Abstract
The frequency with which fake news or misinformation is published on social networks is constantly increasing. Users of social networks are confronted with many different posts every day, often with sensationalist titles and content of dubious veracity. The problem is particularly common in times of sensitive social or political situations, such as epidemics of contagious diseases or elections. As such messages can have an impact on democratic processes or cause panic among the population, many countries and the European Commission itself have recently stepped up their activities to combat disinformation campaigns on social networks. Since previous research has shown that there are no tools available to combat disinformation in the Croatian language, we proposed a framework to detect potentially misinforming content in the comments on social media. The case study was conducted with real public comments published on Croatian Facebook pages. The initial results of this framework were encouraging as it can successfully classify and detect disinformation content.
1. Introduction
Social networks and online news platforms have become integral parts of modern digital ecosystems and serve as primary channels for the dissemination of information. The Internet itself, and one of its first popular services—the World Wide Web [1]—were originally conceived as platforms for the exchange of information, but the widespread creation and publication of user-generated content became prominent only later, with the advent of social media and Web 2.0 technologies. In the wealth of data available to us every day in the online world, so-called fake news has emerged in recent years. Fake news or misinformation is defined as intentionally false posts that are presented as true [2]. In this paper, the terms “misinformation” and “disinformation” are used synonymously for false or misleading information, regardless of intent, as the focus is on recognizing and classifying such content and not on the motivation for its dissemination.
The result of successfully marketed misinformation is a change in the belief or behavior of the consumer of that misinformation [3]. Research has shown that the average consumer is more inclined to believe dubious facts that are generally consistent with their beliefs (political, religious, etc.) than those that run counter to their beliefs, regardless of the strength of the arguments used to support them [4].
Social networks have proven to be an ideal place for the unhindered spread of misinformation. A very large number of social network users and easy access to and sharing of content, which are at the core of the architecture of any social network, provide the ideal setting for a phenomenon that has proven to be one of the greatest threats to democracy and freedom of expression. The issue becomes especially critical during sensitive periods, such as political elections, public health crises, or other events that amplify the impact of false information.
The emergence of disinformation during the 2016 US presidential election and disinformation surrounding the 2017 referendum on the United Kingdom of Great Britain and Northern Ireland’s exit from the European Union have led to a decline in public trust in the governance structures of these countries.
As an example, we can use the analysis of posts on the social network Facebook during the 2016 presidential election campaign in the US [5]. In the last three months of the campaign, the 20 most widely shared fake campaign posts were shared more than 8,700,000 times. At the same time, the 20 most widely shared news items from verified sources (19 leading national news portals) were shared around 7,350,000 times by users of this social network. The fake news content that was most successful with users (so that they shared it with their friends on the social network) consisted of announcements that Pope Francis was supporting a candidate in the elections and that another candidate was involved in the sale of American weapons to ISIS. Furthermore, research shows that the publication of such misinformation may have even influenced the outcomes of these processes [6,7], clearly pointing to the need to recognize, flag, and remove such misinformation from the public sphere.
Despite the increasing presence of the Croatian language on digital platforms, the Croatian language remains underrepresented in natural language processing (NLP) research, leaving a gap in tools and frameworks tailored to the linguistic and cultural characteristics of the Croatian language. This study takes an initial step toward exploring the intersection of disinformation and hate speech in the Croatian language by proposing a novel framework for detecting potentially misinformative content in social media comments. It addresses the existing research gap and provides a foundation for future studies to expand the scope with additional datasets and broader thematic contexts. The framework focuses on real public comments from Croatian Facebook pages and uses text analysis techniques to classify and identify disinformation.
The remainder of the paper is organized as follows: Section 2 presents related work in the field of disinformation detection in social media, with a focus on the research that uses an approach similar to the one proposed in this paper. Section 3 presents the description of the proposed framework for detecting disinformation created and disseminated through social media in Croatian. Section 4 presents a case study and the results obtained from the experience with the available test data. Finally, Section 5 discusses the results and future research in this area.
2. Related Work
The proliferation of fake news on social media platforms has attracted considerable attention from researchers, particularly in relation to its impact on public opinion and democratic processes. A variety of methods have been proposed to detect and contain the spread of misinformation, reflecting the complexity of the problem and the different approaches to tackling it.
2.1. Disinformation Detection in English
The landscape of fake news detection is characterized by a diverse array of methodologies, ranging from conceptual modeling to advanced machine learning techniques. The integration of social context, emotional analysis, and hybrid models reflects the complexity of the issue and the necessity for multifaceted approaches to effectively combat misinformation on social media platforms.
One notable approach is the integration of conceptual modeling in fake news detection. Belloir et al. [8] emphasize the importance of accurately characterizing fake news through a conceptual model, which serves as a foundation for developing reliable detection frameworks. This conceptual clarity is essential for creating automated systems capable of distinguishing between various forms of misinformation, thereby enhancing the effectiveness of detection mechanisms.
In machine learning, researchers have increasingly explored hybrid models that combine various techniques to enhance the accuracy of fake news detection. For instance, Liu [9] proposed a method that integrates Long Short-Term Memory (LSTM) networks with Context-Free Grammar (CFG) rules to identify deceptive content, achieving an accuracy of 91.20% on a dataset of hotel reviews. This approach illustrates the potential of combining traditional linguistic analysis with advanced machine learning techniques to improve classification outcomes. Similarly, the work by Saleh et al. [10] introduced an optimized Convolutional Neural Network (CNN) model specifically designed for fake news detection, demonstrating that hybrid architectures can significantly outperform standard models. Similarly, Zhao et al. [11] introduced a hybrid feature extraction method that integrates event categorization to enhance early detection capabilities. These hybrid models demonstrate a trend toward utilizing multiple methodologies to tackle the multifaceted nature of fake news.
Advancements in deep learning have led to the development of sophisticated frameworks for fake news detection. For example, the Knowledge-aware Attention Network (KAN) incorporates external knowledge from knowledge graphs to improve detection accuracy by considering the relationships among news entities [12]. This approach highlights the necessity of contextual understanding in the detection process, as it enables a more detailed interpretation of news content. Additionally, the use of transformer-based models, such as BERT, has been shown to significantly enhance detection capabilities by utilizing pre-trained language representations [13].
The role of the social context in the spread of fake news is also a key topic. Raza’s work [14] emphasizes the importance of user interactions—such as comments and shared messages—in determining the veracity of news. This perspective is in line with the findings of other studies that argue for the inclusion of social dynamics in detection systems, as understanding how information spreads through social networks is crucial for the development of effective countermeasures against misinformation [15].
In addition, the emotional and affective dimensions of news content have been researched as indicators of fake news. Ghanem et al. [16] proposed a model that considers the flow of affective information in texts and claims that fake news exhibits different emotional patterns compared to real news. This approach adds another layer of complexity to the detection process and suggests that emotional analysis could be a valuable tool for identifying misinformation.
The need for contextual models of recognition has been emphasized by recent studies. Bezerra’s work [17] on a contextual framework for tweet similarity emphasizes the importance of considering both content and context in the recognition process. This is in line with the general trend of developing multimodal approaches that integrate different types of data—textual, visual, and contextual—to improve recognition accuracy.
In the field of fake news detection, the Term Frequency–Inverse Document Frequency (TF-IDF) technique has proven to be a fundamental feature extraction method that enables the identification of significant terms in news articles. Holla [18] has proposed an improved fake news detection model using a hybrid approach that combines TF-IDF for feature extraction with the AdaBoost ensemble model as a classifier. Research has shown that this combination improves recognition accuracy compared to traditional methods. This study highlights the effectiveness of TF-IDF in capturing the relevance of terms in different documents, thus facilitating the classification of news content as genuine or misleading. Furthermore, Aji [19] has shown that while TF-IDF serves as a robust basis for text classification, it can achieve higher accuracy in detecting hoax content on social media by integrating it with advanced techniques such as Bi-LSTM and RNN. Furthermore, in his work on hoax detection in Indonesian tweets, Karo [20] used the TF-IDF method for feature extraction together with the Naïve Bayes classifier and achieved remarkable improvements in accuracy, highlighting the utility of TF-IDF in various linguistic contexts.
Alaee and Taghiyareh [21] use an ontology-based approach to categorize the content available in an e-learning system. The approach to the problem was to use reweighting and clustering techniques. The algorithm itself was implemented in two steps, and the ICVL dataset was used. The authors developed an ontology using materials from a well-known international conference on e-learning. Using the clustering technique, the weights of the ideas were calculated by computing the TF-IDF of the words and the associated weights between the words as defined in the created ontology. After deleting the last words and roots and combining synonyms and unifying complex terms, a vectorization of the word weights of these texts was performed, which were then grouped. The results of the experiments show that reweighting improves the clustering of documents.
Niu and Shen [22] propose a model to extract the interests and preferences of users who have posted them on microblogs (which have become increasingly popular in social media recently). They improve the TextRank model to analyze the interests published by users in their microblogs. After constructing the catalog of user interests, the framework proposes a modification of the TF-IDF method based on the characteristics of microblog users’ behavior and imports TF-IDF as a factor into the TextRank model. The output of the mechanism is the tags corresponding to user interests, and the preliminary results based on Sina Weibo data indicate an improvement over similar methods.
Majdabadi et al. [23] developed a model for ranking tweets and hashtags that is based on the extraction of trends and considers tweets without hashtags. Since the usual Twitter/X trend extraction mechanism uses hashtags to find relevant content generated in a relatively short period of time, the authors proposed a graph-based approach where the nodes represent tweets, words, and hashtags (depending on the originally published content). The framework uses TF-IDF, co-occurrence scores, and a modified RankClus algorithm to extract trends from available Twitter/X datasets, and the results were consistent and coherent.
2.2. Disinformation Research in Slavic Languages
The detection of disinformation in Slavic languages is an emerging field of research that has gained attention due to the increasing prevalence of disinformation campaigns, particularly in the context of geopolitical conflicts. Despite the growing importance of automated disinformation detection, the literature on Slavic languages remains underrepresented compared to English and other widely spoken languages.
The morphological complexity, rich inflectional systems, and syntactic variability of Slavic languages pose additional challenges, making the direct adaptation of English-centric approaches ineffective. Furthermore, the scarcity of annotated disinformation datasets, limited language resources, and the geopolitical significance of disinformation campaigns in Slavic-speaking regions further widen the research gap. Addressing this underrepresentation is crucial for developing effective multilingual fact-checking systems and combating the spread of misinformation across diverse linguistic and cultural contexts.
While some progress has been made for Russian [24], Ukrainian [25,26], Czech [27], Polish [28], and Slovak [29], many Slavic languages, including Croatian, lack dedicated datasets and robust computational models.
The study by Přibáň et al. [30] addresses the challenge of automated fact-checking in West Slavic languages—specifically Czech, Polish, and Slovak. The authors compiled datasets for each language by extracting claims from fact-checking websites and employed standard machine learning techniques to establish baseline performance metrics for these datasets. They utilized features such as bag-of-words and TF-IDF representations, and applied classifiers including Support Vector Machines (SVMs) and Logistic Regression. The results highlighted the complexity of automated fact-checking in these languages, with performance varying across languages and categories.
2.3. NLP Research in Croatian Language
The Croatian language is classified as an under-resourced language [31], with limited availability of annotated datasets, linguistic resources, and tools for natural language processing (NLP). Despite these challenges, recent advancements in NLP research have increasingly focused on tasks such as sentiment analysis [32,33] and text processing [34,35] in Croatian. These studies have leveraged domain-specific datasets and adapted existing methodologies to address the unique morphological and syntactic complexities of the language. Recently, notable research has also been carried out relating to the specific area of disinformation published in the Croatian language. One significant initiative is the Early Disinformation Detection (EDD) system developed by the European Digital Media Observatory [36], which uses NLP algorithms to detect potential disinformation in Croatian news and on social media platforms such as Facebook and Twitter/X. This system continuously scans relevant text data, classifies topics, and extracts named entries, all tailored to the Croatian language.
Kocijan et al. [37] investigated hate speech detection in Croatian online comments and emphasized the challenges posed by the highly inflectional nature of the language, particularly when combined with informal and non-standard user-generated content. Although the study did not focus specifically on disinformation, it highlighted the importance of effective text normalization strategies—including lemmatization—for improving detection performance. Their findings suggest that lemmatization can play a crucial role in reducing lexical sparsity and enhancing the model’s ability to generalize across morphologically diverse expressions of harmful content. This insight is directly relevant to disinformation detection, where subtle variations in language can obscure misleading or manipulative narratives.
Additionally, studies have explored various methodologies for detecting fake news in social media, emphasizing the effectiveness of larger models and the challenges posed by content generated by large language models (LLMs) [38]. While specific research papers focusing solely on Croatian language detection systems were not detailed in the provided contexts, the general trends in automatic detection methods can be applied to this area [39,40].
Brautović and John [41] highlight the organization’s efforts to identify and debunk false narratives during the pandemic. The study highlights the challenges of fact-checking in the digital age, including the amplification of misinformation by Facebook’s algorithms and the limited reach of fact-checking measures. The research underscores the need for systemic changes in platform governance to effectively combat the spread of disinformation. This study contributes to a broader understanding of the limitations of fact-checking as a tool to curb misinformation in online environments. It also investigates the effectiveness of fact-checking initiatives in combating COVID-19 misinformation on social media platforms in Croatia. The study uncovered several critical limitations of current fact-checking practices, including challenges in the distribution and communication process. The findings suggest that traditional fact-checking methods may need to be complemented by more innovative approaches to increase their impact and reach.
The current landscape of automatic disinformation detection tools demonstrates a clear lack of language-specific models tailored for Croatian. However, recently, a novel LLM, named the croBERT, model was developed by Štefanec et al. [42]. It is a transformer-based language model specifically developed for the Croatian language. The research behind croBERT focuses on addressing the unique challenges of processing and understanding Croatian text, which is considered a moderately resourced language. The model is trained on a large corpus of Croatian text, enabling it to perform various natural language processing (NLP) tasks such as text classification, named entity recognition, and machine translation. By adopting a monolingual approach, croBERT ensures that the model’s performance is not influenced by the presence of other languages, which is a common issue in multilingual models. This makes croBERT a valuable resource for researchers and developers working with Croatian text.
Existing studies often do not address the context-specific challenges of Croatian disinformation, such as the impact of regional dialects, cultural references, and localized slang. This gap highlights the need for dedicated research efforts to develop and fine-tune models that can accurately identify disinformation in Croatian text by incorporating these contextual factors.
3. Framework Design and Methodology
The problem of the use of social media to spread disinformation has been recognized by many governments, including the European Commission, which declared disinformation to be one of the most threatening security challenges in 2015. Based on a broad public debate and expert recommendations, the Commission has published a document entitled “Tackling online disinformation: A European approach” [43], which provides guidance and a political commitment to the long-term suppression of disinformation. The document highlights that the spread of misinformation is also taking place in the context of major changes in the media, which are undergoing a deep transformation to adapt their business models. The major social media outlets (including Facebook and Twitter/X) have signed the document and have begun self-regulatory efforts to combat disinformation.
Based on the principles of the European approach, various tools need to be implemented to make the fight against disinformation more efficient. In this paper, we propose an algorithm for detecting potentially harmful content (essentially disinformation) posted by social media users in comments on social media. The novelty of this research lies in its focus on analyzing and detecting disinformation within user-generated comments written in the Croatian language, addressing a significant gap in existing natural language processing studies for under-resourced languages. Croatian, a South Slavic language spoken primarily in Croatia, is known for its rich linguistic heritage and complex grammatical structure [44]. One of the most daunting aspects of Croatian grammar is its case system. Croatian uses seven grammatical cases: nominative, genitive, dative, accusative, vocative, locative, and instrumental. Each case serves a specific syntactic function and alters the endings of nouns, pronouns, and adjectives. Croatian verbs are conjugated based on person, number, tense, mood, and aspect. Due to these intricate features, developing an automated tool for disinformation detection proves to be a worthy research challenge. To the best of our knowledge, there are currently no available tools that can classify disinformation published in the Croatian language.
While the research of Brautović and John [41] identifies key local actors and disinformation narratives, offering valuable insights into the human-driven dissemination of false information, it does not propose a solution that can be used to utilize machine learning techniques to analyze text data, detect patterns, and flag potential disinformation with high accuracy, as our proposed model does.
The selected methodology balances practical limitations with the necessity for a detailed examination of disinformation dynamics, ensuring that the research remains relevant and applicable to the specific issues at hand. In this study, we started by using the traditional ML techniques but have also started to explore the use of transformer-based models, such as BERT, due to several key considerations. Although transformer-based models have demonstrated superior performance in various natural language processing (NLP) tasks, they do require substantial computational resources and extensive datasets for training, which can be a limiting factor, especially in domain-specific studies or languages with scarce labeled data. In contexts where data may be limited or where computational efficiency is paramount, traditional machine learning models can provide a more accessible and practical solution [45].
Furthermore, traditional models offer greater interpretability and practical applicability, particularly in detecting disinformation in Croatian social media, where traditional approaches have proven effective and are easier to analyze. Given the dataset size and the scope of our research, employing transformers would not have been computationally efficient or practical.
Additionally, deep learning models often require extensive pre-training and fine-tuning on domain-specific data to achieve optimal performance, which was beyond the scope of this study. Our focus is not solely on achieving the highest possible accuracy but rather on understanding the underlying dynamics of disinformation and hate speech in specific social contexts.
In our approach, we assume that there is a natural distinction between the data groups (i.e., between harmful and non-harmful comments). The problem described belongs to the classification problems, as there are two possible outcomes. The first is that a published comment is harmful, and the second is that a published comment is not harmful. For classification problems, the first step is to create vectorized representation of the data. We used TF-IDF to vectorize the comments. TF-IDF was chosen for this research because it has proven to be very effective in representing textual data by quantifying the meaning of terms within a document compared to a corpus. Its computational efficiency and simplicity make it a suitable choice for the initial phase of text analysis, especially in contexts where interpretability and scalability play an important role [46].
TF-IDF is a statistical measure used to evaluate the importance of a word in a document relative to a collection (or corpus) of documents [47]. While TF-IDF itself does not directly determine a vector space, it is commonly used to construct feature vectors for text data in vector space models. In this context, each unique word in the corpus can be treated as an axis in the vector space, and the TF-IDF score represents the weight of that word along its corresponding axis for a given document.
In Equation (1), tf is a term frequency part of the TF-IDF vectorization. In the equation, the symbol Nt represents the number of occurrences of the word t in one document, and the symbol N represents the number of words in the same document. In this work, term frequency is important because it gives more attention to words that are mentioned multiple times than to words that are mentioned less often. It is to be expected that, due to the nature of language, there are many words that are mentioned multiple times in multiple comments. Words such as “a”, “the”, and “like” are examples of such words. The term frequency for these words in a comment results in a larger number, but the information gained from these words is small. To reduce the effect of these words, the inverse document frequency factor is added.
In (2), Ndt is the sum of the occurrences of some exact word in all documents, and the symbol Nn represents the sum of all words in all documents. With the inverse document frequency, the effect of normalization is achieved, since it can be assumed that there is a set of words that have no meaning for comments, other than providing a structure.
To scale down the effect of several words in a dataset , which can be extremely high, the function is used, so the whole expression is the following:
In this work, the scikit-learn [48] implementation of TF-IDF was used.
Lemmatization was not included in the current preprocessing pipeline. While we acknowledge its potential to enhance text normalization—particularly in highly inflected languages such as Croatian—this study aimed to establish a foundational benchmark for disinformation detection in an under-researched linguistic context. Given the limited prior work on Croatian-language datasets and the broader lack of resources tailored to this language, our focus was on evaluating baseline model performance using standard preprocessing techniques. We recognize that incorporating lemmatization could further improve classification accuracy by reducing lexical sparsity, and we view it as a valuable avenue for future research.
4. Model Evaluation on Croatian Social Media Dataset
The TF-IDF algorithm receives an array of words as input; each word is called a token. Due to the nature of the grammar of the Croatian language (i.e., there are many grammatical rules and cases and, consequently, many different forms of the same word with the same meaning), we have adapted the tokenization of the input using a classla library [49], a fork of the official Stanford NLP Python library [50], to obtain the word roots.
The corpus is available in vertical format, compatible with Sketch Engine and CWB concordances, and provides information at the text, paragraph, sentence, and token levels:
- Each text is accompanied by metadata including text id, title, URL, domain, top-level domain (e.g., “com”), and predicted genre category.
- Paragraphs are annotated with paragraph id, the automatically identified language, and paragraph quality, with labels such as “short” or “good” assigned based on length, URL, and stopword [51].
- Sentences within paragraphs have their sentence id as metadata.
- Tokens are provided in tabular format with their linguistic annotation.
In our adaptation of the tokenization process, randomly selected words from the text are replaced with a [MASK] token, which serves as a learnable parameter. The model subsequently attempts to predict the index of the word from the dictionary that corresponds to the position of the [MASK] token. This approach enables the network to discern dependencies between the masked word and its surrounding context. Following the pre-training phase, the model undergoes fine-tuning on a specific dataset to address tasks, such as question answering or text classification. Tokenization is pivotal in this process, as it segments the text into manageable units, thereby facilitating effective processing by the model.
The following example demonstrates the principle used in the presented approach. Suppose that the dataset is represented by the following three comments:
- “Danas idemo na piće” (in English: We are going to drink today).
- “Sutra će biti bolje” (in English: It will be better tomorrow).
- “Svaki dan je novi početak” (in English: Every day is the new beginning).
In the first step, the TF-IDF analysis determines which words will represent the axes in vector space. After that, in the second step, the vector representations are created by counting the number of words that appear in comments. So, using the example, the output will be the following:
Axis: ["dan", "danas"]
Representation:
[[0. 1.],
[0. 0.],
[1. 0.]].
This matrix indicates the TF-IDF values for each term in each document:
- The first comment, “Danas idemo na piće.”, has a TF-IDF value of 1 for “danas” and 0 for “dan”. This suggests that “danas” is a significant term in this comment.
- The second comment, “Sutra će biti bolje.”, has TF-IDF values of 0 for both “danas” and “dan”, indicating that neither term is significant in this comment.
- The third comment, “Svaki dan je novi početak.”, has a TF-IDF value of 1 for “dan” and 0 for “danas”. This highlights “dan” as a significant term in this comment.
We used a basic spelling checker to address the grammatical inaccuracies found in the dataset, with a particular focus on the omission of Croatian diacritic marks (č, ć, š, ž, and đ) [44]. The spell-checking process was applied to identify comments with missing diacritical marks, ensuring the text’s orthographic accuracy. Incorporating this spelling correction step before vectorization improved the text representation quality, facilitating precise word identification and processing. This approach maintained the dataset’s linguistic integrity, enabling subsequent analyses to be conducted on grammatically corrected text data. Consequently, the erroneous comments were marked as null vectors, which led to more reliable and valid outcomes. By implementing this approach, approximately 1400 comments were excluded from the dataset as null vectors.
4.1. Features of the Dataset Used
We can observe that the second comment represents a problem, because it is a null vector, meaning it does not contain words that have representation in the defined vector space. Following a closer examination of the input dataset, we decided that all sentences resulting in null vectors would be ignored. The reasoning for such a decision is that there are many sentences that have incorrect grammar (wrong spelling or using incorrect diacritic symbols specific to the Croatian language—diacritic marks on letters like č, ć, š, ž, and đ are omitted) and in the process of vectorization, written words in those comments would not be recognized as grammatically correct words. By implementing this approach, approximately 1400 comments were excluded from the dataset as null vectors. The exclusion of these null vectors from the final analysis was crucial to preserving the integrity and accuracy of the data. This ensured that only comments with grammatically correct and recognized words were included in the vectorization and subsequent analyses.
For our research, we used the offensive language dataset of Croatian, English, and Slovenian comments, FRENK 1.1 [52]. The dataset consists of public Facebook comments published on Croatian platforms.
The FRENK datasets provide a crucial resource for analyzing socially unacceptable discourse (SUD) on Facebook, with a specific focus on remarks about immigrants and LGBTQ+ individuals, chosen due to the high prevalence and significant social impact of hate speech directed at these groups. The Croatian dataset, part of the broader FRENK project, was created by analyzing comments on Facebook posts from mainstream media sources. The selection criteria ensured that the data were representative and comparable across different languages and contexts. Posts related to migrants and LGBTQ+ topics were identified through a combination of manual and automated methods, resulting in a robust training set that accurately represents these issues.
The public comments were annotated for different types of SUD and their targets. Key characteristics of the dataset include the following:
- The average text length is 218 characters—comments vary in length, providing a comprehensive overview of different discourse styles.
- Annotations include six types of SUDs, such as background violence and offensive speech, and five targets, including migrants, LGBTQ+ individuals, and journalists.
- The average number of annotations is 8.59.
Since there are very few available Croatian language-based datasets that could have been used for this research, and this research focused on Facebook remarks about immigrants and LGBTQ+ individuals, we decided to train our model on this dataset. The rationale lies in the observed trend of hate speech and disinformation targeting these vulnerable groups. Disinformation often fuels hate speech by spreading false or misleading information that incites fear, prejudice, and hostility. By analyzing the discourse on these topics, the dataset aims to uncover patterns of disinformation that contribute to the spread of hate speech, ultimately informing strategies to counteract both phenomena.
While the FRENK 1.1 dataset offers a valuable resource for disinformation detection in the Croatian language, its thematic focus on migrants and LGBTQ+ topics inherently constrains the generalizability of our findings. The dataset captures disinformation strategies and narratives within these specific domains, which may not comprehensively reflect the linguistic patterns or rhetorical devices used in disinformation targeting other social, political, or economic issues. Consequently, the performance of the proposed models might vary when applied to datasets encompassing a broader array of topics. This issue will be addressed in future work using this framework, expanding the scope of training data by incorporating diverse thematic categories, thus enhancing the robustness and applicability of disinformation detection systems across different contexts.
We acknowledge that the original annotation scheme of the FRENK 1.1 dataset was primarily designed to distinguish between “offensive” and “acceptable” speech. However, a closer qualitative analysis of the offensive category reveals a high incidence of speech acts that rely on or propagate misleading, false, or manipulative content—hallmarks of disinformation. Given the sociopolitical sensitivity of the dataset’s themes, many of the offensive statements include narratives that are demonstrably false or misleading, designed to foster prejudice and shape public opinion through misinformation. Therefore, while the dataset was not explicitly labeled for disinformation, its content reflects a considerable overlap with known disinformation patterns, particularly in contexts where disinformation is used as a vehicle for hate speech or social manipulation, and in under-resourced languages like Croatian.
In this study, we leverage this overlap by treating such instances as proxies for disinformation, while fully acknowledging the limitations of this approach. As part of future work, we intend to refine the annotation process and construct a more targeted dataset that includes explicit disinformation labeling based on factual verification and content analysis. This will allow for a clearer distinction between offensive, hateful, and misleading content, improving the precision of disinformation detection efforts and further strengthening the theoretical foundations of our framework.
Although hate speech and disinformation serve different purposes (one targets individuals or groups, while the other manipulates beliefs), their textual patterns, social functions, and computational challenges overlap considerably. Therefore, insights from NLP research on hate speech detection can serve as a basis for methods, datasets, and interpretation techniques for disinformation research.
Each comment was categorized either as offensive or acceptable. The prevalent topics of the comments were LGBTQ+ persons and immigrants. This dataset can be considered a disinformation dataset, as any hateful comment that objectively insults another person constitutes disinformation.
The dataset was filled with emojis, and, therefore, all symbols that were not letters were ignored. After removing comments that did not provide any information (the empty comments), the number of comments in the dataset used for training was 7900, but this number was reduced again after removing the comments in the origin of the vector space (as we explained in the previous section).
Disinformation on social media often manifests itself through inflammatory and derogatory comments, which can spread rapidly and influence public opinion. Disinformation, which involves deliberately spreading false information, can amplify hate speech by providing false narratives that fuel prejudice and discrimination.
Both disinformation and hate speech can lead to the stigmatization and dehumanization of individuals or groups. Disinformation can spread unfounded rumors or conspiracy theories that portray certain groups as dangerous or inferior, which hate speech then exploits to justify discriminatory actions. Although the provided dataset consists of comments containing various forms of harmful speech, including insults, hate speech, and incitements to violence, we used it to train our model due to the interconnection of disinformation and hate speech. For instance, comments like “Budale svasta majka rodi” (eng. “fools are born every day”) and “cime se budala hvali pametan se srami” (eng. “what a fool boasts about, a wise person is ashamed of”) are derogatory and dismissive, contributing to a hostile online environment.
Hate speech is evident in comments such as “Jebem vam mater pedersku” (eng. literally “I f*** the mother of you gays”) and “Pedercine” (eng. “faggots”), which target individuals based on their sexual orientation, promoting discrimination and intolerance. Incitements to violence are seen in phrases like “Udrite tu gamad” (eng. “Hit those bastards”) and “Jos ce ih drotovi tuc” (eng. “The cops will beat them more”), which can encourage real-world aggression and conflict.
Such language not only fosters a toxic online environment but also undermines constructive discourse and can lead to consequences in the real world. Tackling disinformation requires a multifaceted approach that includes teaching digital literacy, robust moderation guidelines, and promoting respectful online communication. By understanding and mitigating the impact of these harmful comments, we can work toward a better-informed and more respectful digital community.
The offensive and the acceptable comments in the dataset are almost equally distributed. In the dataset that was used for this research, 3600 comments are in the acceptable category, while the offensive category contains 4400 comments. The classification mechanism primarily distinguishes between offensive and acceptable speech based on linguistic features, context, and intent. This distinction underscores the dataset’s reliance on context and intent rather than merely the presence of sensitive words, ensuring a more detailed classification of harmful versus neutral statements.
4.2. The Density of Vector Space
It is to be expected that the comments that have offensive content will be positioned very closely in the vector space, and the same applies to the acceptable comments. Consequently, there will be space between these two groups. First, we decided to select the first 100 comments and determine their vector representation using TF-IDF. We opted for the vector space with the two axes.
The output of vectorization resulted in the two-dimensional vector space. The axes were two words, one ordinary and the other offensive: “imati” (eng. “to have”) and “peder” (eng. “faggot”).
It is apparent that there is a clear distinction between classes. All acceptable comments are at the origin, but there is also a group of the offensive comments around the origin. Figure 1 illustrates the distribution of the first 100 comments projected into a two-dimensional space for visualization.
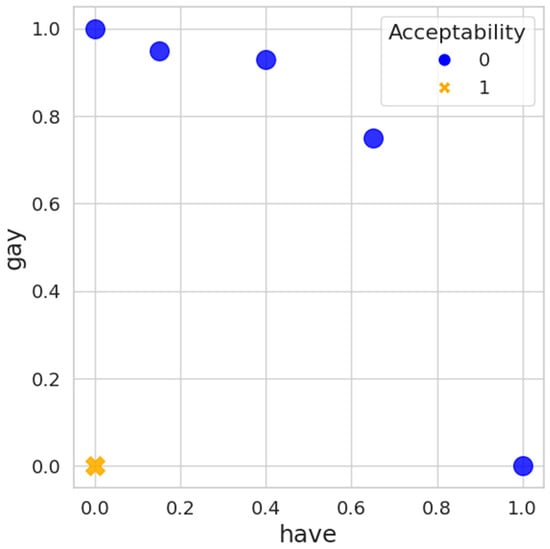
Figure 1.
The first 100 comments projected in 2D space.
Due to the complexity of accurately representing high-dimensional data in only two dimensions, this plot primarily serves to demonstrate the general distinction between categories rather than providing a precise representation. Notably, comments positioned at the origin (0,0) are not meaningful and are excluded from the analysis. This plot is a simplified example to highlight the distinction between acceptable and offensive comments but cannot fully capture the complex relationships present in the original high-dimensional data space.
To automate the process of determining the number of groupings, the Density-based Spatial Clustering of Applications with Noise (DBSCAN) algorithm was used, and the results are shown in Figure 2. The scikit-learn [48] implementation of the DBSCAN library was used. DBSCAN is an unsupervised classification algorithm that calculates the groupings by computing the distances between the points [53].
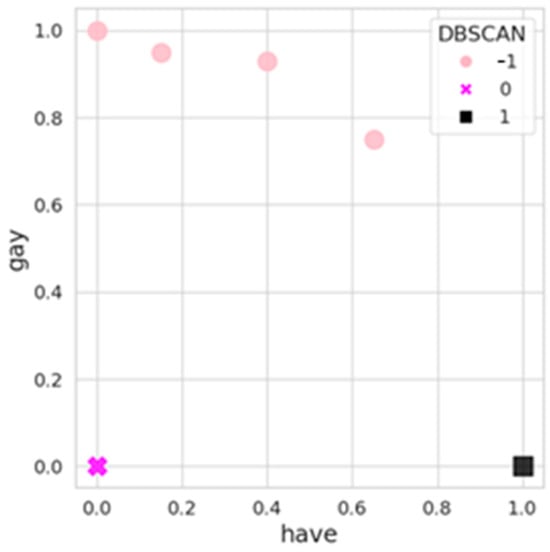
Figure 2.
The output of DBSCAN on the first 100 comments.
The DBSCAN algorithm receives the minimal distance and the minimum number of points (MinPts) as the input parameters. The parameter ϵ defines the radius of the neighborhood around each data point, determining which points are considered neighbors. Points within this radius are classified in the same cluster as the anchor point. MinPts specifies the minimum number of points needed to form a dense region, or cluster. The selection of the DBSCAN clustering parameters, specifically the ϵ and the MinPts, is crucial for the algorithm’s effectiveness. In our study, we selected ϵ and MinPts based on a combination of domain knowledge and empirical testing. We initially set MinPts to twice the number of dimensions in our dataset, following a common heuristic. Subsequently, we conducted a grid search to fine-tune ϵ, evaluating the clustering results using silhouette scores and visual inspection of the clusters. This approach ensured that the chosen parameters effectively captured the underlying structure of the data, balancing the identification of meaningful clusters with the exclusion of noise points.
4.3. Vector Dimensionality
It is to be expected that with the expansion of dimensionality, the points in space will be farther and farther apart. To neutralize this effect, the standard deviation is added to the previous ϵ in each epoch. Figure 3 shows the expected increase in ϵ with the increase in dimensions. It is interesting to note that the increase in ϵ slows down after 50 dimensions.
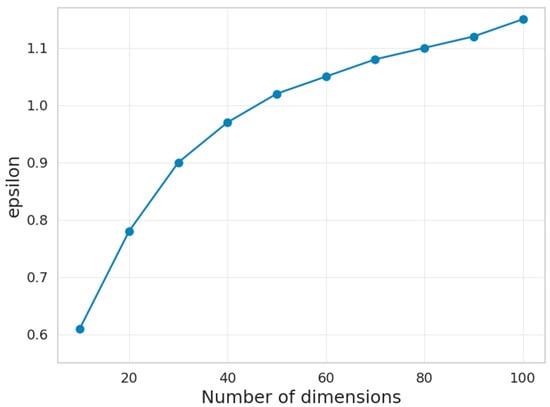
Figure 3.
Epsilon over number of dimensions.
We calculate the goodness of the vector dimensionality by calculating the Rand Index [54]. The first step in determining the final dimensionality is calculating a standard deviation and an average value of all the distances between all the points. In Equation (4), N stands for the number of classes acquired from DBSCAN. The first will be set as . If the DBSCAN outputs several labels greater than three, the value will be corrected accordingly:
Figure 4 shows the goodness of grouping with the increase in dimensionality. After dimension 50, the Rand Index does not increase (marked by the red x mark), so the dimension that is used for representing comments in this paper is 50.
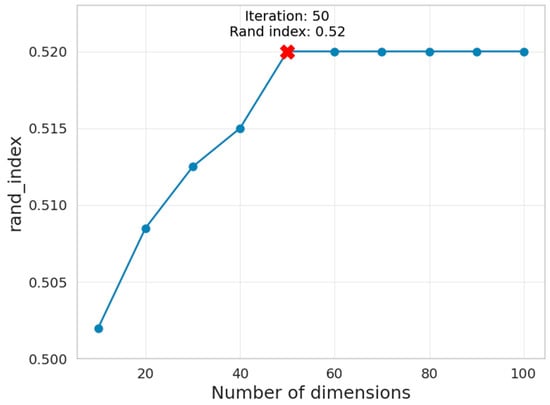
Figure 4.
Rand Index over number of dimensions.
4.4. Training the Classification Models
To train the classification models for disinformation detection, we used three different machine learning algorithms: a Support Vector Machine (SVM), a Random Forest, and a neural network. These models were selected due to their proven effectiveness in text classification tasks, with the SVM excelling in high-dimensional spaces, the Random Forest offering robust performance and interpretability, and neural networks providing the ability to capture complex, non-linear patterns in the data. The SVM model was trained with a Radial Basis Function (RBF) kernel to account for non-linear relationships in the data. For the Random Forest model, an ensemble of decision trees was used to improve classification accuracy and robustness against overfitting. The neural network model was designed with a single hidden layer of 10 neurons and optimized with the stochastic gradient descent (SGD) algorithm to efficiently minimize the loss function. Each model was trained on a labeled dataset of social media posts, extracting features from the text data, such as word embeddings and sentiment scores. The training process involved splitting the dataset into a training set and a validation set, tuning the hyperparameters through cross-validation, and evaluating the model performance using metrics such as accuracy, precision, recall, and F1 score. This comprehensive approach ensured that our models were well equipped to effectively identify and classify disinformation. Figure 5a–c show the confusion matrix for each model.
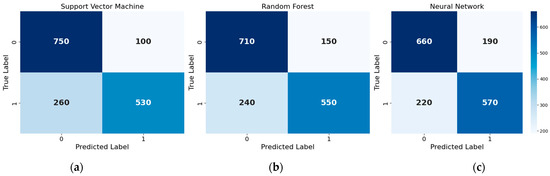
Figure 5.
The confusion matrixes for (a) SVM, (b) Random Forest, and (c) neural network models.
The results are also shown in Table 1. From the data displayed in the confusion matrix, we can calculate the metric performance parameters for every learning mechanism that we used for our model. Despite employing relatively simple methods, this approach involved extensive pre-training of the model over multiple epochs using the annotated dataset. This rigorous training process enabled the model to discern subtle differences in intent and sentiment, thereby enhancing the accuracy of hate speech detection.

Table 1.
Metric parameters for learning mechanisms.
The Support Vector Machine (SVM) model achieved a classification accuracy of 78.05%, indicating that it correctly identified disinformation in 78.05% of the cases. The high precision of 84.13% indicates that the model effectively identifies positive instances with minimal false alarms. However, the recall of 67.09% suggests that the model misses a notable proportion of actual positive cases. The F1 score of 74.62% confirms a reasonable balance between precision and recall, making the model suitable for applications where both false positives and false negatives have significant implications. This result suggests that the SVM model is effective in distinguishing between disinformation and legitimate content, though there is still room for improvement. The accuracy reflects the model’s ability to generalize from the training data to unseen data, which is crucial for real-world applications. However, to further enhance performance, it may be beneficial to explore additional feature engineering techniques, optimize hyperparameters, or consider combining an SVM with other models in an ensemble approach. Overall, the SVM’s performance is promising and provides a solid foundation for detecting disinformation on social media.
The Random Forest model achieved an overall accuracy of 76.36%, indicating a reasonable balance between correct and incorrect predictions. The precision of 78.57% suggests that most of the positive predictions are accurate, reducing the likelihood of false alarms. However, the recall of 69.62% reveals that the model misses a significant proportion of actual positive cases, which could be critical depending on the application. The F1 score of 73.84% underscores a moderate balance between precision and recall, making the model suitable for contexts where both false positives and false negatives are consequential. This result is slightly lower than the SVM model’s performance but still demonstrates a reasonable level of effectiveness. The Random Forest’s ability to handle many features and its robustness against overfitting are strengths, but the slightly lower accuracy suggests there may be room for optimization. To improve the Random Forest model’s performance, we could consider increasing the number of trees in the forest, tuning hyperparameters such as the maximum depth of the trees or experimenting with different feature selection methods. Additionally, combining the Random Forest with other models in an ensemble approach might enhance overall accuracy.
The neural network model is configured with one hidden layer consisting of 10 neurons. Each neuron in the hidden layer utilizes the ReLU (Rectified Linear Unit) activation function, which introduces non-linearity to the model and helps in learning complex patterns. To prevent overfitting, dropout regularization is applied with a dropout rate of 0.5, randomly setting 50% of the neurons to zero during each training iteration. This technique helps in improving the generalization of the model by reducing the reliance on specific neurons. Additionally, L2 regularization (also known as weight decay) is employed to further mitigate overfitting by penalizing large weights. The model is optimized using the stochastic gradient descent (SGD) algorithm, which iteratively updates the weights to minimize the loss function. This configuration demonstrates balanced classification performance, achieving a 75% accuracy and an F1 score of 73.55%.
Its higher recall relative to precision suggests the model prioritizes detecting positive instances, which is crucial in applications like disease detection, fraud prevention, or security threat monitoring. However, the elevated false positive rate (190 instances) indicates that the model is more likely to generate false alarms, potentially leading to inefficiencies in practical deployment. While this accuracy is also slightly lower than that of the SVM and Random Forest models, it still demonstrates a reasonable level of effectiveness. The performance of the neural network could potentially be improved by experimenting with different network architectures, such as adding more hidden layers or neurons, or by using more advanced optimization algorithms like Adam or RMSprop. Additionally, fine-tuning the learning rate and other hyperparameters might enhance the model’s accuracy. Further optimization and experimentation could help unlock its full potential.
To further understand the models’ discriminative capabilities, we include the Area Under the Receiver Operating Characteristic (AUC-ROC) curve as an additional and critical metric. To plot the AUC-ROC curves for each model—Support Vector Machine (SVM), Random Forest (RF), and neural network (NN)—specific parameters need to be calculated, including the true positive rate (TPR) and false positive rate (FPR). The parameters achieved in our study are presented in Table 2.
Table 2.
Parameters needed to plot AUC-ROC curves.
Figure 6, Figure 7 and Figure 8 show the AUC-ROC curves for the SVM, RF, and NN models, respectively. The performance of the three models—Support Vector Machine (SVM), Random Forest (RF), and neural network (NN)—as assessed by their AUC-ROC curves indicates moderate discriminatory power in classifying positive and negative instances. The SVM model achieves the highest AUC (0.78), suggesting slightly better class separation, followed by the Random Forest (0.76) and neural network (0.75) models.
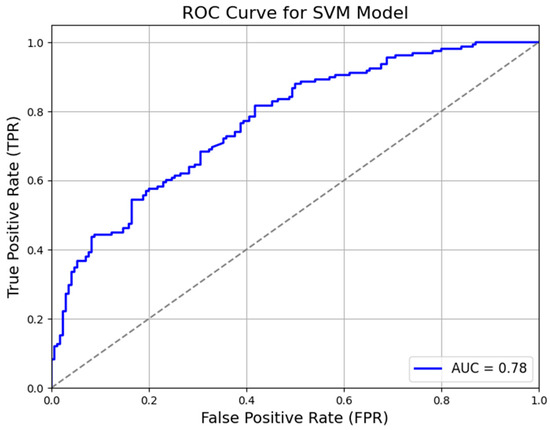
Figure 6.
AUC-ROC curve for SVM model.
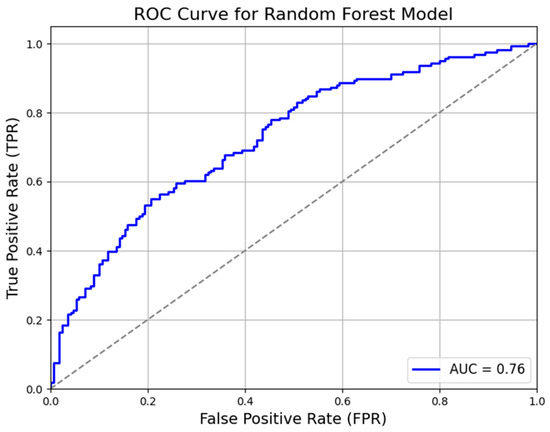
Figure 7.
AUC-ROC curve for Random Forest model.
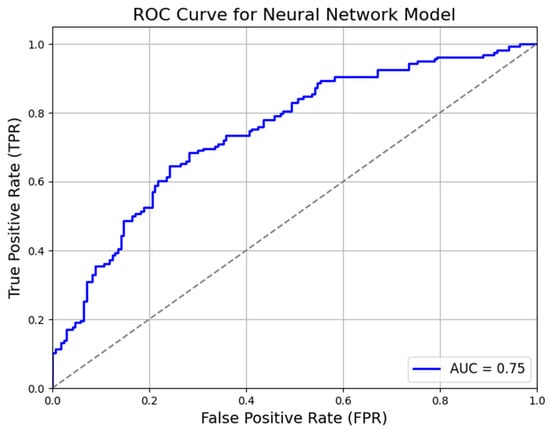
Figure 8.
AUC-ROC curve for neural network model.
All three models exhibit a gradual increase in the true positive rate (TPR) across a broad range of false positive rate (FPR) values, indicating balanced trade-offs between sensitivity and specificity. However, none of the models demonstrate a steep initial rise in the ROC curve, highlighting their limited ability to achieve near-perfect class separation. The mid-range FPR values (approximately 0.3–0.6) present challenges for all models, as the TPR does not increase as sharply as expected, likely due to overlapping feature distributions. Additionally, the NN model’s curve does not approach the upper-left corner sharply, suggesting it struggles to achieve high sensitivity at low false positive rates. While the SVM shows slightly better overall classification performance, all three models maintain reasonable effectiveness in handling the classification task.
Similar F1 scores for the three models—Support Vector Machine (SVM) with 74.62%, Random Forest (RF) with 73.84%, and neural network with 73.55%—suggest that the proposed framework performs consistently across different algorithms. This consistency indicates that the framework is robust and generalizes well across various machine learning techniques. However, the close F1 scores also highlight that the models may not sufficiently distinguish themselves in terms of performance. This could be due to the inherent limitations of the dataset, or the features used for training.
To provide a further evaluation of model performance, a qualitative comparison of the models was made, and the results are presented in Table 3. While the AUC-ROC serves as a key measure of overall discriminatory ability, additional metrics such as accuracy, precision, recall, and F1 score offer deeper insights into each model’s strengths and limitations.
Table 3.
Comparison table of model strengths and weaknesses.
Among the three models, the SVM achieves the highest accuracy and precision, indicating its strong capability to correctly classify positive instances while minimizing false positives. This makes the SVM particularly well suited for scenarios where high precision is critical, such as medical diagnostics or fraud detection. However, its moderate recall suggests that it may struggle with correctly identifying all positive instances, potentially leading to higher false negatives in imbalanced datasets.
The Random Forest model offers a balanced trade-off between precision and recall, with moderate-to-high performance across all metrics. While its AUC-ROC (0.76) is slightly lower than that of the SVM, it demonstrates robustness to noise and variability in feature importance, making it a more adaptable choice for real-world classification tasks. The model’s ability to capture complex feature interactions contributes to its moderate-high recall, making it more effective in applications where missing positive cases must be minimized. However, its interpretability is lower compared to the SVM, and computational efficiency may decrease with large datasets.
The neural network model exhibits the highest recall, making it particularly effective in scenarios where identifying all positive instances is a priority, even at the expense of increased false positives. This high recall performance is beneficial in applications such as anomaly detection and medical screening, where missing positive cases could have significant consequences. However, its moderate precision and accuracy indicate that it may produce a higher number of false positives, requiring careful postprocessing or threshold optimization. Furthermore, the NN model may require more extensive training data to generalize effectively, and its computational demands are typically higher than those of traditional machine learning models.
Finally, to fully evaluate whether the observed performance differences between models are due to actual improvements or just random variations in the dataset, we performed a statistical significance analysis using the DeLong test. The results of the DeLong test indicate that there is no statistically significant difference in the AUC values between the evaluated models. Specifically, the p-value for the SVM vs. the RF is 0.488; for the SVM vs. the NN, it is 0.512; and for the RF vs. the NN, it is 0.511. Since all p-values are greater than the conventional significance threshold (p = 0.05), we fail to reject the null hypothesis, which states that the models exhibit equivalent discriminative ability in terms of the AUC. These findings suggest that while slight variations in the AUC do exist, they are likely attributable to random fluctuations rather than a meaningful performance difference. Consequently, selecting among these models should be based on other considerations, such as computational efficiency, interpretability, or application-specific constraints, rather than AUC superiority.
A qualitative error analysis was conducted to examine prevalent patterns in misclassified instances and to clarify model limitations. False positives—instances in which acceptable comments were erroneously classified as disinformation—commonly exhibited characteristics such as emotionally charged yet factually accurate language, rhetorical constructs, or satirical expressions. These linguistic forms, while not inherently deceptive or offensive, frequently mimicked the tonal and structural features of actual disinformation, thereby leading to misclassification. In contrast, false negatives—disinformation instances that the model failed to detect—often involved implicit biases, insinuations, or syntactically complex formulations that subtly conveyed misleading narratives. Such cases occasionally employed coded language or euphemisms, which avoided detection by models reliant on surface-level textual features.
This analysis underscores the inherent limitations of traditional machine learning models in capturing the deeper contextual and pragmatic dimensions of language. Borderline instances—such as those containing sarcasm, speculative opinion, or veiled manipulation—were particularly difficult to classify accurately, thereby exposing the need for more context-sensitive approaches. These findings support the integration of transformer-based architectures, which demonstrated an improved capacity for handling semantically layered content.
Our model, trained on the FRENK 1.1 dataset, using traditional machine learning algorithms, achieved an F1 score of 74%, outperforming several models using more advanced BERT transformer-based architectures reported in the literature. Notably, a BERT model fine-tuned for propaganda detection attained F1 scores of 46.06% for span identification and 54.30% for technique classification [55]. Additionally, a BERT-based approach for COVID-19 rumor detection reached a maximum F1 score of 64.7% [56]. These results show that our model exhibits competitive performance despite the lack of transformer-based architectures, likely due to the careful feature engineering and domain-specific focus provided by the FRENK 1.1 dataset. While other transformer models, such as BERTweet-large and the domain-adapted BERT for fake news detection, achieved higher F1 scores—89.4% and 89.7%, respectively—these models often benefit from extensive pre-training and computational resources [57]. Our study shows that traditional models, when trained on well-curated and domain-relevant data, can still provide robust results in disinformation detection. However, to further improve generalizability and capture more complex linguistic patterns, we investigated the integration of pre-trained transformation models such as croBERT into our system.
4.5. Expanding the Framework: Testing with croBERT
Our initial experiments with traditional machine learning techniques, such as Support Vector Machines (SVMs), Random Forests (RFs), and neural networks (NNs), achieved only modest F1 results. Another incentive was the need to mitigate the limitations posed by the domain specificity of the FRENK dataset. Those reasons prompted us to extend our research by integrating croBERT, a transformer-based model trained specifically for the Croatian language. CroBERT excels at capturing intricate linguistic structures, contextual relations, and semantic subtleties—capabilities that traditional machine learning models often lack, especially for tasks involving context-rich discourse in social media. Considering that disinformation often exploits subtle linguistic manipulations, the use of croBERT increases the sophistication of text analysis in this study. Furthermore, the inclusion of croBERT in our framework not only expands the scope of our experiments, but also provides a more robust power measure. Despite being fine-tuned on the same corpus, croBERT demonstrated a stronger ability to capture subtle, implicit, and context-dependent forms of disinformation compared to traditional models. Its performance on borderline and semantically complex instances suggests a degree of generalization beyond overt lexical cues, reinforcing the value of transformer-based architectures in handling complex and context-sensitive language, even within a domain-constrained setting. This brings our methodology in line with state-of-the-art natural language processing (NLP) techniques and underscores the scientific rigor and current relevance of our research. Finally, the comparative evaluation of traditional models and advanced transformers provides valuable insights into the trade-offs between model complexity, computational efficiency, and prediction accuracy, further enriching the results of this study.
The croBERT experiments were executed on a MacBook Pro equipped with a 3.49 GHz 8-Core Apple M2 processor, 8 GB of RAM, and a 10-Core Apple GPU with shared memory. The fine-tuning process of an already pre-trained model required approximately 1 h and 20 min, which reflects the computational complexity inherent to transformer-based models in processing linguistic structures and contextual semantics. Conversely, the neural network (NN) model, trained under identical hardware conditions, completed its training within roughly 10 min. This discrepancy in training duration underscores the substantial computational demands associated with advanced transformer architectures relative to traditional neural networks, emphasizing the inherent trade-offs between model sophistication, resource intensity, and processing efficiency.
The results (presented in Table 4) demonstrated a substantial improvement in performance compared to traditional machine learning models. While our previous experiments achieved a modest F1 score of around 0.74, croBERT yielded an F1 score of 0.89 after three epochs of training. We opted for a limited number of epochs due to practical constraints related to computational resources and time limitations. Fine-tuning transformer models can be computationally intensive, often requiring significant processing power and time. Given the resources available for this study, we focused on balancing thorough model evaluation with the efficient use of time and hardware. Despite the limited number of epochs, the model demonstrated strong and stable performance, with a clear downward trend in both training and evaluation loss. This approach ensured that we could still provide meaningful insights into croBERT’s capabilities within the scope of our research.
Table 4.
CroBERT experiment results.
The confusion matrix for the croBERT model (shown in Figure 9), compared against the confusion matrices of the Support Vector Machine (SVM), Random Forest (RF), and neural network (NN) models, also shows significant improvements when using this approach. The croBERT model achieved a significantly higher F1 score (0.893), with an accuracy of 0.9 and recall of 0.9, outperforming the traditional machine learning models across all key metrics. While the SVM, RF, and NN models struggled with false negatives, croBERT demonstrated a more balanced performance, correctly identifying a larger proportion of true positives. For instance, SVM misclassified 260 positive samples as negative, while croBERT reduced this error considerably. Additionally, croBERT maintained a lower number of false positives compared to the RF and NN models, indicating its superior ability to distinguish between disinformation and non-disinformation content. These results highlight the effectiveness of transformer-based models in handling complex language patterns, as seen in the FRENK 1.1 dataset, which focuses on detecting disinformation in Facebook comments related to immigrants and LGBTQ+ individuals.
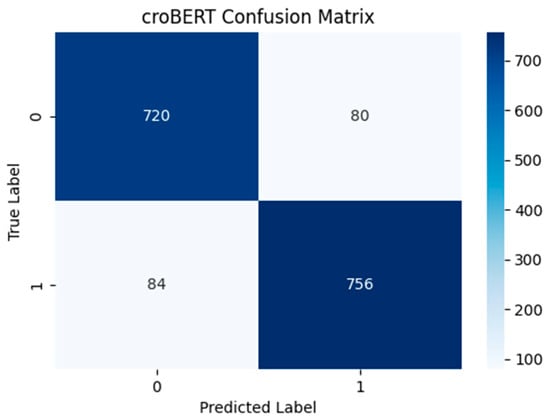
Figure 9.
CroBERT confusion matrix.
The ROC curve for the croBERT model, shown in Figure 10, illustrates the trade-off between the true positive rate (TPR) and false positive rate (FPR) across various classification thresholds. The curve rises steeply toward the top-left corner, indicating strong discriminatory power. The area under the curve (AUC) is 0.92, reflecting the model’s high ability to distinguish between disinformation and non-disinformation instances. If we compare this to the traditional models like the SVM (where the AUC was 0.78), croBERT demonstrates a substantial improvement, likely due to its contextual language understanding and pre-training on large-scale datasets. This enhanced performance confirms the effectiveness of transformer-based models in capturing the complex linguistic patterns present in the dataset.
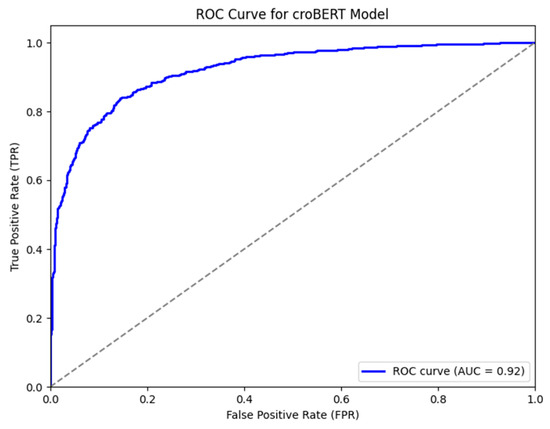
Figure 10.
AUC-ROC curve for CroBERT model.
This result represents an increase of over 15 percentage points, highlighting the advantages of transformer-based architectures in capturing complex linguistic patterns and contextual relationships—critical components for accurately detecting disinformation. Additionally, croBERT achieved an accuracy of 90% and a recall of 90%, further supporting the model’s ability to balance precision and recall. The loss values followed a stable downward trajectory, with the training loss reducing from 0.67 to 0.27 and the evaluation loss dropping from 0.61 to 0.34 by the final epoch, as shown in Figure 11. These results reinforce the notion that transformer models, like croBERT, outperform traditional techniques by leveraging their deep contextual understanding of language, which is especially valuable in the often subtle manipulations found in disinformation narratives.
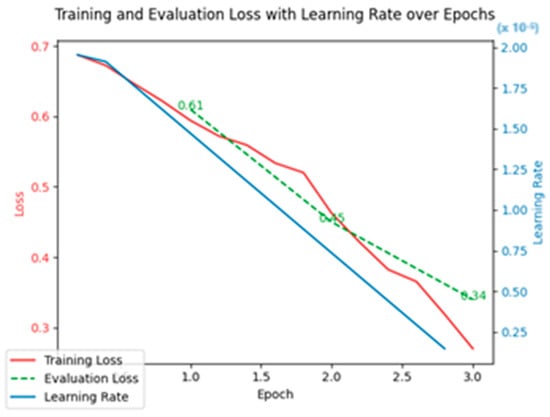
Figure 11.
Training and evaluation loss with learning rate over epochs.
5. Conclusions and Future Work
This paper provides an overview of the challenges that the spread of misinformation, especially in social networks, poses to the modern information society. As can be seen from their definitions, misinformation, fake news, and similar synonyms are often created and spread to make a profit for their creators. As this profit often contradicts the goals of a democratic society, science and state authorities have made great efforts in recent years to find mechanisms to prevent the influence of misinformation on society.
This paper presents initial research and an early version of the novel framework for classifying disinformation found in content published on social networks (i.e., X) in the Croatian language. The model attempts to overcome problems with orthography and grammar (e.g., spelling and grammar errors that are common in social networks).
The proposed framework for classifying disinformation in social networks published in the Croatian language addresses several critical challenges in automatic disinformation detection. Our approach addresses the widespread problem of non-standard language usage and grammatical deviations that are common in social media communication.
The framework shows promising results in detecting disinformation despite these linguistic challenges and offers several important insights. The framework’s ability to deal with common misspellings and grammatical irregularities represents a significant advance over traditional text classification methods. This adaptability is crucial considering that disinformation is often spread via informal, user-generated content where standard language rules are often disregarded.
Our model accounts for character constraints and platform-specific conventions (e.g., hashtags, mentions, and shortened URLs) that influence how disinformation is structured and disseminated. The model shows that it can capture contextual differences despite linguistic irregularities, although there is still room for improvement in understanding more complex forms of deception such as sarcasm and implicit messages.
This study presents a comprehensive approach to disinformation detection by exploring both traditional machine learning techniques—Support Vector Machines (SVMs), Random Forests (RFs), and neural networks (NNs)—and transformer-based models, specifically croBERT. The inclusion of both methods serves a dual purpose: first, to establish a performance baseline using well-understood, computationally efficient models, and second, to assess the advantages offered by modern transformer architectures in handling complex linguistic patterns. While traditional ML models provide interpretability and faster training times, the croBERT model demonstrated superior performance, achieving an F1 score of 0.893, underscoring the effectiveness of pre-trained language models in capturing the semantics of disinformation. This comparison not only highlights the evolution of disinformation detection techniques but also emphasizes the trade-offs between computational complexity and model accuracy, offering a balanced perspective for future research.
Several promising directions for future research emerge from this initial framework. Future research will focus on developing more sophisticated methods for dealing with emerging forms of multimedia disinformation, developing more robust validation methods for evaluating the performance of the framework, establishing standardized metrics for evaluating disinformation detection systems, and investigating the role of network effects in the spread of disinformation and how to incorporate them into the classification framework. To address the limitation of the dataset used for training the model, future work will focus on constructing an extended dataset that encompasses a wider range of disinformation topics, beyond migrants and LGBTQ+ issues. This expanded corpus will include content related to political discourse, public health, climate change, and other socially relevant subjects. By diversifying the dataset, we aim to capture a broader spectrum of linguistic patterns and misinformation tactics, ultimately enhancing the generalizability and robustness of the proposed disinformation detection models.
In addition to expanding the dataset, future work will also explore the cross-domain performance of croBERT. Given its demonstrated ability to handle context-dependent disinformation within the current scope, evaluating its effectiveness on a more diverse range of datasets will provide deeper insight into its generalizability. This will help determine the extent to which pre-trained transformer models can adapt to varied linguistic and rhetorical strategies across domains, and inform the development of more robust, domain-agnostic detection systems.
Other promising research paths can leverage the advancements made by the croBERT model [42] to enhance the accuracy and robustness of this framework detection algorithm. The croBERT model, with its pre-trained transformer-based architecture, has demonstrated significant improvements in natural language processing tasks specific to the Croatian language. By further using the features of the croBERT model, our framework can be enhanced with more precise identification of disinformation patterns and nuances unique to Croatian text. Additionally, some fine-tuning of the croBERT model can be performed for the specific task of disinformation detection, utilizing its monolingual approach to minimize potential biases and improve detection performance. This integration will not only build upon the foundation of this research but also contribute to the ongoing efforts in combating disinformation in the Croatian digital landscape.
Future work will also explore the integration of lemmatization into the preprocessing workflow. As Croatian is a morphologically rich language, lemmatization can reduce the number of unique word forms by consolidating inflected variants into their base forms, potentially enhancing model performance. We anticipate that this addition will not only improve model generalization but also contribute to a more detailed understanding of language-specific challenges in low-resource settings.
Noticeably, the model has achieved similar F1 scores for the three different models, which may indicate that the current feature set and model configurations are not fully exploiting the potential distinctions among the models. To further improve the models and achieve better performance differentiation, future research will explore advanced feature engineering, hyperparameter tuning, and the inclusion of additional relevant features. By addressing these aspects, we can achieve more distinct performance metrics and enhance the overall effectiveness of the proposed framework.
While future work may explore the integration of transformer-based architectures to assess potential improvements in accuracy and robustness, the current methodology is justified by its alignment with the study’s objectives and the practical constraints of the research environment. To further augment the model’s ability to differentiate between acceptable and hateful speech, we can employ sophisticated word embedding techniques, such as Word2Vec and BERT, which effectively capture subtle meanings and contextual relationships among words.
The advancements we presented in this paper are expected to enhance the comprehensiveness and effectiveness of systems designed to counter disinformation on social media platforms. Furthermore, they ensure adaptability to evolving communication patterns and platform-specific characteristics, underscoring the necessity of the ongoing development and refinement of this framework.
Author Contributions
Conceptualization, I.L. and M.V.; methodology, I.L.; software, Z.G. and I.L.; validation, M.V. and G.G.; formal analysis, I.L., M.V. and G.G.; investigation, Z.G. and I.L.; resources, I.L. and Z.G.; data curation, I.L. and Z.G.; writing—original draft preparation, I.L. and Z.G.; writing—review and editing, M.V. and G.G.; visualization, I.L.; supervision, M.V. and G.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Berners-Lee, T.; Cailliau, R.; Groff, J.; Pollermann, B. World-Wide Web: The Information Universe. Internet Res. 1992, 2, 52–58. [Google Scholar] [CrossRef]
- Shin, J.; Jian, L.; Driscoll, K.; Bar, F. The Diffusion of Misinformation on Social Media: Temporal Pattern, Message, and Source. Comput. Hum. Behav. 2018, 83, 278–287. [Google Scholar] [CrossRef]
- Uscinski, J.E.; Klofstad, C.; Atkinson, M.D. What Drives Conspiratorial Beliefs? The Role of Informational Cues and Predispositions. Polit. Res. Q 2016, 69, 57–71. [Google Scholar] [CrossRef]
- Weeks, B.E. Emotions, Partisanship, and Misperceptions: How Anger and Anxiety Moderate the Effect of Partisan Bias on Susceptibility to Political Misinformation. J. Commun. 2015, 65, 699–719. [Google Scholar] [CrossRef]
- Silverman, C. This Analysis Shows How Viral Fake Election News Stories Outperformed Real News on Facebook. 2016. Available online: https://www.buzzfeednews.com/article/craigsilverman/viral-fake-election-news-outperformed-real-news-on-facebook (accessed on 15 January 2025).
- Allcott, H.; Gentzkow, M. Social Media and Fake News in the 2016 Election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Marshall, H.; Drieschova, A. Post-Truth Politics in the UK’s Brexit Referendum. New Perspect. 2018, 26, 89–106. [Google Scholar] [CrossRef]
- Belloir, N.; Ouerdane, W.; Pastor, O. Characterizing Fake News: A Conceptual Modeling-Based Approach; Springer: Berlin/Heidelberg, Germany, 2022; pp. 115–129. [Google Scholar]
- Liu, S. Social Media Fake Information Identification Method Based on LSTM. Highlights Bus. Econ. Manag. 2023, 21, 703–709. [Google Scholar] [CrossRef]
- Saleh, H.; Alharbi, A.; Alsamhi, S.H. OPCNN-FAKE: Optimized Convolutional Neural Network for Fake News Detection. IEEE Access 2021, 9, 129471–129489. [Google Scholar] [CrossRef]
- Zhao, B.; Deng, H.; Hao, J. A Hybrid Feature Method for Early Fake News Detection via Event Categorizer; SSRN: Atlanta, GA, USA, 2022. [Google Scholar]
- Dun, Y.; Tu, K.; Chen, C.; Hou, C.; Yuan, X. KAN: Knowledge-Aware Attention Network for Fake News Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Tianjin, China, 2–9 February 2021; Volume 35, pp. 81–89. [Google Scholar] [CrossRef]
- Jwa, H.; Oh, D.; Park, K.; Kang, J.; Lim, H. ExBAKE: Automatic Fake News Detection Model Based on Bidirectional Encoder Representations from Transformers (BERT). Appl. Sci. 2019, 9, 4062. [Google Scholar] [CrossRef]
- Raza, S. Automatic Fake News Detection in Political Platforms—A Transformer-Based Approach. In Proceedings of the 4th Workshop on Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2021), Online, 10 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 68–78. [Google Scholar]
- Sitaula, N.; Mohan, C.K.; Grygiel, J.; Zhou, X.; Zafarani, R. Credibility-Based Fake News Detection; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Ghanem, B.; Ponzetto, S.P.; Rosso, P.; Rangel, F. FakeFlow: Fake News Detection by Modeling the Flow of Affective Information. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Association for Computational Linguistics, Online, 19–23 April 2021; pp. 679–689. [Google Scholar]
- Bezerra, J.F.R.; Kozierkiewicz, A.; Pietranik, M. A Novel Approach for Tweet Similarity in a Context-Aware Fake News Detection Model; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Holla, L.; Kavitha, K.S. An Improved Fake News Detection Model Using Hybrid Time Frequency-Inverse Document Frequency for Feature Extraction and AdaBoost Ensemble Model as a Classifier. J. Adv. Inf. Technol. 2024, 15, 202–211. [Google Scholar] [CrossRef]
- Aji, H.B.; Setiawan, E.B. Detecting Hoax Content on Social Media Using Bi-LSTM and RNN. Build. Inform. Technol. Sci. (BITS) 2023, 5, 114–125. [Google Scholar] [CrossRef]
- Karo Karo, I.M.; Romia, R.; Dewi, S.; Fadilah, P.M. Hoax Detection on Indonesian Tweets Using Naïve Bayes Classifier with TF-IDF. J. Inf. Syst. Res. (JOSH) 2023, 4, 914–919. [Google Scholar] [CrossRef]
- Alaee, S.; Taghiyareh, F. A Semantic Ontology-Based Document Organizer to Cluster Elearning Documents. In Proceedings of the 2016 Second International Conference on Web Research (ICWR), Tehran, Iran, 27–28 April 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–7. [Google Scholar]
- Niu, R.; Shen, B. Microblog User Interest Mining Based on Improved TextRank Model. J. Comput. 2019, 30, 42–51. [Google Scholar]
- Majdabadi, Z.; Sabeti, B.; Golazizian, P.; Ashrafi Asli, S.A.; Momenzadeh, O.; Fahmi, R. Twitter Trend Extraction: A Graph-Based Approach for Tweet and Hashtag Ranking, Utilizing No-Hashtag Tweets. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; Calzolari, N., Béchet, F., Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Isahara, H., Maegaard, B., Mariani, J., et al., Eds.; European Language Resources Association: Marseille, France, 2020; pp. 6213–6219. [Google Scholar]
- Solopova, V.; Popescu, O.-I.; Benzmüller, C.; Landgraf, T. Automated Multilingual Detection of Pro-Kremlin Propaganda in Newspapers and Telegram Posts. Datenbank-Spektrum 2023, 23, 5–14. [Google Scholar] [CrossRef]
- Padalko, H.; Chomko, V.; Yakovlev, S.; Morita, P.P. Classification of Disinformation in Hybrid Warfare: An Application of XLNet during the Russia’s War against Ukraine. Radioelectron. Comput. Syst. 2024, 2024, 46–58. [Google Scholar] [CrossRef]
- Vysotska, V.; Nazarkevych, M.; Vladov, S.; Lozynska, O.; Markiv, O.; Romanchuk, R.; Danylyk, V. Devising a Method for Detecting Information Threats in the Ukrainian Cyber Space Based on Machine Learning. East.-Eur. J. Enterp. Technol. 2024, 6, 36–48. [Google Scholar] [CrossRef]
- Burda, B.; Procházka, J. Network Analysis of Disinformation Actors During COVID-19 Pandemics and Beyond: The Case of Czech Facebook. Obrana Strateg. (Def. Strategy) 2024, 24, 19–39. [Google Scholar] [CrossRef]
- Popiołek, M.; Hapek, M.; Barańska, M. Infodemia—An Analysis of Fake News in Polish News Portals and Traditional Media During the Coronavirus Pandemic. Commun. Soc. 2021, 34, 81–98. [Google Scholar] [CrossRef]
- Gombár, M.; Šišulák, S.; Cíchová, M.; Krásná, P.; Malíček, V. Propaganda and Disinformation in the Slovak and Czech Republic. Entrep. Sustain. Issues 2024, 11, 375–386. [Google Scholar] [CrossRef]
- Přibáň, P.; Hercig, T.; Steinberger, J. Machine Learning Approach to Fact-Checking in West Slavic Languages. In Proceedings of the Natural Language Processing in a Deep Learning World, Varna, Bulgaria, 22 October 2019; INCOMA Ltd.: Shoumen, Bulgaria; pp. 973–979. [Google Scholar]
- Tadić, M.; Brozović-Rončević, D.; Kapetanović, A. The Croatian Language in the Digital Age; Rehm, G., Uszkoreit, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; ISBN 978-3-642-30881-9. [Google Scholar]
- Hanić, S.; Bagić Babac, M.; Gledec, G.; Horvat, M. Comparing Machine Learning Models for Sentiment Analysis and Rating Prediction of Vegan and Vegetarian Restaurant Reviews. Computers 2024, 13, 248. [Google Scholar] [CrossRef]
- Horvat, M.; Gledec, G.; Leontić, F. Hybrid Natural Language Processing Model for Sentiment Analysis during Natural Crisis. Electronics 2024, 13, 1991. [Google Scholar] [CrossRef]
- Srdić, I.; Gledec, G. Confusion Matrices for Croatian Language (in Croatian). Available online: https://ispravi.me/confusion/ (accessed on 7 April 2023).
- Gledec, G.; Horvat, M.; Mikuc, M.; Blašković, B. A Comprehensive Dataset of Spelling Errors and Users’ Corrections in Croatian Language. Data 2023, 8, 89. [Google Scholar] [CrossRef]
- European Digital Media Observatory AI and Disinformation: EDMO Hubs Initiatives. Available online: https://edmo.eu/edmo-news/ai-and-disinformation-edmo-hubs-initiatives/ (accessed on 15 January 2025).
- Kocijan, K.; Košković, L.; Bajac, P. Detecting Hate Speech Online: A Case of Croatian; Springer: Berlin/Heidelberg, Germany, 2020; pp. 185–197. [Google Scholar]
- Sallami, D.; Chang, Y.-C.; Aïmeur, E. From Deception to Detection: The Dual Roles of Large Language Models in Fake News. arXiv 2024, arXiv:2409.17416. [Google Scholar]
- Janze, C.; Risius, M. Automatic Detection of Fake News on Social Media Platforms. In Proceedings of the Pacific-Asia Conference on Information Systems 2017 Proceedings, Langkawi Island, Malaysia, 16 July 2017; p. 261. [Google Scholar]
- Beliga, S.; Martinčić-Ipšić, S.; Matešić, M.; Petrijevčanin Vuksanović, I.; Meštrović, A. Infoveillance of the Croatian Online Media During the COVID-19 Pandemic: One-Year Longitudinal Study Using Natural Language Processing. JMIR Public Health Surveill. 2021, 7, e31540. [Google Scholar] [CrossRef]
- Brautovic, M.; John, R. Limitations of Fact-Checking on Debunking COVID-19 Misinformation on Facebook: Case of Faktograf.Hr. Cent. Eur. J. Commun. 2023, 16, 40–58. [Google Scholar] [CrossRef]
- Štefanec, V.; Farkaš, D.; Thakkar, G.; Tadić, M. Building a Large Language Model for Croatian. In Proceedings of the International Conference on New Trends in Translation and Technology Conference, Shoumen, Bulgaria, 3–6 July 2024; INCOMA Ltd.: London, UK; pp. 204–209. [Google Scholar]
- European Commission. Tackling Online Disinformation: A European Approach. Ph.D. Thesis, European Commission, Brussels, Belgium, 2018.
- Gledec, G.; Sokele, M.; Horvat, M.; Mikuc, M. Error Pattern Discovery in Spellchecking Using Multi-Class Confusion Matrix Analysis for the Croatian Language. Computers 2024, 13, 39. [Google Scholar] [CrossRef]
- Demilie, W.B.; Salau, A.O. Detection of Fake News and Hate Speech for Ethiopian Languages: A Systematic Review of the Approaches. J. Big. Data 2022, 9, 66. [Google Scholar] [CrossRef]
- Sammut, C.; Webb, G.I. (Eds.) Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2010; ISBN 978-0-387-30768-8. [Google Scholar]
- Salton, G.; Buckley, C. Term-Weighting Approaches in Automatic Text Retrieval. Inf. Process Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Scikit-Learn. Available online: https://scikit-learn.org/ (accessed on 15 January 2025).
- CLARIN Knowledge Centre for South Slavic languages CLASSLA Fork of the Official Stanford NLP Python Library for Many Human Languages. Available online: https://github.com/clarinsi/classla (accessed on 15 January 2025).
- Stanford NLP StanfordNLP 0.2.0—Python NLP Library for Many Human Languages. Available online: https://stanfordnlp.github.io/stanfordnlp/ (accessed on 15 January 2025).
- Schmidt, C.W.; Reddy, V.; Zhang, H.; Alameddine, A.; Uzan, O.; Pinter, Y.; Tanner, C. Tokenization Is More Than Compression. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 May 2024; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 678–702. [Google Scholar]
- Ljubešić, N.; Fišer, D.; Erjavec, T.; Šulc, A. Offensive Language Dataset of Croatian, English and Slovenian Comments FRENK 1.1. Available online: https://www.clarin.si/repository/xmlui/handle/11356/1462 (accessed on 15 January 2025).
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; AAAI Press: Cambridge, MA, USA, 1996; pp. 226–231. [Google Scholar]
- Gates, A.J.; Ahn, Y.-Y. The Impact of Random Models on Clustering Similarity. J. Mach. Learn. Res. 2017, 18, 1–28. [Google Scholar]
- Da San Martino, G.; Barrón-Cedeño, A.; Wachsmuth, H.; Petrov, R.; Nakov, P. SemEval-2020 Task 11: Detection of Propaganda Techniques in News Articles. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 12–13 December 2020; International Committee for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1377–1414. [Google Scholar]
- Nguyen, D.Q.; Vu, T.; Tuan Nguyen, A. BERTweet: A Pre-Trained Language Model for English Tweets. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 9–14. [Google Scholar]
- Tziafas, G.; Kogkalidis, K.; Caselli, T. Fighting the COVID-19 Infodemic with a Holistic BERT Ensemble. In Proceedings of the Fourth Workshop on NLP for Internet Freedom: Censorship, Disinformation, and Propaganda, Online, 6 June 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 119–124. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).