Abstract
What is the boundary between a vigorous argument and a breakdown of relations? What drives a group of individuals across it? Taking Wikipedia as a test case, we use a hidden Markov model to approximate the computational structure and social grammar of more than a decade of cooperation and conflict among its editors. Across a wide range of pages, we discover a bursty war/peace structure where the systems can become trapped, sometimes for months, in a computational subspace associated with significantly higher levels of conflict-tracking “revert” actions. Distinct patterns of behavior characterize the lower-conflict subspace, including tit-for-tat reversion. While a fraction of the transitions between these subspaces are associated with top-down actions taken by administrators, the effects are weak. Surprisingly, we find no statistical signal that transitions are associated with the appearance of particularly anti-social users, and only weak association with significant news events outside the system. These findings are consistent with transitions being driven by decentralized processes with no clear locus of control. Models of belief revision in the presence of a common resource for information-sharing predict the existence of two distinct phases: a disordered high-conflict phase, and a frozen phase with spontaneously-broken symmetry. The bistability we observe empirically may be a consequence of editor turn-over, which drives the system to a critical point between them.
1. Introduction
Many societies are characterized by periods of cooperation separated by significant periods of intra-group conflict. Both cooperation and conflict are themselves complex phenomena: cooperation is not the absence of conflict, nor is the presence of conflict incompatible with cooperation. One can talk of a lull in fighting, for example, or, conversely, of antagonistic interactions that are part of the internal logic of a resilient and cooperative society. Two questions, then suggest themselves: can we define the boundary between cooperation and conflict, and can transitions across this boundary be explained, controlled, or predicted before they happen?
We approach this pair of fundamental questions by examining a social system in terms of how it processes information. As we shall show, a system’s computational process—how it moves through an abstract state space that both responds to past antagonism and predicts its future development—connects directly to large-scale features that are immediately perceptible to human participants.
Our system of study is social behavior observed in the debates on the website Wikipedia. Wikipedia is an ideal case study for the computational properties of conflict. By design, actions on the system are logged at extremely high resolution, allowing us to track the actions and interactions of tens of thousands of users second-by-second for nearly fifteen years. A natural binary classification of actions (“revert” and “non-revert”), that tracks conflict between users, allows us to use sequence analysis and the language of symbolic timeseries [1,2] to operationalize the boundary between conflict and cooperation with Hidden Markov Models (HMMs).
Using HMMs to detect hidden structure in social behavior is a natural extension to how they have been used in the engineering, linguistic, and biological sciences. HMMs are in wide use when we believe that a noisy observable signal tracks some more complex underlying process, such as when the garbled sound of a noisy room includes someone speaking a sentence (speech recognition [3,4]), the individual words in a sentence give clues to that sentence’s hidden syntactic structure (part of speech tagging [5,6]), or the A, C, T, and G symbols of DNA code for genes [7]. The volume of data on Wikipedia makes it possible to model the information processing of the system itself, an approach becoming increasingly common in large-scale studies of social media [8]. At the same time, our understanding of the products of this analysis are enhanced by ethnographic and quantitative studies of the system [9] that allow us to interpret individual actions, users, and their social contexts, and allow us to test narrative accounts of the causes and patterns of conflict.
Our analysis of Wikipedian conflict through the lens of the revert/non-revert distinction reveals two long-lived behavioral patterns associated with higher and lower levels of these conflict-tracking revert actions. While the modes themselves are defined by reference to short sequences, or motifs, of interactions that can take only a few minutes to happen, the system as a whole will stay in one mode or another for weeks and, sometimes, even months or years. This separation of timescales provides a bottom-up definition of the boundary between cooperation and conflict that depends on the existence of persistent, hidden system memories. In the first part of this paper, we demonstrate the existence of these unexpectedly long-term memories, and the distinct local patterns of interaction to which they give rise. Detected by reference to apparently abstract properties of the system’s computational description using hidden Markov models, these memories are tied to human-scale and group-level properties that form the basis of the system’s self-understanding.
In addition to providing a novel means for the description of the boundaries and distinctions between conflict and cooperation, our model allows us to pin-point the transitions between these two coarse-grained computational states. In the second part of our paper, we use this information to study the influence of administrative actions, individual users, and exogenous events over this society’s history. We find that top-down actions have only limited effectiveness in triggering a transition in either direction.
2. Methods
Our study here is based on the time series of edits made on sixty-two of the most-edited pages on Wikipedia. This sample was chosen because each page then provided us with sufficient data to model each page independently; we thus were able to avoid making the (strong) assumption that editing practices were uniform. While our sample is by definition exceptional, and includes articles with tens of thousands of individual edits, it also covers a wide range of different topics and themes including (1) biographies of figures in both politics and entertainment, living and dead, from Genghis Khan to George W. Bush, Paul McCartney to Britney Spears (30% of the sample); (2) other non-biographical pages associated with the arts and entertainment (16% of the sample); (3) pages associated with countries, such as Cuba, Argentina and the United States (18% of the sample); (4) natural events ranging from the sinking of the Titanic to Hurricane Katrina; (5) political events, such as World War II and the 2006 War in Lebanon (13% of the sample); (6) technology topics, such as the iPhone (9% of the sample); and (7) religious topics, such as the Catholic Church and Islam (6% of the sample). See Appendix A; past work on Wikipedia editing practices has ranged from the histories of individual articles [10,11] to the full Wikipedia dataset [12]; ours is of a similar scale and selectivity to a number of other conflict studies [13,14,15], and the article list overlaps with two prior studies [1,16].
Data for this paper, and accompanying analysis code, can be found at [17,18].
2.1. Tracking Conflict through Page Reverts
When editors interact on Wikipedia, they can disagree on what to do and how to behave. The resulting conflicts that emerge can be tracked by reference to “reverts”. Reverts are when one user takes a page to a previously-seen state, effectively undoing and discarding the work of others. For each page in our sample, the edit time series was coarse-grained into “revert” (R) and non-revert (C) actions, as described in Ref. [1]. We define a revert as an edit that takes the page to a previously-seen state (as detected by the MD5 page hash provided by the Wikipedia API), but exclude the relatively small number of cases where a user’s revert only undoes work contributed by that user herself (i.e., we exclude self-reverts). More details on these methods, and additional robustness checks, are described in [16].
Reverts are noisy, imperfect signals of conflict; research has shown how more qualitative, interpretive, “thicker” [19] measures of conflict among users are strongly associated with these easily-tracked reverts [20], which can degenerate into edit wars [13]. Researchers have shown that reverts play a central role in marking both conflict and controversy [21,22,23], and that a great deal of information is encoded in reverts, including patterns of alliances among editors [10]. Reverts play a major role in the social norms of Wikipedia itself [24], including highly central pages in the norm network such as the “three-revert rule”, and strong norms against edit warring (see [16] for further discussion).
Reverts, however, are not equivalent to conflict. In general, reverts are best used to track the presence of task conflict [15], as opposed to other dimensions of conflict identified in the organizational behavior literature, such as affective conflict and process conflict [25,26]. While the task conflict represented by reverts is more ambiguous than other forms of conflict, it is still highly correlated with affective and relational conflict [27]; for example, the perception of rejection associated with being reverted is a significant factor in dissuading female contributors from participation [28]. At the same time, the tension between the need to change and to retain text can manifest itself in many different and more subtle ways [11,29,30]. There are multiple pathways for conflict to manifest itself that do not lead deterministically to reverts, an example being conflict associated with Wikipedia policies [12] and conflict that takes place in discussion on article talk pages [31].
In short: while we rely on reverts in our analysis here, we emphasize that this is only one signal of conflict on Wikipedia and that conflict itself is a far richer notion than the binary presence-absence data of our time series. The fact that reverts are only noisy, partial signals of conflict leads us to use a particular tool, the hidden Markov model. Hidden Markov models are ideally suited to cases where a complex system leaves only a low-dimensional trace in an observable time-stream, allowing us to reconstruct, in part, some of the structure of the hidden, underlying process.
2.2. Hidden Markov Models
For each page, we have a binary time series of Wikipedian conflict, consisting of Rs and Cs. Page-by-page, we approximate this time series as a probabilistic finite state machine, more commonly known as a Hidden Markov Model (HMM, or machine). In an HMM, the observed behavior of the system—here the registering of a new edit of type R or C—is (probabilistically) conditioned on the system’s position in a hidden, internal state space.
Our use of the HMM is conceptually simple. Each page is associated with a distinct machine. The evolution of the page is represented by the machine as it moves from one hidden, internal state to another, from edit to edit. At each edit, and depending on the state that the machine finds itself in, it will produce an observed edit behavior (probabilistically; here, R or C), and transition to a new internal state. The chance of going from one hidden state to another is dictated by a fixed probability. The origins of the HMM paradigm go back to [32]; for a recent, technical introduction to hidden Markov models, including the Baum–Welch algorithm used in this paper, see [33]; Figure 1 provides an example from the George W. Bush page.
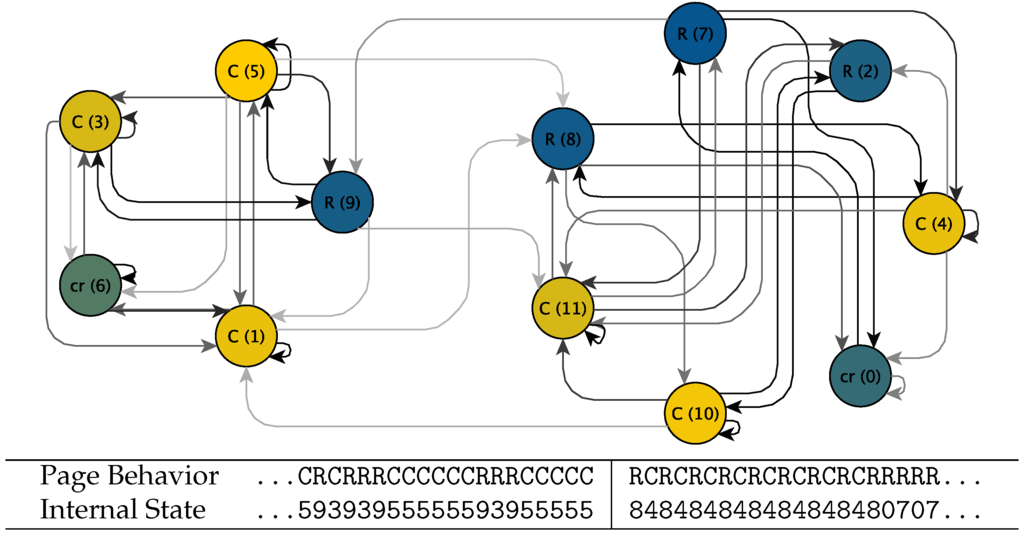
Figure 1.
Top panel: Hidden Markov model for cooperation and conflict on the George W. Bush page. States are labeled by the probability of emitting each of the two output symbols; “C” (, lighter yellow), “R” (, darker blue) or “cr” (otherwise). Edge weights show transition probabilities; the lightest lines, connecting the two subspaces, correspond to probabilities of order . Despite its complexity, the system is dominated by a transition logic that, on short timescales, confines the system to one of two separate modules with a high density of internal transitions. Bottom panel: below the diagram, as an example of our method, we show the Viterbi reconstruction in the neighborhood of one of the sixteen between-subspace transitions in our data. As the system wanders, during this period, among internal States 5, 9, 3, 8 and 4, it emits the symbols C and R probabilistically depending on which particular state it is in. On 8 November 2004 at 9:11 UTC (Coordinated Universal Time), long runs of cooperation and conflict gave way to more rapid-fire conflict and vandal-repair as the system crossed from the left module to the right, via the bridge between State 5 and State 8.
In contrast to many simple time series models, a hidden Markov model does not make a “no history” assumption: instead, the system memory is encoded by the position within the hidden state space. From the point of view of an external observer, this memory can extend arbitrarily far into the past. Strong theorems exist about the way in which this memory must, eventually, decay, but there is no “hard” cutoff where (for example) an observed event t steps in the past has zero influence when t is greater than some critical, finite T and one includes the more recent past as a predictor. For these reasons, an HMM is more general than the standard auto-regressive (AR [34]) models familiar from econometrics. AR models condition the current state of the system on a fixed and finite number of steps of the observable sequence in the recent past; usually less than ten. By contrast, an HMM can encode arbitrarily long path dependencies; as we shall see, the correlation lengths our methods do detect in Wikipedia suggest that AR models would be very poor descriptions of the data indeed.
2.3. Fitting and Characterizing HMMs
We find the parameters for the HMM associated with the time series on each page using the Expectation-Maximization algorithm (EM [32,33]); for each page, we run this hill-climbing algorithm 3200 times with random initial seeds to study the ruggedness of the underlying likelihood landscape.
The one externally-fixed parameter in an HMM is the total number of hidden states; once this choice is made, the other parameters are determined by the data. Increasing the number of states means that the model is better able to predict the data. Using too many states, however, can mean that the model structure includes features that are due to random, one-off fluctuations in the data; this is called over-fitting. We use the Akaike Information Criterion (AIC [35]) to select the number of states for each page’s model. Extensive tests, and a comparison to the main competing model selection method, the Bayesian Information Criterion (BIC [36]), suggest that AIC is, for the systems we encounter here, preferred; see Appendix B for further discussion. For simplicity, and in keeping with usual practice, we work solely with the maximum-likelihood model, rather than attempting to model the full distribution over distinct, but less-preferred, models.
2.4. Subspaces, Trapping Time, and Viterbi Reconstruction for HMMs
In general, as a system evolves in the HMM paradigm, it will spread out over its internal state space. A characteristic feature of this spreading out is the so-called relaxation time, which determines how long the system stays confined in a particular subspace of its possible internal states before returning to its characteristic stationary distribution. Once the best-fit HMM has been found, we can compute the relaxation time, τ, by reference to the second eigenvalue of the transition matrix, ,
Informally, and for the cases we consider here, when is very close to unity (small spectral gap), the system can take a long time to return to the stationary distribution (see Appendix C for further discussion). This can be understood by writing down an approximation for the probability that the system will be found in a particular state at time t, ,
where is the stationary distribution of the chain, equal to the first eigenvector of the transition matrix, is the second eigenvector, and α depends on the initial conditions. The remaining terms are exponentially suppressed relative to ; the approximation in the second line holds in the limit that is close to unity.
The second eigenvector, , describes the perturbation that takes the longest time to die away. It allows us to split the system into two subspaces based on the signs of its entries; we define all of the states where is, say, positive, as “subspace one”, and the remaining states as “subspace two”. One set of states is associated with the positive values; the complementary set with those that are strictly negative. Informally, initial conditions that are weighted towards states solely in one of these two sets (all positive values or all negative) take the longest to decay to the stationary distribution. It is these two spaces that will define the system epochs.
The use of the sign structure of an HMM’s eigenvectors is a natural way to identify these subspaces; similar methods have been applied to, for example, the identification of metastable states in chemical reaction networks through what is called Perron Cluster Cluster Analysis (PCCA) [37,38,39]. Use of just the second eigenvector naturally splits the system into the two most significant subspaces. The sign structure of the third and higher eigenvectors can be used to further decompose the space in a hierarchical fashion, potentially subdividing these larger modules (see, e.g., [40]). In this paper, we focus solely on the first division, and do not attempt to identify substructures within either of the two main clusters.
Once we know the parameters of the HMM, we can use Viterbi path reconstruction [41] to reconstruct the maximum-likelihood path through the state space. We then know, at any point in the time series, where we are in the underlying computational state space.
This allows us to associate an internal state of the HMM to each step in the time series and, thus, to each edit on the page itself. We can also pinpoint when a transition from one subspace to the other occurs. When a system switches subspaces, there can be some flickering, with rapid shifting back and forth between subspaces before the system settles down. We only count a transition from one subspace to another when the system remains in the new subspace for more than ten time steps.
Given this definition, we can then study time spent within each subspace; we call this empirical quantity the “trapping time”, ; per the definition of τ and the Levin–Peres–Wilmer theorem (see Appendix C), we expect the trapping time to be of order τ. We report both the trapping time and the relaxation time in our results here. The trapping time is the more empirical quantity, since it describes the actual behavior of the system: what state the system was actually in at a particular time, and how long the system was trapped in one subspace or the other during its evolution; we can report for each subspace separately or just consider the average. Meanwhile, the relaxation time is the more theoretical quantity, characterizing the HMM in isolation, in terms of the generic properties of the kinds of time series it tends to generate.
In order to test the extent to which τ (and ) are driven by system-wide patterns of linking between internal states (rather than just, for example, generic sparseness, or an overall tendency for any state to link to only a small number of other states), we consider a null model for τ, where we shuffle the entries of each state’s probability vector. This scrambles the overall structure machine while keeping the list of transition probabilities for each state constant.
On the simplest level, subspaces can be defined by their average levels of conflict: the fraction of time they lead to the emission of a revert symbol, R. We track this using the revert ratio: the fraction of reverts in the higher-conflict subspace divided by the fraction of reverts in the lower-conflict subspace.
Subspaces are defined by more than just their levels of reverting. What distinguishes them in a deeper sense are the relationships between their hidden internal states, which make some sequences more likely than others. System response to a revert will be different, and lead to different characteristic futures, in one subspace compared to the other.
We characterize subspaces by reference to the relative frequency of motifs: short sequences of system behaviors. We measure the probability of different motifs in each subspace, and then consider the motifs with the highest partial-KL. In particular, if the probability of motif i in the first subspace is , and the probability of i in the second subspace is , we first define the mixture distribution, , equal to . Then, the partial-KL for motif i in the first subspace is . Partial-KL provides an information theoretic measure of the extent to which a particular motif is a signal of the underlying subspace [42]; a motif i is characteristic of a subspace if the partial-KL is large; see Ref. [43] for further discussion.
2.5. Causes of State Transitions
Given an identification of transition points, we return to the original time series to catalog features of the system at these critical points, and to determine potential causes for the transition. We consider three types of potential causes. In all three cases, we look for associations between these potential causes, and transitions between subspaces. An association is defined as a potential cause occurring within a particular time window of a transition event.
First, we track page protection events, points at which administrators changed the access permissions of a particular page to either prevent or allow editing by different user classes. Records of page protection events are reliably logged beginning on 10 November 2003. Page protection is a crucial, hidden element of the system’s conflict management, and has a significant impact on the composition of a page’s editing population [44]. We expect page protection events to be the main source of top-down control that can switch the system between trapping subspaces. We characterize a protection event as “hard” when it leads to a restriction on who may edit the page; “soft” when it releases the page from a restriction. The bulk of protection events shift pages between “anyone can edit” and “semi-protected”; the latter restricts edits to users who have been registered for a sufficient number of days, and have made a sufficient number of edits on other pages.
Second, we track anti-social user events. Transitions between subspaces may, potentially, be induced by unusually anti-social users who instigate self-sustaining conflict by, for example, publicly violating the norms of interaction. Rather than define an externally-imposed standard that may not reflect the reality of online interaction, we define anti-sociality by reference to community norms, as expressed by so-called user blocking events. Wikipedia administrators are able to block users from editing for a period of time. Receiving a block is a signal that one has (in the opinion of at least one administrator) violated a community norm.
We define a user as anti-social in the context of a particular page if that user has a blocking rate (number of blocks per total number of edits) higher than 95% of randomly-selected editors on the same page. For any transition, we check to see if the user with the most edits within a certain window meets this anti-social criterion; if so, we consider this a potential explanation of the transition. This provides a quantitative measure of the extent of internal opposition to dominant norms.
Finally, we track major external events; transition dates associated with major events concerning the topic of the page itself, and defined as significant increases in news coverage for the article subject.
To do this, we rely on two well-curated, public databases from the New York Times [45] the Guardian [46], and track sudden increases in the density of news coverage. We quantify news spikes by reference to the rate of articles in a four-day window around the position in question, and define a major external event as one that leads to a fluctuation in this ratio over and above the null rate at 95% confidence. We search for news articles using the full text of the article’s title.
Time series data, resultant best-fit HMMs, and code for both estimation of Markov chains and for Viterbi reconstruction, are available online as the package SFIHMM [18], and in the open data release [17].
3. Results
For all sixty-two pages, the EM algorithm converged, and we were able to find best-fit hidden Markov models. For the majority of pages (56 of 62), model selection preferred models with at least six internal states.
The network of transitions between states was sparse; any internal state had significantly non-zero transition probabilities to only a small number of others. States themselves usually had near-deterministic emission rules; a particular state usually had a near-unity probability of emitting one of the two possible R or C symbols. Informally, this implies the existence of a variety of interaction motifs, particular patterns of Rs and Cs, at the multi-symbol level.
An example of the underlying computation process for a page is shown in Figure 1, for the most-edited page in Wikipedia: that associated with George W. Bush. The sparseness of the internal state connectivity can be seen in the small number of high-probability transitions for each node; the determinism of the internal states from the fact that nearly all states are strongly biased, at at least 80–20, towards one or other of the two symbols. Also clearly visible is the modular structure of the hidden system; most transitions occur within one of two clearly separated subsets of the states. Over the course of nearly fifteen years and 45,448 edits, the page switched between these two subspaces only sixteen times; we show the time series surrounding one switch, which happened on 8 November 2004. The motifs on either side of the transition are visibly distinct; we discuss and quantify this effect below.
Table 1 then shows the recovered machines for the top ten pages by number of edits; the layout for each of the machines is dictated by the recovered modules, with states that are in the same module grouped together visually.

Table 1.
Hidden Markov models and derived parameters for cooperation and conflict on the ten most-edited pages on Wikipedia. Editing patterns are characterized by high levels of determinism, and long timescale trapping in distinct higher and lower conflict spaces.
3.1. Epoch Detection
The distribution of relaxation times, τ, is shown in Figure 2. For all sixty-two pages, τ is exceptionally long. The average relaxation time in our sample is 698 steps, corresponding to a of roughly ; the median is 287 steps. The effect size is large; the median relaxation time for the null model is only 12 steps, and for any particular page, the observed relaxation time is on average 50 times longer than the null expectation. In the majority of cases (52 of 62), there is significant evidence that global machine structure, in addition to transition sparseness, is leading to these long relaxation times.
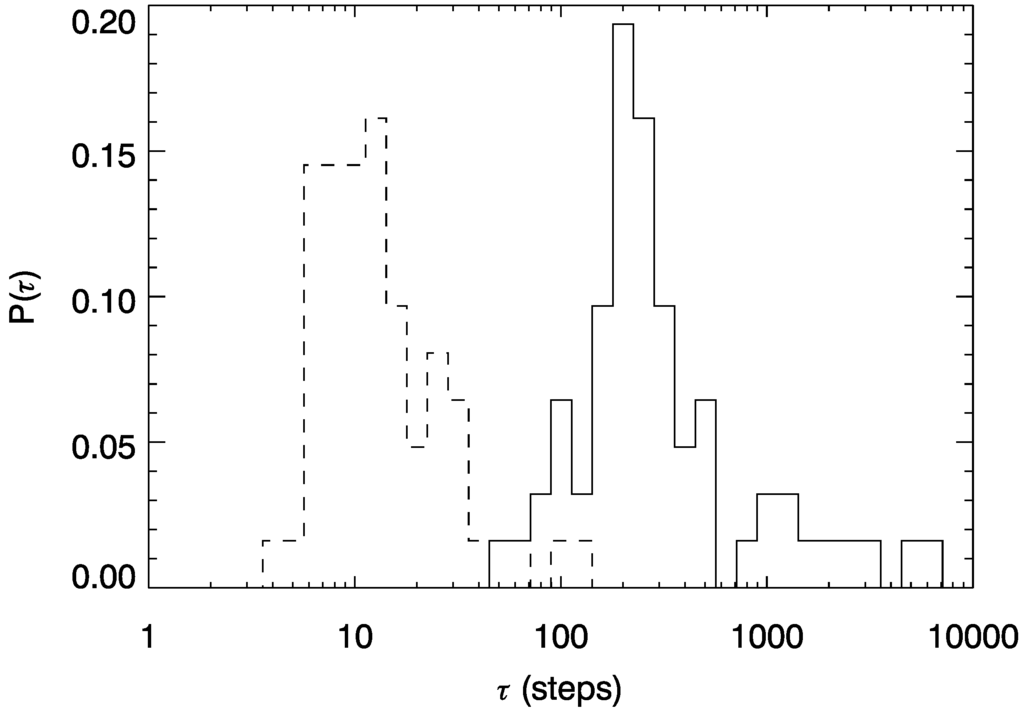
Figure 2.
Relaxation time, τ, for the sixty-two pages in our sample (solid line). Times are exceptionally long, an average of 698 steps, and, on average, a factor of 50 times longer than expected for Markov models with similar sparseness (dotted line). The longest trapping times are for the pages associated with the Gaza War, the Russo-Georgian War, and the page describing Wikipedia itself.
Using Viterbi reconstruction, we can infer the actual transitions that occur on the pages. Coarse-graining subspace transitions to remove flickering, we find a total of 1390 transition events over the sixty-two pages. The average trapping time, page-by-page, is 1201 steps or 190 days. Trapping times are longer than relaxation times. Epoch switching events in our sample do not appear to be concentrated at any special range of time in the last fifteen years; the distribution of switching times is indistinguishable, in a Kolmogorov–Smirnov test, from the distribution of edit times in general.
The two subspaces have distinct levels of expected reverts. We refer to the subspace with higher levels of reverting as “high-conflict” (type one) and the one with lower levels of reverting as “low-conflict” (type two). We emphasize that reverts track only one feature of conflict and that the lower conflict subspace not only shows significant amounts of reverting, but also that (as we shall see) the lower conflict subspace may have more examples of norm-violating conflict. We suggest use of the phrase “type one conflict”, rather than “conflict associated with being in the higher-conflict subspace” (and similarly for “type two conflict”) for simplicity. While we use this language informally, we refer the reader to our discussion above regarding the limitations of reverts as a tracer of more elaborate notions of conflict.
On average, the higher-conflict subspace is roughly 2.5 times more revert-prone than the “low-conflict” subspace. Residency times are also slightly longer in the high-conflict state (207 days vs. 149 days). When the system is trapped in the higher conflict subspace, we find that editing usually, though not always, accelerates: the spacing between edits declines. In the mean, across all pages, users edit on average 2.6 times faster when in the higher conflict subspace; 46 of the 62 pages show this acceleration (high conflict faster than low conflict). The differences in edit rate are driven in part by a long tail of wait times; if we consider not the average time between edits, but the median time between edits, the difference shrinks, and only 37 of 62 pages show acceleration. An example of the distribution of edit timescales is shown in Figure 3, for the case of the George W. Bush page; when the system is in the high-conflict subspace, edits occur almost every three minutes, compared to once every 16 min in the low-conflict subspace. Other differences appear; 37% of edits are made by unregistered users (“IP addresses”) in the high-conflict subspace, compared to 21% of edits in the low-conflict subspace.
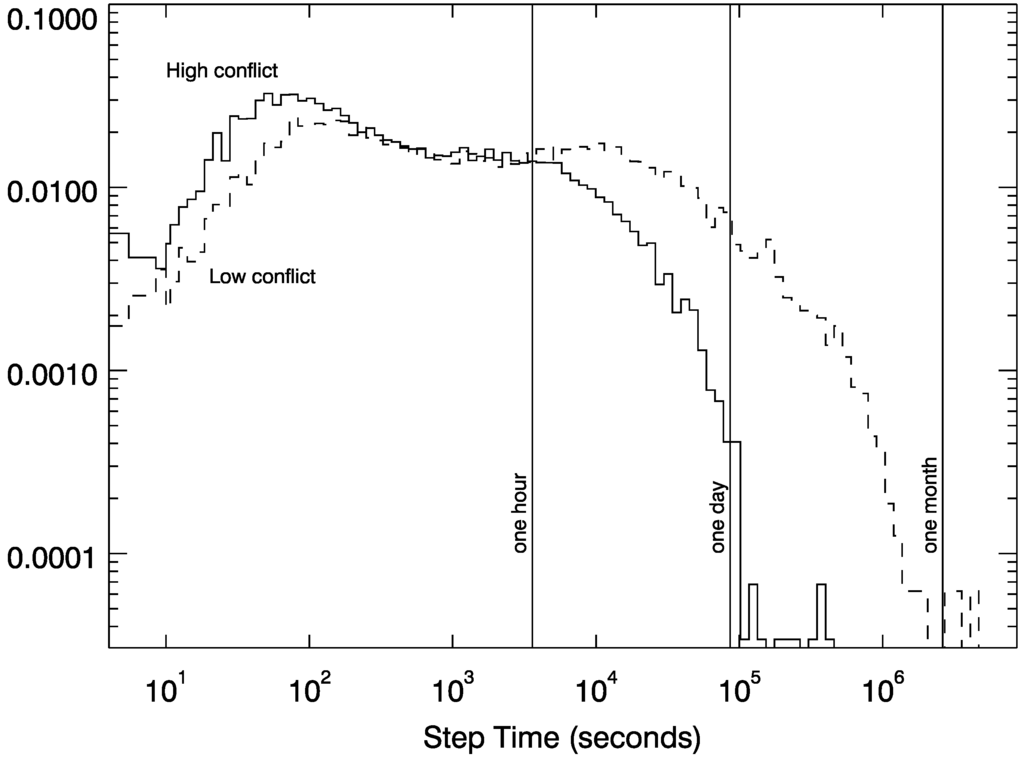
Figure 3.
Distribution of edit rates for type one (high conflict) and type two (low conflict) subspaces. Shown here, as an example, is the spacing between edits on the George W. Bush page. When the system is in the high-conflict subspace, edits occur once every 212 s (median; 3.5 min); in the low-conflict subspace, once every 951 s, or every 16 min. When the system is in the high-conflict subspace, users almost never wait more than a day to take action.
As can be seen in the sample Viterbi reconstruction in Figure 1, the transition from one state to the other is characterized by more than just an increase in revert rate. High- and low-conflict subspaces are characterized by very different interaction styles. Table 2 shows the characteristic motifs over the full set of 62 pages. As expected, the low-conflict subspaces are distinguished by runs of cooperation; however, they are also, unexpectedly, distinguished by runs of reverts. When reverts follow each other, they are usually part of an edit war [20], involving a small number of users repeatedly undoing each other’s work in a tit-for-tat pattern.
Table 2.
Characteristic motifs of the higher (type one) and lower (type two) conflict subspaces across all 62 pages, ranked by partial-KL (see Ref. [43], Equation 2). The lower-conflict subspace is characterized by long runs of cooperation, but also by long runs of reversion. Conversely, the higher-conflict subspace is characterized by more rapid patterns of alternation between R and C moves.
Conversely, vandalism (when a user inserts patently offensive or nonsense content into a page) followed by a (pro-social) revert is one of the characteristics of the high-conflict subspace; the vandal appears as a C move, and the pro-social repair as R. CR events are roughly 2.7 times as common when the system is in the high-conflict subspace, and edit comments that report vandalism (using the keywords “vandal” or the shorthand “rvv”) are 1.9 times as common.
Not all CR motifs are simple vandalism, however. The underlying CR pattern is simply a rejected proposal; repeated CRs in a time series are a signature of repeated rejection of different proposals. As an example, we take a (randomly chosen) short period when the Hillary Clinton page is in the high-conflict subspace [47]; the system entered the high-conflict subspace on 8 February 2007, 09:21 UTC, and left on 17 February 2007, 20:14 UTC). Of the eighty edits of that epoch, there are twelve CR pairs; six of them revert simple vandalism (introduction of sexual slurs), while five involve rejection of content that was contributed by a single editor apparently acting in good faith, and one is ambiguous.
CR motifs are a significant source of the higher levels of system conflict: while 28% of all edits in the high-conflict subspace are reverts, only 8% of reverts remain once CR motifs are dropped. Removing CR motifs, however, increases the relative rates of conflict; the high-conflict subspace has 2.7 times more reverts than the low-conflict subspace when CR pairs are removed, compared to 2.5 in the base condition. When comparing conflict rates between the subspaces, the residue is worse than the mixture.
Transitions are not accompanied by significant population shifts. On average, 20.2% of the users that have appeared in the 100 edits just prior to a transition point also appear in the 100 edits just following. This is, in fact, slightly higher than the persistence we expect across an arbitrary point (17.7%) in our data. Transitions to the high (or low) conflict subspace are not associated with unusual rates of turnover.
3.2. Drivers of Conflict Transitions
For the three event types that may be causal drivers of the transition to or from the high-conflict state—page protection, anti-social users, and external events—there are three potentially relevant questions:
- How many events are there and what fraction are associated with a transition? (Effectiveness)
- What fraction of transitions are associated with an event? (Explanatory power)
- For those transitions that we can associate with an event, what fraction have the expected effect? (Valence)
Item 1 considers a measure of event effectiveness; an event type that more often leads to a transition is more effective. Item 2 considers the extent to which an event type can explain an observed transition; if more transitions are associated with such an event type, that type is the more influential in explaining state switching. Item 3, valence, measures the extent to which the event has the expected effect; when an administrator locks a page, for example, it is natural to assume that the goal is to push the system out of a high-conflict state. Measures of valence only make sense when an event type is effective or has explanatory power.
These measures should be kept distinct, just as they are, for example, in the testing of a new drug. Taking a drug may correlate with a change in the patient’s symptoms (apparent effect); a patient’s symptoms may fluctuate independently of his or her use of the drug (low explanatory power); the drug may increase, rather than reduce, the severity of the symptoms (wrong valence).
3.2.1. Page Protection Events
Administrators can exercise direct control over who edits a page. These page protection events are the primary mechanism for authorities to influence the patterns of editing on the page; they are a blunt and top-down instrument that restricts editing on a particular page to increasingly smaller populations (“hard” protection) or, conversely, opens it up to the wider community (“soft” protection events). Releasing a page from protection can occur by explicit action or by default, when a prior restriction is given an expiration date.
Page protection is mostly ineffective in inducing a transition. Of the 1545 protection events in our data, only 136 (8.8%) occur within ten edits of a transition event; while the effect is statistically significant (35, or 2.3% expected; ), the effect size is small.
Page protection can explain some, but far from all, transition events. There are 1387 transition events that we can, potentially, associate with a page protection (this is less than the total number of transitions, because we do not have reliable records of protection events prior to 10 November 2003); thus, at most, about 9.8% of observed transitions can be associated with page protections (2.5% expected; ).
Norms on the encyclopedia itself urge the use of page protection as a response to conflict. We thus might expect protections to lead to a transition to the low-conflict state; and, conversely, weakening of protection to lead to a transition to the high-conflict state. This happens 80% and 72% of the time, respectively. Interventions are not usually successful in changing a page state, but when they do, their effects do have the correct valence. Page protection appears to operate in the direction administrators expect.
Increasing the window increases the number of transitions we can potentially associate with a protection event. When we enlarge the window size to one hundred edits, 397 of the transition events, or 29%, are now associated with a page protection event. The signal is statistically significant (), but the false detection rate is higher (240, or 17% expected) and the valence less certain (65% rather than 80%). Post-selecting for the optimal window provides an upper bound: at most, only about 11% of transitions can be reliably explained by page protection events.
Top-down control thus has at best only weak effects on the transition between the high- and low-conflict subspace. This is surprising, given the association between vandal-like CR patterns and the high-conflict subspace. “Locking down” a page may lighten the burden for pro-social users who police vandalism, but the high-conflict subspace describes more than just vandalism, and excluding users, even large classes of them, only rarely induces lasting effects on long-term patterns of cooperation and conflict. Conversely, opening up a page rarely leads to an emergence of new conflict. Most top-down actions are unsuccessful in causing a page transition; most transitions can not be explained by reference to top-down action. Comfortingly, however, when associations can be found, they do have the correct valence. It is unusual for a hard protection event, for example, to be associated with a transition to the high-conflict subspace.
3.2.2. Anti-Social User Events
A transition to the high-conflict state could be occasioned by the appearance of particularly anti-social users. Recall that anti-social users are defined by having an average blocking rate higher than 95% of users who have appeared on the page. Anti-social users are said to “dominate” a transition when they make the plurality of edits within the window in question.
There are a total of 710 transitions to the high-conflict state in our data. Of those transitions, 212 are associated, within 10 steps, with the dominance of an anti-social user, compared to an expected 208 in the null. We do not find above-null evidence of anti-social users triggering a transition (). Anti-social user events do not explain the transitions we see in the data. Expanding the range to 100 steps leaves the results unchanged: 255 transitions can be associated with an anti-social user event, compared to 263 in the null. Despite a significant focus on the management of problematic users within the encyclopedia [9,24], their appearance at a particular point does not appear to be a proximate cause of conflict.
This high null-expectation rate (35%) implies that a significant fraction of edits, at least on high-traffic pages, is made by users who have received significant numbers of administratively-imposed sanctions compared to their total number of edits. The simple appearance of this kind of user, however, is ineffective in inducing a transition. They seem to play many roles in the system, including roles consistent with the system remaining in the low-conflict subspace, perhaps due to preference change and dynamical learning of social norms [48].
Anti-social users do not explain transition events, and they are ineffective in inducing a transition.
3.2.3. Major External Events
Not all pages are associated with a topic sufficiently newsworthy that external events can be tracked; once we eliminate pages where less than 10% of months have an article during the page lifetime, we are left with a sample of 59 pages.
Epoch transitions associated with external events include George W. Bush’s election win in November 2004, Bob Dylan’s first number one hit in thirty years in September 2006 and Barack Obama’s election win in November 2008 and his inauguration in January 2009. However, many significant news events are not associated with epoch transitions, including the death of Michael Jackson in 2009 (which left other significant traces on the page [20]) and John Kerry’s election loss in November 2004. Our sample of most-edited pages on Wikipedia includes a page on the 2006 Lebanon War, begun during the war itself. Previous work on breaking news collaborations has found distinctive editing patterns associated with events of this form [49]; in the Lebanon case, the two transitions (to high conflict, on 9 October 2006; and back to low conflict, on 13 August 2013) occur after the war itself has concluded.
There are a total of 1367 transitions that we could potentially associate with newsworthy events. A total of 146 of these transitions are associated (10.6%) with such an event. We expect, on average, 126 events in the null case (9.2%). While there is weak evidence for some above-null association (), the effect size appears to be small: less than 2% of all transition events can be reliably associated with outlier news coverage.
Unusual spikes of real-world news coverage do not explain transition events, and, because of the lack of association, we can also assert that they are ineffective in inducing a transition.
4. Discussion
The results described here provide novel evidence for the existence of an epoch-like structure of conflict and cooperation on Wikipedia, distinguished by behavioral motifs. When we model page editing as a finite state machine, we find that pages can be trapped in one or another subset of their computational subspaces, often for hundreds of days at a time.
At the most coarse-grained level, this trapping places the system in either a low- or high-conflict state. In the high-conflict state, we also see an acceleration of activity by a factor of two or more. Subspaces are characterized by more than just overall levels of conflict: they have distinct motifs of interaction, including tit-for-tat (repeated reverting) in the low-conflict subspace, and propose-reject (C then R) and strong signals of vandal repair in the high-conflict subspace.
The epoch structure revealed by our finite state analysis is defined by far more than just the density of reverts. As can be seen in the example time series in Figure 1, the low-conflict subspace can have long runs of reverting and edit warring. Low-conflict, in other words, does not mean zero conflict and may even mean norm violation; repeated reverting is likely to violate the “three revert rule” (3RR) that prohibits a single user from making three reverts to a page in a row.
In game theoretic accounts of behavior on Wikipedia, reverts can be likened to “defect” moves, and repeated reverts by different users are something we might expect from a tit-for-tat like strategy under noise [16]. The association of long strings of reverts with the low-conflict subspace fits with accounts that put tit-for-tat at the heart of successful resolution of collective action problems from asocial beginnings [50]. The fact that they violate the Wikipedia-specific 3RR norm suggests that this more ancient tit-for-tat strategy may still play an important functional role in managing conflict. Individuals may be banding together: past work on Wikipedia conflict has examined the influence of edit wars that draw in multiple mutually-reverting subgroups, and these more structured interactions may characterize the low-conflict subspace. In the case of edits to the Terri Schiavo page, for example, a network analysis finds three groups of antagonists: one group of administrators, and two groups associated with a particular point of view [10].
The patterns we describe here extend over thousands of edits; our epoch structure is on a longer timescale than the laws that describe short-term, repeated cooperation on timescales of minutes and hours [1]. It is consistent with findings of the importance of long-term system memory in the bursty structure of edit wars [13,31,51,52,53]. Our work goes beyond previous studies to explicitly construct an approximation to the full social grammar of system conflict [54]. Since the number of users far exceeds the number of states, each state is an irreducible coarse-graining of an (implicit) fine-grained, complete account of the mental states of hundreds of individuals acting in a context set by the text on the page itself.
A natural language for the discussion of the transition between conflict and cooperation comes from the critical transitions literature. This work draws on tools from catastrophe theory, critical bifurcations, and phase transitions [55,56]. They focus on the unusual and potentially chaotic dynamics that emerge from the interaction of large numbers of heterogeneously-coupled units. These accounts are often mechanism-neutral and focus on abstract properties of a time series of events. In the literature on critical transitions, for example, one looks for properties such as spatial correlation [57], critical slowing down [58] or flickering [59], and can apply their logic to clinical depression just as well as ecosystem collapse [60]. In its focus on discrete states, rather than continuous fields, our work is complementary to this tradition. It can be thought of as the extension of linguistics to the construction of collectively-implemented social grammars [54].
We have focused on the binary classification revert/non-revert. Recent work [2] has studied the motifs associated with more fine-grained classifications of Wikipedia editing, focusing in particular on the nature of the user making the edit (for example: is this the user’s first edit on Wikipedia, the first on this article, the first in this “session”?). In a mixed strategy that combines quantitative and qualitative analysis, they looked at short timescale motifs of these more complex patterns associated with content co-production “routines” [61,62]. Our work suggests that extending this analysis, using the hidden Markov model tools presented here, to longer timescales may well reveal correspondingly longer timescale epochs, which may or may not be nested within the conflict and cooperation structure we find here. Indeed, a parallel analysis of different time series would allow us to determine the extent to which different cultural practices coexist and interact: how the strategies people use to improve content vary in the presence of the strategies people use to defuse conflict. Indeed, one of the most influential essays in Wikipedia’s norm network explicitly combines the two: the so-called “BOLD, revert, discuss cycle” [63], which explicitly links content improvement and content reverting [24].
Our work also connects to the now-extensive literature in organizational behavior on Wikipedia and Computer-Supported Collaborative Work (CSCW). Our findings on the dynamic switching between patterns of interaction is consistent with work that has emphasized the different ways that Wiki-like organizations can deal with resource flows that lead to either generative or constrained tensions [64]. Studies in this literature have emphasized the role of the community structure [14,65] and describe systems like Wikipedia as a knowledge conversation [66], where the interaction between participants, and between participants and the wider context of content on the encyclopedia [67,68,69], rather than just between participant and content, determines the system’s evolution over time.
We have chosen a particularly simple computational model for our system; formally, a system at the base of the Chomsky hierarchy [70]. A finite-state machine can, in short runs, approximate more sophisticated grammars, but the pumping lemma (and its simple probabilistic extension; see [1,71]) means that, on sufficiently long timescales, it must fail. Indeed, our epoch-like structure already suggests the existence of long-range memory: repeated CR motifs, for example, in one month, correlate with the presence of CR motifs many months later. Examination of the detailed structure of our machines may suggest priors for higher-order grammars, such as the context-free languages that allow for nested pairing.
Within the field of time series analysis itself, an open question concerns the relationship between these simple finite-state models and the epsilon machines [72,73,74]; while hidden Markov models generically imply infinite-state epsilon machines, recent progress has suggested ways to lossily compress these representations to a finite system [75]. These results currently suggest that, because of the exceedingly long relaxation times (small spectral gaps) seen in Wikipedia, estimating some of the quantities relevant to the computational mechanics paradigm is impossible even for the very longest sequences (~ data points) we can observe. However, other recent work in this tradition suggests that, with a sufficiently explicit phenomenological model, estimation of quantities such as excess entropy may be possible [76]. Our current belief is that the discovery of these very small spectral gaps suggests that a finite-state machine is only an approximate model, and that the true nature of memory storage and processing is likely to be more interesting yet. Its description may demand novel mathematical structures beyond the simple cases currently found in the quantitative literature.
We examined three prima facie plausible mechanisms for switching the system between these two states: top-down administrative actions, the appearance of unusually anti-social editors and major external events in the real world. In only one case, administrator action, did we find statistically-significant associations compatible with a causal role for state-space switching.
One of the characteristics of the high-conflict subspace are motifs often (though not always) associated with vandalism—the repeated CR pairs. Part of the explanation of the transition to the high-conflict subspace ought to involve new sources of this particular behavior. Efforts to exclude anonymous IP addresses, or registered but untrusted users, suggest that administrators are able to recognize sources of vandalism and intervene to prevent them. However, while vandalism is more commonly associated with the higher-conflict type one state, the majority of edits do not show signatures of vandalism, and locking down a page is largely ineffective in shifting the system to the lower-conflict type two state. Moreover, transitions in (or out) of the higher conflict state are not associated with higher user turnover and so cannot be explained by an unexpected influx of new users.
Top-down effects are not the only thing that can drive pages between higher and lower conflict states: the effects of multiple user-user and user-page interactions can conspire to leave long-term traces on the page, as shown by the mathematical model of [77,78]. In this model, user behavior is dictated by a set of parameters that describe when a user will attempt to alter the page or, conversely, adapt to the page as it stands and, via discussion, to the opinions of others. When the user population is fixed, this process drives the system to consensus. However, when user turnover is sufficiently high (and the tolerance of different opinions sufficiently low), the system can be driven into a state of permanent conflict. Between these two phases is a line of critical coexistence, where, paralleling what we see in our analysis here, periods of consensus are interrupted by stretches of war.
These simple mathematical models provide an intriguing way for explaining our results. The bistability we observe empirically may be the consequence of an underlying process of belief revision when augmented by the presence of a common resource for information sharing. The question then becomes: what drives Wikipedia to the critical line separating these two phases?
While we are able to rule out spikes in news coverage as deterministic exogenous drivers, one of the key limitations of our work here is our inability to rule out more complicated interactions with the larger world. Long-term system memory may reside in users, in the text of the page, or well beyond the bounds of the encyclopedia. In the end, Wikipedia is not an isolated system. Its internal logic is coupled to the wider world, one rich in its own bursty and autocorrelated structure [79,80,81,82,83], and there is no clear division between the two [84,85]. It is this joint process we observe and must analyze: a small and shifting fragment of the Internet as a whole.
5. Conclusions
Conflict is endemic to social life. Rather than exclude conflict altogether, however, most societies attempt to manage the ways in which conflict and cooperation interact. The co-existence of conflict and cooperation is a basic theme of studies of intra-group conflict in the biological sciences [86,87]. Quarreling and fighting are not simply unstructured forms of letting off steam. They are complex phenomena that make significant cognitive demands on individuals [88,89] and that result in epochs that decouple from day-night cycles and far outlast any particular clash [90,91]. Wikipedia and IT-mediated social participation systems more generally, are unusual in the extent to which their underlying system norms foreground, and even valorize, conflict during co-production. In their broader structures, however, the phenomena we see here would be familiar to researchers studying regularities in conflict across the biological world.
Finite-state modeling of Wikipedia’s social grammar provides new insight into how individual-level complexity leaves a trace on the system as a whole. In a large-scale, virtual environment, with many tens of thousands of participants drawn from the wider Internet, we find that conflict retains a complex logical structure, with context-dependent system memory, which means that any particular event must be understood in a wider context that extends many months back, and may help define the system’s future years hence. The dynamics of this memory and its associated patterns of conflict cannot be captured by simple top-down accounts.
Our results indicate new points of contact for the mathematical, social, and biological sciences. By measuring the essentially computational properties of a social world—its spectral gap or the logic of its subspaces—we gain new insight into the ways in which our species can trap itself in the very patterns it creates.
Acknowledgments
I thank Bradi Heaberlin (Indiana University), Taha Yasseri (Oxford Internet Institute), Brian Keegan (Harvard Business School), Cosma Shalizi (Carnegie Mellon University), and my three anonymous referees for comments on early versions of this manuscript, as well as the Global Brain Institute of Vrije Universiteit Brussel, Belgium, at which this work was presented. I thank Nate Metheny (Santa Fe Institute) for the construction of the machines Ganesha, Saraswati and Laxmi, which made the calculations in this paper possible. This work was supported in part by National Science Foundation Grant EF-1137929.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. Articles in Our Analysis
The number of edits in each page’s time series is listed in parentheses after the article title, along with a simple classification: George_W._Bush (45,448; biography, politician), United_States (33,725; geography), Wikipedia (32,592; technology), Michael_Jackson (27,587; biography, entertainment), Catholic_Church (24,813, religion), Barack_Obama (23,889; biography, politician), World_War_II (23,173; event, political), Global_warming (20,003; science), 2006_Lebanon_War (19,972; event, political), Islam (18,523; religion), Canada (18,150; geography), Eminem (18,066; biography, entertainment), September_11_attacks (17,564; event), Paul_McCartney (16,973; biography, entertainment), Israel (16,790; geographic), Hurricane_Katrina (16,753; event), Xbox_360 (16,753; technology), Pink_Floyd (16,037; biography, entertainment), Iraq_War (15,891; event), Blackout_(Britney_Spears_album) (15,832; entertainment), Turkey (15,663; geography), Super_Smash_Bros._Brawl (15,432; technology), World_War_I (15,292; event), Gaza_War (14,920; event), Lost_(TV_series) (14,897; entertainment), Blink-182 (14,789; entertainment), Scientology (14,727; religion), John_Kerry (14,307; biography, political), Heroes_(TV_series) (14,223; entertainment), Australia (14,186; geography), China (14,023; geography), Bob_Dylan (13,916; biography, entertainment), Neighbors (13,547; entertainment), The_Holocaust (13,346; event), Atheism (13,295; religion), Hilary_Duff (13,222; biography, entertainment), Mexico (13,213; geography), The_Dark_Knight_(film) (13,025; entertainment), France (12,800; geographic), John_F._Kennedy (12,788; biography, politician), Lindsay_Lohan (12,757; biography, entertainment), Girls’_Generation (12,746; entertainment), Argentina (12,745; geography), Virginia_Tech_massacre (12,682; event), RMS_Titanic (12,451; event), Russo-Georgian_War (12,365; event), Homosexuality (12,170; science), Circumcision (12,149; religion, science), Hillary_Rodham_Clinton (11,981; biography, politician), Star_Trek (11,919; entertainment), Shakira (11,712; biography, entertainment), Sweden (11,666; geography), New_Zealand (11,639; geography), Paris_Hilton (11,635; biography, entertainment), Wizards_of_Waverly_Place (11,520; entertainment), Genghis_Khan (11,410; biography, politician), Cuba (11,390; geography), Linux (11,316; technology), Che_Guevara (11,250; biography, politician), Golf (11,141; entertainment), iPhone (11,085; technology), God (10,731; religion).
Appendix B. Choosing the Number of States in an HMM
Table B1.
Using AIC and BIC to choose the number of states in a hidden Markov model fit. Here, we take an actual model from our data (the 8-state best fit model for the God page), use that model to generate a new time series of equal length (10,731 samples) and attempt to fit a new model, using either AIC or BIC to select the preferred number of states in a manner similar to Refs. [92,93]. The table lists the fraction of the time this process led to a preferred machine of each size, for the two different penalties. Both AIC and BIC tend to underestimate model complexity; in general, BIC performs worse, significantly underestimating the true number of states. AIC performs better, recovering the correct number of states nearly half the time.
| Number of States | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 (Truth) | 9 | 10 |
| AIC | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 37.5% | 7.2% | 45.8% | 9.3% | 0.0% |
| BIC | 0.0% | 0.0% | 0.0% | 20.8% | 54.1% | 23.9% | 1.0% | 0.0% | 0.0% | 0.0% |
Choosing the number of states to include in an HMM is an example of a model selection problem; one is selecting between models with different numbers of states. In general, the larger the HMM, the better the data can be fit: when does one stop improving the fit because the model is becoming “too complex”? A generic solution to model selection is cross-validation: one fits the model using a subset of the data (the “training set”), and sees how well the model performs when predicting out of sample (the “test set” or “hold-out” set).
Cross-validation uses the phenomenon of over-fitting to determine when a model is too complex: if a model has too many parameters, it will overfit to the training set, finding “patterns” that are really due to coincidence. These patterns will fail to hold in the test set, and will degrade performance on the fit; this degradation can be measured, and one stops increasing model complexity when performance on the test set first starts to decline. Standard cross-validation techniques work best when the data are independently sampled, i.e., when it is possible to construct a test set that is uncorrelated with the training set conditional on the underlying model. As increasing levels of correlation appear in the data, the construction of an appropriate training set becomes difficult.
When, as is the case for HMMs, the model is Bayesian, another method is possible: the likelihood penalty. To use a likelihood penalty, you fit the model to all of the data and note the posterior log-likelihood. You then apply a penalty, reducing the log-likelihood depending on features related to the complexity of the model, including, usually, the total number of parameters. After applying this penalty, it is usually the case that one particular model, often not the most complex one, maximizes the penalized log-likelihood, and this is the one considered preferred. Numerous likelihood penalties exist, including the Bayesian Information Criterion (BIC [36]), the Bayesian Evidence (introduced in [94]; used on Wikipedia data in [1,16]) and the Akaike Information Criterion (AIC; introduced in [35]).
The existence of both long- and short-range correlations in data fit using an HMM makes the use of cross-validation and hold-out techniques difficult. The work in [92] proposes two methods for cross-validation on HMMs that attempt to compensate for the failure of independence. Both methods have difficulties, and work well only on a subset of HMMs, where correlations are not particularly long-range and the transition matrix is not too sparse. Because we find that both conditions are violated in our data, we do not attempt cross-validation tests. The work in [92] also considers the AIC and BIC methods; they find that both work well in recovering the true size of an HMM used to generate simulated data. We are not aware of work that has tested the use of Bayesian Evidence on simulated data and defer this interesting, but involved, question to later work.
The authors of Ref. [92] find that, when it fails, BIC tends to slightly underestimate, and AIC to slightly overestimate, the true number of states, although both criteria work well. Work by [93] confirms this result. However, both papers consider regimes that do not directly apply here, and both papers found cases where (for example) BIC significantly underestimated model complexity. In addition, both papers consider problems with an order of magnitude less data than we have and true model HMM sizes much smaller than ten. In the main text, we use the AIC penalty, a common choice made across the biological and signal processing communities, and strongly argued for on general grounds by [95] when the goal is minimizing prediction loss.
To validate our choice and, in particular, to determine whether AIC or BIC produces more valid results for the regimes relevant here, we did an in-depth test with a particular model: the eight-state HMM associated with the God page. We took the derived HMM for this page and used it to generate 96 simulated datasets of equal length to the original. We then ran our fitting code on each of these datasets and compared what happened when we used the AIC and the BIC criteria to select the preferred number of states. Consistent with [92,93], we found that BIC tended to underestimate model complexity, choosing machines significantly smaller than the true number and, in fact, never recovering the true system size. We found, by contrast, that AIC worked better; like BIC, it still often underestimated model complexity, but did so by smaller amounts. Conversely, a small fraction of the time (less than 10%), it preferred a model that was one state more complex than reality.
Because our main concern is to minimize overfitting and the introduction of fictitious structure, without losing too much of the actual structure in the process, AIC’s slight tendency to underestimate model complexity is not a major concern. A small fraction of the time (roughly 10%), AIC preferred a machine that was one state larger; however, robustness tests show that none of our main conclusions depend on the exact number of states being that chosen by the AIC criterion. We recover the same conclusions, for example, if we arbitrarily fix the number of states equal to twelve. It is worth noting that we do not believe the “true” model of Wikipedian conflict is itself a finite-state machine [1]; i.e., the fundamental problem is finding the best approximation, rather than locating the correct model within a known class.
Appendix C. Relaxation Time, Mixing Time, Decay Time, Trapping Time
By the Levin–Peres–Wilmer theorem [96], the relaxation time, τ, defined in Equation (1) above, provides an upper bound on the mixing time, , the maximum time it takes an arbitrary initial condition to be no further than a small distance ϵ from the stationary distribution, where distance is defined as the maximum absolute value difference for any state occupation probability. In particular, we have
where is the smallest value in the stationary probability distribution; of characteristic order in the HMMs considered in this paper. These relationships hold when the HMM is “reversible” and “irreducible”; in empirical work, such as that presented here, those conditions are almost always satisfied. For example, they hold when states in an HMM have a small self-loop probability, no matter how small, and a directed path exists between any two states; both of which are true by default when using a Dirichlet prior and are true by inspection in our EM fits. This justifies a useful and intuitive interpretation of τ as a measure of how quickly an arbitrary initial condition converges to the average, as well as suggesting more sophisticated measures that take into account the allowable level of deviation (ϵ) and inhomogeneities in the stationary distribution itself ().
The relaxation time τ is related to another natural quantity, the decay time of the second eigenvector. The time constant for decay, , is related to as
which implies that
On doing a Laurent series expansion around equal to unity, we find
which implies that, to zeroth order in (i.e., when relaxation times are long), as used in Equation (2). All of the machines in this paper are in the regime where the relaxation time and decay time are nearly equivalent.
In contrast to relaxation, mixing, and decay time, trapping time is an empirically-measured quantity. To compute trapping time, you define a set of internal states of interest, and then use the Viterbi algorithm to reconstruct the maximum-likelihood path through a particular time series. Trapping time is then defined as the average length of time the system spends in the set of interest before it leaves. In this paper, we track trapping time for the two main subspaces as defined by the sign structure of the second eigenvector.
References
- DeDeo, S. Collective Phenomena and Non-Finite State Computation in a Human Social System. PLoS ONE 2013, 8, e75818. [Google Scholar] [CrossRef] [PubMed]
- Keegan, B.C.; Lev, S.; Arazy, O. Analyzing Organizational Routines in Online Knowledge Collaborations: A Case for Sequence Analysis in CSCW. In Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work and Social Computing, San Francisco, CA, USA, 27 February–2 March 2016.
- Jelinek, F. Continuous speech recognition by statistical methods. Proc. IEEE 1976, 64, 532–556. [Google Scholar] [CrossRef]
- Bahl, L.; Baker, J.; Cohen, P.; Dixon, N.; Jelinek, F.; Mercer, R.; Silverman, H. Preliminary results on the performance of a system for the automatic recognition of continuous speech. In Proceedings of the ICASSP ’76 IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 12–14 April 1976; Volume 1, pp. 425–429.
- DeRose, S.J. Grammatical category disambiguation by statistical optimization. Comput. Linguist. 1988, 14, 31–39. [Google Scholar]
- Church, K.W. A Stochastic Parts Program and Noun Phrase Parser for Unrestricted Text. In Proceedings of the ANLC ’88 Second Conference on Applied Natural Language Processing, Association for Computational Linguistics, Stroudsburg, PA, USA, 22–27 August 1988; pp. 136–143.
- Salzberg, S.L.; Delcher, A.L.; Kasif, S.; White, O. Microbial gene identification using interpolated Markov models. Nucleic Acids Res. 1998, 26, 544–548. [Google Scholar] [CrossRef] [PubMed]
- Darmon, D.; Sylvester, J.; Girvan, M.; Rand, W. Predictability of user behavior in social media: Bottom-up v. top-down modeling. In Proceedings of the 2013 IEEE International Conference on Social Computing (SocialCom), Washington, DC, USA, 8–14 September 2013; pp. 102–107.
- Reagle, J.M. Good Faith Collaboration: The Culture of Wikipedia; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Kittur, A.; Suh, B.; Pendleton, B.A.; Chi, E.H. He Says, She Says: Conflict and Coordination in Wikipedia. In Proceedings of the CHI ’07 SIGCHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 30 April–3 May 2007; ACM: New York, NY, USA, 2007; pp. 453–462. [Google Scholar]
- Kane, G.C.; Johnson, J.; Majchrzak, A. Emergent Life Cycle: The Tension Between Knowledge Change and Knowledge Retention in Open Online Coproduction Communities. Manag. Sci. 2014, 60, 3026–3048. [Google Scholar] [CrossRef]
- Kriplean, T.; Beschastnikh, I.; McDonald, D.W.; Golder, S.A. Community, Consensus, Coercion, Control: Cs*W or How Policy Mediates Mass Participation. In Proceedings of the GROUP ’07 2007 International ACM Conference on Supporting Group Work, Sanibel Island, FL, USA, 4–7 November 2007; ACM: New York, NY, USA, 2007; pp. 167–176. [Google Scholar]
- Viégas, F.B.; Wattenberg, M.; Dave, K. Studying Cooperation and Conflict Between Authors with History Flow Visualizations. In Proceedings of the CHI ’04 SIGCHI Conference on Human Factors in Computing Systems, Vienna, Austria, 24–29 April 2004; ACM: New York, NY, USA, 2004; pp. 575–582. [Google Scholar]
- Kane, G.C. A Multimethod Study of Information Quality in Wiki Collaboration. ACM Trans. Manag. Inf. Syst. 2011, 2. [Google Scholar] [CrossRef]
- Arazy, O.; Nov, O.; Patterson, R.; Yeo, L. Information Quality in Wikipedia: The Effects of Group Composition and Task Conflict. J. Manag. Inf. Syst. 2011, 27, 71–98. [Google Scholar] [CrossRef]
- DeDeo, S. Group Minds and the Case of Wikipedia. Hum. Comput. 2014, 1, 5–29. [Google Scholar] [CrossRef]
- Open Data for the paper Conflict and Computation on Wikipedia:A Finite-State Machine Analysis of Editor Interactions. Available online: https://bit.ly/wikihmm (accessed on 5 July 2016).
- SFIHMM. high-speed C code for the estimation of Hidden Markov Models (finite state machines) on arbitrary time series, for Viterbi Path Reconstruction, PCCA+ (Perron-Cluster Cluster Analysis), and for the generation of simulated data from HMMs. Available online: http://bit.ly/sfihmm (accessed on 5 July 2016).
- Geertz, C. Thick description: Toward an interpretive theory of culture. In Readings in the Philosophy of Social Science; Martin, M., McIntyre, L.C., Eds.; MIT Press: Cambridge, MA, USA, 1994; pp. 213–231. [Google Scholar]
- Yasseri, T.; Sumi, R.; Rung, A.; Kornai, A.; Kertész, J. Dynamics of Conflicts in Wikipedia. PLoS ONE 2012, 7, e38869. [Google Scholar] [CrossRef] [PubMed]
- Kittur, A.; Chi, E.H.; Suh, B. What’s in Wikipedia?: Mapping Topics and Conflict Using Socially Annotated Category Structure. In Proceedings of the CHI ’09 SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009; ACM: New York, NY, USA, 2009; pp. 1509–1512. [Google Scholar]
- Brandes, U.; Lerner, J. Visual Analysis of Controversy in User-Generated Encyclopedias? Inf. Vis. 2008, 7, 34–48. [Google Scholar] [CrossRef]
- Suh, B.; Chi, E.H.; Pendleton, B.A.; Kittur, A. Us vs. them: Understanding social dynamics in Wikipedia with revert graph visualizations. In Proceedings of the IEEE Symposium on Visual Analytics Science and Technology, Sacramento, CA, USA, 30 October–1 November 2007; pp. 163–170.
- Heaberlin, B.; DeDeo, S. The Evolution of Wikipedia’s Norm Network. Future Internet 2016, 8. [Google Scholar] [CrossRef]
- Hinds, P.J.; Bailey, D.E. Out of sight, out of sync: Understanding conflict in distributed teams. Organ. Sci. 2003, 14, 615–632. [Google Scholar] [CrossRef]
- Jehn, K.A. A qualitative analysis of conflict types and dimensions in organizational groups. Adm. Sci. Q. 1997, 42, 530–557. [Google Scholar] [CrossRef]
- Kittur, A.; Kraut, R.E. Beyond Wikipedia: Coordination and Conflict in Online Production Groups. In Proceedings of the CSCW ’10 2010 ACM Conference on Computer Supported Cooperative Work, Savannah, GA, USA, 6–10 February 2010; ACM: New York, NY, USA, 2010; pp. 215–224. [Google Scholar]
- Collier, B.; Bear, J. Conflict, Criticism, or Confidence: An Empirical Examination of the Gender Gap in Wikipedia Contributions. In Proceedings of the CSCW ’12 ACM 2012 Conference on Computer Supported Cooperative Work, Seattle, WA, USA, 11–15 February 2012; ACM: New York, NY, USA, 2012; pp. 383–392. [Google Scholar]
- Auray, N.; Poudat, C.; Pons, P. Democratizing scientific vulgarization. The balance between cooperation and conflict in French Wikipedia. Obs. (OBS*) J. 2007, 1. [Google Scholar] [CrossRef]
- Reagle, J.M., Jr. “Be Nice”: Wikipedia norms for supportive communication. New Rev. Hypermedia Multimedia 2010, 16, 161–180. [Google Scholar] [CrossRef]
- Viégas, F.B.; Wattenberg, M.; Kriss, J.; van Ham, F. Talk before you type: Coordination in Wikipedia. In Proceedings of the 40th IEEE Annual Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 3–6 January 2007; p. 78.
- Baum, L.E.; Petrie, T. Statistical Inference for Probabilistic Functions of Finite State Markov Chains. Ann. Math. Stat. 1966, 37, 1554–1563. [Google Scholar] [CrossRef]
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes, 3rd edition: The Art of Scientific Computing; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Mills, T.C. time series Techniques for Economists; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Deuflhard, P.; Dellnitz, M.; Junge, O.; Schütte, C. Computation of essential molecular dynamics by subdivision techniques. In Computational Molecular Dynamics: Challenges, Methods, Ideas; Springer: New York, NY, USA, 1999; pp. 98–115. [Google Scholar]
- Cordes, F.; Weber, M.; Schmidt-Ehrenberg, J. Metastable Conformations via Successive Perron-Cluster Cluster Analysis of Dihedrals; Konrad-Zuse-Zentrum für Informationstechnik Berlin (ZIB): Berlin, Germany, 2002. [Google Scholar]
- Deuflhard, P.; Weber, M. Robust Perron cluster analysis in conformation dynamics. Linear Algebra Appl. 2005, 398, 161–184. [Google Scholar] [CrossRef]
- Noé, F.; Horenko, I.; Schütte, C.; Smith, J.C. Hierarchical analysis of conformational dynamics in biomolecules: Transition networks of metastable states. J. Chem. Phys. 2007, 126, 155102. [Google Scholar] [CrossRef] [PubMed]
- Forney, G.D., Jr. The Viterbi algorithm. Proc. IEEE 1973, 61, 268–278. [Google Scholar] [CrossRef]
- DeDeo, S.; Hawkins, R.X.D.; Klingenstein, S.; Hitchcock, T. Bootstrap Methods for the Empirical Study of Decision-Making and Information Flows in Social Systems. Entropy 2013, 15, 2246–2276. [Google Scholar] [CrossRef]
- Klingenstein, S.; Hitchcock, T.; DeDeo, S. The civilizing process in London’s Old Bailey. Proc. Natl. Acad. Sci. USA 2014, 111, 9419–9424. [Google Scholar] [CrossRef] [PubMed]
- Hill, B.M.; Shaw, A. Page Protection: Another Missing Dimension of Wikipedia Research. In Proceedings of the OpenSym ’15 11th International Symposium on Open Collaboration, San Francisco, CA, USA, 25 May 2015; ACM: New York, NY, USA, 2015; pp. 15:1–15:4. [Google Scholar]
- New York Times Developer Network. Search interface for New York Times Archives. Available online: http://developer.nytimes.com (accessed on 5 July 2016).
- The Guardian Open Platform. Search interface for Guardian Archives. Available online: http://open-platform.theguardian.com (accessed on 5 July 2016).
- Hillary Clinton: Revision history. Available online: https://en.wikipedia.org/w/index.php?title=HillaryClintonoffset=20070217204656limit=87action=history (accessed on 5 July 2016).
- DeDeo, S. Major Transitions in Political Order. In From Matter to Life: Information and Causality; Walker, S.I., Davies, P.C.W., Ellis, G., Eds.; Cambridge University Press: Cambridge, UK,, 2015; Available online: http://arxiv.org/abs/1512.03419 (accessed on 5 July 2016).
- Keegan, B.; Gergle, D.; Contractor, N. Staying in the Loop: Structure and Dynamics of Wikipedia’s Breaking News Collaborations. In Proceedings of the WikiSym ’12 Eighth Annual International Symposium on Wikis and Open Collaboration, Linz, Austria, 27–29 August 2012.
- Axelrod, R.; Hamilton, W. The evolution of cooperation. Science 1981, 211, 1390–1396. [Google Scholar] [CrossRef] [PubMed]
- Sumi, R.; Yasseri, T.; Rung, A.; Kornai, A.; Kertész, J. Characterization and prediction of Wikipedia edit wars. In Proceedings of the ACM WebSci ’11, Koblenz, Germany, 14–17 June 2011; pp. 1–3.
- Sumi, R.; Yasseri, T.; Rung, A.; Kornai, A.; Kertész, J. Edit Wars in Wikipedia. In Proceedings of the IEEE Third International Conference on Social Computing (SocialCom), Boston, MA, USA, 9–11 October 2011; pp. 724–727.
- Yasseri, T.; Kertész, J. Value production in a collaborative environment. J. Stat. Phys. 2013, 151, 414–439. [Google Scholar] [CrossRef]
- Jackendoff, R. Language, Consciousness, Culture: Essays on Mental Structure; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Scheffer, M.; Bascompte, J.; Brock, W.A.; Brovkin, V.; Carpenter, S.R.; Dakos, V.; Held, H.; van Nes, E.H.; Rietkerk, M.; Sugihara, G. Early-warning signals for critical transitions. Nature 2009, 461, 53–59. [Google Scholar] [CrossRef] [PubMed]
- Lade, S.J.; Gross, T. Early warning signals for critical transitions: A generalized modeling approach. PLoS Comput. Biol. 2012, 8, e1002360. [Google Scholar] [CrossRef] [PubMed]
- Dakos, V.; van Nes, E.H.; Donangelo, R.; Fort, H.; Scheffer, M. Spatial correlation as leading indicator of catastrophic shifts. Theor. Ecol. 2010, 3, 163–174. [Google Scholar] [CrossRef]
- Dakos, V.; Scheffer, M.; van Nes, E.H.; Brovkin, V.; Petoukhov, V.; Held, H. Slowing down as an early warning signal for abrupt climate change. Proc. Natl. Acad. Sci. USA 2008, 105, 14308–14312. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Dearing, J.A.; Langdon, P.G.; Zhang, E.; Yang, X.; Dakos, V.; Scheffer, M. Flickering gives early warning signals of a critical transition to a eutrophic lake state. Nature 2012, 492, 419–422. [Google Scholar] [CrossRef] [PubMed]
- Van de Leemput, I.A.; Wichers, M.; Cramer, A.O.; Borsboom, D.; Tuerlinckx, F.; Kuppens, P.; van Nes, E.H.; Viechtbauer, W.; Giltay, E.J.; Aggen, S.H.; et al. Critical slowing down as early warning for the onset and termination of depression. Proc. Natl. Acad. Sci. USA 2014, 111, 87–92. [Google Scholar] [CrossRef] [PubMed]
- Feldman, M.S.; Pentland, B.T. Reconceptualizing organizational routines as a source of flexibility and change. Adm. Sci. Q. 2003, 48, 94–118. [Google Scholar] [CrossRef]
- Pentland, B.T.; Hærem, T. Organizational Routines as Patterns of Action: Implications for Organizational Behavior. Annu. Rev. Organ. Psychol. Organ. Behav. 2015, 2, 465–487. [Google Scholar] [CrossRef]
- Wikipedia:BOLD, revert, discuss cycle. Available online: https://en.wikipedia.org/wiki/Wikipedia:BOLD,revert,discusscycle (accessed on 5 July 2016).
- Faraj, S.; Jarvenpaa, S.; Majchrzak, A. Knowledge Collaboration in Online Communities. Organ. Sci. 2011, 22, 1224–1239. [Google Scholar] [CrossRef]
- Gerald, C.; Kane, R.G.F. The Shoemaker’s Children: Using Wikis for Information Systems Teaching, Research, and Publication. MIS Q. 2009, 33, 1–17. [Google Scholar]
- Majchrzak, A.; Faraj, S.; Kane, G.C.; Azad, B. The Contradictory Influence of Social Media Affordances on Online Communal Knowledge Sharing. J. Comput. Med. Commun. 2013, 19, 38–55. [Google Scholar] [CrossRef]
- Hansen, S.; Berente, N.; Lyytinen, K. Wikipedia, Critical Social Theory, and the Possibility of Rational Discourse. Inf. Soc. 2009, 25, 38–59. [Google Scholar] [CrossRef]
- Ransbotham, S.; Kane, G.C. Membership turnover and collaboration success in online communities: Explaining rises and falls from grace in Wikipedia. MIS Q. 2011, 35, 613–627. [Google Scholar]
- Ransbotham, S.; Kane, G.; Lurie, N. Network Characteristics and the Value of Collaborative User-Generated Content. Mark. Sci. 2012, 31, 387–405. [Google Scholar] [CrossRef]
- Chomsky, N. Aspects of the Theory of Syntax; MIT Press: Cambridge, MA, USA, 1965. [Google Scholar]
- Rabin, M.O.; Scott, D. Finite Automata and Their Decision Problems. IBM J. Res. Dev. 1959, 3, 114–125. [Google Scholar] [CrossRef]
- Crutchfield, J.P.; Young, K. Inferring statistical complexity. Phys. Rev. Lett. 1989, 63. [Google Scholar] [CrossRef] [PubMed]
- Crutchfield, J.P. The calculi of emergence: Computation, dynamics and induction. Phys. D Nonlinear Phenom. 1994, 75, 11–54. [Google Scholar] [CrossRef]
- Crutchfield, J.P.; Shalizi, C.R. Thermodynamic depth of causal states: Objective complexity via minimal representations. Phys. Rev. E 1999, 59. [Google Scholar] [CrossRef]
- Marzen, S.E.; Crutchfield, J.P. Predictive Rate-Distortion for Infinite-Order Markov Processes. J. Stat. Phys. 2016, 163, 1312–1338. [Google Scholar] [CrossRef]
- Marzen, S.E.; Crutchfield, J.P. Statistical signatures of structural organization: The case of long memory in renewal processes. Phys. Lett. A 2016, 380, 1517–1525. [Google Scholar] [CrossRef]
- Török, J.; Iñiguez, G.; Yasseri, T.; San Miguel, M.; Kaski, K.; Kertész, J. Opinions, conflicts, and consensus: Modeling social dynamics in a collaborative environment. Phys. Rev. Lett. 2013, 110, 088701. [Google Scholar] [CrossRef] [PubMed]
- Iñiguez, G.; Török, J.; Yasseri, T.; Kaski, K.; Kertész, J. Modeling social dynamics in a collaborative environment. EPJ Data Sci. 2014, 3, 1–20. [Google Scholar] [CrossRef]
- Barabasi, A.L. The origin of bursts and heavy tails in human dynamics. Nature 2005, 435, 207–211. [Google Scholar] [CrossRef] [PubMed]
- Leskovec, J.; McGlohon, M.; Faloutsos, C.; Glance, N.; Hurst, M. Patterns of Cascading Behavior in Large Blog Graphs. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; Chapter 60. pp. 551–556.
- Stehlé, J.; Barrat, A.; Bianconi, G. Dynamical and bursty interactions in social networks. Phys. Rev. E 2010, 81, 035101. [Google Scholar] [CrossRef] [PubMed]
- Zhi-Dan, Z.; Hu, X.; Ming-Sheng, S.; Tao, Z. Empirical analysis on the human dynamics of a large-scale short message communication system. Chin. Phys. Lett. 2011, 28, 068901. [Google Scholar]
- Karsai, M.; Kaski, K.; Barabási, A.L.; Kertész, J. Universal features of correlated bursty behaviour. Sci. Rep. 2012, 2. [Google Scholar] [CrossRef] [PubMed]
- Wellman, B.; Salaff, J.; Dimitrova, D.; Garton, L.; Gulia, M.; Haythornthwaite, C. Computer Networks as Social Networks: Collaborative Work, Telework, and Virtual Community. Annu. Rev. Sociol. 1996, 22, 213–238. [Google Scholar] [CrossRef]
- Wellman, B. Computer Networks As Social Networks. Science 2001, 293, 2031–2034. [Google Scholar] [CrossRef] [PubMed]
- Flack, J.C.; Krakauer, D.C.; de Waal, F.B. Robustness mechanisms in primate societies: A perturbation study. Proc. R. Soc. B Biol. Sci. 2005, 272, 1091–1099. [Google Scholar] [CrossRef] [PubMed]
- Flack, J.C.; Girvan, M.; De Waal, F.B.; Krakauer, D.C. Policing stabilizes construction of social niches in primates. Nature 2006, 439, 426–429. [Google Scholar] [CrossRef] [PubMed]
- DeDeo, S.; Krakauer, D.; Flack, J. Inductive game theory and the dynamics of animal conflict. PLoS Comput. Biol. 2010, 6, e1000782. [Google Scholar] [CrossRef] [PubMed]
- Hobson, E.A.; DeDeo, S. Social Feedback and the Emergence of Rank in Animal Society. PLoS Comput. Biol. 2015, 11, e1004411. [Google Scholar] [CrossRef] [PubMed]
- DeDeo, S.; Krakauer, D.; Flack, J. Evidence of strategic periodicities in collective conflict dynamics. J. R. Soc. Interface 2011, 8, 1260–1273. [Google Scholar] [CrossRef] [PubMed]
- Flack, J.C. Multiple time-scales and the developmental dynamics of social systems. Philos. Trans. R. Soc. B Biol. Sci. 2012, 367, 1802–1810. [Google Scholar] [CrossRef] [PubMed]
- Celeux, G.; Durand, J.B. Selecting hidden Markov model state number with cross-validated likelihood. Comput. Stat. 2008, 23, 541–564. [Google Scholar] [CrossRef]
- Bacci, S.; Pandolfi, S.; Pennoni, F. A comparison of some criteria for states selection in the latent Markov model for longitudinal data. Adv. Data Anal. Classif. 2014, 8, 125–145. [Google Scholar] [CrossRef]
- MacKay, D.J. Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, MA, USA, 2003. [Google Scholar]
- Burnham, K.P.; Anderson, D.R. Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach; Springer Science & Business Media: New York, NY, USA, 2003. [Google Scholar]
- Levin, D.A.; Peres, Y.; Wilmer, E.L. Markov Chains and Mixing Times; American Mathematical Society: Providence, RI, USA, 2009. [Google Scholar]
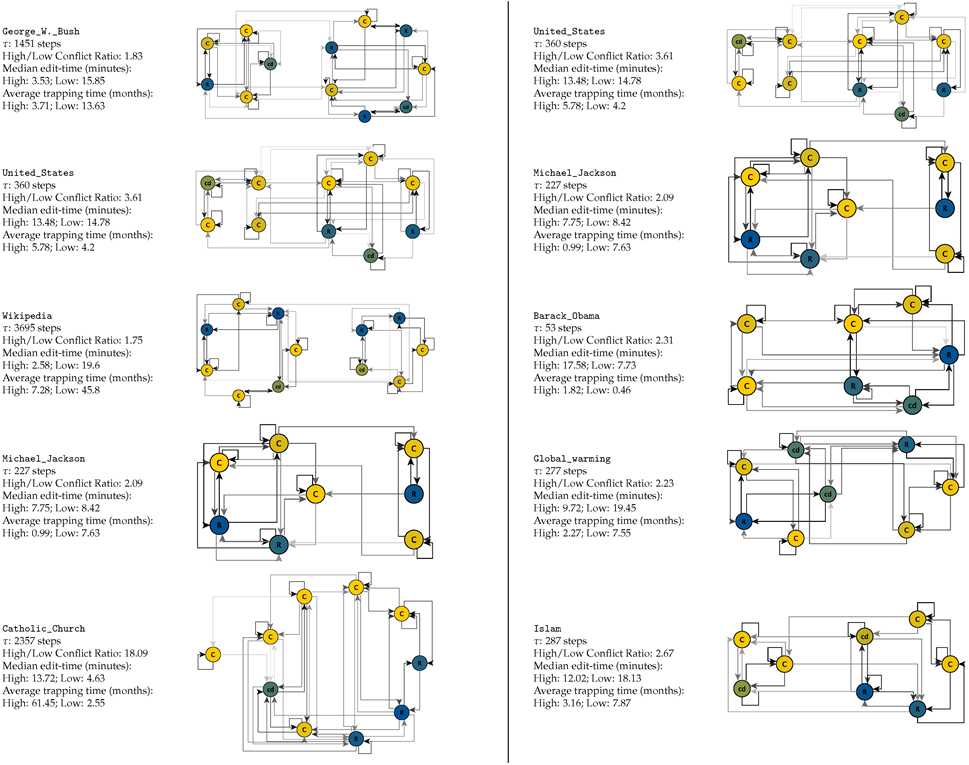
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).