Integrated Understanding of Big Data, Big Data Analysis, and Business Intelligence: A Case Study of Logistics


Abstract
1. Introduction
2. Literature Review
2.1. Toward an Integrated Understanding of Big Data, BDA, and BI
2.2. In-Depth Research through Case Studies
- Zhong et al. examined a big data approach that facilitates several innovations that can guide end-users to implement associated decisions through radio frequency identification (RFID) to support logistics management with RFID-Cuboids, map tables, and a spatiotemporal sequential logistics trajectory [44].
- Marcos et al. studied both the environment and approaches to conduct BDA, such as data management, model development, visualization, user interaction, and business models [45].
- Kim reported several successful cases of big data application. Examples include analysis of competing scenarios through 66,000 simulated elections conducted per day to understand the decisions of individual voters during the 2012 reelection campaign of former US president Barack Obama and delivery routes and time management based on vehicle and parcel locations adopted by UPS, a US courier service company [46].
- Wang et al. redefined big data business analytics of logistics and supply chain management as supply chain analytics and discussed its importance [47].
- Queiroz and Telles studied the level of awareness of BDA in Brazilian companies through surveys conducted via questionnaires and proposed a framework to analyze companies’ maturity in implementing BDA projects in logistics and supply chain management [48].
- Hopkins analyzed the impact of BDA and Internet of things (IoT), such as truck telematics and geo-information in supporting large logistics companies to improve drivers’ safety and operating cost-efficiency [49].
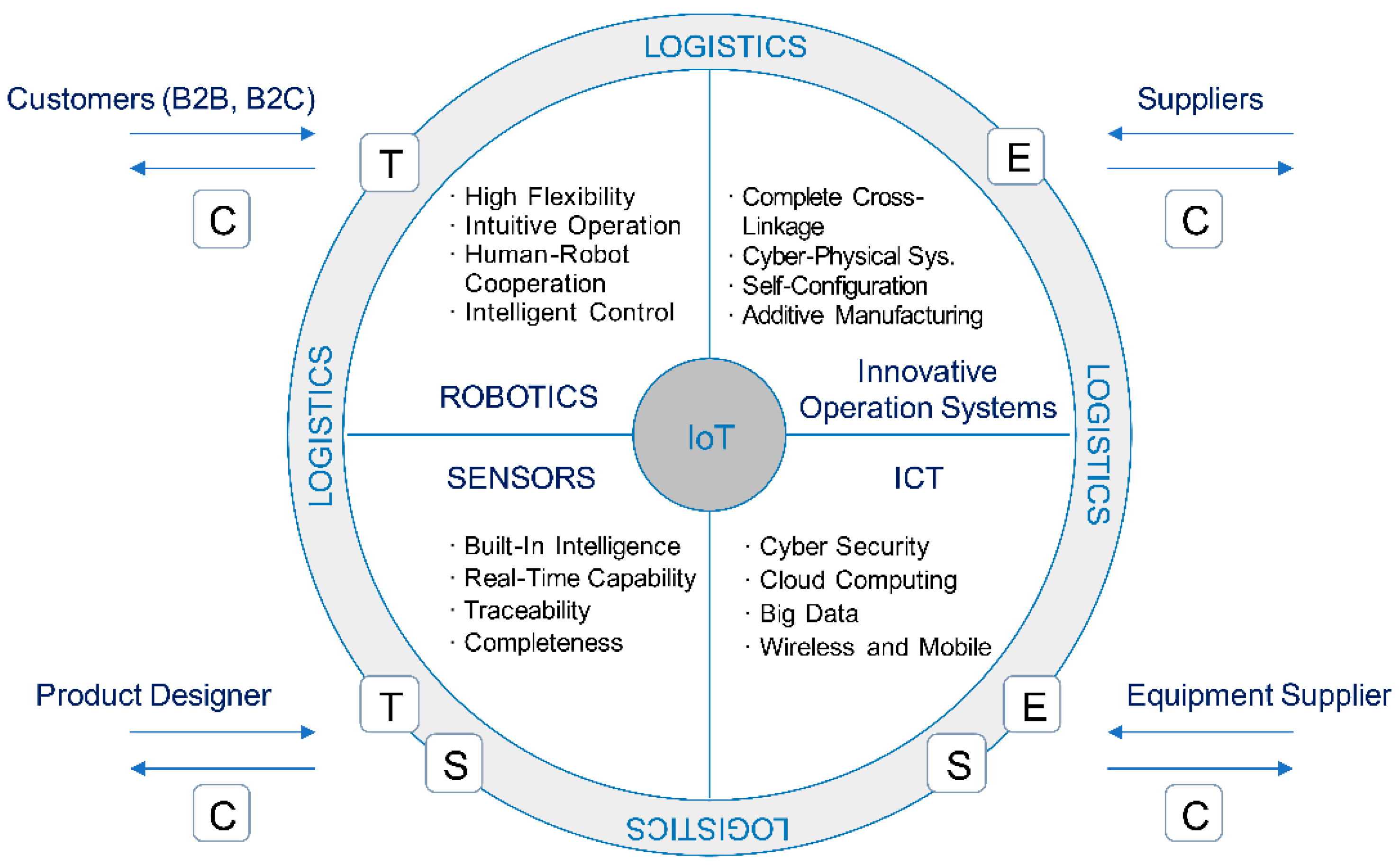
3. Practical Business Application
3.1. Courier Service Overview
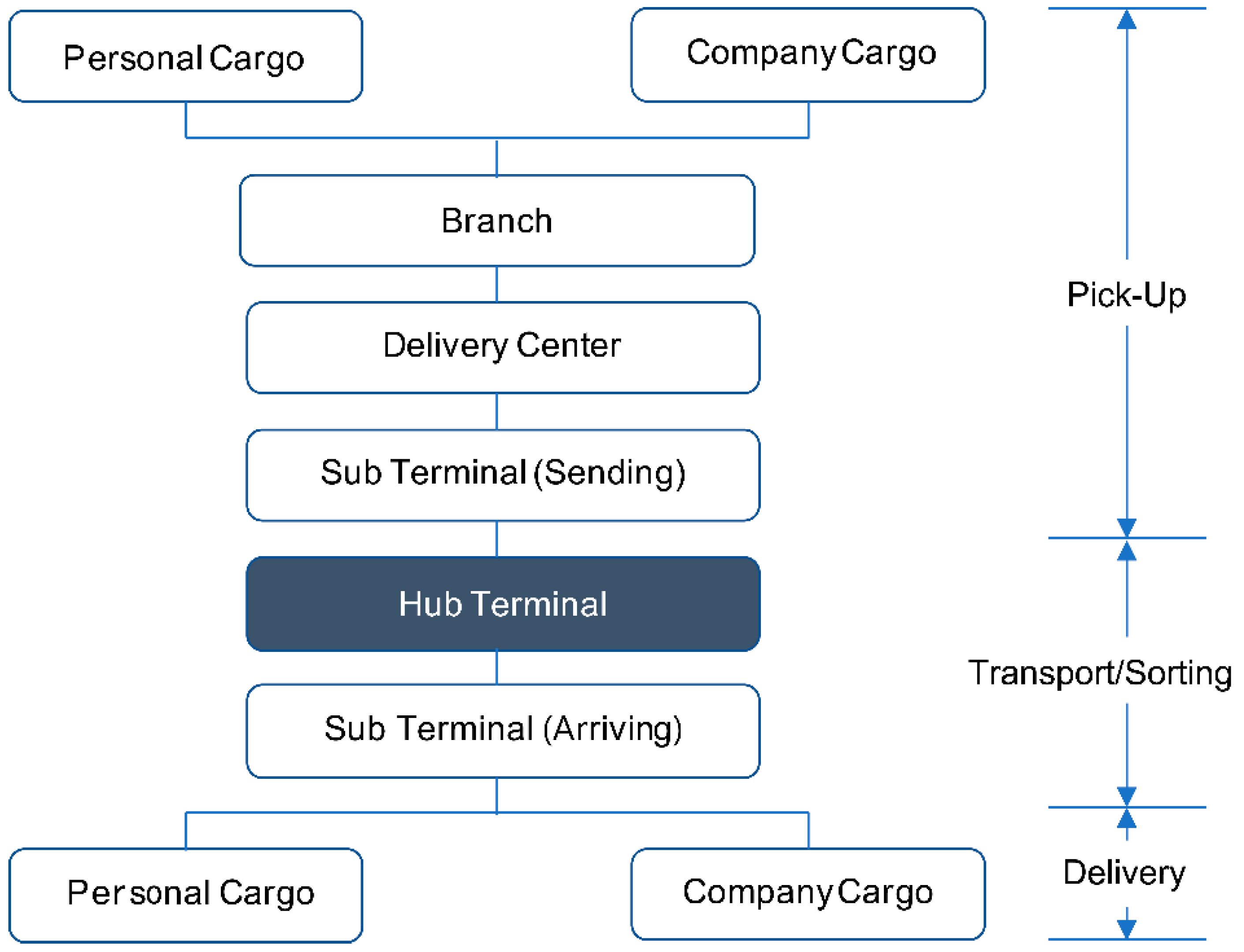
3.2. Case Study: CJ Logistics
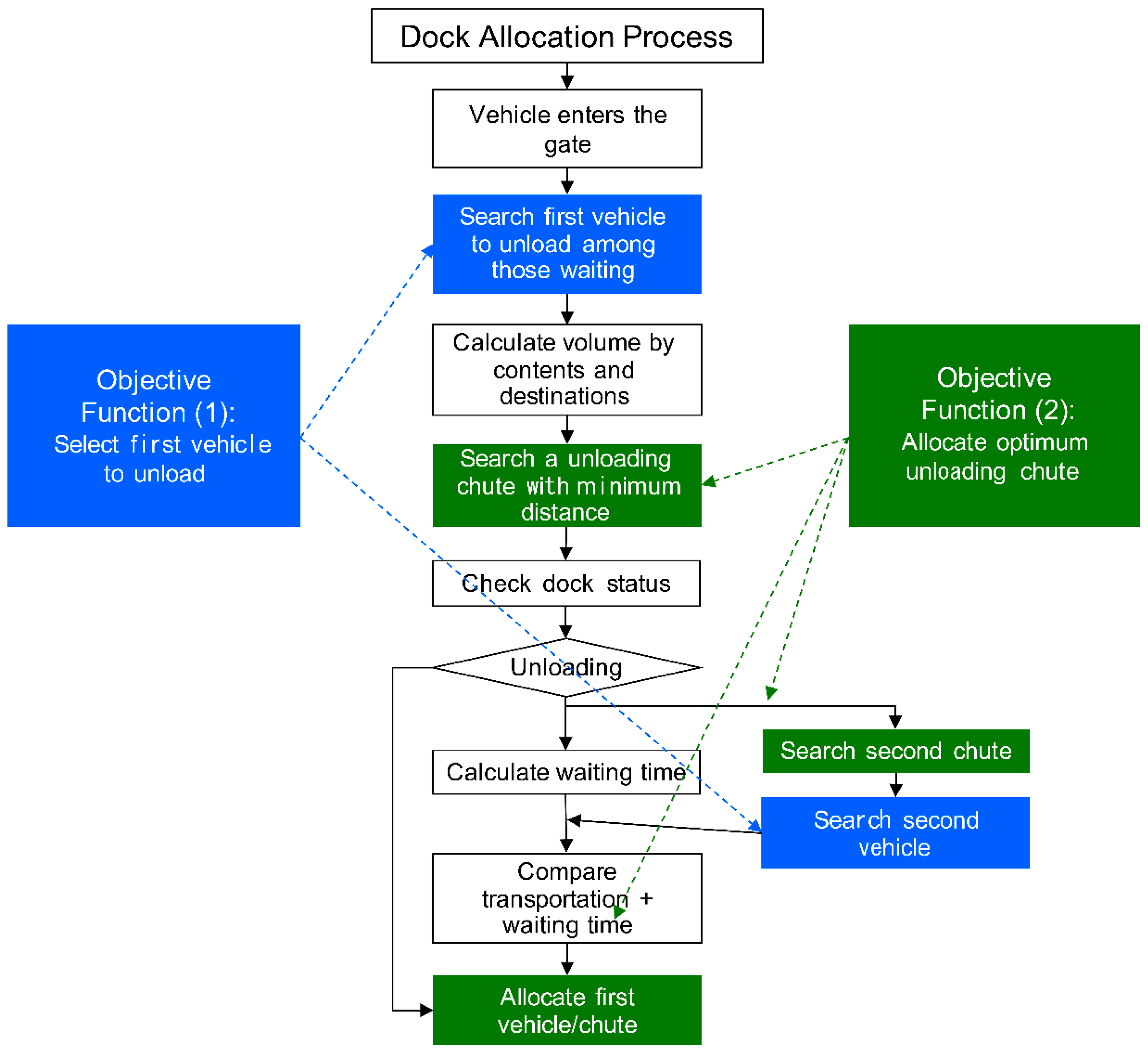
3.2.1. Data and Methodology
3.2.2. Simulation and Adoption Result
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Laney, D. 3D Data Management: Controlling Data Volume, Velocity and Variety; Application Delivery Strategy; META Group: Stamford, CT, USA, 2001; Volume 949. [Google Scholar]
- McAfee, A.; Brynjolfsson, E. Big data: The management revolution. Harv. Bus. Rev. 2012, 90, 60–68. [Google Scholar] [PubMed]
- Fosso Wamba, S.; Akter, S.; Edwards, A.; Chopin, G.; Gnanzou, D. How ‘big data’ can make big impact: Findings from a systematic review and a longitudinal case study. Int. J. Prod. Econ. 2015, 165, 234–246. [Google Scholar] [CrossRef]
- Wang, Y.; Kung, L.; Wang, W.Y.C.; Cegielski, C.G. An integrated big data analytics-enabled transformation model: Application to health care. Inf. Manag. 2018, 55, 64–79. [Google Scholar] [CrossRef]
- White, M. Digital workplaces: Vision and reality. Bus. Inf. Rev. 2012, 209, 205–214. [Google Scholar] [CrossRef]
- Kambatla, K.; Kollias, G.; Kumar, V.; Grama, A. Trends in big data analytics. J. Parallel Distrib. Comput. 2014, 74, 2561–2573. [Google Scholar] [CrossRef]
- Addo-Tenkorang, R.; Helo, P.T. Big data applications in operations/supply-chain management: A literature review. Comput. Ind. Eng. 2016, 101, 528–543. [Google Scholar] [CrossRef]
- Richey, R.G.; Morgan, T.R.; Lindsey-Hall, K.; Adams, F.G. A global exploration of big data in the supply chain. Int. J. Phys. Distrib. Logist. Manag. 2016, 46, 710–739. [Google Scholar] [CrossRef]
- Yu, W.; Chavez, R.; Jacobs, M.A.; Feng, M. Data-driven supply chain capabilities and performance: A resource-based view. Transp. Res. E Logist. 2018, 114, 371–385. [Google Scholar] [CrossRef]
- Roßmann, B.; Canzaniello, A.; Von der Gracht, H.; Hartmann, E. The future and social impact of Big Data Analytics in Supply Chain Management: Results from a Delphi study. Technol. Forecast. Soc. Chang. 2018, 130, 135–149. [Google Scholar] [CrossRef]
- Russom, P. Big Data Analytics. TDWI Best Practices Report, Fourth Quarter. 2011. Available online: tdwi.org (accessed on 12 July 2018).
- Rouse, M. Big Data Analytics. 2012. Available online: http://searchbusinessanalytics.techtarget.com/definition/big-data-analytics (accessed on 12 July 2018).
- LaValle, S.; Lesser, E.; Shockley, R.; Hopkins, M.S.; Kruschwitz, N. Big data, analytics and the path from insights to value. MIT Sloan Manag. Rev. 2013, 52, 21–31. [Google Scholar]
- Loshin, D. Big Data Analytics: From Strategic Planning to Enterprise Integration with Tools, Techniques, NoSQL, and Graph; Elsevier: Waltham, MA, USA, 2013. [Google Scholar]
- Tiwari, S.; Wee, H.M.; Daryanto, Y. Big data analytics in supply chain management between 2010 and 2016: Insights to industries. Comput. Ind. Eng. 2018, 115, 319–330. [Google Scholar] [CrossRef]
- Gilad, B.; Herring, J.P. The Art and Science of Business Intelligence Analysis; JAI Press Ltd.: Greenwich, UK, 1996. [Google Scholar]
- Davenport, T.; Prusak, L. Working Knowledge; HBS Press: Boston, MA, USA, 1998. [Google Scholar]
- Berson, A.; Smith, S.; Thearling, K. Building Data Mining Application for CRM; McGraw-Hill: New York, NY, USA, 2000. [Google Scholar]
- Simon, A.; Shaffer, S. Data Warehousing and Business Intelligence for E-Commerce; Morgan Kaufmann Publishers: San Francisco, CA, USA, 2001. [Google Scholar]
- Solomon, N. Business intelligence. Commun. Assoc. Inf. Syst. 2004, 13, 177–195. [Google Scholar]
- Fan, S.; Raymond, Y.K.; Lau, J.; Zhaob, L. Demystifying big data analytics for business intelligence through the lens of marketing mix. Big Data Res. 2015, 2, 28–32. [Google Scholar] [CrossRef]
- Manyika, J.; Chui, M.; Brown, B.; Bughin, J.; Dobbs, R.; Roxburgh, C.; Byers, A.H. Big Data: The Next Frontier for Innovation, Competition, and Productivity; McKinsey Global Institute: Washington, DC, USA, 2011. [Google Scholar]
- Kang, M.; Kim, S.; Park, S. Analysis and utilization of big data. J. Inf. Sci. Soc. 2012, 30, 25–32. [Google Scholar]
- Liang, T.; Liu, Y. Research landscape of business intelligence and big data analytics: A bibliometrics study. Expert Syst. Appl. 2018, 111, 2–10. [Google Scholar] [CrossRef]
- Tankard, C. Big data security. Netw. Secur. 2012, 7, 5–8. [Google Scholar] [CrossRef]
- Ram, J.; Zhang, C.; Koronios, A. The implications of big data analytics on business intelligence: A qualitative study in China. Procedia Comput. Sci. 2016, 87, 221–226. [Google Scholar] [CrossRef]
- Wang, L.; Alexander, C.A. Big data driven supply chain management and business administration. Am. J. Econ. Bus. Adm. 2015, 7, 60–67. [Google Scholar] [CrossRef]
- Vera-Baquero, A.; Palacios, R.C.; Stantchev, V.; Molloy, O. Leveraging big-data for business process analytics. Learn. Organ. 2015, 22, 215–228. [Google Scholar] [CrossRef]
- Tan, K.H.; Zhan, Y.Z.; Ji, G.; Ye, F.; Chang, C. Harvesting big data to enhance supply chain innovation capabilities: An analytic infrastructure based on deduction graph. Int. J. Prod. Econ. 2015, 165, 223–233. [Google Scholar] [CrossRef]
- Miškuf, M.; Zolotová, I. Application of Business Intelligence Solutions on Manufacturing Data. In Proceedings of the 13th International Symposium on Applied Machine Intelligence and Informatics, Herl’any, Slovakia, 22–24 January 2015. [Google Scholar]
- Luhn, H.P. A business intelligence system. IBM J. Res. Dev. 1958, 2, 314–319. [Google Scholar] [CrossRef]
- Vitt, E.; Luckevich, M.; Misner, S. Business Intelligence; Microsoft Press: Redmond, WA, USA, 2002. [Google Scholar]
- Turban, E.; Aronson, J.E.; Liang, T.P. Decision Support and Intelligence Systems; Prentice-Hall: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Van-Hau, T. Getting value from business intelligence systems: A review and research agenda. Decis. Support Syst. 2017, 93, 111–124. [Google Scholar]
- Turban, E.; Volonino, L. Information Technology for Management, 7th ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2010. [Google Scholar]
- Larsona, D.; Chang, V. A review and future direction of agile, business intelligence, analytics and data science. Int. J. Inf. Manag. 2016, 36, 700–710. [Google Scholar] [CrossRef]
- Chen, H.; Chiang, R.H.; Storey, V.C. Business intelligence and analytics: From big data to big impact. MIS Q. 2012, 36, 1165–1188. [Google Scholar] [CrossRef]
- Wixom, B.; Ariyachandra, T.; Douglas, D.; Goul, M.; Gupta, B.; Iyer, L.; Kulkarni, U.; Mooney, J.G.; Phillips-Wren, G.; Turetken, O. The current state of business intelligence in academia: The arrival of big data. Commun. Assoc. Inf. Syst. 2014, 34, 1–13. [Google Scholar]
- Bala, M.; Balachandran, S.P. Challenges and benefits of deploying big data analytics in the cloud for business intelligence. Procedia Comput. Sci. 2017, 112, 1112–1122. [Google Scholar]
- Davenport, T.H. How strategists use ‘big data’ to support internal business decisions, discovery and production. Strat. Leadersh. 2014, 42, 45–50. [Google Scholar] [CrossRef]
- Narayanan, V. Using big-data analytics to manage data deluge and unlock real-time business insights. J. Equip. Lease Financ. 2014, 32, 1–7. [Google Scholar]
- Erevelles, S.; Fukawa, N.; Swayne, L. Big data consumer analytics and the transformation of marketing. J. Bus. Res. 2016, 69, 897–904. [Google Scholar] [CrossRef]
- Lazer, D.; Kennedy, R.; King, G.; Vespignani, A. The parable of Google flu: Traps in big data analysis. Science 2014, 343, 1203–1205. [Google Scholar] [CrossRef] [PubMed]
- Zhong, R.Y.; Huang, G.Q.; Lan, S.; Dai, Q.Y.; Chen, X.; Zhang, T. A big data approach for logistics trajectory discovery from RFID-enabled production data. Int. J. Prod. Econ. 2015, 165, 260–272. [Google Scholar] [CrossRef]
- Marcos, D.; Assunção, R.N.; Calheiros, S.B.; Marco, A.S.; Netto, R.B. Big data computing and clouds: Trends and future directions. J. Parallel Distrib. Comput. 2015, 79, 3–15. [Google Scholar]
- Kim, Y. Enterprise innovation through the introduction of big data-based advanced analysis system: Case and methodology. IE Mag. 2013, 20, 43–49. [Google Scholar]
- Wang, G.; Gunasekaran, A.; Ngai, E.W.T.; Papadopoulos, T. Big data analytics in logistics and supply chain management: Certain investigations for research and applications. Int. J. Prod. Econ. 2016, 176, 98–110. [Google Scholar] [CrossRef]
- Queiroz, M.M.; Telles, R. Big data analytics in supply chain and logistics: An empirical approach. Int. J. Logist. Manag. 2018, 29, 767–783. [Google Scholar] [CrossRef]
- Hopkins, J.; Hawking, P. Big data analytics and IoT in logistics: A case study. Int. J. Logist. Manag. 2018, 29, 575–591. [Google Scholar] [CrossRef]
- Korean Statistical Information Service. 2018. Available online: http://kostat.go.kr/portal/korea/index.action (accessed on 18 October 2018).
- Jo, Y.; Yoon, M. Analysis of courier service market of South Korea. Korea Technol. Innov. Soc. 2001, 245–270. [Google Scholar]
- Ho, J.S.Y.; Teik, D.O.L.; Tiffany, F.; Kok, L.F.; The, T.Y. Logistic Service Quality among Courier Services in Malaysia. In International Conference on Economics, Business Innovation, IPEDR; IACSIT Press: Singapore, 2012; Volume 38, pp. 113–117. [Google Scholar]
- Lee, C. A study on the strengthening competitiveness of railway logistics business with the growth of the courier business. J. Vocat. Rehabil. 2002, 25, 75–95. [Google Scholar]
- Park, Y. A study on the domestic express courier service’s present situation and further theme in the era of e-commerce. Korean J. Bus. Adm. 2003, 39, 1425–1444. [Google Scholar]
- Jung, J.; Kim, C. A Study on Quality Improvement of Courier Service Using Quality Function Deployment. In Proceedings of the Conference of the Korean Society of Business Administration, Seoul, Korea, 24–25 November 2015; pp. 451–468. [Google Scholar]
- Davis, F.D. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. 1989, 13, 361–391. [Google Scholar] [CrossRef]
- DeLone, W.H.; McLean, E.R. Information system success: The quest for the dependent variable. Inf. Syst. Res. 1992, 3, 60–92. [Google Scholar] [CrossRef]
- Kim, W.; Lim, S.; Park, S. Transportation plan of trunk transport problem with small quantity. Ind. Eng. 2000, 13, 471–478. [Google Scholar]
- Visser, E.J.; Lanzendorf, M. Mobility and accessibility effects of b2c E-commerce: A literature survey. J. Soc. Econ. Geogr. 2004, 95, 189–205. [Google Scholar]
- Jeong, K.; Goh, C.; Shin, J. Model for the assignment and scheduling of container transport vehicles. Logist. Res. 2005, 13, 141–154. [Google Scholar]
- Goh, C.; Min, H. Cargo terminal capacity and order deadline time decision in courier service. Logist. Res. 2006, 14, 43–58. [Google Scholar]
- Sherif, H.L.; Fattouh, M.; Issa, A. Location/allocation and routing decisions in supply chain network design. J. Model. Manag. 2006, 1, 173–183. [Google Scholar]
- Lim, H.; Lim, J.; Lee, H. An exploratory study on the effective operation of the logistics network for courier service by the growth of online shopping. Korea Mark. J. 2007, 9, 97–129. [Google Scholar]
- Park, S.; Kang, Y.; Suh, Y. A study on the success factors of using wireless Internet system in logistics/courier service companies. Inf. Syst. Res. 2009, 18, 127–150. [Google Scholar]
- Kim, S.; Choi, Y. Impact of logistics information technology on the satisfaction of courier service. J. Korea Port Econ. Assoc. 2011, 27, 91–112. [Google Scholar]
- Data Analysis, Retrieval, and Transfer System (DART) of Financial Supervisory Service; Understanding of CJ and Logistics Industry; CJ Group: Seoul, Korea, 2018.
- Lee, S.; Jeong, I. A case study on comparative analysis of courier service information system. Bus. Intell. Res. 2009, 28, 1–24. [Google Scholar]
- Korea Consumer Agency. Use of Courier Service and Survey; Korea Consumer Agency: Seoul, Korea, 2000. [Google Scholar]
- Choi, K. System thinking for increasing the operational efficiency of courier service network. Korean Syst. Dyn. Res. 2011, 12, 89–114. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Order | Category | W (Before 0:00) | W (After 0:00) |
|---|---|---|---|
| 1 | Special sale customer | 50 | 3 |
| 2 | Route for loading first | 30 | 50 |
| 3 | Console volume | 8 | 15 |
| 4 | Produce | 7 | 10 |
| 5 | Premium customer | 3 | 20 |
| 6 | First-in, first-out (FIFO) | 2 | 2 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, D.-H.; Kim, H.-J. Integrated Understanding of Big Data, Big Data Analysis, and Business Intelligence: A Case Study of Logistics. Sustainability 2018, 10, 3778. https://doi.org/10.3390/su10103778
Jin D-H, Kim H-J. Integrated Understanding of Big Data, Big Data Analysis, and Business Intelligence: A Case Study of Logistics. Sustainability. 2018; 10(10):3778. https://doi.org/10.3390/su10103778
Chicago/Turabian StyleJin, Dong-Hui, and Hyun-Jung Kim. 2018. "Integrated Understanding of Big Data, Big Data Analysis, and Business Intelligence: A Case Study of Logistics" Sustainability 10, no. 10: 3778. https://doi.org/10.3390/su10103778
APA StyleJin, D.-H., & Kim, H.-J. (2018). Integrated Understanding of Big Data, Big Data Analysis, and Business Intelligence: A Case Study of Logistics. Sustainability, 10(10), 3778. https://doi.org/10.3390/su10103778