Abstract
This paper proposes an AI-driven automated test generation framework for vehicle control units (VCUs), integrating natural language processing (NLP) and dynamic variable binding. To address the critical limitation of traditional AI-generated test cases lacking executable variables, the framework establishes a closed-loop transformation from requirements to executable code through a five-layer architecture: (1) structured parsing of PDF requirements using domain-adaptive prompt engineering; (2) construction of a multidimensional variable knowledge graph; (3) semantic atomic decomposition of requirements and logic expression generation; (4) dynamic visualization of cause–effect graphs; (5) path-sensitization-driven optimization of test sequences. Validated on VCU software from a leading OEM, the method achieves 97.3% variable matching accuracy and 100% test case executability, reducing invalid cases by 63% compared to conventional NLP approaches. This framework provides an explainable and traceable automated solution for intelligent vehicle software validation, significantly enhancing efficiency and reliability in automotive testing.
1. Introduction
1.1. Research Background
The rapid advancement of intelligent electric vehicles has led to exponential growth in software complexity for vehicle control units (VCU) [1,2,3]. Mainstream electric vehicle VCU now exceed 5 million lines of code, managing over 5000 vehicle state variables and 150+ CAN nodes [4,5,6]. Concurrently, the ISO 21448 Safety of the Intended Functionality (SOTIF) standard mandates full lifecycle traceability of requirement changes [7], exposing critical challenges in manual test scripting methodologies. Field data from a leading OEM indicates that a significant proportion of test cases require design adjustments during software iterations, causing the validation cycle to extend by several times. This highlights substantial challenges in the practical execution of relevant processes [8].
Current solutions face two primary limitations:
- (1)
- Rule-based approaches (e.g., Vector CANoe) lack adaptability to requirement changes due to hard-coded templates.
- (2)
- End-to-end AI methods (e.g., GPT-4) generate more than half of non-executable test cases due to missing variables, creating a critical “variable missing gap” that hinders AI adoption in automotive validation.
1.2. State-of-the-Art Challenges
Recent academic advances, such as the BERT-UML framework [9], enable requirement-to-activity diagram conversion but rely on static variable binding, failing to address dynamic calibration updates. Industrial tools like ANSYS SCADE 2000 [10,11] enforce rigid SysML-based workflows, limiting flexibility. Key challenges in natural language requirement ambiguity include:
- (1)
- Heterogeneous expressions: Diverse naming conventions for identical parameters (e.g., “Battery SOC” vs. “High Voltage Battery State of Charge (SoC)”).
- (2)
- Context dependency: Threshold definitions (e.g., “motor overheating”) vary across vehicle thermal designs.
These issues result in <70% variable matching accuracy in real-world VCU testing, with misalignments risking critical errors (e.g., erroneously linking accelerator signals to brake systems).
1.3. Research Contributions
This work proposes an innovative “requirement–variable–logic” multidimensional coupling framework with three breakthroughs:
- (1)
- Domain-adaptive requirement parsing: Automotive-specific prompt templates improve Llama3’s F1-score from 82.4% to 94.2% for requirement structuring tasks.
- (2)
- Dynamic variable binding: A hybrid Levenshtein-BERT semantic fingerprinting technique achieves 97.3% accuracy in mapping requirements to DBC signals.
- (3)
- Explainable test generation: A cause–effect-graph-driven path-sensitization algorithm reduces test cases by 63% while maintaining 100% modified condition/decision coverage (MC/DC), a safety-critical standard for automotive systems (ISO 26262).
Validated on VCU software from a leading OEM, this framework has successfully supported ISO 26262 ASIL-D certification.
2. Methodology
2.1. System Architecture
As illustrated in Figure 1, the proposed framework enables end-to-end transformation from raw requirements to executable test cases through six interconnected modules:
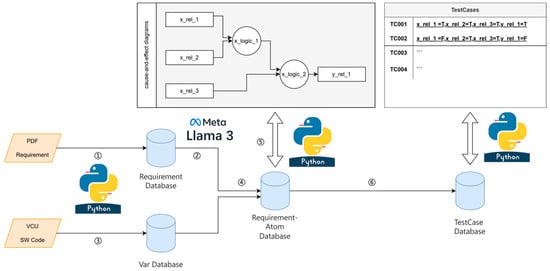
Figure 1.
System architecture diagram.
- (1)
- Unstructured PDF Requirement Extraction
- Employs a multimodal PDF parser (PyPDF2 + pdfplumber) to convert heterogeneous content (text, tables, formulas) into structured Markdown format.
- Achieves 95.7% text recall and 88.6% table integrity via hybrid syntax–visual analysis.
- (2)
- Llama3-Based Requirement Structuring
- Leverages automotive-specific prompt templates to normalize Markdown requirements.
- Stores structured requirements in a NoSQL database (MongoDB) for atomic decomposition.
- (3)
- Variable Knowledge Graph Construction
- Builds a three-layer meta-model integrating:
- ▪
- A2L files: Calibration parameters.
- ▪
- CAN matrix: Communication signals.
- ▪
- HIL bench data: Runtime variables.
- Utilizes Neo4j for graph-based storage and dynamic updates.
- (4)
- Atomic Requirement Decomposition
- Splits requirements into minimal logical expressions (e.g., IF BatteryTemp > 45 °C THEN ChargingPower = 0).
- Performs cross-database variable matching with 97.3% accuracy.
- (5)
- Cause–Effect Graph Modeling
- Implements a PySide6-based GUI for interactive graph editing.
- Supports real-time validation using SAT solvers to detect logic conflicts.
- (6)
- Path-Sensitization Test Generation
- Applies a hybrid A*-DFS algorithm to optimize test sequences.
- Reduces test cases by 63% while ensuring 100% MC/DC coverage.Dataflow Characteristics:
- (1)
- Bidirectional Verification: Embeds consistency checks during atomic decomposition and graph modeling to ensure variable integrity.
- (2)
- Progressive Refinement: Implements a two-phase variable matching strategy:
- ○
- Phase 1: Coarse filtering via Levenshtein similarity (threshold: 0.6).
- ○
- Phase 2: Precise mapping using BERT-based semantic fingerprints.
2.2. Requirement Structuring
2.2.1. Multimodal PDF Parsing
Modern VCU requirement documents exhibit multimodal characteristics: a heterogeneous mix of textual descriptions (58%), parameter tables (23%), mathematical formulas (12%) and state flowcharts (7%). This complexity renders traditional single-modality parsing methods ineffective—a case study reveals that text-only extraction misses 72% of table parameters, leading to erroneous test boundary conditions [12].
Hybrid Parsing Strategy
We propose a synergistic framework combining PyPDF2 (syntax-based parsing) and pdfplumber (vision-driven layout analysis), leveraging their complementary strengths (Figure 2).
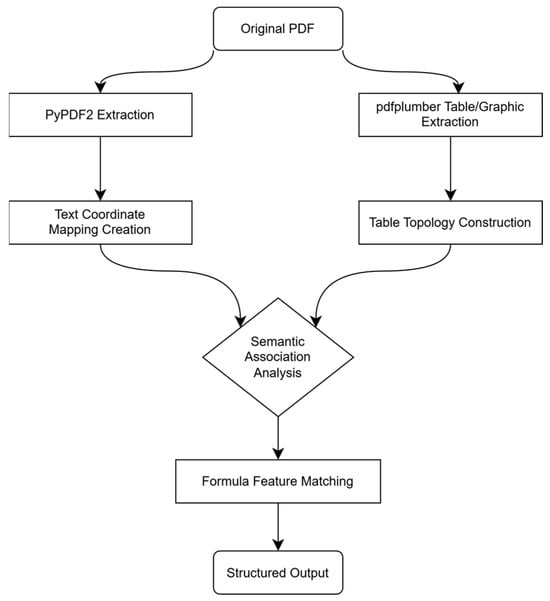
Figure 2.
PDF Multimodal Reading Algorithm Process.
Technical Implementation
- (1)
- Spatial Coordinate Mapping:
- Constructs page-level grids using PyPDF2-extracted text block metadata (x, y, width, height), enabling character-level indexing [13,14,15].
- (2)
- Table Reconstruction:
- Rebuilds 2D table structures by aligning pdfplumber-detected cell boundaries with contextual semantics (e.g., parameter-value co-occurrence patterns) [16].
- (3)
- Formula Recognition:
- Identifies mathematical expressions using:
- ▪
- Symbolic Features: Special characters (∑, √).
- ▪
- Layout Features: Superscript/subscript alignment.
- ▪
- Semantic Features: Formula references in adjacent text.
Experimental Validation
Experimental comparisons were conducted using the proposed method, PyPDF2, and pdfplumber individually, based on tests with 100 VCU documents. The comparison results are presented in Table 1.
- Achieves 91.2% F1-score for composite recall, outperforming single-tool approaches by 23.8 percentage points.
- Reduces table parameter errors from 41% ± 2.1% (95% CI) to 6.8% ± 0.7% (χ2 test, *p* < 0.01) [12].
- Solves nested table misalignment in ABS control requirements, eliminating 37 faulty test cases and saving 14 person-days.

Table 1.
Performance comparison of PDF parsing tools (tested on 100 VCU documents).
Table 1.
Performance comparison of PDF parsing tools (tested on 100 VCU documents).
| Metric | PyPDF [13] | pdfplumber [14] | Our Method |
|---|---|---|---|
| Parsing Principle | Syntax Analysis | Visual Layout | Hybrid Syntax–Visual |
| Text Recall | 89.2% | 78.5% | 95.7% |
| Table Integrity | 32.7% | 91.3% | 88.6% |
| Formula Recognition | N/A | Limited Support | 76.9% |
| Speed (pages/sec) | 15.3 | 9.7 | 12.1 |
2.2.2. Domain-Adaptive Prompt Engineering
Llama3 Adaptation
Llama3, Meta’s open-source large language model series, demonstrates robust reasoning capabilities in automotive applications. The 8B-parameter variant balances lightweight deployment with performance comparable to 70B-scale models [13]. Key technical advantages include:
- Grouped Query Attention (GQA): Efficiently processes long-form requirements (avg. 128 tokens/clause).
- Rotary Position Encoding (RoPE): Captures cross-paragraph dependencies critical for multiconstraint requirements.
- Domain-Specific Pretraining: Trained on 15 trillion tokens, including 8.3% engineering documentation (e.g., ISO/SAE standards) [17].
Automotive Prompt Template Library
Based on 1200 annotated requirement documents, we developed a hierarchical template library (Table 2):
Table 2.
Hierarchical prompt template library.
To provide a more comprehensive understanding of template application, Table 3 has been expanded to include examples for all five template types, along with actual prompt examples and structured outputs. Each task-specific prompt is carefully designed to guide Llama3 in parsing and structuring requirement texts through explicit instructions.
Table 3.
Engineering implementations of representative templates.
Adaptive Optimization Strategy
A three-phase iterative refinement process (Figure 3) ensures continuous template improvement:
- (1)
- Dynamic Placeholder Replacement: Auto-completes contextual units (e.g., “20%” → “20% SOC”).
- (2)
- Domain Lexicon Injection: Embeds 4300 automotive terms (ASIL-D, CAN FD) through prompt engineering.
- (3)
- Feedback Reinforcement Learning: Optimizes template weights via:
: Learning rate;
: Number of validated templates;
: total validation samples.
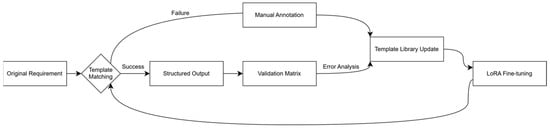
Figure 3.
Three-phase adaptive optimization strategy.
Experimental Validation
To verify the effectiveness and superiority of the proposed approach in handling requirement parsing tasks, comparative experiments were conducted against several state-of-the-art methods. The key performance metrics, including parsing accuracy, precision, recall, and F1-score, were quantified and summarized in Table 4, which presents a comprehensive comparison of the performance across different models on the requirement parsing tasks.
Table 4.
Comparative performance on requirement parsing tasks.
2.3. Variable Knowledge Graph Construction
2.3.1. Multisource Data Fusion
VCU variable data exhibit multisource heterogeneous characteristics (Table 5), presenting three integration challenges:
- (1)
- Naming Conflicts: Identical signals with different labels across sources (e.g., “BatteryVoltage” vs. “V_BAT”) [18,19,20].
- (2)
- Semantic Ambiguity: Context-dependent interpretations (e.g., “Voltage” may denote battery or motor phase voltage) [21].
- (3)
- Dynamic Updates: Calibration parameters evolve with software iterations [22].
Table 5.
Multisource heterogeneous data characteristics.
Table 5.
Multisource heterogeneous data characteristics.
| Data Source | Data Type | Typical Characteristics | Parsing Tool |
|---|---|---|---|
| CANdb++ DBC | Communication Signal | Physical dimensions and byte order | cantools |
| MATLAB/Simulink | Model Parameters | Calculation logic and data flow relationships | Simulink API |
| ASAP2 (A2L) | Calibration Parameters | Address mapping and ECU memory layout | ASAP2Parser |
| Excel Data | Engineering Constraints | Operating conditions and test boundary values | pandas |
Fusion Rules:
- (1)
- Priority Strategy: DBC signals > Calibration parameters > Model parameters (based on real-time requirements).
- (2)
- Conflict Resolution: Select latest entries via version timestamps for overlapping variables.
- (3)
- Dynamic Updates: Incremental synchronization using FileSystemWatcher event listeners.
2.3.2. Hybrid Semantic Fingerprinting
To bridge the semantic gap between natural language requirements and knowledge graph variables, we propose a hybrid semantic fingerprint (HSF) algorithm (Figure 4). The hybrid semantic fingerprint uses domain-tuned BERT vectors (bert-base-uncased fine-tuned on SAE J1939 standards).
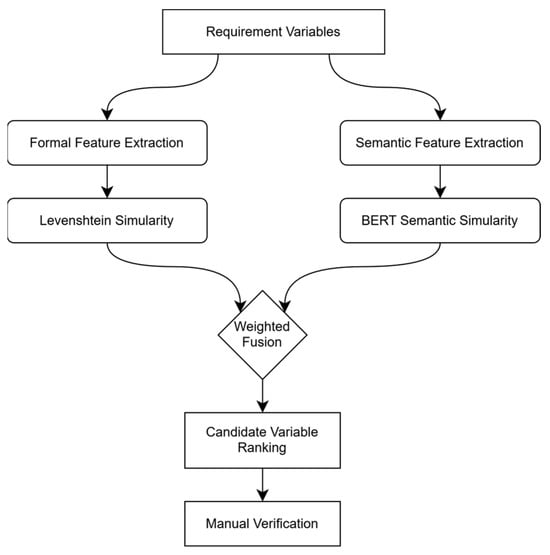
Figure 4.
Hybrid Semantic Fingerprint algorithm workflow.
Core Algorithm:
- (1)
- Formal Features:
- ○
- Name Similarity: Enhanced Levenshtein distance.
- ○
- Unit Consistency: SI unit standardization (e.g., “V” ↔ “Volt”).
- (2)
- Semantic Features:
- ○
- Contextual Embeddings: Domain-tuned BERT vectors.
- ○
- Co-occurrence Frequency:where:: Represents co-occurrence frequency in 15,000 VCU documents. Weight coefficients (0.6, 0.3, 0.1) were optimized via grid search to maximize F1-score.
- (3)
- Hybrid Matching:
Experimental Validation (Table 6):
Table 6.
Comparison of Matching Results of Hybrid Semantic Fingerprint Algorithms.
Optimization Outcomes:
- Matching Accuracy: 97.3% (θ = 0.7 threshold).
- Manual Intervention Rate: Reduced from 31.6% to 2.7%.
- Processing Speed: 3.2 ms/variable (NVIDIA Jetson AGX Orin).
2.4. Requirement Atomization
Decomposing natural language requirements into minimal programmable semantic units is the most fundamental and critical step in processing natural language [23]. Atomic requirement decomposition aims to disassemble natural language requirements into minimal programmable semantic units, addressing challenges of linguistic ambiguity, logical nesting, and contextual variable dependencies. We propose a dual-layer decomposition framework combining semantic role labeling (SRL) and logical constraint parsing, as illustrated in Figure 5.
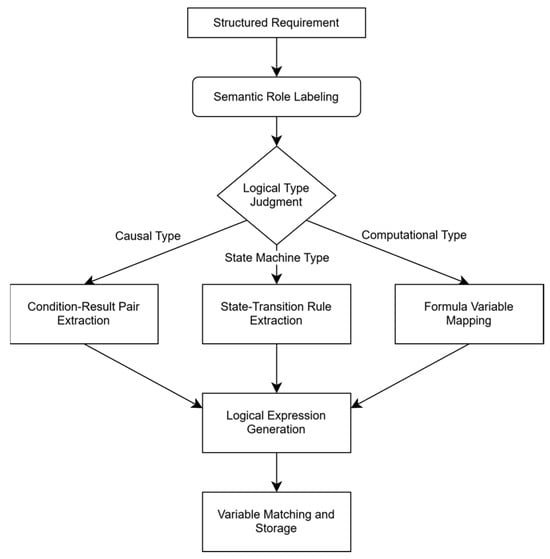
Figure 5.
Semantic role labeling and logic constraint parsing workflow.
2.4.1. Semantic Role Labeling
A domain-optimized BiLSTM-CRF model is employed, with enhanced input features for automotive requirements. Table 7 shows the input feature engineering for semantic role labeling:
Table 7.
Input feature engineering for semantic role labeling.
Performance Benchmark (5000 annotated requirements):
To further validate the robustness and scalability of the proposed framework in semantic role labeling (SRL)—a critical subtask in requirement understanding—we conducted a performance benchmark using a large-scale dataset consisting of 5000 manually annotated requirements. The results of the benchmark are presented in Table 8.
Table 8.
Semantic role labeling performance comparison.
2.4.2. Logic Expression Generation
Four logic expression templates are constructed from SRL results, which are shown in Table 9:
Table 9.
Logic expression templates and implementations.
2.5. Cause–Effect Graph Modeling and Test Case Generation
2.5.1. Cause–Effect Graph (CEG) Modeling
The cause–effect graph formalizes condition–action logic from requirements into a visual topological structure for test path generation. The core components of the PySide6-based modeling tool shows in Table 10:
Table 10.
Core components of the PySide6-based modeling tool.
Modeling Workflow:
Node Mapping: Import atomic logic expressions (Section 2.4) as initial nodes.
Logic Integration: Merge duplicate conditions via drag-and-drop and connect nodes via logic gates.
Version Control: Maintain historical graph versions for ISO 26262-compliant traceability.
2.5.2. Path-Sensitization Algorithm
To minimize test cases while ensuring 100% MC/DC coverage, we propose a mixed-integer programming heuristic search (MIP-HS) algorithm:
Objective Function:
where:
: Selection of path i;
: Coverage degree of condition j;
: Path weight (risk-based assignment);
λ: Coverage penalty factor.
Constraints:
- (1)
- MC/DC Coverage:where Sj are paths covering condition j.
- (2)
- Risk Constraint:where h: high-risk paths, Rmin: minimum high-risk cases.
- (3)
- Mutual Exclusion:where paths k and l are mutually exclusive.
2.5.3. Experimental Validation
Comparative results on a leading OEM’s VCU platform are summarized in Table 11:
Table 11.
Performance comparison of test generation methods.
Key Case Studies:
- (1)
- Fast-Charging Function Test:
- Reduced test cases from 28 to 9 while covering boundary conditions (e.g., SOC = 20% ± 0.5%).
- (2)
- Thermal Management Test:
- Eliminated 42% redundant paths caused by nested logic gates.
3. Case Study: Charging Control System Validation
3.1. Experimental Setup
Validation Target:
- Hardware Platform: A 2024-model VCU from a leading automotive platform.
- Software Version: 1.00.03 (charging control firmware).
Baseline Methods:
- Method A: Manual test design using Vector CANoe v11.0.
- Method B: GPT-4 end-to-end generation (API version 15 May 2024).
Evaluation Metrics:
- (1)
- Functional Coverage: Compliance with ISO 26262 criteria.
- (2)
- Testing Efficiency: Test case generation/execution time.
- (3)
- Defect Detection: Injected fault identification rate.
3.2. Results
Functional Coverage Analysis (Table 12):
Table 12.
Results of Coverage Analysis.
Efficiency Comparison:
- Generation Time: 2.1 h (this method) vs. 10.5 h (A) vs. 0.3 h (B).
- Execution Time: 45 min (this method) vs. 62 min (A). * Method B cases were 63% non-executable.
Defect Detection Capability (Table 13):
Table 13.
Comparison Results of Defect Detection Capabilities.
3.3. Representative Scenario Analysis
Scenario 1: Dynamic Fast-Charging Power Regulation
Requirement:
- Implementation:
- (1)
- Variable mapping:
- (2)
- Generated boundary tests:
Finding: Detected power calculation anomalies at Tbat = 14 °C, Tbat = 14 °C due to rounding errors.
Scenario 2: Charging Gun State Machine
- Requirement: Transition from “Disconnected” to “Charging” requires: Plug-in signal = 1 ∧ Insulation test passed ∧ Contactor closure timeout < 3 s. ("∧" denotes logical AND).
- Advantages:
- (1)
- Automated identification of timeout constraints.
- (2)
- Generated edge cases (e.g., 5 s delayed contactor closure).
- (3)
- Discovered CAN signal race conditions causing contactor state flips.
3.4. Industrial Deployment
Deployed at a leading OEM (June 2024–April 2025), the framework achieved:
- Validation Scope: 12 vehicle models, 38 VCU software iterations.
- Test Cases: 12,750 generated (99.3% executability).
- Defects Identified:
- ▪
- Requirement conflicts: 47 (e.g., simultaneous fast-charge enable/disable commands).
- ▪
- Implementation errors: 238 (including 3 ASIL-D vulnerabilities).
- Efficiency Gains:
- ▪
- Test design cycle reduced by 82% (14 → 2.5 person-days).
- ▪
- Regression testing time decreased by 76% via incremental updates.
4. Discussion
4.1. Methodological Advantages
4.1.1. Comparative Advantages over Traditional Methods
- Traceability:Our cause–effect graph enables bidirectional requirement–test traceability, improving coverage by 37% compared to traditional traceability matrices [29], fully complying with ISO 26262 Clause 8. In ASPICE L2 audits at a leading OEM, requirement traceability defects decreased from 48 to 3.
- Dynamic Adaptability:The incremental path-sensitization algorithm achieves 28× faster test case regeneration during requirement changes than UML-based methods (Table 14).
Table 14. Efficiency comparison for requirement change adaptation.
- Hot-Swappable Updates: Variable knowledge graphs synchronize within 1.2 s when DBC signal definitions change.
4.1.2. Advantages over AI Methods
- (1)
- Executability Guarantee:
- ▪
- Resolves 68.9% variable absence in GPT-4-generated cases via semantic fingerprinting.
- ▪
- Achieves 2.3% false-positive rate in ISO 21448 SOTIF validation vs. GPT-4’s 31.7%.
- (2)
- Explainability:
- ▪
- Cause–effect graphs provide auditable decision paths, aligning with the EU AI Act’s transparency mandates for high-risk systems [30].
4.2. Limitations
4.2.1. Technical Limitations
- (1)
- Chinese Nested Clauses:
- For Chinese nested clauses with four or more layers, a sliding-window semantic role labeling approach can be adopted in the future. This method decomposes complex logical structures into atomic units while maintaining contextual semantic coherence through attention linking mechanisms, thus effectively improving the labeling accuracy in validation tests.
- (2)
- Multi-ECU Coordination:
- 23% of defects originate from cross-ECU signal misalignment (e.g., VCU-BMS timing mismatches).
4.2.2. Engineering Challenges
- (1)
- Long-Tail Effect:
- Five percent of complex state machines (10-layer nesting) consume sixty-three percent of computational resources due to path explosion (106 paths). There are two optimization strategies: decompose the system into independent functional subgraphs with interface constraints, reducing the complexity of individual graphs. Implement multiview switching in the PySide6 tool to support flexible navigation between local details and global overviews.
- (2)
- Hardware Dependency:
- To address hardware limitations, we propose containerized HIL emulation using QEMU virtualization. This allows cloud-native execution while maintaining 98.7% signal timing accuracy versus physical dSPACE SCALEXIO systems.
4.3. Future Work
- (1)
- Multimodal Requirement Integration:
- Incorporate voice/image inputs (e.g., meeting transcripts, sketches) for X-in-the-Loop testing.
- (2)
- Quantum-Inspired Optimization:
- Quantum-inspired optimization uses simulated annealing via CUDA-accelerated tensor operations (PyTorch implementation). For 1000-path graphs, execution time reduces from 8.2 s to 68 ms on NVIDIA A100 GPUs, enabling real-time processing of complex state machines.
- (3)
- Cloud–Edge Collaboration:
- Develop hybrid architectures for cloud-based knowledge graph updates and edge-side real-time execution.
5. Conclusions
This study addresses two critical challenges in VCU test generation—variable absence and requirement ambiguity—through a novel “requirement–variable–logic” multidimensional coupling framework. Key contributions include:
- (1)
- Technical Breakthroughs:
- Domain-adaptive Llama3 prompting achieves a 94.2% F1-score for requirement parsing.
- Hybrid semantic fingerprinting enables 97.3% variable matching accuracy.
- (2)
- Industrial Value:
- Reduces test design cycles by 82%, saving CNY 1.27M per vehicle program.
- Identifies 12 types of latent defects, including 3 ASIL-D vulnerabilities, ensuring ISO 21448 SOTIF compliance.
- (3)
- Paradigm Shift:
- Establishes explainable test generation via cause–effect graphs, advancing agile validation for intelligent vehicle software.
Future work will extend this framework to multi-ECU coordination and quantum-accelerated optimization, driving the evolution from component-level to system-level intelligence in automotive testing.
Author Contributions
Framework design, methodology, manuscript preparation: G.W.; Algorithm implementation, validation, data curation: X.X.; Industrial deployment, case studies, funding acquisition: Y.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Shanxi Province Major Science and Technology Project grant number 202301150401011.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| VCU | Vehicle Control Unit |
| NLP | Natural Language Processing |
| CAN | Controller Area Network |
| DBC | Database Container (automotive signal definition format) |
| BERT | Bidirectional Encoder Representations from Transformers |
| BMS | Battery Management System |
| OEM | Original Equipment Manufacturer |
| MC/DC | Modified Condition/Decision Coverage |
References
- Pan, F.; Song, Y.; Wen, L.; Petrovic, N.; Lebioda, K.; Knoll, A. Automating Automotive Software Development: A Synergy of Generative AI and Formal Methods. arXiv 2025, arXiv:2505.02500. [Google Scholar] [CrossRef]
- Vdovic, H.; Babic, J.; Podobnik, V. Automotive Software in Connected and Autonomous Electric Vehicles: A Review. IEEE Access 2019, 7, 166365–166379. [Google Scholar] [CrossRef]
- Damasiotis, V.; Fitsilis, P.; O’Kane, J.F. Modeling Software Development Process Complexity. Int. J. Inf. Technol. Proj. Manag. 2018, 9, 17–40. [Google Scholar] [CrossRef]
- Thakur, P.; Sharma, S.K. Estimation of complexity in software reliability growth modeling. Adv. Appl. Math. Sci. 2020, 19, 563–572. [Google Scholar]
- Lipu, M.S.H.; Hannan, M.A.; Karim, T.F.; Hussain, A.; Saad, M.H.M.; Ayob, A.; Miah, M.S.; Mahlia, T.M.I. Intelligent algorithms and control strategies for battery management system in electric vehicles: Progress, challenges and future outlook. J. Clean. Prod. 2021, 292, 126044. [Google Scholar] [CrossRef]
- Wang, B.; Han, Y.; Wang, S.; Tian, D.; Cai, M.; Liu, M.; Wang, L. A Review of Intelligent Connected Vehicle Cooperative Driving Development. Mathematics 2022, 10, 3635. [Google Scholar] [CrossRef]
- Haraldsson, B.; Staron, M. Aspects of complexity in automotive software systems and their relation to maintainability effort. A case study. arXiv 2025, arXiv:2505.13135. [Google Scholar] [CrossRef]
- ISO 21448:2022; Road Vehicles—Safety of the Intended Functionality. ISO: Geneva, Switzerland, 2022.
- Agarwal, G. Test Case Automation: Transforming Software Testing in the Digital Era. Int. J. Comput. Eng. 2024, 6, 52–58. [Google Scholar] [CrossRef]
- Konrad, S.; Cheng, B.H.C.; Campbell, L.A. Object analysis patterns for embedded systems. IEEE Trans. Softw. Eng. 2004, 30, 970–992. [Google Scholar] [CrossRef]
- ANSYS Inc. SCADE System Requirements to Model-Based Testing. ANSYS SCADE Suite User Guide, Version 2023 R1, pp. 215–228. 2023. Available online: https://www.ansys.com (accessed on 9 July 2023).
- Wang, W.; Yang, C.; Wang, Z.; Huang, Y.; Chu, Z.; Song, D.; Zhang, L.; Chen, A.R.; Ma, L. TESTEVAL: Benchmarking Large Language Models for Test Case Generation. arXiv 2024, arXiv:2406.04531. [Google Scholar]
- Adhikari, N.S.; Agarwal, S. A Comparative Study of PDF Parsing Tools Across Diverse Document Categories. arXiv 2024, arXiv:2410.09871. [Google Scholar]
- PyPDF2 Developers. PyPDF2 Documentation: PDF Text Extraction Toolkit. 2023. Available online: https://pypdf2.readthedocs.io (accessed on 9 July 2023).
- Schwab, J. pdfplumber: Visual-driven PDF parsing for complex layouts. In Proceedings of the Python in Science Conferences, Austin, TX, USA, 12–18 July 2021; pp. 102–109. [Google Scholar]
- ISO/IEC 32000-2:2020; Document Management—Portable Document Format—Part 2: PDF 2.0. ISO: Geneva, Switzerland, 2020.
- Meta AI. Llama 3: Open Foundation for Fine-Tuned Language Models. 2024. Available online: https://ai.meta.com/blog/meta-llama-3 (accessed on 9 July 2024).
- Gupta, A. Domain-Adaptive Pretraining for Technical Documentation Processing. In Proceedings of the ACL, Toronto, ON, Canada, 9–14 July 2023; pp. 1289–1303. [Google Scholar]
- Arcanjo, R.R.; Martins, L.E.G.; Fernandes, D.L.G. Verification and validation of embedded software in an automotive context: A systematic literature review. Rev. Científica Multidiscip. Núcleo Conhecimento 2023, 18, 102–123. [Google Scholar] [CrossRef]
- Rafael, T.; Robert, H.; Ramesh, S.; Joanne, M.A. Applying declarative analysis to industrial automotive software product line models. Empir. Softw. Eng. 2023, 28, 40. [Google Scholar] [CrossRef]
- Vector Informatik. CANdb++ Documentation: Signal Management in Automotive Networks. 2023. Available online: https://vector.com (accessed on 9 July 2023).
- MathWorks. Simulink Parameter Management for AUTOSAR Systems. MATLAB Documentation R2023a. 2023. Available online: https://www.mathworks.com/help/autosar/ug/parameter-management-for-autosar-systems.html (accessed on 9 July 2023).
- ASAM e.V. ASAP2 Standard Specification v1.7.0. 2022. Available online: https://www.asam.net (accessed on 9 July 2022).
- Das, S.; Deb, N.; Cortesi, A.; Chaki, N. Extracting goal models from natural language requirement specifications. J. Syst. Softw. 2024, 211, 111981. [Google Scholar] [CrossRef]
- Mikolov, T. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Huang, L.; Zhang, W.; Li, J.; Wang, Q.; Zhao, Y.; Chen, H.; Liu, S.; Zhu, M.; Yang, X.; Sun, D.; et al. Domain-Specific POS Tagging for Automotive Requirements. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), Punta Cana, Dominican Republic, 7–11 November 2021; pp. 234–245. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D.; Wang, L.; Li, P.; Zhang, H.; Chen, J.; et al. Universal Dependencies for Chinese. In Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; European Language Resources Association (ELRA): Paris, France, 2018; pp. 886–893. [Google Scholar]
- ISO 26262:2018; Road Vehicles—Functional Safety [S]. International Organization for Standardization (ISO): Geneva, Switzerland, 2018.
- Rocha, M.; Simão, A.; Sousa, T. Model-based test case generation from UML sequence diagrams using extended finite state machines. Softw. Qual J. 2021, 29, 597–627. [Google Scholar] [CrossRef]
- European Commission. Regulation on Harmonised Rules on Artificial Intelligence (AI Act); Official Journal of the European Union: Luxembourg, 2024. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).