1. Introduction
TTP has important information that travelers rely on increasingly, and meanwhile, it is also essential for transportation agencies and traffic management authorities. Short-term TTP is a key component of the Advanced Travelers Information System (ATIS) in which in-vehicle route guidance systems (RGS) and real-time TTP enable the generation of the shortest path for travelers, which connects the destinations and current locations [
1]. Accurate TTP on the future state of traffic enables travelers and transportation agencies to plan their trips and mitigate congestion along with specific road segments (such as rerouting traffic or optimising the signaling time of traffic lights), leading to the overall reduction of total travel time and cost. These measures can also help reduce greenhouse gas emissions, as the CO
2 emission rates in congested conditions can be up to 40% higher than those seen in free-flow conditions [
2]. Travel time also can be used as a performance measure to evaluate the utility of investments such as the widening of expressways, subways, and roads. TTP has been an interesting and challenging research area for decades to which many researchers have applied various traditional statistical and machine learning algorithms to improve prediction accuracy and stability. The paper develops different machine learning prediction models and compares their performance based on a case study from the City of Charlotte, North Carolina.
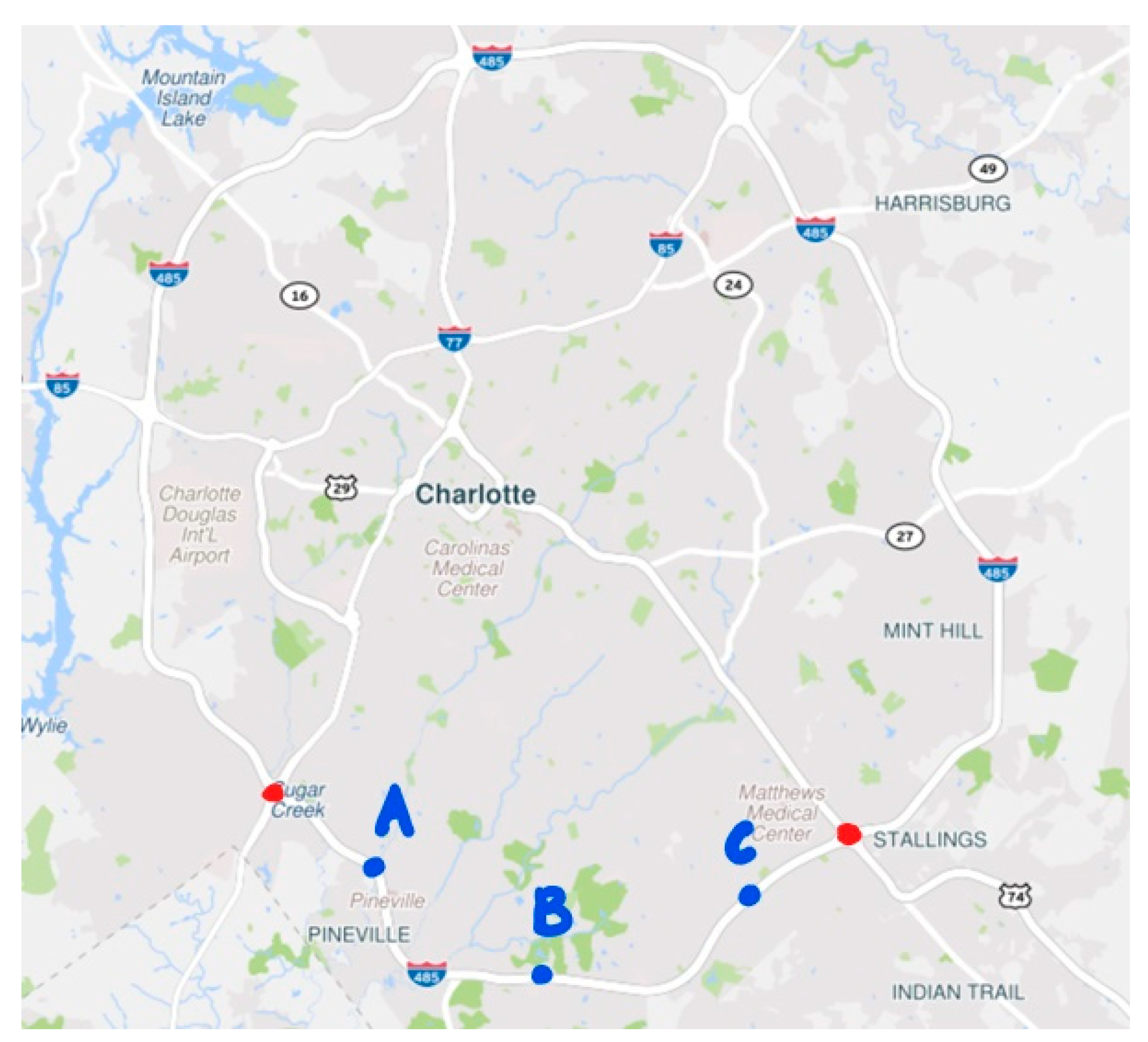
In the field of logistics, TTP for minutes or hours is important for dispatching, e.g., when assigning customers to drivers for the deliveries of food or goods. The objective of this study was to develop a series of dynamic machine learning models that can efficiently predict travel time. An unbiased and low-variance prediction of travel time is the ultimate goal. Different machine learning algorithms have been developed, which include DT, RF, XGBoost, and LSTM. Such TTP models were tested and compared using the probe vehicle-based traffic data for selected road segments (i.e., a freeway corridor in Charlotte, North Carolina) from the RITIS. Mean Absolute Percent Error (MAPE) was selected and used as evaluation and comparison criteria. The advantages and disadvantages of the proposed models are also identified and provided. Finally, the effectiveness and efficiency of the proposed models are discussed.
In the field of TTP, the prediction scheme can be classified into short, medium, and long-term horizons based on the prediction duration. Van Lint (2004) defined short term TTP as horizons ranging from several minutes to 60 min [
3], while the long-term TTP horizon can take more than a day. Long-term travel times are typically impacted more by the factors such as weather and congestion conditions [
4]. Shen (2008) found that setting a proper TTP horizon is a vital factor in evaluating the performance of TTP models [
5]. Furthermore, the road characteristics of signalized streets, arterials or freeways, is another classification method. Due to additional factors such as signal timing plans and controls at multiple intersections, the TTP on signalized urban roads is inherently more complex than on freeways [
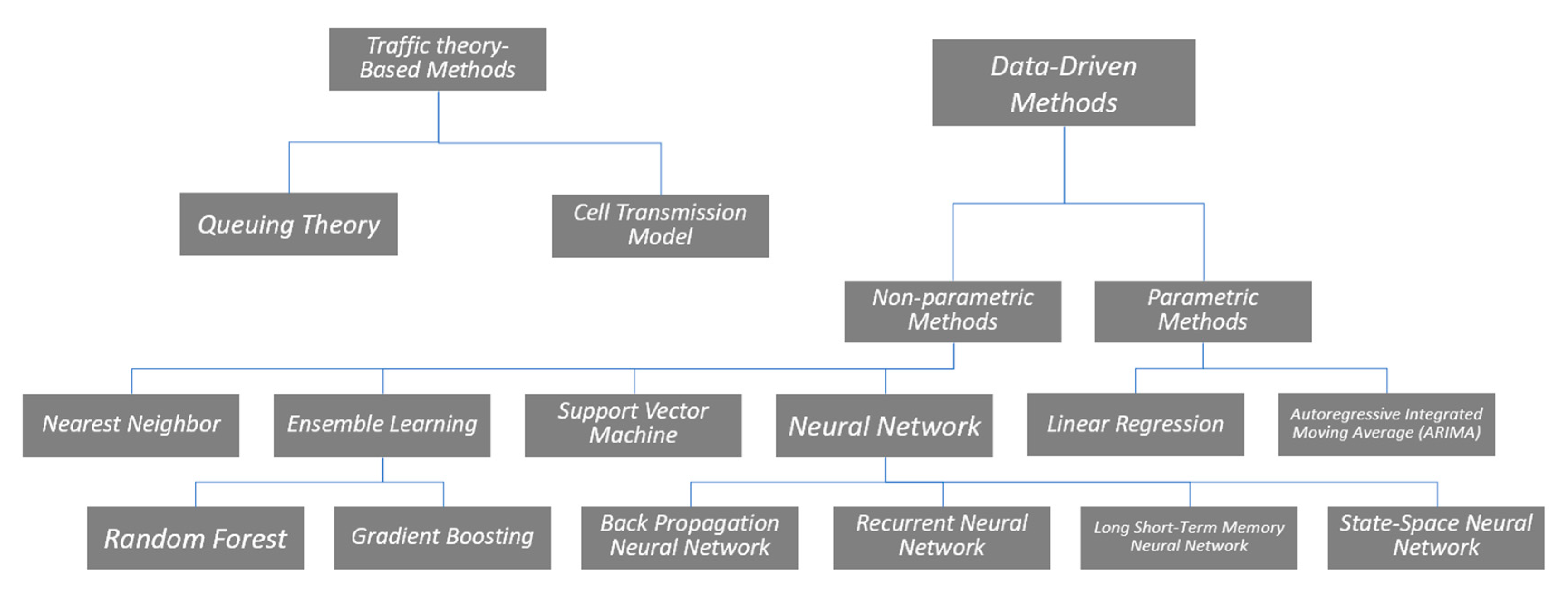
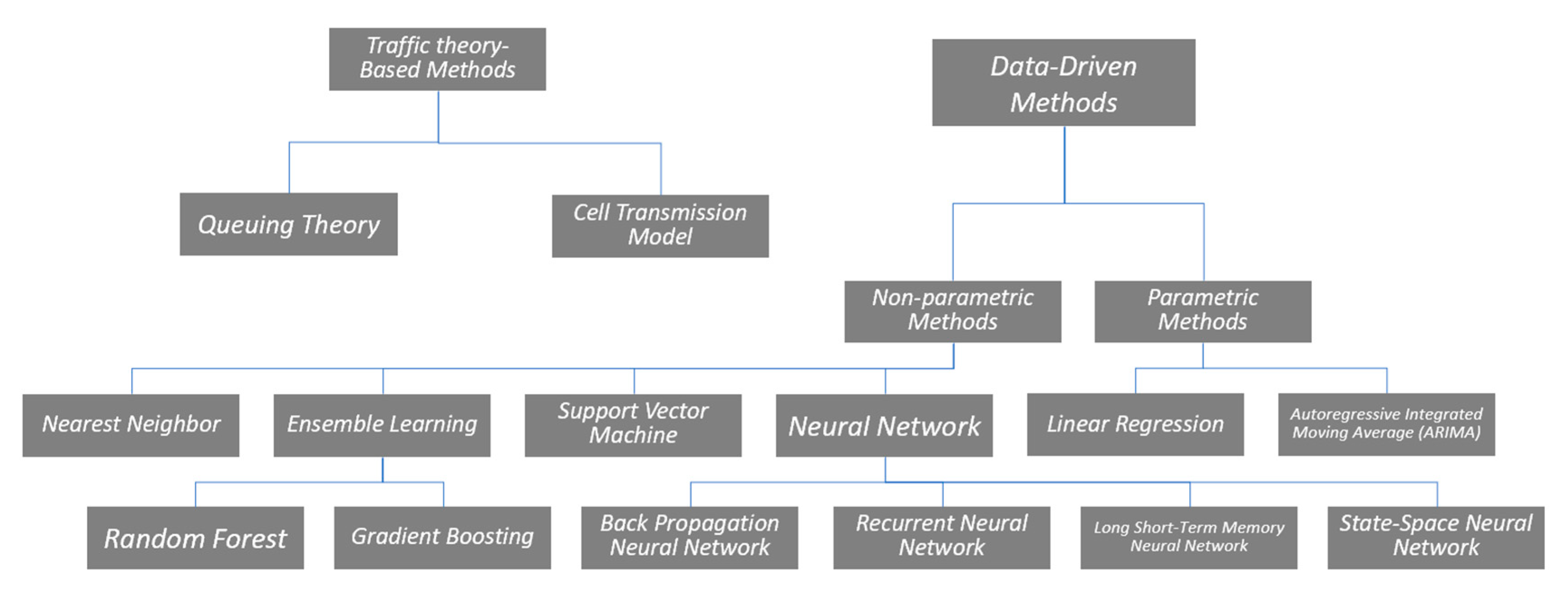
6]. The studies have been conducted in the field to develop and improve the accuracy and reliability of TTP, which can generally be classified into traffic theory-based methods and data-based methods. With the rapid development of machine learning methods and the increasing availability of the collected traffic data, data-based methods have become increasingly popular in the last two decades, which can be further divided into two major categories: parametric models and non-parametric models [
3]. Parametric methods are model-based methods in which the model structure is predetermined under the specific statistical assumption, and the parameters can be estimated with the sample dataset. Owing to the simplicity of statistical interpretation, the most typical parametric model is linear regression, where the dependent variable is a linear function of the explanatory (independent) input variables. In the TTP, the independent variables are generally traffic factors gathered in several past time intervals. Time series models are another typical type of widely applied parametric model in TTP, where the explanatory variables are a series of data points indexed in the time order. Owing to its statistical principles, the prediction results of the time series model are always highly based on the previously observed values. Autoregressive integrated moving average (ARIMA) model is the most widely used for TTP. The ARIMA model combines two models, which include the autoregressive (AR) and the moving average (MA) models.
Different from parametric models, both the structure and the parameters of the model are not predetermined in the non-parametric models. However, it does not mean that there are no parameters that can be estimated. Instead, the number typology of such parameters is indeterminate or even uncountable. From the taxonomy of the data-driven approach to TTP, the level of model complexity can vary from high to low, from linear regression and time series to artificial intelligence (neural networks, ensemble learning) and pattern searching (nearest neighborhood). The taxonomy of TTP methods is shown in detail in
Figure 1.
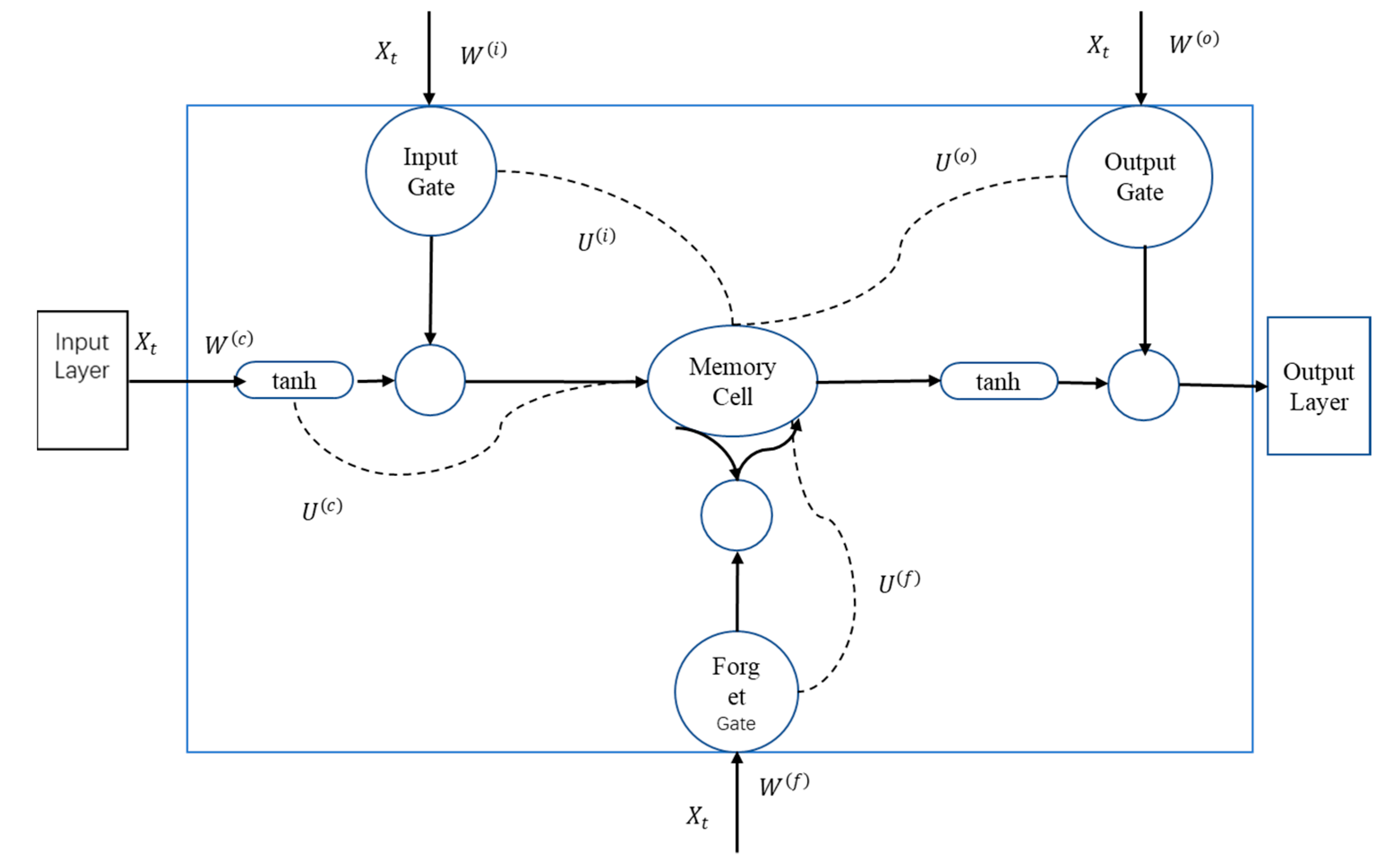
Benefiting from the rapid development of non-parametric machine learning methods, real-time TTP has become a reality. In the literature of TTP, artificial neural network (ANN) is the most widely used method due to its ability to capture complex relationships in large data sets [
7]. ANN is a typical non-parametric model which can be developed without the need to specify the model structure. Therefore, the multicollinearity of the explanatory variables can be overcome to some extent. In the past two decades, researchers in different fields have applied different types of neural networks in the field of traffic prediction using the ANN method (
Table 1). Park and Rilett used the regular multilayer feedforward neural networks to predict the freeway travel times in Houston, Texas in 1999 [
8]. Yildirimoglu and Geroliminis applied spectral basis neural networks to predict the freeway travel time in Los Angeles in California in 2013 [
9]. The variables selection is generally a crucial step in machine learning model estimation depending on the data availability and the model training process. In the variable selection, different variations of the backward algorithm consider different types of neural networks. Ensemble tree-based methods are another popular choice for TTP. RF is a tree-based ensemble method, which has become popular in the prediction field. From the name of RF, the forest is made up of separate DTs. Simple DT has ‘poor’ performance, while RFs have a large number of trees that usually produce high prediction accuracy by the swarm intelligence. The gradient boosting machine also combines DTs and starts the combing process at the beginning instead of doing so at the end. Unlike some machine learning methods that work as black-boxes, tree-based ensemble methods can provide more interpretable results and fit complex nonlinear relationships [
10].
Support vector machine (SVM) theory was created by Vapnik of AT&T Bell Laboratories [
11]. SVM is superior from a theoretical point of view and always performs well in practice [
12]. The SVM model is good for TTP based on historical travel time data, and therefore, there are several applications of SVM for TTP [
13,
14]. Kernel function is the key point in the SVM algorithm, which can map the input data into a higher-dimensional space. The mapping process stops until the flattest linear function is found (i.e., when the error is smaller than a predefined threshold). This linear function was used to map the initial space and obtain the final model, which was used for TTP. However, a crucial problem-overfitting arises from the complicated structure of SVM and ANN algorithms (i.e., the large number of parameters that need to be estimated), which commonly exists in the non-parameter machine learning algorithm.
Another popular non-parametric approach to TTP is the local regression approach. Local linear regression can be used to optimize and balance the use of historical and real time data [
15], which can yield accurate prediction results. In the local regression algorithm, a set of historical data with similar characteristics to the current data record are selected by the algorithm.
Semi-parametric models are a combination of specific parametric and non-parametric methods. The main idea of the semi-parametric method is to loosen some of the assumptions created in the parametric model to get a more flexible structure [
16]. In the application of TTP, semi-parametric models are always in the form of varying coefficient regression models in which the model coefficient varies depending on the departure time and prediction horizon [
17]. Therefore, travel time can be estimated by a linear combination of the naive historical and instantaneous predictors.
With the increasing and wide applications of machine learning algorithms in the field of TTP, mainstream machine learning methods have been deployed in different countries using various types of data sources. Many methodologies have been developed and applied by researchers, which include, but are not limited to, the following: SVM, neural network (e.g., state-and-space neural network, long short-term memory neural network), nearest neighbor algorithm (e.g., k-nearest neighbor), and ensemble learning (e.g., RF and gradient boosting), etc. Nonlinear modelling machine learning methods have also been widely applied and proven successful in many other fields, such as building models for taxi carpooling with simulation [
18], predicting the portfolio of stock price affected by the news with multivariate Bayesian structural time series model [
19], and evolving fuzzy models for prosthetic hand myoelectric-based control [
20].
Table 1 summarizes the studies reviewed that are classified based on the prediction method employed as shown in the last column of the respective studies.
The main innovative idea (and also the main contribution) of this paper is to apply and compare four different machine learning algorithms (i.e., DT, RF, XGBoost, and LSTM) for the TTP. To the authors’ best knowledge, this is the first effort made to systematically develop and compare such four algorithms in the TTP area.
4. Discussion
Previous studies [
10,
21] indicated that the input variables of the model usually have different effects on the dependent variable. Exploring the impact of a single input variable on the dependent variable can help reveal hidden information about the data. The greater the importance value of a variable, the stronger its influence on the model. In the feature selection process, we used the RF model to rank the relative importance from the original dataset. The features that had an importance of more than 0.1% were selected in the model training, and 23 features were selected in this study from the original 35 features (with the least important feature being the length of the road segment at 0.17%). The model result showed that the variable
(travel time 15 min before) contributed the most (34.85%) to the predicted travel time result. This result was expected and consistent with a previous study [
10] which demonstrated that the immediate and previous traffic condition will directly influence traffic condition in the near future. TOD was the second highest ranked variable with a relative importance value of 30.12%; this result was also expected. Adding up the most important eight variables’ relative importance values (
, TOD, speed,
DOW, weather, road ID, month) in
Table 7 is as high as 94.77%, which means that these eight selected variables include most of the information needed for the travel time prediction.
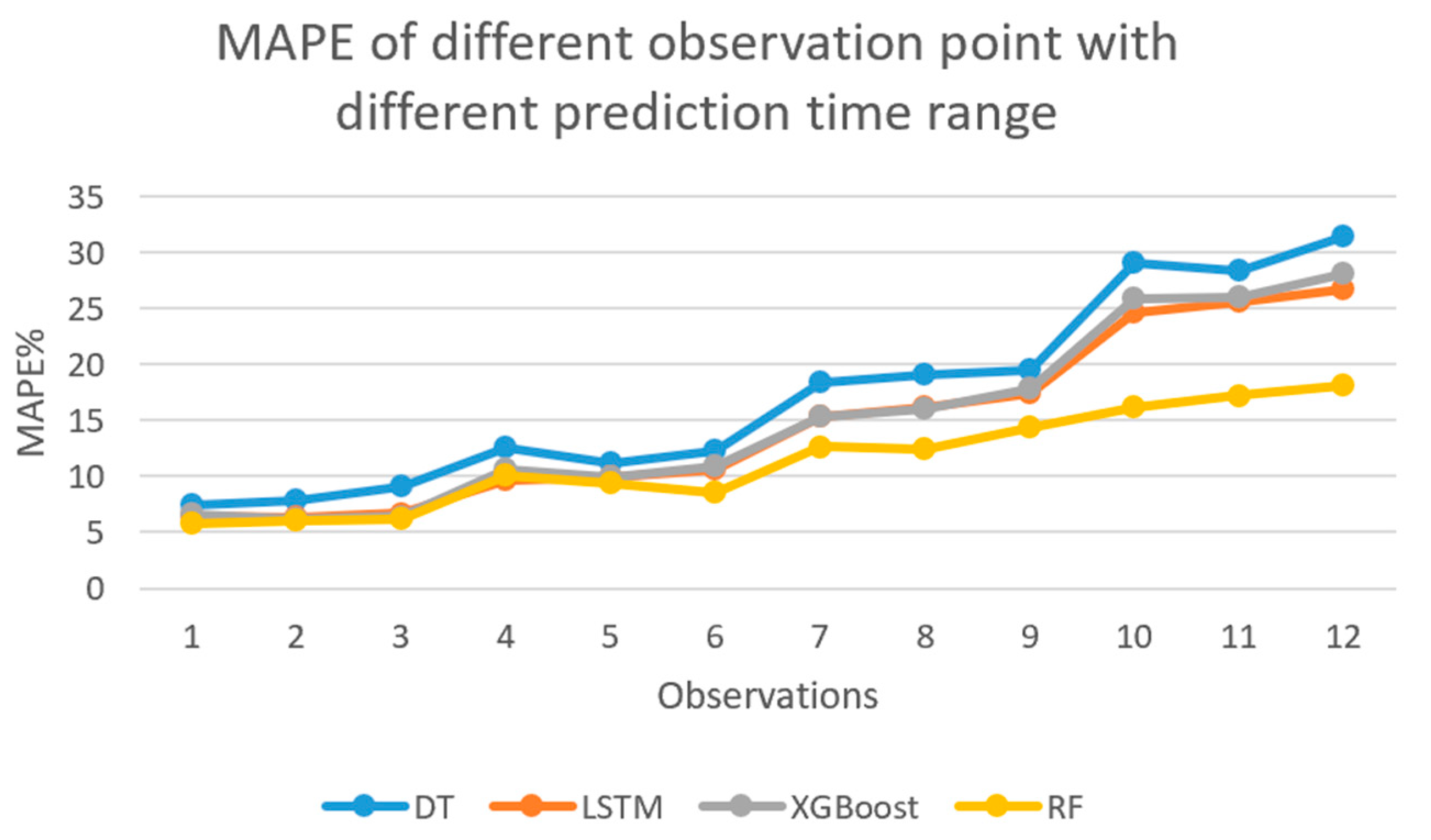
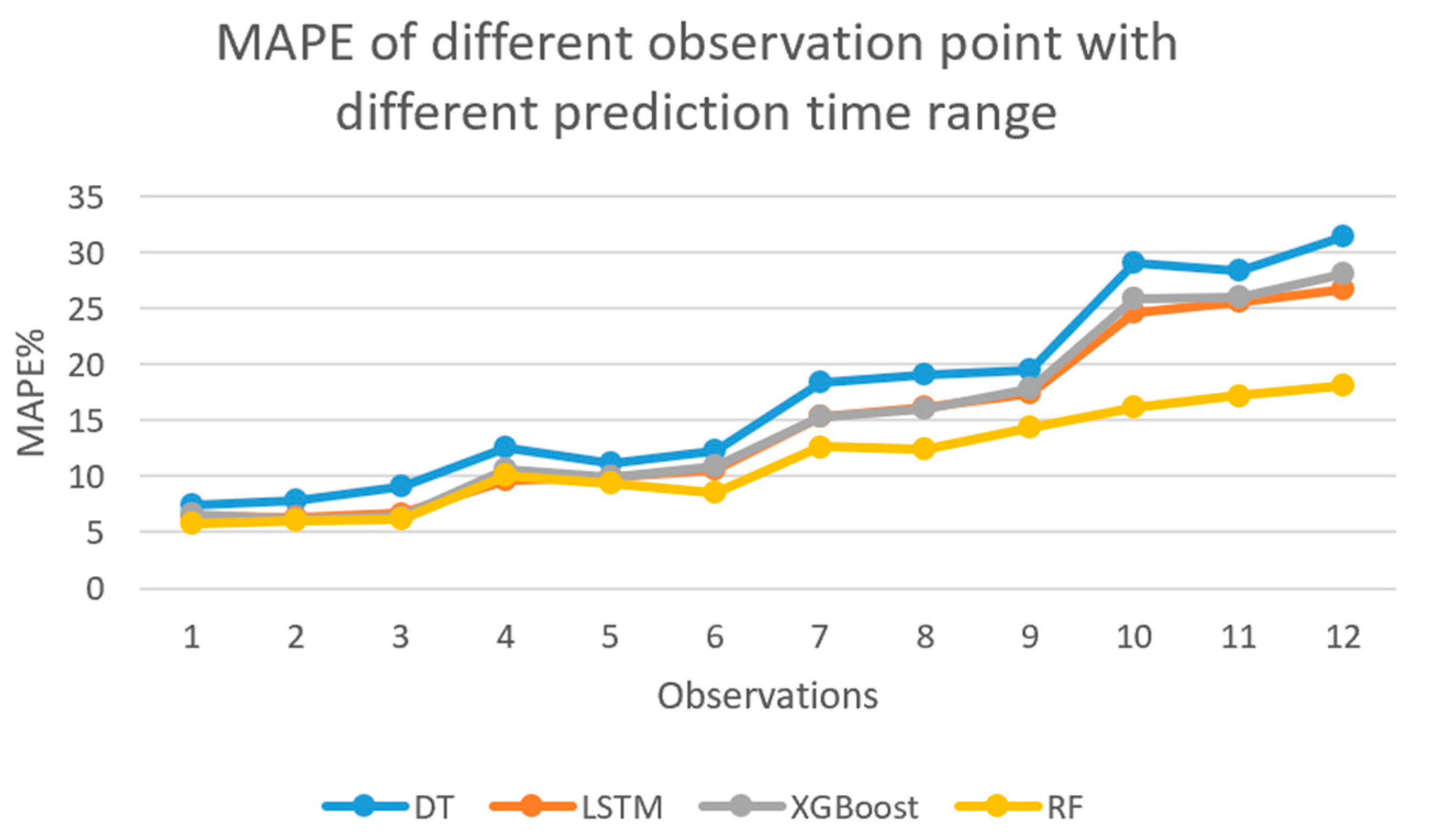
Table 7 shows the relative importance of each variable in the RF model for different prediction horizons. For different prediction horizons, the four most important variables are the same, and they are: travel time at prediction segment 15 min before, TOD, speed, and travel time 1 week before. As expected, the travel time of the current period has the greatest influence on the travel time of the next period.
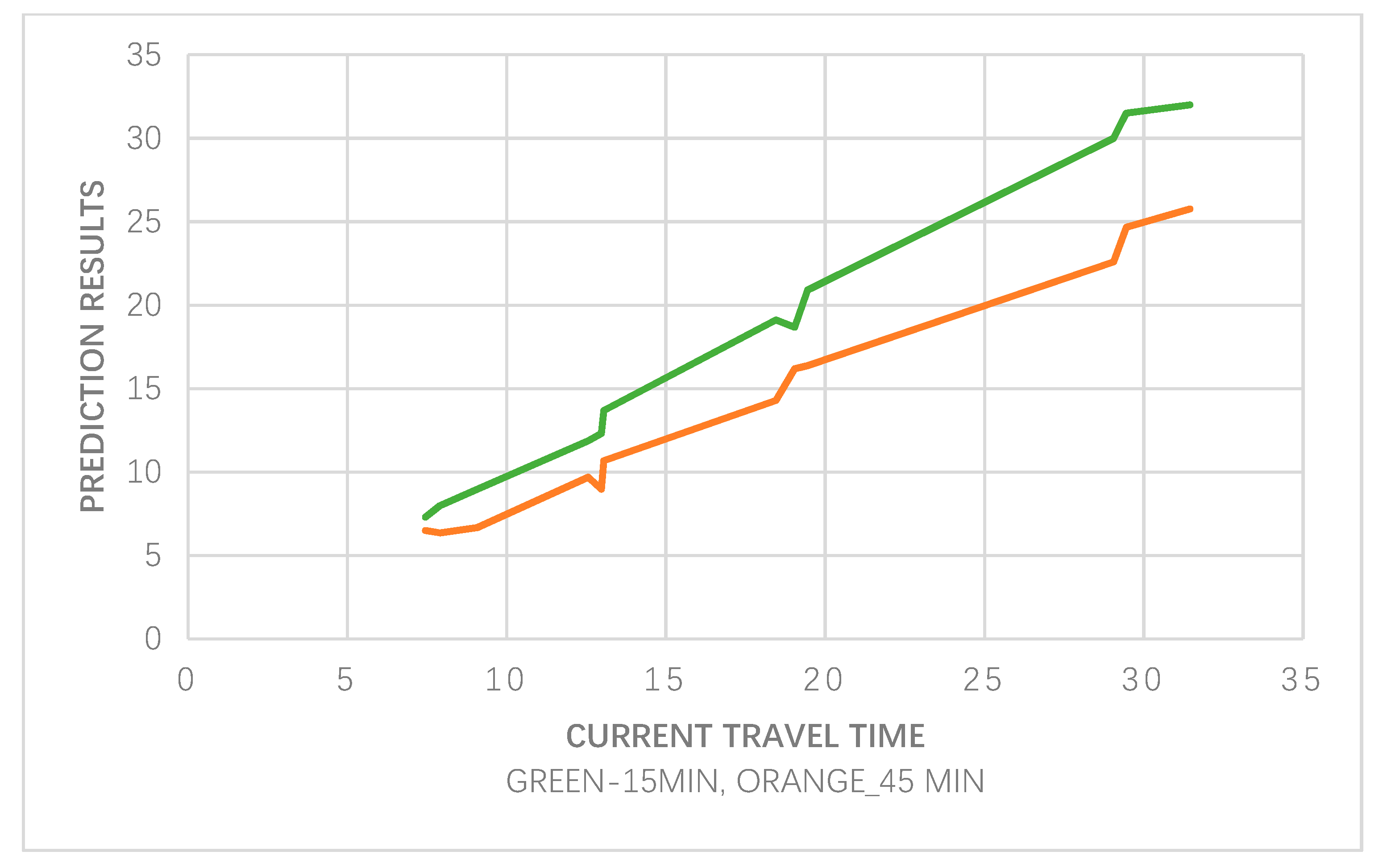
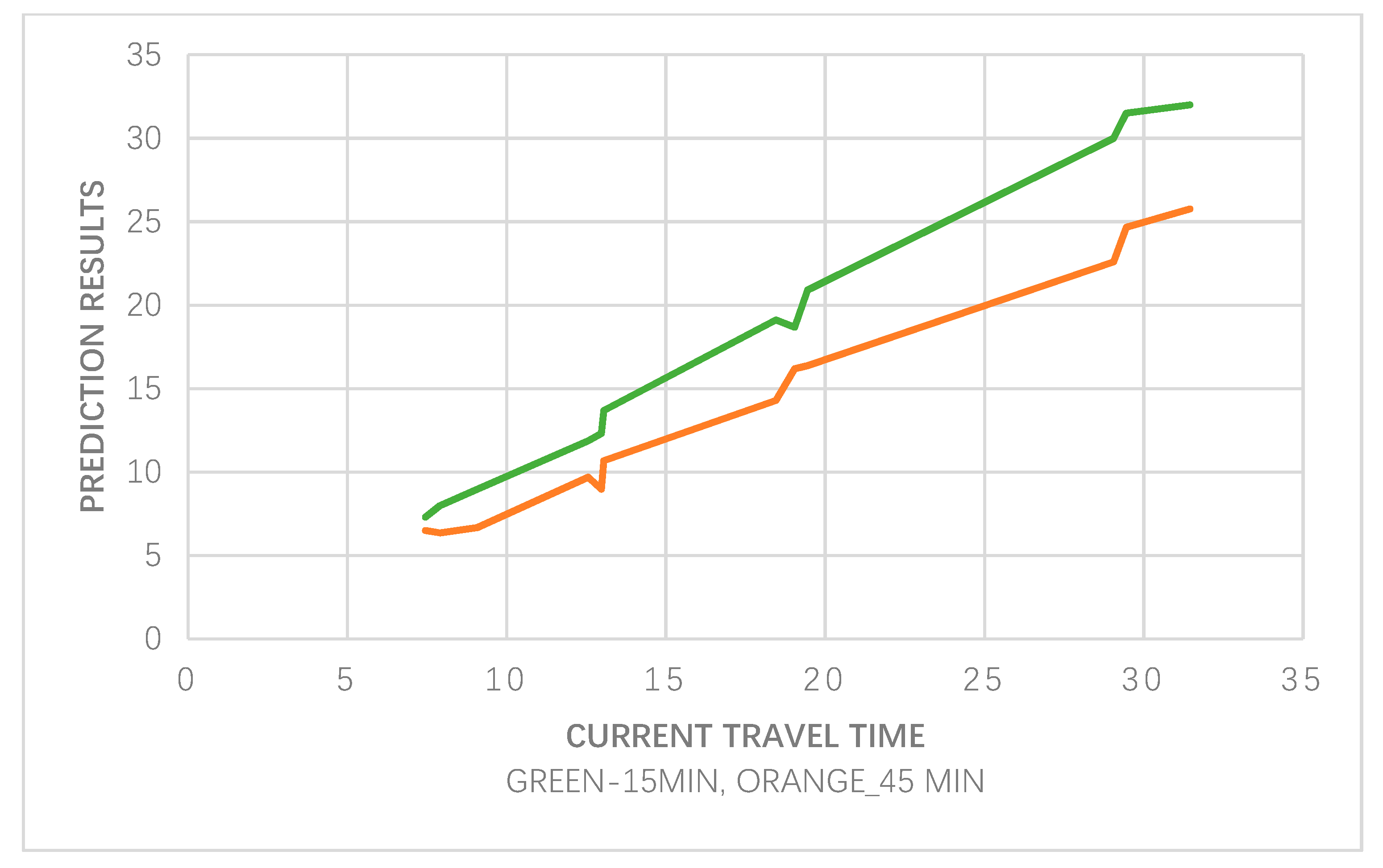
Since the most important relative feature is the same for different prediction horizons, the partial dependence function graphs between predicted travel time and actual travel time in the current period are shown in
Figure 8. It can be found that current travel time has a highly linear relationship with the predicted travel time; however, the curve behaves differently for different prediction horizons. Furthermore, when the prediction horizon increases (from 15 to 45 min), the change rate of the curve gradually decreases, which demonstrates that travel time in the current period has less impact on the TTP. It indicates that the model’s predicted performance decreases as the prediction horizon increases.
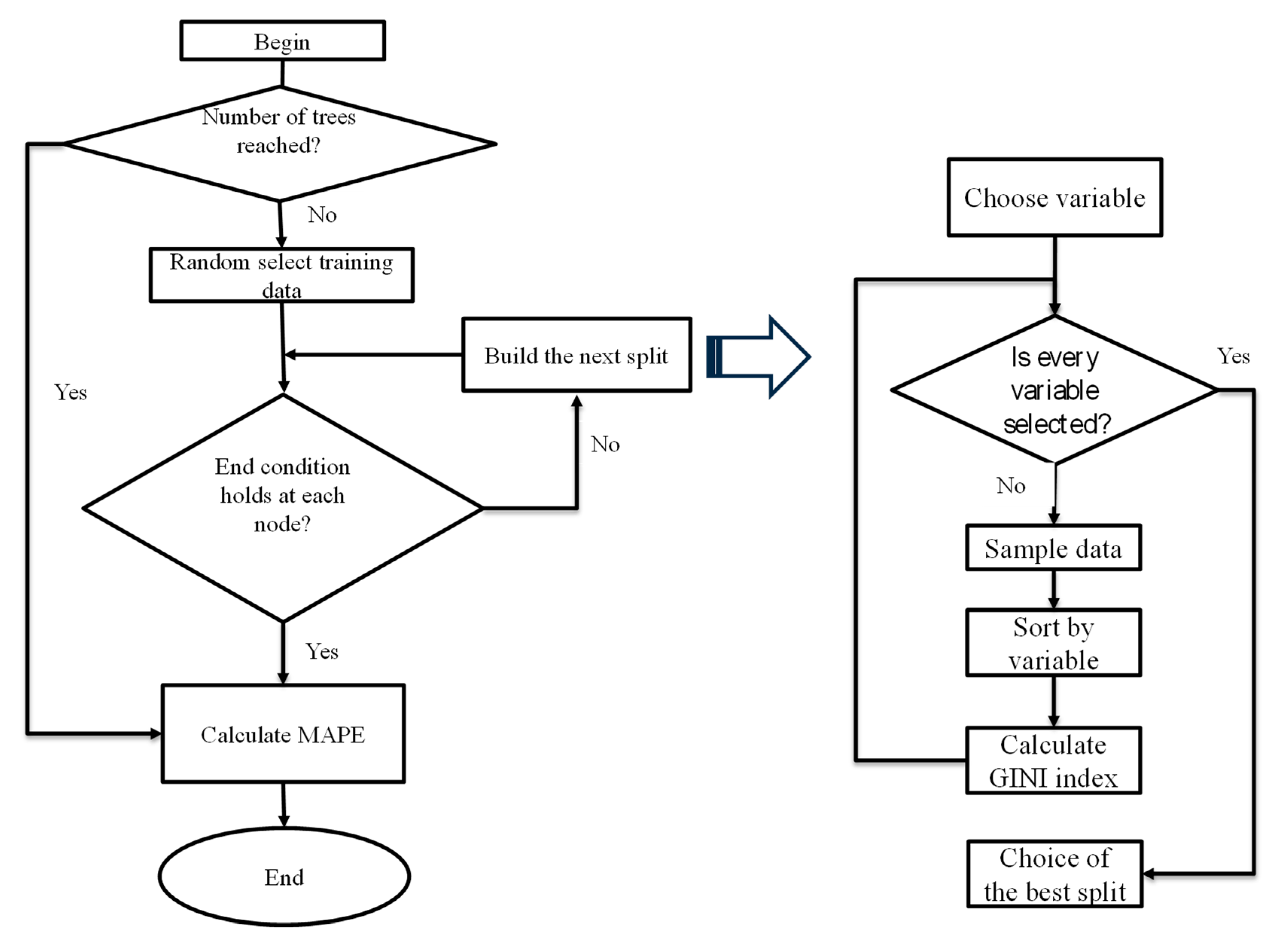
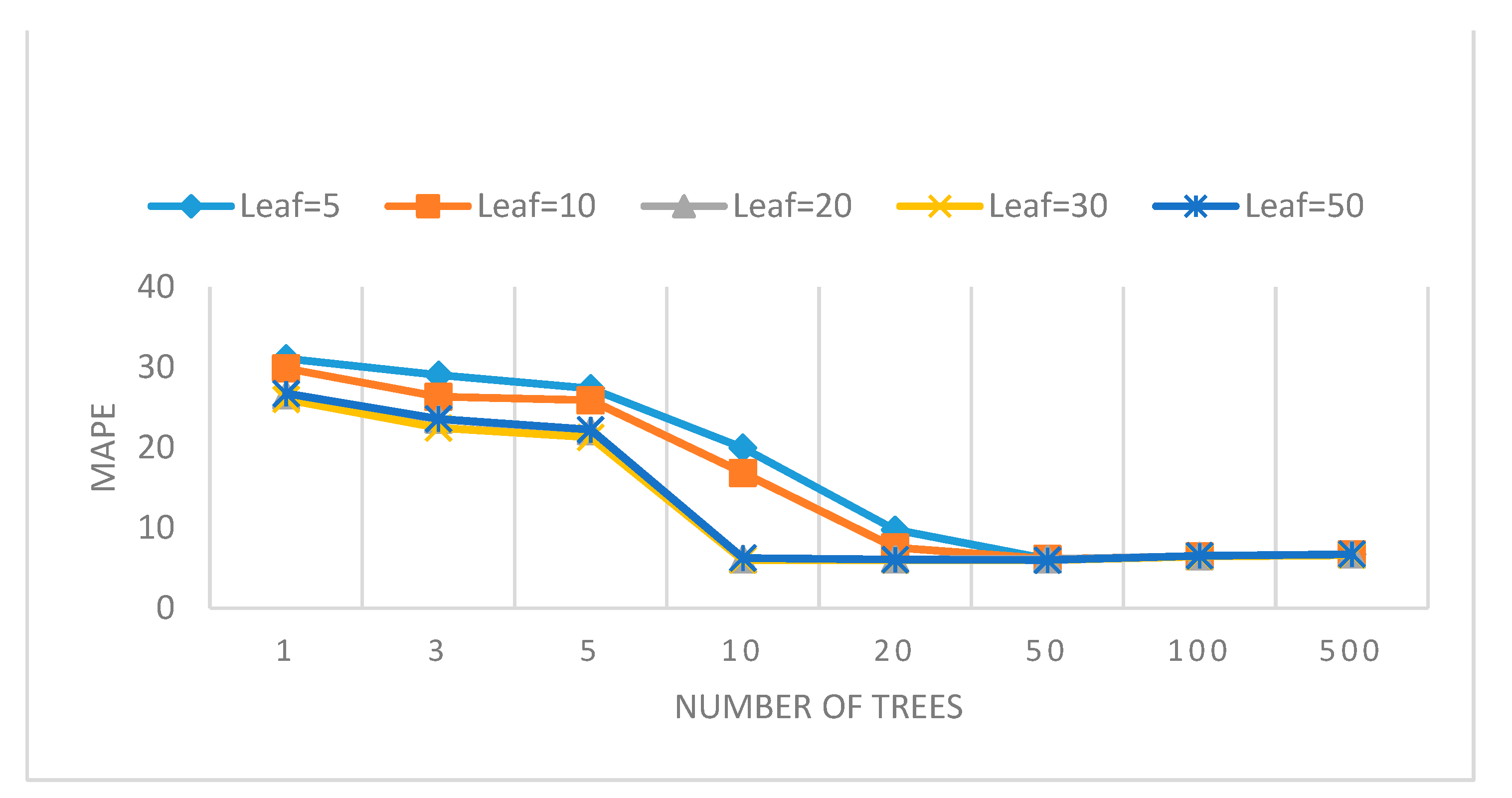
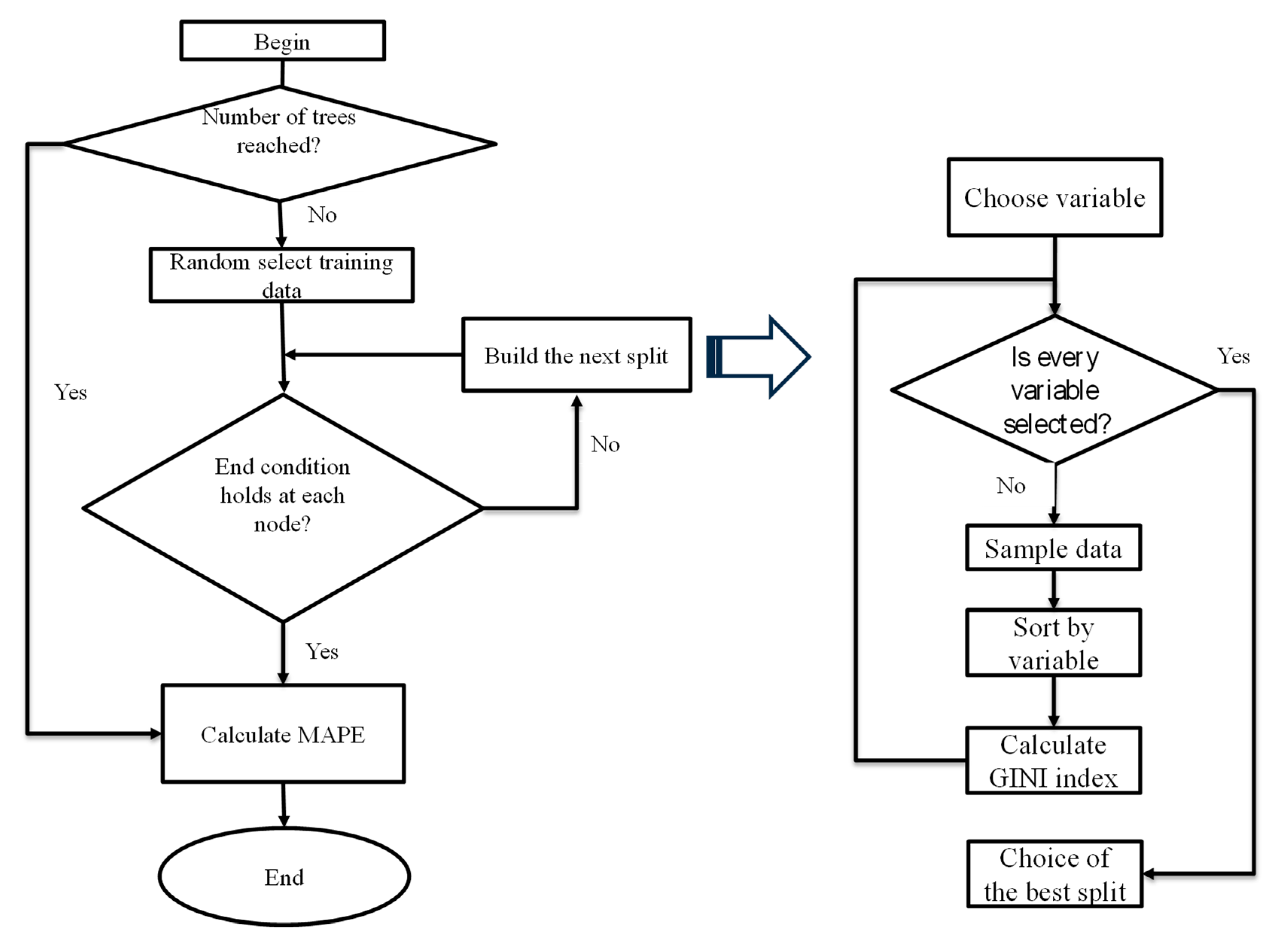
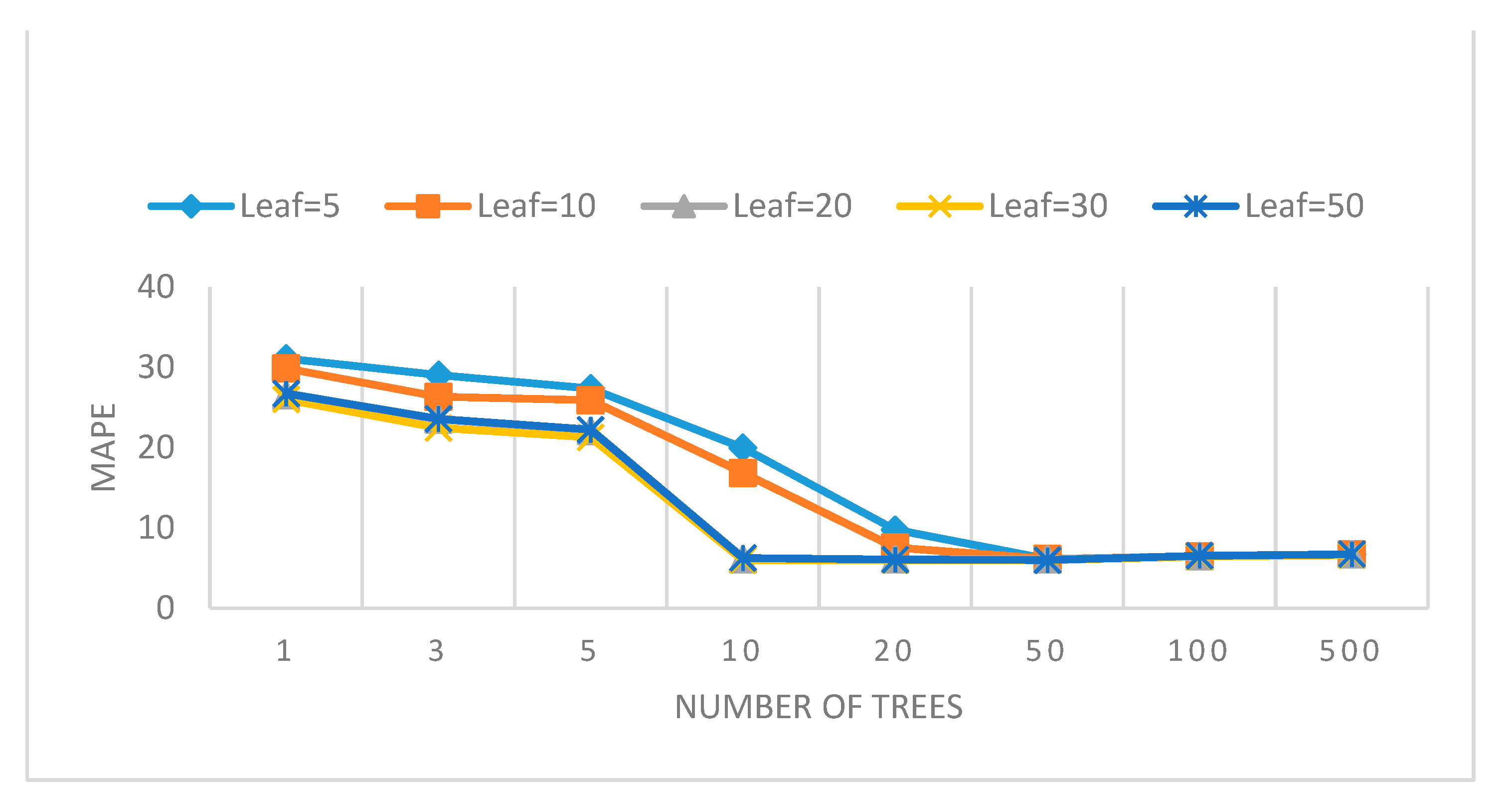
In machine learning, overfitting typically occurs when the model corresponds perfectly to the sample set of data, and therefore, the model may fail to fit additional data or predict future observations reliably. RF is an ensemble of DTs. The single DT is sensitive to data variations, which can overfit to noise in the data. While in the RF model, as the number of trees increases, the tendency of overfitting decreases. Among the four applied algorithms, due to the bagging and random feature selection process, the RF was deemed as not prone to overfitting and very noise-resistant. However, it can still be improved, and in order to avoid overfitting in RF, the hyper-parameters of the algorithm should be tuned very carefully.
5. Conclusions and Recommendations
Short-term TTP can be an important planning tool for both individual and public transportation. In general, the benefits of TTP come from three aspects [
6]: Saving travel time and improving reliability for the travelers; improving the reliability of delivery and the service quality and cutting costs for logistics [
40]. TTP is the key to traffic system management. Machine learning algorithms base on large data are generally more capable of searching and aggregating previously undetectable patterns and nonlinearity, and therefore possess the power to predict more accurate results. In both cases, it is expected that the application of accurate TTP can greatly help improve the level of service and enhance travel planning by reducing errors between the actual and predicted travel time. In this study, four non-parametric state-of-the-art machine learning methods, i.e., DT, XGBoost, RF, and LSTM (three from ensemble tree-based learning, and one from neural network), were developed and compared. After the data processing and feature selection process, all four methods were estimated, and the best combination of model parameters inherent in each model was also identified and used. In the model training and validation process, the sample dataset from selected road segments in I-485 Charlotte are used. Experimental results indicated that the RF is the most promising approach among all the methods that were developed and tested. The results also showed that all ensemble learning methods (i.e., RF and XGBoost) achieved high estimation accuracy and significantly outperformed the other methods. Furthermore, the ensemble learning methods run efficiently on large data sets due to the reduced model complexity of tree-based methods. Moreover, from a statistical point of view, these methods can overcome overfitting to some extent. It is well known that overfitting means that the estimated model fits the training data too well, which is typically caused by the model function being too complicated to consider each data point and even outliers.
However, this study still has some limitations. First, the TTP models were developed under normal traffic conditions and do not consider unexpected conditions (e.g., special events such as accidents and work zone activities). In addition, the data collected from the selected freeway segments were limited in diversity. There is the hope that with the development and popularization of real-time collection and uploading of traffic data acquisition technology (such as GPS trajectories, smartphones), sufficient data will provide the possibility for developing a more accurate TTP model. Furthermore, to identify whether the TTP is region-specific, further research is needed to replicate this study in other road categories using other types of data sources. Further results need to be achieved to compare all methods to further demonstrate whether the ensemble tree-based learning methods have better predictive accuracy in short-term TTP. Moreover, variables such as the characteristics of drivers and the impact of sun glare and other environmental hazards that could increase congestion will need to be incorporated into the model. Some experimental results have shown that the combination methods have a better prediction result than using one method alone [
41,
42,
43]. Even though the combination models have proven to be superior in terms of prediction accuracy and stability, they should be carefully considered in future research.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}