1. Introduction
Unmanned Tracked Vehicles (UTVs) play a pivotal role in construction engineering, search and rescue missions, and planetary exploration tasks due to their exceptional ability to move over unstructured terrains [
1,
2,
3]. In real-world off-road exploration, to ensure safety and stability during navigation, UTVs are required to make decisions automatically using the collected real-time environmental information [
4].
In recent years, DRL techniques have contributed greatly to solving complex non-linear problems in autonomous planning and decision making [
5,
6]. For instance, researchers have proposed dueling double deep Q-networks with prioritized experience replay (D3QN-PER) to enhance dynamic path planning performance by balancing exploration and exploitation more effectively [
7]. Maoudj and Hentout [
8] refined traditional Q-learning via new reward functions and state–action selection strategies to speed up convergence. Zhou et al. [
9] tackled multiagent path planning under high risk by employing dual deep Q-networks that discretize the environment and separate action selection from evaluation, enhancing convergence speed and inter-agent collaboration. Moreover, hybrid methods merge deep reinforcement learning with external optimization, such as immune-based strategies [
10], sum-tree prioritized experience replay [
11] or heuristic algorithms [
12] to ensure safer routes, shorter travel distances, and better path quality, demonstrating improved adaptability in unknown or dynamic environments. To enable the robots to move in off-road environments, multidimensional sensor data, including the global elevation map and the robot pose, are used as input to learn planning policies [
13,
14].
However, the global elevation map is unavailable in unknown off-road environments, making it more suitable to use local sensing technology during exploration. Zhang et al. [
15] employed deep reinforcement learning to process raw sensor data for local navigation, enabling reliable obstacle avoidance in disaster-like environments without prior terrain knowledge. Weerakoon et al. [
16] combined a cost map and an attention mechanism to highlight unstable zones in the elevation map, filter out risky paths, and ensure safe and efficient routes, which improved success rates on uneven outdoor terrain. Nguyen et al. [
17] introduced a multimodal network that fuses RGB images, point clouds, and laser data, effectively handling challenging visuals and structures in collapsed or cave-like settings and enhancing navigation accuracy and stability.
Moreover, energy efficiency is a growing priority in intelligent transportation and autonomous navigation systems. Viadero-Monasterio et al. [
18] proposed a traffic signal optimization framework that improves energy consumption by adapting to heterogeneous vehicle powertrains and driver preferences. Their method achieved up to 9.67% energy savings for diesel vehicles by customizing velocity profiles and acceleration behaviors. Although their work focuses on signalized intersection traffic, the idea of embedding energy-aware policy adaptation inspires us to explore lightweight reward shaping strategies. In this study, we introduce a velocity-stabilizing term in the reward to indirectly suppress excessive acceleration and promote smoother, energy-conscious navigation.
Apart from the abovementioned problem, the sample efficiency and deployment safety of DRL limit the navigation performance [
19]. In terms of the sample efficiency, especially in cases with sparse rewards, DRL agents might converge to local optima, thereby hindering the learning of optimal policies [
20]. Due to the black box nature of deep networks, DRL is unable to handle hard constraints effectively, which limits the generalization of the model and increases the difficulty of deployment safety [
6]. These two problems can be alleviated by integrating prior knowledge using functional regularization [
21,
22].
This paper proposes an end-to-end DRL-based planner for real-time autonomous motion planning of UTVs on unknown rugged terrains. To enhance the training efficiency of UTVs and improve its adaptability in unknown environments, a prior-based ensemble learning framework, called SAC-based Hybrid Policy (SAC-HP), is introduced. The main contributions of this paper are as follows:
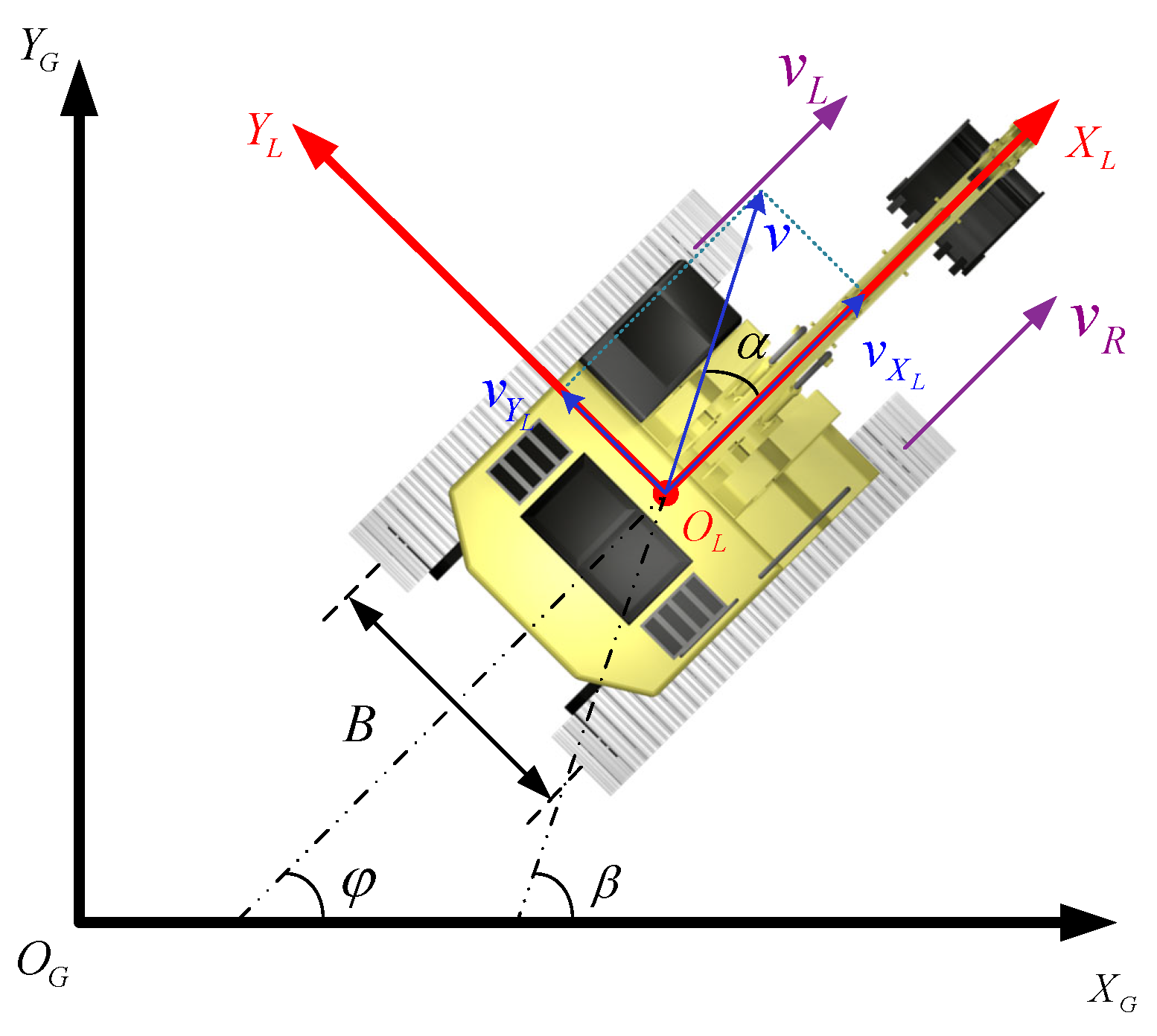
This paper proposes a novel action and state space considering terrains and disturbances from the environment, which allows the UTVs to autonomously learn how to traverse on continuous rugged terrains with collision avoidance, as well as mitigate the effects of track slip problems without an explicit model.
This paper introduces a comprehensive reward function considering obstacle avoidance, safe navigation, and energy optimization. Additionally, a novel optimization metric based on off-road environmental characteristics is proposed to enhance the algorithm’s robustness in complex environments. This reward function enables a shorter and faster exploration with smooth movement.
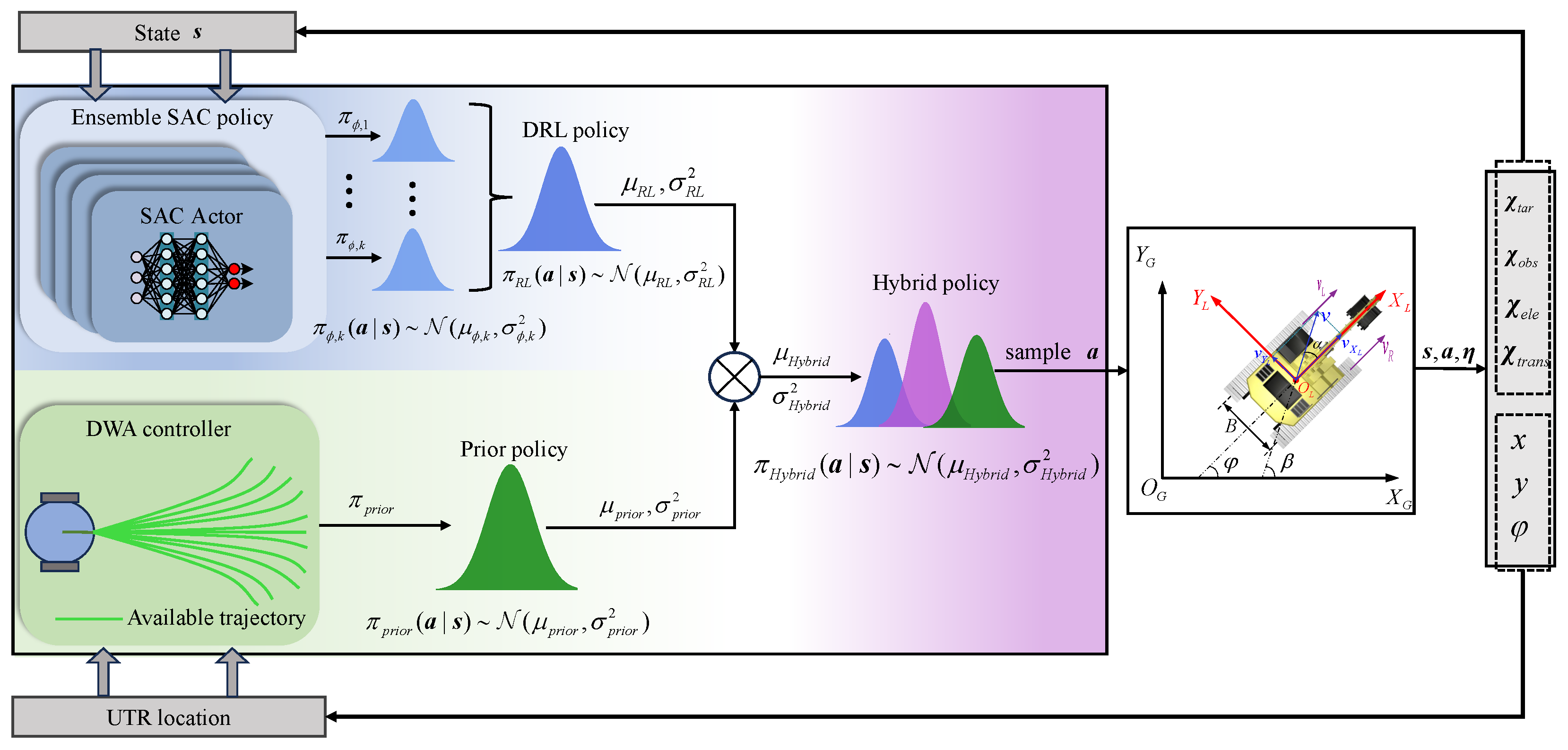
To address the issues of low exploration efficiency and deployment safety in traditional DRL-based methods, we propose an ensemble Soft Actor–Critic (SAC) learning framework, which introduces the Dynamic Window Approach (DWA) as a behavioral prior, called SAC-based Hybrid Policy (SAC-HP). We combine the DRL actions with the DWA method by reconstructing the hybrid Gaussian distribution of both. This method employs a suboptimal policy to accelerate learning while still allowing the final policy to discover the optimal behaviors.
Notations: In this article, several symbols and variables are used, which are defined in
Table 1. Note that the bold variables in this paper represent vectors and matrices.
4. SAC-Based Hybrid Policy
In this section, we provide a detailed explanation of the implementation details of the proposed SAC-based Hybrid Policy (SAC-HP) algorithm.
Although the standard SAC algorithm [
24] demonstrates outstanding performance in navigation tasks, its performance is limited by the following reasons. Firstly, when the dimensions of the state and action spaces are high, the agent requires significant exploration time at the beginning to collect sufficient experience. Secondly, due to the black box nature of deep networks, DRL policies might overfit the training environment, reducing the safety and adaptability in new environments.
The SAC-HP framework is illustrated in
Figure 5. SAC-HP consists of two primary components: the DRL policy and the classical (prior) policy. The robot’s actions are determined jointly by these two policies and can be expressed using the following equation:
where
represents the DRL policy, and
denotes the prior policy derived from classical controllers (i.e., DWA).
is a normalization factor. Specifically,
ensures that the resulting hybrid policy distribution remains a valid probability distribution after the multiplicative fusion of the learned DRL policy
and the prior controller distribution
. When both components are Gaussian distributions, their product results in an unnormalized Gaussian, and
corresponds to the integral of this product over the action space. In practice, the parameters of the fused distribution (mean and variance) can be derived in closed form using Gaussian product rules (i.e., Equation (
31)), and the normalization constant is implicitly handled within this derivation.
In the SAC algorithm, the output actions from the Actor network obey an independent Gaussian distribution,
, where
represents the mean of the output actions, and
denotes the variance of the output actions. To leverage the advantage of stochastic policies and reduce variance, we utilize ensemble learning-based uncertainty estimation techniques [
26]. The ensemble consists of
K agents to construct an approximately uniform and robust mixture model. The predicted outputs of the ensemble are fuses to a single Gaussian distribution with a mean
and variance
, which is written as
where
and
represent the mean and variance of the individual DRL policy
, respectively.
Once the DWA controller predicts the optimal linear velocity
and angular velocity
, the optimal angular velocities of the left and right driving wheels can be calculated based on Equations (
1) and (
3) as
Furthermore, the preliminary action output from the DWA controller can be obtained. To acquire a distributional action from a prior controller, assuming the variance of the prior policy is , with a mean corresponding to the prior controller’s deterministic output . Thus, the prior policy can be expressed as . The prior policy is able to guide the agent within a certain range of area at the beginning, thereby avoiding unnecessary high-risk exploratory actions.
Furthermore, Equation (
26) can be rewritten as
The details of the hybrid policy are described in Algorithm 1.
| Algorithm 1 SAC-based Hybrid Policy |
Require: Initialize ensemble of K SAC policies ; prior variance ; Initialize experience replay buffer ; Set update frequency and max iteration .
- 1:
for to do - 2:
Randomly select one agent from the ensemble - 3:
for to K do - 4:
Get current state - 5:
Sample action from k-th SAC agent: - 6:
Compute mean and variance of action distribution - 7:
end for - 8:
Compute SAC ensemble Gaussian: - 9:
Predict DWA prior action - 10:
Set prior distribution: - 11:
Compute hybrid Gaussian policy: - 12:
Sample action - 13:
Execute and observe - 14:
Store transition in buffer - 15:
if then - 16:
Reset environment - 17:
end if - 18:
if then - 19:
Update all K SAC agents by minimizing Equations ( 6) and ( 8) - 20:
end if - 21:
end for
Ensure: Optimal policy |
In the SAC-HP framework, each iteration begins by sampling actions from an ensemble of
K SAC policies. These
K outputs are first aggregated to form a robust and approximately uniform Gaussian distribution
(i.e., Equations (
27) and (
28)), which captures policy uncertainty and reduces overfitting. In parallel, the DWA controller produces a deterministic action based on the current robot state, which is modeled as a fixed-variance Gaussian distribution
. These two distributions are then fused into a hybrid Gaussian policy
using Equation (
31). An action is sampled from
, executed in the environment, and the resulting transition is stored in the replay buffer. All ensemble SAC agents are updated based on the collected experience. This hierarchical fusion structure ensures both safe exploration and generalizable policy learning under rugged terrain conditions. Note that the hybrid action is sampled at every decision-making step during both training and evaluation. This ensures that the prior (DWA) continuously guides the exploration throughout training and contributes to policy robustness during testing.
5. Simulation Results
Compared against baselines, several experiments were designed to verify the performance of the proposed hybrid policy controller for navigation.
5.1. Simulation Environment Setting
The simulation area (i.e.,
) with unstructured obstacles was configured as shown in
Figure 6. Purple cylindrical shapes represent discrete binary obstacles, while the contour regions indicate continuous rugged terrains. Assuming that the UTV will encounter random slipping disturbances within the rugged terrain areas, the task objective is to enable the UTV to navigate from the blue starting point to the red endpoint. The experimental configuration parameters and SAC training hyperparameters are listed in
Table 2 and
Table 3, respectively. Notably, the maximum rotational speed of the UTV’s left and right drive wheels is
.
The control time step was set to 0.2 s throughout training and evaluation. This choice was motivated by three considerations: (1) The dynamic response delay of tracked vehicles is typically around 0.15–0.2 s, making finer control updates less impactful [
1]. (2) The onboard sensor suite, including LiDAR, operates at a sampling frequency of 5 Hz, corresponding to one observation every 0.2 s. (3) Empirical tests indicate that this step size provides a good tradeoff between control accuracy and computational efficiency, especially in long-horizon navigation scenarios. This setting ensures stable policy learning without excessive computational overhead.
5.2. Performance of the Extended State Space
To evaluate the impact of the extended state space on the navigation performance of UTV, we trained four separate agents. The state space and training environment configurations for these agents are detailed in
Table 4.
During training, each episode started with different initial positions and target points, enabling the agent to explore various behaviors and regions. For Agents 3 and 4, the map area within was configured as a low-friction region. When the UTV operates in this region, random slipping rates are applied to the left and right tracks. The slipping rates were uniformly sampled from the range .
Figure 7 highlights the performance differences among the four agents. According to the blue curve in
Figure 7c, the results demonstrate that incorporating elevation information into the state space allowed the UTV to detect terrain undulations, enabling it to avoid deep pits and steep slopes while navigating through relatively smooth regions toward the target (i.e., Agent 2). In contrast, the UTV failed to avoid rugged terrain and fell into a deep pit at approximately the 200th time step according to the red curve in
Figure 7c.
Under slipping disturbances, the trajectory planned by Agent 3 exhibited significant oscillations and failed to reach the goal according to the yellow curve in
Figure 7c. In contrast, the trajectory planned by Agent 4 was much smoother, indicating that the introduction of agent pose changes in the state space allows the UTV to effectively mitigate the effects of slip disturbances.
5.3. Reward Function Evaluation
To validate the influence of the
in the reward function (
24), we recorded the linear velocity curve over time during the driving stage.
Figure 8 illustrates the velocity outputs of two agents (i.e., one trained with
and the other without) during the driving stage. Both agents were trained using the complete state space, with random slip disturbances introduced in the environment (i.e., same as the configuration of Agent 4 described in
Section 5.2). As shown in
Table 5, when
was included in the reward function, the UTV reached the destination at the 287th time step, with an average linear velocity of 0.69 and a variance of 0.0019 (i.e., represented by the red curve). In contrast, when
was excluded, the UTV took 483 time steps to reach the destination, with an average linear velocity of 0.42 and a variance of 0.0152 (i.e., represented by the blue curve). The experimental results indicate that the energy optimization term in the reward function (
24) significantly reduces velocity oscillations in the UTV, enabling it to operate more smoothly and at higher speeds.
5.4. Performance of SAC-HP
The SAC algorithm based on the extended state space enables the robot to handle continuous rugged terrain and slip disturbances, thereby improving the safety and robustness of the navigation process. However, in large-scale environments (i.e., long-sequence navigation environments) with extensive map coverage, it becomes difficult for the robot to reach the target with a larger exploration space. Additionally, deep reinforcement learning generally suffers from poor generalization performance. When the robot enters an unknown environment, it is challenging to plan a collision-free path to the target using the overfitted model obtained from the previous experience.
To address the issue of slow exploration and difficulty in reaching the target point in long-sequence environments, the SAC-based Hybrid Policy (SAC-HP) algorithm is proposed.
We trained the agent in a long-sequence environment of 60 m by 100 m. The robot was able to avoid obstacles and navigate to the target with the trained model.
As shown in
Figure 9, the cumulative reward value obtained by the agent in each episode is plotted as the number of algorithm iterations increases. Compared to the classic SAC algorithm, the blue curve in
Figure 9 represents that the SAC-HP algorithm, with the reward curve converging at approximately 3400, has a 16% improvement compared to SAC, showing a significantly faster convergence rate. This indicates that the learning efficiency in long-sequence environments is enhanced by introducing DWA as a prior policy to guide the agent’s early exploration.
To validate the generalization performance of the model, we conducted tests in a random environment. As shown in
Figure 10, the robot’s navigation trajectory in scenarios with random obstacles and terrains is plotted. The experimental results demonstrate that, in the random environment, the robot was able to successfully reach the target and avoid obstacles and rugged terrain.
5.5. Comparison Between Baselines
To evaluate the superiority of the proposed SAC-HP algorithm, five baselines were selected for comparison experiments (i.e., SAC [
24], Twin Delayed Deep Deterministic Policy Gradient (TD3) [
27], Proximal Policy Optimization (PPO) [
28], APF [
29], and DWA [
30]). The experiments were conducted in two scenarios: one was with slipping disturbance (i.e., Env.a), and the other one was without slipping disturbance (i.e., Env.b), using a randomly generated 50 × 100 map. Each experiment was repeated for 500 episodes.
We established four metrics to evaluate the performance of various algorithms, including Average Path Length (APL), Average Time Steps (ATS), Elevation Standard Deviation (ESD), and Success Rates (SR):
APL (Average Path Length): APL represents the mean total length of the path traveled by the robot from the starting point to the target point across all successful experimental episodes. It is used to assess the efficiency of path planning algorithms:
where
is the total path length in the
i-th successful episode, and
is the total number of successful episodes.
ATS (Average Time Steps): ATS reflects the mean number of time steps required for the robot to complete the navigation task, measuring the temporal efficiency of the algorithm:
where
is the total number of time steps in the
i-th successful episode.
ESD (Elevation Standard Deviation): The elevation standard deviation for each episode represents the variation in the robot’s height along the navigation path during that episode. It is used to assess the smoothness of the planned trajectory and the robot’s adaptability to complex terrains:
where
is the height of the
j-th point on the path,
is the mean height, and
is the total number of path points. Next, calculate the average of all episodes:
where
is the total number of episodes.
SR (Success Rates): SR quantifies the proportion of episodes in which the robot successfully reached the target point, providing a measure of the algorithm’s reliability and robustness
where
is the number of successful episodes.
As shown in
Table 6, in the cases without slipping disturbances (i.e., Env.a), it can be observed that SAC-HP outperformed traditional DRL algorithms, achieving a success rate improvement of over 6%. Moreover, compared to SAC, it has a 1.9% improvement on APL, 4.5% improvement on ATS, and 35% improvement on ESD. In the cases with slipping disturbances (i.e., Env.b), the performance of the DRL baseline model dropped sharply, while the success rate of SAC-HP was able to maintain over 90%. The results demonstrate its robustness and reliability in completing navigation tasks, even in challenging environments.
In the cases without slipping disturbances, APF and DWA exhibited higher success rates than some DRL algorithms. However, when slipping disturbances are introduced, the performance of traditional local planning algorithms deteriorates significantly. This indicates that DRL-based algorithms, particularly SAC-HP, have a stronger capability to cope with random disturbances. Furthermore, traditional planning algorithms struggle to handle rugged terrains, as evidenced by their significantly higher elevation standard deviations in each experimental episode compared to DRL algorithms. This confirms the advantage of DRL algorithms in generating smoother trajectories and maintaining stability under complex terrain conditions.
6. Conclusions
This paper presents a novel approach for real-time autonomous path planning of UTVs in unknown off-road environments, utilizing the SAC-based Hybrid Policy (SAC-HP) algorithm. By integrating the kinematic analysis of tracked vehicles, a new state space and action space are designed to account for rugged terrain features and the interaction between the tracks and the ground. This enables the UTV to implicitly learn policies for safely traversing rugged terrains while minimizing the effects of slipping disturbances.
The proposed SAC-HP algorithm combines the advantages of deep reinforcement learning (DRL) with prior control policies (i.e., Dynamic Window Approach) to enhance exploration efficiency and generalization performance in long-sequence environments. Experimental results show that SAC-HP converged 16% faster than the traditional SAC algorithm and achieved a more than 6% higher success rate in rough terrain scenarios. Additionally, it reduced the elevation standard deviation by 35% (from 0.175 m to 0.113 m), indicating smoother trajectories, and decreased the average time steps by 4.5%. The introduction of the energy optimization term in the reward function also effectively reduced velocity oscillations, allowing the robot to operate more smoothly and at higher speeds.
Tests conducted in random environments with obstacles and rugged terrain demonstrate the robustness of the model, as the robot was able to autonomously avoid obstacles and navigate to the target location, even in unknown environments. These results highlight the potential of the SAC-HP algorithm to enhance the safety, robustness, and efficiency of UTV in complex environments.
Although the SAC-HP algorithm demonstrates strong performance in autonomous navigation for UTVs, several potential improvements can be explored in future work. First, incorporating additional environmental factors, such as water currents and dynamic obstacles, could enhance the algorithm’s adaptability to complex off-road environments. Secondly, the scalability of the algorithm for larger and more complex terrains, particularly in high-dimensional state and action spaces, warrants further investigation. Moreover, although the SAC-HP agent significantly reduces training time compared to vanilla SAC, achieving satisfactory performance within extremely low iteration counts remains a challenge. To address this, future work could explore few-shot reinforcement learning [
31] or RL with expert demonstrations [
32] to enable rapid policy adaptation in resource-constrained or time-critical deployment scenarios.
In addition, real-world deployment remains a major challenge for DRL-based methods. Potential remedies such as domain randomization [
33], noise injection during training [
34], and human-guided RL [
35] may help close the simulation-to-reality gap. Moreover, robust sensor fusion using IMU, LiDAR, and visual input can enhance policy generalization under uncertain terrain conditions [
36,
37]. Future extensions of SAC-HP will integrate these mechanisms to facilitate more reliable and scalable deployment in the field.
Future work could also explore extending the SAC-HP framework to aerial systems, such as fixed-wing UAVs. For example, the ensemble-based policy fusion used in our UTV strategy could be adapted to address UAV-specific constraints (e.g., roll angle limits and aerodynamic load factors). Insights from UAV trajectory optimization studies [
38] could inform such extensions, bridging the gap between ground and aerial autonomous navigation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}