

Evaluating the Efficacy of ChatGPT in Navigating the Spanish Medical Residency Entrance Examination (MIR): Promising Horizons for AI in Clinical Medicine

 , , , , and
, , , , and _MD__MPH_PhD.png)
Abstract
:1. Introduction
2. Materials and Methods
2.1. Context—The Graduate Medication Education System in Spain
2.2. The Spanish Medical Intern Examination-MIR Exam
- Category A. Circumstances or events that have the capacity to cause error.
- Category B. An error occurred, but the error did not reach the patient.
- Category C. An error occurred that reached the patient but did not cause the patient harm.
- Category D. An error occurred that reached the patient and required monitoring to confirm that it resulted in no harm to the patient or required intervention to preclude harm.
- Category E. An error that may have contributed to or resulted in temporary harm to the patient and required intervention.
- Category F. An error occurred that may have contributed to or resulted in temporary harm to the patient and required initial or prolonged hospitalization.
- Category G. An error occurred that may have contributed to or resulted in permanent patient harm.
- Category H. An error occurred that required intervention necessary to sustain life.
- Category I. An error occurred that may have contributed to or resulted in the patient’s death [51].
2.3. Image Processing
2.4. Statistical Analysis
3. Results
Image Processing Capabilities
4. Discussion
4.1. LLM Variable Responses
4.2. Analysis of Errors
4.2.1. Pharmacology Errors
4.2.2. Infectious Diseases Errors
4.2.3. Critical Care Errors
4.2.4. Cardiovascular Errors
4.2.5. Errors in Obstetrics and Gynecology
4.3. Limitations of the Study
4.4. Future Developments of IA in Medicine
4.5. GPT-4 in Teaching and Examinations
4.6. Implications of This Study
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krishnan, G.; Singh, S.; Pathania, M.; Gosavi, S.; Abhishek, S.; Parchani, A.; Dhar, M. Artificial Intelligence in Clinical Medicine: Catalyzing a Sustainable Global Healthcare Paradigm. Front. Artif. Intell. 2023, 6, 1227091. [Google Scholar] [CrossRef] [PubMed]
- Alowais, S.A.; Alghamdi, S.S.; Alsuhebany, N.; Alqahtani, T.; Alshaya, A.I.; Almohareb, S.N.; Aldairem, A.; Alrashed, M.; Bin Saleh, K.; Badreldin, H.A.; et al. Revolutionizing Healthcare: The Role of Artificial Intelligence in Clinical Practice. BMC Med. Educ. 2023, 23, 689. [Google Scholar] [CrossRef]
- Sezgin, E. Artificial Intelligence in Healthcare: Complementing, Not Replacing, Doctors and Healthcare Providers. Digit. Health 2023, 9, 20552076231186520. [Google Scholar] [CrossRef] [PubMed]
- Raza, M.A.; Aziz, S.; Noreen, M.; Saeed, A.; Anjum, I.; Ahmed, M.; Raza, S.M. Artificial Intelligence (AI) in Pharmacy: An Overview of Innovations. Innov. Pharm. 2022, 13, 13. [Google Scholar] [CrossRef]
- FDA. Artificial Intelligence and Machine Learning (AI/ML)-Enabled Medical Devices. Available online: https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-and-machine-learning-aiml-enabled-medical-devices (accessed on 7 November 2023).
- Yousefi, S. Clinical Applications of Artificial Intelligence in Glaucoma. J. Ophthalmic Vis. Res. 2023, 18, 97–112. [Google Scholar] [CrossRef]
- Da Soh, Z.; Tan, M.; Nongpiur, M.E.; Xu, B.Y.; Friedman, D.; Zhang, X.; Leung, C.; Liu, Y.; Koh, V.; Aung, T.; et al. Assessment of Angle Closure Disease in the Age of Artificial Intelligence: A Review. Prog. Retin. Eye Res. 2023, 98, 101227. [Google Scholar] [CrossRef]
- Zhou, J.; Wu, L.; Wan, X.; Shen, L.; Liu, J.; Zhang, J.; Jiang, X.; Wang, Z.; Yu, S.; Kang, J.; et al. A Novel Artificial Intelligence System for the Assessment of Bowel Preparation (with Video). Gastrointest. Endosc. 2020, 91, 428–435.e2. [Google Scholar] [CrossRef]
- Yang, L.; Li, Z.; Ma, S.; Yang, X. Artificial Intelligence Image Recognition Based on 5G Deep Learning Edge Algorithm of Digestive Endoscopy on Medical Construction. Alex. Eng. J. 2022, 61, 1852–1863. [Google Scholar] [CrossRef]
- Jost, E.; Kosian, P.; Jimenez Cruz, J.; Albarqouni, S.; Gembruch, U.; Strizek, B.; Recker, F. Evolving the Era of 5D Ultrasound? A Systematic Literature Review on the Applications for Artificial Intelligence Ultrasound Imaging in Obstetrics and Gynecology. J. Clin. Med. 2023, 12, 6833. [Google Scholar] [CrossRef]
- Sloan, M.; Li, H.; Lescay, H.A.; Judge, C.; Lan, L.; Hajiyev, P.; Giger, M.L.; Gundeti, M.S. Pilot Study of Machine Learning in the Task of Distinguishing High and Low-Grade Pediatric Hydronephrosis on Ultrasound. Investig. Clin. Urol. 2023, 64, 588. [Google Scholar] [CrossRef]
- Jin, B.; Krishnan, B.; Adler, S.; Wagstyl, K.; Hu, W.; Jones, S.; Najm, I.; Alexopoulos, A.; Zhang, K.; Zhang, J.; et al. Automated Detection of Focal Cortical Dysplasia Type II with Surface-based Magnetic Resonance Imaging Postprocessing and Machine Learning. Epilepsia 2018, 59, 982–992. [Google Scholar] [CrossRef] [PubMed]
- Young, A.L.; Marinescu, R.V.; Oxtoby, N.P.; Bocchetta, M.; Yong, K.; Firth, N.C.; Cash, D.M.; Thomas, D.L.; Dick, K.M.; Cardoso, J.; et al. Uncovering the Heterogeneity and Temporal Complexity of Neurodegenerative Diseases with Subtype and Stage Inference. Nat. Commun. 2018, 9, 4273. [Google Scholar] [CrossRef] [PubMed]
- Rava, R.A.; Seymour, S.E.; Snyder, K.V.; Waqas, M.; Davies, J.M.; Levy, E.I.; Siddiqui, A.H.; Ionita, C.N. Automated Collateral Flow Assessment in Patients with Acute Ischemic Stroke Using Computed Tomography with Artificial Intelligence Algorithms. World Neurosurg. 2021, 155, e748–e760. [Google Scholar] [CrossRef]
- Saillard, C.; Dubois, R.; Tchita, O.; Loiseau, N.; Garcia, T.; Adriansen, A.; Carpentier, S.; Reyre, J.; Enea, D.; von Loga, K.; et al. Validation of MSIntuit as an AI-Based Pre-Screening Tool for MSI Detection from Colorectal Cancer Histology Slides. Nat. Commun. 2023, 14, 6695. [Google Scholar] [CrossRef]
- Pantanowitz, L.; Quiroga-Garza, G.M.; Bien, L.; Heled, R.; Laifenfeld, D.; Linhart, C.; Sandbank, J.; Albrecht Shach, A.; Shalev, V.; Vecsler, M.; et al. An Artificial Intelligence Algorithm for Prostate Cancer Diagnosis in Whole Slide Images of Core Needle Biopsies: A Blinded Clinical Validation and Deployment Study. Lancet Digit. Health 2020, 2, e407–e416. [Google Scholar] [CrossRef] [PubMed]
- Sorace, L.; Raju, N.; O’Shaughnessy, J.; Kachel, S.; Jansz, K.; Yang, N.; Lim, R.P. Assessment of Inspiration and Technical Quality in Anteroposterior Thoracic Radiographs Using Machine Learning. Radiography 2023, 30, 107–115. [Google Scholar] [CrossRef]
- Gawrieh, S.; Sethunath, D.; Cummings, O.W.; Kleiner, D.E.; Vuppalanchi, R.; Chalasani, N.; Tuceryan, M. Automated Quantification and Architectural Pattern Detection of Hepatic Fibrosis in NAFLD. Ann. Diagn. Pathol. 2020, 47, 151518. [Google Scholar] [CrossRef]
- Pérez-Sanz, F.; Riquelme-Pérez, M.; Martínez-Barba, E.; de la Peña-Moral, J.; Salazar Nicolás, A.; Carpes-Ruiz, M.; Esteban-Gil, A.; Legaz-García, M.D.C.; Parreño-González, M.A.; Ramírez, P.; et al. Efficiency of Machine Learning Algorithms for the Determination of Macrovesicular Steatosis in Frozen Sections Stained with Sudan to Evaluate the Quality of the Graft in Liver Transplantation. Sensors 2021, 21, 1993. [Google Scholar] [CrossRef]
- Cao, Y.; Raoof, M.; Szabo, E.; Ottosson, J.; Näslund, I. Using Bayesian Networks to Predict Long-Term Health-Related Quality of Life and Comorbidity after Bariatric Surgery: A Study Based on the Scandinavian Obesity Surgery Registry. J. Clin. Med. 2020, 9, 1895. [Google Scholar] [CrossRef]
- Caetano dos Santos, F.L.; Michalek, I.M.; Laurila, K.; Kaukinen, K.; Hyttinen, J.; Lindfors, K. Automatic Classification of IgA Endomysial Antibody Test for Celiac Disease: A New Method Deploying Machine Learning. Sci. Rep. 2019, 9, 9217. [Google Scholar] [CrossRef]
- Busnatu, Ș.; Niculescu, A.-G.; Bolocan, A.; Petrescu, G.E.D.; Păduraru, D.N.; Năstasă, I.; Lupușoru, M.; Geantă, M.; Andronic, O.; Grumezescu, A.M.; et al. Clinical Applications of Artificial Intelligence—An Updated Overview. J. Clin. Med. 2022, 11, 2265. [Google Scholar] [CrossRef] [PubMed]
- Makimoto, H.; Kohro, T. Adopting Artificial Intelligence in Cardiovascular Medicine: A Scoping Review. Hypertens. Res. 2023. [Google Scholar] [CrossRef] [PubMed]
- Tison, G.H.; Sanchez, J.M.; Ballinger, B.; Singh, A.; Olgin, J.E.; Pletcher, M.J.; Vittinghoff, E.; Lee, E.S.; Fan, S.M.; Gladstone, R.A.; et al. Passive Detection of Atrial Fibrillation Using a Commercially Available Smartwatch. JAMA Cardiol. 2018, 3, 409–416. [Google Scholar] [CrossRef]
- Eberhard, M.; Nadarevic, T.; Cousin, A.; von Spiczak, J.; Hinzpeter, R.; Euler, A.; Morsbach, F.; Manka, R.; Keller, D.I.; Alkadhi, H. Machine Learning-Based CT Fractional Flow Reserve Assessment in Acute Chest Pain: First Experience. Cardiovasc. Diagn. Ther. 2020, 10, 820–830. [Google Scholar] [CrossRef] [PubMed]
- Kristiansen, T.B.; Kristensen, K.; Uffelmann, J.; Brandslund, I. Erroneous Data: The Achilles’ Heel of AI and Personalized Medicine. Front. Digit. Health 2022, 4, 862095. [Google Scholar] [CrossRef] [PubMed]
- Shamszare, H.; Choudhury, A. Clinicians’ Perceptions of Artificial Intelligence: Focus on Workload, Risk, Trust, Clinical Decision Making, and Clinical Integration. Healthcare 2023, 11, 2308. [Google Scholar] [CrossRef]
- Tanana, M.J.; Soma, C.S.; Kuo, P.B.; Bertagnolli, N.M.; Dembe, A.; Pace, B.T.; Srikumar, V.; Atkins, D.C.; Imel, Z.E. How Do You Feel? Using Natural Language Processing to Automatically Rate Emotion in Psychotherapy. Behav. Res. Methods 2021, 53, 2069–2082. [Google Scholar] [CrossRef]
- Goldberg, S.B.; Flemotomos, N.; Martinez, V.R.; Tanana, M.J.; Kuo, P.B.; Pace, B.T.; Villatte, J.L.; Georgiou, P.G.; Van Epps, J.; Imel, Z.E.; et al. Machine Learning and Natural Language Processing in Psychotherapy Research: Alliance as Example Use Case. J. Couns. Psychol. 2020, 67, 438–448. [Google Scholar] [CrossRef]
- Hasikin, K.; Lai, K.W.; Satapathy, S.C.; Sabanci, K.; Aslan, M.F. Editorial: Emerging Applications of Text Analytics and Natural Language Processing in Healthcare. Front. Digit. Health 2023, 5, 1227948. [Google Scholar] [CrossRef]
- Sohail, S.S. A Promising Start and Not a Panacea: ChatGPT’s Early Impact and Potential in Medical Science and Biomedical Engineering Research. Ann. Biomed. Eng. 2023. [Google Scholar] [CrossRef]
- Goktas, P.; Karakaya, G.; Kalyoncu, A.F.; Damadoglu, E. Artificial Intelligence Chatbots in Allergy and Immunology Practice: Where Have We Been and Where Are We Going? J. Allergy Clin. Immunol. Pract. 2023, 11, 2697–2700. [Google Scholar] [CrossRef] [PubMed]
- Wiens, J.; Mihalcea, R.; Nallamothu, B.K. Current Large Language Models Will Not Fix Health Care. Here’s What Could; Stat News: Boston, MA, USA, 2023. [Google Scholar]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in Medicine: An Overview of Its Applications, Advantages, Limitations, Future Prospects, and Ethical Considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef] [PubMed]
- Dunn, C.; Hunter, J.; Steffes, W.; Whitney, Z.; Foss, M.; Mammino, J.; Leavitt, A.; Hawkins, S.D.; Dane, A.; Yungmann, M.; et al. Artificial Intelligence–Derived Dermatology Case Reports Are Indistinguishable from Those Written by Humans: A Single-Blinded Observer Study. J. Am. Acad. Dermatol. 2023, 89, 388–390. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Heacock, L.; Elias, J.; Hentel, K.D.; Reig, B.; Shih, G.; Moy, L. ChatGPT and Other Large Language Models Are Double-Edged Swords. Radiology 2023, 307, e230163. [Google Scholar] [CrossRef]
- Johnson, D.; Goodman, R.; Patrinely, J.; Stone, C.; Zimmerman, E.; Donald, R.; Chang, S.; Berkowitz, S.; Finn, A.; Jahangir, E.; et al. Assessing the Accuracy and Reliability of AI-Generated Medical Responses: An Evaluation of the Chat-GPT Model. Res. Sq. 2023. [Google Scholar] [CrossRef]
- Suchman, K.; Garg, S.; Trindade, A.J. Chat Generative Pretrained Transformer Fails the Multiple-Choice American College of Gastroenterology Self-Assessment Test. Am. J. Gastroenterol. 2023, 10-14309. [Google Scholar] [CrossRef]
- Lahat, A.; Shachar, E.; Avidan, B.; Glicksberg, B.; Klang, E. Evaluating the Utility of a Large Language Model in Answering Common Patients’ Gastrointestinal Health-Related Questions: Are We There Yet? Diagnostics 2023, 13, 1950. [Google Scholar] [CrossRef]
- Brin, D.; Sorin, V.; Vaid, A.; Soroush, A.; Glicksberg, B.S.; Charney, A.W.; Nadkarni, G.; Klang, E. Comparing ChatGPT and GPT-4 Performance in USMLE Soft Skill Assessments. Sci. Rep. 2023, 13, 16492. [Google Scholar] [CrossRef]
- Epstein, R.H.; Dexter, F. Variability in Large Language Models’ Responses to Medical Licensing and Certification Examinations. Comment on “How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education a. JMIR Med. Educ. 2023, 9, e48305. [Google Scholar] [CrossRef]
- Jung, L.B.; Gudera, J.A.; Wiegand, T.L.T.; Allmendinger, S.; Dimitriadis, K.; Koerte, I.K. ChatGPT Passes German State Examination in Medicine with Picture Questions Omitted. Dtsch. Arztebl. Int. 2023, 120, 373–374. [Google Scholar] [CrossRef]
- Wang, H.; Wu, W.; Dou, Z.; He, L.; Yang, L. Performance and Exploration of ChatGPT in Medical Examination, Records and Education in Chinese: Pave the Way for Medical AI. Int. J. Med. Inform. 2023, 177, 105173. [Google Scholar] [CrossRef] [PubMed]
- Kao, Y.-S.; Chuang, W.-K.; Yang, J. Use of ChatGPT on Taiwan’s Examination for Medical Doctors. Ann. Biomed. Eng. 2023. [Google Scholar] [CrossRef] [PubMed]
- Takagi, S.; Watari, T.; Erabi, A.; Sakaguchi, K. Performance of GPT-3.5 and GPT-4 on the Japanese Medical Licensing Examination: Comparison Study. JMIR Med. Educ. 2023, 9, e48002. [Google Scholar] [CrossRef] [PubMed]
- Levin, G.; Horesh, N.; Brezinov, Y.; Meyer, R. Performance of ChatGPT in Medical Examinations: A Systematic Review and a Meta-analysis. BJOG 2023, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Orden SND/840/2022, de 26 de Agosto, por la que se aprueba la oferta de plazas y la convocatoria de pruebas selectivas 2022 para el acceso en el año 2023, a plazas de formación sanitaria especializada para las titulaciones universitarias de Grado/Licenciado. Boletín Oficial del Estado 2022, 211, 122047–122309. Available online: https://www.boe.es/diario_boe/txt.php?id=BOE-A-2022-14414 (accessed on 5 November 2023).
- Gamarra, M. Resultados de Los Extracomunitarios en el MIR. 2023. Available online: https://www.consalud.es/especial-mir/mir-2023-46-plazas-han-ido-parar-extranjeros_129841_102.html (accessed on 5 November 2023).
- Ministerio de Sanidad. Pruebas Selectivas 2021, Cuaderno de Examen, Medicina—Versión 0; Ministerio de Sanidad: Madrid, Spain, 2022. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- NCC-MERP. National Coordinating Council for Medication Error Reporting and Prevention. Taxonomy of Medication Errors. Available online: https://www.nccmerp.org/sites/default/files/taxonomy2001-07-31.pdf (accessed on 15 August 2023).
- OpenAI. ChatGPT (September 25 Version) [Large Language Model]. 2023. Available online: https://Chat.Openai.Com (accessed on 5 November 2023).
- Nori, H.; King, N.; McKinney, S.M.; Carignan, D.; Horvitz, E. Capabilities of GPT-4 on Medical Challenge Problems. arXiv 2023, arXiv:2303.13375. [Google Scholar] [CrossRef]
- Dean, A.G.; Sullivan, K.M.; Soe, M.M. OpenEpi: Open Source Epidemiologic Statistics for Public Health, Versión 2.3.1; ScienceOpen: Lexington, MA, USA; Berlin, Germany; Budapest, Hungary, 2013. [Google Scholar]
- He, N.; Yan, Y.; Wu, Z.; Cheng, Y.; Liu, F.; Li, X.; Zhai, S. Chat GPT-4 Significantly Surpasses GPT-3.5 in Drug Information Queries. J. Telemed. Telecare 2023, 1357633X231181922. [Google Scholar] [CrossRef]
- Kleebayoon, A.; Wiwanitkit, V. Correspondence on Chat GPT-4, GPT-3.5 and Drug Information Queries. J. Telemed. Telecare 2023, 1357633X231189760. [Google Scholar] [CrossRef]
- Galvan, A. Patricia Andrés, Número 1 del Examen MIR 2023, Elige Dermatología Para Realizar su Residencia. Available online: https://aedv.es/patricia-andres-elige-dermatologia-para-realizar-residencia/#:~:text=Natural%20de%20Bilbao%20y%20alumna,y%20116%2C9836%20puntos%20totales (accessed on 5 November 2023).
- Examen MIR 2023: ¿Qué Preguntas Podrían ser Impugnables? Available online: https://www.diariomedico.com/medicina/medico-joven/mir/examen-mir-2023-que-preguntas-podrian-ser-impugnables.html (accessed on 6 November 2023).
- Carrasco, J.P.; García, E.; Sánchez, D.A.; Porter, E.; De La Puente, L.; Navarro, J.; Cerame, A. ¿Es Capaz “ChatGPT” de Aprobar El Examen MIR de 2022? Implicaciones de La Inteligencia Artificial En La Educación Médica En España. Rev. Española Educ. Médica 2023, 4, 12–18. [Google Scholar] [CrossRef]
- Rao, A.; Pang, M.; Kim, J.; Kamineni, M.; Lie, W.; Prasad, A.K.; Landman, A.; Dreyer, K.; Succi, M.D. Assessing the Utility of ChatGPT throughout the Entire Clinical Workflow: Development and Usability Study. J. Med. Internet Res. 2023, 25, e48659. [Google Scholar] [CrossRef] [PubMed]
- Xv, Y.; Peng, C.; Wei, Z.; Liao, F.; Xiao, M. Can Chat-GPT a Substitute for Urological Resident Physician in Diagnosing Diseases?: A Preliminary Conclusion from an Exploratory Investigation. World J. Urol. 2023, 41, 2569–2571. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.C.; Kaminski, E.; Koduri, L.; Singer, A.; Singer, J.; Couldwell, M.; Delashaw, J.; Dumont, A.; Wang, A. Chat GPT as a Neuro-Score Calculator: Analysis of a Large Language Model’s Performance on Various Neurological Exam Grading Scales. World Neurosurg. 2023, 179, e342–e347. [Google Scholar] [CrossRef] [PubMed]
- Guerra, G.; Hofmann, H.; Sobhani, S.; Hofmann, G.; Gomez, D.; Soroudi, D.; Hopkins, B.S.; Dallas, J.; Pangal, D.; Cheok, S.; et al. GPT-4 Artificial Intelligence Model Outperforms ChatGPT, Medical Students, and Neurosurgery Residents on Neurosurgery Written Board-like Questions. World Neurosurg. 2023, 179, e160–e165. [Google Scholar] [CrossRef]
- Kleebayoon, A.; Mungmunpuntipanitp, R.; Wiwanitkit, V. Chat GPT in Stereotactic Radiosurgery: Correspondence. J. Neurooncol. 2023, 163, 727–728. [Google Scholar] [CrossRef]
- Ismail, A.M.A. Chat GPT in Tailoring Individualized Lifestyle-Modification Programs in Metabolic Syndrome: Potentials and Difficulties? Ann. Biomed. Eng. 2023, 51, 2634–2635. [Google Scholar] [CrossRef]
- Arslan, S. Exploring the Potential of Chat GPT in Personalized Obesity Treatment. Ann. Biomed. Eng. 2023, 51, 1887–1888. [Google Scholar] [CrossRef]
- Zhou, Z. Evaluation of ChatGPT’s Capabilities in Medical Report Generation. Cureus 2023, 15, e37589. [Google Scholar] [CrossRef]
- Grewal, H.; Dhillon, G.; Monga, V.; Sharma, P.; Buddhavarapu, V.S.; Sidhu, G.; Kashyap, R. Radiology Gets Chatty: The ChatGPT Saga Unfolds. Cureus 2023, 15, e40135. [Google Scholar] [CrossRef]
- Iftikhar, S.; Naz, I.; Zahra, A.; Zaidi, S.; Zainab, Y. Report Generation of Lungs Diseases from Chest X-Ray Using NLP. Int. J. Innov. Sci. Technol. 2022, 3, 223–233. [Google Scholar] [CrossRef]
- Perlis, R.H. Research Letter: Application of GPT-4 to Select next-Step Antidepressant Treatment in Major Depression. medRxiv 2023. [Google Scholar] [CrossRef]
- Gilson, A.; Safranek, C.W.; Huang, T.; Socrates, V.; Chi, L.; Taylor, R.A.; Chartash, D. How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education and Knowledge Assessment. JMIR Med. Educ. 2023, 9, e45312. [Google Scholar] [CrossRef]
- Singh, S.; Deep, R. Pharmacological Treatment of Bipolar Disorder in Pregnancy: An Update on Safety Considerations. Indian J. Pharmacol. 2022, 54, 443–451. [Google Scholar] [CrossRef] [PubMed]
- Uguz, F. Pharmacological Prevention of Mood Episodes in Women with Bipolar Disorder during the Perinatal Period: A Systematic Review of Current Literature. Asian J. Psychiatr. 2020, 52, 102145. [Google Scholar] [CrossRef]
- Sagué-Vilavella, M.; Solé, E.; Pinzón-Espinosa, J.; Sandra-Hernández, A.; Roda, E.; Vieta, E.; Roca, A. Obstetric Outcomes Regarding the Use of Lithium in Pregnant Women with Bipolar Disorders: A Prospective Cohort Study. Arch. Womens Ment. Health 2022, 25, 729–737. [Google Scholar] [CrossRef] [PubMed]
- Albertini, E.; Ernst, C.L.; Tamaroff, R.S. Psychopharmacological Decision Making in Bipolar Disorder During Pregnancy and Lactation: A Case-by-Case Approach to Using Current Evidence. Focus 2019, 17, 249–258. [Google Scholar] [CrossRef] [PubMed]
- Scrandis, D.A. Bipolar Disorder in Pregnancy: A Review of Pregnancy Outcomes. J. Midwifery Women’s Health 2017, 62, 673–683. [Google Scholar] [CrossRef]
- Epstein, R.; Moore, K.; Bobo, W. Treatment of Bipolar Disorders during Pregnancy: Maternal and Fetal Safety and Challenges. Drug Healthc. Patient Saf. 2014, 7, 7–29. [Google Scholar] [CrossRef]
- Uguz, F. Prophylactic Use of Olanzapine and Quetiapine from Pregnancy to the Postpartum Period in Women with Bipolar Disorder: A Case Series. J. Matern. Fetal Neonatal Med. 2017, 30, 2569–2571. [Google Scholar] [CrossRef]
- Gentile, S. Prophylactic Treatment of Bipolar Disorder in Pregnancy and Breastfeeding: Focus on Emerging Mood Stabilizers. Bipolar Disord. 2006, 8, 207–220. [Google Scholar] [CrossRef]
- Pepine, C.J.; Gurbel, P.A. Cardiovascular Safety of NSAIDs: Additional Insights after PRECISION and Point of View. Clin. Cardiol. 2017, 40, 1352–1356. [Google Scholar] [CrossRef]
- Chan, F.K.L.; Ching, J.Y.L.; Tse, Y.K.; Lam, K.; Wong, G.L.H.; Ng, S.C.; Lee, V.; Au, K.W.L.; Cheong, P.K.; Suen, B.Y.; et al. Gastrointestinal Safety of Celecoxib versus Naproxen in Patients with Cardiothrombotic Diseases and Arthritis after Upper Gastrointestinal Bleeding (CONCERN): An Industry-Independent, Double-Blind, Double-Dummy, Randomised Trial. Lancet 2017, 389, 2375–2382. [Google Scholar] [CrossRef] [PubMed]
- Angiolillo, D.J.; Weisman, S.M. Clinical Pharmacology and Cardiovascular Safety of Naproxen. Am. J. Cardiovasc. Drugs 2017, 17, 97–107. [Google Scholar] [CrossRef] [PubMed]
- Schjerning, A.-M.; McGettigan, P.; Gislason, G. Cardiovascular Effects and Safety of (Non-Aspirin) NSAIDs. Nat. Rev. Cardiol. 2020, 17, 574–584. [Google Scholar] [CrossRef]
- Scarpignato, C.; Lanas, A.; Blandizzi, C.; Lems, W.F.; Hermann, M.; Hunt, R.H. Safe Prescribing of Non-Steroidal Anti-Inflammatory Drugs in Patients with Osteoarthritis—An Expert Consensus Addressing Benefits as Well as Gastrointestinal and Cardiovascular Risks. BMC Med. 2015, 13, 55. [Google Scholar] [CrossRef] [PubMed]
- Giles, T.D.; Miller, A.B.; Elkayam, U.; Bhattacharya, M.; Perez, A. Pioglitazone and Heart Failure: Results from a Controlled Study in Patients with Type 2 Diabetes Mellitus and Systolic Dysfunction. J. Card. Fail. 2008, 14, 445–452. [Google Scholar] [CrossRef] [PubMed]
- Rådholm, K.; Figtree, G.; Perkovic, V.; Solomon, S.D.; Mahaffey, K.W.; de Zeeuw, D.; Fulcher, G.; Barrett, T.D.; Shaw, W.; Desai, M.; et al. Canagliflozin and Heart Failure in Type 2 Diabetes Mellitus. Circulation 2018, 138, 458–468. [Google Scholar] [CrossRef]
- Juurlink, D.N.; Gomes, T.; Lipscombe, L.L.; Austin, P.C.; Hux, J.E.; Mamdani, M.M. Adverse Cardiovascular Events during Treatment with Pioglitazone and Rosiglitazone: Population Based Cohort Study. BMJ 2009, 339, b2942. [Google Scholar] [CrossRef]
- DeHaan, E.; McGowan, J.P.; Fine, S.M.; Vail, R.; Merrick, S.T.; Radix, A.; Hoffmann, C.J.; Gonzalez, C.J. PEP to Prevent HIV Infection; Johns Hopkins University: Baltimore, MD, USA, 2022. [Google Scholar]
- ASHM. HIV Management Guidelines. Available online: https://hivmanagement.ashm.org.au/biomedical-prevention-of-hiv-infection/post-exposure-prophylaxis/#:~:text=PEP%20is%20NOT%20RECOMMENDED%20following,up%20and (accessed on 6 November 2023).
- National Institute for Health and Care Excellence. Scenario: Post-Exposure Prophylaxis for HIV. Available online: https://cks.nice.org.uk/topics/hiv-infection-aids/management/post-exposure-prophylaxis/#:~:text=PEP is generally no longer, infection status is not known (accessed on 6 November 2023).
- Webster, D. Is HIV Post-exposure Prophylaxis Required Following Occupational Exposure to a Source Patient Who Is Virologically Suppressed on Antiretroviral Therapy? HIV Med. 2015, 16, 73–75. [Google Scholar] [CrossRef]
- Gordon, A.; Rabold, E.; Thirumala, R.; Husain, A.A.; Patel, S.; Cheema, T. Prone Positioning in ARDS. Crit. Care Nurs. Q. 2019, 42, 371–375. [Google Scholar] [CrossRef]
- Frazier, P. A Local Project to Reduce Teen Pregnancy. N. C Med. J. 1987, 48, 270–271. [Google Scholar] [PubMed]
- Rodriguez, B.; Larsson, L.; Z’Graggen, W.J. Critical Illness Myopathy: Diagnostic Approach and Resulting Therapeutic Implications. Curr. Treat. Options Neurol. 2022, 24, 173–182. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, U.; Hati, A.; Chandra, A. COVID-19 Associated Guillain-Barré Syndrome: A Series of a Relatively Uncommon Neurological Complication. Diabetes Metab. Syndr. Clin. Res. Rev. 2021, 15, 102326. [Google Scholar] [CrossRef] [PubMed]
- Cheung, K.; Rathbone, A.; Melanson, M.; Trier, J.; Ritsma, B.R.; Allen, M.D. Pathophysiology and Management of Critical Illness Polyneuropathy and Myopathy. J. Appl. Physiol. 2021, 130, 1479–1489. [Google Scholar] [CrossRef]
- Shepherd, S.; Batra, A.; Lerner, D.P. Review of Critical Illness Myopathy and Neuropathy. Neurohospitalist 2017, 7, 41–48. [Google Scholar] [CrossRef]
- Oancea, A.; Furnică, C.; Chistol, R.O.; Mitu, F.; Leon-Constantin, M.-M.; Tinică, G. Surgical versus Transvalvular Aortic Valve Replacement in Elderly Patients—The Impact of Frailty. Diagnostics 2021, 11, 1861. [Google Scholar] [CrossRef] [PubMed]
- Ho, E.; Mathur, M.N.; Brady, P.W.; Marshman, D.; Brereton, R.J.; Ross, D.E.; Bhindi, R.; Hansen, P.S. Surgical Aortic Valve Replacement in Very Elderly Patients Aged 80 Years and Over: Evaluation of Early Clinical Outcomes. Heart Lung Circ. 2014, 23, 242–248. [Google Scholar] [CrossRef]
- Shavit, L.; Silberman, S.; Tauber, R.; Merin, O.; Bitran, D.; Fink, D. Outcomes of Transcatheter Aortic Valve Implantation Compared with Surgical Aortic Valve Replacement in Geriatric Patients with Chronic Kidney Disease. Clin. Nephrol. 2018, 90, 87–93. [Google Scholar] [CrossRef]
- Baxter, G.M.; Kincaid, W.; Jeffrey, R.F.; Millar, G.M.; Porteous, C.; Morley, P. Comparison of Colour Doppler Ultrasound with Venography in the Diagnosis of Axillary and Subclavian Vein Thrombosis. Br. J. Radiol. 1991, 64, 777–781. [Google Scholar] [CrossRef]
- Meissner, M.H. Axillary-Subclavian Venous Thrombosis. Rev. Cardiovasc. Med. 2002, 3 (Suppl. S2), S76-33. [Google Scholar]
- Lindblad, B.; Tengborn, L.; Bergqvist, D. Deep Vein Thrombosis of the Axillary-Subclavian Veins: Epidemiologic Data, Effects of Different Types of Treatment and Late Sequele. Eur. J. Vasc. Surg. 1988, 2, 161–165. [Google Scholar] [CrossRef] [PubMed]
- Zerangian, N.; Erabi, G.; Poudineh, M.; Monajjem, K.; Diyanati, M.; Khanlari, M.; Khalaji, A.; Allafi, D.; Faridzadeh, A.; Amali, A.; et al. Venous Thromboembolism in Viral Diseases: A Comprehensive Literature Review. Health Sci. Rep. 2023, 6, e1085. [Google Scholar] [CrossRef]
- Kesieme, E.; Kesieme, C.; Jebbin, N.; Irekpita, E.; Dongo, R. Deep Vein Thrombosis: A Clinical Review. J. Blood Med. 2011, 2, 59–69. [Google Scholar] [CrossRef] [PubMed]
- Lueck, T.; Young, B.C. Operative Vaginal Birth: Neonatal Implications for Vacuum and Forceps-Assisted Vaginal Delivery. Neoreviews 2023, 24, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Burande, A.P.; Jayaraj, V.; Pai, A.V.; Akkarappatty, P.; Arathi, V.L.; Pradeep, M.; Paily, V.P. Assisted Vaginal Birth Using the Paily Obstetric Forceps vs Ventouse—A Randomized Clinical Trial. Eur. J. Obstet. Gynecol. Reprod. Biol. 2023, 280, 40–47. [Google Scholar] [CrossRef] [PubMed]
- Nikolov, A.; Nashar, C.; Pavlova, E.; Dimitrov, A. Frequency and Indication for Vacuum Extractor Delivery. Akush. Ginekol. 2009, 48, 3–10. [Google Scholar]
- Murphy, D.; Strachan, B.; Bahl, R. Assisted Vaginal Birth. BJOG Int. J. Obstet. Gynaecol. 2020, 127, E70–E112. [Google Scholar] [CrossRef]
- Sociedad Española de Ginecología y Obstetricia. Protocolos de Procedimientos Diagnósticos y Terapéuticos en Obstetricia; Ventosa Obstétrica: Madrid, Spain, 2002. [Google Scholar]
- Száva-Kováts, E. Unfounded Attribution of the “Half-Life” Index-Number of Literature Obsolescence to Burton and Kebler: A Literature Science Study. J. Am. Soc. Inf. Sci. Technol. 2002, 53, 1098–1105. [Google Scholar] [CrossRef]
- Gorbea-Portal, S.; Atrián-Salazar, M.L. Medición de La Obsolescencia de La Información En Revistas de Salud Pública de México. Gac. Med. Mex. 2018, 154, 335–341. [Google Scholar] [CrossRef]
- Sallam, M. ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef]
- Grech, V.; Cuschieri, S.; Eldawlatly, A. Artificial Intelligence in Medicine and Research—The Good, the Bad, and the Ugly. Saudi J. Anaesth. 2023, 17, 401–406. [Google Scholar] [CrossRef] [PubMed]
- Tay, T.H.C. Response to: “Medical Teacher’s First ChatGPT’s Referencing Hallucinations: Lessons for Editors, Reviewers, and Teachers”. Med. Teach. 2023, 1. [Google Scholar] [CrossRef] [PubMed]
- Emsley, R. ChatGPT: These Are Not Hallucinations—They’re Fabrications and Falsifications. Schizophrenia 2023, 9, 52. [Google Scholar] [CrossRef] [PubMed]
- Koubaa, A. GPT-4 vs. GPT-3.5: A Concise Showdown. Preprints 2023, 2023030422. [Google Scholar] [CrossRef]
- Masters, K. Medical Teacher ’s First ChatGPT’s Referencing Hallucinations: Lessons for Editors, Reviewers, and Teachers. Med. Teach. 2023, 45, 673–675. [Google Scholar] [CrossRef]
- Frosolini, A.; Gennaro, P.; Cascino, F.; Gabriele, G. In Reference to “Role of Chat GPT in Public Health”, to Highlight the AI’s Incorrect Reference Generation. Ann. Biomed. Eng. 2023, 51, 2120–2122. [Google Scholar] [CrossRef]
- Rawashdeh, B.; Kim, J.; AlRyalat, S.A.; Prasad, R.; Cooper, M. ChatGPT and Artificial Intelligence in Transplantation Research: Is It Always Correct? Cureus 2023, 15, e42150. [Google Scholar] [CrossRef]
- Harrington, L. ChatGPT Is Trending: Trust but Verify. AACN Adv. Crit. Care 2023, e1–e7. [Google Scholar] [CrossRef]
- Markov, T.; Zhang, C.; Agarwal, S.; Eloundou, T.; Lee, T.; Adler, S.; Jiang, A.; Weng, L. A Holistic Approach to Undesired Content Detection in the Real World. Proc. AAAI Conf. Artif. Intell. 2022, 37, 15009–15018. [Google Scholar] [CrossRef]
- OpenAI. How should AI Systems Behave, and Who should Decide? Available online: https://openai.com/blog/how-should-ai-systems-behave (accessed on 6 November 2023).
- Tamkin, A.; Brundage, M.; Clark, J.; Ganguli, D. Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models. arXiv 2021, arXiv:2102.02503. [Google Scholar]
- Copeland-Halperin, L.R.; O’Brien, L.; Copeland, M. Evaluation of Artificial Intelligence–Generated Responses to Common Plastic Surgery Questions. Plast. Reconstr. Surg. Glob. Open 2023, 11, e5226. [Google Scholar] [CrossRef] [PubMed]
- Huo, W.; Yuan, X.; Li, X.; Luo, W.; Xie, J.; Shi, B. Increasing Acceptance of Medical AI: The Role of Medical Staff Participation in AI Development. Int. J. Med. Inform. 2023, 175, 105073. [Google Scholar] [CrossRef]
- Henry, K.E.; Kornfield, R.; Sridharan, A.; Linton, R.C.; Groh, C.; Wang, T.; Wu, A.; Mutlu, B.; Saria, S. Human–Machine Teaming Is Key to AI Adoption: Clinicians’ Experiences with a Deployed Machine Learning System. NPJ Digit. Med. 2022, 5, 97. [Google Scholar] [CrossRef] [PubMed]
- Panayides, A.S.; Amini, A.; Filipovic, N.D.; Sharma, A.; Tsaftaris, S.A.; Young, A.; Foran, D.; Do, N.; Golemati, S.; Kurc, T.; et al. AI in Medical Imaging Informatics: Current Challenges and Future Directions. IEEE J. Biomed. Health Inform. 2020, 24, 1837–1857. [Google Scholar] [CrossRef] [PubMed]
- Siriborvornratanakul, T. Advanced Artificial Intelligence Methods for Medical Applications; Springer: Cham, Switzerland, 2023; pp. 329–340. [Google Scholar] [CrossRef]
- Shah, S.I.H.; Naeem, M.; Paragliola, G.; Coronato, A.; Pechenizkiy, M. An AI-Empowered Infrastructure for Risk Prevention during Medical Examination. Expert. Syst. Appl. 2023, 225, 120048. [Google Scholar] [CrossRef]
- ORDEN 47/2017, de 13 de Enero, de la Consejería de Educación Juventud y Deporte, por la que se desarrollan determinados aspectos de la evaluación final de bachillerato para el acceso a la Universidad. Boletín Of. De La Comunidad De Madrid. 2017, 16, 8–16. Available online: https://www.comunidad.madrid/sites/default/files/doc/educacion/univ/bocm-20170119-1.pdf (accessed on 6 November 2023).
- Ley 3/2022, de 24 de Febrero, de Convivencia UniversitariaBoletín Oficial del Estado. 2022; pp. 1–18. Available online: https://www.boe.es/buscar/act.php?id=BOE-A-2022-2978 (accessed on 6 November 2023).
- Universidad Pública de Navarra. Normativa Reguladora de los Procesos de Evaluación En la Universidad Pública de Navarra (Texto Consolidado). Acuerdo de Consejo de Gobierno, de 15 de Diciembre de 2011 Modificado por Acuerdos de Consejo de Gobierno, de 4 de Julio de 2017, 7 de Mayo de 2019. Universidad Publica de Navarra: Pamplona. 2020. Available online: https://www2.unavarra.es/gesadj/seccionNormativa/texto_consolidado_normativa_evaluacion.pdf (accessed on 6 November 2023).
- Costa, C.; Alvelos, H.; Teixeira, L. The Use of Moodle E-Learning Platform: A Study in a Portuguese University. Procedia Technol. 2012, 5, 334–343. [Google Scholar] [CrossRef]
- De Panfilis, L.; Peruselli, C.; Tanzi, S.; Botrugno, C. AI-Based Clinical Decision-Making Systems in Palliative Medicine: Ethical Challenges. BMJ Support. Palliat. Care 2023, 13, 183–189. [Google Scholar] [CrossRef]
- Coakley, S.; Young, R.; Moore, N.; England, A.; O’Mahony, A.; O’Connor, O.J.; Maher, M.; McEntee, M.F. Radiographers’ Knowledge, Attitudes and Expectations of Artificial Intelligence in Medical Imaging. Radiography 2022, 28, 943–948. [Google Scholar] [CrossRef]
- Kim, Y.-W.; Barach, P.; Melzer, A. The Seoul Declaration: A Manifesto for Ethical Medical Technology. Minim. Invasive Ther. Allied Technol. 2019, 28, 69–72. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Language | GPT-4 % (95% CI) | GPT-3.5 % (95% CI) | Sig ** |
|---|---|---|---|
| Spanish | 86.81 (81.13–90.98) | 63.18 (55.98 -69.85) | <0.001 |
| English | 87.91 (82.38–91.88) | 66.48 (59.35 –72.94) | <0.001 |
| Sig * | 0.824 | 0.441 | N = 182 |
| GPT-4 % Correct Answers (N = 182) | Significance † | |
|---|---|---|
| Type of questions | 0.927 | |
| Theoretical | 87.1% (85) | |
| Practical | 86.6% (97) |
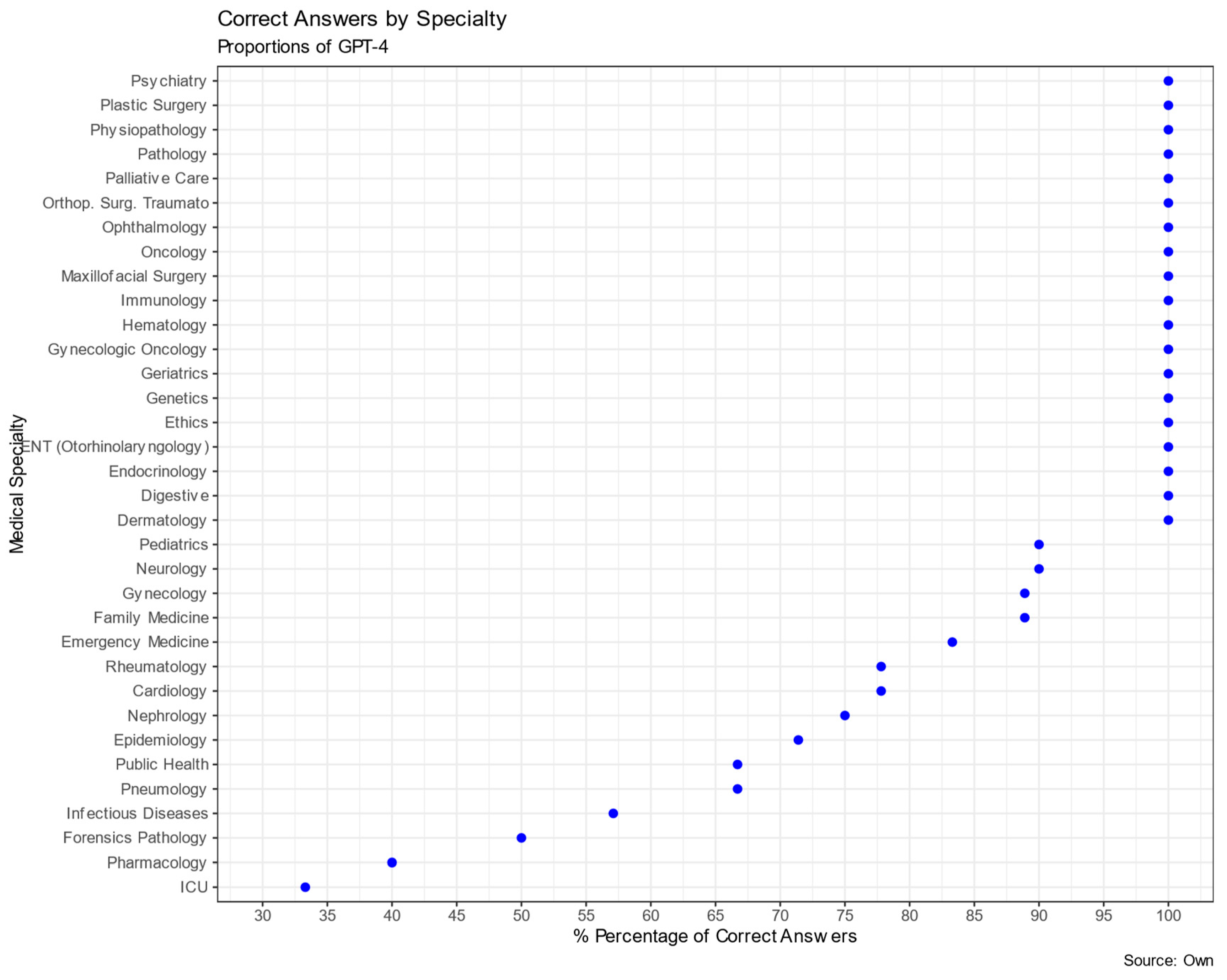
| Specialty | % Correct | N | Specialty | % Correct | N |
|---|---|---|---|---|---|
| Pathology | 100% | 1 | Forensics & Legal Medicine | 50.0% | 2 |
| Cardiology | 77.8% | 9 | Family Medicine | 88.9% | 9 |
| Orthopedic Surgery and Traumatology | 100% | 10 | Nephrology | 75.0% | 4 |
| dermatology | 100% | 1 | Pneumology | 66.7% | 6 |
| digestive | 100% | 6 | Neurology | 90.0% | 10 |
| endocrinology | 100% | 8 | Ophthalmology | 100% | 3 |
| epidemiology | 71.4% | 7 | gynecologic oncology | 100% | 2 |
| Plastic Surgery | 100% | 2 | Oncology | 100% | 2 |
| Ethics | 100% | 4 | ENT (Otorhinolaryngology) | 100% | 3 |
| pharmacology | 40% *** | 5 | palliative care | 100% | 2 |
| physiopathology | 100% | 7 | Pediatrics | 90.0% | 10 |
| genetics | 100% | 2 | Public Health | 66.7% | 3 |
| geriatrics | 100% | 6 | Psychiatry | 100% | 8 |
| gynecology | 88.9% | 9 | Rheumatology | 77.8% | 9 |
| hematology | 100% | 5 | Critical Care | 33.3% ** | 3 |
| infectious diseases | 57.1% * | 7 | emergency medicine | 83.3% | 6 |
| immunology | 100% | 7 | |||
| Maxillofacial surgery | 100% | 2 | TOTAL | 182 |
| Second Attempt | |||
|---|---|---|---|
| First Attempt | Wrong | Correct | Total |
| Wrong | 17 | 7 | 24 |
| Correct | 3 | 155 | 158 |
| Total | 20 | 162 | 182 |
| Original Question Sequence | Random Question Sequence | |||
|---|---|---|---|---|
| Test Scenario | 1st Attempt | 2nd Attempt | Evaluated with the Original Sequence | Evaluated with the Random Order |
| Test Value Median | 1 | 1 | 1 | 1 |
| Wrong answers | 24 | 20 | 23 | 23 |
| Correct answers | 158 | 162 | 159 | 159 |
| Total Questions | 182 | 182 | 182 | 182 |
| Number of Runs | 35 | 31 | 35 | 41 |
| Z | −2.507 | −2.148 | −2.097 | −0.063 |
| Exact Significance (2-tailed) | 0.017 | 0.032 | 0.040 | 1.000 |
| Univariate Logistic Regression | Multivariate Logistic Regression | |||
|---|---|---|---|---|
| Length of the Question | OR (95% CI) | p | OR (95% CI) | p |
| Number of Words * | 1.82 (95% CI 0.51–6.47) | 0.351 | 1.33 (95% CI 0.03–53.57) | 0.880 |
| Number of Characters * | 1.09 (95% CI 0.90–1.34) | 0.370 | 1.70 (95% CI 0.01–259.69) | 0.835 |
| Number of Tokens * | 1.30 (95% CI 0.74–2.33) | 0.361 | 0.92 (95% CI 0.24–3.45) | 0.896 |
| Univariate Polynomial Logistic Regression | ||
|---|---|---|
| Length of the Question | OR (95% CI) | p |
| Words | ||
| words | 1.86 (0.51–6.80) | 0.344 |
| Words 2 | 0.84 (0.06–11.10) | 0.893 |
| Characters | ||
| Characters | 1.11 (0.91–1.36) | 0.293 |
| Characters 2 | 0.983 (0.92–1.05) | 0.588 |
| Tokens | ||
| Tokens | 1.38 (0.77–2.50) | 0.283 |
| Tokens 2 | 0.88 (0.55–1.41) | 0.597 |
| Type of Error | N | % | Rate % (95% CI) |
|---|---|---|---|
| 1. No error | 10 | 41.7 | 5.5 (3.0–9.8) |
| 2. Error no harm | 8 | 33.3 | 4.4 (2.2–8.4) |
| 3. Error harm | 6 | 25.0 | 3.3 (1.5–7.0) |
| Total Incorrect Answers | 24 | 100 | |
| Correct Answers | 158 | ||
| Total Questions | 182 |
| Type of Error | N | % | Rate % (95% CI) |
|---|---|---|---|
| 10 | 41.7 | 5.5 (3.0–9.8) |
| 1 | 4.4 | 5.4 (0.9–3.0) |
| 3 | 12.5 | 1.6 (0.6–4.7) |
| 4 | 16.7 | 2.2 (0.9–5.5) |
| 2 | 8.3 | 1.1 (0.3–3.9) |
| 2 | 8.3 | 1.1 (0.3–3.9) |
| 2 | 8.3 | 1.1 (0.3–3.9) |
| 0 | 0 | 0 (0–2.0) |
| 0 | 0 | 0 (0–2.0) |
| Total Incorrect Answers | 24 | 100 | |
| Correct Answers | 158 | ||
| Total Questions | 182 |
| Specialty | No Error N (%) | No Harm N (%) | Harm N (%) | Total |
|---|---|---|---|---|
| Cardiovascular | 0 | 0 | 2 ** (100%) | 2 (100%) |
| Epidemiology | 2 (100%) | 0 | 0 | 2 (100%) |
| Pharmacology | 0 | 2 (66.6%) | 1 (33.3%) | 3 (100%) |
| Gynecology | 0 | 1 (100%) | 0 | 1 (100%) |
| Infectious Diseases | 0 | 2 (66.6%) | 1 (33.3%) | 3 (100%) |
| Forensics & Legal Medicine | 1 (100%) | 0 | 0 | 1 (100%) |
| Family Medicine | 1 (100%) | 0 | 0 | 1 (100%) |
| Nephrology | 1 (100%) | 0 | 0 | 1 (100%) |
| Pneumology | 0 | 2 * (100%) | 0 | 2 (100%) |
| Neurology | 1 (100%) | 0 | 0 | 1 (100%) |
| Pediatrics | 1 (100%) | 0 | 0 | 1 (100%) |
| Public Health | 0 | 1 (100%) | 0 | 1 (100%) |
| Rheumatology | 2 (100%) | 0 | 0 | 2 (100%) |
| Critical Care | 0 | 0 | 2 ** (100%) | 2 (100%) |
| Emergency medicine | 1 (100%) | 0 | 0 | 1 (100%) |
| TOTAL | 10 (41.7%) | 8 (33.3%) | 6 (25%) | 24 (100%) |
| Language | Number of Questions | Number of Correct Answers | % (95% CI) |
|---|---|---|---|
| Spanish | 23 | 3 | 13.0 (4.5–32.1) |
| English | 23 | 6 | 26.1 (12.6–46.5) |
| Language N= 24 | % Correct Answers Using Images | % Correct Answers No Using Images | p * |
|---|---|---|---|
| Spanish | 13.0% | 17.4% | 1.000 |
| English | 26.1% | 21.7% | 1.000 |
| p * | 0.250 | 0.625 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guillen-Grima, F.; Guillen-Aguinaga, S.; Guillen-Aguinaga, L.; Alas-Brun, R.; Onambele, L.; Ortega, W.; Montejo, R.; Aguinaga-Ontoso, E.; Barach, P.; Aguinaga-Ontoso, I. Evaluating the Efficacy of ChatGPT in Navigating the Spanish Medical Residency Entrance Examination (MIR): Promising Horizons for AI in Clinical Medicine. Clin. Pract. 2023, 13, 1460-1487. https://doi.org/10.3390/clinpract13060130
Guillen-Grima F, Guillen-Aguinaga S, Guillen-Aguinaga L, Alas-Brun R, Onambele L, Ortega W, Montejo R, Aguinaga-Ontoso E, Barach P, Aguinaga-Ontoso I. Evaluating the Efficacy of ChatGPT in Navigating the Spanish Medical Residency Entrance Examination (MIR): Promising Horizons for AI in Clinical Medicine. Clinics and Practice. 2023; 13(6):1460-1487. https://doi.org/10.3390/clinpract13060130
Chicago/Turabian StyleGuillen-Grima, Francisco, Sara Guillen-Aguinaga, Laura Guillen-Aguinaga, Rosa Alas-Brun, Luc Onambele, Wilfrido Ortega, Rocio Montejo, Enrique Aguinaga-Ontoso, Paul Barach, and Ines Aguinaga-Ontoso. 2023. "Evaluating the Efficacy of ChatGPT in Navigating the Spanish Medical Residency Entrance Examination (MIR): Promising Horizons for AI in Clinical Medicine" Clinics and Practice 13, no. 6: 1460-1487. https://doi.org/10.3390/clinpract13060130
APA StyleGuillen-Grima, F., Guillen-Aguinaga, S., Guillen-Aguinaga, L., Alas-Brun, R., Onambele, L., Ortega, W., Montejo, R., Aguinaga-Ontoso, E., Barach, P., & Aguinaga-Ontoso, I. (2023). Evaluating the Efficacy of ChatGPT in Navigating the Spanish Medical Residency Entrance Examination (MIR): Promising Horizons for AI in Clinical Medicine. Clinics and Practice, 13(6), 1460-1487. https://doi.org/10.3390/clinpract13060130