
Identity-Preserved Human Posture Detection in Infrared Thermal Images: A Benchmark


Abstract
1. Introduction
- We formulate a novel task of identity-preserved human posture detection in thermal images, which underpins various applications where privacy matters and which may also draw attention to more informative object detection other than identification and localization.
- We present the IPHPDT dataset, which is the first benchmark dedicated to identity-preserved human posture detection in thermal images.
- We develop three baseline detectors based on three state-of-the-art detectors, i.e., YOLOF, YOLOX, and TOOD, to facilitate and encourage further research on IPHPDT.
2. Related Work
2.1. Traditional Methods of Human Detection in Infrared Thermal Images
2.2. Deep Learning Methods for Human Detection Based on Infrared Thermal Images
2.3. Human Pose Estimation
3. Benchmark for Detecting Posture of Human
3.1. IPHPDT Collection
3.2. Annotation
- category: person.
- bounding box: a bounding box with axis-alignment around the visible human in the image.
- human posture: one of standing, sitting, lying, and bending.
3.3. Image Processing
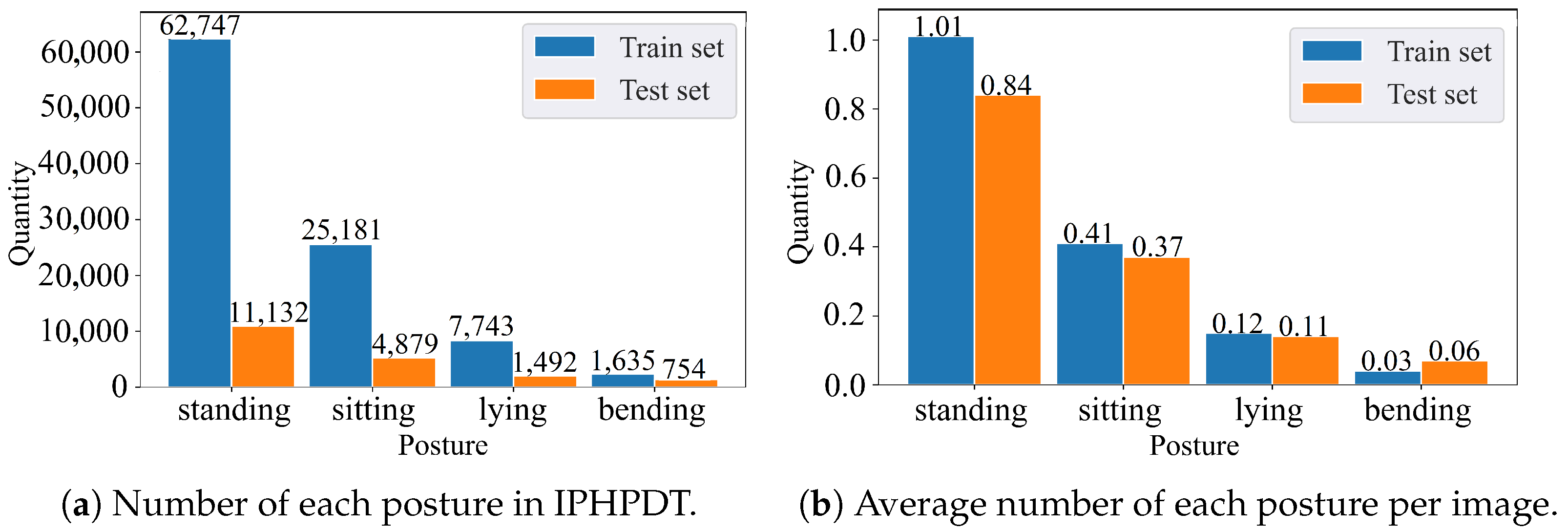
3.4. Dataset Statistics
4. Baseline Detectors for Detecting Human Posture in Thermal Images
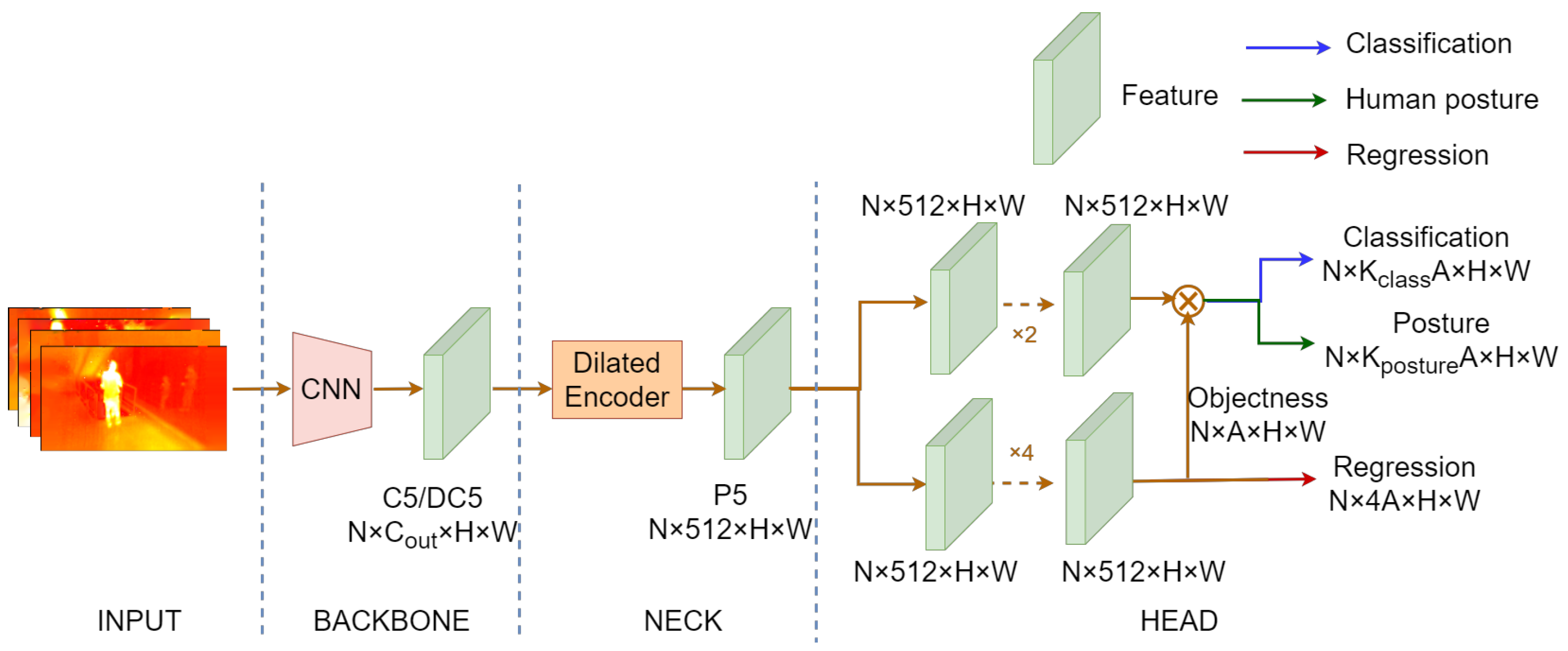
4.1. IPH-YOLOF
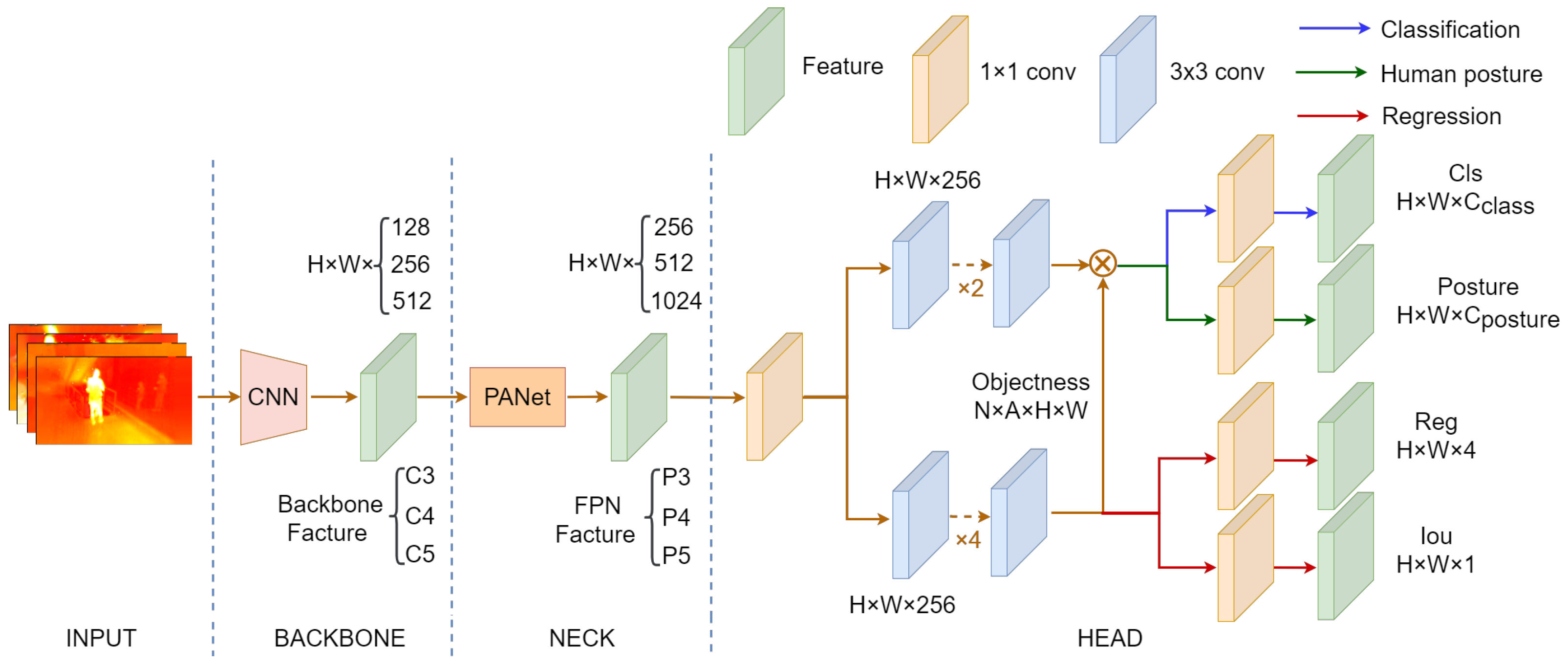
4.2. IPH-YOLOX
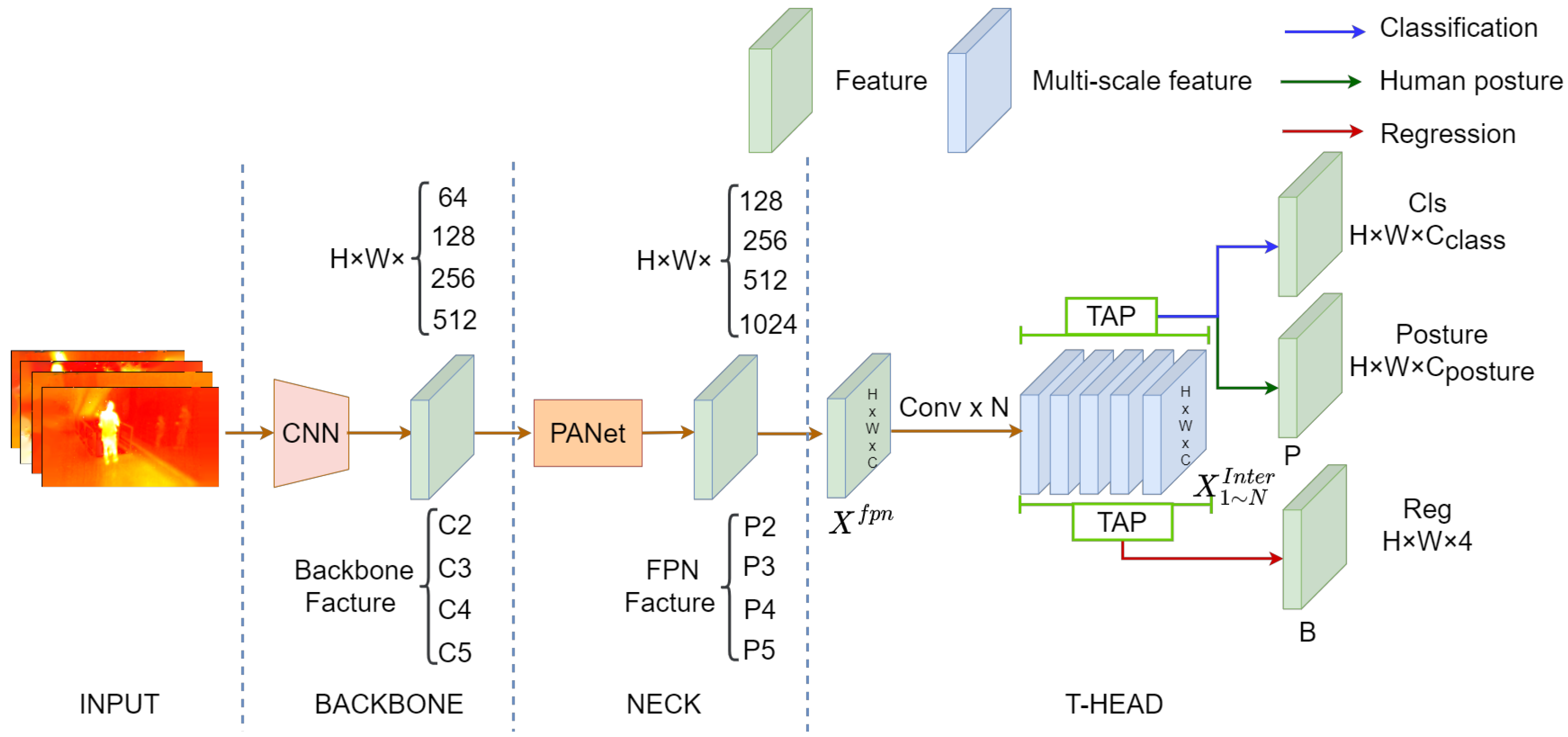
4.3. IPH-TOOD
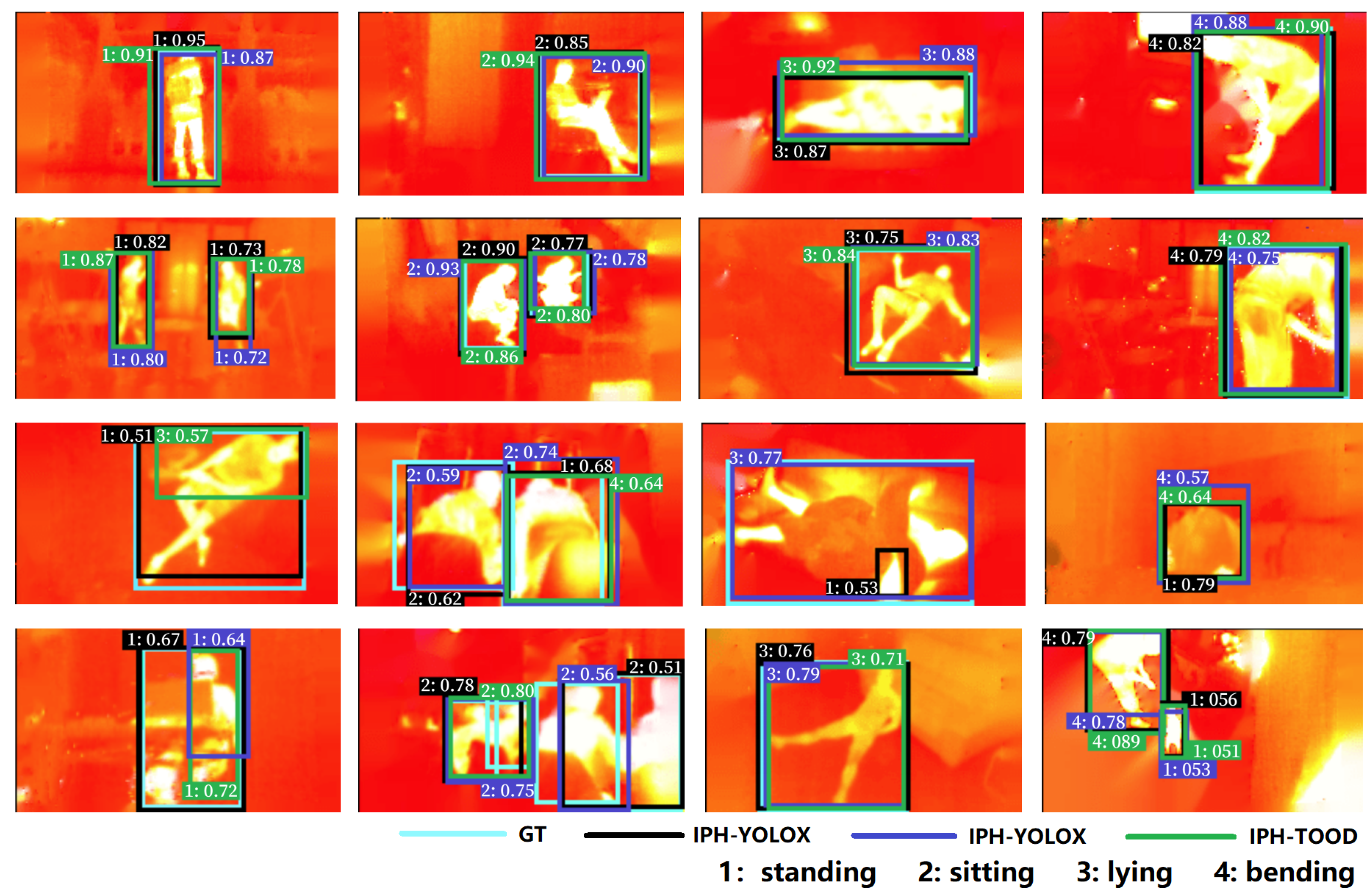
5. Evaluation
5.1. Evaluation Metrics
5.2. Evaluation Results
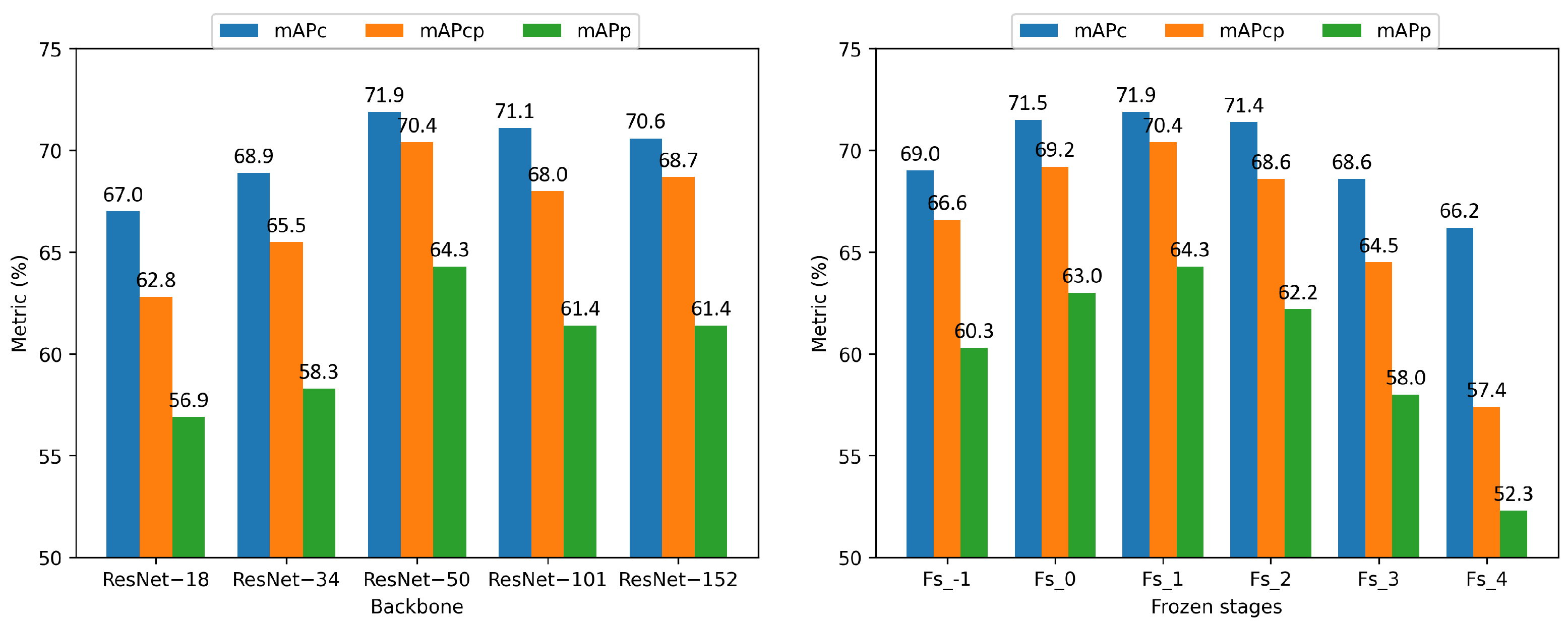
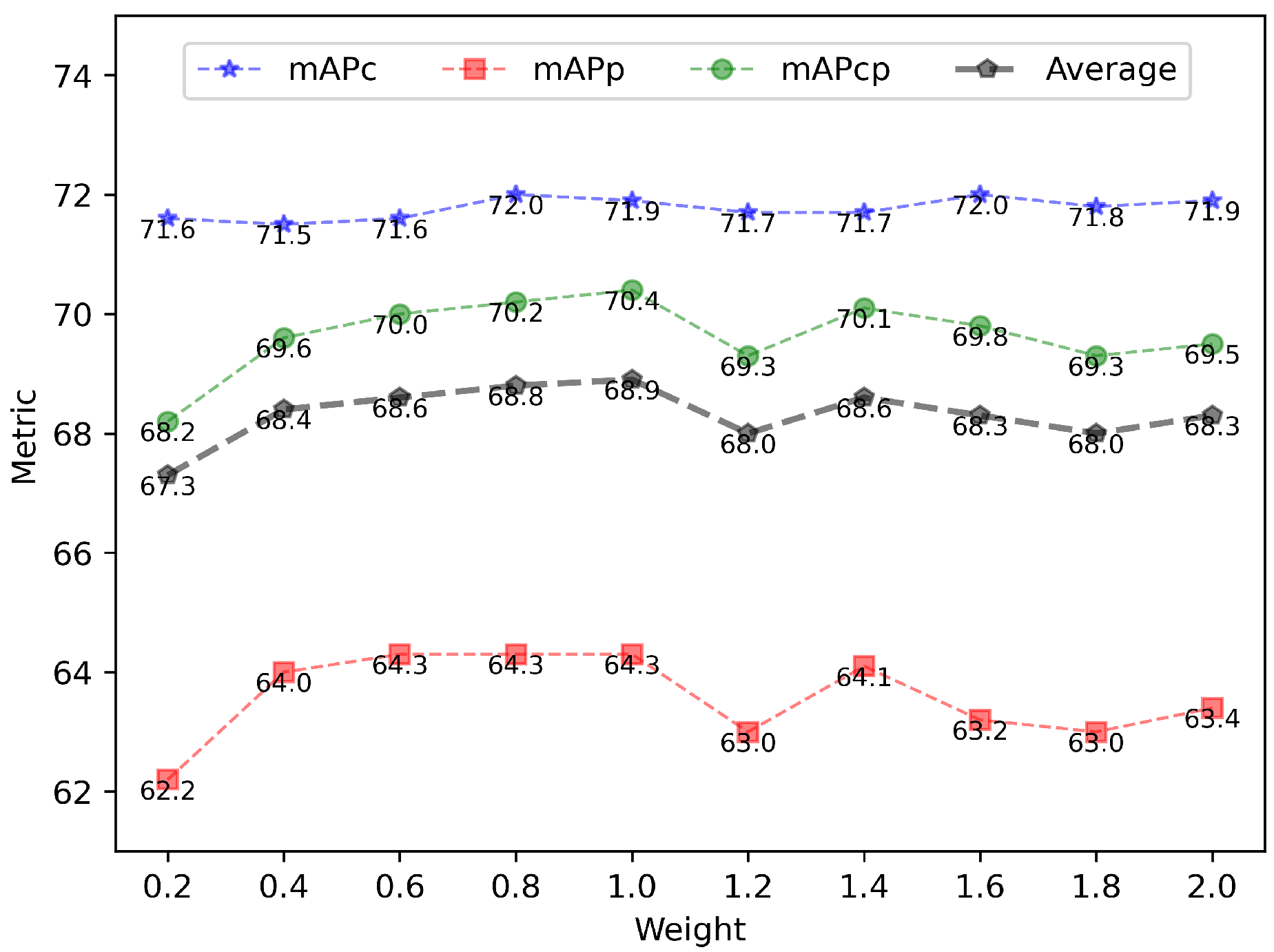
5.3. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moon, G.; Kwon, H.; Lee, K.M.; Cho, M. IntegralAction: Pose-driven Feature Integration for Robust Human Action Recognition in Videos. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Online, 19–25 June 2021; pp. 3334–3343. [Google Scholar]
- Baradel, F.; Wolf, C.; Mille, J. Human Action Recognition: Pose-Based Attention Draws Focus to Hands. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 604–613. [Google Scholar]
- Rutjes, H.; Willemsen, M.C.; IJsselsteijn, W.A. Beyond Behavior: The Coach’s Perspective on Technology in Health Coaching. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019. [Google Scholar]
- Boerner, P.; Polasek, K.M.; True, L.; Lind, E.; Hendrick, J.L. Is What You See What You Get? Perceptions of Personal Trainers’ Competence, Knowledge, and Preferred Sex of Personal Trainer Relative to Physique. J. Strength Cond. Res. 2019, 35, 1949–1955. [Google Scholar] [CrossRef]
- Adamkiewicz, M.; Chen, T.; Caccavale, A.; Gardner, R.; Culbertson, P.; Bohg, J.; Schwager, M. Vision-Only Robot Navigation in a Neural Radiance World. IEEE Robot. Autom. Lett. 2022, 7, 4606–4613. [Google Scholar] [CrossRef]
- Deng, X.; Xiang, Y.; Mousavian, A.; Eppner, C.; Bretl, T.; Fox, D. Self-supervised 6D Object Pose Estimation for Robot Manipulation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 3665–3671. [Google Scholar]
- Tang, F.; Wu, Y.; Hou, X.; Ling, H. 3D Mapping and 6D Pose Computation for Real Time Augmented Reality on Cylindrical Objects. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2887–2899. [Google Scholar] [CrossRef]
- Desmarais, Y.; Mottet, D.; Slangen, P.R.L.; Montesinos, P. A review of 3D human pose estimation algorithms for markerless motion capture. Comput. Vis. Image Underst. 2021, 212, 103275. [Google Scholar] [CrossRef]
- Zanfir, M.; Leordeanu, M.; Sminchisescu, C. The Moving Pose: An Efficient 3D Kinematics Descriptor for Low-Latency Action Recognition and Detection. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2752–2759. [Google Scholar]
- Thyagarajmurthy, A.; Ninad, M.G.; Rakesh, B.; Niranjan, S.K.; Manvi, B. Anomaly Detection in Surveillance Video Using Pose Estimation. In Emerging Research in Electronics, Computer Science and Technology; Lecture Notes in Electrical Engineering; Springer: Singapore, 2019. [Google Scholar]
- Lamas, A.; Tabik, S.; Montes, A.C.; Pérez-Hernández, F.; Fernández, J.G.T.; Olmos, R.; Herrera, F. Human pose estimation for mitigating false negatives in weapon detection in video-surveillance. Neurocomputing 2022, 489, 488–503. [Google Scholar] [CrossRef]
- Paul, M.; Haque, S.M.E.; Chakraborty, S. Human detection in surveillance videos and its applications—A review. EURASIP J. Adv. Signal Process. 2013, 2013, 1–16. [Google Scholar] [CrossRef]
- Khalifa, A.F.; Badr, E.; Elmahdy, H.N. A survey on human detection surveillance systems for Raspberry Pi. Image Vis. Comput. 2019, 85, 1–13. [Google Scholar] [CrossRef]
- Sumit, S.S.; Rambli, D.R.A.; Mirjalili, S.M. Vision-Based Human Detection Techniques: A Descriptive Review. IEEE Access 2021, 9, 42724–42761. [Google Scholar] [CrossRef]
- Li, Y.; Liu, X.; Wu, X.; Huang, X.; Xu, L.; Lu, C. Transferable Interactiveness Knowledge for Human-Object Interaction Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3870–3882. [Google Scholar]
- Nakashima, S.; Kitazono, Y.; Zhang, L.; Serikawa, S. Development of privacy-preserving sensor for person detection. Procedia Soc. Behav. Sci. 2010, 2, 213–217. [Google Scholar] [CrossRef][Green Version]
- Clapés, A.; Jacques, J.C.S.; Morral, C.; Escalera, S. ChaLearn LAP 2020 Challenge on Identity-preserved Human Detection: Dataset and Results. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 801–808. [Google Scholar]
- Younsi, M.; Diaf, M.; Siarry, P. Automatic multiple moving humans detection and tracking in image sequences taken from a stationary thermal infrared camera. Expert Syst. Appl. 2020, 146, 113171. [Google Scholar] [CrossRef]
- Trofimova, A.; Masciadri, A.; Veronese, F.; Salice, F. Indoor Human Detection Based on Thermal Array Sensor Data and Adaptive Background Estimation. J. Comput. Commun. 2017, 05, 16–28. [Google Scholar] [CrossRef]
- Ivasic-Kos, M.; Krišto, M.; Pobar, M. Human Detection in Thermal Imaging Using YOLO. In Proceedings of the 2019 5th International Conference on Computer and Technology Applications, Istanbul, Turkey, 16–17 April 2019. [Google Scholar]
- Haider, A.M.; Shaukat, F.; Mir, J. Human detection in aerial thermal imaging using a fully convolutional regression network. Infrared Phys. Technol. 2021, 116, 103796. [Google Scholar] [CrossRef]
- Wang, Y.; Meng, L. Application of Infrared Thermal Imaging Device in COVID-19 Prevention and Control. Med. Equ. 2020, 33, 22–24. [Google Scholar]
- Arthur, D.T. Towards Application of Thermal Infrared Imaging in Medical Diagnosis: Protocols and Investigations. Ph.D. Thesis, Curtin University, Perth, Australia, 2014. [Google Scholar]
- Yu, Y.; Liu, C.; Wang, C.; Shi, J. Thermal Infrared Salient Human Detection Model Combined with Thermal Features in Airport Terminal. Trans. Nanjing Univ. Aeronaut. Astronaut. 2022, 39, 434–449. [Google Scholar]
- Usamentiaga, R.; Venegas, P.; Guerediaga, J.; Vega, L.; Molleda, J.; Bulnes, F.G. Infrared Thermography for Temperature Measurement and Non-Destructive Testing. Sensors 2014, 14, 12305–12348. [Google Scholar] [CrossRef]
- Chou, E.; Tan, M.; Zou, C.; Guo, M.; Haque, A.; Milstein, A.; Fei-Fei, L. Privacy-Preserving Action Recognition for Smart Hospitals using Low-Resolution Depth Images. arXiv 2018, arXiv:1811.09950. [Google Scholar]
- Priya, R.L.; Jinny, S.V. Elderly Healthcare System for Chronic Ailments using Machine Learning Techniques—A Review. Iraqi J. Sci. 2021, 62, 3138–3151. [Google Scholar] [CrossRef]
- Orman, K. Thermovision in medical and environmental applications. Struct. Environ. 2022, 14, 18–23. [Google Scholar] [CrossRef]
- Gutfeter, W.; Pacut, A. Fusion of Depth and Thermal Imaging for People Detection. J. Telecommun. Inf. Technol. 2021, 53–60. [Google Scholar] [CrossRef]
- Luo, H.; Li, S.; Zhao, Q. Towards Silhouette-Aware Human Detection in Depth Images. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–23 June 2021; pp. 1–8. [Google Scholar]
- Xia, Z.X.; Lai, W.C.; Tsao, L.W.; Hsu, L.F.; Yu, C.C.H.; Shuai, H.H.; Cheng, W.H. A Human-Like Traffic Scene Understanding System: A Survey. IEEE Ind. Electron. Mag. 2021, 15, 6–15. [Google Scholar] [CrossRef]
- Chen, Y.; Tian, Y.; He, M. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 2020, 192, 102897. [Google Scholar] [CrossRef]
- Zhu, X.; Guo, Z.; Liu, X.; Li, B.; Peng, J.; Chen, P.; Wang, R. Complex Human Pose Estimation via Keypoints Association Constraint Network. IEEE Access 2020, 8, 205938–205947. [Google Scholar] [CrossRef]
- Chen, L.; Zhou, D.; Liu, R.; Zhang, Q. SAMKR: Bottom-up Keypoint Regression Pose Estimation Method Based On Subspace Attention Module. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padova, Italy, 18–23 July 2022; pp. 1–9. [Google Scholar]
- Zhang, W.; Wang, J.; Guo, X.; Chen, K.; Wang, N. Two-Stream RGB-D Human Detection Algorithm Based on RFB Network. IEEE Access 2020, 8, 123175–123181. [Google Scholar] [CrossRef]
- Comaniciu, D.; Ramesh, V.; Meer, P. Real-time tracking of non-rigid objects using mean shift. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No.PR00662), Hilton Head, SC, USA, 15 June 2000; Volume 2, pp. 142–149. [Google Scholar]
- Nanda, H.; Davis, L. Probabilistic template based pedestrian detection in infrared videos. In Proceedings of the Intelligent Vehicle Symposium, Versailles, France, 17–21 June 2002; Volume 1, pp. 15–20. [Google Scholar]
- Fernández-Caballero, A.; López, M.; Serrano-Cuerda, J. Thermal-Infrared Pedestrian ROI Extraction through Thermal and Motion Information Fusion. Sensors 2014, 14, 6666–6676. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhou, F.; Li, L.; Bai, X.; Sun, C. Mutual Guidance-Based Saliency Propagation for Infrared Pedestrian Images. IEEE Access 2019, 7, 113355–113371. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Y.; Wei, W.; Meng, Q. An associative saliency segmentation method for infrared targets. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 4264–4268. [Google Scholar]
- Biswas, S.; Milanfar, P. Linear Support Tensor Machine With LSK Channels: Pedestrian Detection in Thermal Infrared Images. IEEE Trans. Image Process. 2017, 26, 4229–4242. [Google Scholar] [CrossRef]
- Tan, Y.; Yan, W.; Huang, S.; Du, D.; Xia, L. Thermal Infrared Human Recognition Based on Multi-scale Monogenic Signal Representation and Deep Learning. IAENG Int. J. Comput. Sci. 2020, 47, 540–549. [Google Scholar]
- Akula, A.; Shah, A.K.; Ghosh, R. Deep Learning Approach for Human Action Recognition in Infrared Images. Cogn. Syst. Res. 2018, 50, 146–154. [Google Scholar] [CrossRef]
- Wu, X.; Sun, S.; Li, J.; Li, D. Infrared behavior recognition based on spatio-temporal two-stream convolutional neural networks. J. Appl. Opt. 2018, 39, 743–750. [Google Scholar]
- Ma, X.; Fang, Y.; Wang, B.; Wu, Z. An Improved YOLO v3 Infrared Image Pedestrian Detection Method. J. Hubei Inst. Technol. 2020, 36, 19–24+38. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding. In Proceedings of the ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007. [Google Scholar]
- Shi, J.; Zhang, G.; Tao, J.; Wu, L. Pedestrian detection algorithm in infrared image based on improved YOLOv4. Intell. Comput. Appl. 2021, 11, 31–34+41. [Google Scholar]
- Adel Musallam, M.; Baptista, R.; Al Ismaeil, K.; Aouada, D. Temporal 3D Human Pose Estimation for Action Recognition from Arbitrary Viewpoints. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; pp. 253–258. [Google Scholar]
- Zhang, J.; Chen, Z.; Tao, D. Towards High Performance Human Keypoint Detection. Int. J. Comput. Vis. 2021, 129, 2639–2662. [Google Scholar] [CrossRef]
- Bai, X.; Wang, P.; Zhou, F. Pedestrian Segmentation in Infrared Images Based on Circular Shortest Path. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2214–2222. [Google Scholar] [CrossRef]
- Li, L.; Zhou, F.; Bai, X. Infrared Pedestrian Segmentation Through Background Likelihood and Object-Biased Saliency. IEEE Trans. Intell. Transp. Syst. 2018, 19, 2826–2844. [Google Scholar] [CrossRef]
- Liu, H.; Chen, Y.; Zhao, W.; Zhang, S.; Zhang, Z. Human pose recognition via adaptive distribution encoding for action perception in the self-regulated learning process. Infrared Phys. Technol. 2021, 114, 103660. [Google Scholar] [CrossRef]
- Bai, X.; Wang, Y.; Liu, H.; Guo, S. Symmetry Information Based Fuzzy Clustering for Infrared Pedestrian Segmentation. IEEE Trans. Fuzzy Syst. 2018, 26, 1946–1959. [Google Scholar] [CrossRef]
- Zang, Y.; Fan, C.; Zheng, Z.; Yang, D. Pose estimation at night in infrared images using a lightweight multi-stage attention network. Signal Image Video Process. 2021, 15, 1757–1765. [Google Scholar] [CrossRef]
- Everingham, M.; Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Reynolds, D.A. Gaussian mixture models. Encycl. Biom. 2009, 741, 659–663. [Google Scholar]
- Bertalmio, M.; Bertozzi, A.; Sapiro, G. Navier-stokes, fluid dynamics, and image and video inpainting. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-level Feature. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 13034–13043. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. TOOD: Task-aligned One-stage Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3490–3499. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Qin, L.; Zhou, H.; Wang, Z.; Deng, J.; Liao, Y.; Li, S. Detection Beyond What and Where: A Benchmark for Detecting Occlusion State. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Shenzhen, China, 4–7 November 2022; pp. 464–476. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Dataset | Learning Method | Supervisio Method | YOLO | Attention | FPN | Posture Prediction Head |
|---|---|---|---|---|---|---|---|---|
| [40] | 2013 | OSU-T | Traditional learning | Supervised | × | √ | × | × |
| [50] | 2016 | Non-public | × | × | × | × | ||
| [39] | 2019 | OSU IMS DIP | × | × | × | × | ||
| [51] | 2018 | Non-public | Traditional learning | Semi- supervised | × | √ | × | × |
| [52] | 2021 | IRPSRL MS COCO | Deep learning | × | × | × | × | |
| [53] | 2018 | Non-public | Deep learning | Unsupervised | × | × | × | × |
| [45] | 2020 | Non-public | √ | × | √ | × | ||
| [41] | 2017 | OSU-T OSU-CT LSI KAIST | Deep learning | Supervised | × | × | × | × |
| [47] | 2021 | OSU-T | √ | √ | √ | × | ||
| [54] | 2021 | MPII-HPD AI-CD | × | √ | × | × | ||
| IPH-YOLOF | 2022 | IPHPTD | √ | √ | × | √ | ||
| IPH-YOLOX | 2022 | IPHPTD | √ | √ | √ | √ | ||
| IPH-TOOD | 2022 | IPHPTD | × | √ | √ | √ |
| Dataset | Train Set | Valid Set | Test Set |
|---|---|---|---|
| IPHD | 84,818 | 12,974 | 15,115 |
| IPHPDT | 62,010 | - | 13,267 |
| {,,}@0.5 | {,,}@0.75 | {,,} | |
|---|---|---|---|
| IPH-YOLOF | (0.944,0.833,0.867) | (0.848,0.768,0.834) | (0.706,0.630,0.692) |
| IPH-YOLOX | (0.955,0.804,0.836) | (0.863,0.737,0.771) | (0.737,0.625,0.677) |
| IPH-TOOD | (0.935,0.826,0.863) | (0.850,0.771,0.836) | (0.719,0.643,0.704) |
| Standing | Sitting | Lying | Bending | |
|---|---|---|---|---|
| (IPH-YOLOF) | 0.723 | 0.666 | 0.720 | 0.665 |
| (IPH-YOLOX) | 0.743 | 0.625 | 0.721 | 0.619 |
| (IPH-TOOD) | 0.737 | 0.652 | 0.725 | 0.695 |
| Backbone | {,,}@0.5 | {,,}@0.75 | {,,} |
|---|---|---|---|
| ResNet-18 | (0.912,0.771,0.804) | (0.797,0.678,0.744) | (0.670,0.569,0.628) |
| ResNet-34 | (0.924,0.776,0.831) | (0.820,0.694,0.777) | (0.689,0.583,0.655) |
| ResNet-50 | (0.935,0.826,0.863) | (0.850,0.771,0.836) | (0.719,0.643,0.704) |
| ResNet-101 | (0.925,0.792,0.835) | (0.839,0.728,0.798) | (0.711,0.614,0.680) |
| ResNet-152 | (0.933,0.796,0.840) | (0.833,0.726,0.797) | (0.706,0.614,0.687) |
| Frozen Stages | {,,}@0.5 | {,,}@0.75 | {,,} |
|---|---|---|---|
| fs_−1 | (0.924,0.791,0.835) | (0.824,0.723,0.794) | (0.690,0.603,0.666) |
| fs_0 | (0.932,0.811,0.851) | (0.847,0.751,0.817) | (0.715,0.630,0.692) |
| fs_1 | (0.935,0.826,0.863) | (0.850,0.771,0.836) | (0.719,0.643,0.704) |
| fs_2 | (0.934,0.804,0.847) | (0.847,0.744,0.814) | (0.714,0.622,0.686) |
| fs_3 | (0.923,0.773,0.818) | (0.820,0.695,0.769) | (0.686,0.580,0.645) |
| fs_4 | (0.902,0.718,0.740) | (0.785,0.622,0.678) | (0.662,0.523,0.574) |
| {,,}@0.5 | {,,}@0.75 | {,,} | |
|---|---|---|---|
| 0.2 | (0.934,0.805,0.843) | (0.848,0.751,0.815) | (0.716,0.622,0.682) |
| 0.4 | (0.935,0.827,0.860) | (0.846,0.764,0.825) | (0.715,0.640,0.696) |
| 0.6 | (0.935,0.828,0.862) | (0.848,0.766,0.829) | (0.716,0.643,0.700) |
| 0.8 | (0.935,0.822,0.857) | (0.850,0.768,0.833) | (0.720,0.643,0.702) |
| 1.0 | (0.935,0.826,0.863) | (0.850,0.771,0.836) | (0.719,0.643,0.704) |
| 1.2 | (0.936,0.811,0.853) | (0.848,0.753,0.822) | (0.717,0.630,0.693) |
| 1.4 | (0.935,0.820,0.857) | (0.850,0.769,0.833) | (0.717,0.641,0.701) |
| 1.6 | (0.937,0.805,0.852) | (0.850,0.756,0.830) | (0.720,0.632,0.698) |
| 1.8 | (0.935,0.815,0.855) | (0.849,0.754,0.824) | (0.718,0.630,0.693) |
| 2.0 | (0.935,0.814,0.853) | (0.849,0.759,0.825) | (0.719,0.634,0.695) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Chen, Y.; Deng, J.; Li, S.; Zhou, H. Identity-Preserved Human Posture Detection in Infrared Thermal Images: A Benchmark. Sensors 2023, 23, 92. https://doi.org/10.3390/s23010092
Guo Y, Chen Y, Deng J, Li S, Zhou H. Identity-Preserved Human Posture Detection in Infrared Thermal Images: A Benchmark. Sensors. 2023; 23(1):92. https://doi.org/10.3390/s23010092
Chicago/Turabian StyleGuo, Yongping, Ying Chen, Jianzhi Deng, Shuiwang Li, and Hui Zhou. 2023. "Identity-Preserved Human Posture Detection in Infrared Thermal Images: A Benchmark" Sensors 23, no. 1: 92. https://doi.org/10.3390/s23010092
APA StyleGuo, Y., Chen, Y., Deng, J., Li, S., & Zhou, H. (2023). Identity-Preserved Human Posture Detection in Infrared Thermal Images: A Benchmark. Sensors, 23(1), 92. https://doi.org/10.3390/s23010092