
Comparison of Logistic Regression, Information Value, and Comprehensive Evaluating Model for Landslide Susceptibility Mapping




Abstract
1. Introduction
2. Methodology
2.1. LR Model
2.2. AHPIV Model
2.2.1. AHP Method
2.2.2. IV Method
2.3. The Comprehensive Evaluating (CLSI) Model
2.4. BPNN Method
2.5. FR Method
3. Case Study Features
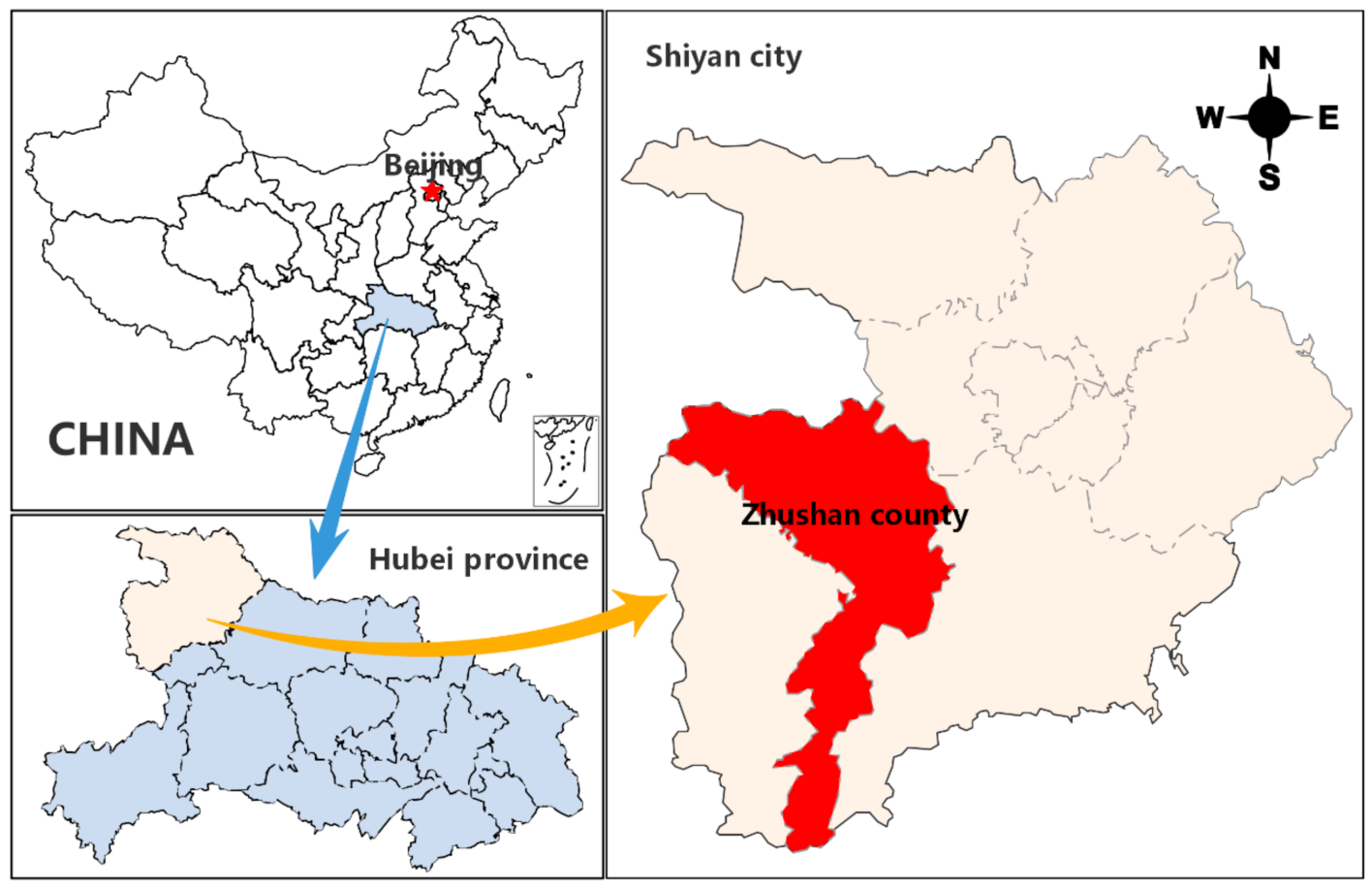
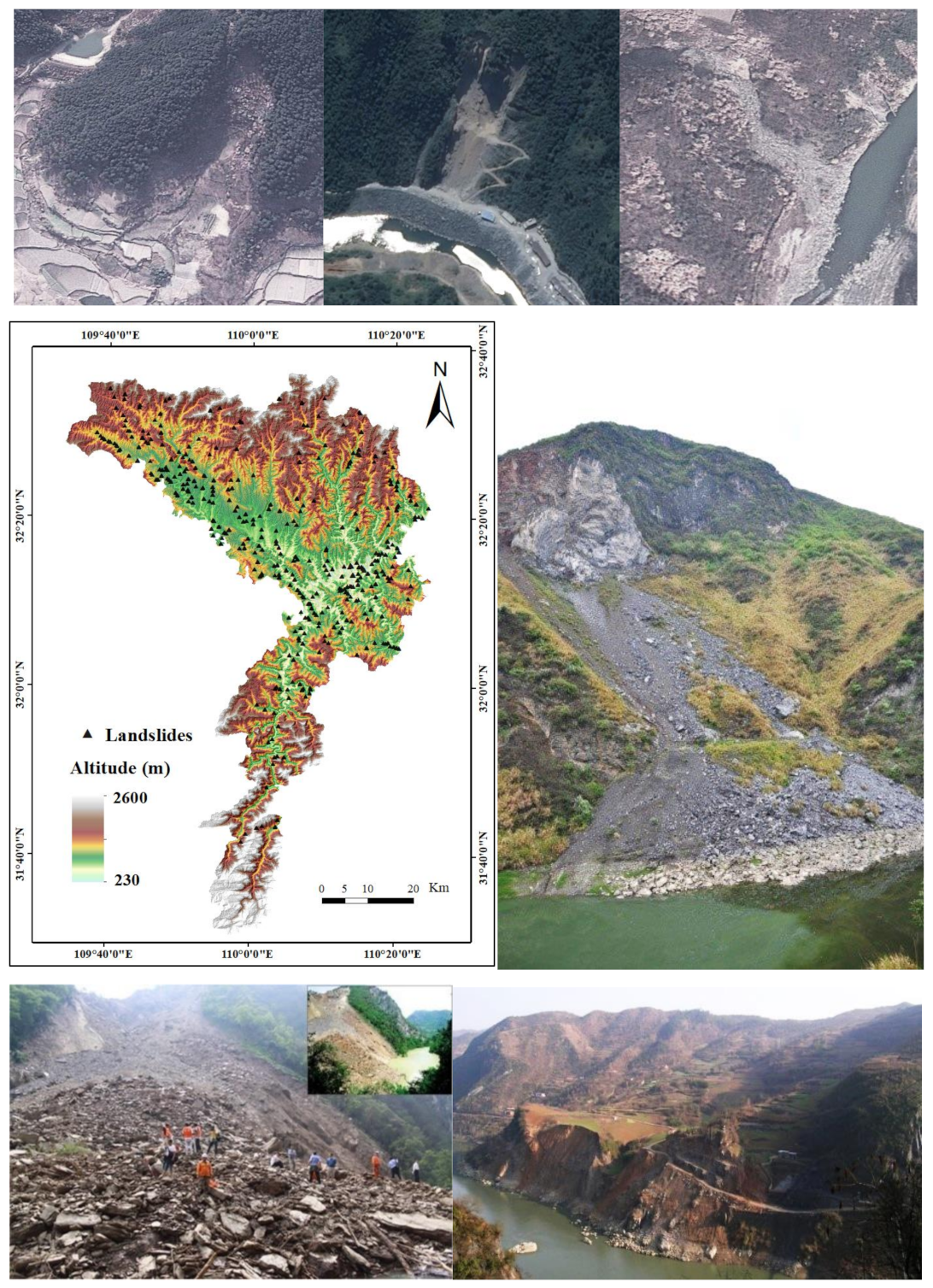
3.1. Description of Study Area
3.2. Landslide Inventory
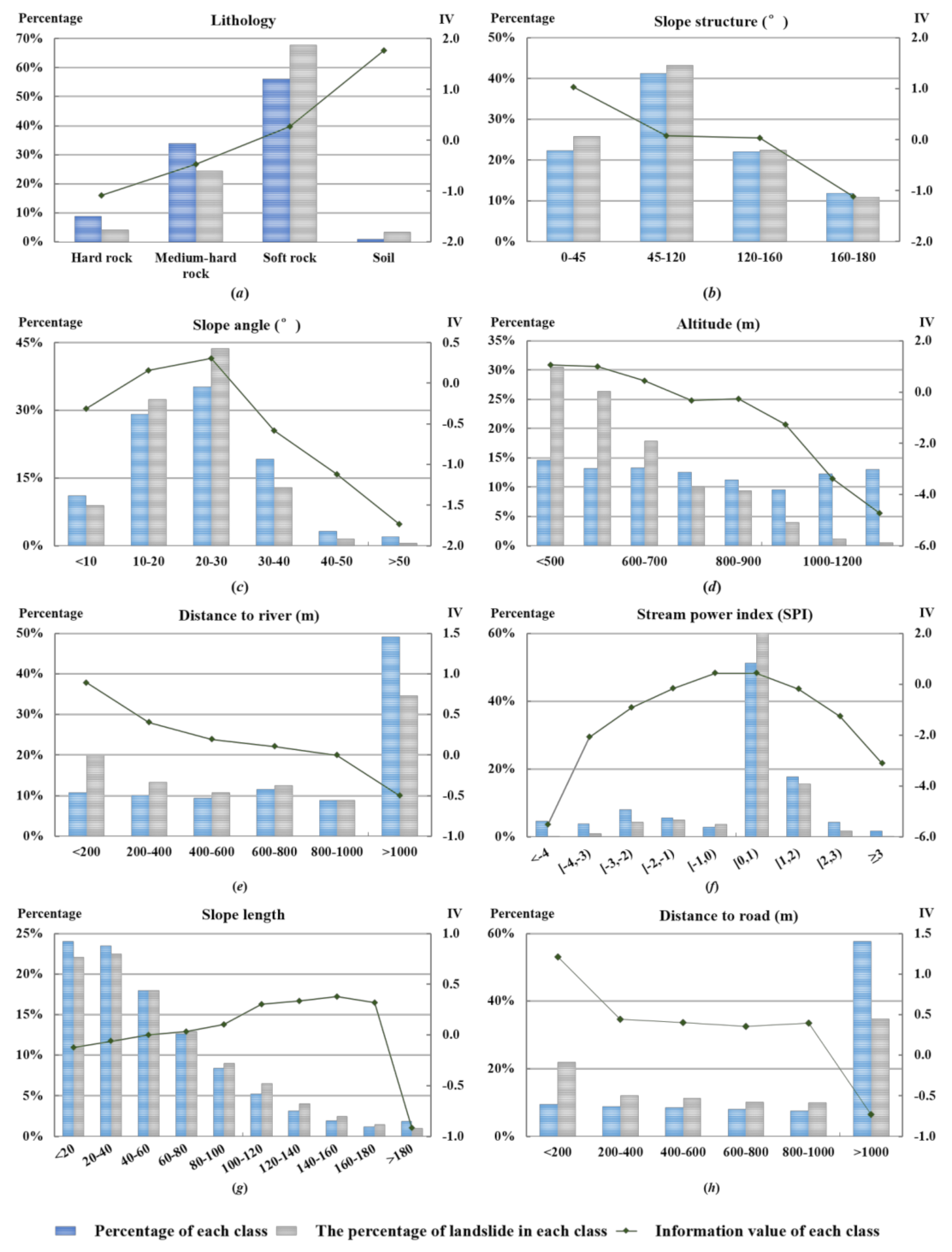
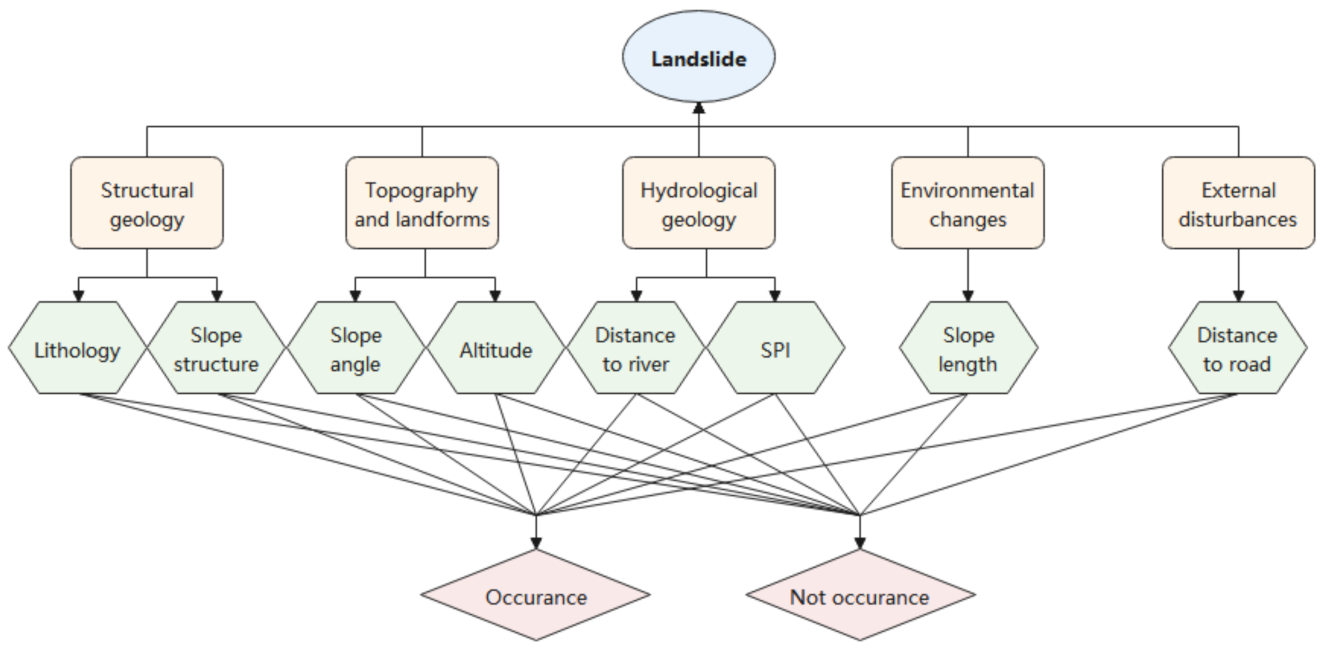
3.3. Conditioning Factors
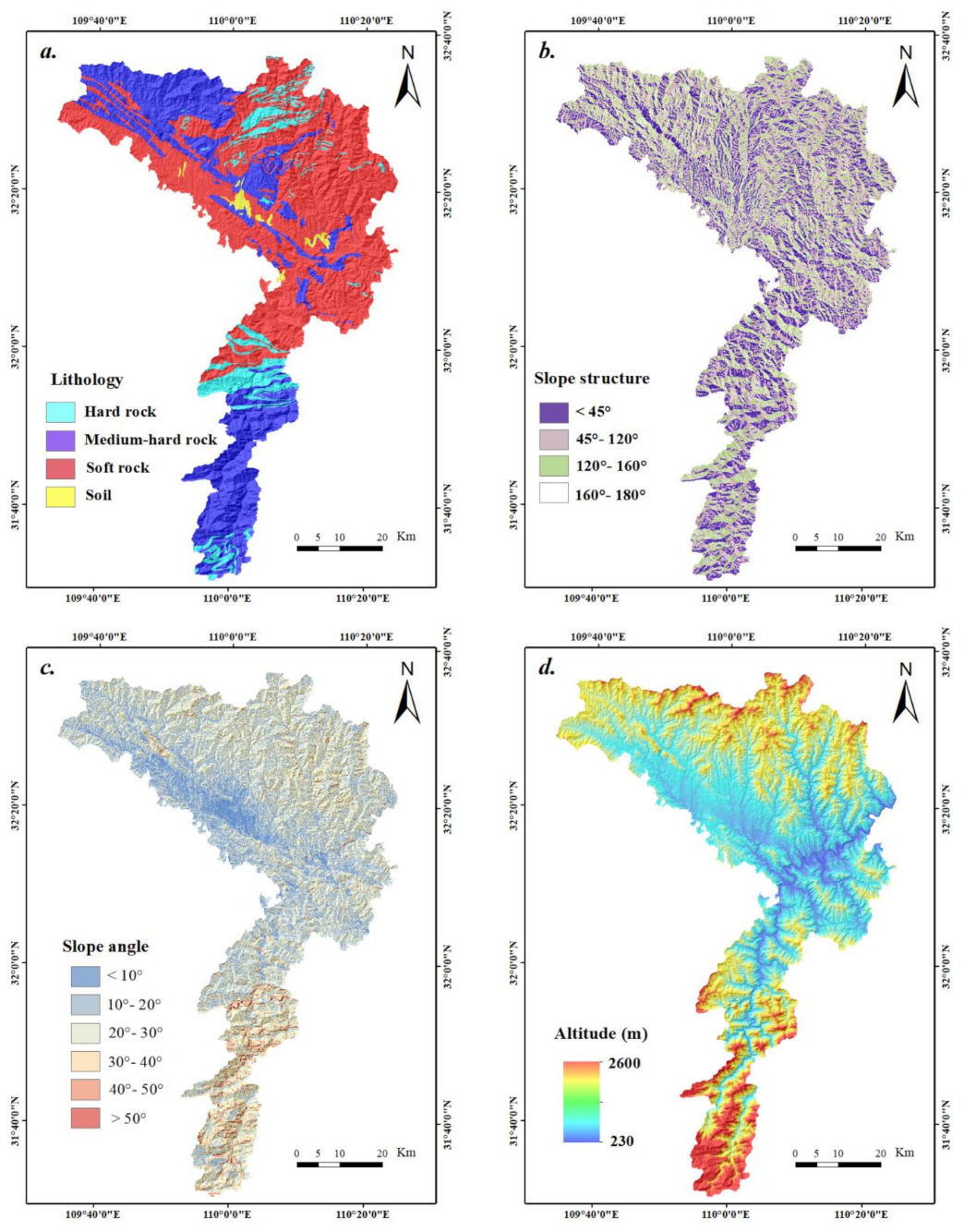
3.4. Lithology
3.5. Slope Structure
3.6. Slope Angle
3.7. Altitude
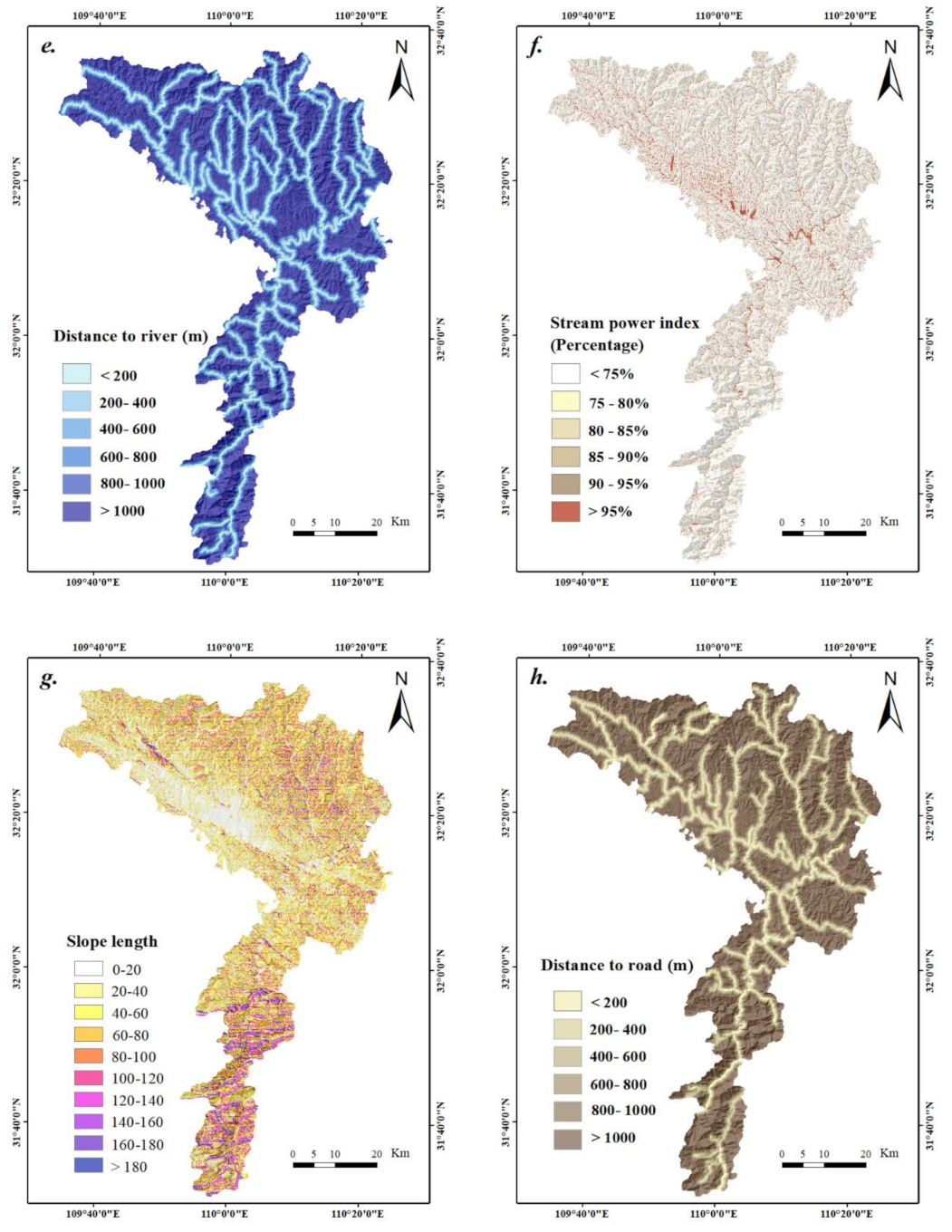
3.8. Distance to River
3.9. Stream Power Index (SPI)
3.10. Slope Length
3.11. Distance to Road
4. Landslide Susceptibility Mapping
4.1. LSM Using LR Model
4.2. LSM Using AHPIV Model
4.3. LSM Using the CLSI Model
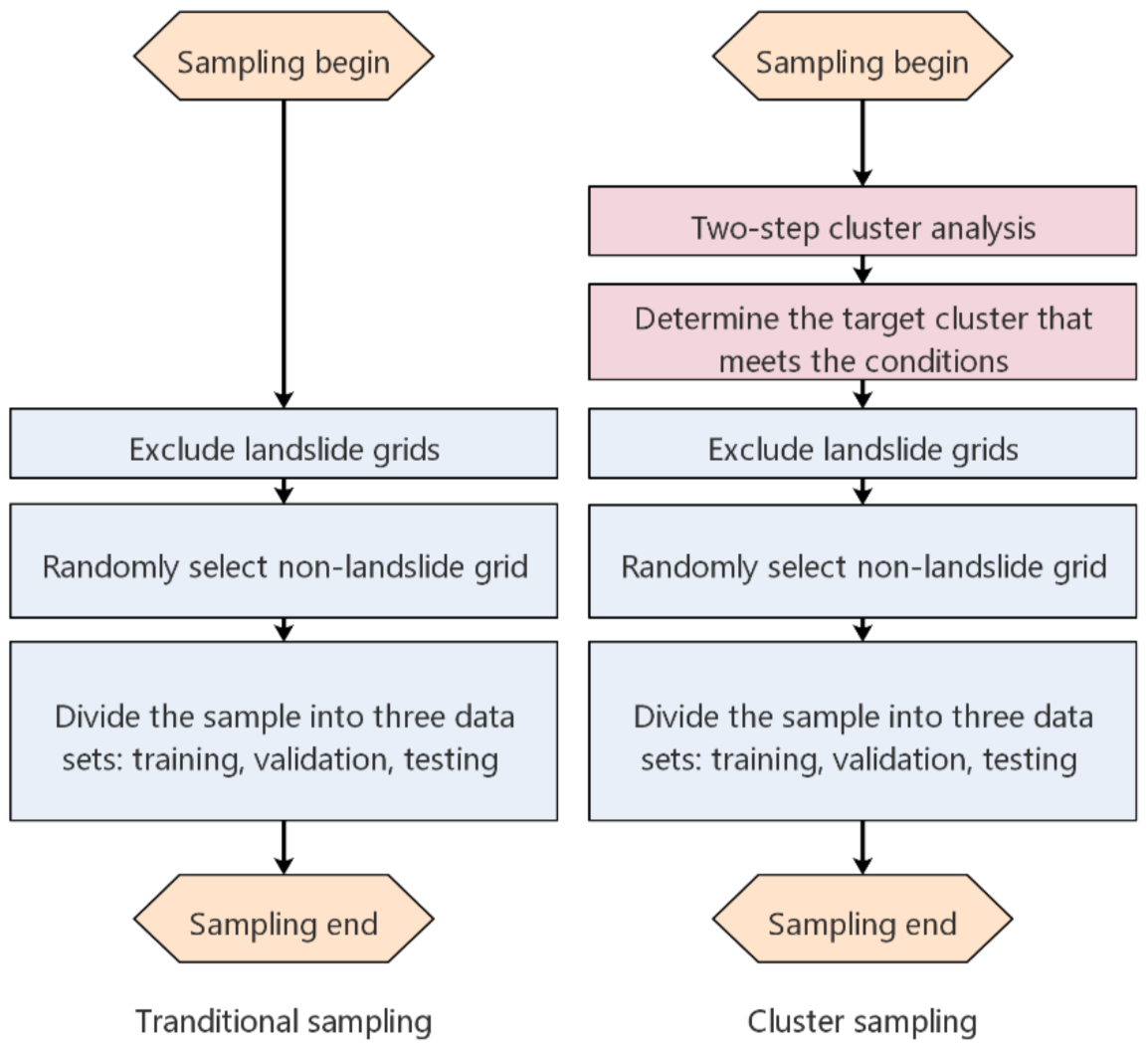
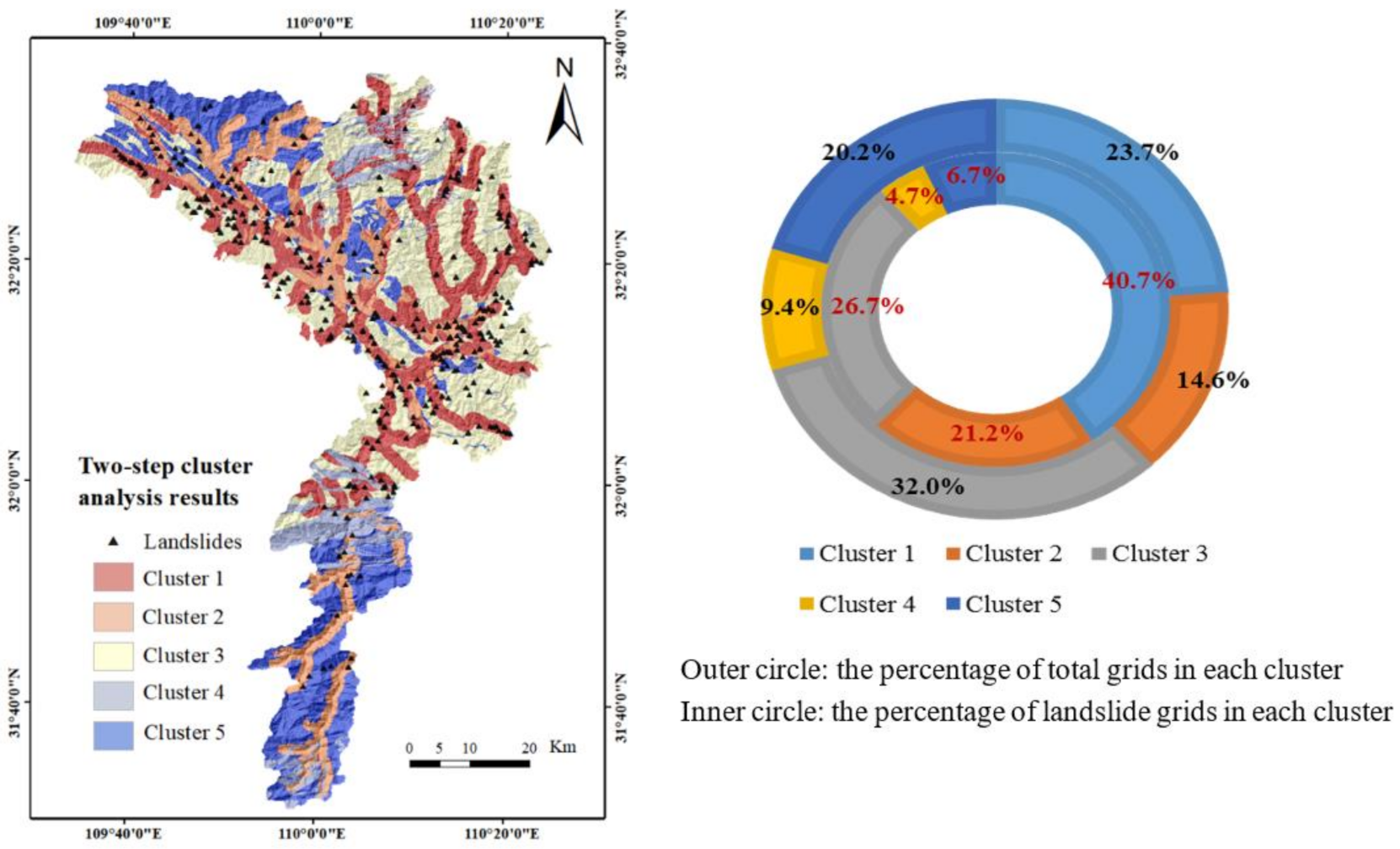
4.3.1. Non-Landslide Area Selection
4.3.2. Weight Determination for Each Factor
4.3.3. Landslide Susceptibility Map
5. Validation and Analysis
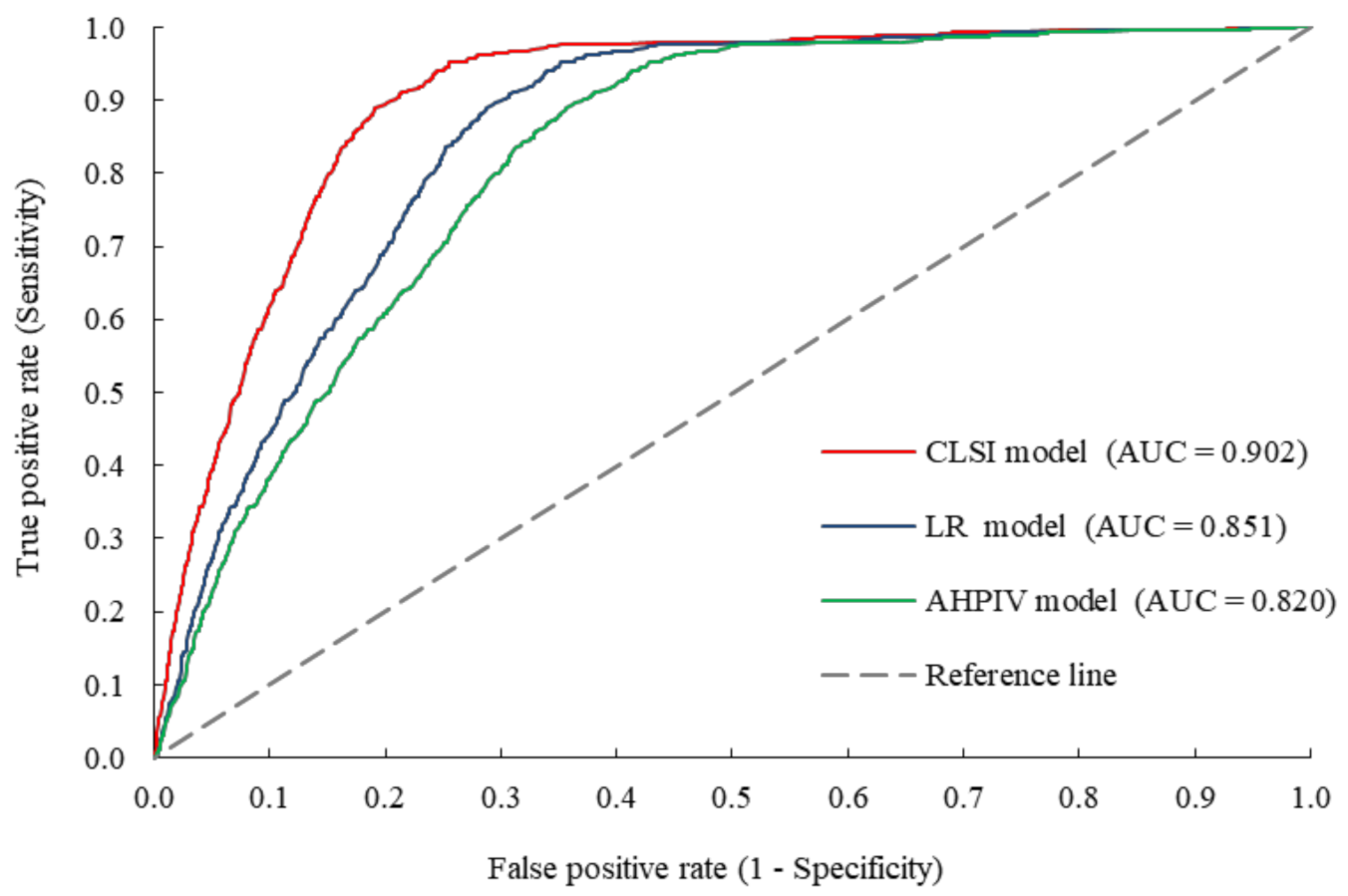
5.1. Validation Based on AUC Accuracy
5.2. Validation Based on Seed Cell Area Index
5.3. Validation Based on Landslide Points
6. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| Acronyms | |
| CA | cluster analysis |
| CF | conditioning factor |
| CR | consistency ratio |
| FR | frequency ratio |
| IV | information value |
| LR | logistic regression |
| LS | landslide susceptibility |
| RI | random consistency index |
| AHP | analytic hierarchy process |
| ANN | artificial neural network |
| AUC | area under receiver operating feature curve |
| DEM | digital elevation model |
| GIS | geographic information system |
| LSI | landslide susceptibility index |
| LSM | landslide susceptibility mapping |
| ROC | receiver operating feature curve |
| SPI | stream power index |
| SVM | support vector machine |
| BPNN | back-propagation neural network |
| CLSI | comprehensive landslide susceptibility index |
| SCAI | seed cell area index |
| TSCA | two-step cluster analysis |
| USLE | revised universal soil loss equation |
| AHPIV | analytic hierarchy process information value |
References
- Nadim, F.; Kjekstad, O.; Peduzzi, P.; Herold, C.; Jaedicke, C. Global landslide and avalanche hotspots. Landslides 2006, 3, 159–173. [Google Scholar] [CrossRef]
- Nhu, V.-H.; Mohammadi, A.; Shahabi, H.; Ahmad, B.B.; Al-Ansari, N.; Shirzadi, A.; Geertsema, M.; Kress, V.R.R.; Karimzadeh, S.; Kamran, K.; et al. Landslide Detection and Susceptibility Modeling on Cameron Highlands (Malaysia): A Comparison between Random Forest, Logistic Regression and Logistic Model Tree Algorithms. Forests 2020, 11, 830. [Google Scholar] [CrossRef]
- Arabameri, A.; Saha, S.; Roy, J.; Chen, W.; Blaschke, T.; Bui, D.T. Landslide Susceptibility Evaluation and Management Using Different Machine Learning Methods in The Gallicash River Watershed, Iran. Remote Sens. 2020, 12, 475. [Google Scholar] [CrossRef]
- Maurizio, L.; Maria, D. A multi temporal kernel density estimation approach for new triggered landslides forecasting and susceptibility assessment. Disaster Adv. 2012, 5, 100–108. [Google Scholar]
- Melchiorre, C.; Matteucci, M.; Azzoni, A.; Zanchi, A. Artificial neural networks and cluster analysis in landslide susceptibility zonation. Geomorphology 2008, 94, 379–400. [Google Scholar] [CrossRef]
- Tang, R.; Kulatilake, P.H.S.W.; Yan, E.-C.; Cai, J.-S. Evaluating landslide susceptibility based on cluster analysis, probabilistic methods, and artificial neural networks. Bull. Int. Assoc. Eng. Geol. 2020, 79, 2235–2254. [Google Scholar] [CrossRef]
- Tang, R. Research on Stability Evaluation of Individual Colluvial Landslides and Regional Landslide Susceptibility Analysis; China University of Geoscience: Wuhan, China, 2017; p. 170. [Google Scholar]
- Du, G.; Zhang, Y.; Yang, Z.; Guo, C.; Yao, X.; Sun, D. Landslide susceptibility mapping in the region of eastern Himalayan syntaxis, Tibetan Plateau, China: A comparison between analytical hierarchy process information value and logistic regression-information value methods. Bull. Int. Assoc. Eng. Geol. 2019, 78, 4201–4215. [Google Scholar] [CrossRef]
- Ayalew, L.; Yamagishi, H.; Marui, H.; Kanno, T. Landslides in Sado Island of Japan: Part II. GIS-based susceptibility mapping with comparisons of results from two methods and verifications. Eng. Geol. 2005, 81, 432–445. [Google Scholar] [CrossRef]
- Wang, L.-J.; Guo, M.; Sawada, K.; Lin, J.; Zhang, J. A comparative study of landslide susceptibility maps using logistic regression, frequency ratio, decision tree, weights of evidence and artificial neural network. Geosci. J. 2016, 20, 117–136. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Pradhan, B.; Gokceoglu, C. Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed, Iran. Nat. Hazards 2012, 63, 965–996. [Google Scholar] [CrossRef]
- Myronidis, D.; Papageorgiou, C.; Theophanous, S. Landslide susceptibility mapping based on landslide history and analytic hierarchy process (AHP). Nat. Hazards 2016, 81, 245–263. [Google Scholar] [CrossRef]
- Moragues, S.; Lenzano, M.G.; Lanfri, M.; Moreiras, S.; Lannutti, E.; Lenzano, L. Analytic hierarchy process applied to landslide susceptibility mapping of the North Branch of Argentino Lake, Argentina. Nat. Hazards 2021, 105, 915–941. [Google Scholar] [CrossRef]
- Kayastha, P.; Dhital, M.; De Smedt, F. Application of the analytical hierarchy process (AHP) for landslide susceptibility mapping: A case study from the Tinau watershed, west Nepal. Comput. Geosci. 2013, 52, 398–408. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Landslide susceptibility assessment in the Hoa Binh province of Vietnam: A comparison of the Levenberg–Marquardt and Bayesian regularized neural networks. Geomorphology 2012, 171–172, 12–29. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S. Delineation of landslide hazard areas on Penang Island, Malaysia, by using frequency ratio, logistic regression, and artificial neural network models. Environ. Earth Sci. 2010, 60, 1037–1054. [Google Scholar] [CrossRef]
- Poudyal, C.P.; Chang, C.; Oh, H.-J.; Lee, S. Landslide susceptibility maps comparing frequency ratio and artificial neural networks: A case study from the Nepal Himalaya. Environ. Earth Sci. 2010, 61, 1049–1064. [Google Scholar] [CrossRef]
- Lee, S.; Sambath, T. Landslide susceptibility mapping in the Damrei Romel area, Cambodia using frequency ratio and logistic regression models. Environ. Earth Sci. 2006, 50, 847–855. [Google Scholar] [CrossRef]
- Aditian, A.; Kubota, T.; Shinohara, Y. Comparison of GIS-based landslide susceptibility models using frequency ratio, logistic regression, and artificial neural network in a tertiary region of Ambon, Indonesia. Geomorphology 2018, 318, 101–111. [Google Scholar] [CrossRef]
- Yao, X.; Tham, L.; Dai, F. Landslide susceptibility mapping based on Support Vector Machine: A case study on natural slopes of Hong Kong, China. Geomorphology 2008, 101, 572–582. [Google Scholar] [CrossRef]
- Wang, J.; Yin, K.; Xiao, L. Landslide Susceptibility Assessment Based on Gis and Weighted Information Valuea: A Case Study of Wanzhou District, Three Gorges Reservoir. Chin. J. Rock Mech. Eng. 2014, 33, 797–808. [Google Scholar]
- Lee, C.F.; Li, J.; Xu, Z.W.; Dai, F.C. Assessment of landslide susceptibility on the natural terrain of Lantau Island, Hong Kong. Environ. Earth Sci. 2001, 40, 381–391. [Google Scholar] [CrossRef]
- Gorsevski, P.V.; Gessler, P.E.; Foltz, R.B.; Elliot, W.J. Spatial Prediction of Landslide Hazard Using Logistic Regression and ROC Analysis. Trans. GIS 2006, 10, 395–415. [Google Scholar] [CrossRef]
- Catani, F.; Casagli, N.; Ermini, L.; Righini, G.; Menduni, G. Landslide hazard and risk mapping at catchment scale in the Arno River basin. Landslides 2005, 2, 329–342. [Google Scholar] [CrossRef]
- Marjanović, M.; Kovačević, M.; Bajat, B.; Voženílek, V. Landslide susceptibility assessment using SVM machine learning algorithm. Eng. Geol. 2011, 123, 225–234. [Google Scholar] [CrossRef]
- Huang, F.; Yin, K.; Huang, J.; Gui, L.; Wang, P. Landslide susceptibility mapping based on self-organizing-map network and extreme learning machine. Eng. Geol. 2017, 223, 11–22. [Google Scholar] [CrossRef]
- Vasu, N.N.; Lee, S.-R. A hybrid feature selection algorithm integrating an extreme learning machine for landslide susceptibility modeling of Mt. Woomyeon, South Korea. Geomorphology 2016, 263, 50–70. [Google Scholar] [CrossRef]
- Liu, C.-N.; Wu, C.-C. Mapping susceptibility of rainfall-triggered shallow landslides using a probabilistic approach. Environ. Earth Sci. 2008, 55, 907–915. [Google Scholar] [CrossRef]
- Wang, W.; He, Z.; Han, Z.; Li, Y.; Dou, J.; Huang, J. Mapping the susceptibility to landslides based on the deep belief network: A case study in Sichuan Province, China. Nat. Hazards 2020, 103, 3239–3261. [Google Scholar] [CrossRef]
- Zhou, S.; Chen, G.; Fang, L.; Nie, Y. GIS-Based Integration of Subjective and Objective Weighting Methods for Regional Landslides Susceptibility Mapping. Sustainability 2016, 8, 334. [Google Scholar] [CrossRef]
- Zhang, G.; Cai, Y.; Zheng, Z.; Zhen, J.; Liu, Y.; Huang, K. Integration of the Statistical Index Method and the Analytic Hierarchy Process technique for the assessment of landslide susceptibility in Huizhou, China. Catena 2016, 142, 233–244. [Google Scholar] [CrossRef]
- Umar, Z.; Pradhan, B.; Ahmad, A.; Jebur, M.N.; Tehrany, M.S. Earthquake induced landslide susceptibility mapping using an integrated ensemble frequency ratio and logistic regression models in West Sumatera Province, Indonesia. Catena 2014, 118, 124–135. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pradhan, B.; Jebur, M.N.; El-Harbi, H.M. Landslide susceptibility mapping using ensemble bivariate and multivariate statistical models in Fayfa area, Saudi Arabia. Environ. Earth Sci. 2015, 73, 3745–3761. [Google Scholar] [CrossRef]
- Du, G.-L.; Zhang, Y.-S.; Iqbal, J.; Yang, Z.-H.; Yao, X. Landslide susceptibility mapping using an integrated model of information value method and logistic regression in the Bailongjiang watershed, Gansu Province, China. J. Mt. Sci. 2017, 14, 249–268. [Google Scholar] [CrossRef]
- Fang, Z.; Wang, Y.; Peng, L.; Hong, H. Integration of convolutional neural network and conventional machine learning classifiers for landslide susceptibility mapping. Comput. Geosci. 2020, 139, 104470. [Google Scholar] [CrossRef]
- Kanungo, D.; Arora, M.; Sarkar, S.; Gupta, R. A comparative study of conventional, ANN black box, fuzzy and combined neural and fuzzy weighting procedures for landslide susceptibility zonation in Darjeeling Himalayas. Eng. Geol. 2006, 85, 347–366. [Google Scholar] [CrossRef]
- Chen, T.; Niu, R.; Jia, X. A comparison of information value and logistic regression models in landslide susceptibility mapping by using GIS. Environ. Earth Sci. 2016, 75, 867. [Google Scholar] [CrossRef]
- Nefeslioglu, H.A.; Gokceoglu, C.; Sonmez, H. An assessment on the use of logistic regression and artificial neural networks with different sampling strategies for the preparation of landslide susceptibility maps. Eng. Geol. 2008, 97, 171–191. [Google Scholar] [CrossRef]
- Yilmaz, I. Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: A case study from Kat landslides (Tokat—Turkey). Comput. Geosci. 2009, 35, 1125–1138. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar] [CrossRef]
- Zhang, Y.; Ge, T.; Tian, W.; Liou, Y.-A. Debris Flow Susceptibility Mapping Using Machine-Learning Techniques in Shigatse Area, China. Remote Sens. 2019, 11, 2801. [Google Scholar] [CrossRef]
- Huang, F.; Cao, Z.; Guo, J.; Jiang, S.-H.; Li, S.; Guo, Z. Comparisons of heuristic, general statistical and machine learning models for landslide susceptibility prediction and mapping. Catena 2020, 191, 104580. [Google Scholar] [CrossRef]
- Nhu, V.-H.; Zandi, D.; Shahabi, H.; Chapi, K.; Shirzadi, A.; Al-Ansari, N.; Singh, S.K.; Dou, J.; Nguyen, H. Comparison of Support Vector Machine, Bayesian Logistic Regression, and Alternating Decision Tree Algorithms for Shallow Landslide Susceptibility Mapping along a Mountainous Road in the West of Iran. Appl. Sci. 2020, 10, 5047. [Google Scholar] [CrossRef]
- Cross, M. Landslide susceptibility mapping using the Matrix Assessment Approach: A Derbyshire case study. Geol. Soc. Eng. Geol. Spec. Publ. 1998, 15, 247–261. [Google Scholar] [CrossRef]
- Lee, S.; Ryu, J.-H.; Kim, I.-S. Landslide susceptibility analysis and its verification using likelihood ratio, logistic regression, and artificial neural network models: Case study of Youngin, Korea. Landslides 2007, 4, 327–338. [Google Scholar] [CrossRef]
- Mondal, S.; Maiti, R. Integrating the Analytical Hierarchy Process (AHP) and the frequency ratio (FR) model in landslide susceptibility mapping of Shiv-khola watershed, Darjeeling Himalaya. Int. J. Disaster Risk Sci. 2013, 4, 200–212. [Google Scholar] [CrossRef]
- Saaty, R.W. The Analytic Hierarchy Process: Planning, Priority Setting, Resource Allocation (Decision Making Series). Math. Model. 1980, 287. [Google Scholar] [CrossRef]
- Saaty, T.L. Fundamentals of the analytic network process—Dependence and feedback in decision-making with a single network. J. Syst. Sci. Syst. Eng. 2004, 13, 129–157. [Google Scholar] [CrossRef]
- Li, D.; Huang, F.; Yan, L.; Cao, Z.; Chen, J.; Ye, Z. Landslide Susceptibility Prediction Using Particle-Swarm-Optimized Multilayer Perceptron: Comparisons with Multilayer-Perceptron-Only, BP Neural Network, and Information Value Models. Appl. Sci. 2019, 9, 3664. [Google Scholar] [CrossRef]
- Sharma, L.P.; Patel, N.; Ghose, M.K.; Debnath, P. Development and application of Shannon’s entropy integrated information value model for landslide susceptibility assessment and zonation in Sikkim Himalayas in India. Nat. Hazards 2015, 75, 1555–1576. [Google Scholar] [CrossRef]
- Zhou, W. Verification of the nonparametric characteristics of backpropagation neural networks for image classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 771–779. [Google Scholar] [CrossRef]
- Lee, S.; Ryu, J.-H.; Won, J.-S.; Park, H.-J. Determination and application of the weights for landslide susceptibility mapping using an artificial neural network. Eng. Geol. 2004, 71, 289–302. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S. Landslide susceptibility assessment and factor effect analysis: Backpropagation artificial neural networks and their comparison with frequency ratio and bivariate logistic regression modelling. Environ. Model. Softw. 2010, 25, 747–759. [Google Scholar] [CrossRef]
- He, S.; Pan, P.; Dai, L.; Wang, H.; Liu, J. Application of kernel-based Fisher discriminant analysis to map landslide susceptibility in the Qinggan River delta, Three Gorges, China. Geomorphology 2012, 171–172, 30–41. [Google Scholar] [CrossRef]
- Wu, X.; Ren, F.; Niu, R. Landslide susceptibility assessment using object mapping units, decision tree, and support vector machine models in the Three Gorges of China. Environ. Earth Sci. 2014, 71, 4725–4738. [Google Scholar] [CrossRef]
- Lin, G.-F.; Chang, M.-J.; Huang, Y.-C.; Ho, J.-Y. Assessment of susceptibility to rainfall-induced landslides using improved self-organizing linear output map, support vector machine, and logistic regression. Eng. Geol. 2017, 224, 62–74. [Google Scholar] [CrossRef]
- Wang, J. Landslide Risk Assessment in Wanzhou County, Three Gorges Reservoir. Ph.D. Thesis, China University of Geosciences, Wuhan, China, 2015; p. 166. [Google Scholar]
- Anbalagan, R. Landslide hazard evaluation and zonation mapping in mountainous terrain. Eng. Geol. 1992, 32, 269–277. [Google Scholar] [CrossRef]
- Guzzetti, F.; Carrara, A.; Cardinali, M.; Reichenbach, P. Landslide hazard evaluation: A review of current techniques and their application in a multi-scale study, Central Italy. Geomorphology 1999, 31, 181–216. [Google Scholar] [CrossRef]
- Jakob, M. The impacts of logging on landslide activity at Clayoquot Sound, British Columbia. Catena 2000, 38, 279–300. [Google Scholar] [CrossRef]
- Pachauri, A.; Pant, M. Landslide hazard mapping based on geological attributes. Eng. Geol. 1992, 32, 81–100. [Google Scholar] [CrossRef]
- Akgun, A. A comparison of landslide susceptibility maps produced by logistic regression, multi-criteria decision, and likelihood ratio methods: A case study at İzmir, Turkey. Landslides 2012, 9, 93–106. [Google Scholar] [CrossRef]
- Ding, M.; Hu, K. Susceptibility mapping of landslides in Beichuan County using cluster and MLC methods. Nat. Hazards 2014, 70, 755–766. [Google Scholar] [CrossRef]
- Motamedi, M.; Liang, R.Y. Probabilistic landslide hazard assessment using Copula modeling technique. Landslides 2014, 11, 565–573. [Google Scholar] [CrossRef]
- Ercanoglu, M.; Gokceoglu, C.; Van Asch, T.W.J. Landslide Susceptibility Zoning of North of Yenice (NW Turkey) by Multivariate Statistical Techniques. Nat. Hazards 2004, 32, 1–23. [Google Scholar] [CrossRef]
- Shahabi, H.; Hashim, M. Landslide susceptibility mapping using GIS-based statistical models and Remote sensing data in tropical environment. Sci. Rep. 2015, 5, 9899. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Guo, Q.; Li, Z.; Xiao, J.; Qin, Y.; Chen, D.; Kong, C. Landslide susceptibility evaluation based on BPNN and GIS: A case of Guojiaba in the Three Gorges Reservoir Area. Int. J. Geogr. Inf. Sci. 2015, 29, 1111–1124. [Google Scholar] [CrossRef]
- Regmi, A.D.; Yoshida, K.; Pourghasemi, H.R.; Dhital, M.R.; Pradhan, B. Landslide susceptibility mapping along Bhalubang—Shiwapur area of mid-Western Nepal using frequency ratio and conditional probability models. J. Mt. Sci. 2014, 11, 1266–1285. [Google Scholar] [CrossRef]
- Pérez-Peña, J.V.; Azañón, J.M.; Azor, A.; Delgado, J.; González-Lodeiro, F. Spatial analysis of stream power using GIS: SLk anomaly maps. Earth Surf. Process. Landf. 2009, 34, 16–25. [Google Scholar] [CrossRef]
- Hickey, R. Slope Angle and Slope Length Solutions for GIS. Cartography 2000, 29, 1–8. [Google Scholar] [CrossRef]
- Gómez, H.; Kavzoglu, T. Assessment of shallow landslide susceptibility using artificial neural networks in Jabonosa River Basin, Venezuela. Eng. Geol. 2005, 78, 11–27. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Sahin, E.K.; Colkesen, I. Landslide susceptibility mapping using GIS-based multi-criteria decision analysis, support vector machines, and logistic regression. Landslides 2013, 11, 425–439. [Google Scholar] [CrossRef]
- Chaplot, V.; Le Bissonnais, Y. Field measurements of interrill erosion under different slopes and plot sizes. Earth Surf. Process. Landf. 2000, 25, 145–153. [Google Scholar] [CrossRef]
- Liu, B.Y.; Nearing, M.A.; Shi, P.J.; Jia, Z.W. Slope Length Effects on Soil Loss for Steep Slopes. Soil Sci. Soc. Am. J. 2000, 64, 1759–1763. [Google Scholar] [CrossRef]
- Conforti, M.; Aucelli, P.P.C.; Robustelli, G.; Scarciglia, F. Geomorphology and GIS analysis for mapping gully erosion susceptibility in the Turbolo stream catchment (Northern Calabria, Italy). Nat. Hazards 2011, 56, 881–898. [Google Scholar] [CrossRef]
- Lai, T.; Dragićević, S.; Schmidt, M. Integration of multicriteria evaluation and cellular automata methods for landslide simulation modelling. Geomat. Nat. Hazards Risk 2013, 4, 355–375. [Google Scholar] [CrossRef]
- Lee, S.; Talib, J.A. Probabilistic landslide susceptibility and factor effect analysis. Environ. Earth Sci. 2005, 47, 982–990. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Kolmogorov’s Mapping Neural Network Existence Theorem. In Proceedings of the International Conference on Neural Networks, San Diego, CA, USA, 21 June 1987; IEEE Press: New York, NY, USA, 1987; Volume 3, pp. 11–14. [Google Scholar]
- Lawrence, J.; Fredrickson, J. Brainmaker User’s Guide and Reference Manual. 1998. Available online: https://www.amazon.com/BrainMaker-Network-Simulation-Software-Reference/dp/B006K16WKU (accessed on 18 December 2017).
- Baum, E.B.; Haussler, D. What Size Net Gives Valid Generalization? Neural Comput. 1989, 1, 151–160. [Google Scholar] [CrossRef]
- Kulatilake, P.; Qiong, W.; Hudaverdi, T.; Kuzu, C. Mean particle size prediction in rock blast fragmentation using neural networks. Eng. Geol. 2010, 114, 298–311. [Google Scholar] [CrossRef]
- Chen, W.; Chen, Y.; Tsangaratos, P.; Ilia, I.; Wang, X. Combining Evolutionary Algorithms and Machine Learning Models in Landslide Susceptibility Assessments. Remote Sens. 2020, 12, 3854. [Google Scholar] [CrossRef]
- Süzen, M.L.; Doyuran, V. A comparison of the GIS based landslide susceptibility assessment methods: Multivariate versus bivariate. Environ. Geol. 2004, 45, 665–679. [Google Scholar] [CrossRef]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; ThaiPham, B.; Bui, D.T.; Avtar, R.; Abderrahmane, B. Machine learning methods for landslide susceptibility studies: A comparative overview of algorithm performance. Earth Sci. Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Banerjee, P.; Ghose, M.K.; Pradhan, R. Analytic hierarchy process and information value method-based landslide susceptibility mapping and vehicle vulnerability assessment along a highway in Sikkim Himalaya. Arab. J. Geosci. 2018, 11, 139. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RI | 0 | 0 | 0.58 | 0.90 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 | 1.49 | 1.51 | 1.53 | 1.56 | 1.57 | 1.59 |
| First-Level | Structural Geology | Topography and Landforms | Hydrological Geology | Environmental Changes | External Disturbances |
|---|---|---|---|---|---|
| Structural geology | 1 | 4 | 3 | 2 | 1 |
| Topography and landforms | 1/4 | 1 | 2 | 2 | 1/3 |
| Hydrogeological geology | 1/3 | 1/2 | 1 | 3 | 1/2 |
| Environmental changes | 1/2 | 1/2 | 1/3 | 1 | 1/2 |
| External disturbances | 1 | 3 | 2 | 2 | 1 |
| Structural Geology | Lithology | Slope Structure |
| Lithology | 1 | 3 |
| Slope structure | 1/3 | 1 |
| Topography and Landforms | Slope angle | Altitude |
| Slope angle | 1 | 2 |
| Altitude | 1/2 | 1 |
| Hydrological Geology | Distance to river | SPI |
| Distance to river | 1 | 1/2 |
| SPI | 2 | 1 |
| Conditioning Factor | Lithology | Slope Structure | Slope Angle | Altitude | Distance to River | SPI | Slope Length | Distance to Road |
|---|---|---|---|---|---|---|---|---|
| (W1) | (W2) | (W3) | (W4) | (W5) | (W6) | (W7) | (W8) | |
| Weight | 0.2512 | 0.0837 | 0.0979 | 0.0490 | 0.0464 | 0.0929 | 0.0968 | 0.2821 |
| Conditioning Factor | Classes | Total Grid Cells (Tim) | Landslide Grid Cells (Lim) | aim (%) | bim (%) | FR Rim | Ii |
|---|---|---|---|---|---|---|---|
| Lithology (W1) | Hard rock | 124,990 | 42 | 4.16 | 8.85 | 0.47 | −1.09 |
| Medium-hard rock | 480,072 | 248 | 24.55 | 33.97 | 0.72 | −0.47 | |
| Soft rock | 794,086 | 685 | 67.82 | 56.17 | 1.21 | 0.27 | |
| Soil | 14,460 | 35 | 3.47 | 1.02 | 3.39 | 1.76 | |
| Slope structure (W2) | <45° | 155,227 | 226 | 22.38 | 10.97 | 2.04 | 1.03 |
| 45–120° | 582,184 | 437 | 43.27 | 41.18 | 1.05 | 0.07 | |
| 120–160° | 311,450 | 227 | 22.48 | 22.03 | 1.02 | 0.03 | |
| 160–180° | 364,747 | 120 | 11.88 | 25.81 | 0.46 | −1.12 | |
| Slope angle (W3) | <10° | 156,748 | 90 | 8.91 | 11.09 | 0.80 | −0.32 |
| 10–20° | 412,342 | 328 | 32.48 | 29.17 | 1.11 | 0.15 | |
| 20–30° | 498,615 | 441 | 43.66 | 35.27 | 1.24 | 0.31 | |
| 30–40° | 272,172 | 130 | 12.87 | 19.26 | 0.67 | −0.58 | |
| 40–50° | 45,756 | 15 | 1.49 | 3.24 | 0.46 | −1.12 | |
| >50° | 27,975 | 6 | 0.59 | 1.98 | 0.30 | −1.74 | |
| Altitude (W4) | <500 | 207,120 | 308 | 30.50 | 14.64 | 2.08 | 1.06 |
| 500–600 | 186,742 | 267 | 26.44 | 13.20 | 2.00 | 1.00 | |
| 600–700 | 187,723 | 181 | 17.92 | 13.28 | 1.35 | 0.43 | |
| 700–800 | 178,184 | 102 | 10.10 | 12.61 | 0.80 | −0.32 | |
| 800–900 | 159,811 | 95 | 9.41 | 11.31 | 0.83 | −0.27 | |
| 900–1000 | 135,327 | 40 | 3.96 | 9.58 | 0.41 | −1.27 | |
| 1000–1200 | 174,245 | 12 | 1.19 | 12.33 | 0.10 | −3.37 | |
| >1200 | 184,456 | 5 | 0.50 | 13.06 | 0.04 | −4.72 | |
| Distance to river (W5) | <200 | 151,769 | 201 | 19.90 | 10.73 | 1.85 | 0.89 |
| 200–400 | 142,958 | 135 | 13.37 | 10.11 | 1.32 | 0.40 | |
| 400–600 | 133,464 | 109 | 10.79 | 9.44 | 1.14 | 0.19 | |
| 600–800 | 164,189 | 126 | 12.48 | 11.61 | 1.07 | 0.10 | |
| 800–1000 | 124,826 | 89 | 8.81 | 8.83 | 1.00 | 0.00 | |
| >1000 | 696,402 | 350 | 34.65 | 49.27 | 0.70 | −0.51 | |
| SPI (W6) | <−4 | 64,980 | 1 | 0.10 | 4.60 | 0.02 | −5.54 |
| [−4,−3) | 53,501 | 9 | 0.89 | 3.79 | 0.24 | −2.09 | |
| [−3,−2) | 114,181 | 43 | 4.26 | 8.08 | 0.53 | −0.92 | |
| [−2,−1) | 79,720 | 50 | 4.95 | 5.64 | 0.88 | −0.19 | |
| [−1,0) | 39,862 | 38 | 3.76 | 2.82 | 1.33 | 0.42 | |
| [0,1) | 724,507 | 692 | 68.51 | 51.24 | 1.34 | 0.42 | |
| [1,2) | 251,458 | 157 | 15.54 | 17.79 | 0.87 | −0.19 | |
| [2,3) | 60,901 | 18 | 1.78 | 4.31 | 0.41 | −1.27 | |
| ≥3 | 24,498 | 2 | 0.20 | 1.73 | 0.11 | −3.13 | |
| Slope length (W7) | <20 | 340,160 | 223 | 22.08 | 24.06 | 0.92 | −0.12 |
| 20–40 | 332,350 | 228 | 22.57 | 23.51 | 0.96 | −0.06 | |
| 40–60 | 254,211 | 182 | 18.02 | 17.98 | 1.00 | 0.00 | |
| 60–80 | 178,444 | 130 | 12.87 | 12.62 | 1.02 | 0.03 | |
| 80–100 | 118,495 | 91 | 9.01 | 8.38 | 1.07 | 0.10 | |
| 100–120 | 74,451 | 66 | 6.53 | 5.27 | 1.24 | 0.31 | |
| 120–140 | 44,743 | 40 | 3.96 | 3.16 | 1.25 | 0.32 | |
| 140–160 | 27,200 | 25 | 2.48 | 1.92 | 1.29 | 0.36 | |
| 160–180 | 16,913 | 15 | 1.49 | 1.20 | 1.24 | 0.31 | |
| >180 | 26,641 | 10 | 0.99 | 1.89 | 0.53 | −0.93 | |
| Distance to road (W8) | <200 | 133,540 | 221 | 21.88 | 9.44 | 2.32 | 1.21 |
| 200–400 | 125,709 | 122 | 12.08 | 8.89 | 1.36 | 0.44 | |
| 400–600 | 119,462 | 113 | 11.19 | 8.45 | 1.32 | 0.40 | |
| 600–800 | 112,835 | 103 | 10.20 | 7.98 | 1.28 | 0.35 | |
| 800–1000 | 106,124 | 100 | 9.90 | 7.51 | 1.32 | 0.40 | |
| >1000 | 815,938 | 351 | 34.75 | 57.74 | 0.60 | −0.73 |
| Cluster Number | 1 | 2 | 3 | 4 | 5 | Total in the Study Area |
|---|---|---|---|---|---|---|
| Number of landslide grid cells | 411 | 214 | 270 | 47 | 68 | 1010 |
| Number of non-landslide grid cells | 334,504 | 206,144 | 452,506 | 133,266 | 286,178 | 1,412,598 |
| Total number of grid cells | 334,915 | 206,358 | 452,776 | 133,313 | 286,246 | 1,413,608 |
| Sampling condition 1 () | 0.41 | 0.21 | 0.27 | 0.05 | 0.07 | |
| Sampling condition 2 () | 1.72 | 1.45 | 0.83 | 0.49 | 0.33 |
| Table 1 | Training Method | Epochs | Learning Rate | RMSE Goal | |
|---|---|---|---|---|---|
| Hidden (f1) | Output (f2) | ||||
| Logsig | Purelin | LM | 1000 | 0.01 | 0.01 |
| Conditioning Factor | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | COV | Mean | Weight |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lithology | 1.653 | 1.655 | 1.661 | 1.687 | 1.618 | 1.646 | 1.871 | 1.875 | 1.715 | 1.744 | 0.0921 | 1.71 | 2.35 |
| Slope structure | 0.728 | 0.731 | 0.749 | 0.762 | 0.777 | 0.785 | 0.829 | 0.838 | 0.912 | 0.946 | 0.0749 | 0.81 | 1.10 |
| Slope angle | 1.110 | 1.018 | 1.087 | 1.119 | 1.121 | 1.130 | 1.246 | 1.264 | 1.297 | 1.198 | 0.0885 | 1.16 | 1.59 |
| Altitude | 0.774 | 0.778 | 0.854 | 0.895 | 0.928 | 0.939 | 0.948 | 0.977 | 0.983 | 0.998 | 0.0814 | 0.91 | 1.24 |
| Distance to river | 0.800 | 0.803 | 0.770 | 0.793 | 0.799 | 0.839 | 0.853 | 0.854 | 0.896 | 0.900 | 0.0446 | 0.83 | 1.14 |
| SPI | 0.650 | 0.683 | 0.688 | 0.695 | 0.719 | 0.740 | 0.749 | 0.749 | 0.805 | 0.826 | 0.0552 | 0.73 | 1.00 |
| Slope length | 0.647 | 0.662 | 0.678 | 0.709 | 0.723 | 0.731 | 0.782 | 0.798 | 0.813 | 0.826 | 0.0645 | 0.74 | 1.01 |
| Distance to road | 1.391 | 1.409 | 1.412 | 1.488 | 1.409 | 1.538 | 1.438 | 1.445 | 1.460 | 1.483 | 0.0455 | 1.45 | 1.98 |
| LSM Model | Class | Number of Total Grid Cells | Area (%) | Number of Landslide Grid Cells | Seed (%) | SCAI | D-Value |
|---|---|---|---|---|---|---|---|
| LR model | Very high | 156,409 | 11.06% | 325 | 32.18% | 0.34 | |
| 0.31 | |||||||
| High | 414,279 | 29.31% | 455 | 45.05% | 0.65 | ||
| 0.62 | |||||||
| Moderate | 217,990 | 15.42% | 123 | 12.18% | 1.27 | ||
| 1.24 | |||||||
| Low | 203,160 | 14.37% | 58 | 5.74% | 2.50 | ||
| 3.65 | |||||||
| Very low | 421,770 | 29.84% | 49 | 4.85% | 6.15 | ||
| AHPIV model | Very high | 54,789 | 3.88% | 153 | 15.15% | 0.26 | |
| 0.24 | |||||||
| High | 264,874 | 18.74% | 385 | 38.12% | 0.49 | ||
| 0.36 | |||||||
| Moderate | 372,714 | 26.37% | 313 | 30.99% | 0.85 | ||
| 1.30 | |||||||
| Low | 427,744 | 30.26% | 142 | 14.06% | 2.15 | ||
| 10.18 | |||||||
| Very low | 293,487 | 20.76% | 17 | 1.68% | 12.33 | ||
| CLSI model | Very high | 139,830 | 9.89% | 306 | 30.30% | 0.33 | |
| 0.32 | |||||||
| High | 380,421 | 26.91% | 418 | 41.39% | 0.65 | ||
| 0.47 | |||||||
| Moderate | 329,194 | 23.29% | 210 | 20.79% | 1.12 | ||
| 2.32 | |||||||
| Low | 288,611 | 20.42% | 60 | 5.94% | 3.44 | ||
| 8.87 | |||||||
| Very low | 275,552 | 19.49% | 16 | 1.58% | 12.30 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, R.-X.; Yan, E.-C.; Wen, T.; Yin, X.-M.; Tang, W. Comparison of Logistic Regression, Information Value, and Comprehensive Evaluating Model for Landslide Susceptibility Mapping. Sustainability 2021, 13, 3803. https://doi.org/10.3390/su13073803
Tang R-X, Yan E-C, Wen T, Yin X-M, Tang W. Comparison of Logistic Regression, Information Value, and Comprehensive Evaluating Model for Landslide Susceptibility Mapping. Sustainability. 2021; 13(7):3803. https://doi.org/10.3390/su13073803
Chicago/Turabian StyleTang, Rui-Xuan, E-Chuan Yan, Tao Wen, Xiao-Meng Yin, and Wei Tang. 2021. "Comparison of Logistic Regression, Information Value, and Comprehensive Evaluating Model for Landslide Susceptibility Mapping" Sustainability 13, no. 7: 3803. https://doi.org/10.3390/su13073803
APA StyleTang, R.-X., Yan, E.-C., Wen, T., Yin, X.-M., & Tang, W. (2021). Comparison of Logistic Regression, Information Value, and Comprehensive Evaluating Model for Landslide Susceptibility Mapping. Sustainability, 13(7), 3803. https://doi.org/10.3390/su13073803