Detecting the Influencer on Social Networks Using Passion Point and Measures of Information Propagation † †


Abstract
1. Introduction
2. Related Work
3. Model for Representing Relations on Social Networks
- Tags in this paper are text-based posts only.
- All users on the social network understand the meaning of a tag.
- TIME is the data type as the timestamp.
- #(A) is the number of elements in set A.
3.1. U–Set of Users on a Social Network
- Profile: includes the personal information of a user, such as ID, name, DOB, and phone number.
- ListTags = [t1,…,tn]: list of tags ti in T-set, which are related to the corresponding user (i = 1…n).
- ListFriends = [f1,…,fm]: list of other users fj in U-set, which are friends with the corresponding user (j = 1…m).
- ListFollowers = [l1,…,lp]: list of other users lk in U-set, which are followers of the corresponding user (k = 1…p).
3.2. T–Set of Tags on a Social Network
- Content: describes the content of the tag.
- Owner ∈ U: this is the user as the seeder of the corresponding tag.
- Mention: list of users mentioned in the tag.
- τ ∈ Time: a timestamp of the corresponding tag.
- Interaction: is a set of users who interacted with the corresponding tag.
- Interaction: = {(u, πu) ∈ U × Time | interact(u, *this), *this is the corresponding tag,
- πu ∈ Time is the timestamp of the interaction corresponding tag of user u}
- Sh is a set of users who shared the corresponding tag.
- Sh: = {(u, πu) ∈ U × Time | share(u, *this), *this is the corresponding tag,
- πu ∈ Time is the timestamp of the corresponding sharing tag of user u}
- Com is a set of users who have comments on the corresponding tag.
- Com: = {(u, πu) ∈ U × Time | comment(u, *this), *this is the corresponding tag,
- πu ∈ Time is the timestamp of the comment of user u}
3.3. R–Set of Relations on a Social Network
- RU: a set of relations between two users.
- RT: a set of relations between a user and a tag.
4. Measures of Influence for a User
4.1. Influential Vector of a User
4.2. Information Propagation
- (a)
- Let u, v∈ U be users on F. The user u is more influent than the user v in the time windowδ, denoted v << u, if:
- ii
- IU(v) ≤ IU(u) and
- iii
- or
- (b)
- Let G ⊆ U, a user w ∈ G is an influencer on F in the time window δ if:where μ is a constant, 0 <μ < 1.#({v ∈ G | v << w}) ≥μ × #(G)
5. Determine the Influencer on a Social Network
5.1. The Graph for Connections between Users
- If follower (vi, vj), then w(eij) = 1.
- If friends (vi, vj), then w(eij) = w(eij) = 2.
- If interacted (vi, t), then w(eik) += 1 with vk = t.Owner
- For each relation comment (vi, t), w(eik) += 2 with vk = t.Owner
- If shared (vi, t), then w(eik) += 1 with vk = t.Owner.
5.2. Creating Graphs for Specific Brands/Products/News
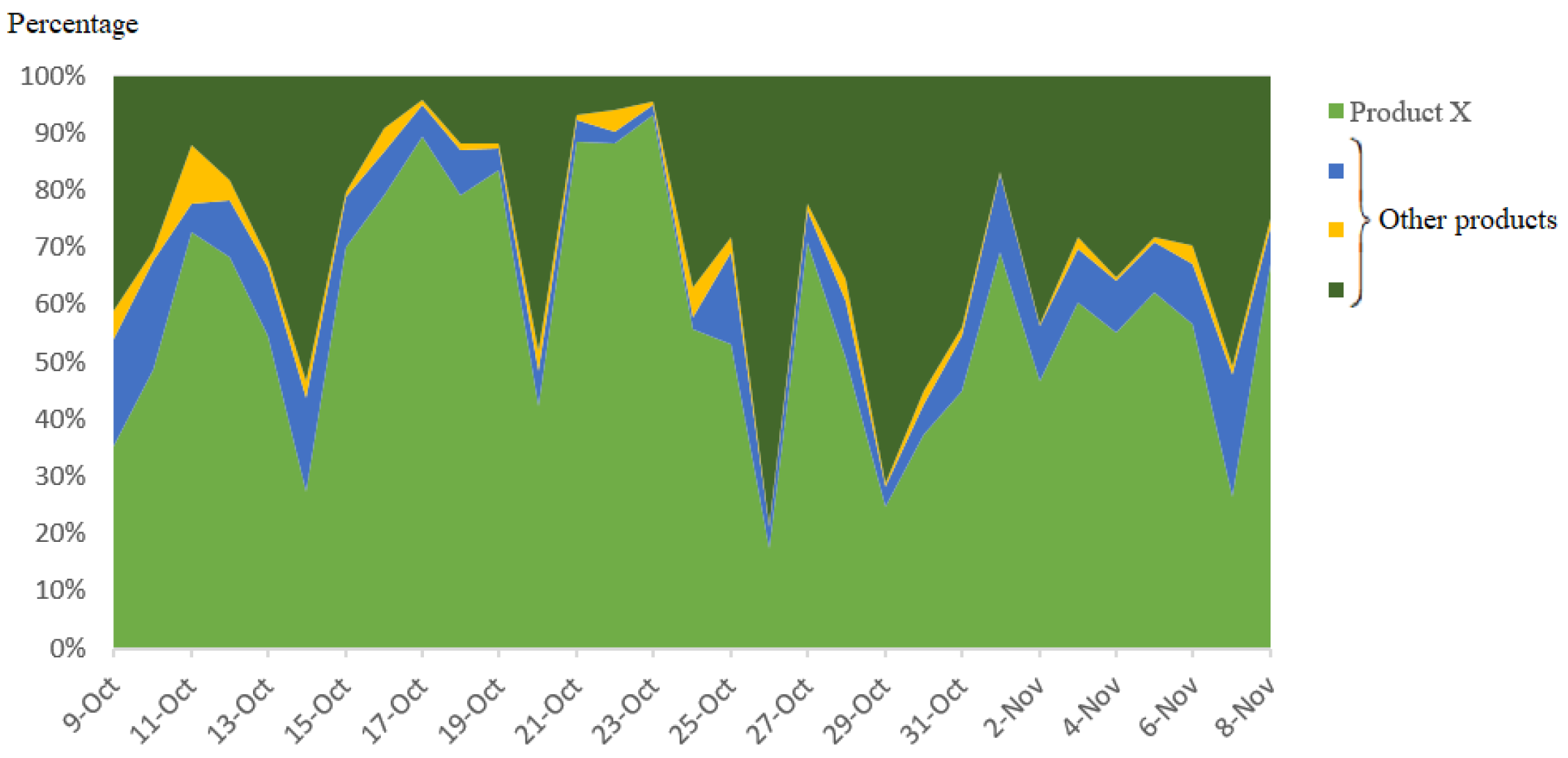
5.2.1. Passion Point
5.2.2. Graphs for Specific Brands/Products/News
| Algorithm 1: Creating a sub-graph representing the connection between brand-loving users. |
| Input: A social network F = (U, T, R) as the SNet model. |
| Graph G is represents the connections between users. |
| A specific brand/product/news X. |
| Output: Extract a sub-graph of users engaging with brand X. |
| The process of creating sub-graphs is as follows: |
| Step 1: Traverse each node v in Graph G. |
| Let ω > 0 be a constant, showing the minimum passion point of a user with brand X. |
| Check v.ListTags to see whether the corresponding user mentioned brand X in the tags. |
| If PPv(X) ≥ ω, with PPv(X) is computed by Formula (13). |
| Insert the node v into the sub-graph and go to Step 2; |
| Otherwise, go to Step 3. |
| Step 2: Expand the search space to the node’s neighbors. |
| Insert edges between the current node and its neighbors into the sub-graph if: |
| (1) the neighbors also mentioned brand/product/news X, or |
| (2) the neighbors interact or have comments on the tags of the current node related to X. |
| In Case (1): if the current user posts the tag t related to the product/brand/news, which is shared from another user y = t.Owner, create an edge between the current user and the user y. |
| Update the edge’s weight, as shown Definition 7. |
| Step 3: If there are untraversed nodes in the network, go back to Step 1. |
5.3. Determine the Influencer on a Social Network
| Algorithm 2: Determine the most influential user |
| ∙ Stage 1: Determine a group of users who are interested in brand X. |
| Step 1: Create Graph G, as shown in Definition 7, representing connections between users on the social network. |
| Step 2: Create a sub-graph of G by the algorithm in Section 5.3 to determine a group of users who are interested in brand X. |
| This group is denoted GX. |
| ∙ Stage 2: Determine the most influential user to other people in the time window δ. |
| Step 3: With each u ∈ GX, compute the influence measures of the user u. |
| • Influence vector IU(u):= (Impress(u), Popularity(u)) as Formula (5) in Definition 2. |
| • The average of the interaction of u’s tags AIu(δ) is computed by Formula (9). |
| Step 4: Determine the set of influencers in GX as Definition 6. |
| S:= { }; |
| for w in GX do |
| { |
| Sw(δ):= {v ∈ GX | v << u}, with the relation “<<” is defined in Definition 6. |
| If #(Sw(δ)) ≥ μ × #(G) then |
| S: = S ∪ {w}; |
| } |
| ReturnS is a set of influencers in GX. |
6. Testing and Experimental Results
6.1. Testing
- The values of (α1, α2, α3) in Formula (1), (β1, β2, β3) in Formula (2), and (γ1, γ2, γ3) in Formula (3) were chosen by the assumption that: the weight of a follower’s interaction was higher than a friend’s, and the weight of an unrelated user’s interaction was higher than other users. Despite the opinions from the experts and managers in online marketing, the values of parameters in formulas were chosen as follows:α1 = 0.25 α2 = 0.5 α3 = 0.75β1 = 0.25 β2 = 0.5 β3 = 0.75γ1 = 0.25 γ2 = 0.5 γ3 = 0.75
- The values of (α, β, γ) in Formula (6) are α = β = γ = 0.5.
- The value of μ in Formula (12) is 0.8, which means a user is an emerging influencer if he/she is more influential than 80% of users in the group GX.
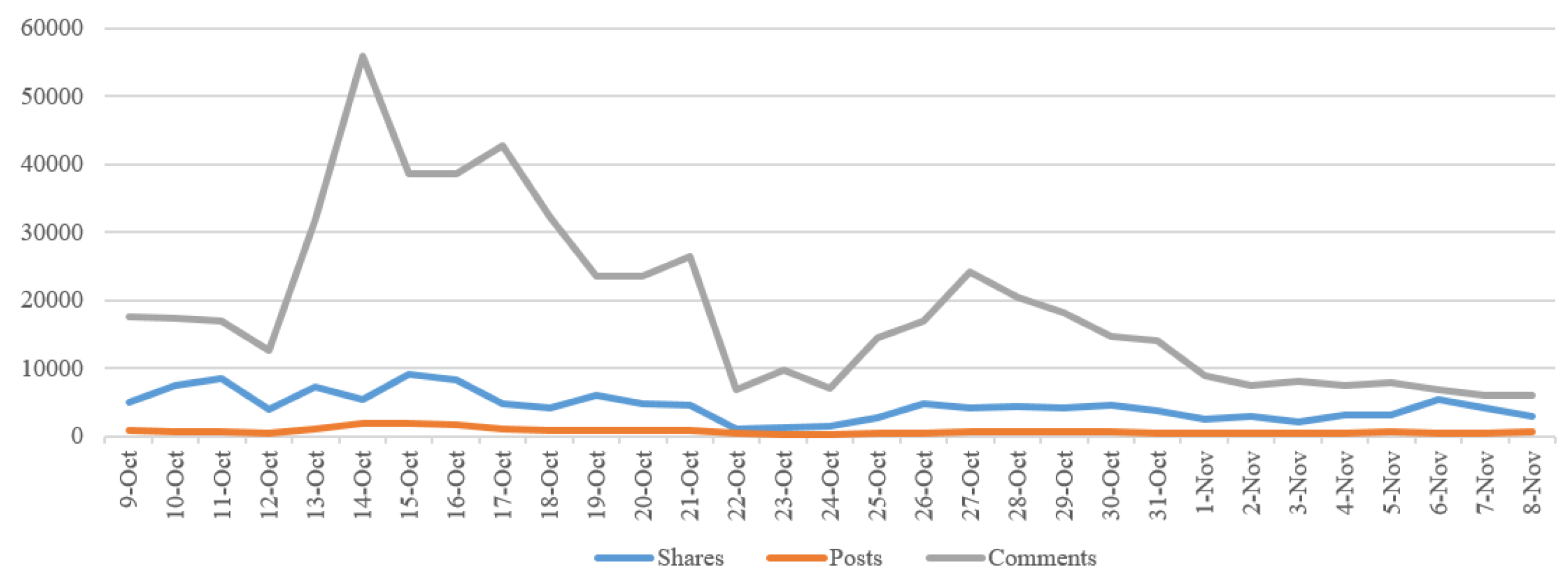
6.2. Experimental Results
- Phase 1: Our customer used four users in our list for their influencer marketing strategy from 9–16 October.
- Phase 2: Our customer used other users—who were famous Key Opinion Leaders (KOLs) in Vietnam—for the marketing from 27–31 October 2018.
6.3. Discussions
7. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Guille, A.; Hacid, H.; Favre, C.; Zighed, D.A. Information diffusion in online social networks: A survey. ACM SIGMOD Rec. Arch. 2013, 42, 17–28. [Google Scholar] [CrossRef]
- Gomez-Rodriguez, M.; Leskovec, J.; Schoelkopf, B. Modeling Information Propagation with Survival Theory. In Proceedings of the International Conference on Machine Learning (ICML 2013), Atlanta, GA, USA, 16–21 June 2013; pp. 666–674. [Google Scholar]
- Weng, L.; Menczer, F.; Ahn, Y. Virality Prediction and Community Structure in Social Networks. Nat. Sci. Rep. 2013, 3. [Google Scholar] [CrossRef]
- Kucher, K.; Paradis, C.; Kerren, A. The State of the Art in Sentiment Visualization. Comput. Graph. 2018, 37, 71–96. [Google Scholar] [CrossRef]
- Gil, P. What is Twitter & How does it Work? Available online: https://www.lifewire.com/what-exactly-is-twitter-2483331 (accessed on 4 February 2020).
- Riquelme, F.; Gonzalez-Cantergiani, P. Measuring user influence on Twitter: A survey. Int. J. Inf. Process. Manag. 2016, 52, 949–975. [Google Scholar] [CrossRef]
- Chai, W.; Xu, W.; Zuo, M.; Wen, X. ACQR: A novel framework to identify and predict influential users in micro-blogging. In Proceedings of the 17th Pacific Asia Conference on Information Systems (PACIS 2013), Jeju, Korea, 18–22 June 2013. [Google Scholar]
- Bouguessa, M.; Romdhane, L.B. Identifying authorities in online communities. ACM Trans. Intell. Syst. Technol. 2015, 6, 30. [Google Scholar] [CrossRef]
- Gayo-Avello, D. Nepotistic relationships in Twitter and their impact on rank prestige algorithms. Inf. Process. Manag. 2013, 49, 1250–1280. [Google Scholar] [CrossRef]
- Liu, N.; Li, L.; Xu, G.; Yang, Z. Identifying domain-dependent influential microblog users: A post-feature based approach. In Proceedings of the 28th AAAI Conference on Artificial Intelligence (AAAI 2014), Quebec, QC, Canada, 27–31 July 2014; pp. 3122–3123. [Google Scholar]
- Zimaitis, I.; Degutis, M.; Urbonavicious, S. Social Media Use and Paranoia: Factors That Matter in Online Shopping. Sustainability 2020, 12, 904. [Google Scholar] [CrossRef]
- Chen, W.; Lakshmanan, L.; Castillo, C. Information and Influence Propagation in Social Networks: Synthesis Lecturers on Data Management; Morgan & Claypool Publishers: San Rafael, CA, USA, 2013. [Google Scholar]
- Laroche, M.; Habibi, M.R.; Richard, M.O.; Sankaranarayanan, R. The effects of social media based brand communities on brand community markers, value creation practices, brand trust, and brand loyalty. Comput. Hum. Behav. 2012, 28, 1755–1767. [Google Scholar] [CrossRef]
- Do, N.; Nguyen, H. A reasoning method on Computational Network and Its applications. In Proceedings of the 2011 International Multi Conference of Engineers and Computer Scientists (IMECS 2011), Hongkong, 16–18 March 2011; pp. 137–141. [Google Scholar]
- Do, N.V.; Nguyen, H.D.; Selamat, A. Knowledge-Based model of Expert Systems using Rela-model. Int. J. Softw. Eng. Knowl. Eng. 2018, 28, 1047–1090. [Google Scholar] [CrossRef]
- Charalampakis, B.; Spathis, D.; Kouslis, E.; Kermanidis, K. A comparison between semi-supervised and supervised text mining techniques on detecting irony in greek political tweets. Eng. Appl. Artif. Intell. 2016, 51, 50–57. [Google Scholar] [CrossRef]
- Lawrence, B.; Cai, T.; Anirban, D. Interval Estimation for a Binomial Proportion. Stat. Sci. 2001, 16, 101–133. [Google Scholar]
- Valdiviezo, O.; Sánchez, J.A.; Cervantes, O. Visualizing sentiment change in social networks. In Proceedings of the 8th Latin American Conference on Human-Computer Interaction (CLIHC’17), New York, NY, USA, 8–10 November 2017. [Google Scholar] [CrossRef]
- Mañas-Viniegra, L.; Veloso, A.I.; Cuesta, U. Fashion Promotion on Instagram with Eye Tracking: Curvy Girl Influencers versus Fashion Brands in Spain and Portugal. Sustainability 2019, 11, 3977. [Google Scholar] [CrossRef]
- Pham, X.H.; Jung, J.; Hwang, D. Beating Social Pulse: Understanding Information Propagation via Online Social Tagging Systems. J. Univers. Comput. Sci. 2012, 18, 1022–1031. [Google Scholar]
- Huynh, T.; Zelinka, I.; Pham, X.H.; Nguyen, H.D. Some influence measures to detect the influencer on social network based on Information Propagation. In Proceedings of the 9th International Conference on Web Intelligence, Mining and Semantics (WIMS 2019), Seoul, Korea, 26–28 June 2019. [Google Scholar] [CrossRef]
- Morente-Molinera, J.A.; Kou, G.; Peng, Y.; Torres-Albero, C.; Herrera-Viedma, E. Analysing discussions in social networks using group decision-making methods and sentiment analysis. Inf. Sci. 2018, 447, 157–168. [Google Scholar] [CrossRef]
- Zimmerman, J.; Ng, D. Social Media Marketing All-in-One, 4th ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2017. [Google Scholar]
- Zhou, T.; Medo, M.; Cimini, G.; Zhang, Z.K.; Zhang, Y.C. Emergence of Scale-Free Leadership Structure in Social Recommender Systems. PLoS ONE 2011, 6. [Google Scholar] [CrossRef]
- Aleahmad, A.; Karisani, P.; Rahgozar, M.; Oroumchian, F. OLFinder: Finding opinion leaders in online social networks. SAGE J. Inf. Sci. 2015. [Google Scholar] [CrossRef]
- Perikos, I.; Hatzilygeroudis, I. Recognizing emotions in text using ensemble of classifiers. Eng. Appl. Artif. Intell. 2016, 51, 191–201. [Google Scholar] [CrossRef]
- Wallis, S.A. Binomial confidence intervals and contingency tests: Mathematical fundamentals and the evaluation of alternative methods. J. Quant. Linguist. 2013, 20, 178–208. [Google Scholar] [CrossRef]
- Wilson, E.B. Probable inference, the law of succession, and statistical inference. J. Am. Stat. Assoc. 1927, 22, 209–212. [Google Scholar] [CrossRef]
- JSON. Available online: https://www.json.org/ (accessed on 4 February 2020).
- Nguyen, H.; Huynh, T.; Hoang, S.; Pham, V.; Zelinka, I. Language-oriented Sentiment Analysis based on the grammar structure and improved Self-attention network. In Proceedings of the 15th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE 2020), Prague, Czech Public, 5–6 May 2020. [Google Scholar]
- Gang, L.; Fei, L. Application of a clustering method on sentiment analysis. SAGE J. Inf. Sci. 2012, 38, 127–139. [Google Scholar]
- Urena, R.; Chiclana, F.; Herrera-Viedma, E. A new influence based network for opinion progpagation in social network based scenarios. Procedia Comput. Sci. 2018, 139, 329–337. [Google Scholar] [CrossRef]
- Song, J.; Jamous, N.; Turowski, K. Influence in Social Media Marketing: A Quantitative Evaluation Framework from a Large Scale of Empirical Evidence. In Proceedings of the International Conference on Enterprise Systems (ES), Melbourne, Australia, 2–3 November 2016; pp. 136–142. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kind | Relation | Meaning |
|---|---|---|
| Relations between two users (RU) | friend ⊆ U × U | friend(u, v): the user u is a friend of the user v. |
| follower ⊆ U × U | follower(u, v): the user u is a follower of the user v. | |
| Relations between a user and a tag (RT) | interact ⊆ U × T | interact(u, t): the user u interacts with a tag t, such as u likes/views/searches the tag t. |
| comment ⊆ U × T | comment(u, t): the user u has a comment on a tag t. | |
| share ⊆ U × T | share(u, t): the user u shares a tag t. |
| Duration | Posts | Comments | Shares | Total | Rate |
|---|---|---|---|---|---|
| October, 2018 | 22,511 | 638,278 | 140,782 | 801,571 | |
| September, 2018 | 15,193 | 24,2714 | 86,052 | 343,959 | 133% |
| November, 2018 | 8883 | 218,341 | 83,673 | 310,897 | −61% |
| Phase | Duration | Posts | Comments | Shares |
|---|---|---|---|---|
| Phase 1 | 9–16 October | 9108 | 229,158 | 54,934 |
| 17–24 October | 5350 | 171,701 | 28,256 | |
| Total | 14,458 | 400,859 | 83,190 | |
| Phase 2 | 26–31 October | 3241 | 108,519 | 25,504 |
| 1–8 November | 3691 | 58,427 | 25,993 | |
| Total | 6932 | 166,946 | 51,497 | |
| Rate 1 | 36% | 47% | 46% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huynh, T.; Nguyen, H.; Zelinka, I.; Dinh, D.; Pham, X.H. Detecting the Influencer on Social Networks Using Passion Point and Measures of Information Propagation †. Sustainability 2020, 12, 3064. https://doi.org/10.3390/su12073064
Huynh T, Nguyen H, Zelinka I, Dinh D, Pham XH. Detecting the Influencer on Social Networks Using Passion Point and Measures of Information Propagation †. Sustainability. 2020; 12(7):3064. https://doi.org/10.3390/su12073064
Chicago/Turabian StyleHuynh, Tai, Hien Nguyen, Ivan Zelinka, Dac Dinh, and Xuan Hau Pham. 2020. "Detecting the Influencer on Social Networks Using Passion Point and Measures of Information Propagation †" Sustainability 12, no. 7: 3064. https://doi.org/10.3390/su12073064
APA StyleHuynh, T., Nguyen, H., Zelinka, I., Dinh, D., & Pham, X. H. (2020). Detecting the Influencer on Social Networks Using Passion Point and Measures of Information Propagation †. Sustainability, 12(7), 3064. https://doi.org/10.3390/su12073064