A Machine Learning Approach to the Residential Relocation Distance of Households in the Seoul Metropolitan Region


Abstract
:1. Introduction
2. Literature Review
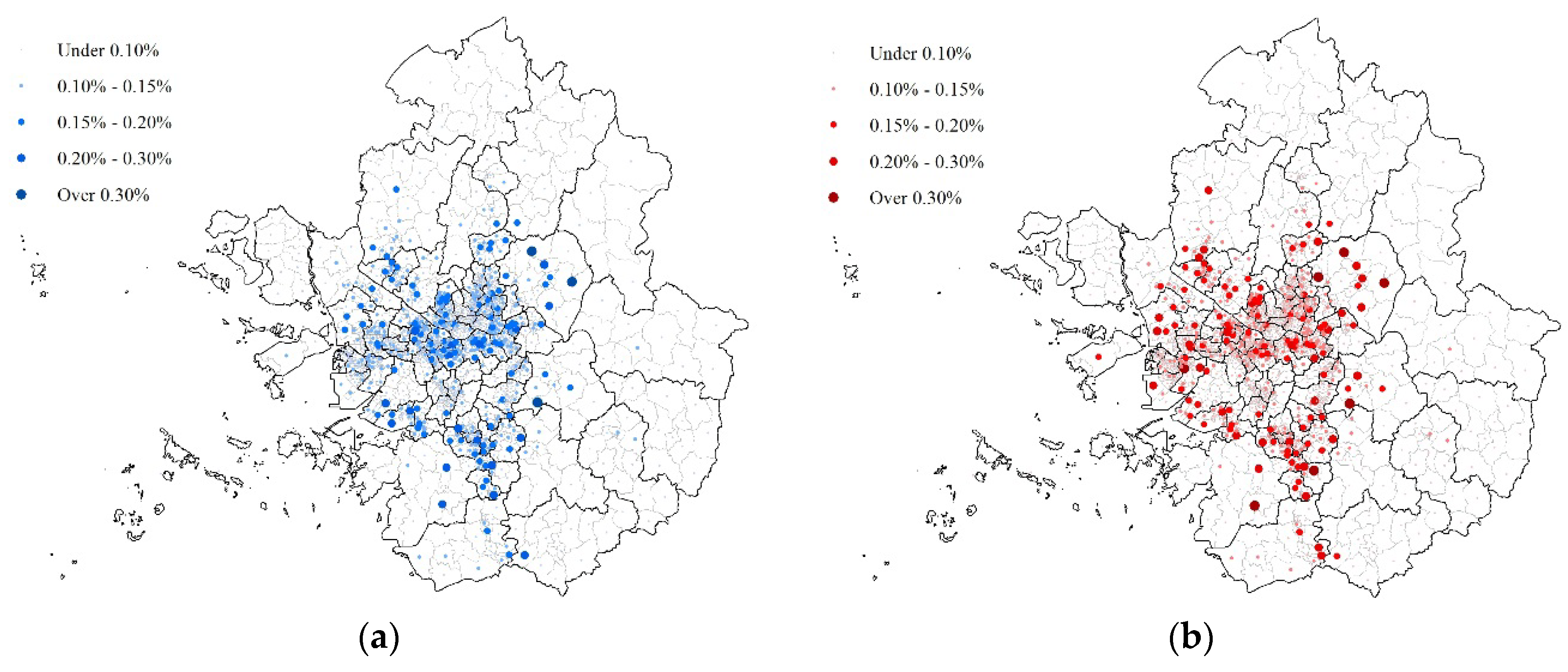
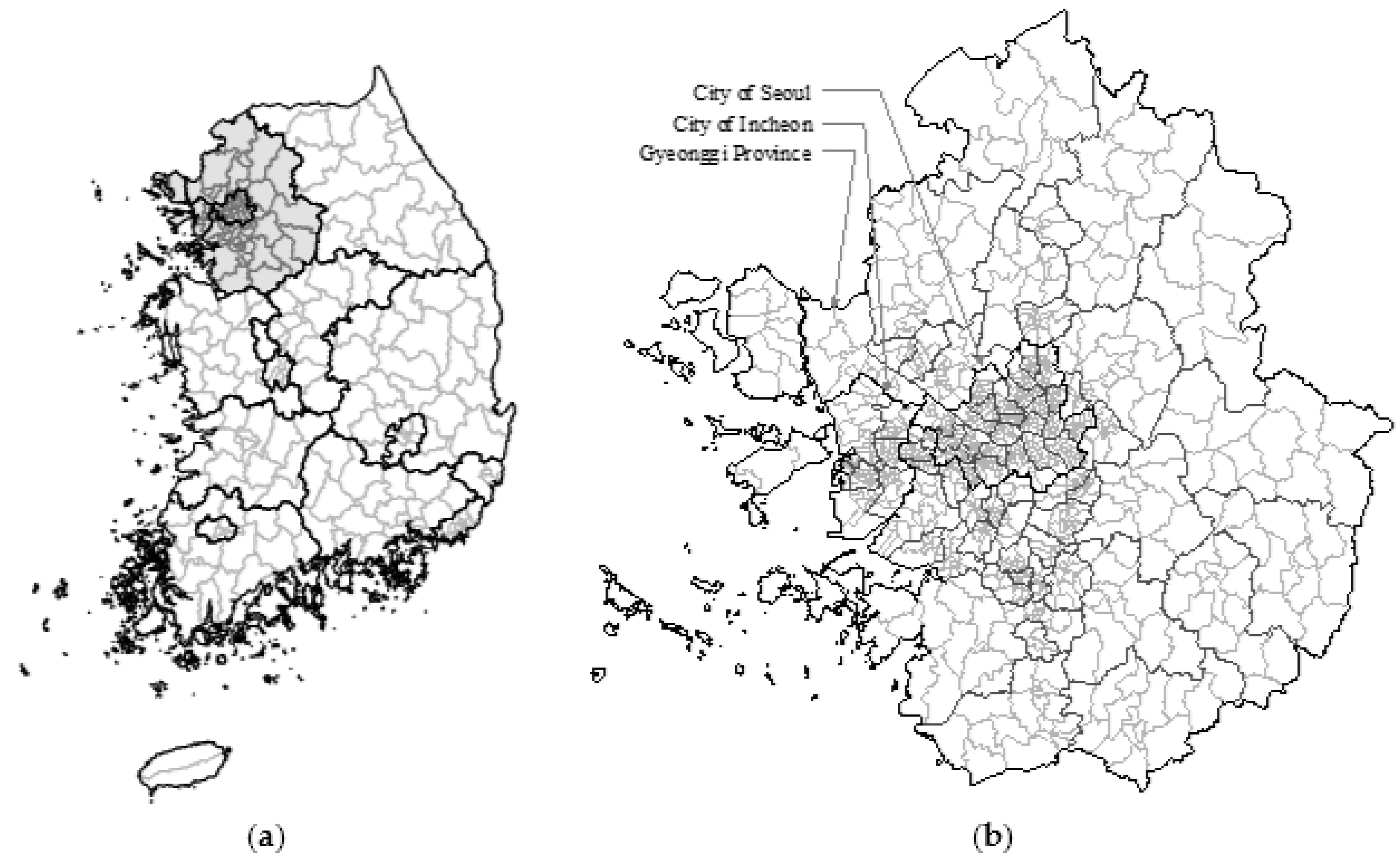
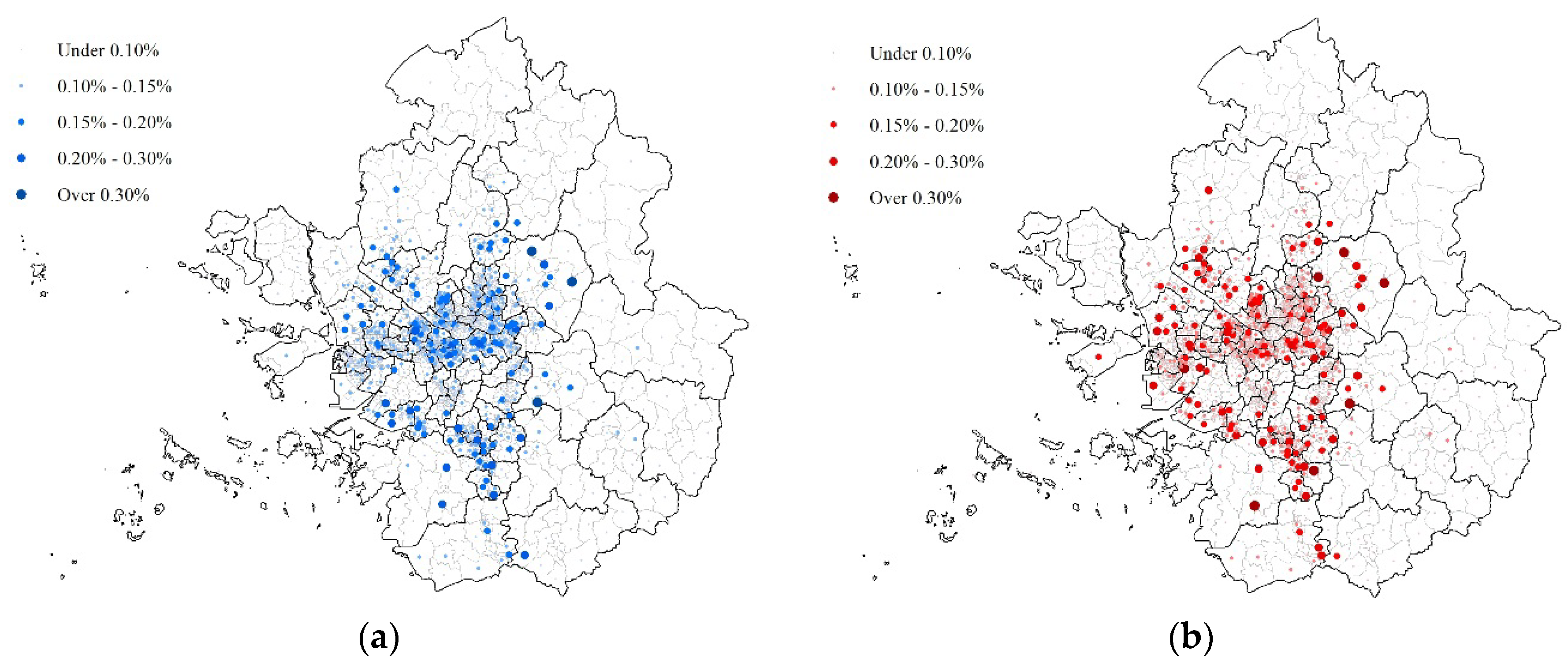
3. Characteristics of Residential Relocation Distance in SMR
4. Materials and Methods
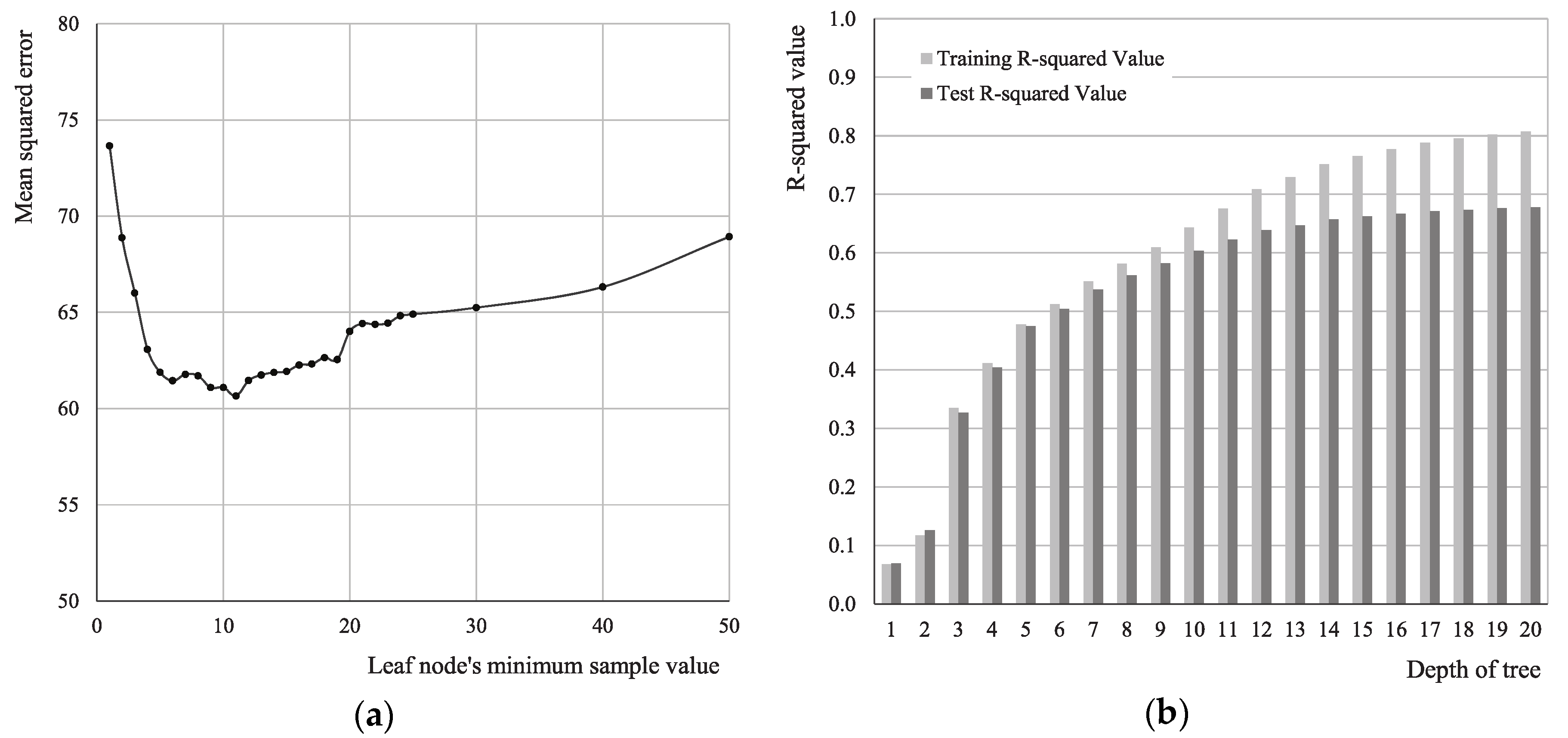
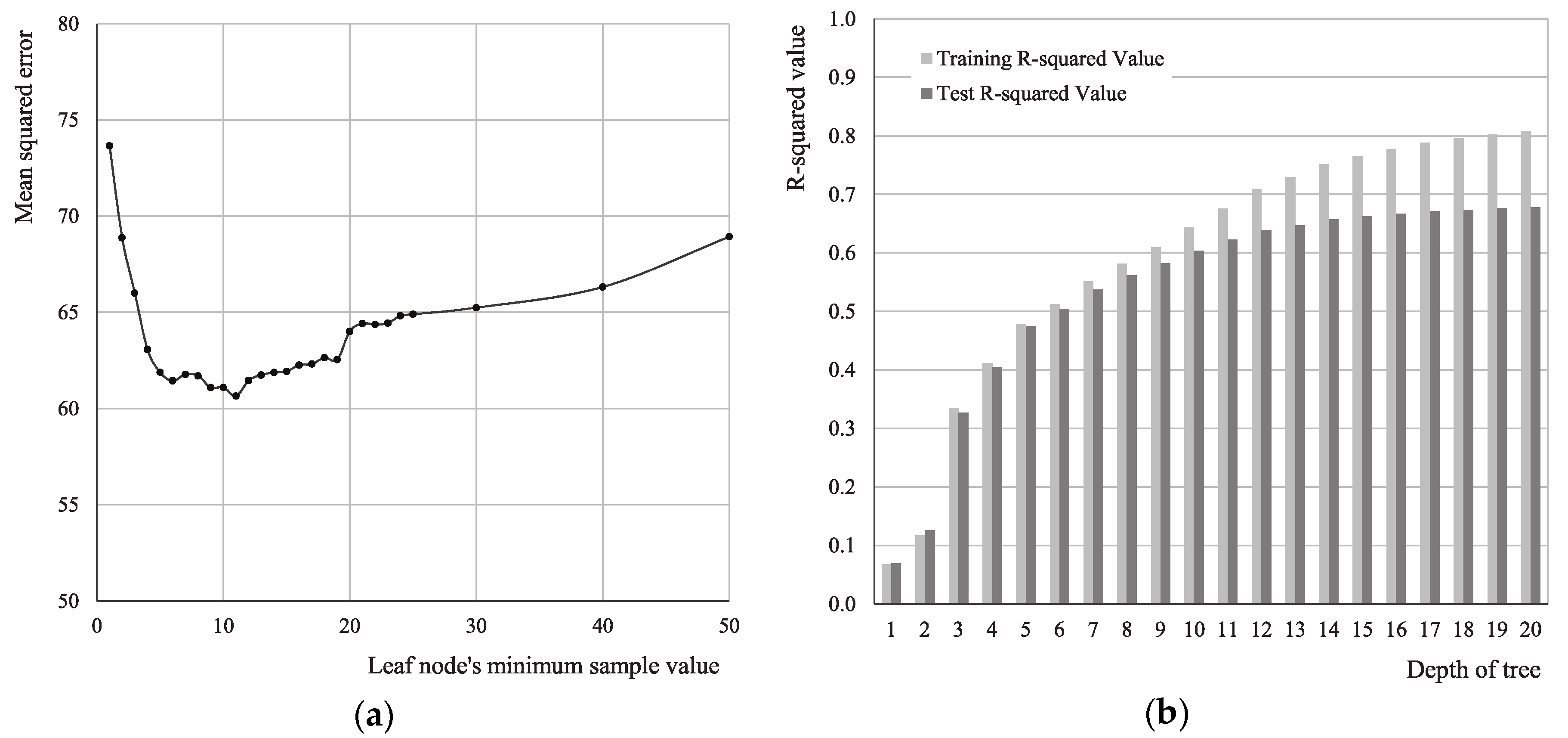
4.1. Decision Tree Using Machine Learning
4.2. Selection of Explanatory Variables and Generation of Analysing Data
4.3. Descriptive Statistics
5. Results and Discussion
5.1. Comparison of the Empirical Results Between Ordinary Least Squares and Decision Tree Regressions
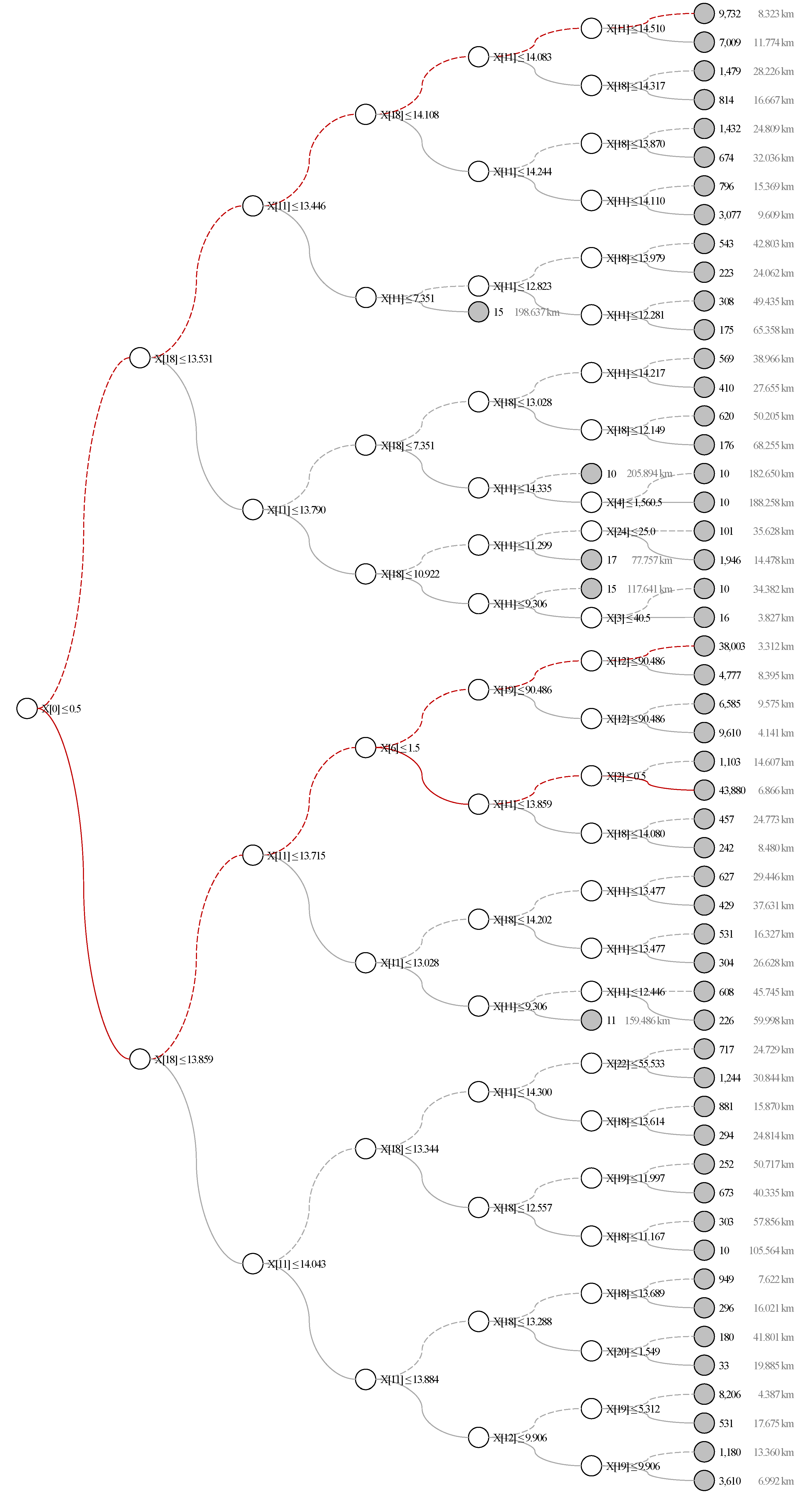
5.2. Application of Ordinary Least Squares Regression and Decision Tree Regression Models
6. Summary and Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix B
References
- Seo, D.; Kwon, Y. In-migration and housing choice in Ho Chi Minh City: Toward sustainable housing development in Vietnam. Sustainability 2017, 9, 1738. [Google Scholar] [CrossRef]
- Rossi, P.H. Why Families Move: A Study in The Social Psychology of Urban Residential Mobility; Free Press: New York, NY, USA, 1955. [Google Scholar]
- Hoyt, H. The Structure and Growth of Residential Neighborhoods in American Cities; U.S. Government Printing Office: Washington, DC, USA, 1939.
- Ravenstein, E.G. The Laws of Migration. J. Stat. Soc. Lond. 1885, 48, 167–235. [Google Scholar] [CrossRef]
- Park, E.; Lee, J.W. A study on policy literacy and public attitudes toward government innovation-focusing on Government 3.0 in South Korea. J. Open Innov. Technol. Mark. Complex. 2015, 1, 1–13. [Google Scholar] [CrossRef]
- Nho, H.J. Research ethics education in Korea for overcoming culture and value system differences. J. Open Innov. Technol. Mark. Complex. 2016, 2, 1–11. [Google Scholar] [CrossRef]
- Yi, C.; Lee, S. An empirical analysis of the characteristics of residential location choice in the rapidly changing Korean housing market. Cities 2014, 39, 156–163. [Google Scholar] [CrossRef]
- OECD. OECD Regions at a Glance 2016; OECD Publishing: Paris, France, 2016; ISBN 9789264252097. [Google Scholar]
- Kwon, W.Y. An examination of residential location behavior in the Seoul metropolitan area. Ann. Reg. Sci. 1984, 18, 33–48. [Google Scholar] [CrossRef]
- The Seoul Institute. Seoul Statistical Series Section 04. Housing; The Seoul Institute: Seoul, Korea, 2014.
- Hong, S.; Lee, Y. Limitation of residential mobility distance in seoul metropolitan area -focused on migration region and family size-. Korea Real Estate Acad. Rev. 2015, 60, 115–126. [Google Scholar]
- Brown, L.A.; Moore, E.G. The inter-urban migration process: A perspective. Geogr. Ann. Ser. B Hum. Geogr. 1970, 52, 1–13. [Google Scholar] [CrossRef]
- Chun, H.S. The characteristics of housing mobility of the residents’ in new town areas. Gyeonggi Forum 2004, 6, 91–111. [Google Scholar]
- Wu, F. Intraurban residential relocation in Shanghai: Modes and stratification. Environ. Plan. A 2004, 36, 7–25. [Google Scholar] [CrossRef]
- Moore, E.G. Residential Mobility in The City; Association of American Geographers: Washington, DC, USA, 1972. [Google Scholar]
- Loren, D.L.; Eva, K.; Boaz, K. Residential relocation of amenity migrants to Florida: “Unpacking” post-amenity moves. J. Aging Health 2010, 22, 1001–1028. [Google Scholar] [CrossRef]
- Lee, B.H.Y.; Paul, W. Residential mobility and location choice: A nested logit model with sampling of alternatives. Transportation (Amst.) 2010, 37, 587–601. [Google Scholar] [CrossRef]
- Stapleton, C.M. Reformulation of the family life-cycle concept: Implications for residential mobility. Environ. Plan. A 1980, 12, 1103–1118. [Google Scholar] [CrossRef]
- Pickvance, C.G. Life cycle, housing tenure and residential mobility: A path analytic approach. Urban Stud. 1974, 11, 171–188. [Google Scholar] [CrossRef]
- Morris, E.W.; Crull, S.R.; Winter, M. Housing Norms, housing satisfaction and the propensity to move. J. Marriage Fam. 1976, 38, 309–320. [Google Scholar] [CrossRef]
- Chevan, A. Family growth, household density, and moving. Demography 1971, 8, 451–458. [Google Scholar] [CrossRef] [PubMed]
- Eluru, N.; Sener, I.N.; Bhat, C.R.; Pendyala, R.M.; Axhausen, K.W. Understanding residential mobility: joint model of the reason for residential relocation and stay duration. Transp. Res. Rec. 2009, 2133, 64–74. [Google Scholar] [CrossRef]
- Zanganeh, Y.; Hamidian, A.; Karimi, H. The analysis of factors affecting the residential mobility of afghan immigrants residing in mashhad (case study: Municipality regions 4, 5 and 6). Asian Soc. Sci. 2016, 12, 61–69. [Google Scholar] [CrossRef]
- Ha, S.K. Housing Policy and Practice in Korea, 3rd ed.; Pakyoungsa: Seoul, Korea, 2006. [Google Scholar]
- Min, B.; Byun, M. Residential mobility of the population of seoul: Spatial analysis and the classification of residential mobiltiy. Seoul Stud. 2017, 18, 850102. [Google Scholar]
- Clark, W.A.V.; Onaka, J.L. Life cycle and housing adjustment as explanations of residential mobility. Urban Stud. 1983, 20, 47–57. [Google Scholar] [CrossRef]
- Yi, C.; Lee, S. Analyzing the factors on residential mobility according to the household member’s change—In consideration of residential duration of the households in the Seoul metropolitan area. J. Korea Plan. Assoc. 2012, 47, 205–217. [Google Scholar]
- Yee, W.; van Arsdol, M.D.J. Residential mobility, age, and the life cycle. J. Gerontol. 1977, 32, 211–221. [Google Scholar] [CrossRef]
- Clark, W.A.V. Life course events and residential change: Unpacking age effects on the probability of moving. J. Popul. Res. 2013, 30, 319–334. [Google Scholar] [CrossRef]
- Burnley, I.H.; Murphy, P.A.; Jenner, A. Selecting suburbia: Residential relocation to outer Sydney. Urban Stud. 1997, 34, 1109–1127. [Google Scholar] [CrossRef]
- Yang, J. Transportation implications of land development in a transitional economy: Evidence from housing relocation in Beijing. Transp. Res. Rec. 1996, 1954, 7–14. [Google Scholar] [CrossRef]
- Clark, W.A.V.; Dieleman, F.M. Households and Housing: Choice and Outcomes in The Housing Market; Center for Urban Policy Research: New Brunswick, NJ, USA, 1996; ISBN 9780882851563. [Google Scholar]
- Dieleman, F.M. Modelling residential mobility: A review of recent trends in research. J. Hous. Built Environ. 2001, 16, 249–265. [Google Scholar] [CrossRef]
- Niedomysl, T. How migration motives change over migration distance: Evidence on variation across socio-economic and demographic groups. Reg. Stud. 2011, 45, 843–855. [Google Scholar] [CrossRef]
- Niedomysl, T.; Fransson, U. On distance and the spatial dimension in the definition of internal migration. Ann. Assoc. Am. Geogr. 2014, 104, 357–372. [Google Scholar] [CrossRef]
- Niedomysl, T.; Ernstson, U.; Fransson, U. The accuracy of migration distance measures. Popul. Space Place 2017, 23. [Google Scholar] [CrossRef]
- Shalev-Shwartz, S.; Ben-david, S. Understanding Machine Learning: From Theory to Algorithms, 1st ed.; Cambridge University Press: New York, NY, USA, 2014; ISBN 9781107057135. [Google Scholar]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques, 2nd ed.; Morgan Kaufmann: San Francisco, CA, USA, 2005; ISBN 0120884070. [Google Scholar]
- Zhang, H.; Wu, P.; Yin, A.; Yang, X.; Zhang, M.; Gao, C. Prediction of soil organic carbon in an intensively managed reclamation zone of eastern China: A comparison of multiple linear regressions and the random forest model. Sci. Total Environ. 2017, 592, 704–713. [Google Scholar] [CrossRef] [PubMed]
- Estelles-lopez, L.; Ropodi, A.; Pavlidis, D.; Fotopoulou, J.; Gkousari, C.; Peyrodie, A.; Panagou, E.; Nychas, G.J.; Mohareb, F. An automated ranking platform for machine learning regression models for meat spoilage prediction using multi-spectral imaging and metabolic profiling. Food Res. Int. 2017, 99, 206–215. [Google Scholar] [CrossRef] [PubMed]
- Chagas, C.; Junior, W.; Bhering, S.; Filho, B. Spatial prediction of soil surface texture in a semiarid region using random forest and multiple linear regressions. Catena 2016, 139, 232–240. [Google Scholar] [CrossRef]
- Oliveira, M.; Gama, J. An overview of social network analysis. WIREs Data Min. Knowl. Discov. 2012, 2, 99–105. [Google Scholar] [CrossRef]
- Tso, G.K.F.; Yau, K.K.W. Predicting electricity energy consumption: A comparison of regression analysis, decision tree and neural networks. Energy 2007, 32, 1761–1768. [Google Scholar] [CrossRef]
- Xu, M.; Watanachaturaporn, P.; Varshney, P.K.; Arora, M.K. Decision tree regression for soft classification of remote sensing data. Remote Sens. Environ. 2005, 97, 322–336. [Google Scholar] [CrossRef]
- Prasad, A.M.; Iverson, L.R.; Liaw, A. Newer classification and regression tree techniques: bagging and random forests for ecological prediction. Ecosystems 2006, 9, 181–199. [Google Scholar] [CrossRef]
- Hansen, W.G. How accessibility shapes land use. J. Am. Inst. Plann. 1959, 25, 73–76. [Google Scholar] [CrossRef]
- Wilson, A.G. Entropy in Urban and Regional Modeling; Pion: London, UK, 1970. [Google Scholar]
- Yi, Y.; Kim, E.; Choi, E. Linkage among school performance, housing prices, and residential mobility. Sustainability 2017, 9, 1075. [Google Scholar] [CrossRef]
- Choi, Y.; Yim, H.K. Determinants of the Residents’ Settlements Employing Poission Regression. Korea Spat. Plan. Rev. 2005, 46, 99–114. [Google Scholar]
- Pagliara, F.; Simmonds, D. Conclusions. In Residential Location Choice-Models and Applications; Pagliara, F., Preston, J., Simmonds, D., Eds.; Springer: Berlin, Germany, 2010; pp. 243–248. [Google Scholar]
- Simmonds, D. The DELTA residential location model. In Residential Location Choice-Models and Applications; Pagliara, F., Preston, J., Simmonds, D., Eds.; Springer: Berlin, Germany, 2010; pp. 77–97. [Google Scholar]
- Waddell, P. Modelling residential location in UrbanSim. In Residential Location Choice-Models and Applications; Pagliara, F., Preston, J., Simmonds, D., Eds.; Springer: Berlin, Germany, 2010; pp. 165–180. [Google Scholar]
- Cadwallader, M. Migration and Residential Mobility: Macro and Micro Approaches; University of Wisconsin Press: Madision, WI, USA, 1992. [Google Scholar]
- Cluttons. Residential Mobility in London: Unlocking Migration Patterns; Cluttons LLP: London, UK, 2017. [Google Scholar]
- Mueller, A.C.; Guido, S. Introduction to Machine Learning With Python; O’Reilly: Sebastopol, CA, USA, 2016; ISBN 9781491917213. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
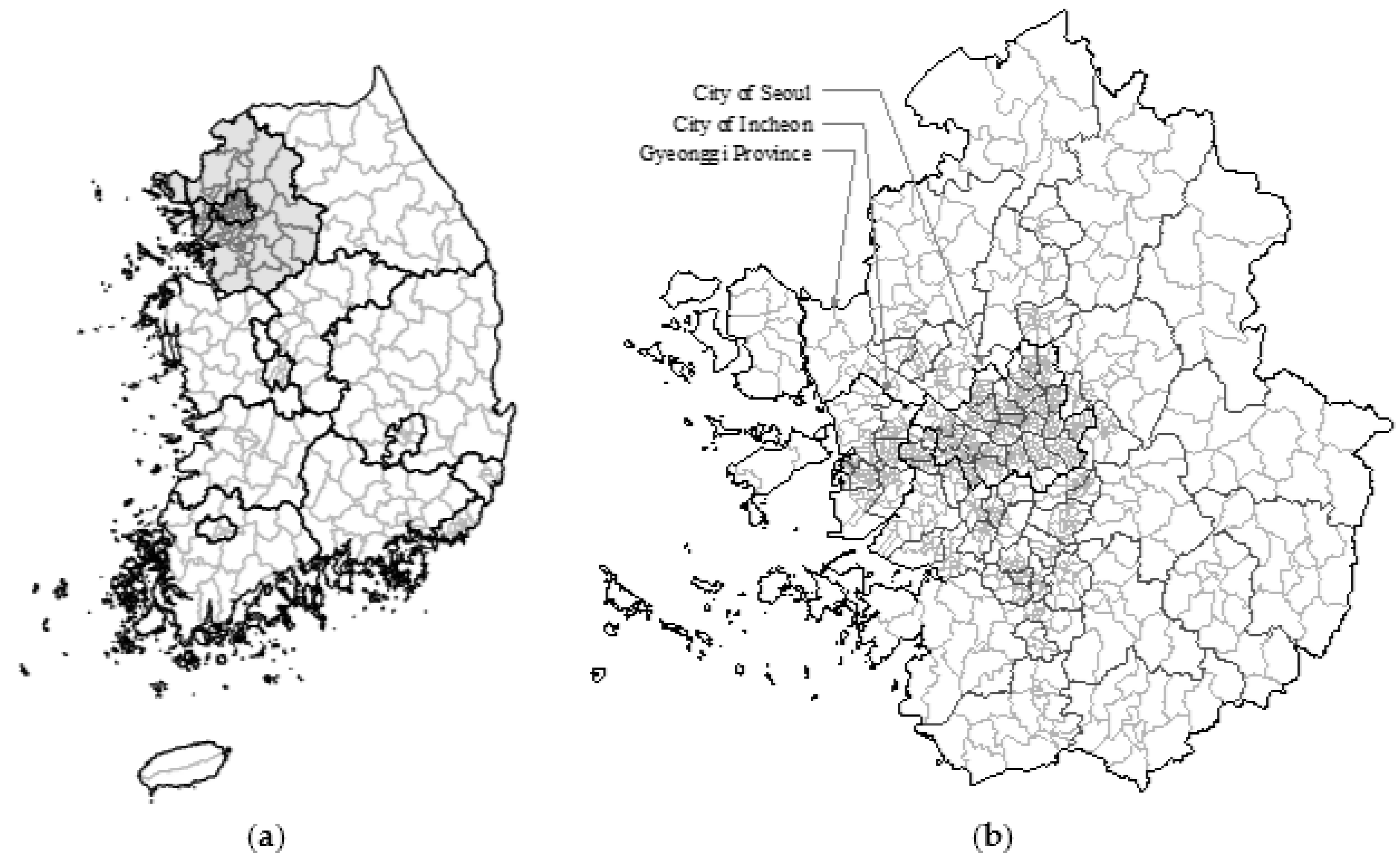
| Item | Total | Seoul | Incheon | Gyeonggi | |
|---|---|---|---|---|---|
| Population (million people) | 23.906 | 9.395 | 2.767 | 11.744 | |
| Household (million households) | 9.519 | 3.915 | 1.066 | 4.538 | |
| Area (km2) | 11,828 | 605 | 1048 | 10,175 | |
| City, county and borough level | Si | 28 | - | - | 28 |
| Gun | 5 | - | 2 | 3 | |
| Gu | 53 | 25 | 8 | 20 | |
| Minimum-sized administrative area level | Eup | 34 | - | 1 | 33 |
| Myeon | 127 | - | 19 | 108 | |
| Dong | 972 | 424 | 129 | 419 | |
| Item | SMR | Seoul | Incheon | Gyeonggi | |
|---|---|---|---|---|---|
| Frequency of residential movements | Total | 3,107,134 (100.0%) | 1,287,379 (100.0%) | 352,488 (100.0%) | 1,467,267 (100.0%) |
| Inside | 2,747,380 (88.4%) | 882,299 (68.5%) | 247,760 (70.3%) | 1,081,897 (73.7%) | |
| Outside | 359,754 (11.6%) | 405,080 (31.5%) | 104,728 (29.7%) | 385,370 (26.3%) | |
| Movement per household | 0.326 | 0.329 | 0.331 | 0.323 | |
| Residential relocation distance 1 (km) | Total | 9.123 | 7.753 | 8.894 | 10.391 |
| Inside | - | 3.940 | 4.304 | 7.965 | |
| Outside | - | 23.909 | 29.112 | 25.412 | |
| Variable | Description | Unit | Source | |
|---|---|---|---|---|
| Household attributes | Moving reason | Major reasons for residential relocation: job, house, education | - | The microdata of Internal Migration Statistics |
| Age | Age of householder | Year | ||
| Sex | Male and female | - | ||
| Members | Number of household members | People | ||
| Elderly people | Number of elderly household members | People | ||
| Children | Number of school-aged children: primary, secondary | People | ||
| Proportion of men | Proportion of male household members | % | ||
| Location characteristics 1 | Accessibility | Accessibility to employment market | - | Census on Establishments |
| Density | Population density | People/ha | Population Census | |
| New building | Proportion of new building; 1 year/5 years | % | Housing Census | |
| Housing ownership | Ratio of owner-occupied housing | % | Population Census | |
| Rail availability | Ratio of rail catchment area | % | Korea Transport Database | |
| Bus availability | Number of metropolitan bus routes | EA | ||
| Variable | Unit | Average | SD | Minimum | Maximum | |
|---|---|---|---|---|---|---|
| - | Relocation distance | km | 9.12 | 13.66 | 0.24 | 267.31 |
| Household attributes | Moving reason: Job 1 | - | 0.19 | 0.39 | 0.00 | 1.00 |
| Moving reason: House 1 | - | 0.60 | 0.49 | 0.00 | 1.00 | |
| Moving reason: Education 1 | - | 0.02 | 0.14 | 0.00 | 1.00 | |
| Age | Years | 44.32 | 13.79 | 0.00 | 103.00 | |
| Sex: Male 1 | - | 0.66 | 0.47 | 0.00 | 1.00 | |
| Members | People | 2.10 | 1.30 | 1.00 | 9.00 | |
| Elderly people | People | 0.14 | 0.41 | 0.00 | 4.00 | |
| Children: Primary | People | 0.12 | 0.40 | 0.00 | 4.00 | |
| Children: Secondary | People | 0.14 | 0.42 | 0.00 | 7.00 | |
| Proportion of men | % | 53.52 | 38.27 | 0.00 | 100.00 | |
| Location characteristics in origin | Accessibility | - | 14.26 | 0.53 | 6.40 | 14.79 |
| Density | People/ha | 174.25 | 129.14 | 0.00 | 550.00 | |
| New building: 1 year | % | 2.93 | 2.46 | 0.27 | 17.36 | |
| New building: 5 years | % | 13.69 | 6.12 | 1.83 | 34.89 | |
| Housing ownership | % | 48.55 | 8.45 | 29.38 | 79.26 | |
| Rail availability | % | 25.39 | 27.76 | 0.00 | 100.00 | |
| Bus availability | EA | 7.54 | 10.11 | 0.00 | 71.00 | |
| Location characteristics in destination | Accessibility | - | 14.23 | 0.54 | 6.40 | 14.79 |
| Density | People/ha | 167.34 | 129.29 | 0.00 | 550.00 | |
| New building: 1 year | % | 3.11 | 2.74 | 0.27 | 17.36 | |
| New building: 5 years | % | 14.04 | 6.26 | 1.83 | 34.89 | |
| Housing ownership | % | 48.81 | 8.39 | 29.38 | 79.26 | |
| Rail availability | % | 24.46 | 27.58 | 0.00 | 100.00 | |
| Bus availability | EA | 7.66 | 10.28 | 0.00 | 71.00 | |
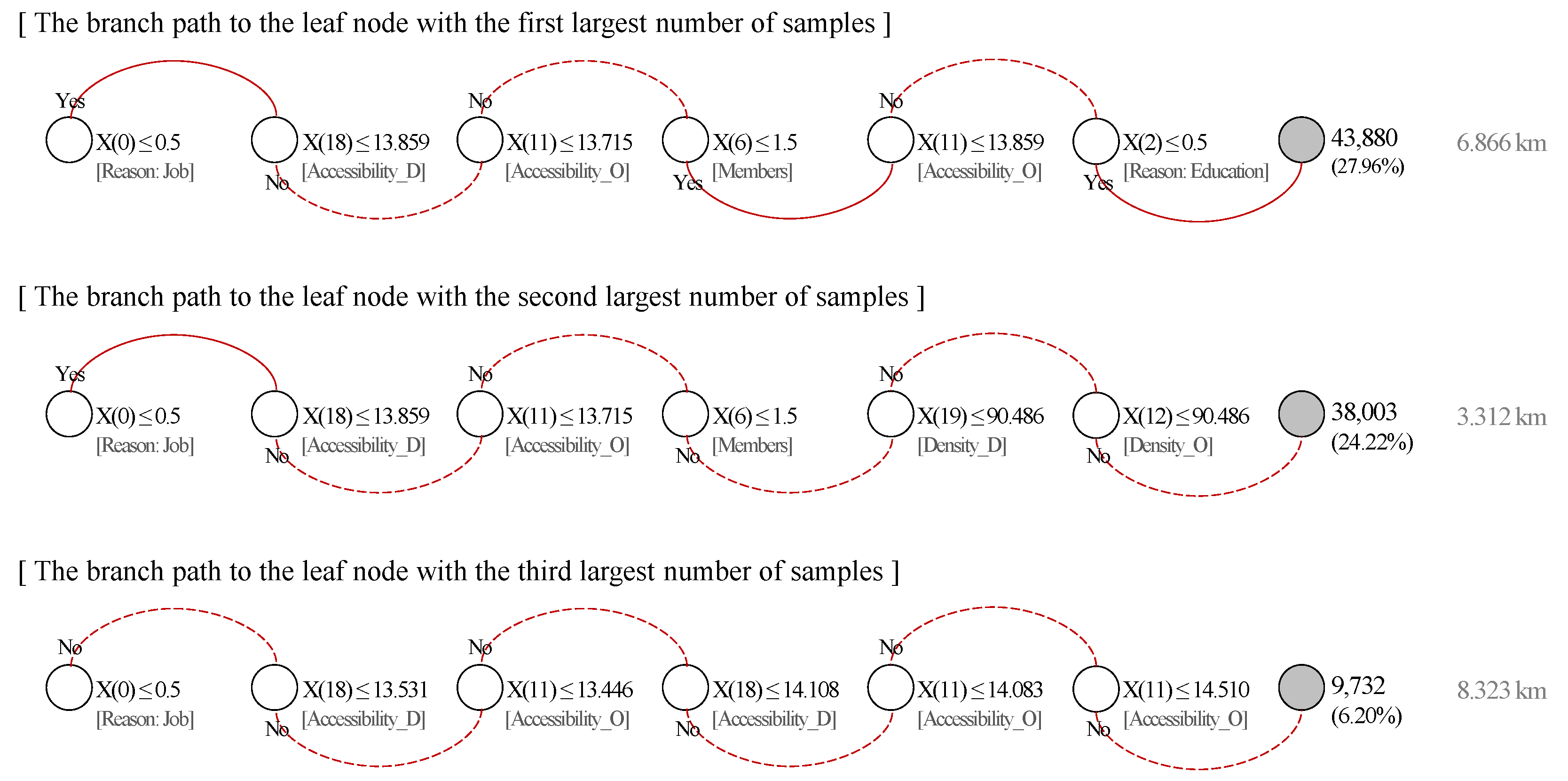
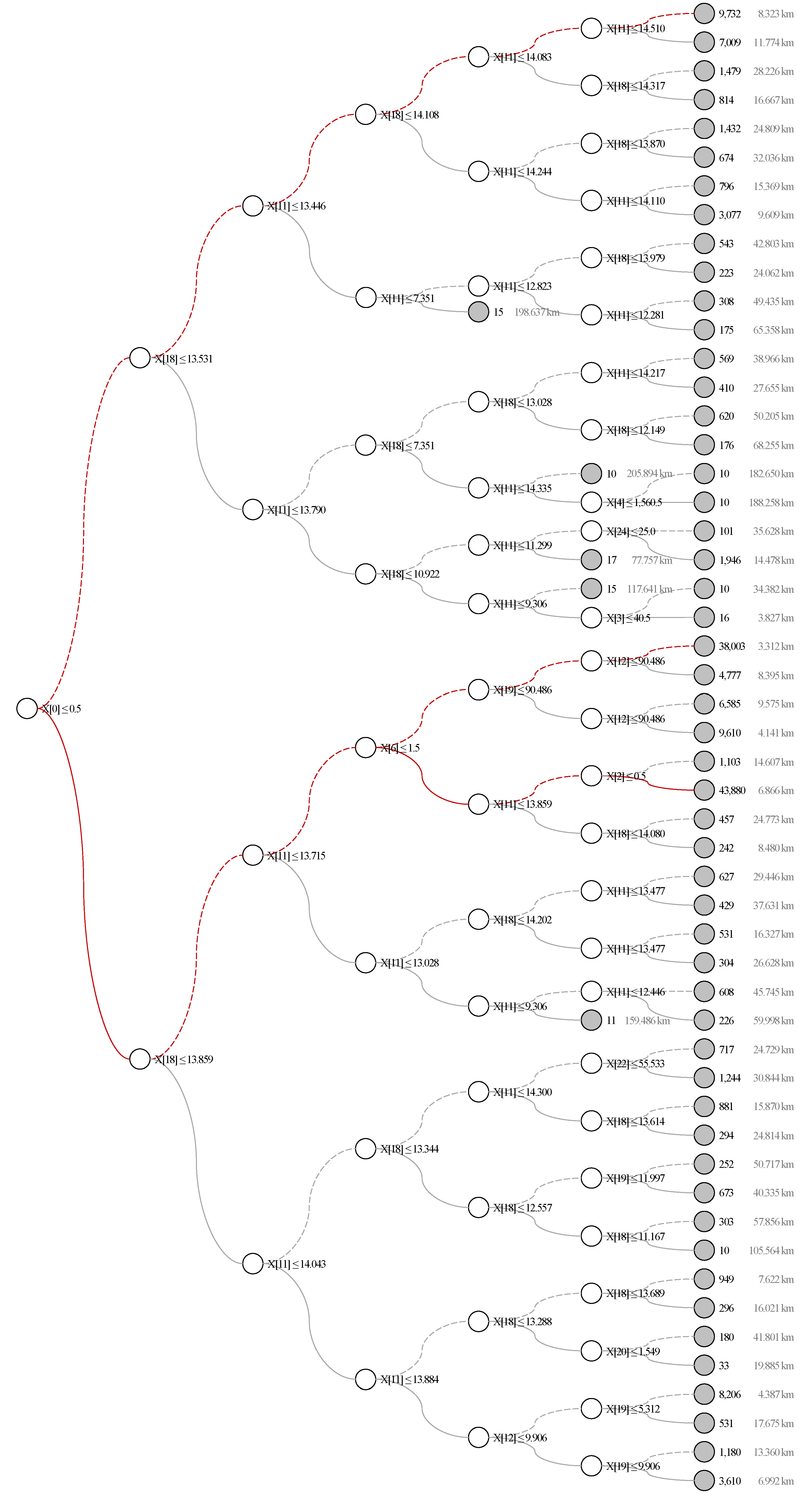
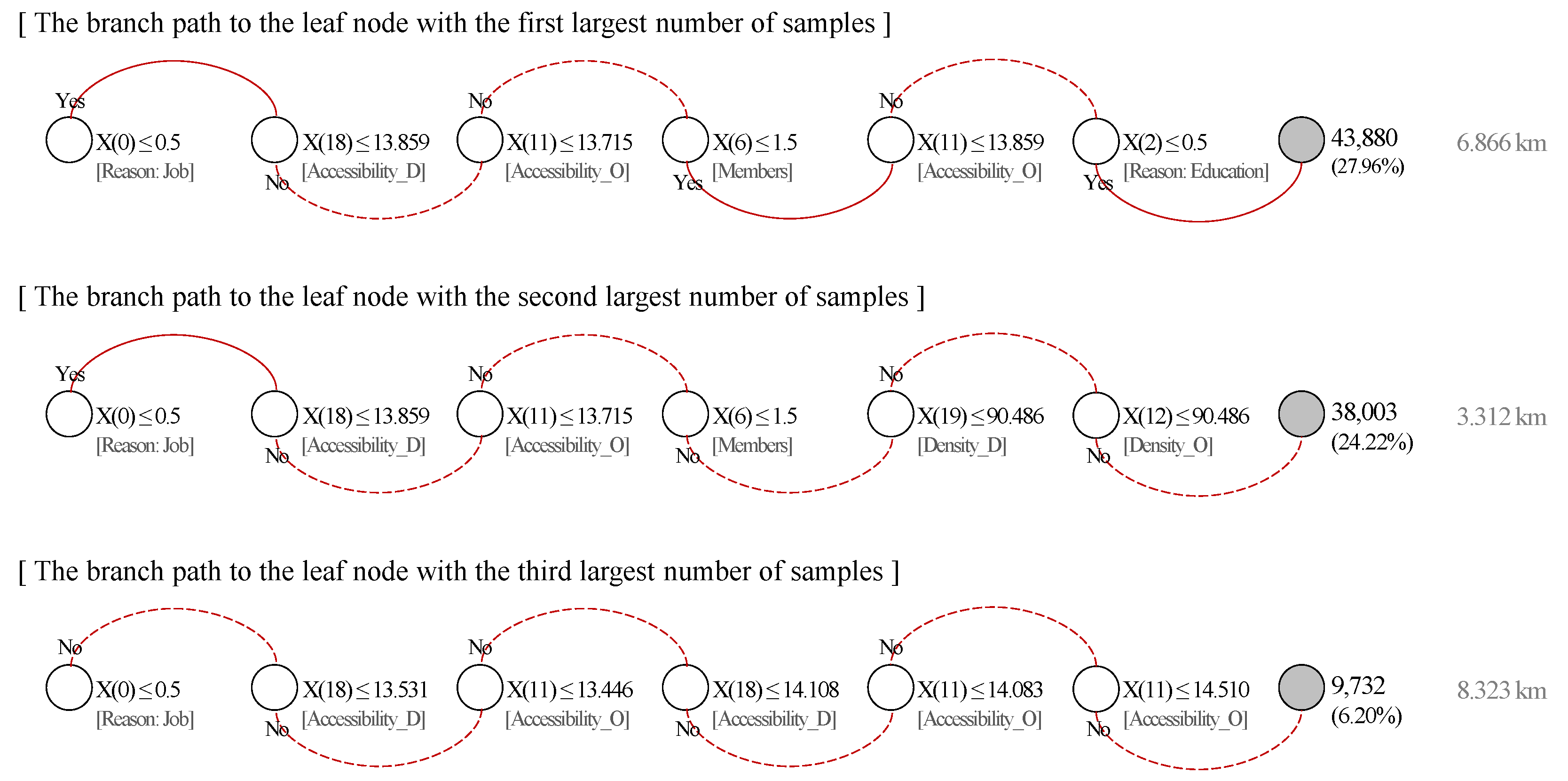
| Variable (Feature) | Ordinary Least Squares Regression | Decision Tree Regression | ||||||
|---|---|---|---|---|---|---|---|---|
| β | Std. β | Sig. | Importance | Rank | ||||
| (Constant) | 136.3587 | 0.000 | ** | |||||
| Household attributes | X(0) | Moving reason: Job | 5.6836 | 2.2401 | 0.000 | ** | 0.13180 | 3 |
| X(1) | Moving reason: House | –1.9648 | –0.9630 | 0.000 | ** | - | - | |
| X(2) | Moving reason: Education | 5.4827 | 0.7688 | 0.000 | ** | 0.00289 | 8 | |
| X(3) | Age | –0.2362 | –3.2602 | 0.000 | ** | 0.00114 | 9 | |
| X(4) | Squared Age | 0.0020 | 2.7813 | 0.000 | ** | - | - | |
| X(5) | Sex: Male | 0.5935 | 0.2809 | 0.000 | ** | - | - | |
| X(6) | Members | –1.0025 | –1.3052 | 0.000 | ** | 0.01246 | 6 | |
| X(7) | Elderly people | 0.1631 | 0.0668 | 0.140 | - | - | ||
| X(8) | Children: Primary | –0.5795 | –0.2338 | 0.000 | ** | - | - | |
| X(9) | Children: Secondary | –0.8717 | –0.3697 | 0.000 | ** | - | - | |
| X(10) | Proportion of men | 0.0019 | 0.0739 | 0.154 | - | - | ||
| Location characteristics in origin | X(11) | Accessibility | –2.0368 | –1.0766 | 0.000 | ** | 0.57976 | 1 |
| X(12) | Density | 0.0008 | 0.1081 | 0.015 | * | 0.01450 | 5 | |
| X(13) | New building: 1 year | –0.1787 | –0.4411 | 0.000 | ** | - | - | |
| X(14) | New building: 5 years | –0.0461 | –0.2824 | 0.000 | ** | 0.00434 | 7 | |
| X(15) | Housing ownership | –0.0417 | –0.3523 | 0.000 | ** | 0.00001 | 12 | |
| X(16) | Rail availability | 0.0014 | 0.0392 | 0.352 | - | - | ||
| X(17) | Bus availability | 0.0055 | 0.0553 | 0.138 | - | - | ||
| Location characteristics in destination | X(18) | Accessibility | –6.1138 | –3.2953 | 0.000 | ** | 0.23433 | 2 |
| X(19) | Density | –0.0026 | –0.3358 | 0.000 | ** | 0.01749 | 4 | |
| X(20) | New building: 1 year | 0.1147 | 0.3156 | 0.000 | ** | - | - | |
| X(21) | New building: 5 years | 0.0434 | 0.2719 | 0.000 | ** | - | - | |
| X(22) | Housing ownership | –0.0271 | –0.2277 | 0.000 | ** | 0.00039 | 11 | |
| X(23) | Rail availability | 0.0019 | 0.0526 | 0.219 | - | - | ||
| X(24) | Bus availability | 0.0434 | 0.4457 | 0.000 | ** | 0.00090 | 10 | |
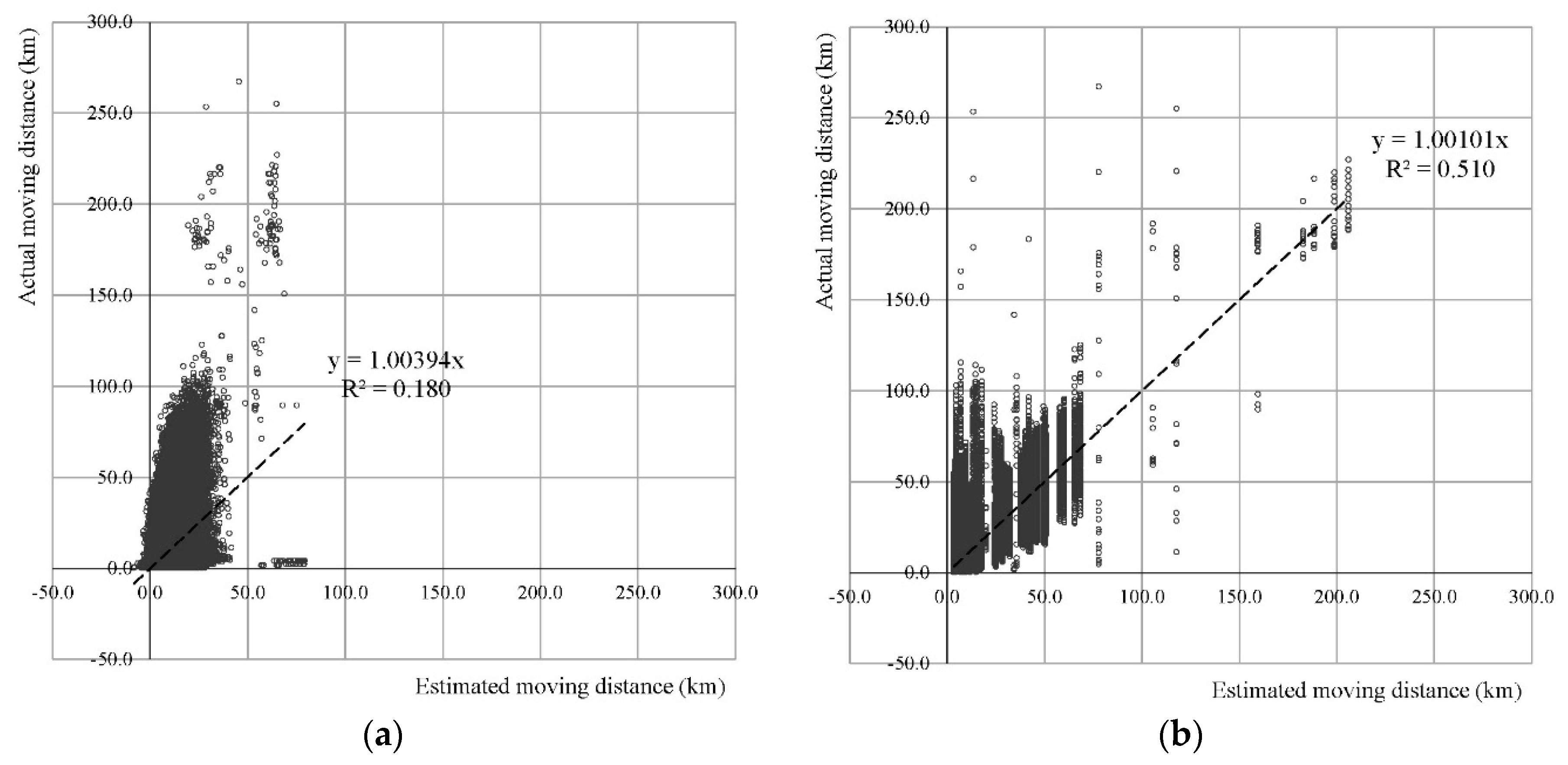
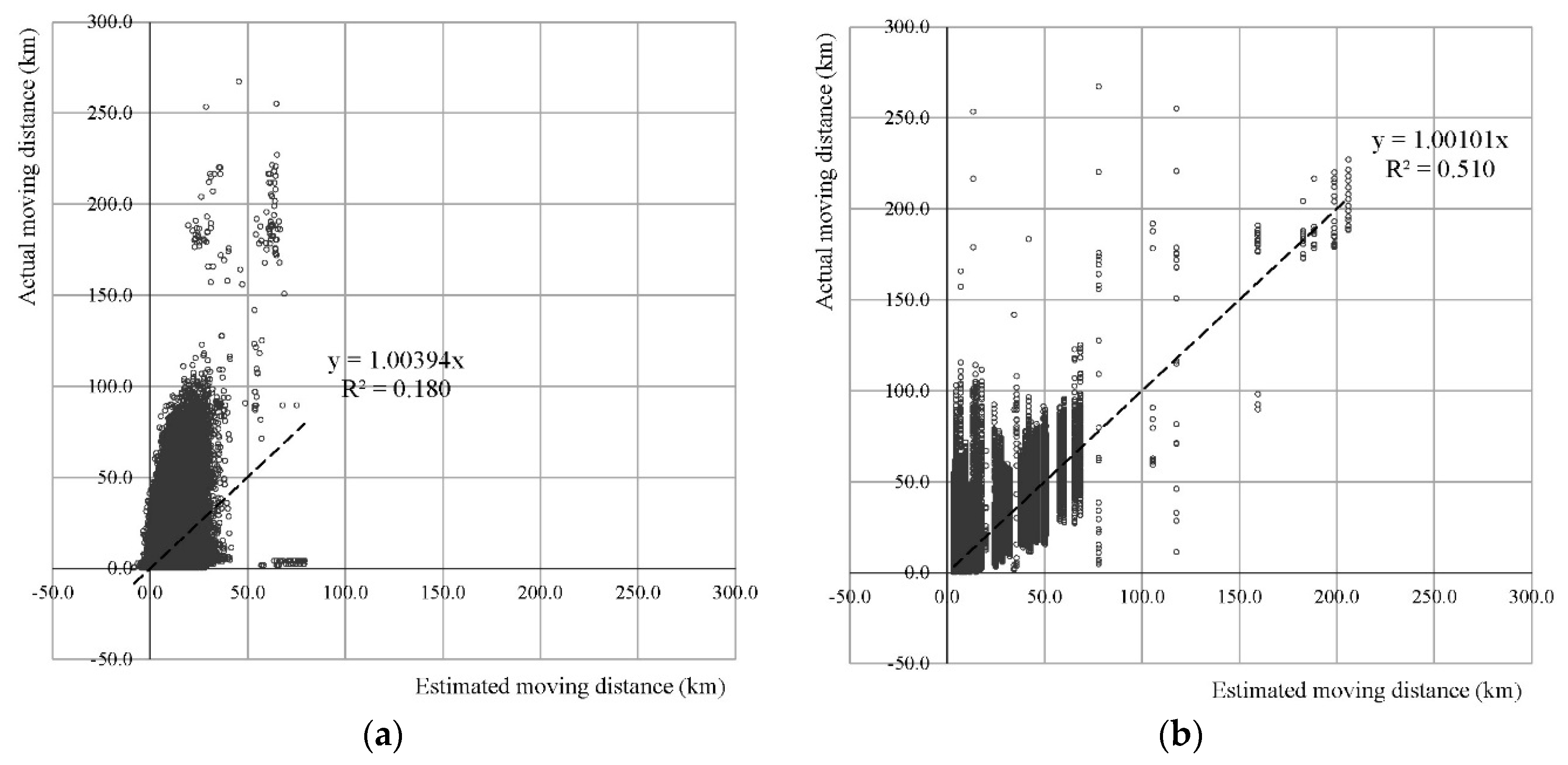
| Explanatory Power | Training R2: 0.180 Test R2: 0.190 | Training R2: 0.512 Test R2: 0.504 | ||||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, C.; Kim, K. A Machine Learning Approach to the Residential Relocation Distance of Households in the Seoul Metropolitan Region. Sustainability 2018, 10, 2996. https://doi.org/10.3390/su10092996
Yi C, Kim K. A Machine Learning Approach to the Residential Relocation Distance of Households in the Seoul Metropolitan Region. Sustainability. 2018; 10(9):2996. https://doi.org/10.3390/su10092996
Chicago/Turabian StyleYi, Changhyo, and Kijung Kim. 2018. "A Machine Learning Approach to the Residential Relocation Distance of Households in the Seoul Metropolitan Region" Sustainability 10, no. 9: 2996. https://doi.org/10.3390/su10092996
APA StyleYi, C., & Kim, K. (2018). A Machine Learning Approach to the Residential Relocation Distance of Households in the Seoul Metropolitan Region. Sustainability, 10(9), 2996. https://doi.org/10.3390/su10092996