
Visual Odometry Based on Improved Oriented Features from Accelerated Segment Test and Rotated Binary Robust Independent Elementary Features

Abstract
1. Introduction
- (1)
- To propose a matching algorithm based on the weight of feature point response values by studying the homogenization of ORB features in visual odometry.
- (2)
- To incorporate a predictive motion model in keyframe pose estimation.
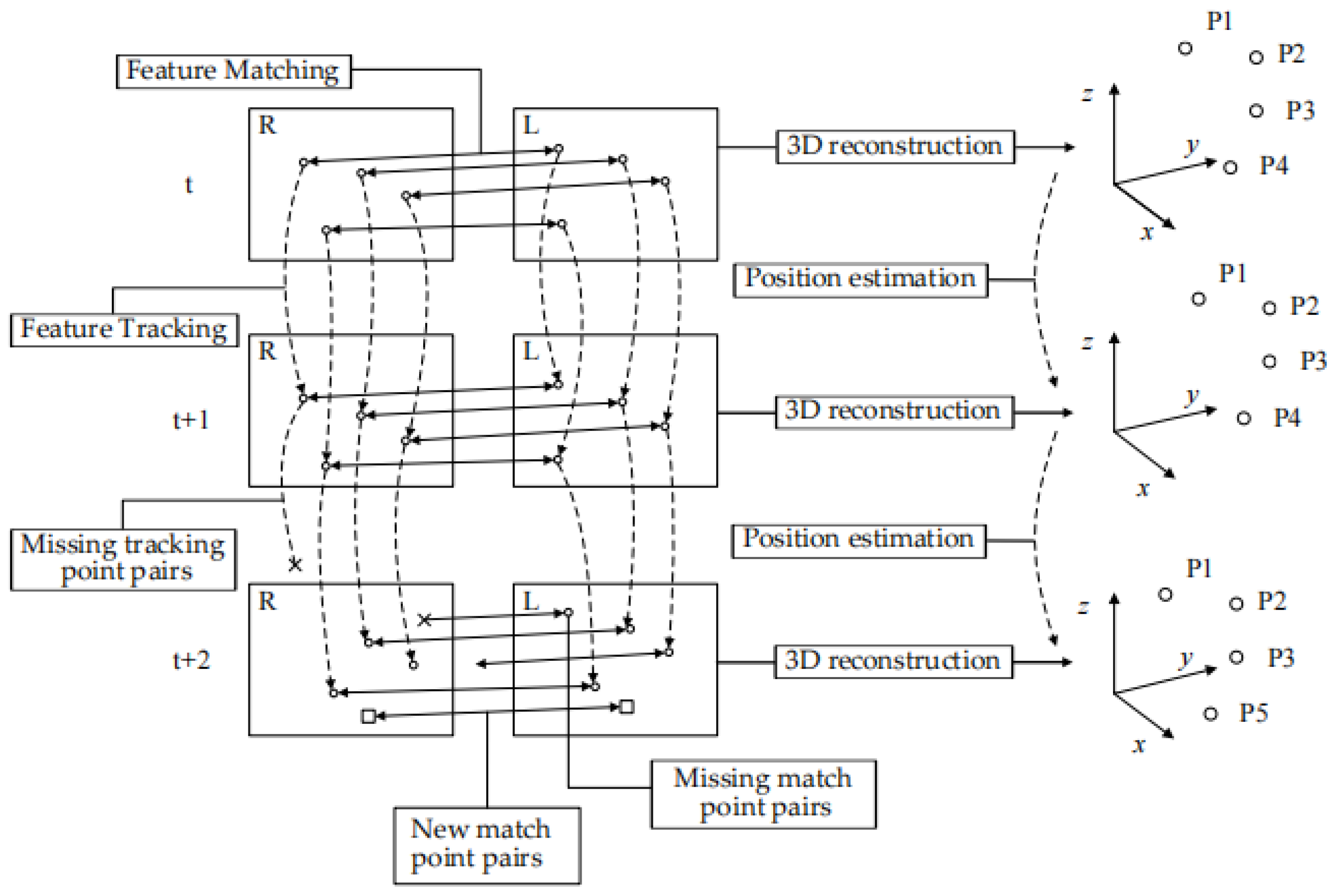
2. Visual Odometry
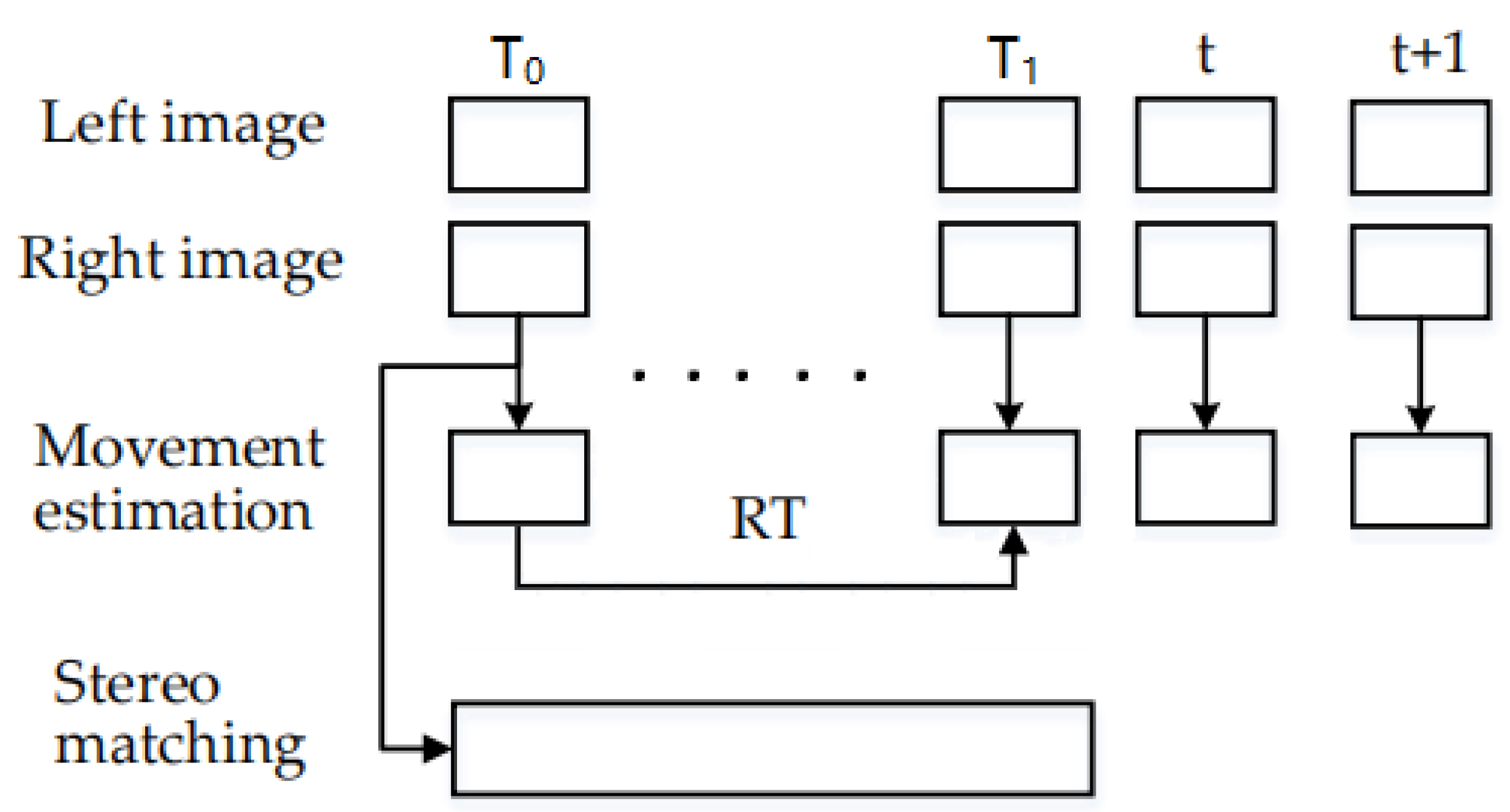
2.1. System Framework
- (1)
- Extracting feature points on the left- and right-eye images;
- (2)
- Matching feature points based on Euclidean distance and polar line constraints;
- (3)
- Reconstructing the 3D coordinates of matched feature point pairs;
- (4)
- Tracking feature points in the next frame of the image;
- (5)
- Calculating the camera pose by solving the minimum reprojection error problem for the feature points.
2.2. ORB Algorithm Parameter Selection
3. Improvement of ORB Features
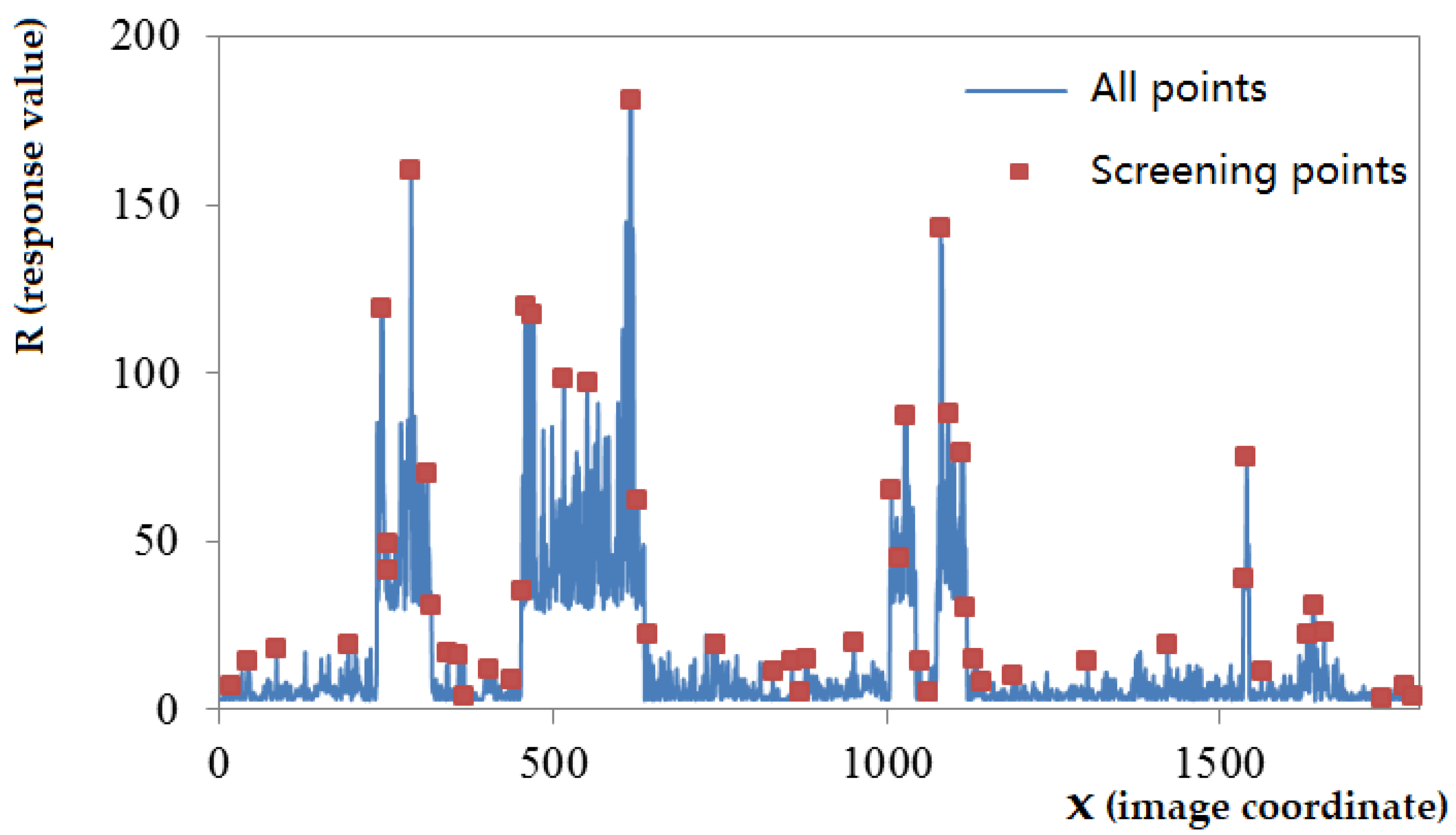
3.1. Calculation of Different Texture Area Weights
- Segmentation of the image;
- Extracting feature points;
- Axing the extraction condition and extracting again if the number of feature points in the region is less than the minimum threshold.
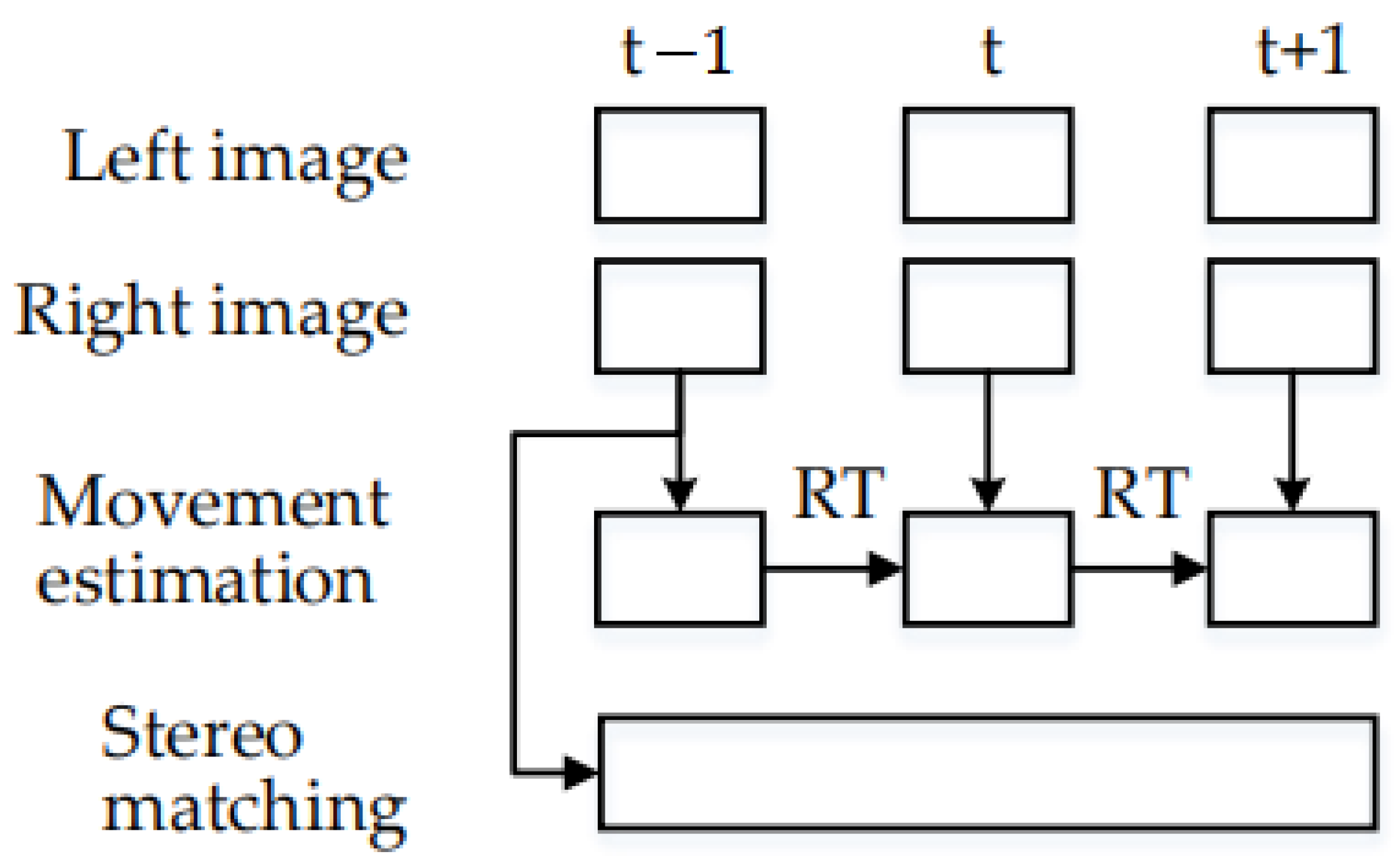
3.2. Keyframe-Based Predictive Motion Model
- —the minimum value of the distance threshold;
- —the maximum value of the distance threshold;
- —the mean value of the Euclidean distance of the 3D coordinates of all matching points of the th keyframe and the th keyframe.
3.3. Three-Dimensional Reconstruction
- represents the 3D space coordinates;
- is the camera’s intrinsic parameter matrix;
- represents the 2D spatial coordinates;
- is the of the Lie group form; and and are the rotation and translation matrices of the camera in motion.
4. Experimental Verification
4.1. System Validation
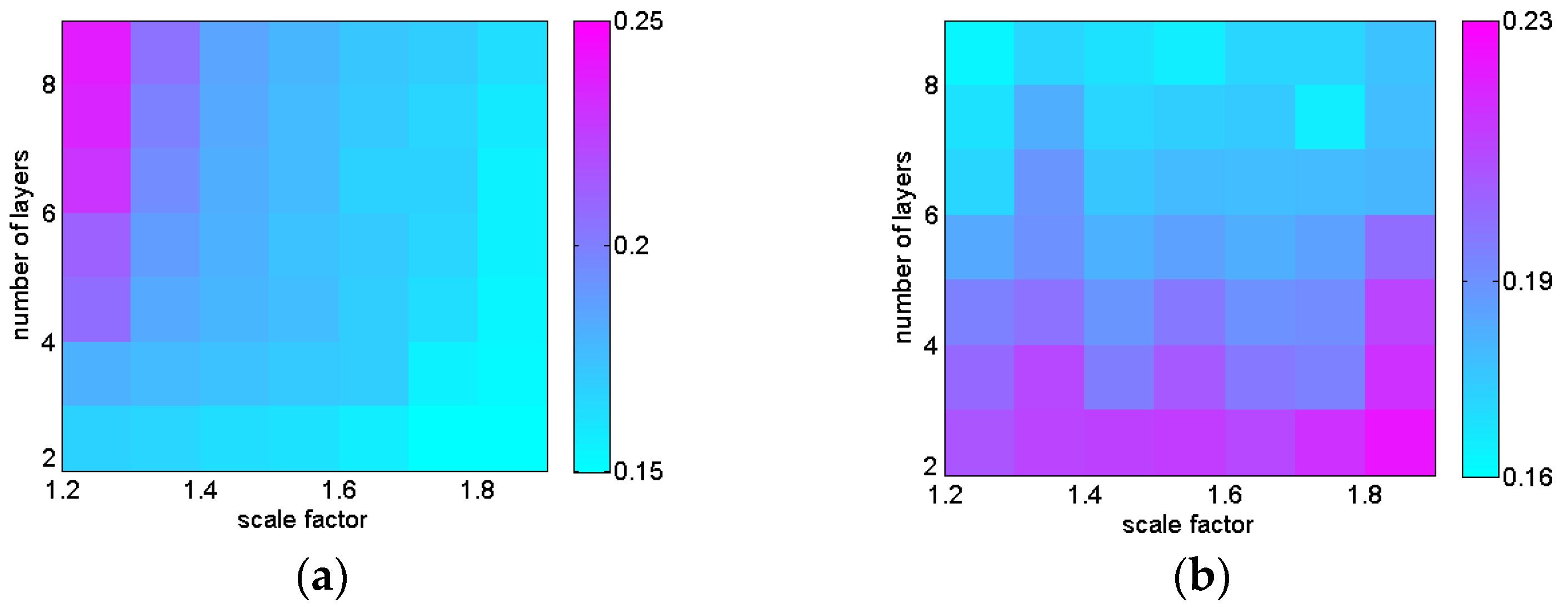
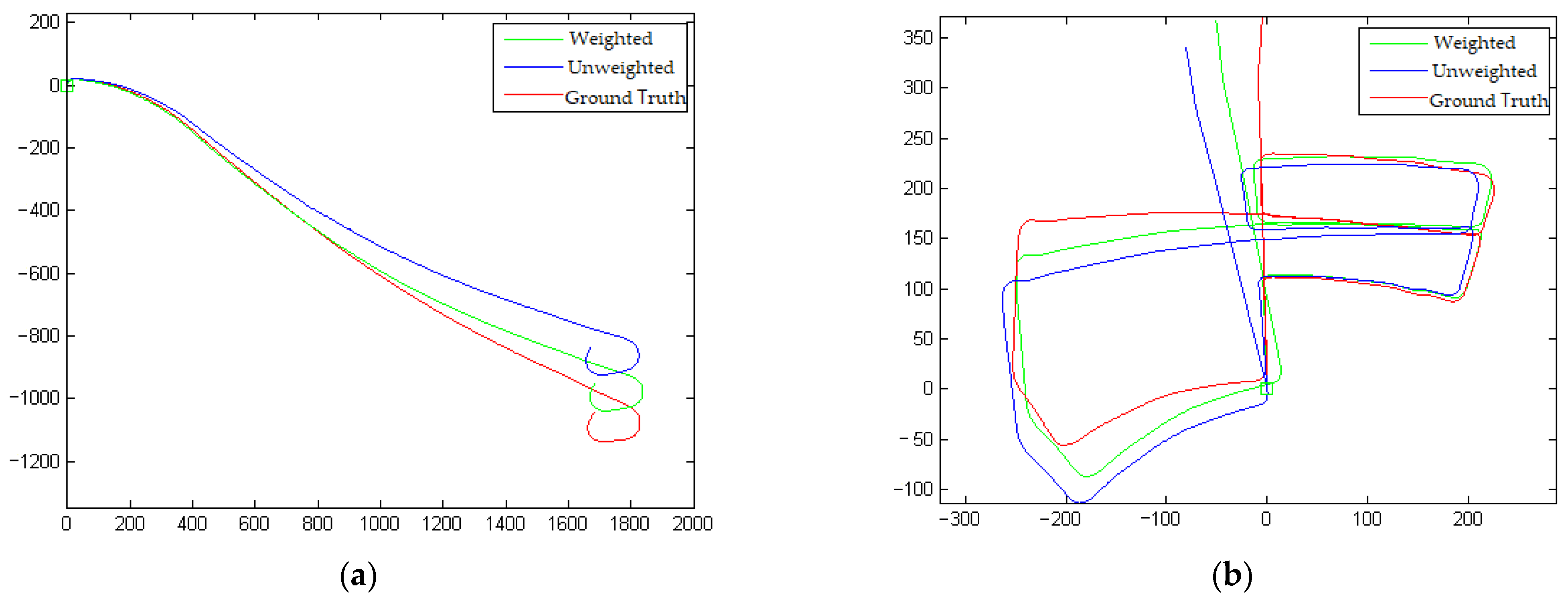
4.2. Verification of Texture Weighting Impact
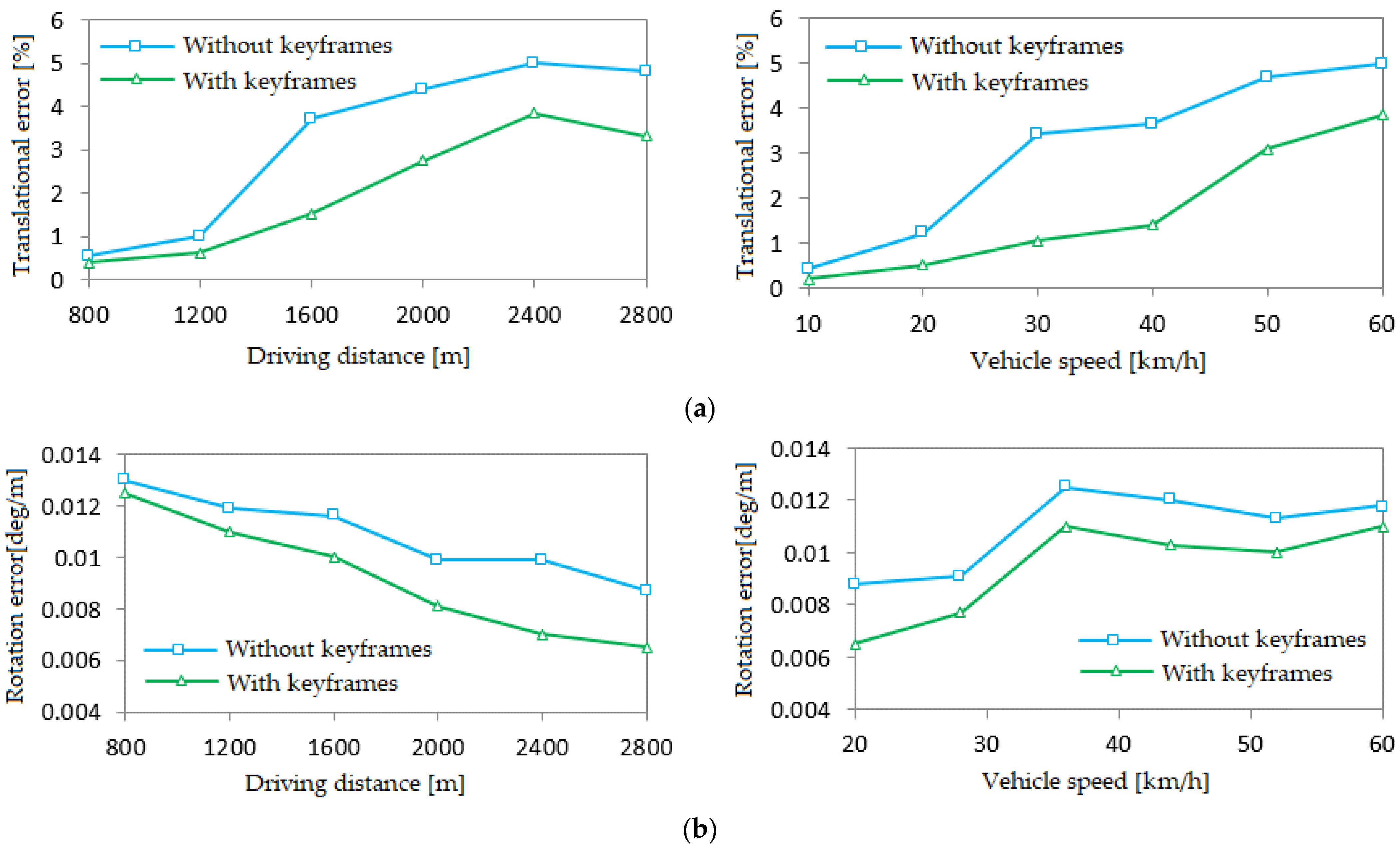
4.3. Verification of Keyframes
5. Conclusions
- The feature extraction part uses weight calculation for regions with different textures. High-texture regions have a greater matching weight, and low-texture regions have a smaller matching weight. So, the feature points can be evenly dispersed in the whole image.
- In the part involving motion estimation, a predictive motion model of key frames is used. This makes the motion of feature points between neighboring keyframes obvious and improves efficiency. According to the test using the KITTI dataset, the key frame rate reaches 10–12% error minimization. Compared the translation and rotation errors with and without keyframes using the KITTI dataset, the translation and rotation errors are reduced.
- A comparison is made with other open-source solutions. It is found that the visual odometer rotation error in this paper is significantly reduced from the other two rotation errors, but the translation error is not improved much. The stability of the system is improved considerably.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, S.; Wang, G.; Yu, H.; Wang, X. Engineering Project: The Method to Solve Practical Problems for the Monitoring and Control of Driver-Less Electric Transport Vehicles in the Underground Mines. World Electr. Veh. J. 2021, 12, 64. [Google Scholar] [CrossRef]
- Boersma, R.; Van Arem, B.; Rieck, F. Application of Driverless Electric Automated Shuttles for Public Transport in Villages: The Case of Appelscha. World Electr. Veh. J. 2018, 9, 15. [Google Scholar] [CrossRef]
- Latif, R.; Saddik, A. SLAM algorithms implementation in a UAV, based on a heterogeneous system: A survey. In Proceedings of the 2019 4th World Conference on Complex Systems (WCCS), Ouarzazate, Morocco, 22–25 April 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, C.; Lei, L.; Ma, X.; Zhou, R.; Shi, Z.; Guo, Z. Map Construction Based on LiDAR Vision Inertial Multi-Sensor Fusion. World Electr. Veh. J. 2021, 12, 261. [Google Scholar] [CrossRef]
- Wu, D.; Ma, Z.; Xu, W.; He, H.; Li, Z. Research progress of monocular vision odometer for unmanned vehicles. J. Jilin Univ. Eng. Ed. 2020, 50, 765–775. [Google Scholar]
- Zeng, Q.H.; Luo, Y.X.; Sun, K.C. A review on the development of SLAM technology for vision and its fused inertia. J. Nanjing Univ. Aeronaut. Astronaut. 2022, 54, 1007–1020. [Google Scholar]
- Wu, D.; Ma, Z.; Xu, W.; He, H.; Li, Z. Methods and techniques for multi-motion visual odometry. J. Shandong Univ. Eng. Ed. 2021, 51, 1–10. [Google Scholar]
- Campos, C.; Elvira, R.; Rodriguez, J.J.G.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM. IEEE Trans. Robot. 2020, 37, 1874–1890. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, L. Navigable Space Construction from Sparse Noisy Point Clouds. IEEE Robot. Autom. Lett. 2021, 6, 4720–4727. [Google Scholar] [CrossRef]
- Zhang, B.; Zhu, D. A Stereo SLAM System with Dense Mapping. IEEE Access 2021, 9, 151888–151896. [Google Scholar] [CrossRef]
- Seichter, D.; Köhler, M.; Lewandowski, B.; Wengefeld, T.; Gross, H.M. Efficient RGB-D Semantic Segmentation for Indoor Scene Analysis. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13525–13531. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 3, 1147–1163. [Google Scholar] [CrossRef]
- Bei, Q.; Liu, H.; Pei, Y.; Deng, L.; Gao, W. An Improved ORB Algorithm for Feature Extraction and Homogenization Algorithm. In Proceedings of the 2021 IEEE International Conference on Electronic Technology, Communication and Information (ICETCI), Changchun, China, 27–29 August 2021; pp. 591–597. [Google Scholar]
- Chen, J.S.; Yu, L.L.; Li, X.N. Loop detection based on uniform ORB. J. Jilin Univ. 2022, 1–9. [Google Scholar]
- Yao, J.; Zhang, P.; Wang, Y.; Luo, C.; Li, H. An algorithm for uniform distribution of ORB features based on improved quadtrees. Comput. Eng. Des. 2020, 41, 1629–1634. [Google Scholar]
- Zhao, C. Research on the Uniformity of SLAM Feature Points and the Construction Method of Semantic Map in Dynamic Environment. Master’s Dissertation, Xi’an University of Technology, Xi’an, China, 2022. [Google Scholar]
- Lai, L.; Yu, X.; Qian, X.; Ou, L. 3D Semantic Map Construction System Based on Visual SLAM and CNNs. In Proceedings of the IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 18–21 October 2020; pp. 4727–4732. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision Transformers for Dense Prediction. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 12159–12168. [Google Scholar]
- Li, G.; Zeng, Y.; Huang, H.; Song, S.; Liu, B.; Liao, X. A Multi-Feature Fusion Slam System Attaching Semantic In-Variant to Points and Lines. Sensors 2021, 21, 1196. [Google Scholar] [CrossRef]
- Al-Mutib, K.N.; Mattar, E.A.; Alsulaiman, M.M.; Ramdane, H. Stereo vision SLAM based indoor autonomous mobile robot navigation. In Proceedings of the IEEE International Conference on Robotics and Biomimetics, Zhuhai, China, 6–9 December 2015; pp. 1584–1589. [Google Scholar]
- Fan, X.N.; Gu, Y.F.; Ni, J.J. Application of improved ORB algorithm in image matching. Comput. Mod. 2019, 282, 5–10. [Google Scholar]
- Xu, H.; Yang, C.; Li, Z. OD-SLAM: Real-Time Localization and Mapping in Dynamic Environment through Multi-Sensor Fusion. In Proceedings of the 2020 5th International Conference on Advanced Robotics and Mechatronics (ICARM), Shenzhen, China, 18–21 December 2020; pp. 172–177. [Google Scholar]
- Kitt, B.; Geiger, A.; Lategahn, H. Visual odometry based on stereo image sequences with RANSAC-based outlier rejection scheme. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010. [Google Scholar]
- Zhao, L.; Liu, Z.; Chen, J.; Cai, W.; Wang, W.; Zeng, L. A Compatible Framework for RGB-D SLAM in Dynamic Scenes. IEEE Access 2019, 7, 75604–75614. [Google Scholar] [CrossRef]
- Geiger, A.; Ziegler, J.; Stiller, C. StereoScan: Dense 3d reconstruction in real-time. IEEE Intell. Veh. Symp. 2011, 32, 963–968. [Google Scholar]
- Comport, A.I.; Malis, E.; Rives, P. Real-time Quadrifocal Visual Odometry. Int. J. Robot. Res. 2012, 29, 245–266. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Gomez-Ojeda, R.; Moreno, F.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A Stereo SLAM System Through the Combination of Points and Line Segments. IEEE Trans. Robot. 2019, 35, 734–746. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Focal Length/mm | Coordinates of Main Point | Aberration Factor | Baseline/m |
|---|---|---|---|
| 718.86 | (607.19, 185.22) | 0.00 | 0.54 |
| Serial Number | Number of Frames | Key Frame Count | Key Frame Rate (%) |
|---|---|---|---|
| 1 | 1101 | 66 | 5.99 |
| 2 | 1101 | 88 | 8.00 |
| 3 | 1101 | 110 | 10.00 |
| 4 | 1101 | 133 | 12.05 |
| 5 | 1101 | 167 | 15.15 |
| Serial Number | Number of Frames | Key Frame Count | Key Frame Rate (%) |
|---|---|---|---|
| 1 | 2761 | 236 | 8.55 |
| 2 | 2761 | 277 | 10.03 |
| 3 | 2761 | 312 | 11.30 |
| 4 | 2761 | 358 | 12.97 |
| 5 | 2761 | 410 | 14.85 |
| 6 | 2761 | 456 | 16.52 |
| 7 | 2761 | 495 | 17.93 |
| 8 | 2761 | 534 | 19.34 |
| Time (ms) | Min | Max | Avg |
|---|---|---|---|
| Feature extraction and matching | 14.6 | 34.6 | 20.7 |
| 3D reconstruction | 5.1 | 12.6 | 8.5 |
| Movement estimation | 2.9 | 10.7 | 6.4 |
| Total time | 23.9 | 52.3 | 35.6 |
| KITTI Dataset | ORB-SLAM2 | PL-SLAM | Our | |||
|---|---|---|---|---|---|---|
| Translation Error (%) | Rotation Error (deg/m) | Translation Error (%) | Rotation Error (deg/m) | Translation Error (%) | Rotation Error (deg/m) | |
| 01 | 2.75 | 0.0182 | 3.29 | 0.0301 | 2.74 | 0.0180 |
| 05 | 1.77 | 0.0450 | 1.67 | 0.0189 | 1.76 | 0.0451 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, D.; Ma, Z.; Xu, W.; He, H.; Li, Z. Visual Odometry Based on Improved Oriented Features from Accelerated Segment Test and Rotated Binary Robust Independent Elementary Features. World Electr. Veh. J. 2024, 15, 123. https://doi.org/10.3390/wevj15030123
Wu D, Ma Z, Xu W, He H, Li Z. Visual Odometry Based on Improved Oriented Features from Accelerated Segment Test and Rotated Binary Robust Independent Elementary Features. World Electric Vehicle Journal. 2024; 15(3):123. https://doi.org/10.3390/wevj15030123
Chicago/Turabian StyleWu, Di, Zhihao Ma, Weiping Xu, Haifeng He, and Zhenlin Li. 2024. "Visual Odometry Based on Improved Oriented Features from Accelerated Segment Test and Rotated Binary Robust Independent Elementary Features" World Electric Vehicle Journal 15, no. 3: 123. https://doi.org/10.3390/wevj15030123
APA StyleWu, D., Ma, Z., Xu, W., He, H., & Li, Z. (2024). Visual Odometry Based on Improved Oriented Features from Accelerated Segment Test and Rotated Binary Robust Independent Elementary Features. World Electric Vehicle Journal, 15(3), 123. https://doi.org/10.3390/wevj15030123