A Novel One-Dimensional CNN with Exponential Adaptive Gradients for Air Pollution Index Prediction

 ,
,  ,
,  ,
,
Abstract
1. Introduction
2. Related Work
3. One Dimensional Convolutional Neural Networks
3.1. Convolutional Layer
| Algorithm 1. Training procedure for 1D-CNN model. |
| * Input: Training and validation dataset |
| * Output: Trained 1D-CNN model |
| 1Initialize: weights and biases (randomly, of the network. |
| 2For each iteration Do: |
| 3 Process records of the training data |
| 4 Compare actual and predicted values |
| 5 Calculate loss function |
| 6 Backpropagate error and adjust weights |
| 7 If better loss Do: |
| 8 Save network (model, weights) |
| 9 End If |
| 10End For |
3.2. Batch Normalization
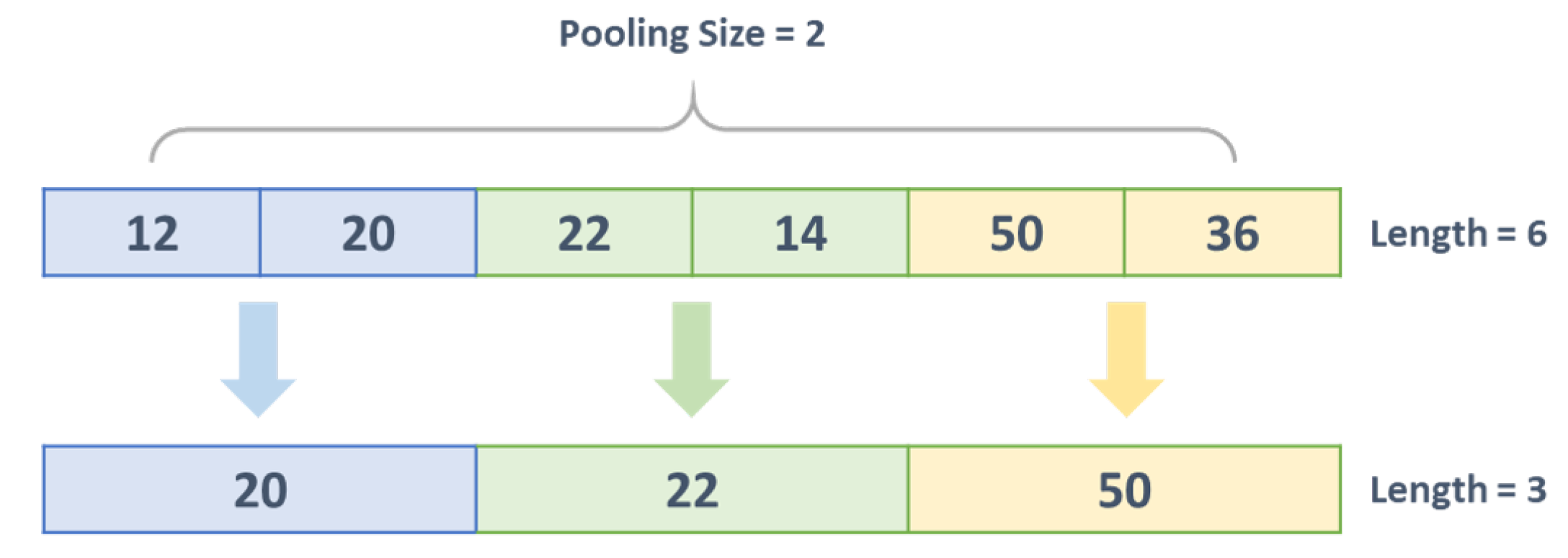
3.3. Pooling Layer
3.4. Dropout Layer
3.5. Fully Connected Layer
3.6. Network Optimization
| Algorithm 2. Proposed Exponential Adaptive Gradients (EAG) Algorithm. |
| 1Input: |
| 2Initialize: |
| 3For to Do: |
| 4 |
| 5: |
| 6 |
| 7 and |
| 8 |
| 9End For |
4. Experiments
4.1. Data Description and Pre-Processing
4.2. Hyper-Parameter Selection
4.3. Evaluation Metrics
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Huang, C.J.; Kuo, P.H. A deep cnn-lstm model for particulate matter (PM2.5) forecasting in smart cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef] [PubMed]
- Bourdrel, T.; Bind, M.A.; Béjot, Y.; Morel, O.; Argacha, J.F. Cardiovascular effects of air pollution. Arch. Cardiovasc. Dis. 2017, 110, 634–642. [Google Scholar] [CrossRef] [PubMed]
- Rahman, N.H.A.; Lee, M.H.; Suhartono, M. Evaluation performance of time series approach for forecasting air pollution index in johor, malaysia. Sains Malays. 2016, 45, 1625–1633. [Google Scholar]
- Özkaynak, H.; Glenn, B.; Qualters, J.R.; Strosnider, H.; Mcgeehin, M.A.; Zenick, H. Summary and findings of the EPA and CDC symposium on air pollution exposure and health. J. Expo. Sci. Environ. Epidemiol. 2009, 19, 19–29. [Google Scholar] [CrossRef] [PubMed]
- Spiru, P.; Simona, P.L. A review on interactions between energy performance of the buildings, outdoor air pollution and the indoor air quality. Energy Procedia 2017, 128, 179–186. [Google Scholar] [CrossRef]
- Haidar, A.; Verma, B. Monthly rainfall forecasting using one-dimensional deep convolutional neural network. IEEE Access 2018, 6, 69053–69063. [Google Scholar] [CrossRef]
- Alyousifi, Y.; Othman, M.; Faye, I.; Sokkalingam, R.; Silva, P.C. Markov Weighted Fuzzy Time-Series Model Based on an Optimum Partition Method for Forecasting Air Pollution. Int. J. Fuzzy Syst. 2020, 22, 1468–1486. [Google Scholar] [CrossRef]
- Szczurek, A.; Maciejewska, M.; Połoczański, R.; Teuerle, M.; Wyłomańska, A. Dynamics of carbon dioxide concentration in indoor air. Stoch. Environ. Res. Risk Assess. 2015, 29, 2193–2199. [Google Scholar] [CrossRef]
- Choon, S.W.; Ong, H.B.; Tan, S.H. Does risk perception limit the climate change mitigation behaviors? Environ. Dev. Sustain. 2019, 21, 1891–1917. [Google Scholar] [CrossRef]
- Razak, M.I.M.; Ahmad, I.; Bujang, I.; Talib, A.H.; Ibrahim, Z. Economics of air pollution in Malaysia. Int. J. Humanit. Soc. Sci. 2013, 3, 173–177. [Google Scholar]
- Alyousifi, Y.; Othman, M.; Sokkalingam, R.; Faye, I.; Silva, P.C. Predicting Daily Air Pollution Index Based on Fuzzy Time Series Markov Chain Model. Symmetry 2020, 12, 293. [Google Scholar] [CrossRef]
- Wong, T.W.; San Tam, W.W.; Yu, I.T.S.; Lau, A.K.H.; Pang, S.W.; Wong, A.H. Developing a risk-based air quality health index. Atmos. Environ. 2013, 76, 52–58. [Google Scholar] [CrossRef]
- Jiang, D.; Zhang, Y.; Hu, X.; Zeng, Y.; Tan, J.; Shao, D. Progress in developing an ANN model for air pollution index forecast. Atmos. Environ. 2004, 38, 7055–7064. [Google Scholar] [CrossRef]
- Aghamohammadi, N.; Isahak, M. Climate Change and Air Pollution in Malaysia. In Climate Change and Air Pollution; Springer: New York, NY, USA, 2018; pp. 241–254. [Google Scholar]
- Donnelly, A.; Misstear, B.; Broderick, B. Real time air quality forecasting using integrated parametric and non-parametric regression techniques. Atmos. Environ. 2015, 103, 53–65. [Google Scholar] [CrossRef]
- Zhou, Q.; Jiang, H.; Wang, J.; Zhou, J. A hybrid model for PM2.5 forecasting based on ensemble empirical mode decomposition and a general regression neural network. Sci. Total Environ. 2014, 496, 264–274. [Google Scholar] [CrossRef]
- Abdulkadir, S.J.; Yong, S.P. Unscented kalman filter for noisy multivariate financial time-series data. In International Workshop on Multi-Disciplinary Trends in Artificial Intelligence; Springer: York, NY, USA, 2013; pp. 87–96. [Google Scholar]
- Abdulkadir, S.J.; Yong, S.P. Scaled UKF–NARX hybrid model for multi-step-ahead forecasting of chaotic time series data. Soft Comput. 2015, 19, 3479–3496. [Google Scholar] [CrossRef]
- Abdulkadir, S.J.; Yong, S.P.; Marimuthu, M.; Lai, F.W. Hybridization of ensemble Kalman filter and non-linear auto-regressive neural network for financial forecasting. In Mining Intelligence and Knowledge Exploration; Springer: York, NY, USA, 2014; pp. 72–81. [Google Scholar]
- Kamaruzzaman, A.; Saudi, A.; Azid, A.; Balakrishnan, A.; Abu, I.; Amin, N.; Rizman, Z. Assessment on air quality pattern: A case study in Putrajaya, Malaysia. J. Fundam. Appl. Sci. 2017, 9, 789–800. [Google Scholar] [CrossRef]
- Tsai, Y.T.; Zeng, Y.R.; Chang, Y.S. Air pollution forecasting using RNN with LSTM. In Proceedings of the 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), IEEE, Athens, Greece, 12–15 August 2018; pp. 1074–1079. [Google Scholar]
- Salman, A.G.; Heryadi, Y.; Abdurahman, E.; Suparta, W. Single layer & multi-layer long short-term memory (LSTM) model with intermediate variables for weather forecasting. Procedia Comput. Sci. 2018, 135, 89–98. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Abimannan, S.; Chang, Y.S.; Lin, C.Y. Air Pollution Forecasting Using LSTM-Multivariate Regression Model. In International Conference on Internet of Vehicles; Springer: New York, NY, USA, 2019; pp. 318–326. [Google Scholar]
- Chang, Y.S.; Chiao, H.T.; Abimannan, S.; Huang, Y.P.; Tsai, Y.T.; Lin, K.M. An LSTM-based aggregated model for air pollution forecasting. Atmos. Pollut. Res. 2020, 11, 1451–1463. [Google Scholar] [CrossRef]
- Abdulkadir, S.J.; Yong, S.P. Empirical analysis of parallel-NARX recurrent network for long-term chaotic financial forecasting. In Proceedings of the 2014 International Conference on Computer and Information Sciences (ICCOINS), IEEE, Kuala Lumpur, Malaysia, 3–5 June 2014; pp. 1–6. [Google Scholar]
- Abdulkadir, S.J.; Yong, S.P.; Foong, O.M. Variants of Particle Swarm Optimization in Enhancing Artificial Neural Networks. Aust. J. Basic Appl. Sci. 2013, 7, 388–400. [Google Scholar]
- Abdulkadir, S.J.; Yong, S.P.; Zakaria, N. Hybrid neural network model for metocean data analysis. J. Inform. Math. Sci. 2016, 8, 245–251. [Google Scholar]
- Abdulkadir, S.J.; Yong, S.P.; Alhussian, H. An enhanced ELMAN-NARX hybrid model for FTSE Bursa Malaysia KLCI index forecasting. In Proceedings of the 2016 3rd International Conference on Computer and Information Sciences (ICCOINS), Kuala Lumpur, Malaysia, 15–17 August 2016; pp. 304–309. [Google Scholar]
- Abdulkadir, S.J.; Alhussian, H.; Nazmi, M.; Elsheikh, A.A. Long Short Term Memory Recurrent Network for Standard and Poor’s 500 Index Modelling. Int. J. Eng. Technol. 2018, 7, 25–29. [Google Scholar] [CrossRef]
- Abdulkadir, S.J.; Yong, S.P. Lorenz time-series analysis using a scaled hybrid model. In Proceedings of the 2015 International Symposium on Mathematical Sciences and Computing Research (iSMSC), Ipon, Malaysia, 19–20 May 2015; pp. 373–378. [Google Scholar]
- Pysal, D.; Abdulkadir, S.J.; Shukri, S.R.M.; Alhussian, H. Classification of children’s drawing strategies on touch-screen of seriation objects using a novel deep learning hybrid model. Alex. Eng. J. 2020. [Google Scholar] [CrossRef]
- Wang, B.; Yan, Z.; Luo, H.; Li, T.; Lu, J.; Zhang, G. Deep uncertainty learning: A machine learning approach for weather forecasting. CoRR 2018, 19, 2087–2095. [Google Scholar]
- Xie, J. Deep neural network for PM2.5 pollution forecasting based on manifold learning. In Proceedings of the 2017 International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Shanghai, China, 16–18 August 2017; pp. 236–240. [Google Scholar]
- Athira, V.; Geetha, P.; Vinayakumar, R.; Soman, K. Deepairnet: Applying recurrent networks for air quality prediction. Procedia Comput. Sci. 2018, 132, 1394–1403. [Google Scholar]
- Yan, L.; Wu, Y.; Yan, L.; Zhou, M. Encoder-decoder model for forecast of PM2.5 concentration per hour. In Proceedings of the 2018 1st International Cognitive Cities Conference (IC3), Okinawa, Japan, 7–9 August 2018; pp. 45–50. [Google Scholar]
- Coşkun, M.; YILDIRIM, Ö.; Ayşegül, U.; Demir, Y. An overview of popular deep learning methods. Eur. J. Technol. 2017, 7, 165–176. [Google Scholar] [CrossRef]
- Bengio, Y.; Goodfellow, I.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Huang, S.; Tang, J.; Dai, J.; Wang, Y. Signal status recognition based on 1DCNN and its feature extraction mechanism analysis. Sensors 2019, 19, 2018. [Google Scholar] [CrossRef]
- Zhang, B.; Quan, C.; Ren, F. Study on CNN in the recognition of emotion in audio and images. In Proceedings of the 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), Okayama, Japan, 26–29 June 2016; pp. 1–5. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A new deep learning model for fault diagnosis with good anti-noise and domain adaptation ability on raw vibration signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Liu, Z.; Peng, D.; Qin, Y. Understanding and Learning Discriminant Features based on Multi-Attention 1DCNN for Wheelset Bearing Fault Diagnosis. IEEE Trans. Ind. Inform. 2019, 16, 5735–5745. [Google Scholar] [CrossRef]
- Huang, S.; Tang, J.; Dai, J.; Wang, Y.; Dong, J. 1DCNN Fault Diagnosis Based on Cubic Spline Interpolation Pooling. Shock Vib. 2020, 2020. [Google Scholar] [CrossRef]
- Soon, F.C.; Khaw, H.Y.; Chuah, J.H.; Kanesan, J. Hyper-parameters optimisation of deep CNN architecture for vehicle logo recognition. IET Intell. Transp. Syst. 2018, 12, 939–946. [Google Scholar] [CrossRef]
- Zhao, X.; Solé-Casals, J.; Li, B.; Huang, Z.; Wang, A.; Cao, J.; Tanaka, T.; Zhao, Q. Classification of Epileptic IEEG Signals by CNN and Data Augmentation. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 926–930. [Google Scholar]
- Eren, L.; Ince, T.; Kiranyaz, S. A generic intelligent bearing fault diagnosis system using compact adaptive 1D CNN classifier. J. Signal Process. Syst. 2019, 91, 179–189. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2019, 47, 312–323. [Google Scholar]
- Shao, S.; Wang, P.; Yan, R. Generative adversarial networks for data augmentation in machine fault diagnosis. Comput. Ind. 2019, 106, 85–93. [Google Scholar] [CrossRef]
- Abdoli, S.; Cardinal, P.; Koerich, A.L. End-to-end environmental sound classification using a 1D convolutional neural network. Expert Syst. Appl. 2019, 136, 252–263. [Google Scholar] [CrossRef]
- Courville, A. Recurrent Batch Normalization. arXiv 2016, arXiv:1603.09025. [Google Scholar]
- Meliboev, A.; Alikhanov, J.; Kim, W. 1D CNN Based Network Intrusion Detection with Normalization on Imbalanced Data. arXiv 2020, arXiv:2003.00476. [Google Scholar]
- Wang, S.; Jiang, Y.; Hou, X.; Cheng, H.; Du, S. Cerebral micro-bleed detection based on the convolution neural network with rank based average pooling. IEEE Access 2017, 5, 16576–16583. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Learning deep features to recognise speech emotion using merged deep CNN. IET Signal Process. 2018, 12, 713–721. [Google Scholar] [CrossRef]
- Lv, M.; Xu, W.; Chen, T. A hybrid deep convolutional and recurrent neural network for complex activity recognition using multimodal sensors. Neurocomputing 2019, 362, 33–40. [Google Scholar] [CrossRef]
- Jeon, B.; Park, N.; Bang, S. Dropout Prediction over Weeks in MOOCs via Interpretable Multi-Layer Representation Learning. arXiv 2020, arXiv:2002.01598. [Google Scholar]
- Fu, Q.; Niu, D.; Zang, Z.; Huang, J.; Diao, L. Multi-Stations’ Weather Prediction Based on Hybrid Model Using 1D CNN and Bi-LSTM. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 3771–3775. [Google Scholar]
- Gal, Y.; Ghahramani, Z. A theoretically grounded application of dropout in recurrent neural networks. In Advances in Neural Information Processing Systems; Barcelona, Spain, 2016; pp. 1019–1027. [Google Scholar]
- Xiong, J.; Zhang, K.; Zhang, H. A Vibrating Mechanism to Prevent Neural Networks from Overfitting. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 1737–1742. [Google Scholar]
- Swapna, G.; Kp, S.; Vinayakumar, R. Automated detection of diabetes using CNN and CNN-LSTM network and heart rate signals. Procedia Comput. Sci. 2018, 132, 1253–1262. [Google Scholar]
- Fukuoka, R.; Suzuki, H.; Kitajima, T.; Kuwahara, A.; Yasuno, T. Wind Speed Prediction Model Using LSTM and 1D-CNN. J. Signal Process. 2018, 22, 207–210. [Google Scholar] [CrossRef]
- Soni, S.; Dey, S.; Manikandan, M.S. Automatic Audio Event Recognition Schemes for Context-Aware Audio Computing Devices. In Proceedings of the 2019 Seventh International Conference on Digital Information Processing and Communications (ICDIPC), Trabzon, Turkey, 2–4 May 2019; pp. 23–28. [Google Scholar]
- Tsirikoglou, P.; Abraham, S.; Contino, F.; Lacor, C.; Ghorbaniasl, G. A hyperparameters selection technique for support vector regression models. Appl. Soft Comput. 2017, 61, 139–148. [Google Scholar] [CrossRef]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
- Botev, A.; Lever, G.; Barber, D. Nesterov’s accelerated gradient and momentum as approximations to regularised update descent. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, Alaska, USA, 14–19 May 2017; pp. 1899–1903. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the convergence of adam and beyond. arXiv 2019, arXiv:1904.09237. [Google Scholar]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. Coursera Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wilson, A.C.; Roelofs, R.; Stern, M.; Srebro, N.; Recht, B. The marginal value of adaptive gradient methods in machine learning. In Advances in Neural Information Processing Systems; The MIT Press: Long Beach, CA, USA, 2017; pp. 4148–4158. [Google Scholar]
- Shazeer, N.; Stern, M. Adafactor: Adaptive learning rates with sublinear memory cost. arXiv 2018, arXiv:1804.04235. [Google Scholar]
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive gradient methods with dynamic bound of learning rate. arXiv 2019, arXiv:1902.09843. [Google Scholar]
- Wierichs, D.; Gogolin, C.; Kastoryano, M. Avoiding local minima in variational quantum eigensolvers with the natural gradient optimizer. arXiv 2020, arXiv:2004.14666. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation ({OSDI} 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Ahmad, Z.; Rahim, N.A.; Bahadori, A.; Zhang, J. Air polluiton index prediction using multiple neural networks. IIUM Eng. J. 2017, 18, 1–12. [Google Scholar] [CrossRef]
- Rani, N.L.A.; Azid, A.; Khalit, S.I.; Juahir, H.; Samsudin, M.S. Air Pollution Index Trend Analysis in Malaysia, 2010–15. Pol. J. Environ. Stud. 2018, 27, 801–807. [Google Scholar] [CrossRef]
- Sahani, M.; Zainon, N.A.; Mahiyuddin, W.R.W.; Latif, M.T.; Hod, R.; Khan, M.F.; Tahir, N.M.; Chan, C.C. A case-crossover analysis of forest fire haze events and mortality in Malaysia. Atmos. Environ. 2014, 96, 257–265. [Google Scholar] [CrossRef]
- Zakaria, U.; Saudi, A.; Abu, I.; Azid, A.; Balakrishnan, A.; Amin, N.; Rizman, Z. The assessment of ambient air pollution pattern in Shah Alam, Selangor, Malaysia. J. Fundam. Appl. Sci. 2017, 9, 772–788. [Google Scholar] [CrossRef]
- Krstajic, D.; Buturovic, L.J.; Leahy, D.E.; Thomas, S. Cross-validation pitfalls when selecting and assessing regression and classification models. J. Cheminform. 2014, 6, 1–15. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Levy, E.; David, O.E.; Netanyahu, N.S. Genetic algorithms and deep learning for automatic painter classification. In Proceedings of the 2014 Annual Conference on Genetic and Evolutionary Computation, Vancouver, BC, Canada, July 2014; pp. 1143–1150. [Google Scholar]
- Fornarelli, G.; Giaquinto, A. Adaptive particle swarm optimization for CNN associative memories design. Neurocomputing 2009, 72, 3851–3862. [Google Scholar] [CrossRef]
- Syulistyo, A.R.; Purnomo, D.M.J.; Rachmadi, M.F.; Wibowo, A. Particle swarm optimization (PSO) for training optimization on convolutional neural network (CNN). J. Ilmu Komput. Dan Inf. 2016, 9, 52–58. [Google Scholar] [CrossRef]
- Bhat, P.C.; Prosper, H.B.; Sekmen, S.; Stewart, C. Optimizing event selection with the random grid search. Comput. Phys. Commun. 2018, 228, 245–257. [Google Scholar] [CrossRef]
- Shuai, Y.; Zheng, Y.; Huang, H. Hybrid Software Obsolescence Evaluation Model Based on PCA-SVM-GridSearchCV. In Proceedings of the 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018; pp. 449–453. [Google Scholar]
- Song, H.; Dai, J.; Luo, L.; Sheng, G.; Jiang, X. Power transformer operating state prediction method based on an LSTM network. Energies 2018, 11, 914. [Google Scholar] [CrossRef]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- Scarpa, G.; Gargiulo, M.; Mazza, A.; Gaetano, R. A cnn-based fusion method for feature extraction from sentinel data. Remote Sens. 2018, 10, 236. [Google Scholar] [CrossRef]
- Al-Tashi, Q.; Abdulkadir, S.J.; Rais, H.M.; Mirjalili, S.; Alhussian, H.; Ragab, M.G.; Alqushaibi, A. Binary Multi-Objective Grey Wolf Optimizer for Feature Selection in Classification. IEEE Access 2020, 8, 106247–106263. [Google Scholar] [CrossRef]
- Al-Tashi, Q.; Abdulkadir, S.J.; Rais, H.M.; Mirjalili, S.; Alhussian, H. Approaches to Multi-Objective Feature Selection: A Systematic Literature Review. IEEE Access 2020, 8, 125076–125096. [Google Scholar] [CrossRef]
- Li, T.; Hua, M.; Wu, X. A hybrid CNN-LSTM model for forecasting particulate matter (PM2.5). IEEE Access 2020, 8, 26933–26940. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Kernel × Filter | Other Parameters |
|---|---|---|---|
| 1 | Convolution1D | 2 × 64 | Activation = ReLU, Strides = 2 |
| 2 | MaxPooling1D | — | Size = 2, Strides = 2 |
| 3 | Convolution1D | 2 × 128 | Activation = ReLU, Strides = 2 |
| 4 | MaxPooling1D | Size = 2, Strides = 2 | |
| 5 | Flatten | — | — |
| 6 | Dense | 1 × 128 | Activation = ReLU |
| 8 | Dropout | — | Rate = 0.3 |
| 9 | Dense (Output) | {1 × 12} | Activation = Hyperbolic Tangent |
| Filters | MAE | RMSE | MAPE | Time(s) | |
|---|---|---|---|---|---|
| 32 | 2.407 | 2.7015 | 4.992 | 0.958 | 188.83 |
| 64 | 2.069 | 2.384 | 4.293 | 0.966 | 254.45 |
| 128 | 2.026 | 2.335 | 4.184 | 0.968 | 363.50 |
| 256 | 2.134 | 2.431 | 4.450 | 0.963 | 508.97 |
| 512 | 2.186 | 2.496 | 4.355 | 0.963 | 1013.34 |
| Iterations | LSTM | CNN | ||||||
|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | |||
| 1 | 20.699 | 22.357 | 35.649 | −0.768 | 9.732 | 11.491 | 17.422 | 0.541 |
| 2 | 8.061 | 8.616 | 13.855 | 0.710 | 5.336 | 5.985 | 10.413 | 0.847 |
| 4 | 6.440 | 7.026 | 11.421 | 0.819 | 4.809 | 5.128 | 9.622 | 0.872 |
| 8 | 5.090 | 5.482 | 9.340 | 0.883 | 3.768 | 4.106 | 7.390 | 0.916 |
| 16 | 4.253 | 4.443 | 7.457 | 0.921 | 3.100 | 3.420 | 6.053 | 0.941 |
| 32 | 3.005 | 3.358 | 5.702 | 0.950 | 2.841 | 3.113 | 5.550 | 0.949 |
| 64 | 2.999 | 3.228 | 5.624 | 0.956 | 2.423 | 2.714 | 5.021 | 0.959 |
| 128 | 2.997 | 3.277 | 5.117 | 0.944 | 2.291 | 2.600 | 4.632 | 0.962 |
| 256 | 2.951 | 3.170 | 5.222 | 0.955 | 2.023 | 2.341 | 4.212 | 0.969 |
| 512 | 2.103 | 2.392 | 4.266 | 0.969 | 2.044 | 2.367 | 4.178 | 0.968 |
| 1024 | 2.636 | 2.865 | 4.716 | 0.963 | 1.894 | 2.222 | 3.765 | 0.974 |
| Optimizer | Evaluation | LSTM | CNN |
|---|---|---|---|
| Adadelta | MAE (Loss) | 3.270 | 3.118 |
| RMSE | 3.480 | 3.342 | |
| MAPE | 5.915 | 5.785 | |
| 0.947 | 0.946 | ||
| Adagrad | MAE (Loss) | 3.215 | 2.934 |
| RMSE | 3.430 | 3.181 | |
| MAPE | 5.966 | 6.012 | |
| 0.952 | 0.943 | ||
| Adamax | MAE (Loss) | 2.918 | 2.502 |
| RMSE | 3.150 | 2.784 | |
| MAPE | 5.016 | 5.180 | |
| 0.950 | 0.957 | ||
| Nadam | MAE (Loss) | 3.142 | 2.728 |
| RMSE | 3.360 | 2.976 | |
| MAPE | 5.428 | 5.616 | |
| 0.947 | 0.950 | ||
| RMSprop | MAE (Loss) | 2.609 | 2.893 |
| RMSE | 2.861 | 3.124 | |
| MAPE | 4.650 | 5.419 | |
| 0.956 | 0.951 | ||
| Adam | MAE (Loss) | 2.541 | 2.414 |
| RMSE | 2.803 | 2.677 | |
| MAPE | 4.641 | 4.760 | |
| 0.954 | 0.959 | ||
| EAG | MAE (Loss) | 2.374 | 2.034 |
| RMSE | 2.631 | 2.344 | |
| MAPE | 4.347 | 4.214 | |
| 0.954 | 0.967 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ragab, M.G.; Abdulkadir, S.J.; Aziz, N.; Al-Tashi, Q.; Alyousifi, Y.; Alhussian, H.; Alqushaibi, A. A Novel One-Dimensional CNN with Exponential Adaptive Gradients for Air Pollution Index Prediction. Sustainability 2020, 12, 10090. https://doi.org/10.3390/su122310090
Ragab MG, Abdulkadir SJ, Aziz N, Al-Tashi Q, Alyousifi Y, Alhussian H, Alqushaibi A. A Novel One-Dimensional CNN with Exponential Adaptive Gradients for Air Pollution Index Prediction. Sustainability. 2020; 12(23):10090. https://doi.org/10.3390/su122310090
Chicago/Turabian StyleRagab, Mohammed G., Said J. Abdulkadir, Norshakirah Aziz, Qasem Al-Tashi, Yousif Alyousifi, Hitham Alhussian, and Alawi Alqushaibi. 2020. "A Novel One-Dimensional CNN with Exponential Adaptive Gradients for Air Pollution Index Prediction" Sustainability 12, no. 23: 10090. https://doi.org/10.3390/su122310090
APA StyleRagab, M. G., Abdulkadir, S. J., Aziz, N., Al-Tashi, Q., Alyousifi, Y., Alhussian, H., & Alqushaibi, A. (2020). A Novel One-Dimensional CNN with Exponential Adaptive Gradients for Air Pollution Index Prediction. Sustainability, 12(23), 10090. https://doi.org/10.3390/su122310090