
A Method for Style Transfer from Artistic Images Based on Depth Extraction Generative Adversarial Network
Abstract
1. Introduction
2. Basic Theory
2.1. GAN
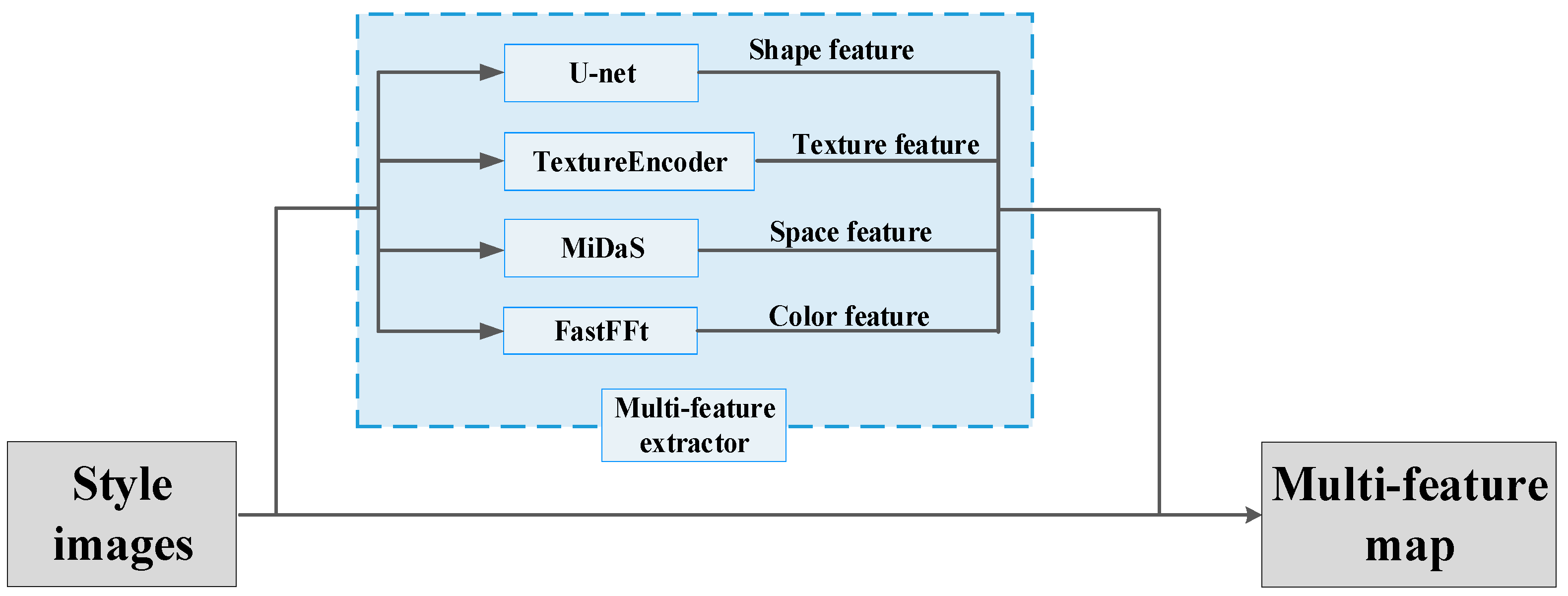
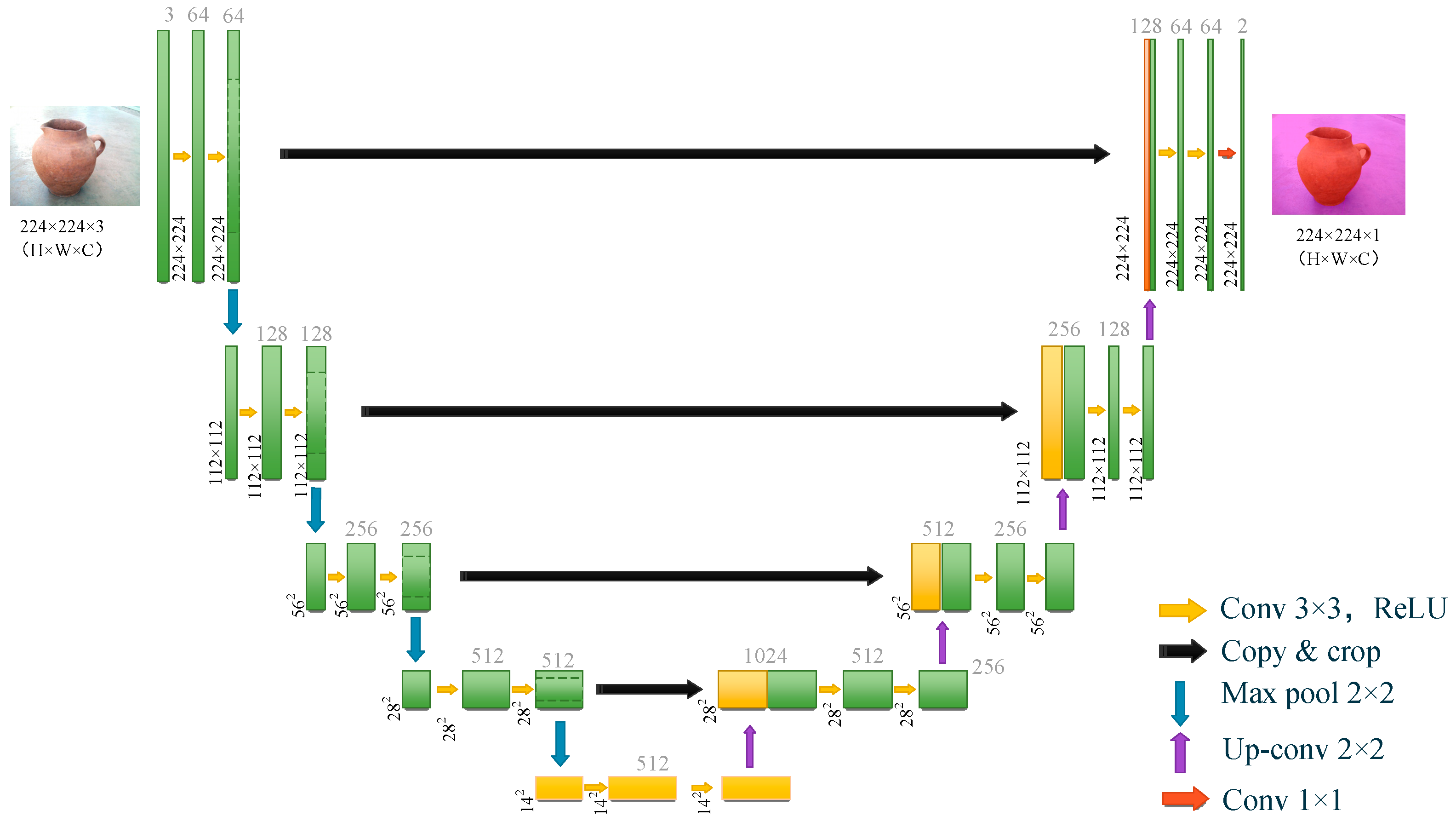
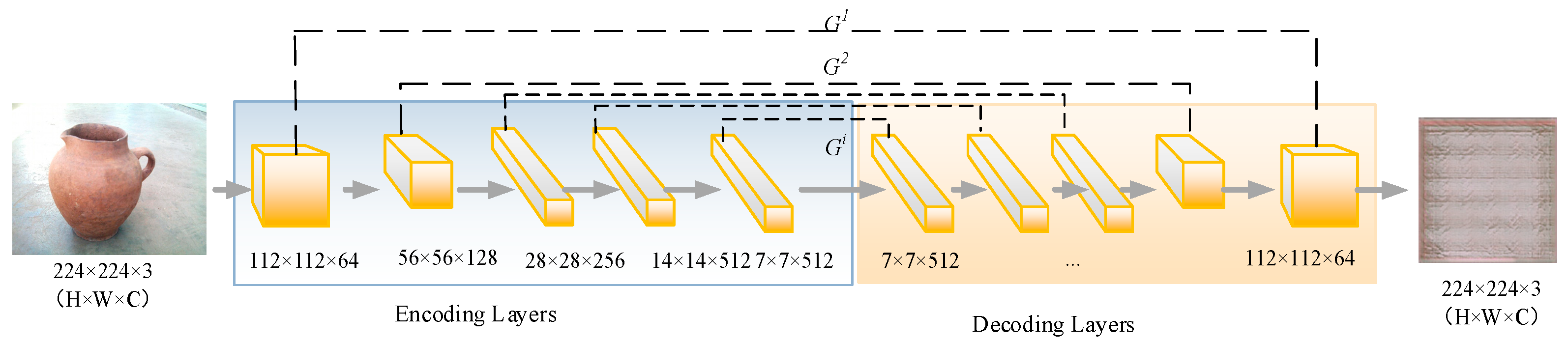
2.2. Depth Extraction GAN
2.3. Loss Function
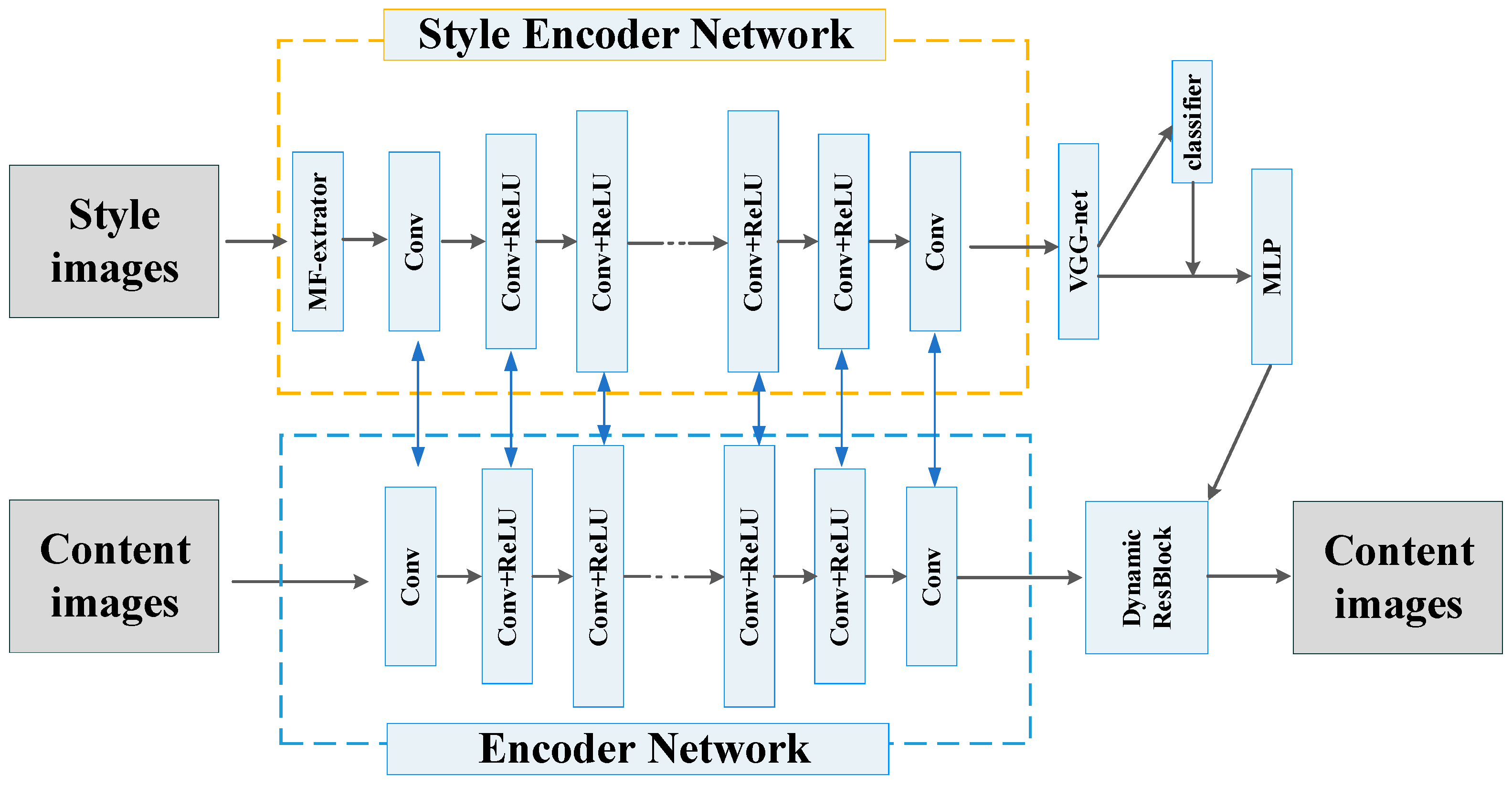
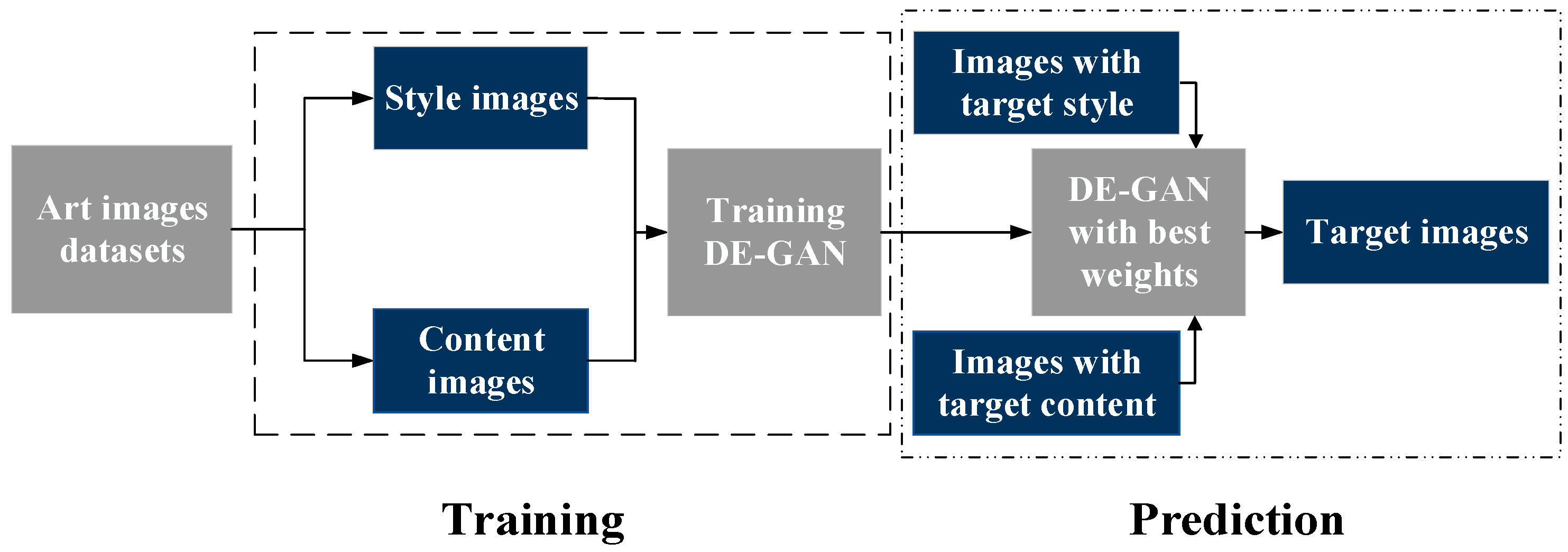
3. Process of Artistic Style Transfer Based on DE-GAN
4. Experiment and Discussion
4.1. Convergence of Loss Function
4.2. Experimental Setup
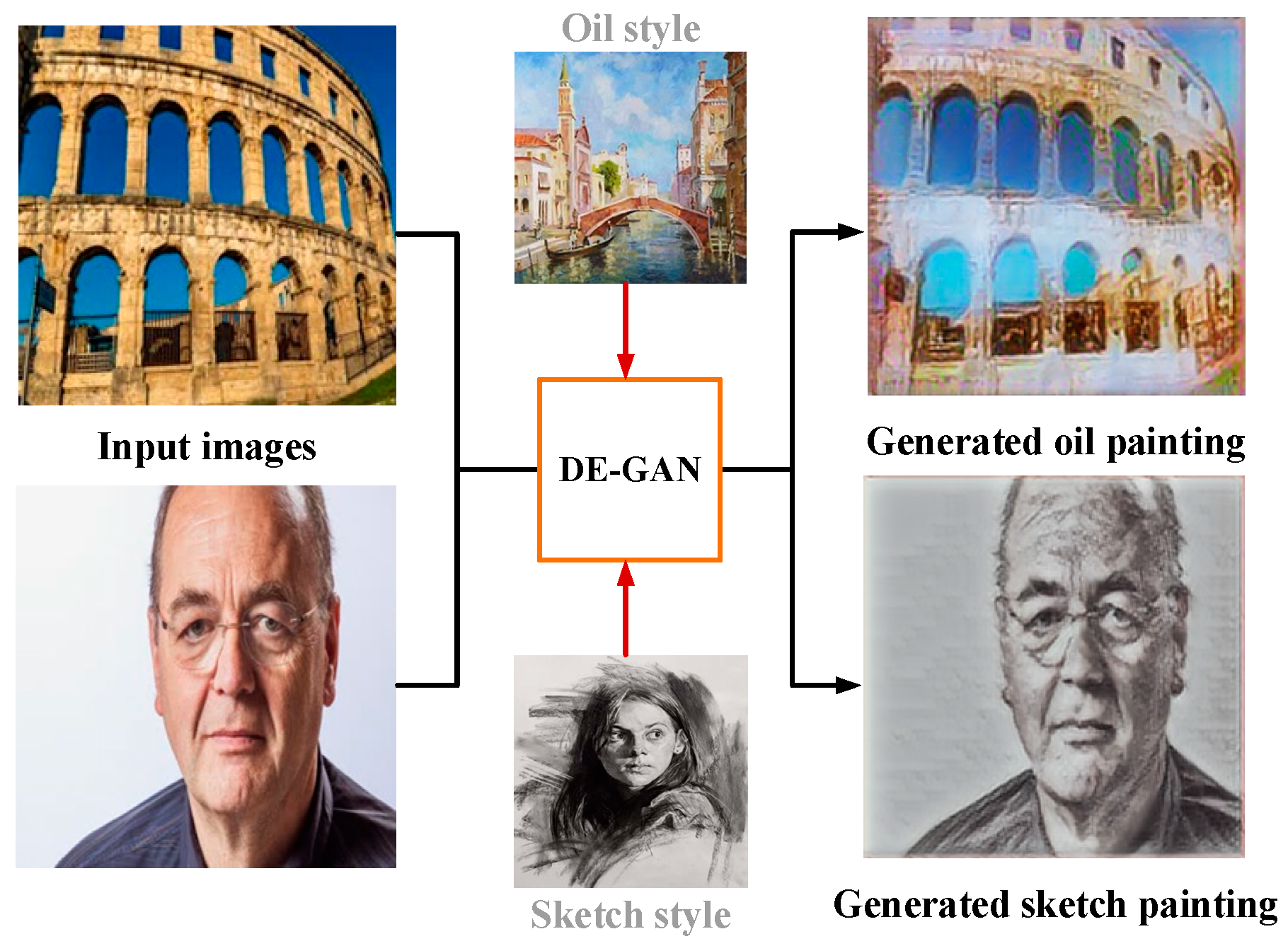
4.3. Qualitative Evaluation
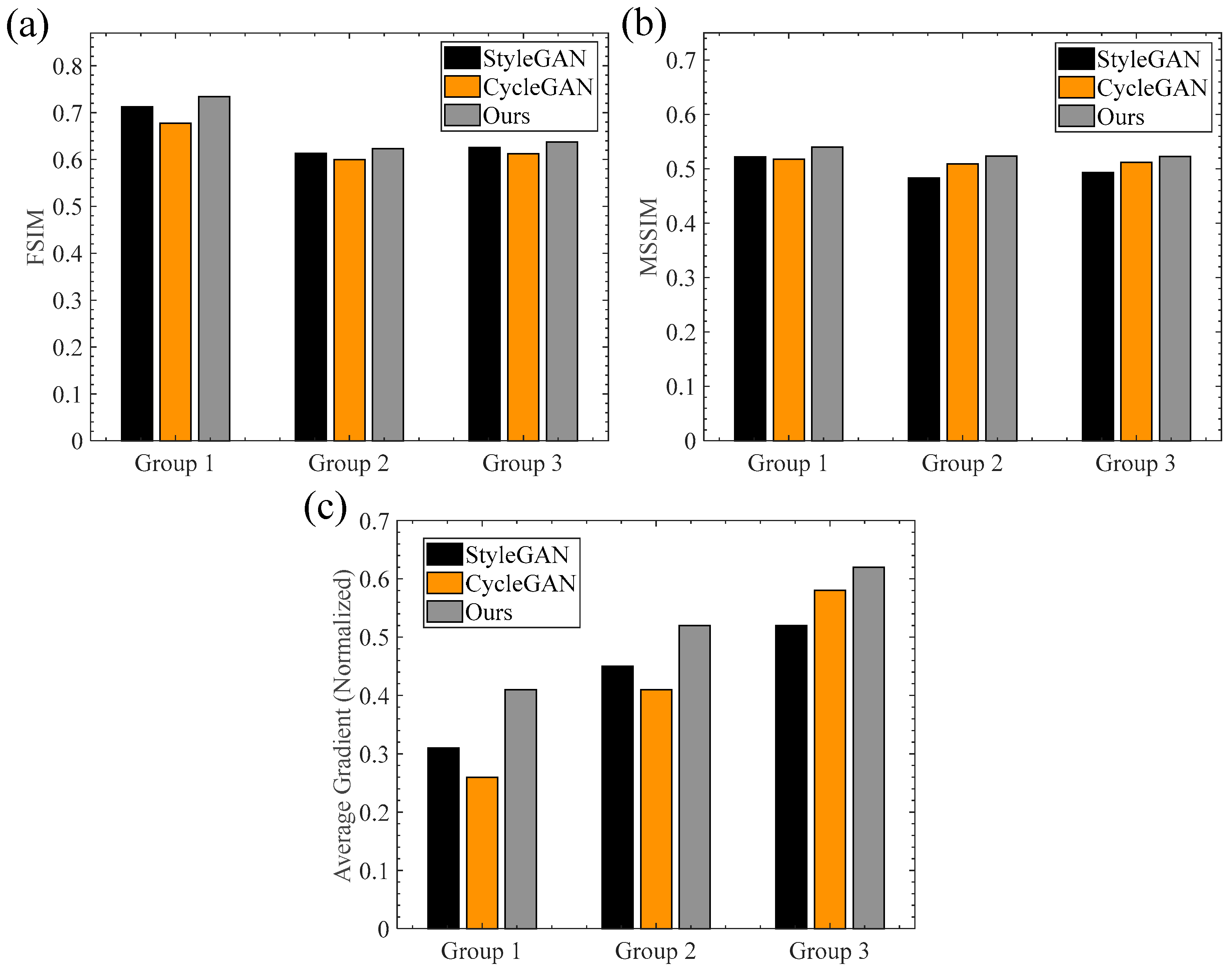
4.4. Quantitative Evaluation
- Feature similarity index (FSIM)
- Mean SSIM index (MSSIM)
- Image average gradient
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Efros, A.A.; Freeman, W.T. Image quilting for texture synthesis and transfer. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 12–17 August 2001; pp. 341–346. [Google Scholar]
- Efros, A.A.; Leung, T.K. Texture synthesis by non-parametric sampling. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–27 September 1999; Volume 2, pp. 1033–1038. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M.H. Universal style transfer via feature transforms. Adv. Neural Inf. Process. Syst. 2017, 30, 386–396. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Benaim, S.; Wolf, L. One-sided unsupervised domain mapping. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 752–762. [Google Scholar]
- Yu, Y.; Gong, Z.; Zhong, P.; Shan, J. Unsupervised representation learning with deep convolutional neural network for remote sensing images. In Proceedings of the International Conference on Image and Graphics, Shanghai, China, 13–15 September 2017; pp. 97–108. [Google Scholar]
- Mokhayeri, F.; Granger, E. A paired sparse representation model for robust face recognition from a single sample. Pattern Recognit. 2020, 100, 107129. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Chen, C.; Liang, P.; Guo, X.; Jiang, J. Pan-GAN: An unsupervised pan-sharpening method for remote sensing image fusion. Inf. Fusion 2020, 62, 110–120. [Google Scholar] [CrossRef]
- Chen, Y.; Lai, Y.K.; Liu, Y.J. Cartoongan: Generative adversarial networks for photo cartoonization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9465–9474. [Google Scholar]
- He, B.; Gao, F.; Ma, D.; Shi, B.; Duan, L.Y. Chipgan: A generative adversarial network for chinese ink wash painting style transfer. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1172–1180. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Upchurch, P.; Gardner, J.; Pleiss, G.; Pless, R.; Snavely, N.; Bala, K.; Weinberger, K. Deep feature interpolation for image content changes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7064–7073. [Google Scholar]
- Li, Y.; Huang, C.; Loy, C.C. Dense intrinsic appearance flow for human pose transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3693–3702. [Google Scholar]
- Hicsonmez, S.; Samet, N.; Akbas, E.; Duygulu, P. GANILLA: Generative adversarial networks for image to illustration translation. Image Vis. Comput. 2020, 95, 103886. [Google Scholar] [CrossRef]
- Ge, Y.; Xiao, Y.; Xu, Z.; Wang, X.; Itti, L. Contributions of Shape, Texture, and Color in Visual Recognition. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–24 October 2022; pp. 369–386. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Gatys, L.; Ecker, A.S.; Bethge, M. Texture synthesis using convolutional neural networks. Adv. Neural Inf. Process. Syst. 2016, 28, 1–6. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1623–1637. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Average Reasoning Time for a Single Picture (ms) |
|---|---|
| StyleGAN | 15.64 |
| CycleGAN | 26.78 |
| DE-GAN | 42.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, X.; Wu, Y.; Wan, R. A Method for Style Transfer from Artistic Images Based on Depth Extraction Generative Adversarial Network. Appl. Sci. 2023, 13, 867. https://doi.org/10.3390/app13020867
Han X, Wu Y, Wan R. A Method for Style Transfer from Artistic Images Based on Depth Extraction Generative Adversarial Network. Applied Sciences. 2023; 13(2):867. https://doi.org/10.3390/app13020867
Chicago/Turabian StyleHan, Xinying, Yang Wu, and Rui Wan. 2023. "A Method for Style Transfer from Artistic Images Based on Depth Extraction Generative Adversarial Network" Applied Sciences 13, no. 2: 867. https://doi.org/10.3390/app13020867
APA StyleHan, X., Wu, Y., & Wan, R. (2023). A Method for Style Transfer from Artistic Images Based on Depth Extraction Generative Adversarial Network. Applied Sciences, 13(2), 867. https://doi.org/10.3390/app13020867