1. Introduction
With recent advances in computing technology, massive amounts of data and information are being constantly accumulated. Big data is being used as a key mechanism to support the innovation of artificial intelligence (AI) techniques, which are undergoing rapid development in recent years, and it is expected to play an important role in improving social and environmental sustainability. This study adopts big data and AI techniques in the field of finance, in order to manage the potential risks of financial market and help achieve socioeconomic sustainability.
In the field of finance, we have great opportunities to create useful insights by analyzing this information, because the financial market produces a tremendous amount of real-time data, including transaction records. Accordingly, this study intends to develop a novel stock market prediction model using the available financial data. We adopt a deep learning technique, since one of the main advantages of this technique is the excellent learning ability from massive datasets.
Stock market predictions have an important role, since they can significantly impact the global economy. Due to of its functional importance, analyzing stock market volatility has become a major research issue in various areas, including finance, statistics, and mathematics [
1]. However, most stock indices behave very similarly to a random walk, because the financial time series data is noisy and non-stationary in nature [
2]. Undoubtedly, it is very difficult to predict the stock market, since the volatility is too large to be captured in a model [
3].
Despite these difficulties, there has been a constant desire to develop a reliable stock market prediction model [
4]. Several approaches, in recent decades, have been made to forecast stock markets using statistics and soft computing skills. Most early studies tend to employ statistical methods, but these approaches have limitations when applied to the complicated real-world financial data, due to many statistical assumptions, such as linearity and normality [
5]. Accordingly, various machine learning techniques, including artificial neural network (ANN) and support vector machine (SVM), that can reflect nonlinearity and complex characteristics of financial time series, have started being applied to stock market prediction. These approaches have provided prominent skills in predicting the chaotic environments of stock markets by capturing their nonlinear and unstructured nature [
6,
7].
In recent years, there have been increasing attempts to apply deep learning techniques to stock market prediction. Deep learning is a generic term for an ANN with multiple hidden layers between the input and output layers. They have been attracting significant attention for their excellent predictability in image classification and natural language processing (NLP). Deep belief network (DBN), convolution neural network (CNN), and recurrent neural network (RNN) are representative methodologies of deep learning. In particular, RNN is mainly used for time series analysis, because it has feedback connections inside the network that allow past information to persist, and time series and nonlinear prediction capabilities. Conventional ANNs do not take the “temporal effects” of past significant events into account [
8]. The temporal representation capabilities of RNN have advantages in tasks that process sequential data, such as financial predictions, natural language processing, and speech recognition [
9]. Traditional neural networks cannot handle this type of data effectively, which is one of their major weaknesses. This study intends to overcome this limitation by applying RNN to stock market predictions. We adopt long short-term memory (LSTM) units for sequence learning of financial time series. LSTM is a state-of-the-art unit of RNN, and RNN composed of LSTM units is generally referred to as “LSTM networks”. They are one of the most advanced deep learning algorithms, but less commonly applied to the area of financial prediction, yet inherently appropriate for this domain.
Despite LSTM network being used as a powerful tool in time series and pattern recognition problems, there are several drawbacks in using an LSTM network. First, neural network models, including LSTM network, suffer from a lack of ability to explain the final decision that models acquire. The neural network models have a highly complex computational process, which can achieve a prominent solution for the target problem to be solved. However, they are not able to provide specific explanations for their prediction results. To avoid this problem, Shin and Lee (2002) proposed a hybrid approach of integrating genetic algorithm (GA) and ANN, and extracted rules from the bankruptcy prediction model [
10]. Castro et al. (2002) investigated fuzzy rules from an ANN to provide an interpretation of classification decisions that were made by neural network model [
11]. Second, like other neural network models, LSTM network has numerous parameters that must be modified by the researcher, such as the number of layers, neurons per layer, and number of time lags. However, time and computation limitations make it impossible to sweep through a parameter space and find the optimal set of parameters. In previous research, the determination of those control parameters has heavily depended on the experience of researchers. In spite of its importance, there is little research on investigation of optimal parameters for LSTM networks. Accordingly, we comprehensively handle these aspects of LSTM models that significantly affect the performance of stock market prediction models. This study proposes a hybrid model that integrates LSTM network with a GA to search for a suitable model for prediction of the next-day index of the stock market. We focus on the optimization of architectural factors related to the detection of temporal patterns of a given dataset, such as the size of time window and number of LSTM units in hidden layers. GA is used to determine the size of the trends to be considered in a model, and simultaneously investigate the optimal topology for hidden layers of LSTM network. Especially, detecting the appropriate size for the time window that can contain the context of the dataset is a crucial task when designing the LSTM network. If the time window is too small, significant signals may be missed, whereas if the size of time window is too big, unsuitable information may act as noise. Regarding the investigation of the time window of RNN, many studies have suggested general approaches based on statistical methods or trial and error, along with various heuristics. We apply GA technique to obtain the best solution and optimize the prediction efficacy [
12]. To the best of our knowledge, most research on LSTM network does not take this aspect into account. We tested our method on the Korea Composite Stock Price Index (KOSPI) for 2000–2016, and found that it was more predictable than other methods.
The remainder of this paper is organized as follows:
Section 2 provides a brief overview of the theoretical literature.
Section 3 describes the methodologies that are used in this study, and introduces the hybrid model of LSTM network and GA.
Section 4 describes data and variables that are used in this study.
Section 5 presents the experimental results and compares the proposed method to a benchmark model.
Section 6 summarizes the findings and provides suggestions for further research.
3. Methodology
3.1. Long Short-Term Memory (LSTM) Network
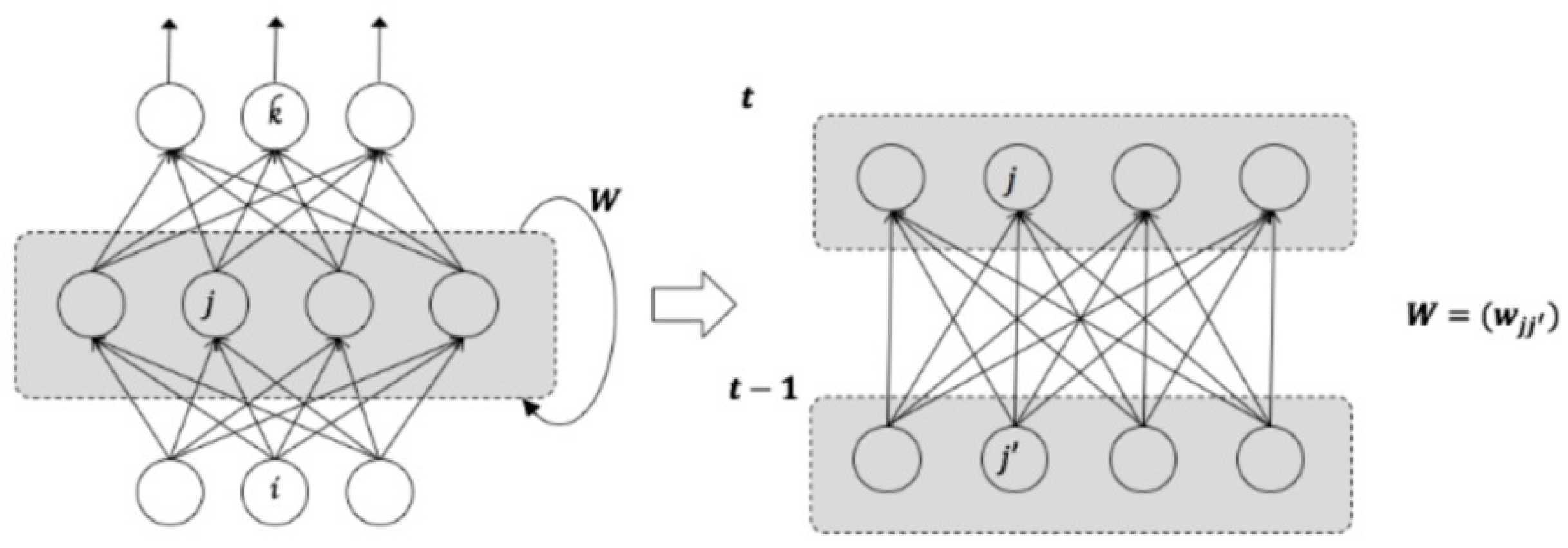
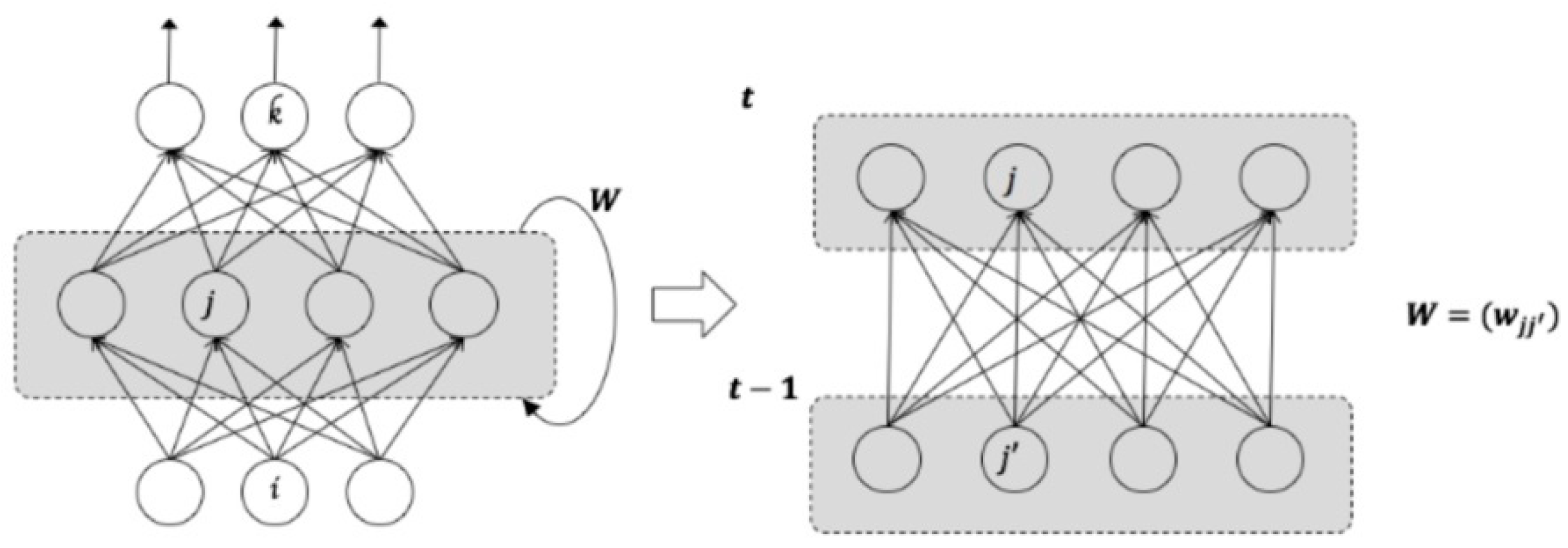
LSTM network is a type of deep RNN model composed of LSTM units. As discussed earlier, RNN is a deep learning network with internal feedback between neurons. These internal feedbacks enable the memorization of significant past events and incorporate past experience. Unlike a traditional fully connected feedforward network, RNN shares parameters across all the parts of a model, so it can be generalized to sequence lengths that have not been seen during training.
Figure 1 presents an example of RNN architecture that produces an output at every time step, and has recurrent connections among hidden neurons [
45].
The RNN has weight matrices
that connects the input-to-hidden weight matrix
, that connects hidden-to-hidden, and a weight matrix
, that connects hidden-to-output. Forward propagation proceeds by defining the initial state of the hidden unit
. Then, for each time step from
, we apply the following update equations. The input value of hidden neuron
at time
is given as
where
is the weight between input neuron
and hidden neuron
, and
is input value at time
.
denotes the weight between hidden neuron
and
, and
is output value of hidden neuron
at time
.
The transfer function of hidden neuron is named , and the output of hidden neuron is expressed as
Finally, the output value of the hidden layer
is fed into output neuron
, and the output value of output layer is given as
where
is the weight between hidden and output neurons.
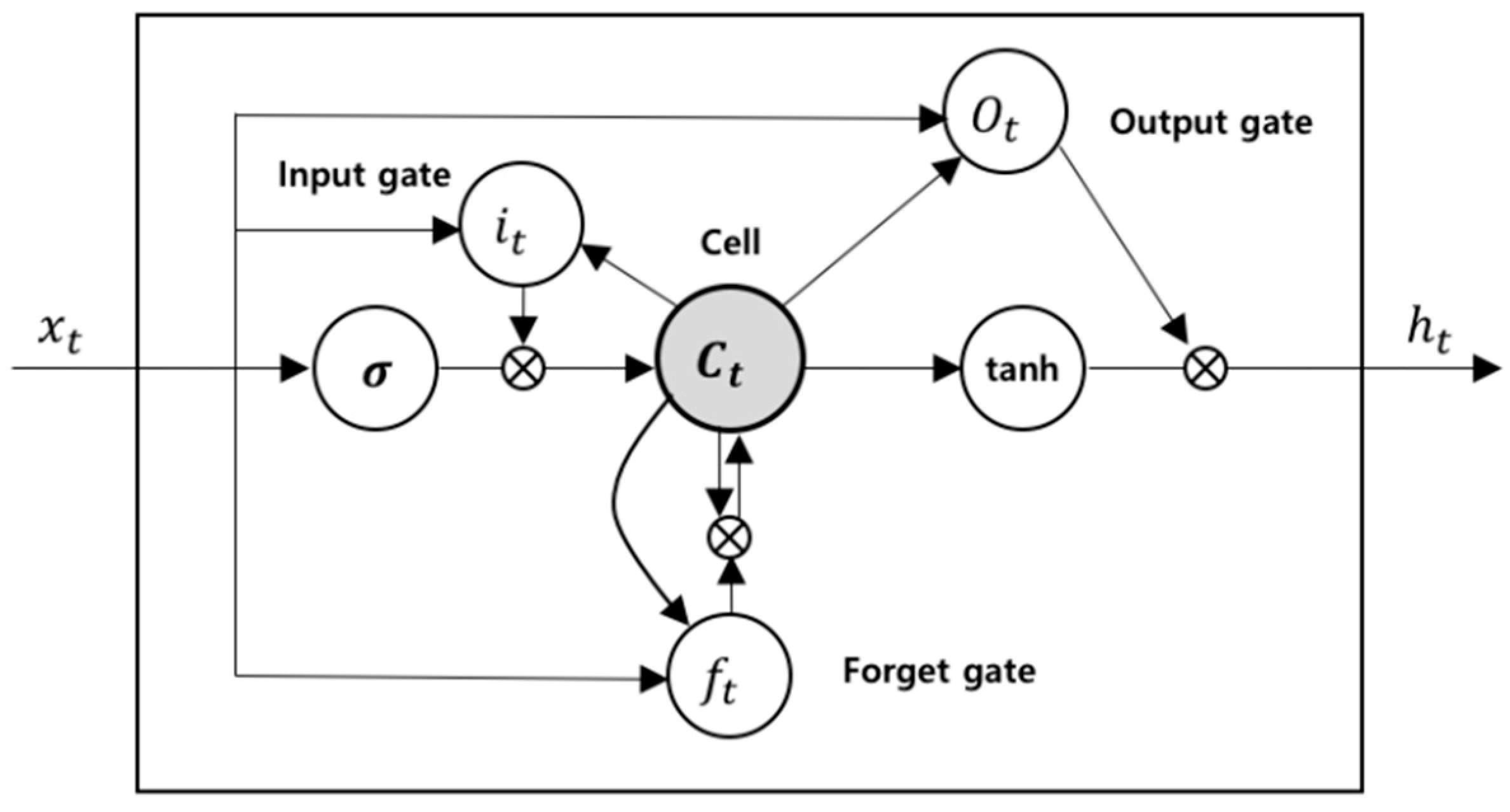
However, RNN has difficulty in learning long time-dependencies that are more than a few time steps in length [
46]. As the number of time steps to consider increases, information from the past events exponentially disappears. LSTM is proposed as a way to overcome the long-term dependency problem. LSTM networks can contain past information of more than 1000 time steps. LSTM can scale to much longer sequences than simple RNN, overcoming the intrinsic drawbacks of simple RNN, i.e., vanishing and exploding gradients. Today, LSTM is widely used in many sequential modeling tasks, including speech recognition, motion detection, and natural language processing [
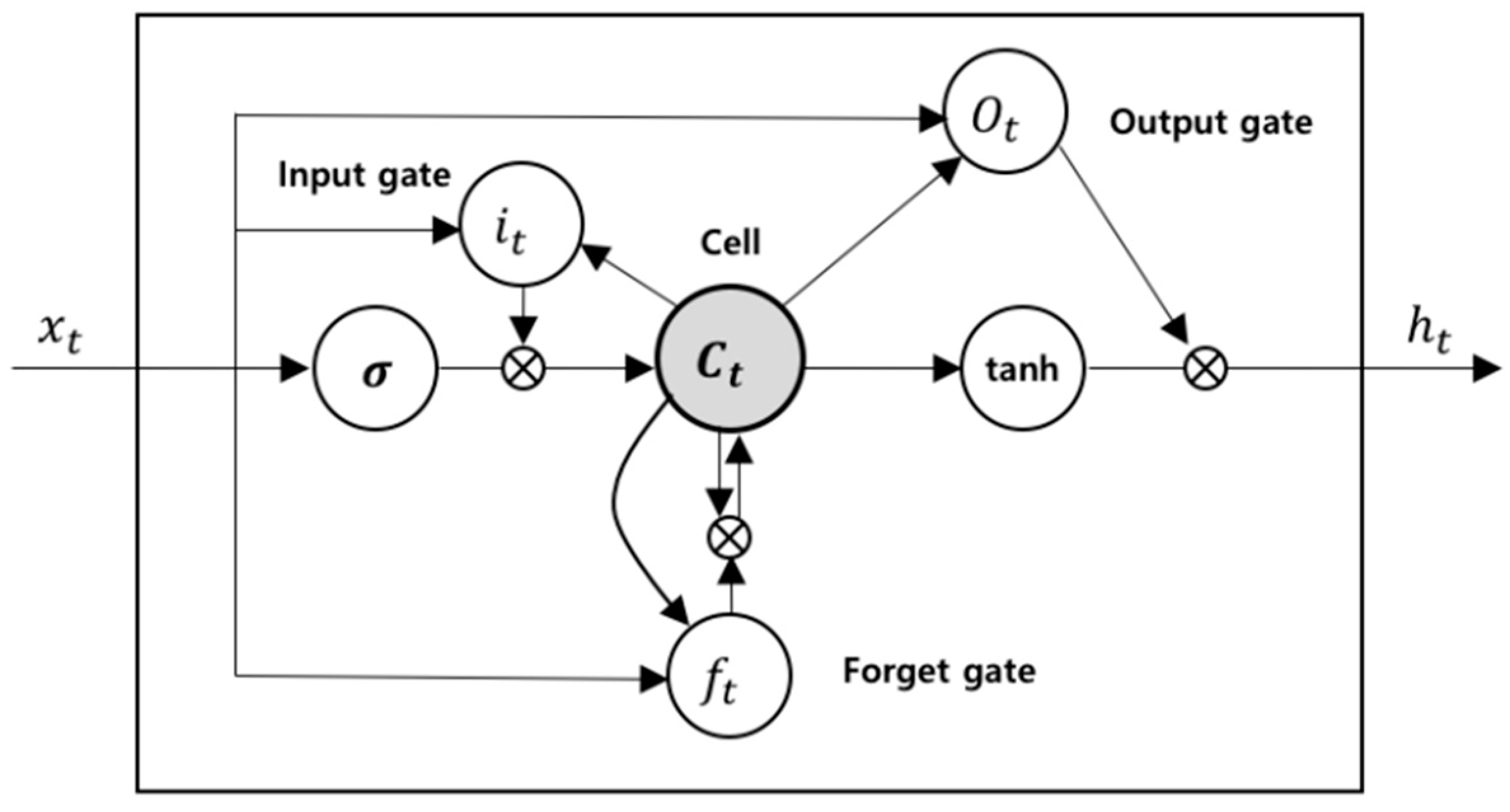
47]. The LSTM block diagram is depicted in
Figure 2.
The LSTM block contains memory cell and three multiplicative gating units; an input, an output, and a forget gate. There are recurrent connections between the cells, and each gate provides continuous operations for the cells. The cell is responsible for conveying “state” values over arbitrary time intervals, and each gate conducts write, read, and reset operations for the cells [
45,
46,
47].
The computation process within an LSTM block is as follows. The input value can only be preserved in the state of the cell if the input gate permits it. The input value of
and the candidate value of the memory cells,
, at time step,
t, is calculated as follows:
where
,
,
represent the weight matrices and bias, respectively.
The weight of the state unit is managed by the forget gate and the value of forget gate is computed as
Through this process, the new state of memory cell is updated as
With the new state of memory cell, the output value of the gate is calculated as follows:
The final output value of cell is defined as
The output of the cell can be blocked by the output gate, and all gates use sigmoidal nonlinearity, and the state unit can perform as an extra input to other gating units [
45,
46,
47]. Through this process, the LSTM architecture can solve the problem of long-term dependencies at small computational costs [
48].
3.2. Genetic Algorithm (GA)
GA is metaheuristic and stochastic optimization algorithm inspired by the process of natural evolution [
49]. They are widely used to find near-optimal solutions to optimization problems with large search spaces. The process of GA includes operators that imitate natural genetic and evolutionary principles, such as crossover and mutation. The major feature of GA is the population of “chromosomes”. Each chromosome acts as a potential solution to a target problem, and is usually expressed in the form of binary strings. These chromosomes are generated randomly, and the one that provides the better solution gets more chance to reproduce [
15].
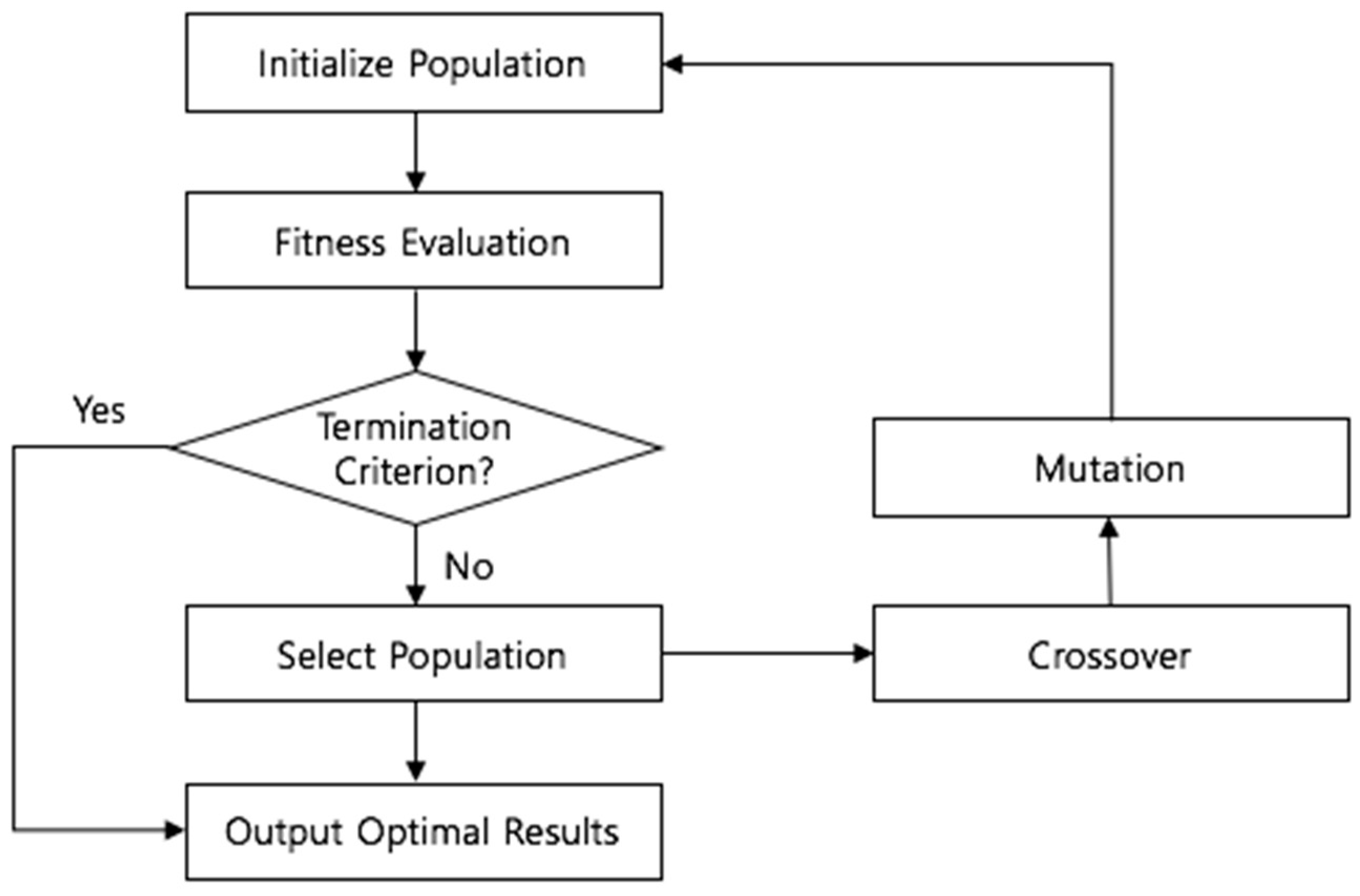
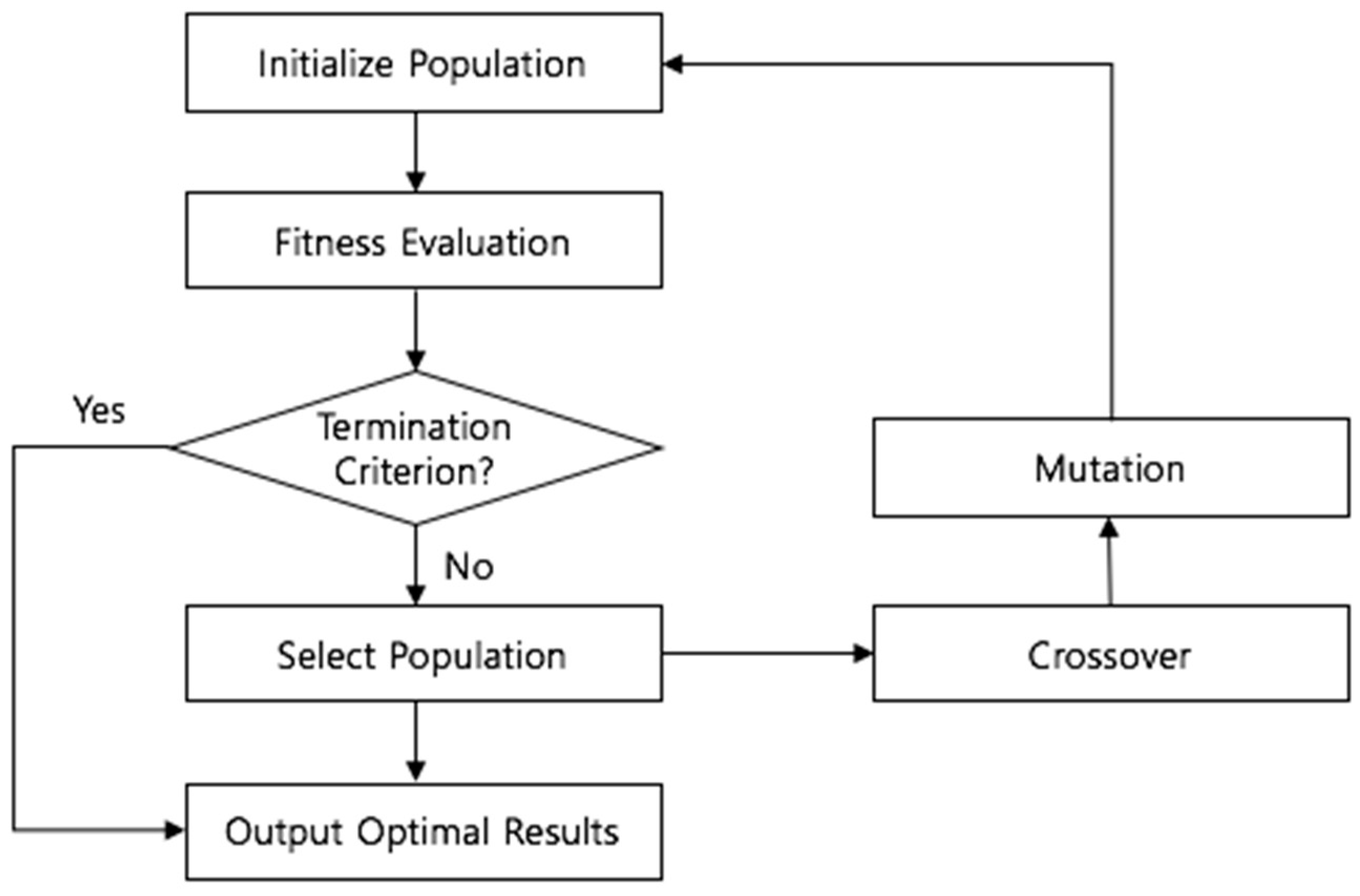
Processing the GA can be divided into six stages: initialization, fitness calculation, termination condition check, selection, crossover, and mutation, as shown in
Figure 3 [
50]. In the initialization stage, a chromosome in the search space is arbitrarily selected, and then the fitness of each selected chromosome is calculated in accordance with the predefined fitness function. The fitness function is a concept used to numerically encode a chromosome’s performance [
5]. In optimization algorithms, such as GA, the definition of a fitness function is a crucial factor that affects the performance. Through the process of calculating the fitness for the fitness function, only solutions with excellent performance are preserved for further reproduction processes. Some chromosomes are selected several times through the selection process, and chromosomes that disappear without selection are generated because they are chosen stochastically according to the adaptability of fitness function. That is, the chromosomes with prominent performance have a higher probability of being inherited by the next generation. Selected superior chromosomes produce offspring by interchanging corresponding parts of the string and changing gene combinations. The crossover process leads to new solutions being created from existing ones. In the mutation process, one of the chromosomes is selected to change one randomly chosen bit. The aim of this process is to introduce diversity and novelty into the solution pool by arbitrarily swapping or turning off solution bits. The crossover process has the limitation in that completely new information cannot be generated. However, these limitations can be overcome by the mutation operation by changing corresponding bits to completely new values.
The newly generated chromosome through selection, crossover, and mutation processes calculates the fitness to the model, and verifies the termination criteria. The standard procedure of GA is over when the termination criteria have been satisfied. If some termination criteria are not satisfied, the selection, crossover, and mutation processes are repeated, to generate a superior chromosome with higher performance. In this study, chromosomes are represented as binary arrays and the mean squared error (MSE) of the prediction model is acting as the fitness value.
3.3. A Hybrid Approach to Optimization in LSTM Network with GA
Evolutionary algorithms, mostly GA, have been widely applied to neural network models, such as MLP and RNN, and used in various hybrid approaches for financial time series forecasting to optimize technical analysis or train the neural network [
23,
36]. Muhammad and King (1997) exploited evolutionary fuzzy networks in the foreign exchange market forecasting [
51], and Kai and Wenhua (1997) proposed an ANN model trained with GA to predict the stock price [
52]. Kim and Han (2000) optimized the connection weights between layers and conducted the feature discretization with GA, reducing the dimensionality of feature space [
23]. Kim et al. (2006) also predicted the stock index using a GA-based multiple classifier combination technique to incorporate classifiers that stem from machine learning, experts, and users [
53]. Meanwhile, combining optimized size of time window with LSTM networks in time series forecasting has not been studied extensively.
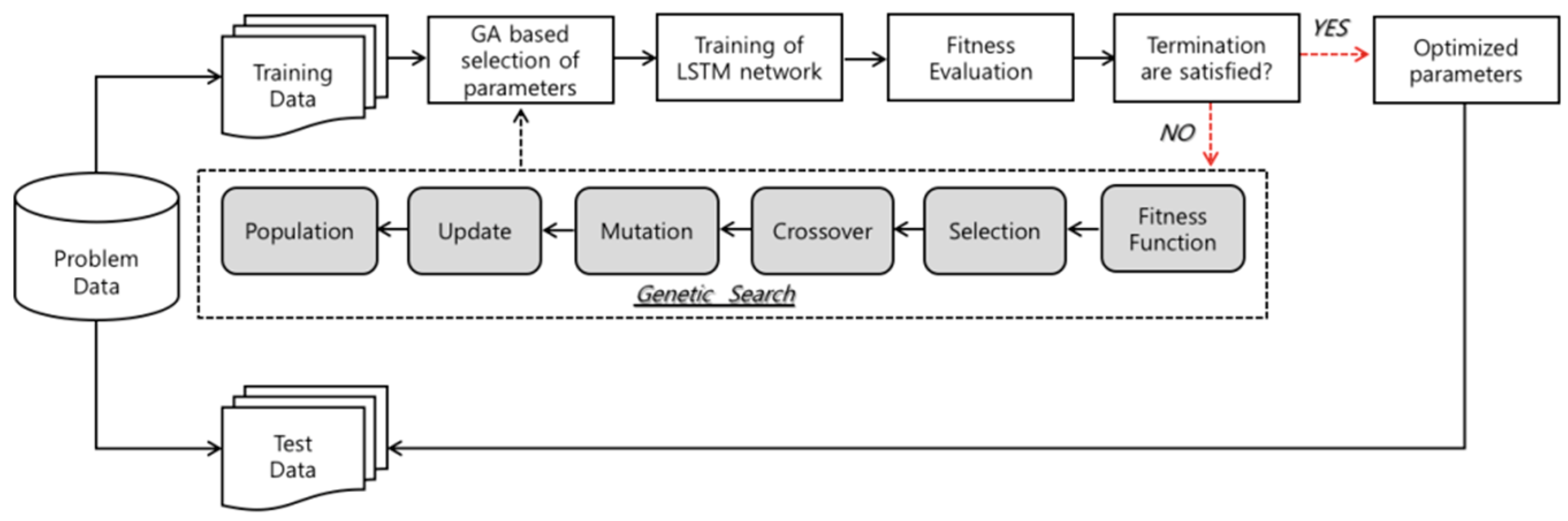
In this study, we propose a hybrid approach of LSTM network integrating GA to find the customized time window and number of LSTM units for financial time series prediction. Since LSTM network uses past information during the learning process, a suitably chosen time window plays an important role in the promising performance. If the window is too small, the model will neglect important information, while, if the window is too large, the model will be overfitted on the training data.
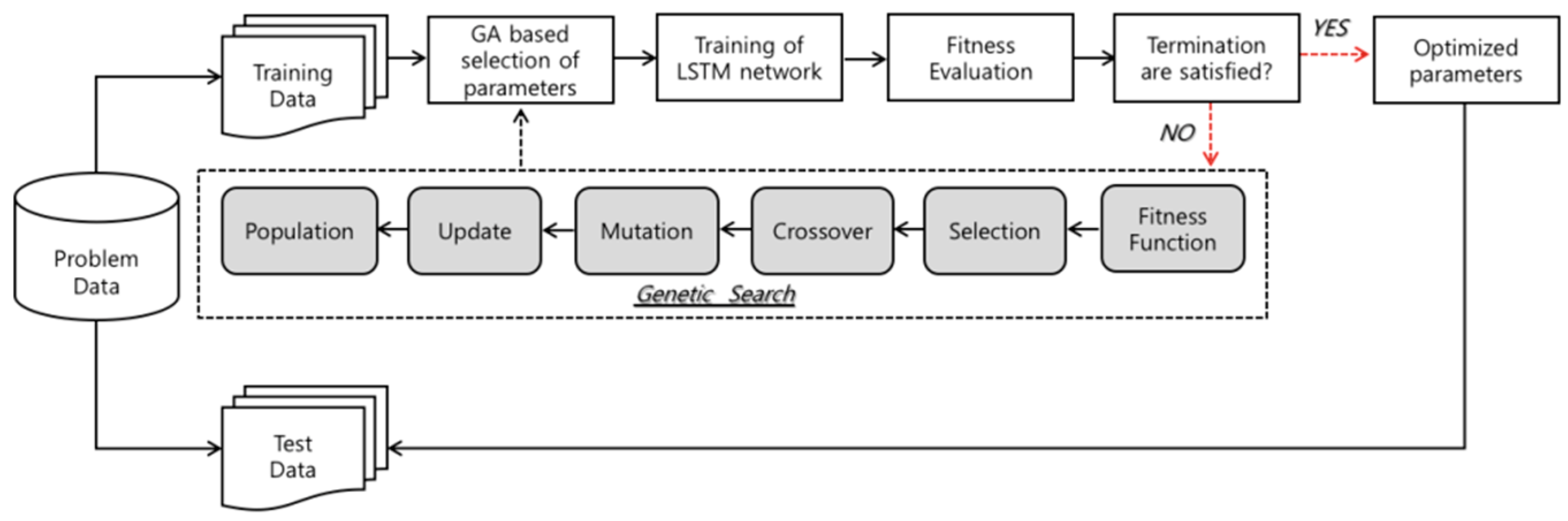
Figure 4 depicts the flowchart of the model proposed in our work.
This study consists of two stages, which are as follows. The first stage of the experiment involves designing the appropriate network parameters for the LSTM network. We use a LSTM network with sequential input layer followed by two hidden layers, and optimal number of hidden neurons in each hidden layer is investigated by GA. In LSTM–RNN model, the hyperbolic tangent function is utilized as an activation function of the input nodes and hidden nodes. The hyperbolic tangent function is a scaled sigmoid function, and returns input value into a range between −1 and 1. The activation function of output node is designated as a linear function, since our goal is the prediction of closing price of the next day which can be formulated as a problem of regression. Initial weights of network are set as random values, and the network weight is adjusted by using a gradient-based “Adam” optimizer, which is famous for its simplicity, straightforwardness, and computational efficiency. The method is appropriate for problems which have large data and parameters, and also has strength in dealing with non-stationary problems with very noisy and sparse gradients [
54].
As described above, we employ one of the evolutionary search algorithms, GA, to investigate the optimal size of time windows and architectural factors of LSTM network. In the second stage, various sizes of time windows and different numbers of LSTM units of each hidden layer are applied to evaluate the fitness of GA. The populations that are composed with possible solutions are initialized with random values, before the genetic operators start to explore the search space. The chromosomes used in this study are encoded in binary bits that represent the size of the time window and number of LSTM cells. Based on the population, the selection and recombination operators begin to search for the superior solution. The solutions are evaluated by predefined fitness function, and strings with prominent performance are selected for the reproduction. Fitness function is a crucial part of GA, and has to be chosen carefully. In this research, we use the MSE to calculate the fitness of each chromosome, and the subset of architectural factors that returns the smallest MSE is selected as the optimal solution. If the output of the reproduction process satisfies the termination criteria, derived optimal or near-optimal solution is applied to the prediction model. If not, the whole process of selection, crossover, and mutation are repeated again. In order to acquire the outstanding solution for the problem, genetic parameters, such as crossover rate, mutation rate, and population size, can affect the result. In this study, we use a population size of 70, 0.7 crossover rate, and 0.15 mutation rate in the experiment. As a stopping condition, the number of generations is assigned as 10.
5. Result and Analysis
As discussed earlier, this study applies GA to investigate the optimal architectural factors, including the size of the time window to be fed a LSTM network, and derives results through this genetic search. The best time window size for stock market prediction has been chosen as 10 by GA. In other words, it is most effective to analyze the stock market by using the information of the past 10 trading days in stock market prediction. Moreover, the best number of LSTM units, that is composing two hidden layers, have been derived as 15 and 7, respectively.
We apply input embedding of the last 10 time steps, and optimized the architecture to verify the effectiveness of GA–LSTM model on holdout data. The derived result of the GA-optimized LSTM network is measured by computing the mean squared error (
MSE), mean absolute error (
MAE), and the mean absolute percentage error (
MAPE) of the actual closing price of stock market, and the output of the proposed hybrid model. MSE is defined as
where
is the predicted output value of the model’s
th observation,
is the desired one, and
denotes the number of samples.
MAE is defined as follows:
MAPE is given as
These performance measures have been widely used in several studies, and provide the means with which to determine the effectiveness of the model for forecasting the daily stock index [
24,
35,
36,
37]. The results are compared to a simple algorithm that predicts no day-to-day change, tested against the same dataset used in this study, to test the efficacy of proposed model.
Table 4 presents the experimental results of the proposed approach in this study.
As shown in
Table 4, GA-optimized LSTM network presents better performance than the benchmark in all error measures. The predict MSE of benchmark model is 209.45, while the predicted MSE of the combined GA model and LSTM network is 181.99, and the prediction result enhances by 13.11% compared to the benchmark model. The predicted MAE of the benchmark model is 11.71, while the predicted MAE of the proposed model is 10.21, and the prediction result enhances 12.80% compared to the benchmark model. Lastly, the predicted MAPE of the benchmark, which expresses accuracy as a percentage of error, is 1.10%, while the MAPE of the GA–LSTM hybrid model is 0.91%. The normalized prediction output of GA-optimized LSTM network model is presented in
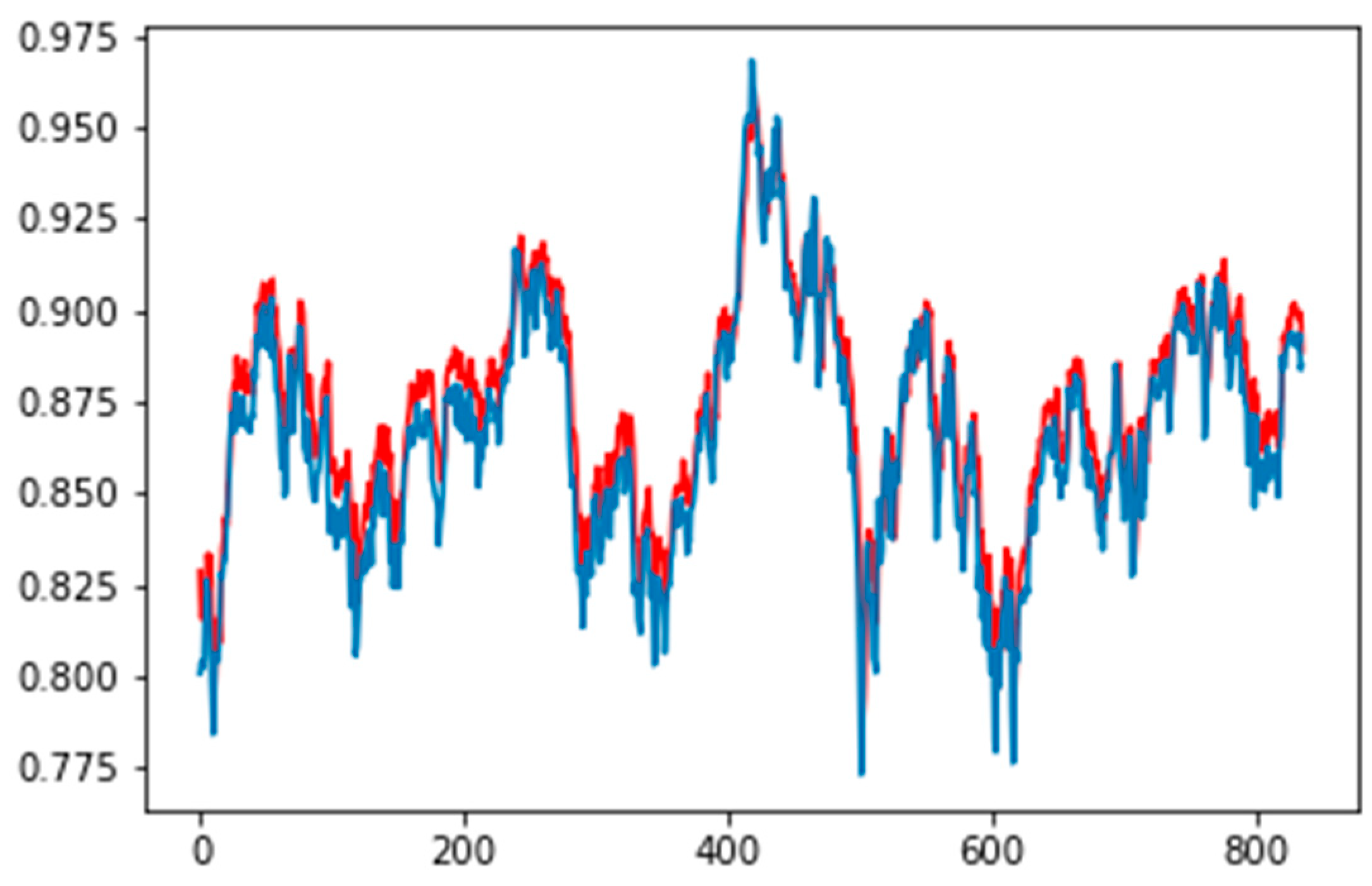
Figure 5, of which the blue line presents the actual closing price, while the red line is the prediction output of the proposed model in this research.
The superior performance derived from the GA–LSTM model may be explained by the fact that the globally investigated time window and architecture of LSTM network enhanced the efficiency of learning process and prevented unnecessary computations. The results suggest that appropriate tuning of the parameters is an important condition to achieve satisfactory performance. Despite the fast growth of deep learning algorithms, it is very difficult task to find an optimal set of parameters of deep architectures by expert knowledge. However, the experimental results demonstrate that the method used in this study can be an effective tool to determine the optimal or near-optimal model for deep learning algorithms, and showed the potential for its applicability.
One form of statistical verification, called
t-test has been conducted to investigate whether GA–LSTM outperforms the benchmark significantly. A
t-test is employed to investigate the difference in unknowns of two groups, comparing the mean values of two samples extracted from each group. The
t-test result of prediction performance, between proposed model and benchmark, is summarized in
Table 5. The
p-value of
t-test results of the predictive performance, between the GA based model and the benchmark, is derived as 0.015, which means that the difference between two models is statistically significant at a 5% significance level. This result verifies that the GA–LSTM network performs better than the benchmark model, and indicates the capability of the proposed model to consider the temporal properties in the stock market prediction problem.
We also applied the GA–LSTM model on individual stocks included in the KOSPI, to validate the efficiency of the proposed model. In addition to forecasting of the market index, predictability for individual stocks is also important for investment decisions. We start by identifying the ten largest stocks in terms of market capitalization, among which we eliminate the stocks with no price records over the sample period. Six stocks are left, the list of which is presented in
Table 6. The experimental results for those individual stocks are shown in
Table 7.
As reported in
Table 7, the integrated model of GA and LSTM network proves to be as performant on the individual stocks, as on the index. GA–LSTM even shows better prediction performance and statistical significance.
Based on these empirical results, we conclude that the optimization of time window and topology of LSTM network is an important task which can improve the performance of prediction models significantly. The integrating approach of combining GA and LSTM network has advantages in financial time series prediction problems, and this is evident when the simultaneous optimization over time lag and composing units is accomplished. The proposed hybrid model learned to capture some aspects of the market’s chaotic behavior, and was able to predict the price index of the next day with prominent performance compared to the benchmark.
In this research, we use GA technique, and prove that it is able to find the optimal solution for the model effectively. Through the overall results, we identify the superiority of the GA–LSTM network to predict the stock market. Experimental results suggest that using a suitably chosen time window and architectural factors on financial time series tasks can significantly improve the predictability of the LSTM network. The proposed GA–LSTM model could also tradeoff the limitations of commonly used methods, which are known as heuristic approaches.
In recent years, research on stock prediction using deep learning has been increasing. Chen et al. (2015) adopted LSTM network for forecasting the return of the Chinese stock market, which demonstrated poor performance [
58]. Hiransha et al. (2018) predicted the price of different companies from the National Stock Exchange (NSE) of India and New York Stock Exchange (NYSE) using several deep networks, including LSTM network and CNN, and compared their performance [
59]. The recent work by Dixon (2018) also used a LSTM network, and predicted short-term price movements on the S&P500 E-mini futures level II data [
40]. However, these studies do not deal with the problem of network architecture when it comes to defining the number of hidden layers and nodes it can include. This is where our model comes in handy, as it provides the solution based on GA, rather than a simple rule of thumb, which was shown to achieve better performance along with higher efficiency. This hybrid deep learning method can make better predictions, and it successfully deals with complex high dimensional data by offering an optimal model for financial prediction.
6. Conclusions
The prediction of the stock market can generate an actual financial loss or gain, so it is practically important to enhance the predictability of models. Consequently, many studies have been trying to model and predict financial time series, using statistical or soft computational skills that are capable of examining the complex and chaotic financial market. In recent years, deep learning techniques have been actively applied, based on their excellent achievements in various classification problems.
In this study, we constructed a stock price prediction model based on RNN using LSTM units, which is one of the typical methodologies of deep learning. We integrated GA and LSTM network to consider the temporal properties of the stock market, and utilized the customized architectural factors of a model. The LSTM network used in this study is composed with two hidden layers, which is a deep architecture for expressing nonlinear and complex features of the stock market more effectively. GA was employed to search the optimal or near-optimal value for the size of the time window and number of LSTM units in an LSTM network.
To verify the effectiveness of this approach, we perform the experiment on 17 years’ worth of KOSPI values, and predicted the closing price one day after, and the result is compared with a simple benchmark model that predicts no day-to-day change. The experimental results presented show that our proposed approach has lower MSE, MAE, and MAPE, and the improvements are found to be statistically significant. These overall results demonstrate that a GA–LSTM approach can be an effective method for stock market forecasting to reflect temporal patterns.
This study suggests useful implications for designing the proper architecture for LSTM network, which affects the detection of temporal patterns. Defining the time window is particularly crucial, because it plays an important role in investigating the temporal properties of given a dataset, but when processing the LSTM network, they are not specifically fine-tuned to the purpose of the problem, which causes the model to learn the least significant patterns. Much of the existing literature, that uses LSTM network in time series problems, usually employs subjective approaches based on trial and error, rather than systematic approaches to find the optimal size of the time window. Furthermore, other approaches that using statistical methods have the limitations that come from various statistical assumptions. However, we solved this problem by adapting an evolutionary search algorithm, GA, and our empirical results support the efficacy of the proposed model. We suggest a purpose-specific model with less restrictions, that can capture more significant leading signals in financial time series. The ability of the proposed model to track noisy patterns of financial time series may be applicable to various domains.
Although the proposed integrated model has a prominent predictive performance, it still has some insufficiencies. First, we did not take into consideration the trading commission in the analysis, and only forecasted the value of stock index and prices. However, in real-world investment environments, it is necessary to consider the trading commissions for higher returns, which can be a good topic for further discussion. Second, this study is conducted using only Korean stock market data. Therefore, further research can include data from various stock markets. Third, as mentioned earlier, the decision output of LSTM network is not easy to comprehend. Another improvement can be derived, providing an interpretable LSTM model in association with other machine learning techniques. Finally, there are some requirements to consider when designing the LSTM network architecture: restriction of overfitting phenomena and the influence of noise. These difficulties are particularly relevant for the financial time series, which are chaotic and require complex learning algorithms. To prevent these problems, learning parameters of the neural network should be properly selected, thus, further research can be conducted to optimize various other hyperparameters in LSTM networks. In addition, when it also comes to setting control parameters of GA, like the crossover rate and mutation rate, many suitable combinations can be derived that can improve the performance of research.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}