1. Introduction
In recent years, the field of text classification has gained increasing relevance due to the proliferation of social media, blogs, forums, and online academic libraries, alongside advancements in AI technologies. The main objective of text classification is to assign predefined labels to textual sequences. It is a fundamental task in many NLP applications, including sentiment analysis, topic labeling, and question answering. Additionally, it is widely used for spam detection, customer feedback analysis, and language identification. This makes text classification useful in a wide range of fields [
1,
2,
3].
Despite the growing interest in text classification, research on Moroccan dialect text classification remains limited even though Moroccan dialect is widely used on social media and digital platforms. The increasing availability of Moroccan dialect content necessitates the deployment of effective NLP solutions for dataset processing [
4]. However, classifying Moroccan dialect presents challenges due to its lexical diversity, influenced by Arabic and loanwords from languages such as French, Spanish, and Portuguese, as a result of colonization. This complexity is further compounded by the presence of Amazigh and Saharan dialects, each with distinct sub-dialects. In this sense, different linguists propose various classifications of Moroccan dialect types.
Morocco’s current population is nearly 40 million, distributed across 12 regions, each characterized by its own dialect. The Moroccan dialect, known as Darija, is highly diverse, encompassing urban, Amazigh, and Saharan variants. Within these dialects, there are other sub-dialects, such as Tamazight, which includes Rifia (from the Rif region) and Soussia (from the Middle and High Atlas regions), among others. Linguistic classifications of the Moroccan dialect vary according to specialists. For example, Sadiqi (2002) identifies five varieties of Darija: (1) the Shamali variety in northern Morocco, (2) the Fassi variety in the central region, (3) the Rabat/Casablanca variety around these cities, (4) the Marrakshi/Agadiri variety in the south, and (5) the Hassaniya variety in the Sahara. On the other hand, researchers such as Boukous and Amour propose a classification of four categories: Mdini (city dwellers), Jebli (mountain dwellers), Arubi (Bedouins), and Aribi (Hassani from southern Morocco) [
4].
Traditional text classification models dominated from 1960 to 2010. These include such models as K-Nearest Neighbor, Support Vector Machine (SVM), and Naïve Bayes. For instance, a Naïve Bayesian classifier is used to classify documents as it needs less memory and computation. It is also considered the most commonly used classifier in traditional machine learning. Although these models have clear advantages in terms of accuracy and stability, they still require extensive feature engineering, which is time-consuming. Since 2010, text classification has advanced towards deep learning models, which omit human-designed rules and features and automatically provide representations that are semantically meaningful for text mining [
1,
2].
Over the past few years, LLMs, such as BERT, RoBERTa, and OpenAI GPT, among others, have been employed for a range of text analysis tasks, such as text categorization and question answering [
3,
5]. These models are usually trained on large multilingual corpora, which might contain more than a hundred languages, or on monolingual ones, particularly in English. This, however, presents the following challenge: training an LLM with large amounts of data makes it robust, but it becomes too generalized and not specialized in a particular domain. Therefore, fine-tuning LLMs for specific use cases is crucial in enhancing their performance. For example, well-known, pre-trained LLMs can be refined and applied to tasks such as text classification for more focused results.
Currently, two primary architectures dominate LLM research: (1) Masked Language Models (MLM) such as BERT and (2) Causal Language Models (CLM) like GPT. Both are based on the transformer architecture that forms the basis of modern LLMs. The key distinction between the two is that in MLMs, the model learns by predicting the hidden tokens in the input sequence (for example, a sentence), while in CLMs, the model is trained to predict the next token in the sequence. Although both architectures target NLP tasks, their applications differ considerably. MLMs are commonly used for tasks such as text classification, sentiment analysis and named entity recognition, whereas CLMs excel at tasks such as text generation and summarization [
3,
5].
The Moroccan dialect is largely under-researched in the field of text classification, presenting an opportunity to test several algorithms and select the one with the best performance for developing a multiclass classification model for Moroccan dialect. Initially, we used a small dataset of 3000 rows, then we adopted the AugGPT (GPT-4o) approach, which enabled us to generate at least 10,200 rows from this initial dataset. We opted for this step because the initial small dataset does not lend itself to text classification models, which are typically trained on very larger datasets.
Subsequently, we conducted a benchmark study of several supervised machine learning algorithms, including Support Vector Machine (SVM), Naïve Bayes, and Decision Tree. We also tested deep learning algorithms and methods such as Deep Neural Networks (DNNs), Recurrent Neural Networks (RNNs), and Long Short-Term Memory (LSTM) networks. Furthermore, we performed tests using LLMs to highlight their potential for classification tasks. Even though they were not initially conceived for this purpose, the accuracy of the various algorithms was satisfactory. Finally, we proposed the development of a chatbot that would integrate our model, making it accessible and beneficial to citizens.
The remainder of this paper is organized as follows.
Section 2 provides a review of research studies related to text classification in foreign language as well as Arabic.
Section 3 describes the creation, augmentation, processing, and classification models of our dataset. Models for text classification are discussed in
Section 4. Experiments and results are presented in
Section 5. Finally, we conclude our work and discuss the future direction in
Section 6.
2. Related Works
Several studies have faced the challenge of classifying texts in different domains and languages, with a particular focus on English texts and tweets. The texts were classified in several phases, each with its own advantages and limitations. However, research on other languages such as Turkish, Portuguese, Arabic, and dialectal texts remains relatively rare because these lack standardized spelling and extensive annotated corpora.
A large number of research studies deal with low-resource languages in the field of text classification. Paper [
6] presented a study based on sentiment detection and text classification in Turkish. Most of the research dealing with text classification focuses on more commonly used languages, such as English and French, but neglects languages like Turkish. This study evaluated the performance of ChatGPT-3.5 and ChatGPT-4 in sentiment detection and text classification, using a dataset composed of comments collected on YouTube, with manually tagged news tweets.
The authors in [
7] treated the Greek language as a low-resource language. They evaluated a classification dataset created based on Greek social networks. This analysis compared machine learning models with a text classification model based on GREEK-BERT. To encourage further research in this area, the authors shared the source code of the best-performing model.
Article [
8] treated the Serbian language as a low-resource language. This language is distinguished by a limited number of corpora and processing tools. The authors of this study created a dataset based on poems written in Serbian. The aim was to analyze and evaluate the classification of the text, ranging from linear models to large language models.
The authors in [
9] stated that their aim was to diversify the sources of the data collected in order to fight the lack of datasets in Portuguese. This research compared different models of text classifiers. It covered both classical methods and current technologies in order to demonstrate the capabilities of the models and the challenges faced.
All the research mentioned above focused on foreign languages with limited resources. In spite of its morphological and syntactic richness, Arabic is also considered an under-researched language. The following paragraphs in this section review research on text classification in Arabic.
The study in [
10] focused on classifying Arabic tweets into five categories: News, Conversation, Questions, Wishes, and Other. Two text representation methods were explored: (1) extracted text with TF-IDF and (2) word embeddings (Word2Vec). Three classifiers—SVM, Gaussian Naïve Bayes (GNB), and Random Forest (RF)—were evaluated. The findings revealed that traditional machine learning models, particularly SVM with an RBF kernel and RF, achieved the highest performance, with macro-F1 scores ranging from 98.09% to 98.14% when combined with stemming and TF-IDF. This exceeded the previous best score of 92.95% obtained by an RNN-GRU deep learning model. Interestingly, the use of word embeddings negatively impacted the performance of all classifiers, particularly GNB.
Similarly, the authors in [
11] investigated automatic text categorization for Arabic news articles, addressing both single-label and multi-label classification tasks. Two datasets were constructed: a single-label dataset comprising 90,000 articles across four domains (business, Middle East, technology, and sports) and a multi-label dataset containing over 290,000 articles. For single-label classification, ten surface-learning classifiers were evaluated, with SVM achieving the highest accuracy (97.9%). For multi-label classification, deep learning models—particularly CGRU—demonstrated superior performance, achieving an accuracy of 94.85%, while LSTM yielded the lowest accuracy (90.17%). These findings underscore the effectiveness of deep learning for multi-label text categorization in Arabic.
The authors in [
12] proposed a BERT model transformer to examine the impact of data diversity on topic classification in Arabic. They compared BERT models pre-trained on formal text with those pre-trained on a combination of formal and informal Arabic data. Their findings indicate that expanding the training data—either by incorporating diverse data during model pre-training or by using varied datasets for specific topic classification—consistently enhances classification performance.
The study in [
13] addressed the complex task of classifying the Arab patient experience (PX). The authors developed models to categorize patient comments into 25 distinct classes. To overcome the limitations of manual annotation, they explored deep learning and BERT-based models. They then evaluated various architectures, including BiLSTM, BiGRU, several pre-trained Arabic BERT models, and a newly developed domain-specific BERT model (PX-BERT) fine-tuned on the PX dataset. The results showed that AraBERTv02 achieved the best performance on a dataset of 19,000 comments, while PX-BERT outperformed other models when tested on a subset of 13,000 exclusively negative comments. These findings stress the potential of domain-specific BERT models, highlighting the effectiveness of high-quality, pre-trained domain-specific models for classifying Arabic PX comments.
Other studies examined sentiment analysis as a sub-branch of text classification, for Arabic and Arabic dialect. For instance, the authors in [
14] explored a deep learning approach to Arabic sentiment analysis based on three architectures: DNN, Deep Belief Networks (DBN), and Deep Autoencoders. The experiments were conducted on the Linguistic Data Consortium Arabic Treebank (LDC ATB) dataset, using sentiment scores from the ArSenL lexicon as feature vectors. The deep autoencoders provided a more accurate representation of the sparse input data. Additionally, the study introduced a fourth model, the Recursive Autoencoder (RAE), which achieved the best performance without relying on a sentiment lexicon.
In [
15], the authors proposed a new model for classifying tweets into three categories: positive, negative, and neutral. The dataset consisted of pre-processed tweets in Jordanian dialectal Arabic. A comprehensive evaluation was performed using supervised machine learning techniques. The results demonstrated that an SVM classifier with light stemming on Arabic text outperformed a Naïve Bayes (NB) classifier. Furthermore, incorporating a correlation analysis between the three sentiment categories and reducing the training set to include only the most frequent instances significantly improved the model’s accuracy, yielding an SVM accuracy of 82.1%.
Overall, traditional ML seem to dominate classification of small datasets ([
10,
15]) whereas BERT models show promise when data is heavy or domain-tailored ([
12,
13]).
This paper aims to fill important research gaps on the classification of texts in the Moroccan dialect. While previous work has explored various techniques for classifying Arabic texts in other dialects and in formal standard Arabic, the specific challenges of the Moroccan dialect continue to be under-investigated. Existing studies typically utilize significantly larger datasets. To address the limited labelled data available for Moroccan dialect, we worked with 10,200 rows after employing the AugGPT approach to augment our initial dataset of 3000 rows. This study examined a range of algorithms, including traditional machine learning, deep learning, and large language models, for multi-class classification. The best performing model will later be integrated into a chatbot for public use.
3. Comprehensive Data Workflow
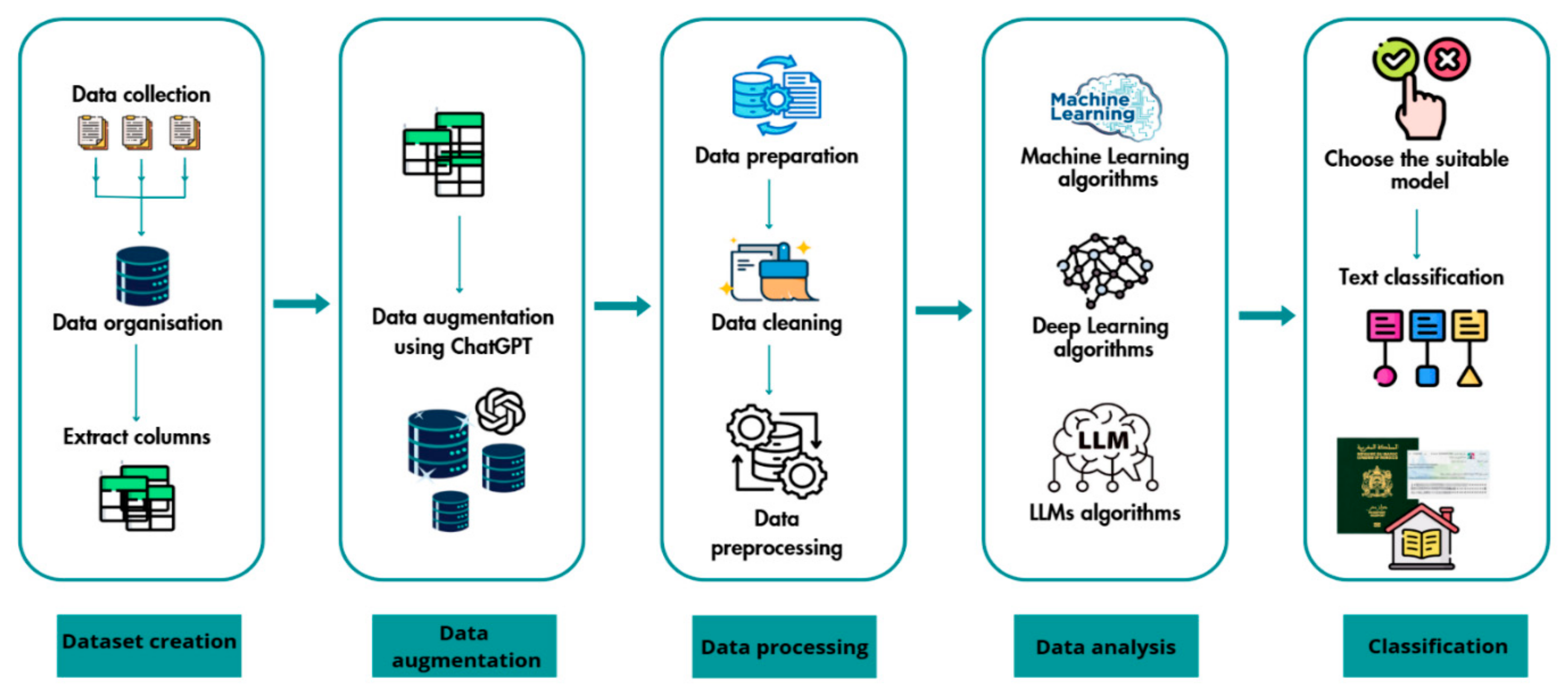
The data pipeline architecture illustrated in
Figure 1 consists of five different steps, each of which is discussed in the following sections.
3.1. Dataset Creation
To build a robust dataset, the first step in the pipeline is data creation. We started with the collection of samples of the Moroccan dialect using different platforms and then we exacted the relevant columns for our work.
3.1.1. Data Collection
We have generated this dataset using a free web chatbot. First, we determined the exact target questions that would provide the desired answers. These questions were typed into the chatbot and then the answers were saved in an Excel file. In order to collect a variety of answers and reach a wide audience, from different regions of the country, we shared the chatbot’s link created on the website:
https://collect.chat (accessed on 3 August 2023) with an influencer who is active in Instagram and who has a community spread around the country. Within 24 h, we collected more than 1000 responses from people of different demographics.
3.1.2. Data Organization
We first organized the dataset manually into two components: Intent and Questions, which allowed us to classify questions according to their intent based on appropriate models. Additional columns were then incorporated to facilitate later stages of the development process. We ended up with three classes in the dataset: BC => Birth Certificate, CIN => National Identity Card, PASS => Passport. Each class contains more than 1000 questions in different Moroccan dialects, which produced a dataset with more than 3000 rows.
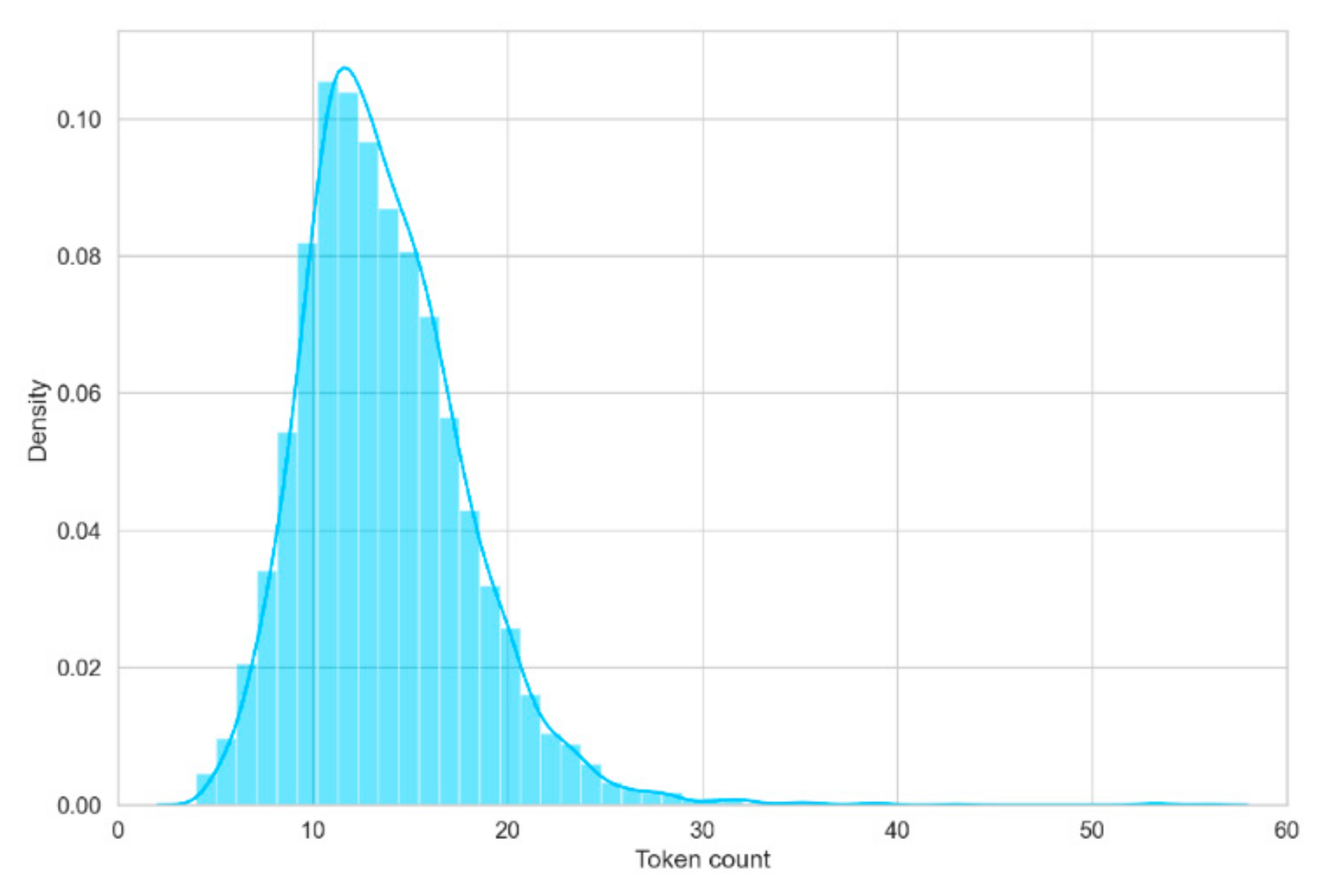
Figure 2 presents a distribution of intent counts.
Figure 3 similarly illustrates the distribution of counts for each token.
Figure 4 displays the frequency of the top 20 words within the question column while
Figure 5 provides a word cloud visualization of the 100 most frequent words in the question column.
Table 1 contains the translation of the most frequent words in questions, as illustrated in
Figure 4 and
Figure 5 above.
3.1.3. Extract Columns
The dataset comprised several columns, including IP address, timestamp, and device information, among other relevant attributes. To ensure participant privacy, these identifying columns were removed, retaining only the essential response data. This resulted in a reduction from twelve initial columns to the final five columns used in the analysis.
3.2. Data Augmentation
The process of data augmentation has been shown to enhance the quantity and quality of training data by applying various transformations to an existing dataset, thereby generating new, meaningful data instances. In NLP, particularly for underserved languages such as the Moroccan dialect, challenges arise due to the limited availability of datasets. This scarcity has resulted in a lack of focus on data augmentation in this area, as no standardized approach exists. The three stages below outline the data enrichment techniques applied in this study [
16,
17,
18]:
- –
Easy Data Augmentation (EDA): This approach is based on four straightforward but effective operations: synonym replacement, random insertion, random permutation, and random deletion. EDA produces particularly convincing results for small datasets.
- –
Hierarchical Data Augmentation (HAD): This technique employs an attention mechanism to distil important content from hierarchical text into summaries, Thesauruses, translation, and transformers. Experiments reveal that HAD is a promising technique compared to EDA.
- –
Keyword-Driven Data Augmentation (KDA): This method retrieves keywords based on category labels and completes them accordingly.
Maintaining contextual integrity is particularly critical when dealing with administrative data, where preserving each word is essential to retain meaning. In this regard, research confirms that transformer models used for data augmentation yield satisfactory results in maintaining textual coherence.
Therefore, we adopted a novel data augmentation method: ‘AugGPT’, which leverages ChatGPT to generate auxiliary samples for text classification. While AugGPT was not the only possible solution, it proved to be the most effective. This solution was the most efficient as it saved time and energy, and generated correct sentences in the Moroccan dialect, since the latest version of ChatGPT masters the Moroccan dialect. An alternative approach considered was back-translation, where Moroccan dialect text would first be translated into French or English and then back into Moroccan dialect. However, this method is more effective for longer sentences, whereas our dataset consisted primarily of short sentences, which tended to retain the same words after back-translation. Moreover, it is more time-consuming, and not free of charge.
Thus, the ‘AugGPT’ approach allowed us to augment the dataset in a way that introduced variation while preserving semantic coherence. Through detailed and focused prompting, ChatGPT successfully generated a dataset of over 10,000 sentences from an initial 3000-line dataset.
Large language models such as GPT offer new opportunities for generating human-like text. Their large parameter space enables them to store vast amounts of linguistic information, while extensive pre-training allows them to encode factual knowledge for language generation—even in highly specific domains and languages, such as Moroccan dialect text generation for Public Administration papers [
19].
3.3. Data Processing
The third phase in the data pipeline consists of three sub-phases, which will be described in more detail below:
3.3.1. Data Preparation
Before the data cleaning, which consisted of removing all foreign characters and punctuation, the entire dataset was checked for grammatical correctness and completeness of the textual content of each line. Once this validation was completed, the data cleaning process was started.
3.3.2. Data Cleaning
The dataset initially contained several extraneous columns; therefore, we retained only the three columns corresponding to the responses to the questions asked. Following this, we launched the data cleaning process. After a thorough review of all the data, we defined the criteria and guidelines for the data cleansing procedures.
When we asked the questions, we provided users with a number of suggestions to make their answers easier. Unfortunately, some users referred to our suggestions using numerical values in their answers. As a result, we systematically cross-referenced and replaced these numerical entries with the corresponding alphabetical values to ensure data consistency and accuracy.
We initially aimed to collect responses in the Moroccan dialect using Arabic script. However, some users, lacking an Arabic keyboard, opted to respond using Latin letters to represent Arabic words. Our objective was to convert these entries into Moroccan dialect expressions rendered in Arabic characters, ensuring the preservation of their original meaning.
Additionally, we identified irrelevant responses, prompting us to either remove them or invest time in generating contextually appropriate answers that aligned with the users’ intended expressions. We also encountered several unanswered entries, which we subsequently deleted.
Furthermore, we removed emojis, as they did not contribute to meaningful textual data. Some sentences exhibited an inaccurate structure due to reversed meaning, necessitating corrective measures. A meticulous review also revealed spelling errors; rather than discarding these responses, we saved them in a separate sheet for future use in testing the model’s performance and refining the dataset. Next, we eliminated special characters, replacing them with blank spaces. Finally, we removed all unnecessary spaces to ensure data uniformity [
20,
21].
3.3.3. Data Preprocessing
Tokenization: For Arabic texts, tokenization rules are applied to segment the text into tokens, while accounting for changes introduced by prefixes and suffixes. This process presents a significant challenge due to the morphological complexity of Arabic and the presence of clitics [
22].
Stemming: This is a technique that involves shortening words to their root form. It plays a crucial role in Arabic linguistics, contributing to both text analysis as well as other research tasks.
Lemmatization: This is an essential process in Arabic that involves identifying the root form or dictionary form of words. This procedure accounts for morphological changes in lemmas, considering factors such as root, pattern, and other linguistic features [
21].
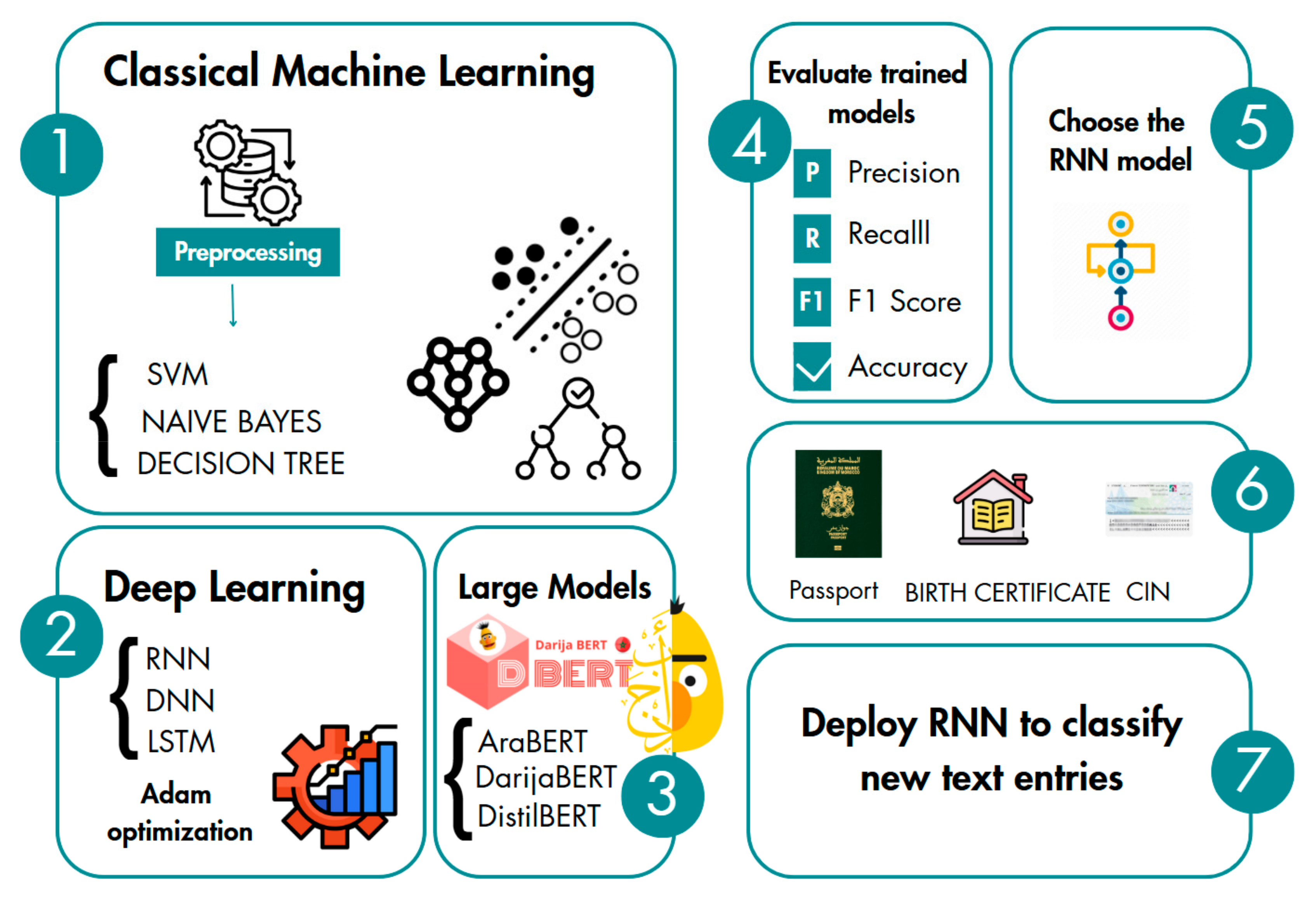
3.4. Data Analysis
This important part allowed us to train several models to analyze them and select the most appropriate one to classify Moroccan dialect. Our methodology followed a structured pipeline:
Classical Machine Learning: We evaluated suitable models for text classification like SVM, Naïve Bayes, and Decision Tree. Firstly, we started with preprocessing, which is a crucial step in this pipeline, removing special characters and stop words. Then, we applied tokenization, lemmatization, stemming, and TF-IDF vectorization. Secondly, the dataset was split into 80% training and 20% testing according to classes for SVM, Naïve Bayes (70% training, 30% testing), and Decision Tree (75% training, 25% testing).
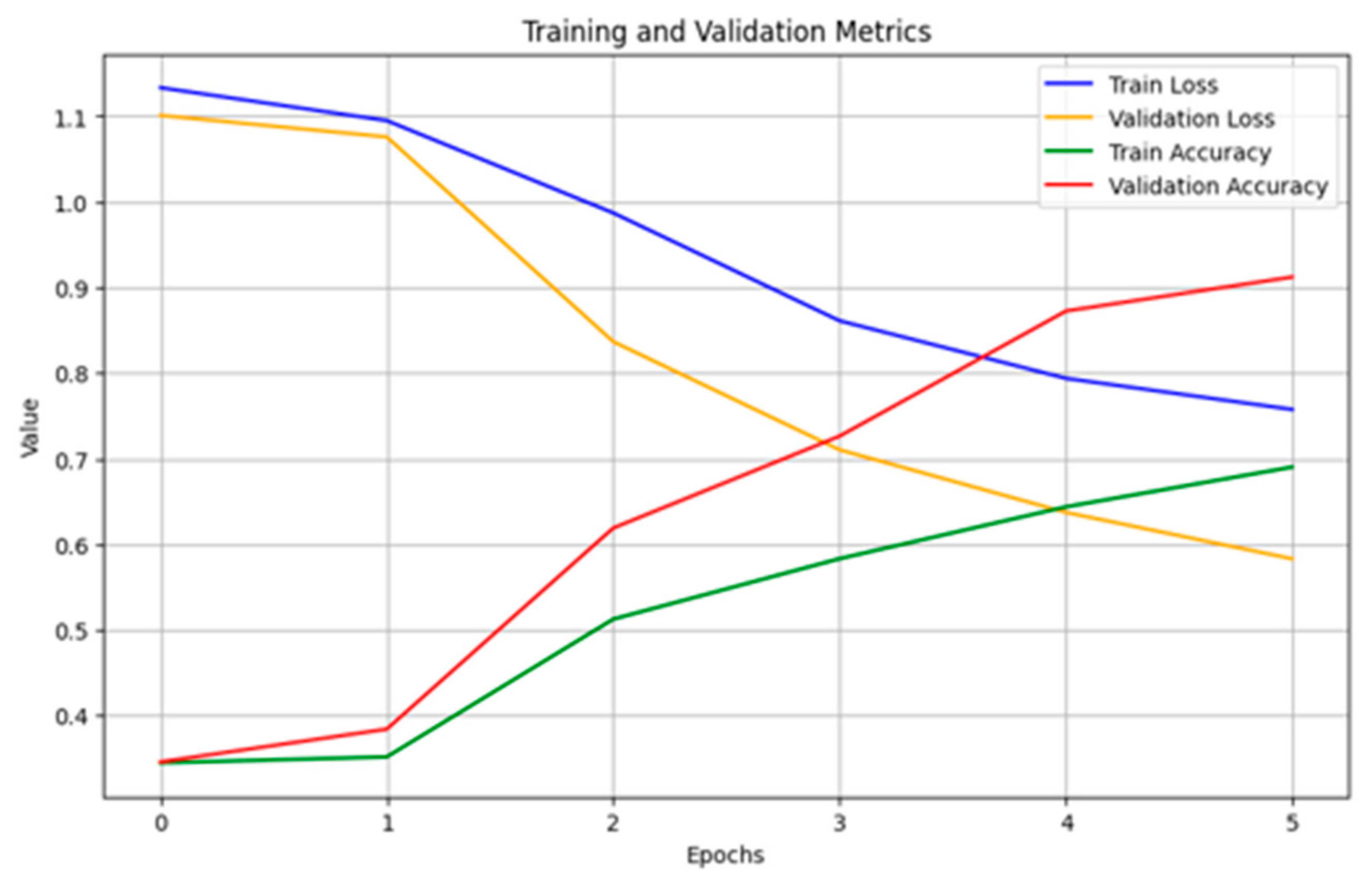
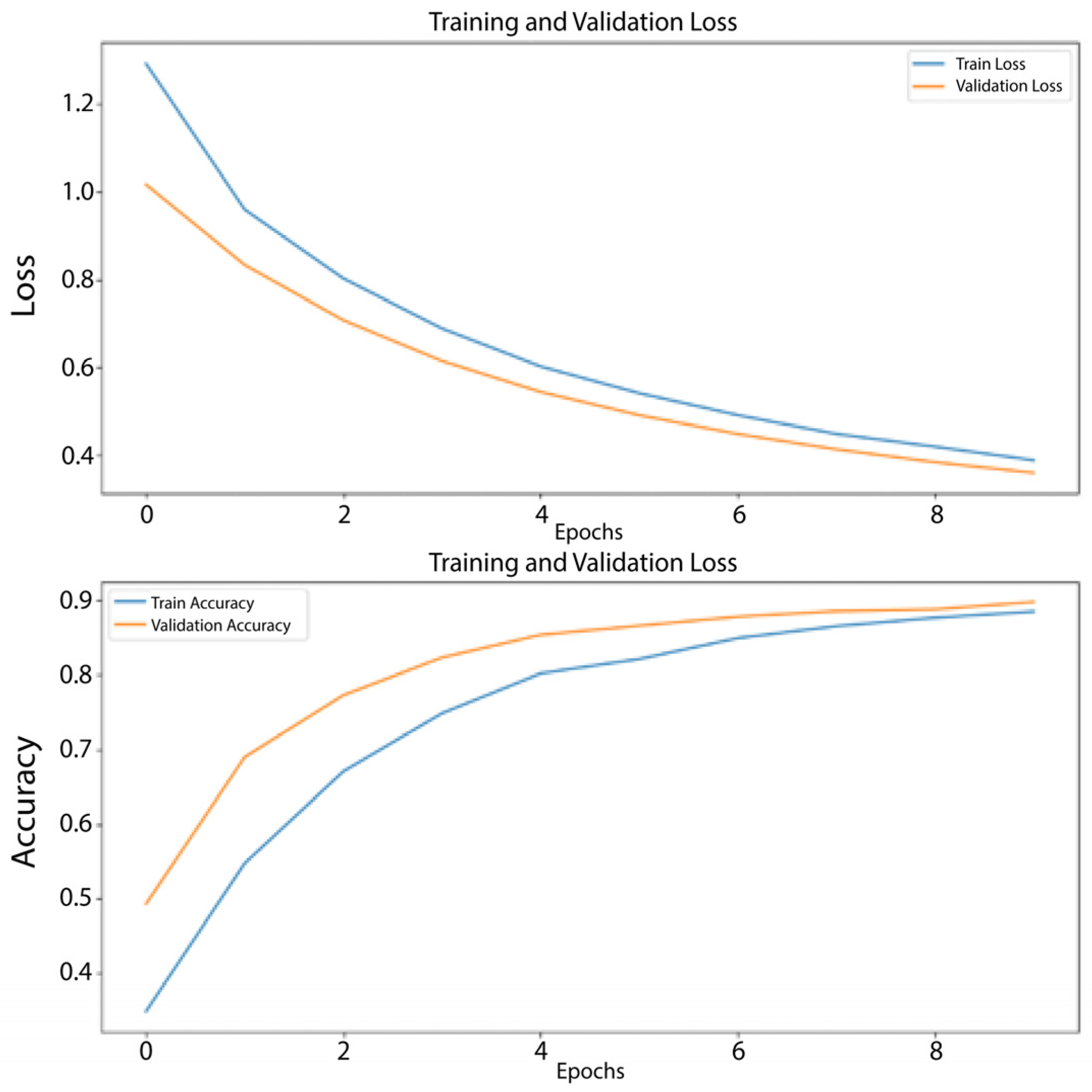
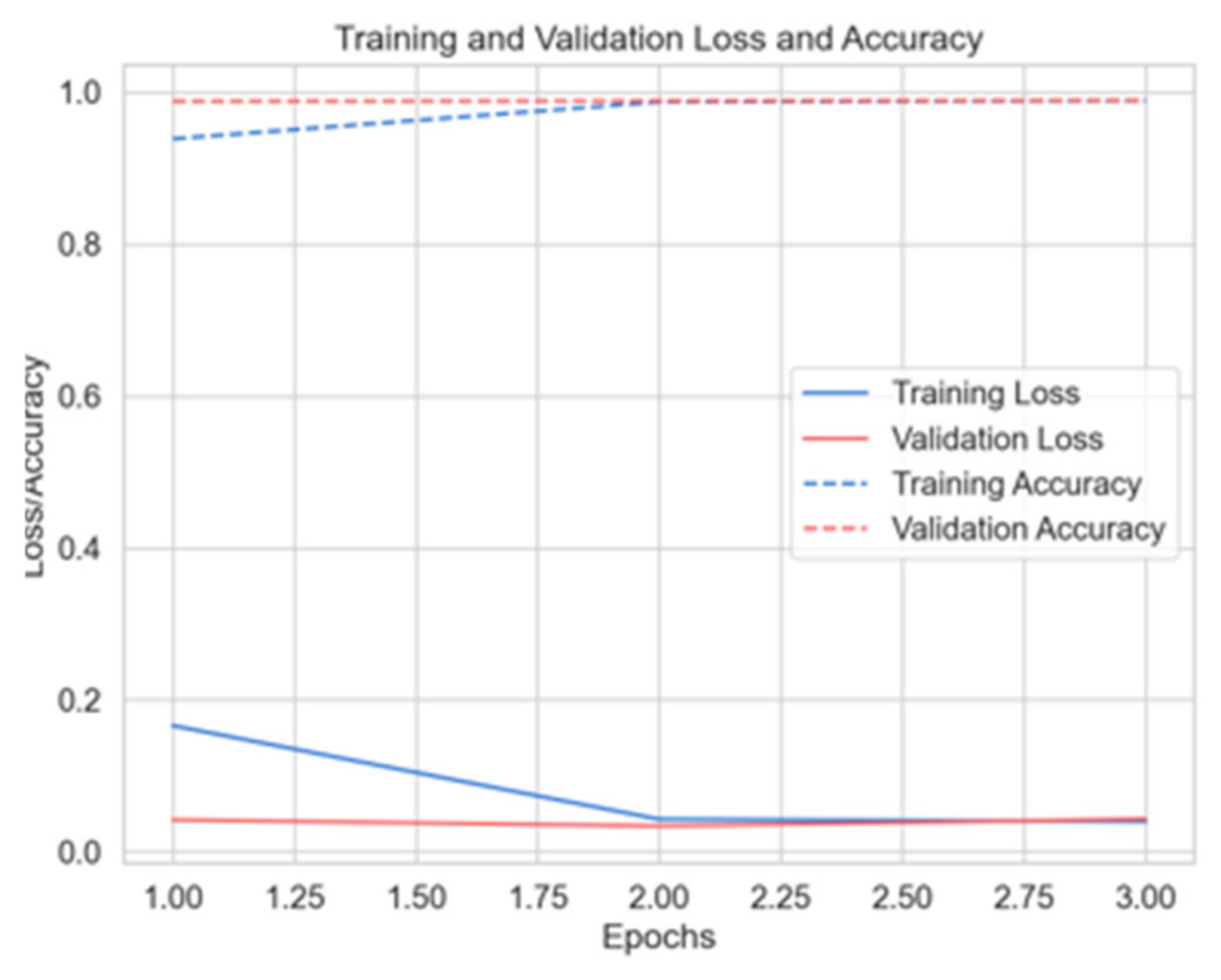
Deep Learning: For DNN, RNN, and LSTM architectures. all models used Adam optimization. The RNN was trained on 10 epochs with a batch size of 32, while the DNN used 3 epochs with an identical batch size of 32. In comparison, the LSTM used 15 epochs and a larger batch size of 64. These variations highlight the different configurations adapted to each network.
Large Language Models: We fine-tuned DistilBERT, DarijaBERT, and AraBERT to meet the specific challenges of the Moroccan dialect. DarijaBERT was pre-trained on Moroccan Darija, and AraBERT was optimized for Arabic social media. DistilBERT was monolingual (English). All models used Adam’s optimization.
3.5. Classification
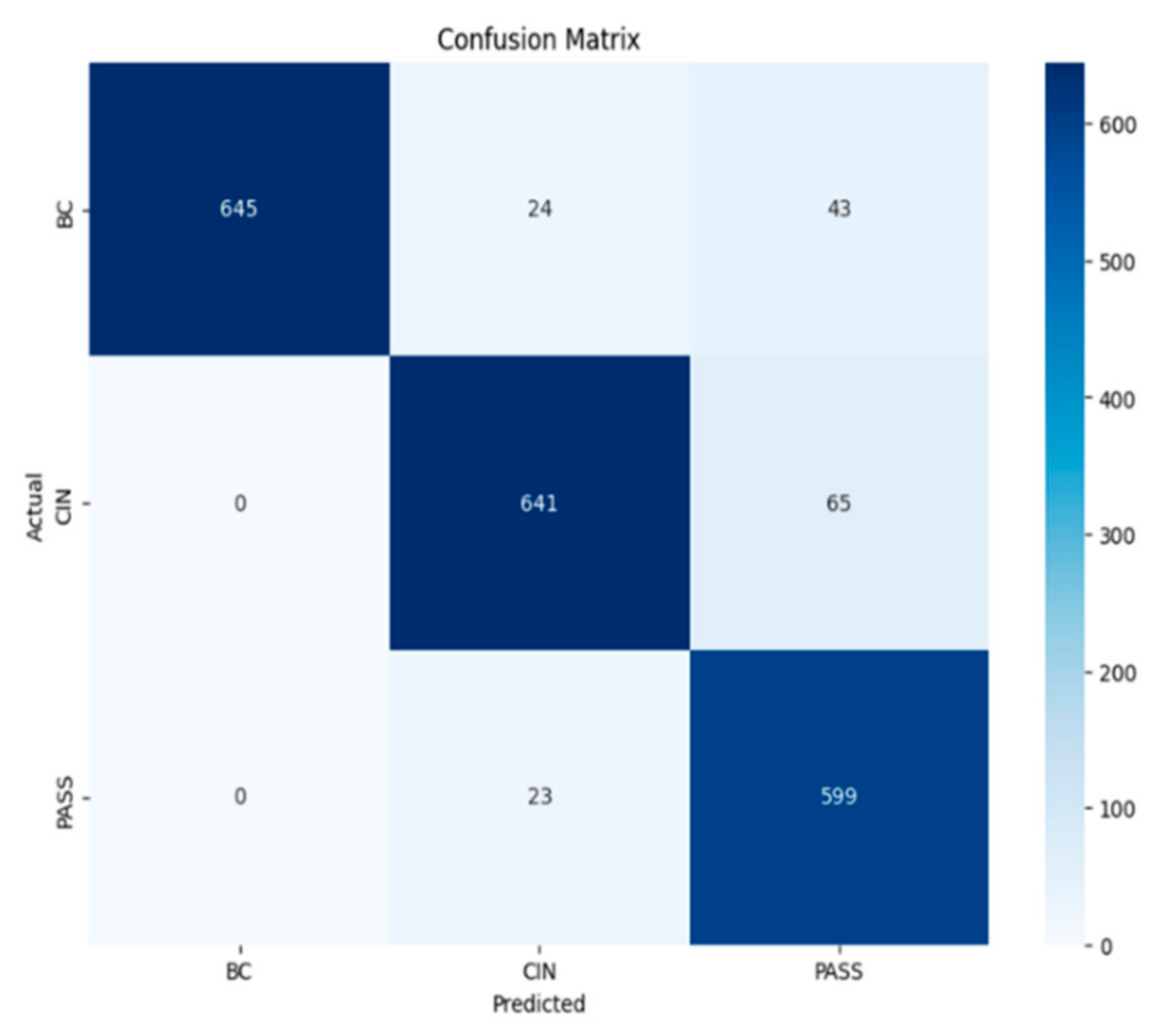
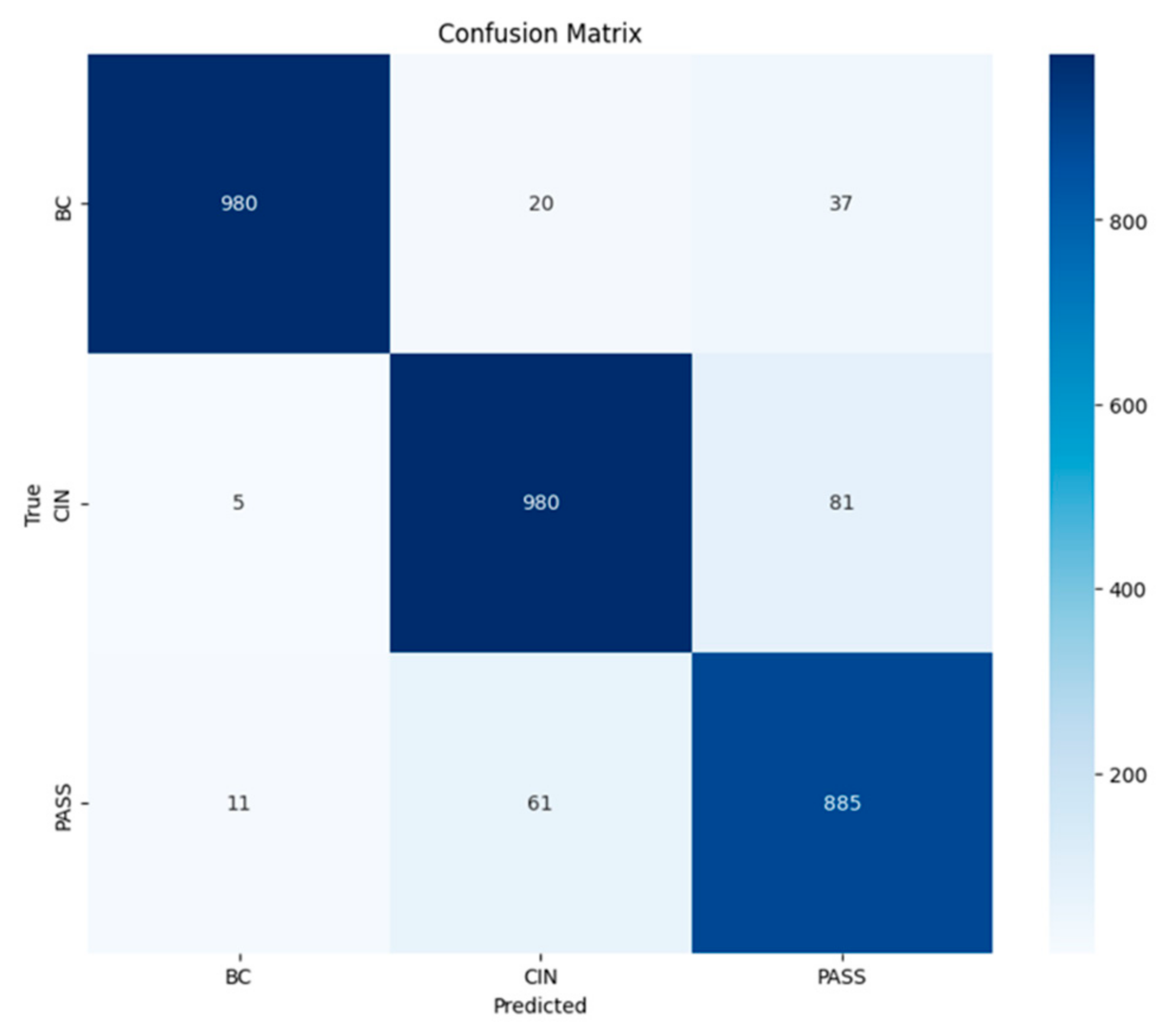
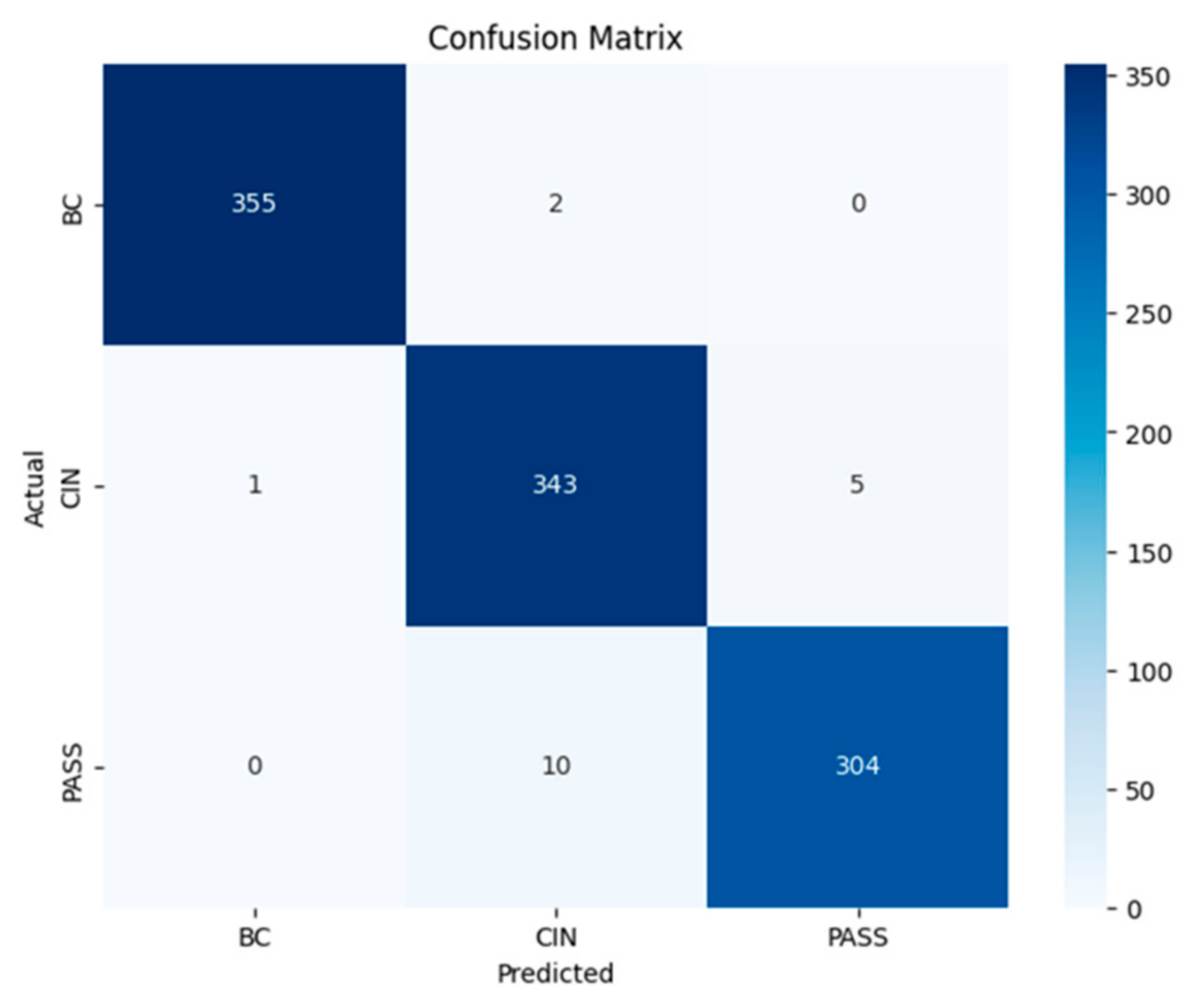
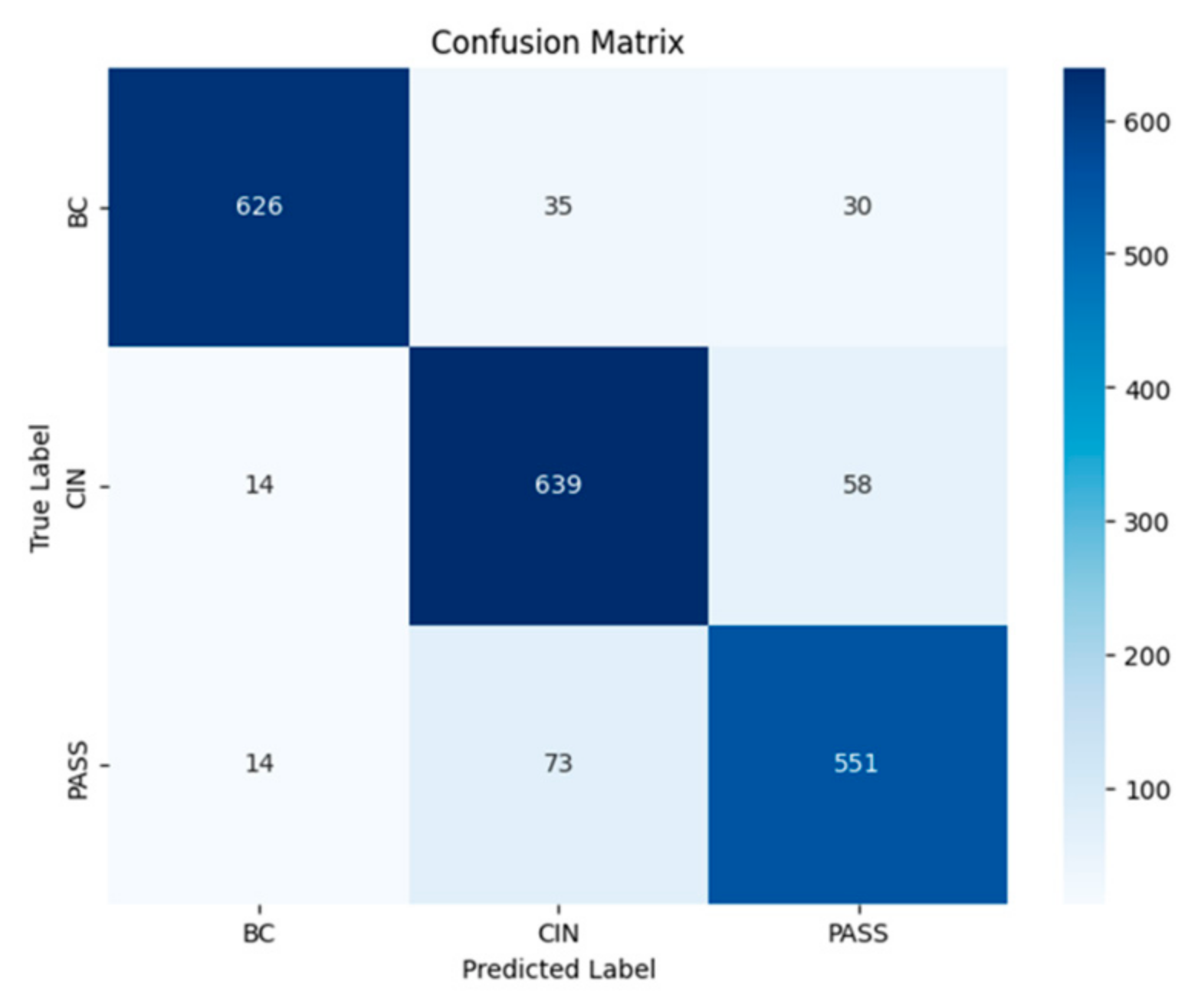
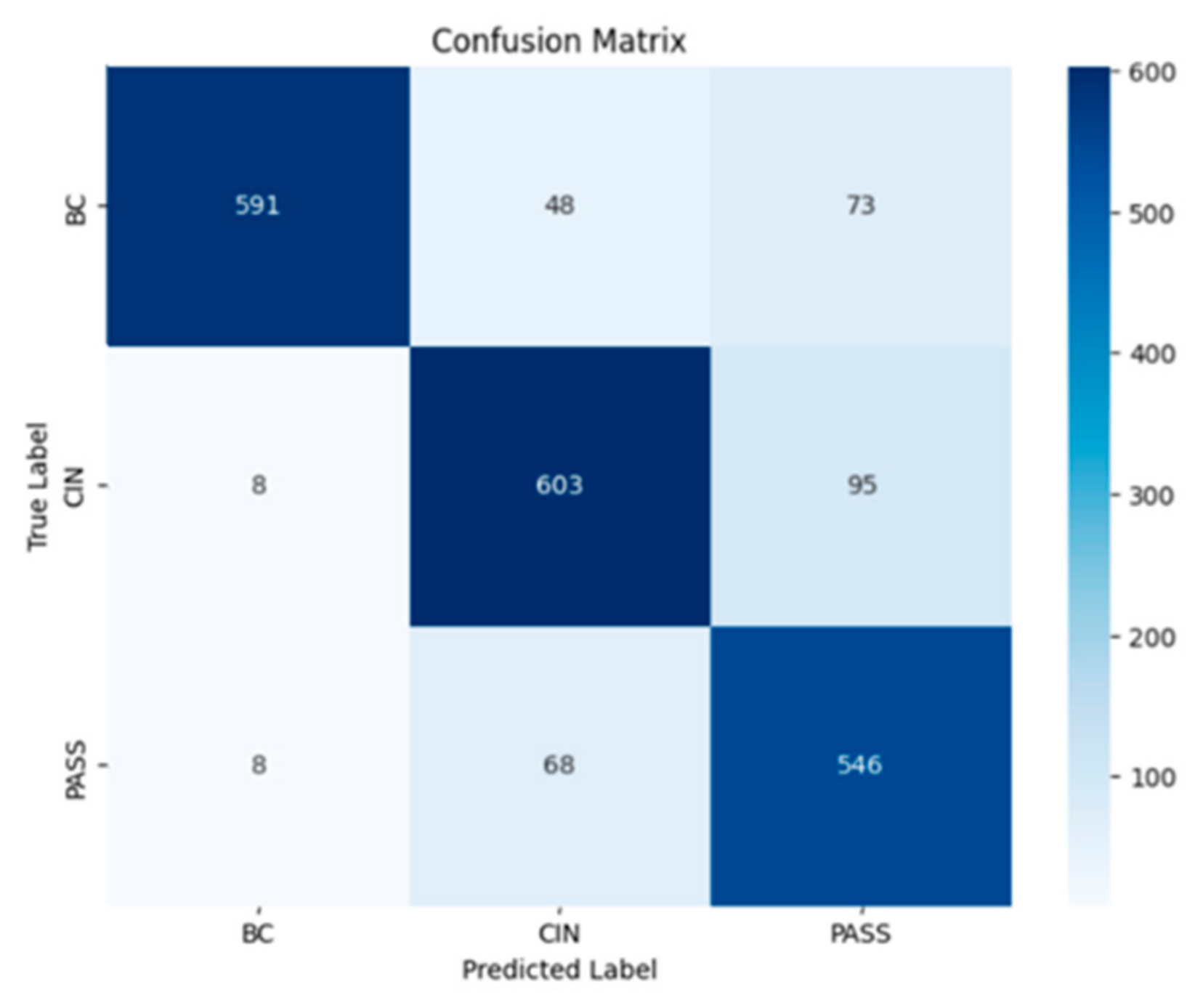
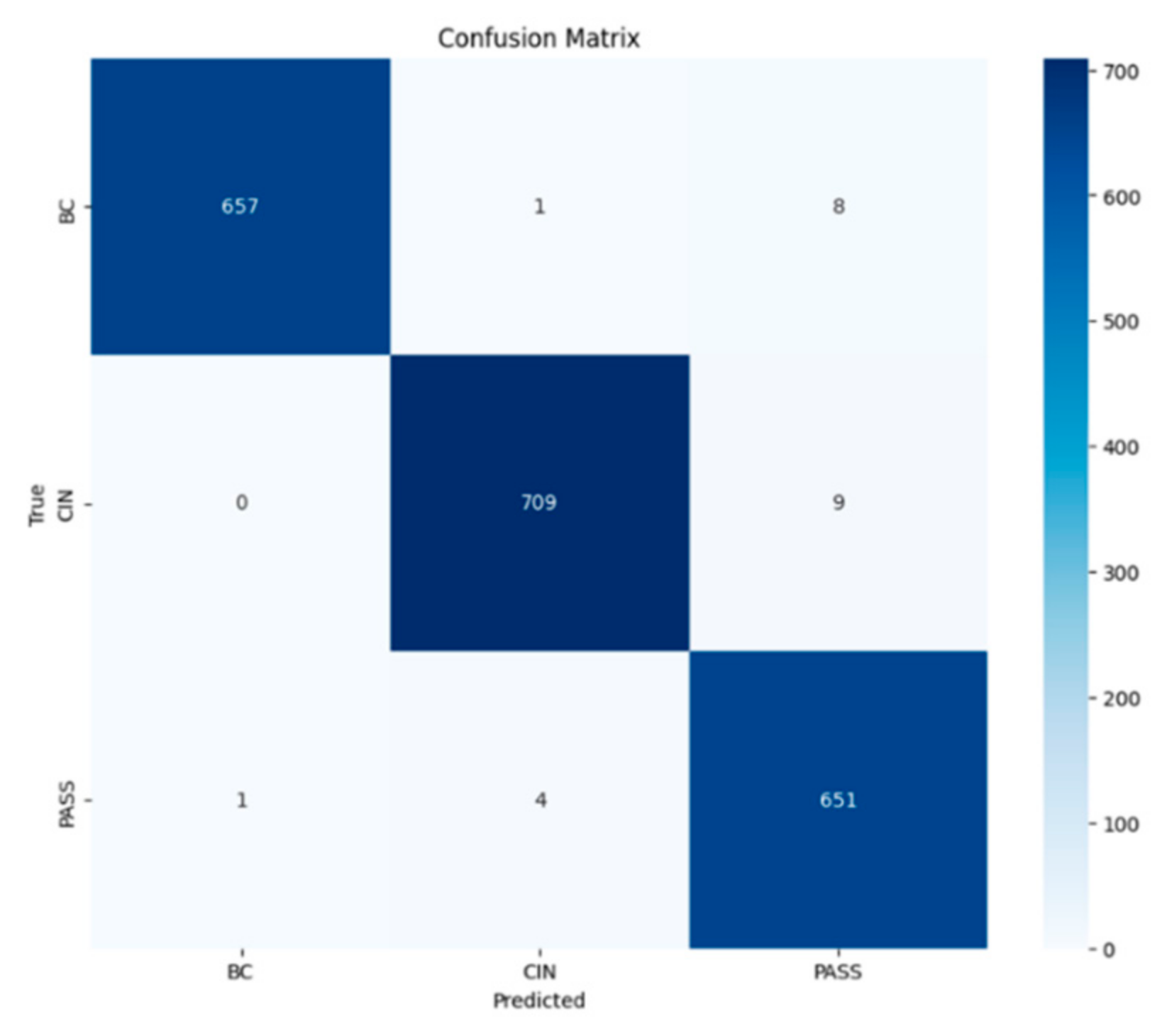
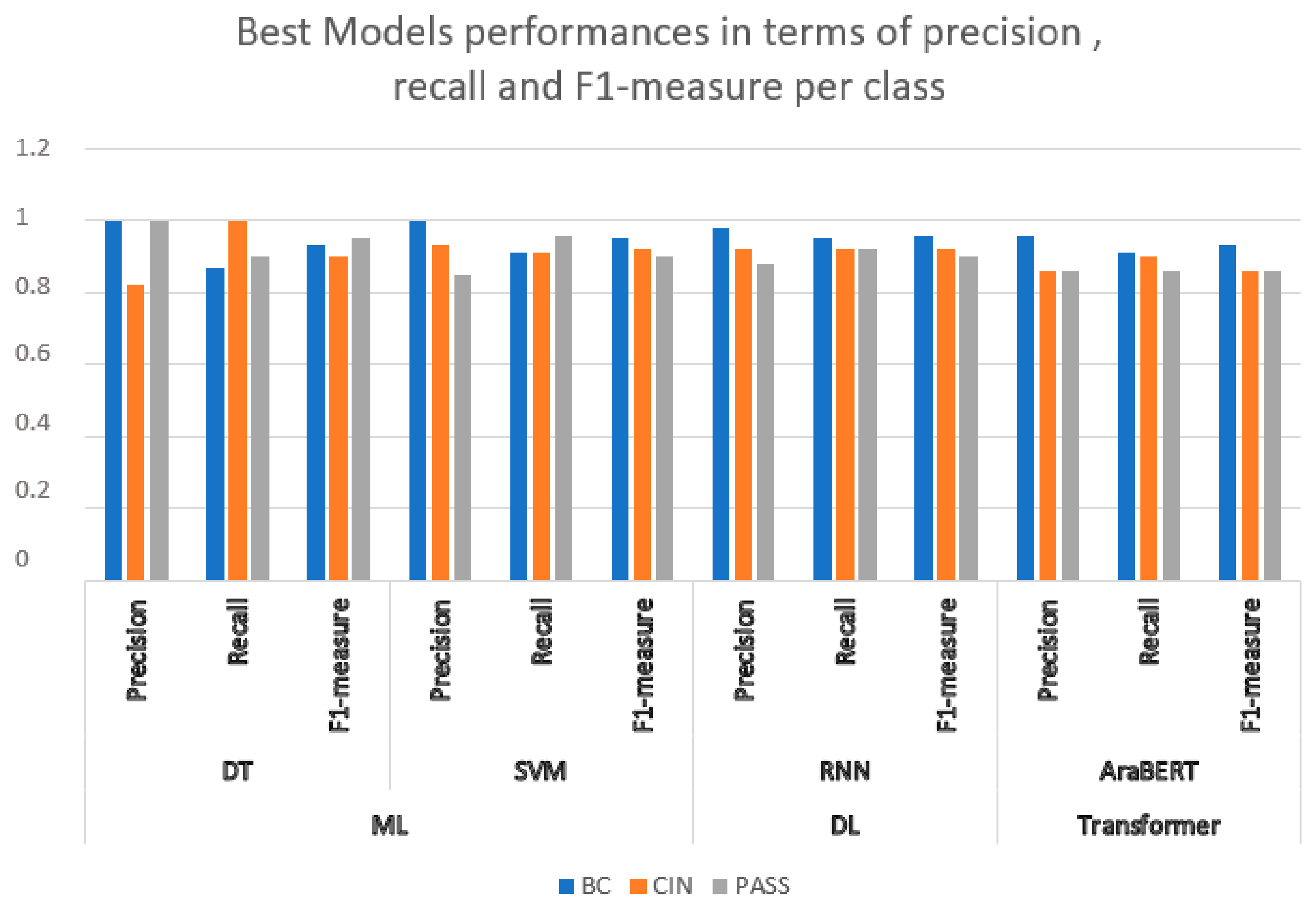
In order to select the most effective model for classifying the texts of passports, birth certificates, and national identity cards. We evaluated the trained models by comparing the main performance measures—precision, recall, F1 measure, and accuracy. After analyzing the results, we chose the recurrent neural network (RNN) model because it offers an optimal balance between robust performance and computational efficiency, and in particular excels at capturing sequential patterns in the textual data essential to our task.
A RNN is deployed to classify new text entries. For example, it processes text to determine whether it is a passport or a birth certificate, enabling efficient and accurate categorization. It is not surprising that the RNN model achieves this accuracy. It is powerful in text classification, as we can see in the article [
10] where an accuracy of 90.30% was achieved using the RNN-GRU model to classify tweets in Arabic. Other research proves this ability, such as the article [
23] which deals with text classification using the RNN model enhanced with BiLSTM and attention mechanisms. They showed significant improvements in accuracy.
Figure 6 provides an overview of the steps involved in data analysis and Moroccan dialect classification.
4. Models for Text Classification
4.1. Machine Learning Models
Machine learning is an important area of research within artificial intelligence. It is defined as a domain that focuses on the ability of computer systems to learn from data without requiring explicit programming. The main aim of machine learning is to enable systems to make decisions and predictions based on future data, all without human intervention. Recently, machine learning has seen extensive application across various fields, including healthcare, industry, and biology [
24,
25].
In this section, we discuss the state-of-the-art machine learning algorithms applied to our dataset. We used Support Vector Machines (SVMs), Decision Trees (DT), and Naïve Bayes (NB) for text classification on the Moroccan dialect dataset, evaluating their performance using appropriate metrics. The proposed ML classification approach includes several stages, such as preprocessing, tokenization, and classification.
4.1.1. Decision Tree (DT)
The decision tree is a supervised learning algorithm. It is considered to be one of the most powerful methods used in machine learning, applicable to both classification and regression tasks. The decision tree model is a method that recursively constructs a tree structure from data by creating a series of decision nodes.
The goal is to predict the class of target variables by learning decision rules from the training data. The application of decision tree models in text classification focuses on predicting the category of texts by learning decision rules from text features. First, it is necessary to extract features from the textual data, such as word frequency and key terms in the documents. These features are then used to build the decision tree [
26,
27].
4.1.2. Naïve Bayes (NB)
The Naïve Bayes algorithm is widely used for classification, employing a simple probabilistic classifier method based on Bayes’ theorem, with the assumption of feature independence given the class. Despite this ‘naïve’ assumption, which assumes that features are independent, Naïve Bayes consistently delivers reliable performance, especially in scenarios with limited data and computing resources. The Naïve Bayes classifier is highly scalable, with its performance depending directly on the number of variables (features/predictors) in a learning problem [
24,
28].
4.1.3. Support Vector Machines (SVM)
The Support Vector Machine is a supervised method used for both regression and classification tasks. SVMs use the ideal hyperplane to separate classes, forming a large margin separating data points called vectors. It is widely used for text classification due to its excellent classification performance, which depends largely on the quality of feature selection and extraction [
29].
4.2. Deep Learning Models
Deep learning is a branch of artificial intelligence and a subset of machine learning methods that has garnered significant attention in recent years, becoming dominant in various application fields. The operating mechanism of deep learning models is inspired by the structure and function of neurons in the human brain, which are responsible for processing information. The fundamental unit of deep learning networks consists of small nodes called artificial neurons, which are typically organized in layers. Each neuron is connected to all neurons in the subsequent layer through weighted connections. Recently, deep learning models have demonstrated outstanding results in various text classification tasks, achieving higher accuracy levels than traditional machine learning algorithms for several NLP sub-problems. The advantages of deep learning over machine learning include better handling of noisy data, higher accuracy, and improved identification of relationships between input and output features. In this section, we provide an overview of the state-of-the-art deep learning algorithms applied to our dataset. We tested Deep Neural Networks (DNNs), Long Short-Term Memory (LSTM), and Recurrent Neural Networks (RNNs) on our Moroccan dataset for text classification, measuring their performance using appropriate evaluation metrics [
1,
30].
4.2.1. Recurrent Neural Network (RNN)
RNN is a deep learning architecture that repeatedly uses the values from the previous step at each stage of the loop for sequential data. This iterative approach allows RNNs to produce learning outputs that are significantly more complete than those of other basic neural network methods. In addition, a similar architecture manages historical data during computation and provides the ability to process input data of any length. Specifically, the previous input form is stored and merged with the newly acquired input value through iterative processes, thereby establishing a link between the newly acquired input and the previous data in memory. As a result, RNNs have been successfully applied to a variety of NLP tasks. Moreover, RNN-based models treat text as a sequence of words and are designed to capture the dependencies between words and text structures, making them highly effective for text classification [
31,
32].
4.2.2. Long Short-Term Memory (LSTM)
Long short-term memory (LSTM) is an improvement and specific class of recurrent neural networks (RNNs), specifically designed to preserve long-term dependencies in sequential data more efficiently than basic RNNs. Consequently, LSTM networks have enormous information storage capacity and are the most commonly used models for NLP. LSTM networks are well suited for textual phase analysis because they can classify text into predefined categories by learning from sequences of words and their contextual dependencies. This linguistic inference improves classification by understanding the deeper meaning of the text [
33,
34].
4.2.3. Deep Neural Network (DNN)
Deep Neural Networks (DNNs) are artificial neural networks capable of learning high-level features from data, mimicking processes in the human brain to achieve better results compared to traditional models in areas like speech recognition, image processing, and text understanding. DNNs include many variants of architectures that have proven their effectiveness in a variety of domains such as sentiment classification, question answering, and event prediction. One of the most widely used and fundamental DNN architectures is the feedforward neural network (FNN). The goal of FNNs is to learn the correspondence between a fixed-size input (e.g., a signal vector) and a fixed-size output (e.g., a probability for each label) [
1,
31,
35].
4.3. Large Language Models
Every day, millions of people rely on LLMs for their exceptional capabilities in specific NLP tasks, such as planning travel itineraries, drafting professional emails, and preparing cover letters for job applications. LLMs have transformed the field of NLP, achieving groundbreaking advancements in diverse tasks, including content creation, text classification, and question answering (QA). Trained on massive amounts of text data, LLMs can address a wide range of problems, including those they were not explicitly designed for, often without direct supervision.
Although LLMs were not originally intended for text classification, their advanced NLP capabilities, rooted in deep learning principles that have reshaped the domain, enable them to excel in this area. Their ability to capture subtle linguistic patterns and context not only makes them highly effective across various domains but also opens the door to new applications harnessing this powerful technology.
Text classification, a fundamental application of NLP, is extensively used for tasks like spam detection, sentiment analysis, and more. While LLMs are generally more powerful than traditional NLP methods, they are often considered “black boxes” due to the complexity and opacity of their decision-making processes [
36,
37].
Although BERT is no longer classified as a large language model (LLM) in the current context (2025), its size and historical influence make it a direct precursor to this category. In our analysis, we included BERT among LLMs for two main reasons:
In 2018, it set standards for scale with its 340 million parameters and its pre-training on massive corpora such as BookCorpus and Wikipedia, redefining expectations for language models [
38].
Its comparison with recent LLMs helps illustrate technical advances, particularly in terms of size and generative capabilities. This approach is in line with the time perspective of our study, conducted more than a year ago, when these criteria were still largely aligned with the definition of LLMs.
4.3.1. AraBERT
AraBERT was the first pre-trained Arabic language model inspired by Google’s BERT architecture. The AraBERT model has been trained on a large dataset of modern standard Arabic and various Arabic dialects, and evaluated on several downstream tasks, helping to advance the field of Arabic NLP. Six variants of the same model are available for testing. It is currently one of the most widely used architecture modelling languages. Some of the potential benefits of using AraBERT have been tested on a large dataset of Arabic texts. Its generalization features allow it to be adapted to different downstream tasks, depending on the user’s needs, such as answering questions, analyzing sentiments or classifying texts with high accuracy [
39,
40].
4.3.2. DarijaBERT
AIOX LAB has developed DarijaBERT, a linguistic model specifically designed for Moroccan Darija written in Arabic characters. The BERT model for the Moroccan Arabic dialect was trained on a dataset compiled from various sources, including tweets, YouTube comments, and stories written in Moroccan Darija. The dataset comprises 3 million sequences, with a total size of 691 MB. In relation to text classification tasks, DarijaBERT has yielded excellent results in terms of accuracy, precision, recall, and F-measure [
41,
42].
4.3.3. DistilBERT
DistilBERT is a streamlined version that is smaller, faster, and lighter than the original BERT model. It introduces knowledge distillation to the standard BERT (Bidirectional Encoder Representations from Transformers) model. DistilBERT decreases the size of a BERT model to 40% while preserving 97% of the Natural Language Understanding performance. It also boasts a 60% increase in speed. Its high performance on generic text classification challenges qualifies it as a suitable model [
43,
44].
7. Conclusions and Future Work
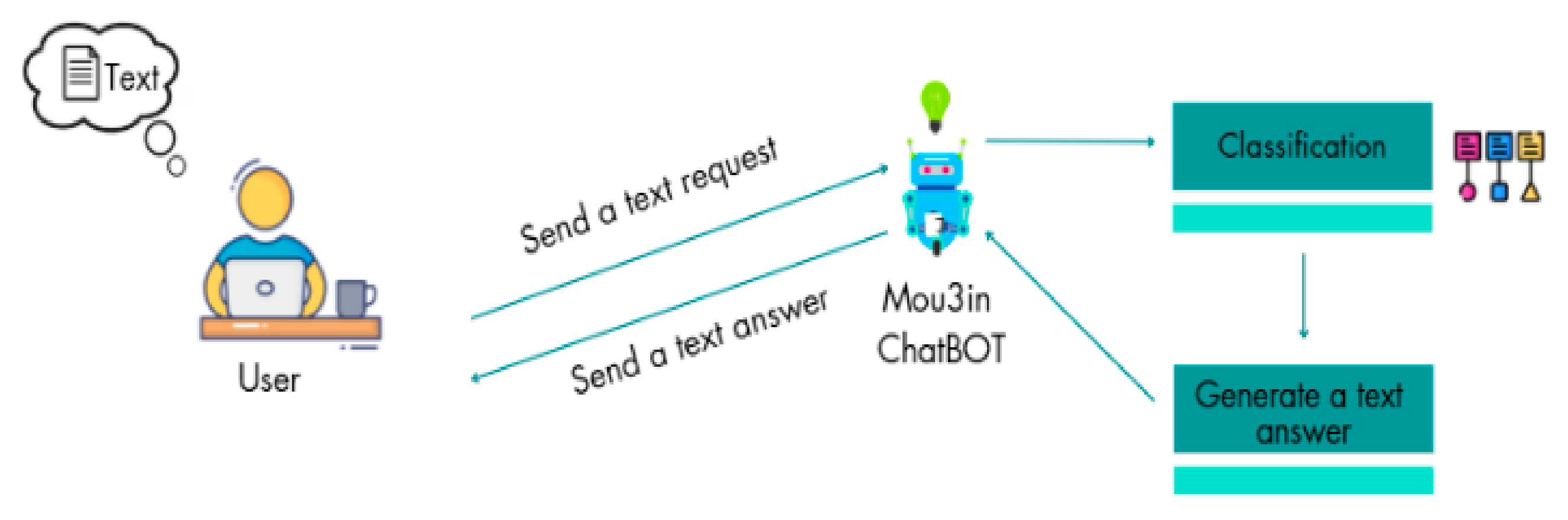
In this paper, we presented an approach for classifying requests for public administration documents in Moroccan dialect (Darija). The proposed method is based on machine learning algorithms which include supervised learning, deep learning, and large language models. The solution also includes the potential for implementing the appropriate model on a chatbot. First, we collected a dataset of 3000 rows and three classes: birthday certificate, national identity card and passport. Then, we applied a new data augmentation technique based on ChatGPT, called ‘AugGPT’, to cope with the overfitting problem arising from the small size of the initial dataset. Then, we conducted a comparative study of various supervised learning, deep learning, and LLM algorithms. Findings from the experimental study showed that deep learning algorithms improved the performance of the classification system compared to supervised learning and LLMs algorithms. RNN performed best among deep learning-based algorithms, with an accuracy of 93%. Ultimately, the optimal model will be deployed in a chatbot designed to generate responses in Moroccan dialect for users requesting documents from the public administration, provided that requests remain short, not exceeding two or three sentences, to ensure high accuracy.
For future research, we will focus on expanding and refining the dataset to facilitate the integration of LLMs, given the current advancements in chatbot development. Additionally, we plan to convert the text dataset into an audio dataset, establishing the first Moroccan dialect audio dataset dedicated to treating administrative document requests. This will pave the way to the development of a voice assistant designed to help illiterate individuals formulate requests more fluently and effectively.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}