


Autonomous Parking Space Detection for Electric Vehicles Based on Improved YOLOV5-OBB Algorithm

Abstract
:1. Introduction
- Improved RFB and CA modules are added to the original yolov5-OBB algorithm to enhance the generalization ability of the model in complex scenarios such as darkness, while replacing the Focus and SSP structures to reduce the number of parameters in the computation and accelerate the model inference rate.
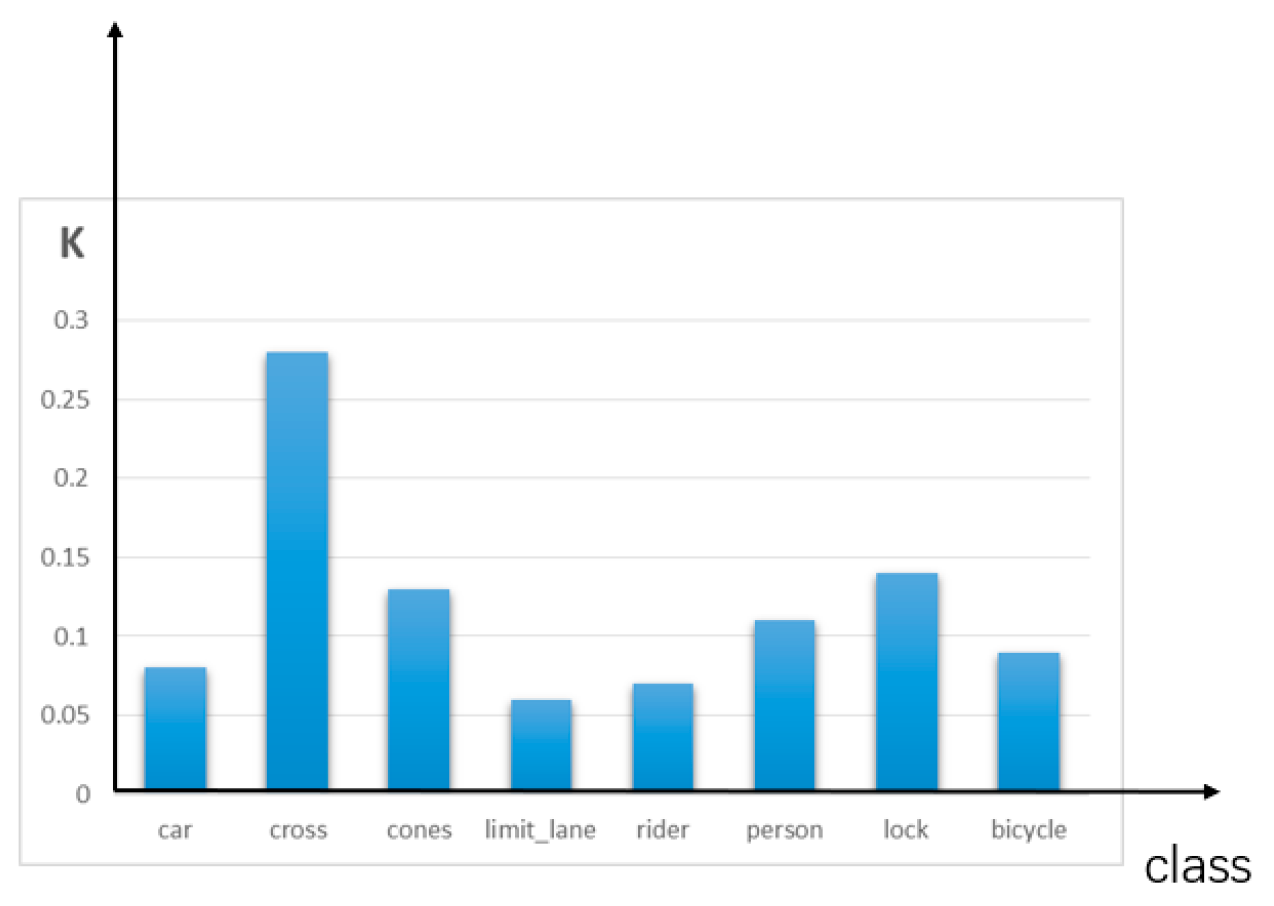
- Correlation modeling of the existing a priori knowledge of the simultaneous occurrence of parking spaces and storage corners and setting the penalty factor K to improve the confidence level of the detection of parking spaces and storage corners.
- A standard evaluation method for target detection was used through comparative experiments and ablation experiments of the original algorithm on a homemade parking space detection dataset as well as on a publicly available dataset, and the results show that our algorithm is competitive in terms of real-time and detection accuracy in complex scenarios such as nighttime.
2. YOLOv5-OBB Detection Algorithm
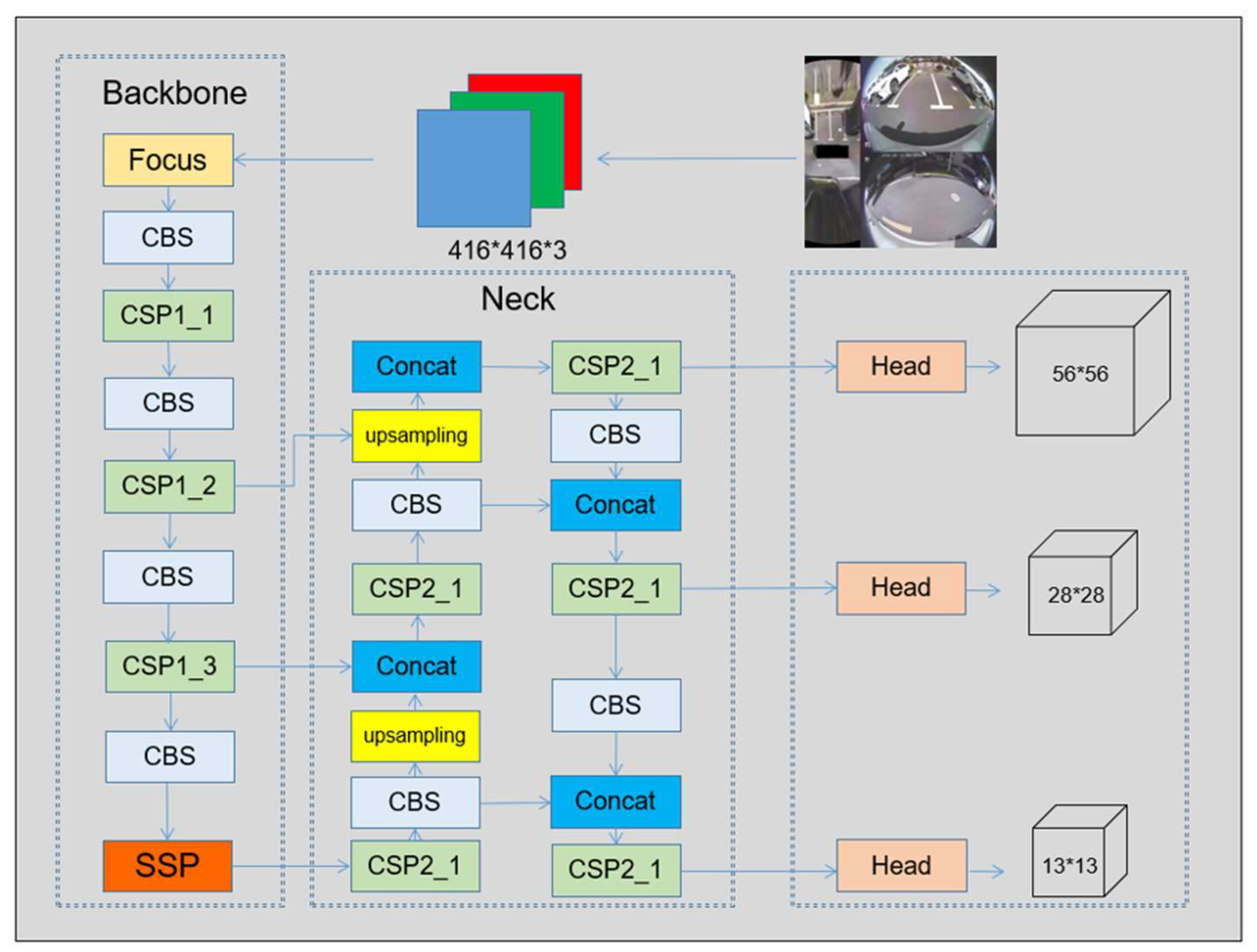
2.1. YOLOv5s Model
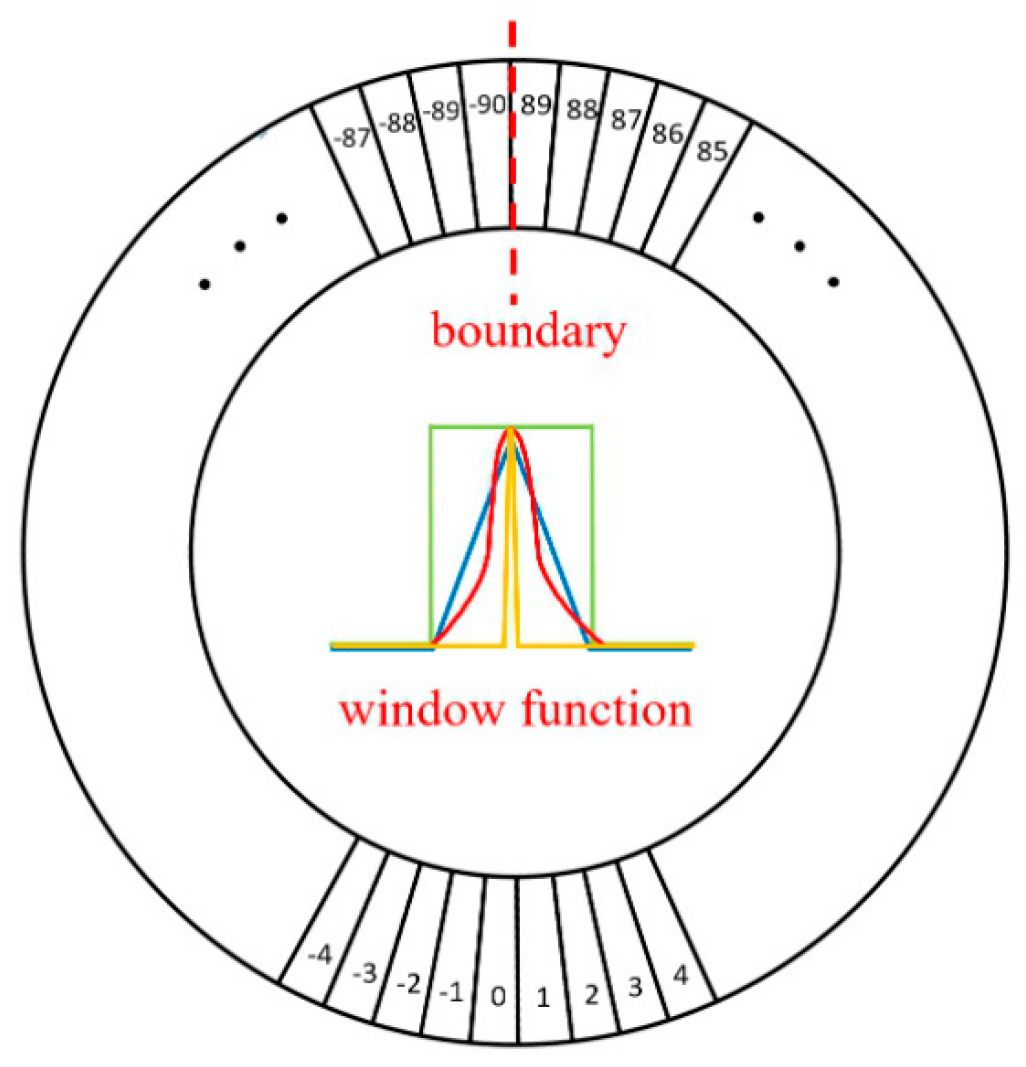
2.2. Circular Smooth Labels for Angle Classification
3. Improvement of YOLOv5-OBB
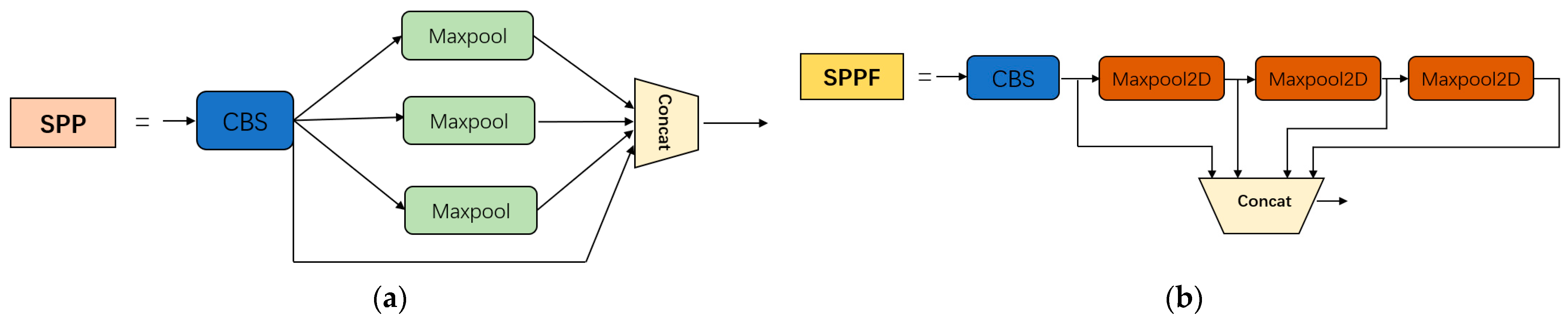
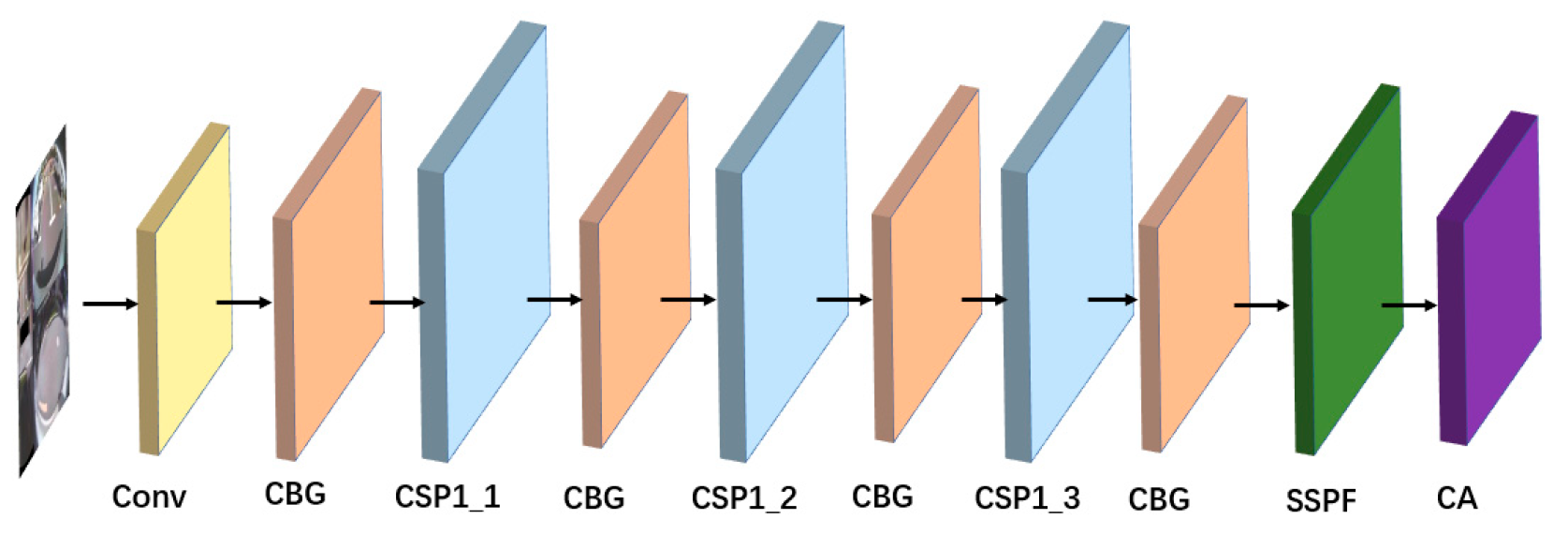
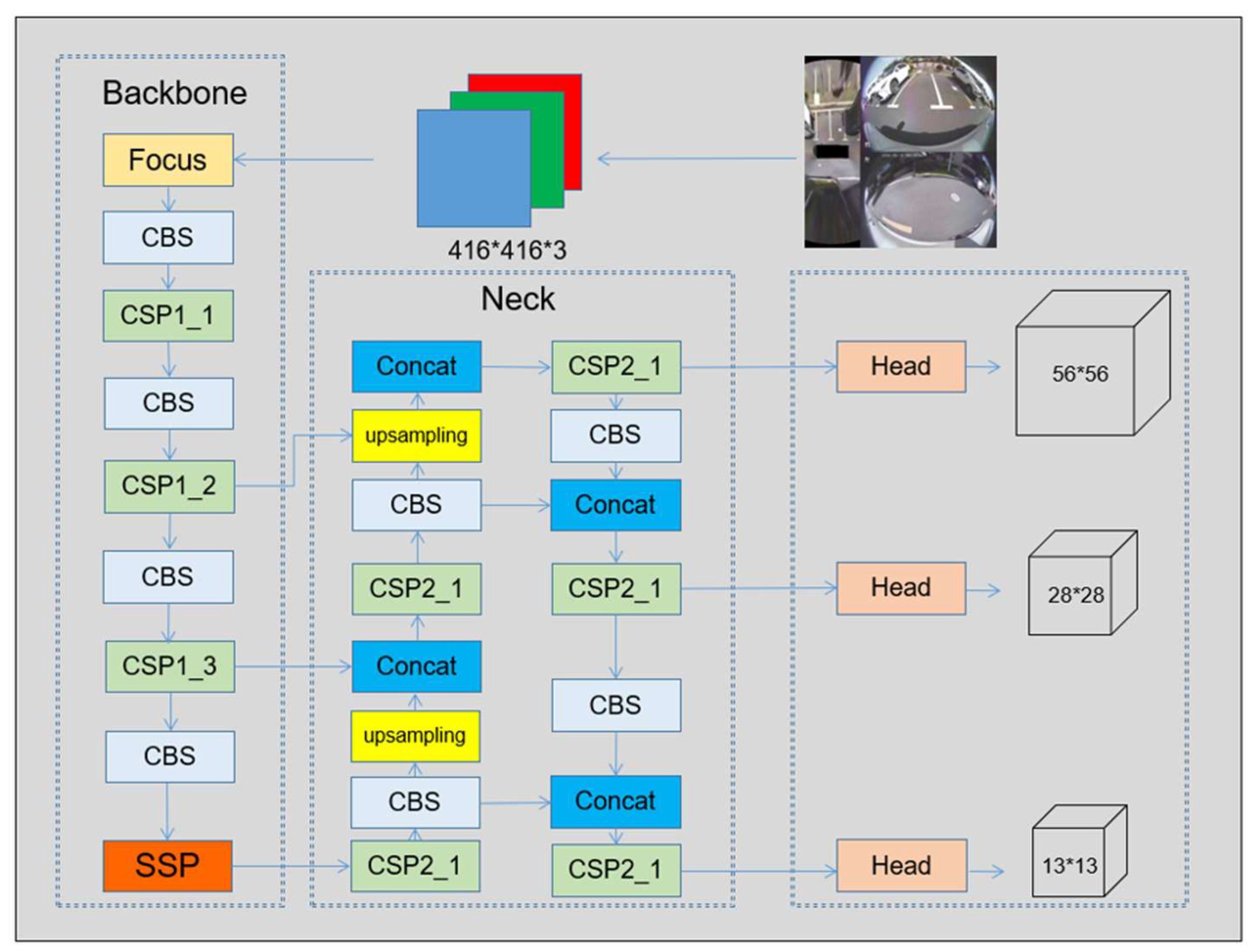
3.1. Optimizing the Backbone Extraction Module
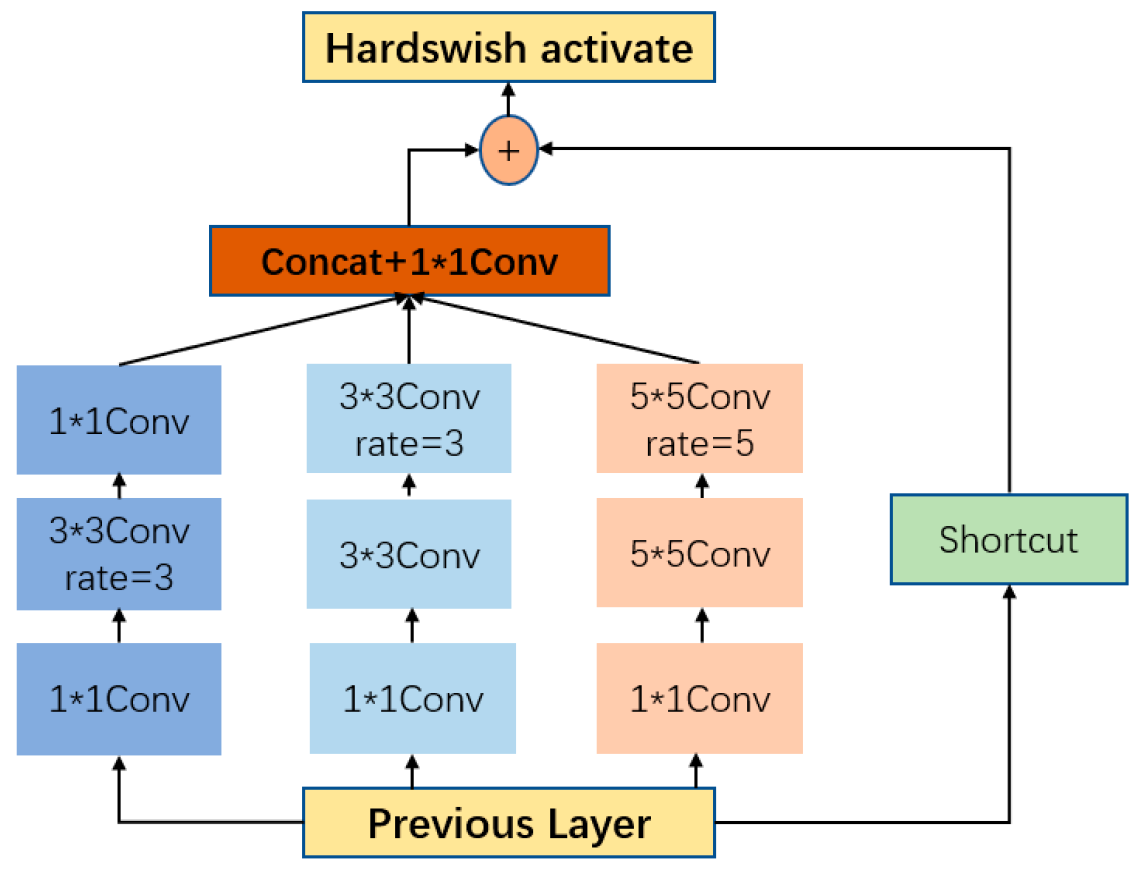
3.2. Introduction of Improved RFB Modules
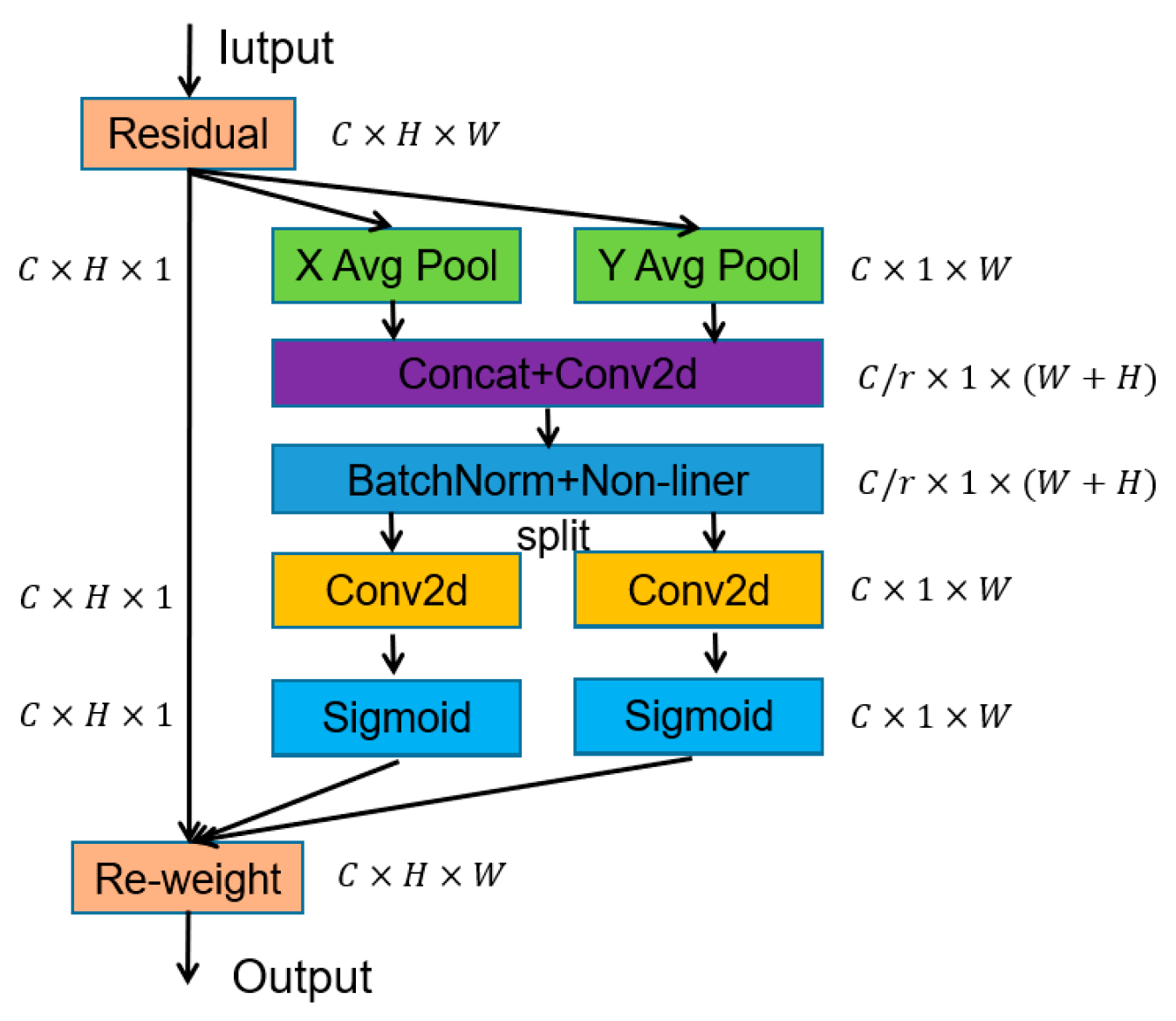
3.3. Increased CA Mechanisms
3.4. Location-Rule-Based NMS Improvement
4. Experimental Results and Analyses
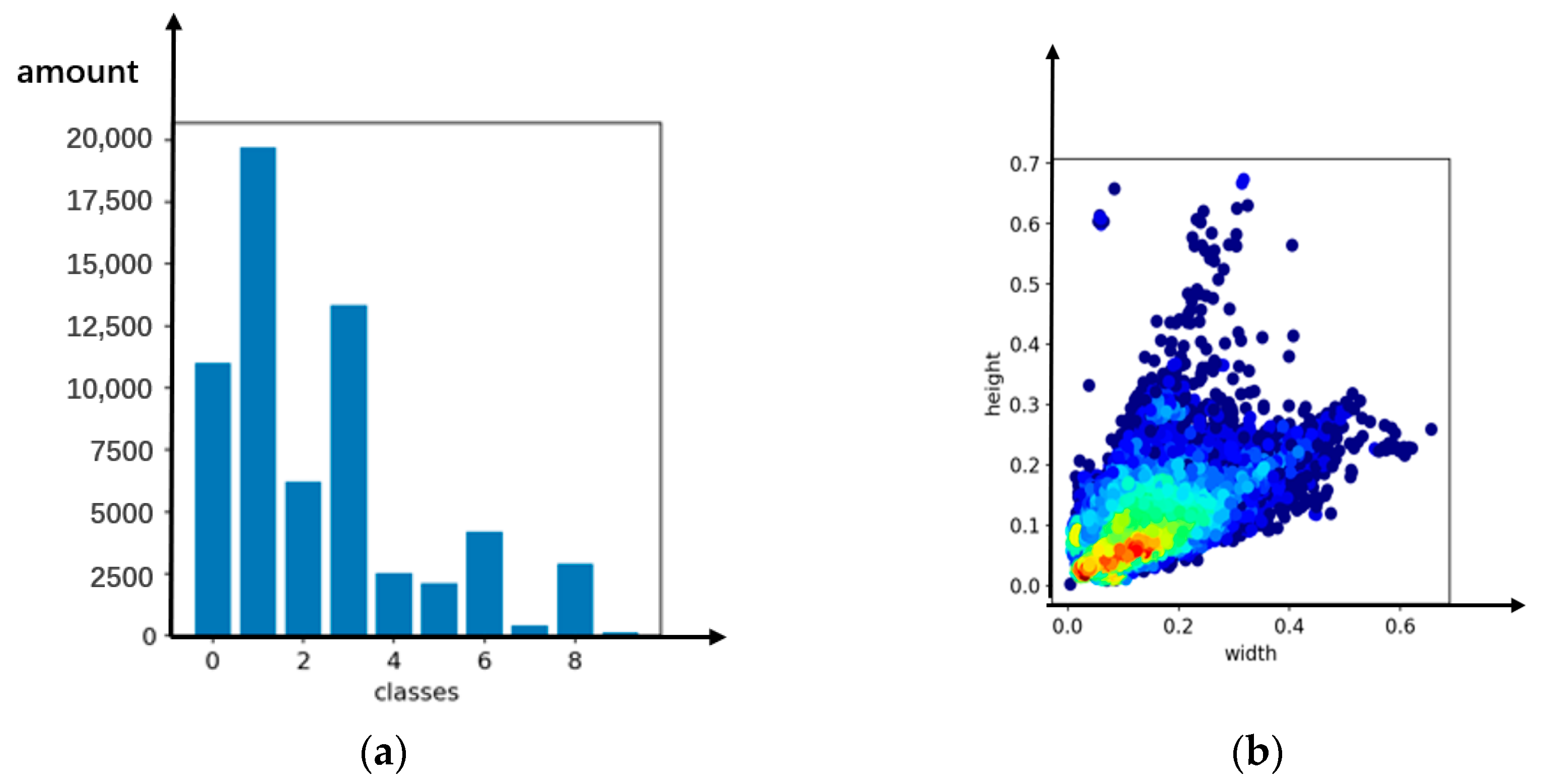
4.1. Datasets
4.2. Experimental Environment
4.3. Evaluation Criteria
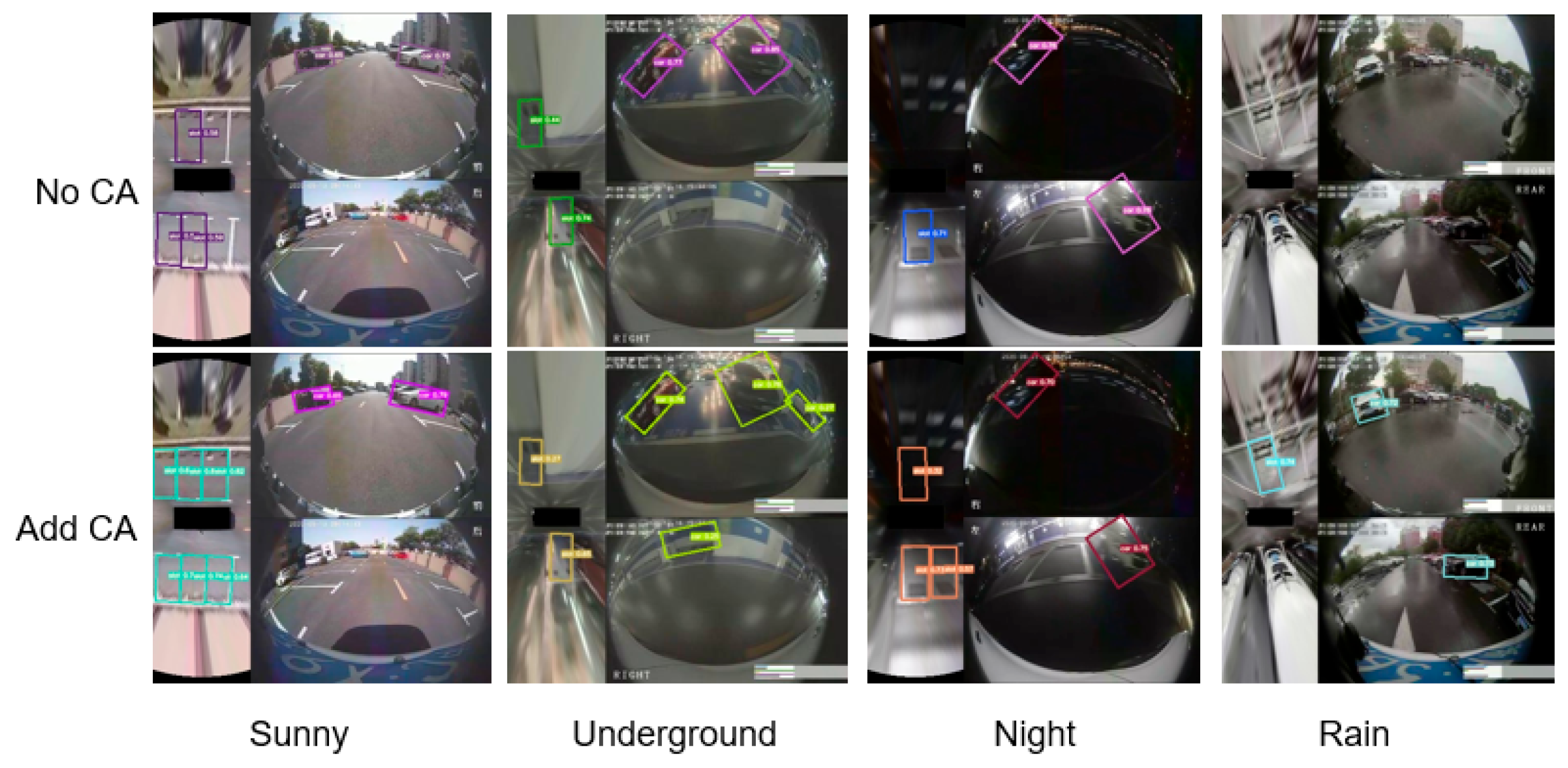
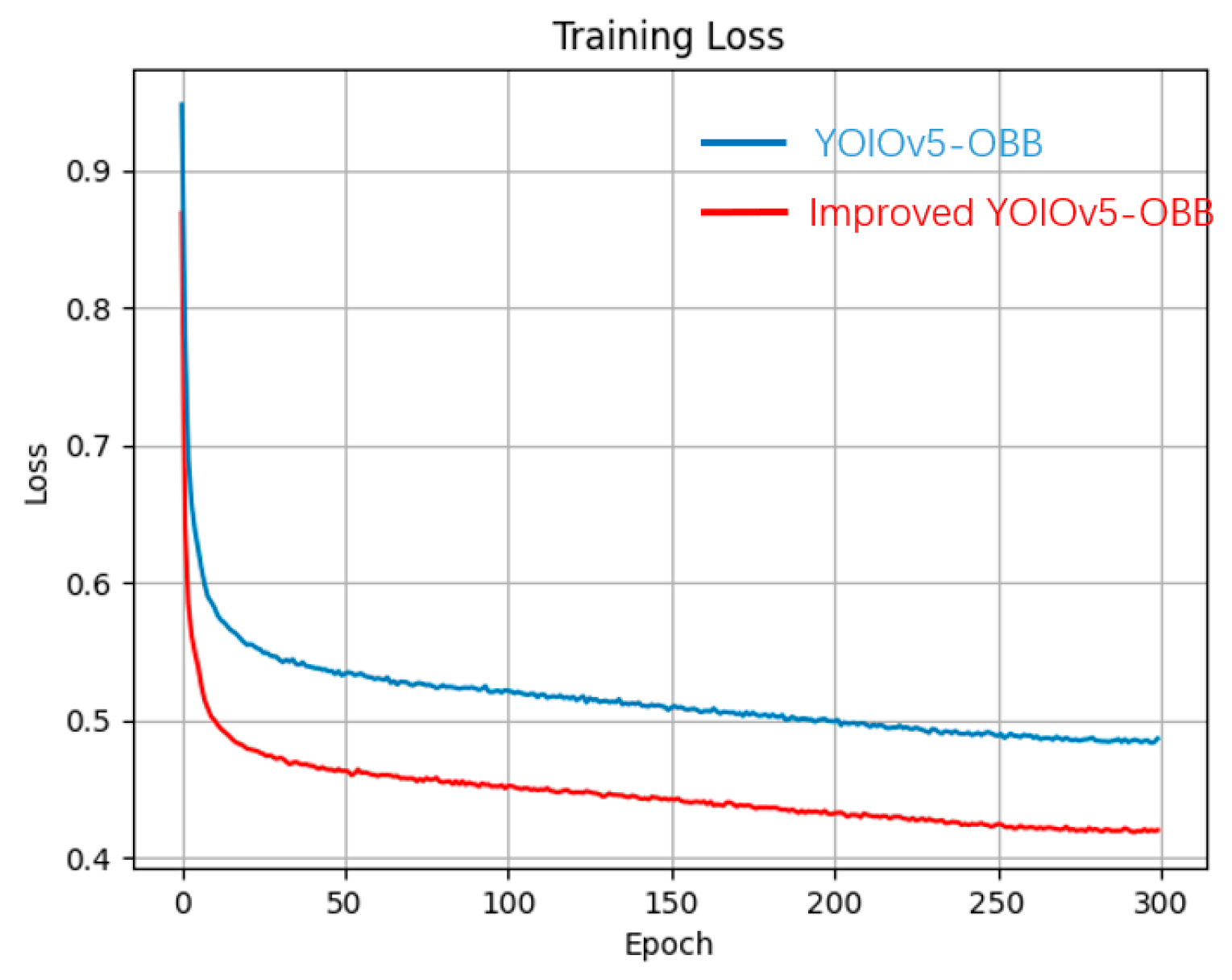
4.4. Analysis of the Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, H. Research on Vehicle Detection Based on Improved YOLO and Implementation of Vehicle Position Detection System; Jilin University: Changchun, China, 2022. [Google Scholar]
- Wong, G.S.; Goh, K.O.M.; Tee, C.; Sabri, A.Q.M. Review of Vision-Based Deep Learning Parking Slot Detection on Surround View Images. Sensors 2023, 23, 6869. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Liu, Y.; Shao, S.; Zhao, J.; Tang, J. Review of Research on Vision-Based Parking Space Detection Method. Int. J. Web Serv. Res. 2022, 19, 1–25. [Google Scholar] [CrossRef]
- Suhr, J.K.; Jung, H.G. Fully-automatic recognition of various parking slot markings in Around View Monitor (AVM) image sequences. In Proceedings of the 2012 15th International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, H.; Yang, M.; Wang, X.; Ye, L.; Guo, C. Automatic Parking Based on a Bird’s Eye View Vision System. Adv. Mech. Eng. 2014, 6, 847406. [Google Scholar] [CrossRef]
- Li, L.; Li, C.; Zhang, Q.; Guo, T.; Miao, Z. Automatic parking slot detection based on around view monitor (AVM) systems. In Proceedings of the 2017 9th International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 11–13 October 2017; pp. 1–6. [Google Scholar]
- Suhr, J.K.; Jung, H.G. A Universal Vacant Parking Slot Recognition System Using Sensors Mounted on Off-the-Shelf Vehicles. Sensors 2018, 18, 1213. [Google Scholar] [CrossRef] [PubMed]
- Hamada, K.; Hu, Z.; Fan, M.; Chen, H. Surround view based parking lot detection and tracking. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Republic of Korea, 28 June–1 July 2015; pp. 1106–1111. [Google Scholar]
- Bui, Q.H.; Suhr, J.K. CNN-Based Two-Stage Parking Slot Detection Using Region-Specific Multi-Scale Feature Extraction. IEEE Access 2023, 11, 58491–58505. [Google Scholar] [CrossRef]
- Li, Q.; Lin, C.; Zhao, Y. Geometric features-based parking slot detection. Sensors 2018, 18, 2821. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Huang, J.; Li, X.; Xiong, L. Vision-based parking-slot detection: A DCNN-based approach and a large-scale benchmark dataset. IEEE Trans. Image Process. 2018, 27, 5350–5364. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Yin, D.; Lu, Y. PASSIM: Parking Slot Recognition Using Attentional Semantic Segmentation and Instance Matching. In Proceedings of the IEEE 5th International Conference on Big Data and Artificial Intelligence (BDAI), Fuzhou, China, 8–10 July 2022; pp. 169–175. [Google Scholar]
- Cao, L.; Yue, P.; Zhang, Z.; Liu, J.; Huang, M. Automatic parking system based on panoramic image and human-computer interaction. Automot. Technol. 2023, 6, 24–29. [Google Scholar]
- Li, W.; Cao, L.; Yan, L.; Li, C.; Feng, X.; Zhao, P. Vacant parking slot detection in the around view image based on deep learning. Sensors 2020, 20, 2138. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Zhang, L.; Li, X.; Liu, X.; Shen, Y.; Xiong, L. Vision-based parking-slot detection: A benchmark and a learning-based approach. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 649–654. [Google Scholar]
- Lai, C.; Yang, Q.; Guo, Y.; Bai, F.; Sun, H. Semantic Segmentation of Panoramic Images for Real-Time Parking Slot Detection. Remote Sens. 2022, 14, 3874. [Google Scholar] [CrossRef]
- Do, H.; Choi, J.Y. Context-based parking slot detection with a realistic dataset. IEEE Access 2020, 8, 171551–171559. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 677–694. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Pebrianto, W.; Mudjirahardjo, P.; Pramono, S.H.; Setyawan, R.A. YOLOv3 with Spatial Pyramid Pooling for Object Detection with Unmanned Aerial Vehicles. arXiv 2023, arXiv:2305.12344. [Google Scholar]
- Seferbekov, S.; Iglovikov, V.; Buslaev, A.; Shvets, A. Feature Pyramid Network for Multi-class Land Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 272–275. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Xie, C.; Wu, J.; Xu, H. Improved YOLOv5 algorithm for small target detection of UAV images. Comput. Eng. Appl. 2023, 59, 198–206. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS--improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Wu, Y.; Yang, T.; Zhao, J.; Guan, L.; Jiang, W. VH-HFCN Based Parking Slot and Lane Markings Segmentation on Panoramic Surround View. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1767–1772. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sence | Train | Val | Total |
|---|---|---|---|
| Sunny | 5500 | 500 | 6000 |
| Night | 3500 | 500 | 4000 |
| Rain | 2500 | 500 | 3000 |
| Underground | 6500 | 500 | 7000 |
| Improved Name | A | B | C | D | mAP | FPS | Size/MB |
|---|---|---|---|---|---|---|---|
| No improvement | × | × | × | × | 62.32% | 49.26 | 34.1 |
| Improvement 1 | √ | × | × | × | 63.27% | 52.66 | 32.7 |
| Improvement 2 | √ | √ | × | × | 66.69% | 52.47 | 32.9 |
| Improvement 3 | √ | √ | √ | × | 69.65% | 52.13 | 33.1 |
| Improvement 4 | √ | √ | √ | √ | 70.72% | 52.13 | 33.1 |
| Model Name | mAP | FPS | Size/MB |
|---|---|---|---|
| VPSNet [33] | 64.99% | 41.2 | 134.1 |
| DeepPS | 68.69% | 38.6 | 232.9 |
| YOLOV5-OBB | 62.32% | 49.26 | 34.1 |
| Ours | 70.72% | 52.13 | 33.1 |
| Model Name | GT | TP | FP | Precision Rate | Recall Rate |
|---|---|---|---|---|---|
| DeepPS | 1593 | 1396 | 63 | 95.68% | 87.63% |
| VPSNet [33] | 1593 | 1507 | 54 | 96.54% | 94.60% |
| Ours | 1593 | 1510 | 51 | 97.21% | 95.61% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Wang, X.; Zhang, W.; Yao, G.; Li, D.; Zeng, L. Autonomous Parking Space Detection for Electric Vehicles Based on Improved YOLOV5-OBB Algorithm. World Electr. Veh. J. 2023, 14, 276. https://doi.org/10.3390/wevj14100276
Chen Z, Wang X, Zhang W, Yao G, Li D, Zeng L. Autonomous Parking Space Detection for Electric Vehicles Based on Improved YOLOV5-OBB Algorithm. World Electric Vehicle Journal. 2023; 14(10):276. https://doi.org/10.3390/wevj14100276
Chicago/Turabian StyleChen, Zhaoyan, Xiaolan Wang, Weiwei Zhang, Guodong Yao, Dongdong Li, and Li Zeng. 2023. "Autonomous Parking Space Detection for Electric Vehicles Based on Improved YOLOV5-OBB Algorithm" World Electric Vehicle Journal 14, no. 10: 276. https://doi.org/10.3390/wevj14100276
APA StyleChen, Z., Wang, X., Zhang, W., Yao, G., Li, D., & Zeng, L. (2023). Autonomous Parking Space Detection for Electric Vehicles Based on Improved YOLOV5-OBB Algorithm. World Electric Vehicle Journal, 14(10), 276. https://doi.org/10.3390/wevj14100276