

Context-Driven Service Deployment Using Likelihood-Based Approach for Internet of Things Scenarios

 , , , , ,
, , , , ,  and
and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
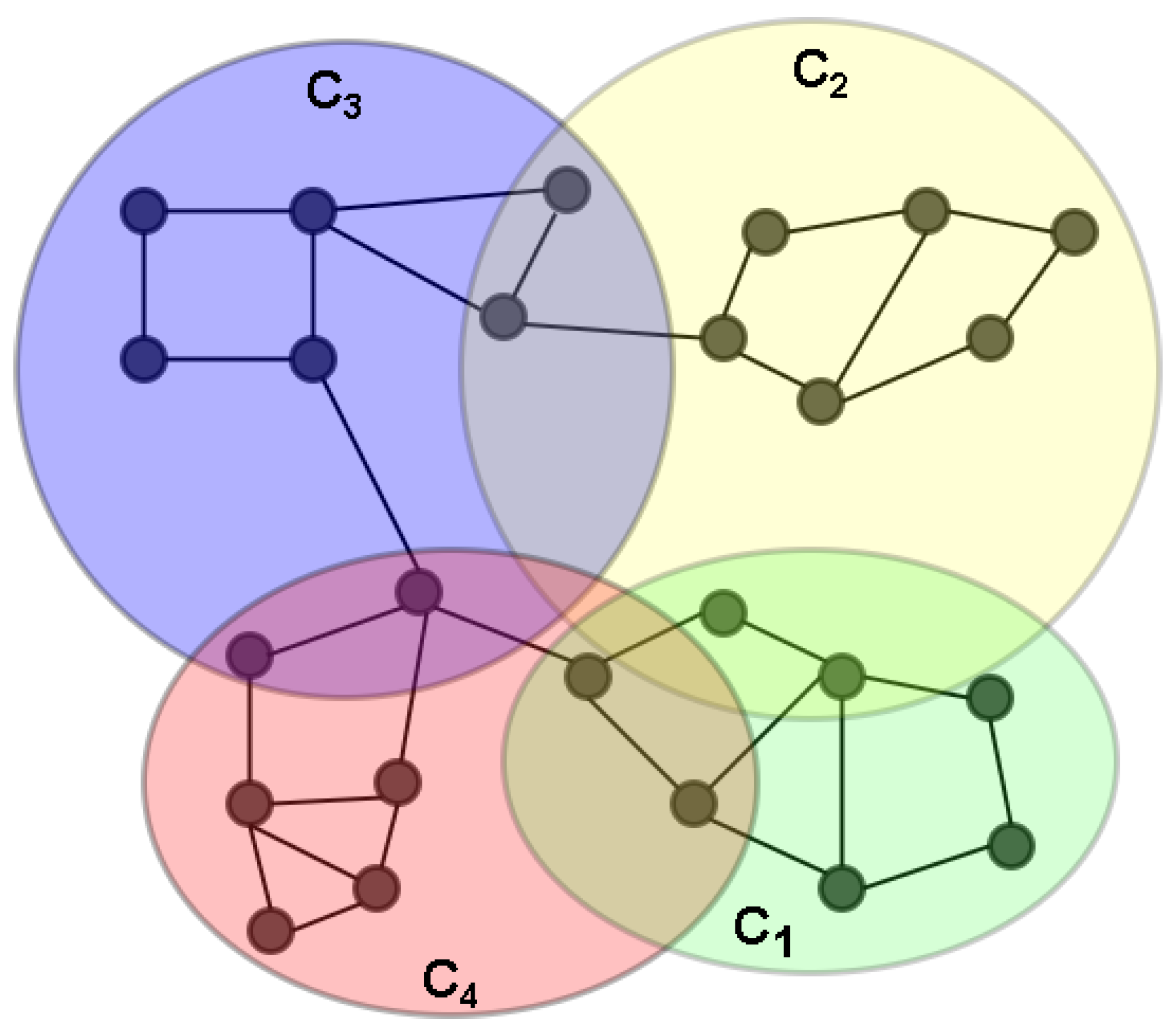
1.1. Combined Context
1.2. Research Contributions
- The necessary search space is reduced by leveraging the concept of combined context.
- Further, this reduction takes place due to a time-variant correlation among the previously consumed services. This reduction has a subsequent effect on minimizing the average service discovery time, service-completion time, and service-advertisement time (at the time of service registration).
- Additionally, this extends to the efficient utilization of system resources. This provides the advantage that the system will be able to serve more clients with the same resources, and this ultimately increases its overall efficiency.
1.3. Paper Structure
2. Related Work
3. Background
3.1. Least Recently Used
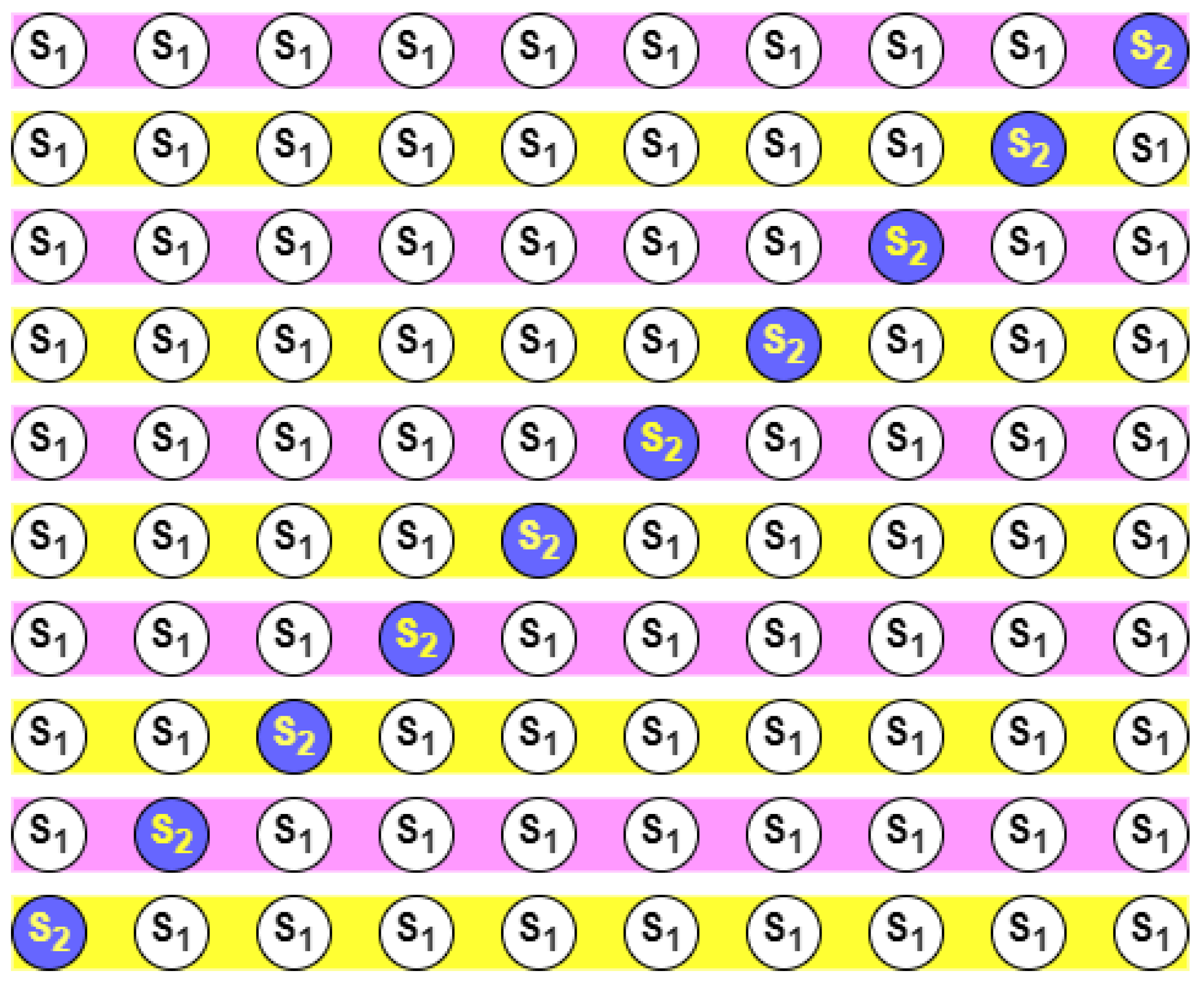
3.2. Maximum Likelihood Estimation
- The likelihood function is defined asthat is, it is the product of the n density function terms (where the ith term is the density function evaluated at ) viewed as a function of .
- Take the natural logarithm of the likelihood and collect terms involving .
- Find the value of , , for which is maximized, for example by differentiation. If is a single parameter, find by solvingin the parameter space . If is vector-valued, say , then find by simultaneously solving the k equations given byin parameter space . If is a bounded interval, then the MLE may lie on the boundary of .
- We then have to check that the estimate obtained from Equation (4) truly corresponds to a maximum in the (log) likelihood function by inspecting the second-order derivative of with respect to .
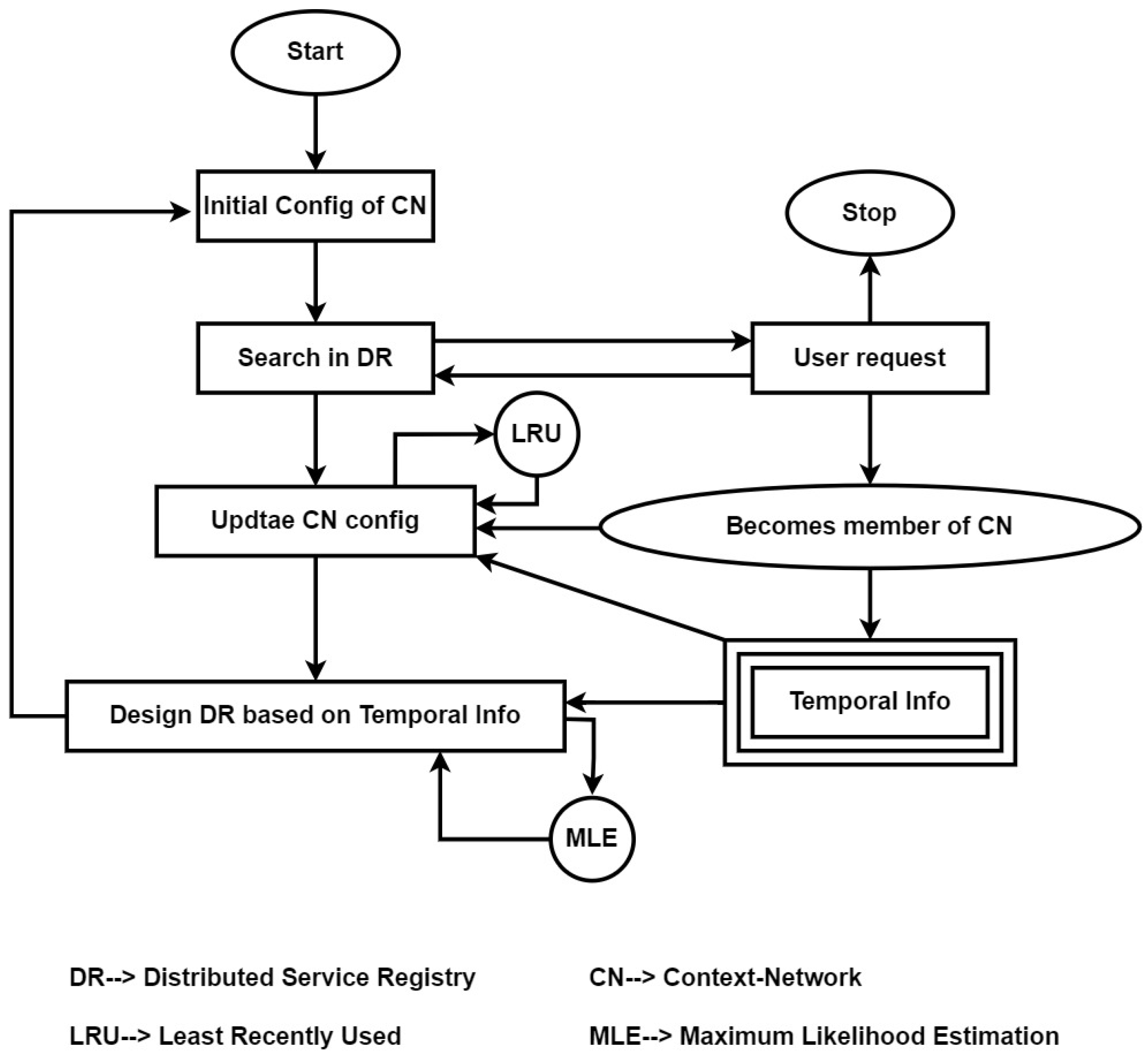
4. Proposed Technique
- Nodes or devices gather the initial configuration by exchanging their functional-context information and physical neighborhood via message passing. Each node gathers its functional-context information from its service consumption in the recent past and its physical neighborhood by a standard neighbor-discovery protocol. In Figure 2, this combined context neighborhood information is referred to as CN.
- Through exchanging the combined information about the functional context and physical neighborhood, the context networks are formed. Subsequently, the distributed service registry (DR in Figure 2) is configured for each context network.
- The system starts attending to the service consumption requests from users. The DR has the information related to each service. The search procedure starts by searching the URL of the service provider for the requested service inside the DR. As the DR is constructed by considering the concept of combined-context awareness, the number of nodes inside a particular context network is relatively small compared to those in the entire network. This is the benefit that the system is likely to obtain by leveraging context awareness through the service consumption patterns of nodes.
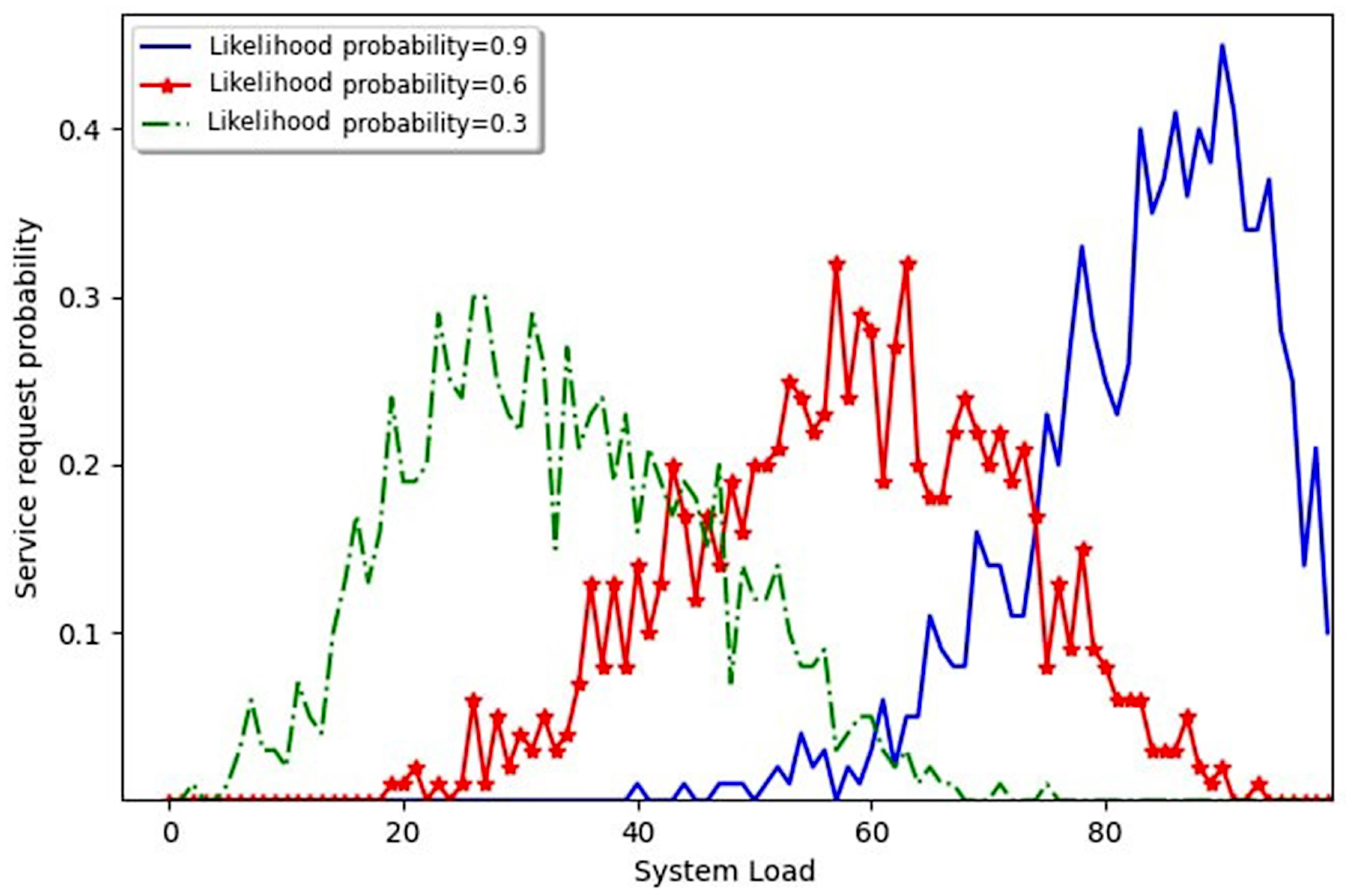
- MLE plays a crucial role here by finding the services that have a high probability of being used according to the consumption history of the recent past. This likelihood is obtained by configuring the CN with those nodes that have similar service consumption patterns. This enhances the chance that a node will be stably inside a particular context network and thus participate in holding the distributed registry shares.
- The memberships of nodes in certain functional contexts and the context networks themselves will subsequently change over time. If the consumption of a node’s service(s) has a higher likelihood score, that node will be more stable inside a particular context network; this is beneficial for the construction of a stable service registry, which is desirable in IoT scenarios.
- The entire process is executed in a finite-time window-based approach. The execution is carried out rigorously with finite intervals to capture the dynamics of the IoT system, including topological vulnerabilities and node failures.
4.1. System Model
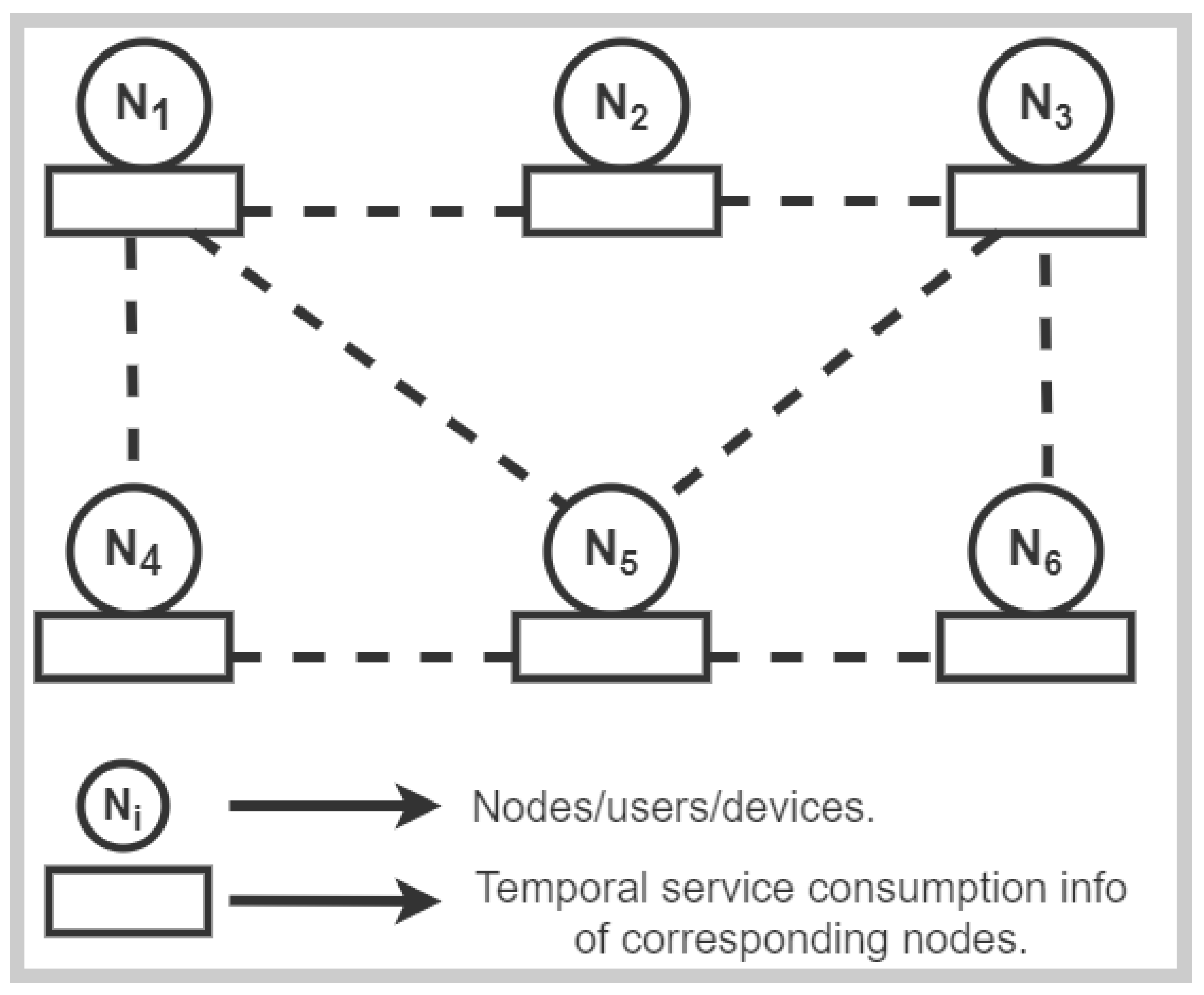
4.2. Estimation Based on Consumption Frequency
Distributed Estimation Scheme
4.3. Changes in IoT Device Contexts
4.4. Changes in Distributed Service Registry
4.4.1. Service Registration
4.4.2. Joining of a New Node
- Situation-I: if the cache of an existing shareholder is already full, a newly joined node can take some shares from it, preventing the necessary service information from being lost.
- Situation-II: if an existing node is leaving the system, the shares held by that leaving node can be transferred to the newly joined node.
4.4.3. Removal of an Existing Node
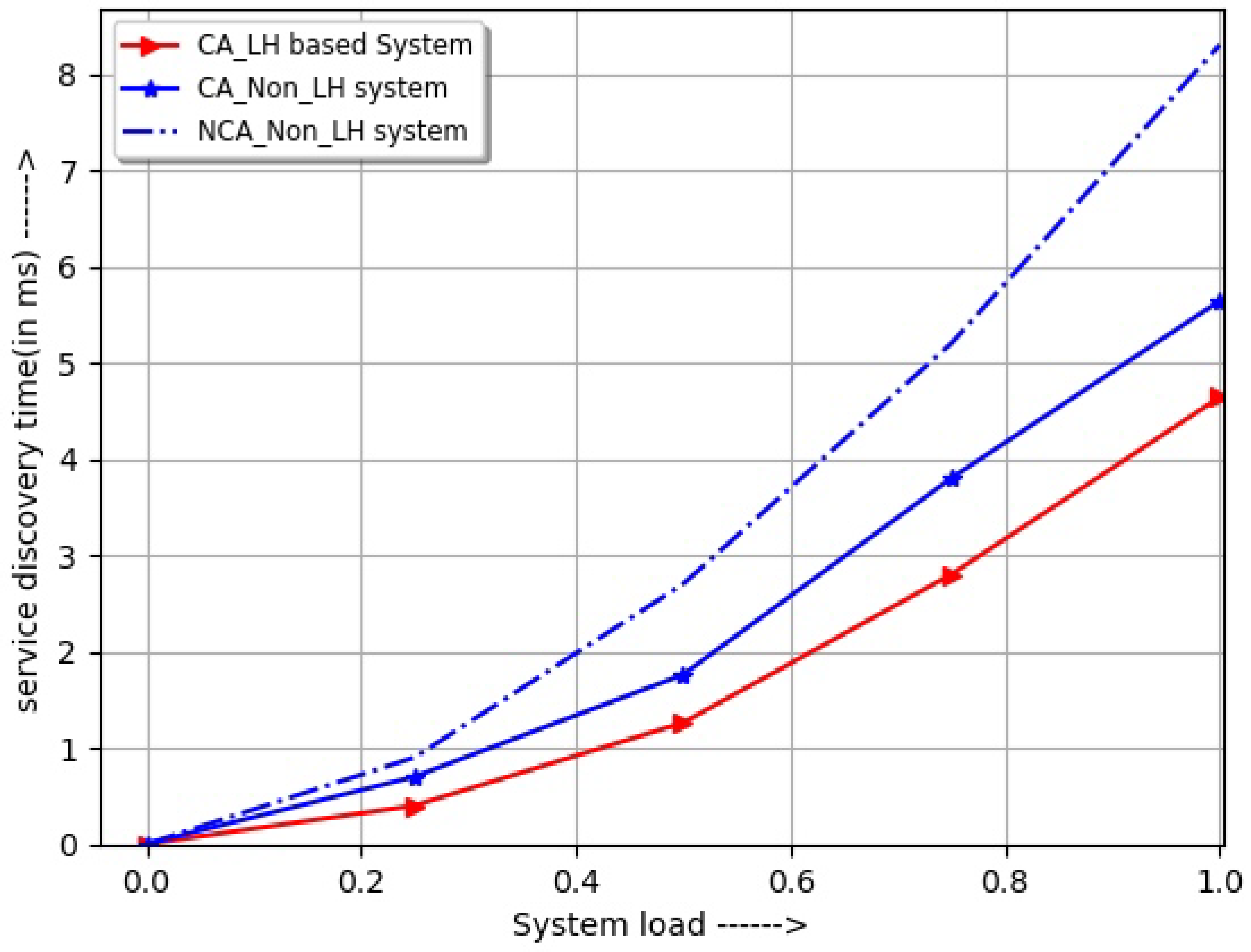
4.5. Improvement in Service Discovery/Search Time
5. Results and Discussion
5.1. Challenges Addressed
- Dynamic Contextual Changes. Contextual elements in IoT contexts—such as device locations, user activity, and network circumstances—can undergo rapid changes. If these modifications are not appropriately handled, they can potentially create security risks. The approach proposed herein is a likelihood-based method that adjusts service deployment tactics in response to dynamic contextual changes. This approach helps to reduce security risks that arise from using obsolete or wrong contextual information.
- Time-Variant Consumption Patterns. This paper focuses on the issue of time-varying consumption patterns, in which the preferences of users for service consumption may change over time. These modifications can have an effect on both the efficiency of the system and its level of protection against potential threats. The system uses MLE to measure the effect of altering consumption patterns on system performance, aiding in the identification of potential security vulnerabilities linked to variations in user behavior.
5.2. Scope for Future Research
- User Consent and Control. Users should have authority over the gathering and use of their contextual data during the process of deploying context-driven services. Ensuring user privacy and trust requires transparency in data collection processes, explicit permission mechanisms, and the provision of opportunities for users to opt out or modify their data preferences. The insufficient provision of user consent and control methods may result in privacy breaches and erode user trust in the system.
- Data Privacy. The deployment of services driven by context relies primarily on the collection and analysis of contextual data from an IoT device and their users. This often contains sensitive information such as location data, behavioral patterns, and user preferences. The acquisition and manipulation of such data give rise to issues relating to the violation of privacy. Any unauthorized attempt to access this data—whether by individuals with malevolent intent or to exploit weaknesses in the system—has the potential to result in privacy breaches and undermine the confidentiality of users.
- System Vulnerabilities. Similar to other software systems, the likelihood-based approach may have weaknesses that can be exploited by attackers to compromise the system’s security. If vulnerabilities such as buffer overflows, injection attacks, or insecure authentication techniques are not swiftly recognized and corrected, they could provide substantial hazards. Performing regular security assessments, code reviews, and vulnerability scans is crucial to detecting and addressing any potential vulnerabilities in the system.
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zisman, A.; Spanoudakis, G.; Dooley, J.; Siveroni, I. Proactive and Reactive Runtime Service Discovery: A Framework and Its Evaluation. IEEE Trans. Softw. Eng. 2013, 39, 954–974. [Google Scholar] [CrossRef]
- Choudhury, B.; Choudhury, S.; Dutta, A. A Proactive Context-Aware Service Replication Scheme for Adhoc IoT Scenarios. IEEE Trans. Netw. Serv. Manag. 2019, 16, 1797–1811. [Google Scholar] [CrossRef]
- Nguyen, T.; Huh, E.; Jo, M. Decentralized and Revised Content-Centric Networking-Based Service Deployment and Discovery Platform in Mobile Edge Computing for IoT Devices. IEEE Internet Things J. 2019, 6, 4162–4175. [Google Scholar] [CrossRef]
- Hammoud, A.; Otrok, H.; Mourad, A.; Dziong, Z. On demand fog federations for horizontal federated learning in IoV. IEEE Trans. Netw. Serv. Manag. 2022, 19, 3062–3075. [Google Scholar] [CrossRef]
- Saab, S.S.; Jaafar, R.H. A proportional-derivative-double derivative controller for robot manipulators. Int. J. Control. 2021, 94, 1273–1285. [Google Scholar] [CrossRef]
- Saab, S.S.; Shen, D.; Orabi, M.; Kors, D.; Jaafar, R.H. Iterative learning control: Practical implementation and automation. IEEE Trans. Ind. Electron. 2021, 69, 1858–1866. [Google Scholar] [CrossRef]
- Helwan, A.; Ma’aitah, M.K.S.; Uzelaltinbulat, S.; Altobel, M.Z.; Darwish, M. Gaze prediction based on convolutional neural network. In Proceedings of the International Conference on Emerging Technologies and Intelligent Systems: ICETIS 2021 Volume 2; Springer: Berlin/Heidelberg, Germany, 2021; pp. 215–224. [Google Scholar]
- Gerges, F.; Shih, F.; Azar, D. Automated diagnosis of acne and rosacea using convolution neural networks. In Proceedings of the 2021 4th International Conference on Artificial Intelligence and Pattern Recognition, Yibin, China, 20–22 August 2021; pp. 607–613. [Google Scholar]
- Stigler, S.M. The Epic Story of Maximum Likelihood. Stat. Sci. 2007, 22, 598–620. [Google Scholar] [CrossRef]
- Banerji, N.; Choudhury, S. Auction inspired service replication for context-aware IoT environment. Concurr. Comput. Pract. Exp. 2023, 35, e7641. [Google Scholar] [CrossRef]
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of Things: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Commun. Surv. Tutorials 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Stankovic, J.A. Research Directions for the Internet of Things. IEEE Internet Things J. 2014, 1, 3–9. [Google Scholar] [CrossRef]
- Perera, C.; Liu, C.H.; Jayawardena, S.; Chen, M. A Survey on Internet of Things From Industrial Market Perspective. IEEE Access 2014, 2, 1660–1679. [Google Scholar] [CrossRef]
- Perera, C.; Zaslavsky, A.; Christen, P.; Georgakopoulos, D. Context Aware Computing for The Internet of Things: A Survey. IEEE Commun. Surv. Tutorials 2014, 16, 414–454. [Google Scholar] [CrossRef]
- Zhiliang, W.; Yi, Y.; Lu, W.; Wei, W. A SOA based IOT communication middleware. In Proceedings of the 2011 International Conference on Mechatronic Science, Electric Engineering and Computer (MEC), Jilin, China, 19–22 August 2011; pp. 2555–2558. [Google Scholar] [CrossRef]
- Bellur, U.; Narendra, N.C.; Mohalik, S.K. AUSOM: Autonomic Service-Oriented Middleware for IoT-Based Systems. In Proceedings of the 2017 IEEE World Congress on Services (SERVICES), Honolulu, HI, USA, 25–30 June 2017; pp. 102–105. [Google Scholar] [CrossRef]
- Chen, I.R.; Guo, J.; Bao, F. Trust Management for SOA-Based IoT and Its Application to Service Composition. IEEE Trans. Serv. Comput. 2016, 9, 482–495. [Google Scholar] [CrossRef]
- Zhang, Y.; Duan, L.; Chen, J.L. Event-Driven SOA for IoT Services. In Proceedings of the 2014 IEEE International Conference on Services Computing, Anchorage, AK, USA, 27 June–2 July 2014; pp. 629–636. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, J.L.; Cheng, B. Integrating Events into SOA for IoT Services. IEEE Commun. Mag. 2017, 55, 180–186. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, Y.; He, Y. A two-layered P2P model for semantic service discovery. In Proceedings of the 4th International Conference on New Trends in Information Science and Service Science, Gyeongju, Republic of Korea, 11–13 May 2010; pp. 41–46. [Google Scholar]
- Jia, B.; Li, W.; Zhou, T. A Novel P2P Service Discovery Algorithm Based on Markov in Internet of Things. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; Volume 2, pp. 26–31. [Google Scholar] [CrossRef]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C.S. Spray and Wait: An Efficient Routing Scheme for Intermittently Connected Mobile Networks. In Proceedings of the 2005 ACM SIGCOMM Workshop on Delay-Tolerant Networking, Philadelphia, PA, USA, 26 August 2005; WDTN ’05. pp. 252–259. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, S.; Qi, F.; Cai, M. Self-Organized P2P Approach to Manufacturing Service Discovery for Cross-Enterprise Collaboration. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 263–276. [Google Scholar] [CrossRef]
- Benghida, A.; Boufaida, M. Web services discovery in P2P networks based on clustering. In Proceedings of the 2014 1st International Conference on Information and Communication Technologies for Disaster Management (ICT-DM), Algiers, Algeria, 24–25 March 2014; pp. 1–7. [Google Scholar] [CrossRef]
- Singh, S.P.; Viriyasitavat, W.; Juneja, S.; Alshahrani, H.; Shaikh, A.; Dhiman, G.; Singh, A.; Kaur, A. Dual adaption based evolutionary algorithm for optimized the smart healthcare communication service of the Internet of Things in smart city. Phys. Commun. 2022, 55, 101893. [Google Scholar] [CrossRef]
- Yulin, N.; Huayou, S.; Weiping, L.; Zhong, C. PDUS: P2P-Based Distributed UDDI Service Discovery Approach. In Proceedings of the 2010 International Conference on Service Sciences, Hangzhou, China, 13–14 May 2010; pp. 3–8. [Google Scholar] [CrossRef]
- Cirani, S.; Davoli, L.; Ferrari, G.; Léone, R.; Medagliani, P.; Picone, M.; Veltri, L. A Scalable and Self-Configuring Architecture for Service Discovery in the Internet of Things. IEEE Internet Things J. 2014, 1, 508–521. [Google Scholar] [CrossRef]
- Zhen, S.; Surender, R.; Dhiman, G.; Rani, K.R.; Ashifa, K.; Reegu, F.A. Intelligent-based ensemble deep learning model for security improvement in real-time wireless communication. Optik 2022, 271, 170123. [Google Scholar] [CrossRef]
- Tripathy, S.S.; Mishra, K.; Roy, D.S.; Yadav, K.; Alferaidi, A.; Viriyasitavat, W.; Sharmila, J.; Dhiman, G.; Barik, R.K. State-of-the-Art Load Balancing Algorithms for Mist-Fog-Cloud Assisted Paradigm: A Review and Future Directions. In Archives of Computational Methods in Engineering; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–36. [Google Scholar]
- Nayak, J.; Swapnarekha, H.; Naik, B.; Dhiman, G.; Vimal, S. 25 Years of Particle Swarm Optimization: Flourishing Voyage of Two Decades. In Archives of Computational Methods in Engineering; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–63. [Google Scholar]
- Guinard, D.; Trifa, V.; Karnouskos, S.; Spiess, P.; Savio, D. Interacting with the SOA-Based Internet of Things: Discovery, Query, Selection, and On-Demand Provisioning of Web Services. IEEE Trans. Serv. Comput. 2010, 3, 223–235. [Google Scholar] [CrossRef]
- Crasso, M.; Zunino, A.; Campo, M. Easy web service discovery: A query-by-example approach. Sci. Comput. Program. 2008, 71, 144–164. [Google Scholar] [CrossRef]
- Singh, N.; Hamid, Y.; Juneja, S.; Srivastava, G.; Dhiman, G.; Gadekallu, T.R.; Shah, M.A. Load balancing and service discovery using Docker Swarm for microservice based big data applications. J. Cloud Comput. 2023, 12, 1–9. [Google Scholar] [CrossRef]
- Tarhini, A.; Danach, K.; Harfouche, A. Swarm intelligence-based hyper-heuristic for the vehicle routing problem with prioritized customers. Ann. Oper. Res. 2022, 308, 549–570. [Google Scholar] [CrossRef]
- Stoica, I.; Morris, R.; Liben-Nowell, D.; Karger, D.; Kaashoek, M.; Dabek, F.; Balakrishnan, H. Chord: A scalable peer-to-peer lookup protocol for Internet applications. IEEE ACM Trans. Netw. 2003, 11, 17–32. [Google Scholar] [CrossRef]
- Kaffille, S.; Loesing, K.; Wirtz, G. Distributed Service Discovery with Guarantees in Peer-to-Peer Networks using Distributed Hashtables. In Proceedings of the International Conference on Parallel and Distributed Processing Techniques and Applications, PDPTA 2005, Las Vegas, NV, USA, 27–30 June 2005; pp. 578–584. [Google Scholar]
- Hammoud, A.; Otrok, H.; Mourad, A.; Dziong, Z. Stable federated fog formation: An evolutionary game theoretical approach. Future Gener. Comput. Syst. 2021, 124, 21–32. [Google Scholar] [CrossRef]
- Banerji, N. Distributed Machine Learning—An Intuitive Approach. In Proceedings of the Machine Intelligence and Soft Computing; Presented at 2nd International Conference on Machine Intelligence and Soft Computing (ICMISC-2021), Held at KLEF, 22–24 September 2021, Vaddeswaram Campus, Green Fields, Guntur-522302, Andhra Pradesh, India; Springer: Singapore, 2022; pp. 9–15. [Google Scholar]
- Abdellatef, H.; Khalil-Hani, M.; Shaikh-Husin, N.; Ayat, S.O. Accurate and compact convolutional neural network based on stochastic computing. Neurocomputing 2022, 471, 31–47. [Google Scholar] [CrossRef]
- Abbas, N.; Nasser, Y.; Shehab, M.; Sharafeddine, S. Attack-specific feature selection for anomaly detection in software-defined networks. In Proceedings of the 2021 3rd IEEE Middle East and North Africa COMMunications Conference (MENACOMM), Virtual Conference, 3–5 December 2021; pp. 142–146. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banerji, N.; Paul, C.; Debnath, B.; Das, B.; Chhabra, G.S.; Mohanta, B.K.; Awad, A.I. Context-Driven Service Deployment Using Likelihood-Based Approach for Internet of Things Scenarios. Future Internet 2024, 16, 349. https://doi.org/10.3390/fi16100349
Banerji N, Paul C, Debnath B, Das B, Chhabra GS, Mohanta BK, Awad AI. Context-Driven Service Deployment Using Likelihood-Based Approach for Internet of Things Scenarios. Future Internet. 2024; 16(10):349. https://doi.org/10.3390/fi16100349
Chicago/Turabian StyleBanerji, Nandan, Chayan Paul, Bikash Debnath, Biplab Das, Gurpreet Singh Chhabra, Bhabendu Kumar Mohanta, and Ali Ismail Awad. 2024. "Context-Driven Service Deployment Using Likelihood-Based Approach for Internet of Things Scenarios" Future Internet 16, no. 10: 349. https://doi.org/10.3390/fi16100349
APA StyleBanerji, N., Paul, C., Debnath, B., Das, B., Chhabra, G. S., Mohanta, B. K., & Awad, A. I. (2024). Context-Driven Service Deployment Using Likelihood-Based Approach for Internet of Things Scenarios. Future Internet, 16(10), 349. https://doi.org/10.3390/fi16100349