
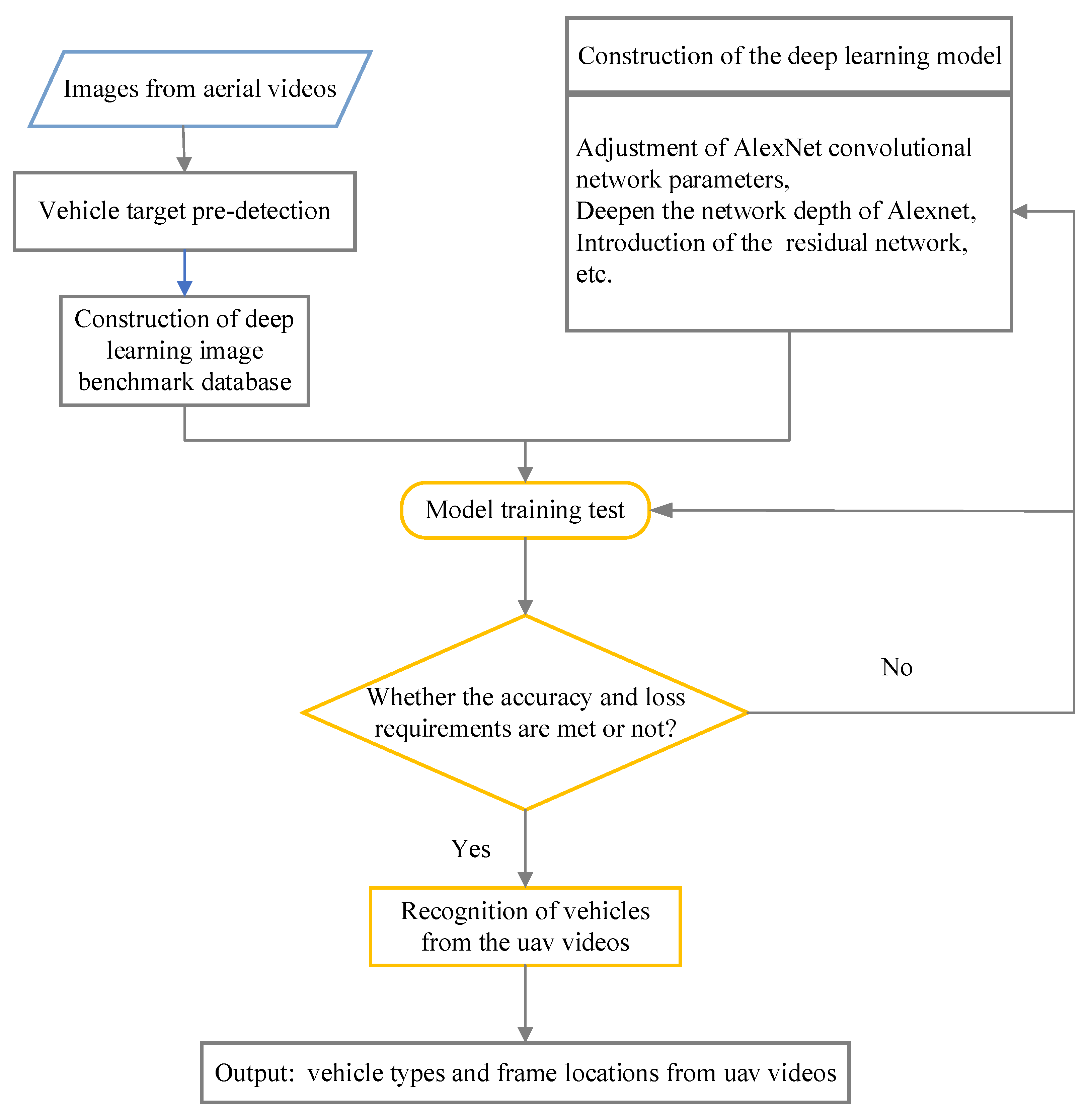
Vehicle Recognition from Unmanned Aerial Vehicle Videos Based on Fusion of Target Pre-Detection and Deep Learning


Abstract
:1. Introduction
- UAV high-resolution video vehicles target pre-detection: we used techniques including edge detection, morphology analysis, image skeleton structure reconstruction, and connected domain feature analysis to identify the connected domains that satisfy the preset conditions. The connected domains were used as candidate vehicle target regions.
- Image benchmark library construction: the candidate vehicle target areas were taken and sorted manually. The image benchmark library was constructed containing training image sets, test image sets, and validation image sets of bus, car, and non-vehicle. Non-vehicle in the present paper includes lane lines, trees, railings, other traffic signs, etc.
- Deep learning model construction and test: the AlexNet was used as the prototype. The deep learning model was reconstructed by optimizing the convolutional network parameters and adding convolutional and residual layers. Thereafter, the reconstructed deep learning model was trained and tested with feedback optimization.
- Reconstructed deep learning model performance evaluation: the multiple reconstructed deep learning models were constructed as alternatives and the optimal model that met the precision requirement was selected. The optimal model could identify the candidate vehicle target type (bus, car, or non-vehicle) and localize it in the original image. The details of the proposed detection framework are shown in Figure 1.
2. Methodologies
2.1. UAV High-Resolution Video Vehicle Target Pre-Detection
2.2. Skeleton Image Skeleton Analysis and Processing
2.2.1. Canny Edge Detection
- (1)
- Eliminate image noise with Gaussian filtering. The basic principle of Gaussian smoothing is to recalculate the value of each point in the image. When calculating, the weighted average of the point and its adjacent points is taken, and the weight fits the Gaussian distribution. It can suppress the high-frequency part of the image, and let the low-frequency part pass through [19].
- (2)
- Image gradient intensity and direction were obtained by convolution with the Sobel operator convolution. Sobel operator is the weighted difference between the gray values of the upper, lower, left, and right fields of each pixel in the image and reaches the extreme value at the edge to detect the edge. It has a smooth suppression effect on noise and has a good detection effect [20].
- (3)
- The non-maximum suppression technique was used to retain the maximum value of the gradient intensity at each pixel and delete the other values.
- (4)
- Image weak edge and strong edge were defined by double thresholding, and edge-connected processing was performed to obtain edge images.
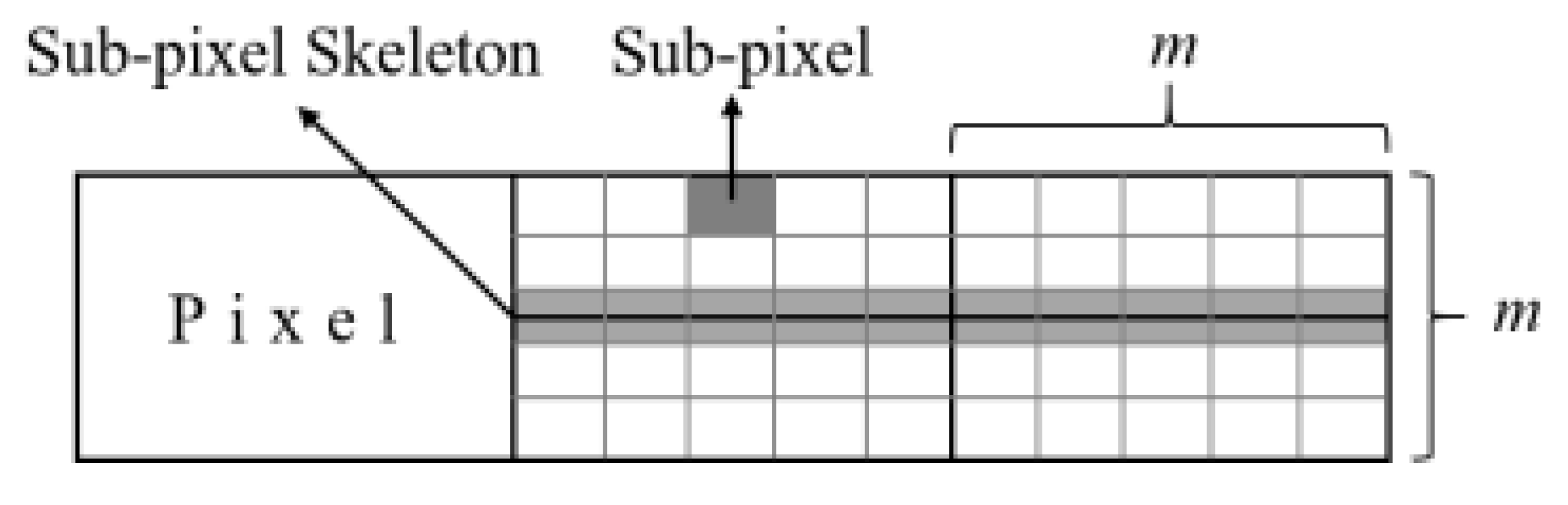
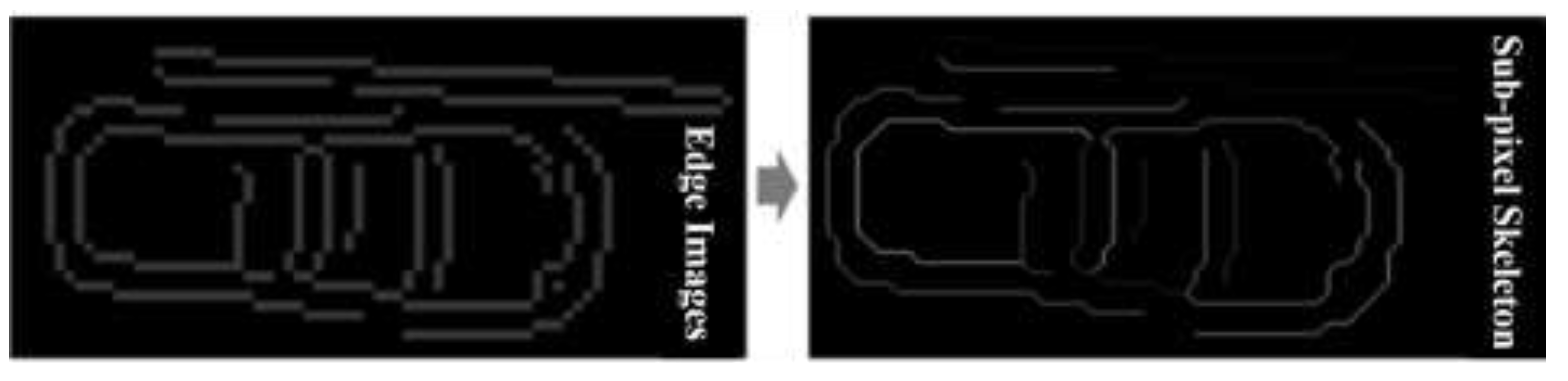
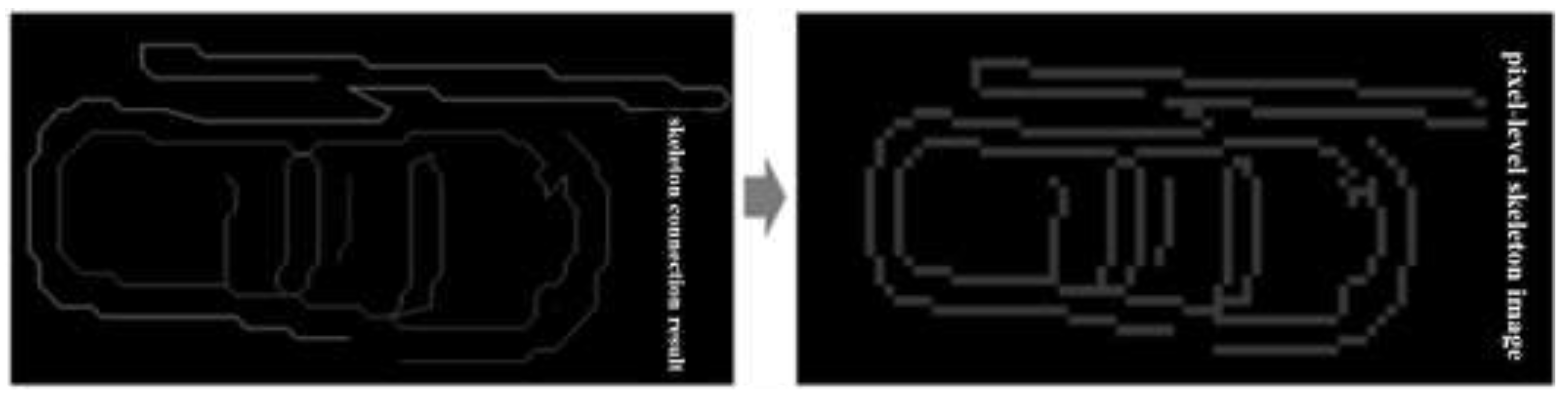
2.2.2. Skeleton Image Generation
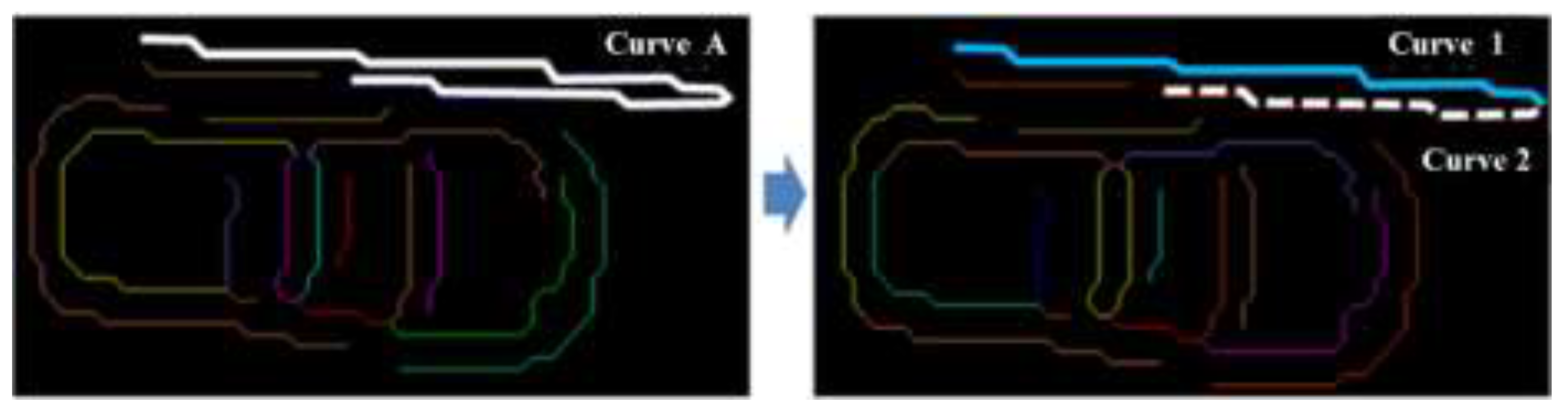
2.2.3. Skeleton Image Decomposition
- (1)
- Assigning several points along the edge as initial points and connecting the initial points to form the initial polygon.
- (2)
- Between any two neighborhood breakpoints, along the skeleton curve segment, the point with the greatest vertical distance from the line formed by the two breakpoints was found. If the distance satisfies d > d1, then the point would be used as a new breakpoint to continue the segmentation.
- (3)
- Continue to decompose the skeleton until all the threshold conditions d ≤ d1 are met.
- (4)
- We assumed that the threshold d2 is d2 < d1. Then, with d2 as the threshold, refer to steps (1)–(3) for segmentation. Eventually, the decomposition result of the skeleton was obtained. Figure 7 shows an example of the result of skeleton decomposition; Curve A in Figure 7 was decomposed into Curve 1 and Curve 2.
| Algorithm 1: Image skeleton decomposition algorithm (“←” means assignment) |
| ①: int SkeletonNumber←The number of curves in the skeleton image; |
| ②: int d1←Distance thresholds; |
| ③: For int i = 1 to SkeletonNumber; |
| ④: Curve[i]←The i-th skeleton curve; |
| ⑤: InitPt[]←The initial set of breakpoints for Curve[i]; |
| ⑥: Line[]←The set of line segments formed by any initial breakpoint; |
| ⑦: maxDist←The maximum vertical distance between Curve[i] and ∀ Line; |
| ⑧: pTemp←The point on Curve[i] that generates maxDist; |
| ⑨: If maxDist > d1; |
| ⑩: Split Curve[i] from breakpoint pTemp; |
| ⑪: InitPt[]=Merge{InitPt[], pTemp}// Adding new breakpoints; |
| ⑫: return to ⑤//Enter the ⑤ loop operation; |
| ⑬: Else; |
| ⑭: i++//Segmentation of the next skeleton curve; |
| ⑮: End For |
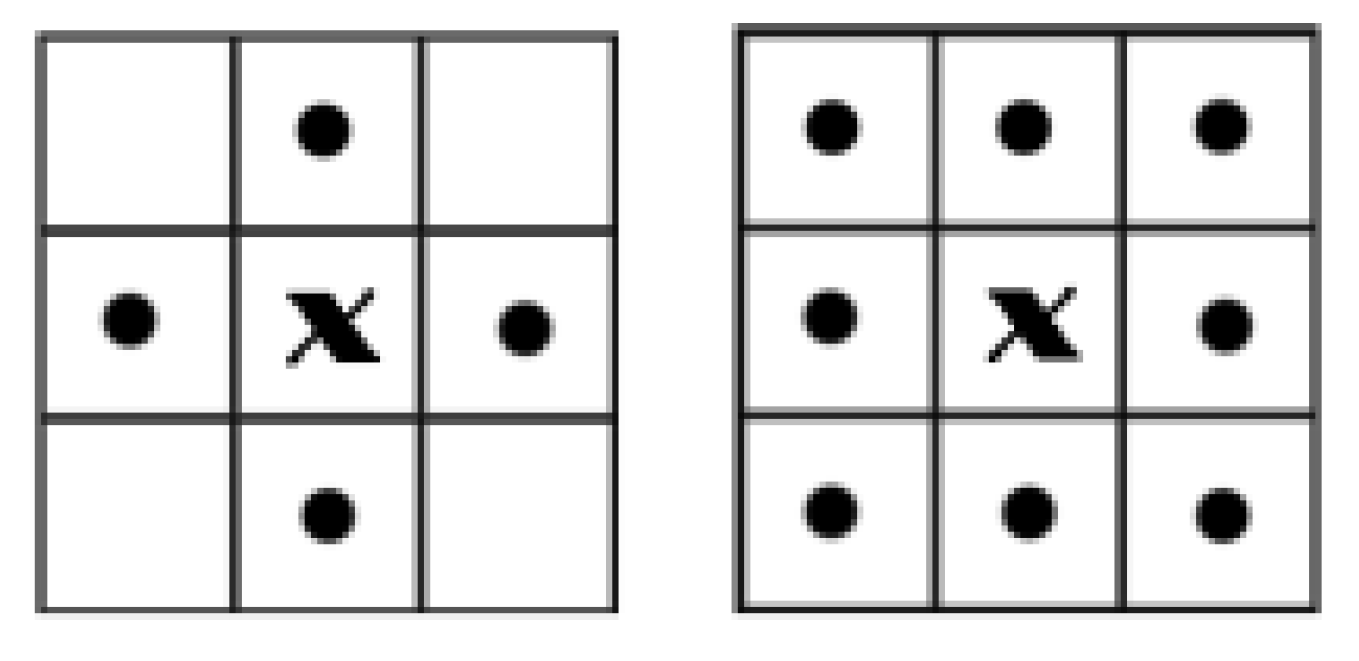
2.3. Morphological Detection
- (1)
- Area, S: the total number of pixels in the connected domain.
- (2)
- Rectangularity, R: the ratio of the connected domain area S to the minimum external rectangular area W, reflects the fullness of the connected domain area to its outer rectangle, as shown in Figure 13.
- (3)
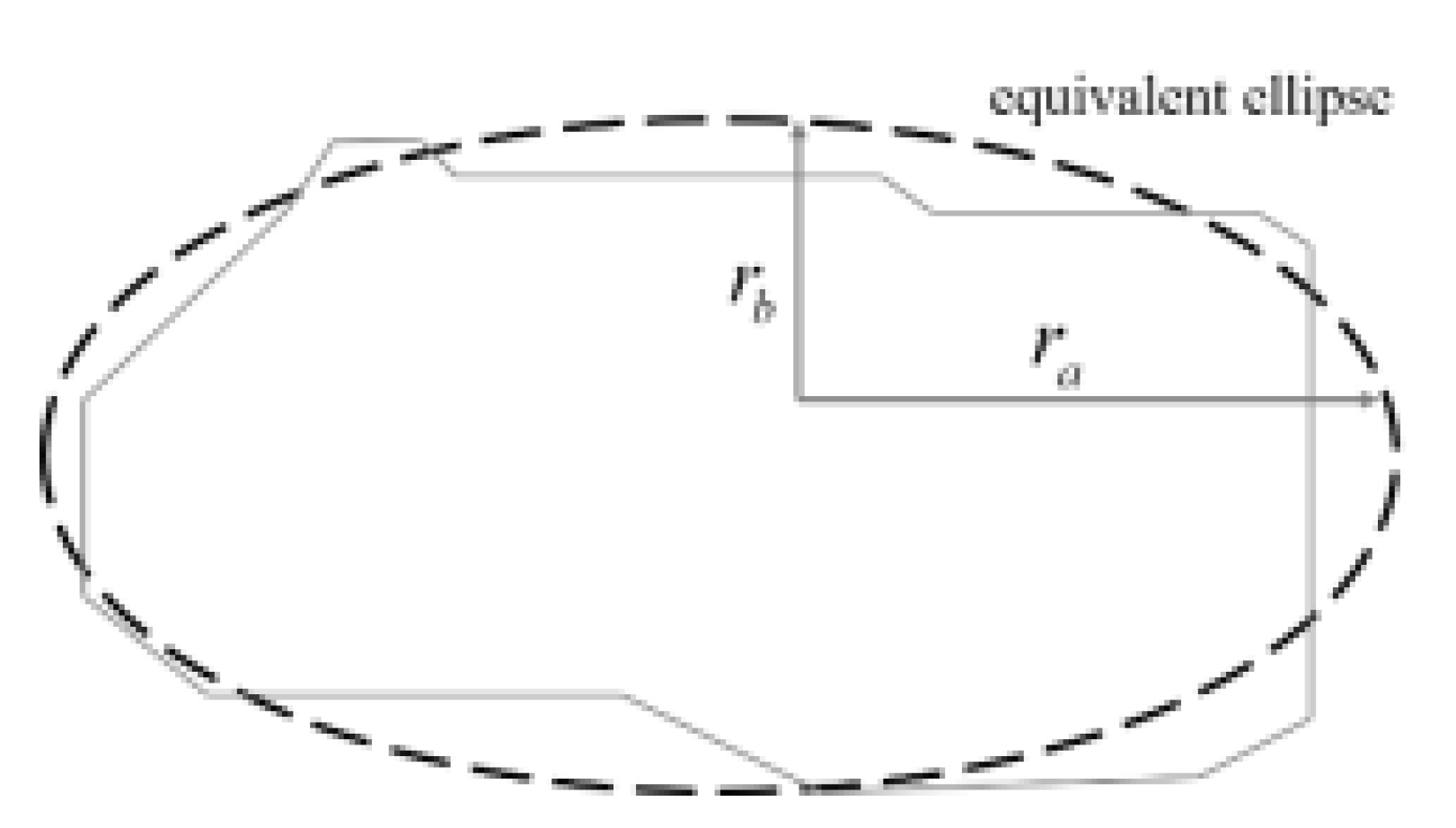
- Equivalent ellipse with major and minor axes [26]: a corresponding ellipse can be obtained for each connected domain; the elliptic equation is in the same form as the moment of inertia in the connected domain. Assuming that an ellipse region is homogeneous and has the same moment of inertia as the connected domain, the ellipse parameters can reflect the characteristics of the aforementioned connected domain. This ellipse is called an equivalent ellipse. Accordingly, the major axis ra and minor axis rb of the equivalent ellipse can be solved, as shown in Figure 14.
- (1)
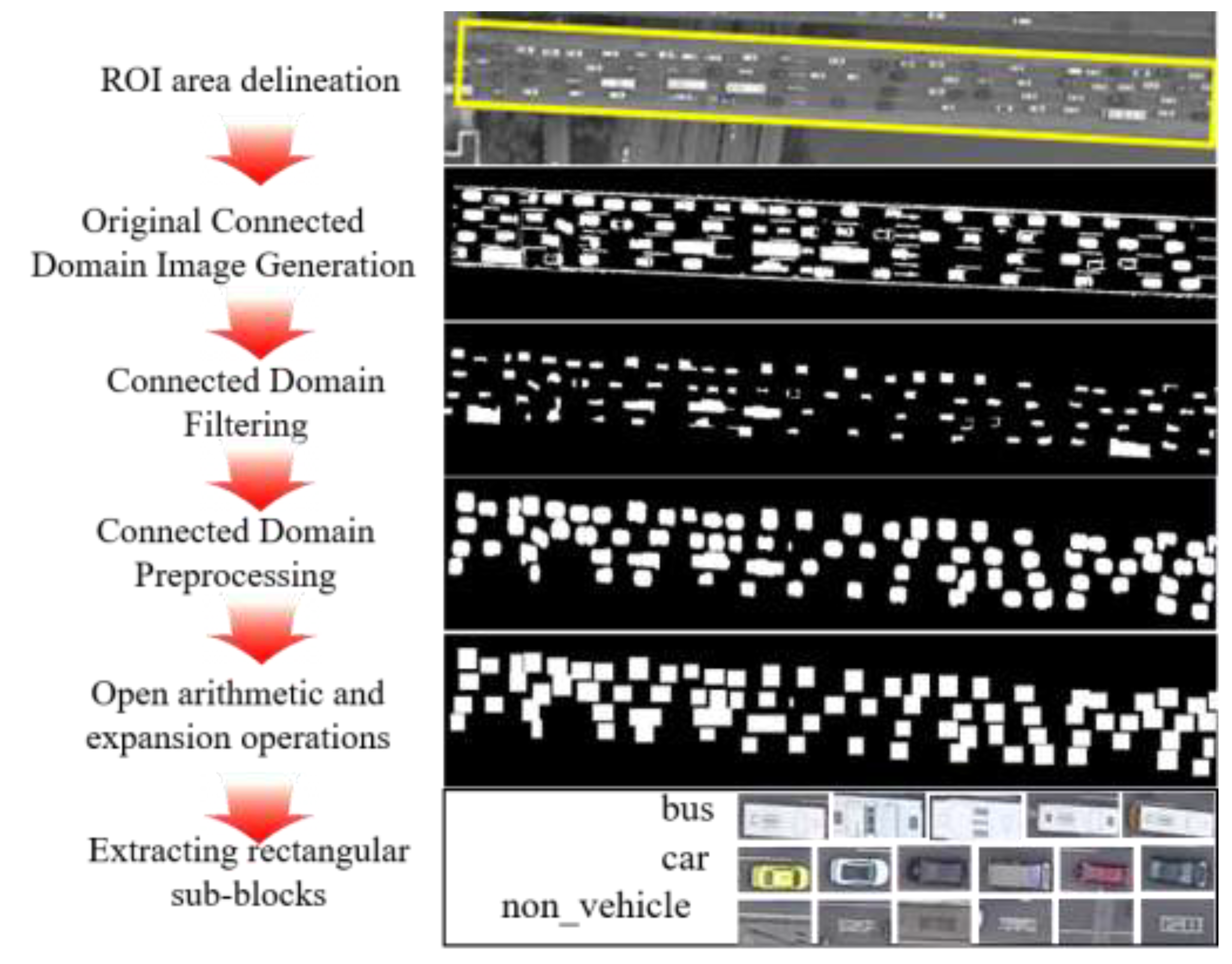
- Connected domain screening: The dilation and filling operations were performed on the skeleton reconstruction image to obtain the connected domain image. The results are shown in Figure 15a. Based on the connected domain rectangularity, area, and equivalent elliptic minor axis thresholds, the connected domains that satisfied conditions (1)–(3) were extracted. As shown in Figure 15b, this step removes some small areas and narrow lanes markings.where , , and are the rectangularity, the area, and the equivalent elliptic short axis length of the connected domain, respectively. , , , , and are threshold parameters (, , , , and , respectively, in this paper).
- (2)
- The larger connected domain was chosen based on the area and equivalent elliptic major axis and minor axis thresholds. If condition (4) is satisfied, then perform the closing operation and dilation operation on it; the results are shown in Figure 15c. Next, the smaller connected domain was chosen. If condition (5) is satisfied, perform the opening operation and dilation operation on it. This step effectively divides the large, connected domain and further eliminates narrow lane markings and road edges, as shown in Figure 15c.where is the length of the equivalent elliptic major axis in the connected domain; , , , and are threshold parameters (, , , and , respectively); and the rest of the symbols have the same meaning as before.
- (3)
- According to the area and equivalent ellipse minor axis threshold, if condition (6) is satisfied, perform the opening operation and dilation operation on it. Finally, all subblocks were converted to rectangular subblock results.where and are threshold parameters ( and , respectively), and the rest of the symbols have the same meaning as before.
- (4)
- Extract the rectangular subblock coverage area images as candidate targets, as shown in Figure 15d,e.
| Algorithm 2: Vehicle recognition algorithm based on morphological analysis (“←” means assignment): |
| ①: Skeleton←skeleton reconstruction image; |
| ②: Image0←Dilation and filling of Skeleton; |
| ③: R[i], A[i]←The rectangularity, area of the ith connected domain; |
| ④: ra[i], rb[i]←The length of the major axis, the length of the minor axis of the equivalent ellipse of the ith connected domain; |
| ⑤: For int i = 1 to M//M is the number of concatenated domains of Image0; |
| ⑥: If R[i]∈[r1,r2] or A[i] > s1 or rb[i]∈[b1, b2]; |
| ⑦: Retain the ith connected domain of Image0 // r1, r2, s1, b1, b2 are threshold parameters; |
| ⑧: End For//Let be Image1; |
| ⑨: For int j = 1 to N//N is the number of connected domains of Image1; |
| ⑩: If A[j] > s2 or ra[j] > a2//s2, a2 is the threshold parameter; |
| ⑪: Closing operation and erosion operation on the jth connected domain of Image1; |
| ⑫: End For//The first large target segmentation result is obtained, let it be Image2; |
| ⑬: Image3 ← The result of the dilation process of Image2; |
| ⑭: s3←Connected domain area threshold parameter; |
| ⑮: a3←The length threshold parameter of the major axis of the equivalent ellipse of the connected domain; |
| ⑯: Return to ⑨~⑪//Image3 is processed with thresholds s3 and a3 // the result is named Image4; |
| ⑰: For int k = 1 to W//W is the number of connected domains of Image4; |
| ⑱: If A[k] < s4 or rb[k] < b3 or rb[k] > b4; |
| ⑲: Remove the kth connected domain//s4, b3, b4 are the threshold parameters; |
| ⑳: End For//The binary image of vehicle recognition is obtained. |
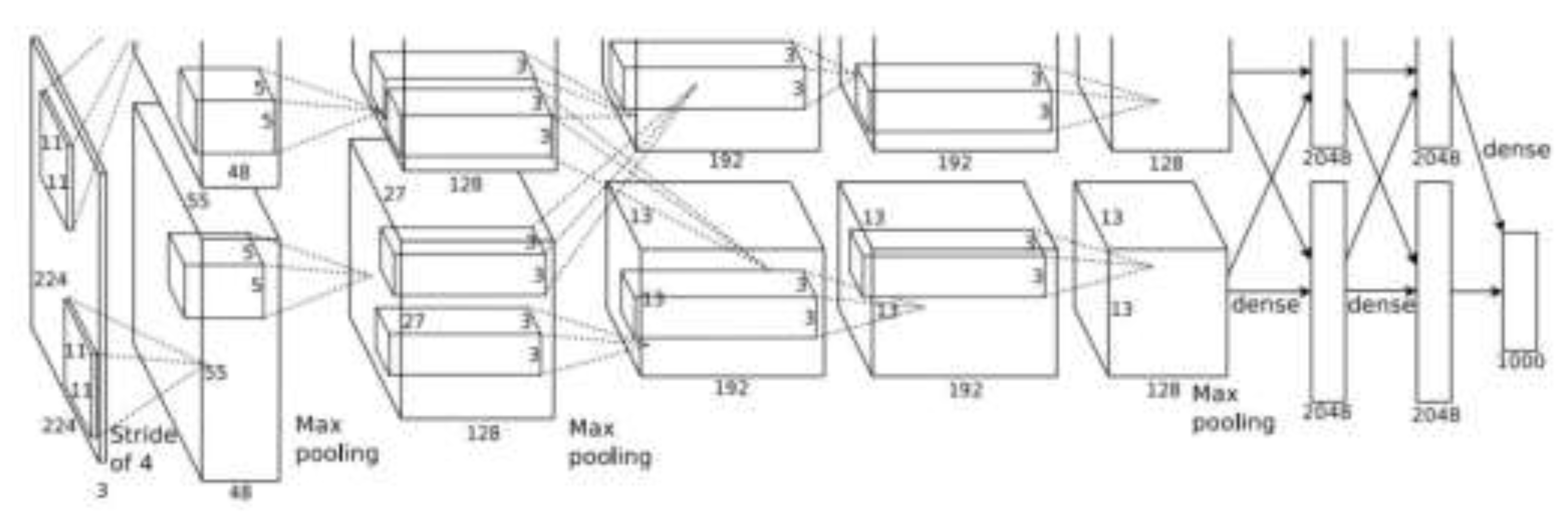
2.4. AlexNet Model
3. Data Set
3.1. Experimental Data
- (1)
- JPEGImages folder: store training images, verification images, and test images.
- (2)
- Annotations folder: store the xml format information file corresponding to each image, including the image file name, image size, vehicle annotation outline information, etc.
- (3)
- ImageSets folder: store txt files containing image category labels, and record the image names used for training, validation, and test in train.txt, val.txt, and test.txt files, respectively.
3.2. Deep Learning Image Benchmark Library Construction
3.3. Test Environment
4. Experiments and Analysis
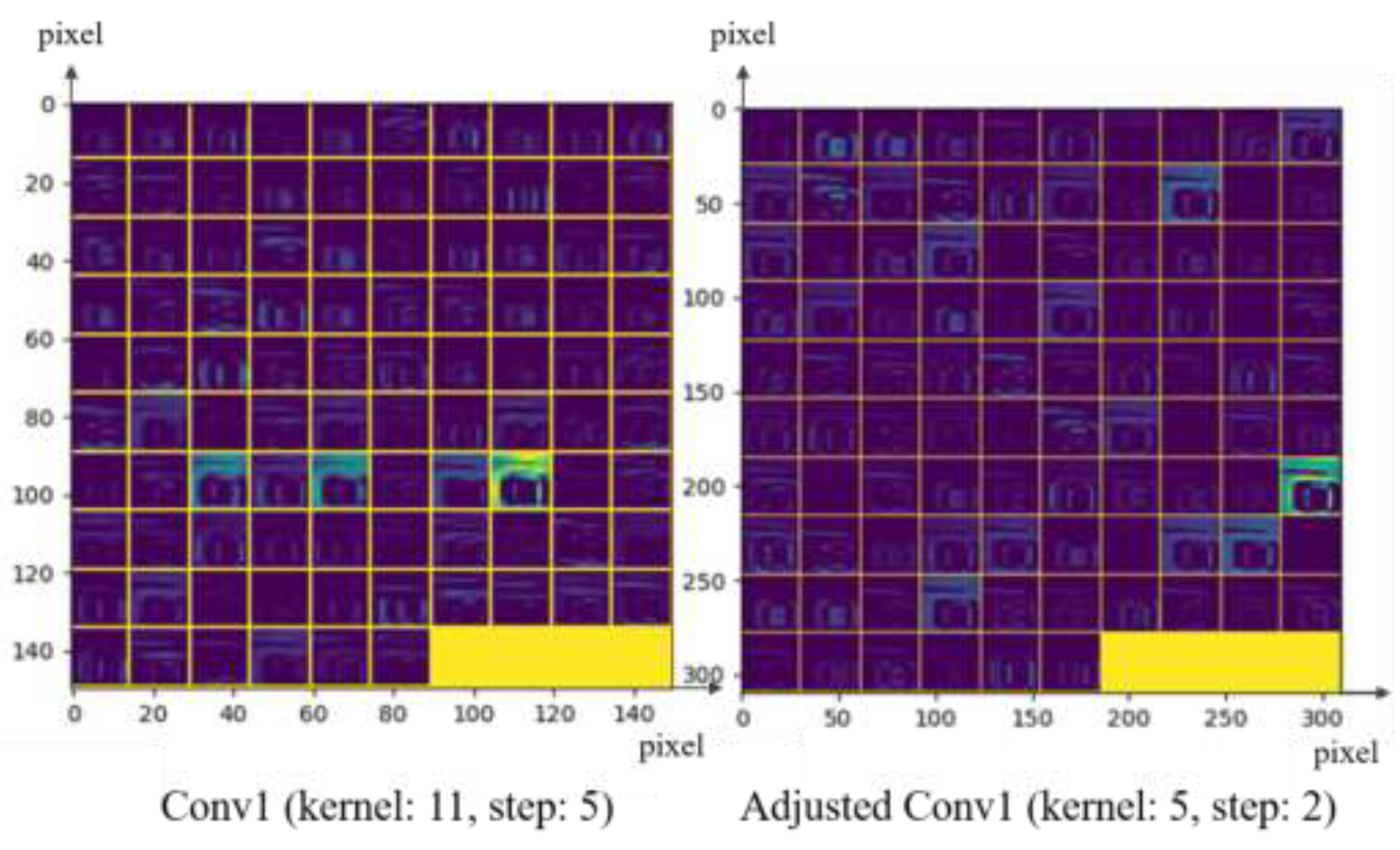
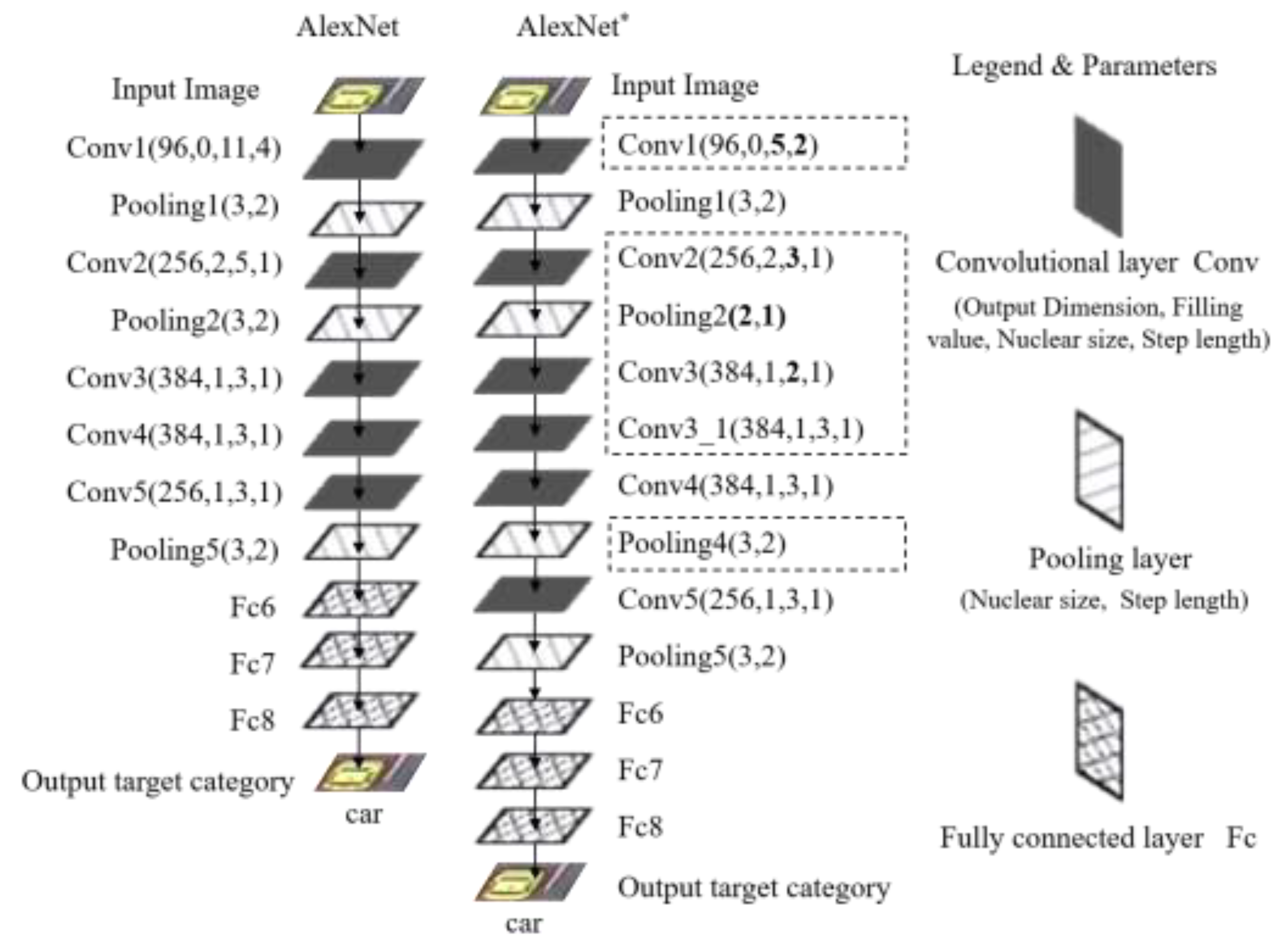
4.1. AlexNet Model Improvement
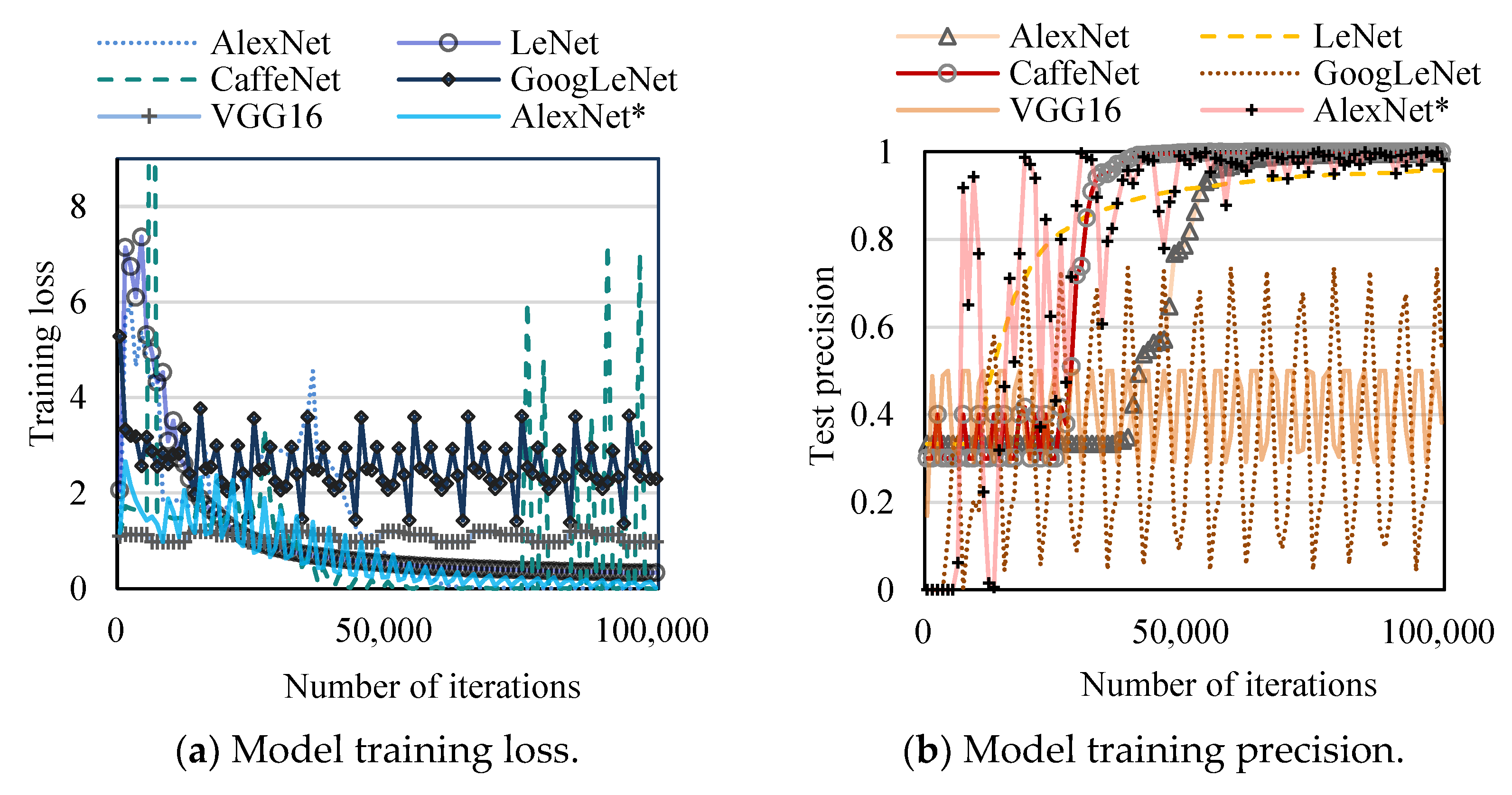
4.2. Model Training
4.3. Comparative Analysis between AlexNet* and Traditional CNN Models
4.3.1. Evaluation Indicators
- (1)
- : the number of targets that have been correctly identified;
- (2)
- : the number of targets that have been identified as other objects;
- (3)
- : the number of other objects that have been detected as targets;
- (4)
- : the number of non-target objects that have been recognized as targets.
4.3.2. Comparison and Evaluation of AlexNet* and Common Models
- (1)
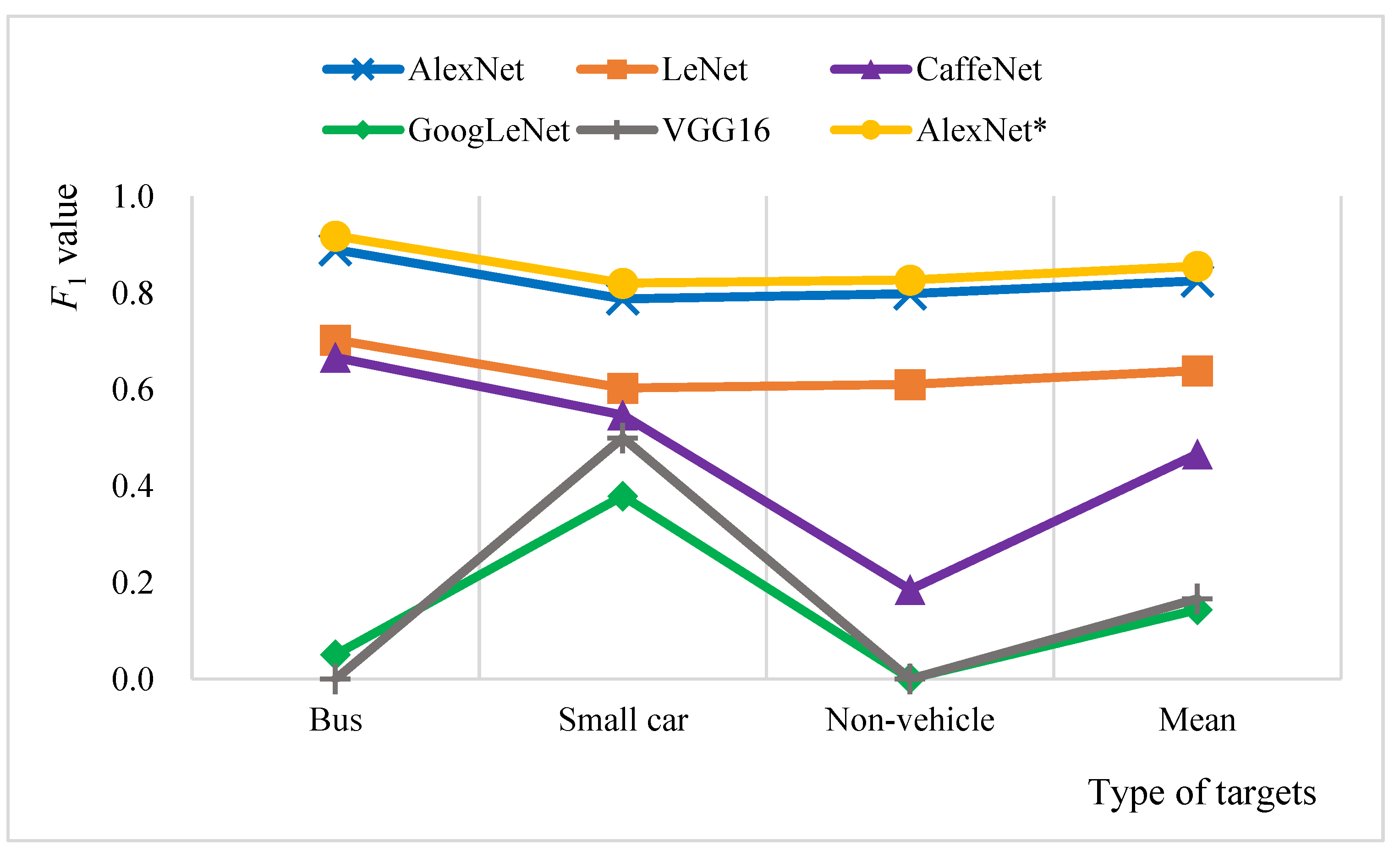
- The precision of car recognition of AlexNet* was 79.91%, 8.72% higher than AlexNet (= 71.19%). The precision of bus and non-vehicle recognition of AlexNet* were 88.65% and 88.80%, respectively, 2.63% and 0.39% lower than these of AlexNet (= 91.28%, = 89.19%). Thus, AlexNet* is more accurate for car recognition, while bus and non-vehicle recognition are slightly worse than AlexNet.
- (2)
- The recall of bus and non-vehicle of AlexNet* were 8.45% and 5.02% higher than AlexNet, respectively, but the recall of car recognition was 3.87% lower. It indicates that AlexNet* is less likely to miss bus and non-vehicle targets, but more likely to miss cars.
- (3)
- of AlexNet* for the bus recognition (91.82%) was 2.85% higher than that of AlexNet ( = 88.97%), and of car and non-vehicles recognition also increased by 3.27% and 2.97%, respectively. Therefore, the comprehensive performance of AlexNet* for all three types of target recognition is better than AlexNet, indicating that the model improvement in this paper produces better results.
- (1)
- The precision and recall of LeNet and CaffeNet have no significant differences, but of LeNet (70.28%, 60.31%, 61.06%) are better than CaffeNet (66.63%, 54.75%, 18.55%) for bus, car, and non-vehicle recognitions.
- (2)
- of GoogLeNet and VGG16 for three types of target recognition are not higher than 50%, largely due to the poor training effect.
4.4. Evaluation of Vehicle Test Results
4.4.1. Evaluation Indicators
- (1)
- The vehicle is correctly detected: a vehicle is identified as the correct vehicle category;
- (2)
- Vehicle misdetection: a vehicle is recognized as another object, denotes the number of vehicles misdetected in a certain frame;
- (3)
- Vehicle redetection: a vehicle is detected as two or more vehicles, and the detection of large objects (such as buses) is prone to such phenomena;
- (4)
- Missing vehicle detection.
4.4.2. Analysis of Results
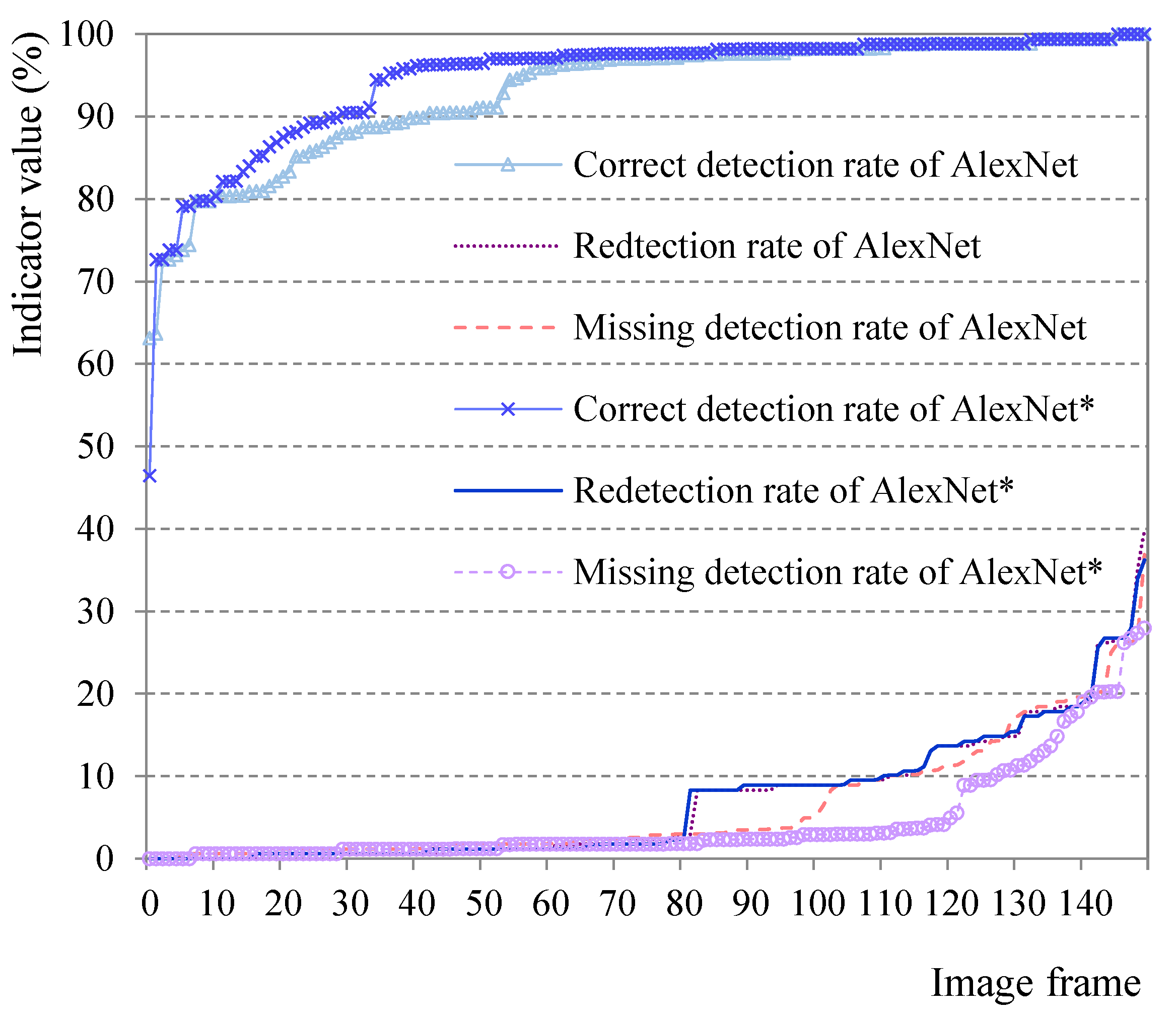
- (1)
- Under the standard that is higher than 90%, the AlexNet* algorithm has 123 images (82% of the total sample), which is higher than the 111 images of the AlexNet algorithm (74% of the total sample). It indicates that of the AlexNet* algorithm has reached a higher level;
- (2)
- For of 150 images, the identification results by AlexNet and AlexNet* algorithm are almost identical, and there is no significant difference. It indicates that both algorithms have better overall segmentation effects on the vehicle and can ensure the integrity of the vehicle;
- (3)
- The AlexNet* algorithm has a lower probability of missing detection of most sample vehicles.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Carroll, E.A.; Rathbone, D.B. Using an unmanned airborne data acquisition system (ADAS) for traffic surveillance, monitoring, and management. In Proceedings of the ASME International Mechanical Engineering Congress and Exposition, New Orleans, LA, USA, 17–22 November 2002. [Google Scholar] [CrossRef]
- Bethke, K.H.; Baumgartner, S.; Gabele, M.; Hounam, D.; Kemptner, E.; Klement, D.; Krieger, G.; Erxleben, R. Air-and spaceborne monitoring of road traffic using SAR moving target indication—Project TRAMRAD. ISPRS J. Photogramm. Remote Sens. 2006, 61, 243–259. [Google Scholar] [CrossRef]
- Hoang, V.D.; Hernandez, D.C.; Filonenko, A.; Jo, K.H. Path Planning for Unmanned Vehicle Motion Based on Road Detection Using Online Road Map and Satellite Image. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Springer: Cham, Switzerland, 2014. [Google Scholar] [CrossRef]
- Kanistras, K.; Martins, G.; Rutherford, M.J.; Valavanis, K.P. A survey of unmanned aerial vehicles (UAVs) for traffic monitoring. In Proceedings of the 2013 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 28–31 May 2013. [Google Scholar] [CrossRef]
- Barmpounakis, E.N.; Vlahogianni, E.I.; Golias, J.C.; Babinec, A. How accurate are small drones for measuring microscopic traffic parameters? Transp. Lett. 2019, 11, 332–340. [Google Scholar] [CrossRef]
- Abdulla, A.A.; Graovac, S.; Papic, V.; Kovacevic, B. Triple-feature-based particle filter algorithm used in vehicle tracking applications. Adv. Electr. Comput. Eng. 2021, 21, 3–14. [Google Scholar] [CrossRef]
- Li, W.; Li, H.; Wu, Q.; Chen, X.; Ngan, K.N. Simultaneously detecting and counting dense vehicles from drone images. IEEE Trans. Ind. Electron. 2019, 66, 9651–9662. [Google Scholar] [CrossRef]
- Kim, K.J.; Kim, P.K.; Chung, Y.S.; Choi, D.H. Multi-scale detector for accurate vehicle detection in traffic surveillance data. IEEE Access 2019, 7, 78311–78319. [Google Scholar] [CrossRef]
- Chen, Y.; Ding, W.; Li, H.; Wang, M.; Wang, X. Video detection in UAV image based on video interframe motion estimation. J. Beijing Univ. Aeronaut. Astronaut. 2020, 46, 634–642. [Google Scholar] [CrossRef]
- Kim, B.; Min, H.; Heo, J.; Jung, J. Dynamic computation offloading scheme for drone-based surveillance systems. Sensors 2018, 18, 2982. [Google Scholar] [CrossRef] [Green Version]
- Munishkin, A.A.; Hashemi, A.; Casbeer, D.W.; Milutinović, D. Scalable markov chain approximation for a safe intercept navigation in the presence of multiple vehicles. Auton. Robot. 2019, 43, 575–588. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Processing Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Mo, L.F.; Jiang, H.L.; Li, X.P. Review of deep learning-based video prediction. CAAI Trans. Intell. Syst. 2018, 13, 85–96. [Google Scholar]
- Ammour, N.; Alhichri, H.; Bazi, Y.; Benjdira, B.; Alajlan, N.; Zuair, M. Deep learning approach for car detection in UAV imagery. Remote Sens. 2017, 9, 312. [Google Scholar] [CrossRef] [Green Version]
- Koga, Y.; Miyazaki, H.; Shibasaki, R. A CNN-based method of vehicle detection from aerial images using hard example mining. Remote Sens. 2018, 10, 124. [Google Scholar] [CrossRef] [Green Version]
- Suhao, L.; Jinzhao, L.; Guoquan, L.; Tong, B.; Huiqian, W.; Yu, P. Vehicle type detection based on deep learning in traffic scene. Procedia Comput. Sci. 2018, 131, 564–572. [Google Scholar] [CrossRef]
- Sharma, P.; Singh, A.; Singh, K.K.; Dhull, A. Vehicle identification using modified region based convolution network for intelligent transportation system. Multimed. Tools Appl. 2021, 1–25. Available online: https://link.springer.com/article/10.1007/s11042-020-10366-x. (accessed on 27 April 2022). [CrossRef]
- Song, Z.; Chen, S.; Huang, Y.; Wang, H. Improved contour polygon piecewise approximation algorithm. Sens. Microsyst. 2020, 39, 117–119, 123. [Google Scholar] [CrossRef]
- D’Haeyer, J.P. Gaussian filtering of images: A regularization approach. Signal Process. 1989, 18, 169–181. [Google Scholar] [CrossRef]
- Kanopoulos, N.; Vasanthavada, N.; Baker, R.L. Design of an image edge detection filter using the Sobel operator. IEEE J. Solid-State Circuits 1988, 23, 358–367. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Ramer, U. An iterative procedure for the polygonal approximation of plane curves. Comput. Graph. Image Process. 1972, 1, 244–256. [Google Scholar] [CrossRef]
- Wang, Y.; Lin, Z.; Shen, X.; Cohen, S.; Cottrell, G.W. Skeleton key: Image captioning by skeleton-attribute decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Serra, J. Introduction to mathematical morphology. Comput. Vis. Graph. Image Process. 1986, 35, 283–305. [Google Scholar] [CrossRef]
- Lézoray, O. Hierarchical morphological graph signal multi-layer decomposition for editing applications. IET Image Process. 2020, 14, 1549–1560. [Google Scholar] [CrossRef]
- Ma, Y.H.; Zhan, L.J.; Xie, C.J.; Qin, C.Z. Parallelization of connected component labeling algorithm. Geogr. Geo-Inf. Sci. 2013, 29, 67–71. [Google Scholar] [CrossRef]
- Banerji, A.; Goutsias, J.I. Detection of minelike targets using grayscale morphological image reconstruction. In Proceedings of the SPIE 2496, Detection Technologies for Mines and Minelike Targets, Orlando, FL, USA, 20 June 1995. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Candidates | Training | Test | Validation |
|---|---|---|---|---|
| bus | 5152 | 10,000 | 3000 | 50,000 |
| car | 34,699 | 10,000 | 3000 | 50,000 |
| non_vehicle | 15,669 | 10,000 | 3000 | 50,000 |
| Total | 55,520 | 30,000 | 9000 | 150,000 |
| Experimental Model | Adjustment Method | (Bus) | (Car) | (Non_Vehicle) | Mean Value |
|---|---|---|---|---|---|
| AlexNet1 | Reduce the first two layers of convolution kernels; add Conv3_1 after Conv3. | 0.48% | −13.46% | −7.39% | −6.79% |
| AlexNet2 | Reduce the first two layers of convolution kernels; add Conv4_1 after Conv4. | −2.32% | −22.24% | −9.82% | −11.46% |
| AlexNet3 | Reduce the first three layers of convolution kernels; add Conv4_1, Pooling4 after Conv4. | 2.42% | 1.32% | 0.91% | 1.55% |
| AlexNet4 | Reduce the first three layers of convolution kernels; add Conv3_1 after Conv3. | 0.55% | −1.52% | −1.54% | −0.84% |
| AlexNet5 | Add residual layer “res” after Conv5. | −2.68% | −5.57% | −0.13% | −2.79% |
| AlexNet* | Reduce the first three layers of convolution kernels; add Conv3_1 after Conv3; add Pooling4 after Conv4. | 2.85% | 3.27% | 2.80% | 2.97% |
| AlexNet | LeNet | CaffeNet | GoogLeNet | VGG16 | AlexNet* | |
|---|---|---|---|---|---|---|
| Test_Interval | 500 | 1000 | 300 | 100 | 100 | 100 |
| Base_lr | 0.001 | 0.0001 | 0.001 | 0.001 | 0.0001 | 0.0001 |
| Max_iter | 100,000 | 100,000 | 100,000 | 100,000 | 100,000 | 100,000 |
| lr_Policy | inv | inv | inv | Step | Step | inv |
| Gamma | 0.001 | 0.0001 | 0.0001 | 0.001 | 0.01 | 0.0001 |
| Solver_Mode | GPU | GPU | GPU | GPU | GPU | GPU |
| Models | Bus Evaluation Indicators (%) | Small Car Evaluation Indicators (%) | Non-Vehicle Evaluation Indicators (%) | Average (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AlexNet | 91.28 | 86.77 | 88.97 | 71.19 | 88.16 | 78.77 | 89.19 | 72.33 | 79.88 | 82.54 |
| LeNet | 98.41 | 54.66 | 70.28 | 51.52 | 72.71 | 60.31 | 60.08 | 62.08 | 61.06 | 63.88 |
| CaffeNet | 52.25 | 91.95 | 66.63 | 52.90 | 56.72 | 54.75 | 64.38 | 10.84 | 18.55 | 46.64 |
| GoogLeNet | 4.62 | 5.63 | 5.07 | 29.64 | 52.65 | 37.93 | 12.40 | 0.06 | 0.12 | 14.38 |
| VGG16 | 0.00 | 0.00 | 0.00 | 33.33 | 100.00 | 50.00 | 0.00 | 0.00 | 0.00 | 16.67 |
| AlexNet* | 88.65 | 95.22 | 91.82 | 79.91 | 84.29 | 82.04 | 88.80 | 77.35 | 82.68 | 85.51 |
| AlexNet*- AlexNet | −2.63 | 8.45 | 2.85 | 8.72 | −3.87 | 3.27 | −0.39 | 5.02 | 2.80 | 2.97 |
| Statistical Values | AlexNet (%) | AlexNet* (%) | ||||
|---|---|---|---|---|---|---|
| Average | 93.10 | 6.87 | 6.25 | 94.63 | 6.89 | 4.40 |
| Median | 97.02 | 2.27 | 2.56 | 97.65 | 1.97 | 1.79 |
| Variance | 7.77 | 7.95 | 7.30 | 7.47 | 7.87 | 6.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, B.; Zhang, H.; Yang, N.; Xie, J. Vehicle Recognition from Unmanned Aerial Vehicle Videos Based on Fusion of Target Pre-Detection and Deep Learning. Sustainability 2022, 14, 7912. https://doi.org/10.3390/su14137912
Peng B, Zhang H, Yang N, Xie J. Vehicle Recognition from Unmanned Aerial Vehicle Videos Based on Fusion of Target Pre-Detection and Deep Learning. Sustainability. 2022; 14(13):7912. https://doi.org/10.3390/su14137912
Chicago/Turabian StylePeng, Bo, Hanbo Zhang, Ni Yang, and Jiming Xie. 2022. "Vehicle Recognition from Unmanned Aerial Vehicle Videos Based on Fusion of Target Pre-Detection and Deep Learning" Sustainability 14, no. 13: 7912. https://doi.org/10.3390/su14137912
APA StylePeng, B., Zhang, H., Yang, N., & Xie, J. (2022). Vehicle Recognition from Unmanned Aerial Vehicle Videos Based on Fusion of Target Pre-Detection and Deep Learning. Sustainability, 14(13), 7912. https://doi.org/10.3390/su14137912