
A Review of Decision-Making and Planning for Autonomous Vehicles in Intersection Environments


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
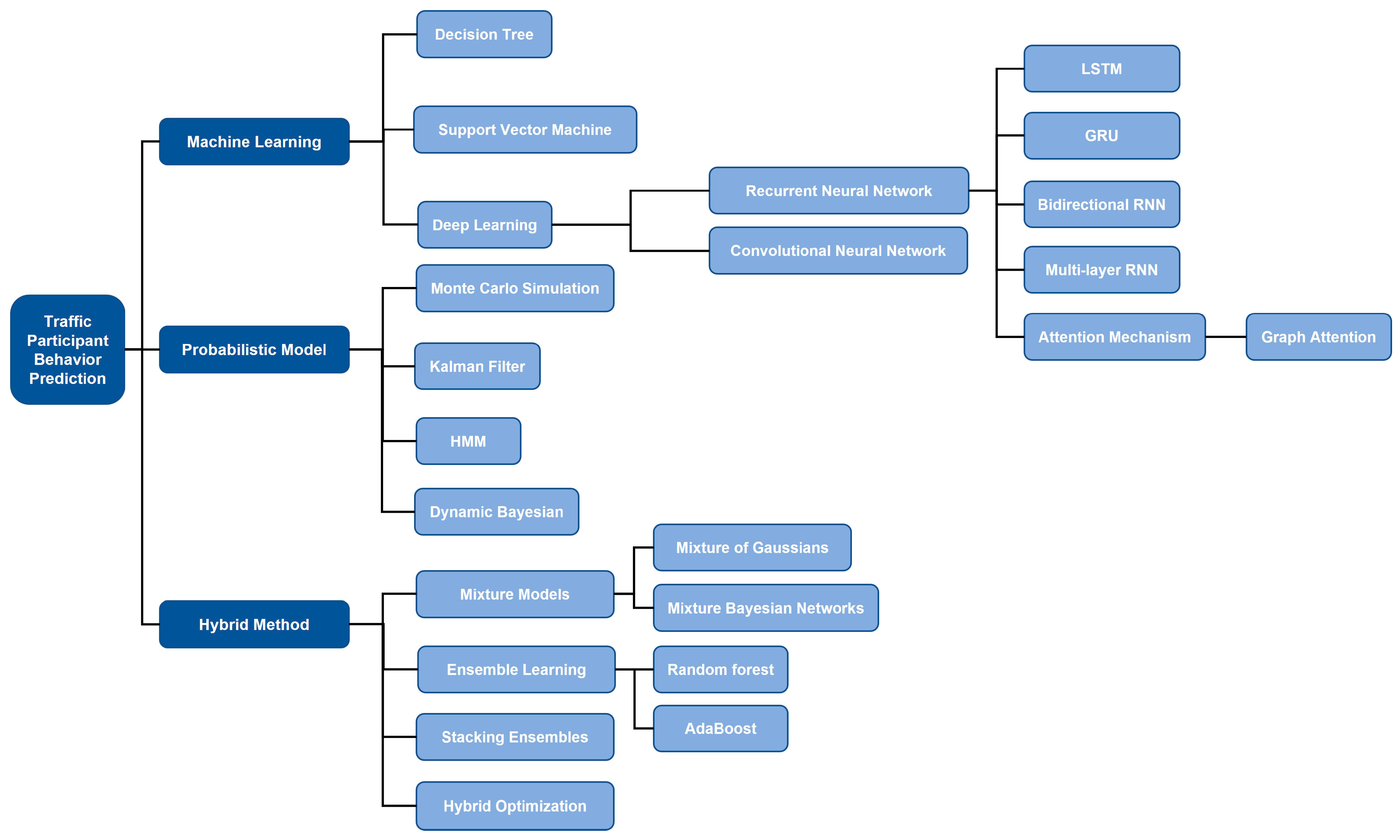
2. Behavioral Prediction of Traffic Participant
2.1. Machine Learning
2.2. Probabilistic Model
2.3. Hybrid Method
3. Behavioral Decision-Making in AVs
3.1. Reactive Decision-Making
3.2. Learning Decision-Making
3.3. Interactive Decision-Making
4. Path Planning for AVs
4.1. Planning Graph Search Methods
4.2. Planning Sampling Methods
4.3. Planning Numerical Methods
5. End-to-End Decision-Making and Path Planning for AVs
6. Research Perspectives
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rusca, F.; Rusca, A.; Rosca, E.; Rosca, M.; Dinu, O.; Ghionea, F. Algorithm for Traffic Allocation When Are Developed Park and Ride Facilities. In Proceedings of the 12th International Conference Interdisciplinarity in Engineering (INTER-ENG), Tirgu Mures, Romania, 4–5 October 2018; pp. 936–943. [Google Scholar]
- Ma, Y.J.; Xu, J.L.; Gao, C.; Mu, M.H.; E, G.X.; Gu, C.W. Review of Research on Road Traffic Operation Risk Prevention and Control. J. Int. J. Environ. Res. Public Health 2022, 19, 26. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, S.J.; Hao, J.M.; Liu, H.; Wu, X.M.; Hu, J.N.; Walsh, M.P.; Wallington, T.J.; Zhang, K.M.; Stevanovic, S. On-road vehicle emissions and their control in China: A review and outlook. J. Sci. Total Environ. 2017, 574, 332–349. [Google Scholar] [CrossRef]
- Kerner, B.S. Failure of classical traffic flow theories: Stochastic highway capacity and automatic driving. J. Phys. A 2016, 450, 700–747. [Google Scholar] [CrossRef]
- Hu, L.; Ou, J.; Huang, J.; Chen, Y.M.; Cao, D.P. A Review of Research on Traffic Conflicts Based on Intelligent Vehicles. IEEE Access 2020, 8, 24471–24483. [Google Scholar] [CrossRef]
- Paden, B.; Cáp, M.; Yong, S.Z.; Yershov, D.; Frazzoli, E. A Survey of Motion Planning and Control Techniques for Self-Driving Urban Vehicles. J. IEEE T. Intell. Veh. 2016, 1, 33–55. [Google Scholar] [CrossRef]
- Zhao, J.Y.; Zhao, W.Y.; Deng, B.; Wang, Z.H.; Zhang, F.; Zheng, W.X.; Cao, W.K.; Nan, J.R.; Lian, Y.B.; Burke, A.F. Autonomous driving system: A comprehensive survey. Expert Syst. Appl. 2024, 242, 27. [Google Scholar] [CrossRef]
- Li, S.; Shu, K.Q.; Chen, C.Y.; Cao, D.P. Planning and Decision-making for Connected Autonomous Vehicles at Road Intersections: A Review. J. Chin. J. Mech. Eng. 2021, 34, 18. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, H.L.; Tang, J.J.; Lee, A.E.Y.; Meng, X.W. Driving angle prediction of lane changes based on extremely randomized decision trees considering the harmonic potential field method. J. Transp. A. 2022, 18, 1601–1625. [Google Scholar] [CrossRef]
- Li, M.; Chen, X.Q.; Lin, X.; Xu, D.Y.; Wang, Y.H. Connected vehicle-based red-light running prediction for adaptive signalized intersections. J. Intell. Transport. Syst. 2018, 22, 229–243. [Google Scholar] [CrossRef]
- Rahman, M.; Kang, M.W.; Biswas, P. Predicting time-varying, speed-varying dilemma zones using machine learning and continuous vehicle tracking. Transp. Res. Part C Emerg. Technol. 2021, 130, 103310. [Google Scholar] [CrossRef]
- Paszek, K.; Grzechca, D. Using the LSTM Neural Network and the UWB Positioning System to Predict the Position of Low and High Speed Moving Objects. J. Sens. 2023, 23, 19. [Google Scholar] [CrossRef]
- Zhou, S.; Xu, H.; Zhang, G.; Ma, T.; Yang, Y. Deep learning-based pedestrian trajectory prediction and risk assessment at signalized intersections using trajectory data captured through roadside LiDAR. J. Intell. Transport. Syst. 2023. [Google Scholar] [CrossRef]
- Li, Q.Y.; Cheng, R.J.; Ge, H.X. Short-term vehicle speed prediction based on BiLSTM-GRU model considering driver heterogeneity. J. Phys. A 2023, 610, 14. [Google Scholar] [CrossRef]
- Cao, Q.; Zhao, Z.; Zeng, Q.; Wang, Z.; Long, K. Real-Time Vehicle Trajectory Prediction for Traffic Conflict Detection at Unsignalized Intersections. J. Adv. Transp. 2021, 2021, 8453726. [Google Scholar] [CrossRef]
- Lian, J.; Yu, F.; Li, L.; Zhou, Y. Early intention prediction of pedestrians using contextual attention-based LSTM. J. Multimed. Tools Appl. 2023, 82, 14713–14729. [Google Scholar] [CrossRef]
- Alghodhaifi, H.; Lakshmanan, S. Holistic Spatio-Temporal Graph Attention for Trajectory Prediction in Vehicle-Pedestrian Interactions. J. Sens. 2023, 23, 7361. [Google Scholar] [CrossRef] [PubMed]
- Ji, Z.; Shen, G.; Wang, J.; Collotta, M.; Liu, Z.; Kong, X. Multi-Vehicle Trajectory Tracking towards Digital Twin Intersections for Internet of Vehicles. J. Electron. 2023, 12, 275. [Google Scholar] [CrossRef]
- Yao, R.; Zeng, W.; Chen, Y.; He, Z. A deep learning framework for modelling left-turning vehicle behaviour considering diagonal-crossing motorcycle conflicts at mixed-flow intersections. Transp. Res. Part C Emerg. Technol. 2021, 132, 103415. [Google Scholar] [CrossRef]
- Liang, E.; Stamp, M. Predicting pedestrian crosswalk behavior using Convolutional Neural Networks. J. Traffic Inj. Prev. 2023, 24, 338–343. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Qi, X.; Xu, Y.; Tian, Y. Vehicle Turning Behavior Modeling at Conflicting Areas of Mixed-Flow Intersections Based on Deep Learning. J. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3674–3685. [Google Scholar] [CrossRef]
- Komol, M.M.R.; Pinnow, J.; Elhenawy, M.; Yasmin, S.; Masoud, M.; Glaser, S.; Rakotonirainy, A. A Review on Drivers’ Red Light Running Behavior Predictions and Technology Based Countermeasures. IEEE Access 2022, 10, 25309–25326. [Google Scholar] [CrossRef]
- Jeong, Y. Stochastic Model-Predictive Control with Uncertainty Estimation for Autonomous Driving at Uncontrolled Intersections. J. Appl. Sci. 2021, 11, 9397. [Google Scholar] [CrossRef]
- Chen, Q.; Zhu, S.; Wu, J.; Chang, H.; Wang, H. An Acceleration Denoising Method Based on an Adaptive Kalman Filter for Trajectory in Merging Zones. J. Adv. Transp. 2023, 2023, 2661136. [Google Scholar] [CrossRef]
- Qian, L.P.; Feng, A.; Yu, N.; Xu, W.; Wu, Y. Vehicular Networking-Enabled Vehicle State Prediction via Two-Level Quantized Adaptive Kalman Filtering. IEEE Internet Things J. 2020, 7, 7181–7193. [Google Scholar] [CrossRef]
- Tan, C.; Zhou, N.; Wang, F.; Tang, K.; Ji, Y. Real-Time Prediction of Vehicle Trajectories for Proactively Identifying Risky Driving Behaviors at High-Speed Intersections. J. Transp. Res. Record. 2018, 2672, 233–244. [Google Scholar] [CrossRef]
- Mao, C.; Bao, L.; Yang, S.; Xu, W.; Wang, Q. Analysis and Prediction of Pedestrians’ Violation Behavior at the Intersection Based on a Markov Chain. Sustainability. 2021, 13, 5690. [Google Scholar] [CrossRef]
- Nasernejad, P.; Sayed, T.; Alsaleh, R. Modeling pedestrian behavior in pedestrian-vehicle near misses: A continuous Gaussian Process Inverse Reinforcement Learning (GP-IRL) approach. Accid. Anal. Prev. 2021, 161, 106355. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Fu, R.; Morris, D.D.; Wang, C. A Framework for Turning Behavior Classification at Intersections Using 3D LIDAR. IEEE Trans. Veh. Technol. 2019, 68, 7431–7442. [Google Scholar] [CrossRef]
- Sun, L.; Zhan, W.; Wang, D.; Tomizuka, M. Interactive Prediction for Multiple, Heterogeneous Traffic Participants with Multi-Agent Hybrid Dynamic Bayesian Network. In Proceedings of the IEEE Intelligent Transportation Systems Conference (IEEE-ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1025–1031. [Google Scholar]
- Xu, Q.; Wu, H.; Wang, J.; Xiong, H.; Liu, J.; Li, K. Roadside pedestrian motion prediction using Bayesian methods and particle filter. J. IET Intell. Transp. Syst. 2021, 15, 1167–1182. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, R.; Zhou, Z.; Qiao, Q. Modeling the Behavior of Pedestrians in a Group at Signalized Intersections Using Dynamic Bayesian Method. In Proceedings of the 19th COTA International Conference of Transportation Professionals (CICTP)—Transportation in China 2025, Nanjing, China, 6–8 July 2019; pp. 112–123. [Google Scholar]
- Hardy, J.; Havlak, F.; Campbell, M. Multi-step prediction of nonlinear Gaussian Process dynamics models with adaptive Gaussian mixtures. Int. J. Rob. Res. 2015, 34, 1211–1227. [Google Scholar] [CrossRef]
- Jiang, Y.D.; Zhu, B.; Yang, S.; Zhao, J.; Deng, W.W. Vehicle Trajectory Prediction Considering Driver Uncertainty and Vehicle Dynamics Based on Dynamic Bayesian Network. IEEE Trans. Syst. Man Cybern.-Syst. 2023, 53, 689–703. [Google Scholar] [CrossRef]
- Yang, S.; Wang, W.S.; Jiang, Y.D.; Wu, J.; Zhang, S.M.; Deng, W.W. What contributes to driving behavior prediction at unsignalized intersections? Transp. Res. Part C Emerg. Technol. 2019, 108, 100–114. [Google Scholar] [CrossRef]
- Jahangiri, A.; Rakha, H.; Dingus, T.A. Red-light running violation prediction using observational and simulator data. J. Accid. Anal. Prev. 2016, 96, 316–328. [Google Scholar] [CrossRef]
- Sethuraman, R.; Sellappan, S.; Shunmugiah, J.; Subbiah, N.; Govindarajan, V.; Neelagandan, S. An optimized AdaBoost Multi-class support vector machine for driver behavior monitoring in the advanced driver assistance systems. Expert Syst. Appl. 2023, 212, 12. [Google Scholar] [CrossRef]
- Xu, D.; Liu, M.F.; Yao, X.P.; Lyu, N.C. Integrating Surrounding Vehicle Information for Vehicle Trajectory Representation and Abnormal Lane-Change Behavior Detection. Sensors 2023, 23, 9800. [Google Scholar] [CrossRef] [PubMed]
- Liu, P.F.; Fan, W. Extreme Gradient Boosting (XGBoost) Model For Vehicle Trajectory Prediction in Connected and Autonomous Vehicle Environment. Promet-Traffic Transp. 2021, 33, 767–774. [Google Scholar] [CrossRef]
- Khoshkangini, R.; Mashhadi, P.; Tegnered, D.; Lundström, J.; Rögnvaldsson, T. Predicting Vehicle Behavior Using Multi-task Ensemble Learning. Expert Syst. Appl. 2023, 212, 16. [Google Scholar] [CrossRef]
- Horng, G.-J.; Huang, Y.-C.; Yin, Z.-X. Using Bidirectional Long-Term Memory Neural Network for Trajectory Prediction of Large Inner Wheel Routes. Sustainability 2022, 14, 5935. [Google Scholar] [CrossRef]
- Zhou, X.; Ren, H.Y.; Zhang, T.T.; Mou, X.A.; He, Y.; Chan, C.Y. Prediction of Pedestrian Crossing Behavior Based on Surveillance Video. Sensors 2022, 22, 1467. [Google Scholar] [CrossRef] [PubMed]
- Xie, G.T.; Gao, H.B.; Huang, B.; Qian, L.J.; Wang, J.Q. A Driving Behavior Awareness Model based on a Dynamic Bayesian Network and Distributed Genetic Algorithm. Int. J. Comput. Intell. Syst. 2018, 11, 469–482. [Google Scholar] [CrossRef]
- Wang, C.; Sun, Q.Y.; Li, Z.; Zhang, H.J.; Ruan, K.L. Cognitive Competence Improvement for Autonomous Vehicles: A Lane Change Identification Model for Distant Preceding Vehicles. IEEE Access 2019, 7, 83229–83242. [Google Scholar] [CrossRef]
- Hu, X.H.; Chen, S.Z.; Zhao, J.H.; Cao, Y.S.; Wang, R.; Zhang, T.T.; Long, B.; Xu, Y.M.; Chen, X.H.; Zheng, M.T.Y.; et al. Bayesian Global Optimization Gated Recurrent Unit Model for Human-Driven Vehicle Lane-Change Trajectory Prediction Considering Hyperparameter Optimization. Transp. Res. Rec. 2023, 2023, 03611981231182390. [Google Scholar] [CrossRef]
- Rahman, M.S.; Abdel-Aty, M.; Lee, J.; Rahman, M.H. Safety benefits of arterials’ crash risk under connected and automated vehicles. Transp. Res. Part C Emerg. Technol. 2019, 100, 354–371. [Google Scholar] [CrossRef]
- Shi, X.; Wong, Y.D.; Li, M.Z.F.; Chai, C. Key risk indicators for accident assessment conditioned on pre-crash vehicle trajectory. Accid. Anal. Prev. 2018, 117, 346–356. [Google Scholar] [CrossRef] [PubMed]
- Rasekhipour, Y.; Khajepour, A.; Chen, S.K.; Litkouhi, B. A Potential Field-Based Model Predictive Path-Planning Controller for Autonomous Road Vehicles. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1255–1267. [Google Scholar] [CrossRef]
- Yang, L.; Luo, X.; Zuo, Z.; Zhou, S.; Huang, T.; Luo, S. A novel approach for fine-grained traffic risk characterization and evaluation of urban road intersections. Accid. Anal. Prev. 2023, 181, 106934. [Google Scholar] [CrossRef] [PubMed]
- Hamid, U.Z.A.; Zamzuri, H.; Rahman, M.A.A.; Saito, Y.; Raksincharoensak, P. Collision avoidance system using artificial potential field and nonlinear model predictive control: A case study of intersection collisions with sudden appearing moving vehicles. In Proceedings of the 25th International Symposium of the International-Association-of-Vehicle-System-Dynamics (IAVSD) on Dynamics of Vehicles on Roads and Tracks, Cent Queensland Univ, Ctr Railway Engn, Rockhampton, Australia, 14–18 August 2017; pp. 367–372. [Google Scholar]
- Xu, Y.; Ma, Z.; Sun, J. Simulation of turning vehicles’ behaviors at mixed-flow intersections based on potential field theory. Transp. B Transp. Dyn. 2019, 7, 498–518. [Google Scholar] [CrossRef]
- Noh, S. Decision-Making Framework for Autonomous Driving at Road Intersections: Safeguarding Against Collision, Overly Conservative Behavior, and Violation Vehicles. IEEE Trans. Ind. Electron. 2019, 66, 3275–3286. [Google Scholar] [CrossRef]
- Sun, C.; Leng, J.; Lu, B. Interactive Left-Turning of Autonomous Vehicles at Uncontrolled Intersections. IEEE Trans. Autom. Sci. Eng. 2022. [Google Scholar] [CrossRef]
- Xin, X.; Jia, N.; Ling, S.; He, Z. Prediction of pedestrians’ wait-or-go decision using trajectory data based on gradient boosting decision tree. Transp. B Transp. Dyn. 2022, 10, 693–717. [Google Scholar] [CrossRef]
- Zhang, T.; Fu, M.; Song, W. Risk-Aware Decision-Making and Planning Using Prediction-Guided Strategy Tree for the Uncontrolled Intersections. IEEE Trans. Intell. Transp. Syst. 2023, 24, 10791–10803. [Google Scholar] [CrossRef]
- Tian, D.; Wang, Y.; Yu, T. Fuzzy Risk Assessment Based on Interval Numbers and Assessment Distributions. Int. J. Fuzzy Syst. 2020, 22, 1142–1157. [Google Scholar] [CrossRef]
- Chu, H.Q.; Guo, L.L.; Yan, Y.J.; Gao, B.Z.; Chen, H. Self-Learning Optimal Cruise Control Based on Individual Car-Following Style. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6622–6633. [Google Scholar] [CrossRef]
- Xu, X.; Zuo, L.; Li, X.; Qian, L.L.; Ren, J.K.; Sun, Z.P. A Reinforcement Learning Approach to Autonomous Decision Making of Intelligent Vehicles on Highways. IEEE Trans. Syst. Man, Cybern. Syst. 2020, 50, 3884–3897. [Google Scholar] [CrossRef]
- Hu, T.; Luo, B.; Yang, C.; Huang, T. MO-MIX: Multi-Objective Multi-Agent Cooperative Decision-Making with Deep Reinforcement Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12098–12112. [Google Scholar] [CrossRef]
- Gutierrez-Moreno, R.; Barea, R.; Lopez-Guillen, E.; Araluce, J.; Bergasa, L.M. Reinforcement Learning-Based Autonomous Driving at Intersections in CARLA Simulator. Sensors 2022, 22, 8373. [Google Scholar] [CrossRef]
- Xu, S.-Y.; Chen, X.-M.; Wang, Z.-J.; Hu, Y.-H.; Han, X.-T. Decision-Making Models for Autonomous Vehicles at Unsignalized Intersections Based on Deep Reinforcement Learning. In Proceedings of the 7th IEEE International Conference on Advanced Robotics and Mechatronics, Guilin, China, 7–9 August 2022; pp. 672–677. [Google Scholar]
- Shu, H.; Liu, T.; Mu, X.; Cao, D. Driving Tasks Transfer Using Deep Reinforcement Learning for Decision-Making of Autonomous Vehicles in Unsignalized Intersection. IEEE Trans. Veh. Technol. 2022, 71, 41–52. [Google Scholar] [CrossRef]
- Kamran, D.; Lopez, C.F.; Lauer, M.; Stiller, C. Risk-Aware High-level Decisions for Automated Driving at Occluded Intersections with Reinforcement Learning. In Proceedings of the 31st IEEE Intelligent Vehicles Symposium (IV), Electr Network, Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1205–1212. [Google Scholar]
- Li, G.; Lin, S.; Li, S.; Qu, X. Learning Automated Driving in Complex Intersection Scenarios Based on Camera Sensors: A Deep Reinforcement Learning Approach. IEEE Sens. J. 2022, 22, 4687–4696. [Google Scholar] [CrossRef]
- Nan, J.; Deng, W.; Zheng, B. Intention Prediction and Mixed Strategy Nash Equilibrium-Based Decision-Making Framework for Autonomous Driving in Uncontrolled Intersection. IEEE Trans. Veh. Technol. 2022, 71, 10316–10326. [Google Scholar] [CrossRef]
- Furda, A.; Vlacic, L. Enabling Safe Autonomous Driving in Real-World City Traffic Using Multiple Criteria Decision Making. IEEE Intell. Transp. Syst. Mag. 2011, 3, 4–17. [Google Scholar] [CrossRef]
- Desjardins, C.; Chaib-Draa, B. Cooperative Adaptive Cruise Control: A Reinforcement Learning Approach. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1248–1260. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 4909–4926. [Google Scholar] [CrossRef]
- Abdoos, M. A Cooperative Multiagent System for Traffic Signal Control Using Game Theory and Reinforcement Learning. IEEE Intell. Transp. Syst. Mag. 2021, 13, 6–16. [Google Scholar] [CrossRef]
- Stryszowski, M.; Longo, S.; Velenis, E.; Forostovsky, G. A Framework for Self-Enforced Interaction between Connected Vehicles: Intersection Negotiation. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6716–6725. [Google Scholar] [CrossRef]
- Wang, H.; Meng, Q.; Chen, S.; Zhang, X. Competitive and cooperative behaviour analysis of connected and autonomous vehicles across unsignalised intersections: A game-theoretic approach. Transp. Res. Part B Methodol. 2021, 149, 322–346. [Google Scholar] [CrossRef]
- Cheng, C.; Yao, D.; Zhang, Y.; Li, J.; Guo, Y. A Vehicle Passing Model in Non-signalized Intersections based on Non-cooperative Game Theory. In Proceedings of the IEEE Intelligent Transportation Systems Conference (IEEE-ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2286–2291. [Google Scholar]
- Cheng, Y.; Zhao, Y.; Zhang, R.; Gao, L. Conflict Resolution Model of Automated Vehicles Based on Multi-Vehicle Cooperative Optimization at Intersections. Sustainability. 2022, 14, 3838. [Google Scholar] [CrossRef]
- Jia, S.Z.; Zhang, Y.X.; Li, X.; Na, X.X.; Wang, Y.H.; Gao, B.Z.; Zhu, B.; Yu, R.J. Interactive Decision-Making With Switchable Game Modes for Automated Vehicles at Intersections. IEEE Trans. Intell. Transp. Syst. 2023, 15, 11785–11799. [Google Scholar] [CrossRef]
- Shu, K.Q.; Mehrizi, R.V.; Li, S.; Pirani, M.; Khajepour, A. Human Inspired Autonomous Intersection Handling Using Game Theory. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11360–11371. [Google Scholar] [CrossRef]
- Darko, J.; Folsom, L.; Pugh, N.; Park, H.; Shirzad, K.; Owens, J.; Miller, A. Adaptive personalized routing for vulnerable road users. IET Intell. Transp. Syst. 2022, 16, 1011–1025. [Google Scholar] [CrossRef]
- Zhao, X.; Su, J.; Cai, J.; Yang, H.; Xi, T. Vehicle anomalous trajectory detection algorithm based on road network partition. Appl Intell. 2022, 52, 8820–8838. [Google Scholar] [CrossRef]
- Wei, W.; Gao, F.; Scherer, R.; Damasevicius, R.; Polap, D. Design and Implementation of Autonomous Path Planning for Intelligent Vehicle. J. Internet Technol. 2021, 22, 957–965. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, J.; Shen, X.; Li, Y.S. Autonomous land vehicle path planning algorithm based on improved heuristic function of A-Star. Int. J. Adv. Rob. Syst. 2021, 18, 10. [Google Scholar] [CrossRef]
- Xidias, E.; Zacharia, P.; Nearchou, A. Intelligent fleet management of autonomous vehicles for city logistics. Appl. Intell. 2022, 52, 18030–18048. [Google Scholar] [CrossRef]
- Lukyanenko, A.; Camphire, H.; Austin, A.; Schmidgall, S.; Soudbakhsh, D. Optimal Localized Trajectory Planning of Multiple Non-holonomic Vehicles. In Proceedings of the 5th IEEE Conference on Control Technology and Applications (IEEE CCTA), San Diego, CA, USA, 8–11 August 2021; pp. 820–825. [Google Scholar]
- Wu, X.; Eskandarian, A. Predictive Motion Planning of Vehicles at Intersection Using a New GPR and RRT Approach. In Proceedings of the 23rd IEEE International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020. [Google Scholar]
- Lukyanenko, A.; Soudbakhsh, D. Probabilistic motion planning for non-Euclidean and multi-vehicle problems. Rob. Auton. Syst. 2023, 168, 104487. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Zhang, J.Z.; He, C.K.; Huang, M.Q.; Ji, Y.; Liu, W.L. Collision-free emergency planning and control methods for CAVs considering intentions of surrounding vehicles. ISA Trans. 2023, 136, 535–547. [Google Scholar] [CrossRef] [PubMed]
- Bian, Y.; Li, S.E.; Ren, W.; Wang, J.; Li, K.; Liu, H.X. Cooperation of Multiple Connected Vehicles at Unsignalized Intersections: Distributed Observation, Optimization, and Control. IEEE Trans. Ind. Electron. 2020, 67, 10744–10754. [Google Scholar] [CrossRef]
- Katriniok, A.; Sopasakis, P.; Schuurmans, M.; Patrinos, P. Nonlinear Model Predictive Control for Distributed Motion Planning in Road Intersections Using PANOC. In Proceedings of the 58th IEEE Conference on Decision and Control (CDC), Nice, France, 11–13 December 2019; pp. 5272–5278. [Google Scholar]
- Wang, Y.; Cai, P.; Lu, G. Cooperative autonomous traffic organization method for connected automated vehicles in multi-intersection road networks. Transp. Res. Part C Emerg. Technol. 2020, 111, 458–476. [Google Scholar] [CrossRef]
- Huang, Y.J.; Ding, H.T.; Zhang, Y.B.; Wang, H.; Cao, D.P.; Xu, N.; Hu, C. A Motion Planning and Tracking Framework for Autonomous Vehicles Based on Artificial Potential Field Elaborated Resistance Network Approach. IEEE Trans. Ind. Electron. 2020, 67, 1376–1386. [Google Scholar] [CrossRef]
- Huang, T.L.; Pan, H.H.; Sun, W.C.; Gao, H.J. Sine Resistance Network-Based Motion Planning Approach for Autonomous Electric Vehicles in Dynamic Environments. IEEE Trans. Transp. Electrif. 2022, 8, 2862–2873. [Google Scholar] [CrossRef]
- Ding, Z.; Sun, C.; Zhou, M.; Liu, Z.; Wu, C. Intersection Vehicle Turning Control for Fully Autonomous Driving Scenarios. Sensors 2021, 21, 3995. [Google Scholar] [CrossRef]
- Liang, W.; Xing, H. Investigations on Speed Planning Algorithm and Trajectory Tracking Control of Intersection Scenarios Without Traffic Signs. IEEE Access 2023, 11, 8467–8480. [Google Scholar] [CrossRef]
- Storani, F.; di Pace, R.; de Schutter, B. A traffic responsive control framework for signalized junctions based on hybrid traffic flow representation. J. J. Intell. Transp. Syst. 2023, 27, 606–625. [Google Scholar] [CrossRef]
- Caban, J.; Nieoczym, A.; Dudziak, A.; Krajka, T.; Stopková, M. The Planning Process of Transport Tasks for Autonomous Vans-Case Study. Appl. Sci. 2022, 12, 18. [Google Scholar] [CrossRef]
- Luo, J.F.; Li, S.J.; Li, H.Q.; Xia, F.H. Intelligent network vehicle driving risk field modeling and path planning for autonomous obstacle avoidance. Proc. Inst. Mech. Eng. Part C J. Eng. Mech. Eng. Sci. 2022, 236, 8621–8634. [Google Scholar] [CrossRef]
- Luo, L.; Sheng, L.; Yu, H.; Sun, G. Intersection-Based V2X Routing via Reinforcement Learning in Vehicular Ad Hoc Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 5446–5459. [Google Scholar] [CrossRef]
- Cao, Z.; Fan, Z.; Kim, J. Intersection-Based Routing with Fuzzy Multi-Factor Decision for VANETs. Appl. Sci. 2021, 11, 7304. [Google Scholar] [CrossRef]
- Chen, L.; Hu, X.; Tang, B.; Cheng, Y. Conditional DQN-Based Motion Planning With Fuzzy Logic for Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2966–2977. [Google Scholar] [CrossRef]
- Guo, Y.; Ma, J. DRL-TP3: A learning and control framework for signalized intersections with mixed connected automated traffic. Transp. Res. Part C Emerg. Technol. 2021, 132, 103416. [Google Scholar] [CrossRef]
- Naderi, M.; Mahdaee, K.; Rahmani, P. Hierarchical traffic light-aware routing via fuzzy reinforcement learning in software-defined vehicular networks. Peer-Peer Netw. Appl. 2023, 16, 1174–1198. [Google Scholar] [CrossRef]
- Zhu, M.X.; Wang, X.S.; Wang, Y.H. Human-like autonomous car-following model with deep reinforcement learning. Transp. Res. Part C Emerg. Technol. 2018, 97, 348–368. [Google Scholar] [CrossRef]
- Wang, J.; Huang, H.; Li, Y.; Zhou, H.; Liu, J.; Xu, Q. Driving risk assessment based on naturalistic driving study and driver attitude questionnaire analysis. Accid. Anal. Prev. 2020, 145, 105680. [Google Scholar] [CrossRef] [PubMed]
- Zablocki, E.; Ben-Younes, H.; Pérez, P.; Cord, M. Explainability of Deep Vision-Based Autonomous Driving Systems: Review and Challenges. Int. J. Comput. Vis. 2022, 130, 2425–2452. [Google Scholar] [CrossRef]
- Zhu, B.; Yan, S.D.; Zhao, J.; Deng, W.W. Personalized Lane-Change Assistance System With Driver Behavior Identification. IEEE Trans. Veh. Technol. 2018, 67, 10293–10306. [Google Scholar] [CrossRef]
- Yu, K.P.; Lin, L.; Alazab, M.; Tan, L.; Gu, B. Deep Learning-Based Traffic Safety Solution for a Mixture of Autonomous and Manual Vehicles in a 5G-Enabled Intelligent Transportation System. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4337–4347. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Hu, X.; Zhao, J.; Wang, R.; Qiao, M. A Review of Decision-Making and Planning for Autonomous Vehicles in Intersection Environments. World Electr. Veh. J. 2024, 15, 99. https://doi.org/10.3390/wevj15030099
Chen S, Hu X, Zhao J, Wang R, Qiao M. A Review of Decision-Making and Planning for Autonomous Vehicles in Intersection Environments. World Electric Vehicle Journal. 2024; 15(3):99. https://doi.org/10.3390/wevj15030099
Chicago/Turabian StyleChen, Shanzhi, Xinghua Hu, Jiahao Zhao, Ran Wang, and Min Qiao. 2024. "A Review of Decision-Making and Planning for Autonomous Vehicles in Intersection Environments" World Electric Vehicle Journal 15, no. 3: 99. https://doi.org/10.3390/wevj15030099
APA StyleChen, S., Hu, X., Zhao, J., Wang, R., & Qiao, M. (2024). A Review of Decision-Making and Planning for Autonomous Vehicles in Intersection Environments. World Electric Vehicle Journal, 15(3), 99. https://doi.org/10.3390/wevj15030099