


Investigation of Phishing Susceptibility with Explainable Artificial Intelligence


Abstract
1. Introduction
- To the best of our knowledge, this is the first attempt at employing XAI techniques to analyze susceptibility to phishing attacks. Our study aims to investigate various human factors associated with susceptibility to phishing attacks and to support decision-making through local interpretations;
- To the best of our knowledge, our study is the first of its kind to offer personalized recommendations aimed at mitigating the risk of potential future phishing attacks. These recommendations are based on local explanations tailored to each individual’s unique circumstances.
2. Related Literature
2.1. Factors Related to Phishing Susceptibility
2.2. ML and XAI in Phishing Study
3. Materials and Methods
3.1. Data
3.1.1. Demographic Data
3.1.2. Pre-Campaign Survey Data
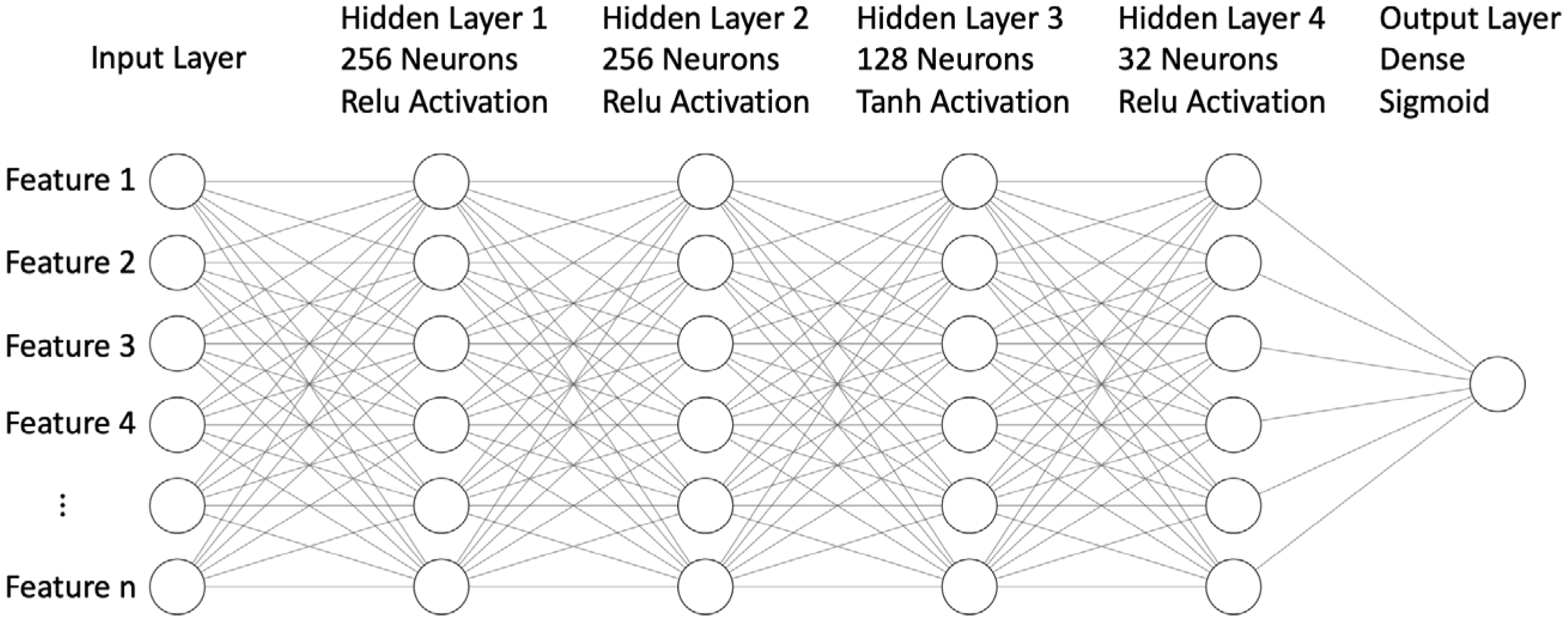
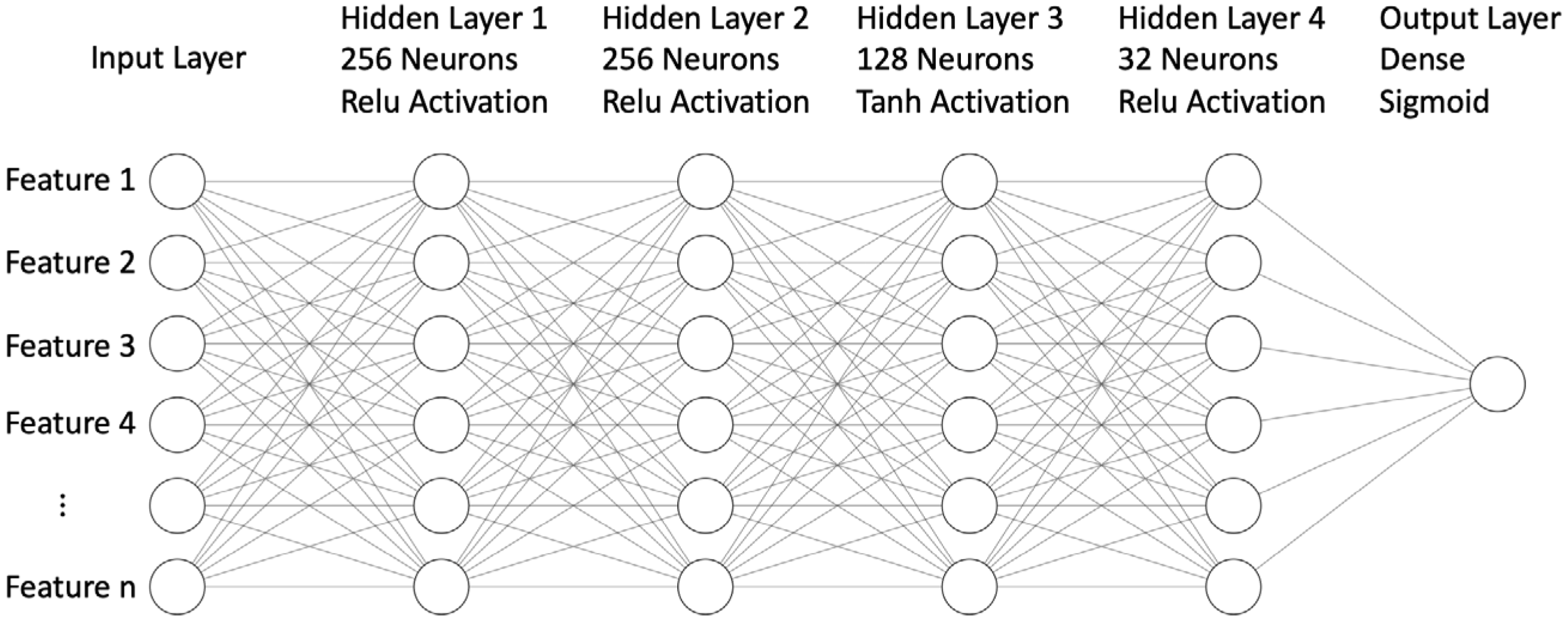
3.2. Deep Neural Networks
3.3. SHAP
4. Results and Discussion
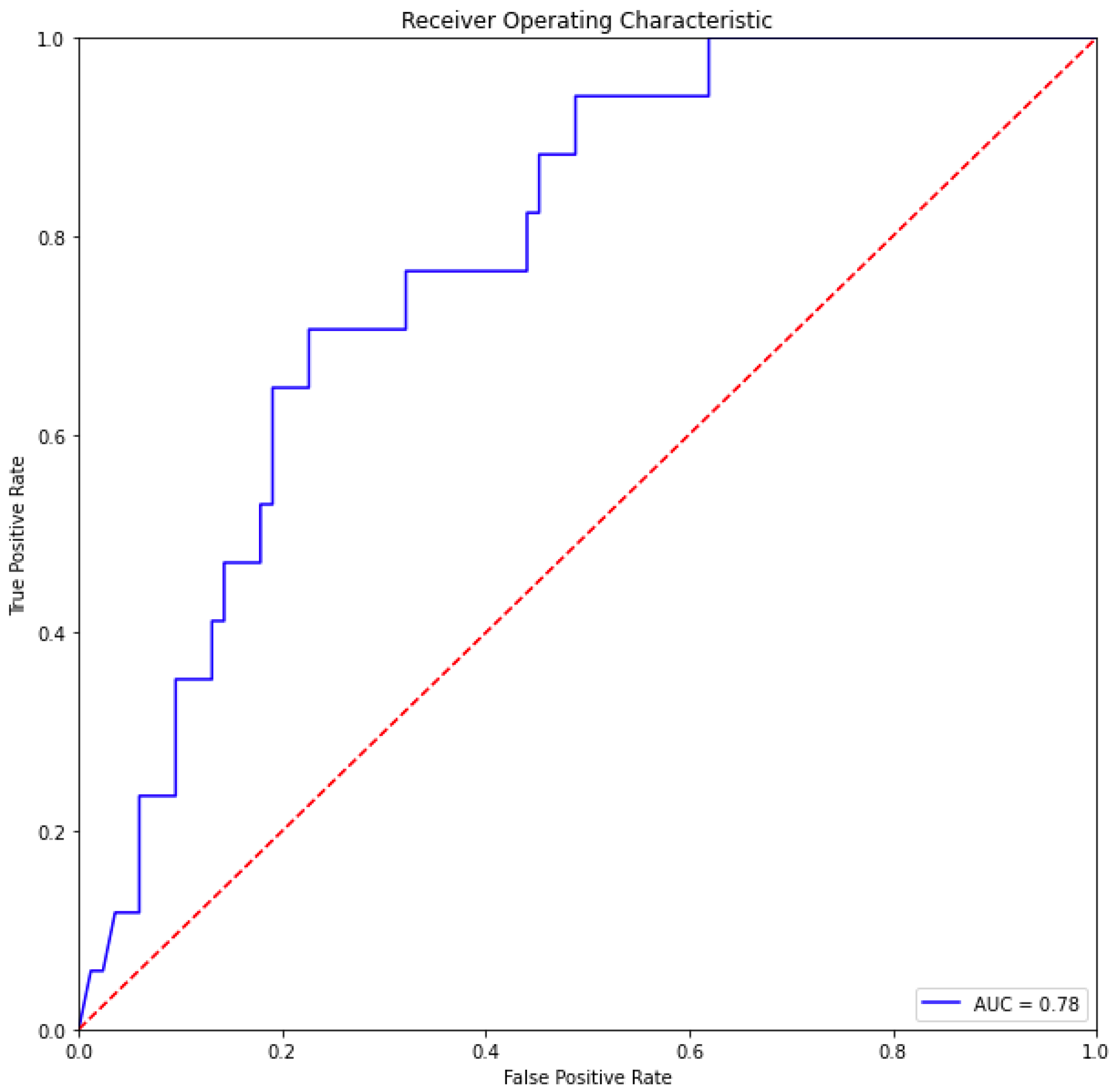
4.1. Deep Learning Predictor
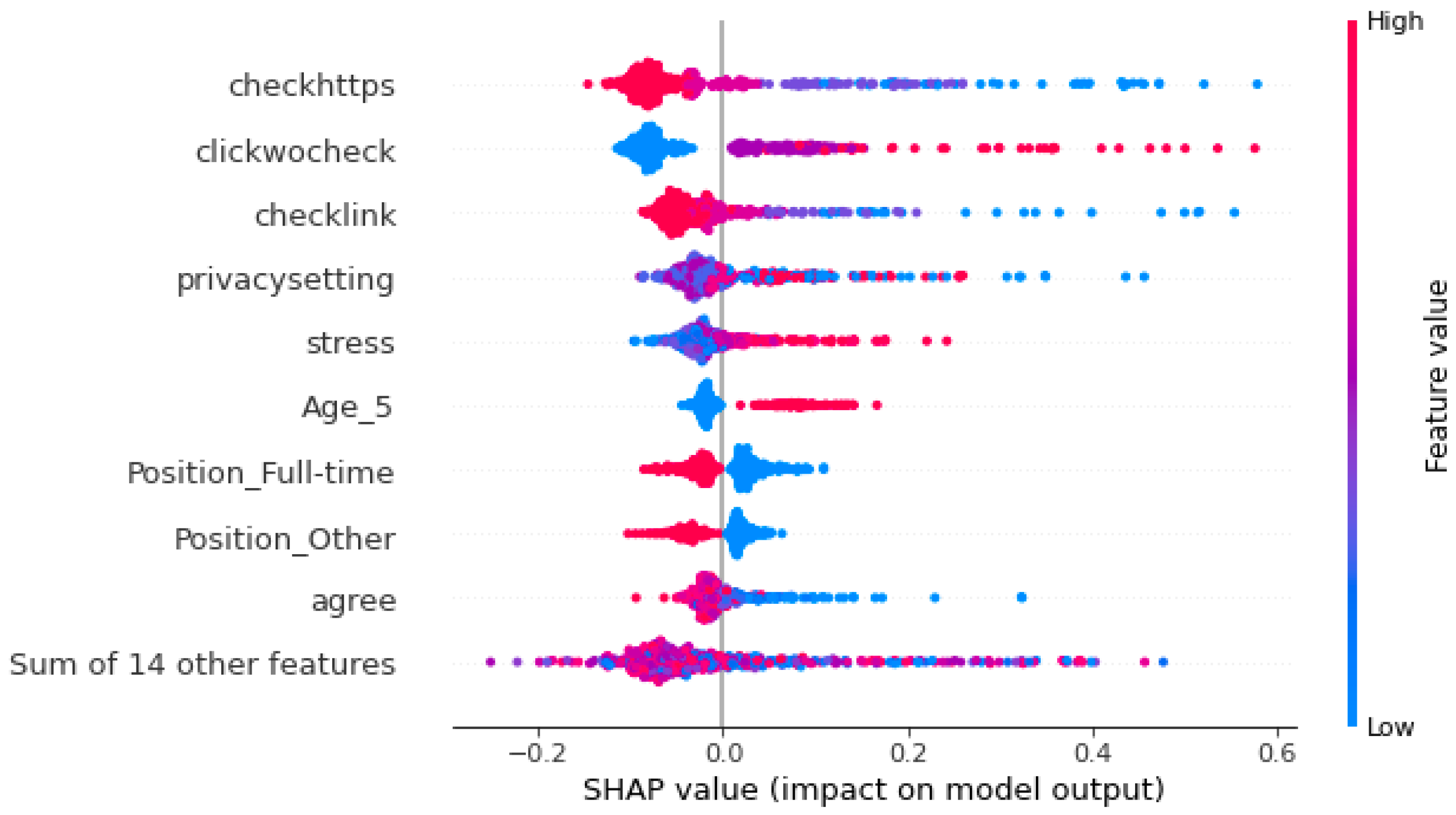
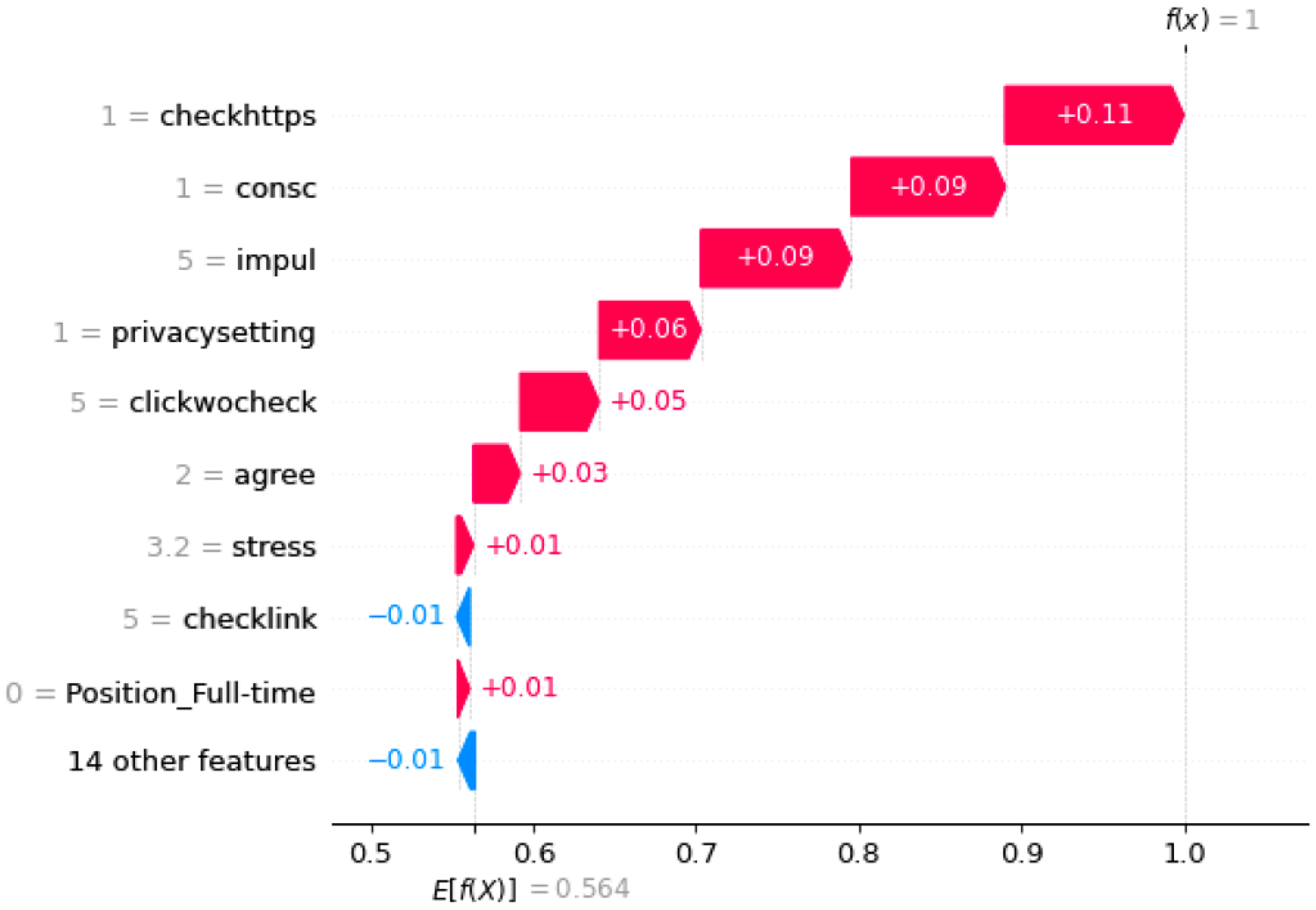
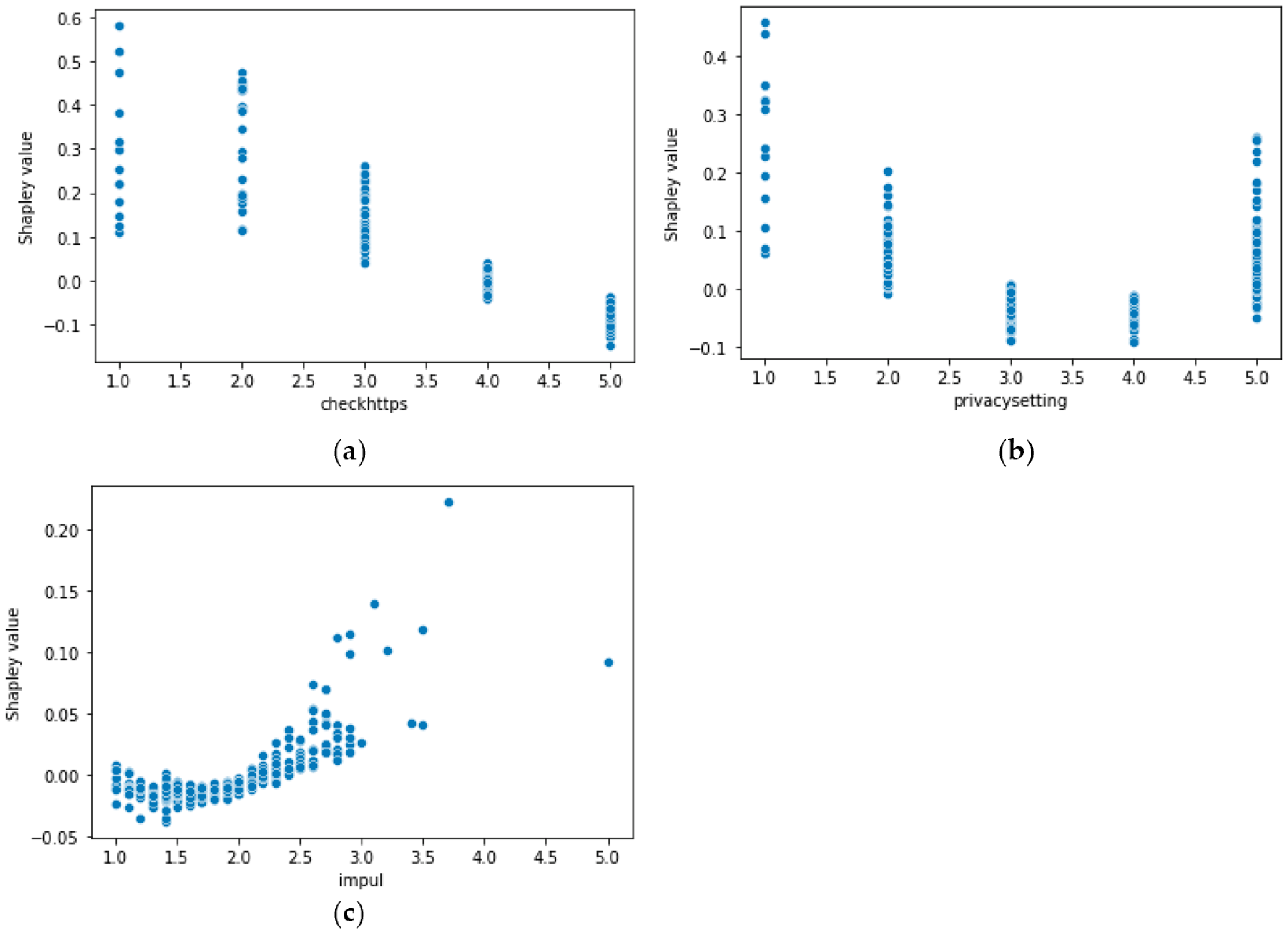
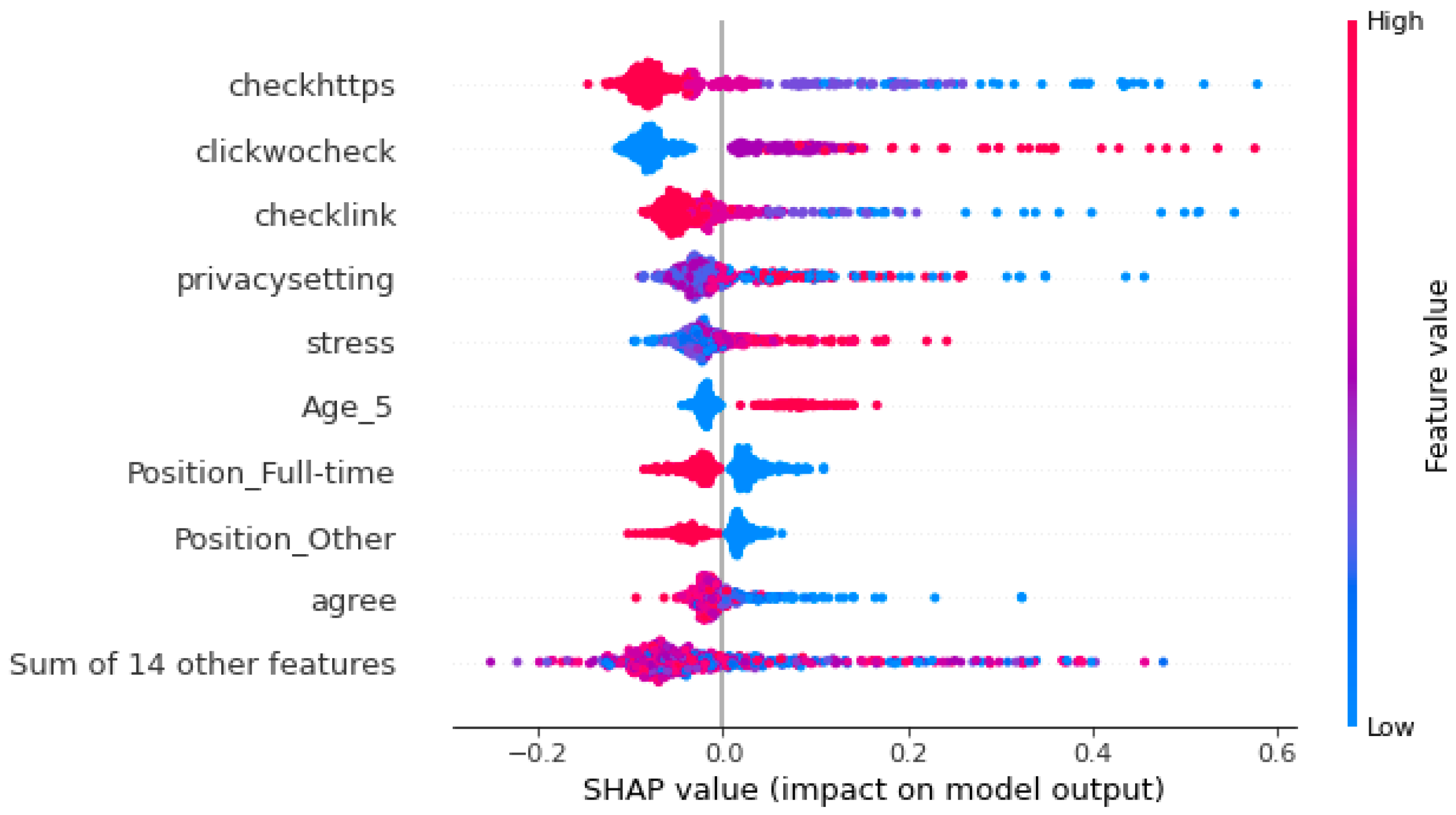
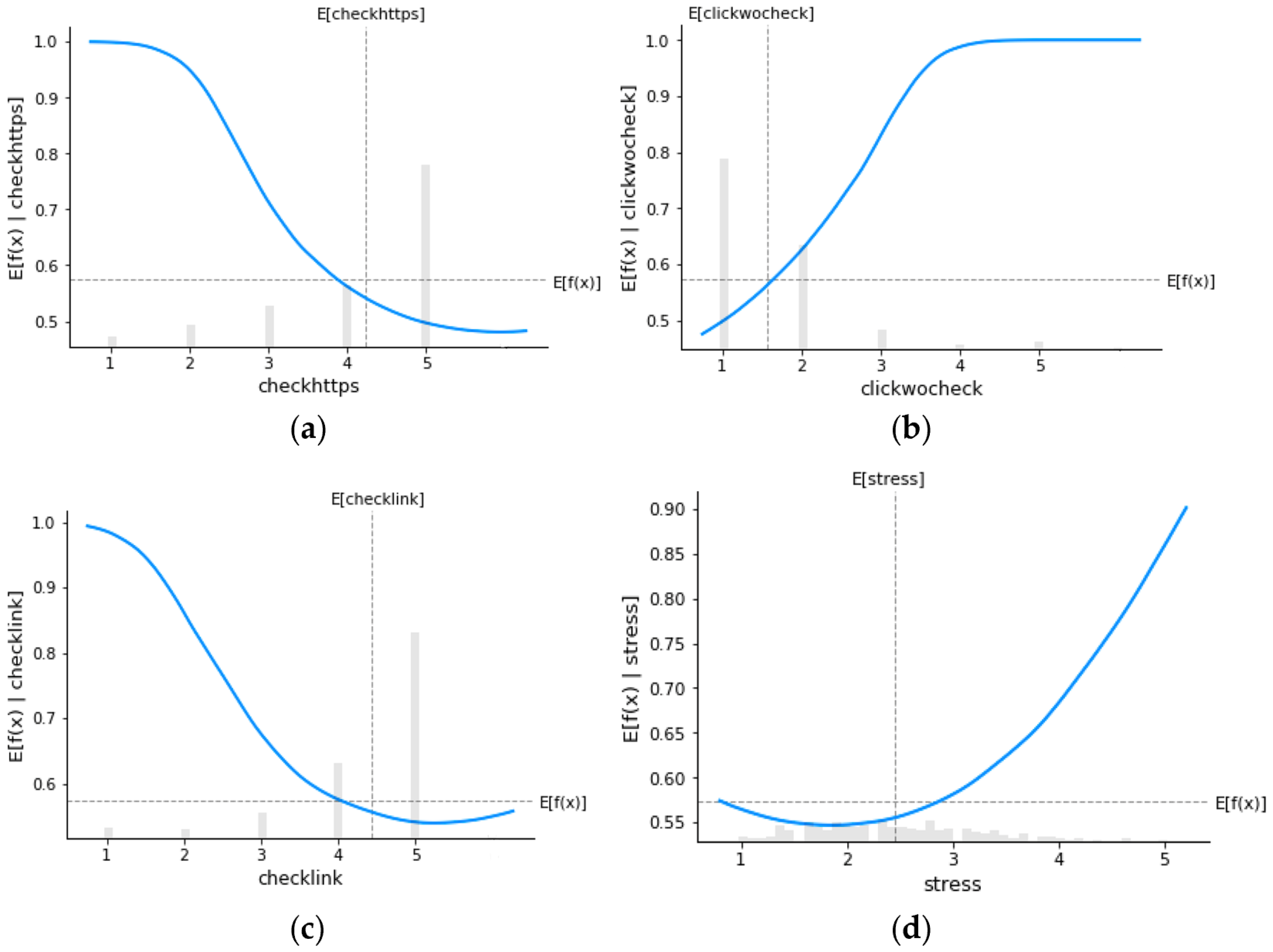
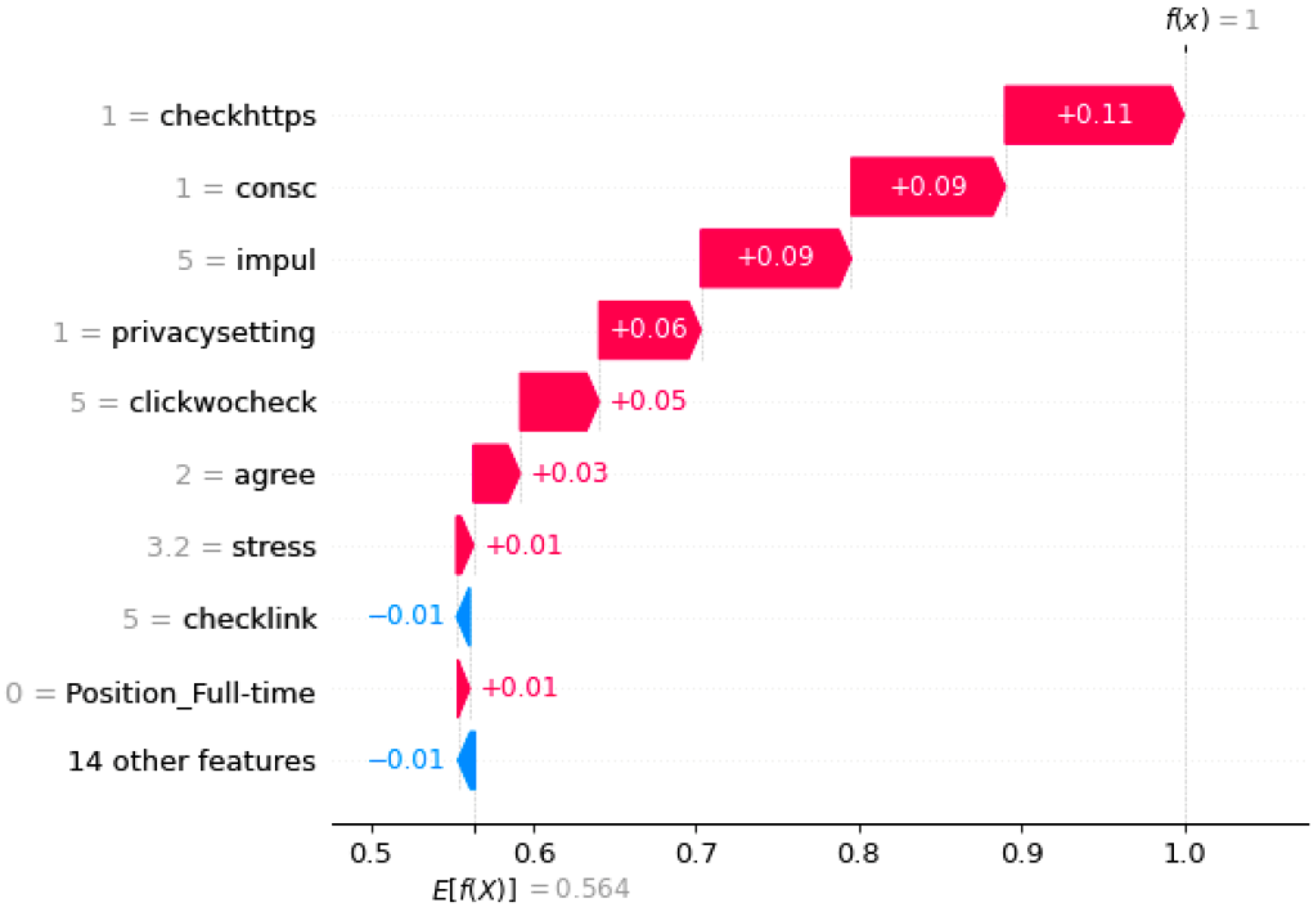
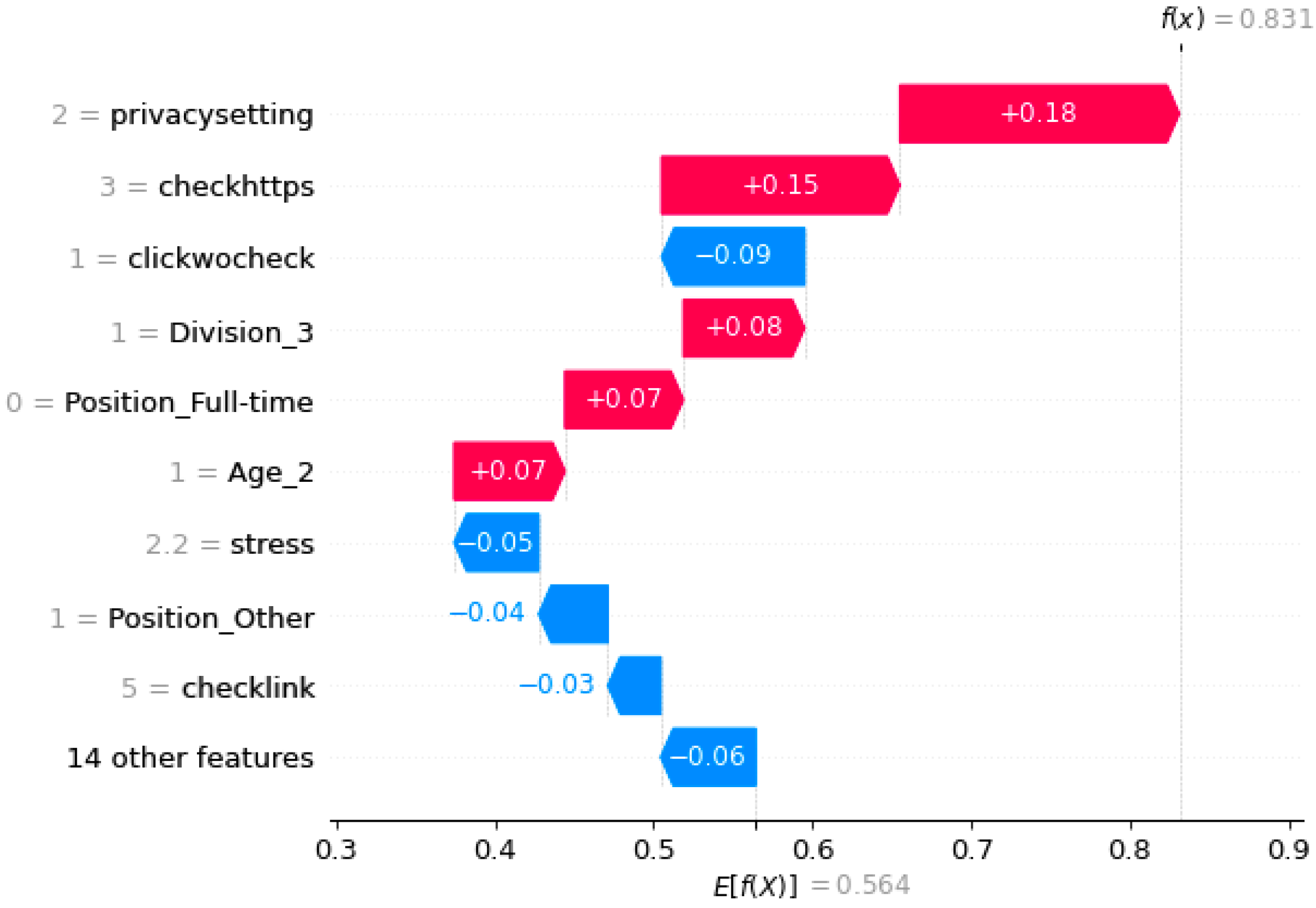
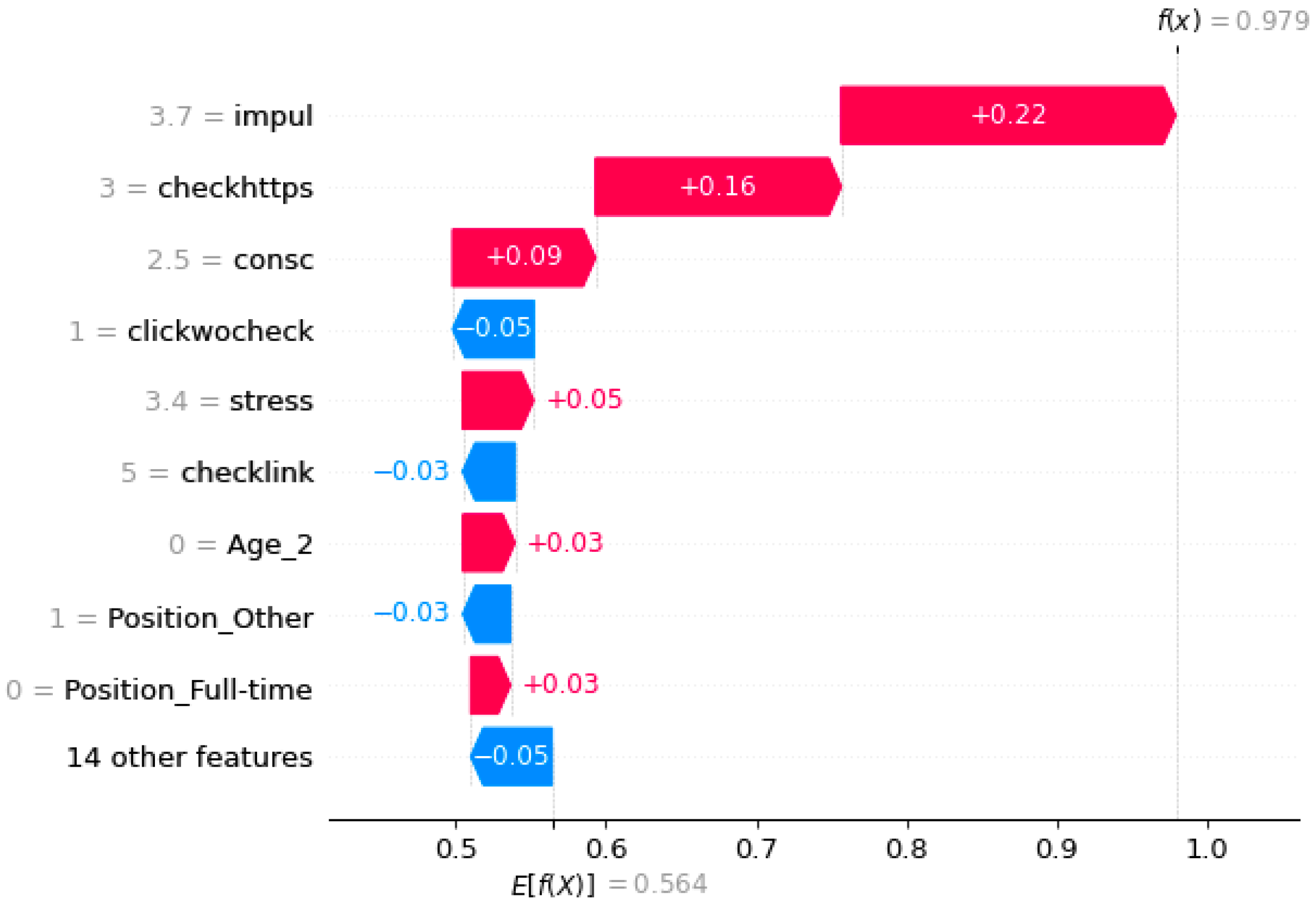
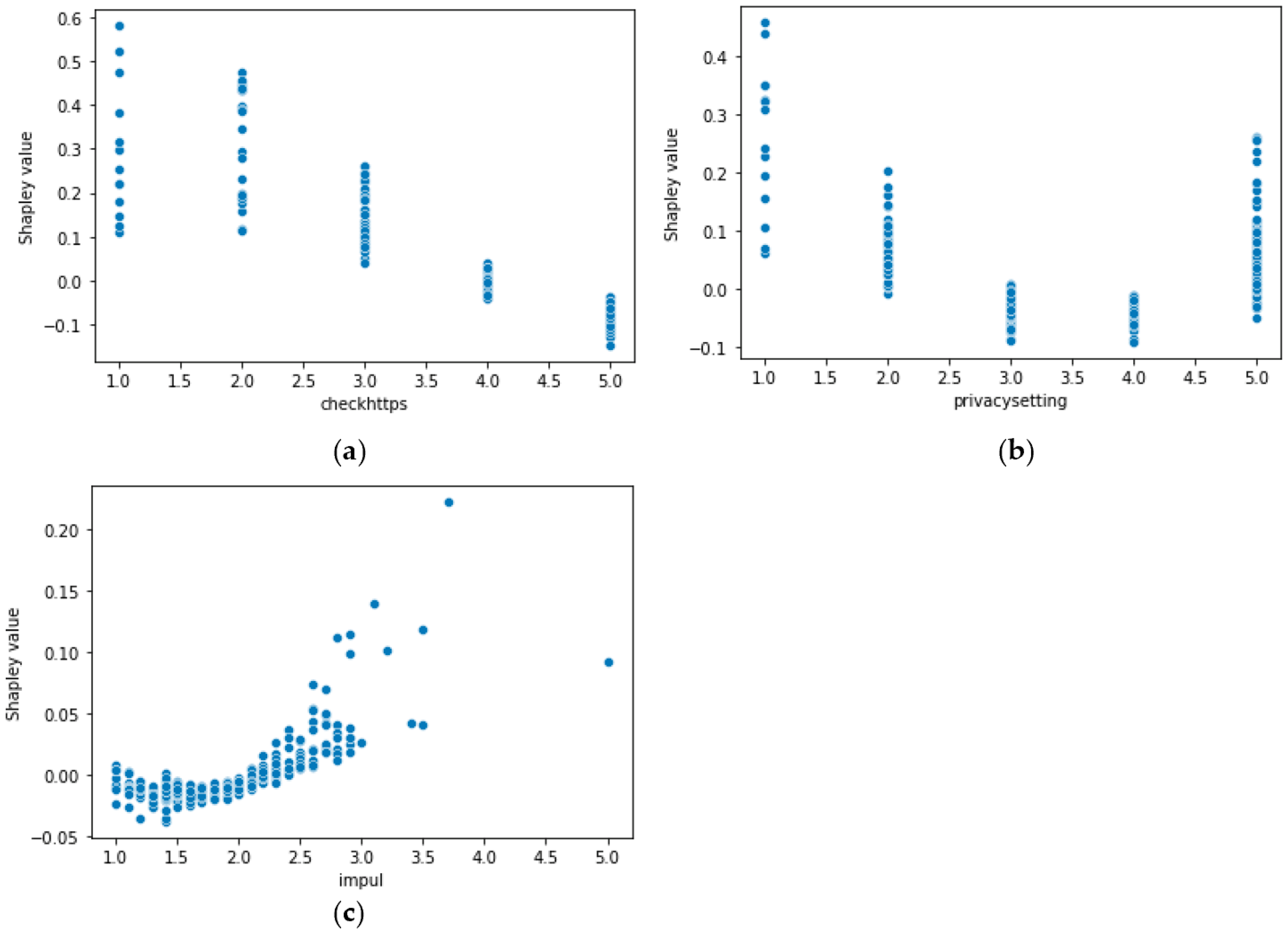
4.2. SHAP Explanation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Greitzer, F.L.; Strozer, J.R.; Cohen, S.; Moore, A.P.; Mundie, D.; Cowley, J. Analysis of Unintentional Insider Threats Deriving from Social Engineering Exploits. In Proceedings of the 2014 IEEE Security and Privacy Workshops, San Jose, CA, USA, 17–18 May 2014; pp. 236–250. [Google Scholar]
- Li, W.; Lee, J.; Purl, J.; Greitzer, F.; Yousefi, B.; Laskey, K. Experimental Investigation of Demographic Factors Related to Phishing Susceptibility; University of Hawaii Manoa Library: Honolulu, HI, USA, 2020; ISBN 978-0-9981331-3-3. [Google Scholar]
- Gunning, D.; Aha, D. DARPA’s Explainable Artificial Intelligence (XAI) Program. AI Mag. 2019, 40, 44–58. [Google Scholar] [CrossRef]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Diaz, A.; Sherman, A.T.; Joshi, A. Phishing in an Academic Community: A Study of User Susceptibility and Behavior. Cryptologia 2020, 44, 53–67. [Google Scholar] [CrossRef]
- Halevi, T.; Lewis, J.; Memon, N. Phishing, Personality Traits and Facebook. arXiv 2013, arXiv:1301.7643. [Google Scholar]
- Pethers, B.; Bello, A. Role of Attention and Design Cues for Influencing Cyber-Sextortion Using Social Engineering and Phishing Attacks. Future Internet 2023, 15, 29. [Google Scholar] [CrossRef]
- Qi, Q.; Wang, Z.; Xu, Y.; Fang, Y.; Wang, C. Enhancing Phishing Email Detection through Ensemble Learning and Undersampling. Appl. Sci. 2023, 13, 8756. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Greitzer, F.L.; Li, W.; Laskey, K.B.; Lee, J.; Purl, J. Experimental Investigation of Technical and Human Factors Related to Phishing Susceptibility. ACM Trans. Soc. Comput. 2021, 4, 1–48. [Google Scholar] [CrossRef]
- James, P.J.; Bailey, J.; Courtney, J. A Personality Based Model for Determining Susceptibility to Phishing Attacks. In Proceedings of the Southwest Decision Sciences Institute Annu. Meeting (SDSI ’09), Oklahoma, OK, USA, 24–28 February 2009; pp. 285–296. [Google Scholar]
- Jagatic, T.N.; Johnson, N.A.; Jakobsson, M.; Menczer, F. Social Phishing. Commun. ACM 2007, 50, 94–100. [Google Scholar] [CrossRef]
- Sheng, S.; Holbrook, M.; Kumaraguru, P.; Cranor, L.F.; Downs, J. Who Falls for Phish? A Demographic Analysis of Phishing Susceptibility and Effectiveness of Interventions. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New York, NY, USA, 10 April 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 373–382. [Google Scholar]
- Blythe, M.; Petrie, H.; Clark, J.A. F for Fake: Four Studies on How We Fall for Phish. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New York, NY, USA, 7 May 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 3469–3478. [Google Scholar]
- Mohebzada, J.G.; Zarka, A.E.; Bhojani, A.H.; Darwish, A. Phishing in a University Community: Two Large Scale Phishing Experiments. In Proceedings of the 2012 International Conference on Innovations in Information Technology (IIT), Abu Dhabi, United Arab Emirates, 18–20 March 2012; pp. 249–254. [Google Scholar]
- Lin, T.; Capecci, D.E.; Ellis, D.M.; Rocha, H.A.; Dommaraju, S.; Oliveira, D.S.; Ebner, N.C. Susceptibility to Spear-Phishing Emails: Effects of Internet User Demographics and Email Content. ACM Trans. Comput.-Hum. Interact. 2019, 26, 1–28. [Google Scholar] [CrossRef]
- Parsons, K.; Butavicius, M.; Delfabbro, P.; Lillie, M. Predicting Susceptibility to Social Influence in Phishing Emails. Int. J. Hum.-Comput. Stud. 2019, 128, 17–26. [Google Scholar] [CrossRef]
- Downs, J.S.; Holbrook, M.B.; Cranor, L.F. Decision Strategies and Susceptibility to Phishing. In Proceedings of the Second Symposium on Usable Privacy and Security, New York, NY, USA, 12 July 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 79–90. [Google Scholar]
- Canham, M.; Posey, C.; Strickland, D.; Constantino, M. Phishing for Long Tails: Examining Organizational Repeat Clickers and Protective Stewards. SAGE Open 2021, 11, 2158244021990656. [Google Scholar] [CrossRef]
- Digman, J.M. Personality Structure: Emergence of the Five-Factor Model. Annu. Rev. Psychol. 1990, 41, 417–440. [Google Scholar] [CrossRef]
- Alseadoon, I.; Chan, T.; Foo, E.; Nieto, J.G. Who Is More Susceptible to Phishing Emails?: A Saudi Arabian Study. In Proceedings of the 23rd Australasian Conference on Information Systems, Geelong, Australia, 3–5 December 2012; pp. 1–11. [Google Scholar]
- Workman, M. Wisecrackers: A Theory-Grounded Investigation of Phishing and Pretext Social Engineering Threats to Information Security. J. Am. Soc. Inf. Sci. Technol. 2008, 59, 662–674. [Google Scholar] [CrossRef]
- Desolda, G.; Ferro, L.S.; Marrella, A.; Catarci, T.; Costabile, M.F. Human Factors in Phishing Attacks: A Systematic Literature Review. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Zhuo, S.; Biddle, R.; Koh, Y.S.; Lottridge, D.; Russello, G. SoK: Human-Centered Phishing Susceptibility. ACM Trans. Priv. Secur. 2023, 26, 1–27. [Google Scholar] [CrossRef]
- Abbasi, A.; Zahedi, F.M.; Chen, Y. Phishing Susceptibility: The Good, the Bad, and the Ugly. In Proceedings of the 2016 IEEE Conference on Intelligence and Security Informatics (ISI), Tucson, AZ, USA, 28–30 September 2016; pp. 169–174. [Google Scholar]
- Yang, R.; Zheng, K.; Wu, B.; Li, D.; Wang, Z.; Wang, X. Predicting User Susceptibility to Phishing Based on Multidimensional Features. Comput. Intell. Neurosci. 2022, 2022, e7058972. [Google Scholar] [CrossRef]
- Yang, R.; Zheng, K.; Wu, B.; Wu, C.; Wang, X. Prediction of Phishing Susceptibility Based on a Combination of Static and Dynamic Features. Math. Probl. Eng. 2022, 2022, e2884769. [Google Scholar] [CrossRef]
- Rahman, A.U.; Al-Obeidat, F.; Tubaishat, A.; Shah, B.; Anwar, S.; Halim, Z. Discovering the Correlation between Phishing Susceptibility Causing Data Biases and Big Five Personality Traits Using C-GAN. IEEE Trans. Comput. Soc. Syst. 2022, 1–9. [Google Scholar] [CrossRef]
- Cranford, E.; Jabbari, S.; Ou, H.-C.; Tambe, M.; Gonzalez, C.; Lebiere, C. Combining Machine Learning and Cognitive Models for Adaptive Phishing Training. In Proceedings of the 20th Annual Meeting of the International Conference on Cognitive Modeling, Toronto, ON, Canada, 23–27 July 2022. [Google Scholar]
- Bozkir, A.S.; Aydos, M. LogoSENSE: A Companion HOG Based Logo Detection Scheme for Phishing Web Page and E-Mail Brand Recognition. Comput. Secur. 2020, 95, 101855. [Google Scholar] [CrossRef]
- Chiew, K.L.; Chang, E.H.; Sze, S.N.; Tiong, W.K. Utilisation of Website Logo for Phishing Detection. Comput. Secur. 2015, 54, 16–26. [Google Scholar] [CrossRef]
- Chiew, K.L.; Choo, J.S.-F.; Sze, S.N.; Yong, K.S.C. Leverage Website Favicon to Detect Phishing Websites. Secur. Commun. Netw. 2018, 2018, e7251750. [Google Scholar] [CrossRef]
- Panda, P.; Mishra, A.K.; Puthal, D. A Novel Logo Identification Technique for Logo-Based Phishing Detection in Cyber-Physical Systems. Future Internet 2022, 14, 241. [Google Scholar] [CrossRef]
- Liu, D.-J.; Geng, G.-G.; Zhang, X.-C. Multi-Scale Semantic Deep Fusion Models for Phishing Website Detection. Expert Syst. Appl. 2022, 209, 118305. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, J.; Wang, X.; Li, Z.; Li, Z.; He, Y. An Improved ELM-Based and Data Preprocessing Integrated Approach for Phishing Detection Considering Comprehensive Features. Expert Syst. Appl. 2021, 165, 113863. [Google Scholar] [CrossRef]
- Sahingoz, O.K.; Buber, E.; Demir, O.; Diri, B. Machine Learning Based Phishing Detection from URLs. Expert Syst. Appl. 2019, 117, 345–357. [Google Scholar] [CrossRef]
- Akinyelu, A.A.; Adewumi, A.O. Classification of Phishing Email Using Random Forest Machine Learning Technique. J. Appl. Math. 2014, 2014, e425731. [Google Scholar] [CrossRef]
- AlEroud, A.; Karabatis, G. Bypassing Detection of URL-Based Phishing Attacks Using Generative Adversarial Deep Neural Networks. In Proceedings of the Sixth International Workshop on Security and Privacy Analytics, New York, NY, USA, 16 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 53–60. [Google Scholar]
- Yerima, S.Y.; Alzaylaee, M.K. High Accuracy Phishing Detection Based on Convolutional Neural Networks. In Proceedings of the 2020 3rd International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 19–21 March 2020; pp. 1–6. [Google Scholar]
- Fang, Y.; Zhang, C.; Huang, C.; Liu, L.; Yang, Y. Phishing Email Detection Using Improved RCNN Model with Multilevel Vectors and Attention Mechanism. IEEE Access 2019, 7, 56329–56340. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, W.; Xu, H.; Liu, Y.; Yin, P. A Lightweight Multi-View Learning Approach for Phishing Attack Detection Using Transformer with Mixture of Experts. Appl. Sci. 2023, 13, 7429. [Google Scholar] [CrossRef]
- Roy, S.S.; Awad, A.I.; Amare, L.A.; Erkihun, M.T.; Anas, M. Multimodel Phishing URL Detection Using LSTM, Bidirectional LSTM, and GRU Models. Future Internet 2022, 14, 340. [Google Scholar] [CrossRef]
- Butnaru, A.; Mylonas, A.; Pitropakis, N. Towards Lightweight URL-Based Phishing Detection. Future Internet 2021, 13, 154. [Google Scholar] [CrossRef]
- Wen, T.; Xiao, Y.; Wang, A.; Wang, H. A Novel Hybrid Feature Fusion Model for Detecting Phishing Scam on Ethereum Using Deep Neural Network. Expert Syst. Appl. 2023, 211, 118463. [Google Scholar] [CrossRef]
- Alhogail, A.; Alsabih, A. Applying Machine Learning and Natural Language Processing to Detect Phishing Email. Comput. Secur. 2021, 110, 102414. [Google Scholar] [CrossRef]
- Divakaran, D.M.; Oest, A. Phishing Detection Leveraging Machine Learning and Deep Learning: A Review. arXiv 2022, arXiv:2205.07411. [Google Scholar] [CrossRef]
- Singh, C. Meenu Phishing Website Detection Based on Machine Learning: A Survey. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 398–404. [Google Scholar]
- Galego Hernandes, P.R.; Floret, C.P.; Cardozo De Almeida, K.F.; Da Silva, V.C.; Papa, J.P.; Pontara Da Costa, K.A. Phishing Detection Using URL-Based XAI Techniques. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 5–7 December 2021; pp. 1–6. [Google Scholar]
- Chai, Y.; Zhou, Y.; Li, W.; Jiang, Y. An Explainable Multi-Modal Hierarchical Attention Model for Developing Phishing Threat Intelligence. IEEE Trans. Dependable Secure Comput. 2022, 19, 790–803. [Google Scholar] [CrossRef]
- Lin, Y.; Liu, R.; Divakaran, D.M.; Ng, J.Y.; Chan, Q.Z.; Lu, Y.; Si, Y.; Zhang, F.; Dong, J.S. Phishpedia: A Hybrid Deep Learning Based Approach to Visually Identify Phishing Webpages. In Proceedings of the 30th USENIX Security Symposium (USENIX Security), Vancouver, BC, Canada, 11–13 August 2021; pp. 3793–3810. [Google Scholar]
- Kluge, K.; Eckhardt, R. Explaining the Suspicion: Design of an XAI-Based User-Focused Anti-Phishing Measure. In Innovation through Information Systems; Ahlemann, F., Schütte, R., Stieglitz, S., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 247–261. [Google Scholar]
- Inderjeet, M.; Zhang, J. kNN Approach to Unbalanced Data Distributions: A Case Study Involving Information Extraction. Proc. Workshop Learn. Imbalanced Datasets 2003, 126, 1–7. [Google Scholar]
- Heartfield, R.; Loukas, G.; Gan, D. You Are Probably Not the Weakest Link: Towards Practical Prediction of Susceptibility to Semantic Social Engineering Attacks. IEEE Access 2016, 4, 6910–6928. [Google Scholar] [CrossRef]
- Wright, R.T.; Marett, K. The Influence of Experiential and Dispositional Factors in Phishing: An Empirical Investigation of the Deceived. J. Manag. Inf. Syst. 2010, 27, 273–303. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Year | Method | Description |
|---|---|---|---|
| Abbasi et al. [25] | 2016 | K-mean clustering | Using clustering method to identify user segments with high susceptibility, focusing on perceptions, demographics, and website traversal behavior. |
| Yang et al. [26] | 2022 | Logistic regression, boosting, and support vector machine | Using various supervised learning methods to identify the relation between demographics, personality, knowledge experience, security behavior, cognitive processes, and susceptibility. |
| Yang et al. [27] | 2022 | Hybrid LSTM and LightGBM | Combining static and dynamic features, together with a hybrid algorithm to predict phishing susceptibility. |
| Rahman et al. [28] | 2022 | C-GAN | Investigate the relationship between phishing susceptibility and personality traits using C-GAN |
| Cranford et al. [29] | 2022 | Multi-armed bandit | Using a restless multi-armed bandit framework to strategically target users for intervention in phishing email detection. |
| Bozkir and Aydos [30] | 2020 | Max margin object detection | Employing a histogram of oriented gradients and a max-margin object detector to localize and classify brand logos in phishing web page screenshots. |
| Chiew et al. [31] | 2015 | SVM | Utilizing SVM for logo extraction and Google image search for identity verification. |
| Panda et al. [33] | 2022 | Random forest | Developed a logo-based phishing detection mechanism using hue value distribution as a feature. |
| Liu et al. [34] | 2022 | CNN and RNN | Developed three multi-scale semantic deep fusion networks using URLs to identify phishing websites. |
| Yang et al. [35] | 2021 | Extreme learning machine | Proposed a non-inverse matrix extreme learning machine for phishing website detection, together with denoising autoencoder and adaptive synthetic sampling. |
| Sahingoz et al. [36] | 2019 | Random forest | Developed a real-time anti-phishing system using a random forest classifier with NLP-based features. |
| Akinyelu et al. [37] | 2014 | Random forest | Using random forest to classify phishing attacks with hand-crafted URL-based features. |
| AlEroud et al. [38] | 2020 | GAN | Utilizing a generative model to generate URL-based phishing examples that can deceive Blackbox detection models |
| Yerima et al. [39] | 2020 | CNN | Developed a 1D CNN-based detection model using website URLs as features. |
| Fang et al. [40] | 2019 | Recurrent CNN | Developed a phishing email detection model based on recurrent CNN with multilevel vectors and attention mechanisms. |
| Wang et al. [41] | 2023 | Transformer | Designed a Transformer model with an expert-mixture mechanism for phishing website detection, utilizing website URLs, attributes, content, and behavioral information. |
| Roy et al. [42] | 2022 | Using LSTM, bidirectional LSTM, and gated recurrent unit to identify malicious URLs. | |
| Butnaru et al. [43] | 2021 | Random forest | Using random forest for blocking phishing attacks using URLs. |
| Wen et al. [44] | 2023 | LSTM | Developed a hybrid detection model that integrates LSTM and a fully convolutional network to detect phishing scam accounts on the Ethereum blockchain. |
| Alhogail et al. [45] | 2021 | Graph convolutional network (GCN) | Using GCN and NLP over an email body text to identify phishing emails. |
| Hernandes et al. [48] | 2021 | LIME | Using LIME to detect phishing websites, aiming to provide insights into the categorization of phishing URLs |
| Chai et al. [49] | 2022 | Hierarchical attention | Developed a multi-modal hierarchical attention model for phishing website detection, jointly learning deep fraud cues from three modalities. |
| Lin et al. [50] | 2021 | Faster RCNN object detection | A hybrid system designed to address technical challenges in phishing identification by accurately recognizing identity logos on webpage screenshots and matching logo variants. |
| Data Type | Description |
|---|---|
| Demographic Data | Age, gender, position, and department type. Collected from HR records |
| Behavioral and Psychological Data | Personality (impulsivity, conscientiousness, emotional stability, agreeableness, perceived stress) and technical/cybersecurity-related experience. Collected from the pre-campaign survey |
| Variable Name | Value Type | Description |
|---|---|---|
| Age | Categorical | 5 values: [19, 27), [27, 41), [41, 49), [49, 59), [59+) |
| Gender | Categorical | 2 values: Female, Male |
| Department | Categorical | 3 values: Technical college, Administrative, Other College |
| Position | Categorical | 4 values: Full-time faculty, adjunct faculty, wage staff, other staff |
| Variable Name | Value Type | Description |
|---|---|---|
| Impulsivity (impul) | Numeric | Averaged over question 1–10 of Section 1. Range from 1.0 to 5.0 to measure impulsivity score |
| Conscientiousness (consc) | Numeric | Averaged over questions 11–14 of Section 1. Range from 1.0 to 5.0 to measure conscientiousness score |
| Emotional Stability (emo) | Numeric | Averaged over questions 15–18 of Section 1. Range from 1.0 to 5.0 to measure the emotional stability score |
| Agreeableness (agree) | Numeric | Averaged over question 19–22 of Section 1. Range from 1.0 to 5.0 to measure the agreeableness score |
| Perceived Stress (stress) | Numeric | Averaged over questions 23–32 of Section 2. Range from 1.0 to 5.0 to measure the perceived stress score |
| Check Link (checklink) | Numeric | Response to the corresponding survey question in Section 3. Range from 1.0 (never) to 5.0 (very often) |
| Privacy Setting (privacysetting) | Numeric | Response to the corresponding survey question in Section 3. Range from 1.0 (never) to 5.0 (very often) |
| Check HTTPS (checkhttps) | Numeric | Response to the corresponding survey question in Section 3. Range from 1.0 (never) to 5.0 (very often) |
| Click w/o Check (clickwocheck) | Numeric | Response to the corresponding survey question in Section 3. Range from 1.0 (never) to 5.0 (very often) |
| Phished Before (phishbefore) | Binary | Response to the corresponding survey question in Section 3. Binary valued: Yes = 1, No = 0 |
| Phished in Last 3 Months (phishlast3mon) | Binary | Response to the corresponding survey question in Section 3. Binary valued: Yes = 1, No = 0 |
| Lose Info Due to Phishing (loseinfo) | Binary | Response to the corresponding survey question in Section 3. Binary valued: Yes = 1, No = 0 |
| Download Malware (downmalware) | Binary | Response to the corresponding survey question in Section 3. Binary valued: Yes = 1, No = 0 |
| Evaluation Metric | Value |
|---|---|
| Accuracy | 0.78 |
| Precision | 0.57 |
| Recall | 0.71 |
| F-1 Score | 0.64 |
| True Positive Rate | 0.75 |
| True Negative Rate | 0.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, Z.; Li, W.; Laskey, K.B.; Chang, K.-C. Investigation of Phishing Susceptibility with Explainable Artificial Intelligence. Future Internet 2024, 16, 31. https://doi.org/10.3390/fi16010031
Fan Z, Li W, Laskey KB, Chang K-C. Investigation of Phishing Susceptibility with Explainable Artificial Intelligence. Future Internet. 2024; 16(1):31. https://doi.org/10.3390/fi16010031
Chicago/Turabian StyleFan, Zhengyang, Wanru Li, Kathryn Blackmond Laskey, and Kuo-Chu Chang. 2024. "Investigation of Phishing Susceptibility with Explainable Artificial Intelligence" Future Internet 16, no. 1: 31. https://doi.org/10.3390/fi16010031
APA StyleFan, Z., Li, W., Laskey, K. B., & Chang, K.-C. (2024). Investigation of Phishing Susceptibility with Explainable Artificial Intelligence. Future Internet, 16(1), 31. https://doi.org/10.3390/fi16010031