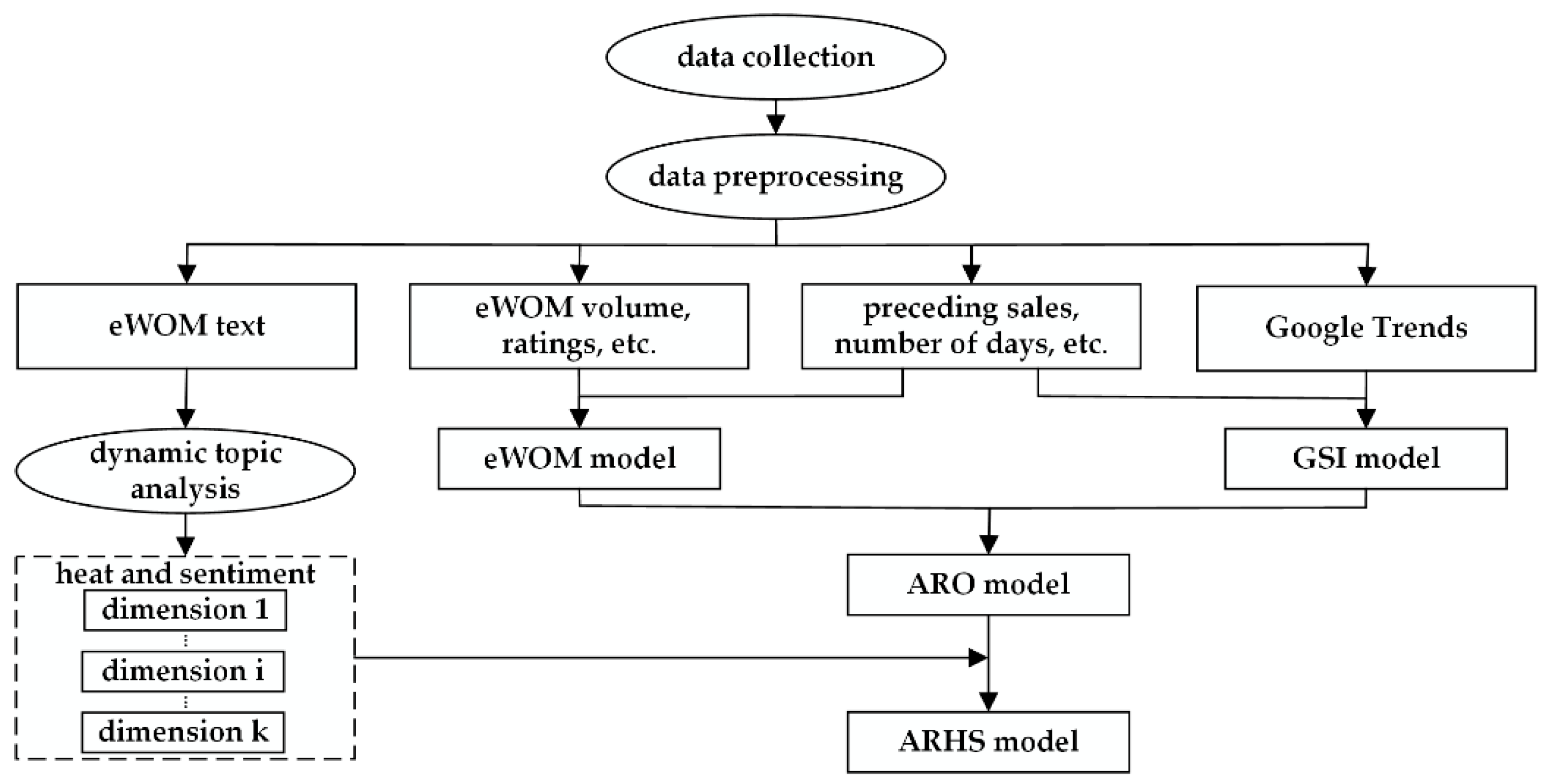
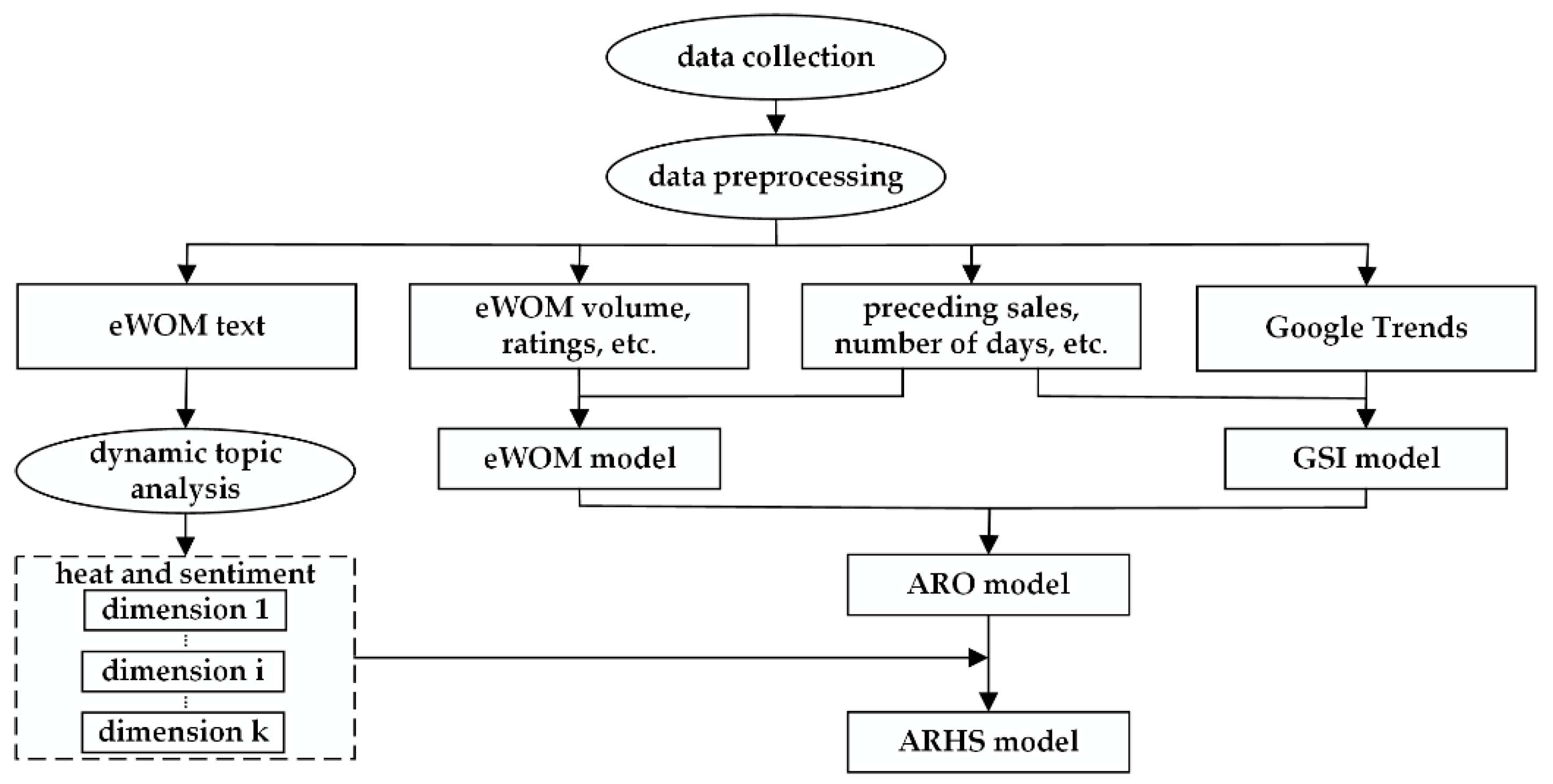
3.2.1. Data Collection
This paper focuses on online reviews of movies because within the film industry, online reviews are more popular than other types of eWOM [
29]. In this study, IMDb.com, Google.com, and BoxOfficeMojo.com are the data sources. We examined movie reviews on IMDb.com, the most popular and authoritative information source for movies worldwide, for approximately seven weeks after movie releases. We then collected daily data on box-office revenues, budgets, and distributors as well as other movie information from BoxOfficeMojo.com. Our unit of time was one day; however, we aggregated the reviews published before the release day into one time window. The weekly Google Trends before a movie release and the daily Google Trends one day before and 49 days after a movie release were obtained and reviewed. Because the unit of time was one day, we had a sufficiently long study period with enough observations to provide credible results. The final dataset included Google Trends and eWOM information for 50 consecutive time windows and revenue information for 49 time windows. All movies were released in the US from 2010 to 2016.
After filtering out movies with fewer than 100 reviews by the end of the data period, we identified 349,269 reviews for 122 sample movies. We chose a threshold of 100 reviews to ensure that we have sufficient reviews to train the topic model used in the DTA. As shown in
Table 1, our sample movies exhibited great diversity in terms of film distributor, movie genre, release month, and Motion Picture Association of America (MPAA) rating.
Table 2 indicates that the total domestic gross and production budgets of the movies are right-skewed; that is, all but a few movies have low box-office revenues and product budgets.
Table 3 and
Table 4 list the definitions of and statistics regarding eWOM, Google Trends, and our film-related variables. First, we measured the eWOM volume and valence, which are represented by
and
, respectively. Volume is the log-transformation of the daily number of reviews. We added one to the daily number of reviews to ensure that the log-transformation result was not negative [
47]. Valence is the mean of the daily review ratings, reflecting the overall sentiment of reviewers with regard to a specific movie [
28]. If there were no reviews on one day, then we used the average valence of the preceding days as a proxy [
48]. Second, we used the variable
to denote the number of days since the movie release to consider the time effect. Third, we set the dummy variable
to one if the day was on the weekend and zero otherwise to consider the seasonal effect. Fourth, the variable
represents the number of cinemas at which a film was being shown [
17]. Finally, we used the Google Trends of movie names, and the initial trends range from 0 to 100 in terms of online search data.
Table 4 shows that sales, volume (
), and theaters (
) have right-skewed distributions and that the skewness of volume and sales is very large. This result means that very few movies had high box-office revenues or high heat and that most movies had low box-office revenues or low heat. The distributions of valence (
) are relatively evenly distributed.
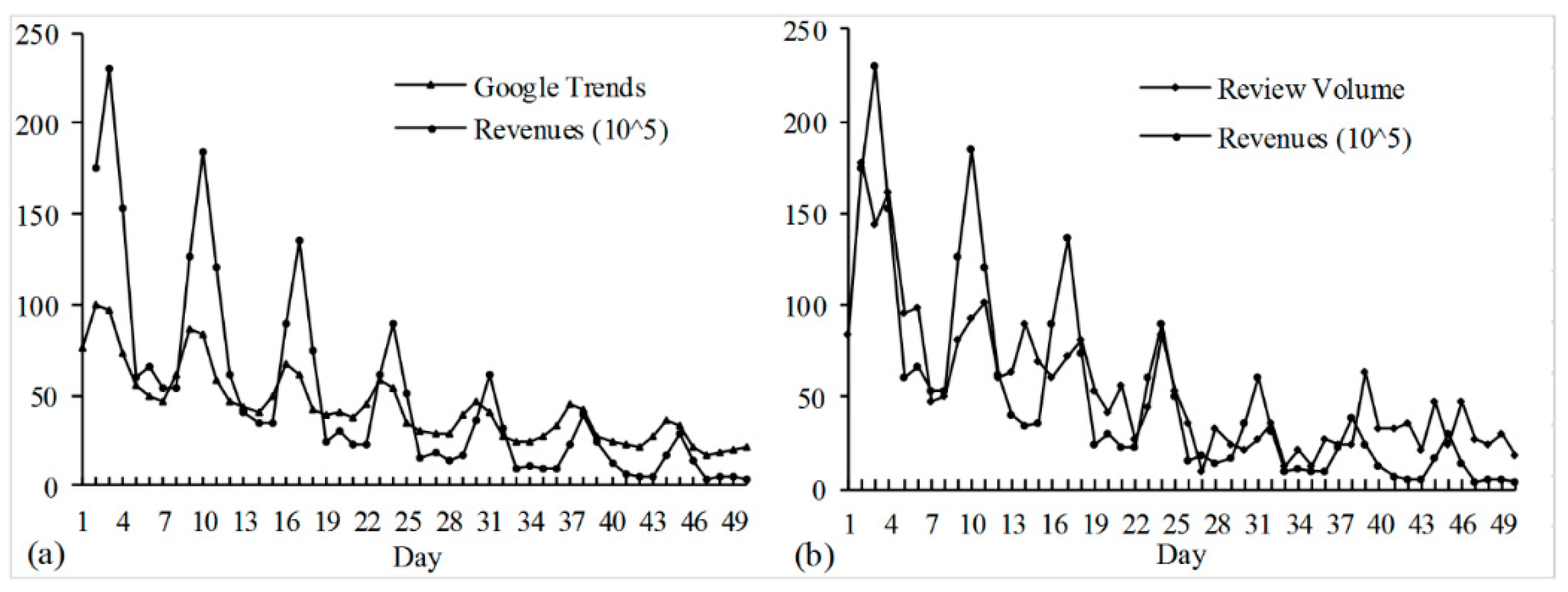
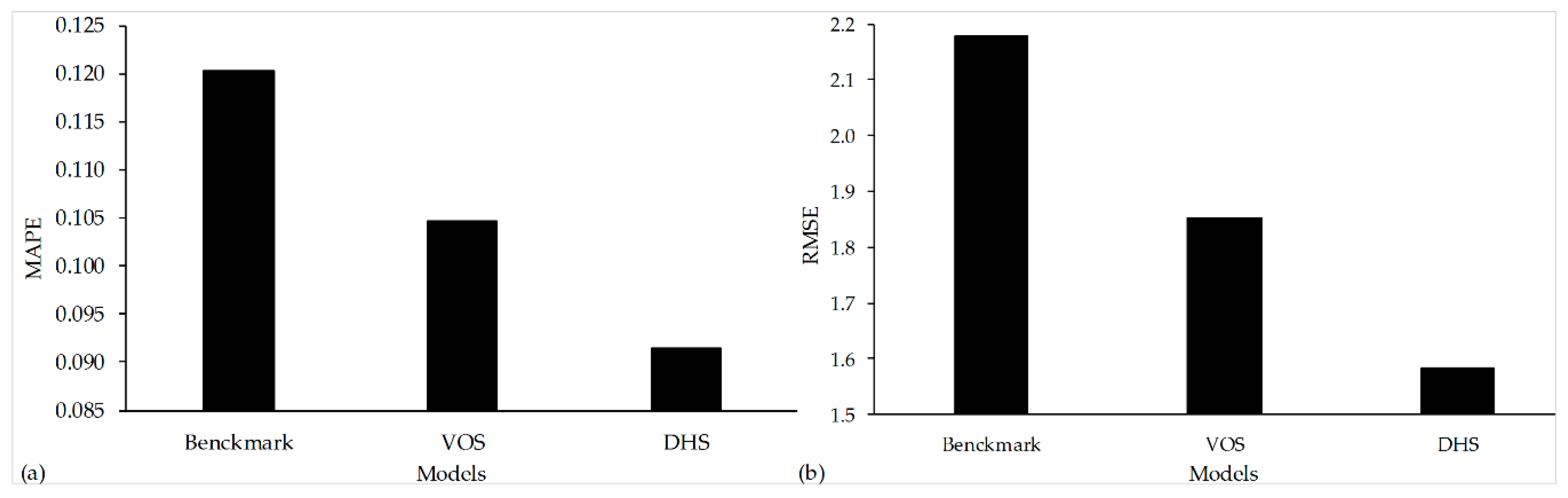
Figure 2a shows the relationship between Google Trends and the box-office revenues of the movie Gravity.
Figure 2b shows the relationship between eWOM volume and the box-office revenues of the movie Gravity. We observe that both the eWOM and GSI data have high correlations with movie box-office revenues.
3.2.2. Dynamic Topic Analysis
For 122 movies, we constructed a DTA framework by integrating the dynamic topic model (DTM) [
49], the lexicon-based method [
50], and the Stanford natural language processing (NLP) technique [
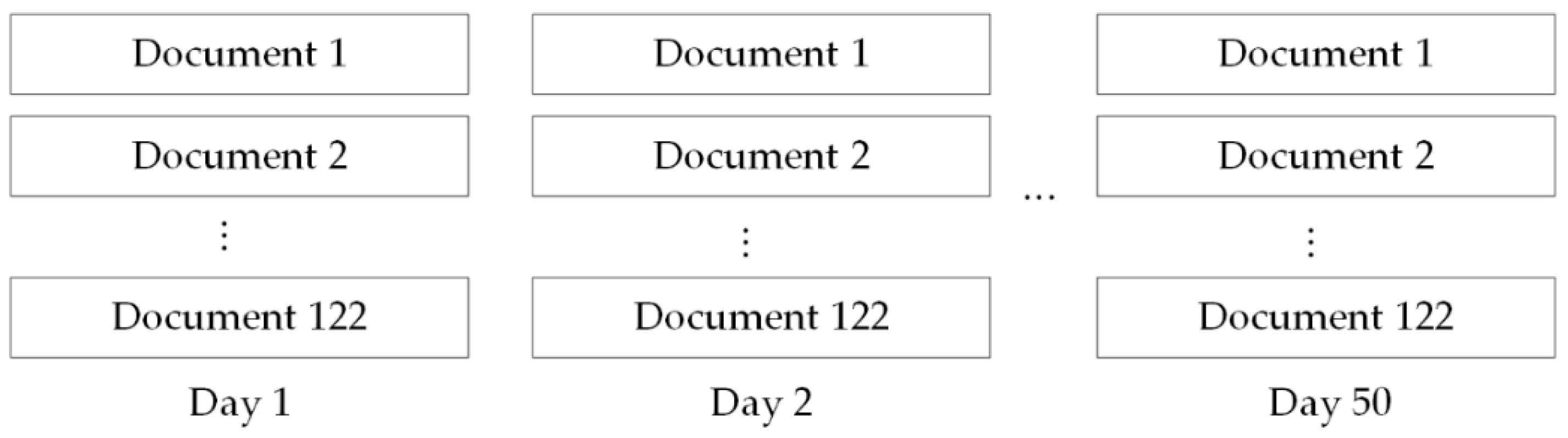
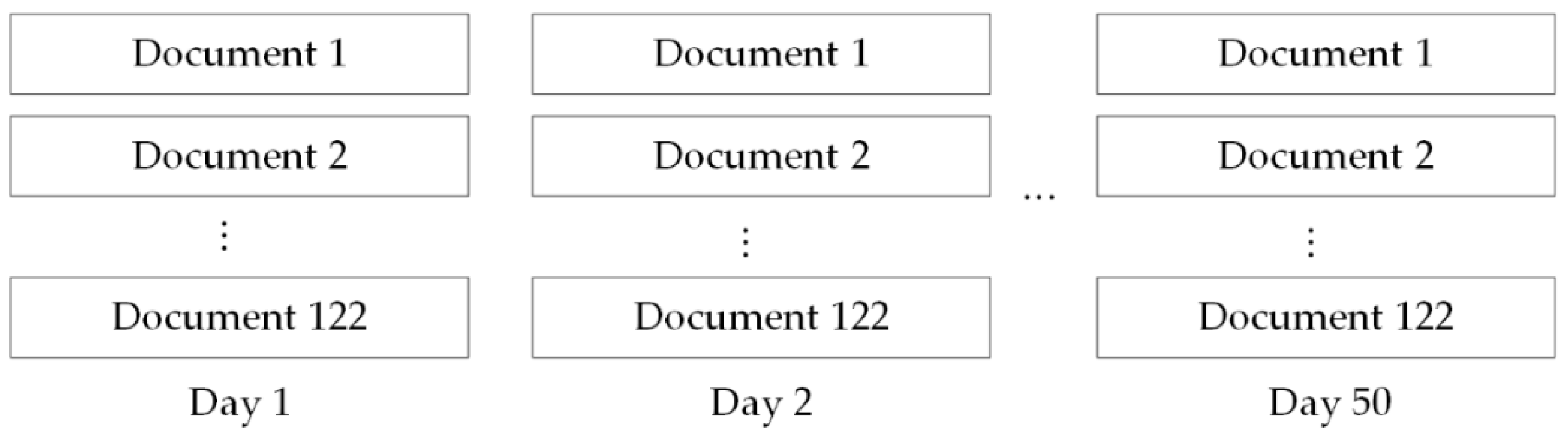
51] to derive the heat and sentiments of dimensions from online reviews. We obtained 122 daily documents by integrating hundreds of daily reviews for each movie into one document. Finally, the daily documents compiled over 50 days constitute our review corpus, which contains 349,269 reviews.
Figure 3 shows the structure of the corpus.
We preprocessed each document by using the steps used in a study by Guo et al. [
45]. First, we eliminated non-English words and spelling errors, such as web sites, punctuation marks, and numbers. We then used the Stanford NLP package for word text tokenization, part-of-speech tagging, and word stemming. Finally, each document became a word-of-bag.
To extract key product dimensions from a large corpus of text data in an effective manner, previous studies have used the latent Dirichlet allocation (LDA) model [
44,
45]. The DTM is more suitable for extracting key product dimensions from our structured review set [
49] and is an extended LDA method [
52]. The DTM can quickly identify a conglomeration of connected topics from a very large number of documents over different time windows, which LDA alone cannot do.
As a machine-learning method, the DTM is highly efficient in handling online big data. We used the DTM to extract key product dimensions, the heat of these dimensions, words that represent each dimension and the changes in these factors over different time windows. The DTM assumes that a review comprises a sequence of words, , reviews form a review set, , and review sets form a corpus over time windows, . The DTM also assumes that reviewers share dimensions across the corpus over the time windows. In each time window, the DTM assumes that reviewers express their experience with a product or service over dimensions. For instance, a reviewer may comment about a movie in a review by focusing on three dimensions with different heat and sentiments: 30% and 4.9 for movie stars, 40% and 3.4 for the story plot, and 30% and 2.1 for the background music. Thirty percent is the dimension heat of movie stars, which means that one-third of the review is about movie stars; additionally, 4.9 is the sentiment strength of movie stars, which means that the reviewer has a strong sentiment toward movie stars.
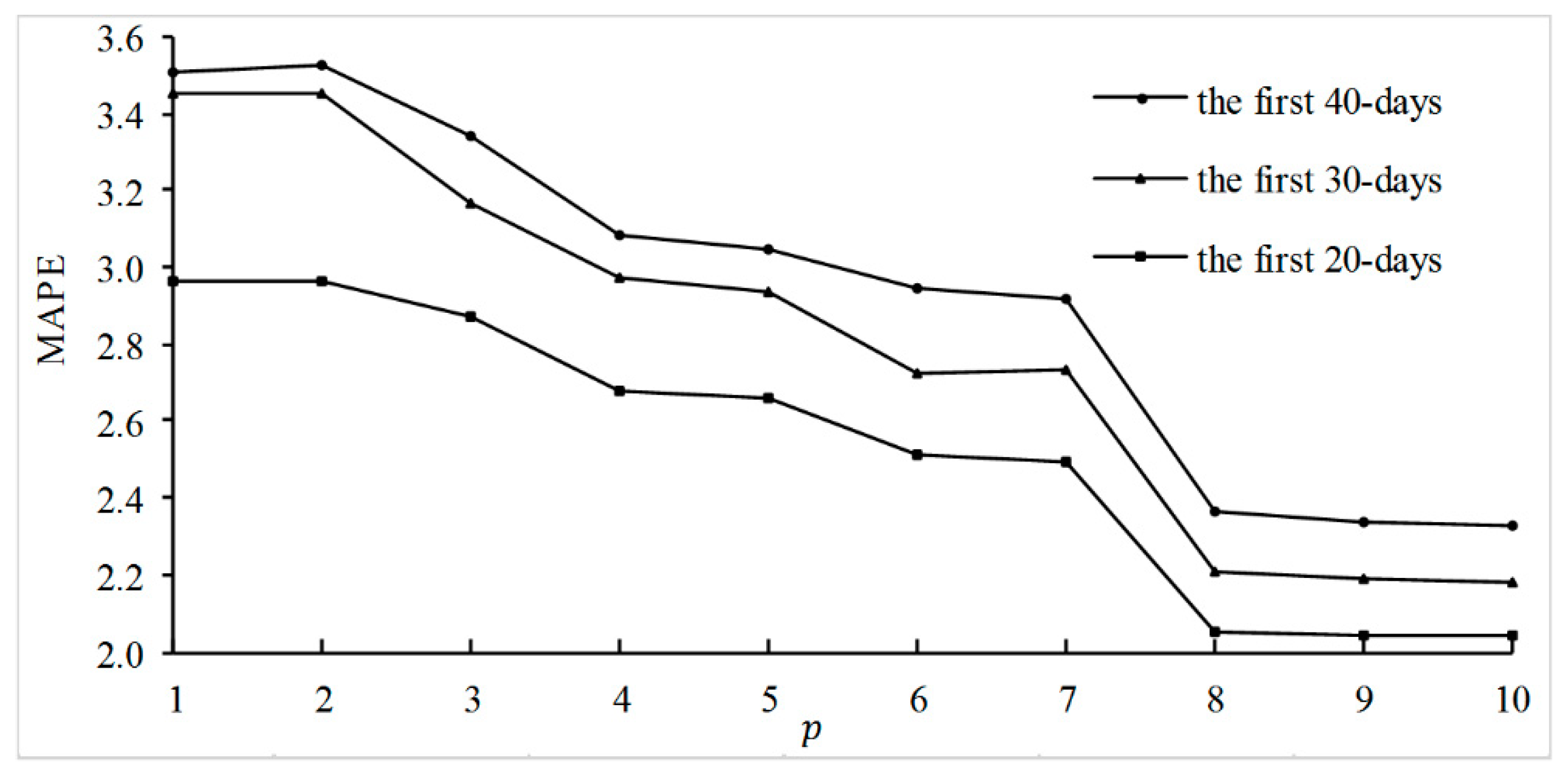
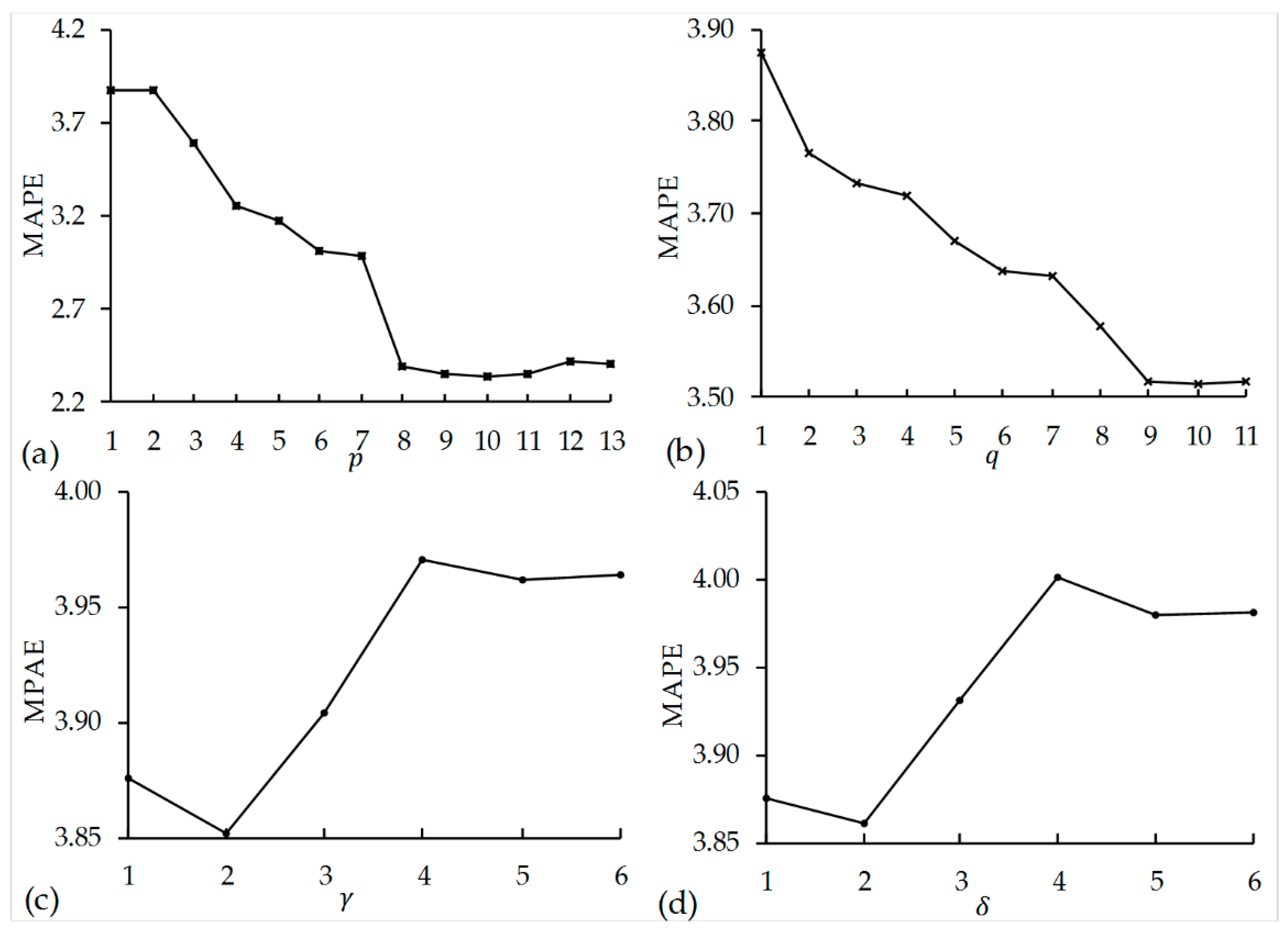
Comparing the perplexity of the DTM and the semantics of the dimensions when using different values of
K, we determine the optimal number of key product dimensions [
11]. Ultimately, we find three movie dimensions that can perfectly represent the review corpus. The formula for the perplexity of the DTM for the document set on day
is as follows:
where
is the document set on day
;
is the number of documents on day
;
is the number of words in document
;
is the number of dimensions;
is the heat of word
in dimension
;
is the heat of dimension
in document
. DTM learning with Gibbs sampling can simultaneously generate the heat of the words in each dimension and the heat of the dimensions in each document. Readers can refer to [
49] for details on the DTM. Let
be the heat of the
th dimension of the
th movie on day
.
can be calculated as follows:
where
is the heat of dimension
k in document
d of movie
i, and
is the number of documents for movie
i on day
t. In our research context,
equals one.
We name the three dimensions
plot,
star, and
genre, following the method of Guo et al. [
45]; these dimensions have been regarded as the three most important attributes of movies [
7,
53].
Table 5 shows the changes in the dimension
plot in different time windows.
The heat of a dimension refers to the proportion of reviewers’ discussion concerned with the dimension of a product in eWOM. For example, the heat of the dimension
plot denotes the proportion of consumers’ discussion concerned with
plot-related information in reviews.
Figure 4 shows the changes in the heat of the three movie dimensions over 50 days. Consumers talk more about movie stars and the story plot in the early days after a movie’s release than they do at the end of the release.
We then used the sentiment lexicon and syntax relation to calculate the sentiments of dimensions. Lexicon-based methods that use a publicly recognized sentiment lexicon are more objective and suitable for big data sentiment analysis than machine-learning-based methods that require expert annotations because expert annotation has a high cost and there are artificial deviations. Most studies on dimension sentiment analysis divide dimensions into positive and negative classes [
54], and sentiment analysis methods are different based on different applications. We calculated the sentiment strength of each dimension that can forecast movie box-office revenues. We extracted the syntactic relations between the dimension words and sentiment words in the daily review sentences using the Stanford NLP package, and we obtained the sentiments of the dimension words based on the extracted relations.
Table 6 shows the main sentiment mining rules used in our framework.
Finally, we calculated the average daily sentiment strength of the dimensions for each movie. Let
be the sentiment value for the
th dimension word at the
th time (location) in document
d for one movie. The sentiment of the
th dimension for one movie on the
th day can then be formulated as follows:
Intuitively,
represents the average strength of the sentiment of the
th dimension.
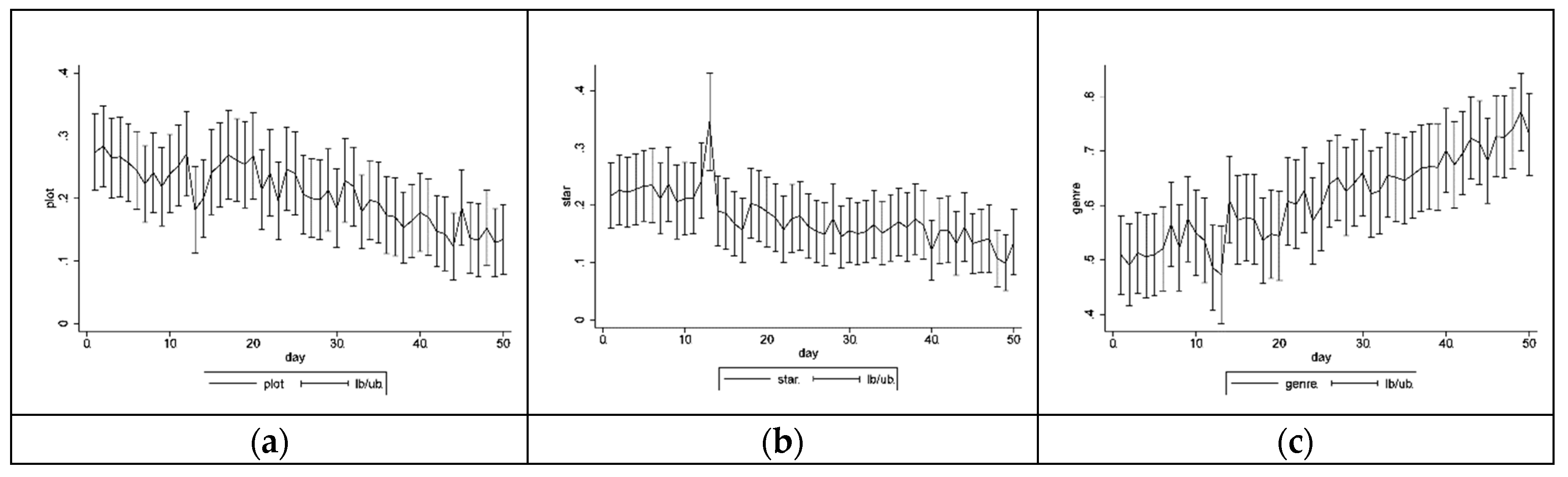
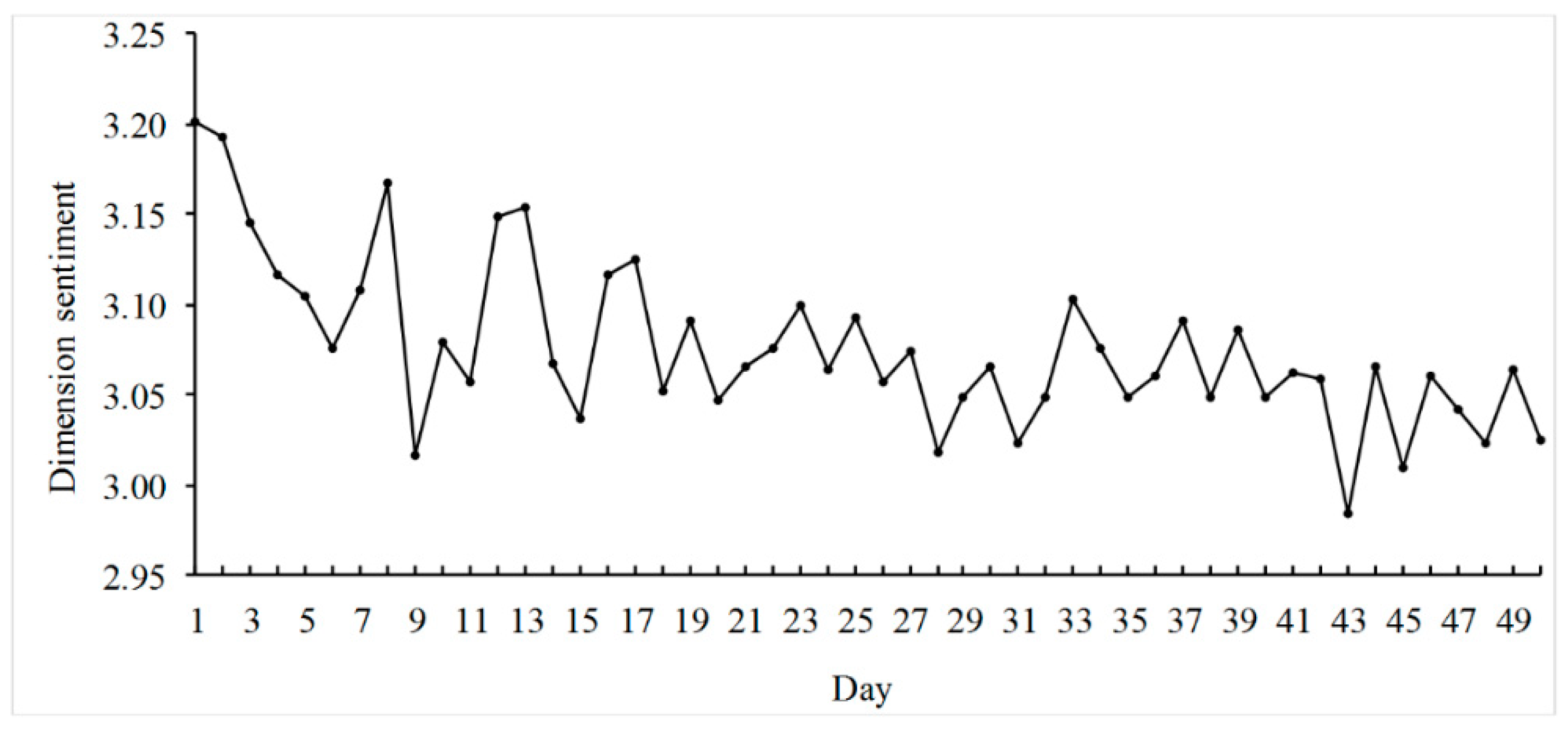
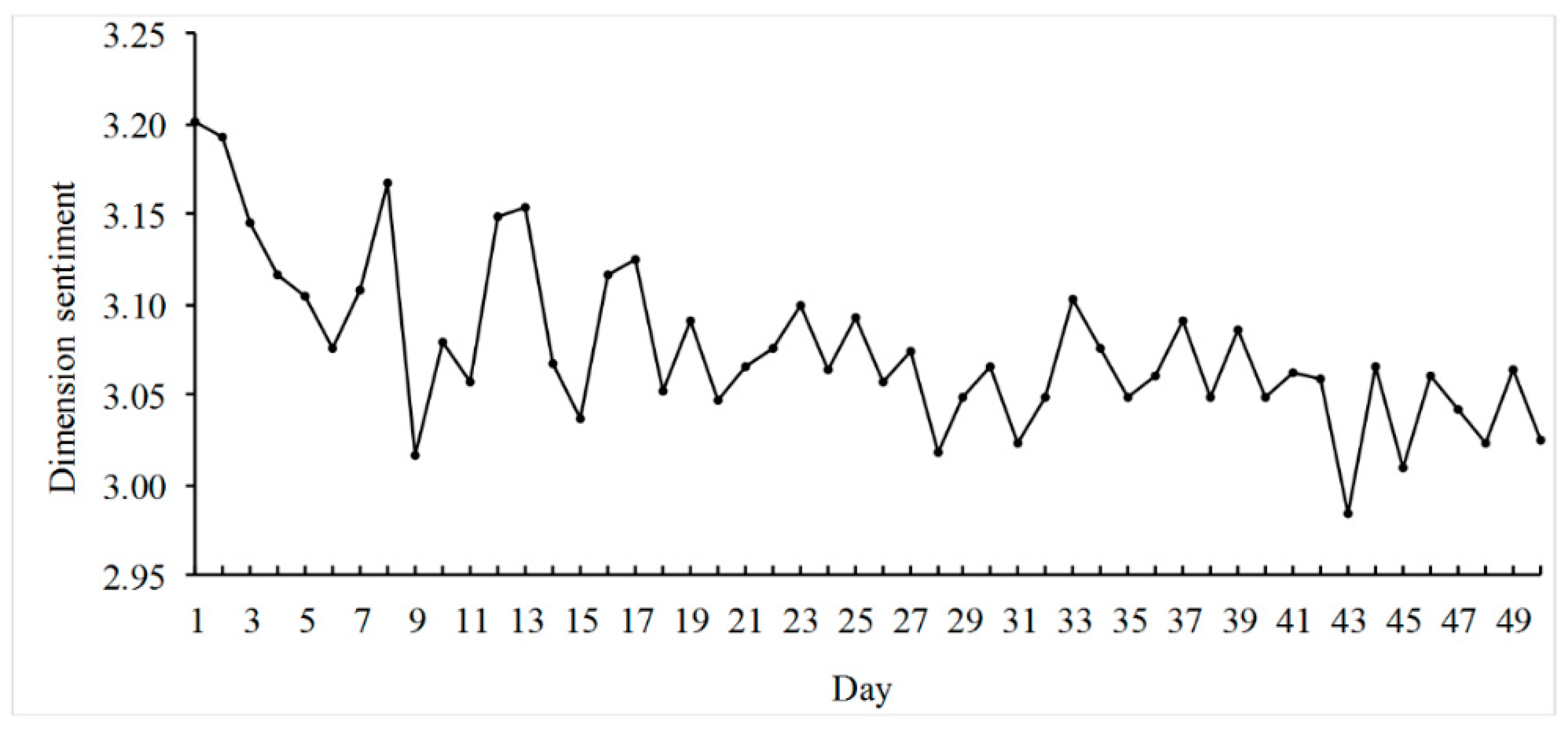
Figure 5 shows the average sentiments of the dimension
plot for 122 movies. Using
Figure 4 and
Figure 5, we can easily monitor consumer feedbacks (heat and sentiments) on product dimensions over time.
In
Table 7, we describe the key variables of the dimensions.
Table 8 shows the summary statistics of the variables. The heat of the dimensions (
) is between zero and one. The median of the sentiments of the dimensions (
) is three.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}