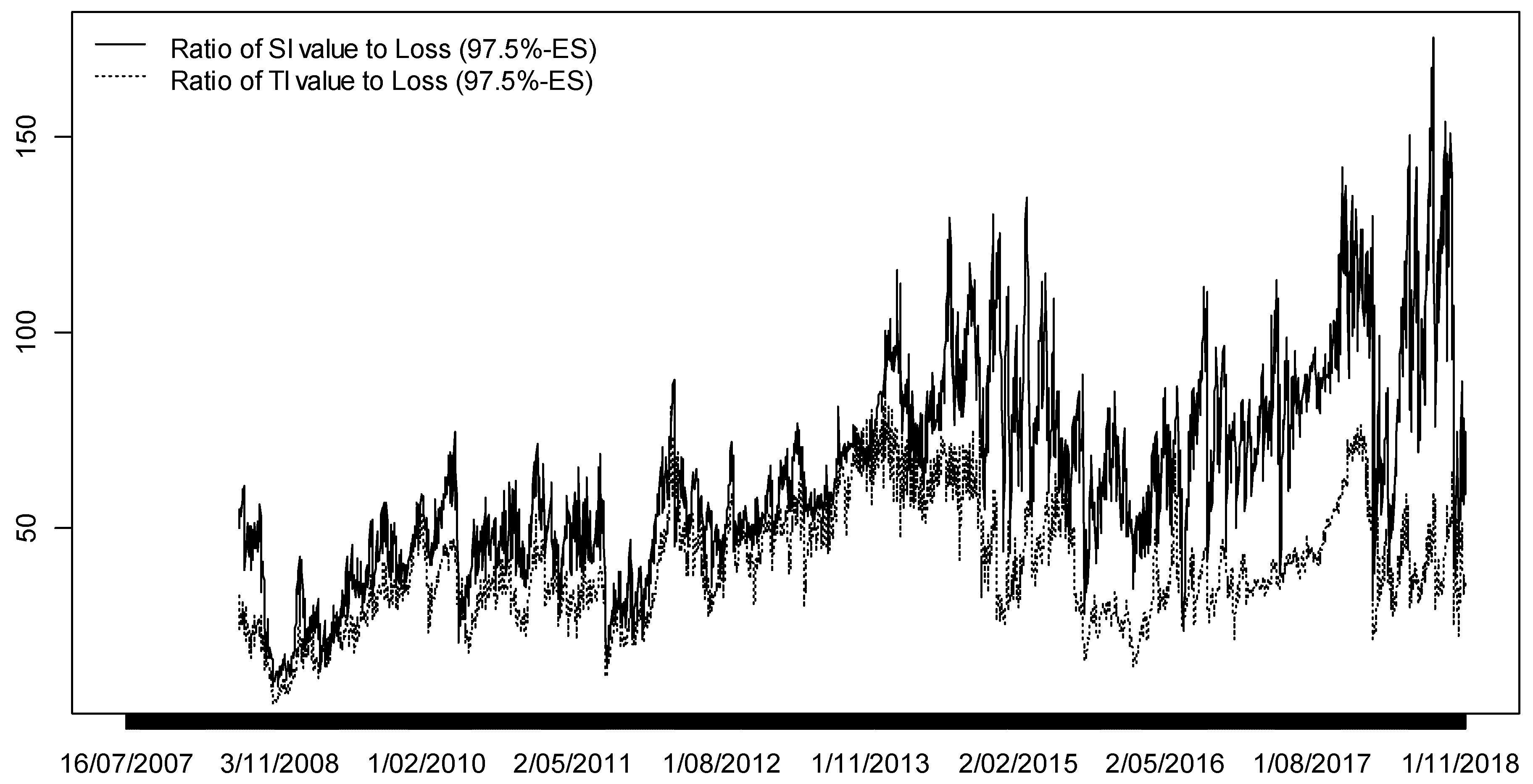
This study is an attempt to shed light on the correct measurement of risk in the traditional energy industry, which has a particularly interesting behaviour in the financial markets for portfolio managers. It maintains a very low or even negative correlation with sustainable portfolios, which is an excellent tool for diversifying risks. However, investing in the traditional energy industry requires precise validation measures of the risk measurement models used to make predictions. In this section, we focus on ES and study different strategies to model the asset returns on which we will calculate ES and test the validity of the different predictions obtained. Backtesting ES remains an open question and we implement a novel method that produce quite satisfactory results compared with existing procedures.
3.1. Modelling Asset Returns
VaR and ES approaches model the left tail of the return distribution or, similarly, the right tail of the loss distribution. The losses or negative log-returns over the next day are defined here as
Lt+1 = −100log (
Pt+1/
Pt), where
Pt represents the corresponding index prices. As it is commonly employed in the literature (see, e.g., [
49]), we suppose that conditional on the location-scale parameters
and
, negative log-returns follow
and the innovations are
. The random variables
are assumed to be independently distributed with a common cumulative distribution function (CDF)
that, for certain cases, depends on unknown parameters. We discuss several possibilities for
in the next section. The parameter
is modelled by an ARMA (1,1) process and a GARCH (1,1) process is employed for
, that is,
where
and
are the parameters associated of AR (1) and MA (1) respectively. Apart from the variables of the standard GARCH (1,1) model, the variances of oil, gas and coal price returns are considered as external regressors. Thus, our empirical results consider two methods of backtesting. One method excludes the external regressors (i.e.,
) from the GARCH model and the other method takes into account these variables in the variance equation of the GARCH model. Given a probability level
, the VaR can be expressed as
where
is the
quantile of
. The ARMA-GARCH model is implemented by using rugarch package in R [
50].
In the ARMA (1,1)-GARCH (1,1) setting above, the location and variability of negative log-returns are modelled through the parameters and . The distribution should be free of any such parameters (to avoid identifiability issues) and must account for other important features, such as asymmetry and/or kurtosis. In particular, the statistical models we consider are: (i) normal (used for comparative purposes), (ii) Student’s t, (iii) –stable and (iv) generalized Pareto.
(i) Normal distribution
The CDF of a standard normal distribution is given by
(ii) Student’s t distribution
The CDF of a Student’s t distribution is given by
where
represents the gamma function and
is the degrees of freedom parameter that controls the kurtosis (small values of
correspond to heavier tails). The Cauchy distribution is a particular case when
.
(iii) –stable distribution
The
–stable distribution is commonly described by its characteristic function, since the probability density function (PDF) is not available in closed-form.
where the
function is defined as 1 if
; 0 if
and −1 otherwise.
The parameters in this distribution are the index of stability (characteristic exponent) and a skewness parameter . There are three cases with known closed-form expressions for their densities: the normal (when and ), Cauchy ( and ) and Lévy distributions ( and ). The smaller the value of , the heavier the distribution tail. The stable package for R developed by Nolan is employed to fit Stable distribution (Robust Analysis Inc. (2013). STABLE. R package, version 5.3.).
(iv) The generalized Pareto distribution (GPD)
The CDF of the GPD is given by
where
is the shape parameter and
is the scale parameter. When
, the GPD is the Pareto distribution; when
, it is the exponential distribution; and when
, the distribution is the Pareto type II distribution. Heavy-tailed empirical distributions usually follow a GPD with a positive shape parameter
.
When is either a normal or a Student’s t distribution, the parameters for the ARMA (1,1)-GARCH (1,1) and for the innovations are estimated jointly by employing the Maximum Likelihood (ML) estimation. A two-step approach is used to estimate the parameters for the cases where is either a -stable or a generalized Pareto distribution. First, the Quasi-ML (QML) method is used to estimate the parameters in the ARMA (1,1)-GARCH (1,1), thus allowing estimations of the underlying innovations to be produced, say, . Specific methods are then performed in a second step to estimate the parameters in :
For the
-stable distribution, the ML approach is employed by using the direct integration method in Reference [
51].
For the generalized Pareto distribution, the peaks over threshold (POT) method is employed to estimate the parameters. According to [
49], the VaR or
-quantile is obtained from
where
u is the chosen threshold,
and
are the scale and shape parameters, respectively,
is the threshold exceedances and
is the sample size. Therefore,
is an empirical estimator for the excess distribution. In this paper, the threshold is chosen as the 10th percentile of the standardized residuals of the negative log-returns as is typical in the literature [
19,
48,
52,
53,
54]. The evir package in R is employed to implement the EVT-GPD model [
55].
3.2. Backtesting ES
As mentioned above, the method to be used to validate the results of the application of the ES remains an open question [
56] show that ES and VaR are jointly elicitable and the authors propose a scoring function that is more complicated than the well-known scoring function for VaR. Comparative tests can then be performed following the Diebold-Mariano test (e.g., [
57]). Based on the Monte Carlo simulations, [
58] propose other tests for ES; following the argument that VaR and ES are jointly elicitable, in this paper, we employ the simple approach proposed by [
2] to validate ES calculations in an implicit manner. ES can be approximated by a weighted sum of VaR levels [
59] and then, a multinomial test can be performed rather than the binomial test for each VaR level. This paper extends applications of [
2] to traditional energy and sustainable indexes. Moreover, our work considers an ARMA-GARCH model with external regressors to filter the negative log-returns of the analysed assets, whereas [
2] employ the ARCH and GARCH models.
Following the [
2] notation, ES can be calculated as in Reference [
60]
A simple approximation can be obtained from different quantiles [
59]
where
. [
2] then propose backtesting for ES by simultaneously backtesting multiple VaR estimates. Backtesting is based on multinomial tests of VaR exceptions. It is worthwhile to mention that the approximation can be generalized as
where
is the number of quantiles to be used in the approximation. Although a higher
results in a better estimation of ES, simulations performed by [
2] show that four quantiles provide reasonable size and power for the backtest. It is also noteworthy that the previous notation implies that risk measures are calculated over the loss distribution, that is, the right tail of the distribution.
The number of exceptions (violations) are estimated given a certain model (distribution) and for each confidence level. As is typical in the literature, the exception indicator at each time
is defined as a function that takes value 1 if a loss has exceeded the VaR level. That is,
where
is as follows:
for
, with
and
.
Then, the number of exceptions
at each time
is given by
As the number of exceptions follows a multinomial distribution, the unconditional coverage property can be written as
Our interest is a measure that counts the outcomes
with probabilities
that sum to one. The cell counts
are then given by
where
is the backtesting period and
. Then, the random vector should follow the multinomial distribution
The null and alternative hypotheses are given by
where
is an arbitrary sequence of parameters from a specific model and
[
2].
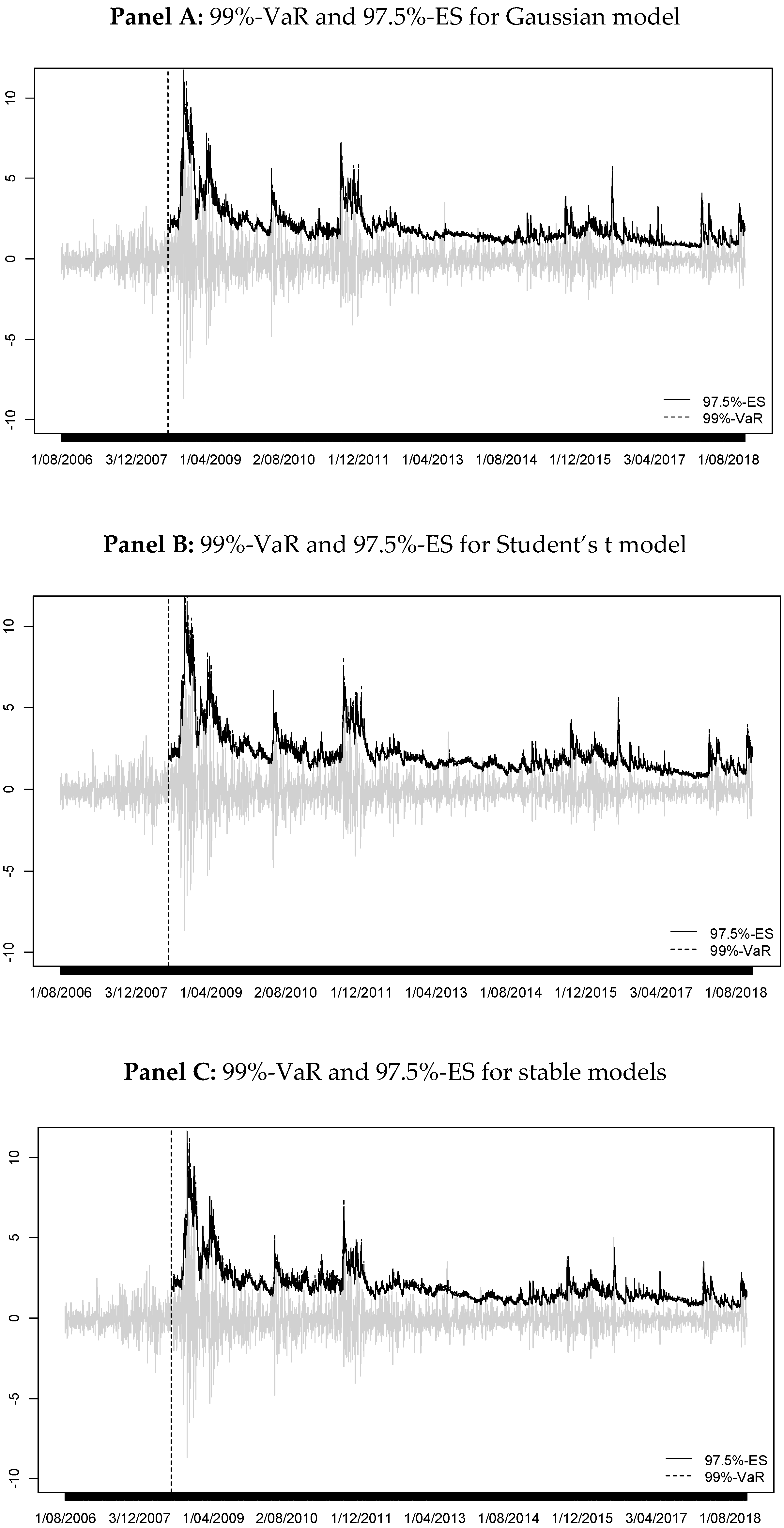
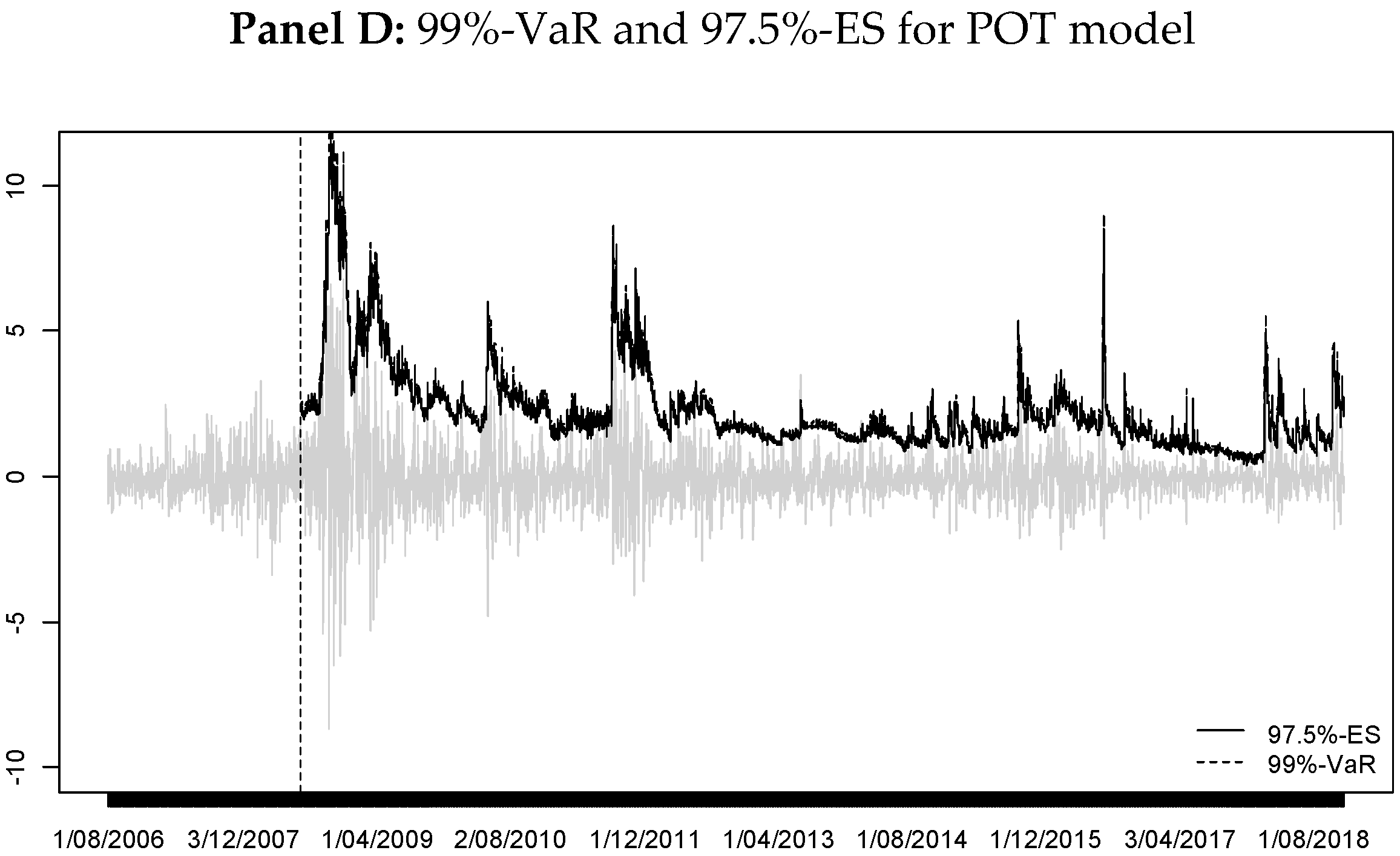
Figure 1 illustrates an example for our case (97.5%-ES and
).
For this case, the number of exceptions
for each
is calculated as
The cell counts
are given by
There are several multinomial tests; the most common is the Pearson chi-squared test, for which the test statistic
follows a
distribution under the null hypothesis:
The null hypothesis is rejected at a prespecified type I error when .
Another test is the Nass test, which is an improvement over the previous test when cell probabilities are small [
2]. The test statistic is
distributed under the null hypothesis:
where
,
and
.
The null hypothesis is rejected at a prespecified type I error when .











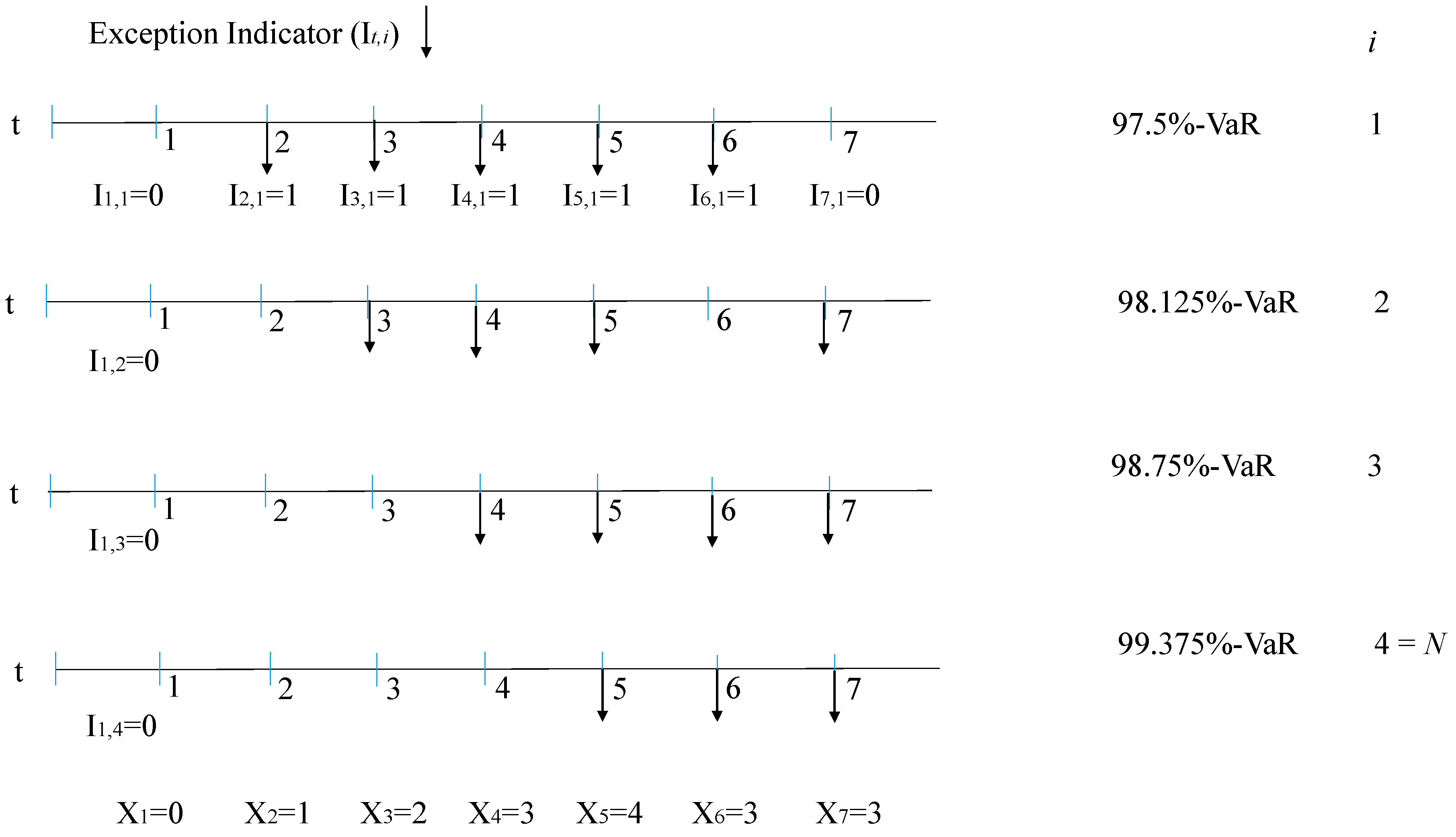{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}