
The Economy and Policy Incorporated Computing System for Social Energy and Power Consumption Analysis

Abstract
:1. Introduction
2. Materials and Methods
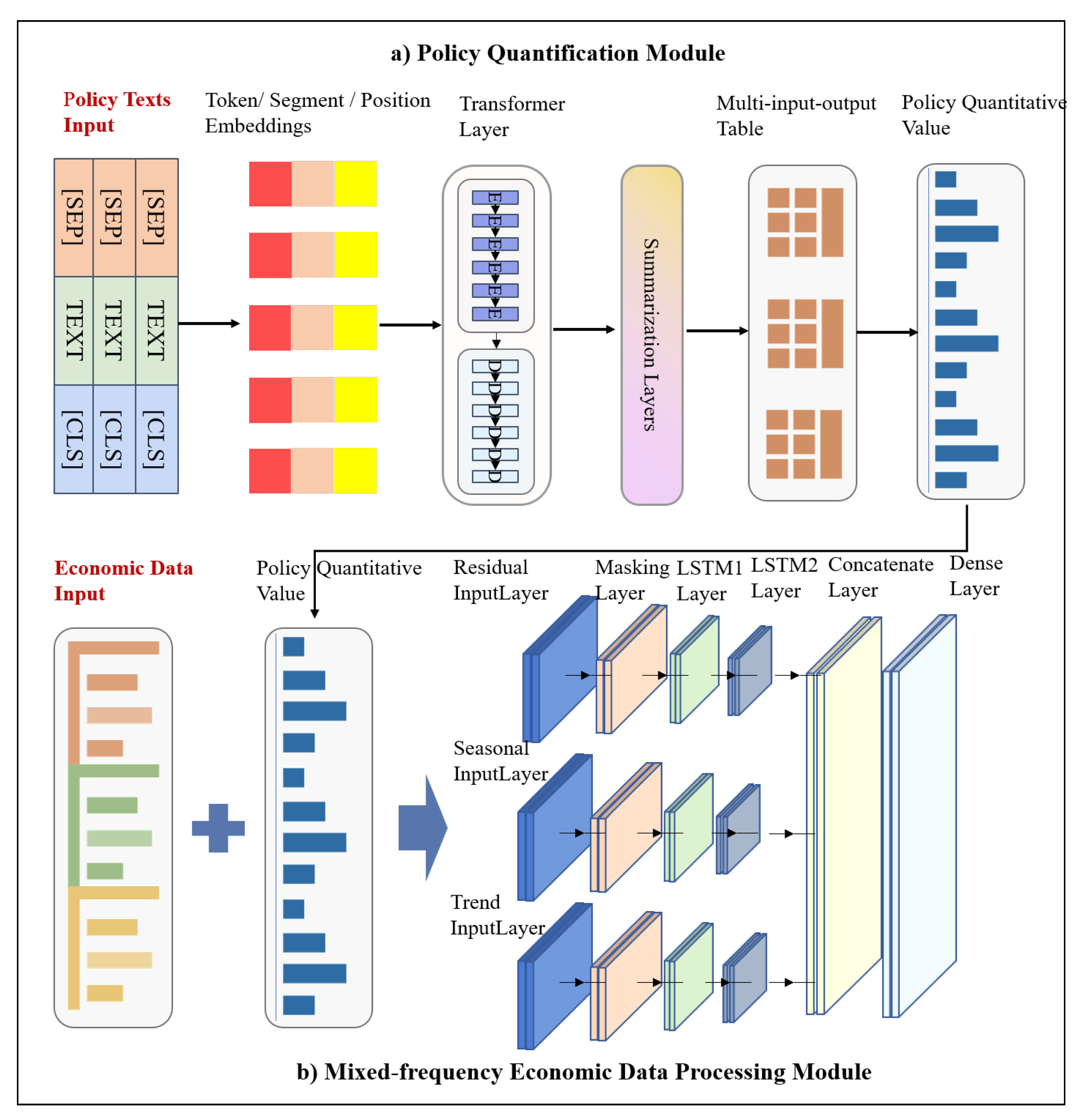
2.1. EPICS Framework
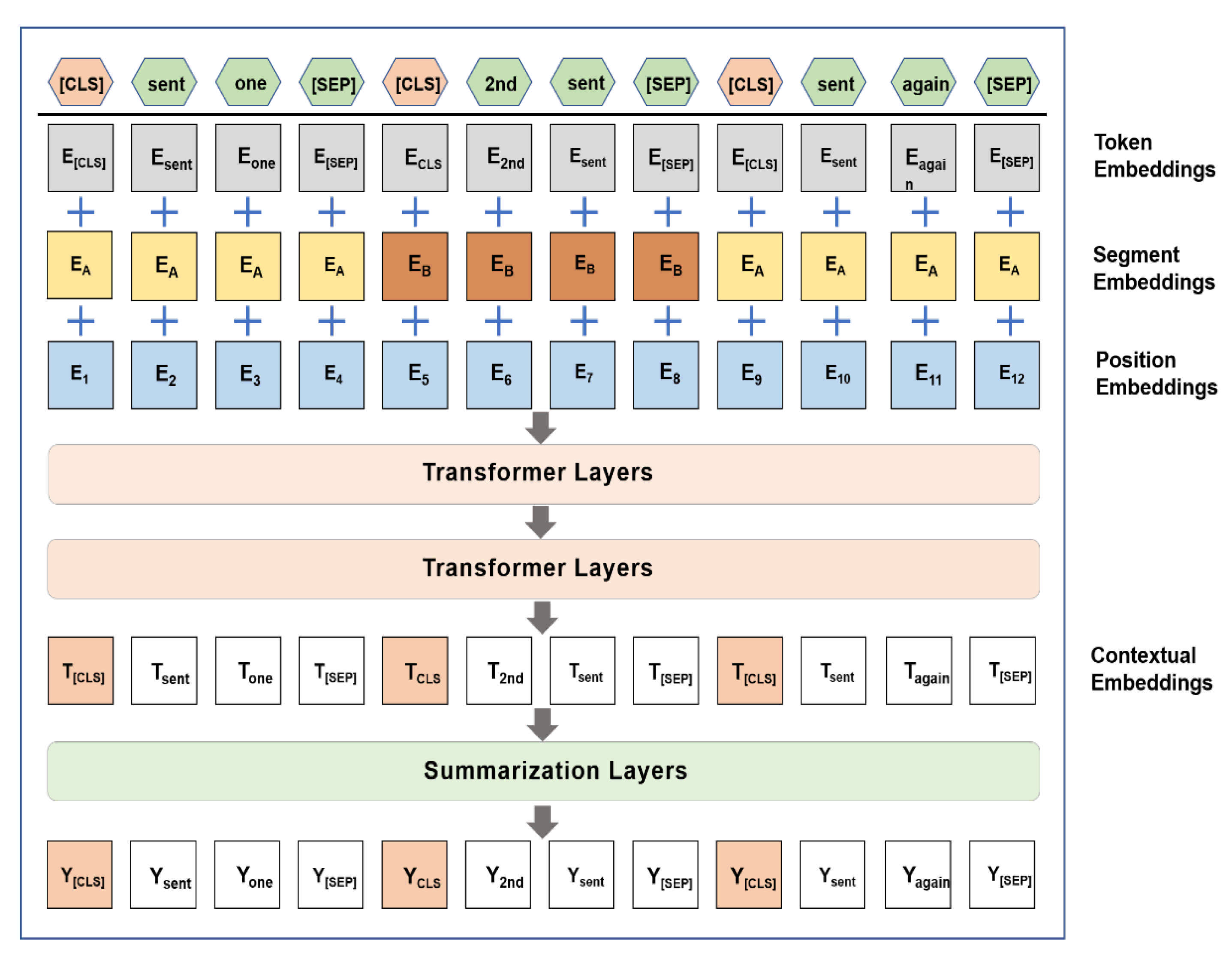
- First, the policy text data is used as the input of the policy quantification module, which can extract a large amount of power policy text summaries through the automatic text summarization technology based on BERT. In addition, the power policy summary can be quantified based on Policy Modeling Consistency Index (PMC-Index) [23]. This method can summarize the main content of policy measures and improve the efficiency of policy quantification.
- Second, the output of the policy quantification module (PMC-Index) and mixed frequency economic data are integrated. This step is to implement the joint processing of structured data and unstructured data.
- Third, the fused data are utilized as the input of the mixed-frequency economic data processing module. The mixing economic data fusion modeling module mainly uses the masking layer of the Keras to cover and filter the vacancy time steps in the data. The masking layer can mask a sequence by using a mask value to skip timesteps. For each timestep in the input tensor, if all values in the input tensor at that timestep are equal to “mask value”, then the timestep will be masked (skipped) in all downstream layers. In addition, this module also uses the LSTM network to realize the automatic feature extraction of the mixed data and constructs the multi-input feature fusion model, which aims to cope with the issue that the data volume of medium- and long-term power consumption is not sufficient for deep network model training.
2.2. EPICS Framework: Policy Quantification Module
- Setting policy variables and parameters: We refer to Estrada’s setting of policy evaluation variables and combine the specific characteristics of China’s power policy to establish 9 primary variables and 33 secondary variables. The detailed variable design is shown in Table 1.
- Establishing a multi-input-output table: Multi-input-output table is a data analysis framework that can store a large amount of data and measure a single variable in multiple dimensions. The multi-input-output table consists of primary variables and secondary variables. Primary variables have no fixed order and are independent of each other. Each primary variable can contain any number of secondary variables. All secondary variables under each primary variable have the same weight, and the value is always 0 or 1. This is because we are concerned about the impact of a policy in a specific field in the process of PMC index modeling.
- Calculating PMC index: (I) Put 9 first-level variables and 33 second-level variables into the multi-input-output table. (II) Determine the value of second-level variables through text mining. As shown in Formula (4), each second-level variable obeys 0–1 distribution, which means that the value of the second-level variable can be 0 or 1. (III) Calculate the first-level variables according to Formula (5). (IV) Sum up the first-level index value of power policy to calculate PMC index, as shown in Formula (6):where represents the first-level variable, represents the second-level variable, and represents the number of second-level variables.
2.3. EPICS Framework: Mixed-Frequency Economic Data Processing Module
2.4. Electricity Consumption Forecasting Methods Considering Economic and Policy Factors
3. Results
3.1. EPICS Policy Quantitative Results
3.2. Mixed-Frequency Economic Data Processing Results
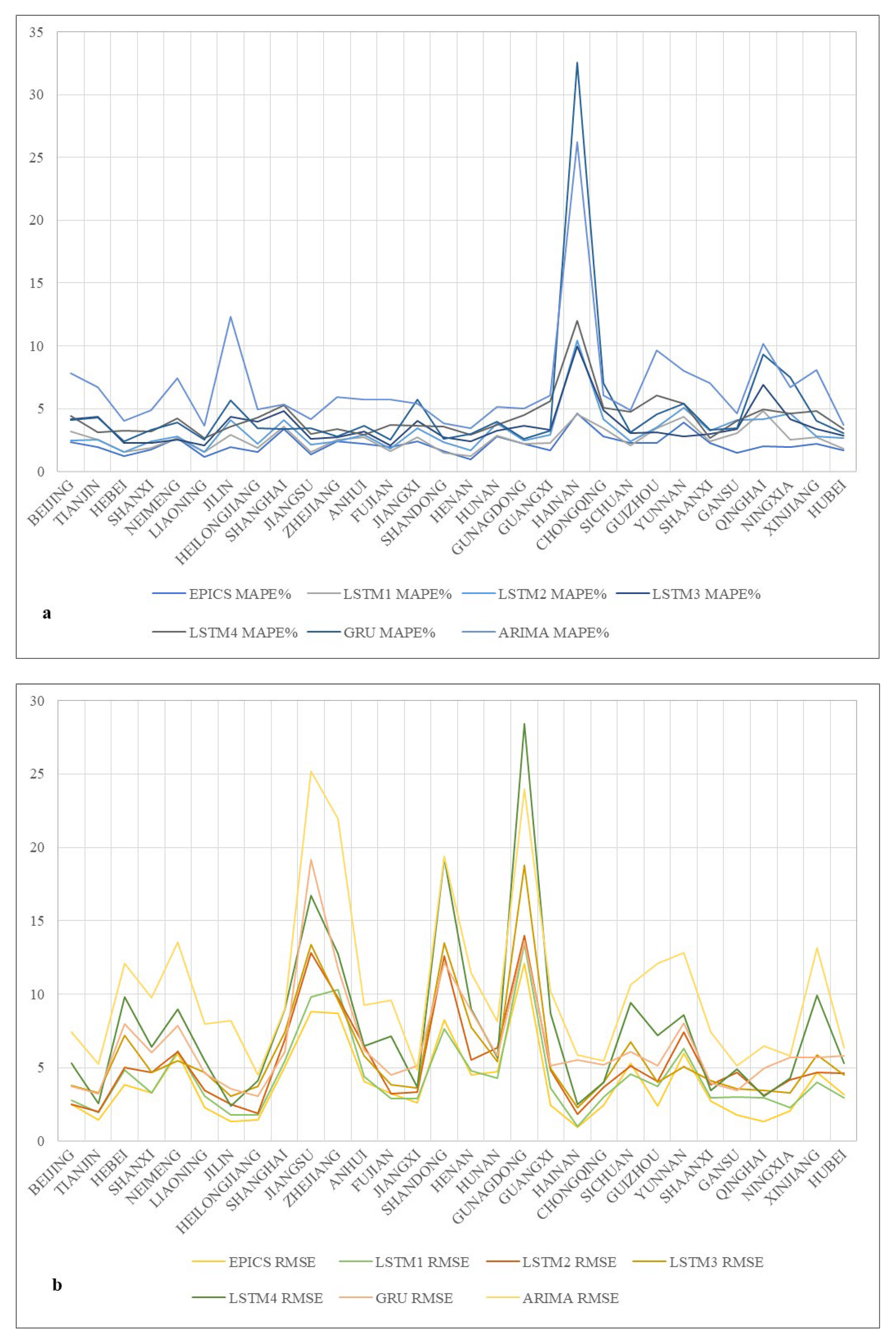
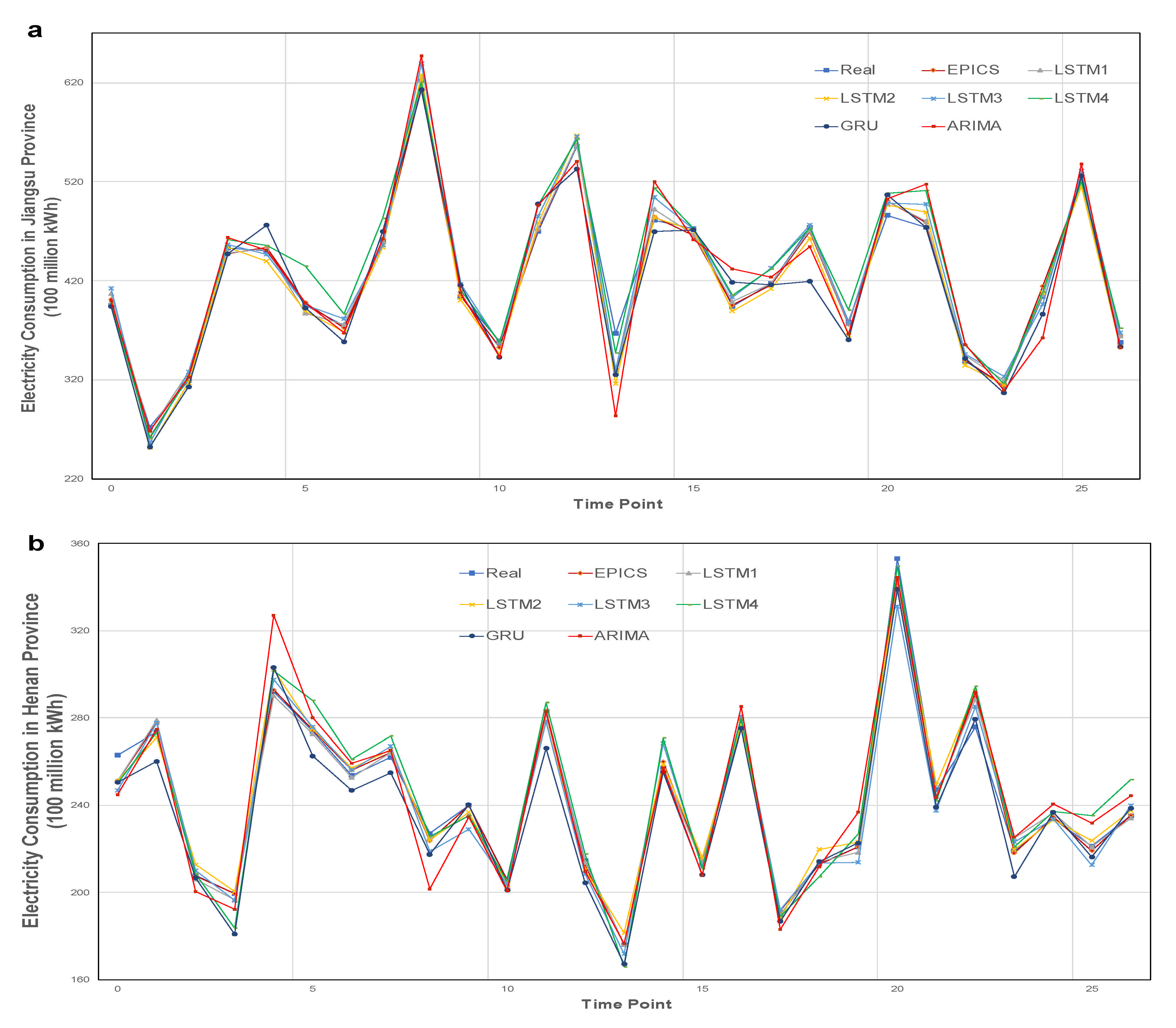
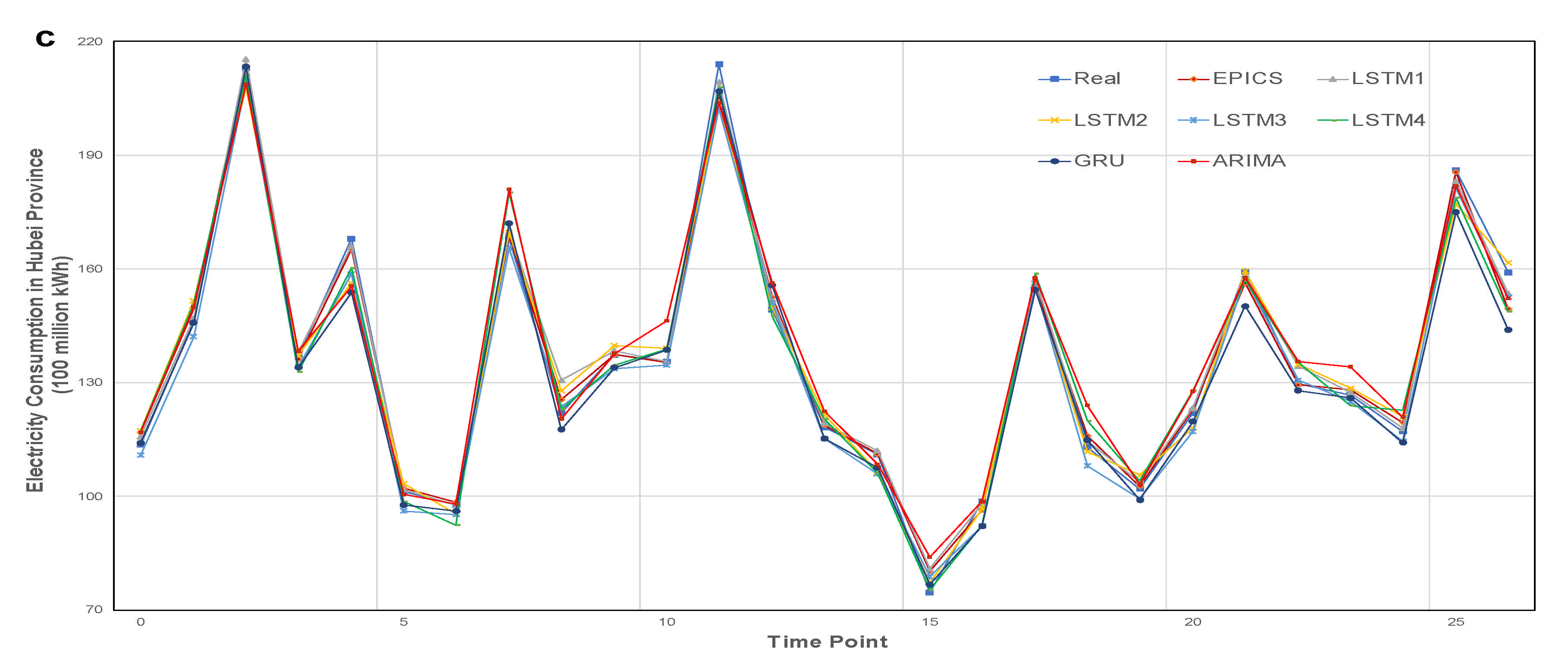
3.3. Electricity Consumption Forecast Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Explanation |
|---|---|
| EPICS | Economy and Policy Incorporated Computing System |
| BERT | Bidirectional Encoder Representation from Transformers |
| GRU | Gate Recurrent Unit |
| LSTM | Long-Short Term Memory |
| PMC | Policy Modeling Consistency |
| Sentence vector of sentence | |
| Gold label of sentence | |
| Each sentence of sentence | |
| Function to add positional embeddings, represents the sentence | |
| Multi-Head Attention | |
| Layer normalization |
References
- Liu, K.; Subbarayan, S.; Shoults, R.R.; Manry, M.T.; Kwan, C.; Lewis, F.L.; Naccarino, J. Comparison of very short-term load forecasting techniques. IEEE Trans. Power Syst. 1996, 11, 877–882. [Google Scholar] [CrossRef]
- Tian, C.J.; Ma, J.; Zhang, C.H.; Zhan, P.P. A Deep Neural Network Model for Short-Term Load Forecast Based on Long Short-Term Memory Network and Convolutional Neural Network. Energies 2018, 11, 3493. [Google Scholar] [CrossRef] [Green Version]
- Barman, M.; Choudhury, N.B.D. A similarity based hybrid GWO-SVM method of power system load forecasting for regional special event days in anomalous load situations in Assam, India. Sustain. Cities Soc. 2020, 61, 102311. [Google Scholar] [CrossRef]
- Li, Y.Y.; Che, J.X.; Yang, Y.L. Subsampled support vector regression ensemble for short term electric load forecasting. Energy 2018, 164, 160–170. [Google Scholar] [CrossRef]
- Porumb, R.; Postolache, P.; Seritan, G.; Vatu, R.; Ceaki, O. Load profiles analysis for electricity market. Comput. Methods Soc. Sci. 2013, 1, 30. Available online: https://www.ceeol.com/search/article-detail?id=416789 (accessed on 15 September 2021).
- Hu, M.; Peng, Y.; Huang, Z.; Li, D. Retrieve, Read, Rerank: Towards End-to-End Multi-Document Reading Comprehension. arXiv 2019, arXiv:1906.04618. [Google Scholar]
- Zhao, L.N.; Zhou, Z.C.; Zhang, Y.P.; Wu, M.K. Study of applicability of the methods of medium and long term load forecasting in new economy normal state. Adv. Eng. Res. 2016, 115, 525–530. [Google Scholar]
- Chen, X.; Qiu, J.; Dong, Z.Y. An Improved Load Forecast Model Using Factor Analysis: An Australian Case Study. In Proceedings of the 2017 IEEE International Conference on Information and Automation (IEEE ICIA 2017), Macau SAR, China, 18–20 July 2017; pp. 903–908. [Google Scholar]
- Zhang, C.; Zhou, K.L.; Yang, S.L.; Shao, Z. On electricity consumption and economic growth in China. Renew. Sustain. Energy Rev. 2017, 76, 353–368. [Google Scholar] [CrossRef]
- Liu, D.; Ruan, L.; Liu, J.C.; Huan, H.; Zhang, G.W.; Feng, Y.; Li, Y. Electricity consumption and economic growth nexus in Beijing: A causal analysis of quarterly sectoral data. Renew. Sustain. Energy Rev. 2018, 82, 2498–2503. [Google Scholar] [CrossRef]
- Jiang, P.; Li, R.R.; Liu, N.N.; Gao, Y.Y. A novel composite electricity demand forecasting framework by data processing and optimized support vector machine. Appl. Energy 2020, 260, 114243. [Google Scholar] [CrossRef]
- He, Y.Y.; Qin, Y.; Wang, S.; Wang, X.; Wang, C. Electricity consumption probability density forecasting method based on LASSO-Quantile Regression Neural Network. Appl. Energy 2019, 233, 565–575. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Yalcinoz, T.; Eminoglu, U. Short term and medium term power distribution load forecasting by neural networks. Energy Convers. Manag. 2005, 46, 1393–1405. [Google Scholar] [CrossRef]
- Han, L.Y.; Peng, Y.X.; Li, Y.H.; Yong, B.B.; Zhou, Q.G.; Shu, L. Enhanced Deep Networks for short-Term and Medium-Term Load Forecasting. IEEE Access 2019, 7, 4045–4055. [Google Scholar] [CrossRef]
- Samuel, O.; Alzahrani, F.A.; Khan, R.J.U.; Farooq, H.; Shafiq, M.; Afzal, M.K.; Javaid, N. Towards Modified Entropy Mutual Information Feature Selection to Forecast Medium-Term Load Using a Deep Learning Model in Smart Homes. Entropy 2020, 22, 68. [Google Scholar] [CrossRef] [Green Version]
- Nalcaci, G.; Ozmen, A.; Weber, G.W. Long-term load forecasting: Models based on MARS, ANN and LR methods. Cent. Eur. J. Oper. Res. 2019, 27, 1033–1049. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Single and Multi-Sequence Deep Learning Models for Short and Medium Term Electric Load Forecasting. Energies 2019, 12, 149. [Google Scholar] [CrossRef] [Green Version]
- Dagdougui, H.; Bagheri, F.; Le, H.; Dessaint, L. Neural network model for short-term and very-short-term load forecasting in district buildings. Energy Build. 2019, 203, 109408. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Hua, J.; Li, X.G.; Fu, T.; Wu, X.H. Chinese Syllable-to-Character Conversion with Recurrent Neural Network based Supervised Sequence Labelling. In Proceedings of the 2015 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Hong Kong, China, 16–19 December 2015; pp. 350–353. [Google Scholar]
- Kim, M.; Choi, W.; Jeon, Y.; Liu, L. A Hybrid Neural Network Model for Power Demand Forecasting. Energies 2019, 12, 931. [Google Scholar] [CrossRef] [Green Version]
- Estrada, M.A.R. Policy modeling: Definition, classification and evaluation. J. Policy Model. 2011, 33, 523–536. [Google Scholar] [CrossRef]
- Liu, Y. Fine-Tune BERT for Extractive Summarization. arXiv 2019, arXiv:1903.10318. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Bai, Y.; Sun, Z.Z.; Zeng, B.; Deng, J.; Li, C.N. A multi-pattern deep fusion model for short-term bus passenger flow forecasting. Appl. Soft Comput. 2017, 58, 669–680. [Google Scholar] [CrossRef]
- Agrawal, R.K.; Muchahary, F.; Tripathi, M.M. Long Term Load Forecasting with Hourly Predictions based on Long-Short-Term-Memory Networks. In Proceedings of the 2018 IEEE Texas Power and Energy Conference (TPEC), College Station, TX, USA, 8–9 February 2018; pp. 1–6. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.J.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.T.; Senellart, J.; Rush, A.M. OpenNMT: Open-Source Toolkit for Neural Machine Translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL 2017): System Demonstrations, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 67–72. [Google Scholar]
- Lin, C.-Y. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out; Moens, M., Szpakowicz, S., Eds.; Association for Computational Linguistics: East Stroudsburg, PA, USA, 2004; pp. 74–81. [Google Scholar]
- Narayan, S.; Cohen, S.B.; Lapata, M. Ranking sentences for extractive summarization with reinforcement learning. arXiv 2018, arXiv:1802.08636. [Google Scholar]
- Kang, K.; Sun, H.B.; Zhang, C.K.; Brown, C. Short-term electrical load forecasting method based on stacked auto-encoding and GRU neural network. Evol. Intell. 2019, 12, 385–394. [Google Scholar]
- Sajjad, M.; Khan, Z.A.; Ullah, A.; Hussain, T.; Ullah, W.; Lee, M.Y.; Baik, S.W. A Novel CNN-GRU-Based Hybrid Approach for Short-Term Residential Load Forecasting. IEEE Access 2020, 8, 143759–143768. [Google Scholar] [CrossRef]
- Havas, A.; Schartinger, D.; Weber, M. The impact of foresight on innovation policy-making: Recent experiences and future perspectives. Res. Eval. 2010, 19, 91–104. [Google Scholar] [CrossRef]
- Vedung, E. Models of evaluation. In Public Policy and Program Evaluation; Evert, V., Ed.; Routledge: New York, NY, USA, 2017; pp. 101–115. [Google Scholar]
- Clements, M.P.; Galvão, A.B. Macroeconomic forecasting with mixed-frequency data: Forecasting output growth in the United States. J. Bus. Econ. Stat. 2008, 26, 546–554. [Google Scholar] [CrossRef]
- Kuzin, V.; Marcellino, M.; Schumacher, C. MIDAS vs. mixed-frequency VAR: Nowcasting GDP in the euro area. Int. J. Forecast. 2011, 27, 529–542. [Google Scholar] [CrossRef] [Green Version]
- Yan, W.H.; Cheng, L.; Yan, S.J.; Gao, W.; Gao, D.W.Z. Enabling and Evaluation of Inertial Control for PMSG-WTG Using Synchronverter With Multiple Virtual Rotating Masses in Microgrid. IEEE Trans. Sustain. Energy 2020, 11, 1078–1088. [Google Scholar] [CrossRef]
- Yan, W.H.; Wang, X.; Gao, W.; Gevorgian, V. Electro-mechanical Modeling of Wind Turbine and Energy Storage Systems with Enhanced Inertial Response. J. Mod. Power Syst. Clean Energy 2020, 8, 820–830. [Google Scholar] [CrossRef]
- Sbrana, G.; Silvestrini, A. Temporal aggregation of cyclical models with business cycle applications. Stat. Method Appl. 2012, 21, 93–107. [Google Scholar] [CrossRef]
- Angelini, E.; Henry, J.; Marcellino, M. Interpolation and backdating with a large information set. J. Econ. Dyn. Control. 2006, 30, 2693–2724. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.C.; Kalnay, E.; Hunt, B.; Bowler, N.E. Weight interpolation for efficient data assimilation with the Local Ensemble Transform Kalman Filter. Q. J. R. Meteorol. Soc. 2009, 135, 251–262. [Google Scholar] [CrossRef]
| Primary Variable | Secondary Variable |
|---|---|
| (X1) Nature of policy | (X1:1) Predicting (X1:2) Proposal (X1:3) Supervise (X1:4) Support (X1:5) Guide |
| (X2) Effect of policy | (X2:1) Long term (X2:2) Medium term (X2:3) Short term |
| (X3) Incentives and constraints | (X3:1) Governmental subsidies (X3:2) Special fund (X3:3) Laws and regulations (X3:4) Talent incentive |
| (X4) Area of policy | (X4:1) Economy (X4:2) Society (X4:3) Environment (X4:4) Science (X4:5) Technological |
| (X5) Level of policy | (X5:1) National level (X5:2) Provincial level (X5:3) Local level |
| (X6) Recipients of policy | (X6:1) Ministries (X6:2) Provinces (X6:3) Autonomous regions (X6:4) State Grid |
| (X7) Focus of policy | (X7:1) Energy prices (X7:2) Energy investment (X7:3) Environmental protection (X7:4) Electric safety (X7:5) Electric reform (X7:6) Energy conservation |
| (X8) Evaluation of policy | (X8:1) Well founded (X8:2) Clear objectives (X8:3) Scientific solution (X8:4) Reasonable planning |
| (X9) Openness of policy | None |
| Model | ROUGE-1 |
|---|---|
| Lead | 31.3 |
| REFRESH | 33.2 |
| Transformer | 32.3 |
| BERT-based | 34.7 |
| Paper-1 | Paper-2 | Paper-3 | |
|---|---|---|---|
| (X1) Nature of policy | 0.4 | 0.2 | 0.4 |
| (X2) Effect of policy | 0.67 | 0.33 | 0.33 |
| (X3) Incentives and constraints | 0.5 | 0.5 | 0.5 |
| (X4) Area of policy | 0.4 | 0.4 | 0.4 |
| (X5) Level of policy | 0.67 | 0.67 | 0.33 |
| (X6) Recipients of policy | 0.5 | 0.75 | 1.0 |
| (X7) Focus of policy | 0.33 | 0.83 | 0.5 |
| (X8) Evaluation of policy | 0.25 | 0.75 | 0.75 |
| (X9) Openness of policy | 1.0 | 1.0 | 1.0 |
| Total (PMC-Index) | 4.72 | 5.43 | 5.21 |
| Level | Bad | Acceptable | Acceptable |
| Index | |
|---|---|
| Monthly data | Year, month, province information, consumer price index, commodity retail price index, power generation, real estate development investment, real estate development enterprise housing construction area, real estate development enterprise housing new construction area, real estate development enterprise housing completion area, general public budget income, financial institutions in foreign currency deposit balance, financial institutions in foreign currency loan balance, value of import, value of export, total value of export import and export, average temperature, average pressure, average relative humidity |
| Quarterly data | GDP, regional GDP index, total output value of construction industry, completed output value of construction industry, construction area of housing construction, newly started area, labor productivity calculated by total output value, per capita completed output value, completed area of housing construction, fixed asset investment price index |
| Annual data | GDP, GDP real growth index, per capita GDP, per capita GDP real growth index, added value of primary industry, added value of secondary industry, added value of tertiary industry, real growth index of added value of primary industry, real growth index of added value of secondary industry, real growth index of added value of tertiary industry, industrial added value, consumption level of residents, consumption level of urban residents, consumption level of rural residents, consumption level comparison between urban and rural areas, completed investment in fixed assets of the whole society, investment in fixed assets (excluding farmers), investment in fixed assets (excluding farmers), total retail value of social consumer goods, added value of construction enterprises, resident population, natural growth rate of resident population, total electricity consumption |
| Month | Monthly Data (19 Columns) | Quarterly Data (10 Columns) | Annual Data (23 Columns) |
|---|---|---|---|
| Jan | 1 | 0 | 0 |
| Feb | 1 | 0 | 0 |
| Mar | 1 | 1 | 0 |
| Apr | 1 | 0 | 0 |
| May | 1 | 0 | 0 |
| Jun | 1 | 1 | 0 |
| Jul | 1 | 0 | 0 |
| Aug | 1 | 0 | 0 |
| Sep | 1 | 1 | 0 |
| Oct | 1 | 0 | 0 |
| Nov | 1 | 0 | 0 |
| Dec | 1 | 1 | 1 |
| Province | EPICS | LSTM1 | LSTM2 | LSTM3 | LSTM4 | GRU | ARIMA | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAPE% | RMSE | MAPE% | RMSE | MAPE% | RMSE | MAPE% | RMSE | MAPE% | RMSE | MAPE% | RMSE | MAPE% | RMSE | |
| Beijing | 2.32 | 2.50 | 3.15 | 2.80 | 2.45 | 2.48 | 4.14 | 3.77 | 4.41 | 5.31 | 4.07 | 3.73 | 7.81 | 7.39 |
| Tianjin | 1.91 | 1.47 | 2.51 | 1.93 | 2.54 | 1.99 | 4.33 | 3.27 | 3.10 | 2.56 | 4.30 | 3.23 | 6.68 | 5.22 |
| Hebei | 1.20 | 3.82 | 1.54 | 4.87 | 1.58 | 5.03 | 2.26 | 7.20 | 3.24 | 9.82 | 2.42 | 7.97 | 4.02 | 12.07 |
| Shanxi | 1.72 | 3.28 | 1.85 | 3.31 | 2.42 | 4.70 | 2.29 | 4.66 | 3.20 | 6.41 | 3.29 | 6.01 | 4.91 | 9.73 |
| Neimeng | 2.67 | 5.97 | 2.69 | 6.11 | 2.78 | 6.09 | 2.54 | 5.43 | 4.24 | 8.99 | 3.90 | 7.87 | 7.45 | 13.52 |
| Liaoning | 1.15 | 2.29 | 1.56 | 3.06 | 1.57 | 3.46 | 2.08 | 4.70 | 2.65 | 5.46 | 2.51 | 4.60 | 3.63 | 7.96 |
| Jilin | 1.97 | 1.33 | 2.95 | 1.78 | 4.08 | 2.50 | 4.36 | 3.06 | 3.56 | 2.41 | 5.68 | 3.54 | 12.31 | 8.21 |
| Heilongjiang | 1.57 | 1.42 | 1.89 | 1.80 | 2.19 | 1.88 | 3.93 | 3.76 | 4.31 | 4.13 | 3.46 | 3.04 | 4.95 | 4.52 |
| Shanghai | 3.35 | 5.09 | 3.56 | 5.47 | 4.10 | 6.90 | 4.84 | 7.39 | 5.29 | 8.96 | 3.39 | 6.09 | 5.36 | 9.01 |
| Jiangsu | 1.37 | 8.81 | 1.55 | 9.78 | 2.15 | 12.80 | 2.58 | 13.38 | 3.00 | 16.72 | 3.47 | 19.17 | 4.14 | 25.17 |
| Zhejiang | 2.38 | 8.69 | 2.54 | 10.31 | 2.41 | 9.77 | 2.73 | 9.61 | 3.40 | 12.74 | 2.80 | 11.77 | 5.94 | 21.97 |
| Anhui | 2.17 | 4.08 | 2.70 | 4.40 | 2.93 | 6.48 | 3.18 | 5.82 | 2.89 | 6.45 | 3.63 | 6.18 | 5.72 | 9.23 |
| Fujian | 1.97 | 3.22 | 1.63 | 2.91 | 1.82 | 3.22 | 2.06 | 3.84 | 3.71 | 7.15 | 2.56 | 4.50 | 5.75 | 9.61 |
| Jiangxi | 2.39 | 2.61 | 2.71 | 2.91 | 3.46 | 3.37 | 4.00 | 3.63 | 3.66 | 3.67 | 5.73 | 5.13 | 5.38 | 4.85 |
| Shandong | 1.64 | 8.23 | 1.46 | 7.62 | 2.32 | 12.57 | 2.75 | 13.50 | 3.57 | 19.27 | 2.59 | 12.14 | 3.82 | 19.40 |
| Henan | 0.99 | 4.52 | 1.25 | 4.77 | 1.66 | 5.53 | 2.39 | 7.73 | 2.93 | 8.96 | 2.97 | 8.84 | 3.42 | 11.42 |
| Hunan | 2.79 | 4.72 | 2.83 | 4.31 | 3.82 | 6.36 | 3.23 | 5.43 | 3.72 | 5.70 | 3.96 | 5.79 | 5.17 | 8.12 |
| Guangdong | 2.23 | 12.12 | 2.22 | 13.42 | 2.46 | 13.96 | 3.61 | 18.75 | 4.49 | 28.41 | 2.57 | 13.62 | 5.00 | 23.97 |
| Guangxi | 1.69 | 2.43 | 2.25 | 3.62 | 2.93 | 4.83 | 3.34 | 4.93 | 5.63 | 8.67 | 3.28 | 5.12 | 6.08 | 10.18 |
| Hainan | 4.65 | 0.92 | 4.53 | 1.03 | 10.44 | 1.83 | 9.96 | 2.30 | 12.01 | 2.48 | 32.58 | 5.54 | 26.21 | 5.85 |
| Chongqing | 2.78 | 2.47 | 3.47 | 3.01 | 4.19 | 3.67 | 4.89 | 4.00 | 5.10 | 4.03 | 7.04 | 5.18 | 6.06 | 5.44 |
| Sichuan | 2.25 | 5.27 | 2.05 | 4.58 | 2.39 | 5.13 | 3.04 | 6.72 | 4.73 | 9.42 | 3.14 | 6.09 | 4.87 | 10.63 |
| Guizhou | 2.25 | 2.39 | 3.47 | 3.71 | 3.51 | 4.07 | 3.09 | 4.03 | 6.04 | 7.18 | 4.57 | 5.10 | 9.65 | 12.08 |
| Yunnan | 3.90 | 5.96 | 4.37 | 6.30 | 5.10 | 7.39 | 2.78 | 5.08 | 5.40 | 8.58 | 5.39 | 8.01 | 8.00 | 12.82 |
| Shaanxi | 2.28 | 2.71 | 2.39 | 2.95 | 3.24 | 3.84 | 3.01 | 4.10 | 2.66 | 3.45 | 3.28 | 3.96 | 7.01 | 7.42 |
| Gansu | 1.50 | 1.76 | 3.06 | 3.00 | 4.08 | 4.70 | 3.35 | 3.55 | 4.03 | 4.93 | 3.43 | 3.47 | 4.61 | 5.15 |
| Qinghai | 1.99 | 1.36 | 4.78 | 2.93 | 4.15 | 3.12 | 6.92 | 3.46 | 4.95 | 3.07 | 9.32 | 4.98 | 10.20 | 6.46 |
| Ningxia | 1.93 | 2.05 | 2.53 | 2.30 | 4.64 | 4.18 | 4.13 | 3.31 | 4.63 | 4.29 | 7.49 | 5.68 | 6.71 | 5.79 |
| Xinjiang | 2.21 | 4.69 | 2.74 | 4.04 | 2.79 | 4.66 | 3.40 | 5.87 | 4.81 | 9.91 | 4.03 | 5.71 | 8.06 | 13.16 |
| Hubei | 1.68 | 3.19 | 1.79 | 2.97 | 2.65 | 4.65 | 2.86 | 4.52 | 3.38 | 5.31 | 3.04 | 5.78 | 3.72 | 6.34 |
| AVERAGE | 2.16 | 3.98 | 2.60 | 4.40 | 3.23 | 5.37 | 3.60 | 5.89 | 4.29 | 7.81 | 5.00 | 6.59 | 6.75 | 10.42 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, H.; Zhang, J.; Wang, X.; Yuan, H.; Gao, T.; Hu, C.; Yan, J. The Economy and Policy Incorporated Computing System for Social Energy and Power Consumption Analysis. Sustainability 2021, 13, 10473. https://doi.org/10.3390/su131810473
Zhao H, Zhang J, Wang X, Yuan H, Gao T, Hu C, Yan J. The Economy and Policy Incorporated Computing System for Social Energy and Power Consumption Analysis. Sustainability. 2021; 13(18):10473. https://doi.org/10.3390/su131810473
Chicago/Turabian StyleZhao, Hang, Jun Zhang, Xiaohui Wang, Hongxia Yuan, Tianlu Gao, Chenxi Hu, and Jing Yan. 2021. "The Economy and Policy Incorporated Computing System for Social Energy and Power Consumption Analysis" Sustainability 13, no. 18: 10473. https://doi.org/10.3390/su131810473
APA StyleZhao, H., Zhang, J., Wang, X., Yuan, H., Gao, T., Hu, C., & Yan, J. (2021). The Economy and Policy Incorporated Computing System for Social Energy and Power Consumption Analysis. Sustainability, 13(18), 10473. https://doi.org/10.3390/su131810473