
Automatic Short Text Summarization Techniques in Social Media Platforms


Abstract
1. Introduction
1.1. Background
1.2. Motivation and Objectives
1.3. Existing Surveys
1.4. Structure of the Paper
2. Types of Short Text on Social Media
2.1. Tweets
2.2. Facebook Posts
2.3. Instagram Captions
2.4. WhatsApp Messages
2.5. YouTube Comments
2.6. Sina Weibo
3. Social Media Datasets
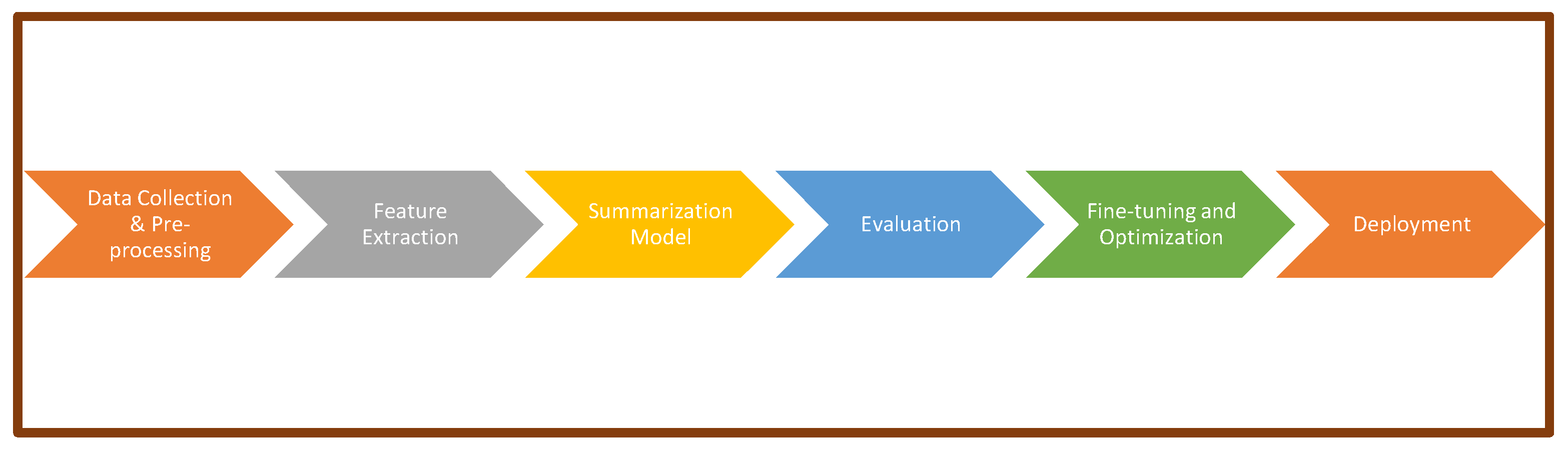
4. ASTS Structure
- Data collection and pre-processing:
- ▪
- Data collection: Gather short text data from social media platforms or other sources, depending on the application.
- ▪
- Data pre-processing: Clean and preprocess the collected data, which includes text cleaning, tokenization, stopword removal, lemmatization, stemming, and sentence segmentation.
- Feature extraction:
- ▪
- Extract relevant features from the preprocessed data to represent the content for the summarization model. Features can include TF-IDF vectors, word embeddings, or contextual embeddings generated using pre-trained language models like BERT or GPT.
- Summarization model:
- ▪
- Extractive summarization: For extractive summarization, use techniques such as graph-based algorithms (e.g., TextRank) [25], attention mechanisms (e.g., Transformer-based models), or neural network-based methods (e.g., LSTM) to identify and select important sentences or phrases from the input text to form the summary.
- ▪
- Abstractive summarization: For abstractive summarization, employ neural network models, such as sequence-to-sequence architectures (e.g., LSTM with attention, Transformer-based models like BART), to generate new sentences that convey the essential information not necessarily present in the original text.
- Evaluation:
- ▪
- Measure the quality and performance of the summarization model using evaluation metrics such as ROUGE (Recall-Oriented Understudy for Gisting Evaluation), BLEU (Bilingual Evaluation Understudy), or other domain-specific metrics. These metrics compare the generated summaries with human-written summaries or ground truth summaries.
- Fine-tuning and optimization:
- ▪
- Fine-tune the summarization model on a domain-specific or task-specific dataset to improve its performance and adapt it to the target domain.
- ▪
- Optimize hyperparameters and model architecture through experimentation and tuning.
- Deployment:
- ▪
- Integrate the trained ASTS model into a larger application or platform to provide automatic short text summarization functionality to users.
- ▪
- Monitor and maintain the system in production to ensure its continued accuracy and effectiveness.
5. Approaches to Summarization
5.1. Extractive Summarization
- ▪
- Frequency-based methods:Frequency-based methods assign importance scores to sentences based on the frequency of important words or phrases in the text. Sentences with a higher frequency of essential terms are considered more important and are selected for the summary.
- ▪
- TF-IDF (Term Frequency–Inverse Document Frequency):TF-IDF is a widely used technique that evaluates the importance of a word in a document relative to a corpus of documents. Sentences containing important terms with high TF-IDF scores are selected for the summary.
- ▪
- TextRank algorithm:TextRank is a graph-based ranking algorithm inspired by PageRank. It treats sentences as nodes in a graph and computes the importance of each sentence based on the similarity and co-occurrence of sentences. High-scoring sentences are chosen for the summary [25].
- ▪
- Sentence embeddings:Sentence embeddings represent sentences as dense vectors in a high-dimensional space, capturing semantic information. Similarity measures between sentences are used to rank sentences, and the most similar ones are included in the summary.
- ▪
- Supervised machine learning:In supervised approaches, models are trained on annotated data with sentence-level labels indicating whether a sentence should be included in the summary. The model then predicts the importance of sentences in new short texts and selects the most important ones for the summary [26].
5.2. Abstractive Summarization
- ▪
- Sequence-to-sequence (Seq2Seq) models:Seq2Seq models, based on recurrent neural networks (RNNs) or transformers, are widely used in abstractive summarization. These models encode the input short text into a fixed-size vector and then decode it to generate a summary. The decoder generates new sentences by predicting the next word based on the context learned from the encoder [27].
- ▪
- Transformer-based models:Transformers, particularly pre-trained models like GPT-2 and BERT, have shown promising results in abstractive summarization. These models use self-attention mechanisms to capture contextual relationships between words and generate coherent and contextually appropriate summaries.
- ▪
- Reinforcement learning:Abstractive summarization can also be approached as a reinforcement learning problem. The model generates candidate summaries, and a reward mechanism is used to evaluate their quality. The model is then fine-tuned using policy gradients to optimize the summary generation process.
- ▪
- Pointer-Generator networks:Pointer-Generator networks combine extractive and abstractive methods. These models have the ability to copy words from the input text (extractive) while also generating new words (abstractive) to create the summary. This approach helps to handle out-of-vocabulary words and maintain the factual accuracy of the summary.
5.3. Hybrid Approaches:
- ▪
- Extract-then-abstract:This approach involves first applying an extractive summarization technique to select important sentences or phrases from the original short text. Then, an abstractive summarization model is used to rephrase and refine the extracted content into a more coherent and concise summary. This way, the final summary benefits from the factual accuracy of extractive methods and the fluency of abstractive methods.
- ▪
- Abstractive pre-processing:In this approach, the original short text undergoes abstractive pre-processing before being fed into an extractive summarization model. The pre-processing step involves paraphrasing and rephrasing the text to enhance its coherence and readability. The extractive model then selects sentences from the pre-processed text to form the final summary. By improving the input text’s quality, this approach aims to generate more coherent and informative summaries.
- ▪
- Extract-then-cluster-then-abstract:This approach combines extractive summarization with clustering techniques. First, important sentences are extracted from the original text. Then, these sentences are clustered based on their similarity, grouping similar content together. Finally, an abstractive summarization model is applied to each cluster to generate concise and coherent summaries for each group of related sentences. This approach helps in handling overlapping information and ensures that important content is not repeated in the final summary.
- ▪
- Reinforcement learning:Hybrid approaches can also involve the use of reinforcement learning to combine extractive and abstractive summarization [28]. The model learns to select important sentences through extractive summarization and generates new sentences using abstractive techniques. Reinforcement learning is used to optimize the summary’s quality by rewarding the model for generating accurate and informative summaries while penalizing for errors.Hybrid approaches in short text summarization aim to address the limitations of individual extractive and abstractive methods and create more effective and informative summaries. These approaches require careful design and optimization to strike the right balance between factual accuracy and fluency while maintaining the summary’s coherence and relevance to the original text. Ongoing research in this area continues to explore innovative ways to combine these techniques and enhance the overall performance of short text summarization models.
6. Evaluation Metrics for Short Text Summarization
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation):ROUGE is one of the most widely used evaluation metrics for text summarization. It measures the overlap between the n-grams (unigrams, bigrams, trigrams, etc.) of the generated summary and the reference summary. The ROUGE score includes metrics such as ROUGE-1 (unigram overlap), ROUGE-2 (bigram overlap), and ROUGE-L (longest common subsequence) [31].
- BLEU (Bilingual Evaluation Understudy):Originally developed for machine translation, BLEU has been adapted for text summarization evaluation. BLEU compares the n-grams in the generated summary with those in the reference summary and calculates precision scores. It is especially useful for measuring the quality of abstractive summaries.
- METEOR (Metric for Evaluation of Translation with Explicit Ordering):METEOR evaluates the quality of summaries by considering exact word matches as well as paraphrased and stemmed matches. It incorporates additional features like stemming, synonym matching, and word order similarity to assess the overall quality of the generated summaries.
- CIDEr (Consensus-based Image Description Evaluation):Originally developed for image captioning, CIDEr has been adjusted to evaluate text summarization. It computes a consensus-based similarity score by comparing n-gram overlaps between the generated and reference summaries while also considering the diversity and quality of the generated summaries.
- ROUGE-WE (ROUGE with word embeddings):ROUGE-WE enhances the traditional ROUGE metrics by incorporating word embeddings to assess the semantic similarity between the generated and reference summaries. It provides a more nuanced evaluation of the generated summaries’ semantic quality.
- BertScore:BertScore utilizes contextual embeddings from pre-trained models like BERT to measure the similarity between the generated and reference summaries. It takes into account the context of the words in the summaries, resulting in a more accurate evaluation [32].
- Human evaluation:In addition to automated metrics, human evaluation is essential for assessing the quality of summarization models. Human evaluators rank or rate the generated summaries based on their coherence, relevance, and informativeness compared to the reference summaries.
7. ASTS Techniques for Social Media Platforms
- ROUGE-1: (F1 score: 0.06 to 0.26, recall: 0.1 to 0.21, and precision: 0.05 to 0.19)
- ROUGE-2: (F1 score: 0.04 to 0.23, recall: 0.01 to 0.19, and precision: 0.03 to 0.17)
- ROUGE-S4: (F1 score: 0.04 to 0.21, recall: 0.01 to 0.18, and precision: 0.03 to 0.15)
- ROUGE-SU4: (F1 score: 0.29 to 0.48, recall: 0.04 to 0.07, and precision: 0.07 to 0.12)

{kind=link}
| Ref. | Objective | Method | Domain | Dataset | Evaluation Metrics | Observation |
|---|---|---|---|---|---|---|
| [46] | Integrity-aware, inconsistency, readability, quality, and efficiency | Deep Neural Network | Event | XMUDM/IAEA (https://github.com/XMUDM/IAEA) (accessed on 7 August 2023) | BLEU-1 = 24 BLEU-2 = 6 ROUGE-1 = 37 ROUGE-2 = 13 ROUGE-L = 33 Accuracy = 0.880 Precision = 0.713 Recall = 0.710 F1 score = 0.705 AUC = 0.814 | This approach is a novel real-time event summarization framework, but it needs to study the efficiency issue in real-time event summarization systems. |
| [69] | Accuracy | Supervised learning | Generic | LCSTS (http://icrc.hitsz.edu.cn/Article/show/139.html) (accessed on 7 August 2023) dataset | ROUGE-1 = 39.2 ROUGE-2 = 26.0 ROUGE-L = 36.2 | This model outperforms the sequence-to-sequence baseline by a large margin and achieves state-of-the-art performances on a Chinese social media dataset. |
| [60] | Accuracy, semantic consistency, and fluency Relatedness Faithfulness | Cross-entropy | Generic | LCSTS dataset | Human ROUGE-1 = 36.2 ROUGE-2 = 24.3 ROUGE-L = 33.8 | This approach improves the semantic consistency by 4% in terms of human evaluation. |
| [55] | To optimize the ROUGE score | Unsupervised cross-entropy and reinforcement | Generic | LCSTS dataset | F1 scores ROUGE-1 = 38.2 ROUGE-2 = 25.2 ROUGE-L = 35.5 | This model decides what information should be retained or removed during summarization, but cannot combine visual information and textual information for social media event summarization. |
| [57] | Redundancy and sentence identification | Ranking | Generic | Collected tweets | ROUGE-1 = 0.49 ROUGE-2 = 0.38 ROUGE-L = 0.45 ROUGE-SU4 = 0.39 | This approach outperforms the baseline approach, but it needs to measure the trustworthiness of tweet content to be included in the summary. |
| [52] | Time-aware | Integer Linear Programming | Epidemic | Two datasets (Ebola and MERS) (http://cse.iitkgp.ac.in/~krudra/epidemic.html) (accessed on 7 August 2023) | ROUGE-1 for Ebola F-scores = 0.4980 Recall = 0.4961 ROUGE-1 for MERS F-scores = 0.4980 Recall = 0.4961 | Using CatE addresses the problem of overlapping keywords across classes. |
| [64] | Social context and high-quality summary | Ranking and Selection SVM | Generic | SoLSCSum, USAToday-CNN, and VSoLSCSum | ROUGE-1 = 0.230 on SoLSCSum | To enhance semantics, more deep analyses should consider LSTMs or CNNs. |
| [63] | Quality and similarity | Classification ILP | Specific disaster events | Disaster datasets | ROUGE-1 F-score = 0.5770 (NEquake) F-score = 0.6602 (HDerail) | There is no consideration for the semantic similarity between two non-English words; this helps reduce errors. |
| [59] | Degree centrality, closeness centrality, and betweenness centrality | Graph-based | Disaster events | Collection of 2921 tweets | Precision = 0.957 Recall = 0.937 F-measure = 0.931 | This a simple and effective method for Tweet summarization, but as future work, other algorithms can be developed that can help predict certain patterns and trends on Twitter. |
| [58] | Quality and similarity | Clustering and Feature selection | Specific (disaster events) | Disaster datasets | CH index = 43.4864 DB index = 0.795 D index = 1.52 I-Index =0.1425 S index = 0.2708 XB = 0.1319 on Hagupit dataset | Simplicity and effectiveness satisfy real-time processing needs. |
| [68] | Identify highlights and characters | LSTM | Event | Collected tweets and around two episodes of GOTS7 | ROUGE-1 = 38 ROUGE-2 = 10 ROUGE-L = 31.5 | No consideration for diversity. |
| [67] | Accuracy | Deep learning | Disaster events | Disaster datasets, Hindi tweets, and dataset | TypHagupit dataset Recall = 98.72% F1 score = 74.37% Accuracy = 65.98% SanHShoot dataset Recall = 95.56% F1 score = 79.53% Accuracy = 75.41% | Deep learning models perform badly on Hindi tweets due to the lack of enough Tweets available. |
| [49] | Similarity and efficiency | Selection methods, clustering, and extraction | Health care | More than one million tweets related to cancer were collected | Similarity and efficiency | The generated summary from the larger-scale dataset was found to be more meaningful than the smaller dataset. |
| [43] | Performance, similarity, and dissimilarity | Unsupervised classification, tf–idf scores | Specific (disaster events) | Disaster datasets | ROUGE-2 = 0.3661 ROUGE-L = 0.5199 | Reported improvement in ROUGE-2 and ROUGE-L scores, but executing time is high. |
| [44] | Quality | SOM, GSOM, and GA | Disaster events | Disaster events UkFlood, Sandyhook, Hblast, and Hagupit | ROUGE-2 = 0.3458 ROUGE-L = 0.5000 | Showed improvement in ROUGE-2 and ROUGE-L score. |
| [40] | Diversity | Supervised learning | Event | Collected tweets and event-based dataset | ROUGE-1 = 0.4787 ROUGE-2 = 0.2391 ROUGE-3 = 0.1652 ROUGE-L = 0.4241 | Reported better topic coverage and conveyed more diverse user emotions. |
| [39] | Credibility, worthiness, accuracy | Supervised | Disaster events | PHEME dataset | ROUGE1-F1 = 0.501 | Extractive technique for summarizing tweets with the task rumor detection. |
| [66] | Coverage and sparsity, diversity, and redundancy | Social Network and Sparse Reconstruction (SNSR) | Generic | UDI-TwitterCrawl-Aug2012 (https://wiki.illinois.edu/wiki/display/forward/Dataset-UDI-TwitterCrawl-Aug2012) (accessed on 7 August 2023) | ROUGE-1 = 0.44887 ROUGE-2 = 0.13882 ROUGE-SU4 = 0.18147 | Social relations help in optimizing the summarization process. |
| [54] | Summary size reduction | Graph-based, Multi-Objective Ant Colony Optimization | Election event | Presidential election in Indonesia Twitter dataset | Cosine distance = 0.127 Word count = 388 | Reliable for producing concise and informative summaries from social media comments. |
| [42] | Similarity and redundancy | Multi-objective binary differential evolution | Specific (disaster events) | Disaster events (UkFlood, Sandyhook, Hblast, and Hagupit) | Best result for MOOTS3 ROUGE-2 = 0.3418 ROUGE-L = 0.5009 | Using BM25 similarity measure and SOM as a genetic operator score showed improvement in the summarization process. |
| [1] | Accuracy | Maximal association rules | Generic | Collected Twitter dataset | ROUGE_N F_measure =0.30 Precision = 0.31 Recall = 0.29 ROUGE_L F_measure = 0 0.20 Precision = 0.20 Recall = 0.19 | Improves the accuracy of a summary. |
| [53] | Contextual relationships and computational cost | Approximate model, graph-based, and clustering | Generic | RepLab2013 (http://nlp.uned.es/replab2013/replab2013-dataset.tar.gz) (accessed on 7 August 2023) and Customer Support on Twitter Dataset (https://www.kaggle.com/thoughtvector/customer-support-on-twitter) (accessed on 7 August 2023) | RepLab2013 Twitter Precision = 0.7098 Recall = 0.833 F1 score = 0.766 Auspol Twitter Precision = 0.718 Recall = 0.695 F1 score = 0.706 Common Diseases Precision = 0.714 Recall = 0.651 F1 score = 0.681 Customer Support on Twitter Precision = 0.51 Recall = 0.651 F1 score = 0.571 | Improved run-time performance for event detection but no consideration for location. |
| [38] | Coverage and diversity | Ontology | Disaster events | 10 disaster datasets | F1 scores ROUGE-1 = 0.58 ROUGE-2 = 0.29 ROUGE-L = 0.31 | Relies on existing ontology; cannot determine the category of tweet. |
| [62] | Diversity, coverage, and relevance | Graph partitioning | News | News articles and Twitter dataset related to articles | ROUGE-I precision = 0.67 Recall = 0.66 F1 score = 0.664 ROUGE-II precision = 0.56 recall = 0.358 F1 score =0.548. | This method of summarizing news article tweets. |
| [65] | Summary quality | Clustering | Sporting events | NBA basketball games | ROUGET−1 F-1 = 0.3970 | Achieves improvement in performance similar to counterpart. |
| [47] | Content score and performance | LDA and WorkGraph | Generic | [48] | Agglomerative clustering with Hybrid TF-IDF F-Measure delta = +0.255 Bisect K-Means++ with Hybrid TF-IDF F-Measure delta = +0.251 Hybrid TF-IDF alone F-Measure delta = +0.249 | This method takes both topic sentiments and topic aspects into account together. |
| [41] | Salience estimation | Semantic types and graph convolutional network | Generic | Collected tweets for 1000 events | ROUGE-2 = 0.647 BLEU = 0.490 | Two extractive strategies were investigated. The first ranks tweets based on semantic terms; the second generates hidden features. |
| [56] | Redundancy and accuracy | Graph-based | Specific events | Iran Election, IranNuclearProgram, and USPresidentialDebates | ROUGE-1 = 0.6239 ROUGE-2 = 0.5476 | This method identifies the significant events, summarizes them, and generates a coherent storyline of their evolution with a reasonable computational cost for large datasets. |
| [61] | Quality | Multi-objective DE | Specific Topic | Dataset collected from NLP&CC | ROUGE-1 = 0.531706 ROUGE-2 = 0.265799 ROUGE-SU = 0.266479 | This method suggests a summary technique that takes the Paragraph Vector and semantic structure into account. |
| [45] | Detection, Fast Happening Subevents, and hierarchy | LSTM | Specific events | FA CUP final, ST, Primaries, and USEs SB (http://www.socialsensor.eu/results/datasets/72-twitter-tdt-dataset) (accessed on 7 August 2023) | Precision, recall, F-measure, and ROUGE-1 Best F-measure = 0.5644 on the USE dataset | This method generates a storyline for an event using summaries at different levels, but it needs a separate deep learning module that can be trained to combat noise in tweets. |
| [26] | Time complexity, fluency, and adequacy | summary-aware attention | Generic | LCSTS dataset (http://icrc.hitsz.edu.cn/Article/show/139.html) (accessed on 7 August 2023) | Automatic and human ROUGE-1 = 40.3 ROUGE-2 = 27.8 ROUGE-L = 38.4 | This model outperforms Seq2Seq baselines and generates summaries in a coherent manner, but increases the computational cost. |
| [50] | Predict the cosine score | Neural model | Specific event | TSSuBERT (https://github.com/JoeBloggsIR/TSSuBERT) (accessed on 7 August 2023) and Rudra et al. [52] | TSSuBERT ROUGE-1 = 0.111 ROUGE-2 = 0.018 COS Embed = 0.741 Rudra et al. dataset ROUGE-1 = 0.412 ROUGE-2 = 0.192 COS Embed = 0.935 | A neural model automatically summarizes enormous Twitter streams, but it needs to learn the thresholds used in the filtering step. |
| [37] | Detecting contextual bullying | hybrid deep learning | Psychology (cyber-bullying) | Collected Twitter dataset | Accuracy = 90.45% Precision = 89.52% Recall = 88.98% F1 score = 89.25% Specificity = 90.94% | They could not perform the analysis in relation to the users’ behavior. |
| [33] | Accuracy and redundancy | open-sourced search engine and a large language model | Emergency events | TREC and CrisisFACTS | Manual BERTScore = 0.4591 ROUGE-2 = 0.0581 | It did not evaluate the reduction in redundancy. |
| [35] | Time, similarity, and efficiency | Latent Dirichlet allocation (LDA) method and K-means clustering | COVID19Vaccine | Collected Twitter dataset | ROUGE-1: (F1 score: 0.06 to 0.26, recall: 0.1 to 0.21, and precision: 0.05 to 0.19) ROUGE-2: (F1 score: 0.04 to 0.23, recall: 0.01 to 0.19, and precision: 0.03 to 0.17) ROUGE-S4: (F1 score: 0.04 to 0.21, recall: 0.01 to 0.18, and precision: 0.03 to 0.15) ROUGE-SU4: (F1 score: 0.29 to 0.48, recall: 0.04 to 0.07, and precision: 0.07 to 0.12) | The ROUGE may not be the most suitable evaluation matrix for assessing extractive summaries’ effectiveness. |
| [36] | Accuracy and relevance | Combination extraction and abstraction algorithms | Events | Collected Instagram posts | Accuracy = 75% Completeness = 82% Precision = 80% Harmonic mean = 81% Error rates = 25% | The accuracy and efficiency of the summarization process can be enhanced. |
8. Discussion
- ▪
- Extractive-based ASTS techniques encompass a range of methodologies, including machine learning and optimization-based, statistical-based, graph-based, and fuzzy-logic-based approaches. Within the machine learning realm, both supervised and unsupervised techniques aim to enhance accuracy [67] quality [52,58,63,65], and similarity [42,59]. Yet, a comprehensive evaluation often requires a broader focus, encompassing diversity, relevancy, completeness, readability, and redundancy.
- ▪
- Supervised classification techniques, although effective, demand substantial training datasets, leading to challenges in their creation. Unsupervised methods, while promising, encounter the complexities inherent in the diversity and noise of tweets. Optimization-based techniques seek to optimize redundancy [44,54,66], diversity, coverage [67], and other objectives. However, their potential to enhance summary quality, accuracy, similarity, sparsity, and computational efficiency deserves deeper exploration. Resolving conflicting objectives should involve multi-objective optimization algorithms.
- ▪
- Considerations in statistical and graph-based ASTS techniques
- ○
- The landscape of automatic short text summarization (ASTS) techniques is enriched by the contributions of both statistical-based and graph-based approaches. However, a nuanced evaluation reveals distinct considerations and priorities within each of these methodologies. Statistical-based techniques emphasize summary quality and relevancy yet often overlook diversity, accuracy, readability, time constraints, and computational costs. In contrast, graph-based methods prioritize diversity, accuracy [1], and performance [12], with less emphasis on quality, similarity, completeness, redundancy, coverage, readability, time, and computational costs. As ASTS techniques continue to evolve, a synthesis of statistical-based and graph-based methodologies holds the potential to elevate summarization outcomes to new heights. By integrating the strengths of both approaches, researchers could create a more versatile and balanced framework that not only prioritizes quality, diversity, and accuracy but also addresses other critical dimensions. A subset of ASTS techniques dabbles in the application of fuzzy logic; however, the extent of its effectiveness remains uncertain. Further exploration is warranted to ascertain its potential contribution to the advancement of ASTS methodologies.
- ▪
- Balancing act for optimal summarization
- ○
- In the pursuit of effective summarization, the choice between extractive, abstractive, or hybrid approaches hinges on the nature of the input data, the desired level of summary coherence, the intended application, and the complexity of the summarization task. Extractive methods often excel when preserving source text information is crucial, while abstractive methods shine when generating concise and engaging summaries is paramount. However, it is the hybrid approach that embodies the quest for a harmonious equilibrium. By integrating the strengths of both extractive and abstractive techniques, hybrids aspire to deliver summaries that capture the core essence of the source while infusing them with creative and contextual innovations. The realm of ASTS is not about choosing one approach over the other, but rather about finding the ideal equilibrium that aligns with the summarization goals. This dynamic interplay ensures that the art of summarization continues to evolve, offering versatile solutions that adapt to the nuances of diverse text inputs and user preferences.
- ▪
- Dataset limitations and multi-lingual evaluation
- ○
- The efficacy of automatic short text summarization (ASTS) techniques is inherently tied to the quality and diversity of the datasets used for evaluation. However, it is important to acknowledge the limitations present within existing datasets, which are summarized in Table 1, as these limitations can impact the generalizability and reliability of the generated summaries. One of the key limitations lies in the scope and representativeness of the datasets. Many existing datasets are primarily centered around a single platform, such as Twitter, which might not fully capture the intricacies and variations present in other social media platforms like Facebook, Instagram, or Sina Weibo. This platform-centric nature of datasets can lead to biased evaluations, where the performance of ASTS techniques might not translate seamlessly across different platforms. Furthermore, the majority of these datasets are predominantly designed for English text, leaving a significant gap in evaluation capabilities for other languages. This language bias restricts the broader applicability of ASTS techniques across multilingual social media platforms. Languages like Arabic, Hindi, Chinese, and others are underrepresented, which hinders a comprehensive evaluation of techniques’ performance on a global scale. A robust evaluation framework should encompass a spectrum of languages, thereby enabling researchers to gauge the effectiveness of their techniques across different linguistic nuances and structures.
- ○
- By incorporating multiple languages in evaluation, ASTS techniques can be assessed for their adaptability, effectiveness, and challenges in accommodating varying grammatical rules, idiomatic expressions, and cultural contexts. A multi-lingual evaluation not only highlights the strengths and weaknesses of techniques across diverse languages but also fuels advancements that are more universally applicable.
- ○
- In addition to expanding the range of languages, evaluating ASTS techniques on different social media platforms is equally crucial. This broader scope ensures that techniques can effectively handle the idiosyncrasies of various platforms and tailor their summarization outputs accordingly.
9. Challenges
- ▪
- Noisy and informal language: Social media platforms are known for their casual and conversational style of communication. Users often employ abbreviations, emojis, slang, and colloquial language, making the text noisy and informal. Deciphering the meaning and extracting valuable insights from such language can be challenging for summarization algorithms.
- ▪
- Abbreviations and acronyms: The prevalence of abbreviations and acronyms used by users further complicates summarization. These shorthand expressions may not always be universally understood, and different communities develop their own unique set of abbreviations, adding to the difficulty of accurately capturing the content’s essence.
- ▪
- Contextual understanding: Short text on social media often lacks explicit context, leading to ambiguity in meaning. ASTS techniques must be capable of interpreting the implicit context surrounding posts, comments, and tweets to generate coherent and relevant summaries.
- ▪
- Multi-modality: Social media content frequently includes multimedia elements such as images, videos, and emojis, which complement the textual information. Summarization must consider these multi-modal aspects to provide comprehensive and informative summaries.
- ▪
- Dynamic language and trends: The language and trends on social media evolve rapidly, with new terms, hashtags, and trending phrases emerging constantly. Keeping up with the ever-changing language requires ASTS techniques to adapt and update regularly.
- ▪
- Nested conversations and replies: Social media conversations often involve nested replies and discussions, requiring summarization techniques to capture the broader context while maintaining conciseness.
- ▪
- Sentiment and emotional analysis: Emojis, punctuation, and sentiment-laden language are common in social media content, indicating the users’ emotions and attitudes. Properly conveying the sentiment and emotional tone in summaries is vital for comprehensive content understanding.
- ▪
- Data volume and real-time processing: Social media platforms generate an enormous volume of short text data every second. Summarization techniques must handle this vast amount of data efficiently, considering the real-time nature of social media communication.
- ▪
- Data sparsity and imbalanced datasets: Some topics or events on social media may attract an overwhelming amount of attention, while others receive limited engagement. Summarization algorithms must account for data sparsity and imbalanced datasets to generate unbiased and comprehensive summaries.
- ▪
- Ethical and biased content: Social media content may include biased or harmful information. ASTS techniques should be sensitive to ethical concerns and avoid promoting or amplifying harmful narratives in summaries.
10. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Phan, H.T.; Hoang, D.T.; Nguyen, N.T.; Hwang, D. Tweet Integration by Finding the Shortest Paths on a Word Graph. In Modern Approaches for Intelligent Information and Database Systems; Springer: Cham, Switzerland, 2018; pp. 87–97. [Google Scholar]
- Nenkova, A.; McKeown, K. Automatic summarization. Found. Trends® Inf. Retr. 2011, 5, 103–233. [Google Scholar] [CrossRef]
- Nallapati, R.; Zhai, F.; Zhou, B. Summarunner: A recurrent neural network based sequence model for extractive summarization of documents. In Proceedings of the AAAI Conference on Artificial Intelligence Palo, Alto, San Francisco, CA, USA, 4–9 February 2017; p. 31. [Google Scholar]
- Liu, Y.; Lapata, M. Text Summarization with Pretrained Encoders. In Proceedings of the 2019 Conference on Empirical Methods in Natural, Hong Kong, China, November 2019; pp. 3728–3738. [Google Scholar]
- Jones, K.S. Automatic summarising: The state of the art. Inf. Process. Manag. 2007, 43, 1449–1481. [Google Scholar] [CrossRef]
- Sharifi, B.P.; Inouye, D.I.; Kalita, J.K. Summarization of twitter microblogs. Comput. J. 2014, 57, 378–402. [Google Scholar] [CrossRef]
- Atefeh, F.; Khreich, W. A survey of techniques for event detection in twitter. Comput. Intell. 2015, 31, 132–164. [Google Scholar] [CrossRef]
- Kawade, P.B.; Pise, N.N. Summarization Approach Of Situational Information from Microblogs During Disaster Events: A Survey. Int. J. Latest Trends Eng. Technol. 2016, 7, 108–112. [Google Scholar]
- Ramachandran, D.; Ramasubramanian, P. Event detection from Twitter—A survey. Int. J. Web Inf. Syst. 2018, 14, 262–280. [Google Scholar] [CrossRef]
- Rudrapal, D.; Das, A.; Bhattacharya, B. A survey on automatic Twitter event summarization. J. Inf. Process. Syst. 2018, 14, 79–100. [Google Scholar]
- Hasan, M.; Orgun, M.A.; Schwitter, R. A survey on real-time event detection from the Twitter data stream. J. Inf. Sci. 2018, 44, 443–463. [Google Scholar] [CrossRef]
- Ermakova, L.; Cossu, J.V.; Mothe, J. A survey on evaluation of summarization methods. Inf. Process. Manag. 2019, 56, 1794–1814. [Google Scholar] [CrossRef]
- Taecharungroj, V. “What Can ChatGPT Do?” Analyzing Early Reactions to the Innovative AI Chatbot on Twitter. Big Data Cogn. Comput. 2023, 7, 35. [Google Scholar] [CrossRef]
- Thakur, N. A Large-Scale Dataset of Twitter Chatter about Online Learning during. Data 2022, 7, 109. [Google Scholar] [CrossRef]
- Anon. Twitter Usage Statistics. 2022. Available online: https://www.internetlivestats.com/twitter-statistics/ (accessed on 7 August 2023).
- Anon. Twitter User Count. 2022. Available online: https://expandedramblings.com/index.php/twitter-stats-facts/ (accessed on 7 August 2023).
- Anon. Counting Character. 2022. Available online: https://developer.twitter.com/en/docs/counting-characters (accessed on 7 August 2023).
- Dixon, S.J. Global Social Networks Ranked by Number of Users. 2023. Available online: https://www.statista.com/statistics/272014/global-social-networks-ranked-by-number-of-users/ (accessed on 27 August 2023).
- Kaplan, A.M.; Haenlein, M. Users of the world, unite! The challenges and opportunities of Social Media. Bus. Horiz. 2010, 53, 59–68. [Google Scholar] [CrossRef]
- Thakur, N. MonkeyPox2022Tweets: A Large-Scale Twitter Dataset on the 2022 Monkeypox Outbreak, Findings from Analysis of Tweets, and Open Research Questions. Infect. Dis. Rep. 2022, 14, 855–883. [Google Scholar] [CrossRef] [PubMed]
- Hayawi, K.; Shahriar, S.; Serhani, M.A.; Taleb, I.; Mathew, S.S. ANTi-Vax: A novel Twitter dataset for COVID-19 vaccine misinformation detection. Public Health 2022, 203, 23–30. [Google Scholar] [CrossRef] [PubMed]
- Caillaut. French Entity-Linking Dataset between Annotated. 2023. Available online: https://zenodo.org/record/7767294 (accessed on 9 August 2023).
- Pano, T.; Kashef, R. A Complete VADER-Based Sentiment Analysis of Bitcoin (BTC) Tweets during the Era of COVID-19. Big Data Cogn. Comput. 2020, 4, 33. [Google Scholar] [CrossRef]
- Abdulateef, S.; Khan, N.A.; Chen, B.; Shang, X. Multidocument Arabic Text Summarization Based on Clustering and Word2Vec to Reduce Redundancy. Information 2020, 11, 59. [Google Scholar] [CrossRef]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 1 July 2004; pp. 404–411. [Google Scholar]
- Wang, Q.; Ren, J. Summary-aware attention for social media short text abstractive summarization. Neurocomputing 2021, 425, 290–299. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Advances in Neural Information Processing Systems 27: Annual Conference; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 3104–3112. [Google Scholar]
- Hariardi, W.; Latief, N.; Febryanto, D.; Suhartono, D. Automatic summarization from Indonesian hashtag on Twitter using TF-IDF and phrase reinforcement algorithm. In Proceedings of the 6th International Computer Science and Engineering, Vienna, Austria, 21–22 May 2016; pp. 17–19. [Google Scholar]
- Moratanch, N.; Chitrakala, S. A survey on extractive text summarization. In Proceedings of the 2017 International Conference on Computer, Communication and Signal Processing (ICCCSP), Chennai, India, 10–11 January 2017; pp. 1–6. [Google Scholar]
- Lloret, E.; Plaza, L.; Aker, A. The challenging task of summary evaluation: An overview. Lang. Resour. Eval. 2018, 52, 101–148. [Google Scholar] [CrossRef]
- Lin, C.-Y. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Zhang, R.; Li, W.; Gao, D.; Ouyang, Y. Automatic twitter topic summarization with speech acts. IEEE Trans. Audio Speech Lang. Process. 2012, 21, 649–658. [Google Scholar] [CrossRef]
- Pereira, J.; Fidalgo, R.; Lotufo, R.; Nogueira, R. Crisis Event Social Media Summarization with GPT-3 and Neural Reranking. In Proceedings of the 20th ISCRAM Conference, Omaha, NE, USA, May 2023; Volume 8. [Google Scholar]
- Track, T.C. CrisisFACTS. 2023. Available online: https://crisisfacts.github.io/#datasets (accessed on 27 August 2023).
- Alabid, N.; Naseer, Z. Summarizing twitter posts regarding COVID-19 based on n-grams. Indones. J. Electr. Eng. Comput. Sci. 2023, 8, 1008–1015. [Google Scholar] [CrossRef]
- Taghandiki, K.; Ahmadi, M.H.; Ehsan, E.R. Automatic summarisation of Instagram social network posts Combining semantic and statistical approaches. arXiv 2023, arXiv:2303.07957v1. [Google Scholar]
- Murshed, B.A.H.; Abawajy, J.; Mallappa, S.; Saif, M.A.N.; Al-Ariki, H.D.E. DEA-RNN: A hybrid deep learning approach for cyberbullying detection in Twitter social media platform. IEEE Access 2022, 10, 25857–25871. [Google Scholar] [CrossRef]
- Garg, P.K.; Chakraborty, R.; Dandapat, S.K. Ontorealsumm: Ontology based real-time tweet summarization. arXiv 2022, arXiv:2201.06545. [Google Scholar]
- Mukherjee, R.; Vishnu, U.; Peruri, H.C.; Bhattacharya, S.; Rudra, K.; Goyal, P.; Ganguly, N. Mtlts: A multi-task framework to obtain trustworthy summaries from crisis-related microblogs. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 755–763. [Google Scholar]
- Panchendrarajan, R.; Hsu, W.; Li Lee, M. Emotion-Aware Event Summarization in Microblogs. In Proceedings of the Companion Proceedings of the Web Conference 2021, New York, NY, USA, April 2021; pp. 486–494. [Google Scholar]
- Li, Q.; Zhang, Q. Twitter event summarization by exploiting semantic terms and graph network. Proc. AAAI Conf. Artif. Intell. 2021, 35, 15347–15354. [Google Scholar] [CrossRef]
- Saini, N.; Saha, S.; Bhattacharyya, P. Microblog summarization using self-adaptive multi-objective binary differential evolution. Appl. Intell. 2022, 52, 1686–1702. [Google Scholar] [CrossRef]
- Saini, N.; Saha, S.; Mansoori, S.; Bhattacharyya, P. Fusion of self-organizing map and granular self-organizing map for microblog summarization. Soft Comput. 2020, 24, 18699–18711. [Google Scholar] [CrossRef]
- Saini, N.; Saha, S.; Mansoori, S.; Bhattacharyya, P. Automatic parameter selection of granual self-organizing map for microblog summarization. In Neural Information Processing, Proceedings of the 27th International Conference, ICONIP 2020, Bangkok, Thailand, 23–27 November 2020; Springer: Cham, Switzerland, 2020; pp. 680–692. [Google Scholar] [CrossRef]
- Goyal, P.; Kaushik, P.; Gupta, P.; Vashisth, D.; Agarwal, S.; Goyal, N. Multilevel event detection, storyline generation, and summarization for tweet streams. IEEE Trans. Comput. Soc. Syst. 2019, 7, 8–23. [Google Scholar] [CrossRef]
- Lin, C.; Ouyang, Z.; Wang, X.; Li, H.; Huang, Z. Preserve integrity in realtime event summarization. ACM Trans. Knowl. Discov. Data (TKDD) 2021, 15, 1–29. [Google Scholar] [CrossRef]
- Ali, S.M.; Noorian, Z.; Bagheri, E.; Ding, C.; Al-Obeidat, F. Topic and sentiment aware microblog summarization for twitter. J. Intell. Inf. Syst. 2020, 54, 129–156. [Google Scholar] [CrossRef]
- Abel, F.; Gao, Q.; Houben, G.-J.; Tao, K. Analyzing user modeling on twitter for personalized news recommendations. In User Modeling, Adaption and Personalization, Proceedings of the 19th International Conference, UMAP 2011, Girona, Spain, 11–15 July 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–12. [Google Scholar]
- Lavanya, P.G.; Kouser, K.; Suresha, M. Efficient pre-processing and feature selection for clustering of cancer tweets. In Proceedings of the Intelligent Systems, Technologies and Applications: Proceedings of ISTA 2018, Bangalore, India, 19–22 September 2020; pp. 17–37. [Google Scholar]
- Dusart, A.; Pinel-Sauvagnat, K.; Hubert, G. Tssubert: Tweet stream summarization using bert. arXiv 2021, arXiv:2106.08770. [Google Scholar]
- Zubiaga, A. A longitudinal assessment of the persistence of twitter datasets. J. Assoc. Inf. Sci. Technol. 2018, 69, 974–984. [Google Scholar] [CrossRef]
- Rudra, K.; Sharma, A.; Ganguly, N.; Imran, M. Classifying and summarizing information from microblogs during epidemics. Inf. Syst. Front. 2018, 20, 933–948. [Google Scholar] [CrossRef] [PubMed]
- Dhiman, A.; Toshniwal, D. An approximate model for event detection from twitter data. IEEE Access 2020, 8, 122168–122184. [Google Scholar] [CrossRef]
- Lucky; Girsang, A.S. Multi-Objective Ant Colony Optimization for Automatic Social Media Comments Summarization. Int. J. Adv. Comput. Sci. Appl. 2019, 10. [Google Scholar] [CrossRef]
- Liang, Z.; Du, J.; Li, C. Abstractive social media text summarization using selective reinforced Seq2Seq attention model. Neurocomputing 2020, 410, 432–440. [Google Scholar] [CrossRef]
- Dehghani, N.; Asadpour, M. SGSG: Semantic graph-based storyline generation in Twitter. J. Inf. Sci. 2019, 45, 304–321. [Google Scholar] [CrossRef]
- Rudrapal, D.; Das, A.; Bhattacharya, B. A new approach for twitter event summarization based on sentence identification and partial textual entailment. Comput. Sist. 2019, 23, 1065–1078. [Google Scholar] [CrossRef]
- Dutta, S.; Ghatak, S.; Das, A.K.; Gupta, M.; Dasgupta, S. Feature selection-based clustering on micro-blogging data. In Computational Intelligence in Data Mining: Proceedings of the International Conference on CIDM 2017; Springer: Singapore, 2019; pp. 885–895. [Google Scholar]
- Dutta, S.; Das, A.K.; Bhattacharya, A. Community detection based tweet summarization. In Emerging Technologies in Data Mining and Information Security: Proceedings of IEMIS 2018; Springer: Singapore, 2019; Volume 2, pp. 797–808. [Google Scholar]
- Wei, B.; Ren, X.; Zhang, Y.; Cai, X.; Su, Q.; Sun, X. Regularizing output distribution of abstractive chinese social media text summarization for improved semantic consistency. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2019, 18, 1–15. [Google Scholar] [CrossRef]
- Wang, R.; Luo, S.; Pan, L.; Wu, Z.; Yuan, Y.; Chen, Q. Microblog summarization using paragraph vector and semantic structure. Comput. Speech Lang. 2019, 57, 1–19. [Google Scholar] [CrossRef]
- Chakraborty, R.; Bhavsar, M.; Dandapat, S.K.; Chandra, J. Tweet summarization of news articles: An objective ordering-based perspective. IEEE Trans. Comput. Soc. Syst. 2019, 6, 761–777. [Google Scholar] [CrossRef]
- Rudra, K.; Ganguly, N.; Goyal, P.; Ghosh, S. Extracting and summarizing situational information from the twitter social media during disasters. ACM Trans. Web (TWEB) 2018, 12, 1–35. [Google Scholar] [CrossRef]
- Nguyen, M.-T.; Tran, D.-V.; Nguyen, L.-M. Social context summarization using user-generated content and third-party sources. Knowl.-Based Syst. 2018, 144, 51–64. [Google Scholar] [CrossRef]
- Huang, Y.; Shen, C.; Li, T. Event summarization for sports games using twitter streams. World Wide Web 2018, 21, 609–627. [Google Scholar] [CrossRef]
- He, R.; Duan, X. Twitter summarization based on social network and sparse reconstruction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; p. 32. [Google Scholar]
- Madichetty, S.; Muthukumarasamy, S. Detection of situational information from Twitter during disaster using deep learning models. Sādhanā 2020, 45, 1–13. [Google Scholar] [CrossRef]
- Andy, A.; Wijaya, D.T.; Callison-Burch, C. Winter is here: Summarizing twitter streams related to pre-scheduled events. In Proceedings of the Second Workshop on Storytelling, Florence, Italy, August 2019; Association for Computational Linguistics: Barcelona, Spain, 2019; pp. 112–116. [Google Scholar]
- Ma, S.; Sun, X.; Lin, J.; Wang, H. Autoencoder as assistant supervisor: Improving text representation for chinese social media text summarization. arXiv 2018, arXiv:1805.04869. [Google Scholar]

| Name | Domain | Source/Language | Size | Ref. |
|---|---|---|---|---|
| A Large-Scale Dataset of Twitter Chatter about Online Learning during the Current COVID-19 Omicron Wave | Education | Twitter—English | 52,984 tweet IDs | https://zenodo.org/record/6837118 [14] (accessed on 7 August 2023) |
| MonkeyPox2022Tweets | Healthcare | Twitter—English | 571,831 tweets | https://doi.org/10.7910/DVN/CR7T5E [20] (accessed on 7 August 2023) |
| ANTiVax | COVID-19 vaccine | Twitter—Arabic and English | 15 Million tweets | https://github.com/SakibShahriar95/ANTiVax [21] (accessed on 7 August 2023) |
| RéSoCIO | Disaster events | Twitter—French | 4617 tweets | https://doi.org/10.5281/zenodo.7767294 [22] (accessed on 7 August 2023) |
| SNAP 2009 | General | Twitter—English | 467 million tweets—from 20 million users | https://snap.stanford.edu/data/twitter7.html (accessed on 7 August 2023) |
| Twitter data 2012 | Popular topics | Twitter—Chinese | 50 million tweets | https://wiki.illinois.edu/wiki/display/forward/Dataset-UDI-TwitterCrawl-Aug2012 (accessed on 7 August 2023) |
| RepLab 2013 | Automotive, banking, universities, and music/artists | Twitter—English and Spanish | more than 142,000 tweets | http://nlp.uned.es/replab2013/replab2013-dataset.tar.gz (accessed on 7 August 2023) |
| Andrei Olariu 2014 | Important events | Twitter—English | 3.4 million tweets | https://github.com/andreiolariu/online-summarizer (accessed on 7 August 2023) |
| UkFlood 2015 | Disaster events | Twitter—English | 2069 tweets | http://cse.iitkgp.ac.in/~krudra/disaster_dataset.html (accessed on 7 August 2023) |
| Sandyhook 2015 | Disaster events | Twitter—English | 2080 tweets | http://cse.iitkgp.ac.in/~krudra/disaster_dataset.html (accessed on 7 August 2023) |
| Hblast 2015 | Disaster events | Twitter—English | 1413 tweets | http://cse.iitkgp.ac.in/~krudra/disaster_dataset.html (accessed on 7 August 2023) |
| Hagupit 2015 | Disaster events | Twitter—English | 1461 tweets | http://cse.iitkgp.ac.in/~krudra/disaster_dataset.html (accessed on 7 August 2023) |
| Nepal Earthquake (NEQuake) 2015 | Disaster events | Twitter—English | 1.87 million messages | http://cse.iitkgp.ac.in/~krudra/nepal_earthquake.html (accessed on 7 August 2023) |
| LCSTS dataset 2016 | Generic | Sina Weibo—Chinese | 2,400,591 text–summary pairs, 10,666 text–summary pairs and 1106 | https://paperswithcode.com/dataset/lcsts (accessed on 7 August 2023) |
| TwitterAAE dataset 2016 | Twitter—English | 60 million tweets | http://slanglab.cs.umass.edu/TwitterAAE (accessed on 7 August 2023) | |
| CrowdFlower AI Gender dataset 2016 | Gender classifier data | Twitter—English | 20,000 posts with user-information | https://www.crowdflower.com/data-for-everyone/ (accessed on 7 August 2023) |
| USPresidentialDebates 2016 | Us election | Twitter—English | 11 million tweets | https://www.kaggle.com/mrisdal/2016-us-presidential-debates (accessed on 7 August 2023) |
| Twitter events 2012–2016 | different real-world events | Twitter—English | 147 million tweets | https://figshare.com/articles/Twitter_event_datasets_2012-2016_/5100460 (accessed on 7 August 2023) |
| Customer Support on Twitter Dataset 2017 | Product complaints (business) | Twitter—English | 3 million tweets | https://www.kaggle.com/thoughtvector/customer-support-on-twitter (accessed on 7 August 2023) |
| TREC Dynamic Domain Track 2017 | Ebola outbreak | Dynamic website—Chinese | 90,823 tweets | http://trec-dd.org/ (accessed on 7 August 2023) |
| Epidemics: 1. Ebola 2. MERS 2018 | Epidemics | Twitter—English | 5.08 million messages, 0.215 million messages | http://cse.iitkgp.ac.in/~krudra/epidemic.html (accessed on 7 August 2023) |
| TSSuBERT 2018 | Generic event | Twitter—English | 150 million tweets | https://github.com/JoeBloggsIR/TSSuBERT (accessed on 7 August 2023) |
| XMUDM/IAEA 2020 | Generic real-time event | Twitter—English | 9,154,025 tweets | https://github.com/XMUDM/IAEA (accessed on 7 August 2023) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghanem, F.A.; Padma, M.C.; Alkhatib, R. Automatic Short Text Summarization Techniques in Social Media Platforms. Future Internet 2023, 15, 311. https://doi.org/10.3390/fi15090311
Ghanem FA, Padma MC, Alkhatib R. Automatic Short Text Summarization Techniques in Social Media Platforms. Future Internet. 2023; 15(9):311. https://doi.org/10.3390/fi15090311
Chicago/Turabian StyleGhanem, Fahd A., M. C. Padma, and Ramez Alkhatib. 2023. "Automatic Short Text Summarization Techniques in Social Media Platforms" Future Internet 15, no. 9: 311. https://doi.org/10.3390/fi15090311
APA StyleGhanem, F. A., Padma, M. C., & Alkhatib, R. (2023). Automatic Short Text Summarization Techniques in Social Media Platforms. Future Internet, 15(9), 311. https://doi.org/10.3390/fi15090311