by Minimizing Area: Towards a New Principle of Self-Organization. J. Phys. Chem. B 2001, 105, 10147–10158. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Number | Number |
|---|---|---|
| Line hanging error | 12 | 1 |
| Magnification error | 42 | 2 |
| Normal | 395 | 3 |
| Total | 449 | / |
| Data Type | Daily Electricity Data. Unit: kwh | Category | |||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | … | 30 | |||
| Input power of line A | 68,800 | 69,200 | 62,800 | … | 42,800 | / | |
| Power consumption of each transformer | transformer 1 | 273 | 263 | 282 | … | 279 | Normal |
| transformer 2 | 77 | 77 | 76 | … | 75 | Line hanging error | |
| … | … | … | … | … | … | … | |
| transformer 22 | 320 | 316 | 400 | … | 524 | Magnification error | |
| The power loss of line A | 65,460 | 65,485 | 59,148 | … | 38,542 | / | |
| Feature | Transformer 1 | Transformer 2 | Transformer 3 | … | Transformer 449 |
|---|---|---|---|---|---|
| 0.24414 | −0.17513 | 0.27490 | … | 0.48841 | |
| 0.24992 | −0.18690 | 0.27370 | … | 0.48176 | |
| 0.12639 | 7.30734 | 0.69886 | … | 0.41743 | |
| 0.12216 | 6.86262 | 0.65633 | … | 0.39203 | |
| −0.00175 | 0.00026 | −0.00016 | … | 0.00094 | |
| −0.02953 | 0.00087 | 0.00164 | … | 0.01527 | |
| −0.00023 | −0.00002 | 0.00002 | … | 0.00028 | |
| 0.00019 | 0.00692 | 0.00058 | … | 0.00064 | |
| 0.00064 | −0.00015 | 0.00088 | … | 0.00114 | |
| −0.00022 | −0.00001 | 0.00002 | … | 0.00027 | |
| 0.00018 | 0.00676 | 0.00057 | … | 0.00062 | |
| 0.00064 | −0.00015 | 0.00088 | … | 0.00115 |
| Line Hanging Error | Magnification Error | Normal | mGM | |
|---|---|---|---|---|
| SMOTE | 86.05% | 83.87% | 77.46% | 82.38% |
| GAN | 97.32% | 92.27% | 98.10% | 95.86% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Zhang, X.; Liu, H.; Li, B.; Yu, J.; Liu, K.; Qin, L. Intelligent Identification of the Line-Transformer Relationship in Distribution Networks Based on GAN Processing Unbalanced Data. Sustainability 2022, 14, 8611. https://doi.org/10.3390/su14148611
Wang Y, Zhang X, Liu H, Li B, Yu J, Liu K, Qin L. Intelligent Identification of the Line-Transformer Relationship in Distribution Networks Based on GAN Processing Unbalanced Data. Sustainability. 2022; 14(14):8611. https://doi.org/10.3390/su14148611
Chicago/Turabian StyleWang, Yan, Xinyu Zhang, Haofeng Liu, Boqiang Li, Jinyun Yu, Kaipei Liu, and Liang Qin. 2022. "Intelligent Identification of the Line-Transformer Relationship in Distribution Networks Based on GAN Processing Unbalanced Data" Sustainability 14, no. 14: 8611. https://doi.org/10.3390/su14148611
APA StyleWang, Y., Zhang, X., Liu, H., Li, B., Yu, J., Liu, K., & Qin, L. (2022). Intelligent Identification of the Line-Transformer Relationship in Distribution Networks Based on GAN Processing Unbalanced Data. Sustainability, 14(14), 8611. https://doi.org/10.3390/su14148611