
E-SAWM: A Semantic Analysis-Based ODF Watermarking Algorithm for Edge Cloud Scenarios


 ,
,
Abstract
:1. Introduction
- 1.
- Transparency: E-SAWM ensures zero interference with the structure and display of the OFD file, preserving its original integrity;
- 2.
- Concealment: E-SAWM utilizes transformations and realistic pseudosentences to effectively conceal the watermark, impeding detection by potential attackers;
- 3.
- Robustness: E-SAWM employs distributed embedding of the watermark across multiple structural files and selects distributed redundant bits within the same file. This approach enhances the robustness of the watermark and hinders attackers from destroying the watermark information in the OFD file;
- 4.
- High capacity: E-SAWM supports unlimited watermark information in terms of length and quantity, enabling the embedding of a substantial amount of watermark data.
2. Related Work
2.1. Application of Edge Computing in the Domain of Financial Data Protection
2.2. Edge Cloud-Based Financial Regulatory Outpost Technology
- 1.
- Elastic and scalable resource allocation: Data processing applications necessitate computational resources, but the overall data volume tends to vary. For instance, during certain periods, the data volume processed by the application side may increase, requiring more CPU performance, memory, hard disk space, and network throughput capacity. Conversely, when the processing data volume decreases, these hardware resources remain underutilized, leading to wastage. Therefore, it is essential for regulatory outposts to support the elastic scaling of resources to minimize input costs associated with data processing operations;
- 2.
- Low bandwidth consumption cost and data processing latency: The application’s data traffic is directed through the regulatory outpost, which can lead to increased bandwidth consumption costs and higher network latency, especially if the outpost is deployed in a remote location like another city. The current backbone network, which is responsible for interconnecting cities, incurs higher egress bandwidth prices, and its latency is relatively higher compared to the metropolitan area network and local area network. To minimize the impact on the application experience, it is essential to maintain low bandwidth utilization costs and minimize data processing latency;
- 3.
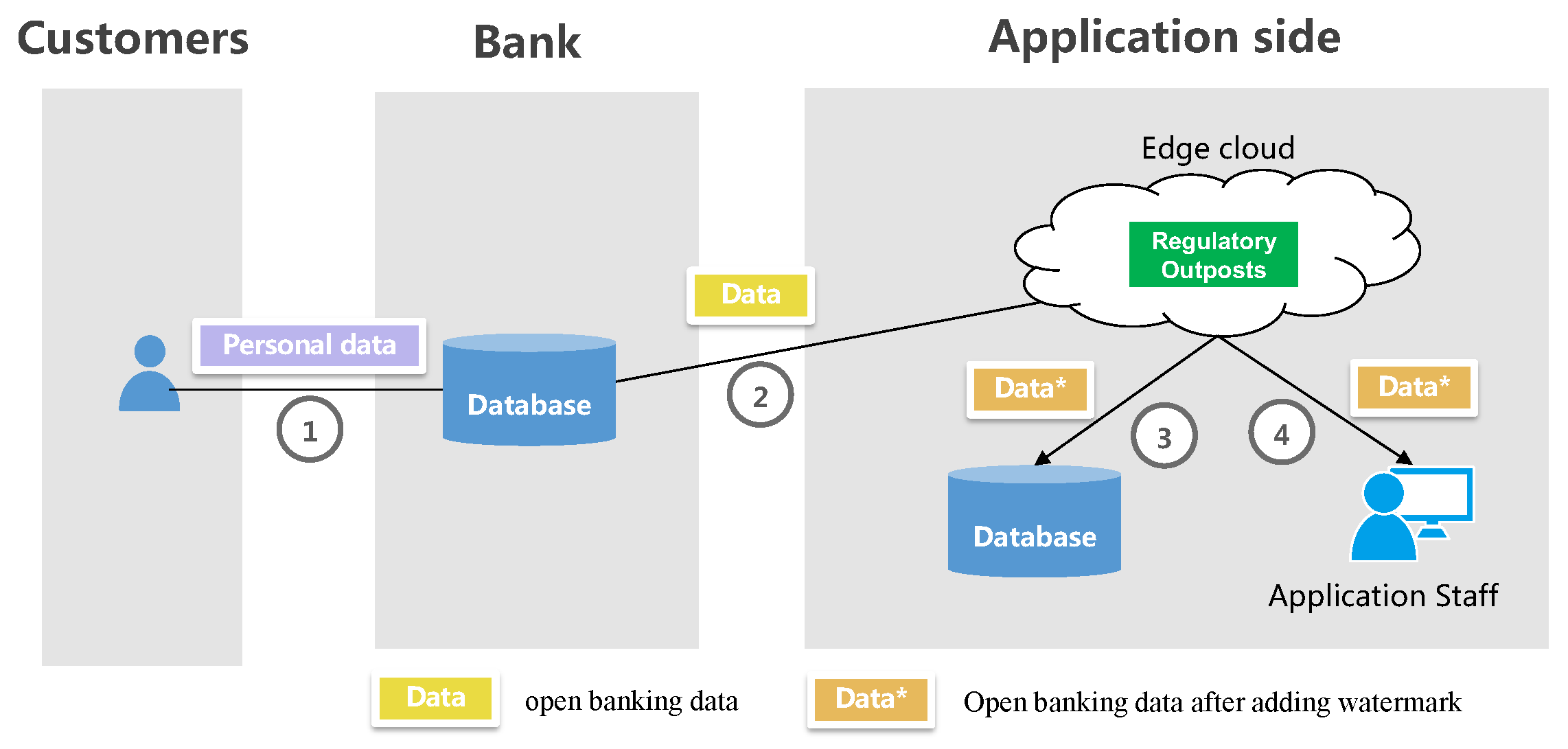
- Data compliance: Due to concerns about open banking data leakage, the application side tends to prefer localized storage of open banking data to the greatest extent possible, which enables the application side to more conveniently monitor the adequacy of security devices and the effectiveness of security management protocols.
2.2.1. Regulatory Outpost—Data Input Processing
2.2.2. Regulatory Outpost—Data Export Processing
2.3. Document Watermarking Techniques
- 1.
- 2.
- Format-based approaches encompass techniques such as line shift coding, word shift coding, space coding, modification of character colors, and adjustment of glyph structures [15];
- 3.
- Document structure-based approaches leverage PDF structures like PageObject, imageObject, and cross-reference tables, enabling the embedding of watermarks while preserving the original explicit location [16].
3. Model and Algorithm
3.1. Dynamic Watermarking Implementation
- 1.
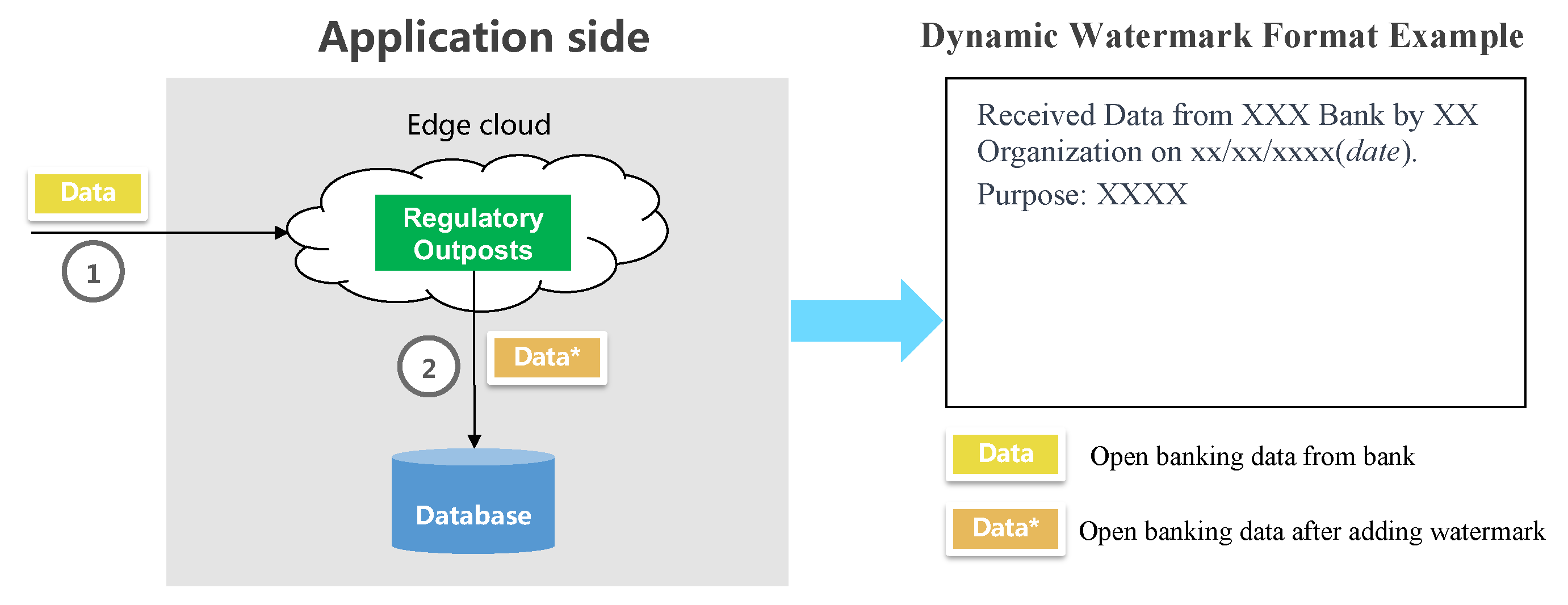
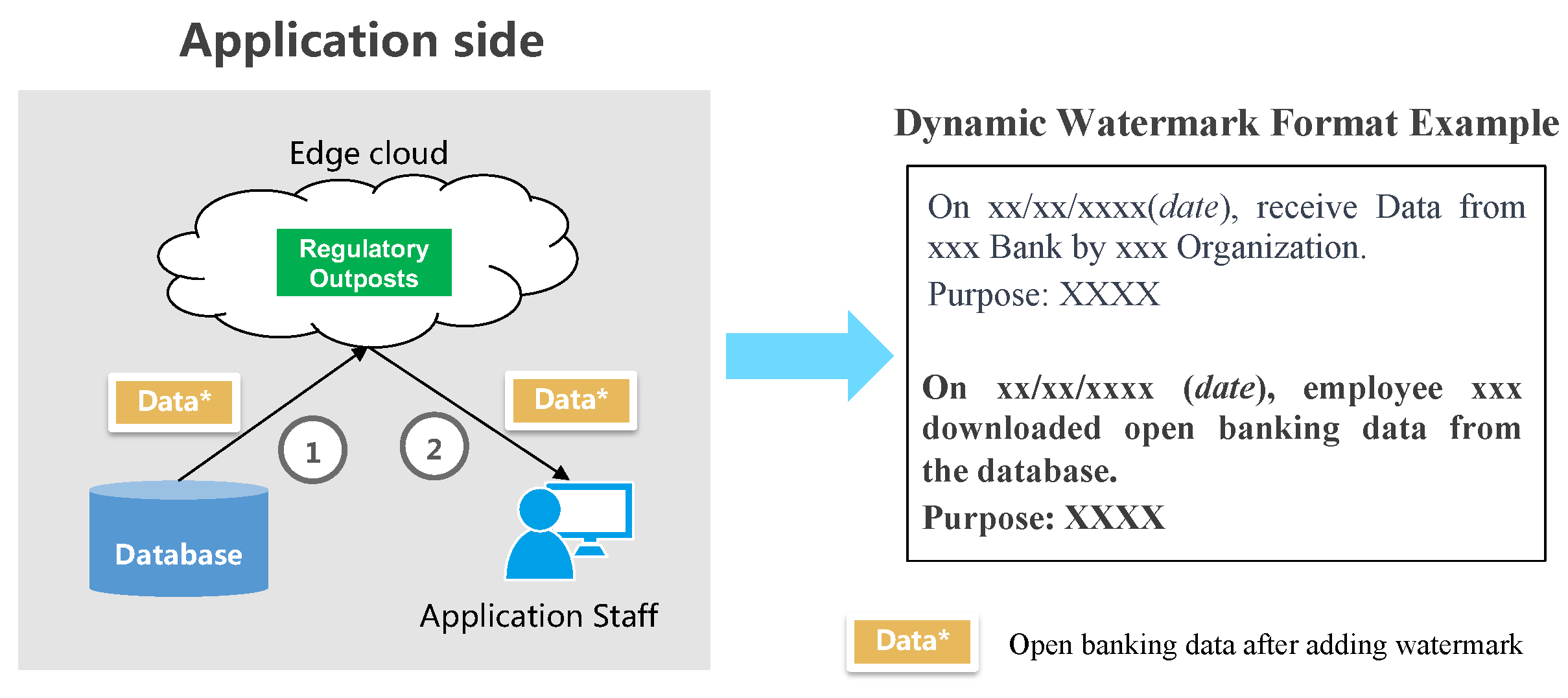
- Adding watermarks during data reception by the application-side database, as depicted in Figure 6. As the application side receives open banking data from a bank, a dynamic watermark is added, either explicitly or implicitly, while the data traverses a supervisory outpost situated in the edge cloud. This watermarking enables traceability in the event of an open banking data breach, allowing for identification of the breaching application side. The standard format typically follows: “Received Data from XXX Bank by XX Organization on xx/xx/xxxx (date). Purpose: XXXX”.;
- 2.
- Adding watermarks during the download of data from the database by application-side employees, as shown in Figure 7. Whenever an application-side employee retrieves data from the application-side database, a dynamic watermark, typically implicit in nature, is embedded. This watermark serves the purpose of identifying the individual responsible for any data leakage when tracing its origin in the context of open banking. The format commonly follows “On xx/xx/xxxx (date), employee xxx downloaded open banking data from the database. Purpose: XXXX”. Remarkably, the newly added watermark can coexist with the original watermark;
- 3.
- Adding watermarks when sharing data with external entities on the application side, as shown in Figure 8. In some cases, the application side needs to desensitize the open banking data, then share it with a partner, such as in the need for business cooperation. Hence, it is necessary to add a watermark to identify the specific partner when the leakage is traced. Typically, the format is “On xx/xx/xxxx (date), xxxx shared open banking data with the collaborator, xxxx. Purpose: XXXX”.
3.2. Dynamic Watermarking Algorithm for OFD
3.2.1. Semantic Analysis Model
- Skip-Gram model
- CBOW model
- Word-embedding model comparison
3.2.2. OFD Watermarking Algorithm Based on Semantic Analysis
- 1.
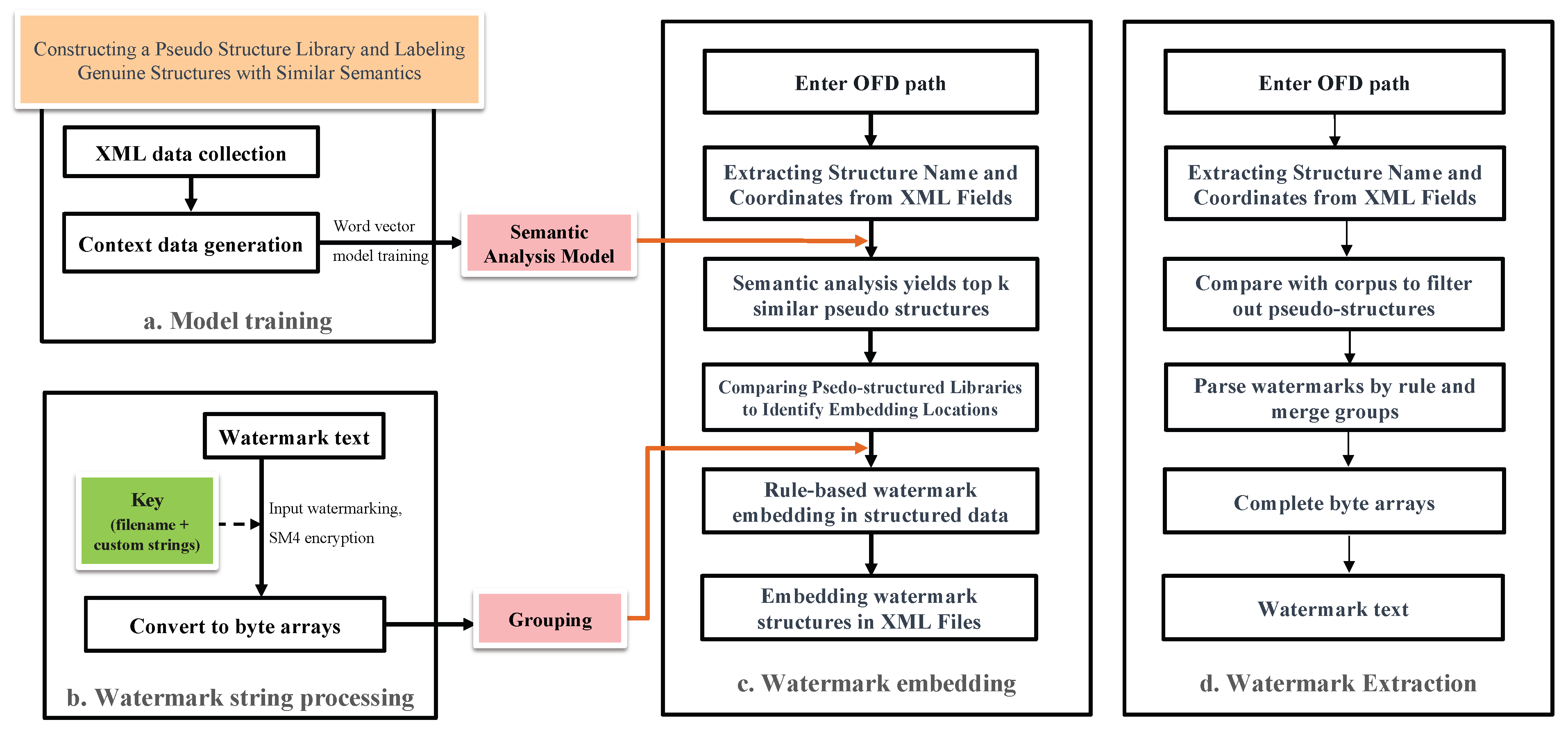
- Semantic analysis model trainingConstruct a pseudo structural library based on the original structural library of OFD. Gather n instances of context data from structured documents in OFD format. Utilizing these context data, along with the pseudo structure body library, generate instances of the context dataset with pseudo structure bodies. These contextual datasets are then trained separately using the CBOW model and the Skip-gram model to develop the semantic analysis model. When conducting semantic analysis on an OFD-structured document, the context is initially extracted. For a context dataset containing a higher frequency of low-frequency structural bodies, the Skip-gram model is preferred for semantic analysis due to its improved performance and efficiency. On the other hand, for the contextual dataset containing a higher frequency of high-frequency structures, CBOW is used for semantic analysis.Assume that m structural files with embeddable watermarks are extracted for an OFD file that requires watermark addition. structural keywords are extracted from file , and the training window size is K. In such cases, the time complexity for training using the CBOW model can be calculated as follows:The time complexity for training using the Skip-gram model is as follows:Based on the size of the text words, we set the threshold () to select the model with the best training effect for calculation:As mentioned in Section 3.2.1, the Skip-gram model exhibited higher accuracy compared to the CBOW model in our experiments. In particular, when the time consumed is similar, the Skip-gram model outperforms CBOW. In our work, this occurred when had a value of 1000.
- 2.
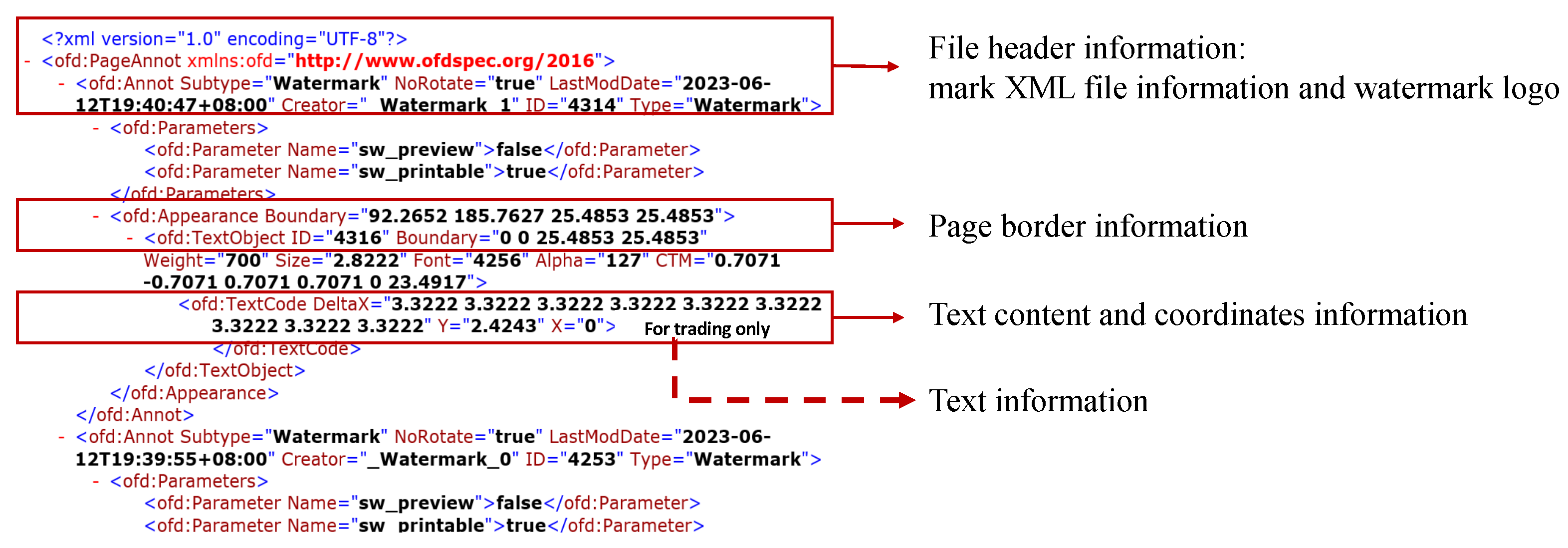
- Watermark content processing. Encrypt the watermark text (originalInfo) using the SM4 algorithm with a key derived from the combination of the file name (fileName) of the watermarked file, and a custom string (myString) provided by the adder. This encryption process is represented by Equation (9).Subsequently, convert the encrypted watermark message into a byte array and perform grouping on the byte array;
- 3.
- Watermark embedding. For each structural file within the target OFD file, conduct structure extraction. Combine these structures as contexts in their original order. Utilize the semantic analysis model trained in step 1 to perform semantic analysis, then obtain pseudo structures with the top K similarity. Insert these pseudo structures into the structural files of the OFD, and embed the watermark grouping acquired in step 2 into each pseudo structure;
- 4.
- Watermark Extraction. Extract structure names and contents from all structural files within the OFD file intended for watermarking, which is compared with the corpus, and filter out any pseudo structures. Based on the grouping information within the structure, combine byte array groups associated with the same watermark. This process results in a complete byte array, which is then parsed into a string and further parsed using a key. Finally, the complete watermark is obtained.
4. Experiments
4.1. Steganography
4.2. Robustness
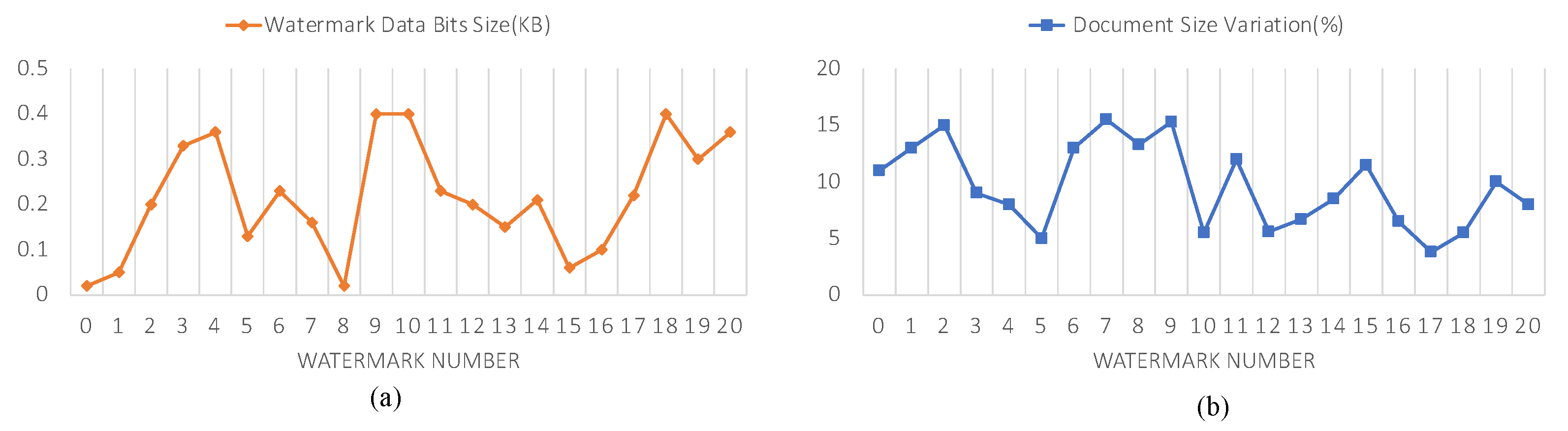
4.3. Watermark Capacity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Premchand, A.; Choudhry, A. Open banking & APIs for Transformation in Banking. In Proceedings of the 2018 International Conference on Communication, Computing and Internet of Things (IC3IoT), Chennai, India, 15–17 February 2018; pp. 25–29. [Google Scholar]
- Longlei, H.; Peiliang, Z.; Hua, J. Research and implementation of format document OFD electronic seal module. Inf. Technol. 2016, 40, 76–80. [Google Scholar]
- Kassab, M.; Laplante, P. Trust considerations in open banking. IT Prof. 2022, 24, 70–73. [Google Scholar]
- Hong, X.; Wang, Y. Edge computing technology: Development and countermeasures. Strateg. Study Chin. Acad. Eng. 2018, 20, 20–26. [Google Scholar]
- Giust, F.; Costa-Perez, X.; Reznik, A. Multi-access edge computing: An overview of ETSI MEC ISG. IEEE Tech Focus 2017, 1, 4. [Google Scholar]
- Cui, G.; He, Q.; Li, B.; Xia, X.; Chen, F.; Jin, H.; Xiang, Y.; Yang, Y. Efficient verification of edge data integrity in edge computing environment. IEEE Trans. Serv. Comput. 2021, 15, 3233–3244. [Google Scholar]
- Gu, L.; Zhang, W.; Wang, Z.; Zeng, D.; Jin, H. Service Management and Energy Scheduling Toward Low-Carbon Edge Computing. IEEE Trans. Sustain. Comput. 2022, 8, 109–119. [Google Scholar]
- Zhang, Z.; Avazov, N.; Liu, J.; Khoussainov, B.; Li, X.; Gai, K.; Zhu, L. WiPOS: A POS terminal password inference system based on wireless signals. IEEE Internet Things J. 2020, 7, 7506–7516. [Google Scholar]
- Ati, M.; Al Bostami, R. Protection of Data in Edge and Cloud Computing. In Proceedings of the 2022 IEEE International Conference on Computing (ICOCO), Sabah, Malaysia, 14–16 November 2022; pp. 169–173. [Google Scholar]
- Chen, L.; Liu, Z.; Wang, Z. Research on heterogeneous terminal security access technology in edge computing scenario. In Proceedings of the 2019 11th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Qiqihar, China, 28–29 April 2019; pp. 472–476. [Google Scholar]
- Song, Z.; Ma, H.; Zhang, R.; Xu, W.; Li, J. Everything Under Control: Secure Data Sharing Mechanism for Cloud-Edge Computing. IEEE Trans. Inf. Forensics Secur. 2023, 18, 2234–2249. [Google Scholar]
- Wang, Z.; Fan, J. Flexible threshold ring signature in chronological order for privacy protection in edge computing. IEEE Trans. Cloud Comput. 2020, 10, 1253–1261. [Google Scholar]
- GB/T 33190; 2016 Electronic Files Storage and Exchange Formats—Fixed Layout Documents. China National Standardization Management Committee: Beijing, China, 2016.
- Yu, Z.; Ting, L.; Yihen, C.; Shiqi, Z.; Sheng, L. Natural Languagetext Watermarking. J. Chin. Inf. Process. 2005, 19, 57–63. [Google Scholar]
- Wang, X.; Jin, Y. A high-capacity text watermarking method based on geometric micro-distortion. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 1749–1755. [Google Scholar]
- Zhao, W.; Guan, H.; Huang, Y.; Zhang, S. Research on Double Watermarking Algorithm Based on PDF Document Structure. In Proceedings of the 2020 International Conference on Culture-oriented Science & Technology (ICCST), Beijing, China, 28–31 October 2020; pp. 298–303. [Google Scholar]
- Zhengyan, Z.; Yanhui, G.; Guoai, X. Digital watermarking algorithm based on structure of PDF document. Comput. Appl. 2012, 32, 2776–2778. [Google Scholar]
- Khadam, U.; Iqbal, M.M.; Habib, M.A.; Han, K. A Watermarking Technique Based on File Page Objects for PDF. In Proceedings of the 2019 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM), Victoria, BC, Canada, 21–23 August 2019; pp. 1–5. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Asgari, E.; Mofrad, M.R. Continuous distributed representation of biological sequences for deep proteomics and genomics. PLoS ONE 2015, 10, e0141287. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Hao, Y.; Chuang, L.; Feng, Q.; Rong, D. A Survey of Digital Watermarking. Comput. Res. Dev. 2005, 42, 1093–1099. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
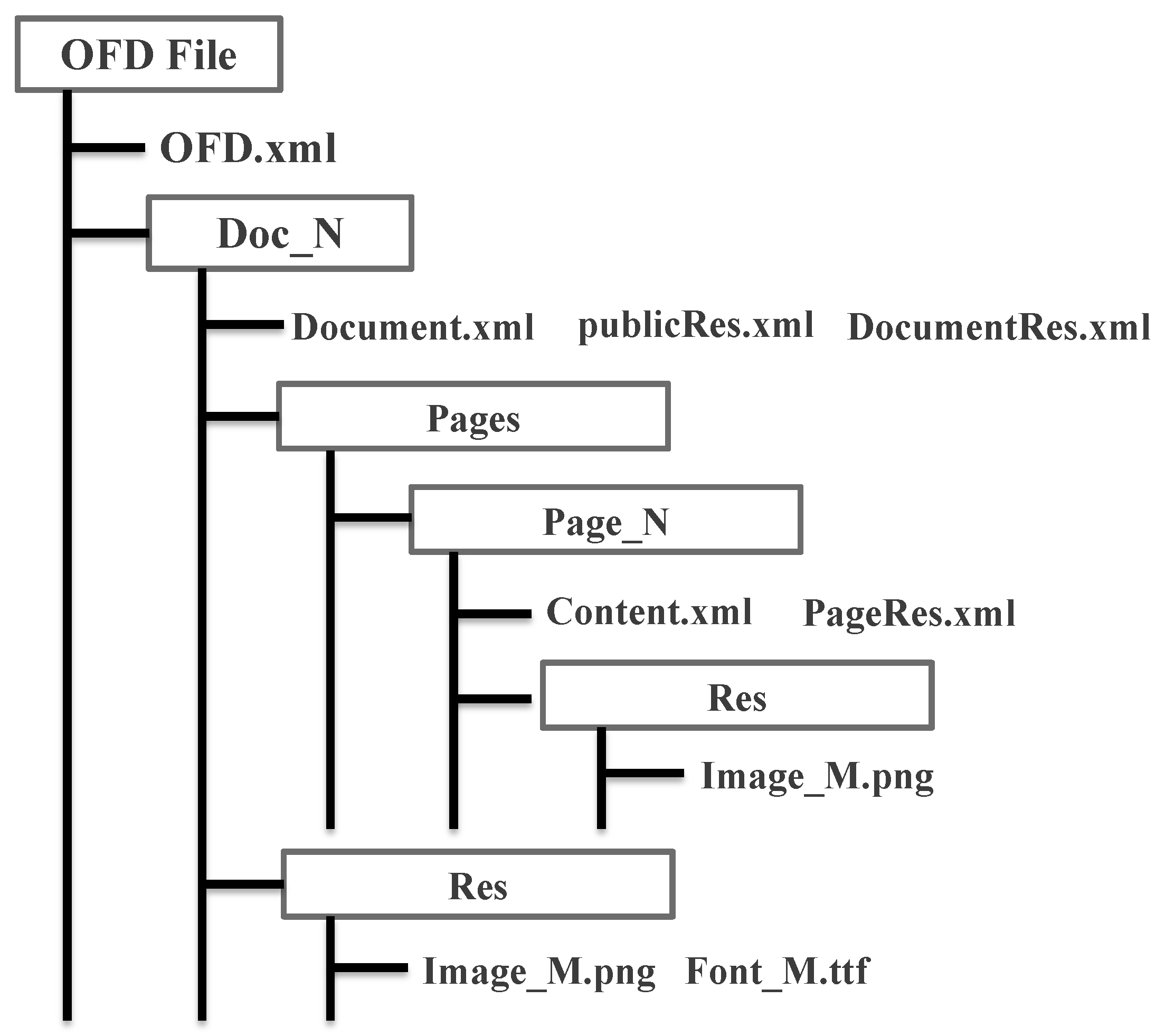
| FLIE/FOLDER | Description |
|---|---|
| OFD.xml | OFD file main entry file; describes the basic OFD file information |
| Doc_N | The Nth document folder |
| Documcnt.xml | Doc_N folder description file, including information about subfiles and subfolders contained under Doc_N |
| Page_N | The Nth page folder |
| Content.xml | Content description on page N |
| PageRes.xml | Resource description on page N |
| Res | Resource folder |
| PublicRes.xml | Document public resources index |
| DocumentRes.xml | Document own resource index |
| Image_M.png/Font_M.ttf | Resource files |
| Attack Type | Example of Attack Content | Watermark Extraction Success Rate |
|---|---|---|
| Highlight | Left Column—Line 1 Right Column—Lines 2–5 | 100% |
| Underline | Left Column—Line 2 Right Column—Lines 2–3 | 100% |
| Strikethrough | Left Column—Line 5 Right Column—Lines 2–3 | 100% |
| Wavy line | Left Column—Line 6 Right Column—Line 4 | 100% |
| Handwritten graffiti | Right Column—Lines 2 | 100% |
| Text overlay | Full Page | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zu, L.; Li, H.; Zhang, L.; Lu, Z.; Ye, J.; Zhao, X.; Hu, S. E-SAWM: A Semantic Analysis-Based ODF Watermarking Algorithm for Edge Cloud Scenarios. Future Internet 2023, 15, 283. https://doi.org/10.3390/fi15090283
Zu L, Li H, Zhang L, Lu Z, Ye J, Zhao X, Hu S. E-SAWM: A Semantic Analysis-Based ODF Watermarking Algorithm for Edge Cloud Scenarios. Future Internet. 2023; 15(9):283. https://doi.org/10.3390/fi15090283
Chicago/Turabian StyleZu, Lijun, Hongyi Li, Liang Zhang, Zhihui Lu, Jiawei Ye, Xiaoxia Zhao, and Shijing Hu. 2023. "E-SAWM: A Semantic Analysis-Based ODF Watermarking Algorithm for Edge Cloud Scenarios" Future Internet 15, no. 9: 283. https://doi.org/10.3390/fi15090283
APA StyleZu, L., Li, H., Zhang, L., Lu, Z., Ye, J., Zhao, X., & Hu, S. (2023). E-SAWM: A Semantic Analysis-Based ODF Watermarking Algorithm for Edge Cloud Scenarios. Future Internet, 15(9), 283. https://doi.org/10.3390/fi15090283