

A Holistic Review of Machine Learning Adversarial Attacks in IoT Networks




Abstract
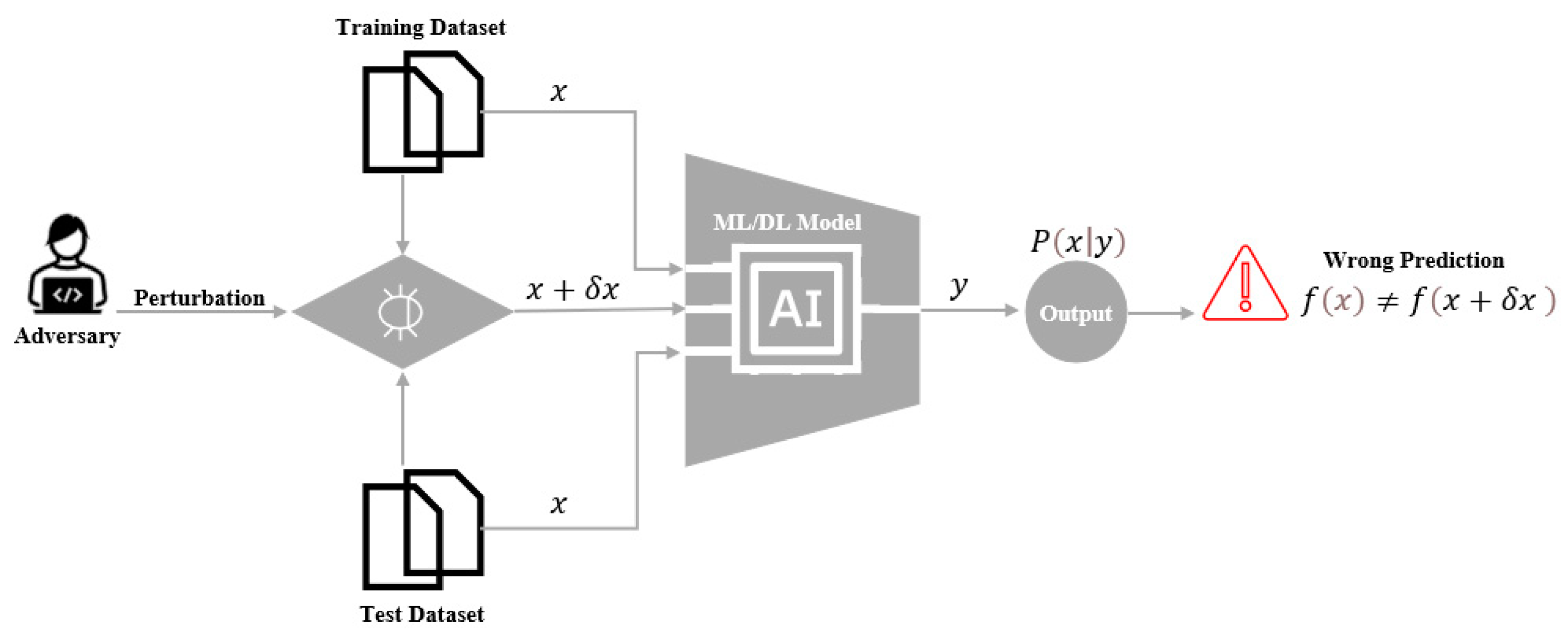
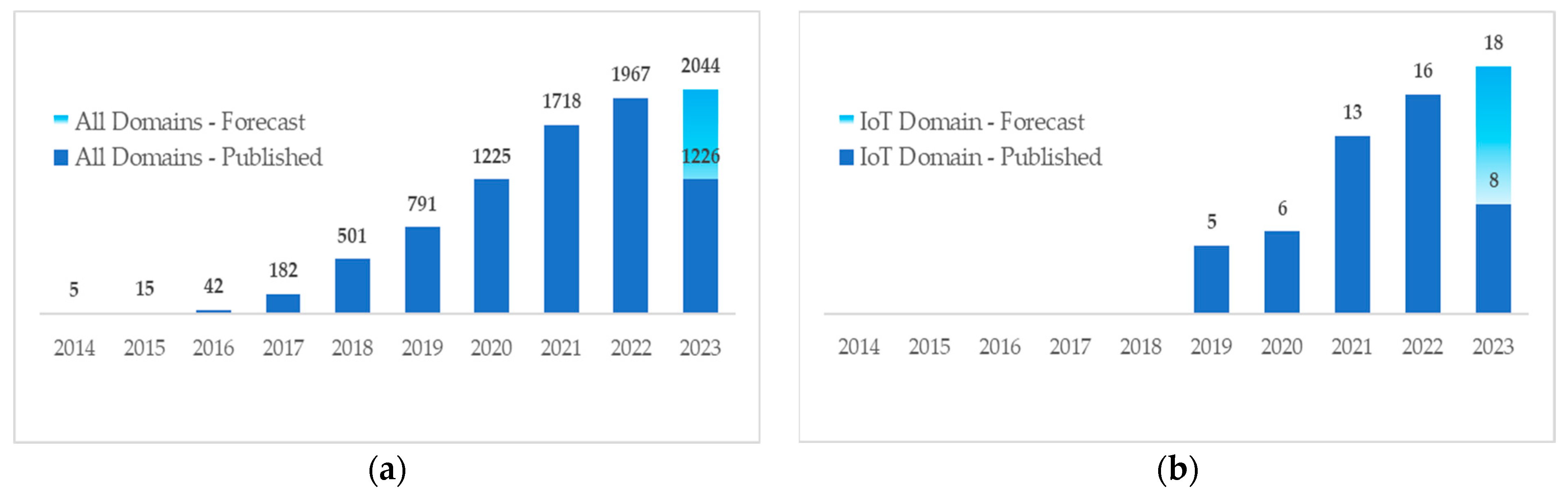
1. Introduction
- Revising and redefining the adversarial attack taxonomy for ML-based IDS, MDS, and DIS in the IoT context.
- Proposing a novel two-dimensional-based classification of adversarial attack generation methods.
- Proposing a novel two-dimensional-based classification of adversarial defense mechanisms.
- Providing intriguing insights and technical specifics on state-of-the-art adversarial attack methods and defense mechanisms.
- Conducting a holistic review of the recent literature on adversarial attacks within three prominent IoT security systems: IDSs, MDSs, and DISs.
2. Background
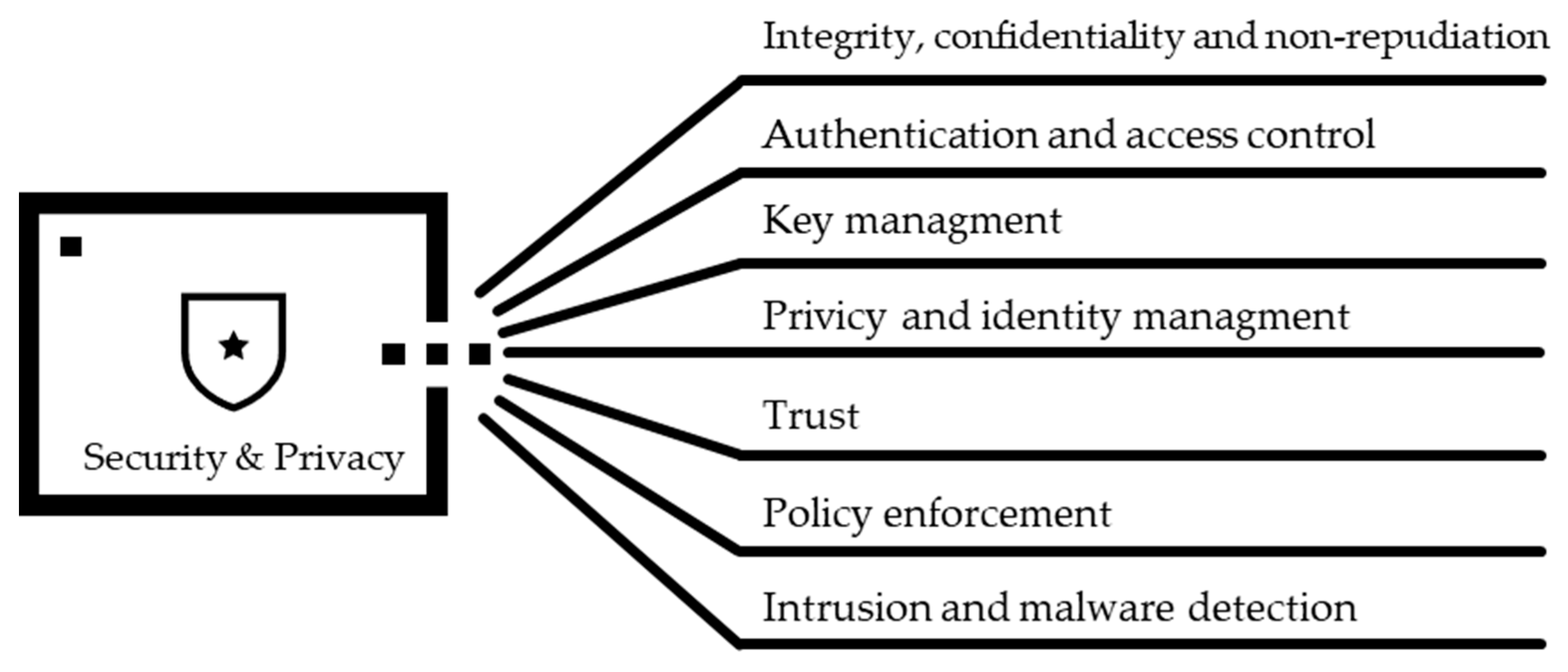
2.1. Security and Privacy Overview
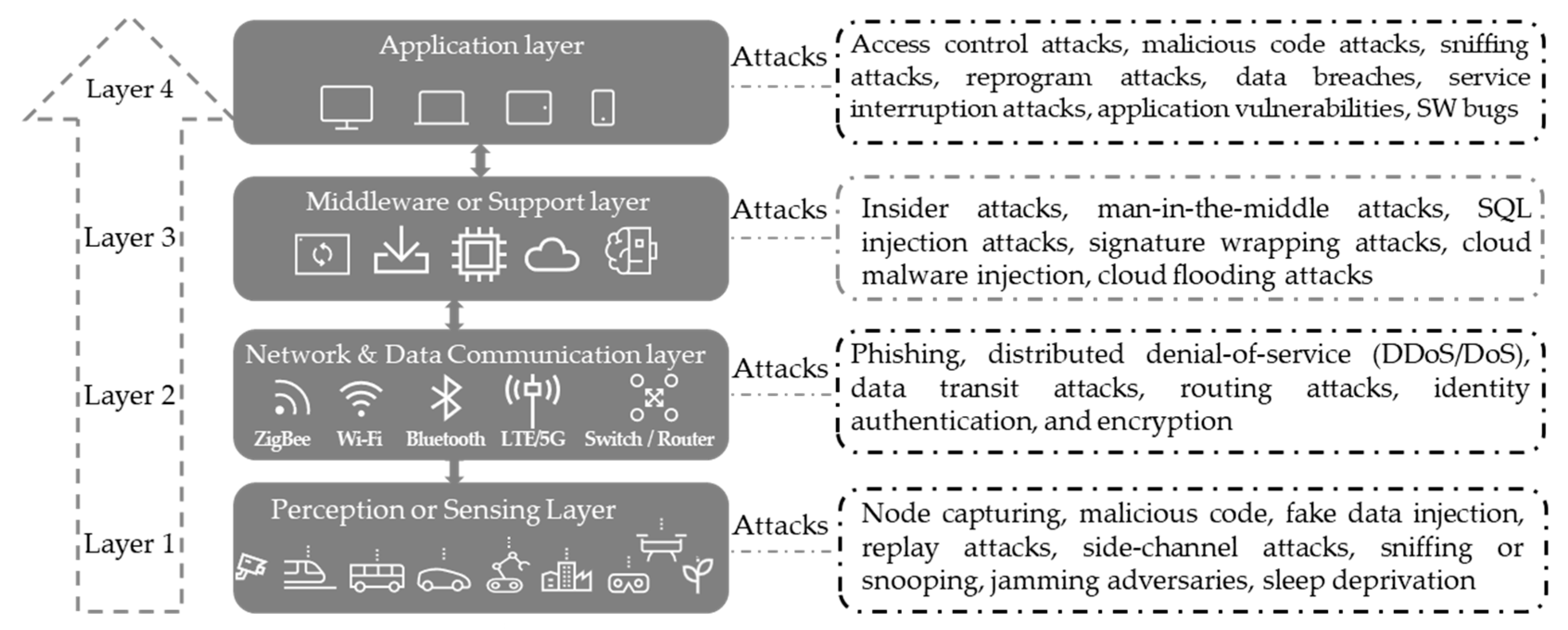
2.2. Internet of Things Overview
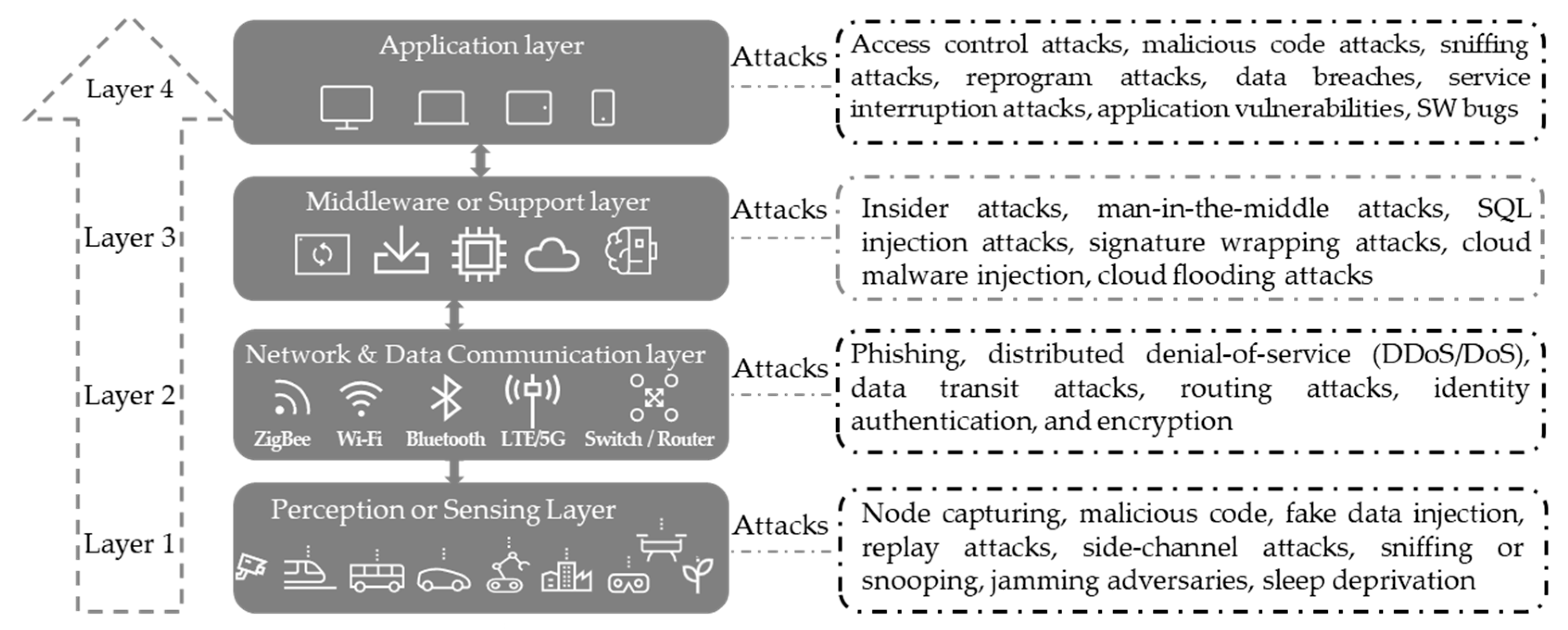
- Perception layer: The bottom layer of any IoT framework involves “things” or endpoint objects that serve as the bridge between the physical and the digital worlds. The perception or sensing layer refers to the physical layer, encompassing sensors and actuators capable of gathering information from the real environment and transmitting it through wireless or wired connections. This layer can be vulnerable to security threats such as insertion of fake data, node capturing, malicious code, side-channel attacks, jamming attacks, sniffing or snooping, replay attacks, and sleep deprivation attacks.
- Network layer: It is known as the second layer connecting the perception layer and middleware layer. It is also called the communication layer because it acts as a communication bridge, enabling the transfer of data acquired in the perception layer to other interconnected devices or a processing unit, conversely. This transmission utilizes various network technologies like LTE, 5G, Wi-Fi, infrared, etc. The data transfer is executed securely, ensuring the confidentiality of the obtained information. Nonetheless, persistent security vulnerabilities can manifest as data transit attacks, phishing, identity authentication, and encryption attacks, and distributed denial-of-service (DDoS/DoS) attacks.
- Middleware layer: It is also commonly known as the support layer or processing layer. It is the brain of the IoT ecosystem, and its primary functions are data processing, storage, and intelligent decision-making. The middleware layer is the best candidate to implement advanced IoT security mechanisms, such as ML-based security systems, thanks to its high computation capacity. Therefore, it is also a target of adversarial attacks and other various attacks such as SQL injection attacks, cloud malware injection, insider attacks, signature wrapping attacks, man-in-the-middle attacks, and cloud flooding attacks.
- Application layer: It is the uppermost layer within the IoT architecture. It serves as the user interface to monitor IoT devices and observe data through various application services and tools, such as dashboards and mobile applications, as well as applying various control activities by the end user. There are various use cases for IoT applications such as smart homes and cities, smart logistics and transportation, and smart agriculture and manufacturing. This layer is also subject to various security threats such as sniffing attacks, service interruption attacks, malicious code attacks, reprogramming attacks, access control attacks, data breaches, application vulnerabilities, and software bugs.
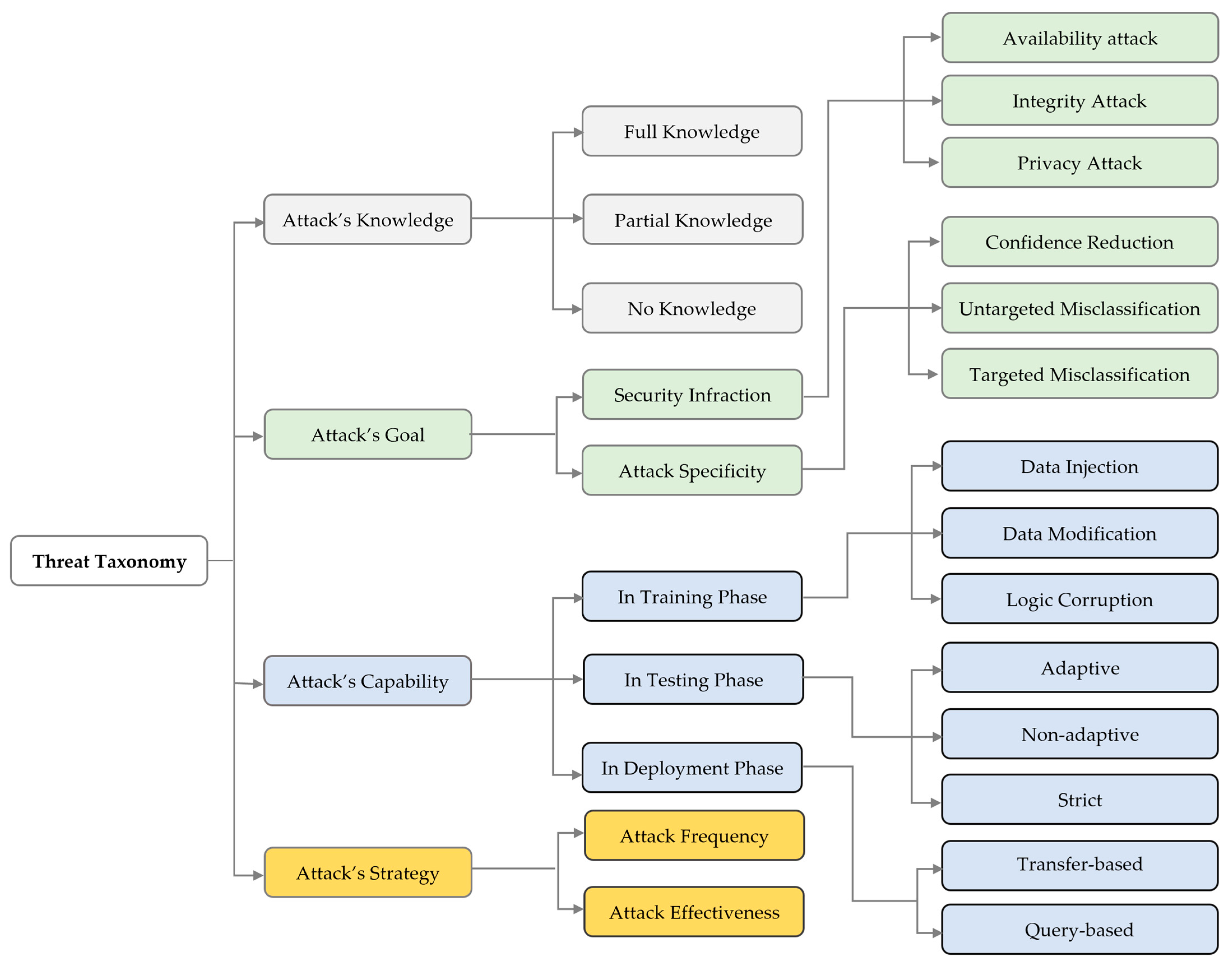
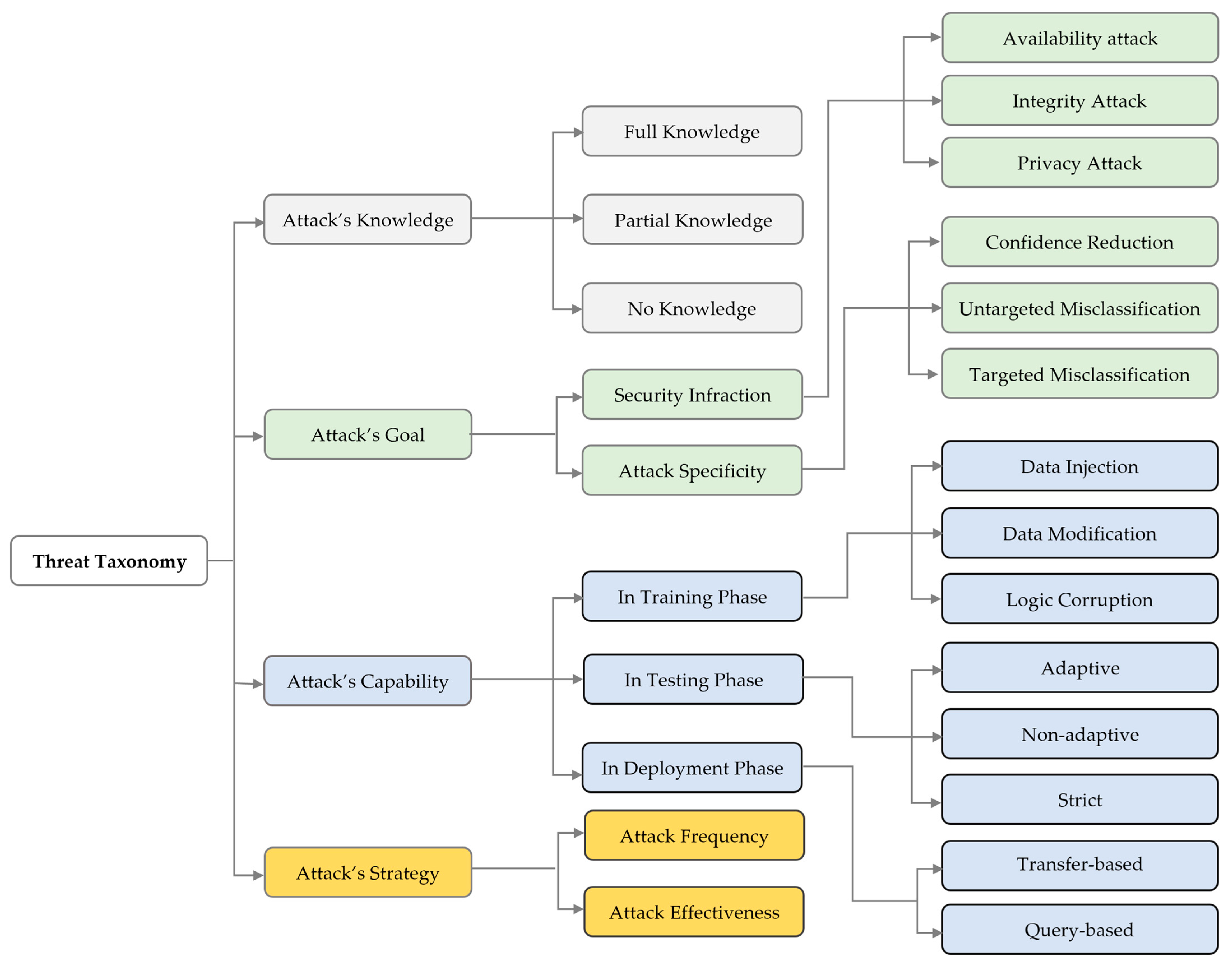
3. Adversarial Attack Taxonomy
3.1. Attacker’s Knowledge
- Full knowledge: This refers to white-box attacks, where the attacker possesses complete awareness of the target ML system’s information. This means that the adversary possesses complete and unrestricted access to the training dataset, ML model architecture, and its hyper-parameters as well as the feature learning. This is generally not feasible in most real adversarial attacks. However, the purpose of studying them is to assess the vulnerability of the target ML system to all possible cases and scenarios.
- Partial knowledge: Referring to gray-box attacks, where the attacker possesses partial information of the target ML system’s inner workings. This means that the adversary may have limited access to the feature representations, training dataset, and learning algorithm’s parameters. Using partial information, the attacker can create a practical strategy to deceive the ML model.
- No knowledge: This corresponds to black-box attacks, where the attacker is entirely unaware of the architecture and parameters of the target model. The adversary relies solely on his capability to query the target ML system by inputting the chosen data and monitoring corresponding results. These attacks are considered the most practical because they operate under the assumption that the attacker can only leverage system interfaces that are readily accessible for typical use.
3.2. Attacker’s Goal
- Security Infraction: Refers to security violations and can be classified into three main dimensions.
- Availability Attack: The attacker intends to minimize the model’s performance at testing or deployment phases, thereby making it unreliable and useless. Availability attacks can be executed through data poisoning when the attacker gains control over a portion of the training dataset, or through model extraction when the attacker predicts some relevant parameters of the target model.
- Integrity Attack: Focuses on undermining the integrity of an ML model’s output, leading to erroneous predictions made by the model. The attacker can induce an integrity breach by executing an evasion attack during the testing or deployment phases or a poisoning attack during the training phase.
- Privacy Attack: The attacker’s objective could involve gaining information about the system data, leading to data privacy attacks, or about the ML model, resulting in model privacy attacks.
- Attack Specificity: Based on their impact on the model output integrity, the attack specificity can be divided into three distinct categories:
- Confidence Reduction: The adversary intends to decrease the prediction certainty of the target model.
- Untargeted Misclassification: The adversary endeavors to change the predicted classification of an input instance to any class other than the original one.
- Targeted Misclassification: The adversary seeks to generate inputs that compel the classification model’s output to become a particular desired target class or endeavors to make the classification output for a specific input correspond to a specific target class.
3.3. Attacker’s Capability
- Training phase: In this phase, attacks on the ML model are more frequent than often realized. The attacker aims to mislead or disrupt the model’s outcomes by directly modifying the training dataset. Those kinds of attacks are known as “poisoning” or “contaminating”, and they require that an adversary has a degree of control over training data. The attacker’s tactics during the training phase are shaped by their adversarial capabilities which can be classified into three distinct categories.
- Data Injection: The attacker lacks access to the learning model’s parameters and training dataset, yet possesses the capability to append new data to the training dataset, thereby inserting adversarial samples to fool or degrade the ML model’s performance.
- Data Modification: The adversary cannot access the learning algorithms but can manipulate the training data, contaminating it before it is used to train the target model.
- Logic Corruption: The adversary can tamper with the learning algorithm of the target ML model. In other words, the learning algorithm is susceptible to interference from the opponent.
- Testing phase: In testing, adversarial attacks do not alter the training data or directly interfere with the model. Instead, they seek to make the model produce incorrect results by maliciously modifying input data. In addition to the level of information at the adversary’s disposal and, the attacker’s knowledge, the efficacy of these attacks depends on three main capabilities: adaptive attack, non-adaptive attack, and strict attack.
- Adaptive Attack: The adversary is crafting an adaptive malicious input that exploits the weak points of the ML model to mistakenly classify the malicious samples as benign. The adaptiveness can be achieved either by meticulously designing a sequence of input queries and observing their outputs in a black-box scenario or through accessing the ML model information and altering adversarial example methods that maximize the error rate in case of a white-box scenario.
- Non-adaptive attack: The adversary’s access is restricted solely to the training data distribution of the target model. The attacker starts by building a local model, choosing a suitable training procedure, and training it using samples from data distribution to mimic the target classifier’s learned model. Leveraging this local model, the adversary creates adversarial examples and subsequently applies these manipulated inputs against the target model to induce misclassifications.
- Strick Attack: The attacker lacks access to the training dataset and is unable to dynamically alter the input request to monitor the model’s response. If the attacker attempts to request valid input samples and introduces slight perturbations to observe the output label, this activity most probably will be flagged by the target ML model as a malicious attack. Hence, the attacker is constrained to perform a restricted number of closely observed queries, presuming that the target ML system will only detect the malicious attacks after a specific number of attempts.
- Deployment phase: Adversarial attacks during the deployment or production phase represent the most realistic scenario where the attacker’s knowledge of the target model is limited to its outputs, which correspond to a black-box scenario. Hence, the attack’s success during deployment time relies on two main capabilities, the presumption of transferability or the feedback to inquiries. Consequently, the attacker’s capability during the deployment phase can be categorized into two distinct groups, namely transfer-based attack and query-based attack.
- Transfer-based Attack: The fundamental concept underlying transfer-based attack revolves around the creation of adversarial examples on local surrogate models in such a way that these adversarial examples can effectively deceive the remote target model as well. The transferability propriety encompasses two types: task-specific transferability which applies to scenarios where both the remote victim model and the local model are concerned with the same task, for instance, classification. Cross-task transferability arises when the remote victim model and the local model are engaged in diverse tasks, such as classification and detection.
- Query-based Attack: The core idea behind query-based attacks lies in the direct querying of the target model and leveraging the outputs to optimize adversarial samples. To do this, the attacker queries the target model’s output by providing inputs and observing the corresponding results, which can take the form of class labels or score values. Consequently, query-based attacks can be further categorized into two distinct types: decision-based and score-based.
3.4. Attacker’s Strategy
- Attack effectiveness: It can be elaborated by the way to inject a bias in the input data to maximize the efficiency of the attack. In other words, it is nothing more than an optimization problem aimed at maximizing the loss function of the target ML algorithm on a validation dataset or to minimize its loss function on a poisoned dataset.
- Attack frequency: Refers to the decision between a one-time attack and an iterative process that updates the attack multiple times to enhance its optimization. While iterative attacks often outperform their one-time counterparts, they come with the trade-off of increased computational time and the chance of being detected by the ML-based security system. In certain situations, opting for a one-time attack may be adequate or the only practical option available.
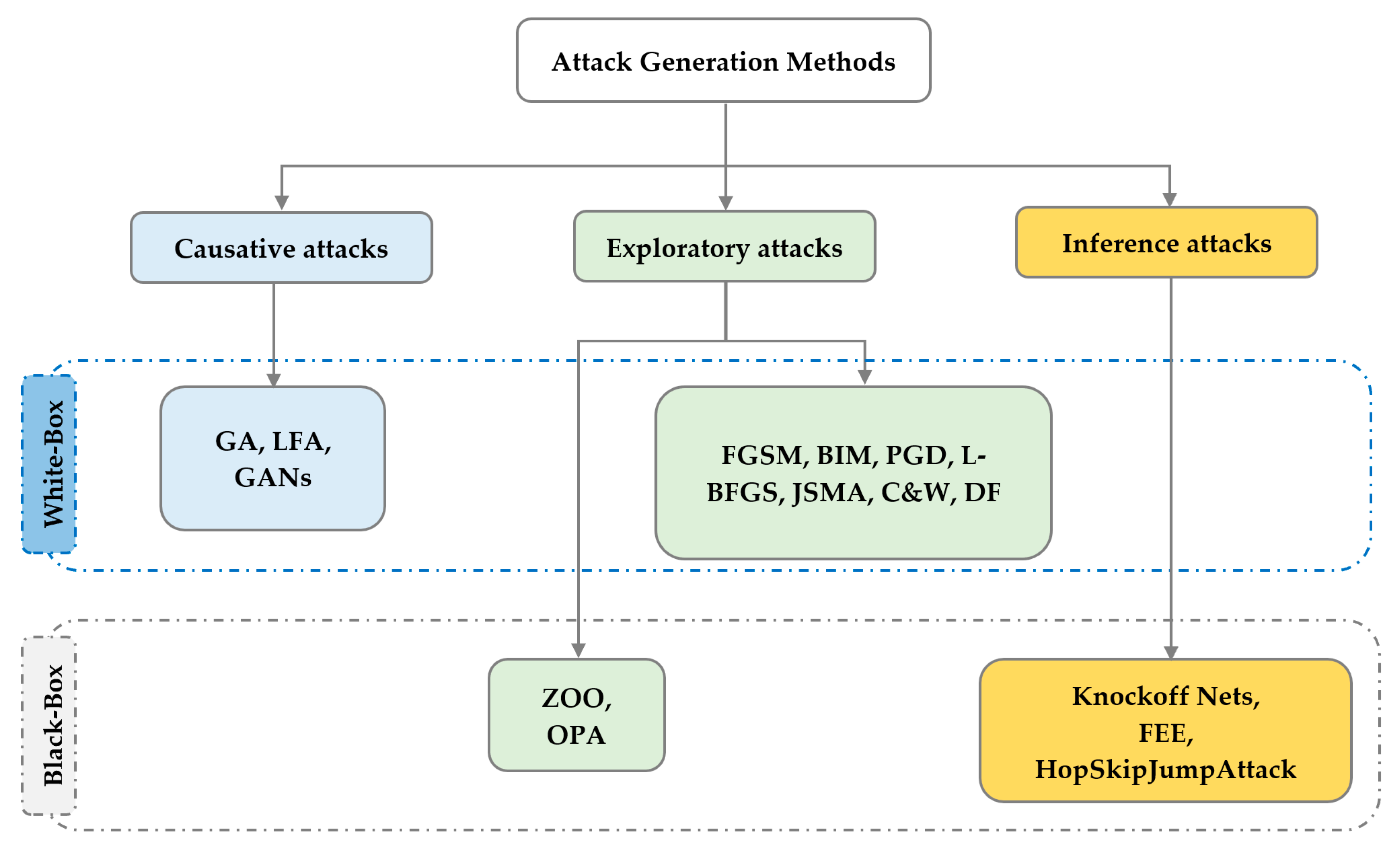
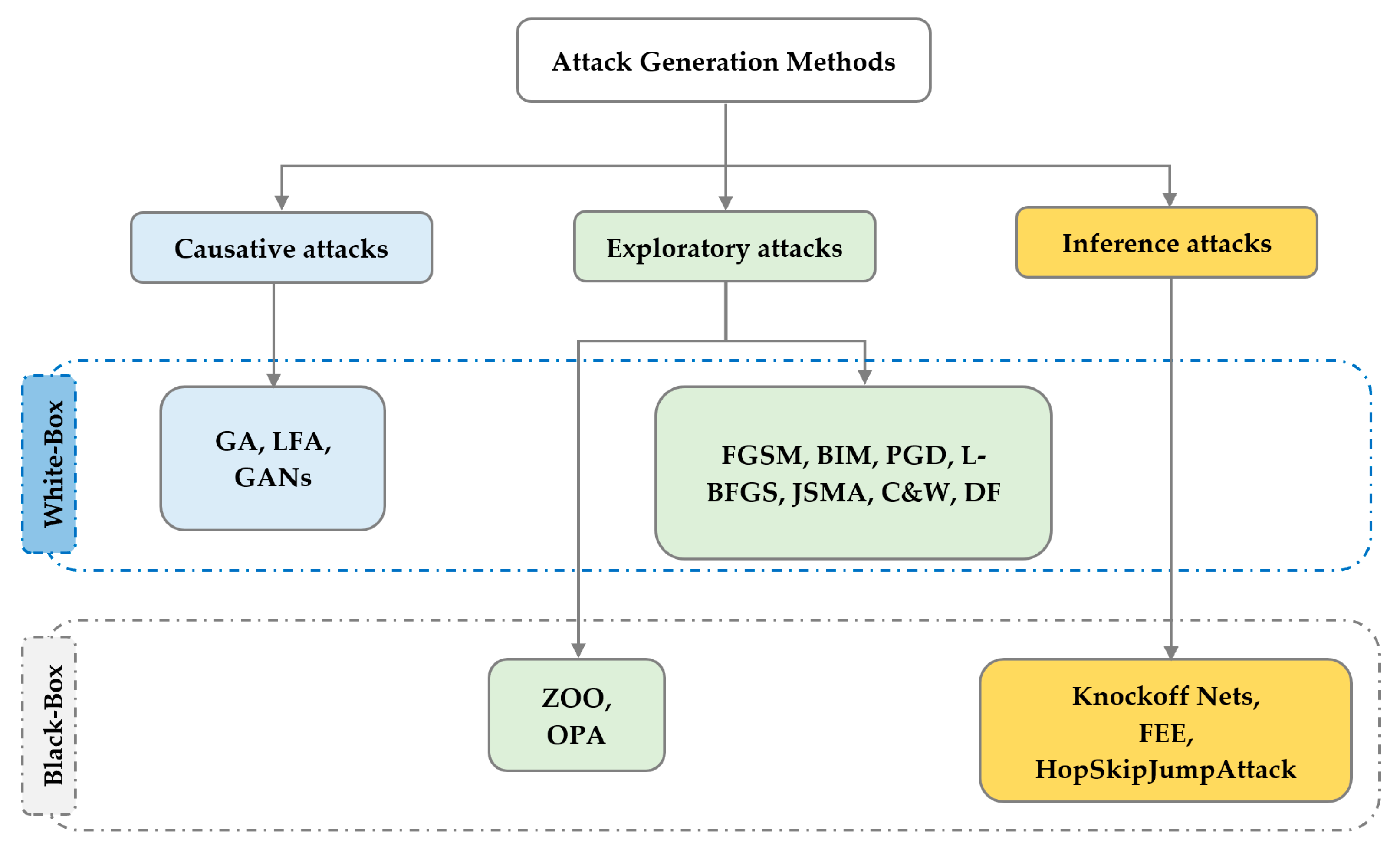
4. Adversarial Attack Generation Methods for IoT Networks
4.1. Exploratory Attack Methods
4.1.1. Fast Gradient Sign Method
4.1.2. Basic Iteration Method
4.1.3. Projected Gradient Descent
4.1.4. Limited-Memory BFGS
4.1.5. Jacobian-Based Saliency Map Attack
4.1.6. Carlini and Wagner
4.1.7. DeepFool Attack
4.1.8. Zeroth-Order Optimization
4.1.9. One-Pixel Attack
4.2. Causative Attack Methods
4.2.1. Gradient Ascent
4.2.2. Label Flipping Attack
4.2.3. Generative Adversarial Networks
4.3. Inference Attack Methods
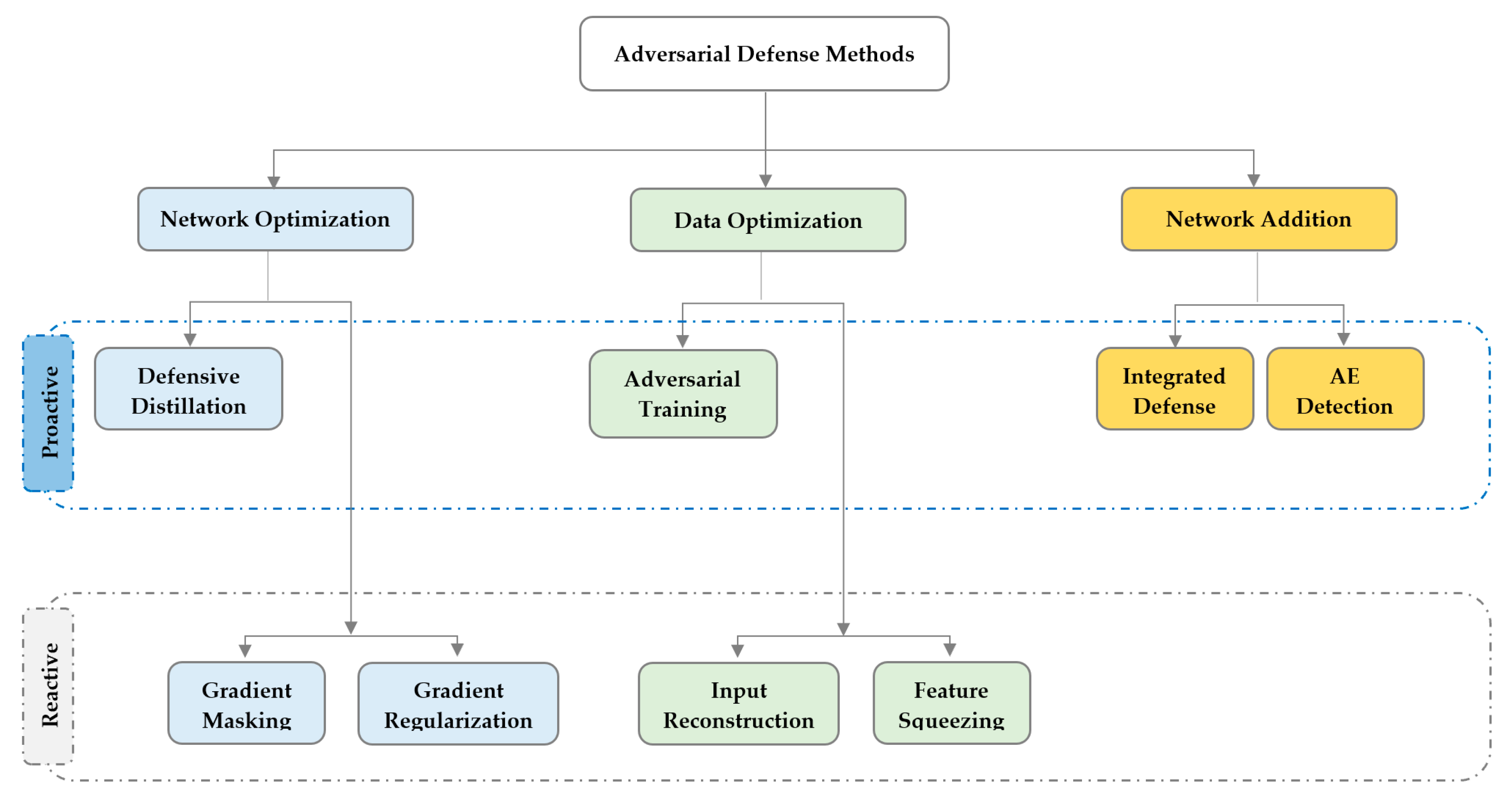
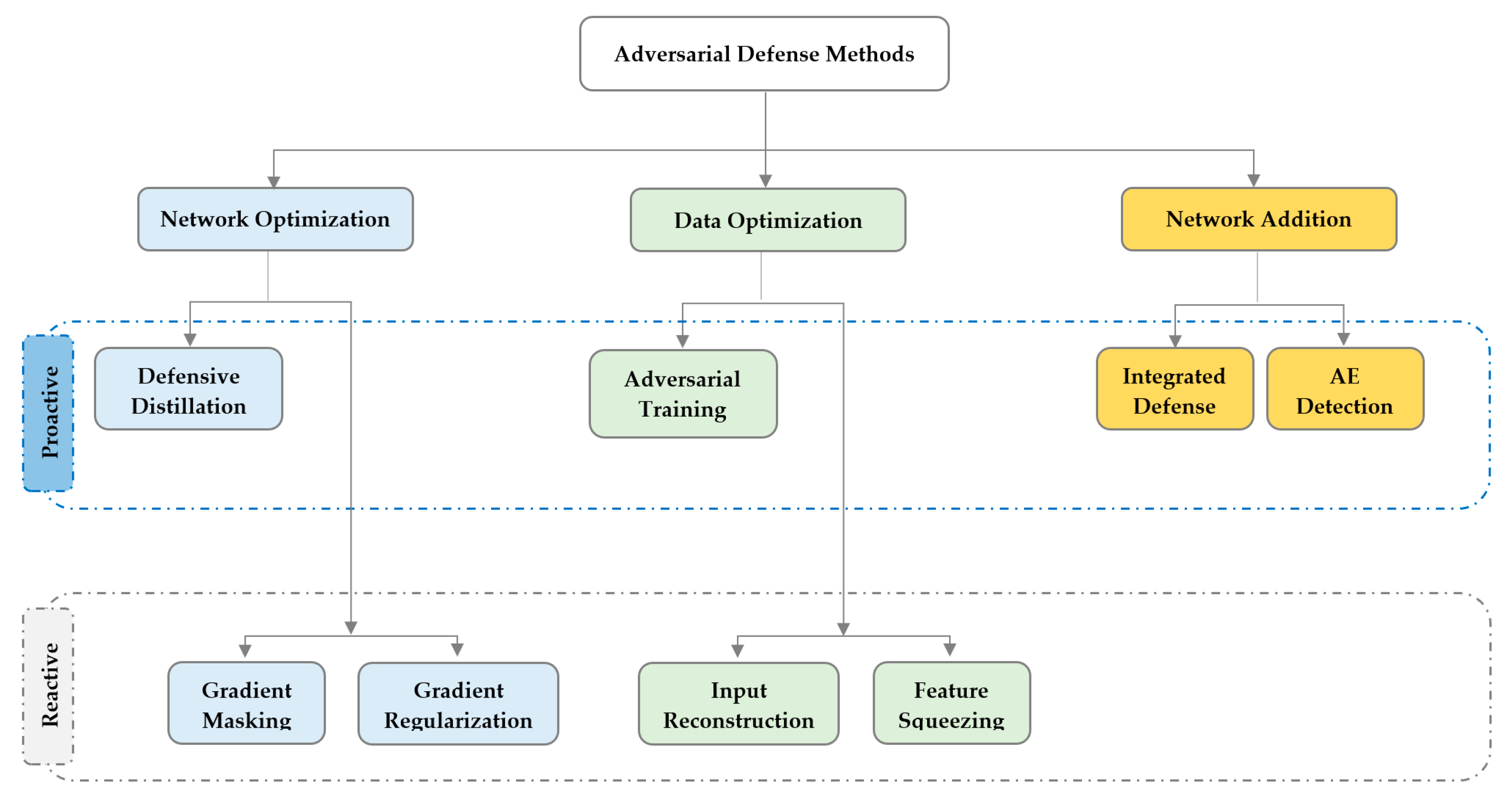
5. Adversarial Defense Methods in IoT Networks
5.1. Network Optimization
5.1.1. Defense Distillation
5.1.2. Gradient Masking
5.1.3. Gradient Regularization
5.2. Data Optimization
5.2.1. Adversarial Training
5.2.2. Feature Squeezing
5.2.3. Input Reconstruction
5.3. External Model Addition
5.3.1. Integrated Defense
5.3.2. Adversarial Example Detection
6. Research Works in ML-Based Security Systems of IoT Networks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Network | Security System(s) | Target Model (s) | Dataset(s) | Adversarial Attack Methods | Threat Model(s) | Threat Scenario | Adversarial Defense Techniques | |
|---|---|---|---|---|---|---|---|---|---|---|
| ML | DL | |||||||||
| [123] | 2019 | IoT | IDS | FNN, SNN | Bot-IoT | FGSM, PGD, BIM |
|
|
| |
| [126] | 2020 | IoT | IDS | SVM | Gaussian Distributions | Gaussian Distributions |
|
| ✗ | |
| [127] | 2021 | IoT | IDS | SVM | ANNs | Bot-IoT | LFA, FGSM |
|
| ✗ |
| [128] | 2021 | IoT | IDS | Kitsune | Kitsune (Mirai) | Saliency Maps, iFGSM |
|
| ✗ | |
| [129] | 2021 | IoT | IDS | CNN, LSTM, GRU | CSE-CIC-IDS2018 | FGSM |
|
|
| |
| [130] | 2021 | IoT | IDS | SVM, DT, RF | MLP | UNSW-NB15, Bot-IoT | JSMA, FGSM, W&C |
|
| ✗ |
| [131] | 2021 | IoT | IDS | 48 DT, RF, BN, SVM | Smart Home Testbed | Rule-Based Approach |
|
|
| |
| [132] | 2021 | IIoT | IDS | DNNs | CIFAR-10, GTSRB | One-Pixel |
|
|
| |
| [115] | 2022 | IoT | IDS | CNN-LSTM | Bot-IoT | C-GAN |
|
|
| |
| [113] | 2022 | IIoT | IDS | DRL | DS2OS | GAN |
|
|
| |
| [133] | 2022 | IoT | IDS | DT | FGMD, LSTM, RNN | MedBIoT, IoTID | Rule-Based Approach |
|
| ✗ |
| [134] | 2022 | IoT | IDS | GCN, JK-Net | UNSW-SOSR2019 | HAA |
|
| ✗ | |
| [135] | 2022 | IoT | IDS | DNNs | CIFAR-10, CIFAR-100 | NGA |
|
|
| |
| [136] | 2021 | IoT | DIS | RF, DT, K-NN | NN | UNSW IoT Trace | IoTGAN |
|
|
|
| [137] | 2021 | IoT | DIS | CVNN | Generated Device Dataset | FGSM, BIM, PGD, MIM |
|
| ✗ | |
| [138] | 2022 | IoT | DIS | GAP | FCN, CNNs | IoT-Trace | CAM, Grad-CAM++ |
|
| ✗ |
| [139] | 2022 | IoT | DIS | LSTM-CNN | LwHBench | FGSM, BIM, MIM, PGD, JSMA, C&W, Boundary Attack |
|
|
| |
| [140] | 2019 | IoT | MDS | CFG-CNN | CFG dataset | GEA |
|
| ✗ | |
| [141] | 2020 | IoT | MDS | CNN | Drebin, Contagio, Genome | SC-LFA |
|
|
| |
| [112] | 2023 | IoT | MDS | GNNs | CMaldroid, Drebin | VGAE-MalGAN |
|
|
| |
7. Challenges
7.1. Dataset
- Under-sampling: Here, entries from the over-represented class are eliminated to equalize the distribution between the minority classes and majority classes. However, if the original dataset is limited, this approach can result in overfitting.
- Over-sampling: In this technique, we replicate entries from the lesser-represented class until its count matches the dominant class. A limitation is that since the minority class has few unique data points, the model might end up memorizing these patterns, leading to overfitting.
- Synthetic Data Generation: This method uses Generative Adversarial Networks (GANs) to mimic the real data’s distribution and create authentic-seeming samples.
7.2. Adversarial Attacks
7.3. Adversarial Defenses
8. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Global IoT and Non-IoT Connections 2010–2025. Available online: https://www.statista.com/statistics/1101442/iot-number-of-connected-devices-worldwide/ (accessed on 10 December 2023).
- Khanna, A.; Kaur, S. Internet of Things (IoT), Applications and Challenges: A Comprehensive Review. Wirel. Pers Commun 2020, 114, 1687–1762. [Google Scholar] [CrossRef]
- Riahi Sfar, A.; Natalizio, E.; Challal, Y.; Chtourou, Z. A Roadmap for Security Challenges in the Internet of Things. Digit. Commun. Netw. 2018, 4, 118–137. [Google Scholar] [CrossRef]
- Chaabouni, N.; Mosbah, M.; Zemmari, A.; Sauvignac, C.; Faruki, P. Network Intrusion Detection for IoT Security Based on Learning Techniques. IEEE Commun. Surv. Tutor. 2019, 21, 2671–2701. [Google Scholar] [CrossRef]
- Namanya, A.P.; Cullen, A.; Awan, I.U.; Disso, J.P. The World of Malware: An Overview. In Proceedings of the 2018 IEEE 6th International Conference on Future Internet of Things and Cloud (FiCloud), Barcelona, Spain, 6–8 August 2018; pp. 420–427. [Google Scholar]
- Liu, Y.; Wang, J.; Li, J.; Niu, S.; Song, H. Machine Learning for the Detection and Identification of Internet of Things Devices: A Survey. IEEE Internet Things J. 2022, 9, 298–320. [Google Scholar] [CrossRef]
- Benazzouza, S.; Ridouani, M.; Salahdine, F.; Hayar, A. A Novel Prediction Model for Malicious Users Detection and Spectrum Sensing Based on Stacking and Deep Learning. Sensors 2022, 22, 6477. [Google Scholar] [CrossRef] [PubMed]
- Ridouani, M.; Benazzouza, S.; Salahdine, F.; Hayar, A. A Novel Secure Cooperative Cognitive Radio Network Based on Chebyshev Map. Digit. Signal Process. 2022, 126, 103482. [Google Scholar] [CrossRef]
- Benazzouza, S.; Ridouani, M.; Salahdine, F.; Hayar, A. Chaotic Compressive Spectrum Sensing Based on Chebyshev Map for Cognitive Radio Networks. Symmetry 2021, 13, 429. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine Learning: Trends, Perspectives, and Prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Talaei Khoei, T.; Kaabouch, N. Machine Learning: Models, Challenges, and Research Directions. Future Internet 2023, 15, 332. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Talaei Khoei, T.; Ould Slimane, H.; Kaabouch, N. Deep Learning: Systematic Review, Models, Challenges, and Research Directions. Neural Comput. Appl. 2023, 35, 23103–23124. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks. arXiv 2013, arXiv:1312.6199. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar] [CrossRef]
- Biggio, B.; Roli, F. Wild Patterns: Ten Years after the Rise of Adversarial Machine Learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef]
- Akhtar, N.; Mian, A. Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey. arXiv 2018, arXiv:1801.00553. [Google Scholar] [CrossRef]
- Akhtar, N.; Mian, A.; Kardan, N.; Shah, M. Advances in Adversarial Attacks and Defenses in Computer Vision: A Survey. IEEE Access 2021, 9, 155161–155196. [Google Scholar] [CrossRef]
- Naitali, A.; Ridouani, M.; Salahdine, F.; Kaabouch, N. Deepfake Attacks: Generation, Detection, Datasets, Challenges, and Research Directions. Computers 2023, 12, 216. [Google Scholar] [CrossRef]
- Xu, H.; Ma, Y.; Liu, H.; Deb, D.; Liu, H.; Tang, J.; Jain, A.K. Adversarial Attacks and Defenses in Images, Graphs and Text: A Review. arXiv 2019, arXiv:1909.08072. [Google Scholar] [CrossRef]
- Zhang, W.E.; Sheng, Q.Z.; Alhazmi, A.; Li, C. Adversarial Attacks on Deep-Learning Models in Natural Language Processing: A Survey. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–41. [Google Scholar] [CrossRef]
- Qin, Y.; Carlini, N.; Goodfellow, I.; Cottrell, G.; Raffel, C. Imperceptible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition. arXiv 2019, arXiv:1903.10346. [Google Scholar] [CrossRef]
- Jmila, H.; Khedher, M.I. Adversarial Machine Learning for Network Intrusion Detection: A Comparative Study. Comput. Netw. 2022, 214, 109073. [Google Scholar] [CrossRef]
- Ibitoye, O.; Abou-Khamis, R.; el Shehaby, M.; Matrawy, A.; Shafiq, M.O. The Threat of Adversarial Attacks on Machine Learning in Network Security—A Survey. arXiv 2019, arXiv:1911.02621. [Google Scholar] [CrossRef]
- Carlini, N. A Complete List of All Adversarial Example Papers. Available online: https://nicholas.carlini.com/writing/2019/all-adversarial-example-papers.html (accessed on 28 October 2023).
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A Detailed Analysis of the KDD CUP 99 Data Set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A Comprehensive Data Set for Network Intrusion Detection Systems (UNSW-NB15 Network Data Set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Alatwi, H.A.; Aldweesh, A. Adversarial Black-Box Attacks Against Network Intrusion Detection Systems: A Survey. In Proceedings of the 2021 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 10 May 2021; pp. 0034–0040. [Google Scholar]
- Joshi, C.; Aliaga, J.R.; Insua, D.R. Insider Threat Modeling: An Adversarial Risk Analysis Approach. IEEE Trans. Inform. Forensic Secur. 2021, 16, 1131–1142. [Google Scholar] [CrossRef]
- Aloraini, F.; Javed, A.; Rana, O.; Burnap, P. Adversarial Machine Learning in IoT from an Insider Point of View. J. Inf. Secur. Appl. 2022, 70, 103341. [Google Scholar] [CrossRef]
- Elrawy, M.F.; Awad, A.I.; Hamed, H.F.A. Intrusion Detection Systems for IoT-Based Smart Environments: A Survey. J. Cloud Comput. 2018, 7, 21. [Google Scholar] [CrossRef]
- Bout, E.; Loscri, V.; Gallais, A. How Machine Learning Changes the Nature of Cyberattacks on IoT Networks: A Survey. IEEE Commun. Surv. Tutor. 2022, 24, 248–279. [Google Scholar] [CrossRef]
- Li, J.; Liu, Y.; Chen, T.; Xiao, Z.; Li, Z.; Wang, J. Adversarial Attacks and Defenses on Cyber–Physical Systems: A Survey. IEEE Internet Things J. 2020, 7, 5103–5115. [Google Scholar] [CrossRef]
- He, K.; Kim, D.D.; Asghar, M.R. Adversarial Machine Learning for Network Intrusion Detection Systems: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2023, 25, 538–566. [Google Scholar] [CrossRef]
- Aryal, K.; Gupta, M.; Abdelsalam, M. A Survey on Adversarial Attacks for Malware Analysis. arXiv 2021, arXiv:2111.08223. [Google Scholar] [CrossRef]
- Alotaibi, A.; Rassam, M.A. Adversarial Machine Learning Attacks against Intrusion Detection Systems: A Survey on Strategies and Defense. Future Internet 2023, 15, 62. [Google Scholar] [CrossRef]
- Perwej, Y.; Haq, K.; Parwej, F.; Hassa, M. The Internet of Things (IoT) and Its Application Domains. IJCA 2019, 182, 36–49. [Google Scholar] [CrossRef]
- Hassija, V.; Chamola, V.; Saxena, V.; Jain, D.; Goyal, P.; Sikdar, B. A Survey on IoT Security: Application Areas, Security Threats, and Solution Architectures. IEEE Access 2019, 7, 82721–82743. [Google Scholar] [CrossRef]
- Balaji, S.; Nathani, K.; Santhakumar, R. IoT Technology, Applications and Challenges: A Contemporary Survey. Wirel. Pers. Commun. 2019, 108, 363–388. [Google Scholar] [CrossRef]
- Tange, K.; De Donno, M.; Fafoutis, X.; Dragoni, N. A Systematic Survey of Industrial Internet of Things Security: Requirements and Fog Computing Opportunities. IEEE Commun. Surv. Tutor. 2020, 22, 2489–2520. [Google Scholar] [CrossRef]
- HaddadPajouh, H.; Dehghantanha, A.M.; Parizi, R.; Aledhari, M.; Karimipour, H. A Survey on Internet of Things Security: Requirements, Challenges, and Solutions. Internet Things 2021, 14, 100129. [Google Scholar] [CrossRef]
- Iqbal, W.; Abbas, H.; Daneshmand, M.; Rauf, B.; Bangash, Y.A. An In-Depth Analysis of IoT Security Requirements, Challenges, and Their Countermeasures via Software-Defined Security. IEEE Internet Things J. 2020, 7, 10250–10276. [Google Scholar] [CrossRef]
- Atlam, H.F.; Wills, G.B. IoT Security, Privacy, Safety and Ethics. In Digital Twin Technologies and Smart Cities; Farsi, M., Daneshkhah, A., Hosseinian-Far, A., Jahankhani, H., Eds.; Internet of Things; Springer International Publishing: Cham, Switzerland, 2020; pp. 123–149. ISBN 978-3-030-18731-6. [Google Scholar]
- Chebudie, A.B.; Minerva, R.; Rotondi, D. Towards a Definition of the Internet of Things (IoT). IEEE Internet Initiat. 2014, 1, 1–86. [Google Scholar]
- Krco, S.; Pokric, B.; Carrez, F. Designing IoT Architecture(s): A European Perspective. In Proceedings of the 2014 IEEE World Forum on Internet of Things (WF-IoT), Seoul, Republic of Korea, 6–8 March 2014; pp. 79–84. [Google Scholar]
- Gupta, B.B.; Quamara, M. An Overview of Internet of Things (IoT): Architectural Aspects, Challenges, and Protocols. Concurr. Comput. 2020, 32, e4946. [Google Scholar] [CrossRef]
- Milenkovic, M. Internet of Things: Concepts and System Design; Springer: Cham, Switzerland, 2020; ISBN 978-3-030-41345-3. [Google Scholar]
- Sarker, I.H.; Khan, A.I.; Abushark, Y.B.; Alsolami, F. Internet of Things (IoT) Security Intelligence: A Comprehensive Overview, Machine Learning Solutions and Research Directions. Mob. Netw. Appl. 2023, 28, 296–312. [Google Scholar] [CrossRef]
- Wang, C.; Chen, J.; Yang, Y.; Ma, X.; Liu, J. Poisoning Attacks and Countermeasures in Intelligent Networks: Status Quo and Prospects. Digit. Commun. Netw. 2022, 8, 225–234. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial Examples in the Physical World. arXiv 2016, arXiv:1607.02533. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The Limitations of Deep Learning in Adversarial Settings. arXiv 2015, arXiv:1511.07528. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 39–57. [Google Scholar]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. arXiv 2015, arXiv:1511.04599. [Google Scholar] [CrossRef]
- Chen, P.-Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.-J. ZOO: Zeroth Order Optimization Based Black-Box Attacks to Deep Neural Networks without Training Substitute Models. arXiv 2017, arXiv:1708.03999. [Google Scholar] [CrossRef]
- Su, J.; Vargas, D.V.; Sakurai, K. One Pixel Attack for Fooling Deep Neural Networks. IEEE Trans. Evol. Computat. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning Attacks against Support Vector Machines. arXiv 2012, arXiv:1206.6389. [Google Scholar] [CrossRef]
- Biggio, B.; Nelson, B. Pavel Laskov Support Vector Machines Under Adversarial Label Noise. In Proceedings of the Asian Conference on Machine Learning, PMLR, Taoyuan, Taiwan, 17 November 2011; Volume 20, pp. 97–112. [Google Scholar]
- Xiao, H.; Eckert, C. Adversarial Label Flips Attack on Support Vector Machines. Front. Artif. Intell. Appl. 2012, 242, 870–875. [Google Scholar] [CrossRef]
- Muñoz-González, L.; Biggio, B.; Demontis, A.; Paudice, A.; Wongrassamee, V.; Lupu, E.C.; Roli, F. Towards Poisoning of Deep Learning Algorithms with Back-Gradient Optimization. arXiv 2017, arXiv:1708.08689. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. arXiv 2015, arXiv:1505.07818. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks. arXiv 2015, arXiv:1511.04508. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar] [CrossRef]
- Hindupur, A. The GAN Zoo. Available online: https://github.com/hindupuravinash/the-gan-zoo (accessed on 28 October 2023).
- Orekondy, T.; Schiele, B.; Fritz, M. Knockoff Nets: Stealing Functionality of Black-Box Models. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4949–4958. [Google Scholar]
- Jagielski, M.; Carlini, N.; Berthelot, D.; Kurakin, A.; Papernot, N. High Accuracy and High Fidelity Extraction of Neural Networks. arXiv 2019, arXiv:1909.01838. [Google Scholar] [CrossRef]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. HopSkipJumpAttack: A Query-Efficient Decision-Based Attack. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–20 May 2020; pp. 1277–1294. [Google Scholar]
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial Examples: Attacks and Defenses for Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2805–2824. [Google Scholar] [CrossRef]
- Barreno, M.; Nelson, B.; Sears, R.; Joseph, A.D.; Tygar, J.D. Can Machine Learning Be Secure? In Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security, Taipei, Taiwan, 21 March 2006; pp. 16–25. [Google Scholar]
- Rosenberg, I.; Shabtai, A.; Elovici, Y.; Rokach, L. Adversarial Machine Learning Attacks and Defense Methods in the Cyber Security Domain. ACM Comput. Surv. 2022, 54, 1–36. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical Black-Box Attacks against Machine Learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2 April 2017; pp. 506–519. [Google Scholar]
- Ross, A.; Doshi-Velez, F. Improving the Adversarial Robustness and Interpretability of Deep Neural Networks by Regularizing Their Input Gradients. AAAI 2018, 32, 1–10. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar] [CrossRef]
- Duddu, V. A Survey of Adversarial Machine Learning in Cyber Warfare. Def. Sc. Jl. 2018, 68, 356. [Google Scholar] [CrossRef]
- Folz, J.; Palacio, S.; Hees, J.; Dengel, A. Adversarial Defense Based on Structure-to-Signal Autoencoders. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 3568–3577. [Google Scholar]
- Lyu, C.; Huang, K.; Liang, H.-N. A Unified Gradient Regularization Family for Adversarial Examples. In Proceedings of the 2015 IEEE International Conference on Data Mining, Atlantic City, NJ, USA, 14–17 November 2015; pp. 301–309. [Google Scholar]
- Nayebi, A.; Ganguli, S. Biologically Inspired Protection of Deep Networks from Adversarial Attacks. arXiv 2017, arXiv:1703.09202. [Google Scholar] [CrossRef]
- Nguyen, L.; Wang, S.; Sinha, A. A Learning and Masking Approach to Secure Learning. arXiv 2017, arXiv:1709.04447. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, Y. Adversarial Defense via Neural Oscillation Inspired Gradient Masking. arXiv 2022, arXiv:2211.02223. [Google Scholar] [CrossRef]
- Drucker, H.; Le Cun, Y. Improving Generalization Performance Using Double Backpropagation. IEEE Trans. Neural Netw. 1992, 3, 991–997. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Q.; Griffin, L.D. Suppressing the Unusual: Towards Robust CNNs Using Symmetric Activation Functions. arXiv 2016, arXiv:1603.05145. [Google Scholar] [CrossRef]
- Dabouei, A.; Soleymani, S.; Taherkhani, F.; Dawson, J.; Nasrabadi, N.M. Exploiting Joint Robustness to Adversarial Perturbations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1119–1128. [Google Scholar]
- Addepalli, S.; Vivek, B.S.; Baburaj, A.; Sriramanan, G.; Venkatesh Babu, R. Towards Achieving Adversarial Robustness by Enforcing Feature Consistency Across Bit Planes. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1017–1026. [Google Scholar]
- Ma, A.; Faghri, F.; Papernot, N.; Farahmand, A. SOAR: Second-Order Adversarial Regularization. arXiv 2021, arXiv:2004.01832. [Google Scholar]
- Yeats, E.C.; Chen, Y.; Li, H. Improving Gradient Regularization Using Complex-Valued Neural Networks. In Proceedings of the Proceedings of the 38th International Conference on Machine Learning PMLR, Online, 18 July 2021; Volume 139, pp. 11953–11963. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. In Proceedings of the 2018 Network and Distributed System Security Symposium, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Gu, S.; Rigazio, L. Towards Deep Neural Network Architectures Robust to Adversarial Examples. arXiv 2014, arXiv:1412.5068. [Google Scholar] [CrossRef]
- Miyato, T.; Dai, A.M.; Goodfellow, I. Adversarial Training Methods for Semi-Supervised Text Classification. arXiv 2016, arXiv:1605.07725. [Google Scholar] [CrossRef]
- Zheng, S.; Song, Y.; Leung, T.; Goodfellow, I. Improving the Robustness of Deep Neural Networks via Stability Training. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4480–4488. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble Adversarial Training: Attacks and Defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar] [CrossRef]
- Song, C.; Cheng, H.-P.; Yang, H.; Li, S.; Wu, C.; Wu, Q.; Chen, Y.; Li, H. MAT: A Multi-Strength Adversarial Training Method to Mitigate Adversarial Attacks. In Proceedings of the 2018 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Hong Kong, 8–11 July 2018; pp. 476–481. [Google Scholar]
- Kannan, H.; Kurakin, A.; Goodfellow, I. Adversarial Logit Pairing. arXiv 2018, arXiv:1803.06373. [Google Scholar] [CrossRef]
- Wang, Y.; Zou, D.; Yi, J.; Bailey, J.; Ma, X.; Gu, Q. Improving Adversarial Robustness Requires Revisiting Misclassified Examples. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Farnia, F.; Zhang, J.M.; Tse, D. Generalizable Adversarial Training via Spectral Normalization. arXiv 2018, arXiv:1811.07457. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, H. Bilateral Adversarial Training: Towards Fast Training of More Robust Models Against Adversarial Attacks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6628–6637. [Google Scholar]
- Shafahi, A.; Najibi, M.; Xu, Z.; Dickerson, J.; Davis, L.S.; Goldstein, T. Universal Adversarial Training. arXiv 2018, arXiv:1811.11304. [Google Scholar] [CrossRef]
- Vivek, B.S.; Venkatesh Babu, R. Single-Step Adversarial Training With Dropout Scheduling. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 947–956. [Google Scholar]
- Song, C.; He, K.; Lin, J.; Wang, L.; Hopcroft, J.E. Robust Local Features for Improving the Generalization of Adversarial Training. arXiv 2019, arXiv:1909.10147. [Google Scholar] [CrossRef]
- Pang, T.; Yang, X.; Dong, Y.; Xu, K.; Zhu, J.; Su, H. Boosting Adversarial Training with Hypersphere Embedding. arXiv 2020, arXiv:2002.08619. [Google Scholar] [CrossRef]
- Xu, W.; Evans, D.; Qi, Y. Feature Squeezing Mitigates and Detects Carlini/Wagner Adversarial Examples. arXiv 2017, arXiv:1705.10686. [Google Scholar] [CrossRef]
- Jiang, W.; He, Z.; Zhan, J.; Pan, W. Attack-Aware Detection and Defense to Resist Adversarial Examples. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2021, 40, 2194–2198. [Google Scholar] [CrossRef]
- Asam, M.; Khan, S.H.; Akbar, A.; Bibi, S.; Jamal, T.; Khan, A.; Ghafoor, U.; Bhutta, M.R. IoT Malware Detection Architecture Using a Novel Channel Boosted and Squeezed CNN. Sci. Rep. 2022, 12, 15498. [Google Scholar] [CrossRef]
- Jia, X.; Wei, X.; Cao, X.; Foroosh, H. ComDefend: An Efficient Image Compression Model to Defend Adversarial Examples. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6077–6085. [Google Scholar]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. PixelDefend: Leveraging Generative Models to Understand and Defend against Adversarial Examples. arXiv 2017, arXiv:1710.10766. [Google Scholar] [CrossRef]
- Ramachandran, P.; Paine, T.L.; Khorrami, P.; Babaeizadeh, M.; Chang, S.; Zhang, Y.; Hasegawa-Johnson, M.A.; Campbell, R.H.; Huang, T.S. Fast Generation for Convolutional Autoregressive Models. arXiv 2017, arXiv:1704.06001. [Google Scholar] [CrossRef]
- Gao, S.; Yao, S.; Li, R. Transferable Adversarial Defense by Fusing Reconstruction Learning and Denoising Learning. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Vancouver, BC, Canada, 10 May 2021; pp. 1–6. [Google Scholar]
- Lee, H.; Han, S.; Lee, J. Generative Adversarial Trainer: Defense to Adversarial Perturbations with GAN. arXiv 2017, arXiv:1705.03387. [Google Scholar] [CrossRef]
- Yumlembam, R.; Issac, B.; Jacob, S.M.; Yang, L. IoT-Based Android Malware Detection Using Graph Neural Network with Adversarial Defense. IEEE Internet Things J. 2023, 10, 8432–8444. [Google Scholar] [CrossRef]
- Benaddi, H.; Jouhari, M.; Ibrahimi, K.; Ben Othman, J.; Amhoud, E.M. Anomaly Detection in Industrial IoT Using Distributional Reinforcement Learning and Generative Adversarial Networks. Sensors 2022, 22, 8085. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Ota, K.; Dong, M.; Wu, J.; Li, J. DeSVig: Decentralized Swift Vigilance Against Adversarial Attacks in Industrial Artificial Intelligence Systems. IEEE Trans. Ind. Inf. 2020, 16, 3267–3277. [Google Scholar] [CrossRef]
- Benaddi, H.; Jouhari, M.; Ibrahimi, K.; Benslimane, A.; Amhoud, E.M. Adversarial Attacks Against IoT Networks Using Conditional GAN Based Learning. In Proceedings of the GLOBECOM 2022—2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4 December 2022; pp. 2788–2793. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. In Proceedings of the 34th International Conference on Machine Learning, PMLR, Sydney, Australia, 6 August 2017; Volume 70, pp. 2642–2651. [Google Scholar]
- Liu, X.; Hsieh, C.-J. Rob-GAN: Generator, Discriminator, and Adversarial Attacker. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–19 June 2019; pp. 11226–11235. [Google Scholar]
- Meng, D.; Chen, H. MagNet: A Two-Pronged Defense against Adversarial Examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October 2017; pp. 135–147. [Google Scholar]
- Cohen, G.; Sapiro, G.; Giryes, R. Detecting Adversarial Samples Using Influence Functions and Nearest Neighbors. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14441–14450. [Google Scholar]
- Paudice, A.; Muñoz-González, L.; Lupu, E.C. Label Sanitization Against Label Flipping Poisoning Attacks. In ECML PKDD 2018 Workshops; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 11329, pp. 5–15. ISBN 978-3-030-13452-5. [Google Scholar]
- Shahid, A.R.; Imteaj, A.; Wu, P.Y.; Igoche, D.A.; Alam, T. Label Flipping Data Poisoning Attack Against Wearable Human Activity Recognition System. In Proceedings of the 2022 IEEE Symposium Series on Computational Intelligence (SSCI), Singapore, 4 December 2022; pp. 908–914. [Google Scholar]
- Abusnaina, A.; Wu, Y.; Arora, S.; Wang, Y.; Wang, F.; Yang, H.; Mohaisen, D. Adversarial Example Detection Using Latent Neighborhood Graph. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 7667–7676. [Google Scholar]
- Ibitoye, O.; Shafiq, O.; Matrawy, A. Analyzing Adversarial Attacks against Deep Learning for Intrusion Detection in IoT Networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. arXiv 2017, arXiv:1706.02515. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the Development of Realistic Botnet Dataset in the Internet of Things for Network Forensic Analytics: Bot-IoT Dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef]
- Luo, Z.; Zhao, S.; Lu, Z.; Sagduyu, Y.E.; Xu, J. Adversarial Machine Learning Based Partial-Model Attack in IoT. In Proceedings of the 2nd ACM Workshop on Wireless Security and Machine Learning, Linz, Austria, 13 July 2020; pp. 13–18. [Google Scholar]
- Papadopoulos, P.; Thornewill Von Essen, O.; Pitropakis, N.; Chrysoulas, C.; Mylonas, A.; Buchanan, W.J. Launching Adversarial Attacks against Network Intrusion Detection Systems for IoT. JCP 2021, 1, 252–273. [Google Scholar] [CrossRef]
- Qiu, H.; Dong, T.; Zhang, T.; Lu, J.; Memmi, G.; Qiu, M. Adversarial Attacks Against Network Intrusion Detection in IoT Systems. IEEE Internet Things J. 2021, 8, 10327–10335. [Google Scholar] [CrossRef]
- Fu, X.; Zhou, N.; Jiao, L.; Li, H.; Zhang, J. The Robust Deep Learning–Based Schemes for Intrusion Detection in Internet of Things Environments. Ann. Telecommun. 2021, 76, 273–285. [Google Scholar] [CrossRef]
- Pacheco, Y.; Sun, W. Adversarial Machine Learning: A Comparative Study on Contemporary Intrusion Detection Datasets. In Proceedings of the 7th International Conference on Information Systems Security and Privacy, Online, 11–13 February 2021; pp. 160–171. [Google Scholar]
- Anthi, E.; Williams, L.; Javed, A.; Burnap, P. Hardening Machine Learning Denial of Service (DoS) Defences against Adversarial Attacks in IoT Smart Home Networks. Comput. Secur. 2021, 108, 102352. [Google Scholar] [CrossRef]
- Husnoo, M.A.; Anwar, A. Do Not Get Fooled: Defense against the One-Pixel Attack to Protect IoT-Enabled Deep Learning Systems. Ad Hoc Netw. 2021, 122, 102627. [Google Scholar] [CrossRef]
- Jiang, H.; Lin, J.; Kang, H. FGMD: A Robust Detector against Adversarial Attacks in the IoT Network. Future Gener. Comput. Syst. 2022, 132, 194–210. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Li, W.; Yan, K.; Shimizu, S.; Wang, K.I.-K. Hierarchical Adversarial Attacks Against Graph-Neural-Network-Based IoT Network Intrusion Detection System. IEEE Internet Things J. 2022, 9, 9310–9319. [Google Scholar] [CrossRef]
- Fan, M.; Liu, Y.; Chen, C.; Yu, S.; Guo, W.; Wang, L.; Liu, X. Toward Evaluating the Reliability of Deep-Neural-Network-Based IoT Devices. IEEE Internet Things J. 2022, 9, 17002–17013. [Google Scholar] [CrossRef]
- Hou, T.; Wang, T.; Lu, Z.; Liu, Y.; Sagduyu, Y. IoTGAN: GAN Powered Camouflage Against Machine Learning Based IoT Device Identification. In Proceedings of the 2021 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Los Angeles, CA, USA, 13 December 2021; pp. 280–287. [Google Scholar]
- Bao, Z.; Lin, Y.; Zhang, S.; Li, Z.; Mao, S. Threat of Adversarial Attacks on DL-Based IoT Device Identification. IEEE Internet Things J. 2022, 9, 9012–9024. [Google Scholar] [CrossRef]
- Kotak, J.; Elovici, Y. Adversarial Attacks Against IoT Identification Systems. IEEE Internet Things J. 2023, 10, 7868–7883. [Google Scholar] [CrossRef]
- Sánchez, P.M.S.; Celdrán, A.H.; Bovet, G.; Pérez, G.M. Adversarial Attacks and Defenses on ML- and Hardware-Based IoT Device Fingerprinting and Identification. arXiv 2022, arXiv:2212.14677. [Google Scholar] [CrossRef]
- Abusnaina, A.; Khormali, A.; Alasmary, H.; Park, J.; Anwar, A.; Mohaisen, A. Adversarial Learning Attacks on Graph-Based IoT Malware Detection Systems. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–9 July 2019; pp. 1296–1305. [Google Scholar]
- Taheri, R.; Javidan, R.; Shojafar, M.; Pooranian, Z.; Miri, A.; Conti, M. On Defending against Label Flipping Attacks on Malware Detection Systems. Neural Comput. Appl. 2020, 32, 14781–14800. [Google Scholar] [CrossRef]
- Understanding the Mirai Botnet; USENIX Association, Ed. 2017. Available online: https://www.usenix.org/system/files/conference/usenixsecurity17/sec17-antonakakis.pdf (accessed on 13 November 2023).
- Sharafaldin, I.; Habibi Lashkari, A.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy, Madeira, Portugal, 22–24 January 2018; pp. 108–116. [Google Scholar]
- Anthi, E.; Williams, L.; Slowinska, M.; Theodorakopoulos, G.; Burnap, P. A Supervised Intrusion Detection System for Smart Home IoT Devices. IEEE Internet Things J. 2019, 6, 9042–9053. [Google Scholar] [CrossRef]
- Weka 3—Data Mining with Open Source Machine Learning Software in Java. Available online: https://www.cs.waikato.ac.nz/ml/weka/ (accessed on 28 October 2023).
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A. CIFAR-10 and CIFAR-100 Datasets. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 28 October 2023).
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. Man vs. Computer: Benchmarking Machine Learning Algorithms for Traffic Sign Recognition. Neural Netw. 2012, 32, 323–332. [Google Scholar] [CrossRef] [PubMed]
- DS2OS Traffic Traces. Available online: https://www.kaggle.com/datasets/francoisxa/ds2ostraffictraces (accessed on 28 October 2023).
- Guerra-Manzanares, A.; Medina-Galindo, J.; Bahsi, H.; Nõmm, S. MedBIoT: Generation of an IoT Botnet Dataset in a Medium-Sized IoT Network. In Proceedings of the 6th International Conference on Information Systems Security and Privacy, Valletta, Malta, 25–27 February 2020; pp. 207–218. [Google Scholar]
- Kang, H.; Ahn, D.H.; Lee, G.M.; Yoo, J.D.; Park, K.H.; Kim, H.K. IoT Network Intrusion Dataset. IEEE Dataport. 2019. Available online: https://ieee-dataport.org/open-access/iot-network-intrusion-dataset (accessed on 28 October 2023).
- Hamza, A.; Gharakheili, H.H.; Benson, T.A.; Sivaraman, V. Detecting Volumetric Attacks on loT Devices via SDN-Based Monitoring of MUD Activity. In Proceedings of the 2019 ACM Symposium on SDN Research, San Jose, CA, USA, 3 April 2019; pp. 36–48. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar] [CrossRef]
- Xu, K.; Li, C.; Tian, Y.; Sonobe, T.; Kawarabayashi, K.; Jegelka, S. Representation Learning on Graphs with Jumping Knowledge Networks. arXiv 2018, arXiv:1806.03536. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Wang, K.I.-K.; Huang, R.; Jin, Q. Academic Influence Aware and Multidimensional Network Analysis for Research Collaboration Navigation Based on Scholarly Big Data. IEEE Trans. Emerg. Top. Comput. 2021, 9, 246–257. [Google Scholar] [CrossRef]
- Sun, Z.; Ambrosi, E.; Pedretti, G.; Bricalli, A.; Ielmini, D. In-Memory PageRank Accelerator with a Cross-Point Array of Resistive Memories. IEEE Trans. Electron. Devices 2020, 67, 1466–1470. [Google Scholar] [CrossRef]
- Ma, J.; Ding, S.; Mei, Q. Towards More Practical Adversarial Attacks on Graph Neural Networks. arXiv 2020, arXiv:2006.05057. [Google Scholar] [CrossRef]
- Wong, E.; Rice, L.; Kolter, J.Z. Fast Is Better than Free: Revisiting Adversarial Training. arXiv 2020, arXiv:2001.03994. [Google Scholar] [CrossRef]
- Bao, J.; Hamdaoui, B.; Wong, W.-K. IoT Device Type Identification Using Hybrid Deep Learning Approach for Increased IoT Security. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 565–570. [Google Scholar]
- Sivanathan, A.; Gharakheili, H.H.; Loi, F.; Radford, A.; Wijenayake, C.; Vishwanath, A.; Sivaraman, V. Classifying IoT Devices in Smart Environments Using Network Traffic Characteristics. IEEE Trans. Mob. Comput. 2019, 18, 1745–1759. [Google Scholar] [CrossRef]
- Trabelsi, C.; Bilaniuk, O.; Zhang, Y.; Serdyuk, D.; Subramanian, S.; Santos, J.F.; Mehri, S.; Rostamzadeh, N.; Bengio, Y.; Pal, C.J. Deep Complex Networks. arXiv 2017, arXiv:1705.09792. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Sánchez Sánchez, P.M.; Jorquera Valero, J.M.; Huertas Celdrán, A.; Bovet, G.; Gil Pérez, M.; Martínez Pérez, G. LwHBench: A Low-Level Hardware Component Benchmark and Dataset for Single Board Computers. Internet Things 2023, 22, 100764. [Google Scholar] [CrossRef]
- De Keersmaeker, F.; Cao, Y.; Ndonda, G.K.; Sadre, R. A Survey of Public IoT Datasets for Network Security Research. IEEE Commun. Surv. Tutor. 2023, 25, 1808–1840. [Google Scholar] [CrossRef]
- Kaur, B.; Dadkhah, S.; Shoeleh, F.; Neto, E.C.P.; Xiong, P.; Iqbal, S.; Lamontagne, P.; Ray, S.; Ghorbani, A.A. Internet of Things (IoT) Security Dataset Evolution: Challenges and Future Directions. Internet Things 2023, 22, 100780. [Google Scholar] [CrossRef]
- Alex, C.; Creado, G.; Almobaideen, W.; Alghanam, O.A.; Saadeh, M. A Comprehensive Survey for IoT Security Datasets Taxonomy, Classification and Machine Learning Mechanisms. Comput. Secur. 2023, 132, 103283. [Google Scholar] [CrossRef]
- Ahmad, R.; Alsmadi, I.; Alhamdani, W.; Tawalbeh, L. A Comprehensive Deep Learning Benchmark for IoT IDS. Comput. Secur. 2022, 114, 102588. [Google Scholar] [CrossRef]

| Ref. | Year | Network | Major Contribution(s) | Limitation(s) | Attacker’s Knowledge | Security Systems | Adversarial Attack Taxonomy | Adversarial Attack Methods | Adversarial Defense Methods | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| White-Box | Black-Box | IDS | MDS | DIS | ||||||||
| [23] | 2022 | Traditional | Robustness evaluation of seven shallow ML-based IDS against adversarial attacks. | IoT network security is just mentioned in four references with no discussion. Only three adversarial defense techniques were mentioned. | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ |
| [24] | 2019 | Traditional | Evaluation of different adversarial attacks to ML models applied in computer and traditional network security. Classification of adversarial attacks based on security applications. Risk identification using adversarial risk grid map. | Mainly focused on traditional network security while IoT network security was very briefly discussed in a very short paragraph. | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ |
| [28] | 2021 | Traditional | Summarize recent research on black-box adversarial attacks against NIDS. | Focused on black-box attacks only. Most popular adversarial attack methods and defense methods were not discussed | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| [30] | 2022 | IoT | Taxonomy of adversarial attacks from insider (internal) perspective. Real-life applications of adversarial insider threats. | Focused on insider (white-box) adversarial attacks only. Model Extraction attacks were not covered as the survey is limited to insider adversarial threats where the adversary has full knowledge of the ML model | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ |
| [31] | 2018 | IoT | Reviewed the existing IDSs used for securing IoT-based smart environments such as Network Intrusion Detection Systems (NIDS) and Hybrid Intrusion Detection Systems (HIDS). | The vulnerability of ML-based IDSs to adversarial attacks was not covered. | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| [32] | 2022 | IoT | Overview of existing ML-based attacks in IoT network. Classification of ML-based attacks based on the type of the used ML algorithm. | Adversarial attacks were briefly discussed as one type of various ML-based attacks in IoT networks. The authors mentioned some adversarial attacks and defense methods with no discussion. | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| [33] | 2020 | CPS | Surveyed adversarial threats within the context of Cyber-Physical Systems (CPS). | Considered only adversarial attacks that exploit sensors in IoT and CPS devices. Limited to sensor-based threats only | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| [35] | 2022 | Traditional | Adversarial attacks on malware detection systems Adversarial malware evasion threat modeling. | They were focused on the computer and cybersecurity domain, while the IoT network security domain was overlooked. | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ |
| [36] | 2023 | Traditional | Highlighting various types of adversarial attacks against IDS in the context of traditional networks. | IoT network security context was not included. Model Extraction attacks were not covered. | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ |
| [34] | 2023 | Traditional | Explored the disparity in adversarial learning within the fields of Network Intrusion Detection Systems (NIDS) and Computer Vision specifically focusing on DL-based NIDS in traditional network. | Mainly focused on traditional network security while IoT network security was very little discussed. Poisoning and model extraction attacks are not covered. | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Our Work | 2023 | IoT | Holistic review of ML adversarial attacks in three prominent IoT security systems: IDSs, MDSs, and DISs. Re-defining taxonomy of threat methods in IoT context. 2D classification of both adversarial attacks and defense methods. | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khazane, H.; Ridouani, M.; Salahdine, F.; Kaabouch, N. A Holistic Review of Machine Learning Adversarial Attacks in IoT Networks. Future Internet 2024, 16, 32. https://doi.org/10.3390/fi16010032
Khazane H, Ridouani M, Salahdine F, Kaabouch N. A Holistic Review of Machine Learning Adversarial Attacks in IoT Networks. Future Internet. 2024; 16(1):32. https://doi.org/10.3390/fi16010032
Chicago/Turabian StyleKhazane, Hassan, Mohammed Ridouani, Fatima Salahdine, and Naima Kaabouch. 2024. "A Holistic Review of Machine Learning Adversarial Attacks in IoT Networks" Future Internet 16, no. 1: 32. https://doi.org/10.3390/fi16010032
APA StyleKhazane, H., Ridouani, M., Salahdine, F., & Kaabouch, N. (2024). A Holistic Review of Machine Learning Adversarial Attacks in IoT Networks. Future Internet, 16(1), 32. https://doi.org/10.3390/fi16010032