
Modeling Interaction Patterns in Visualizations with Eye-Tracking: A Characterization of Reading and Information Styles



Abstract
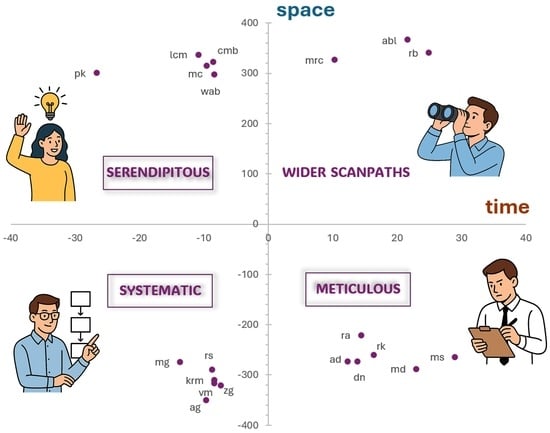
1. Introduction and Motivation
Research Questions
- Fixation time can be a proxy of humans’ reading speed, and ofdata visualization reading complexity;
- Fixation coordinates can be a proxy of humans’ reading patterns, and of data visualization information disposition.
- RQ1
- What can fixation time say about users’ reading speed of data viz (resp. data viz reading complexity)?
- RQ2
- What can scanpath area say about users’ reading style of data viz (resp. data viz information disposition)?
2. Literature Review
2.1. Methodology Studies for Eye-Tracking Data Collection and Treatment
2.2. Eye-Tracking in Human–Computer Interaction
2.3. Eye-Tracking in Data Visualization
2.4. Previous Studies with the MASSVIS Dataset
2.5. Conclusions from the Literature Review
2.6. Scope of the Present Study
- In summary, we build on the previous studies on the MASSVIS Project by applying a bias–noise statistical model [30] to a data visualization eye-tracking dataset, mapping fixation times to reading speed, information complexity, and scanpath areas to reading style and information disposition. Thus, our contribution is to augment this emerging landscape by the following: (i) analyzing eye-tracking data; (ii) extracting distinct reading styles empirically; (iii) offering a generalizable framework in the field of data visualization and Human–Data Interaction performance [31], which links complexity, predictability, and scanpath patterns without requiring prior user profiling.
3. Methodology
3.1. The MASSVIS Dataset
3.2. The Areas of Interest
3.3. The Bias-Noise Model
3.4. The Application of the Model to Eye-Tracking Data
- n: number of data points (fixation time or scanpath area);
- : actual fixation time value or area value (for a minimum of three fixation points/two vectors);
- : expected value–i.e., fixation time average or scanpath area average.
- 1.
- Fixation time bias and noise: the users’ reading speed with data viz and the data viz reading complexity, and their predictability;
- 2.
- Scanpath area bias and noise: the users’ reading patterns (e.g., either “chaotic” or “ordered”) and the data viz information disposition (e.g., either “scattered” or “gathered”), and their predictability.
3.5. Extension of the MASSVIS Dataset to Our Purposes
3.6. Reliability of the Bias-Noise Model
3.7. Experimental Setup
- 1.
- HT-1, HS-1:
- 2.
- HT-2, HS-2:
- 3.
- HT-3, HS-3:
- 4.
- HT-4, HS-4:
- 5.
- HT-5, HS-5:
- 6.
- HT-6, HS-6:
- 7.
- HT-7, HS-7:
- 8.
- HT-8, HS-8:
- 9.
- HT-9, HS-9:
4. Results
4.1. Fixation Time and Scanpath Area: Descriptive Statistics
4.2. Hypotheses Tests
4.3. Fixation Time
4.3.1. Single Participant and Whole Dataset–HT-1
4.3.2. Single Participant and Data Viz Type–HT-2
4.3.3. Single Participant vs. Single Data Viz–HT-3
4.3.4. Single Data Viz and Data Viz Type–HT-4
4.3.5. Data Viz Type and Whole Dataset–HT-5
4.3.6. Single AOI and Whole Dataset–HT-6
4.3.7. Single AOI and Single Data Viz by Type–HT-7
4.3.8. Single AOI Type and Single Participant–HT-8
4.3.9. Single AOI Type and Data Viz Type–HT-9
4.4. Scanpath Area
4.4.1. Single Participant and Whole Dataset–HS-1
4.4.2. Single Participant and Data Viz Type–HS-2
4.4.3. Single Participant and Single Data Viz–HS-3
4.4.4. Single Data Viz and Data Viz Type–HS-4
4.4.5. Data Viz Type and Whole Dataset–HS-5
4.4.6. Single AOI and Whole Dataset–HS-6
4.4.7. Single AOI and Single Data Viz by Type–HS-7
4.4.8. Single AOI and Single Participant–HS-8
4.4.9. Single AOI and Data Viz Type–HS-9
4.5. Computational Complexity
5. Discussion
5.1. Participants’ Reading Speed and Reading Style: HT- and HS- 1,2, and 3
5.2. Data Viz Complexity and Information Disposition: HT- and HS- 4 and 5
5.3. Participants and Data Viz Through AOIs: HTS-6, 7, 8, and 9
5.4. Limitations of the Study
6. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Glossary of Symbols and Abbreviations
| AOI | Area of Interest (plural AOIs); manually annotated region in a data visualization (title, scale, label, encoding, footer). Where figures depict single AOIs, they are abbreviated as follows: enc: encoding; tit: title; foo: footer; lab: labels; sca: scale. |
| Data Visualization | the domain of the study; when written in lowercase or abbreviated as “data viz”, it means a static chart or infographic. Where figures depict single data viz types, they are abbreviated as follows: a–area; b–bars; c–circles; g–diagrams; d–distributions; r–gridmatrix; l–lines; m–maps; p–points; t–tables; n–trees and networks. |
| MASSVIS | Massachusetts (Massive) Visualization Dataset, a public dataset of 393 visualizations with eye-tracking data of 33 participants each. Available at http://MASSVIS.mit.edu/ (accessed on 24 August 2025). For our study, we have exploited the zip folders eyetracking-master.zip and targets393.zip; the former contains: user id with fixation sequence (1, 2, 3…), coordinates of any point of fixation, and time of each fixation in ms; the latter contains the .png image file of the data viz upon which the eye-tracking recording was performed. |
| MSE | Mean Squared Error; scalar , defined as (from [30]); unit depends on variable (milliseconds–ms2–or pixel–px2) |
| Bias | Scalar ; average displacement from the mean value of a variable (fixation time or scanpath area); units: ms (time), px2 (area) |
| Noise | Scalar ; dispersion around the mean value (standard deviation or variance); units: ms (time), px2 (area) |
| Coordinates | Coordinates are first recorded in the screen coordinate system of pixels, then mapped into a page coordinate system corresponding to the bounding box of the data viz, where are the top-left pixel coordinates of the data viz, and its width and height in pixels. Given two coordinates , their position on the page coordinate system is intended as the offset from along and along the . |
| Fixation | Point ; screen coordinates of a fixation point (x,y) in pixels. Each fixation is represented by its centroid coordinates and duration, with successive fixations connected by straight-line segments (saccades). |
| Fixation time | Scalar ; duration of a gaze fixation; unit: ms |
| Fixation vector | Vector ; displacement between two fixation points and ; unit: px |
| Scanpath | Piecewise-linear gaze trajectory in screen space: ordered sequence of fixation vectors , with each the displacement between two successive fixation points . It represents the trajectory (i.e., the succession of fixations and saccades over time) of gaze across the visualization, and it forms the basis for derived measures such as the scanpath area. Units: px for spatial displacements; ms for fixation timing. |
| Scanpath area | Scalar ; area derived from the dot products of successive fixation vectors, proxy of coverage; unit: px2 |
| Dot product | Scalar ; , yields local scanpath area contribution; unit: px2 |
| CV | Coefficient of Variation; dimensionless ratio , used as a reliability indicator to test the fitness of the bias-noise model onto the MASSVIS dataset data |
| RQ | Research Question |
| Kolmogorov–Smirnov | K–S statistical test for normality of the data |
| HT-x | Hypothesis related to fixation time (temporal dimension, reading speed, and its dual information complexity). Hypotheses of this kind are null hypotheses, tested with the t-test (parametric) and the Mann–Whitney (non-parametric) statistical tests (Python 3.13 version, package scipy, 1.15.3 version), whose outputs are dimensionless |
| HS-x | Hypothesis related to scanpath area (spatial dimension, reading style, and its dual information disposition). Hypotheses of this kind are null hypotheses, tested with the t-test (parametric) and Mann–Whitney (non-parametric) statistical tests (Python, 3.13 version, package scipy, 1.15.3 version), whose outputs are dimensionless |
References
- Majaranta, P.; Bulling, A. Eye tracking and eye-based human–computer interaction. In Advances in Physiological Computing; Springer: London, UK, 2014; pp. 39–65. [Google Scholar]
- Hansen, D.W.; Ji, Q. In the Eye of the Beholder: A Survey of Models for Eyes and Gaze. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 478–500. [Google Scholar] [CrossRef]
- Jarodzka, H.; Balslev, T.; Holmqvist, K.; Nyström, M.; Scheiter, K.; Gerjets, P.; Eika, B. Conveying clinical reasoning based on visual observation via eye-movement modelling examples. Instr. Sci. 2012, 40, 813–827. [Google Scholar] [CrossRef]
- Liu, X.; Cui, Y. Eye tracking technology for examining cognitive processes in education: A systematic review. Comput. Educ. 2025, 229, 105263. [Google Scholar] [CrossRef]
- Locoro, A.; Cabitza, F.; Actis-Grosso, R.; Batini, C. Static and interactive infographics in daily tasks: A value-in-use and quality of interaction user study. Comput. Hum. Behav. 2017, 71, 240–257. [Google Scholar] [CrossRef]
- Koyuncu, I.; Firat, T. Investigating reading literacy in PISA 2018 assessment. Int. Electron. J. Elem. Educ. 2020, 13, 263–275. [Google Scholar] [CrossRef]
- Brysbaert, M. How many words do we read per minute? A review and meta-analysis of reading rate. J. Mem. Lang. 2019, 109, 104047. [Google Scholar] [CrossRef]
- Al-Moteri, M.O.; Symmons, M.; Plummer, V.; Cooper, S. Eye tracking to investigate cue processing in medical decision-making: A scoping review. Comput. Hum. Behav. 2017, 66, 52–66. [Google Scholar] [CrossRef]
- Currie, J.; Bond, R.R.; McCullagh, P.; Black, P.; Finlay, D.D.; Peace, A. Eye Tracking the Visual Attention of Nurses Interpreting Simulated Vital Signs Scenarios: Mining Metrics to Discriminate Between Performance Level. IEEE Trans. Hum.-Mach. Syst. 2018, 48, 113–124. [Google Scholar] [CrossRef]
- Lu, Y.; Sarter, N. Eye Tracking: A Process-Oriented Method for Inferring Trust in Automation as a Function of Priming and System Reliability. IEEE Trans. Hum.-Mach. Syst. 2019, 49, 560–568. [Google Scholar] [CrossRef]
- Guo, Y.; Freer, D.; Deligianni, F.; Yang, G.Z. Eye-Tracking for Performance Evaluation and Workload Estimation in Space Telerobotic Training. IEEE Trans. Hum.-Mach. Syst. 2022, 52, 1–11. [Google Scholar] [CrossRef]
- Grundgeiger, T.; Wurmb, T.; Happel, O. Statistical Modeling of Visual Attention of Junior and Senior Anesthesiologists During the Induction of General Anesthesia in Real and Simulated Cases. IEEE Trans. Hum.-Mach. Syst. 2020, 50, 317–326. [Google Scholar] [CrossRef]
- Nielsen, J. F-Shaped Pattern for Reading Web Content, Jakob Nielsen’s Alertbox. 2006. Available online: http://www.useit.com/alertbox/reading_pattern.html (accessed on 24 August 2025).
- Nielsen, J.; Pernice, K. Eyetracking Web Usability; New Riders: Thousand Oaks, CA, USA, 2010. [Google Scholar]
- Gilhooly, K.J.; Sleeman, D.H. To differ is human: A reflective commentary on “Noise. A Flaw in Human Judgment”, by D. Kahneman, O. Sibony & CR Sunstein (2021). London: William Collins. Appl. Cogn. Psychol. 2022, 36, 724–730. [Google Scholar] [CrossRef]
- Burch, M.; Kurzhalis, K.; Weiskapf, D. Eye Tracking Studies in Visualization: Phases, Guidelines, and Checklist. In Proceedings of the 2025 Symposium on Eye Tracking Research and Applications, Tokyo, Japan, 26–29 May 2025; pp. 1–7. [Google Scholar]
- Ke, F.; Liu, R.; Sokolikj, Z.; Dahlstrom-Hakki, I.; Israel, M. Using eye-tracking in education: Review of empirical research and technology. Educ. Technol. Res. Dev. 2024, 72, 1383–1418. [Google Scholar] [CrossRef]
- Oppenlaender, J. Multilaboratory Experiments Are the Next Big Thing in HCI. Interactions 2025, 32, 6–7. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed]
- Borkin, M.A.; Vo, A.A.; Bylinskii, Z.; Isola, P.; Sunkavalli, S.; Oliva, A.; Pfister, H. What makes a visualization memorable? IEEE Trans. Vis. Comput. Graph. 2013, 19, 2306–2315. [Google Scholar] [CrossRef]
- Biber, D.; Reppen, R.; Friginal, E. Using corpus-based methods to investigate grammatical variation. In The Oxford Handbook of Linguistic Analysis; Heine, B., Narrog, H., Eds.; Oxford University Press: Oxford, UK, 2012; pp. 276–296. [Google Scholar]
- Carter, B.T.; Luke, S.G. Best practices in eye tracking research. Int. J. Psychophysiol. 2020, 155, 49–62. [Google Scholar] [CrossRef] [PubMed]
- Ruf, V.; Horrer, A.; Berndt, M.; Hofer, S.I.; Fischer, F.; Fischer, M.R.; Zottmann, J.M.; Kuhn, J.; Küchemann, S. A Literature Review Comparing Experts’ and Non-Experts’ Visual Processing of Graphs during Problem-Solving and Learning. Educ. Sci. 2023, 13, 216. [Google Scholar] [CrossRef]
- Toker, D.; Conati, C.; Steichen, B.; Carenini, G. Individual user characteristics and information visualization: Connecting the dots through eye tracking. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 295–304. [Google Scholar]
- Borkin, M.A.; Bylinskii, Z.; Kim, N.W.; Bainbridge, C.M.; Yeh, C.S.; Borkin, D.; Pfister, H.; Oliva, A. Beyond memorability: Visualization recognition and recall. IEEE Trans. Vis. Comput. Graph. 2015, 22, 519–528. [Google Scholar] [CrossRef] [PubMed]
- Bylinskii, Z.; Borkin, M.A.; Kim, N.W.; Pfister, H.; Oliva, A. Eye fixation metrics for large scale evaluation and comparison of information visualizations. In Eye Tracking and Visualization, Proceedings of the Foundations, Techniques, and Applications, ETVIS 2015, Chicago, IL, USA, 25 October 2015; Springer: Cham, Switzerland, 2017; pp. 235–255. [Google Scholar]
- Kim, N.W.; Bylinskii, Z.; Borkin, M.A.; Gajos, K.Z.; Oliva, A.; Durand, F.; Pfister, H. Bubbleview: An interface for crowdsourcing image importance maps and tracking visual attention. ACM Trans. Comput.-Hum. Interact. (TOCHI) 2017, 24, 1–40. [Google Scholar] [CrossRef]
- Kosara, R. Evidence for area as the primary visual cue in pie charts. In Proceedings of the 2019 IEEE Visualization Conference (VIS), Vancouver, BC, Canada, 20–25 October 2019; pp. 101–105. [Google Scholar]
- Keller, C.; Junghans, A. Does guiding toward task-relevant information help improve graph processing and graph comprehension of individuals with low or high numeracy? An eye-tracker experiment. Med. Decis. Mak. 2017, 37, 942–954. [Google Scholar] [CrossRef]
- Kahneman, D.; Sibony, O.; Sunstein, C. Noise: A Flaw in Human Judgment; William Collins: Glasgow, UK, 2021. [Google Scholar]
- Cabitza, F.; Locoro, A.; Batini, C. Making open data more personal through a social value perspective: A methodological approach. Inf. Syst. Front. 2020, 22, 131–148. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 20, 1254–1259. [Google Scholar] [CrossRef]
- Franzen, L.; Stark, Z.; Johnson, A.P. Individuals with dyslexia use a different visual sampling strategy to read text. Sci. Rep. 2021, 11, 6449. [Google Scholar] [CrossRef] [PubMed]
- Ware, C. Information Visualization: Perception for Design; Morgan Kaufmann: Burlington, MA, USA, 2019. [Google Scholar]
- Liang, K.; Chahir, Y.; Molina, M.; Tijus, C.; Jouen, F. Appearance-based eye control system by manifold learning. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; Volume 3, pp. 148–155. [Google Scholar]
- Wang, D.; Formica, M.K.; Liu, S. Nonparametric Interval Estimators for the Coefficient of Variation. Int. J. Biostat. 2018, 14, 1–15. [Google Scholar] [CrossRef]
- Nakagawa, S. A farewell to Bonferroni: The problems of low statistical power and publication bias. Behav. Ecol. 2004, 15, 1044–1045. [Google Scholar] [CrossRef]
- Hecht, R.M.; Hillel, A.B.; Telpaz, A.; Tsimhoni, O.; Tishby, N. Information Constrained Control Analysis of Eye Gaze Distribution Under Workload. IEEE Trans. Hum.-Mach. Syst. 2019, 49, 474–484. [Google Scholar] [CrossRef]
- Blundell, J.; Collins, C.; Sears, R.; Plioutsias, T.; Huddlestone, J.; Harris, D.; Harrison, J.; Kershaw, A.; Harrison, P.; Lamb, P. Multivariate Analysis of Gaze Behavior and Task Performance Within Interface Design Evaluation. IEEE Trans. Hum.-Mach. Syst. 2023, 53, 875–884. [Google Scholar] [CrossRef]
- Li, F.; Chen, C.H.; Xu, G.; Khoo, L.P. Hierarchical Eye-Tracking Data Analytics for Human Fatigue Detection at a Traffic Control Center. IEEE Trans. Hum.-Mach. Syst. 2020, 50, 465–474. [Google Scholar] [CrossRef]































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trend | Main Approach | Ref. | Advantages | Disadvantages |
|---|---|---|---|---|
|
Methodology and data quality | Best practices for acquisition, calibration, preprocessing, validity, transparent reporting | [21] | Reliability, reproducibility, clear validity guidance | Domain-agnostic; overhead to implement; no direct viz-specific insights |
| HCI | Gaze as input/attention signal (VOG, IR-PCR, EOG) for interfaces, assistive/mobile uses | [1] | Mature tech; broad applicability; informs attentive UIs | Not visualization-specific; comfort/usability limits; transfer to reading tasks is non-trivial |
| Data Visualization | Compare experts vs. non-experts; model AOI transitions; relate cognition and task difficulty to gaze | [22,23] | Reveals discriminative patterns; AOI-level strategies; motivates standardized expertise measures | Relies on exogenous constructs (e.g., literacy/WM); narrow chart sets; task confounds |
| MASSVIS-based | Large-scale memorability/recognition and fixation-metric studies; crowdsourced attention maps | [24,25,26,27] | Scale/diversity; stable properties; role of titles/annotations; comparative evaluation | Secondary, static data; sparse demographics; reliance on labels/crowd proxies |
| This work | Construct-agnostic bias–noise model: fixation time → reading speed/complexity; scanpath area → reading style/information disposition; reader styles & type/AOI patterns | This work | Generalizable without prior profiling; no task mediation; unifies time/space; recovers emergent styles and type/AOI differences | Secondary/static dataset; limited participant metadata; Western-centric corpus; AOI subset for fine-grained analysis |
| Type | Viz | Id | Ids of the Data Viz Selected and the Total |
|---|---|---|---|
| Area |  | from 1 to 18 (19) | 1, 2, 3, 7, 13, 14 (6) |
| Bars |  | from 19 to 117 (98) | 19, 21, 24, 27, 30, 31, 34, 41, 58, 64, 66, 85, 112, 115 (14) |
| Circles |  | from 118 to 134 (16) | 119, 120, 127, 133, 134 (5) |
| Diagrams |  | from 135 to 184 (49) | - |
| Distribution |  | 185, 186 (2) | 186 (1) |
| Gridmatrix |  | from 187 to 193 (5) | 187 (1) |
| Lines |  | from 194 to 252 (58) | 195, 197, 200, 202, 204, 221, 225, 234, 238, 244, 252 (11) |
| Maps |  | from 253 to 294 (39) | 254, 257, 260, 261, 263, 276, 281, 282, 284, 291 (10) |
| Points |  | from 295 to 327 (32) | 295, 296, 297, 298, 299, 300, 315, 319, 320, 321, 323, 324, 325 (13) |
| Table |  | from 328 to 382 (54) | 330 (1) |
| Tree&Netw. |  | from 383 to 393 (10) | - |
| Inclusion Criteria | Exclusion Criteria |
|---|---|
| Resolution between 400 and 1000 pixels | Unpopular visualization types (e.g., Sankey) |
| Popular and frequently published visualization types [20] | Visualization types with very low frequency in dataset |
| Sources: Economist, Nature, US Treasury, Visually, WHO, WSJ (excluding National Post) | Types with incomparable internal variability (e.g., simple vs. intricate diagrams) |
| Balanced ink-ratio: 45% bad, 40% medium, 15% good | Diagram type excluded after review |
| Variable counts: 30% single, 50% double, 20% triple | |
| Visual density below maximum (55% density 1, 45% density 2) |
| Hyp | Sign | % | Hyp | Sign | % |
|---|---|---|---|---|---|
| HT-1 | 31 | 94 | HS-1 | 22 | 67 |
| HT-2 | 203 | 56 | HS-2 | 188 | 52 |
| HT-3 | 1080 | 18 | HS-3 | 2593 | 41 |
| HT-4 | 3 | 27 | HS-4 | 10 | 91 |
| HT-5 | 231 | 59 | HS-5 | 305 | 78 |
| HT-6 | 4 | 80 | HS-6 | 5 | 100 |
| HT-7 | 17 | 31 | HS-7 | 33 | 60 |
| HT-8 | 71 | 43 | HS-8 | 50 | 30 |
| HT-9 | 71 | 23 | HS-9 | 147 | 47 |
| Task | Complexity |
|---|---|
| Pre-processing: build fixation vectors from coordinates | Time: Space: to store vectors in |
| Pre-processing: compute dot products (scanpath-area contributions) | Time: |
| Statistics: mean, variance, bias, MSE on fixation time/scanpath area, aggregated at participant, data viz, data viz type, AOI level | Time: Space: |
| Hypothesis testing: Kolmogorov–Smirnov, Mann–Whitney U, t-test, Cohen’s d on grouped data | Kolmogorov–S: Mann–W: t-test: Cohen’s d: |
| Bootstrap reliability: B resamples for coefficient of variation (CV) | Time: where M is sample size per resample Space: |
| Storage: raw fixations , derived vectors, dot products, aggregates | Overall ; aggregates negligible vs. N |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Locoro, A.; Lavazza, L. Modeling Interaction Patterns in Visualizations with Eye-Tracking: A Characterization of Reading and Information Styles. Future Internet 2025, 17, 504. https://doi.org/10.3390/fi17110504
Locoro A, Lavazza L. Modeling Interaction Patterns in Visualizations with Eye-Tracking: A Characterization of Reading and Information Styles. Future Internet. 2025; 17(11):504. https://doi.org/10.3390/fi17110504
Chicago/Turabian StyleLocoro, Angela, and Luigi Lavazza. 2025. "Modeling Interaction Patterns in Visualizations with Eye-Tracking: A Characterization of Reading and Information Styles" Future Internet 17, no. 11: 504. https://doi.org/10.3390/fi17110504
APA StyleLocoro, A., & Lavazza, L. (2025). Modeling Interaction Patterns in Visualizations with Eye-Tracking: A Characterization of Reading and Information Styles. Future Internet, 17(11), 504. https://doi.org/10.3390/fi17110504