



Model Retraining upon Concept Drift Detection in Network Traffic Big Data

 ,
,  and
and
Abstract
1. Introduction and Background
2. Related Works
2.1. Traditional Drift Detection Methods
2.2. Concept Drift in Machine Learning
2.3. Isolation Forest Algorithm
2.4. Model Retraining Strategies
2.5. Research Gaps and Challenges
3. Data and Preprocessing
3.1. Dataset Overview
3.2. Data Preprocessing
- (i)
- first, columns that were deemed irrelevant to the study (community_id, ts (timestamp)) were dropped;
- (ii)
- duplicate rows were dropped;
- (iii)
- to assess the data quality, the missing values were analyzed;
- (iv)
- the data distribution was determined, mainly to help us determine if numerical features would have to be binned; and finally,
- (v)
- the data was binned.
3.2.1. Missing Values Analysis
3.2.2. Data Distribution
3.2.3. Binning the Data
4. Algorithms and Evaluation Metrics Used
4.1. Random Forest
Evaluating Random Forest
- True Positive (TP): The number of cases where the model correctly predicted the positive class.
- True Negative (TN): The number of cases where the model correctly predicted the negative class.
- False Positive (FP): The number of cases where the model incorrectly predicted the positive class when it was actually negative. This is also known as a Type I error.
- False Negative (FN): The number of cases where the model incorrectly predicted the negative class when it was actually positive. This is also known as a Type II error.
4.2. Isolation Forest
Identifying Concept Drift
5. Experimentation Including the Results and Discussion
5.1. Framework for Concept Drift Detection
- Splitting data into training and testing sets;
- Training an initial model and recording baseline performance;
- Processing new data in batches;
- Detecting drift based on changes in anomaly rates derived from Isolation Forest output;
- Retraining the model upon significant drift detection;
- Validating the retrained model’s performance.
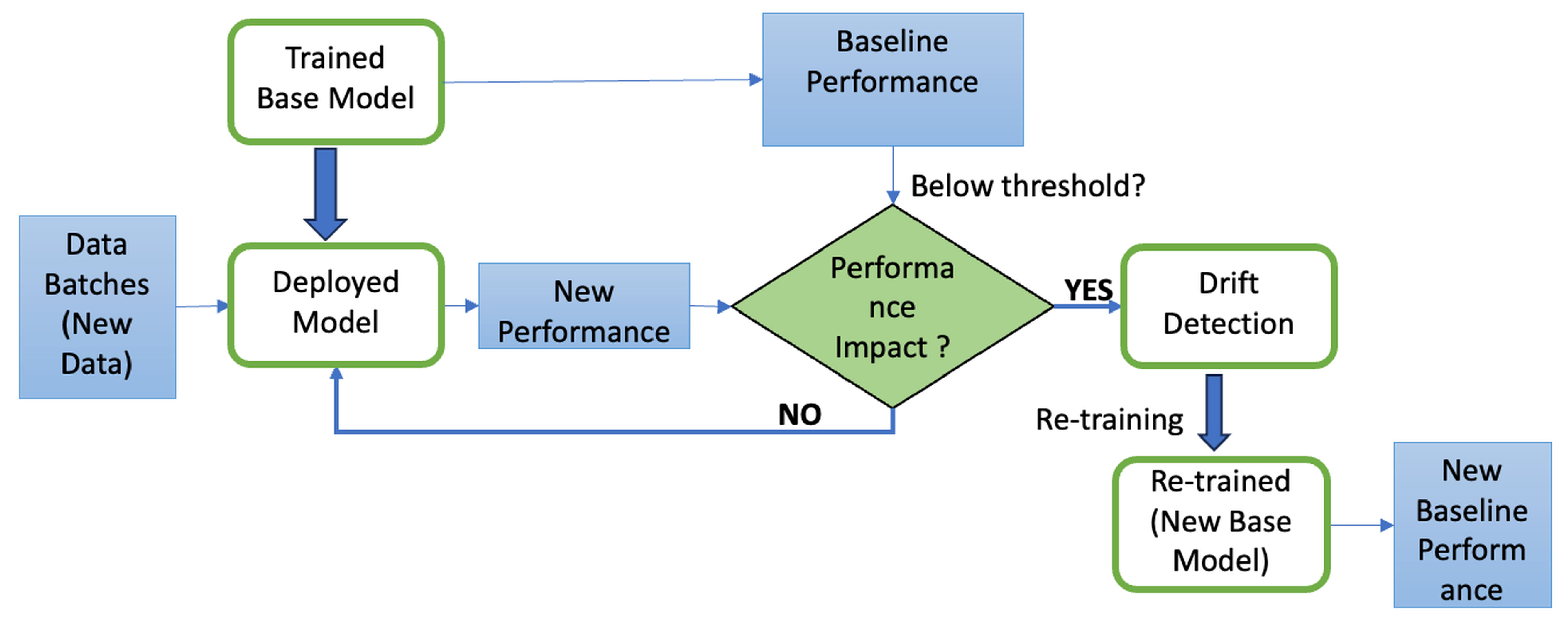


5.2. Experimental Configurations Utilized
5.2.1. Hardware Specifications
5.2.2. Software Specifications
- Apache Spark;
- Isolation Forest (from scikit-learn);
- Mac/Ubuntu OS.
- ○
- Python: 3.6;
- ○
- PySpark: 3.0.0;
- ○
- NumPy: 1.19.0;
- ○
- pandas: 1.2.0;
- ○
- scikit-learn: 0.24.0;
- ○
- matplotlib: 3.3.0;
- ○
- seaborn: ≥0.11.0.
5.2.3. Parameters/Hyperparameters
- ○
- Contamination, which is the expected proportion of anomalies in the dataset, was kept at 0.01;
- ○
- n_estimators, which is the number of base estimators (trees) n the ensemble, was kept at 100;
- ○
- n_jobs, which is the number of parallel jobs to run for model training/testing, was kept at 1;
- ○
- num_iterations, which is the number of times the Isolation Forest algorithm runs with different samples, was kept at 2.
- ○
- sample_fraction, which is the fraction of data to sample for each Isolation Forest run, was kept at 0.01;
- ○
- variance_threshold, which is the threshold for feature selection based on variance, was kept at 0.01;
- ○
- confidence_threshold, which is the threshold for considering an anomaly as high confidence, was kept at 0.7
5.3. Developing the Base Model
5.4. Deploying the Model
5.5. Drift Detection
5.6. Retraining the Model
5.6.1. Testing Statistical Significance
5.6.2. Incremental Retraining or Full Retraining?
5.7. Limitations of This Work
6. Conclusions
7. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label_Technique | Encoded_Value | Count | Technique Name | Technique Description |
|---|---|---|---|---|
| none | 0 | 350,339 | Absence of certain techniques or actions an attacker might use during an attack | |
| T1587 | 2 | 21,405 | Develop Capabilities | Adversaries may internally develop custom tools like malware or exploits to support operations across various stages of their attack lifecycle. |
| T1592 | 2 | 21,405 | Gather Victim Host Information | Adversaries may collect detailed information about a victim’s hosts, such as IP addresses, roles, and system configurations, to aid in targeting. |
| T1590 | 20 | 21,208 | Gather Victim Network Information | Adversaries may collect information about a victim’s networks, such as IP ranges, domain names, and topology, to support targeting efforts. |
| T1046 | 12 | 16,819 | Network Service Discovery | Adversaries may scan remote hosts and network devices to identify running services and potential vulnerabilities for exploitation. |
| T1595 | 22 | 8587 | Active Scanning | Adversaries may conduct active reconnaissance by directly probing target systems through network traffic to gather information useful for targeting. |
| duplicate | 23 | 3068 | Techniques may be duplicated because a single technique can be used to achieve multiple tactics, or because a tactic may have multiple techniques to accomplish it | |
| T1548 | 18 | 3061 | Abuse Elevation Control Mechanism | Adversaries may exploit built-in privilege control mechanisms to escalate their permissions and perform high-risk tasks on a system. |
| T1589 | 3 | 292 | Gather Victim Identity Information | Adversaries may collect personal and sensitive identity details such as employee names, email addresses, credentials, and MFA configurations to facilitate targeted attacks. |
| T1203 | 6 | 18 | Exploitation for Client Execution | Adversaries may exploit software vulnerabilities in client applications to execute arbitrary code, often targeting widely used programs to gain unauthorized access. |
| T1071 | 13 | 14 | Application Layer Protocol | Adversaries may use OSI application layer protocols to embed malicious commands within legitimate traffic, evading detection by blending in with normal network activity. |
| T1210 | 4 | 11 | Exploitation of Remote Services | Adversaries may exploit software vulnerabilities in remote services to gain unauthorized access to internal systems, facilitating lateral movement within a network. |
| T1566 | 19 | 10 | Phishing | Threat adversaries may employ phishing tactics, including spear phishing and mass spam campaigns, to deceive individuals into revealing sensitive information or installing malicious software. |
| T1190 | 15 | 8 | Exploit Public-Facing Application | Adversaries may exploit vulnerabilities in Internet-facing systems such as software bugs, glitches, or misconfigurations to gain unauthorized access to internal networks. |
| T1204 | 5 | 7 | User Execution | Adversaries often manipulate users through social engineering to execute malicious code, such as opening infected attachments or clicking deceptive links. |
| T1059 | 21 | 5 | Command and Scripting Interpreter | Adversaries may exploit command and scripting interpreters such as PowerShell, Python, or Unix Shell to execute malicious commands and scripts across various platforms. |
| T1547 | 8 | 4 | Boot or Logon Autostart Execution | Adversaries may configure system settings to automatically execute programs during boot or logon such as modifying registry keys or placing files in startup folders to maintain persistence or escalate privileges on compromised systems. |
| T1571 | 7 | 3 | Non-Standard Port | Adversaries may exploit non-standard port and protocol pairings |
| T1112 | 9 | 3 | Modify Registry | Adversaries may manipulate the Windows Registry to conceal configuration data, remove traces during cleanup, or implement persistence and execution strategies. |
| T1136 | 14 | 3 | Create Account | Adversaries may create local, domain, or cloud accounts to maintain access to victim systems, enabling credentialed access without relying on persistent remote access tools. |
| T1133 | 10 | 1 | External Remote Services | Adversaries may exploit external-facing remote services to gain initial access or maintain persistence within a network. |
| T1505 | 16 | 1 | Server Software Component | Adversaries may exploit legitimate extensible development features in enterprise server applications to install malicious components that establish persistent access and extend the functionality of the main application. |
| T1546 | 17 | 1 | Event Triggered Execution | Adversaries may exploit system event-triggered mechanisms to establish persistence or escalate privileges on compromised systems. |
| T1557 | 11 | 1 | Adversary-in-the-Middle | Adversaries may position themselves between networked devices using Adversary-in-the-Middle (AiTM) techniques to intercept and manipulate communications, enabling actions like credential theft, data manipulation, or replay attacks. |
References
- Gama, J.; Medas, P.; Castillo, G.; Rodrigues, P. Learning with Drift Detection. In Lecture Notes in Computer Science; Springer: New York, NY, USA, 2004; pp. 286–295. [Google Scholar] [CrossRef]
- Xu, D.; Wang, Y.; Meng, Y.; Zhang, Z. An Improved Data Anomaly Detection Method Based on Isolation Forest. In Proceedings of the 2017 10th International Symposium on Computational Intelligence and Design, Hangzhou, China, 9–10 December 2017; Available online: https://www.researchgate.net/publication/323059482_An_Improved_Data_Anomaly_Detection_Method_Based_on_Isolation_Forest (accessed on 3 October 2024).
- Moomtaheen, F.; Bagui, S.S.; Bagui, S.C.; Mink, D. Extended Isolation Forest for Intrusion Detection in Zeek Data. Information 2024, 15, 404. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]
- Page, E.S. Continuous inspection schemes. Biometrika 1954, 41, 100–115. [Google Scholar] [CrossRef]
- Hinkley, D.V. Inference about the change-point from cumulative sum tests. Biometrika 1971, 58, 509–523. [Google Scholar] [CrossRef]
- Ross, G.J.; Adams, N.M.; Tasoulis, D.K.; Hand, D.J. Exponentially weighted moving average charts for detecting concept drift. Pattern Recognit. Lett. 2012, 33, 191–198. [Google Scholar] [CrossRef]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. 2014, 46, 1–37. [Google Scholar] [CrossRef]
- Baena-Garcia, M.; Campo-Avila, J.; Fidalgo, R.; Bifet, A.; Gavalda, R.; Morales-Bueno, R. Early Drift Detection Method. 2006. Available online: https://www.researchgate.net/publication/245999704_Early_Drift_Detection_Method (accessed on 3 March 2025).
- Bifet, A.; Gavalda, R. Learning from time-changing data with adaptive windowing. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; pp. 443–448. [Google Scholar]
- Webb, G.I.; Hyde, R.; Cao, H.; Nguyen, H.L.; Petitjean, F. Characterizing concept drift. Data Min. Knowl. Discov. 2016, 30, 964–994. [Google Scholar] [CrossRef]
- Žliobaitė, I.; Pechenizkiy, M.; Gama, J. An overview of concept drift applications. In Big Data Analysis: New Algorithms for a New Society; Springer: New York, NY, USA, 2016; pp. 91–114. [Google Scholar]
- Barros, R.S.; Cabral, D.R.; Gonçalves, P.M., Jr.; Santos, S.G. RDDM: Reactive drift detection method. Expert Syst. Appl. 2018, 90, 344–355. [Google Scholar] [CrossRef]
- Ding, Z.; Fei, M. An anomaly detection approach based on isolation forest algorithm for streaming data using sliding window. IFAC Proc. Vol. 2013, 46, 12–17. [Google Scholar] [CrossRef]
- Togbe, M.U.; Chabchoub, Y.; Boly, A.; Barry, M.; Chiky, R.; Bahri, M. Anomalies detection using isolation in concept-drifting data streams. Computers 2021, 10, 13. [Google Scholar] [CrossRef]
- Xu, H.; Pang, G.; Wang, Y.; Wang, Y. Deep Isolation Forest for Anomaly Detection. IEEE Trans. Knowl. Data Eng. 2023, 35, 12591–12604. Available online: https://ieeexplore.ieee.org/document/10108034 (accessed on 3 October 2024). [CrossRef]
- Krawczyk, B.; Minku, L.L.; Gama, J.; Stefanowski, J.; Woźniak, M. Ensemble learning for data stream analysis: A survey. Inf. Fusion 2017, 37, 132–156. [Google Scholar] [CrossRef]
- Losing, V.; Hammer, B.; Wersing, H. Incremental on-line learning: A review and comparison of state of the art algorithms. Neurocomputing 2018, 275, 1261–1274. [Google Scholar] [CrossRef]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under concept drift: A review. IEEE Trans. Knowl. Data Eng. 2018, 31, 2346–2363. [Google Scholar] [CrossRef]
- MITRE ATT&CK®. Available online: https://attack.mitre.org/ (accessed on 18 September 2024).
- Bagui, S.S.; Mink, D.; Bagui, S.C.; Madhyala, P.; Uppal, N.; McElroy, T.; Plenkers, R.; Elam, M.; Prayaga, S. Introducing the UWF-ZeekDataFall22 Dataset to Classify Attack Tactics from Zeek Conn Logs Using Spark’s Machine Learning in a Big Data Framework. Electronics 2023, 12, 5039. [Google Scholar] [CrossRef]
- UWF. Zeekdata22 Dataset. Available online: https://datasets.uwf.edu/ (accessed on 10 January 2025).
- Bagui, S.; Mink, D.; Bagui, S.; Ghosh, T.; McElroy, T.; Paredes, E.; Khasnavis, N.; Plenkers, R. Detecting Reconnaissance and Discovery Tactics from the MITRE ATT&CK Framework in Zeek Conn Logs Using Spark’s Machine Learning in the Big Data Framework. Sensors 2022, 22, 7999. [Google Scholar] [PubMed]
- MITRE ATT&CK®. Resource Development. Resource Development, Tactic TA0042-Enterprise. Available online: https://attack.mitre.org/tactics/TA0042/ (accessed on 10 January 2025).
- MITRE ATT&CK®. Reconnaissance. Reconnaissance, Tactic TA0043-Enterprise. Available online: https://attack.mitre.org/tactics/TA0043/ (accessed on 21 May 2025).
- MITRE ATT&CK®. Discovery. Discovery, Tactic TA0007—Enterprise. Available online: https://attack.mitre.org/tactics/TA0007/ (accessed on 21 May 2025).
- MITRE ATT&CK®. Privilege Escalation. Privilege Escalation, Tactic TA0004—Enterprise. Available online: https://attack.mitre.org/tactics/TA0004/ (accessed on 21 May 2025).
- MITRE ATT&CK®. Defense Evasion. Defense Evasion, Tactic TA0005—Enterprise. Available online: https://attack.mitre.org/tactics/TA0005/ (accessed on 21 May 2025).
- American Registry for Internet Numbers. IPv4 Private Address Space and Filtering. Available online: https://www.arin.net/reference/research/statistics/address_filters/ (accessed on 21 May 2025).
- Bowyer, M. Well-Known TCP/UDP Ports. Available online: https://pbxbook.com/other/netports.html (accessed on 21 May 2025).
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; Chapman & Hall: Boca Raton, FL, USA, 1984. [Google Scholar]
- Bagui, S.; Bennett, T. Optimizing Random Forests: Spark Implementations of Random Genetic Forests. BOHR Int. J. Eng. (BIJE) 2022, 1, 44–52. [Google Scholar] [CrossRef]
- “3.3.2.2. Accuracy Score”, Scikit-Learn. Retrieved 6th of August 2022. Available online: https://scikit-learn.org/stable/modules/model_evaluation.html#accuracy-score (accessed on 20 July 2024).
- Powers, D.M.W. Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]


| Feature | Count | Percentage |
|---|---|---|
| Duration | 317,051 | 45.30% |
| Service | 317,407 | 45.30% |
| History | 8206 | 1.20% |
| Features | Range |
|---|---|
| Duration (seconds) | 0 to 3560 |
| Source Ports | 0 to 65,535 |
| Destination Ports | 0 to 65,535 |
| Original Bytes | 0 to 218,820 |
| Response Bytes | 0 to 2,174,312 |
| … | … |
| Tactics | Binned Value | Definition | Distribution |
|---|---|---|---|
| None | 0 | Benign data | 50.02% |
| Resource Development | 1 | Tactic involves an adversary setting up resources to maintain access and advance their attack [24] | 39.33% |
| Reconnaissance | 2 | The process of collecting initial information or intelligence about a target [25] | 7.35% |
| Discovery | 3 | Adversary will seek information on the system [26] | 2.40% |
| Privilege Escalation | 4 | Tactic involving various techniques adversaries use to gain higher-level permissions within a system or network [27] | 0.44% |
| Defense Evasion | 5 | Uses methods to avoid being detected [28] | 0.44% |
| Other Categories | 6 | Includes the following: Lateral Movement, Execution, Command and Control, Persistence, Collection, and Initial Access [20] | 0.02% |
| Protocols | Binned Value | Distribution |
|---|---|---|
| UDP | 0 | 55.47% (388,470 records) |
| TCP | 1 | 44.39% (310,910 records) |
| ICMP | 2 | 0.14% (960 records) |
| Service | Binned Value | Count |
|---|---|---|
| dns | 0 | 381,896 |
| dhcp | 2 | 633 |
| http | 3 | 168 |
| ntp | 4 | 169 |
| ssl | 5 | 37 |
| radius | 6 | 1 |
| gssapi | 7 | 5 |
| smb,gssapi | 8 | 4 |
| dce_rpc,smb,gssapi,ntlm | 9 | 1 |
| ftp | 10 | 5 |
| gssapi,smb,dce_rpc,ntlm | 11 | 3 |
| ntlm,smb,gssapi | 12 | 3 |
| smb,ntlm,gssapi | 13 | 1 |
| snmp | 14 | 3 |
| gssapi,smb | 15 | 1 |
| gssapi,smb,ntlm | 16 | 2 |
| ntlm,gssapi,dce_rpc,smb | 17 | 1 |
| (blanks) | 18 | 317,407 |
| Category | IP Address |
|---|---|
| Invalid IP | |
| Private (RFC 1918) | Class A 10.0.0.0/8 |
| Private (RFC 1918) | Class B 172.16.0.0/12 |
| Private (RFC 1918) | Class C 192.168.0.0/16 |
| Public IP | Known Services (80, 443, etc.) |
| Public IP | Other |
| Localhost | 127.0.0.0/8 |
| Link-local | 169.254.0.0/16 |
| Special | Multicast, Reserved (RFC 6890) |
| Category | Port Range |
|---|---|
| Well Known | 1–1023 |
| Registered | 1024–49,151 |
| Dynamic | 49,152–65,535 |
| Invalid | 0 or none |
| Conn_State | Binned Value | Count |
|---|---|---|
| S0 | 0 | 587,615 |
| SF | 1 | 75,749 |
| SHR | 2 | 5249 |
| OTH | 3 | 9897 |
| SH | 4 | 20,682 |
| RSTRH | 5 | 338 |
| REJ | 6 | 306 |
| RSTR | 7 | 300 |
| RSTO | 8 | 158 |
| S1 | 9 | 39 |
| S2 | 10 | 7 |
| No Data | 0 Bytes | Explanation |
|---|---|---|
| Tiny | 1–50 bytes | Typically control packets |
| Small | 51–100 bytes | Small requests/responses |
| Medium | 101–500 bytes | Typical web requests |
| Large | 501–1000 bytes | Larger requests/responses |
| Very Large | 1001–10,000 bytes | File transfers |
| Huge | >10,000 bytes | Large file transfers |
| Total Records | Accuracy | Precision | Recall | F1-Score | Total Time (s) | |
|---|---|---|---|---|---|---|
| Training | 534,365 | 98.99% | 98.99% | 98.99% | 98.99% | |
| Testing | 134,398 | 98.95% | 98.95% | 98.95% | 98.95% | |
| 1271.84 |
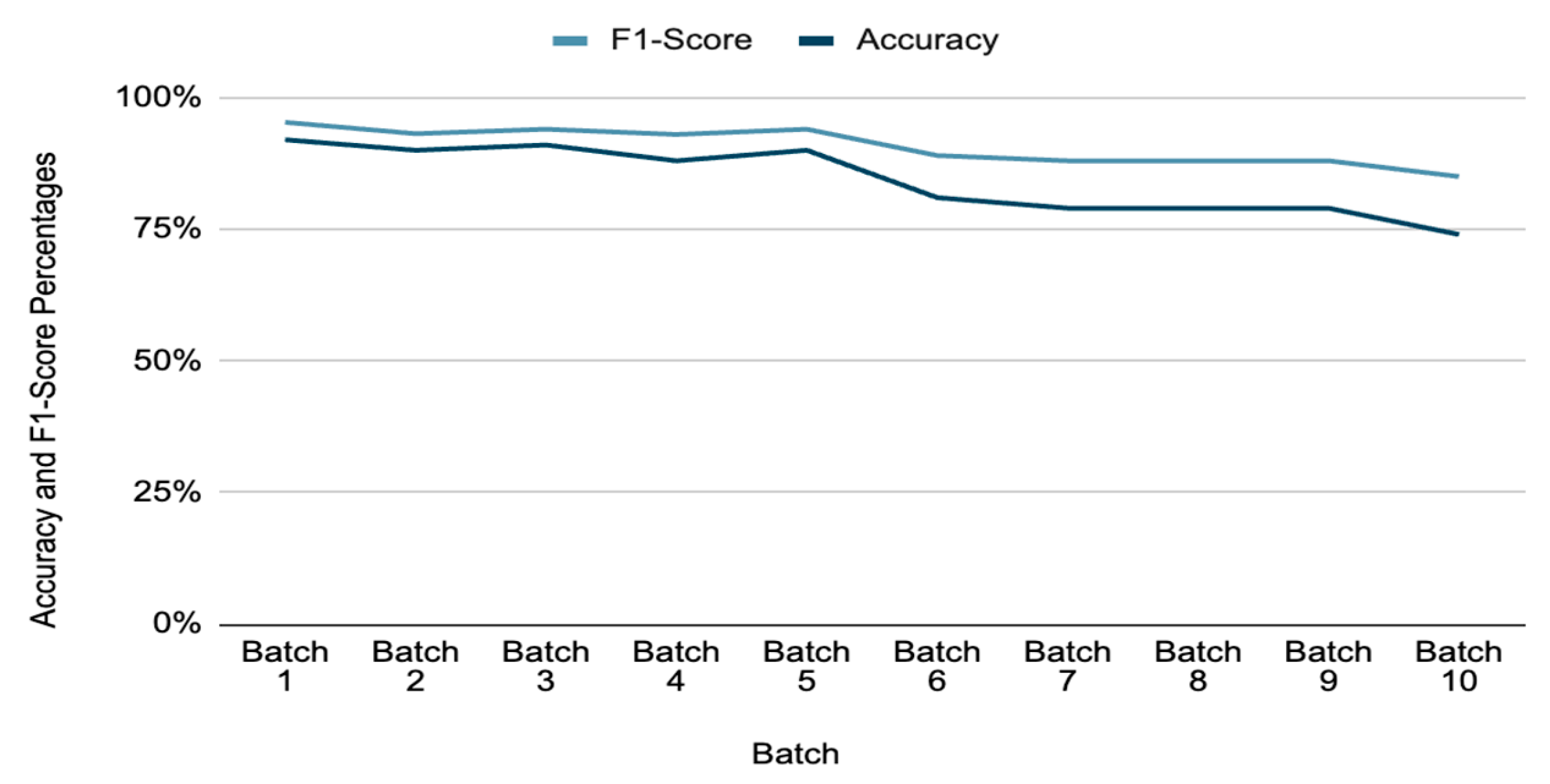
| Batch | Total Records | Accuracy | Precision | Recall | F1 | FN | TP | TN | FP | Run Times (s) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 213 | 92.49% | 0.9941 | 91.85% | 95.48% | 18 | 148 | 36 | 0 | 10.78 |
| 2 | 146 | 89.73% | 100% | 88.28% | 93.78% | 12 | 97 | 21 | 1 | 7.68 |
| 3 | 116 | 90.52% | 100% | 89.52% | 94.47% | 14 | 66 | 7 | 0 | 7.66 |
| 4 | 88 | 87.50% | 100% | 86.08% | 92.52% | 7 | 58 | 5 | 0 | 7.39 |
| 5 | 71 | 90.14% | 100% | 89.06% | 94.21% | 16 | 52 | 8 | 0 | 7.63 |
| 6 | 58 | 81.03% | 100% | 80.36% | 89.11% | 12 | 52 | 3 | 0 | 7.21 |
| 7 | 76 | 78.95% | 100% | 78.67% | 88.06% | 17 | 49 | 2 | 0 | 6.22 |
| 8 | 97 | 79.38% | 100% | 79.38% | 88.51% | 36 | 74 | 0 | 0 | 7.05 |
| 9 | 119 | 78.99% | 100% | 78.99% | 88.27% | 50 | 109 | 1 | 0 | 6.49 |
| 10 | 156 | 73.72% | 100% | 73.38% | 84.64% | 58 | 118 | 2 | 0 | 5.89 |
| Averages | 84.25% | 99.94% | 83.56% | 90.91% |
| Batch Number | Baseline Anomaly Rate | Anomaly Score | New Anomaly Rate | Drift Factor |
|---|---|---|---|---|
| 1 | 0.03 | 0.695162946 | 0.028173105 | 0.9391035 |
| 2 | 0.03 | 0.699885789 | 0.057822131 | 1.92740436 |
| 3 | 0.03 | 0.713253628 | 0.087895827 | 2.92986091 |
| 4 | 0.03 | 0.687121205 | 0.118933493 | 3.96444977 |
| 5 | 0.03 | 0.70820591 | 0.146855251 | 4.89517504 |
| 6 | 0.03 | 0.694885641 | 0.179279279 | 5.97597598 |
| 7 | 0.03 | 0.704640135 | 0.209580838 | 6.98602794 |
| 8 | 0.03 | 0.700928723 | 0.238491238 | 7.94970795 |
| 9 | 0.03 | 0.68240109 | 0.268608414 | 8.95361381 |
| 10 | 0.03 | 0.701152359 | 0.298250729 | 9.94169096 |
| Batch | Total Records | Accuracy | Precision | Recall | F1- Score | FN | FP | TN | FP | Run Times (s) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 213 | 91.58% | 100% | 89.76% | 94.60% | 17 | 149 | 36 | 0 | 10.90 |
| 2 | 146 | 87.02% | 99% | 85.32% | 91.63% | 16 | 93 | 21 | 1 | 7.91 |
| 3 * | 116 | 85.05% | 100% | 83.75% | 91.16% | 13 | 67 | 7 | 0 | 7.25 |
| 4 | 88 | 87.14% | 100% | 86.15% | 92.56% | 9 | 56 | 5 | 0 | 7.30 |
| 5 | 71 | 88.16% | 100% | 86.76% | 92.91% | 9 | 59 | 8 | 0 | 7.84 |
| 6 | 58 | 91.04% | 100% | 90.63% | 95.08% | 6 | 58 | 3 | 0 | 7.67 |
| 7 | 76 | 92.65% | 100% | 92.42% | 96.06% | 5 | 61 | 2 | 0 | 6.27 |
| 8 | 97 | 90.91% | 100% | 90.91% | 95.24% | 10 | 100 | 0 | 0 | 7.19 |
| 9 | 119 | 95.63% | 100% | 95.60% | 97.75% | 7 | 152 | 1 | 0 | 6.76 |
| 10 | 156 | 95.51% | 100% | 95.45% | 97.67% | 8 | 168 | 2 | 0 | 6.08 |
| Averages | 90.47% | 99.90% | 89.68% | 94.47% |
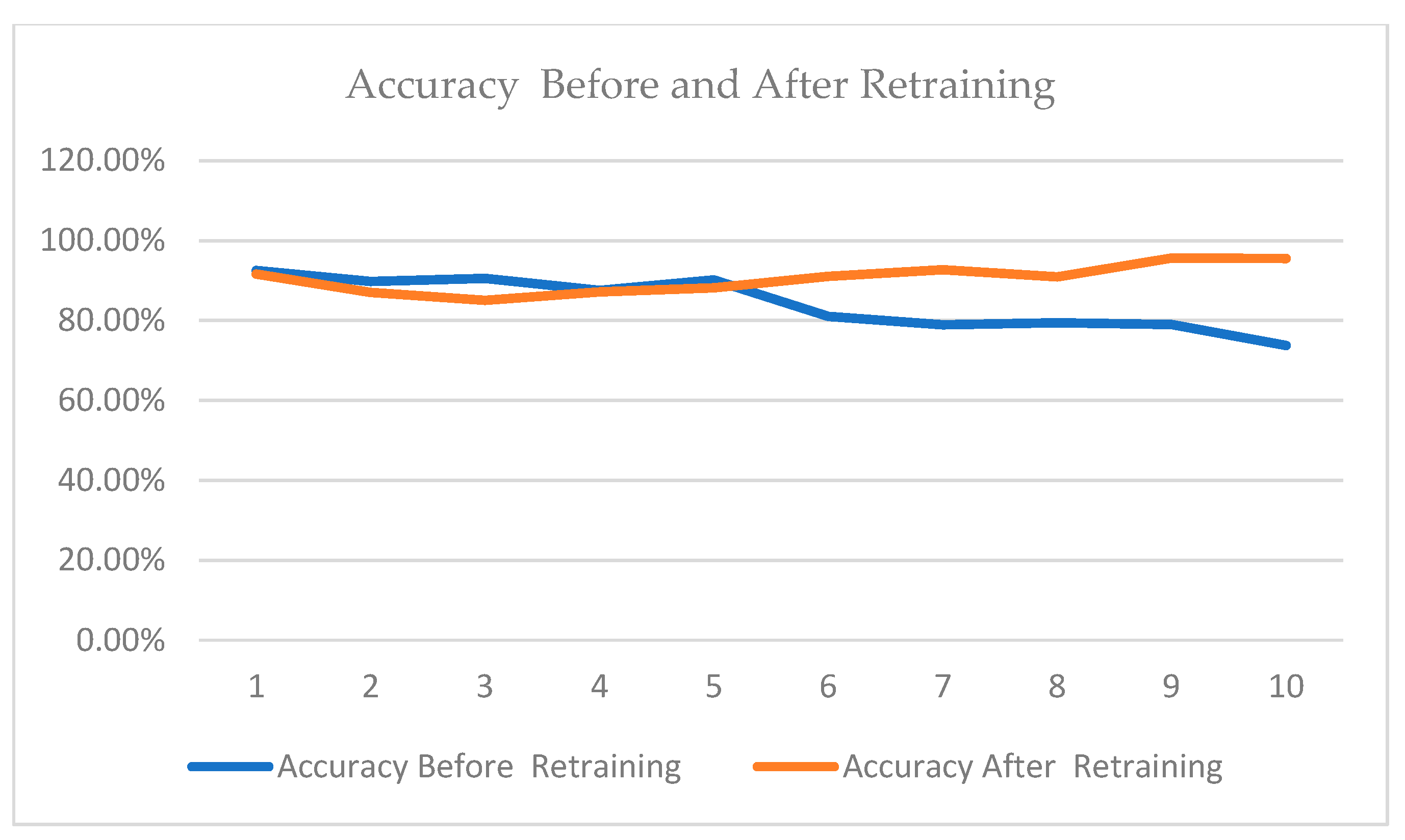
| Accuracy Before Retraining | Accuracy After Retraining | Z-Value | |
|---|---|---|---|
| 1 | 0.9249 | 0.9158 | 8.720846 |
| 2 | 0.8973 | 0.8702 | 21.94895 |
| 3 | 0.9052 | 0.8505 | 43.47297 |
| 4 | 0.875 | 0.8714 | 2.805536 |
| 5 | 0.9014 | 0.8816 | 16.51604 |
| 6 | 0.8103 | 0.9104 | −75.6705 |
| 7 | 0.7895 | 0.9265 | −103.792 |
| 8 | 0.7938 | 0.9091 | −85.1988 |
| 9 | 0.7899 | 0.9563 | −133.898 |
| 10 | 0.7372 | 0.9551 | −164.316 |
| First Batch | Second Batch | Z-Value | |
|---|---|---|---|
| 1 | 0.9158 | 0.8702 | 38.37009294 |
| 2 | 0.8702 | 0.8505 | 14.74603031 |
| 3 | 0.8505 | 0.8714 | −15.6717524 |
| 4 | 0.8714 | 0.8816 | −8.03994758 |
| 5 | 0.8816 | 0.9104 | −24.4902063 |
| 6 | 0.9104 | 0.9265 | −15.2602768 |
| 7 | 0.9265 | 0.9091 | 16.4353907 |
| 8 | 0.9091 | 0.9563 | −49.0737006 |
| 9 | 0.9563 | 0.9551 | 1.512600601 |
| 10 | 0.9551 | #DIV/0! |
| Total Records | Accuracy | Precision | Recall | F1-Score | Total Times (s) | |
|---|---|---|---|---|---|---|
| Training | 557,924 | 99.09% | 99.10% | 99.09% | 99.09% | |
| Testing | 139,348 | 99.03% | 99.03% | 99.03% | 99.03% | |
| 1293.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bagui, S.S.; Khan, M.P.; Valmyr, C.; Bagui, S.C.; Mink, D. Model Retraining upon Concept Drift Detection in Network Traffic Big Data. Future Internet 2025, 17, 328. https://doi.org/10.3390/fi17080328
Bagui SS, Khan MP, Valmyr C, Bagui SC, Mink D. Model Retraining upon Concept Drift Detection in Network Traffic Big Data. Future Internet. 2025; 17(8):328. https://doi.org/10.3390/fi17080328
Chicago/Turabian StyleBagui, Sikha S., Mohammad Pale Khan, Chedlyne Valmyr, Subhash C. Bagui, and Dustin Mink. 2025. "Model Retraining upon Concept Drift Detection in Network Traffic Big Data" Future Internet 17, no. 8: 328. https://doi.org/10.3390/fi17080328
APA StyleBagui, S. S., Khan, M. P., Valmyr, C., Bagui, S. C., & Mink, D. (2025). Model Retraining upon Concept Drift Detection in Network Traffic Big Data. Future Internet, 17(8), 328. https://doi.org/10.3390/fi17080328