1. Introduction
Lithium-ion batteries are widely used in various fields due to their high energy density, long cycle life, and high safety performance. Lithium-ion batteries have become essential in many applications, ranging from portable electronic devices to the rapid development of new energy electric vehicles, aerospace, and other fields [
1,
2,
3,
4,
5]. However, they are also prone to performance degradation and uncertain failure. As the energy supply and core component of the entire power system, battery failure can lead to a decline in overall system performance, safety accidents, and economic losses. The performance degradation process of lithium-ion batteries is complex and involves various physical and chemical changes. In actual operation, the battery is subject to different charging and discharging modes, current magnitude, environmental pressure and temperature, as well as the battery manufacturing process itself, all of which interact with each other, resulting in non-deterministic and non-linear characteristics that make it challenging to accurately predict the battery degradation performance and ensure the stability and safety of lithium-ion batteries in different operating environments. As a result, stability and safety remain major challenges in the development of lithium-ion batteries [
6,
7,
8,
9,
10]. To address this issue, it is essential to develop accurate methods for estimating the State of Health (SoH) and Remaining Useful Life (RUL) of the battery.
In recent times, the growing sophistication of artificial intelligence, machine learning, and data mining methodologies has led to increased interest in data-driven approaches for predicting SoH. Researchers have utilized advanced machine learning techniques to establish the correlation between battery SoH and Remaining Useful Life, and the relevant features to achieve accurate prediction [
11,
12,
13,
14,
15,
16]. In their study, Yue et al. [
17] proposed a fresh health factor for lithium-ion batteries that relies on the amplitude of the instantaneous voltage drop in the initial segment of discharge under a constant-current discharge condition. To minimize noise, they employed multi-order Bezier curves to reconstruct the new health factor data and devised an empirical degradation model for the battery predicated on the number of cycles. Zhou et al. [
18] also proposed a data-driven model for predicting the State of Health (SoH) of batteries in the face of noise. Their approach was based on the Temporal Convolutional Network (TCN), which consists of multilayer causal convolution and can encode the sequence of sampling points on the battery charging curve. They found that the proposed TCN-based SoH estimation model achieved high accuracy and demonstrated good adaptability to different types of batteries. Additionally, Ezemobi E et al. [
19] analyzed a method to enhance the generalization of SoH estimation using the Parallel Layer Extreme Learning Machine (PL-ELM) algorithm to extend the application of a single SoH estimation model to a large number of cells of the same type. Furthermore, in response to the problems of many complicated model parameters and time-consuming existing SoH estimation methods, Feng et al. [
20] propose to characterize the battery capacity degradation using directly measurable battery constant current charging time and discharge voltage sample entropy as HIs (Health Indicators). The hierarchical extreme learning machine (HELM) model is introduced to establish the SoH online estimation framework, and the two newly constructed HIs are used as inputs to train the HELM battery degradation model offline to achieve SoH online estimation.
In data-driven battery SoH prediction, it is necessary to extract typical features from the capacity degradation data of the battery and establish a mapping relationship between these features and the health state. In previous research, Liu et al. [
21] used the ratio of current capacity to the nominal capacity of lithium-ion batteries as HI. However, this approach can ignore useful information during training and degrade generalization performance. Che et al. [
22] proposed an efficient health factor extraction method for battery cells based on partial charge and discharge data while considering a feature generation strategy for battery pack capacity decay and inconsistency and using dual time scale filtering and a battery pack equivalent circuit model to broaden the application scope of the feature extraction method. Finally, a Gaussian process-based regression algorithm framework is used to improve the estimation accuracy and reliability, and the method improves the accuracy of battery system health state estimation as well as its adaptability in widely used scenarios. In their study, Liu et al. [
23] utilized an improved Douglas–Peucker compression algorithm to compress the discharge voltage curve of the battery dataset from the University of Maryland and build an XGBoost model. However, their approach extracted fewer features, and the generalization ability of the model with fewer features in the actual prediction needs to be demonstrated. On the other hand, Zhang et al. [
24] propose a method for estimating the health state of lithium-ion batteries based on the incremental energy method and Bi-directional Gated Recurrent Network (BiGRU) Dropout. Firstly, the maximum peak height in the incremental energy curve is extracted as the new health factor of the battery SoH. The mapping relationship between the health factor and SoH is derived from the BiGRU network built by the flip-flop layer and the gated recurrent network layer, and its experimental results show that the method can estimate the battery SoH quickly and accurately under different charging multiplier conditions.
The technique of curve compression, also known as curve simplification or point set extraction thinning, is a useful data compression technique that reduces the amount of data by removing some data points while ensuring sufficient accuracy. Curve compression is commonly used in mapping, road network analysis, robot path planning, and various other fields. The utilization of curve compression algorithms can significantly reduce the data volume while still maintaining the main shape features and path direction information of the original curve without affecting the importance of the original data. Among curve compression algorithms, the perpendicular distance threshold algorithm and the Douglas–Peucker algorithm are the most widely used. The Douglas–Peucker algorithm requires more computational resources and many iterations. On the other hand, the perpendicular distance threshold algorithm calculates the distance from each point to the line segment, resulting in lower computational complexity and a significant advantage when dealing with large amounts of data. Additionally, the parameters of the perpendicular distance threshold algorithm can be adjusted according to specific needs and have better retention of some key core curve features.
In the field of data-driven SoH and RUL prediction for lithium-ion batteries, neural networks, Unsupervised learning, and ensemble learning algorithms are commonly used. Unsupervised learning can be used to detect abnormal conditions in battery operation, such as excessive temperature, abnormal voltage, capacity drop, etc. By modeling the normal behavior of the battery, the state of the battery can be monitored in real time, and potential problems can be detected in time so that early action can be taken to avoid battery failure [
25]. Ensemble learning algorithms combine multiple learners and have better learning performance. Gradient Boosting Decision Tree (GBDT) is a powerful ensemble learning algorithm that reduces total error and enhances robustness by minimizing bias. It has been successfully applied in various fields, such as transportation, finance, medicine, and lithium battery lifetime prediction. CatBoost, a machine learning library founded by Yandex, is based on the GBDT framework and was introduced in 2017. Compared to other GBDT algorithms like XGBoost and LightGBM, CatBoost offers several improvements. It addresses gradient bias during iteration through the use of the ordering principle, ordering enhancement algorithms, and a greedy strategy to reduce overfitting, optimize model speed, and enhance the model’s robustness and accuracy. Moreover, CatBoost uses a weighted random negative sampling method and symmetric tree splitting to increase the generalization ability of the tree model. It has exhibited excellent performance in transformer fault diagnosis and has become a popular choice when dealing with large-scale datasets with high dimensionality and multiple discrete variables [
26].
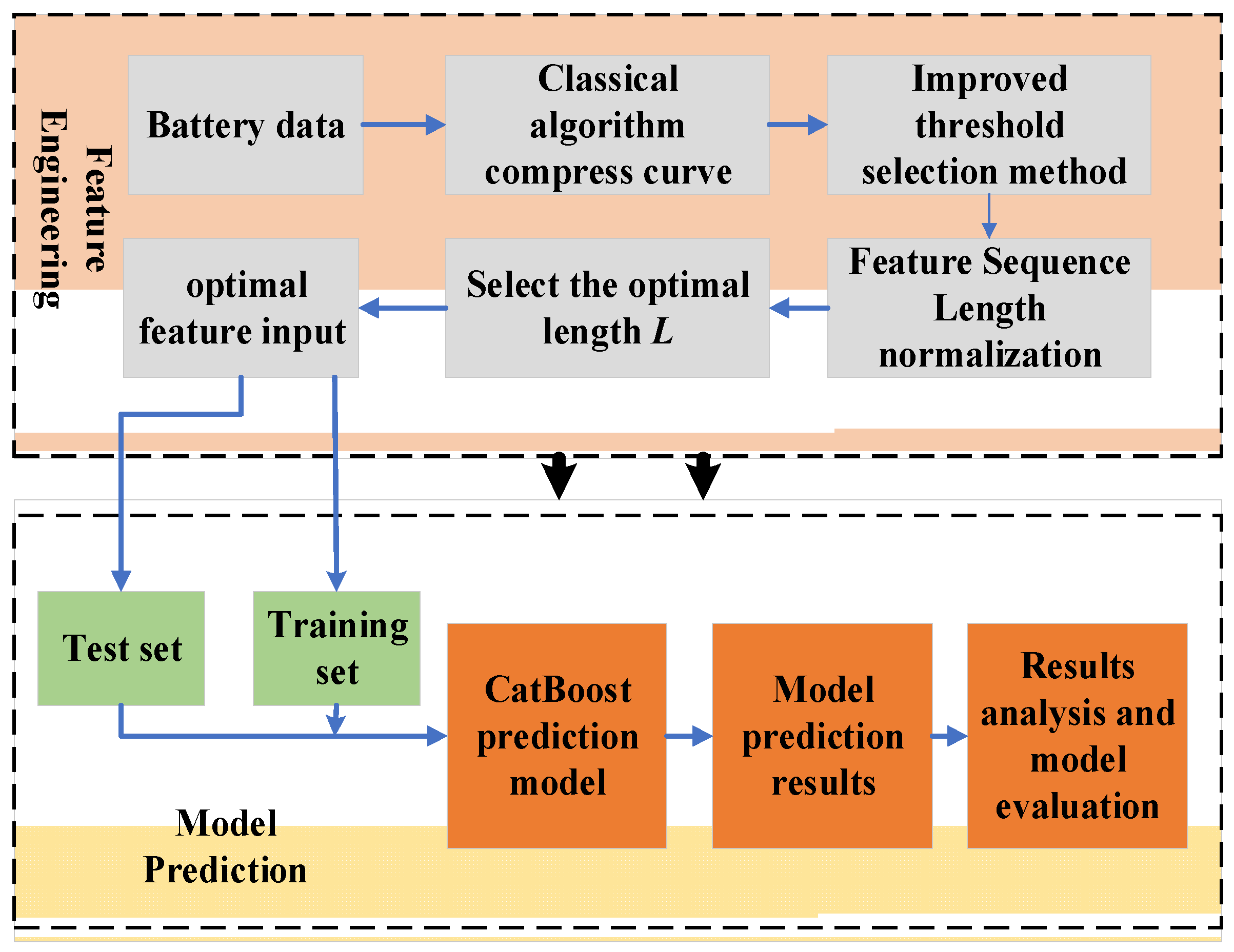
To address the issue of low accuracy in predicting SoH and RUL of lithium-ion batteries due to the difficulty of feature engineering, this study proposes a SoH and RUL prediction model based on curve compression and CatBoost. Firstly, a threshold selection method that integrates curvature analysis for improvement is proposed to improve the unsatisfactory compression results of the classic perpendicular distance threshold algorithm when applied to compressing the original curve. Second, cubic spline interpolation and the Local Outlier Factor (LOF) method are used to fill or eliminate the feature to ensure that the extracted feature sequences are of the same length and can be easily input into the prediction model. Then, the dynamic time regularization algorithm is used to calculate the shortest distance between the feature sequence and the original curve and use it as the basis for judgment to determine the optimal length, and the feature is used as the input to the CatBoost prediction model for SoH estimation and RUL prediction of lithium-ion batteries. Finally, to verify the superiority of the established feature engineering and the model used in this study, experiments such as comparison of the effects of different prediction models, model generalization validation, and model robustness validation are conducted to demonstrate the different dimensions.
5. Instance Validation
This study focuses on dataset A, which is subjected to curve compression and used as the subject of research. A prediction model is developed to forecast the State of Health (SoH) and Remaining Useful Life (RUL) of each battery group. Dataset B is used as a validation dataset to assess the generalizability of the proposed feature engineering approach. Feature engineering is performed again on dataset B, and a prediction model is constructed to evaluate the performance of the prediction.
5.1. Traditional Threshold Selection Method: Compress Curve
In this study, dataset A is selected for experimentation, which comprises various charging and discharging cycles of lithium-ion batteries. Each cycle is composed of ten different attributes: Voltage measured, Current measured, Temperature measured, Current load, and Voltage load for charging, and Voltage measured, Current measured, Temperature measured, Current load, and Voltage load for discharging. To showcase the experimental process of curve compression and threshold selection, the Voltage measured attribute of battery number five is used as an example.
The discharge experiment conducted on battery number five in dataset A generated the Voltage-measured attribute time-domain decay curves shown in
Figure 8.
The charge curves of the Voltage-measured attribute in each cycle of the discharge experiment conducted on dataset A are demonstrated in
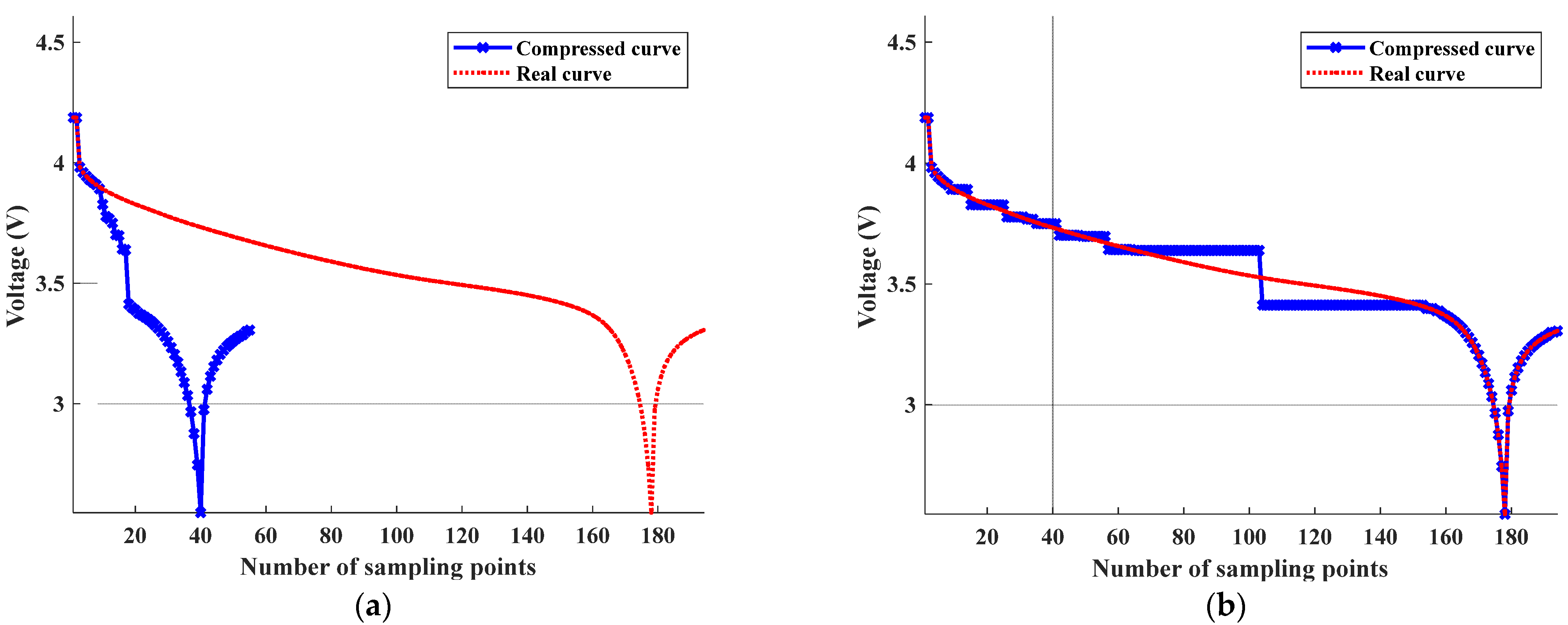
Figure 8. However, when testing and monitoring lithium batteries, different experiments and application scenarios require data collection at different sampling frequencies. Some tests may require a higher sampling frequency to obtain more detailed and accurate data, while others may only require a lower sampling frequency. The inconsistent sampling points in each curve make it challenging to use this attribute directly for battery life prediction, warranting the need for feature extraction. Additionally, the curve shapes under different cycles are similar, with common features such as upper convexity and lower concavity. By capturing curve detail information, the data length can be significantly reduced and the model complexity minimized. The curve compression is performed using the perpendicular distance threshold algorithm for feature point extraction. However, the traditional pendant limit method has limitations in threshold value selection, including (1) uncertainty in threshold value selection, which can lead to inadvertent deletion of feature points, and (2) the selected threshold values are not directly related to the data compression rate, making the number of compression points indeterminate.
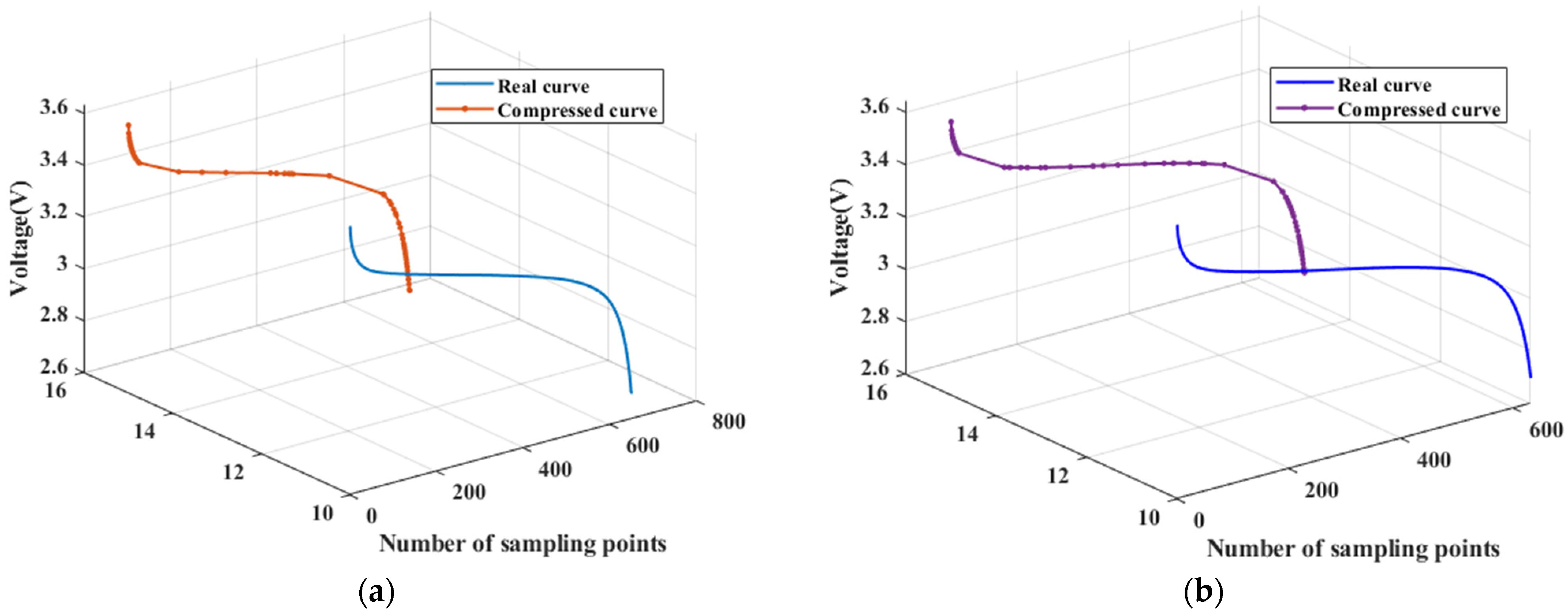
To investigate the threshold selection issue of voltage curve compression using the perpendicular distance threshold algorithm, the Voltage measured curves of the 5th and 105th discharge cycles in
Figure 8 were selected and analyzed using the classical perpendicular distance threshold algorithm under different threshold conditions. The curve compression results under different thresholds are presented in
Figure 9 and
Figure 10, respectively. The conventional thresholds consist of the median of the dip
and the minimum value of the line from each point on the curve to the first and last end points
.
The compression results of different curves in
Figure 9 and
Figure 10 reveal that the feature intervals obtained by the perpendicular distance threshold algorithm differ for different threshold conditions, which significantly impact the compression effect of the final solution. As observed in
Figure 9, selecting the median vertical distance threshold
retains more points for both curves, resulting in a low data compression rate (i.e., ratio of the compressed curve data points to the original curve points) and high spatial complexity, which does not achieve the intended purpose of reducing feature dimension. On the other hand, selecting the minimum distance
as the threshold leads to a high compression rate but a poor fit between the compressed and original real curves. Additionally, curve feature point extraction under different thresholds performed well at curve segments with significant changes in slope but poorly at curve segments with a flat trend, indicating that the traditional threshold selection method does not satisfy the requirements of all points on a given curve.
In summary, the compression results show significant errors under both threshold selections, indicating that excessively large or small thresholds can cause significant measurement errors. It is feasible to adjust the threshold size to adapt to all the Voltage measured curves. The fundamental issue lies in the fact that the threshold judgment criteria of the classical perpendicular distance threshold algorithm cannot adequately capture the deviation of certain curve segments from their corresponding straight lines. Therefore, it is necessary to propose a new threshold judgment criterion that builds on the classical perpendicular distance threshold algorithm to achieve more accurate curve compression.
5.2. Improved Threshold Selection Method Compress Curve
The threshold value in the classical perpendicular distance threshold algorithm cannot effectively capture the linearity of the original curve, leading to different states in the obtained intervals of the original curve. While the linearity of the fitting results can be enhanced by adjusting the threshold, a uniform threshold value cannot be applied to all curves, making it challenging to set the threshold accurately.
Assessing the deviation of the entire curve from the line connecting the first and last points requires considering the curvature of the curve, which can be effectively analyzed using curvature analysis. Conventional curvature analysis evaluates the degree of deviation of discrete data points from the desired curve, where the curvature of a plane curve in two-dimensional plane space is defined as the rotation rate of the tangent direction angle to the arc length at a point on the curve, indicating the extent of curve deviation from the straight line. In this study, curvature is characterized as the deviation of a curve segment from the line connecting the first and last points of a gentle curve segment. Therefore, to calculate the mean curvature at a point
on the curve
, the reciprocal of the radius of a circle that is tangent to the curve at
and two nearby points on the curve is computed as follows:
where
and
denote the first and second order derivatives of the curve
at
, respectively,
, and
denotes the radius of the close circle.
In Equation (12), represents the number of data points of the original curve, and represents the mean curvature of the curve segment.
To identify the flat change area in the original curve segment, the derivatives at each point of the curve are computed, and the area with relatively minor changes in the derivatives is selected. Based on this area, the first and last end points of the gentle line segment can be determined.
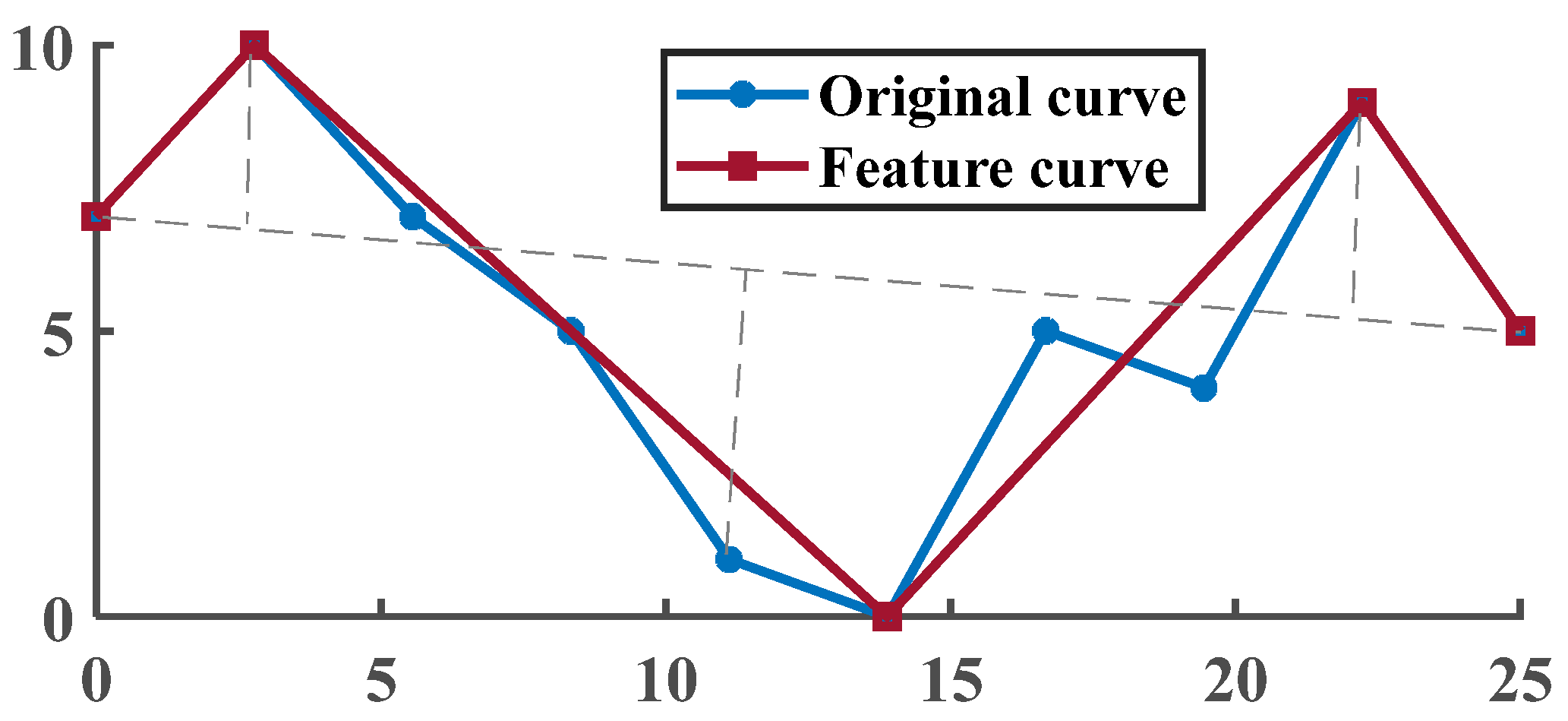
Figure 11 illustrates the first and last end points of the 5th discharge voltage curve’s gentle line segment.
After obtaining the gentle curve segment, the mean curvature of the line connecting each point on the segment to the first and last end points is computed to determine the curvature threshold. The traditional threshold is then replaced with the curvature threshold, and the improved threshold selection method is used in combination with the drape limit algorithm to perform curve compression on the original curve. The compression results for the voltage curve under two different cycles in
Figure 8 are illustrated in
Figure 12.
The experimental results in
Figure 12 demonstrate that the proposed threshold selection method, which replaces the classical dip-limit algorithm thresholds
and
with the mean curvature value
, outperforms the traditional methods shown in
Figure 8. The mean curvature value provides a more accurate reflection of the deviation of the original curve from the straight line, resulting in a better fitting and more accurate representation of the original curve’s elevation characteristics, despite the slight increase in the number of feature points.
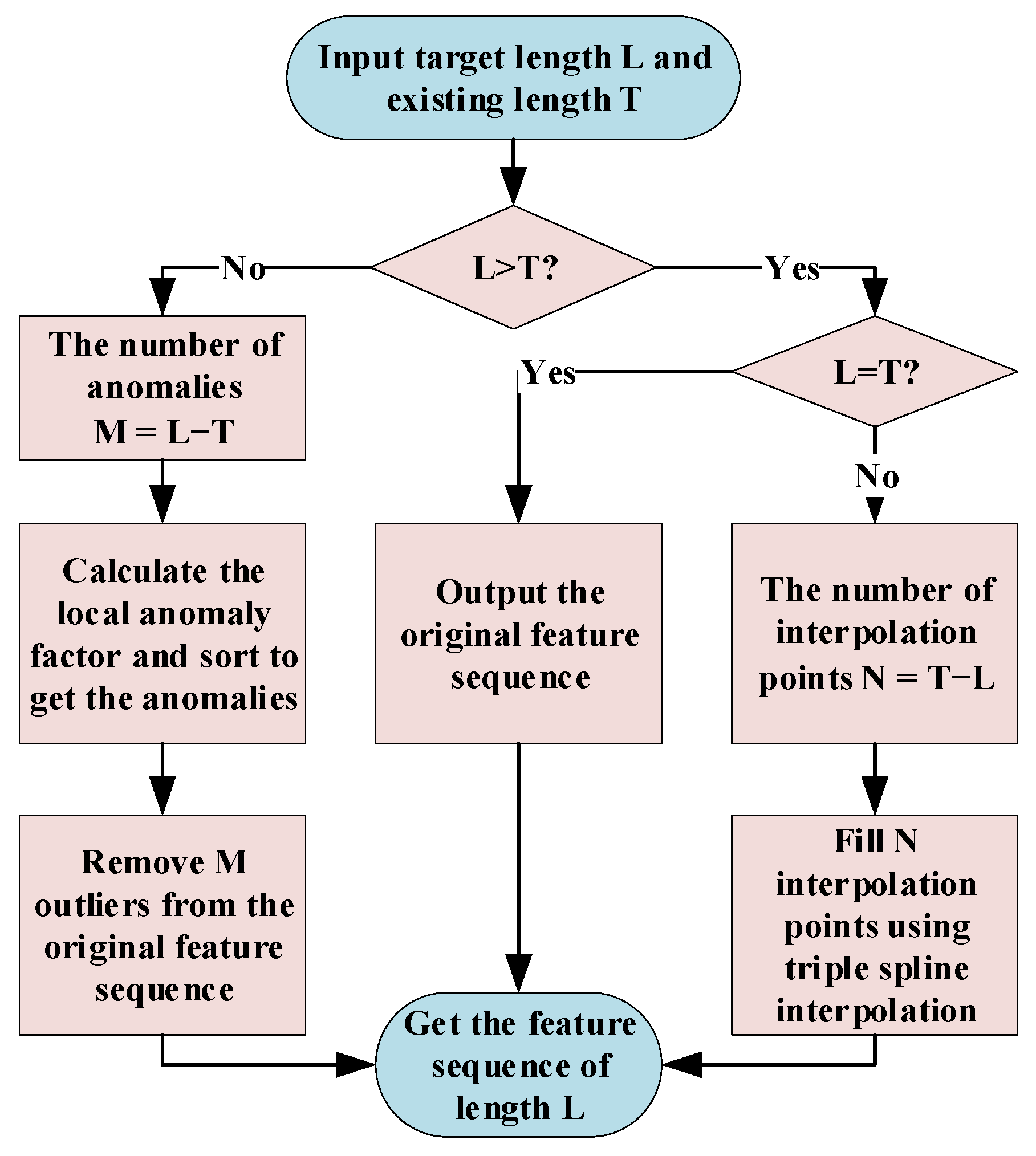
5.3. Length Normalization Based on Cubic Spline Interpolation and Outlier Detection
To ensure that the curves have the same length for input into the prediction model, it is necessary to perform length normalization since the lengths of the curves in different cycles are not the same and the curvature thresholds
on different curves are calculated differently. The feature points extracted from each curve after processing using the method described in the previous section have dimensionalities. The normalization process is shown in
Figure 13.
5.3.1. Cubic Spline Interpolation to Add Feature Points
To obtain a fixed-length feature sequence of L, this study employs cubic spline interpolation to split the original long sequence into several segments, constructing multiple cubic functions. This method enables the segments to process gentle articulation at the joints of the segments while retaining the maximum information of the original feature curve. Sequences of less than L length are added to the feature sequence while ensuring the maximum information of the original feature curve is preserved.
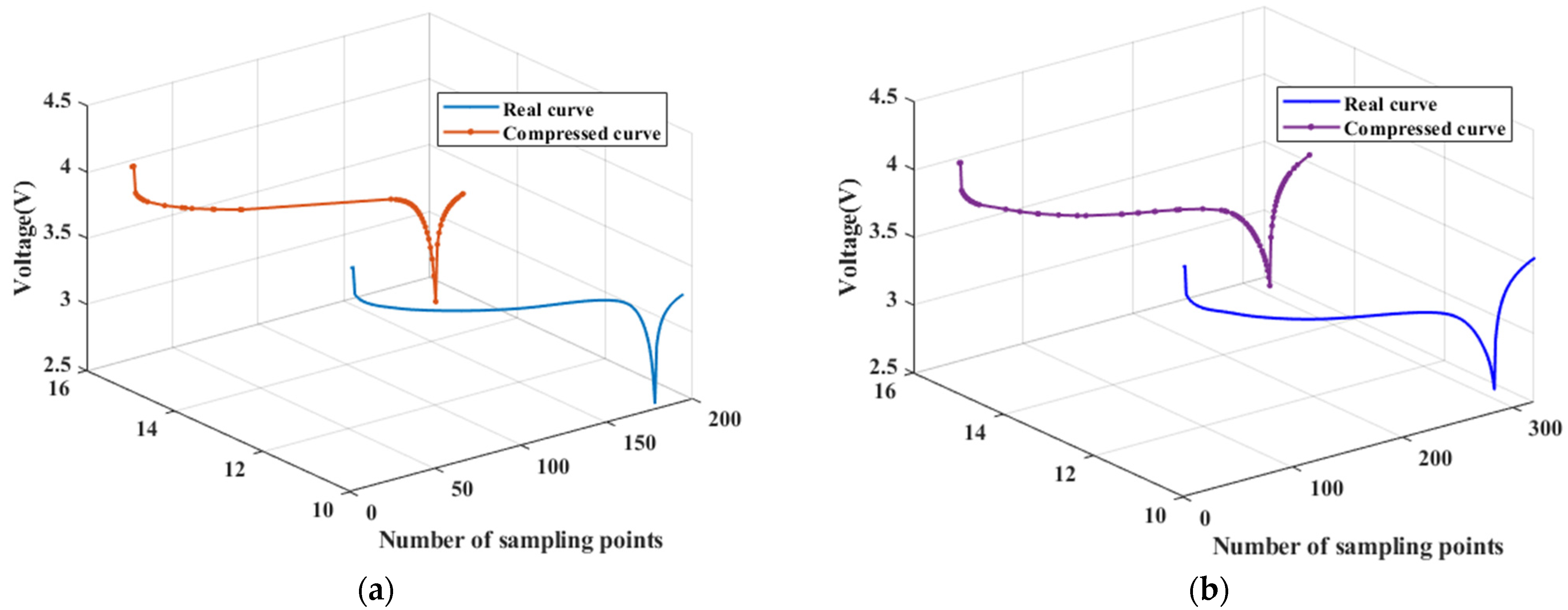
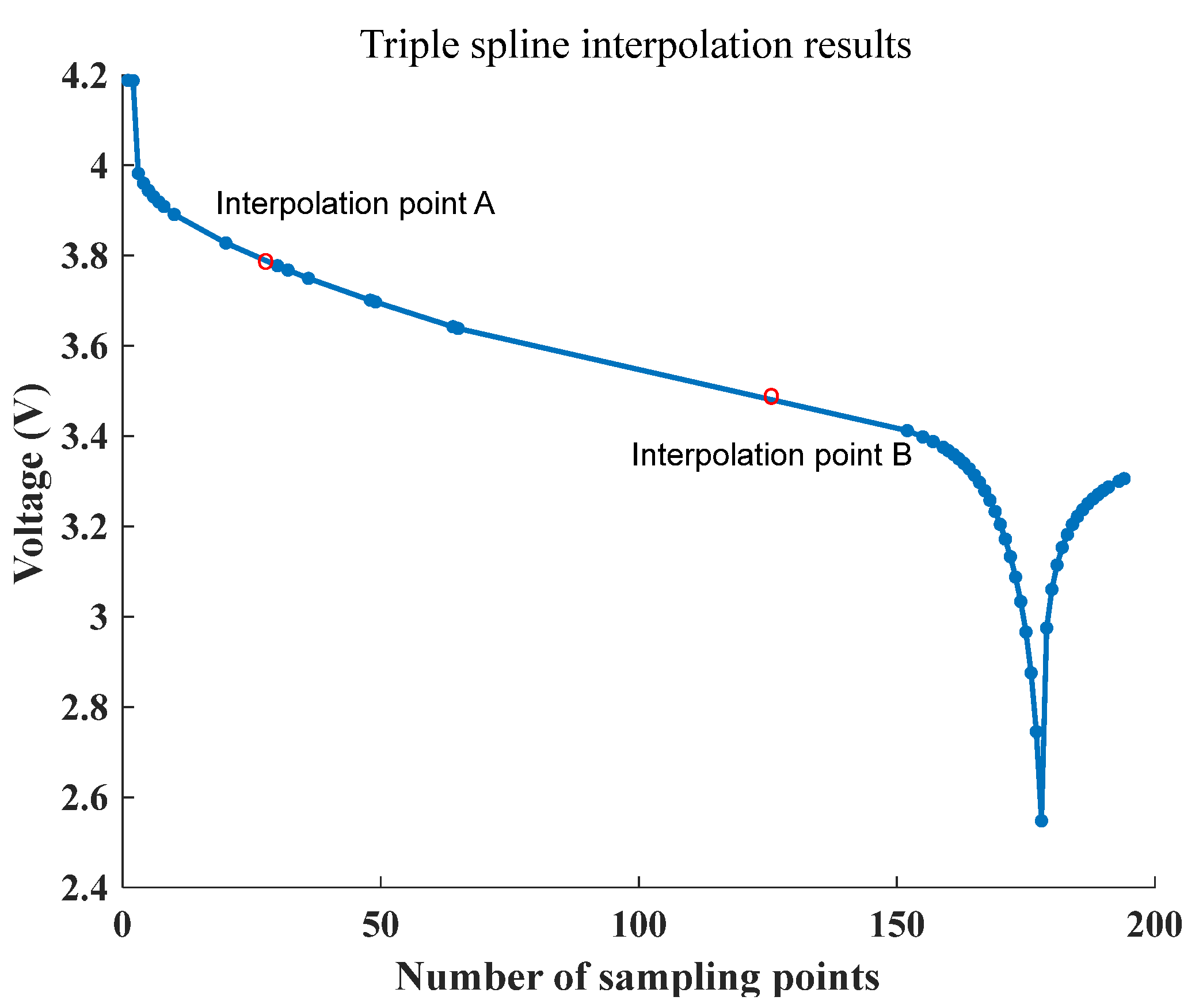
Figure 14 shows the interpolation result of the compressed curve, where the original compressed curve has a length of 53 and is now randomly filled into a feature sequence of length 55.
Figure 14 illustrates that the interpolation points A and B of the curve, which were obtained using cubic spline interpolations, are distributed along the fitted curve, indicating that the interpolation points do not have a significant impact on the elevation characteristic distribution of the original feature curve.
5.3.2. LOF Anomaly Detection to Remove Feature Points
To reduce data points in feature sequences exceeding length L, excess feature points need to be removed, and the local density feature is calculated to reflect the abnormality degree of certain samples. The LOF method is a prominent density-based outlier detection technique that calculates LOF numerically to reflect the abnormality degree of a sample. using the following equations:
For two points in the sample, the reachable distance from
to
can be expressed as follows:
where
denotes the distance neighborhood length.
Assuming there are
sample points in the
distance neighborhood of
, denoted by
, the locally reachable density of
can be expressed as follows:
where
denotes the
sample point in
. The smaller the local reachable density of
, the further away the point
is from its neighborhood, and the higher the probability of it being an anomaly. The local anomaly factor is defined as the ratio of the average density of the sample points around a sample point to the density of the location of the sample point. LOF can be expressed as follows:
The numerator in Equation (15) represents the mean of the locally reachable density of
in the distance between
and all sample points in the neighborhood, while the denominator is the locally reachable density of
. When the density of
is lower than that of the surrounding samples, the Locally Reachable Density
is smaller, leading to a higher
value than one. This indicates that the density of the location of
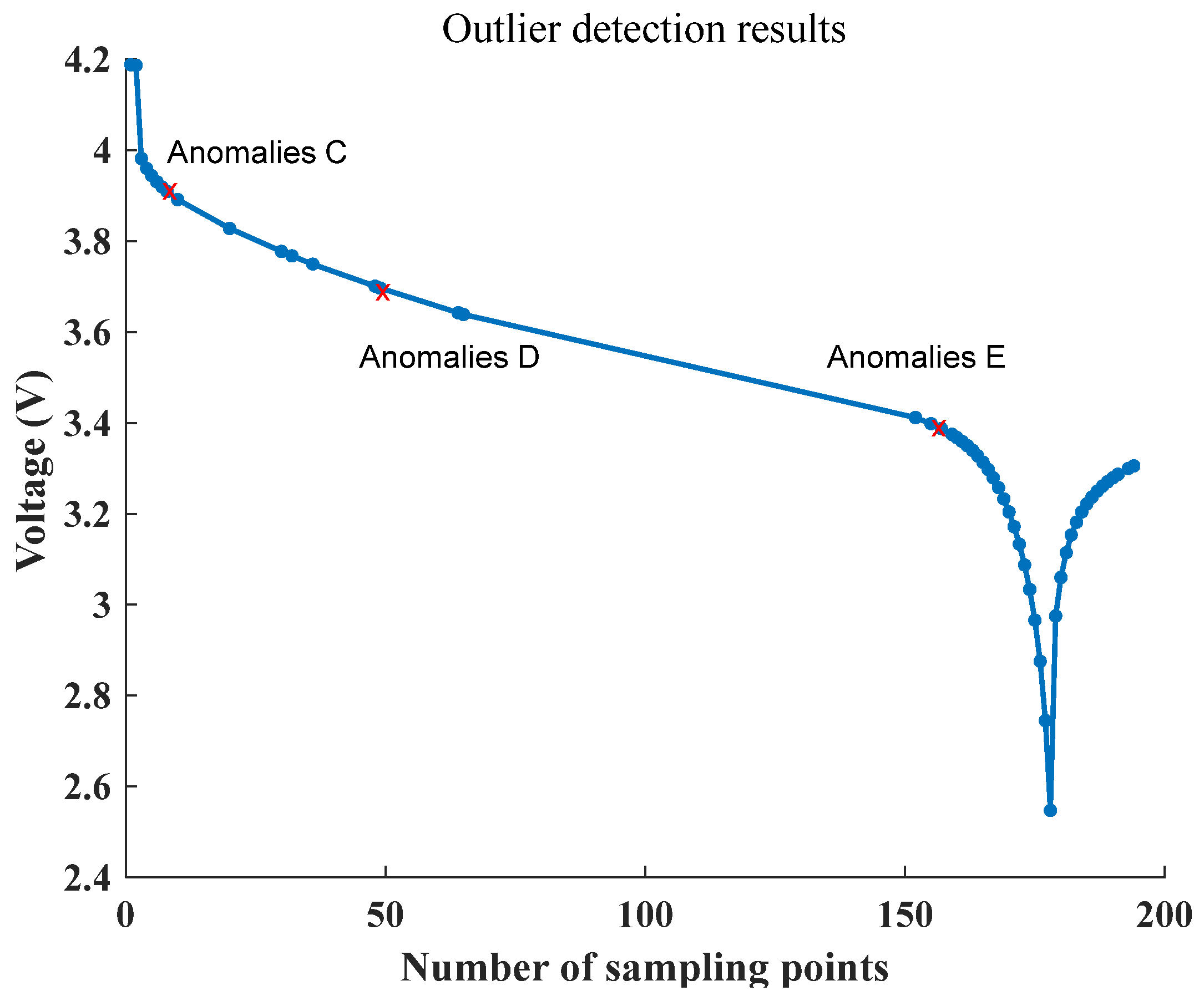
is lower than that of the surrounding samples, making it more likely to be an abnormal sample point. The feature sequences that exceed the length of L are detected as outliers, and redundant feature points are removed. The results of outlier detection on the original feature sequence are illustrated in
Figure 15. The original feature sequence has a length of 53, and by removing the top three feature points with the largest local anomaly factor, a feature sequence of length 50 is obtained.
The results in
Figure 15 demonstrate that the curve maintains its original shape after LOF anomaly detection and removal. This process reduces the length of the feature sequence and achieves length normalization while still retaining the maximum feature information. Therefore, the proposed method effectively detects and removes outliers from the original feature sequence without significantly affecting the overall shape of the curve.
5.3.3. Determination of the Optimal Length L
To determine the final feature length L, the Dynamic Time Warping (DTW) algorithm is used to evaluate the temporal similarity between the compressed curve and the original curve. The DTW algorithm employs a dynamic planning strategy that performs a dynamic time-domain regularization process on two, time series to find the minimum possible distance (i.e., maximum possible similarity) between them. The degree of deformation in the time domain between two, time series that are otherwise similar is not only time-varying but also nonlinearly varying.
Figure 16a illustrates this by showing that the compressed curve and the true curve exhibit different degrees of deformation in the time domain while still having high time similarity. To accurately determine the similarity between the two curves, it is necessary to first perform relative deformation and correction of the local time-domain waveforms between them, which involves implementing dynamic regularization, and then calculating the Euclidean distance, as shown in
Figure 16b.
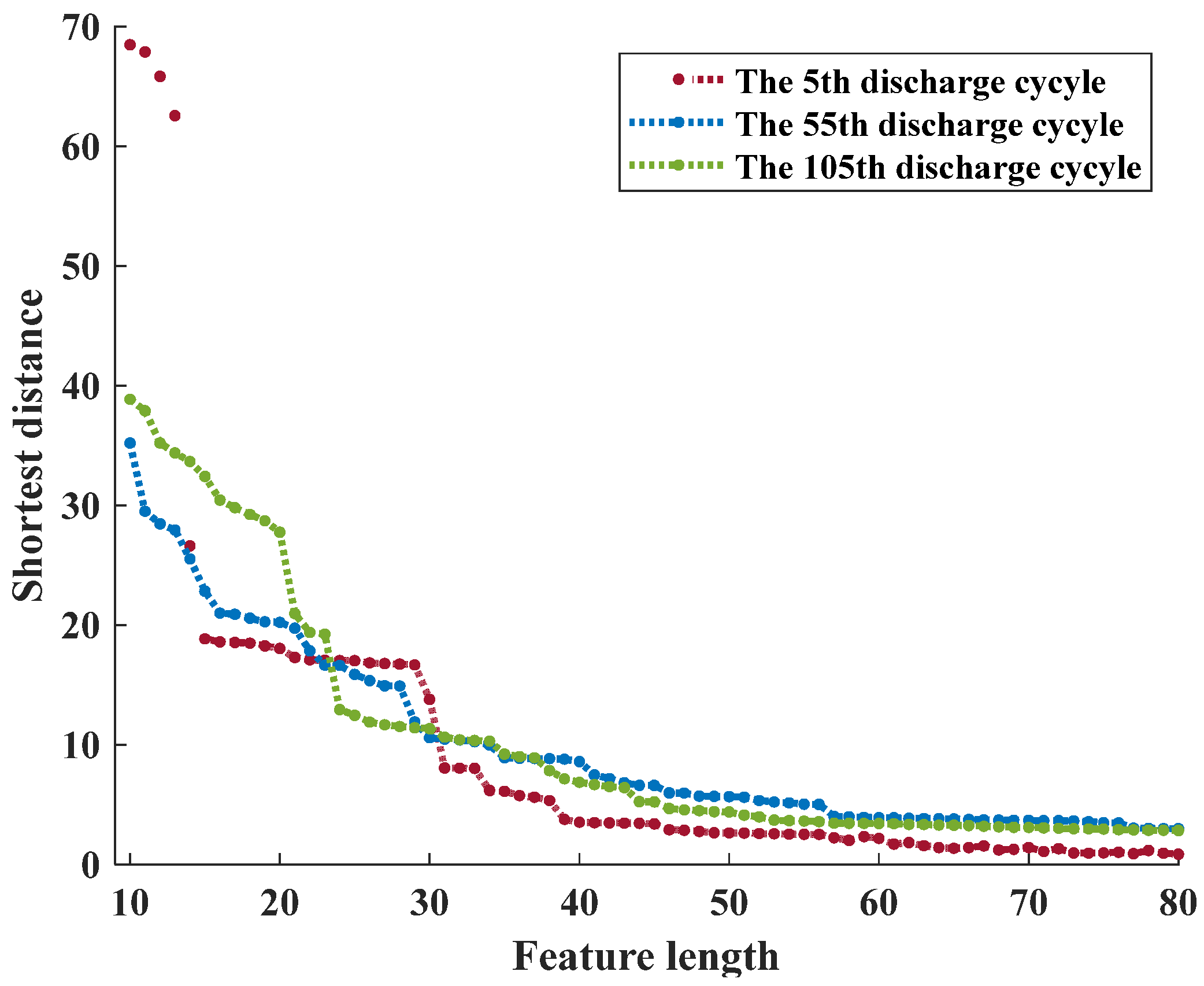
After the dynamic time-domain regularization and estimation of the shortest distance between the two sequences, the time-domain waveforms in the local ranges of the compressed discharge voltage curves are relatively stretched before they correspond. The trend of the shortest distance between the discharge voltage curves in the 5th, 55th, and 105th cycles with different feature sequence lengths and the original curve after processing by the method described earlier is illustrated in
Figure 17. The optimal feature length L is determined by analyzing the variation of the minimum value.
The amount of feature information in a dataset is directly proportional to its dimensionality. Higher dimensionality leads to more feature information, while lower dimensionality results in reduced feature information.
Figure 17 shows that the minimum distance value between the compressed curve and the original curve gradually decreases as the feature point length L decreases. The minimum distance between the curves reaches a plateau when the feature point length L is approximately 40, and it remains constant thereafter. Therefore, for the discharge voltage curves across multiple cycles, the feature sequence length L is fixed at 40. Similarly, the optimal feature sequence length is determined using the improved altitude method for the voltage, current, and power curves in the charging experiment as well as the current and power curves in the discharge experiment.
The proposed method effectively extracts the most essential feature information from the dataset, determines the optimal length of the characteristic sequence, and ensures that the feature sequences have the same length for easy input into the prediction model. This approach mitigates the impact of dimensionality and leads to accurate SoH and RUL prediction results.
In summary, the proposed method provides an effective means of extracting critical information from the dataset and facilitating accurate predictions of SoH and RUL.
5.4. SoH Prediction Based on the CatBoost Model
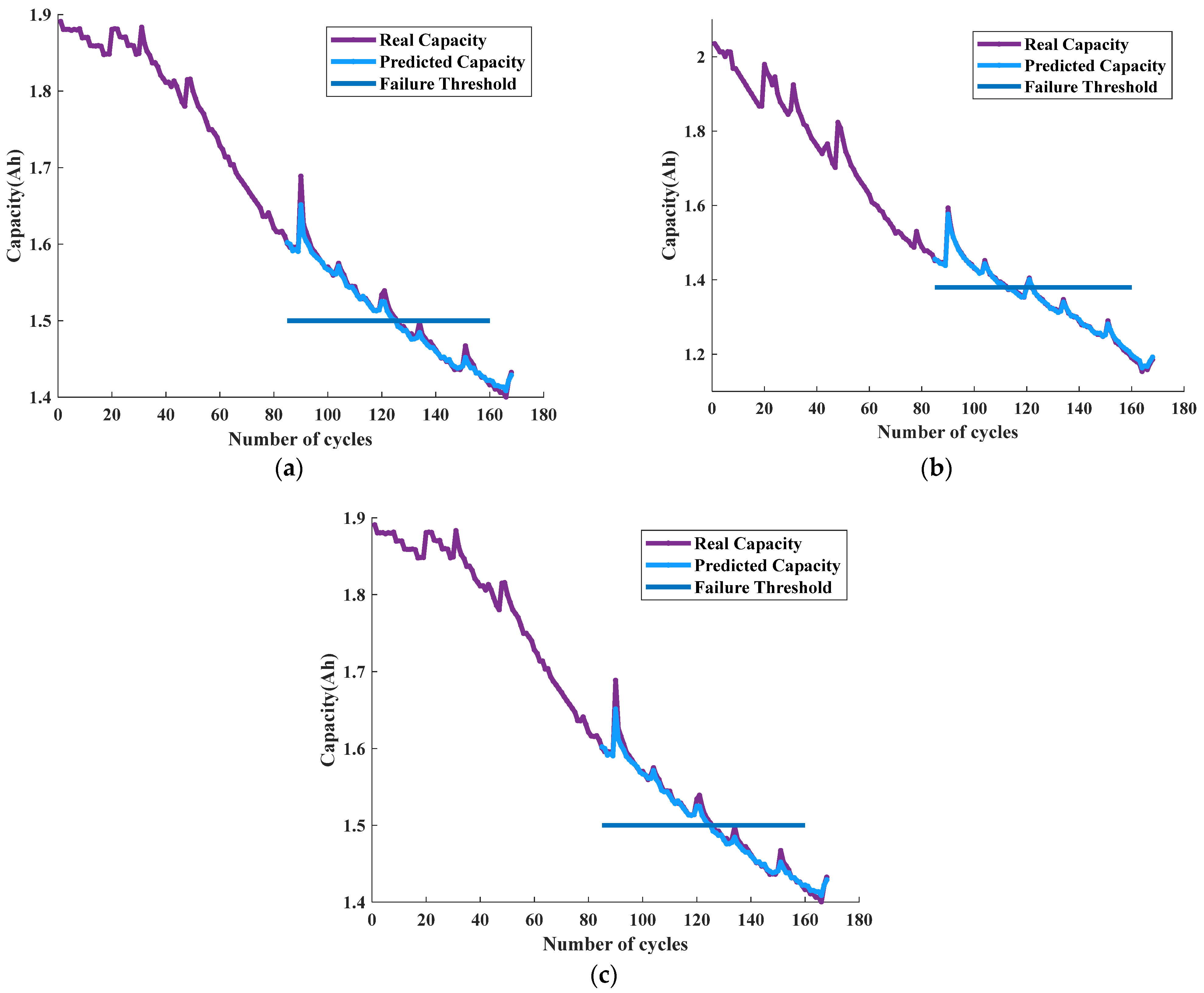
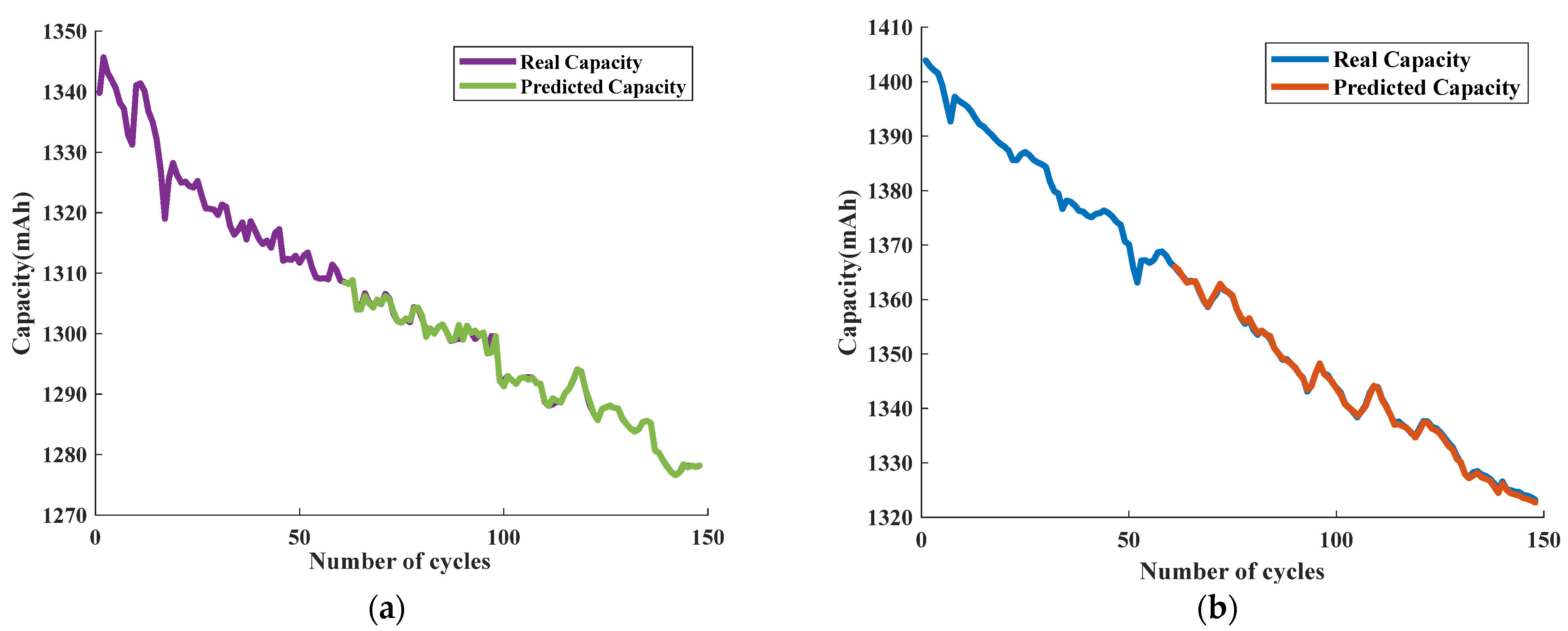
Following the curve compression and feature length normalization, the resulting features were used as input to the CatBoost model for predicting the State of Health (SoH) of the batteries. For the 168 cycles of batteries B0005, B0006, and B0007 obtained after feature processing, the first 84 cycles were used for training, while the remaining 85th to 168th cycles were used for testing. The prediction model established in the previous section was employed to predict the SoH and Remaining Useful Life (RUL) of the three sets of batteries. The test set prediction results for both SoH and RUL are illustrated in
Figure 18, indicating the effectiveness of the model for accurately predicting the SoH and RUL of each battery set.
The findings illustrated in
Figure 18 indicate that the prediction curves obtained from the model closely match the test set results for dataset A. The significant overlap between the predicted curves and the true capacity curves is evidence of the model’s ability to accurately forecast both the State of Health (SoH) estimation and Remaining Useful Life (RUL) prediction for dataset A. This suggests that the model is highly effective in accurately predicting battery capacity and can be employed to reliably forecast the SoH and RUL of batteries.
To assess the accuracy of the prediction models for each battery, several evaluation metrics are used, including Mean Square Error (
MSE), Mean Absolute Error (
MAE), Root Mean Square Error (
RMSE), and goodness-of-fit (
).
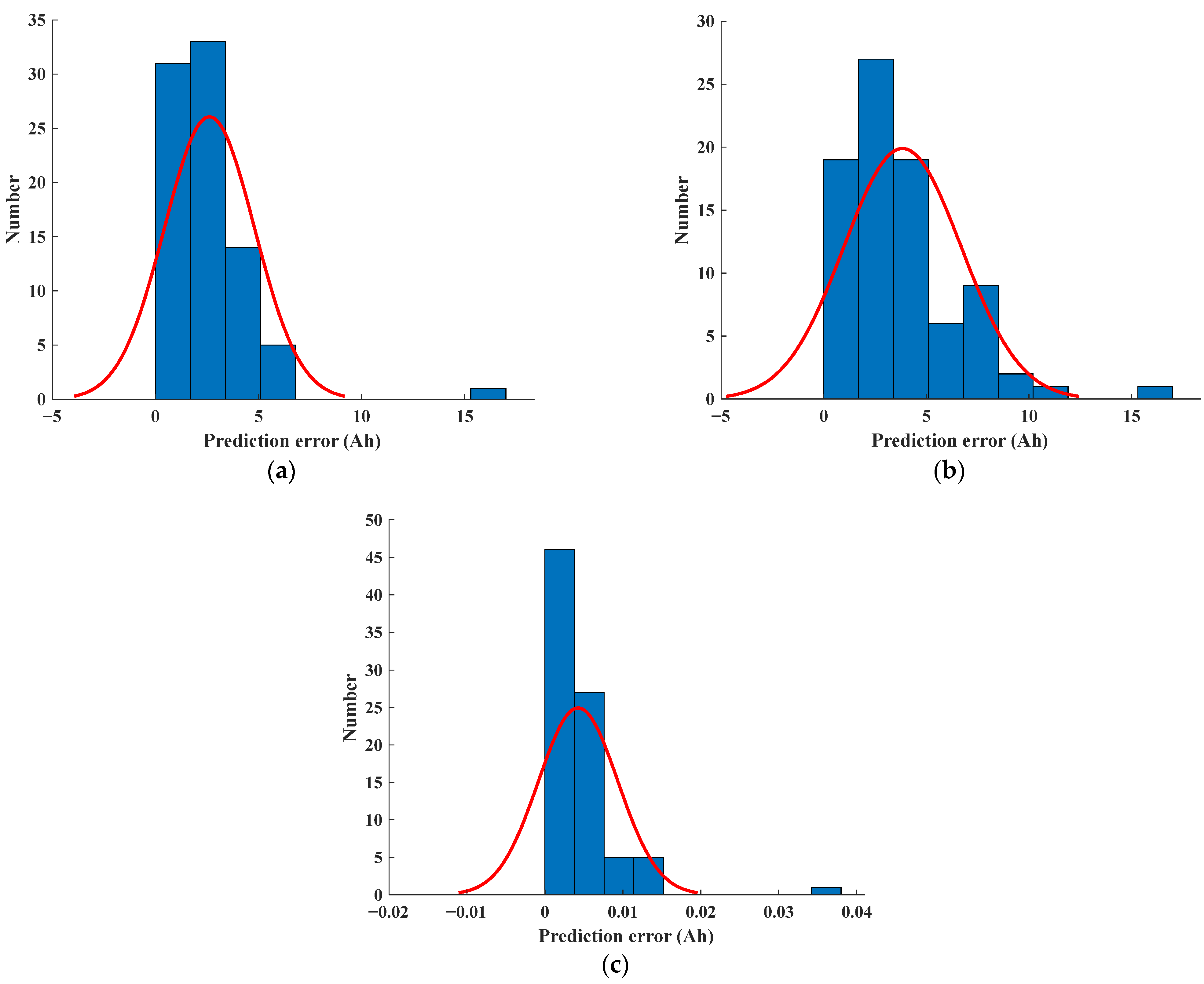
Table 2 provides detailed information regarding the prediction evaluation metrics, such as error distribution, while
Figure 19 illustrates the SoH prediction error distribution. The evaluation metrics are calculated based on the following equations:
where
denotes the true value,
denotes the predicted value,
,
denotes the sample size,
denotes a measure of the overall fit of the regression equation, which has values between [0 and 1], and
denotes the mean value of the actual observed values.
The abbreviation AE in
Table 3 represents the absolute error, which is the absolute difference between the actual RUL and the predicted RUL of each battery.
Figure 19 depicts the error distribution of the predicted Remaining Useful Life (RUL) for batteries five, six, and seven. The horizontal axis displays the difference between the predicted and actual RUL values, while the vertical axis indicates the frequency of occurrence for each error interval. Analysis of both
Figure 18 and
Table 2 reveals that the error intervals for all three batteries exhibit a primary concentration between 0 and 0.05. Additionally, battery number five demonstrates a low error rate, with the majority of the errors falling below 1 × 10
−3. These results indicate that the proposed feature engineering and CatBoost model utilized in this study have significant advantages in the realm of State of Health (SoH) estimation.
5.5. Comparison of the Effects of Different Models
In order to confirm the efficacy of the CatBoost model employed in this study, we conducted a comparative analysis between our chosen model and two other models, namely the Random Forest and XGBoost models. For this analysis, we inputted the capacity features obtained in the previous section and compared the performance of each model in predicting the SoH and RUL of the batteries. The results of this analysis are presented in
Table 3. This comparison enabled us to validate the superiority of the CatBoost model in accurately predicting the SoH and RUL of the batteries as compared to the other two models.
Table 3 shows that CatBoost, XGBoost, and Random Forest algorithms all exhibit good regression prediction ability, with their goodness-of-fit and RMSE being relatively close, indicating the good adaptability of the feature engineering approach used in this study. However, the average MSE value of CatBoost for the three batteries (5.0345 × 10
−5) is significantly lower than that of Random Forest and XGBoot. Additionally, the prediction goodness-of-fit of the CatBoost model is better; the average value of
is 0.9922, improved by 0.0228 and 0.0152, respectively. Therefore, the CatBoost method can effectively enhance the accuracy of SoH estimation and operational efficiency and exhibit good performance in SoH estimation.
5.6. Model Generalizability Validation
To verify the generalization ability of the feature engineering and prediction model proposed in this study, feature extraction is conducted again for dataset B, and SoH prediction is performed using the CatBoost model. Dataset B comprises two batteries, each with 148 cycles. The first 60 cycles are used as the training set, and the remaining 88 cycles are used as the test set. The model established in the previous section is used for training and prediction.
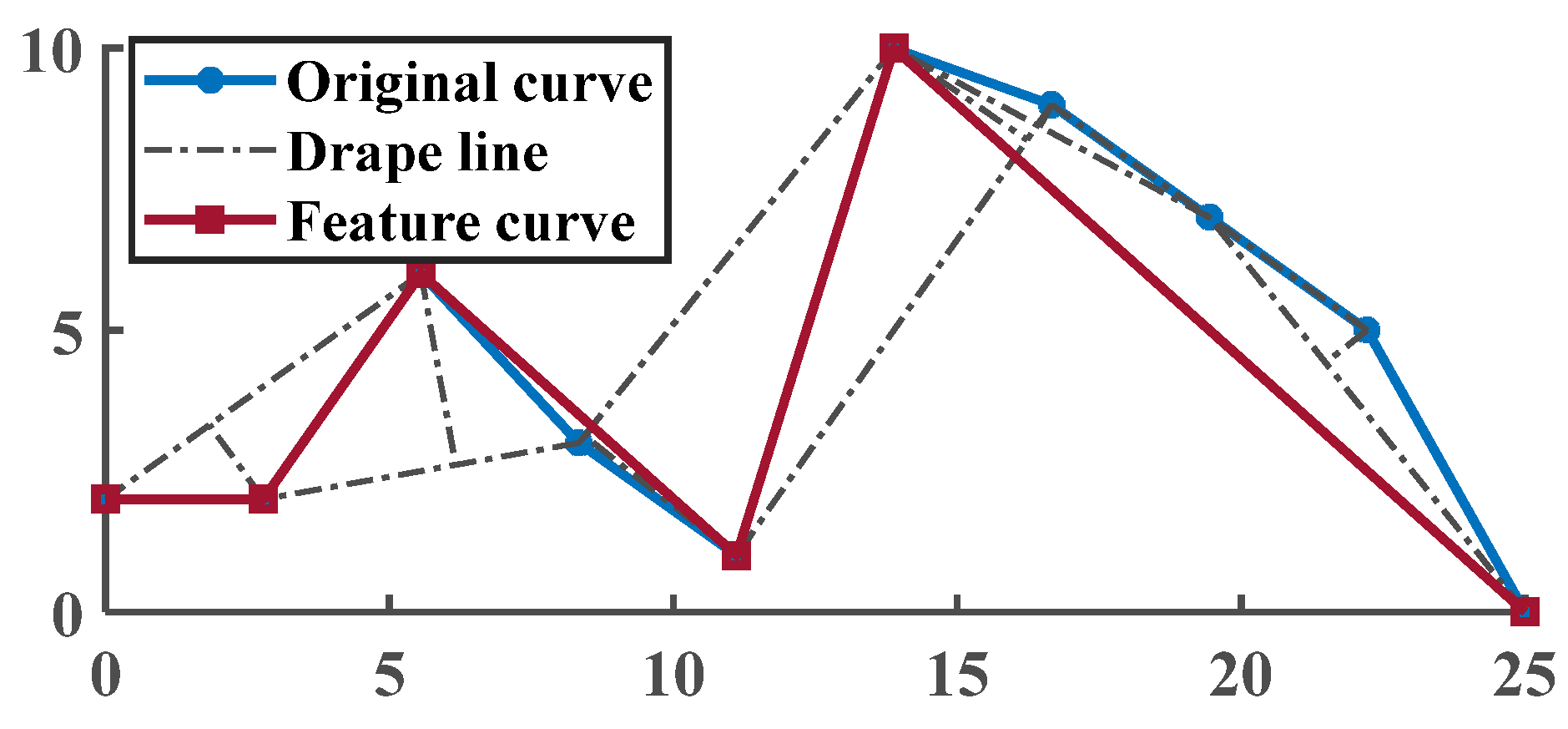
Figure 20 presents the discharge voltage curve of battery number two in dataset B.
Similar to dataset A, the discharge voltage curves in dataset B have non-uniform sampling lengths under different cycles and cannot be directly used as feature input. Therefore, following the method described in the previous section, suitable gentle curve segments are selected, and the mean curvature value is calculated to serve as a judgment threshold. This threshold is then used to compress the discharge voltage curves for each cycle using the drape limit algorithm.
Figure 21 displays the compression results of the discharge voltage curves in the 1st cycle and the 61st cycle for battery number two among the cycle data.
After length normalization and similarity comparison, a feature sequence with a length of 50 is obtained. The model established in the previous section is then used for training and predicting. The prediction results are shown in
Figure 22.
Based on
Figure 22, it is evident that the CatBoost model outperforms the other models in the feature engineering approach proposed in this study for the two batteries in dataset B. In battery number one, the model has an MSE value of 0.2011 and an MAE value of 0.3761, with a goodness-of-fit of 0.9986. For battery number two, the model has an MSE value of 0.1031 and an MAE value of 0.2655, with a goodness-of-fit of 0.9997. These results demonstrate that the model can accurately predict SoH for the same battery.
In summary, the curve compression-based approach and the CatBoost prediction model proposed in this study both demonstrate good prediction accuracy in different datasets, indicating that the model established in this study exhibits strong generalization ability.
5.7. Model Robustness Verification
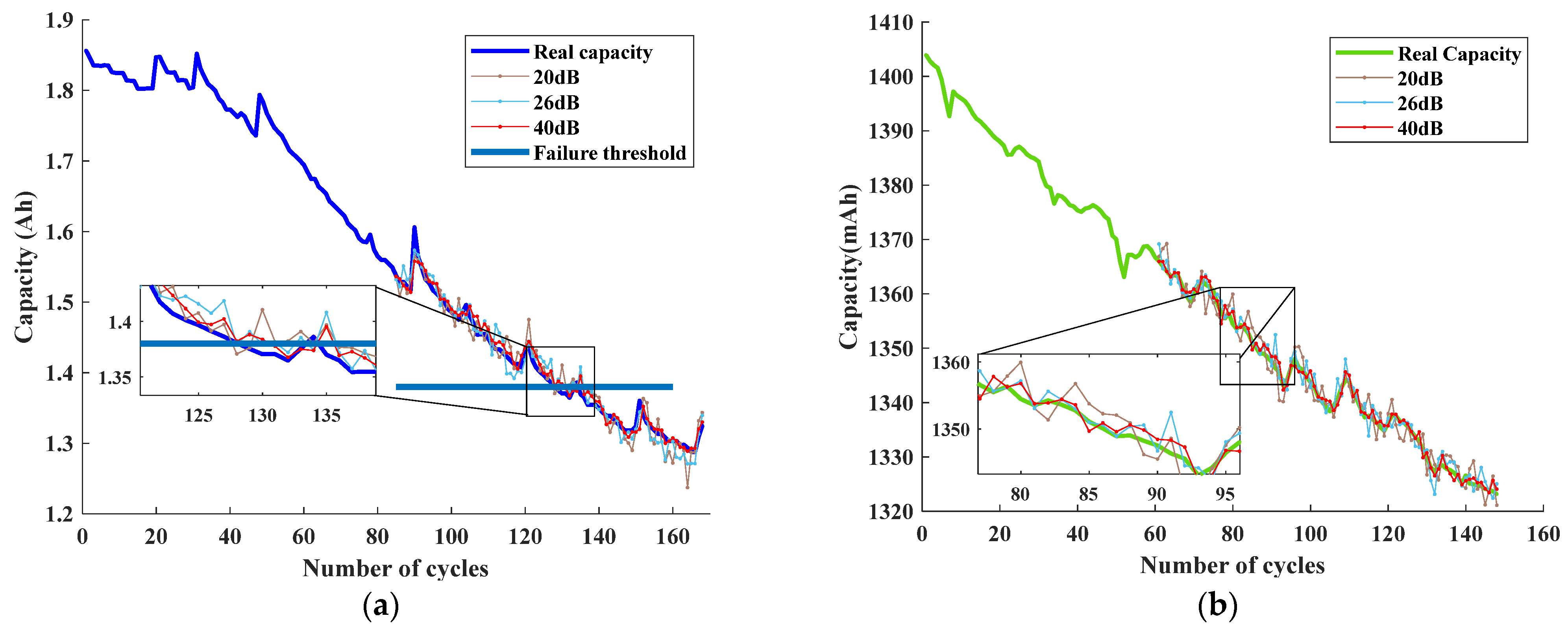
In order to evaluate the performance of the prediction model in real-world sampling environments, robustness experiments were conducted to test its resilience. Gaussian White Noise (GWN) was added to the test set as an interference signal to observe the behavior of the model in the presence of noise with different Signal-to-Noise Ratios (SNRs). A GWN with varying noise ratios, ranging from 1% to 10%, was selected and converted to SNRs before being added to the test set to assess the model’s ability to resist interference. The prediction of Battery B0005 in dataset A and Battery number two in dataset B were taken as examples, and
Figure 23 presents the prediction results obtained under different SNRs. This enabled us to evaluate the robustness and effectiveness of the prediction model under varying conditions, thereby confirming its ability to perform accurately even in the presence of noise and interference.
The performance of the curve compression-based approach and CatBoost model proposed in this study under noisy conditions is demonstrated in
Figure 23. After the addition of interference signals, the predicted curves exhibit some fluctuations and deviations from the true path. However, for cell B0005 in dataset A, as shown in the local enlarged figures, RUL prediction errors are within two cycles, and the goodness-of-fit (
) values are all above 0.95. When SNR is relatively high, especially at SNR = 40 dB, the model’s prediction is hardly affected, with an
value of 0.9817. For cell two in dataset B, it still works well in the noisy environment with a good prediction curve fit. These results indicate that the prediction model proposed in this study has strong adaptability, anti-interference capabilities, and robustness.
6. Conclusions
To address the issue of low accuracy in SoH and RUL prediction arising from the difficulty in establishing feature engineering for lithium-ion batteries, this study proposes a SoH and RUL prediction model based on curve compression and CatBoost. Relevant experiments were conducted, leading to the following conclusions:
(1) The improved perpendicular distance threshold algorithm proposed in this study can capture battery aging information to the maximum extent. The improved threshold selection method does not require manual threshold setting, as the algorithm automatically determines the gentle curve segment based on the derivative and calculates the mean curvature value based on the deviation of this curve segment from the straight line, thereby exhibiting universality across different curves. Additionally, the length normalization method based on cubic spline interpolation and outlier detection can effectively standardize data length while retaining feature information.
(2) In the field of battery SoH estimation, the feature engineering and prediction model proposed in this study have demonstrated accurate prediction capabilities. In dataset A, the battery model exhibited an value higher than 0.98. In dataset B, the feature engineering and model established in this study also produced better prediction results, demonstrating the good generalization of the proposed method.
(3) The CatBoost model utilized in this study revealed significantly better prediction performance than other models. The is improved by 0.0228 and 0.0152 compared to the Random Forest algorithm and XGBoost, respectively.
(4) The curve compression-based approach and the CatBoost model proposed in this study were shown to be almost unaffected by the presence of noise in terms of prediction accuracy, indicating that the model exhibits strong anti-interference capability and robustness.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}