A Virtual Assistant for Natural Interactions in Museums

 ,
,  ,
,
Abstract
1. Introduction
2. Background and Related Work
2.1. Previous Work on Virtual Museum Guides
2.2. Location and Cultural Background
3. Research Challenges
- The virtual agent can be observed by many users, but only one user can interact with the system at any given time
- The virtual agent can be invoked at any given time using a “magic” word
- The virtual agent has a finite set of answers that it can provide to a finite set of questions.
4. System Development
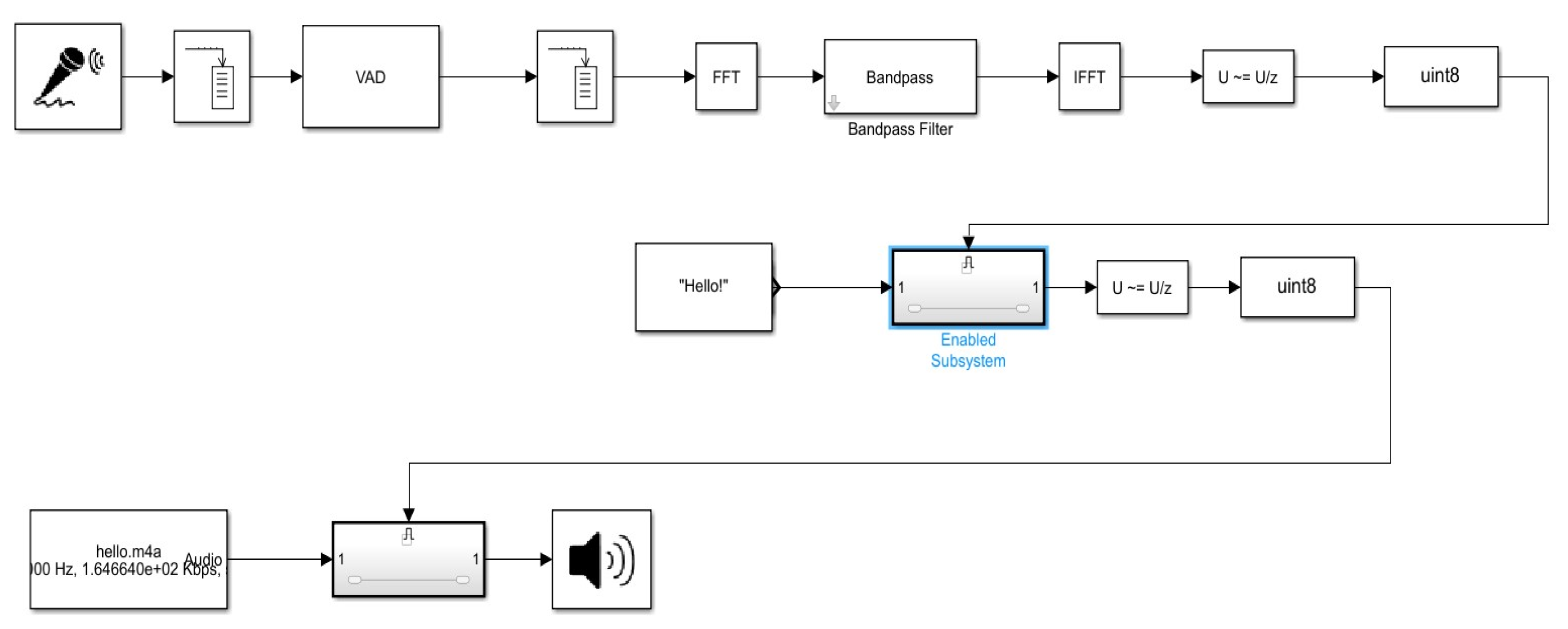
4.1. Principle Simulation
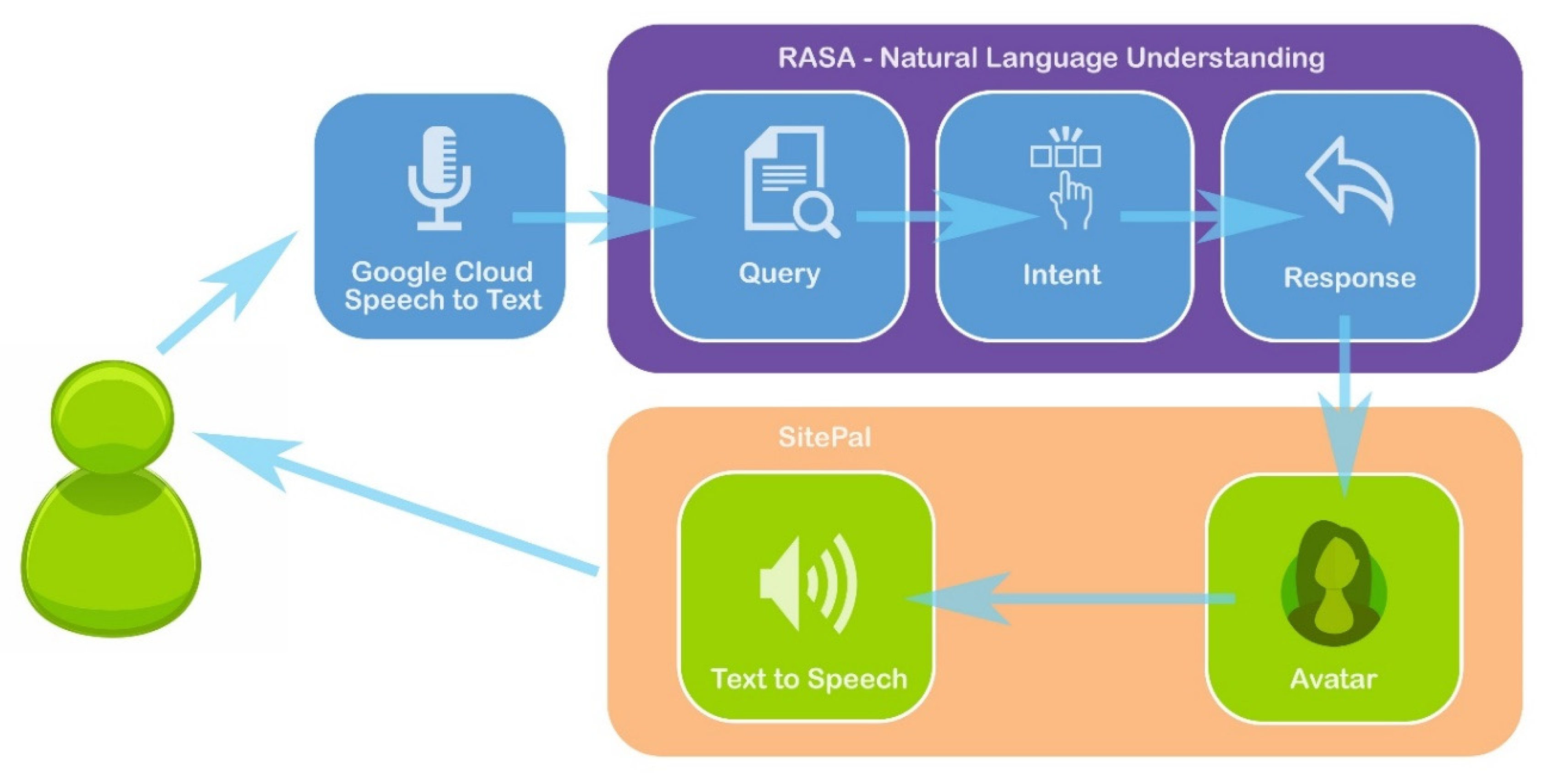
4.2. System Architecture
- Google Cloud Speech to Text [32]. This module takes the audio recording from the user and turns it into text. Google offers an API that recognizes 120 languages, including Romanian. This service is based on the machine-learning technology refined by Google over decades of semantical data collection obtained through its other subsidiaries (Search, Translate, and so on) We decided to use Google Cloud Speech To Text after comparing this framework with several others, such as Vonage, Amazon Transcribe, IBM Watson, Microsoft Bing Speech API, AssemblyAI, Kaldi, or Sayint. Google Cloud Speech To Text is highly scalable and allows rapid development.
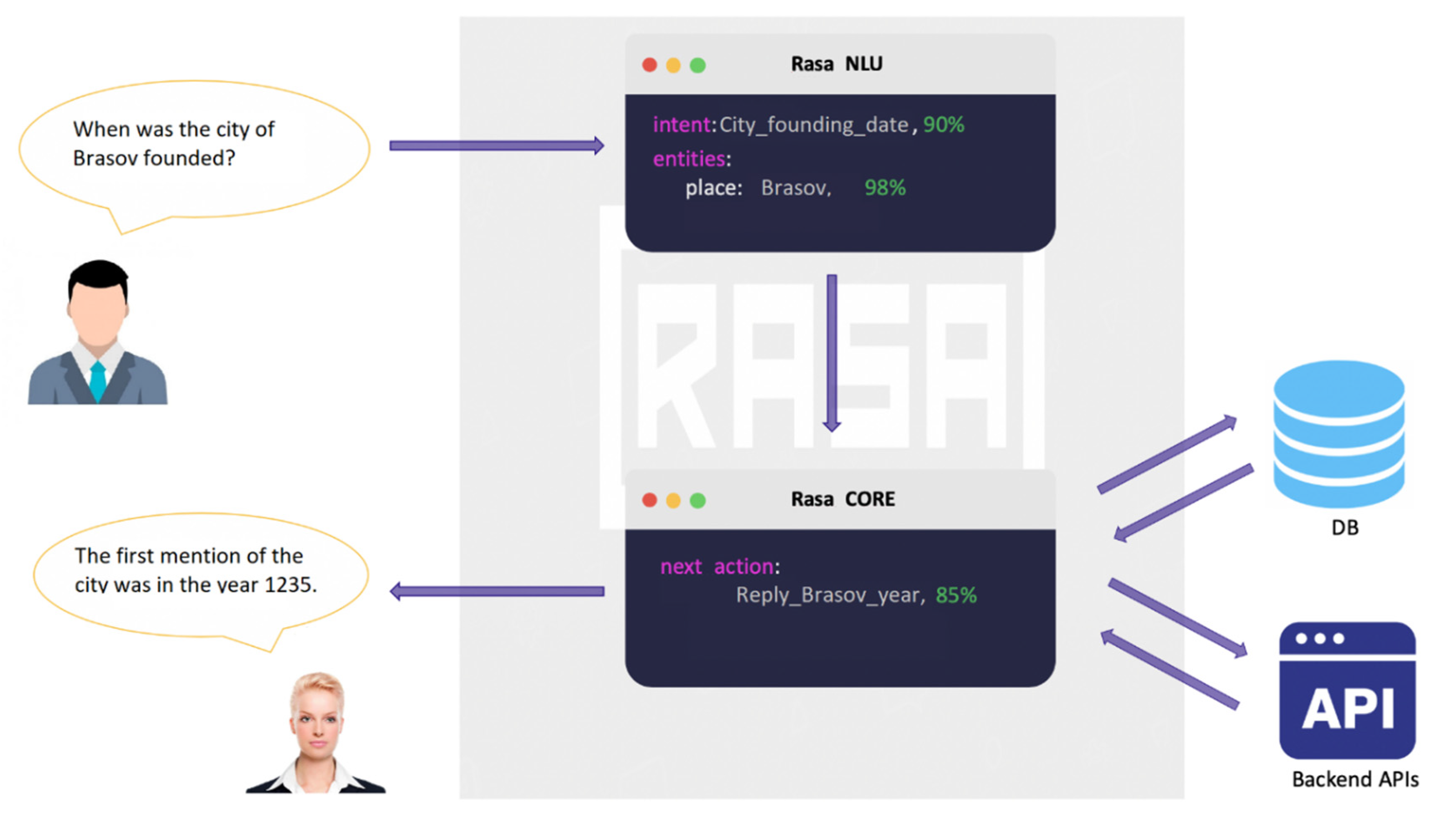
- The application developed using the NLU (Natural Language Understanding) RASA platform [33]. It takes the text and “understands” it, extracting the keywords and determining their semantical meaning. The answer is then processed and served to the user. The analysis and processing are performed directly on Romanian text, as the RASA NLU platform supports any language for its training pipeline. Any language for its training pipeline. We chose RASA NLU over other natural language processors such as NLTK, SpaCy, TensorFlow, Amazon Comprehend or Google Cloud Natural Language API, as this platform allows a facile re-configuration of the smart agent by easily adding new content/answers/narratives.
- The SitePal service [34]. SitePal offers avatars who can be directly displayed on websites and will play the text obtained by RASA NLU by voice (including lip-sync and facial and lip mimicry during speech). The avatar obtained through the SitePal service includes support for Text-to-Speech in Romanian. The SitePal service allows the creation of both bust and standing avatars. Users can choose from a wide range of models, but avatars can also be made based on specific photos. Moreover, the background can be customized or be left transparent. The only drawback of this service is that at the moment, the text-to-speech service in Romanian is available only with a female voice. Luckily, the representatives of the museum “Casa Mureșenilor” were only interested in this type of voice. We chose SitePal over similar services such as Living Actor or Media Semantics as the representatives of the museum found their avatars to be more appealing visually.
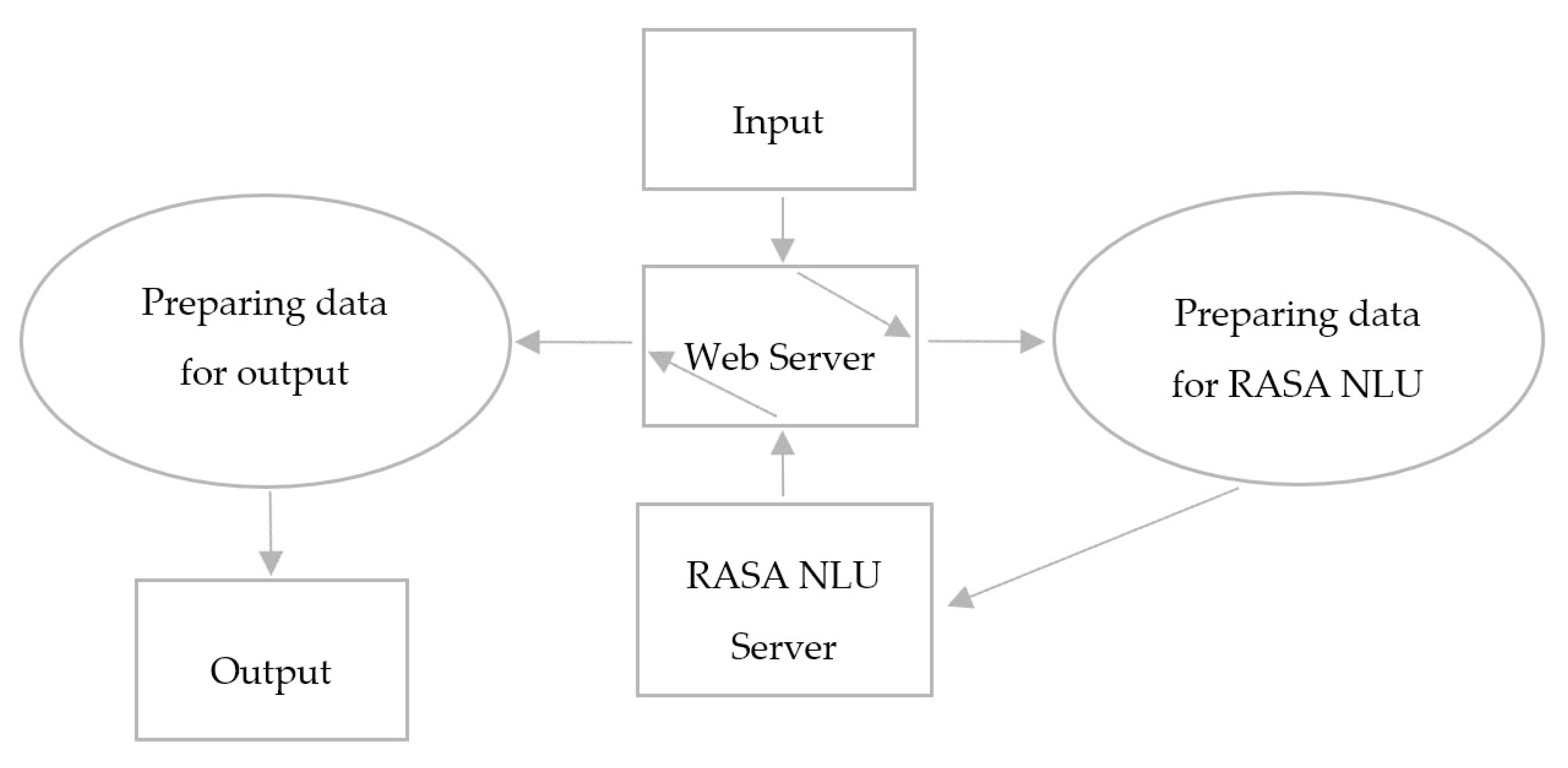
4.3. Natural Language Understanding module
- common examples
- synonyms (used to map several entities to the same name)
- regex formulas (sequences of characters that can be interpreted in different ways following a set of strict rules)
- lookup tables (used to generate regex syntax) [33].
4.4. Virtual Avatar
4.5. Physical Stand
5. Ethical Compliance
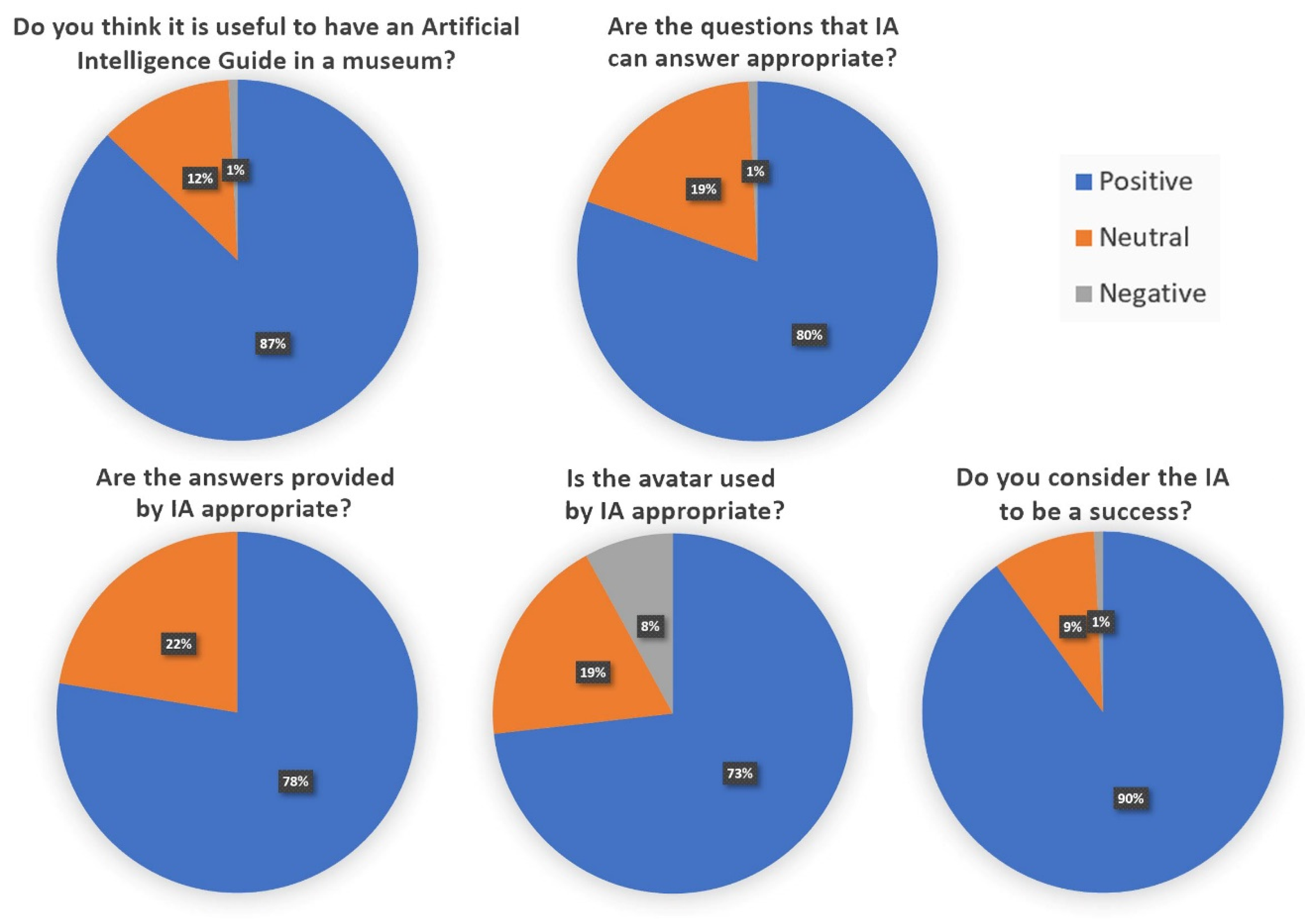
6. User Study
6.1. User Acceptance Evaluation
6.2. A Comparison with Other Virtual Agents for Museums or Related Heritage Applications
7. Results and Discussion
- AI could be the solution for knowledge transfer, especially in the case of young visitors to museums.
- 3D VR avatars are considered innovative by young audiences. Based on this technology, one can imagine a multitude of developments and related events that translate into a more efficient interpretation and promotion of cultural heritage in museums in Romania.
- The introduction of virtual elements allows to increase the level of interaction of visitors with museum products and services, which can lead to an increase in the number of visitors. Interaction is the most important feature of a successful user-centric system [37].
- Given the pioneering nature of this project at the national level and the relative novelty at the international level, the implementation can be expanded, and evaluations could be conducted among other categories of the visiting public.
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chodzko-Zajko, W.J.; Proctor, D.N.; Singh, M.A.F.; Minson, C.T.; Nigg, C.R.; Salem, G.J.; Skinner, J.S. Exercise and physical activity for older adults. Med. Sci. Sports Exerc. 2009, 41, 1510–1530. [Google Scholar] [CrossRef]
- Gordon, J.C.; Shahid, K. Tailoring User Interface Presentations Based on User State. U.S. Patent No. 10,552,183, 4 February 2020. [Google Scholar]
- Tan, B.K.; Hafizur, R. CAAD futures. In Virtual Heritage: Reality and Criticism; De l’Université de Montréal: Montreal, QC, Canada, 2009. [Google Scholar]
- Kopp, S.; Gesellensetter, L.; Kramer, N.C.; Wachsmuth, I. A conversational agent as museum guide–Design and evaluation of a real-world application. In International Workshop on Intelligent Virtual Agents; Springer: Berlin, Germany, 2005; pp. 329–343. [Google Scholar]
- Robinson, S.; Traum, D.R.; Ittycheriah, M.; Henderer, J. What Would you Ask a Conversational Agent? Observations of Human-Agent Dialogues in a Museum Setting; LREC: Marseille, France, 2008. [Google Scholar]
- Swartout, W.; Traum, D.; Artstein, R.; Noren, D.; Debevec, P.; Bronnenkant, K.; Williams, J.; Leuski, A.; Narayanan, S.; Piepol, D. Ada and Grace: Toward realistic and engaging virtual museum guides. In International Conference on Intelligent Virtual Agents; Springer: Berlin, Germany, 2010. [Google Scholar]
- Chaves, A.P.; Aurelio Gerosa, M. Single or multiple conversational agents? An interactional coherence comparison. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018. [Google Scholar]
- Lane, H.C.; Noren, D.; Auerbach, D.; Birch, M.; Swartout, W. Intelligent tutoring goes to the museum in the big city: A pedagogical agent for informal science education. In International Conference on Artificial Intelligence in Education; Springer: Berlin, Germany, 2011. [Google Scholar]
- Bickmore, T.W.; Laura, M.; Vardoulakis, P.; Schulman, D. Tinker: A relational agent museum guide. Auton. Agents Multi-agent Syst. 2013, 27, 254–276. [Google Scholar] [CrossRef]
- SJM Tech. GEN Project. Available online: http://www.sjmtech.net/portfolio/gen/ (accessed on 2 October 2019).
- Mollaret, C.; Mekonnen, A.A.; Ferrané, I.; Pinquier, J.; Lerasle, F. Perceiving user’s intention-for-interaction: A probabilistic multimodal data fusion scheme. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Turin, Italy, 29 June–3 July 2015. [Google Scholar]
- Ghazanfar, A.; Le, H.Q.; Kim, J.; Hwang, S.W.; Hwang, J.I. Design of seamless multi-modal interaction framework for intelligent virtual agents in wearable mixed reality environment. In Proceedings of the 32nd International Conference on Computer Animation and Social Agents, Paris, France, 1–3 July 2019. [Google Scholar]
- Schaffer, S.; Gustke, O.; Oldemeier, J.; Reithinger, N. Towards Chatbots in the Museum; mobileCH@ Mobile HCI: Barcelona, Spain, 2018. [Google Scholar]
- Pavlidis, G. Towards a Novel User Satisfaction Modelling for Museum Visit Recommender Systems. In International Conference on VR Technologies in Cultural Heritage; Springer: Berlin, Germany, 2018. [Google Scholar]
- Tavcar, A.; Antonya, C.; Butila, E.V. Recommender system for virtual assistant supported museum tours. Informatica 2016, 40, 279. [Google Scholar]
- Longo, F.; Nicoletti, L.; Padovano, A. An interactive, interoperable and ubiquitous mixed reality application for a smart learning experience. Int. J. Simul. Process Modell. 2018, 13, 589–603. [Google Scholar] [CrossRef]
- Doyle, P.R.; Edwards, J.; Dumbleton, O.; Clark, L.; Cowan, B.R. Mapping perceptions of humanness in speech-based intelligent personal assistant interaction. arXiv 2019, arXiv:1907.11585. [Google Scholar]
- Rosales, R.; Castañón-Puga, M.; Lara-Rosano, F.; Flores-Parra, J.M.; Evans, R.; Osuna-Millan, N.; Gaxiola-Pacheco, C. Modelling the interaction levels in HCI using an intelligent hybrid system with interactive agents: A case study of an interactive museum exhibition module in Mexico. Appl. Sci. 2018, 8, 446. [Google Scholar] [CrossRef]
- Becker, C.; Kopp, S.; Wachsmuth, I. Why emotions should be integrated into conversational agents. Conversat. Inf. Eng. Approach 2007, 2, 49–68. [Google Scholar]
- Sylaiou, S.; Kasapakis, V.; Gavalas, D.; Dzardanova, E. Avatars as storytellers: Affective narratives in virtual museums. Pers. Ubiquitous Comp. 2020. [Google Scholar] [CrossRef]
- Carrozzino, M.; Colombo, M.; Tecchia, F.; Evangelista, C.; Bergamasco, M. Comparing Different Storytelling Approaches for Virtual Guides in Digital Immersive Museums. In International Conference on Augmented Reality, Virtual Reality and Computer Graphics; Springer: Berlin, Germany, 2018. [Google Scholar]
- Machidon, O.M.; Tavčar, A.; Gams, M.; Duguleană, M. CulturalERICA: A conversational agent improving the exploration of European cultural heritage. J. Cult. Herit. 2020, 41, 152–165. [Google Scholar] [CrossRef]
- Amato, F.; Moscato, F.; Moscato, V.; Pascale, F.; Picariello, A. An Agent-Based approach for recommending cultural tours. Pattern Recognit. Lett. 2020, 131, 341–347. [Google Scholar] [CrossRef]
- Castiglione, A.; Colace, F.; Moscato, V.; Palmieri, F. CHIS: A big data infrastructure to manage digital cultural items. Future Gener. Comp. Syst. 2018, 86, 1134–1145. [Google Scholar] [CrossRef]
- Amato, F.; Chianese, A.; Moscato, V.; Picariello, A.; Sperli, G. SNOPS: A Smart Environment for Cultural Heritage Applications. In Proceedings of the Twelfth International Workshop on Web Information and Data Management, Maui, HI, USA, 29 October–2 November 2012; Association for Computing Machinery: New York, NY, USA, 2012. [Google Scholar]
- Toderean, G.; Ovidiu, B.; Balogh, A. Text-to-speech systems for romanian language. In Proceedings of the 9th International Conference “Microelectronics and Computer Science” & The 6th Conference of Physicists of Moldova, Chișinău, Republic of Moldova, 19–21 October 2017. [Google Scholar]
- Tiberiu, B.; Daniel Dumitrescu, S.; Pais, V. Tools and resources for Romanian text-to-speech and speech-to-text applications. arXiv 2018, arXiv:1802.05583. [Google Scholar]
- Nechita, F.; Demeter, R.; Briciu, V.A.; Kavoura, A.; Varelas, S. Analysing Projected destination images versus visitor-generated visual content in Brasov, Transylvania. In Strategic Innovative Marketing and Tourism; Kavoura, A., Kefallonitis, E., Giovanis, A., Eds.; Springer: Cham, Germany, 2019; pp. 613–622. [Google Scholar] [CrossRef]
- Candrea, A.N.; Ispas, A. Promoting tourist destinations through sport events. The case of Brasov. J. Tour. 2010, 10, 61–67. [Google Scholar]
- Candrea, A.N.; Constantin, C.; Ispas, A. Tourism market heterogeneity in Romanian urban destinations, the case of Brasov. Tour Hosp. Manag. 2012, 18, 55–68. Available online: https://hrcak.srce.hr/83822 (accessed on 12 February 2020).
- eHERITAGE Project. Available online: http://www.eheritage.org/ (accessed on 20 April 2020).
- Google Cloud Speech to Text. Available online: https://cloud.google.com/speech-to-text/ (accessed on 20 April 2020).
- RASA NLU. Available online: https://www.rasa.com/docs/nlu/ (accessed on 20 April 2020).
- SitePal. Available online: https://www.sitepal.com/ (accessed on 20 April 2020).
- Snowboy Hotword Detection Engine. Available online: https://snowboy.kitt.ai/ (accessed on 20 April 2020).
- Machidon, O.M.; Duguleana, M.; Carrozzino, M. Virtual humans in cultural heritage ICT applications: A review. J. Cult. Herit. 2018, 33, 249–260. [Google Scholar] [CrossRef]
- Carrozzino, M.; Voinea, G.D.; Duguleană, M.; Boboc, R.G.; Bergamasco, M. Comparing innovative XR systems in cultural heritage. A case study. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 1, 373–378. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Brașov | Museum | Mureșeanu Family |
|---|---|---|
| Who founded the city? | What is the visiting schedule? | Who were the members of the Mureșeanu family? |
| Who were the people who contributed to the development of the city? | Are all the pieces in the museum original? | What contribution did the Mureșeanu family have for Brașov? |
| How was Brasov in the past? | Where was the furniture brought from? | Did they live here? |
| Are there legends about Brasov? | How old are musical instruments? | Is there an artist in the family? |
| What events are in the city? | Where is the toilet? | Where was the anthem first sung? |
| What other cultural objectives are there in the city? | How many employees does the museum have? |
| 1. Is it useful to have an Artificial Intelligence Guide in a museum? |
| 2. Are the questions that IA can answer appropriate? |
| 3. Are the answers provided by IA appropriate? |
| 4. Is the avatar used by IA appropriate? |
| 5. Do you consider the IA to be a success? |
| 6. Please share any other useful information for this project. |
| Virtual Assistant | Humanoid Look | Non-English Language | Conversational Interactivity | Natural Gestures | Learning Ability |
|---|---|---|---|---|---|
| IA | Yes | Yes | Yes | Yes | Yes |
| Max [4] | Yes | No | Yes | No | No |
| Ada and Grace [6] | Yes | No | Yes | Yes | No |
| Coach Mike [8] | Yes | No | Yes | Yes | No |
| Tinker [9] | No | No | Yes | Yes | No |
| GEN [10] | Yes | Yes | Yes | No | No |
| Recommender [15] | No | Yes | No | No | No |
| CulturalERICA [22] | No | No | Yes | No | Yes |
| Category | Comment |
|---|---|
| Aspect | IA’s blinking is dubious. The avatar looks fake. |
| Make IA a brunette. | |
| IA should have long hair. | |
| IA looks like James Charles. | |
| IA should look friendlier. | |
| IA should not move its eyes, it’s a little scary. | |
| You should use real human avatars. Perhaps the image of a Mureșanu family member would be more appropriate. | |
| Functionality | IA should answer more correctly. |
| The information provided should be more extensive. It should have a setting for a detailed or short answer. | |
| IA should know how to sing. | |
| Occasionally, it does not recognize the activation words. | |
| IA should be able to answer other questions that are not related to the museum; for example, what love means. | |
| IA should know how to make jokes. | |
| Miscellaneous | Subjects should be more accessible to children. |
| Its name should be changed. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duguleană, M.; Briciu, V.-A.; Duduman, I.-A.; Machidon, O.M. A Virtual Assistant for Natural Interactions in Museums. Sustainability 2020, 12, 6958. https://doi.org/10.3390/su12176958
Duguleană M, Briciu V-A, Duduman I-A, Machidon OM. A Virtual Assistant for Natural Interactions in Museums. Sustainability. 2020; 12(17):6958. https://doi.org/10.3390/su12176958
Chicago/Turabian StyleDuguleană, Mihai, Victor-Alexandru Briciu, Ionuț-Alexandru Duduman, and Octavian Mihai Machidon. 2020. "A Virtual Assistant for Natural Interactions in Museums" Sustainability 12, no. 17: 6958. https://doi.org/10.3390/su12176958
APA StyleDuguleană, M., Briciu, V.-A., Duduman, I.-A., & Machidon, O. M. (2020). A Virtual Assistant for Natural Interactions in Museums. Sustainability, 12(17), 6958. https://doi.org/10.3390/su12176958