1. Introduction
With the development of technology and the increasing usage of electrical appliances and automated services, the electric energy needs have been growing steadily for the last century with an annual growth of approximately 3.4% per year in the last decade [
1]. Nowadays residential and commercial buildings account already for roughly 36% of the total electrical demand in the USA and 25% in the EU while they are responsible for roughly 43% of carbon dioxide (
) emissions [
2,
3,
4]. To assure balance between renewable energies,
emissions, political stability and economic growth it is essential to focus on a sustainable development [
5]. To achieve sustainable economic growth energy consumption in industrial and residential areas must be minimized under the consideration of rising volatility of nowadays energy production with increasing amounts of renewable energies [
6]. Under the consideration of sustainable development several studies investigated real time pricing with additional storage systems [
7,
8] or large scale energy buffering [
6] to reduce electrical energy consumption and peak loads. Other studies indicate that detailed analysis and real-time feedback of energy consumption in residential areas can lead to up to 20% savings in energy consumption through detection of faulty devices and poor operational strategies and thus would improve the sustainability of nowadays consumer households [
9,
10]. Therefore in the last few decades extensive research in smart grids, smart systems and demand management was carried out and different optimization techniques have been developed to reduce residential energy consumption [
11,
12,
13]. To make use of those techniques, accurate and fine-grained monitoring of electrical energy consumption is needed [
14]. However nowadays the energy consumption of most households is monitored via monthly aggregated measurements and therefore cannot provide real-time feedback information.
To measure the energy consumption of a household or building with high resolution in the order of seconds or below smart meters are utilized. According to [
15] the largest improvements in terms of energy savings can be made when monitoring energy consumption on device level. Therefore the analysis of energy on device level is performed through energy disaggregation, i.e., the extraction of energy consumption on appliance level based on one or multiple measures from smart meters. When using only one sensor (smart meter) per household or building, therefore measuring only the aggregated consumption, the task is referred to as Non-Intrusive Load Monitoring (
) [
16], in contrast to Intrusive Load Monitoring (
) where multiple sensors are used, usually one per device. The goal of
is to find the inverse of the aggregation function through a disaggregation algorithm using as input only the aggregated power consumption, which makes
a highly under-determined problem and thus impossible to solve analytically [
17].
In order to solve the
problem different approaches have been proposed in literature, which can be split into methods with or without Source Separation (
). Approaches with
consider the task of energy disaggregation as a single channel source separation problem and extract the corresponding signal of each device from the aggregated samples using a set of conditions and constraints (e.g., sparseness or sum-to-one) [
18,
19]. Approaches without
are based on the decomposition of the aggregated signal to a sequence of feature vectors. These feature vectors are then classified to device labels using a machine learning algorithm [
8,
20,
21] or by predefined set of rules or thresholds [
22,
23]. As machine learning classification/regression models a wide variety of algorithms have been used such as Artificial Neural Networks (
) [
8], Decision Trees (
) [
24], Hidden Markov Models (
) [
24,
25,
26,
27,
28,
29], K-Nearest-Neighbours (
) [
30], Random Forests (
) [
20], Support Vector Machines (
) [
24] and ensemble classifiers [
31].
Another classification of
methods is based on the sampling frequency
of the smart meter and thus the features that can be extracted from the measured data [
32]. In detail, depending on the sampling frequency either macroscopic (e.g., active/reactive power [
23,
33,
34]) or microscopic (e.g., transient energy, harmonics, wavelets [
22,
35]) features are extracted to disaggregate energy consumption on appliance level for steady state and transient behaviour, respectively. Macroscopic features are extracted in low sampling frequencies in the order of
Hz to 1 Hz while microscopic features are extracted in high sampling frequencies from 50 Hz up to 30 kHz [
32]. Many researchers have used microscopic features to efficiently detect transient device behaviour and thus improve energy disaggregation [
36,
37]. However measuring the power consumption with high sampling frequency has the drawback of higher cost through hardware and increase of computational power [
38]. Therefore most studies focus on disaggregation algorithms using macroscopic features or only active power samples in combination with low computational cost disaggregation algorithms utilizing sampling rates in the order of seconds and minutes [
28,
39,
40,
41,
42,
43,
44].
Considering the wide range of appliances with either steady-state behaviour [
16], where appliances are modelled as finite state machines [
16,
45] or appliances with transient behaviour including non-linear and continuous appliances [
18,
36,
46], investigation of the effect of different features and classification algorithms is essential. In this paper we evaluate the performance of various well-known and widely used classifiers and various features on the energy disaggregation task for the
task. Specifically, we present a large scale evaluation of several features with respect to the
performance on specific appliance types in combination with several widely used classification algorithms, in order to investigate which feature sets are more appropriate for accurately detecting specific appliance types, e.g non-linear appliances and the effect of using appliance specific features in the overall
performance. The proposed methodology with appliance specific features is evaluated using several combinations of feature sets and classification algorithms.
The remainder of this paper is organized as follows: In
Section 2 the baseline
system is presented. In
Section 3 the experimental setup is described and in
Section 4 the evaluation results are presented. Finally conclusions are provided in
Section 5.
2. NILM Architecture
energy disaggregation can be formulated as the task of determining the power consumption on device level based on the measurements of one sensor, within time windows (frames or epochs). Specifically, for a set of
known devices each consuming power
with
, the aggregated power
measured by the sensor will be
where
is a ‘ghost’ power consumption (noise) consumed by one or more unknown devices and
f is the aggregation function. In
the goal is to find estimations
of the power consumption of each device
m using an estimation method
with minimal estimation error and
, resulting in the total estimated power
, i.e.,
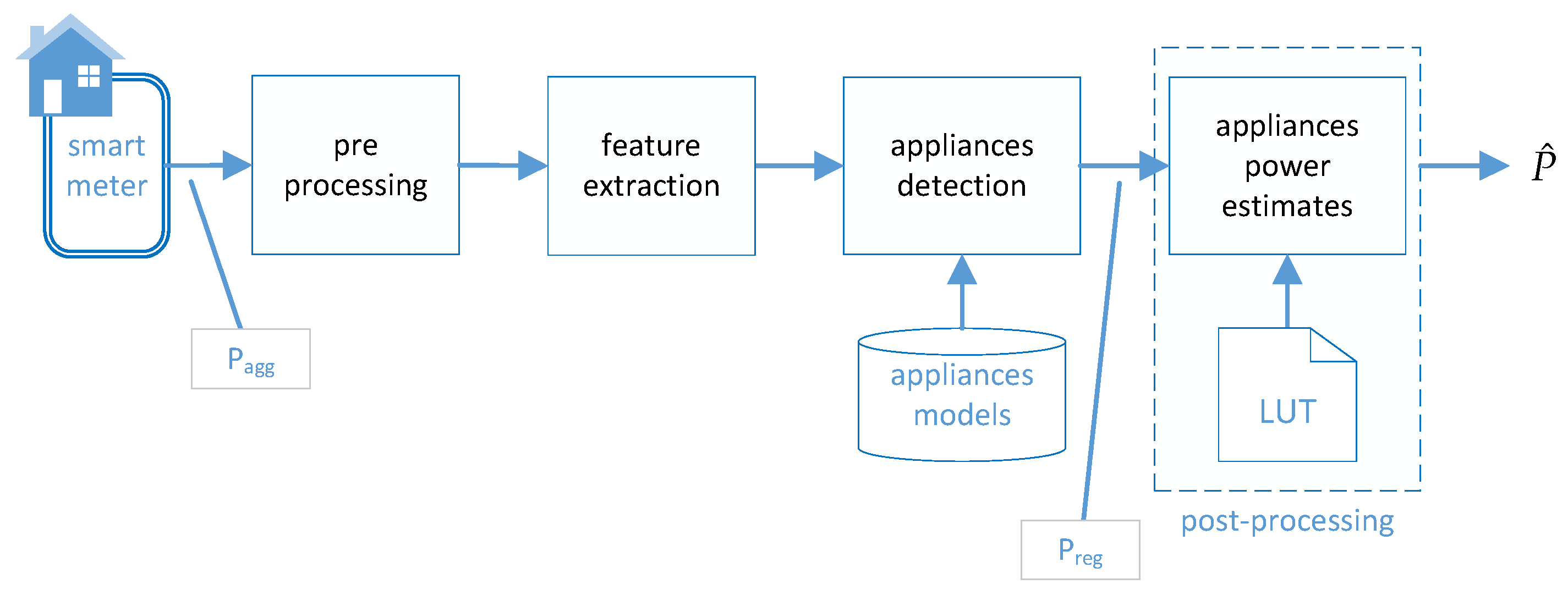
The block diagram of the
architecture adopted in the present evaluation is illustrated in
Figure 1 and consists of of four stages, namely pre-processing, feature extraction, appliance detection and post-processing. In detail, the aggregated power consumption signal calculated from a smart meter is initially pre-processed, i.e., passed through a median filter [
47] and then frame blocked in time frames. After pre-processing feature vectors,
v of length
, one for each frame are calculated. In the appliance detection stage the feature vectors are processed by a regression algorithm using a set of pre-trained appliance models to estimate the power consumption of each device. The output of the regression algorithm (
) estimates the corresponding device consumption and a set of thresholds
with
with
for the each device including the ghost device (
) is used to decide whether a device is switched on or off. The detection of appliances and estimation of their power consumption is performed for each frame of the aggregated signal. A post-processing stage is refining the power estimates form the regression model by mapping them to apriori known device states using a Look-Up-Table (
), i.e., if the distance of the regression output to any state in the device model is larger than
the regression output is mapped to the closest device state. In order to define the number of states per device the K-Means algorithm was used for initialisation followed by Expectation-Maximization (
) clustering to calculate the power consumption for each state of each device and form the
for the post-processing stage [
48].
4. Experimental Results
The
architecture presented in
Section 2 was evaluated according to the experimental setup described in
Section 3 with the optimized parameters shown in
Table 3. The performance was evaluated in terms of power estimation accuracy (
), as proposed in [
55] and defined in Equation (
3). The estimation accuracy is taking into account the estimated power
and the ground-truth power consumption
for each device
m, where
T is the number of frames and
M is the number of disaggregated devices including the ghost power. For evaluating estimation accuracy on device level Equation (
3) is modified by eliminating the summation over
M appliances resulting in Equation (
4) measuring the estimation accuracy on device level (
).
The evaluation results for different experimental protocols and different regression models are tabulated in
Table 4. As can be seen in
Table 4 adding additional statistical and electrical features improves the energy disaggregation performance across all evaluated datasets, with the
regression model outperforming all other regression algorithms. In detail for the
regression model the greatest absolute improvement was observed for the
-6 dataset (9.32%), followed by the
-1 dataset (7.80%), while the lowest absolute improvement was found for the
-3 dataset (5.22%). Moreover, for almost all of the evaluated datasets and regression algorithms the best energy disaggregation performance was achieved when using additional electrical features, i.e., in protocols 5–7.
In order to evaluate the appropriateness of each regression algorithm in the seven experimental protocols the average performance across the five datasets for each of the regression models was calculated. The results are tabulated in
Table 5.
As can be seen in
Table 5, protocol five shows the best average performance for the
,
and
regression models, while the
model shows a slightly higher performance protocol seven followed by protocol five. Moreover, as also shown in
Table 4, the
regression model outperforms the other models (87.6% with 6.5% performance increase), followed by
and
with similar performance (∼83.8% with 2.5% performance increase), while
achieved the lowest performance (79.6% with 1.9% performance increase).
Further analysis of the evaluated results was conducted on appliance type level, as they are described in
Section 3 and tabulated in
Table 1. The results for per device improvement using the best performing classifier (
) are tabulated in
Table 6. The first experimental protocol uses only the mean value of the active power as feature and thus is considered here as baseline system, against which all performance improvements have been calculated in
Table 6 with the corresponding protocol denoted in brackets. Moreover appliances that are not operating during the testing are marked in red and were excluded from further investigation.
As can be seen in
Table 6 high improvements of performance do not necessarily appear in experimental protocols with the highest number of features. To investigate the relation between appliance types and features on the energy disaggregation task we consider two types of linear appliances, either with pure resistive equivalent circuit diagram or complex loads with inductive/capacitive behaviour. Therefore three appliances categories are formed, namely one/multi-state appliances with resistive behaviour, one/multi-state appliances that can be modelled as complex loads (mainly inductive) and non-linear appliances. This appliance categorization is illustrated in
Table 7.
After examining the results from
Table 6 under the consideration of
Table 7 it can be seen that for resistive one/multi-state appliances (e.g., kettle, coffee machine or lamp) where the reactive power is zero (
) the best performing experimental protocol is protocol five in which together with the statistical features the line current is included in the feature vector as an electrical feature. For this appliance type adding the line voltage or the load angle as additional feature is not beneficial, since the load angle or the shift between current and voltage is always zero and thus does not contribute to their parametrized power signature with significant information. Except this, one/multi-state appliances with strong inductive behaviour (e.g., fridges or freezers) benefit from adding the load angle as a feature, as they consume a significant amount of reactive power and thus achieved their best performance with experimental protocol seven. In addition, non-linear devices cannot be described in terms of the active and reactive power consumption including the corresponding load angle, since the current flowing through them is non-sinusoidal as illustrated in
Table 7. Thus their power consumption must be described through different techniques, as for example the Fryze power theory [
56], where time domain analysis of active and non-active currents is used and the reactive power is split into a reactive component caused by the time domain shift between current and voltage and a component caused by the non-linearity of the device. For such appliances (e.g., entertainment, laptop or TV) the best performing experimental protocol was protocol six where line current and line voltage are added as features hence a time domain description is performed as suggested in [
56] and does not include the load angle, since in non-linear appliances the load angle does not carry any device-dependent information.
As regards performance on dataset level the maximum overall performance can be achieved when detecting each device using its own set of optimal features (i.e., the best performing experimental protocol) as tabulated in
Table 6. Additionally to selecting appliance-driven features the disaggregation results can be improved when employing the post-processing step from
Section 2 where the power estimates from the regression stage
are mapped to the appliance states determined through the appliance model during the pre-processing. The per dataset results when choosing the optimal set of features individually for each device and utilizing the post-processing are tabulated in
Table 8 with the best performing datasets shown in bold.
As can be seen in
Table 8, employing the optimal set of features for each device results in further improvement of the disaggregation accuracy varying from 0.1% to 3.2% depending on the dataset and the regression model. The maximum average performance increase for the best performing classifier (
) is 0.8% with an overall average disaggregation accuracy of 89.0%. When further employing the post-processing as described in
Section 2 another performance increase between 0.5% and 1.2% can be observed when utilizing
,
or
. However, no performance increase was observed when using
. The performance increase when using
,
or
is mainly due to one/multi-state linear appliances, which can be modelled as finite-state-machines and benefit from the post-processing step where power estimates are mapped to discrete power states of the corresponding appliance. In terms of absolute improvement
still outperforms all other classifiers when applying the
post-processing with overall disaggregation accuracy equal to 89.5%.





{kind=link}
{kind=link}





