A Hybrid Approach for Multi-Step Wind Speed Forecasting Based on Multi-Scale Dominant Ingredient Chaotic Analysis, KELM and Synchronous Optimization Strategy



Abstract
:1. Introduction
2. Methodology
2.1. Variational Mode Decomposition
- Step 1: Initialize , , and n = 1;
- Step 2: Update and by Formulas (3) and (4);
- Step 3: Update based on Formula (5);
- Step 4: If stop updating; else n = n + 1, and turn to Step 2.
2.2. Singular Spectrum Analysis
- (1)
- Embedding. The original time sequence x = {xi | i =1, 2, ⋯, N} is reconstructed into a Hankel matrix [32] to begin with SSA, which is defined as:where t = N − l + 1 and l denote the window length.
- (2)
- SVD. On the basis of the time series embedded, the i-th eigentriple (σi, Ui, Vi) can be obtained by decomposing the matrix H with SVD, thus deducing the Hankel matrix H as follows:where σi is the singular value, and Ui and Vi denote the singular vectors of matrixes HHT and HTH, respectively.
- (3)
- Grouping. Several discrete subsets of matrices HZ can be partitioned into the grouping procedure. For Z = {Z1, Z2, …, Zr}, the matrix HZ, corresponding to group Z, can be defined as follows:
- (4)
- Diagonal averaging. A new series with length N, corresponding to each matrix grouped in Equation (8) can be transformed in this procedure. Let matrix X to be a W×Q matrix with elements xij, where i ≤ 1 ≤ W and 1 ≤ j ≤ Q. Let xij* = xij when W < Q, otherwise, let xij* = xji. Then, the restructured sequence Vm (m = 1, 2, …, N) can be obtained as:where W* = min (W, Q), Q* = max (W, Q) as well as Q = N-l+1.
2.3. Phase Space Reconstruction
2.4. Kernel Extreme Learning Machine
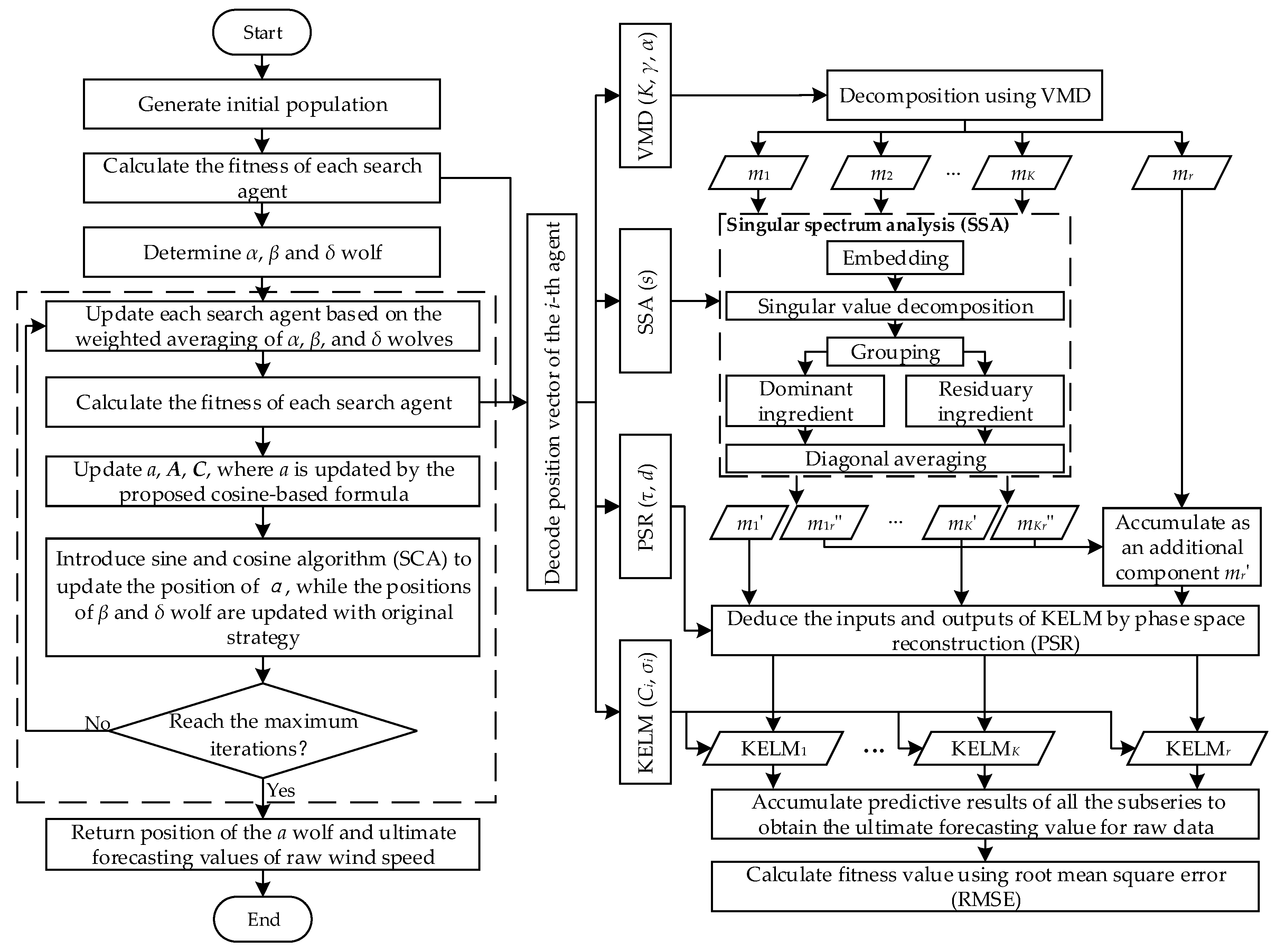
3. The Proposed Approach
3.1. Multi-Scale Dominant Ingredient Chaotic Analysis
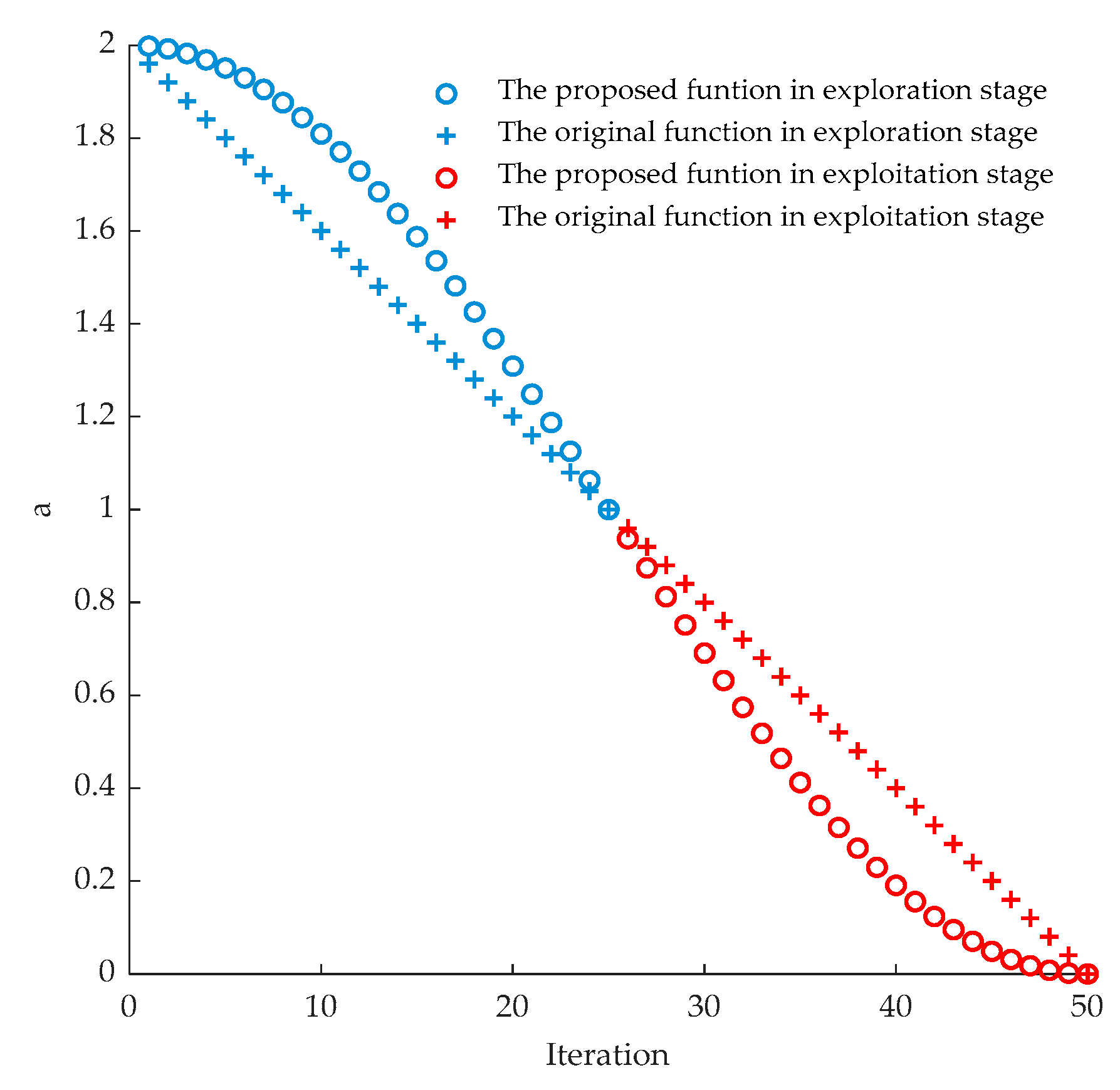
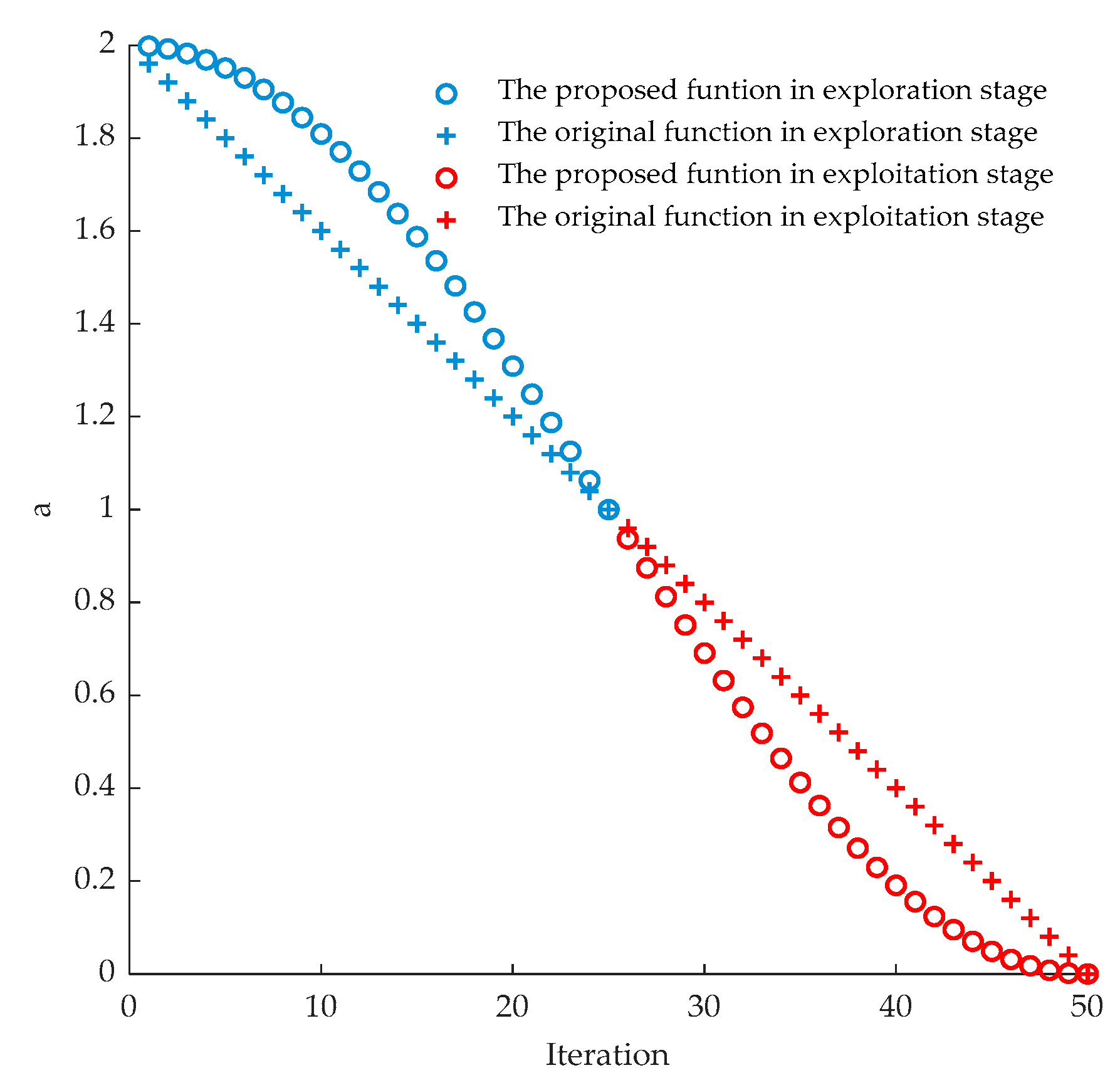
3.2. An Improved Hybrid Grey Wolf Optimizer-Sine Cosine Algorithm
| Algorithm 1. The pseudo code of the proposed IHGWOSCA algorithm | |
| 1: | Initialization the population (i = 1, 2, …, N) |
| 2: | Initialize a, and |
| 3: | Calculate the fitness of each search member |
| 4: | : the best search agents, : the second-best search agent, : the third-best search agent |
| 5: | While (t < maximum number of iterations) |
| 6: | For each search agent: |
| 7: | Update the position of the current search agent on the basis of Equations (25) and (26) |
| 8: | End for: |
| 9: | Update a, , and by Equations (21), (19) and (20), respectively. |
| 10: | Calculate the fitness of all grey wolves |
| 11: | Save the position information owned by the β and δ wolves with Equations (23) and (24), while the position information for α wolf are updated as below: |
| 12: | If rand () < 0.5 |
| 13: | Then: |
| 14 | = rand () × sin (0.5⋅π⋅rand ()) × | × − | |
| 15: | Else: |
| 16: | = rand () × cos (0.5⋅π⋅rand ()) × | × − | |
| 17: | = − · |
| 18: | End if |
| 19: | End else |
| 20: | t = t+1 |
| 21: | End while |
| 22: | Return |
3.3. Optimization Strategy
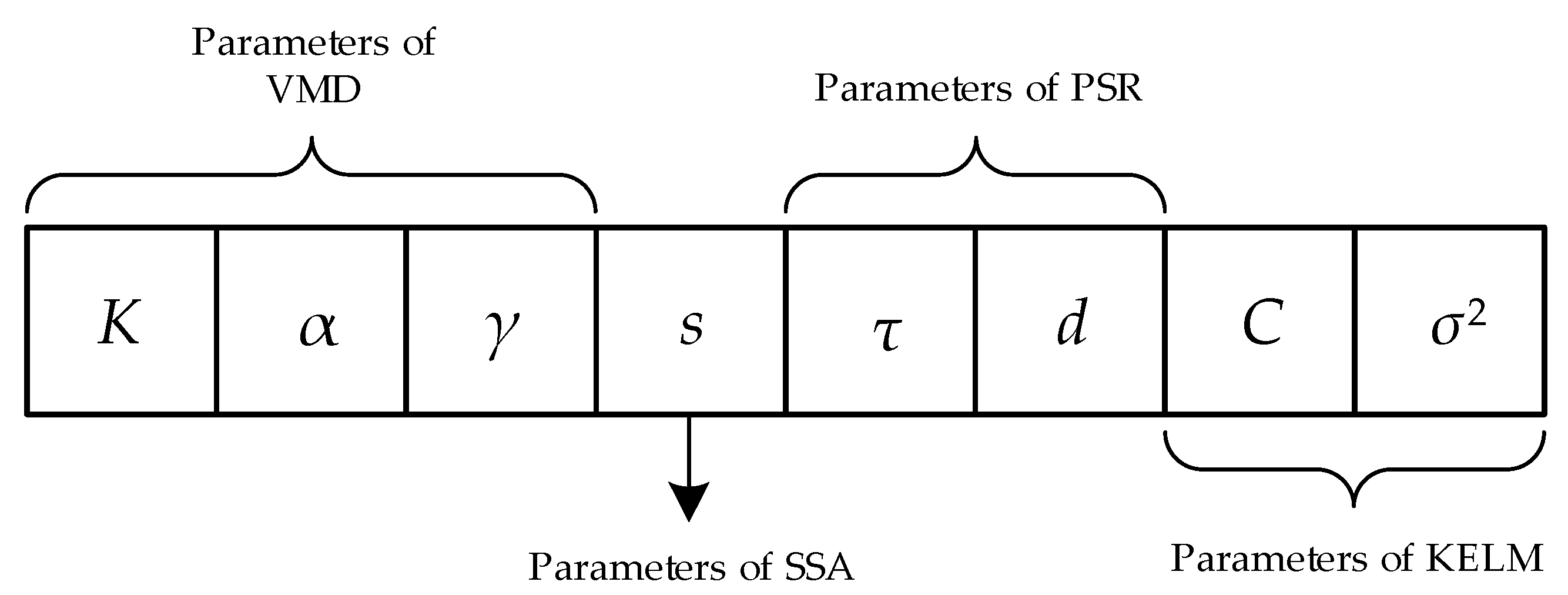
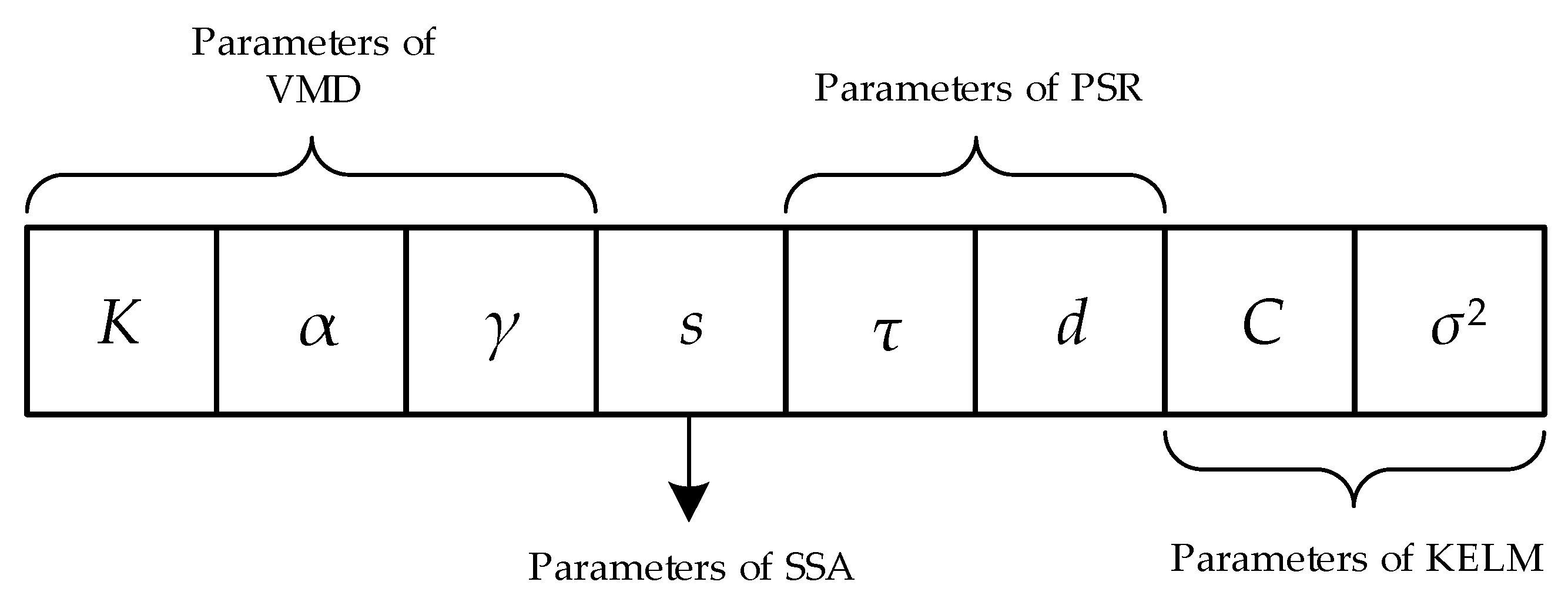
3.4. Specific Procedures
4. Experimental Design
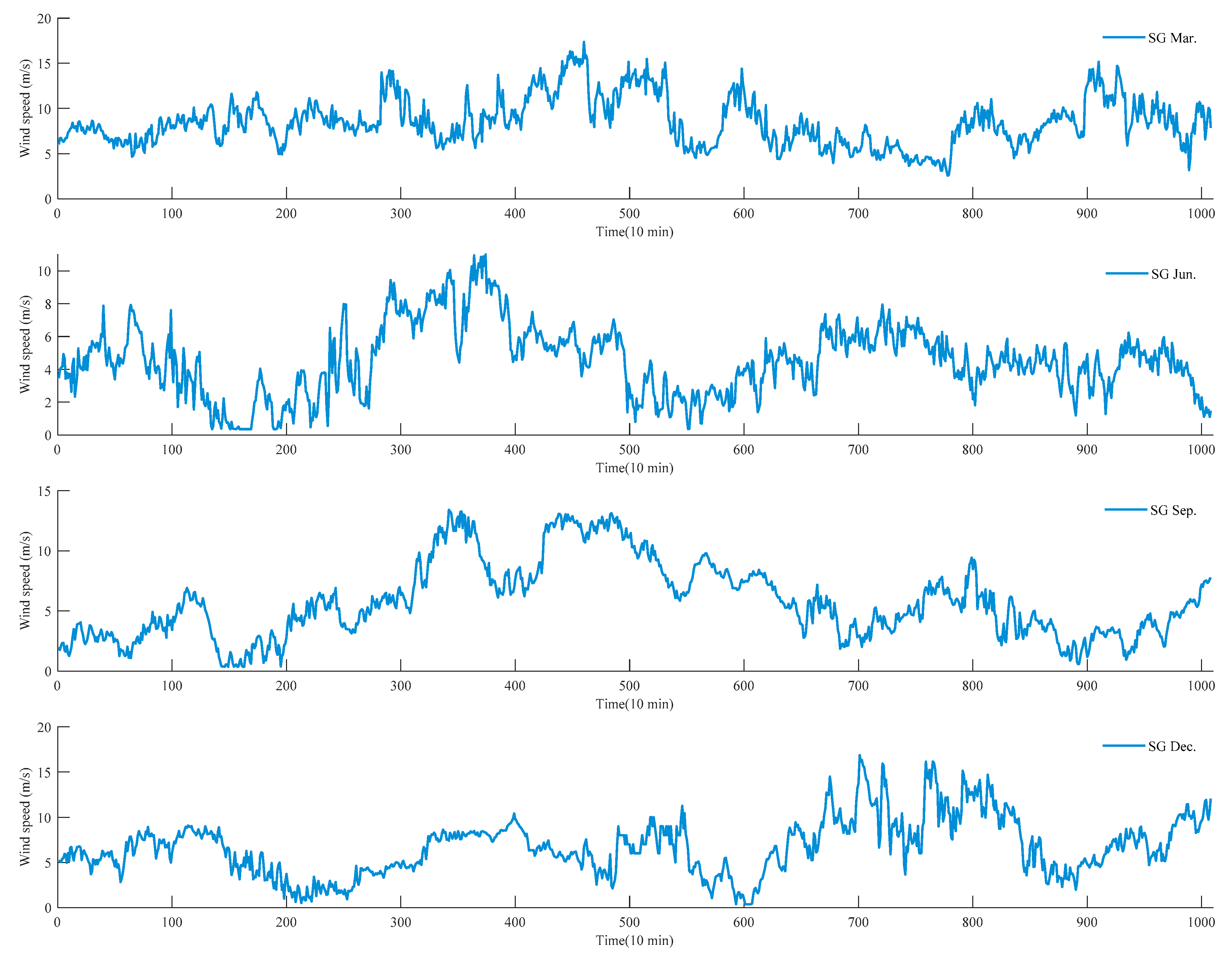
4.1. Data Collection
4.2. Experimental Description
4.3. Contrasting Analyses
- (1)
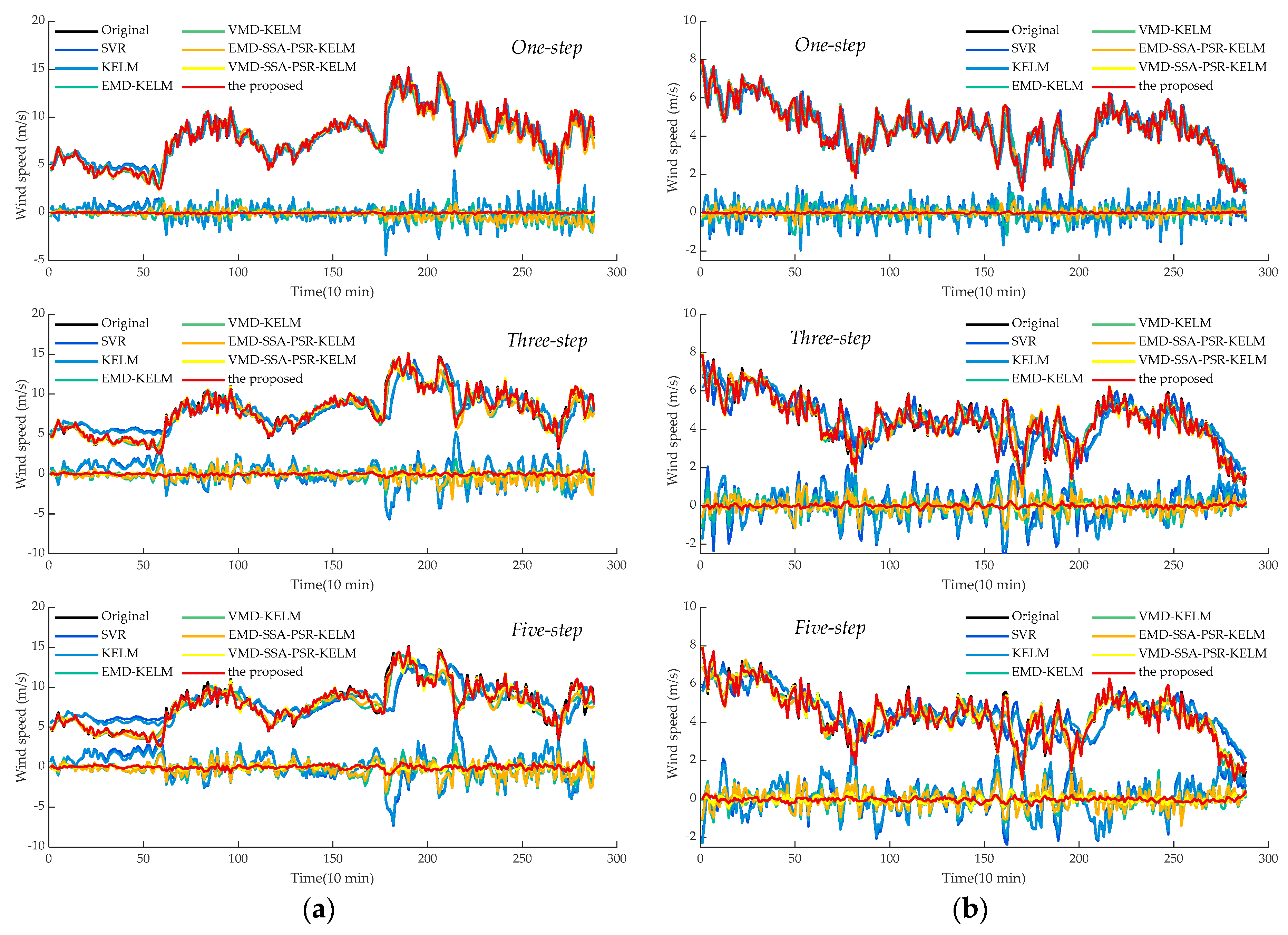
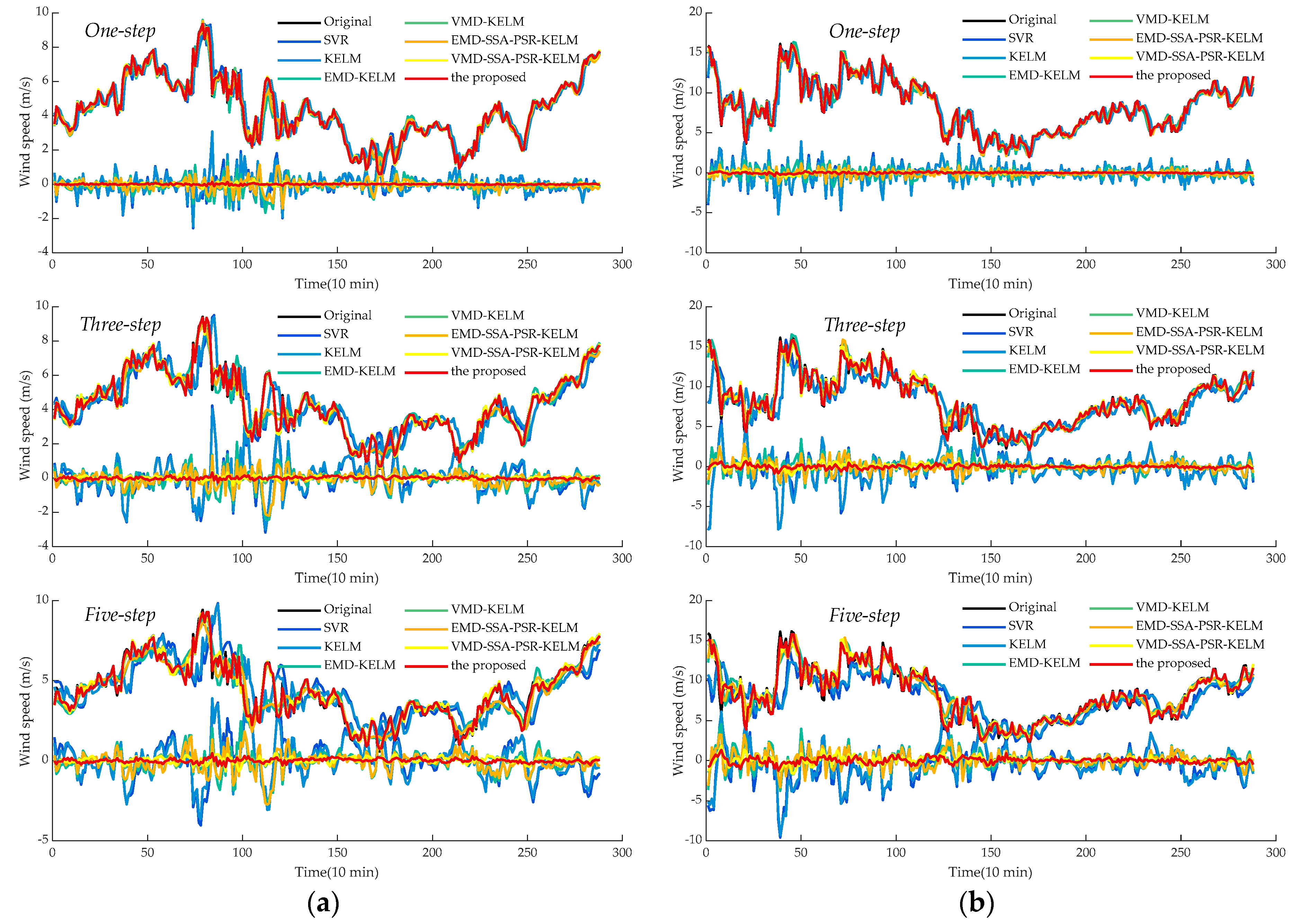
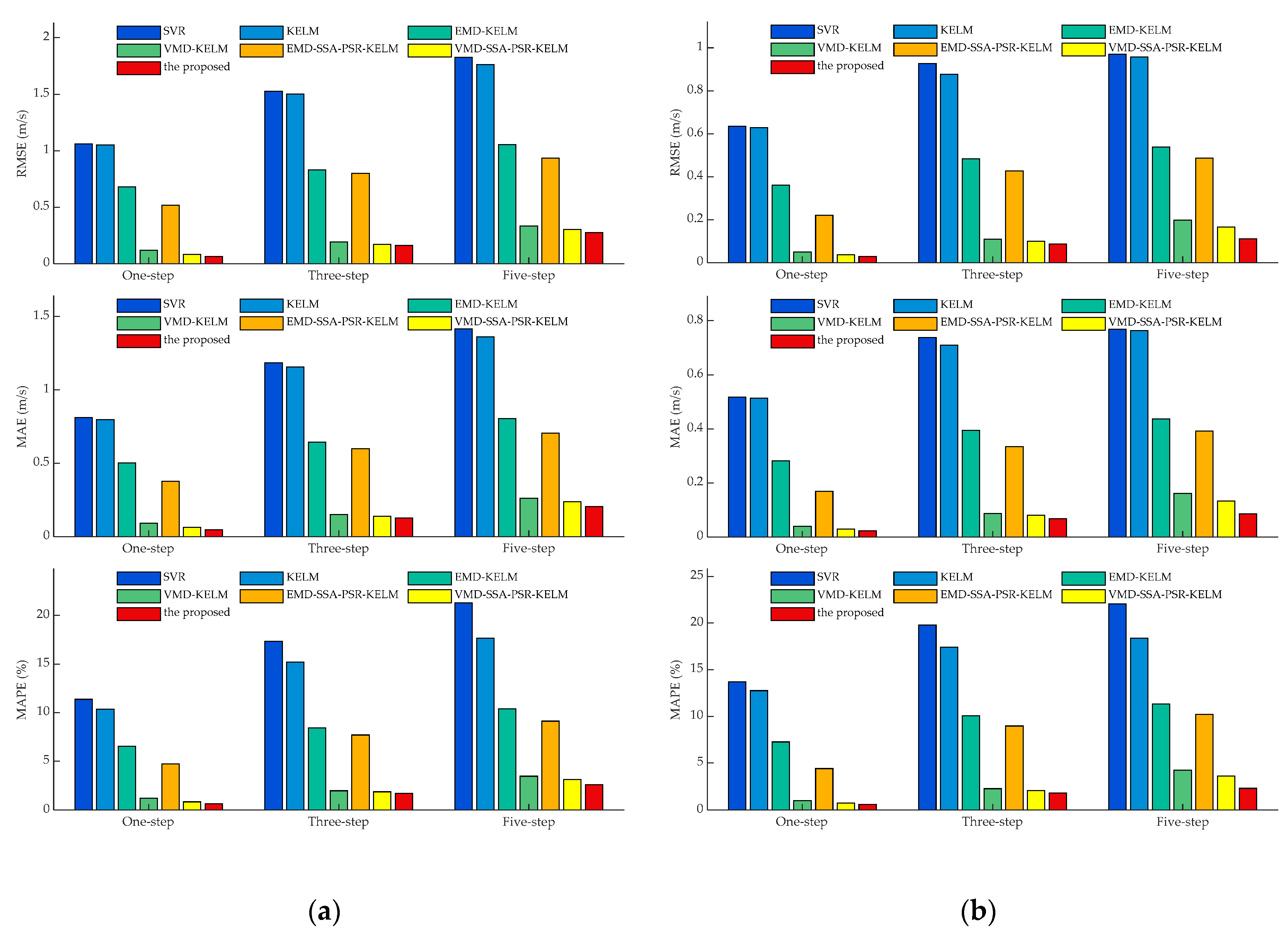
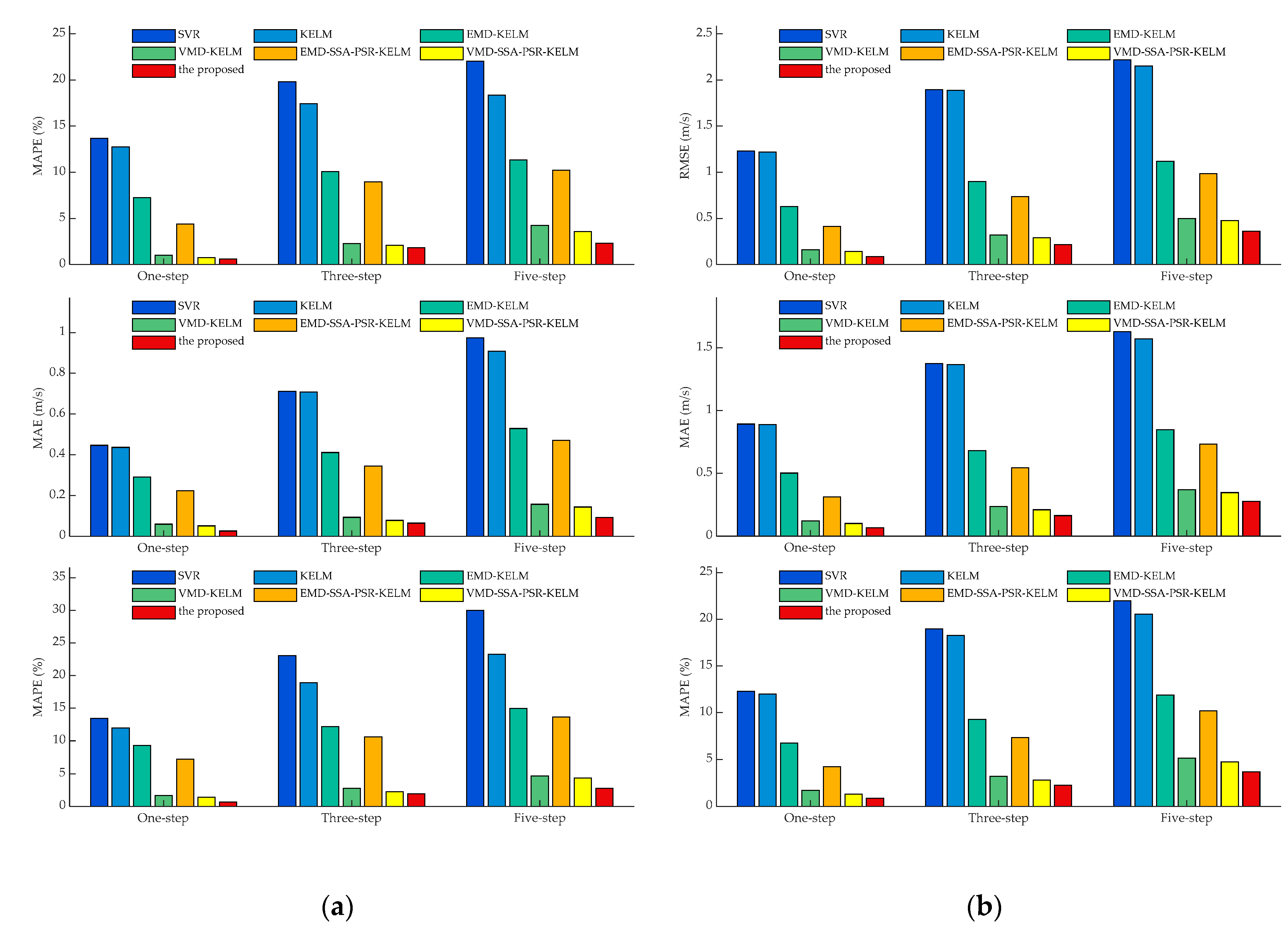
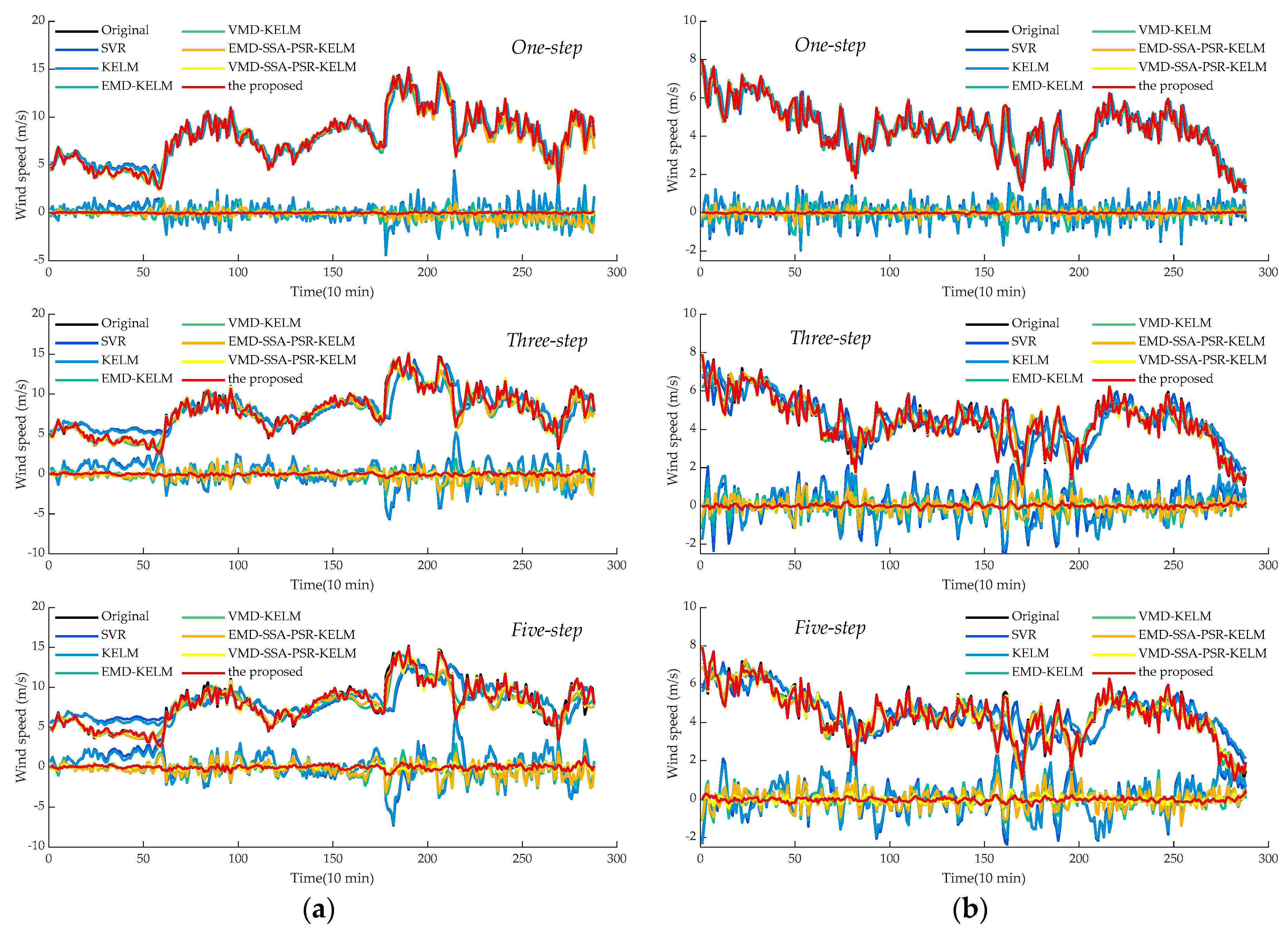
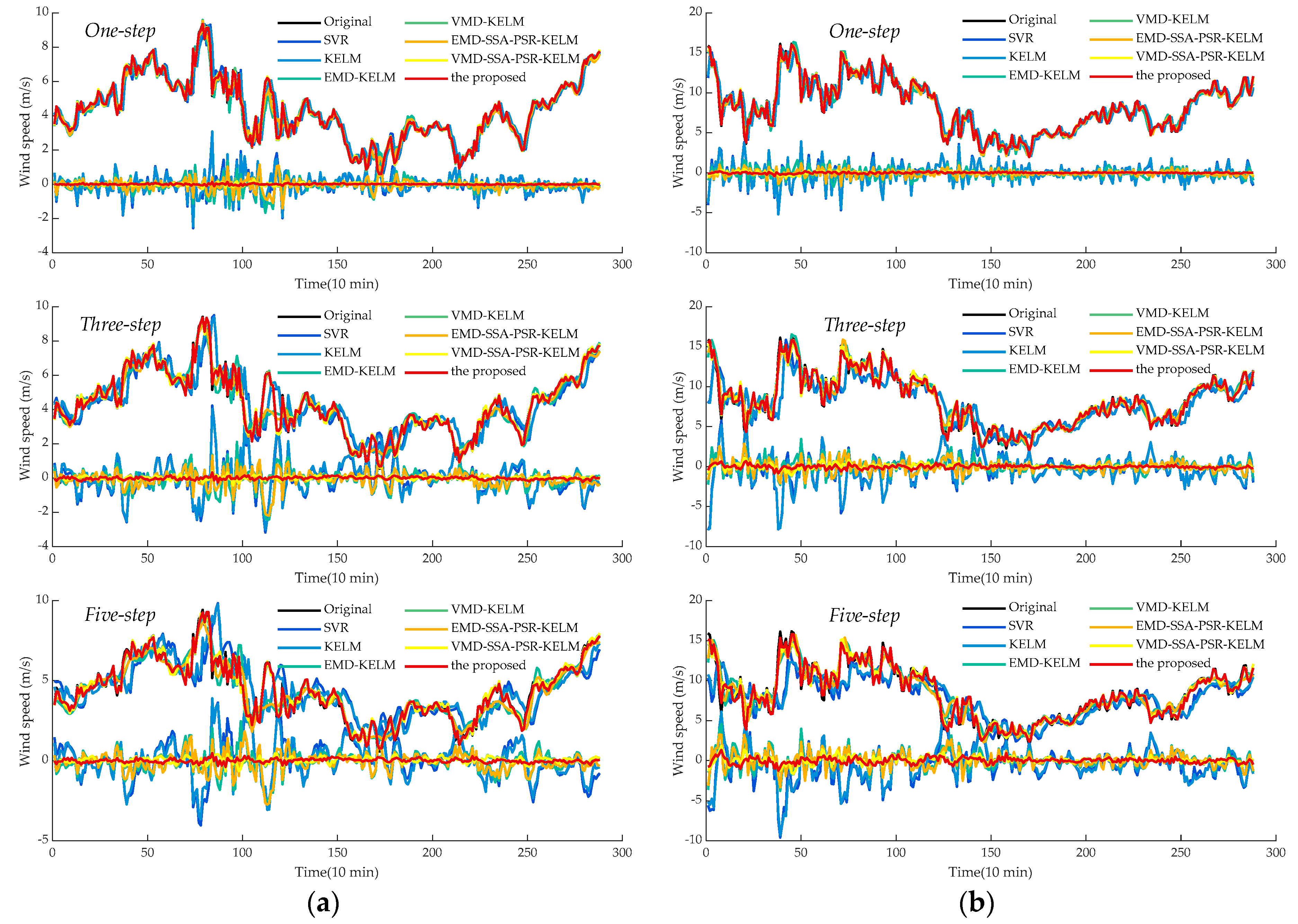
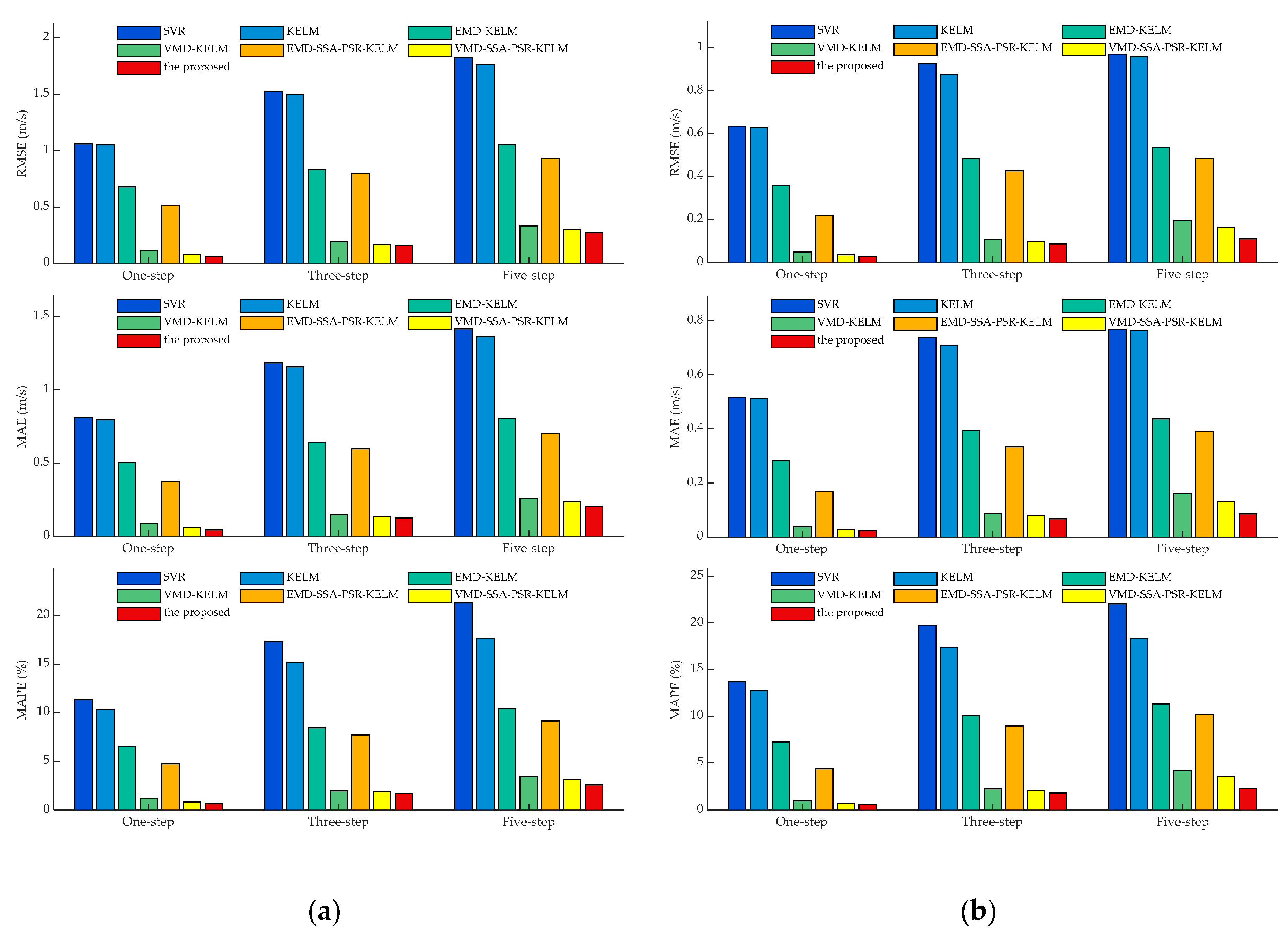
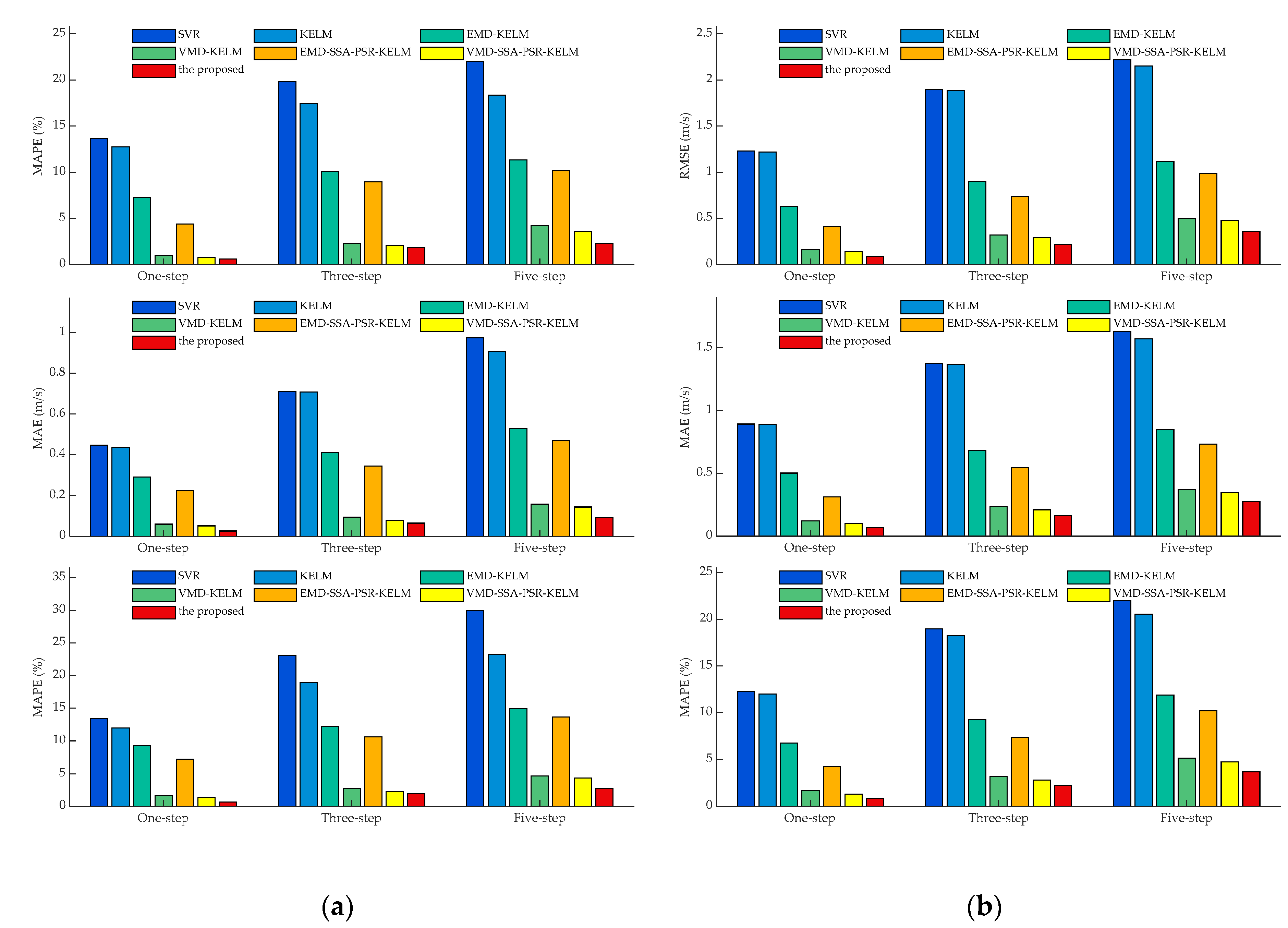
- Comparing the metrics RMSE, MAE, and MAPE, obtained by SVR and KELM in all experimental cases, it can be observed that KELM generally possesses lower metrics than SVR, which means that a better forecasting performance could be obtained by KELM. For instance, in the cases of SG Mar. and SG Jun., the one-step prediction results in terms of MAPE for these two models are 11.37%, 10.35%, and 13.69% 12.76%, of which the reducing ratios of MAPE for KELM are 8.92% and 6.75%, respectively. Furthermore, this trend would be pronounced in the multi-step predictions. In the three-step and five-step predictions in the case of SG Sep., the three employed indicators obtained by SVR and KELM are 0.97 m/s, 0.71 m/s, 23.04% (SVR, three-step), 0.96 m/s, 0.71 m/s, 18.91% (KELM, three-step) and 1.27 m/s, 0.97 m/s, 29.97 (SVR, five-step), 1.19 m/s, 0.91 m/s, 23.27% (KELM, five-step) orderly. It can be seen that the decreasing percentages of the index MAPE for KELM in three-step and five-step forecasting are 17.91% and 22.37%, respectively, with which the superiority of KELM could be demonstrated effectively. It is worth noting that satisfactory results could not be directly achieved by the single models such as SVR and KELM, which could be attributed to the strong non-stationarity and non-linearity of the original wind speed time series. To this end, signal preprocessing technologies are necessary to enhance prediction performance.
- (2)
- Following the comparison of KLEM, EMD-KELM and VMD-KELM, it can be indicated that time-frequency signal processing approaches could greatly improve the prediction accuracy for wind speed. In the case of SG Dec., the evaluation metrics obtained by EMD-KELM in one-step predictions are 0.63 m/s, 0.50 m/s, 6.76%, which are deceased by 48.37%, 43.45%, and 43.74%, compared to the single-model KELM. Meanwhile, the metrics reducing ratio in the three-step and five-step predictions obtained by comparing KELM and EMD-KELM are 52.37%, 50.16%, 49.15% and 47.87%, 46.07%, and 42.20%, respectively. From further comparison of the results of EMD-KELM and VMD-KELM, it can be indicated that the three evaluation indicators obtained by VMD-KELM are decreased by averaging 75.05%, 64.90%, and 56.17% in three experimental prediction horizons, respectively. Hence, it can be concluded that VMD could improve the forecasting accuracy better than EMD. Similar conclusions could be drawn by the same analysis for the remaining experimental cases.
- (3)
- The proposed dominant ingredient chaotic analysis combining SSA and PSR could improve the prediction model performance in an ulterior manner. In the case of SG Mar., compared with EMD-KELM, the metrics obtained by EMD-SSA-PSR-KELM are 0.52 m/s, 0.38 m/s, 4.71%, 0.80 m/s, 0.60 m/s, 7.69%, 0.93 m/s, 0.70 m/s, 9.12% in three variously predicted horizons, of which the corresponding decreasing percentages are averaged by 25.67%, 6.50% and 12.04%. Meanwhile, compared with VMD-KELM, the metrics of VMD-SSA-PSR-KELM have been averaged, decreasing by 31.11%, 8.02% and 9.30% in different predicted horizons, respectively. The comparisons of EMD-KELM, EMD-SSA-PSR-KELM and VMD-KELM, and VMD-SSA-PSR-KELM indicate that the proposed dominant ingredient chaotic analysis could further enhance the forecasting performance on the basis of the signal decomposition approaches implemented. Nevertheless, the performance of the proposed dominant ingredient chaotic analysis would be restricted by the parameters that are settled in SSA and PSR, which makes parameter optimization necessary.
- (4)
- Comparing VMD-SSA-PSR-KELM and the proposed model, both of these two models possess the same frameworks, while the parameters in the proposed one are optimized by the proposed IHGWOSCA algorithm synchronously. In the case of SG Mar. as the example, the metrics decreasing the percentage between VMD-SSA-PSR-KELM and the proposed model in terms of MAPE are 23.05%, 8.71%, and 15.94% in three predicted horizons, respectively. It can be concluded that the forecasting performance obtained by the synchronous optimization strategy-based model is much better; in other words, the appropriate parameters in each module could be optimized by the proposed IHGWOSCA effectively. Additionally, for one-step prediction in all cases, the average decline ratios between these two models in terms of RMSE, MAE, and MAPE are 32.86%, 32.94%, 31.89%, respectively. Furthermore, compared with SVR models in all experimental cases, the maximum decreasing ratio of MAPE in the one-, three- and five-step predictions are 95.57% (in the case of SG Jun.), 91.62% (in the case of SG Sep.), and 90.79% (in the case of SG Sep.), respectively, with which it can be indicated that a large promotion in performance could be achieved by the proposed model.
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ADMM | Alternating direction method of multipliers |
| ANN | Artificial neural network |
| AI | Artificial intelligence |
| AR | Autoregressive |
| ARIMA | Autoregressive integrated moving average |
| ARMA | Autoregressive moving average |
| ELM | Extreme learning machine |
| EMD | Empirical mode decomposition |
| GS | Grid search |
| GWO | Grey wolf optimizer |
| HGWO-SCA | Hybrid grey wolf optimizer-sine cosine algorithm |
| IHGWOSCA | Improved hybrid grey wolf optimizer-sine cosine algorithm |
| IMF | Intrinsic mode function |
| KELM | Kernel extreme learning machine |
| Kurt. | Kurtosis |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error |
| Max. | Maximum |
| Min. | Minimum |
| NWP | Numerical weather prediction |
| PSR | Phase space reconstruction |
| RMSE | Root mean square error |
| SCA | Sine cosine algorithm |
| SG | Sotavento Galicia |
| Skew. | Skewness |
| SLFN | Single hidden layer feed-forward network |
| SSA | Singular spectrum analysis |
| Std. | Standard deviation |
| SVD | Singular value decomposition |
| SVR | Support vector regression |
| VMD | Variational mode decomposition |
| WT | Wavelet transform |
References
- Li, C.; Xiao, Z.; Xia, X.; Zou, W.; Zhang, C. A hybrid model based on synchronous optimisation for multi-step short-term wind speed forecasting. Appl. Energy 2018, 215, 131–144. [Google Scholar] [CrossRef]
- Ma, L.; Luan, S.; Jiang, C.; Liu, H.; Zhang, Y. A review on the forecasting of wind speed and generated power. Renew. Sustain. Energy Rev. 2009, 13, 915–920. [Google Scholar]
- Zhang, J.; Draxl, C.; Hopson, T.; Delle Monache, L.; Vanvyve, E.; Hodge, B.-M. Comparison of numerical weather prediction based deterministic and probabilistic wind resource assessment methods. Appl. Energy 2015, 156, 528–541. [Google Scholar] [CrossRef]
- Karakuş, O.; Kuruoğlu, E.E.; Altınkaya, M.A. One-day ahead wind speed/power prediction based on polynomial autoregressive model. IET Renew. Power Gener. 2017, 11, 1430–1439. [Google Scholar] [CrossRef]
- Erdem, E.; Shi, J. ARMA based approaches for forecasting the tuple of wind speed and direction. Appl. Energy 2011, 88, 1405–1414. [Google Scholar] [CrossRef]
- Yunus, K.; Thiringer, T.; Chen, P. ARIMA-based frequency-decomposed modeling of wind speed time series. IEEE Trans. Power Syst. 2016, 31, 2546–2556. [Google Scholar] [CrossRef]
- Damousis, I.G.; Alexiadis, M.C.; Theocharis, J.B.; Dokopoulos, P.S. A fuzzy model for wind speed prediction and power generation in wind parks using spatial correlation. IEEE Trans. Energy Convers. 2004, 19, 352–361. [Google Scholar] [CrossRef]
- Barbounis, T.; Theocharis, J. A locally recurrent fuzzy neural network with application to the wind speed prediction using spatial correlation. Neurocomputing 2007, 70, 1525–1542. [Google Scholar] [CrossRef]
- Sun, W.; Wang, Y. Short-term wind speed forecasting based on fast ensemble empirical mode decomposition, phase space reconstruction, sample entropy and improved back-propagation neural network. Energy Convers. Manag. 2018, 157, 1–12. [Google Scholar] [CrossRef]
- Niu, D.; Liang, Y.; Hong, W. Wind speed forecasting based on emd and grnn optimized by foa. Energies 2017, 10, 2001. [Google Scholar] [CrossRef]
- Fu, W.; Zhou, J.; Zhang, Y.; Zhu, W.; Xue, X.; Xu, Y. A state tendency measurement for a hydro-turbine generating unit based on aggregated EEMD and SVR. Meas. Sci. Technol. 2015, 26, 125008. [Google Scholar] [CrossRef]
- Fu, C.; Li, G.-Q.; Lin, K.-P.; Zhang, H.-J. Short-term wind power prediction based on improved chicken algorithm optimization support vector machine. Sustainability 2019, 11, 512. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, J.; Li, C.; Fu, W.; Peng, T. A compound structure of ELM based on feature selection and parameter optimization using hybrid backtracking search algorithm for wind speed forecasting. Energy Convers. Manag. 2017, 143, 360–376. [Google Scholar] [CrossRef]
- Zhou, J.; Yu, X.; Jin, B. Short-term wind power forecasting: A new hybrid model combined extreme-point symmetric mode decomposition, extreme learning machine and particle swarm optimization. Sustainability 2018, 10, 3202. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2012, 42, 513–529. [Google Scholar] [CrossRef]
- Shao, Z.; Chao, F.; Yang, S.; Zhou, K. A review of the decomposition methodology for extracting and identifying the fluctuation characteristics in electricity demand forecasting. Renew. Sustain. Energy. Rev. 2017, 75, 123–136. [Google Scholar] [CrossRef]
- Liu, D.; Niu, D.; Wang, H.; Fan, L. Short-term wind speed forecasting using wavelet transform and support vector machines optimized by genetic algorithm. Renew. Energy 2014, 62, 592–597. [Google Scholar] [CrossRef]
- Zhang, C.; Wei, H.; Zhao, J.; Liu, T.; Zhu, T.; Zhang, K. Short-term wind speed forecasting using empirical mode decomposition and feature selection. Renew. Energy 2016, 96, 727–737. [Google Scholar] [CrossRef]
- Wu, Q.; Lin, H. Short-term wind speed forecasting based on hybrid variational mode decomposition and least squares support vector machine optimized by bat algorithm model. Sustainability 2019, 11, 652. [Google Scholar] [CrossRef]
- Fu, W.; Tan, J.; Li, C.; Zou, Z.; Li, Q.; Chen, T. A hybrid fault diagnosis approach for rotating machinery with the fusion of entropy-based feature extraction and SVM optimized by a chaos quantum sine cosine algorithm. Entropy 2018, 20, 626. [Google Scholar] [CrossRef]
- Fu, W.; Wang, K.; Li, C.; Li, X.; Li, Y.; Zhong, H. Vibration trend measurement for a hydropower generator based on optimal variational mode decomposition and an LSSVM improved with chaotic sine cosine algorithm optimization. Meas. Sci. Technol. 2019, 30, 015012. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Liu, H.; Mi, X.; Li, Y. Smart multi-step deep learning model for wind speed forecasting based on variational mode decomposition, singular spectrum analysis, LSTM network and ELM. Energy Convers. Manag. 2018, 159, 54–64. [Google Scholar] [CrossRef]
- Yu, C.; Li, Y.; Zhang, M. Comparative study on three new hybrid models using elman neural network and empirical mode decomposition based technologies improved by singular spectrum analysis for hour-ahead wind speed forecasting. Energy Convers. Manag. 2017, 147, 75–85. [Google Scholar] [CrossRef]
- Packard, N.H.; Crutchfield, J.P.; Farmer, J.D.; Shaw, R.S. Geometry from a time series. Phys. Rev. Lett. 1980, 45, 712. [Google Scholar] [CrossRef]
- Wang, D.; Luo, H.; Grunder, O.; Lin, Y. Multi-step ahead wind speed forecasting using an improved wavelet neural network combining variational mode decomposition and phase space reconstruction. Renew. Energy 2017, 113, 1345–1358. [Google Scholar] [CrossRef]
- Chan, R.H.; Tao, M.; Yuan, X. Constrained total variation deblurring models and fast algorithms based on alternating direction method of multipliers. SIAM J. Imag. Sci. 2013, 6, 680–697. [Google Scholar] [CrossRef]
- Chen, N.; Qian, Z.; Meng, X. Multistep wind speed forecasting based on wavelet and gaussian processes. Math. Probl. Eng. 2013, 2013, 1–8. [Google Scholar] [CrossRef]
- Dong, Q.; Sun, Y.; Li, P. A novel forecasting model based on a hybrid processing strategy and an optimized local linear fuzzy neural network to make wind power forecasting: A case study of wind farms in China. Renew. Energy 2017, 102, 241–257. [Google Scholar] [CrossRef]
- Du, P.; Jin, Y.; Zhang, K. A hybrid multi-step rolling forecasting model based on ssa and simulated annealing—adaptive particle swarm optimization for wind speed. Sustainability 2016, 8, 754. [Google Scholar] [CrossRef]
- Ma, X.; Jin, Y.; Dong, Q. A generalized dynamic fuzzy neural network based on singular spectrum analysis optimized by brain storm optimization for short-term wind speed forecasting. Appl. Soft Comput. 2017, 54, 296–312. [Google Scholar] [CrossRef]
- Golafshan, R.; Sanliturk, K.Y. SVD and Hankel matrix based de-noising approach for ball bearing fault detection and its assessment using artificial faults. Mech. Syst. Signal Process. 2016, 70, 36–50. [Google Scholar] [CrossRef]
- Huang, G.; Zhu, Q.; Siew, C. Extreme learning machine: A new learning scheme of feedforward neural networks. Neural Netw. 2004, 2, 985–990. [Google Scholar]
- Duan, L.; Dong, S.; Cui, S.; Ma, W. Extreme learning machine with gaussian kernel based relevance feedback scheme for image retrieval. Proceedings of ELM-2015 Volume 1; Springer: Cham, Switzerland, 2016; pp. 397–408. [Google Scholar]
- Li, Q.; Chen, H.; Huang, H.; Zhao, X.; Cai, Z.; Tong, C.; Liu, W.; Tian, X. An enhanced grey wolf optimization based feature selection wrapped kernel extreme learning machine for medical diagnosis. Comput. Math. Methods Med. 2017, 2017, 1–15. [Google Scholar] [CrossRef]
- Niu, T.; Wang, J.; Zhang, K.; Du, P. Multi-step-ahead wind speed forecasting based on optimal feature selection and a modified bat algorithm with the cognition strategy. Renew. Energy 2018, 118, 213–229. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, J.; Wei, X. A hybrid wind speed forecasting model based on phase space reconstruction theory and Markov model: A case study of wind farms in northwest China. Energy 2015, 91, 556–572. [Google Scholar] [CrossRef]
- Singh, N.; Singh, S. A novel hybrid GWO-SCA approach for optimization problems. Eng. Sci. Technol. Int. J. 2017, 20, 1586–1601. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Fu, W.; Wang, K.; Li, C.; Tan, J. Multi-step short-term wind speed forecasting approach based on multi-scale dominant ingredient chaotic analysis, improved hybrid GWO-SCA optimization and ELM. Energy Convers. Manage. 2019, 187, 356–377. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.; Liang, X.; Li, Y. New wind speed forecasting approaches using fast ensemble empirical model decomposition, genetic algorithm, Mind Evolutionary Algorithm and Artificial Neural Networks. Renew. Energy 2015, 83, 1066–1075. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, K.; Qin, L.; An, X. Deterministic and probabilistic interval prediction for short-term wind power generation based on variational mode decomposition and machine learning methods. Energy Convers. Manag. 2016, 112, 208–219. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Y.; Li, L.; Infield, D. Short-term wind power forecasting based on clustering pre-calculated CFD method. Energies 2018, 11, 854. [Google Scholar] [CrossRef]
- Li, L.; Liu, Y.; Yang, Y.; Han, S.; Wang, Y. A physical approach of the short-term wind power prediction based on CFD pre-calculated flow fields. J. Hydrodyn. 2013, 25, 56–61. [Google Scholar] [CrossRef]
- Castellani, F.; Astolfi, D.; Mana, M.; Burlando, M.; Meißner, C.; Piccioni, E. Wind Power Forecasting techniques in complex terrain: ANN vs. ANN-CFD hybrid approach. J. Phys. Conf. Ser. 2016, 753, 082002. [Google Scholar] [CrossRef]
- Zhang, C.; Peng, T.; Li, C.; Fu, W.; Xia, X.; Xue, X. Multiobjective optimization of a fractional-order PID controller for pumped turbine governing system using an improved NSGA-III algorithm under multiworking conditions. Complexity 2019, 2019, 5826873. [Google Scholar] [CrossRef]
- Hao, Y.; Tian, C. A novel two-stage forecasting model based on error factor and ensemble method for multi-step wind power forecasting. Appl. Energy 2019, 238, 368–383. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cases | Statistic Indices | |||||
|---|---|---|---|---|---|---|
| Max. (m/s) | Min. (m/s) | Mean (m/s) | Stew. | Kurt. | Std. | |
| SG March | 17.38 | 2.56 | 8.53 | 0.56 | 2.96 | 2.68 |
| SG June | 11.00 | 0.35 | 4.5 | 0.27 | 2.94 | 2.13 |
| SG September | 13.39 | 0.35 | 5.77 | 0.6 | 2.6 | 3.19 |
| SG December | 16.84 | 0.35 | 6.7 | 0.44 | 3.21 | 3.12 |
| Cases | Horizons | Parameters | |||||||
|---|---|---|---|---|---|---|---|---|---|
| K | α | γ | s | τ | d | C | σ2 | ||
| SG March | One-step | 10 | 877 | 0.98 | 167 | 1 | 13 | 358.13 | 118.06 |
| Three-step | 10 | 770 | 0.19 | 118 | 1 | 26 | 514.82 | 242.26 | |
| Five-step | 10 | 968 | 0.29 | 117 | 1 | 15 | 419.53 | 129.29 | |
| SG June | One-step | 10 | 645 | 0.43 | 167 | 1 | 15 | 1000 | 129.48 |
| Three-step | 10 | 1213 | 0.91 | 93 | 1 | 6 | 1000 | 52.61 | |
| Five-step | 10 | 62 | 0.48 | 64 | 1 | 31 | 829.72 | 166.47 | |
| SG September | One-step | 10 | 213 | 0.79 | 154 | 1 | 12 | 1000 | 43.67 |
| Three-step | 10 | 127 | 0.4 | 86 | 1 | 18 | 988.64 | 330.17 | |
| Five-step | 10 | 122 | 0.09 | 84 | 1 | 14 | 875.89 | 129.23 | |
| SG December | One-step | 10 | 728 | 0.99 | 167 | 1 | 9 | 1000 | 201.19 |
| Three-step | 10 | 223 | 0.94 | 83 | 1 | 10 | 686.65 | 116.63 | |
| Five-step | 10 | 531 | 0.61 | 53 | 1 | 13 | 688.51 | 263.35 | |
| Cases | Models | One-Step | Three-Step | Five-Step | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | MAPE | RMSE | MAE | MAPE | RMSE | MAE | MAPE | ||
| (m/s) | (m/s) | (%) | (m/s) | (m/s) | (%) | (m/s) | (m/s) | (%) | ||
| SG March | SVR | 1.06 | 0.81 | 11.37 | 1.53 | 1.18 | 17.33 | 1.83 | 1.42 | 21.29 |
| KELM | 1.05 | 0.80 | 10.35 | 1.50 | 1.16 | 15.20 | 1.76 | 1.36 | 17.67 | |
| EMD-LSSVM | 0.68 | 0.50 | 6.54 | 0.83 | 0.64 | 8.43 | 1.05 | 0.80 | 10.39 | |
| VMD-KELM | 0.12 | 0.09 | 1.21 | 0.19 | 0.15 | 1.98 | 0.33 | 0.26 | 3.44 | |
| EMD-SSA-PSR-KELM | 0.52 | 0.38 | 4.71 | 0.80 | 0.60 | 7.69 | 0.93 | 0.70 | 9.12 | |
| VMD-SSA-PSR-KELM | 0.08 | 0.06 | 0.84 | 0.17 | 0.14 | 1.87 | 0.30 | 0.24 | 3.11 | |
| Proposed | 0.06 | 0.05 | 0.65 | 0.16 | 0.13 | 1.71 | 0.27 | 0.20 | 2.61 | |
| SG June | SVR | 0.64 | 0.52 | 13.69 | 0.93 | 0.74 | 19.79 | 0.97 | 0.77 | 22.05 |
| KELM | 0.63 | 0.51 | 12.76 | 0.88 | 0.71 | 17.41 | 0.96 | 0.76 | 18.37 | |
| EMD-LSSVM | 0.36 | 0.28 | 7.27 | 0.48 | 0.39 | 10.07 | 0.54 | 0.44 | 11.34 | |
| VMD-KELM | 0.05 | 0.04 | 1.00 | 0.11 | 0.09 | 2.29 | 0.20 | 0.16 | 4.24 | |
| EMD-SSA-PSR-KELM | 0.22 | 0.17 | 4.40 | 0.43 | 0.33 | 8.96 | 0.49 | 0.39 | 10.22 | |
| VMD-SSA-PSR-KELM | 0.04 | 0.03 | 0.75 | 0.10 | 0.08 | 2.08 | 0.17 | 0.13 | 3.60 | |
| Proposed | 0.03 | 0.02 | 0.61 | 0.09 | 0.07 | 1.82 | 0.11 | 0.09 | 2.33 | |
| SG September | SVR | 0.63 | 0.45 | 13.44 | 0.97 | 0.71 | 23.04 | 1.27 | 0.97 | 29.97 |
| KELM | 0.61 | 0.44 | 11.96 | 0.96 | 0.71 | 18.91 | 1.19 | 0.91 | 23.27 | |
| EMD-LSSVM | 0.42 | 0.29 | 9.29 | 0.58 | 0.41 | 12.20 | 0.71 | 0.53 | 14.98 | |
| VMD-KELM | 0.08 | 0.06 | 1.70 | 0.12 | 0.09 | 2.76 | 0.20 | 0.16 | 4.69 | |
| EMD-SSA-PSR-KELM | 0.33 | 0.22 | 7.21 | 0.49 | 0.34 | 10.58 | 0.65 | 0.47 | 13.67 | |
| VMD-SSA-PSR-KELM | 0.07 | 0.05 | 1.40 | 0.10 | 0.08 | 2.25 | 0.18 | 0.14 | 4.37 | |
| Proposed | 0.03 | 0.03 | 0.70 | 0.08 | 0.06 | 1.93 | 0.12 | 0.09 | 2.76 | |
| SG December | SVR | 1.23 | 0.89 | 12.29 | 1.89 | 1.38 | 18.95 | 2.22 | 1.63 | 21.96 |
| KELM | 1.22 | 0.89 | 12.01 | 1.89 | 1.37 | 18.28 | 2.15 | 1.57 | 20.53 | |
| EMD-LSSVM | 0.63 | 0.50 | 6.76 | 0.90 | 0.68 | 9.30 | 1.12 | 0.85 | 11.87 | |
| VMD-KELM | 0.16 | 0.12 | 1.71 | 0.32 | 0.24 | 3.24 | 0.50 | 0.37 | 5.14 | |
| EMD-SSA-PSR-KELM | 0.41 | 0.31 | 4.24 | 0.74 | 0.55 | 7.35 | 0.99 | 0.73 | 10.18 | |
| VMD-SSA-PSR-KELM | 0.14 | 0.10 | 1.33 | 0.29 | 0.21 | 2.81 | 0.47 | 0.35 | 4.75 | |
| Proposed | 0.09 | 0.07 | 0.87 | 0.22 | 0.16 | 2.28 | 0.36 | 0.28 | 3.72 | |
| Cases | Extant Models vs Proposed | One-Step | Three-Step | Five-Step | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PRMSE (%) | PMAE (%) | PMAPE (%) | PRMSE (%) | PMAE (%) | PMAPE (%) | PRMSE (%) | PMAE (%) | PMAPE (%) | ||
| SG March | SVR | 94.03 | 94.11 | 94.31 | 89.38 | 89.23 | 90.14 | 84.97 | 85.56 | 87.74 |
| KELM | 93.97 | 94.00 | 93.75 | 89.19 | 88.97 | 88.76 | 84.42 | 84.98 | 85.23 | |
| EMD-KELM | 90.70 | 90.50 | 90.11 | 80.46 | 80.2 | 79.74 | 73.95 | 74.61 | 74.86 | |
| VMD-KELM | 47.03 | 47.76 | 46.56 | 15.78 | 15.39 | 13.89 | 17.91 | 21.75 | 24.18 | |
| EMD-SSA-PSR-KELM | 87.78 | 87.32 | 86.26 | 79.71 | 78.72 | 77.78 | 70.60 | 70.97 | 71.37 | |
| VMD-SSA-PSR-KELM | 22.14 | 24.49 | 23.05 | 5.97 | 8.07 | 8.71 | 9.28 | 14.41 | 15.94 | |
| SG June | SVR | 95.45 | 95.58 | 95.57 | 90.58 | 90.84 | 90.81 | 88.59 | 88.81 | 89.41 |
| KELM | 95.40 | 95.55 | 95.25 | 90.05 | 90.49 | 89.56 | 88.44 | 88.73 | 87.29 | |
| EMD-KELM | 91.98 | 91.87 | 91.66 | 81.96 | 82.87 | 81.94 | 79.48 | 80.30 | 79.41 | |
| VMD-KELM | 41.97 | 42.32 | 39.64 | 20.05 | 23.03 | 20.50 | 44.31 | 46.62 | 44.89 | |
| EMD-SSA-PSR-KELM | 86.89 | 86.49 | 86.22 | 79.55 | 79.83 | 79.72 | 77.25 | 78.07 | 77.16 | |
| VMD-SSA-PSR-KELM | 21.68 | 22.90 | 19.68 | 12.17 | 16.25 | 12.80 | 33.13 | 35.72 | 35.12 | |
| SG September | SVR | 94.51 | 94.29 | 94.81 | 91.63 | 90.92 | 91.62 | 90.60 | 90.52 | 90.79 |
| KELM | 94.32 | 94.16 | 94.17 | 91.55 | 90.88 | 89.79 | 89.95 | 89.82 | 88.14 | |
| EMD-KELM | 91.85 | 91.24 | 92.50 | 85.97 | 84.28 | 84.17 | 83.14 | 82.53 | 81.57 | |
| VMD-KELM | 56.66 | 56.78 | 58.96 | 34.81 | 30.39 | 30.04 | 40.35 | 41.00 | 41.18 | |
| EMD-SSA-PSR-KELM | 89.39 | 88.60 | 90.33 | 83.41 | 81.26 | 81.75 | 81.52 | 80.39 | 79.81 | |
| VMD-SSA-PSR-KELM | 48.58 | 49.90 | 50.28 | 19.70 | 17.39 | 14.26 | 35.44 | 35.70 | 36.76 | |
| SG December | SVR | 92.97 | 92.63 | 92.90 | 88.56 | 88.14 | 87.96 | 83.73 | 82.99 | 83.08 |
| KELM | 92.90 | 92.6 | 92.73 | 88.51 | 88.05 | 87.52 | 83.23 | 82.39 | 81.91 | |
| EMD-KELM | 86.26 | 86.91 | 87.09 | 75.87 | 76.03 | 75.46 | 67.82 | 67.33 | 68.70 | |
| VMD-KELM | 45.80 | 45.89 | 48.98 | 32.69 | 30.69 | 29.62 | 27.79 | 25.07 | 27.76 | |
| EMD-SSA-PSR-KELM | 79.08 | 78.98 | 79.41 | 70.56 | 70.06 | 68.95 | 63.47 | 62.22 | 63.50 | |
| VMD-SSA-PSR-KELM | 39.04 | 34.46 | 34.56 | 25.47 | 22.39 | 18.69 | 24.07 | 19.98 | 21.72 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, W.; Wang, K.; Zhou, J.; Xu, Y.; Tan, J.; Chen, T. A Hybrid Approach for Multi-Step Wind Speed Forecasting Based on Multi-Scale Dominant Ingredient Chaotic Analysis, KELM and Synchronous Optimization Strategy. Sustainability 2019, 11, 1804. https://doi.org/10.3390/su11061804
Fu W, Wang K, Zhou J, Xu Y, Tan J, Chen T. A Hybrid Approach for Multi-Step Wind Speed Forecasting Based on Multi-Scale Dominant Ingredient Chaotic Analysis, KELM and Synchronous Optimization Strategy. Sustainability. 2019; 11(6):1804. https://doi.org/10.3390/su11061804
Chicago/Turabian StyleFu, Wenlong, Kai Wang, Jianzhong Zhou, Yanhe Xu, Jiawen Tan, and Tie Chen. 2019. "A Hybrid Approach for Multi-Step Wind Speed Forecasting Based on Multi-Scale Dominant Ingredient Chaotic Analysis, KELM and Synchronous Optimization Strategy" Sustainability 11, no. 6: 1804. https://doi.org/10.3390/su11061804
APA StyleFu, W., Wang, K., Zhou, J., Xu, Y., Tan, J., & Chen, T. (2019). A Hybrid Approach for Multi-Step Wind Speed Forecasting Based on Multi-Scale Dominant Ingredient Chaotic Analysis, KELM and Synchronous Optimization Strategy. Sustainability, 11(6), 1804. https://doi.org/10.3390/su11061804