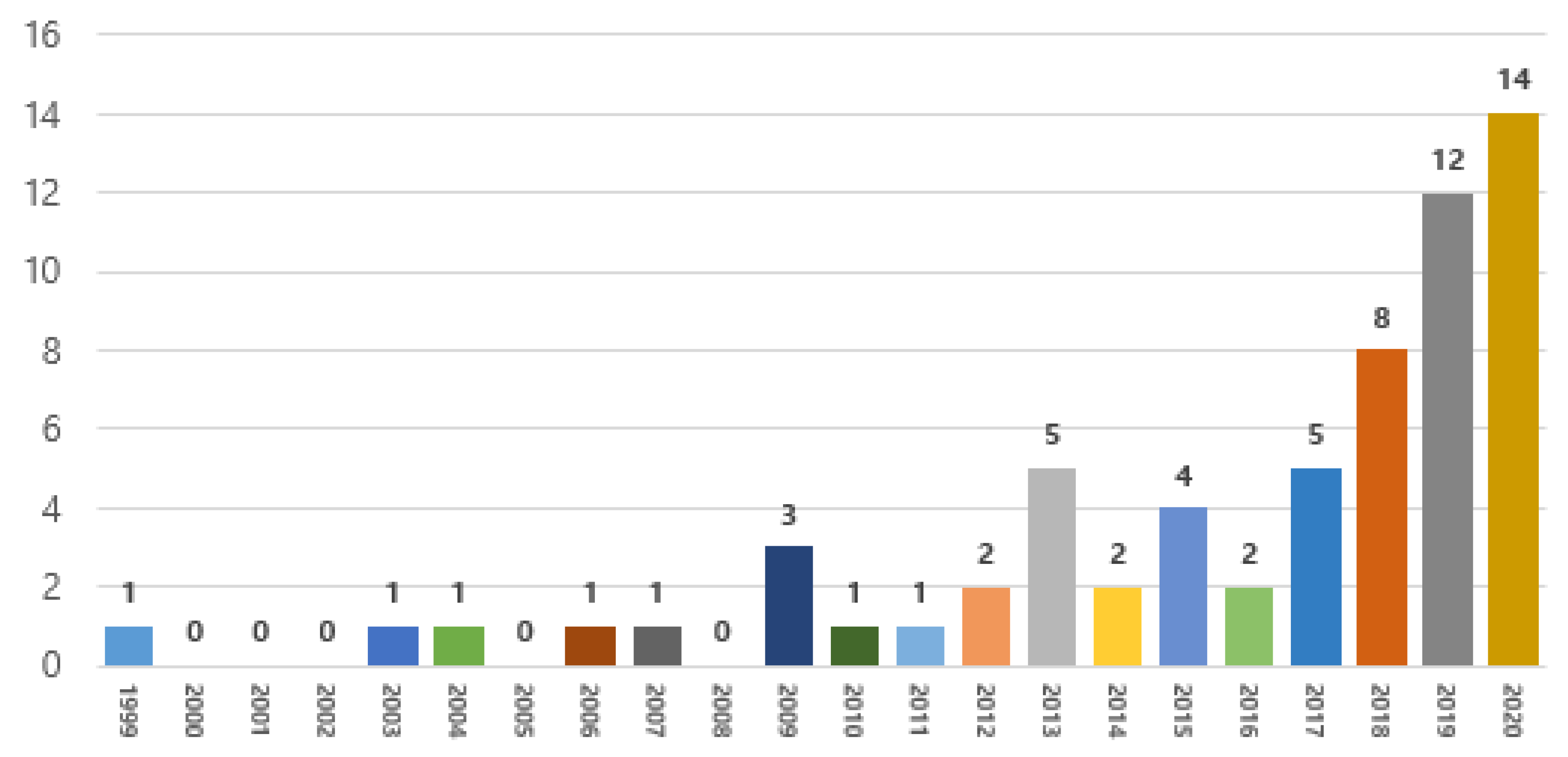
4.1. Algorithms and Methods of Data Analytics
The main data analytics techniques include data mining, AI, statistics, etc. In this study, the approaches and algorithms of the relevant research papers are categorized by applying the taxonomies of these techniques.
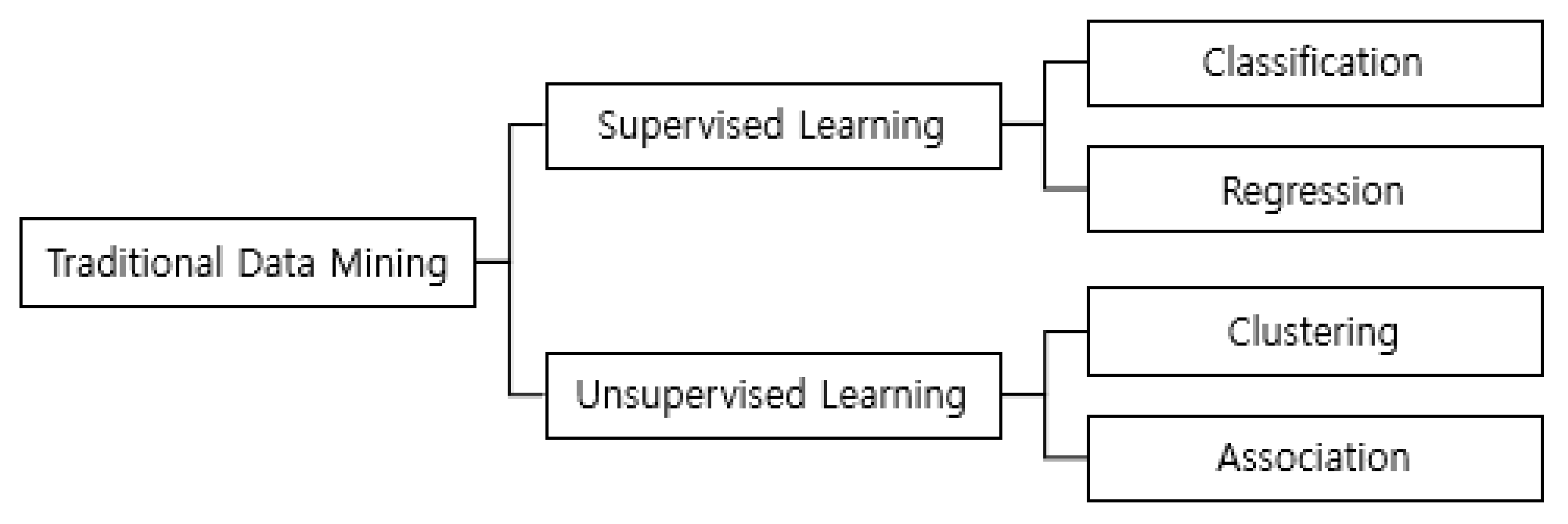
Data mining can be defined as an automated or semi-automated procedure for extracting knowledge, rules, and patterns from large volumes of data [
25]. Typically, data mining techniques are grouped into two categories, namely supervised learning (predictive analytics) and unsupervised learning (descriptive analytics), as shown in
Figure 8.
The ultimate goal of supervised learning is to predict the value of a target variable for new input data. To this end, supervised learning techniques are designed to build a model that explains the relationships between a target variable and predictors by analyzing a training set where the values of the target variable are known [
26]. In other words, training sets for supervised learning contain both predictors and target variables. A target variable is an output value or dependent variable to be estimated, while predictors are independent variables that can affect the target variable [
27]. Supervised learning is subdivided into two types: classification and regression. Classification is used for estimating the value of a categorical target variable [
28]. Examples of classification techniques are decision trees, Bayesian classifiers, and nearest neighbor, etc. [
26,
29,
30]. In contrast, the objective of regression is to estimate a numerical target variable. Examples of regression techniques are linear regression, ridge regression, lasso regression, and artificial neural networks (ANNs), etc. [
31].
Unsupervised learning is used to understand and describe the structure of a given data set. Typically, techniques and algorithms of unsupervised learning do not consider a target variable. Unsupervised learning includes clustering analysis and association analysis. The objective of clustering is to find groups of records, such that similar records belong to an identical group while dissimilar records belong to different groups. Examples of clustering algorithms are k-means, DBSCAN, and hierarchical clustering, etc. [
26,
29,
30]. On the contrary, association analysis is used to extract interesting association rules, which represent the cause-effect relationships among the variables, from a transactional data set [
32]. Association analysis can be performed by applying the well-known Apriori algorithm and its variations [
32,
33] or the FP growth algorithm [
34].
Supervised learning techniques can be used to analyze the relationship between target variables and predictors related to legal decisions. For instance, those techniques enable the prediction of the trial result if appropriate models and predictor variables are given. In contrast, unsupervised learning techniques are typically used to analyze similarities or correlations between legal documents. For instance, sub-groups of similar cases can be identified by applying clustering analysis to legal judgment data.
Recently, much attention has been paid to AI and ML. AI techniques are used to develop computers or machines that can mimic human intelligence. ML provides algorithms that enable machines to learn from given examples. Thus, the definitions of AI and ML are slightly different from that of data mining. Nevertheless, the aforementioned traditional data mining tasks of classification, regression, clustering, and association can also be performed by applying algorithms and techniques of AI and ML [
31,
35].
Additionally, two modern techniques, namely text mining and network analysis, are also important approaches for data analytics-based Legal Tech according to our survey. Text mining is the process of extracting useful information from text data. Text data are unstructured data that are hard to process and analyze. Since raw data for Legal Tech often exist in text form, preprocessing for raw data is an important issue of data analytics-based Legal Tech. The ultimate goal of preprocessing is to obtain useful and refined data to be analyzed by data analytics techniques. Well-known preprocessing techniques include feature selection, feature construction, missing value imputation, data integration, and data transformation, etc. These techniques help to obtain high-quality data more suitable for data analytics [
29]. Among them, data transformation techniques are very important for Legal Tech, because most traditional data analytics algorithms cannot deal with text data directly.
Text mining algorithms provide non-trivial procedures for transforming text data into structured data [
36,
37,
38]. Well-known text mining techniques include TF-IDF, a bag of words (BoW), and word embedding, etc. TF-IDF generates structured data in the form of a document-term matrix, where the importance of a term is calculated by using frequency and inverse document frequency. For a single term, TF (term frequency) and IDF (inverse document frequency) denote the number of occurrences and their reciprocal, respectively [
39]. Let us consider three short documents: document 1, ‘Autonomous Weapons and International Humanitarian Law: Advantages, Open Technical Questions and Legal Issues to be Clarified’; document 2, ‘Autonomous Weapons Systems and the Law of Armed Conflict’; and document 3, ‘On the Right of Citizens to Assemble Peacefully, without Weapons, Freely Conduct Meetings and Demonstrations’. The TF values for the terms within documents 1–3 are summarized in
Table 5.
The IDF value for a specific term is calculated by using DF (document frequency), the number of documents containing the term, as follows:
where
is the number of given documents.
Table 6 summarizes the IDF values for the terms within documents 1–3.
Then, TF-IDF values can be calculated by using (2), and the TF-IDF values for this example are summarized in
Table 7.
In a TF-IDF matrix, a term is frequently found in given documents if the sum of values in the corresponding column is small. For instance, ‘Weapons’ and ‘and’ are frequent terms in
Table 7.
Similarly, BoW generates a document-term matrix by using the frequencies of given terms [
40]. Assume three documents: document 1, ‘Autonomous Weapons and International Humanitarian Law: Advantages, Open Technical Questions, and Legal Issues to be Clarified’; document 2, ‘Autonomous Weapons Systems and the Law of Armed Conflict’; and document 3, ‘On the Right of Citizens to Assemble Peacefully, without Weapons, Freely Conduct Meetings and Demonstrations’. A BoW-based document-term matrix for the terms within documents 1–3 is shown in
Table 8. Note that this document requires the length of each document. In
Table 8, a document is represented as a row vector containing frequency values of the given terms. These vectors can be used to calculate similarity or dissimilarity between documents.
Word embedding is used to convert a term into a dense vector containing continuous values, which can be obtained by learning given documents or corpus data [
41]. Word embedding enables one to represent a term by a vector with lower dimensionality. Moreover, the dense vector of word embedding can reflect similarity or dissimilarity between terms.
Typically, raw data generated and collected during legal service procedures are in the form of text. However, many data analytics algorithms are designed to handle structured data such as table data. Thus, text mining techniques, including TD-IDF, BoW, and word embedding, are important in that they provide useful preprocessing methods for data analytics-based Legal Tech. The transformed data in
Table 5,
Table 6,
Table 7 and
Table 8 are in tabular form, where a record is characterized by a number of variables. Since many data analytics algorithms, supervised and unsupervised techniques, assume tabular structured data, this data structure is most commonly used in the fields of AI, ML, and data mining. In contrast to preprocessing, postprocessing techniques are used to interpret and utilize knowledge and patterns obtained by applying supervised and unsupervised learning techniques more effectively. Data summarization and visualization are examples of postprocessing tasks, however, the postprocessing procedure is out of the scope of this paper.
Another important modern data analysis approach is network analysis. Network analysis is the process of understanding the structures of a given network and the relationships between nodes therein [
23]. For instance, legal documents and their citation relationships can be represented as nodes and edges of a network. Network analysis techniques can be used to find important nodes or a community of some nodes, which are useful for information visualization and document recommendation [
42,
43].
4.2. Input Data and Algorithms
The research papers that applied supervised learning algorithms to legal data are listed in
Table 9, while research papers that used unsupervised learning algorithms are shown in
Table 10. In addition, research papers that are not contained in
Table 9 or
Table 10 are listed in
Table 11.
The ‘Data structure’ columns of
Table 9,
Table 10 and
Table 11 indicate the type of input data for the data analytics algorithms. This paper considers six types of data structure, including bag of words, TF-IDF, word embedding, segmented document, structured document, and text. Data in the form of the first three types—namely, bag of words, TF-IDF, and word embedding—are generated by applying text-mining algorithms. A segmented document can be defined as a set of elements obtained by splitting the contents of a given document. For instance, keywords, sentences, and paragraphs can be used as the elements for creating a segmented document. In structured document-type data, a single document is represented by using a number of features that can be identified from a given document. Examples of features for structured document-type data include information on the victim or defendant, location of judgment, and amount of money involved, etc. [
44,
45]. Moreover, this type of data is sometimes provided in the form of an XML (Extensible Markup Language) document [
44,
46,
47] or electronic database [
42,
48,
49]. Inherently, structured document-type data are a sort of table data. Thus, this type of data can be processed and analyzed in a convenient way if appropriate features are carefully developed [
50,
51]. Finally, documents containing plain text are classified as text-type data in
Table 9,
Table 10 and
Table 11.
For each research paper, the algorithm(s) applied by the authors can be found in the ‘Algorithm’ columns of
Table 9,
Table 10 and
Table 11, where all the ANN-based algorithms, such as multi-layer perceptron (MLP) and DL, are classified as ANN&DL.
Table 9,
Table 10 and
Table 11 provide the following observations. Firstly, preprocessing plays a significant role in most research papers. In other words, input data for data-analytics-based Legal Tech are generally obtained by applying preprocessing techniques to raw legal documents. Several research papers in
Table 9 and
Table 10 proposed methodologies that can be applied to text-type data; however, those methodologies often contain their own preprocessing procedures that transform text-type data into a more structured form [
87,
88]. Thus, it can be concluded that it is difficult to directly use legal documents in the form of text to develop data analytics-based Legal Tech applications.
Secondly, a structured document is also a popular data structure. It is well known that data quality has a significant impact on the usefulness of analysis results [
29]. Moreover, structured documents of high quality can be obtained by creating meaningful features or variables that describe the contents of the raw data well. Such features can be created automatically by using relevant tools such as natural language processing (NLP) [
64]. In this context, it is expected that structured document-type data will continue to be widely adopted by Legal Tech applications.
Thirdly, a significant number of research papers applied supervised learning algorithms to legal judgment data. One reason is that legal judgment is quite an important decision-making process in the legal industry. The other reason is the structure of legal judgment data. In order to apply a supervised learning algorithm, input data should contain both a target variable and predictor variables, such that predictors affect the target variable. In legal judgment data, trial results such as the length of imprisonment and amount of penalty are affected by other information such as the associated law articles and defendant profiles [
87]. In other words, trial results and other information can be used as target variables and predictors, respectively. Thus, legal judgment data can be regarded as a good data source for supervised learning tasks. This led the supervised learning task to be dealt with more frequently than unsupervised learning and other tasks.
Fourthly, among the traditional unsupervised learning tasks, clustering is dealt with more often than association, as shown in
Table 10. For instance, clustering analysis is a useful tool for discovering a group of legal documents to be focused on [
79,
91].
Furthermore, the research papers listed in
Table 11 generally provide methodologies and applications for information extraction. The topics of the research papers include entity recognition [
43,
48,
93,
99], similarity-score-based recommendation or information retrieval [
96,
98], information visualization [
42], and opinion mining [
100], etc.
Lastly, 21 of 64 (32.8%) research papers utilized ANN&DL algorithms, which revealed the good performance and wide applicability of ANN and its variations.
The tasks and algorithms of previous research papers are summarized in
Table 12. Among supervised learning tasks, the classification task is more frequently tackled than regression is. In other words, most research papers that utilize supervised learning techniques consider categorical target variables. For instance, length of imprisonment, which can be used as a target variable related to legal judgment, can be discretized into two intervals,
and
in order to apply classification algorithms. Since trial results, such as length of imprisonment, are sometimes specified by using intervals in law articles, classification is frequently adopted in research on data analytics-based Legal Tech.
The most widely used algorithm for supervised learning tasks is ANN&DL. An ANN is a network of artificial neurons (nodes) and connections between them, used to generate output values for given input values. The nodes within an ANN form two or more layers. The input layer contains input nodes that indicate input values, while the output layer consists of output nodes that produce output values. Moreover, the layers between the input layer and output layer are called hidden layers. Typically, an ANN with many hidden layers is complex and time-consuming to train, although the hidden layers can contribute to obtaining output values appropriate for the given input values [
35,
103]. However, modern computer hardware and efficient activation functions allow for utilizing a number of hidden layers for a wide range of practical purposes. An ANN with many hidden layers is called a deep neural network (DNN), and DL is a set of algorithms that use a DNN [
104].
Table 12 shows that ANN&DL techniques are also widely used in the legal domain.
The most frequently used clustering and association algorithms are
k-means and Apriori, respectively.
K-means is a well-known clustering algorithm that is used to find centroid-based and non-overlapping
clusters from a given data set. The number of clusters,
, should be prespecified by the analyzer, and a single cluster should contain records similar to each other [
26,
29,
30]. In the legal domain, a clustering algorithm is often used to find clusters of similar documents. Association analysis is rarely applied in the legal domain. The Apriori algorithm is a traditional algorithm used for association analysis that is designed to extract useful, interesting association rules from a given transaction data set [
32]. An association rule indicates cause-and-effect relationships or correlations between items within a given transaction data set, and a single association rule is useful if and only if its support and confidence measures simultaneously satisfy minimum threshold values [
29]. Typically, association analysis is used to identify a set of items frequently found together in identical transactions. In the legal domain, Liu et al. [
71] applied the Apriori algorithm to analyze citation relationships between statutes.
4.3. Target Variable
As discussed in the previous section, supervised learning techniques that consider a target variable is widely used in research on data analytics-based Legal Tech. In a training set for supervised learning, both predictors and target variable values should be known, and supervised learning algorithms are generally designed to build models that reflect the relationship between predictors and the target variable. If a model is obtained, it is used to estimate the value of the target variable for a new data object, where only the predictors are known. The target variables of the research papers listed in
Table 9 are summarized in
Table 13. Note that a single research paper can consider two or more types of target variables.
In
Table 13, the most frequently considered target variable type is the trial result, which includes the length of imprisonment, amount of penalty, guiltiness of defendant, and validity of the patent, etc. [
44,
51,
65,
73,
79]. This type of target variable is very popular in research on data analytics-based Legal Tech since it is the primary output of the most important legal service, i.e., legal procedures.
Element type as a target variable is used to specify the type of entity identified in legal documents. For instance, some noun phrases can indicate information, such as the name of the person, location, and time, in legal documents [
21,
45,
64]. Ji et al. [
22] used ANN&DL techniques to classify the type of paragraphs in court record data. Examples of application areas of classification models for element type target variables include annotation of legal documents and transformation of legal documents into structured documents.
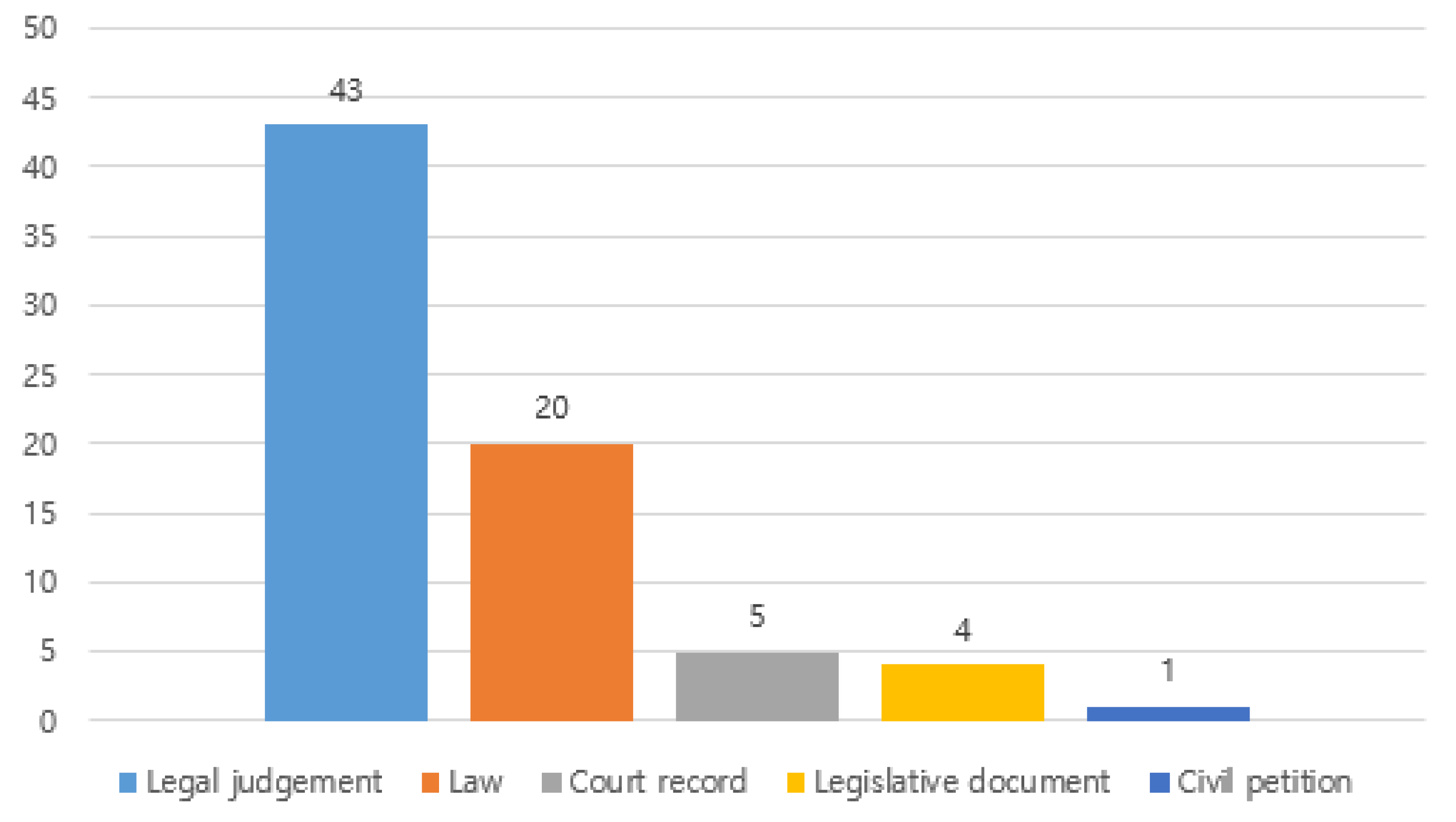
Document type is the third most popular target variable type. Typically, legal experts have to examine a large volume of legal documents in order to provide legal services. Sometimes, a legal expert or a department of an organization will specialize in specific types of documents. Similarly, different types of legal documents are often processed in different ways. Thus, the research papers that focused on document type as the target variable aimed to improve the efficiency of legal service procedures by classifying the involved legal documents into appropriate groups. Examples of document type target variables are case type, complaint type, accusation type, and topic type, etc. [
57,
62,
72,
77,
78].
Law article as a target variable denotes law articles associated with a specific case. In other words, models for this type of target variable are able to find law articles relevant for a given case conveniently [
71]. Moreover, the information about law articles determined by data analytics techniques can be used to estimate trial-result-type target variables [
68,
86].







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}