
Cross-Lingual Cross-Domain Transfer Learning for Rumor Detection



Abstract

1. Introduction
- –
- –
- –
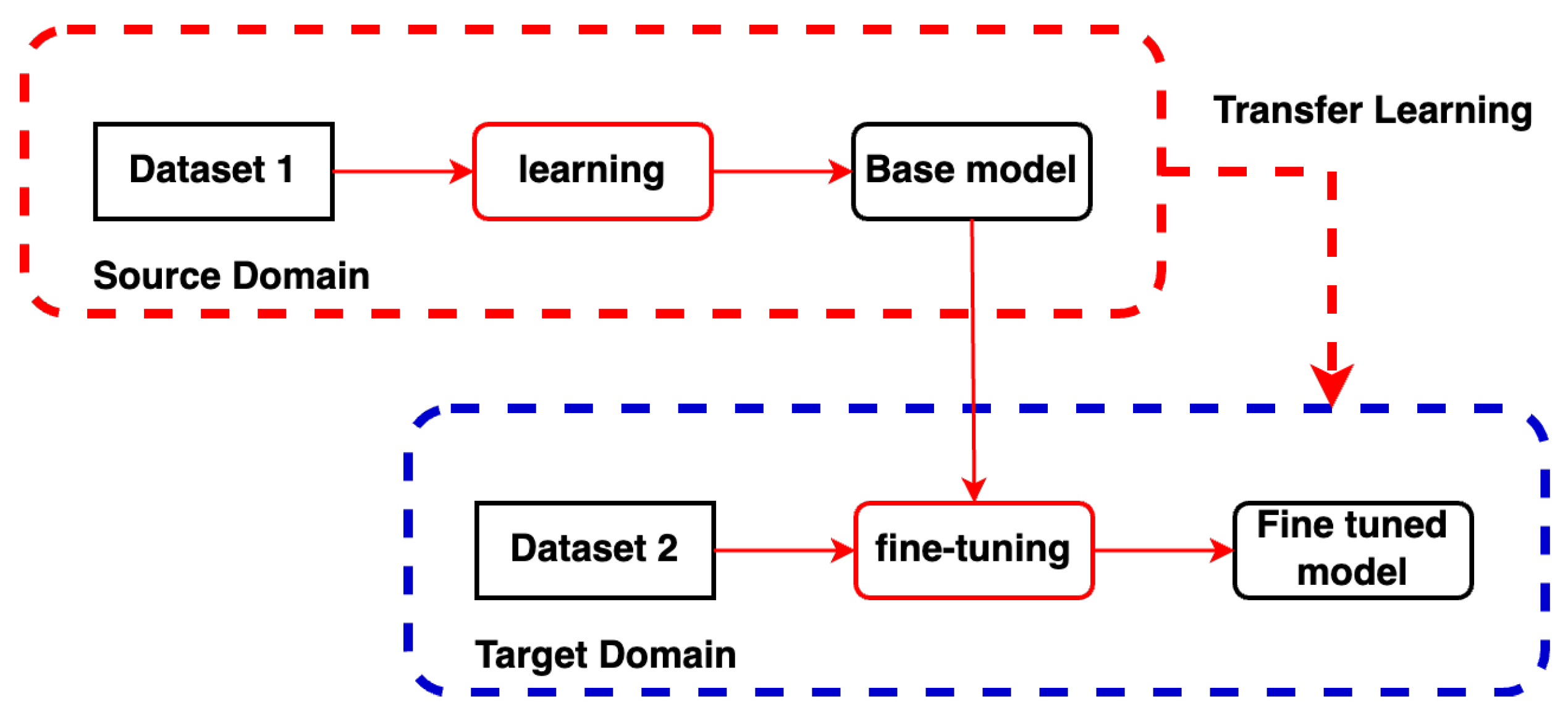
- We introduce a methodology that effectively utilizes diverse datasets—varying in structure, language, and task—without requiring consolidation into a single, fully annotated dataset. Unlike previous work, our experimental approach leverages existing datasets in their current form. It employs a data transfer strategy from high-resource languages, particularly English, to Spanish.
2. Related Work
2.1. Rumor Detection
2.2. Multi-Task Learning in Rumor Detection
2.3. Cross-Lingual Learning
3. Multi-Task Cross-Lingual Learning for Rumor Detection
3.1. Definitions
- Rumor detection task: This task aims to determine the veracity of a root message of a propagation tree . For doing so, it has been shown that it is helpful to consider the complete propagation tree; hence, . The labels used in y vary between works, but a minimal definition is .
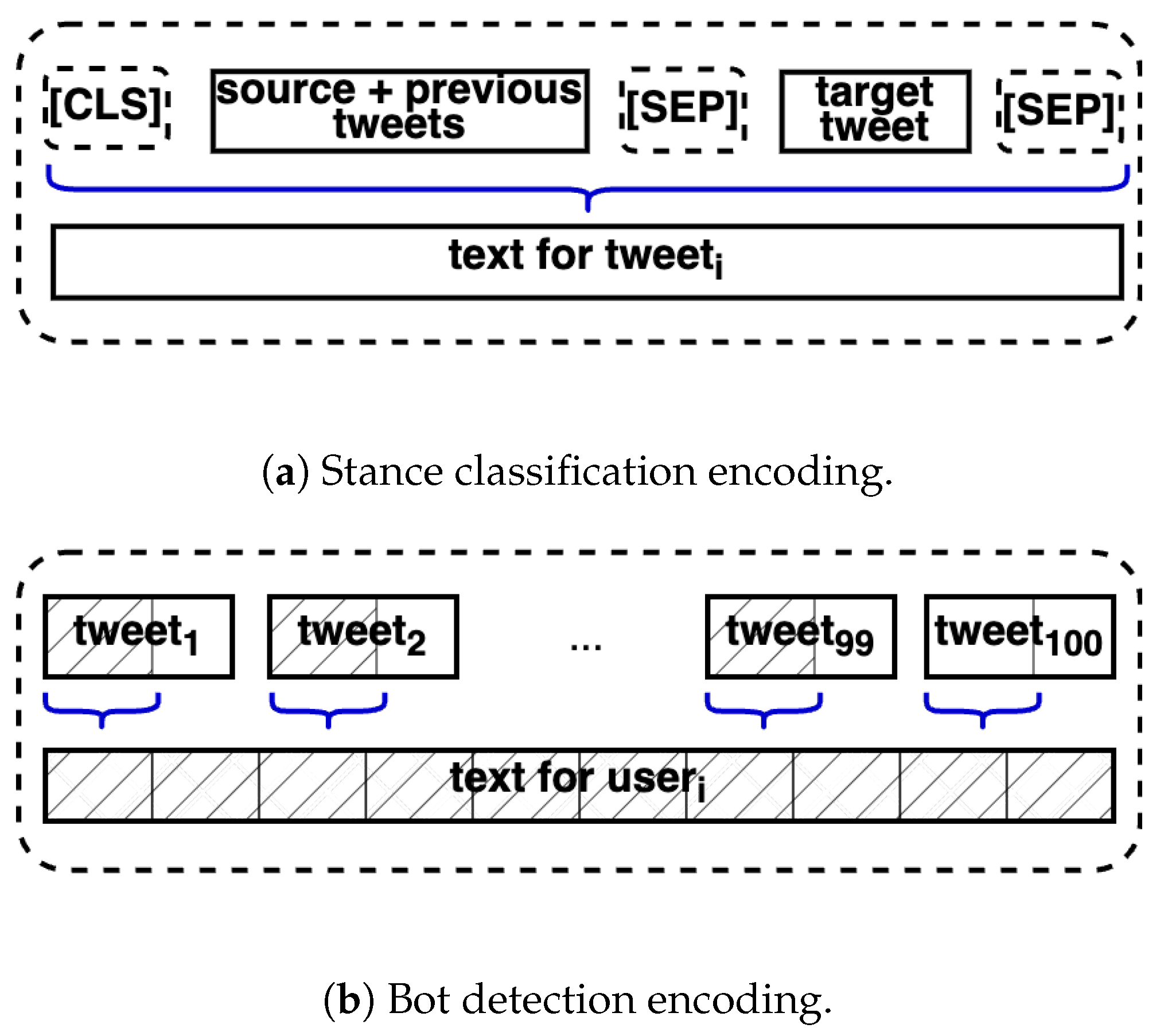
- Stance classification task: This task focuses on classifying the position expressed by a user on the veracity of the root message. If is the response given in the propagation tree , then we can define . The labels in z are generally with , known as stance SDQC.
- Bot detection task: This task classifies whether a user that posts a message is a human or a bot. That is, with .
3.2. Overall Description of the Proposal
- mBERT-embedding: use the embedding layer of the base model.
- mBERT-pooler: use the pooler layer of the base model.
- mBERT-second-to-last: use the second-to-last layer of the base model.
- mBERT-sum-four-last: use the sum of the last four layers of the base model.
- sBERT-default: use the default constructor of embeddings defined for sentence BERT.
- –
- Zero-shot evaluation. It is worth noting that the pre-trained models have not been trained on any Spanish rumor detection data to date. This is why we first assess the zero-shot capabilities of the pre-trained models of stage 3. We also compare their performance with a baseline mBERT model for comprehensive understanding.
- –
- Fine-tuning for Rumor Detection in Spanish. Lastly, we evaluate the potential of the pre-trained models from Stage 3 for fine-tuning to improve their performance in detecting rumors in Spanish.
4. Experiments
4.1. Computational Resources
4.2. Datasets
- Twitter16 [50] (https://www.dropbox.com/s/7ewzdrbelpmrnxu/rumdetect2017.zip?dl=0, accessed on 21 March 2021). This dataset is utilized for the detection of rumors in English. It contains 753 root messages with veracity annotations. Each of these messages comes with propagation trees that detail the replies for the primary message. The veracity of each message was determined by cross-referencing fact-checking websites such as Snopes (http://snopes.com, accessed on 22 June 2025). The messages have been categorized into four veracity labels: true, false, unverified, and non-rumor (abbreviated as TFUN) [50]. To align this dataset with the detection of rumors in Spanish, we exclusively used the categories of true and false rumors, which were also used as an annotation scheme in Spanish. Accordingly, veracity annotations correspond to the following:
- –
- True rumor (true): It has been verified that the message corresponds to a rumor. There are 188 messages with this label.
- –
- False rumor (false): The message indeed does not correspond to a rumor. There are 180 messages with this label.
- RumourEval2019 [92] (https://figshare.com/articles/dataset/RumourEval_2019_data/8845580, accessed on 21 March 2021). The dataset referenced here was used in the RumorEval 2019 competition for Task 7, which consisted of two subtasks. The first subtask involved determining a user’s stance regarding a specific message, while the second aimed to classify the truthfulness of that message. This dataset is exclusively in English. Although the competition provided data from both Twitter and Reddit, our study only incorporates Twitter data, which is detailed in Table 2. This dataset is organized around various significant events, including the Charlie Hebdo shooting in Paris, the Ferguson riots in the U.S., and the plane crash in the French Alps, to name a few. The original dataset is separated into training and testing sets. It comprises 325 propagation trees, totaling 5568 tweets. For rumor detection, this dataset employs three distinct labels: true, false, and unverified (TFU). We did not utilize this specific dataset partition in our study, since our objective is to assess cross-domain transfer capabilities not within the same domain; in this case, it would be from one rumor detection task to another. The data for stance classification was labeled by crowdsourcing, adhering to standard SDQC labels, which stand for support, deny, query, and comment. The distribution of messages per label is as follows: 1145 labeled as support, 507 as deny, 526 as query, and 4456 as comment.
- PAN2019 [27] (https://zenodo.org/record/3692340#.YzxAHexBz0p, accessed on 20 October 2022). This dataset was used for the “Author Profiling PAN (Plagiarism Analysis, Authorship Identification, and Near-Duplicate Detection)” competition at CLEF 2019. The dataset includes Spanish and English data, amalgamating pre-existing sources that had already classified accounts as ‘bot’ or ‘human’. The original dataset is separated into training and testing sets. In addition, the dataset contains gender labels for human accounts. However, this study focuses solely on distinguishing between bot and human accounts. The labeling process was manual, with each author contributing 100 tweets, which were also included in the dataset.
- Disinformation data [14] (https://github.com/marcelomendoza/disinformation-data, accessed on 12 January 2023). This dataset features Chile news labeled by prominent fact-checking organizations, including fastCheck.cl (accessed on 22 June 2025), factChecking.cl (accessed on 22 June 2025), and decodificador (https://www.instagram.com/decodificadorcl/?hl=es, accessed on 22 June 2025). From October 2019 to October 2021, it encompasses significant events such as the Chilean Social Outbreak, the COVID-19 pandemic, the Chilean presidential elections of 2021, and more. In line with other datasets, it presents multiple propagation trees, each stemming from a primary message labeled for its truthfulness. The labels assigned for classification of veracity are ‘true’, ‘false’, and ‘imprecise’ (TFI). The distribution of messages per label includes 129 tweets labeled ‘true’, 113 as ‘false’, and 65 as ‘imprecise’. To align this dataset with the task of detecting rumors in English, we only utilized the categories of true and false rumors. These categories are also used as an annotation scheme in English.
4.3. Performance on Auxiliary Tasks—Stage 1
- , number of tweets per author: 5, 15, 25, 50, 75, and 100.
- Sampling strategies: tail, head, head+tail.
4.4. Results on Rumor Detection in English—Stage 2 and 3
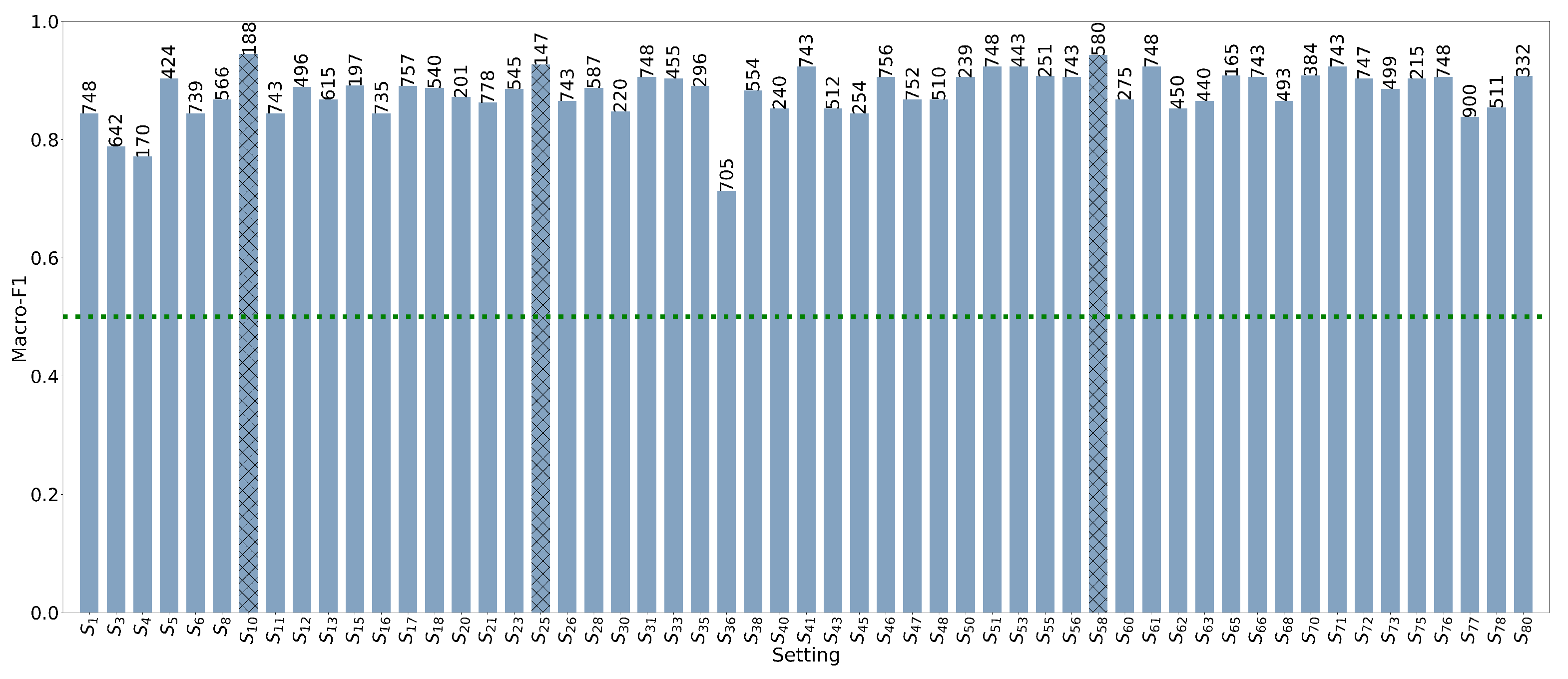
- A proportion of % (3 settings) obtain a score Macro-F1 in the interval .
- A proportion of % (30 settings) obtain a score Macro-F1 in the interval .
- A proportion of % (22 settings) obtain a score Macro-F1 over .
- Bot detection appears in all the best results, such as the first or second model. This suggests that this task is more valuable as a starting point for CLM training.
- More specifically, bot detection in English is the most commonly used first model or task.
- Regarding the third model/task, from the above analysis, it is clear that stance classification appears less frequently (only in one setting in the top three results).
4.5. Results on Rumor Detection in Spanish—Stage 4
4.5.1. Zero-Shot Evaluation
4.5.2. Fine-Tuning for Rumor Detection in Spanish
5. Discussion of Results
5.1. Main Findings of the Study
5.2. Limitations of the Study
5.3. Comparison of Results
5.3.1. Comparison with Base Models
5.3.2. Stylistic Metric Comparison
- In terms of word count, the FN class shows substantial variability: while some texts are extremely short, others are significantly longer. This inconsistency may introduce confusion for the classifier. Additionally, the lower median word count observed in this class indicates that many instances consist of only a few words, which could further impair the accuracy of the classification. In contrast, the FP boxplot reveals that texts in this category tend to be more uniform in length. This regularity might serve as a cue that the classifier relies upon, potentially resulting in systematic misclassification.
- In the case of the number of sentences per message, misclassified instances (FP and FN) tend to include fewer sentences than correctly classified ones (TP and TN). This pattern suggests that shorter texts can hinder the performance of the classifier. Similar to the previous metric, the FN group shows a more noticeable reduction in the median number of sentences—remaining generally low—with the presence of an outlier that could contribute to the classifier’s confusion.
- On average, false positives (FPs) exhibit a greater token length, which may adversely affect the classifier’s performance. In contrast, true negatives (TNs) and false negatives (FNs) typically consist of shorter tokens, potentially reflecting simpler texts. Interestingly, true positives (TPs) include several outliers. Overall, the average token length seems to play a role in the misclassification of FPs compared to the other categories.
- According to the perplexity metric, false positives (FPs) tend to have low values, indicating that the model considered these instances predictable, even though it misclassified them. In contrast, false negatives (FNs) exhibit a wider distribution of perplexity scores, ranging from low to high, which suggests that the model fails on both straightforward and more complex texts. For true negatives (TNs) and true positives (TPs), correct classifications are generally associated with texts of moderate perplexity, reflecting a balanced level of complexity.
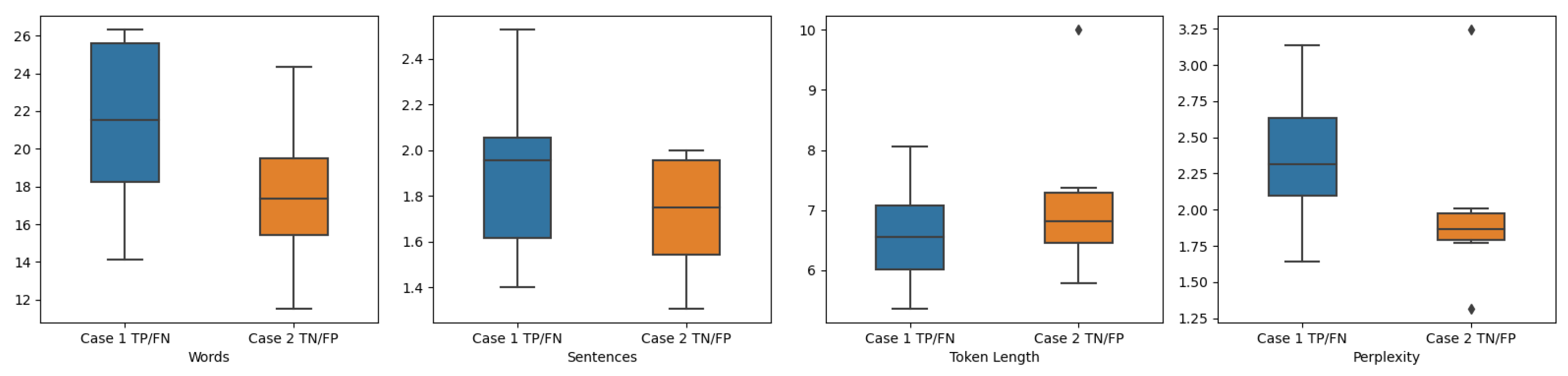
- In the case of words, FP contains a larger number of words. When compared to the results of TP, this difference may contribute to classification errors.
- Regarding the sentence metrics, all groups exhibit similar distributions. In the case of FP, there is a higher number of sentences, indicating greater structural complexity, which could be a potential source of error. Nevertheless, the average number of sentences per tree does not appear to be a strong discriminative feature for classification.
- For the length token metric, as with the previous one, all groups exhibit similar distributions. In the case of the FN group, however, there is an outlier that corresponds to a particularly complex text. This increased complexity may explain the classification error, especially considering that such outliers are absent in the other groups.
- In the case of FP, the texts exhibit higher perplexity, suggesting they are more challenging to classify. This is further evidenced by some out-of-range failures, likely due to the presence of outliers. In contrast, TP and TN texts show lower perplexity, indicating that they are easier to classify.
- In terms of word count, messages that were misclassified as false negatives (FNs) are significantly longer than those misclassified as false positives (FPs). This indicates that texts correctly classified as true positives (TPs) tend to be longer. These findings suggest that the zero-shot classifier struggles to handle longer texts effectively.
- Regarding sentences, the situation is comparable: texts containing a greater number of sentences tended to be classified as false negatives (FNs), which in this context, correspond to true positives (TPs). This suggests that false rumors, in general, exhibit a higher structural complexity than true ones. Once again, the zero-shot classifier failed to account for this aspect.
- In the case of token length, the misclassified texts tended to contain, on average, longer tokens. This suggests that the zero-shot classifier may have mistaken lexical complexity for factual accuracy.
- On the perplexity metric, misclassified false negatives (FNs) exhibit significantly higher values than misclassified false positives (FPs). The zero-shot model appears overly confident in labeling simple texts as true rumors, while it struggles with more complex texts, often misclassifying them as false rumors.
5.3.3. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shu, K.; Bhattacharjee, A.; Alatawi, F.; Nazer, T.H.; Ding, K.; Karami, M.; Liu, H. Combating disinformation in a social media age. WIREs Data Min. Knowl. Discov. 2020, 10, e1385. [Google Scholar] [CrossRef]
- Allcott, H.; Gentzkow, M. Social Media and Fake News in the 2016 Election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Allcott, H.; Gentzkow, M.; Yu, C. Trends in the diffusion of misinformation on social media. Res. Politics 2019, 6, 205316801984855. [Google Scholar] [CrossRef]
- Graves, L.; Nyhan, B.; Reifler, J. Understanding Innovations in Journalistic Practice: A Field Experiment Examining Motivations for Fact-Checking. J. Commun. 2016, 66, 102–138. [Google Scholar] [CrossRef]
- Brandtzaeg, P.B.; Følstad, A.; Chaparro, M. How Journalists and Social Media Users Perceive Online Fact-Checking and Verification Services. J. Pract. 2018, 12, 1109–1129. [Google Scholar] [CrossRef]
- Castillo, C.; Mendoza, M.; Poblete, B. Predicting information credibility in time-sensitive social media. Internet Res. 2013, 23, 560–588. [Google Scholar] [CrossRef]
- Ruchansky, N.; Seo, S.; Liu, Y. CSI: A hybrid deep model for fake news detection. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 1–5 October 2017; Volume 1, pp. 797–806. [Google Scholar]
- Liu, Y.; Wu, Y.-F.B. Early detection of fake news on social media through propagation path classification with recurrent and convolutional networks. In Thirty-Second AAAI Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2018; Volume 1. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K. Rumor detection on Twitter with tree-structured recursive neural networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 1980–1989. [Google Scholar]
- Ma, J.; Gao, W.; Joty, S.R.; Wong, K.-F. An Attention-based Rumor Detection Model with Tree-structured Recursive Neural Networks. ACM Trans. Intell. Syst. Technol. 2020, 11, 42:1–42:28. [Google Scholar] [CrossRef]
- Sun, L.; Rao, Y.; Wu, L.; Zhang, X.; Lan, Y.; Nazir, A. Fighting False Information from Propagation Process: A Survey. ACM Comput. Surv. 2023, 55, 207:1–207:38. [Google Scholar] [CrossRef]
- Mendoza, M.; Poblete, B.; Castillo, C. Twitter under crisis: Can we trust what we RT? In Proceedings of the 1st Workshop on Social Media Analysis, SOMA 2010, Washington, DC, USA, 25 July 2010; Volume 1, pp. 71–79. [Google Scholar]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef]
- Mendoza, M.; Valenzuela, S.; Núñez-Mussa, E.; Padilla, F.; Providel, E.; Campos, S.; Bassi, R.; Riquelme, A.; Aldana, V.; López, C. A study on information disorders on social networks during the Chilean social outbreak and COVID-19 pandemic. Appl. Sci. 2023, 13, 5347. [Google Scholar] [CrossRef]
- Garg, S.; Sharma, D.K. New Politifact: A Dataset for Counterfeit News. In Proceedings of the 2020 9th International Conference System Modeling and Advancement in Research Trends (SMART), Bangalore, India, 17–19 December 2020; Volume 1, pp. 17–22. [Google Scholar]
- Providel, E.; Mendoza, M. Misleading information in Spanish: A survey. Soc. Netw. Anal. Min. 2021, 11, 36. [Google Scholar] [CrossRef]
- De, A.; Bandyopadhyay, D.; Gain, B.; Ekbal, A. A Transformer-Based Approach to Multilingual Fake News Detection in Low-Resource Languages. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 21, 9:1–9:20. [Google Scholar] [CrossRef]
- Shi, Y.; Zhang, X.; Shang, Y.; Yu, N. Don’t Be Misled by Emotion! Disentangle Emotions and Semantics for Cross-Language and Cross-Domain Rumor Detection. IEEE Trans. Big Data 2024, 10, 249–259. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gómez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers). [Google Scholar]
- Lin, Y.; Yang, S.; Stoyanov, V.; Ji, H. A Multi-lingual Multi-task Architecture for Low-resource Sequence Labeling. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 799–809. [Google Scholar]
- Pikuliak, M.; Šimko, M. Combining Cross-lingual and Cross-task Supervision for Zero-Shot Learning. In Text, Speech, and Dialogue; Springer: Berlin/Heidelberg, Germany, 2020; pp. 162–170. [Google Scholar]
- Ahmad, Z.; Jindal, R.; Ekbal, A.; Bhattachharyya, P. Borrow from rich cousin: Transfer learning for emotion detection using cross lingual embedding. Expert Syst. Appl. 2020, 139, 112851. [Google Scholar] [CrossRef]
- Wu, L.; Rao, Y.; Jin, H.; Nazir, A.; Sun, L. Different Absorption from the Same Sharing: Sifted Multi-task Learning for Fake News Detection. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4644–4653. [Google Scholar]
- Chu, Z.; Gianvecchio, S.; Wang, H.; Jajodia, S. Who is Tweeting on Twitter: Human, Bot, or Cyborg? In Proceedings of the 26th Annual Computer Security Applications Conference, Tampa, FL, USA, 6–10 December 2010; pp. 21–30, ACSAC ’10. [Google Scholar]
- Khaund, T.; Al-khateeb, S.; Tokdemir, S.; Agarwal, N. Analyzing Social Bots and Their Coordination During Natural Disasters. In SBP-BRiMS; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Rangel, F.; Rosso, P. Overview of the 7th author profiling task at Pan 2019: Bots and gender profiling in twitter. In Proceedings of the Conference of 20th Working Notes of Conference and Labs of the Evaluation Forum, CLEF, Padua, Italy, 9–11 September 2019; p. 2380. [Google Scholar]
- Castillo, S.; Allende-Cid, H.; Palma, W.; Alfaro, R.; Ramos, H.; Gonzalez, C.; Elortegui, C.; Santander, P. Detection of Bots and Cyborgs in Twitter: A Study on the Chilean Presidential Election in 2017. In Proceedings of the Conference of 11th International Conference on Social Computing and Social Media, SCSM 2019, Madrid, Spain, 9–11 September 2019; pp. 311–323. [Google Scholar]
- Kochkina, E.; Liakata, M.; Zubiaga, A. All-in-one: Multi-task Learning for Rumour Verification. In Proceedings of the 27th International Conference on Computational Linguistics, San Sebastián, Spain, 20–26 August 2018; pp. 3402–3413. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.-F. Detect Rumor and Stance Jointly by Neural Multi-Task Learning. In Proceedings of the Companion Proceedings of the The Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 585–593. [Google Scholar]
- Alsaif, H.F.; Aldossari, H.D. Review of stance detection for rumor verification in social media. Eng. Appl. Artif. Intell. 2023, 119, 105801. [Google Scholar] [CrossRef]
- Castillo, C.; Mendoza, M.; Poblete, B. Information credibility on Twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 675–684. [Google Scholar]
- Qazvinian, V.; Rosengren, E.; Radev, D.R.; Mei, Q. Rumor Has It: Identifying Misinformation in Microblogs. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Edinburgh, UK, 28–31 August 2011; pp. 1589–1599. [Google Scholar]
- Zhao, Z.; Resnick, P.; Mei, Q. Enquiring Minds: Early Detection of Rumors in Social Media from Enquiry Posts. In Proceedings of the 24th International Conference on World Wide Web (WWW), Florence, Italy, 18–22 May 2015; pp. 1395–1405. [Google Scholar]
- Posadas-Durán, J.; Gómez-Adorno, H.; Sidorov, G.; Moreno, J. Detection of Fake News in a New Corpus for the Spanish Language. J. Intell. Fuzzy Syst. 2019, 36, 4868–4876. [Google Scholar] [CrossRef]
- Abonizio, H.; De Morais, J.; Tavares, G.; Barbon Junior, S. Language-Independent Fake News Detection: English, Portuguese, and Spanish Mutual Features. Future Internet 2020, 12, 87. [Google Scholar] [CrossRef]
- Salazar, E.; Tenorio, G.; Naranjo, L. Evaluation of the Precision of the Binary Classification Models for the Identification of True or False News in Costa Rica. Rev. Ibérica Sist. Tecnol. Informação 2020, E38, 156–170. [Google Scholar]
- Boididou, C.; Papadopoulos, S.; Zampoglou, M.; Apostolidis, L.; Papadopoulou, O.; Kompatsiaris, Y. Detection and Visualization of Misleading Content on Twitter. Int. J. Multimed. Inf. Retr. 2018, 7, 71–86. [Google Scholar] [CrossRef]
- Zubiaga, A.; Liakata, M.; Procter, R.; Wong Sak Hoi, G.; Tolmie, P. Analysing How People Orient to and Spread Rumours in Social Media by Looking at Conversational Threads. PLoS ONE 2016, 11, e0150989. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.F.; Cha, M. Detecting Rumors from Microblogs with Recurrent Neural Networks. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI 2016, New York, NY, USA, 9–15 July 2016; Volume 1, pp. 3818–3824. [Google Scholar]
- Yu, F.; Liu, Q.; Wu, S.; Wang, L.; Tan, T. A Convolutional Approach for Misinformation Identification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017; pp. 3901–3907. [Google Scholar]
- Ajao, O.; Bhowmik, D.; Zargari, S. Fake News Identification on Twitter with Hybrid CNN and RNN Models. In Proceedings of the 9th International Conference on Social Media and Society (SMSociety), Vancouver, NA, Canada, 18–20 July 2018; pp. 226–230. [Google Scholar]
- Deepak, S.; Chitturi, B. Deep Neural Approach to Fake-News Identification. Procedia Comput. Sci. 2020, 167, 2236–2243. [Google Scholar]
- Wang, Y.; Ma, F.; Jin, Z.; Yuan, Y.; Xun, G.; Jha, K.; Su, L.; Gao, J. EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 849–857. [Google Scholar]
- Buda, J.; Bolonyai, F. An Ensemble Model Using N-grams and Statistical Features to Identify Fake News Spreaders on Twitter. In Proceedings of the Working Notes of CLEF 2020–Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 22–25 September 2020; Volume 2696. [Google Scholar]
- Zapata, A.; Providel, E.; Mendoza, M. Empirical Evaluation of Machine Learning Ensembles for Rumor Detection. In Proceedings of the Social Computing and Social Media: Design, User Experience and Impact—14th International Conference, SCSM 2022, San Diego, CA, USA, 7–10 August 2022. [Google Scholar]
- Providel, E.; Mendoza, M. Using Deep Learning to Detect Rumors in Twitter. In Proceedings of the Social Computing and Social Media. Design, Ethics, User Behavior, and Social Network Analysis–12th International Conference (SCSM), Madrid, Spain, 12–14 October 2020; pp. 321–334. [Google Scholar]
- Kwon, S.; Cha, M.; Jung, K. Rumor Detection over Varying Time Windows. PLoS ONE 2017, 12, e0168344. [Google Scholar] [CrossRef] [PubMed]
- Zubiaga, A.; Liakata, M.; Procter, R. Exploiting Context for Rumour Detection in Social Media. In Social Informatics—9th International Conference, SocInfo, Oxford, UK, Proceedings, Part I; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.-F. Detect rumors in microblog posts using propagation structure via kernel learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, 30 July–4 August 2017; Volume 1, pp. 708–717. [Google Scholar]
- Li, J.; Ni, S.; Kao, H.-Y. Birds of a Feather Rumor Together? Exploring Homogeneity and Conversation Structure in Social Media for Rumor Detection. IEEE Access 2020, 8, 212865–212875. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W. Debunking Rumors on Twitter with Tree Transformer. In Proceedings of the 28th International Conference on Computational Linguistics, Guadalajara, Mexico, 2–7 November 2020. [Google Scholar]
- Zhao, R.; Arana-Catania, M.; Zhu, L.; Kochkina, E.; Gui, L.; Zubiaga, A.; Procter, R.; Liakata, M.; He, Y. PANACEA: An Automated Misinformation Detection System on COVID-19. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, Zagreb, Croatia, 10–14 April 2023. [Google Scholar]
- Yu, S.; Ren, J.; Li, S.; Naseriparsa, M.; Xia, F. Graph Learning for Fake Review Detection. Front. Artif. Intell. 2022, 5, 922589. [Google Scholar] [CrossRef]
- Mohawesh, R.; Xu, S.; Tran, S.N.; Ollington, R.; Springer, M.; Jararweh, Y.; Maqsood, S. Fake Reviews Detection: A Survey. IEEE Access 2021, 9, 65771–65802. [Google Scholar] [CrossRef]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. A Survey on Multi-Task Learning. IEEE Trans. Knowl. Data Eng. 2022, 34, 5586–5609. [Google Scholar] [CrossRef]
- Pikuliak, M.; Šimko, M.; Bieliková, M. Cross-lingual learning for text processing: A survey. Expert Syst. Appl. 2021, 165, 113765. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems—Volume 2, NIPS’13, Vancouver, BC, Canada, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Enayet, O.; El-Beltagy, S.R. NileTMRG at SemEval-2017 Task 8: Determining Rumour and Veracity Support for Rumours on Twitter. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 470–474. [Google Scholar]
- Li, Q.; Zhang, Q.; Si, L. Rumor Detection by Exploiting User Credibility Information, Attention and Multi-task Learning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 1–6 July 2019; pp. 1173–1179. [Google Scholar]
- Islam, M.R.; Muthiah, S.; Ramakrishnan, N. RumorSleuth: Joint Detection of Rumor Veracity and User Stance. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, ASONAM ’19, Barcelona, Spain, 26–29 August 2019; pp. 131–136. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, Beijing, China, 28 April–1 May 2014; Volume 1. [Google Scholar]
- Wei, P.; Xu, N.; Mao, W. Modeling Conversation Structure and Temporal Dynamics for Jointly Predicting Rumor Stance and Veracity. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4787–4798. [Google Scholar]
- Yu, J.; Jiang, J.; Khoo, L.M.S.; Chieu, H.L.; Xia, R. Coupled Hierarchical Transformer for Stance-Aware Rumor Verification in Social Media Conversations. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Virtual conference, 11–16 December 2020; pp. 1392–1401. [Google Scholar]
- Choudhry, A.; Khatri, I.; Jain, M.; Vishwakarma, D.K. An Emotion-Aware Multitask Approach to Fake News and Rumor Detection Using Transfer Learning. IEEE Trans. Comput. Soc. Syst. 2024, 11, 588–599. [Google Scholar] [CrossRef]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Plutchik, R. A psychoevolutionary theory of emotions. Soc. Sci. Inf. 1982, 21, 529–553. [Google Scholar] [CrossRef]
- Chen, Y.; Yin, C.; Zuo, W. Multi-task Learning for Stance and Early Rumor Detection. Opt. Mem. Neural Netw. 2021, 30, 131–139. [Google Scholar] [CrossRef]
- Li, C.; Peng, H.; Li, J.; Sun, L.; Lyu, L.; Wang, L.; Yu, P.S.; He, L. Joint Stance and Rumor Detection in Hierarchical Heterogeneous Graph. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 2530–2542. [Google Scholar] [CrossRef]
- Jiang, F.; Liang, G.; Yang, J.; Chen, L. MMRDF: An improved multitask multi-modal rumor detection framework. Electron. Lett. 2023, 59, e12811. [Google Scholar] [CrossRef]
- Wan, S.; Tang, B.; Dong, F.; Wang, M.; Yang, G. A writing style-based multi-task model with the hierarchical attention for rumor detection. Int. J. Mach. Learn. Cybern. 2023, 14, 3993–4008. [Google Scholar] [CrossRef]
- Shahriar, S.; Mukherjee, A.; Gnawali, O. Exploring Deceptive Domain Transfer Strategies: Mitigating the Differences among Deceptive Domains. In Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing, Varna, Bulgaria, 18–22 September 2023; pp. 1076–1084. [Google Scholar]
- Abulaish, M.; Saraswat, A.; Fazil, M. A Multi-Task Learning Framework using Graph Attention Network for User Stance and Rumor Veracity Prediction. In Proceedings of the 2023 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, ASONAM ’23, Sydney, Australia, 23–25 August 2023; pp. 149–153. [Google Scholar]
- Liu, Y.; Yang, X.; Zhang, X.; Tang, Z.; Chen, Z.; Zheng, L. Predicting rumor veracity on social media with cross-channel interaction of multi-task. Neural Comput. Appl. 2024, 36, 1–12. [Google Scholar] [CrossRef]
- Chen, Z.; Hui, S.C.; Liao, L.; Huang, H. SSRI-Net: Subthreads Stance–Rumor Interaction Network for rumor verification. Neurocomputing 2024, 583, 127549. [Google Scholar] [CrossRef]
- La-Gatta, V.; Sperlì, G.; De Cegli, L.; Moscato, V. From single-task to multi-task: Unveiling the dynamics of knowledge transfers in disinformation detection. Inf. Sci. 2025, 696, 121735. [Google Scholar] [CrossRef]
- He, Y.; Li, Z.; Li, Z.; Zhou, S.; Yu, T.; Zhang, J. Towards Cross-Lingual Multi-Modal Misinformation Detection for E-Commerce Management. IEEE Trans. Netw. Serv. Manag. 2023, 20, 1040–1050. [Google Scholar] [CrossRef]
- Rodríguez, S.; Allende-Cid, H.; Allende, H. Detecting Hate Speech in Cross-Lingual and Multi-lingual Settings Using Language Agnostic Representations. In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications; Springer: Berlin/Heidelberg, Germany, 2021; pp. 77–87. [Google Scholar]
- Feng, F.; Yang, Y.; Cer, D.; Arivazhagan, N.; Wang, W. Language-agnostic BERT Sentence Embedding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 878–891. [Google Scholar]
- Tian, L.; Zhang, X.; Lau, J.H. Rumour Detection via Zero-Shot Cross-Lingual Transfer Learning. In Machine Learning and Knowledge Discovery in Databases. Research Track; Springer: Berlin/Heidelberg, Germany, 2021; pp. 603–618. [Google Scholar]
- Eisenschlos, J.M.; Ruder, S.; Czapla, P.; Kardas, M.; Gugger, S.; Howard, J. MultiFit: Efficient Multi-lingual Language Model Fine-tuning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5702–5707. [Google Scholar]
- Lin, H.; Ma, J.; Chen, L.; Yang, Z.; Cheng, M.; Chen, G. Detect Rumors in Microblog Posts for Low-Resource Domains via Adversarial Contrastive Learning. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL, Seattle, Washington, DC, USA, 9–14 May 2022; pp. 2543–2556. [Google Scholar]
- Awal, M.R.; Nguyen, M.D.; Lee, R.K.-W.; Choo, K.T.W. MUSCAT: Multilingual Rumor Detection in Social Media Conversations. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 October 2022; pp. 455–464. [Google Scholar]
- Han, S. Cross-lingual Transfer Learning for Fake News Detector in a Low-Resource Language. arXiv 2022, arXiv:2208.12482. [Google Scholar]
- Zhang, H.; Liu, X.; Yang, Q.; Yang, Y.; Qi, F.; Qian, S.; Xu, C. T3RD: Test-Time Training for Rumor Detection on Social Media. In Proceedings of the ACM on Web Conference 2024, WWW 2024, Singapore, 13–17 May 2024; pp. 2407–2416. [Google Scholar]
- Fajcik, M.; Smrz, P.; Burget, L. BUT-FIT at SemEval-2019 Task 7: Determining the Rumour Stance with Pre-Trained Deep Bidirectional Transformers. In Proceedings of the 13th International Workshop on Semantic Evaluation, Hong Kong, China, 3–7 November 2019; pp. 1097–1104. [Google Scholar]
- Polignano, M.; de Pinto, M.G.; Lops, P.; Semeraro, G. Identification Of Bot Accounts In Twitter Using 2D CNNs On User-generated Contents. In Proceedings of the Working Notes of CLEF 2019—Conference and Labs of the Evaluation Forum, Padua, Italy, 9–11 September 2019; Volume 2380. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to Fine-Tune BERT for Text Classification? In Chinese Computational Linguistics; Springer: Cham, Switzerland, 2019; pp. 194–206. [Google Scholar]
- Viola, P.A.; Jones, M.J. Fast and Robust Classification using Asymmetric AdaBoost and a DetectorCascade. In Advances in Neural Information Processing Systems 14 [Neural Information Processing Systems: Natural and Synthetic, NIPS 2001, December 3-8, 2001]; MIT Press: Cambridge, MA, USA, 2001; pp. 1311–1318. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- Gorrell, G.; Kochkina, E.; Liakata, M.; Aker, A.; Zubiaga, A.; Bontcheva, K.; Derczynski, L. SemEval-2019 Task 7: RumourEval, Determining Rumour Veracity and Support for Rumours. In Proceedings of the 13th International Workshop on Semantic Evaluation, Hong Kong, China, 3–7 November 2019; pp. 845–854. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | First Model | Second Model | Third Model |
|---|---|---|---|
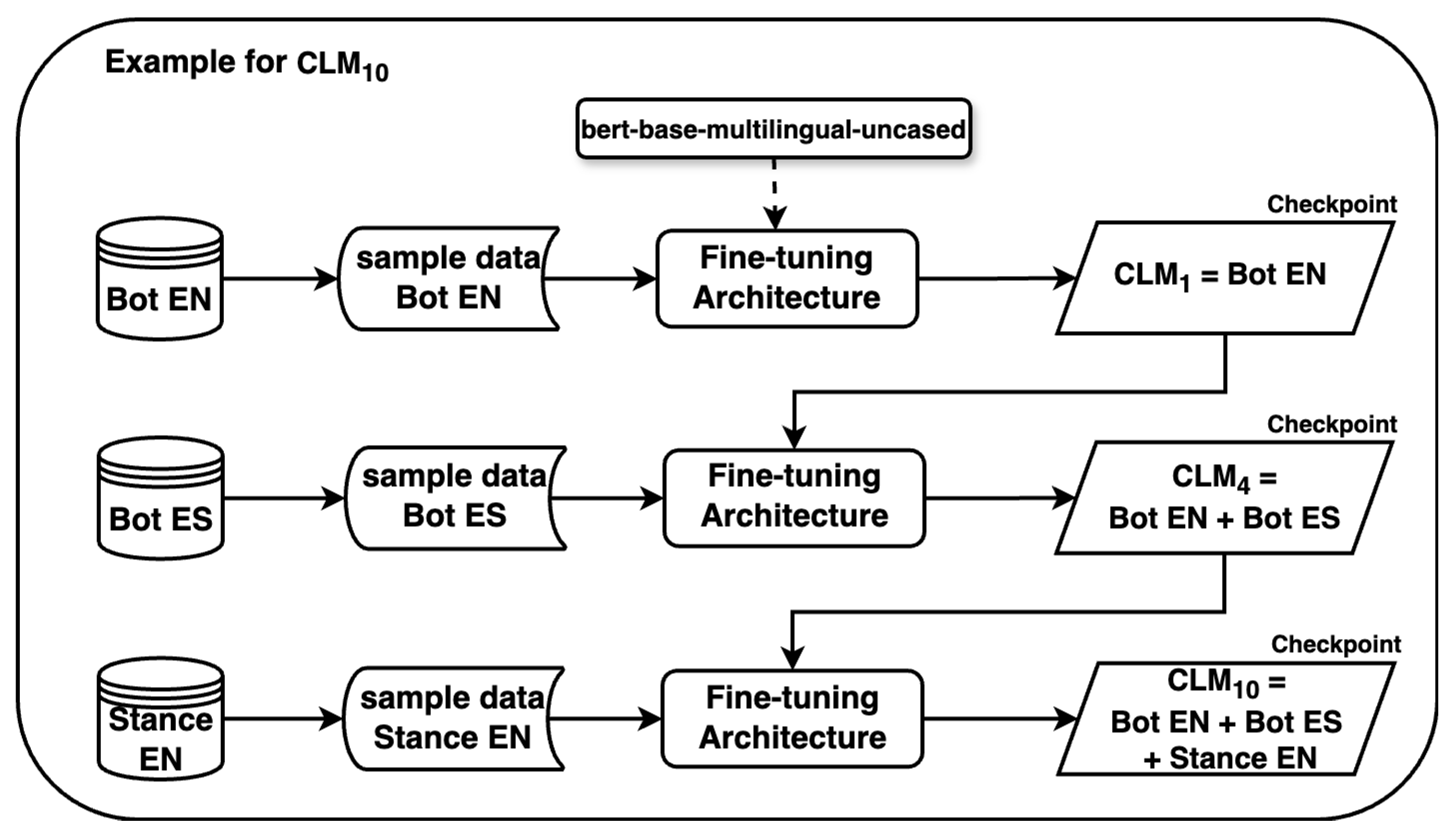
| CLM1 | Bot EN | — | — |
| CLM2 | Bot ES | — | — |
| CLM3 | Stance EN | — | — |
| CLM4 | Bot EN | Bot ES | — |
| CLM5 | Bot ES | Bot EN | — |
| CLM6 | Bot EN | Stance EN | — |
| CLM7 | Bot ES | Stance EN | — |
| CLM8 | Stance EN | Bot EN | — |
| CLM9 | Stance EN | Bot ES | — |
| CLM10 | Bot EN | Bot ES | Stance EN |
| CLM11 | Bot ES | Bot EN | Stance EN |
| CLM12 | Bot EN | Stance EN | Bot ES |
| CLM13 | Bot ES | Stance EN | Bot EN |
| CLM14 | Stance EN | Bot EN | Bot ES |
| CLM15 | Stance EN | Bot ES | Bot EN |
| Dataset | Task | Labels | Instances | Language | Prop. Trees |
|---|---|---|---|---|---|
| Twitter16 [50] | Rumor | true | 188 | English | 753 |
| false | 180 | ||||
| unverified * | 180 | ||||
| non-rumor * | 205 | ||||
| RumourEval2019 [92] | Rumor * | true | 167 | English | 325 |
| false | 104 | ||||
| unverified | 110 | ||||
| Stance | support | 1145 | |||
| deny | 507 | ||||
| query | 526 | ||||
| comment | 4456 | ||||
| Pan2019 [27] | bot | human | 3380 | English | No |
| bot | 3380 | ||||
| human | 2400 | Spanish | No | ||
| bot | 2400 | ||||
| Disinformation-data [14] | Rumor | true | 129 | Spanish | 307 |
| false | 113 | ||||
| imprecise * | 65 |
| MAXLEN | Seed | Best Macro-F1 | Accuracy |
|---|---|---|---|
| 512 | 37,837 | 0.578 | 0.756 |
| 512 | 20,713 | 0.570 | 0.708 |
| 512 | 22,180 | 0.559 | 0.775 |
| 512 | 1261 | 0.605 | 0.780 |
| 512 | 1878 | 0.542 | 0.744 |
| ALEN | Sampling Strategy | English | Spanish | ||
|---|---|---|---|---|---|
| Best Macro-F1 | Accuracy | Best Macro-F1 | Accuracy | ||
| 5 | tail | 0.931 | 0.932 | 0.860 | 0.860 |
| 5 | head | 0.958 | 0.958 | 0.899 | 0.899 |
| 5 | head+tail | 0.947 | 0.947 | 0.916 | 0.916 |
| 15 | tail | 0.966 | 0.966 | 0.921 | 0.922 |
| 15 | head | 0.947 | 0.947 | 0.911 | 0.911 |
| 15 | head+tail | 0.954 | 0.954 | 0.922 | 0.922 |
| 25 | tail | 0.970 | 0.970 | 0.893 | 0.894 |
| 25 | head | 0.939 | 0.939 | 0.927 | 0.927 |
| 25 | head+tail | 0.947 | 0.947 | 0.899 | 0.899 |
| 50 | tail | 0.951 | 0.951 | 0.893 | 0.894 |
| 50 | head | 0.950 | 0.951 | 0.933 | 0.933 |
| 50 | head+tail | 0.947 | 0.947 | 0.893 | 0.894 |
| 75 | tail | 0.939 | 0.939 | 0.870 | 0.872 |
| 75 | head | 0.932 | 0.932 | 0.927 | 0.927 |
| 75 | head+tail | 0.958 | 0.958 | 0.888 | 0.888 |
| 100 | tail | 0.943 | 0.943 | 0.876 | 0.877 |
| 100 | head | 0.935 | 0.935 | 0.899 | 0.899 |
| 100 | head+tail | 0.958 | 0.958 | 0.887 | 0.888 |
| S. | CLM | First Model | Second Model | Third Model | Macro-F1 | F1 True | F1 False |
|---|---|---|---|---|---|---|---|
| 10 | CLM1 | Bot EN | – | – | 0.945 | 0.954 | 0.936 |
| 25 | CLM4 | Bot EN | Bot ES | – | 0.927 | 0.938 | 0.917 |
| 58 | CLM11 | Bot ES | Bot EN | Stance EN | 0.943 | 0.957 | 0.930 |
| S. | CLM | First Model | Second Model | Third Model | Test (%) | Macro-F1 | F1 True | F1 False |
|---|---|---|---|---|---|---|---|---|
| 12 | CLM2 | Bot ES | – | – | 15 | 0.575 | 0.563 | 0.588 |
| 30 | 0.564 | 0.517 | 0.611 | |||||
| 45 | 0.538 | 0.476 | 0.600 | |||||
| 50 | 0.536 | 0.484 | 0.588 | |||||
| 100 | 0.508 | 0.420 | 0.595 | |||||
| 30 | CLM5 | BotES | BotEN | – | 15 | 0.511 | 0.467 | 0.556 |
| 30 | 0.551 | 0.462 | 0.641 | |||||
| 45 | 0.515 | 0.416 | 0.615 | |||||
| 45 | CLM8 | Stance EN | Bot EN | – | 15 | 0.575 | 0.563 | 0.588 |
| 30 | 0.598 | 0.567 | 0.629 | |||||
| 45 | 0.587 | 0.565 | 0.608 | |||||
| 50 | 0.579 | 0.571 | 0.587 | |||||
| 100 | 0.555 | 0.532 | 0.578 | |||||
| 62 | CLM12 | Bot EN | Stance EN | Bot ES | 15 | 0.566 | 0.698 | 0.435 |
| 30 | 0.624 | 0.676 | 0.571 | |||||
| 45 | 0.667 | 0.698 | 0.636 | |||||
| 50 | 0.661 | 0.690 | 0.633 | |||||
| 100 | 0.587 | 0.611 | 0.564 |
| Set. | CLM | First Model | Second Model | Third Model | Macro-F1 |
|---|---|---|---|---|---|
| 73 | CLM14 | Stance EN | Bot EN | Bot ES | 0.783 |
| 6 | CLM1 | Bot EN | — | — | 0.768 |
| 3 | Base0 | — | — | — | 0.768 |
| Model | Embedding | Macro-F1 |
|---|---|---|
| BiGRU | mBERT-sum-four-last | 0.666 |
| Base0 | sBERT-default | 0.701 |
| Base0 | mBERT-sum-four-last | 0.726 |
| BiGRU | mBERT-embedding | 0.726 |
| BiGRU | sBERT-default | 0.729 |
| BiGRU | mBERT-second-to-last | 0.744 |
| Base0 | mBERT-embedding | 0.767 |
| Base0 | mBERT-second-to-last | 0.768 |
| CLM-MTL-RD (CLM14) | mBERT-second-to-last | 0.783 |
| Set. | CLM | First Model | Second Model | Third Model | Macro-F1 |
|---|---|---|---|---|---|
| 18 | CLM3 | Stance EN | – | – | 0.749 |
| 43 | CLM8 | Stance EN | Bot EN | – | 0.764 |
| 48 | CML9 | Stance EN | Bot ES | – | 0.752 |
| 73 | CLM14 | Stance EN | Bot EN | Bot ES | 0.783 |
| 78 | CLM15 | Stance EN | Bot ES | Bot EN | 0.729 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Providel, E.; Mendoza, M.; Solar, M. Cross-Lingual Cross-Domain Transfer Learning for Rumor Detection. Future Internet 2025, 17, 287. https://doi.org/10.3390/fi17070287
Providel E, Mendoza M, Solar M. Cross-Lingual Cross-Domain Transfer Learning for Rumor Detection. Future Internet. 2025; 17(7):287. https://doi.org/10.3390/fi17070287
Chicago/Turabian StyleProvidel, Eliana, Marcelo Mendoza, and Mauricio Solar. 2025. "Cross-Lingual Cross-Domain Transfer Learning for Rumor Detection" Future Internet 17, no. 7: 287. https://doi.org/10.3390/fi17070287
APA StyleProvidel, E., Mendoza, M., & Solar, M. (2025). Cross-Lingual Cross-Domain Transfer Learning for Rumor Detection. Future Internet, 17(7), 287. https://doi.org/10.3390/fi17070287