
Deep Reinforcement Learning-Based Robotic Grasping in Clutter and Occlusion

 ,
,  , , ,
, , ,  and
and 
Abstract
:1. Introduction
- Using multiple views to maximize grasp efficiency in both cluttered and occluded environments;
- Establishing a robust change observation for coordinating the execution of primitive grasp and push actions through a fully self-supervised learning manner;
- Incorporating a multi-view and change observation-based approach to perform push and grasp actions in wide scenarios;
- The learning of MV-COBA is entirely self-supervised, and its performance is validated via simulation.
2. Related Works
2.1. Single View with Grasp-Only Policy
2.2. Suction and Multifunctional Gripper-Based Grasping
2.3. Synergizing Two Primitive Actions
2.4. Multi-View-Based Grasping
2.5. The Knowledge Gap
3. Problem Definitions
The MV-COBA’s Motivation
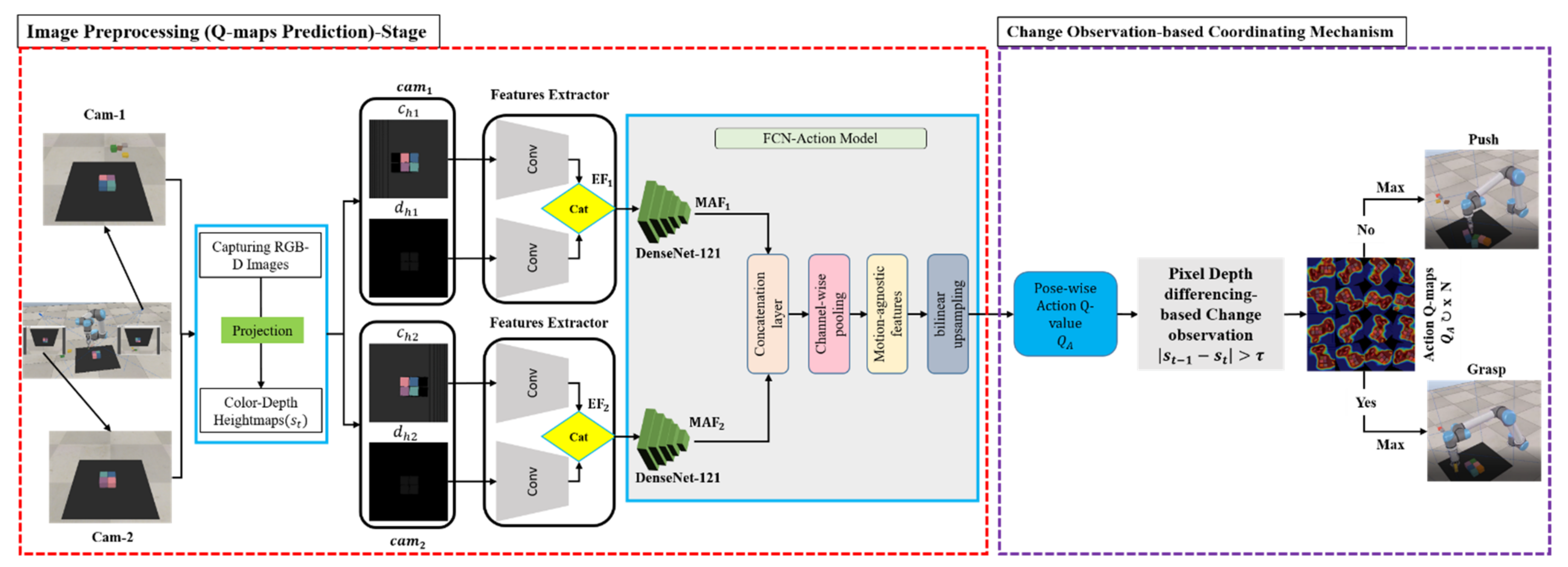
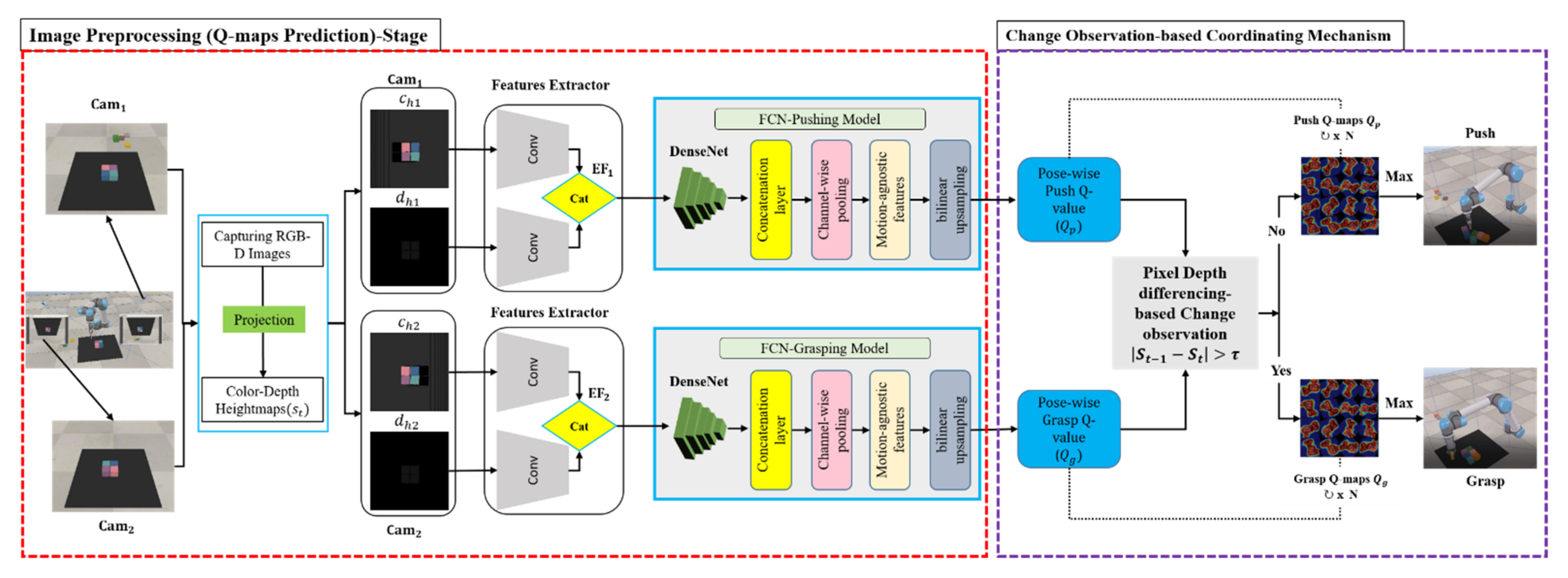
4. Methodology
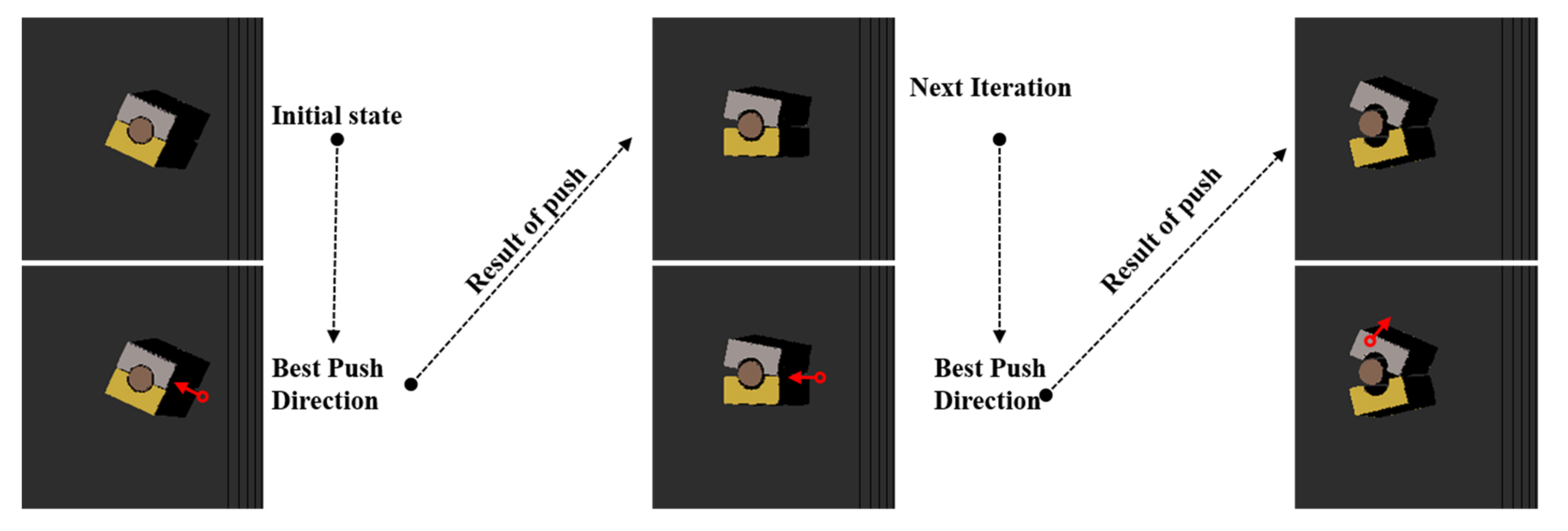
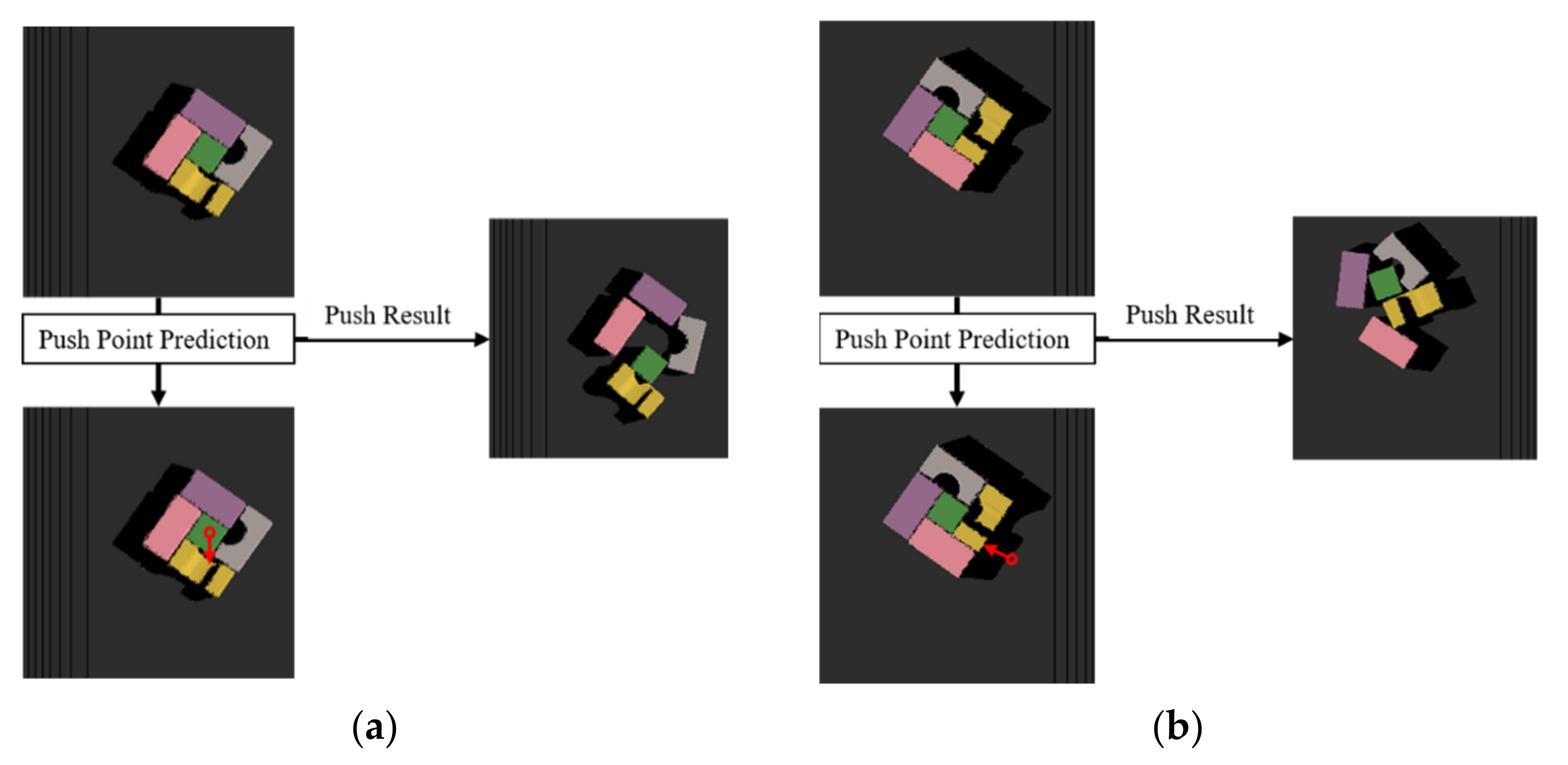
4.1. Change Observation
4.2. Grasp and Push Action Execution
4.3. Problem Formulation
4.4. MV-COBA Overview
5. Simulation of Experiments
5.1. Baseline Comparisons
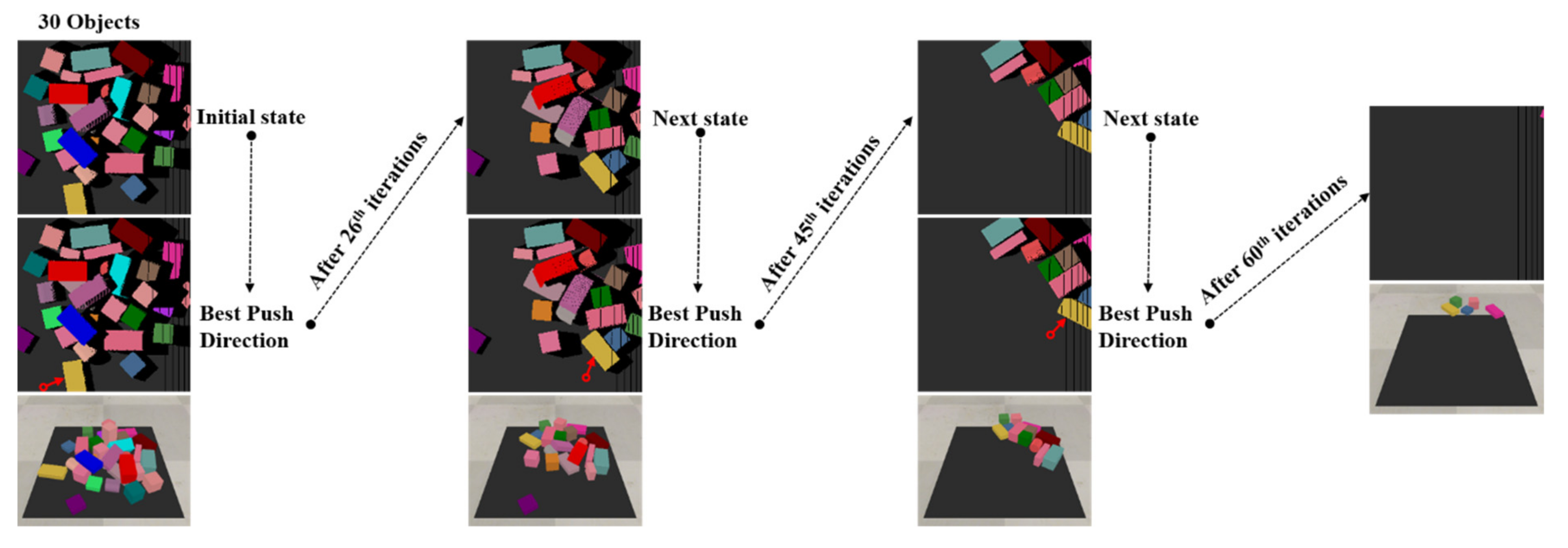
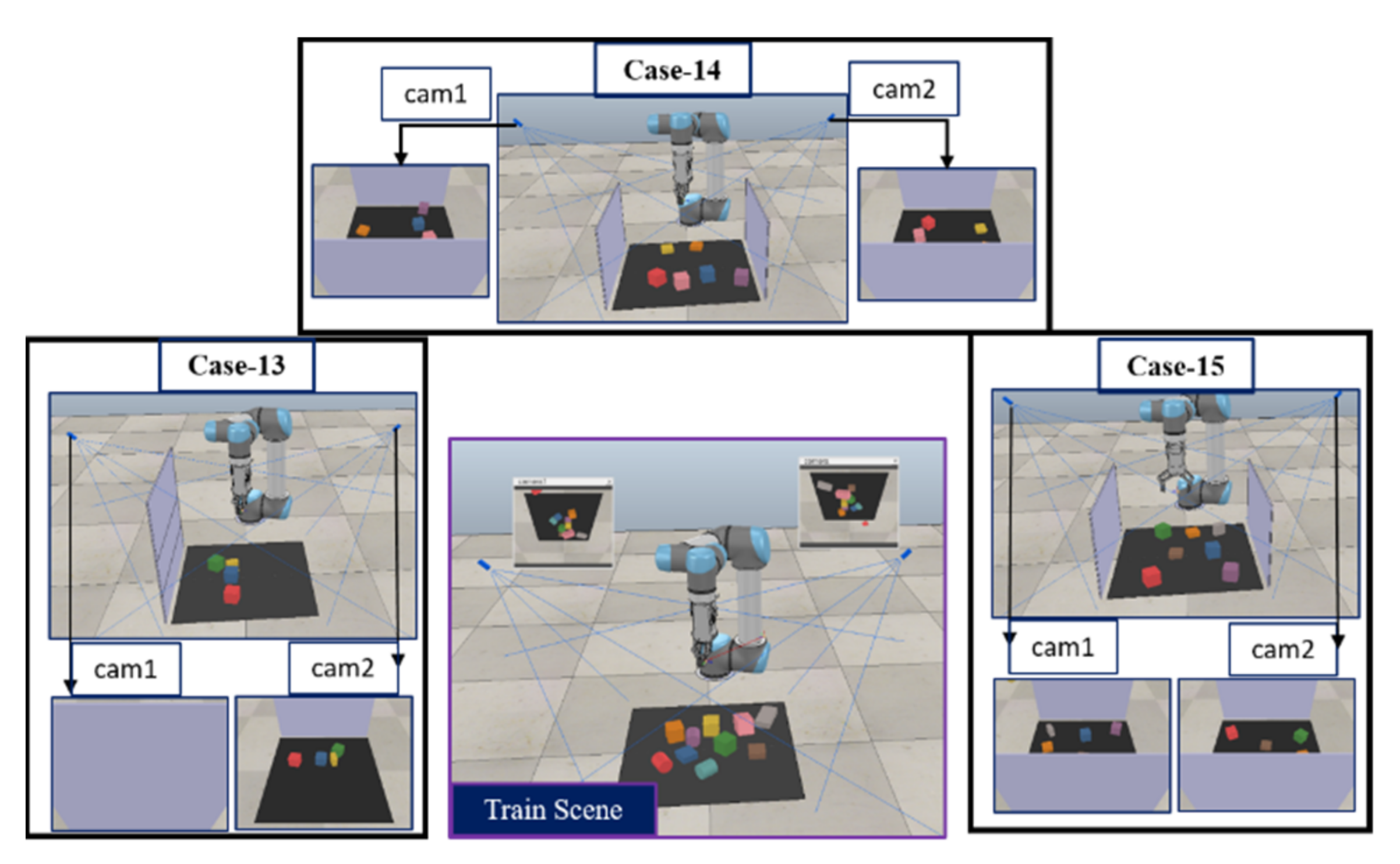
5.2. Training Scenarios
5.3. Testing Scenarios
5.4. Evaluation Metrics
- The grasp success rate: Ratio of successful grasp attempts to the total of executed actions over n test runs per test case.
- The action efficiency rate: Ratio of the number of objects to the number of executed actions before completion. It is used to measure the capability of the model to perform tasks by grasping all objects.
- The completion rate: This is the average of the total number of completed objects divided by the total number of objects. It is used to measure the capability of MV-COBA to grasp all objects in each test case without failing in more than five actions consecutively.
6. Results and Discussion
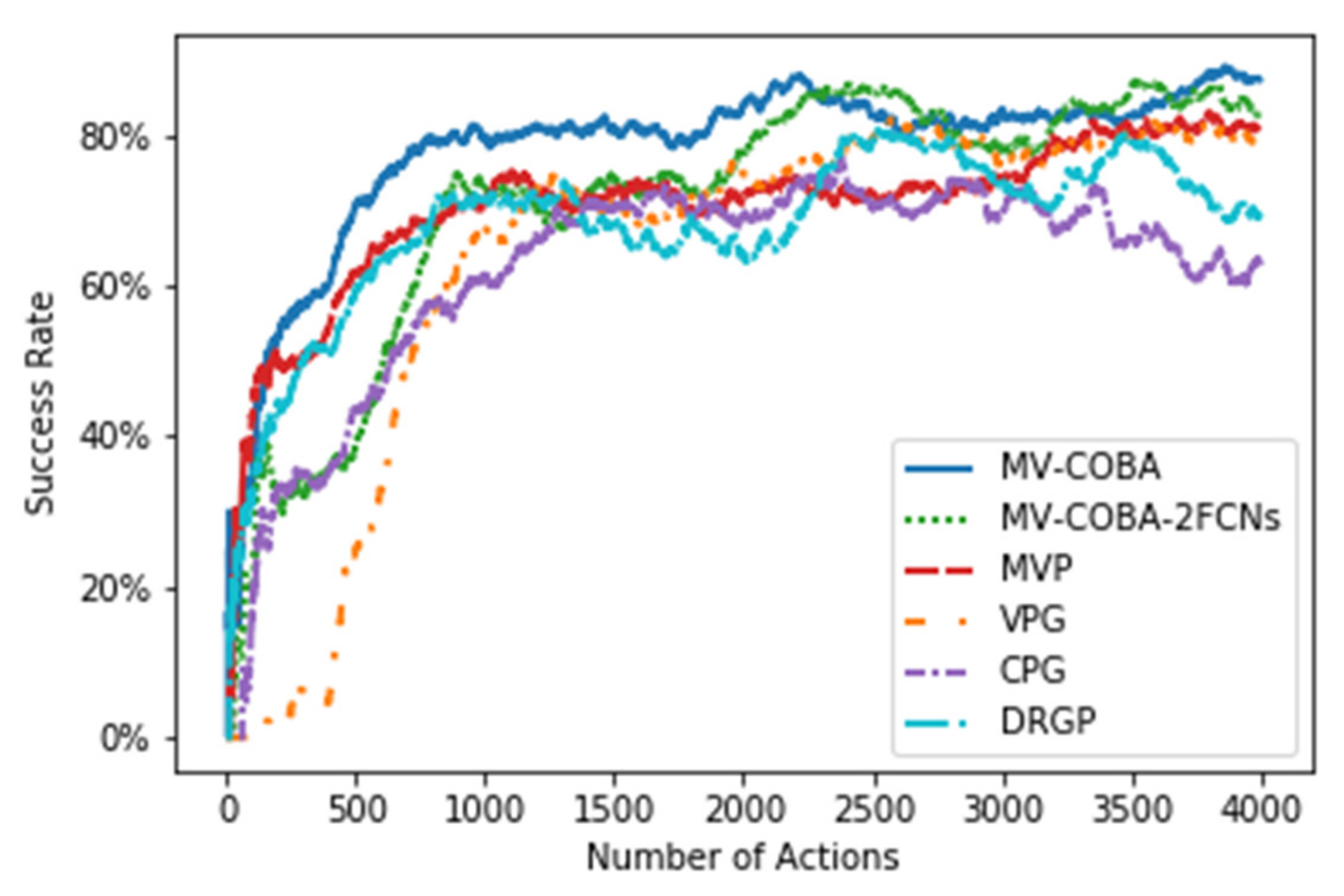
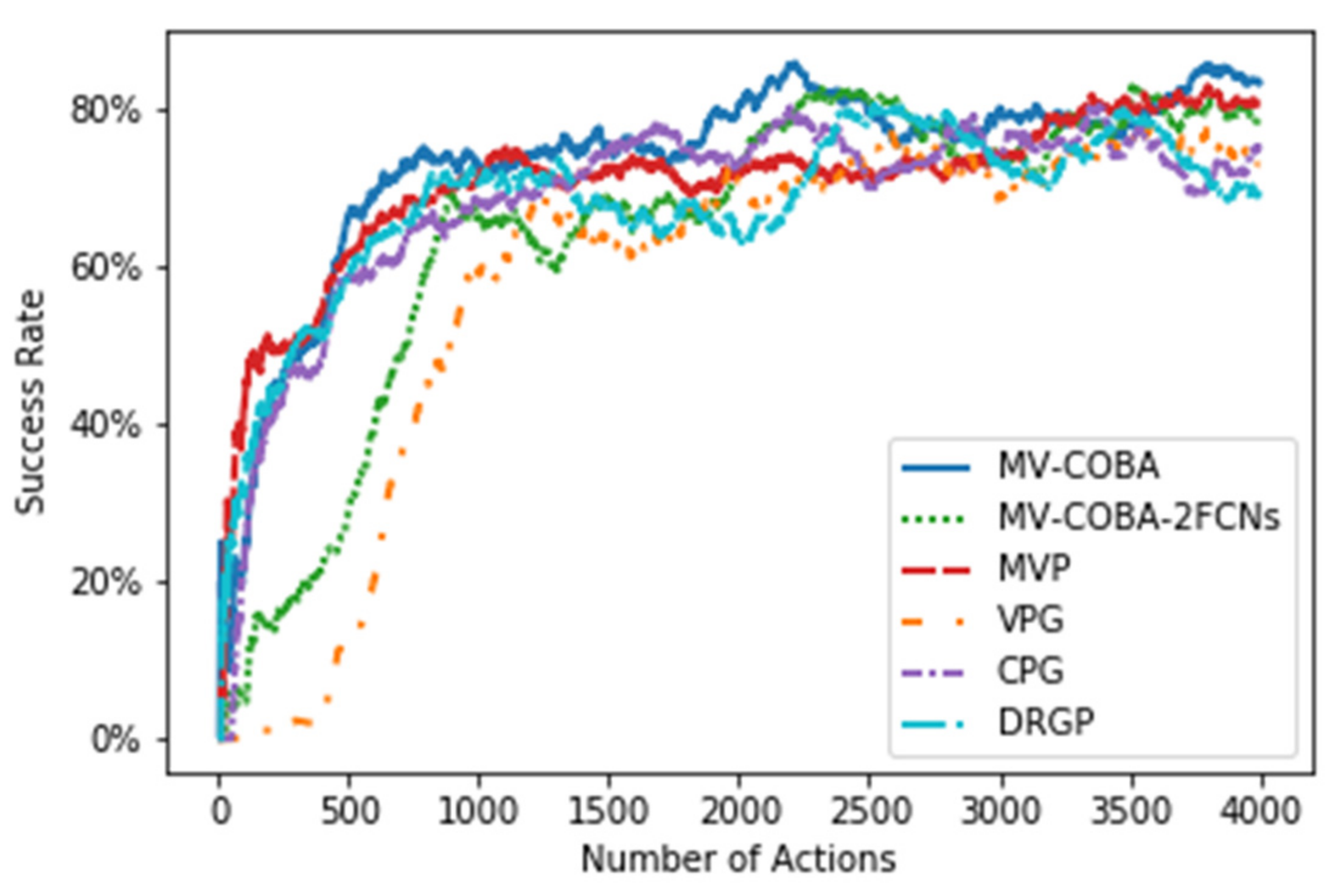
6.1. Training Session Findings
6.2. Testing Session Findings
6.2.1. Randomly Cluttered Object Challenge
6.2.2. Well-Ordered Object Challenge
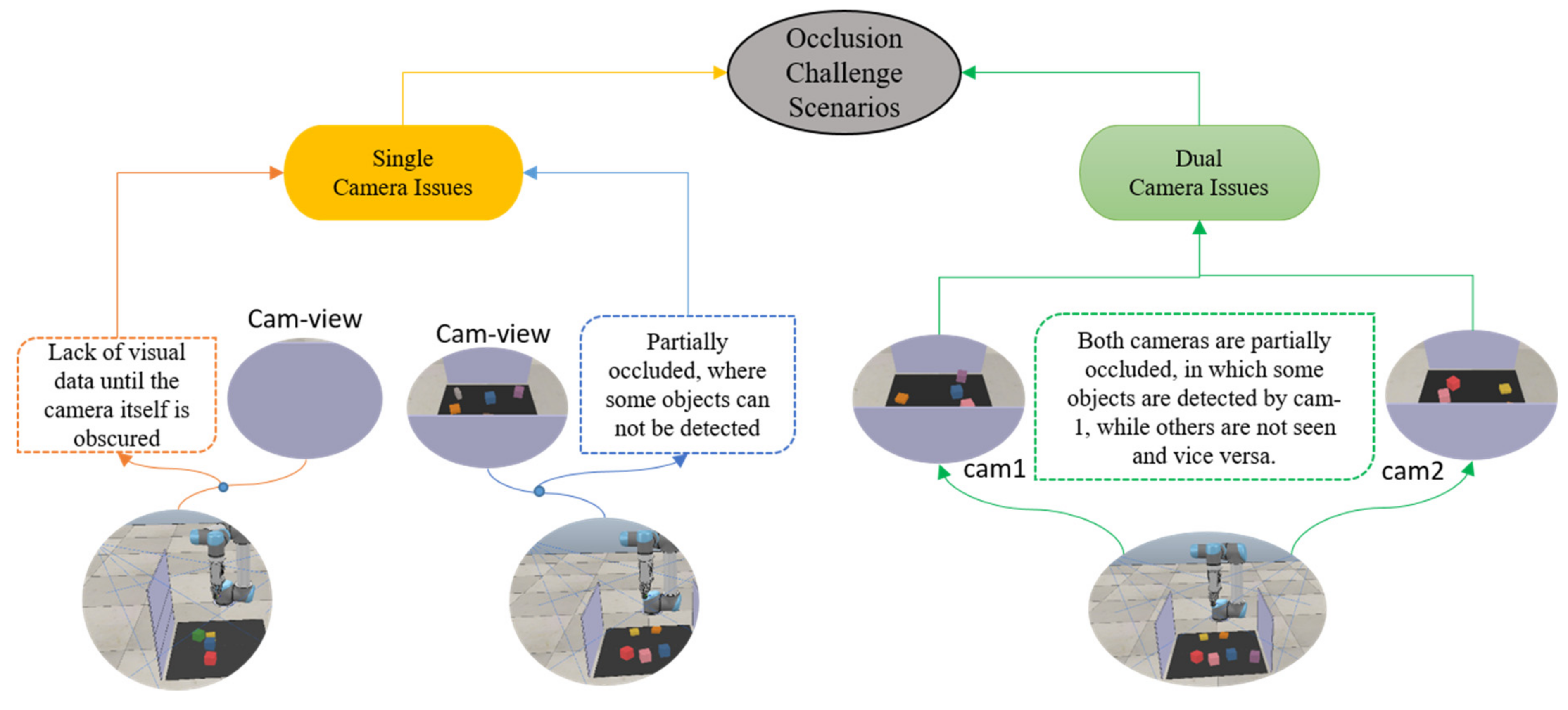
6.2.3. Occluded Object Challenge
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Marwan, Q.M.; Chua, S.C.; Kwek, L.C. Comprehensive Review on Reaching and Grasping of Objects in Robotics. Robotica 2021, 39, 1849–1882. [Google Scholar] [CrossRef]
- Mohammed, M.Q.; Chung, K.L.; Chyi, C.S. Review of Deep Reinforcement Learning-Based Object Grasping: Techniques, Open Challenges, and Recommendations. IEEE Access 2020, 8, 178450–178481. [Google Scholar] [CrossRef]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018; Volume 148, pp. 1–162. [Google Scholar]
- François-lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; François-lavet, V.; Pineau, J.; Bellemare, M.G. An Introduction to Deep Reinforcement Learning. Found. Trends Mach. Learn. 2018, 11, 219–354. [Google Scholar]
- Kumar, N.M.; Mohammed, M.A.; Abdulkareem, K.H.; Damasevicius, R.; Mostafa, S.A.; Maashi, M.S.; Chopra, S.S. Artificial intelligence-based solution for sorting COVID related medical waste streams and supporting data-driven decisions for smart circular economy practice. Process. Saf. Environ. Prot. 2021, 152, 482–494. [Google Scholar] [CrossRef]
- Mohammed, M.Q.; Chung, K.L.; Chyi, C.S. Pick and Place Objects in a Cluttered Scene Using Deep Reinforcement Learning. Int. J. Mech. Mechatron. Eng. IJMME 2020, 20, 50–57. [Google Scholar]
- Deng, Y.; Guo, X.; Wei, Y.; Lu, K.; Fang, B.; Guo, D.; Liu, H.; Sun, F. Deep Reinforcement Learning for Robotic Pushing and Picking in Cluttered Environment. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 619–626. [Google Scholar] [CrossRef]
- Wu, B.; Akinola, I.; Allen, P.K. Pixel-Attentive Policy Gradient for Multi-Fingered Grasping in Cluttered Scenes. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1789–1796. [Google Scholar] [CrossRef] [Green Version]
- Al-Shanoon, A.; Lang, H.; Wang, Y.; Zhang, Y.; Hong, W. Learn to grasp unknown objects in robotic manipulation. Intell. Serv. Robot. 2021, 14, 571–582. [Google Scholar] [CrossRef]
- Mohammed, M.Q.; Kwek, L.C.; Chua, S.C. Learning Pick to Place Objects using Self-supervised Learning with Minimal Training Resources. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 493–499. [Google Scholar]
- Lakhan, A.; Abed Mohammed, M.; Ahmed Ibrahim, D.; Hameed Abdulkareem, K. Bio-Inspired Robotics Enabled Schemes in Blockchain-Fog-Cloud Assisted IoMT Environment. J. King Saud Univ. Comput. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Mostafa, S.A.; Mustapha, A.; Gunasekaran, S.S.; Ahmad, M.S.; Mohammed, M.A.; Parwekar, P.; Kadry, S. An agent architecture for autonomous UAV flight control in object classification and recognition missions. Soft Comput. 2021. [Google Scholar] [CrossRef]
- Zhao, T.; Deng, M.; Li, Z.; Hu, Y. Cooperative Manipulation for a Mobile Dual-Arm Robot Using Sequences of Dynamic Movement Primitives. IEEE Trans. Cogn. Dev. Syst. 2020, 12, 18–29. [Google Scholar] [CrossRef]
- Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Countinuous learning control with deep reinforcement. arXiv 2016, arXiv:1509.02971. [Google Scholar]
- Heess, N.; Tb, D.; Sriram, S.; Lemmon, J.; Merel, J.; Wayne, G.; Tassa, Y.; Erez, T.; Wang, Z.; Eslami, S.M.A.; et al. Emergence of Locomotion Behaviours in Rich Environments. arXiv 2017, arXiv:170702286v2. [Google Scholar]
- Schulman, J.; Eecs, J.; Edu, B.; Abbeel, P.; Cs, P.; Edu, B. Trust Region Policy Optimization. In Proceedings of the 31st International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Mnih, V.; Mirza, M.; Graves, A.; Harley, T.; Lillicrap, T.P.; Silver, D. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Bhagat, S.; Banerjee, H. Deep Reinforcement Learning for Soft, Flexible Robots: Brief Reviewwith Impending Challenges. Robotics 2019, 8, 93. [Google Scholar]
- Fawzi, H.; Mostafa, S.A.; Ahmed, D.; Alduais, N.; Mohammed, M.A.; Elhoseny, M. TOQO: A new Tillage Operations Quality Optimization model based on parallel and dynamic Decision Support System. J. Clean. Prod. 2021, 316, 128263. [Google Scholar] [CrossRef]
- Podder, A.K.; Bukhari, A.A.L.; Islam, S.; Mia, S.; Mohammed, M.A.; Kumar, N.M.; Cengiz, K.; Abdulkareem, K.H. IoT based smart agrotech system for verification of Urban farming parameters. Microprocess Microsyst. 2021, 82, 104025. [Google Scholar] [CrossRef]
- Guo, D.; Kong, T.; Sun, F.; Liu, H. Object discovery and grasp detection with a shared convolutional neural network. In Proceedings of the IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2038–2043. [Google Scholar]
- Zhang, H.; Lan, X.; Bai, S.; Wan, L.; Yang, C.; Zheng, N. A Multi-task Convolutional Neural Network for Autonomous Robotic Grasping in Object Stacking Scenes. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6435–6442. [Google Scholar]
- Park, D.; Seo, Y.; Shin, D.; Choi, J.; Chun, S.Y. A single multi-task deep neural network with post-processing for object detection with reasoning and robotic grasp detection. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 7300–7306. [Google Scholar]
- Morrison, D.; Corke, P.; Leitner, J. Multi-View Picking: Next-best-view Reaching for Improved Grasping in Clutter. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8762–8768. [Google Scholar]
- Eitel, A.; Hauff, N.; Burgard, W. Learning to Singulate Objects Using a Push Proposal Network. Springer Proc. Adv. Robot. 2020, 10, 405–419. [Google Scholar] [CrossRef] [Green Version]
- Berscheid, L.; Meißner, P.; Kröger, T. Robot Learning of Shifting Objects for Grasping in Cluttered Environments. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 612–618. [Google Scholar]
- Zeng, A.; Song, S.; Welker, S.; Lee, J.; Rodriguez, A.; Funkhouser, T. Learning Synergies Between Pushing and Grasping with Self-Supervised Deep Reinforcement Learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4238–4245. [Google Scholar]
- Yang, Y.; Liang, H.; Choi, C. A Deep Learning Approach to Grasping the Invisible. IEEE Robot. Autom. Lett. 2020, 5, 2232–2239. [Google Scholar]
- Mohammed, M.Q.; Kwek, L.C.; Chua, S.C.; Alandoli, E.A. Color Matching Based Approach for Robotic Grasping. In Proceedings of the 2021 International Congress of Advanced Technology and Engineering (ICOTEN), Taiz, Yemen, 4–5 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Xu, K.; Yu, H.; Lai, Q.; Wang, Y.; Xiong, R. Efficient learning of goal-oriented push-grasping synergy in clutter. IEEE Robot. Autom. Lett. 2021, 6, 6337–6344. [Google Scholar]
- Hundt, A.; Killeen, B.; Greene, N.; Wu, H.; Kwon, H.; Paxton, C.; Hager, G.D. “Good Robot!”: Efficient Reinforcement Learning for Multi-Step Visual Tasks with Sim to Real Transfer. IEEE Robot. Autom. Lett. 2020, 5, 6724–6731. [Google Scholar]
- Wu, B.; Akinola, I.; Gupta, A.; Xu, F.; Varley, J.; Watkins-Valls, D.; Allen, P.K. Generative Attention Learning: A “GenerAL” framework for high-performance multi-fingered grasping in clutter. Auton. Robots 2020, 44, 971–990. [Google Scholar]
- Wu, K.; Ranasinghe, R.; Dissanayake, G. Active recognition and pose estimation of household objects in clutter. In Proceedings of the IEEE International Conference on Robotics and Automation, Seattle, WA, USA, 26–30 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 4230–4237. [Google Scholar]
- Novkovic, T.; Pautrat, R.; Furrer, F.; Breyer, M.; Siegwart, R.; Nieto, J. Object Finding in Cluttered Scenes Using Interactive Perception. In Proceedings of the IEEE International Conference on Robotics and Automation, Eth, Autonomous Systems Lab, Zurich, Switzerland, 31 May–31 August 2020; pp. 8338–8344. [Google Scholar] [CrossRef]
- Jiang, D.; Wang, H.; Chen, W.; Wu, R. A novel occlusion-free active recognition algorithm for objects in clutter. In Proceedings of the 2016 IEEE International Conference on Robotics and Biomimetics, ROBIO 2016, Qingdao, China, 3–7 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1389–1394. [Google Scholar]
- Kopicki, M.S.; Belter, D.; Wyatt, J.L. Learning better generative models for dexterous, single-view grasping of novel objects. Int. J. Robot. Res. 2019, 38, 1246–1267. [Google Scholar] [CrossRef] [Green Version]
- Murali, A.; Mousavian, A.; Eppner, C.; Paxton, C.; Fox, D. 6-DOF Grasping for Target-driven Object Manipulation in Clutter. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6232–6238. [Google Scholar]
- Corona, E.; Pumarola, A.; Alenyà, G.; Moreno-Noguer, F.; Rogez, G. GanHand: Predicting Human Grasp Affordances in Multi-Object Scenes. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 5030–5040. [Google Scholar]
- Kiatos, M.; Malassiotis, S.; Sarantopoulos, I. A Geometric Approach for Grasping Unknown Objects With Multifingered Hands. IEEE Trans. Robot. 2021, 37, 735–746. [Google Scholar]
- Zeng, A.; Yu, K.; Song, S.; Suo, D.; Walker, E.; Rodriguez, A.; Xiao, J. Multi-view self-supervised deep learning for 6D pose estimation in the Amazon Picking Challenge. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 9 May–3 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1383–1386. [Google Scholar]
- Chen, X.; Ye, Z.; Sun, J.; Fan, Y.; Hu, F.; Wang, C.; Lu, C. Transferable Active Grasping and Real Embodied Dataset. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 3611–3618. [Google Scholar]
- Berscheid, L.; Rühr, T.; Kröger, T. Improving Data Efficiency of Self-supervised Learning for Robotic Grasping. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2125–2131. [Google Scholar]
- Mahler, J.; Liang, J.; Niyaz, S.; Laskey, M.; Doan, R.; Liu, X.; Ojea, J.A.; Goldberg, K. Dex-Net 2.0: Deep learning to plan Robust grasps with synthetic point clouds and analytic grasp metrics. In Robotics: Science and Systems; Department of EECS, University of California: Berkeley, CA, USA, 2017. [Google Scholar] [CrossRef]
- Mousavian, A.; Eppner, C.; Fox, D. 6-DOF GraspNet: Variational grasp generation for object manipulation. In Proceedings of the IEEE International Conference on Computer Vision, NVIDIA, Seoul, Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2901–2910. [Google Scholar] [CrossRef] [Green Version]
- Shao, Q.; Hu, J.; Wang, W.; Fang, Y.; Liu, W.; Qi, J.; Ma, J. Suction Grasp Region Prediction Using Self-supervised Learning for Object Picking in Dense Clutter. In Proceedings of the 2019 IEEE 5th International Conference on Mechatronics System and Robots (ICMSR), Singapore, 3–5 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7–12. [Google Scholar]
- Han, M.; Pan, Z.; Xue, T.; Shao, Q.; Ma, J.; Wang, W. Object-Agnostic Suction Grasp Affordance Detection in Dense Cluster Using Self-Supervised Learning. arXiv 2019, arXiv:190602995v1. [Google Scholar]
- Mitash, C.; Bekris, K.E.; Boularias, A. A self-supervised learning system for object detection using physics simulation and multi-view pose estimation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 545–551. [Google Scholar]
- Zeng, A.; Song, S.; Yu, K.-T.; Donlon, E.; Hogan, F.R.; Bauza, M.; Ma, D.; Taylor, O.; Liu, M.; Romo, E.; et al. Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. Int. J. Robot. Res 2019, 3750–3757. [Google Scholar] [CrossRef] [Green Version]
- Yen-Chen, L.; Zeng, A.; Song, S.; Isola, P.; Lin, T.-Y. Learning to See before Learning to Act: Visual Pre-training for Manipulation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 7286–7293. [Google Scholar]
- Iriondo, A.; Lazkano, E.; Ansuategi, A. Affordance-based grasping point detection using graph convolutional networks for industrial bin-picking applications. Sensors 2021, 21, 816. [Google Scholar] [CrossRef]
- Sarantopoulos, I.; Kiatos, M.; Doulgeri, Z.; Malassiotis, S. Split Deep Q-Learning for Robust Object Singulation*. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6225–6231. [Google Scholar]
- Boroushaki, T.; Leng, J.; Clester, I.; Rodriguez, A.; Adib, F. Robotic Grasping of Fully-Occluded Objects using RF Perception. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 923–929. [Google Scholar]
- Kiatos, M.; Malassiotis, S. Robust object grasping in clutter via singulation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1596–1600. [Google Scholar]
- Huang, B.; Han, S.D.; Yu, J.; Boularias, A. Visual Foresight Tree for Object Retrieval from Clutter with Nonprehensile Rearrangement. IEEE Robot. Autom. Lett. 2021, 7, 231–238. [Google Scholar]
- Cheong, S.; Cho, B.Y.; Lee, J.; Lee, J.; Kim, D.H.; Nam, C.; Kim, C.; Park, S. Obstacle rearrangement for robotic manipulation in clutter using a deep Q-network. Intell. Serv. Robot. 2021, 14, 549–561. [Google Scholar] [CrossRef]
- Fujita, Y.; Uenishi, K.; Ummadisingu, A.; Nagarajan, P.; Masuda, S.; Castro, M.Y. Distributed Reinforcement Learning of Targeted Grasping with Active Vision for Mobile Manipulators. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2021; IEEE: Piscataway, NJ, USA, 2020; pp. 9712–9719. [Google Scholar]
- Kurenkov, A.; Taglic, J.; Kulkarni, R.; Dominguez-Kuhne, M.; Garg, A.; Martin-Martin, R.; Savarese, S. Visuomotor mechanical search: Learning to retrieve target objects in clutter. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 8408–8414. [Google Scholar] [CrossRef]
- Morrison, D.; Leitner, J.; Corke, P. Closing the Loop for Robotic Grasping: A Real-time, Generative Grasp Synthesis Approach. arXiv 2018, arXiv:180405172v2. [Google Scholar]
- Yaxin, L.; Yiqian, T.; Ming, Z. An Intelligent Composite Pose Estimation Algorithm Based on 3D Multi-View Templates. In Proceedings of the 2018 3rd IEEE International Conference on Image, Vision and Computing, ICIVC 2018, Chongqing, China, 27–29 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 956–960. [Google Scholar]
- Chen, C.; Li, H.; Zhang, X.; Liu, X.; Tan, U. Towards Robotic Picking of Targets with Background Distractors using Deep Reinforcement Learning. In Proceedings of the 2019 WRC Symposium on Advanced Robotics and Automation (WRC SARA), Beijing, China, 21–22 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 166–171. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Abbeel, P.; Zaremba, W. Hindsight experience replay. In Advances in Neural Information Processing Systems; OpenAI: San Francisco, CA, USA, 2017; pp. 5049–5059. [Google Scholar]
- Kalashnikov, D.; Irpan, A.; Pastor, P.; Ibarz, J.; Herzog, A.; Jang, E.; Quillen, D.; Holly, E.; Kalakrishnan, M.; Vanhoucke, V.; et al. QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation. arXiv 2018, arXiv:180610293v3. [Google Scholar]
- Lu, N.; Lu, T.; Cai, Y.; Wang, S. Active Pushing for Better Grasping in Dense Clutter with Deep Reinforcement Learning. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 Nov. 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1657–1663. [Google Scholar]
- Goodrich, B.; Kuefler, A.; Richards, W.D. Depth by Poking: Learning to Estimate Depth from Self-Supervised Grasping. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10466–10472. [Google Scholar]
- Yang, Z.; Shang, H. Robotic Pushing and Grasping Knowledge Learning via Attention Deep Q-Learning Network; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Academy for Engineering and Technology, Fudan University: Shanghai, China, 2020; Volume 12274 LNAI, pp. 223–234. [Google Scholar] [CrossRef]
- Ni, P.; Zhang, W.; Zhang, H.; Cao, Q. Learning efficient push and grasp policy in a totebox from simulation. Adv. Robot. 2020, 34, 873–887. [Google Scholar]
- Yang, Y.; Ni, Z.; Gao, M.; Zhang, J.; Tao, D. Collaborative Pushing and Grasping of Tightly Stacked Objects via Deep Reinforcement Learning. IEEE CAA J. Autom. Sin. 2021, 9, 135–145. [Google Scholar]
- Danielczuk, M.; Angelova, A.; Vanhoucke, V.; Goldberg, K. X-Ray: Mechanical search for an occluded object by minimizing support of learned occupancy distributions. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 24 October–24 January 2021; The Autolab at University of California: Berkeley, CA, USA, 2020; pp. 9577–9584. [Google Scholar] [CrossRef]
- Wu, Y.; Li, J.; Bai, J. Multiple Classifiers-Based Feature Fusion for RGB-D Object Recognition. Int. J. Pattern Recognit. Artif. Intell. 2017, 31, 1750014. [Google Scholar]
- Sajjad, M.; Ullah, A.; Ahmad, J.; Abbas, N.; Rho, S.; Baik, S.W. Integrating salient colors with rotational invariant texture features for image representation in retrieval systems. Multimed. Tools Appl. 2018, 77, 4769–4789. [Google Scholar]
- Singh, A. Review Articlel: Digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar]
- Qin, R.; Tian, J.; Reinartz, P. 3D change detection—Approaches and applications. ISPRS J. Photogramm. Remote Sens. 2016, 122, 41–56. [Google Scholar]
- Lu, D.; Mausel, P.; Brondízio, E.; Moran, E. Change detection techniques. Int. J. Remote Sens. 2004, 25, 2365–2401. [Google Scholar]
- Reba, M.; Seto, K.C. A systematic review and assessment of algorithms to detect, characterize, and monitor urban land change. Remote Sens. Environ. 2020, 242, 111739. [Google Scholar]
- Iii, A.L. Change detection using image differencing: A study over area surrounding Kumta, India. In Proceedings of the 2017 Second International Conference on Electrical, Computer and Communication Technologies (ICECCT), Coimbatore, India, 22–24 February 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Qin, R.; Huang, X.; Gruen, A.; Schmitt, G. Object-Based 3-D Building Change Detection on Multitemporal Stereo Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2125–2137. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018; pp. 1–360. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2261–2269. [Google Scholar]
- Fei-Fei, L.; Deng, J.; Li, K. ImageNet: Constructing a large-scale image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Evaluation Mean (%) | |
|---|---|---|
| Grasp Success | Action Efficiency | |
| MV-COBA | 87.2% | 82.8% |
| MV-COBA-2FCNs | 83.8% | 80.2% |
| MVP | 77.2%, | 77.2%, |
| VPG | 76.7% | 65.2%. |
| CPG | 71.3% | 59.4% |
| DRGP | 74.1%, | 74.1%, |
| Evaluation Mean% | Method | Test Cases | Average | |||||
|---|---|---|---|---|---|---|---|---|
| Case-1 | Case-2 | Case-3 | Case-4 | Case-5 | Case-6 | |||
| Grasp Success Rate | MV-COBA | 86.0 | 82.2 | 83.4 | 81.6 | 89.8 | 78.4 | 83.6 |
| MV-COBA-2FCNs | 84.3 | 70.8 | 69.4 | 66.7 | 67.8 | 65.6 | 70.8 | |
| MVP | 61.1 | 61.5 | 66.7 | 57.2 | 45.0 | 55.2 | 57.8 | |
| VPG | 80.1 | 71.6 | 68.3 | 50.0 | 58.6 | 63.8 | 65.4 | |
| CPG | 65.6 | 63.0 | 57.1 | 57.4 | 82.4 | 61.4 | 64.5 | |
| DRGP | 59.4 | 59.4 | 53.2 | 66.7 | 57.6 | 43.2 | 56.6 | |
| Action Efficiency | MV-COBA | 79.8 | 78.1 | 76.4 | 74.2 | 70.7 | 70.8 | 75.0 |
| MV-COBA-2FCNs | 68.0 | 64.1 | 56.0 | 59.3 | 62.9 | 52.3 | 60.4 | |
| MVP | 61.1 | 61.5 | 66.7 | 57.2 | 45.0 | 55.2 | 57.8 | |
| VPG | 61.9 | 58.0 | 57.7 | 40.0 | 41.0 | 47.6 | 51.1 | |
| CPG | 48.9 | 54.7 | 43.8 | 44.3 | 58.3 | 42.0 | 48.7 | |
| DRGP | 59.4 | 59.4 | 53.2 | 66.7 | 57.6 | 43.2 | 56.6 | |
| Completion Rate | MV-COBA | 100 | 100 | 81.2 | 100 | 100 | 82.5 | 94.0 |
| MV-COBA-2FCNs | 100 | 100 | 60.0 | 70.1 | 100 | 50.0 | 80.1 | |
| MVP | 100 | 66.7 | 33.3 | 33.3 | 36.2 | 33.3 | 50.5 | |
| VPG | 100 | 50.0 | 100 | 50.0 | 75.1 | 50.0 | 70.9 | |
| CPG | 100 | 100 | 50.0 | 50.0 | 50.0 | 51.7 | 67.0 | |
| DRGP | 66.7 | 67.7 | 33.3 | 33.3 | 33.3 | 33.3 | 44.6 | |
| Evaluation Mean% | Method | Test Cases | Average | |||||
|---|---|---|---|---|---|---|---|---|
| Case-7 | Case-8 | Case-9 | Case-10 | Case-11 | Case-12 | |||
| Grasp Success Rate | MV-COBA | 85.7 | 87.1 | 89.5 | 84.1 | 85.6 | 85.6 | 86.3 |
| MV-COBA-2FCNs | 82.1 | 85.5 | 77.4 | 76.8 | 63.3 | 73.3 | 76.4 | |
| MVP | 40.6 | 44.7 | 48.9 | 31.1 | 25.8 | 22.7 | 35.6 | |
| VPG | 65.4 | 69.8 | 72.9 | 74.8 | 54.8 | 53.3 | 65.2 | |
| CPG | 65.4 | 69.8 | 72.9 | 74.8 | 54.8 | 43.3 | 63.5 | |
| DRGP | 36.1 | 56.4 | 48.5 | 31.7 | 44.6 | 36.1 | 42.3 | |
| Action Efficiency | MV-COBA | 75.0 | 77.4 | 83.0 | 81.1 | 82.7 | 82.7 | 80.4 |
| MV-COBA-2FCNs | 70.0 | 80.1 | 74.0 | 68.9 | 60.6 | 58.3 | 68.65 | |
| MVP | 40.6 | 44.7 | 48.9 | 31.1 | 25.8 | 22.7 | 35.6 | |
| VPG | 45.9 | 51.1 | 58.3 | 56.7 | 42.1 | 42.7 | 49.5 | |
| CPG | 58.3 | 52.8 | 59.8 | 50.0 | 53.1 | 44.0 | 53.0 | |
| DRGP | 36.1 | 56.4 | 48.5 | 31.7 | 44.6 | 36.1 | 42.3 | |
| Completion Rate | MV-COBA | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| MV-COBA-2FCNs | 100 | 100 | 100 | 82.7 | 66.7 | 100 | 91.6 | |
| MVP | 33.3 | 66.7 | 33.3 | 30.0 | 0.0 | 0.0 | 27.2 | |
| VPG | 82.7 | 71.4 | 66.7 | 100 | 76.7 | 75.0 | 78.8 | |
| CPG | 81.5 | 100 | 66.7 | 50.0 | 100 | 100 | 83.1 | |
| DRGP | 30.0 | 30.0 | 0.0 | 0.0 | 33.3 | 30.0 | 20.6 | |
| Evaluation Mean (%) | Method | Test Cases | Average | ||
|---|---|---|---|---|---|
| Case-13 | Case-14 | Case-15 | |||
| Grasp Success Rate | MV-COBA | 100 | 93.8 | 100 | 97.8 |
| MV-COBA-2FCNs | 0.0 | 45.2 | 33.3 | 26.2 | |
| MVP | 0.0 | 45.2 | 43.3 | 44.3 | |
| VPG | 0.0 | 51.7 | 33.3 | 28.3 | |
| CPG | 0.0 | 55.7 | 33.3 | 29.7 | |
| DRGP | 0.0 | 45.7 | 33.3 | 26.3 | |
| Completion Rate | MV-COBA | 100 | 100 | 100 | 100.0 |
| MV-COBA-2FCNs | 0.0 | 0.0 | 0.0 | 0.0 | |
| MVP | 0.0 | 0.0 | 0.0 | 0.0 | |
| CPG | 0.0 | 0.0 | 0.0 | 0.0 | |
| VPG | 0.0 | 0.0 | 0.0 | 0.0 | |
| DRGP | 0.0 | 0.0 | 0.0 | 0.0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammed, M.Q.; Kwek, L.C.; Chua, S.C.; Aljaloud, A.S.; Al-Dhaqm, A.; Al-Mekhlafi, Z.G.; Mohammed, B.A. Deep Reinforcement Learning-Based Robotic Grasping in Clutter and Occlusion. Sustainability 2021, 13, 13686. https://doi.org/10.3390/su132413686
Mohammed MQ, Kwek LC, Chua SC, Aljaloud AS, Al-Dhaqm A, Al-Mekhlafi ZG, Mohammed BA. Deep Reinforcement Learning-Based Robotic Grasping in Clutter and Occlusion. Sustainability. 2021; 13(24):13686. https://doi.org/10.3390/su132413686
Chicago/Turabian StyleMohammed, Marwan Qaid, Lee Chung Kwek, Shing Chyi Chua, Abdulaziz Salamah Aljaloud, Arafat Al-Dhaqm, Zeyad Ghaleb Al-Mekhlafi, and Badiea Abdulkarem Mohammed. 2021. "Deep Reinforcement Learning-Based Robotic Grasping in Clutter and Occlusion" Sustainability 13, no. 24: 13686. https://doi.org/10.3390/su132413686
APA StyleMohammed, M. Q., Kwek, L. C., Chua, S. C., Aljaloud, A. S., Al-Dhaqm, A., Al-Mekhlafi, Z. G., & Mohammed, B. A. (2021). Deep Reinforcement Learning-Based Robotic Grasping in Clutter and Occlusion. Sustainability, 13(24), 13686. https://doi.org/10.3390/su132413686