Tourism Review Sentiment Classification Using a Bidirectional Recurrent Neural Network with an Attention Mechanism and Topic-Enriched Word Vectors


Abstract
:1. Introduction
- (1)
- We proposed the BiGRULA recurrent neural network model with topic-enhanced word embedding and an attention mechanism for sentiment classification.
- (2)
- We evaluated and showed the advantage of using topic-enhanced word embedding based on the lda2vec model for document classification compared with other text representations.
- (3)
- We evaluated and compared the performance of BiGRULA for sentiment classification with other neural network models. Our algorithm achieved an accuracy of 89.4% with 3.0% improvement over the best of three baseline algorithms.
- (4)
- We applied our BiGRULA model to a real-world hotel review comment analysis and demonstrated its capability to extract meaningful topics from the reviews and to make accurate sentiment classification.
2. Related Work
3. BiGRULA
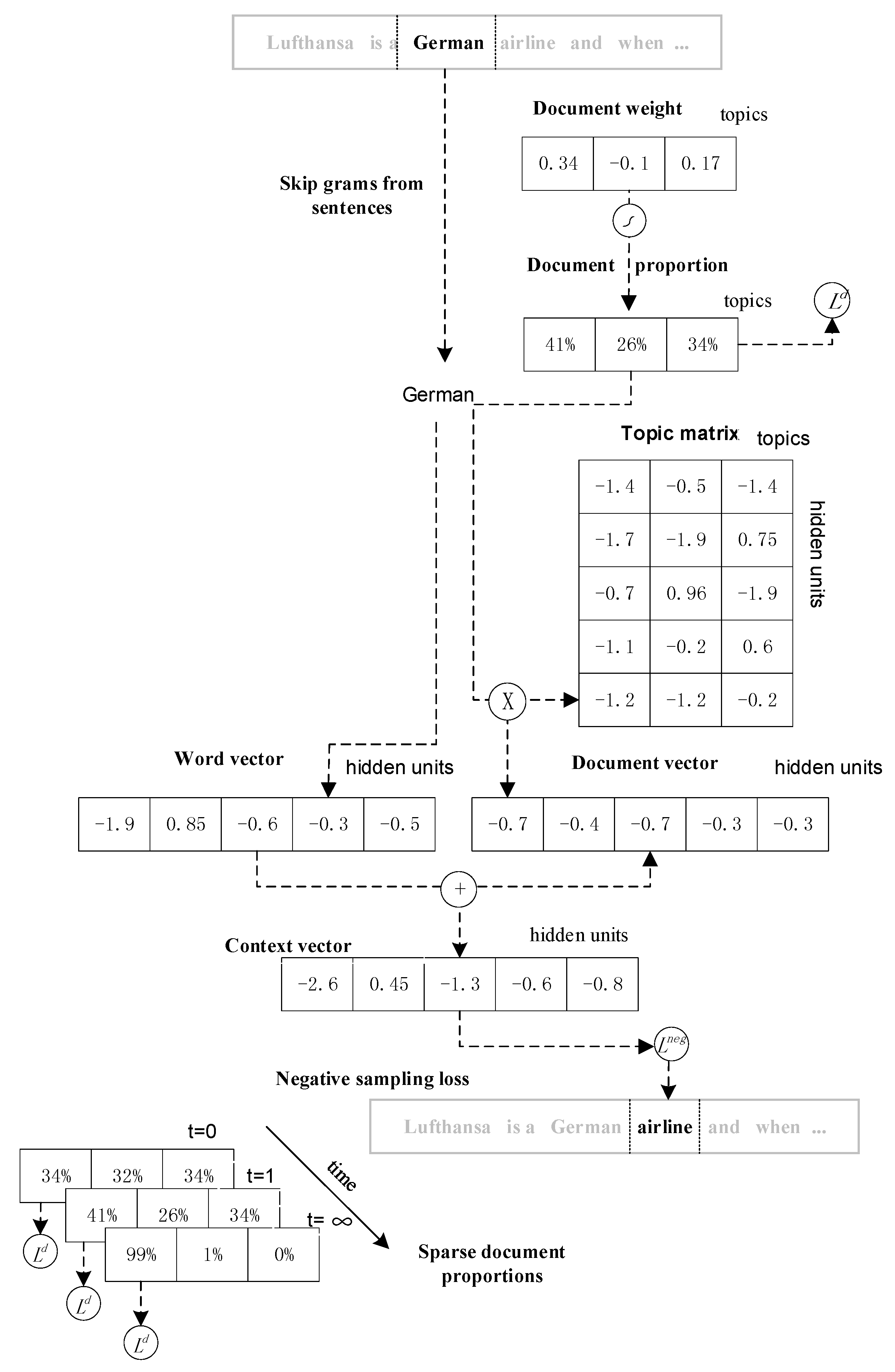
3.1. Lda2vec Architecture
3.1.1. Document Vector
3.1.2. Context Vectors
3.1.3. SGNS (Skip-Gram Negative Sampling)
3.1.4. Loss Function
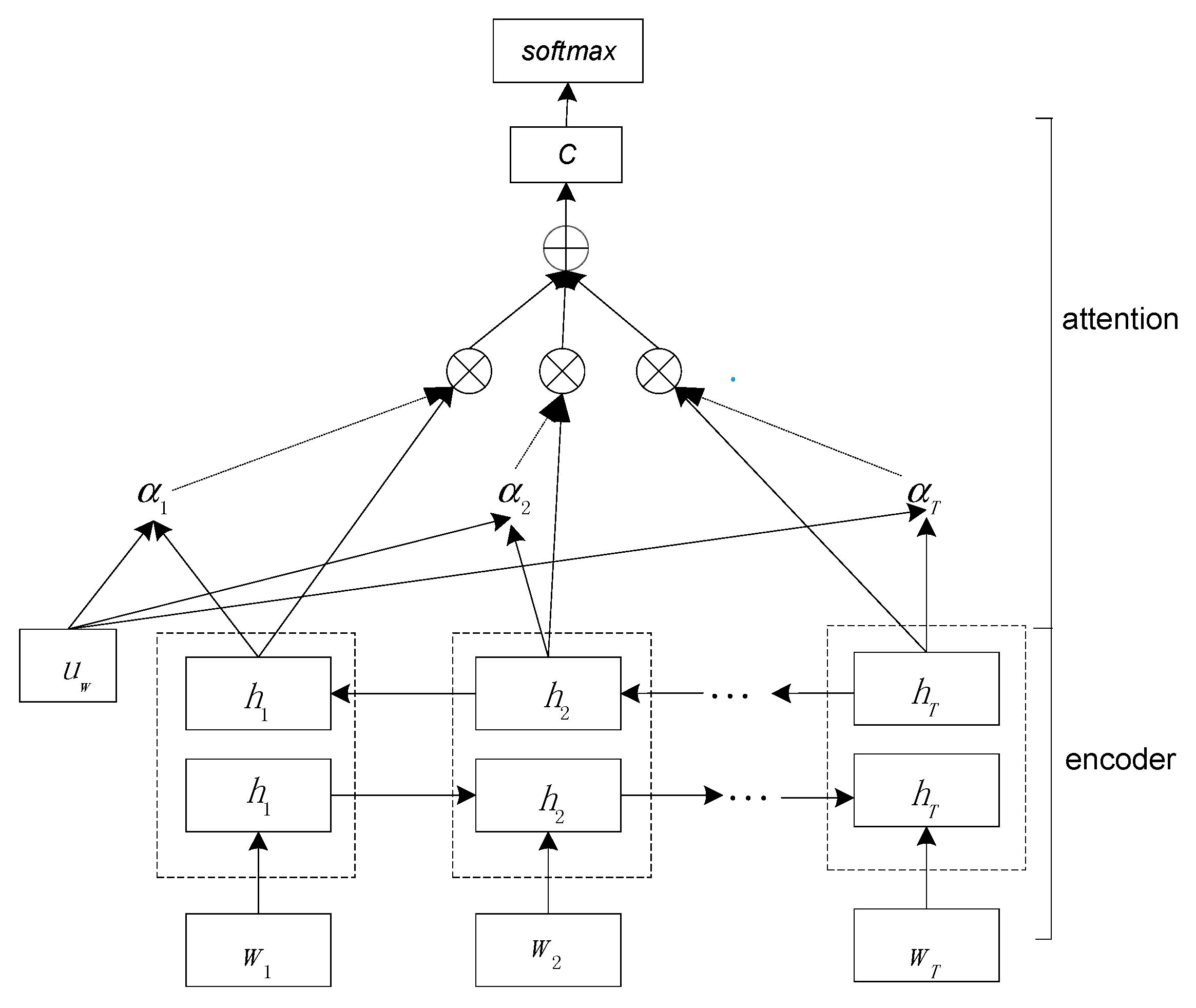
3.2. BiGRU with Attention Mechanism
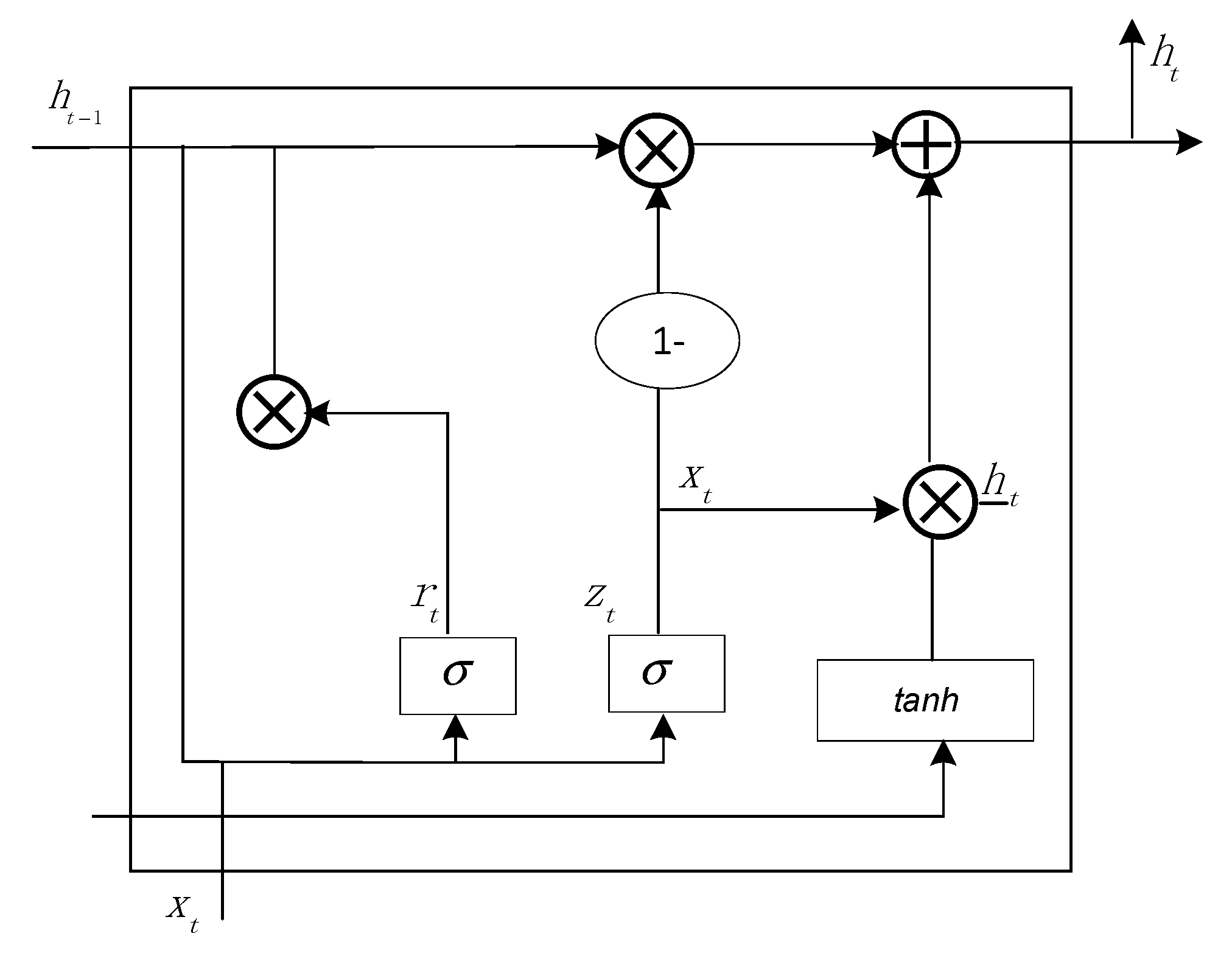
3.2.1. BiGRU
3.2.2. Attention Mechanism
3.2.3 Document Classification
4. Experiment Setting
4.1. Evaluation of Lda2vec
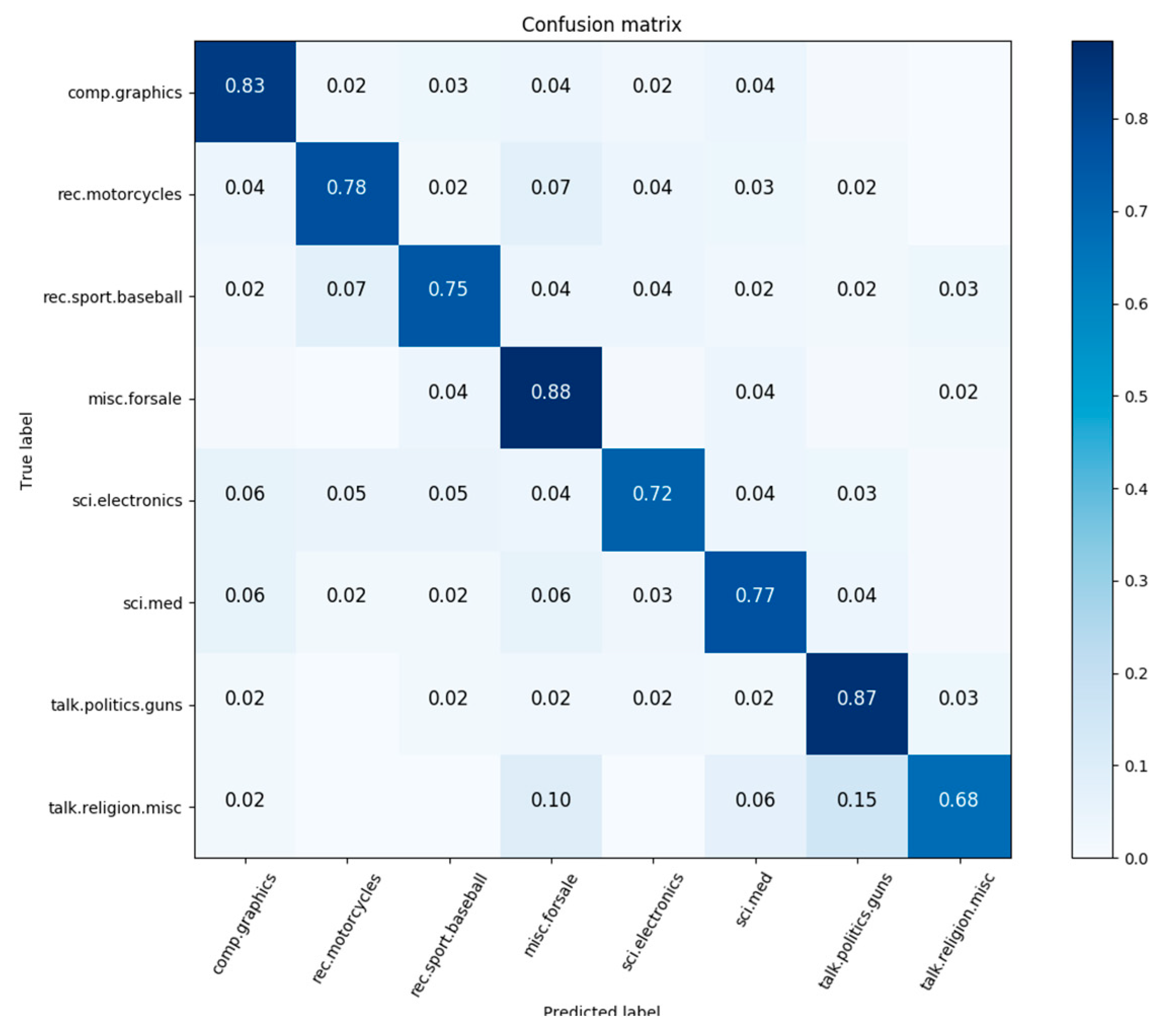
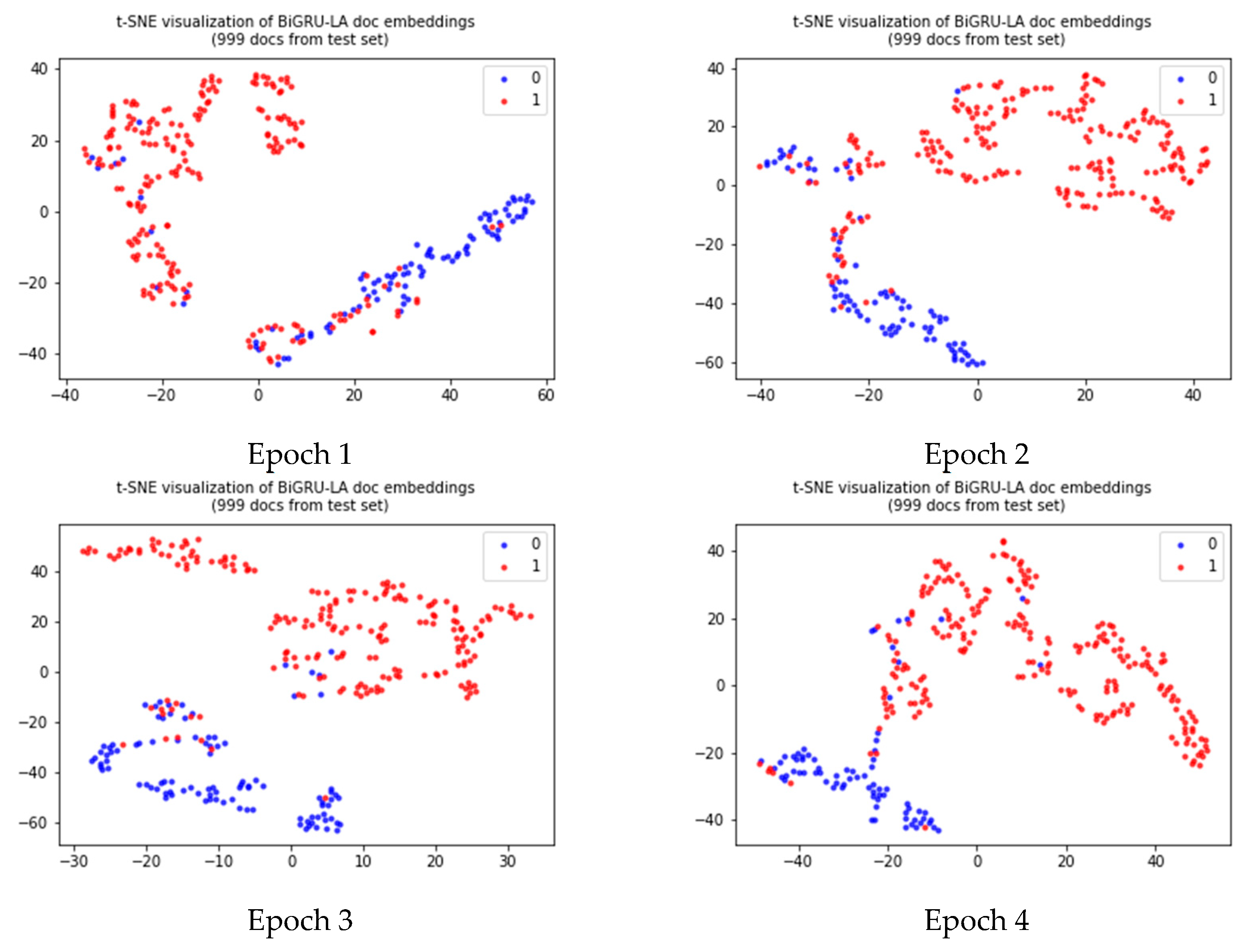
4.2. Evaluation of BiGRULA Model
4.2.1. Dataset and Parameter Settings
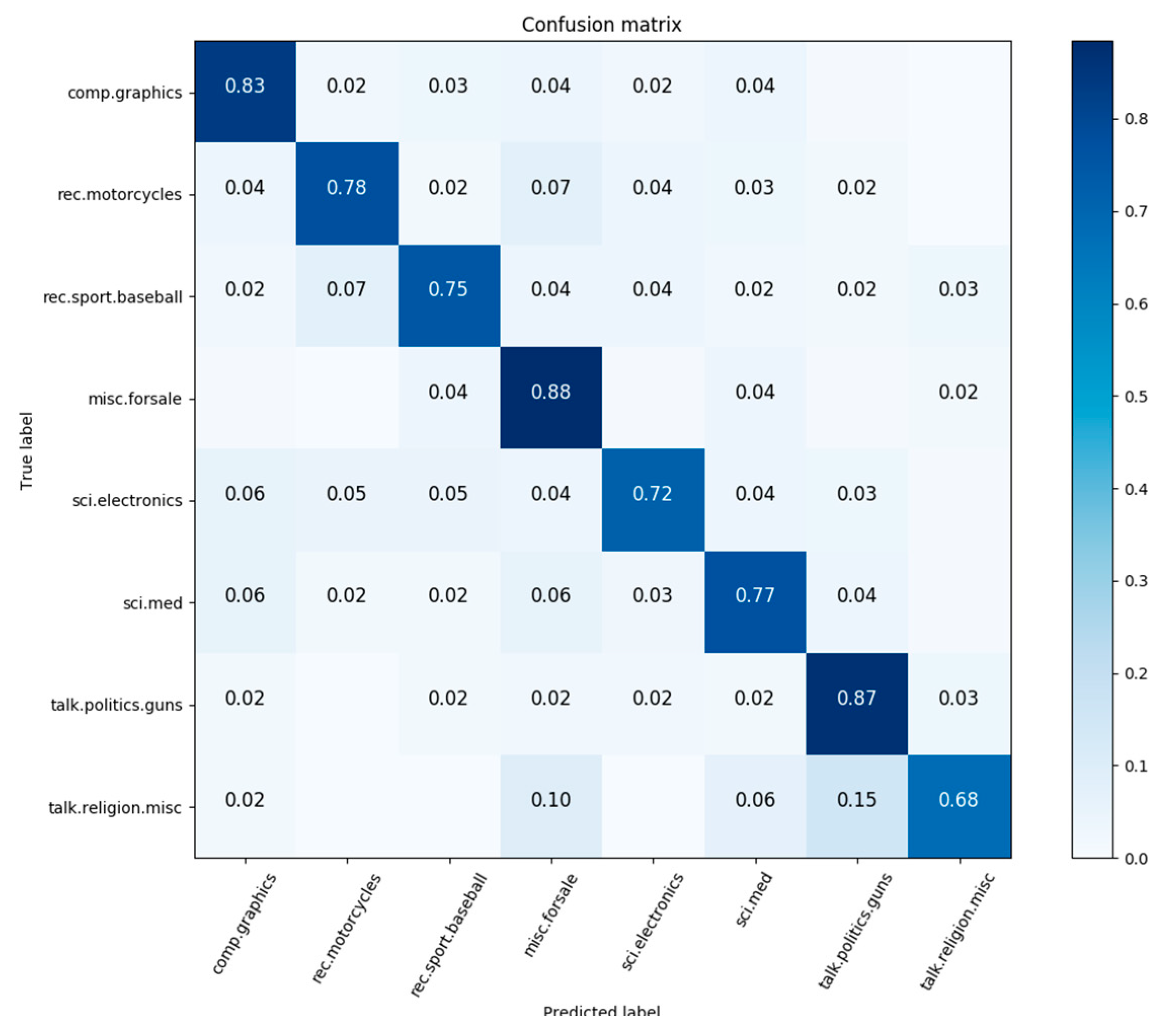
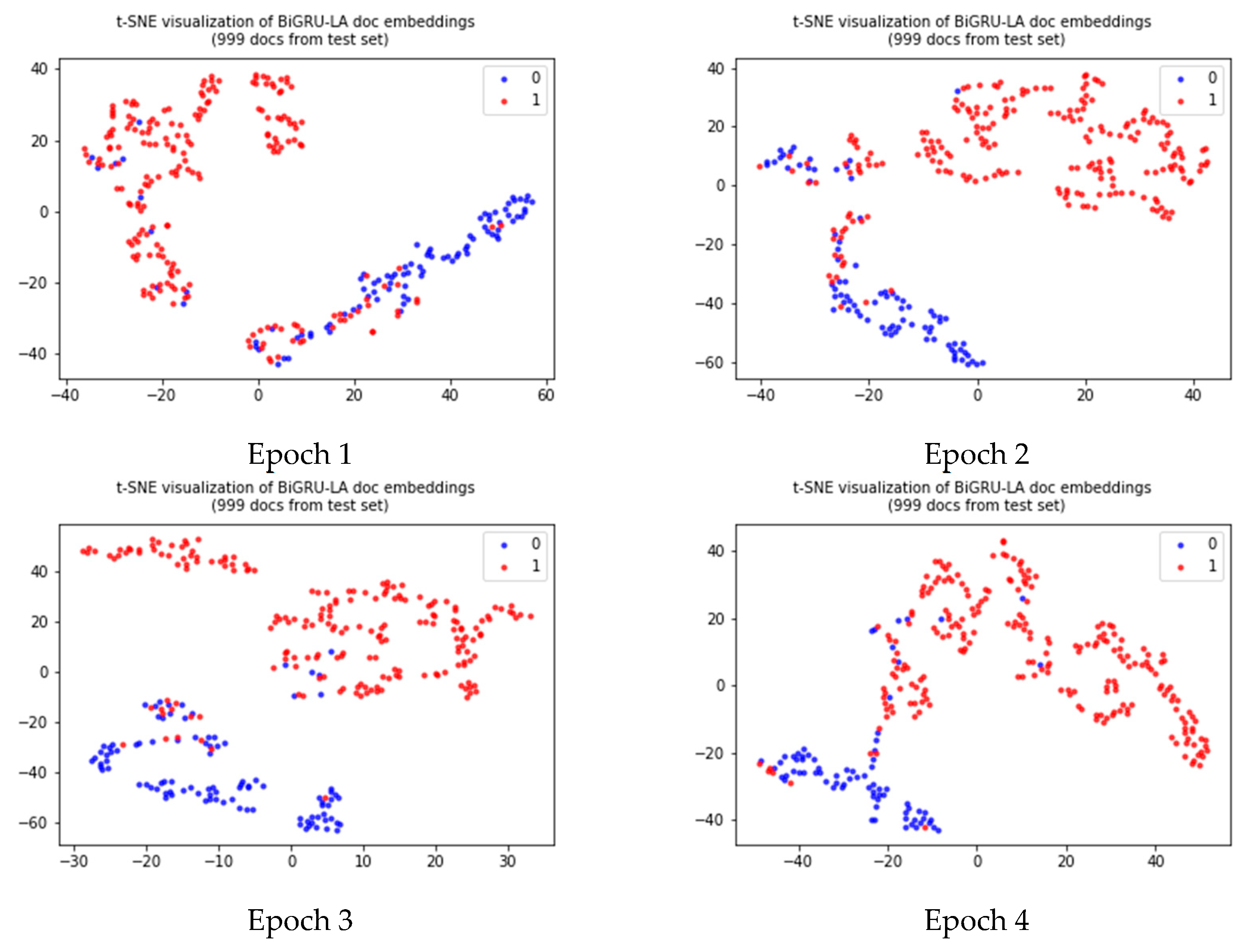
4.2.2. Results and Analysis
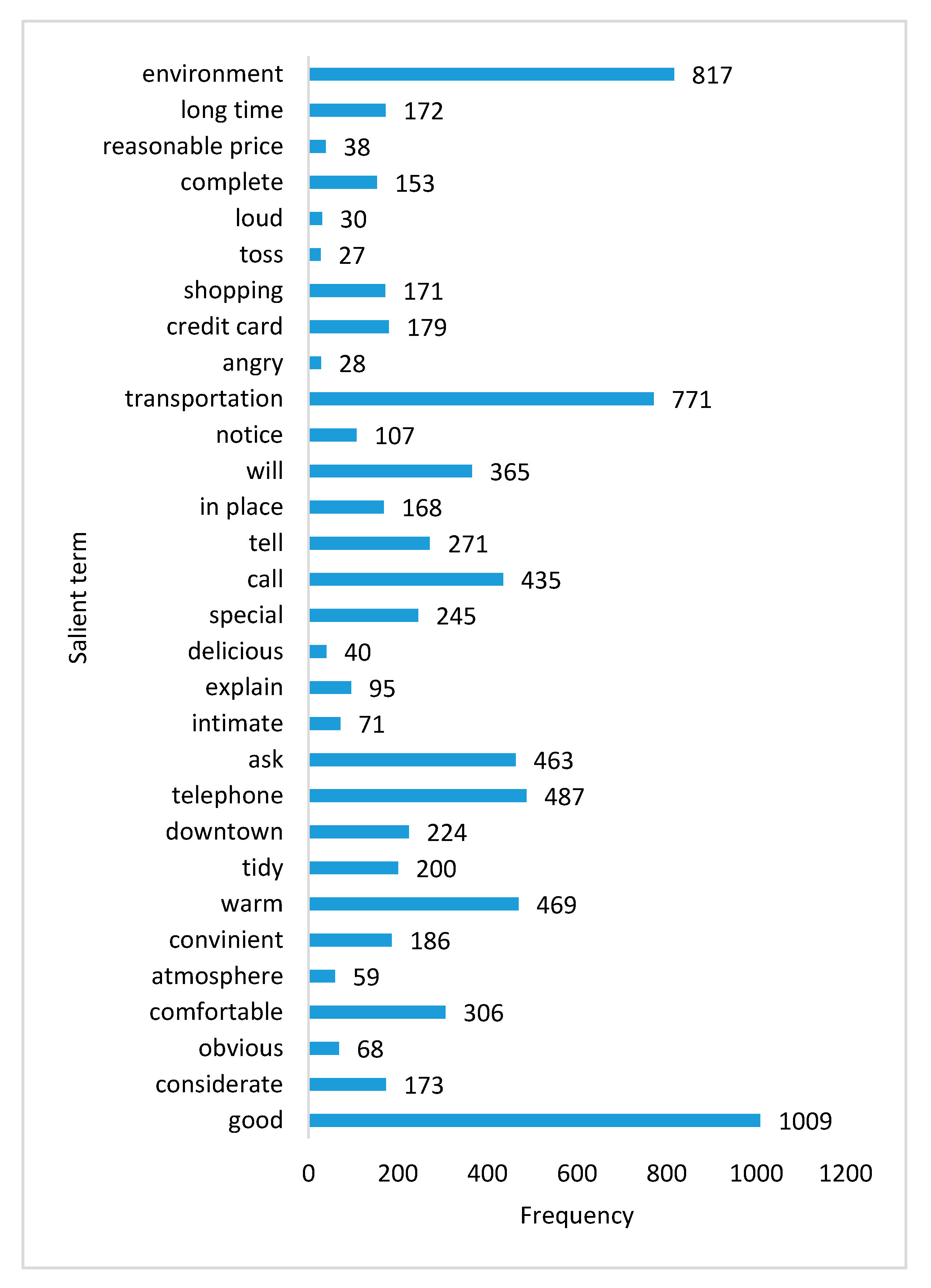
5. Application of BiGRULA to Sentiment Analysis of Tourism Reviews
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zheng, X.; Luo, Y.; Sun, L.; Zhang, J.; Chen, F. A Tourism Destination Recommender System Using Users’ Sentiment and Temporal Dynamics. J. Intell. Inform. Syst. 2018, 6, 1–22. [Google Scholar] [CrossRef]
- Ren, G.; Hong, T. Investigating Online Destination Images Using a Topic-Based Sentiment Analysis Approach. Sustainability 2017, 9, 1765. [Google Scholar] [CrossRef]
- Li, Q.; Wu, Y.; Wang, S.; Lin, M.; Feng, M.; Wang, H. VisTravel: Visualizing Tourism Network Opinion from the User Generated Content. J. Visual. 2016, 19, 489–502. [Google Scholar] [CrossRef]
- Serna, A.; Gerrikagoitia, J.K.; Bernabe, U.; Ruiz, T. A Method to Assess Sustainable Mobility for Sustainable Tourism: The Case of the Public Bike Systems. In Information and Communication Technologies in Tourism 2017; Schegg, R., Stangl, B., Eds.; Springer: Berlin, Germany, 2017. [Google Scholar]
- Application of Social Media Analytics: A Case of Analyzing Online Hotel Reviews. Available online: https://www.emeraldinsight.com/doi/abs/10.1108/OIR-07-2016-0201 (accessed on 4 September 2018).
- Tripathy, A.; Agrawal, A.; Rath, S.K. Classification of Sentiment Reviews Using N-Gram Machine Learning Approach. Expert Syst. Appl. 2016, 15, 117–126. [Google Scholar] [CrossRef]
- Hu, Y.; Li, W. Document Sentiment Classification by Exploring Description Model of Topical Terms. Comput. Speech Lang. 2011, 25, 386–403. [Google Scholar] [CrossRef]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences; Cornell University Library: New York, NY, USA, 2014. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. In Proceedings of the National Conference on Artificial Intelligence, Austin, TX, USA, 25–29 January 2015; Available online: http://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/download/9745/9552 (accessed on 4 September 2018).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. Available online: https://arxiv.org/pdf/1301.3781.pdf (accessed on 4 September 2008).
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Wang, Z.; Ma, L.; Zhang, Y. A Hybrid Document Feature Extraction Method Using Latent Dirichlet Allocation and Word2Vec. In Proceedings of the IEEE First International Conference on Data Science in Cyberspace, Changsha, China, 13–16 June 2016. [Google Scholar]
- Liu, Y.; Liu, Z.; Chua, T.; Sun, M. Topical Word Embeddings. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–29 January 2015; Available online: https://pdfs.semanticscholar.org/9a0a/f9e48aad89512ce3e24b6a1853ed3d5d9142.pdf (accessed on 4 September 2018).
- Yao, L.; Zhang, Y.; Chen, Q.; Qian, H.; Wei, B.; Hu, Z. Mining Coherent Topics in Documents Using Word Embeddings and Large-Scale Text Data. Eng. Appl. Artif. Intell. 2017, 64, 432–439. [Google Scholar] [CrossRef]
- Zhang, D.; Luo, T.; Wang, D. Learning from LDA Using Deep Neural Networks. In Natural Language Understanding and Intelligent Applications; Lin, C.Y., Xue, N., Zhao, D., Huang, X., Feng, Y., Eds.; ICCPOL 2016, NLPCC 2016, Lecture Notes in Computer Science, vol. 10102; Springer: Berlin, Germany, 2016. [Google Scholar]
- Moody, C.E. Mixing Dirichlet Topic Models and Word Embeddings to Make Lda2vec. Available online: https://www.datacamp.com/community/tutorials/lda2vec-topic-model (accessed on 4 September 2018).
- Dieng, A.B.; Wang, C.; Gao, J.; Paisley, J. TopicRNN: A Recurrent Neural Network with Long-Range Semantic Dependency. Available online: https://arxiv.org/abs/1611.01702 (accessed on 4 September 2018).
- Li, S.; Zhang, Y.; Pan, R.; Mao, M.; Yang, Y. Recurrent Attentional Topic Model. In Proceedings of the National Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Available online: http://www.shuangyin.li/publications/ratm.pdf (accessed on 4 September 2018).
- Raffel, C.; Ellis, D.P.W. Feed-Forward Networks with Attention Can Solve Some Long-Term Memory Problems. 2015. Available online: https://arxiv.org/abs/1512.08756 (accessed on 4 September 2018).
- Wang, L.; Yao, J.; Tao, Y.; Zhong, L.; Liu, W.; Du, Q. A Reinforced Topic-Aware Convolutional Sequence-to-Sequence Model for Abstractive Text Summarization. Available online: https://arxiv.org/abs/1805.03616 (accessed on 4 September 2018).
- Fan, R.; Chang, K.; Hsieh, C.; Wang, X.; Lin, C. LIBLINEAR: A Library for Large Linear Classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; Available online: http://proceedings.mlr.press/v32/le14.pdf (accessed on 4 September 2018).
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011. [Google Scholar]
- Chen, X.; Xue, Y.; Zhao, H.; Liu, X.; Hu, X.; Ma, Z. A Novel Feature Extraction Methodology for Sentiment Analysis of Product Reviews. Neural Comput. Appl. 2018, 4, 1–18. [Google Scholar] [CrossRef]
- Zhu, J.; Yu, W. Binary Sentiment Analysis on IMDb Movie Reivews. Available online: https://cseweb.ucsd.edu/classes/wi17/cse258-a/reports/a055.pdf (accessed on 4 September 2018).
- Tan, S. ChnSentiCorp-Htl-unba-10000. Available online: https://download.csdn.net/download/sinat_30045277/9862005 (accessed on 5 September 2018).
- Li, S. sgns.Weibo.word. Available online: http://github.com/Embedding/Chinese-Word-Vectors (accessed on 5 September 2018).
- Sievert, C.; Shirley, K.E. LDAvis: A Method for Visualizing and Interpreting Topics. In Proceedings of the Workshop on Interactive Language Learning, Baltimore, MD, USA, 27 June 2014. [Google Scholar]
- Chuang, J.; Manning, C.D.; Heer, J. Termite: Visualization Techniques for Assessing Textual Topic Models. in Advanced Visual Interfaces. Available online: http://vis.stanford.edu/files/2012-Termite-AVI.pdf (accessed on 4 September 2018).
- Hinton, G.E. Visualizing High-Dimensional Data Using t-SNE. Available online: http://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf (accessed on 4 September 2018).
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Precision | Recall | F-Measure |
|---|---|---|---|---|
| BOW | 79.2% | 79.5% | 79.0% | 79.0% |
| LDA | 72.2% | 70.8% | 70.7% | 70.0% |
| Skip-Gram | 75.4% | 75.1% | 74.3% | 74.2% |
| PV-DM | 72.4% | 72.1% | 71.5% | 71.5% |
| PV-DBOW | 75.4% | 74.9% | 74.3% | 74.3% |
| Glove | 76.6% | 76.7% | 76.5% | 76.5% |
| lda2vec | 80.2% | 81.1% | 80.0% | 80.0% |
| Model | Train set | Test set | |||
|---|---|---|---|---|---|
| Loss | Accuracy | Loss | Accuracy | ||
| BiGRU with attention | Word Embedding | ||||
| Random | 0.177 | 0.944 | 0.357 | 0.864 | |
| Skip-gram | 0.179 | 0.927 | 0.314 | 0.869 | |
| Glove | 0.170 | 0.945 | 0.375 | 0.872 | |
| Lda2vec | 0.211 | 0.914 | 0.259 | 0.894 | |
| CNN | 0.230 | 0.907 | 0.287 | 0.881 | |
| LSTM | 0.011 | 0.997 | 1.094 | 0.812 | |
| CNN + LSTM | 0.198 | 0.925 | 0.346 | 0.858 | |
| G_TF-IDF + FPCD + NB [24] | -- | -- | -- | 0.870 | |
| Word2vec + KNN [24] | -- | -- | -- | 0.773 | |
| FPCD + SVM [24] | -- | -- | -- | 0.857 | |
| N-gram + SVM [6] | -- | -- | -- | 0.889 | |
| N-gram + NB [6] | -- | -- | -- | 0.862 | |
| N-gram + ME [6] | -- | -- | -- | 0.885 | |
| Word2vec + LR [25] | -- | -- | -- | 0.847 | |
| LDA | lda2vec | |
|---|---|---|
| topic 0 | careful; Shandong; you; sleeps; takes; counter; off-season; Sanya; usually | hotel; service; environment; transportation; taxi; opposite; shopping; credit card |
| topic 1 | you; experience; rotate; for a while; reserved rights; cold; enough; switch | room; bathroom; too; carpet; facility; stale; small; poor |
| topic 2 | you; counter; rotate; carefully; reserved; for a while; rights; recruitment; talent | service; Comfortable; enthusiasm; hotel; feel; attentive; features; tell |
| topic 3 | you; bank; careful; signing; settlement | check-in; service; hotel; waiter; room; front desk; warm; guest |
| topic 4 | calling; most; expensive; ladies; items; thank you very much; direction | front desk; ask; phone; tell; Ctrip; waiter; call |
| topic 5 | you; reserved; rotate; rights; careers; copyright1999; agent; advertising business; experience | room; nice; large; bathroom; bed; feeling; facilities; comfortable |
| topic 6 | too few; rotations; enough; counters; most; settlements; a while; banks; off-season; usually | room; check-in; feel; facilities; clean; comfortable; disadvantages; will |
| topic 7 | Careful; slightly; picking up; Shandong; Zhengzhou; expensive; rotating; enough; one bottle; climb | breakfast; hotel; eat; restaurant; variety; taxi; price; delicious |
| topic 8 | you; Shandong; you; apologize; experience; careful; related; Square meters; bank; thank you very much. | hotel; transportation; downtown; price; airport; service; next time |
| topic 9 | you; settlement; counter; a little bit; make; front, climbing; direction; picking up | sound; room; night; soundproofing; hygienic; air conditioning; bathroom; windows |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Li, S.; Hu, J.; Zhang, S.; Hu, J. Tourism Review Sentiment Classification Using a Bidirectional Recurrent Neural Network with an Attention Mechanism and Topic-Enriched Word Vectors. Sustainability 2018, 10, 3313. https://doi.org/10.3390/su10093313
Li Q, Li S, Hu J, Zhang S, Hu J. Tourism Review Sentiment Classification Using a Bidirectional Recurrent Neural Network with an Attention Mechanism and Topic-Enriched Word Vectors. Sustainability. 2018; 10(9):3313. https://doi.org/10.3390/su10093313
Chicago/Turabian StyleLi, Qin, Shaobo Li, Jie Hu, Sen Zhang, and Jianjun Hu. 2018. "Tourism Review Sentiment Classification Using a Bidirectional Recurrent Neural Network with an Attention Mechanism and Topic-Enriched Word Vectors" Sustainability 10, no. 9: 3313. https://doi.org/10.3390/su10093313
APA StyleLi, Q., Li, S., Hu, J., Zhang, S., & Hu, J. (2018). Tourism Review Sentiment Classification Using a Bidirectional Recurrent Neural Network with an Attention Mechanism and Topic-Enriched Word Vectors. Sustainability, 10(9), 3313. https://doi.org/10.3390/su10093313