1. Introduction
In recent manufacturing industries, increasing productivity and minimizing production costs are essential for a sustainable business. Thus, scheduling is becoming more important to minimize production costs by reducing production completion times and allocating resources efficiently. Furthermore, manufacturing industry is directly relevant to energy sustainability. For instance, energy consumption in manufacturing industry accounts for a huge proportion of total energy consumption in the world; in China, about 50% of energy is consumed by manufacturing industry [
1]. From this perspective, scheduling has been considered as a viable and effective way to improve both productivity and energy efficiency, and hence there have been many recent studies applying scheduling at the interface with sustainability in various areas (see, e.g., [
2,
3,
4,
5]).
In this study, we consider a uniform parallel machine scheduling problem with dedicated machines, job splitting properties, and limited setup resources, which can be easily observed in practice. In uniform parallel machines, all jobs can be processed on machines in parallel, but machines have different speeds. Dedicated machines enforce that a certain job can only be processed on a set of designated machines. Jobs can be split into multiple sections that can be processed on several machines simultaneously. When a job type is changed in a machine, a setup is needed by one of the operators who are generally insufficient in number to set up all of machines at the same time. The setup time for a job is sequence-independent, which indicates the setup time only depends on the job to be processed, whereas sequence-dependent setup times are determined by the combination of preceding and next jobs. The objective of our problem is to minimize the maximum of machine completion times, typically denoted as .
This problem is motivated from real systems that manufacture fan or equipment filter units (FFUs or EFUs), automotive pistons, bolts and nuts for automotive engines, textiles, printed circuit boards, and network computing [
6,
7]. FFUs are used to supply purified air to clean rooms, laboratories, and medical facilities by removing harmful airborne particles from recirculating air. The factory we consider in Korea is producing many different types of FFUs and EFUs for semiconductor, automotive, and food industry companies such as Samsung Electronics, SK Hynix, LG, Texas Instruments, and so on. The factory mainly assembles outsourced components and tests the assembled products before delivering them to customers. There are five assembly lines; two of them are automatic and the others are manual, where automatic lines are faster than manual ones. FFUs or EFUs can be assembled in one of dedicated machines, and setups are performed when job types are changed, which are sequence-independent and require a setup operator. In addition, since many units are made for each type of FFUs or EFUs, they can be split into arbitrary sections.
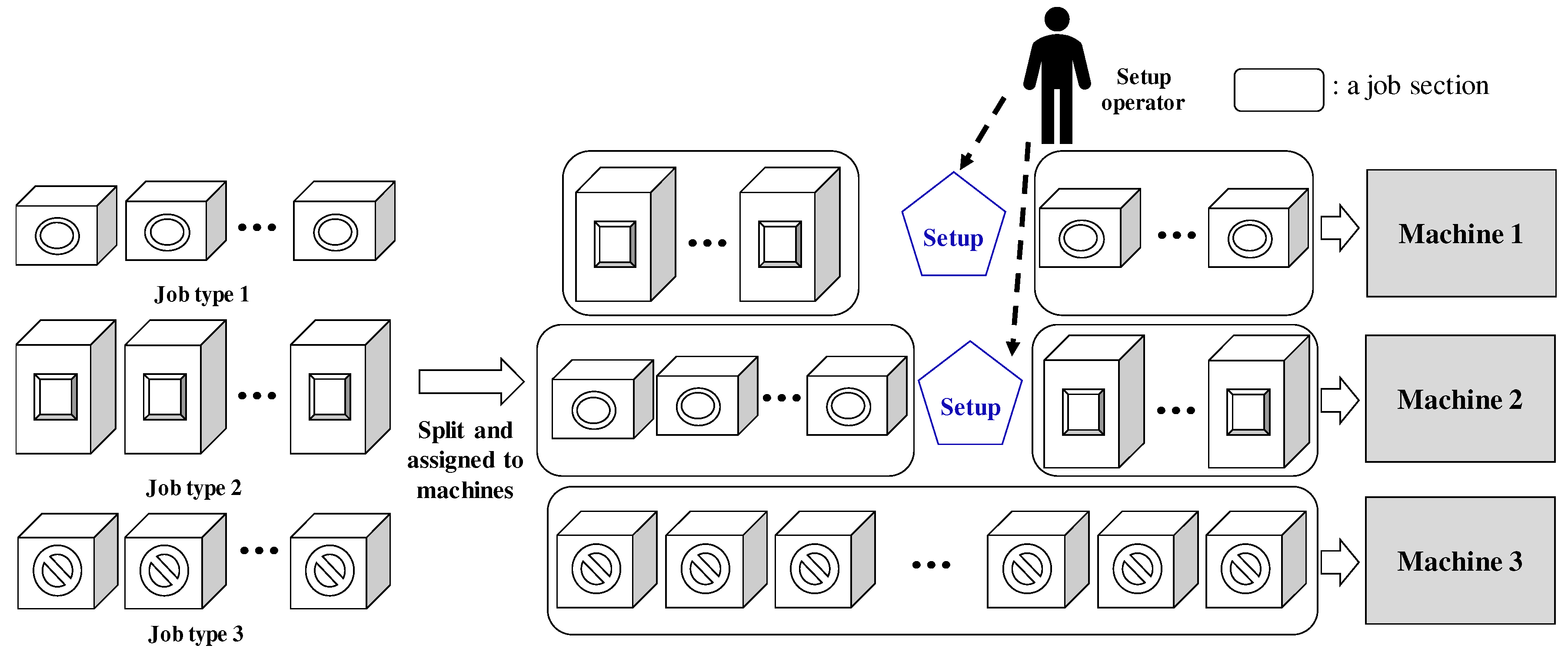
Figure 1 illustrates a simplified example in FFU manufacturing. In the example, there are three job types; many FFUs of Types 1–3 (see the left part of
Figure 1). Jobs of each job type can be slit into multiple job sections, and they are assigned to machines. In this example, jobs of Types 1 and 2 can be processed on Machines 1 and 2, and jobs of Type 3 can only be processed on Machine 3 due to the dedicated machine constraint. In each machine, when job types change, a setup is required and it is performed by a human operator, as shown in
Figure 1. In the example, there is only one human operator for setups and at most two setups can be required at the same time. In that case, one of two setups should be delayed, which makes the scheduling problem complicated.
Another factory we introduce is producing automotive pistons for Hyundai Motor Group, BMW, GM, and so on. Automotive pistons are first cast from aluminum alloys in uniform parallel machines, and then go through machining and assembly process steps. The multiple parallel machines for casting processes are classified into automatic, semi-automatic, and manual machines, and each of them can handle a set of certain piston types because machines are equipped with different tools and some pistons have specific process requirements. In addition, high quality pistons should be tracked in each unit so that all process parameters for each unit are checked. In this case, pistons for those customers should be processed on the machines that have the tracking system, which introduces dedicated-machine constraints. A piston type consists of thousands of units so that they can be divided into several lots, and multiple piston types are produced at the same time. Setups when product types change are performed by an operator, and the setup times do not depend on the preceding product type.
As introduced, the problem considered in this paper has many real applications and is constrained by various scheduling requirements such as parallel machines with different speeds, dedicated machines, and limited setup operators. To the best of our knowledge, no study has considered this problem. Therefore, this paper is intended to contribute to this end by presenting a mathematical optimization model and developing efficient heuristic algorithms.
2. Literature Review
In this section, we review papers related to our problem. Since a uniform parallel machine scheduling problem with dedicated machines, job splitting, and setup resources is considered, relevant literature can be classified into three groups: studies considering parallel machines, job splitting, and resources.
First, there have been numerous papers on scheduling identical parallel machines. Many early studies have analyzed list schedules and the longest processing time (LPT) first rule with the makespan minimization measure on either identical or uniform parallel machines [
8,
9,
10,
11,
12,
13]. The authors of [
8,
9] analyzed the worst-case bound of an arbitrary list schedule and the LPT rule on identical parallel machines. In the work by Garey and Graham [
10], bounds of list schedules on identical parallel machines with a set of resources where each job requires specified units of each resource at all times during its execution were provided. In the paper by Gonzalez et al. [
11], the performance of the LPT schedules on uniform parallel machines was analyzed, and the study by Friesen [
12] provided tighter bounds for the same problem. The work by Cho and Sahni [
13] analyzed the worst-case bound of list schedules for uniform parallel machine scheduling problems. All of them assumed the nonpreemptive schedules for minimizing the makespan. From these papers, we can have insights to develop priority rules for heuristic algorithms presented in this paper.
For uniform parallel machine scheduling, the work by Dessouky et al. [
14] developed many efficient algorithms with scheduling criteria that are nondecreasing in the job completion times, such as makespan, total completion time, maximum lateness, and total tardiness. The study by Dessouky [
15] proposed a branch and bound algorithm for uniform parallel machine scheduling with ready times in order to minimize the maximum lateness. The work by Balakrishnan et al. [
16] examined uniform parallel machine scheduling problems with sequence-dependent setup times in order to minimize the sum of earliness and tardiness costs. They provided a mixed integer formulation that has substantially small 0-1 variables for small-sized problems. In the study by Lee et al. [
17], two heuristic algorithms for uniform parallel machine scheduling were developed to derive an optimal assignment of operators to machines with learning effects in order to minimize the makespan. The work by Elvikis et al. [
18] also considered a uniform parallel machine scheduling problem with two jobs that consist of multiple operations, and derived Pareto optima with makespan and cost functions. In the study by Elvikis and T’kindt [
19], the problem with multiple objectives related with the job completion times was investigated by developing a minimal complete Pareto set enumeration algorithm. The work by Zhou et al. [
20] considered a batch processing problem on uniform parallel machines with arbitrary job sizes in order to minimize the makespan. They developed a mixed integer programming model and an effective differential evolution-based hybrid algorithm. In the work by Jiang et al. [
21], a hybrid algorithm that combines particle swarm optimization and genetic algorithm was developed for scheduling uniform parallel machines with batch transportation. The study by Zeng et al. [
22] examined a bi-objective scheduling problem on uniform parallel machines by considering electricity costs under time-dependent or time-of-use electricity tariffs. All of these studies are not directly applicable to our problem since we consider more complicated problem settings. However, some ideas and approaches used in this paper were inspired by these previous works.
One of the important features of our problem is job splitting. Some papers have considered the job splitting property on parallel machines. Several polynomial time algorithms for scheduling parallel identical, uniform, and unrelated machines with job splitting were developed in order to minimize maximum weighted tardiness [
23]. In the work by Yalaoui and Chu [
6], an efficient heuristic algorithm for parallel machine scheduling with job splitting and sequence-dependent setup times was proposed and its performance was evaluated. They transformed the problem into a traveling salesman problem and solved with Little’s method. It was further analyzed with a linear programming approach [
24]. Kim et al. [
7] developed a two-phase heuristic algorithm for parallel machine scheduling with job splitting where an initial sequence is constructed by an existing heuristic method for parallel machine scheduling in the first phase and then the jobs are rescheduled by considering job splitting in the second phase. Shim and Kim [
25] further analyzed the same problem by developing a branch and bound algorithm with several dominance properties. In the study by Park et al. [
26], heuristic algorithms for minimizing total tardiness of jobs on parallel machines with job splitting were presented. Wang et al. [
27] also examined a parallel machine scheduling problem with job splitting and learning with the total completion time measure, and used a branch and bound algorithm for small-sized problems and heuristics for large-sized ones. Even though most of these previous studies considering job splitting assume simpler manufacturing environment than that of our problem, they provide an idea of algorithm design for the heuristics developed in this paper.
Lastly, many papers have also considered resources in scheduling parallel machines, which is an important scheduling requirement of our problem. In the work by Kellerer and Strusevich [
28], a parallel dedicated machine scheduling problem with a single resource for the makespan minimization was examined. They analyzed the complexity of different variants of the problem and developed heuristic algorithms employing the group technology approach. Kellerer and Strusevich [
29] further considered the problem with multiple resources, and developed polynomial-time algorithms for special cases. In the study by Yeh et al. [
30], several metaheuristic algorithms for uniform parallel machine scheduling were developed given that resource consumption cannot exceed a certain level. These studies assumed that resources are required to process jobs on machines. For setup resource constraints, the study by Hall et al. [
31] dealt with nonpreemptive scheduling of a given set of jobs on several identical parallel machines with a common server was considered. In detail, they considered many classical scheduling objectives in this environment and proposed polynomial or pseudo-polynomial time algorithms for each problem considered. The work by Huang et al. [
32] addressed a parallel dedicated machine scheduling problem with sequence-dependent setup times and a single server. Several papers have examined two-parallel machine scheduling problems with a server and proposed efficient heuristic algorithms [
33,
34,
35]. The study by Cheng et al. [
36] considered a common server and job preemption in parallel machine scheduling with the makespan measure and provided a pseudo-polynomial time algorithm for two machine cases and analyzed the performance ratios of some natural heuristic algorithms. Hamzadayi and Yildiz [
37] also considered the same problem with sequence-dependent setup times and derived metaheuristic methods to minimize the makespan. For multiple servers, the study by Ou et al. [
38] examined a parallel machine scheduling problem where servers perform unloading tasks of jobs and proposed a branch and bound and heuristic algorithms. Unlike the problem in this paper, most of studies considering resources in scheduling parallel machines assume a single resource (or server) or do not take into account other scheduling requirements considered in this paper such as job splitting and dedicated machines. Therefore, methods developed in the previous papers cannot be applied to our problem. For interested readers, reviews on parallel machine scheduling can be found in [
39,
40,
41].
In summary, even though there have been numerous papers on parallel machine scheduling, no study has been performed for our problem; uniform parallel machine scheduling with dedicated machines, job splitting, and setup resource constraints. As explained above, this problem is motivated from real-world systems, and there are many other applications in which the proposed approach can be useful. We first describe the problem in detail and develop a mathematical programming model for the first time. We then provide four lower bounds and propose efficient heuristic algorithms. The performance of the algorithms is evaluated by comparing with lower bounds. An application of our algorithm to a real problem from industry is also introduced.
3. Problem Description & Analysis
In this study, we consider a uniform parallel machine scheduling problem with dedicated machines, job splitting properties, and limited setup resources, which can be easily observed in practice. In uniform parallel machine scheduling,
n jobs are processed on
m machines in parallel, but machines can have different speeds. The processing speed of machine
i where
,
, is denoted by
, which can be regarded as relative speeds. For example, if
, Machine 1 is twice as fast as Machine 2. Job
j,
,
, has the processing time of
if the machine speed is 1. Therefore, in general, the processing time of job
j on machine
i is
. When all machines have the same speed, e.g.,
for all
i, the environment is the same as identical parallel machine scheduling which is a special case of our problem. Dedicated machines enforce that job
j can only be processed on a set of designated machines, denoted as
, and can be split into multiple sections that can be processed on several machines simultaneously. When a job type is changed in a machine, a setup is needed by one of
r (
) operators that are generally insufficient to set up all of
m machines at the same time (see
Figure 1). The setup time for job
j,
, is sequence-independent; that is, the setup time is not affected by the preceding job, and it only depends on the job to be processed. The objective is to minimize the maximum of machine completion times,
where
and
indicates the completion time of machine
i.
The problem considered in this paper can be easily proven to be NP-hard because parallel machine scheduling problems with two machines, which are a special case of our problem with
for all
,
,
for all
, and
for all
, are proven to be NP-hard [
42]. We assume that jobs processed on machines for the first time do not require setup operations. This is because once all jobs are completed for a given period, mostly one or several weeks, preventive maintenance for machines is performed and then they are set up for the next desired states [
6]. Setup times are not affected by different speeds of machines since they are performed by setup operators. The lengths of jobs processed on each machine and their sequence should be determined by considering setup resources and dedicated machines with different speeds in order to minimize the makespan. For a better understanding, we provide the following example.
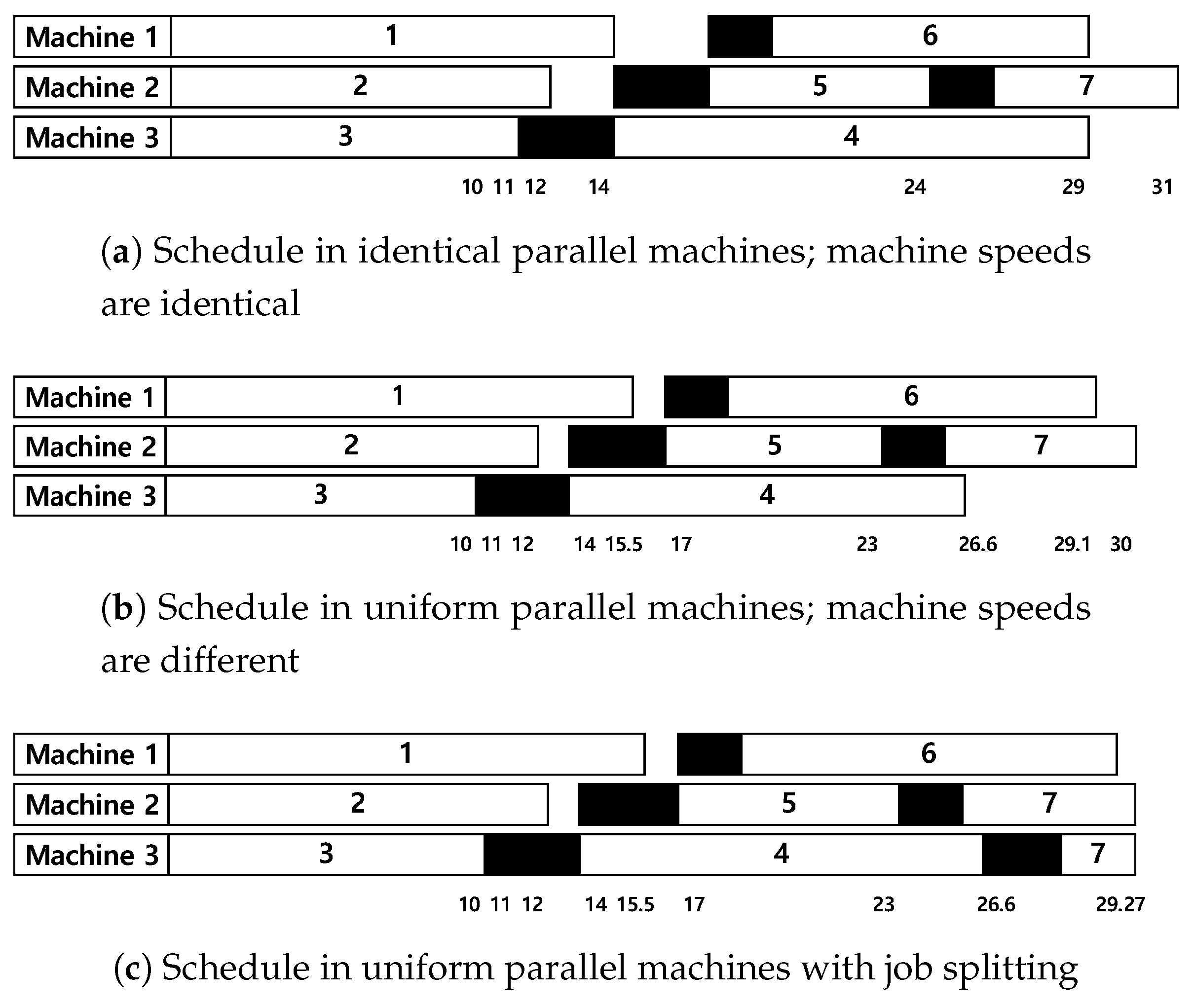
Example 1. Suppose that there are three machines and seven jobs where for all j where are given as . Figure 2 shows three Gantt charts for production schedules in identical or uniform parallel machines with one setup operator. In the Gantt chart, numbers in white bars indicate job indices, and black bars represent setup operations. Numbers in the bottom denote time stamps; for example, in Figure 2a, Machine 2 finishes at 31 while completion time of Machines 1 and 3 is 29. Assume that jobs are processed in their index order, the jobs processed for the first time on each machine do not require setups, and there is no dedicated machine constraint. When jobs are processed on identical parallel machines, their makespan is 31, as illustrated in Figure 2a. However, when the machines have different speeds, i.e., , and are 0.9, 1, and 1.1, respectively, the schedule becomes the same as the Gantt chart in Figure 2b, and the makespan is 30. In this case, the schedule can be improved by splitting Job 7 into two sections and assigning one section with the processing time of 0.73 to Machine 3. Since is 1.1, it takes 0.66 for the section to be completed on Machine 3 and the makespan becomes 29.27. If Job 7 can only be processed on Machines 1 and 2, i.e., , splitting the job cannot improve the schedule. Hence, special considerations on scheduling uniform parallel machines with dedicated machines, job splitting, and setup resource constraints are required. We now propose a mathematical programming model for uniform parallel machine scheduling with dedicated machines, job splitting, and setup resources for the first time.
Table 1 lists the symbols and their descriptions used in the following mathematical programming model. Especially,
H indicates a given scheduling horizon which can be determined by
.
The objective is to minimize
, which indicates the maximum completion time of machines. The constraint in Equation (
2) is used for ensuring that a section of job
j can be assigned to machine
i,
, only once; multiple assignments of sections of the same job type to a certain machine are not allowed. The constraint in Equation (
3) is developed for job splitting property, which indicates that multiple sections of job
j can be processed on different machines in
. The constraint in Equation (
4) associates
and
so that if a section of job
j is assigned to machine
i,
and the sum of
for all
t should be the same. In the constraint in Equation (
5), when a section of job
j starts to be processed on machine
i, the next job
k in
should start after
time units where
D is a large number. The term
is used to eliminate the setup time of the first job on machine
i. The objective,
, is obtained with the constraint in Equation (
6). Once a section of job
j is processed on machine
i, it should have its succeeding and preceding jobs as indicated by the constraints in Equations (
7) and (
8), respectively. The constraints in Equations (
9) and (
10) ensure that dummy jobs 0 and
are the first and last jobs, respectively, on each machine. Since a section of job
j cannot precede or success the same job type,
as in the constraint in Equation (
11). The sum of processing times for job
j on machines in
should be equal to
from the constraint in Equation (
12), and a section of job
j is assigned to machine
i, then
should be larger than 0 from the constraints in Equations (
13) and (
14). The constraints in Equations (
15)–(
18) are used for the setup resource constraints. If a section of job
j starts to be processed on machine
i at time
u,
should be 1 for all
t where
, which is constrained by the constraints in Equations (
15) and (
16). The constraint in Equation (
17) is used for the first jobs on machines because setup times for those jobs are ignored. Since there are
r setup operators, the sum of
at each time
t should be less than or equal to
r. Since
is nonlinear, we introduce
,
, which indicates the length of a section of job
j that is actually processed on machine
i. Then, the commercial solvers such as CPLEX can be used to obtain optimal solutions with the proposed formulation. The following inequalities are added where
D is a large number:
Optimal solutions from the mathematical formulation can be used to evaluate the performance of the proposed algorithm. However, large size problems cannot be solved within an acceptable time even with three machines and four jobs as our problem is NP-hard. Thus, lower bounds are derived and used for the performance evaluation. We define a job set
as one that contains
m jobs so that
is maximized and those
m jobs in
can be assigned to
m machines one by one while satisfying dedicated machine constraints. Suppose that there are two machines and three jobs, and
,
, and
are 2, 1, and 3, respectively. If
and
,
contains Jobs 2 and 3 instead of Jobs 1 and 3 even though
because Jobs 1 and 3 must be processed on Machine 1. A job set
includes jobs that are in
. We used the Hungarian method to obtain set
with
n jobs and
n machines (
m machines + (
) dummy machines) [
43].
indicates a set of jobs that have the same set of dedicated machines, i.e.,
if jobs
j and
k are in
. In the above example, Jobs 1 and 3 are in the same set. We now present several lemmas to derive lower bounds.
Lemma 1. A job-based lower bound is .
Proof. Since job j can only be processed on machines in , the minimum time required to complete job j is . Hence, the maximum value among becomes a job-based lower bound. ☐
Lemma 2. A machine-based lower bound is .
Proof. For a basic parallel machine scheduling problem, a lower bound is . In our problem, since m machines have different speeds, it takes at least to complete all of n jobs. In addition, the setup time of for jobs is required. Hence, a machine-based lower bound is . ☐
Lemma 3. A resource-based lower bound is .
Proof. Except the first m jobs assigned, jobs require setups that take at least as we defined previously. Since those setups are performed by r operators, a resource-based lower bound is . ☐
Lemma 4. A job set-based lower bound is where is a set of machines that can process jobs in , and is a set of jobs in that does not contain jobs with the largest setup times among jobs in .
Proof. For each job set, , a lower bound can be obtained similarly as in Lemma 2. Jobs in can only be processed on machines in , which takes at least . The setups for jobs require at least as much as since jobs can start at first on machines. Hence, the maximum value among for all becomes a job set-based lower bound. ☐
Corollary 1. A lower bound of the makespan of the problem, , is .
4. Heuristic Algorithms
Since no setup is required for the first jobs on machines, assigning jobs with large setup times as the first ones can lead to the makespan reduction. However, sorting jobs in order of nonincreasing setup times and assigning the first m jobs to m machines may not be feasible or may lead to less setup time reductions due to the dedicated machines. Hence, we assign m jobs in to m machines so that the sum of setup times of those jobs is maximized. As mentioned above, the optimal assignment of m jobs to m machines can be found with the Hungarian method. In the method, dummy machines are made and setup times of n jobs on those machines are set to 0. The setup time of job j on machine i, , is also set to 0. Then, the Hungarian method is applied with n jobs and n machines. It is known that the complexity of the Hungarian method is . With this method, we can maximize the sum of setup times of jobs that are first assigned to each machine.
After assigning m jobs, each time machines become available, jobs are chosen according to some of well-known priority rules. The first one is the least flexible job (LFJ) first rule. When machine i finishes processing a job, the job with the smallest among jobs in is chosen and assigned. The LFJ performs well for dedicated parallel machine scheduling. The second one is the LPT rule that selects the job with the largest processing time among jobs in . After assigning all of n jobs, the loads of machines are balanced by splitting last jobs on each machine and assigning those sections to other machines by considering dedicated constraints and different speeds of machines.
We provide the procedures of the two priority rules for assigning jobs. Let as the earliest start time in which a job can be assigned to machine i by considering the setup resource constraints after assigning m jobs by the Hungarian method. The following rules are only applied to jobs in .
LFJ rule
- -
Step 1: For machine l where , select job k in that has the smallest and assign the job to the machine. Ties are broken according to the LPT rule. Update to , to , and to where .
- -
Step 2: If , terminate. Otherwise, update for all and go to Step 1.
LPT rule
- -
Step 1: For machine l where , select job k in that has the longest and assign the job to the machine. Ties are broken according to the LFJ rule. Update to , to , and to where .
- -
Step 2: If , terminate. Otherwise, update for all and go to Step 1.
It is worth noting that another priority rule that combines the LPT and LFJ was also tested but provides a poor performance in the preliminary experiments; when a machine with a high speed becomes idle, a job is assigned according to the LPT rule, and, otherwise, the LFJ rule is applied to select a job.
We now propose a heuristic algorithm that combines the Hungarian method for assigning first
m jobs, one of priority rules (LFJ or LPT) for assigning
jobs and the load balancing step on machines. We tested the above two priority rules and show their performance in
Section 5.
| Algorithm 1: An iterative algorithm for uniform parallel machine scheduling |
- -
Step 1: Using the Hungarian method, select m jobs and assign them to each machine so that the sum of setup times of such m jobs is maximized, and define a set that contains these first m jobs. - -
Step 2: Assign jobs in where according to the LFJ or LPT rule. - -
Step 3: Select machine l where . If maxReducibleTime(l), assign a section of the last job on machine l to machine bestAssignableMachine(l) so that where , and repeat Step 3. Otherwise, go to Step 4. - -
Step 4: Consider where and is the last job on machine l. For each machine , update to maxReducibleTime(i) temporarily, and store its original value. If maxReducibleTime(l) , stop. Otherwise, let bestAssignableMachine(l) and restore to its original value. Assign a section of the last job on machine j to machine k where bestAssignableMachine(j) so that , and go to Step 3.
|
| Algorithm 2: Splitting jobs with long processing times to further improve solutions |
- -
Step 1: Let both N and be the initial job list and . - -
Step 2: Apply Algorithm 1 with jobs in N and update to the resulting makespan. If is equal to the lower bound, stop. Otherwise, go to Step 3. - -
Step 3: If or all of the jobs in have the processing time less than ( is a very small positive real number to avoid an infinite loop), stop. Otherwise, select job l in according to the LPT rule. Split job l into two sections, and , with the same processing time. Apply Algorithm 1 with jobs in . Let the makespan obtained with the updated N be . - -
Step 4: If , set and update both N and by eliminating job l and adding jobs and . Otherwise, update by eliminating l. Go to Step 3.
|
Function: maxReducibleTime()
For a given machine l and its last job , return where .
Function: bestAssignableMachine()
For a given machine l and its last job , return machine i where .
Assign
m jobs with the Hungarian method and
jobs with one of the priority rules in Steps 1 and 2, respectively. Then, the schedule is updated by balancing the loads of machines in Steps 3 and 4. In Step 3, the machine with the largest
which currently determines the makespan is chosen, and for all other machines compute maximum reducible times by splitting and reassigning the last job of the machine with the largest
to another machine. This step is repeated until there is no further improvement in makespan. Step 4 is specially designed to improve the solution under dedicated machine constraints.
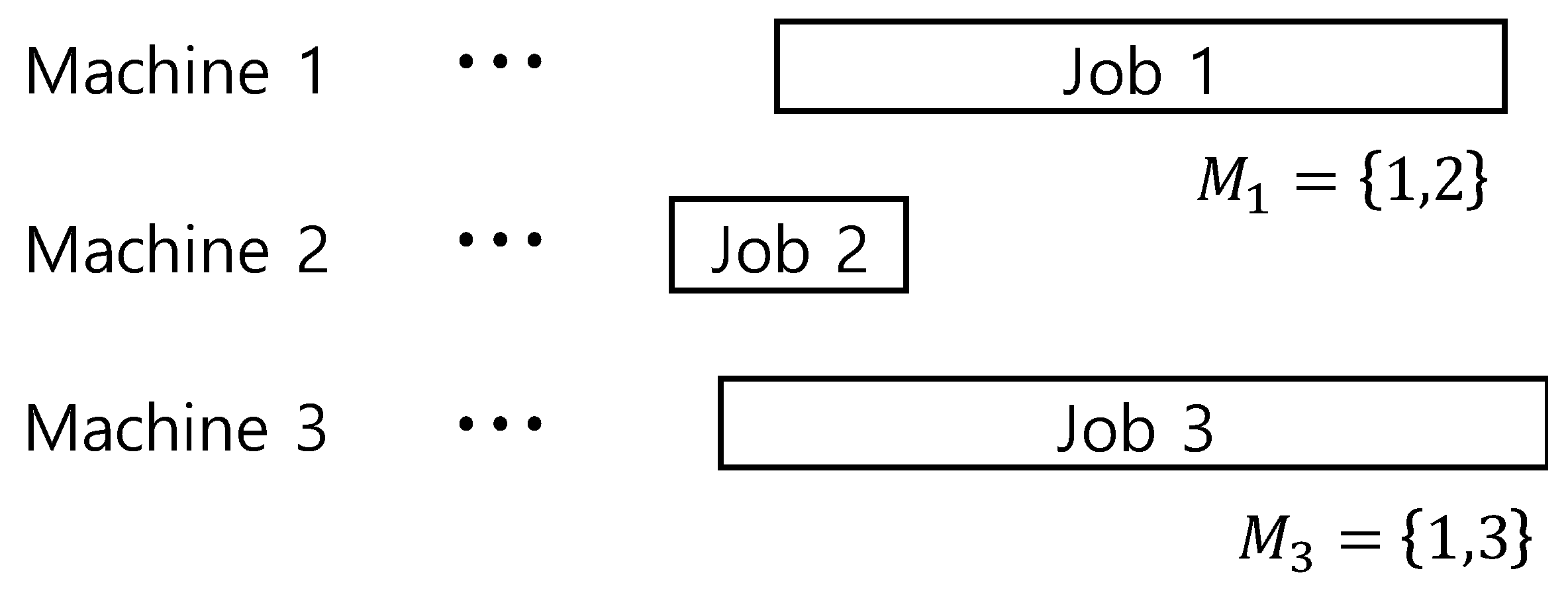
Figure 3 shows an example where Step 4 of Algorithm 1 is effective. In
Figure 3, Machine 3 has the longest completion time and the last job of Machine 3 is Job 3. In Step 3 of Algorithm 1, it is virtually impossible to have any improvement in makespan because Job 3 can be processed in Machines 1 and 3, but completion time of Machine 1 is almost the same as that of Machine 3. However, if the last job of Machine 1, Job 1, is split and reassigned to Machine 2 since
, the completion time of Machine 1 is decreased and thus we can have an additional chance to reduce the makespan. Based on this idea, Step 4 of Algorithm 1 is designed.
With Algorithm 1, we can obtain a feasible and acceptable solution. The solution is updated further by splitting jobs with long processing times at a time in Algorithm 2.
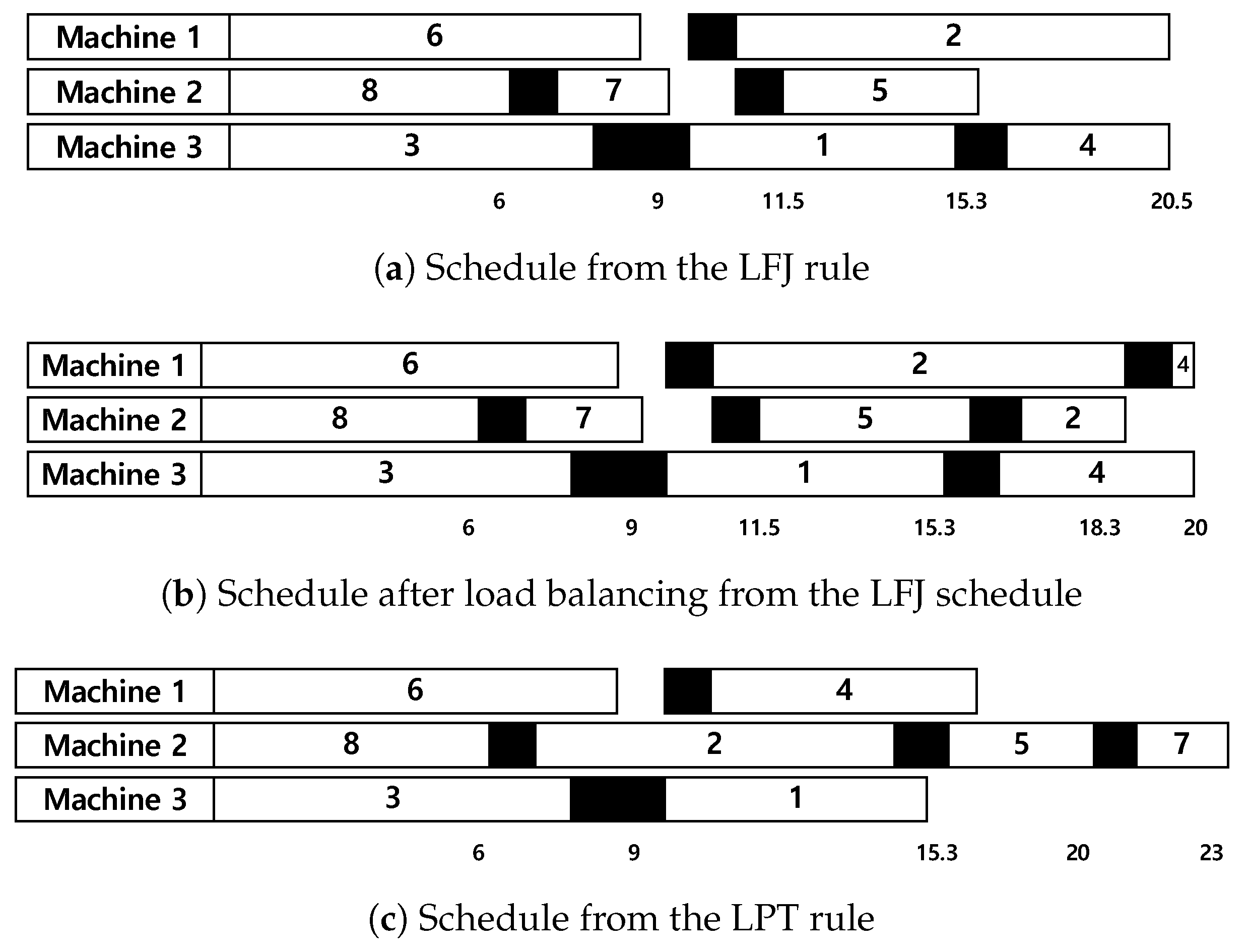
Example 2. Suppose that there are three machines and eight jobs in which , and are 0.8, 1.0, and 1.2, respectively, and for . Assume that , and . Figure 4a,c shows Gantt charts of schedules obtained from the LFJ and LPT rules, respectively, with r of 1. In Algorithm 1, the Hungarian method is first applied, and Jobs 6, 8, and 3 are assigned as the first jobs to Machines 1–3, respectively. Then, Machine 2 becomes idle at 6 time units, and Job 7 is selected since is the smallest one among jobs in according to the LFJ rule. After that, Machines 3 chooses Job 1 because all jobs in have the same value of where and is the largest one. In a similar way, a complete schedule from the LFJ is obtained and its makespan is 20.5, as illustrated in Figure 4a. When the LPT rule is applied, Job 2 is first selected after Job 8 on Machine 2, and then Jobs 1 and 4 are assigned to Machines 3 and 1, respectively. The makespan is 23 since is not considered in the LPT rule. In Figure 4a, the last job, Job 4, on Machine 3 cannot be processed on Machine 2, and splitting the job into two sections and assigning one section to Machine 1 cannot improve the makespan. Hence, Job 2 on Machine 1 is split into two sections, and one is assigned to Machine 2. The schedule is further updated by splitting Job 4 on Machine 3 and assigning one section to Machine 1, as illustrated in Figure 4b. In this schedule, the makespan is 20. The schedules from the LPT rule cannot be improved by splitting the last jobs on machines. After maintaining the schedule, Algorithm 2 is applied. 5. Experimental Results
The proposed algorithms were tested with various scenarios. The machine speed was determined randomly between 0.8 and 1.2, and the setup times for jobs were generated with
where
was selected randomly within
and
. Processing times were generated between 10 and 100. There were three levels of machine dedications, namely high, medium (i.e., mid), and low, and, in each level, jobs could be processed on a machine with the probability of 50%, 50–90%, and 90%, respectively. The scenarios had 5, 10, and 20 machines, each of which had 40, 60, and 80 jobs, respectively. The four algorithms, Algorithm 1 with LFJ (A1 (LFJ)), Algorithm 1 with LPT (A1 (LPT)), Algorithm 2 with LFJ (A2 (LFJ)), and Algorithm 2 with LPT (A2 (LPT)), were compared with lower bounds from Corollary 1. Average gaps were computed as follows:
For each problem with a certain range of setup times, a dedication level, and the specific number of resources, 100 instances were generated, and the average gaps are shown. Note that the mathematical formulation model can only solve small instances with two machines and four jobs to optimality within 1 h. We do not think it is meaningful to compare with such very small-sized instances, and furthermore for such cases gaps between makespans from our algorithm and lower bounds are extremely small.
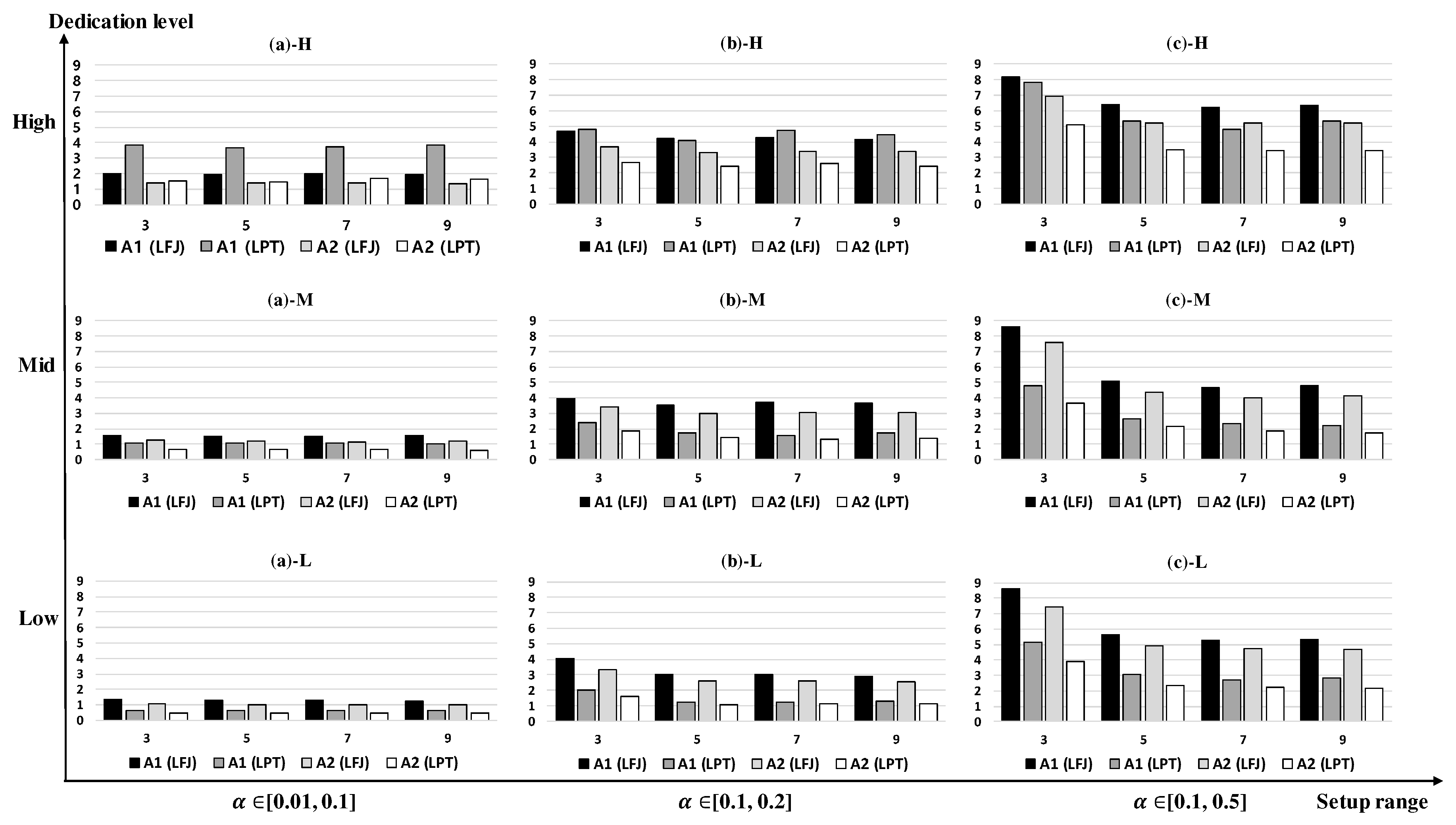
Figure 5,
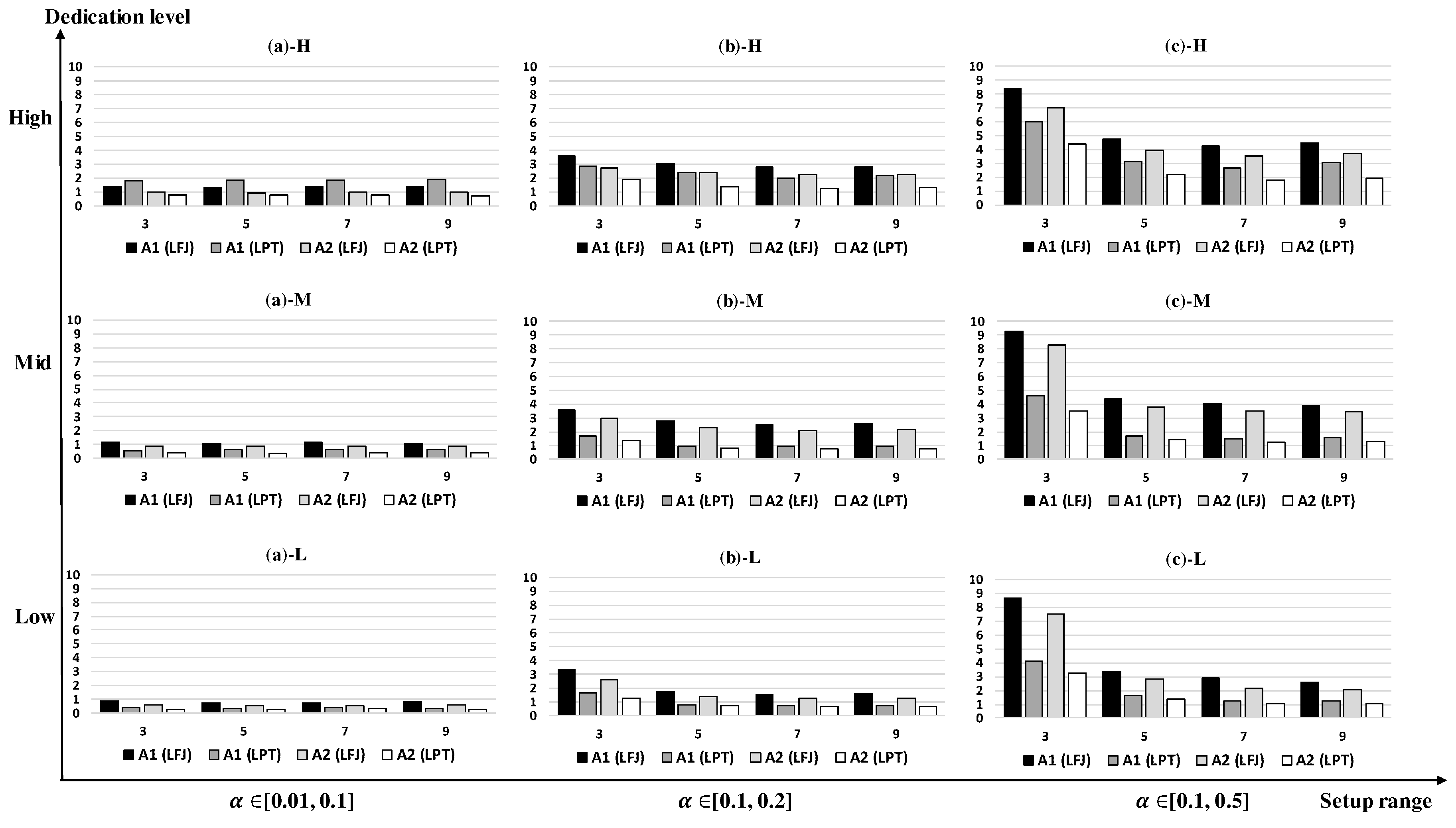
Figure 6 and
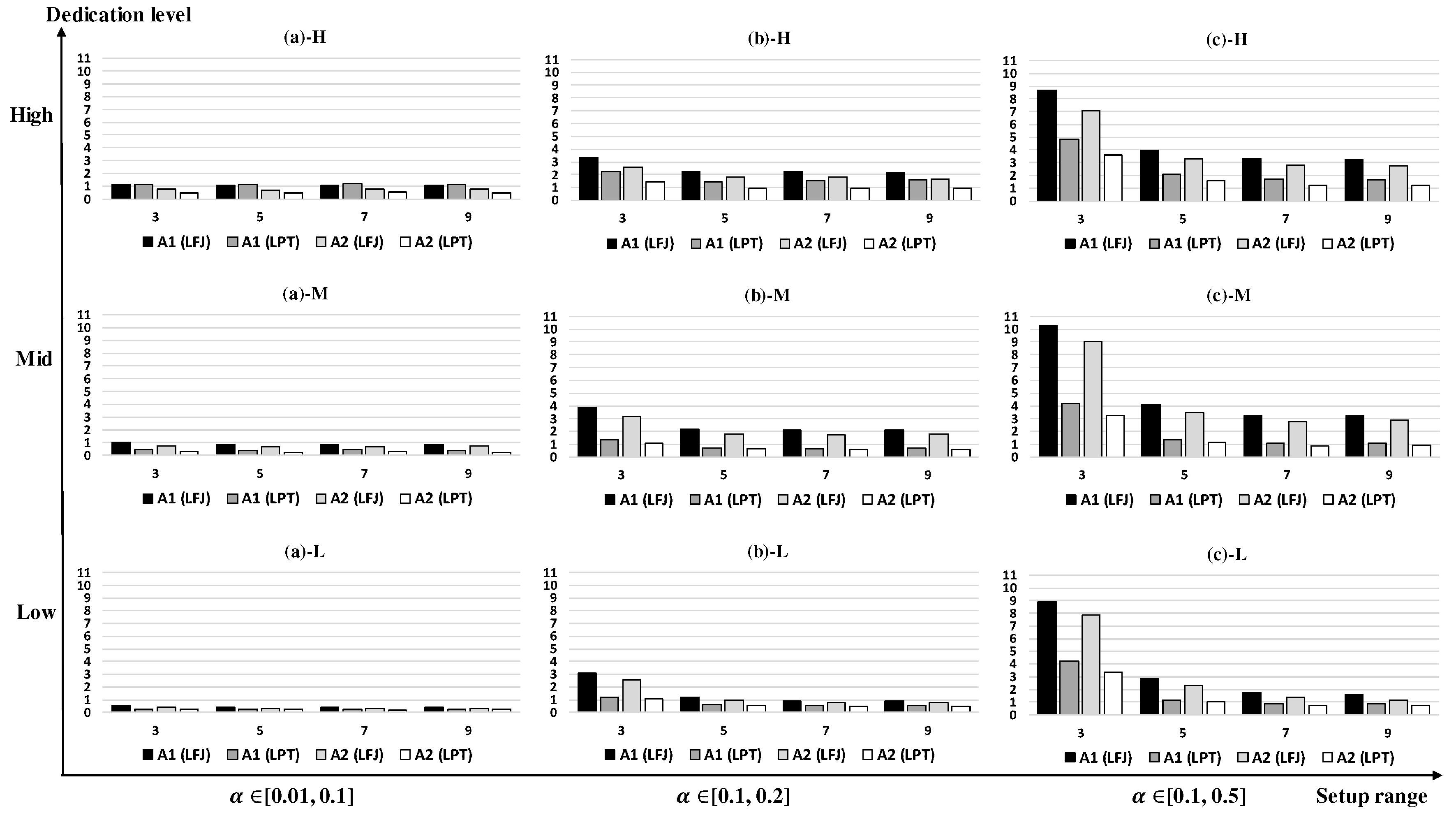
Figure 7 show the experimental results with
m of 10 and
n of 40, 60, and 80, respectively. Each figure has nine graphs for the different setup time ranges and dedication levels. The graphs in those figures are labeled with (a), (b), (c) and H, M, and L according to setup ranges
,
, and
, and the dedication levels, respectively. For example,
Figure 5a-H indicates the result with
and the high dedication level. The number of servers,
r, was set to be less than
to reflect the resource constraints in the schedule. Each graph shows the average gaps of the four algorithms with
r of 3, 5, 7, and 9. In
Figure 5, the average gaps tend to increase as the setup time range is larger and the dedication level becomes high. In addition, as
r becomes large, the gaps become smaller. A1 (LFJ) performs better than A1 (LPT) in
Figure 5a-H,b-H whereas the average gaps of A1 (LPT) are smaller in other cases because LFJ rule works well with the high dedication level. In the case of
Figure 5c-H, A1 (LPT) is slightly better than A1 (LFJ) because the machine loads may be well-balanced with LPT rule under the large setup times. When the machine dedication level is mid or low, A1 (LPT) is always better than A1 (LFJ). The average gap of A1 (LPT) is decreased significantly in
Figure 5c-M compared to
Figure 5c-H. The difference between A1 (LFJ) and A1 (LPT) becomes large under mid and low dedication levels as the setup time ranges increase whereas the difference is small with the high dedication. A2 (LFJ) and A2 (LPT) have patterns similar to A1 (LFJ) and A1 (LPT) in
Figure 5. It is interesting to note that the average gaps of A1 (LFJ) and A2 (LFJ) in
Figure 5c-M,c-L are slightly larger than those in
Figure 5c-H, respectively, when
r is small, whereas the average gaps are mostly large when the dedication level is high. This may indicate that when setup times are large and resource constraints are tight, LFJ rule provides good solutions with the high dedication level. This feature can also be found in
Figure 6 and
Figure 7. A2 (LPT) provides the smallest gaps among the four algorithms for all cases except
Figure 5a-H. A2 (LPT) has the largest average gap of 3.88% in
Figure 5c-H, and the smallest average gap of 0.48% in
Figure 5a-L.
The nine graphs in
Figure 6 have the features similar to those in
Figure 5, but the average gaps are smaller as
n increases. The large gaps are obtained when
and
r is small. A1 (LFJ) performs better than A1 (LPT) in
Figure 6a-H but it is outperformed in all the other cases. A1 (LFJ) and A2 (LFJ) work poorly especially with large setup times and small resources compared to A1 (LPT) and A2 (LPT). A2 (LPT) performs well in most cases, and its largest and smallest average gaps are 2.57% and 0.29% in
Figure 6c-H,b-L, respectively.
Figure 7 shows the results with
n of 80. We can see that A1 (LPT) performs better than A1 (LFJ) in
Figure 7a-H unlike the previous results. The average gaps of the four algorithms are smaller than those in
Figure 6 except for A1 (LFJ) with large setup times and small resources. This may indicate less tight lower bounds or poor performance of LFJ rule with large
n. A2 (LPT) provides the largest and smallest average gaps that are 1.88% and 0.21% in
Figure 7c-H and in
Figure 7b-L, respectively. It is good to use A2 (LFJ) with small
n, high machine dedication, and small setup times. Otherwise, A2 (LPT) is better.
Table 2 summarizes all of the results in
Figure 5,
Figure 6 and
Figure 7 according to the different dedication levels, setup ranges, resources, and the number of jobs.
Table 2 also shows the results with different machine speed ranges, 0.5–1.5. We can see that the average gaps tend to become smaller as the dedication level becomes lower, setup time ranges are smaller, the number of resources is larger, and the number of jobs becomes large. The average gaps of the four algorithms are 3.12%, 1.99%, 2.58%, and 1.33%, and hence we can obtain solutions close to optimal ones with A2 (LPT), respectively. The performances of A1 (LFJ) and A1 (LPT) are improved as much as 17% and 33% by using Algorithm 2, respectively. When the variation of machine speeds is larger, the average gaps also increase. Even if the machine speed is selected between 0.5 and 1.5, the average gaps are less than 5%. We note that the computation times of A1 (LFJ) and A1 (LPT) are less than 1 s, and it takes at most 61 s for A2 (LFJ) and A2 (LPT) with
n of 80.
The detailed experimental results for
m of 5 and 20 with
n of 40, 60, and 80 are given in
Appendix A.
Table 3 and
Table 4 show the summary of the results with
m of 5 and 20, respectively, with the speed between 0.8 and 1.2. We can see the features similar to the results in
Table 2. When
m is 5, A1 (LFJ) and A2 (LFJ) have the largest average gaps when the number of resources is small, whereas A1 (LPT) and A2 (LPT) perform poorly when the dedication level is high. On the other hand, A1 (LFJ) and A2 (LFJ) provide the largest average gaps when the number of jobs is small as
m increases. When
m is 20, the average gaps of A1 (LPT) and A2 (LPT) are also large with
n of 40 compared to other scenarios. By comparing the results in
Table 2,
Table 3 and
Table 4, we can see that the average gaps tend to increase as
m increases. The average gaps of the four algorithms with
m of 5 and 20 are 1.33%, 1.70%, 1.06%, and 0.92%, and 4.71%, 3.21%, 4.07%, and 2.43%, respectively. The gaps are not large by considering the fact that they are computed with lower bounds not the optimal ones. The performance of Algorithm 1 is improved significantly by applying Algorithm 2. We can conclude that practical problems can be solved efficiently especially with A2 (LPT). The computation time for the scenarios with
m of 20 and
n of 60 is 89.43 s on average, and the maximum computation time is 100.17 s.
We further evaluated the four algorithms with extreme cases in which the number of resources is about 20% of the number of machines. In practice,
r was set to be larger than 50% of
m to increase the efficiency of the system. For each of setup time ranges, dedication levels, and the number of jobs, 100 instances were generated.
Table 5 shows the average gaps of the four algorithms with
m of 5, 10, and 20. The large gaps are mostly obtained when
and the dedication level is high. When
m is 5, the gaps tend to decrease as
n increases, whereas the gaps are large with the large number of jobs when
m is 10, especially with A1 (LFJ) and A2 (LFJ). When
m is 20, the instances with
n of 60 provide the smallest gaps. We can see that, even in the extreme cases, A2 (LPT) provides the maximum average gaps of 7.13% when
m and
n are 5 and 40, respectively.
We finally tested our algorithms with a practical instance from an FFU factory in Korea. There were seven parallel machines in which three machines had the speed of 1.2 and the rest had the speed of 1. The setup times were not large,
. The number of jobs was 20, 30, and 40, each of which had processing times of 1–30, 1–20, or 1–10, respectively, to have a one-week production schedule. The number of setup operators was 2, and the dedication level was mid.
Table 6 shows the results with
m of 7 and
n of 20, 30, and 40. We can see that the average gaps are less than 4% with the A2 (LPT). As shown in the table, A2 (LPT) provides very efficient solutions in this case.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






