
The Power of Generative AI: A Review of Requirements, Models, Input–Output Formats, Evaluation Metrics, and Challenges



Abstract
1. Introduction
1.1. Research Purpose
1.2. Research Questions
- RQ1
- What are the requirements necessary for implementing generative AI systems?
- Ans:
- To address this question, we present three distinct categories of requirements for AIGC: hardware, software, and user experience requirements.
- RQ2
- What are the different types of generative AI models described in the literature?
- Ans:
- To explore this, we present a taxonomy of AIGC models based on their architecture, including VAEs, GANs, diffusion models, transformers, language models, normalizing flow models, and hybrid models.
- RQ3
- What specific input and output formats are used for different prescribed tasks in generative AI systems?
- Ans:
- We provide a comprehensive classification of input and output formats for AIGC tasks, along with specific tasks and the corresponding models used in the literature, presented in a tabular format.
- RQ4
- What evaluation metrics are commonly employed to validate the output generated by generative AI models?
- Ans:
- We propose a classification system based on the output types of generative AI and discuss commonly used evaluation metrics in the field.
1.3. Contributions and Research Significance
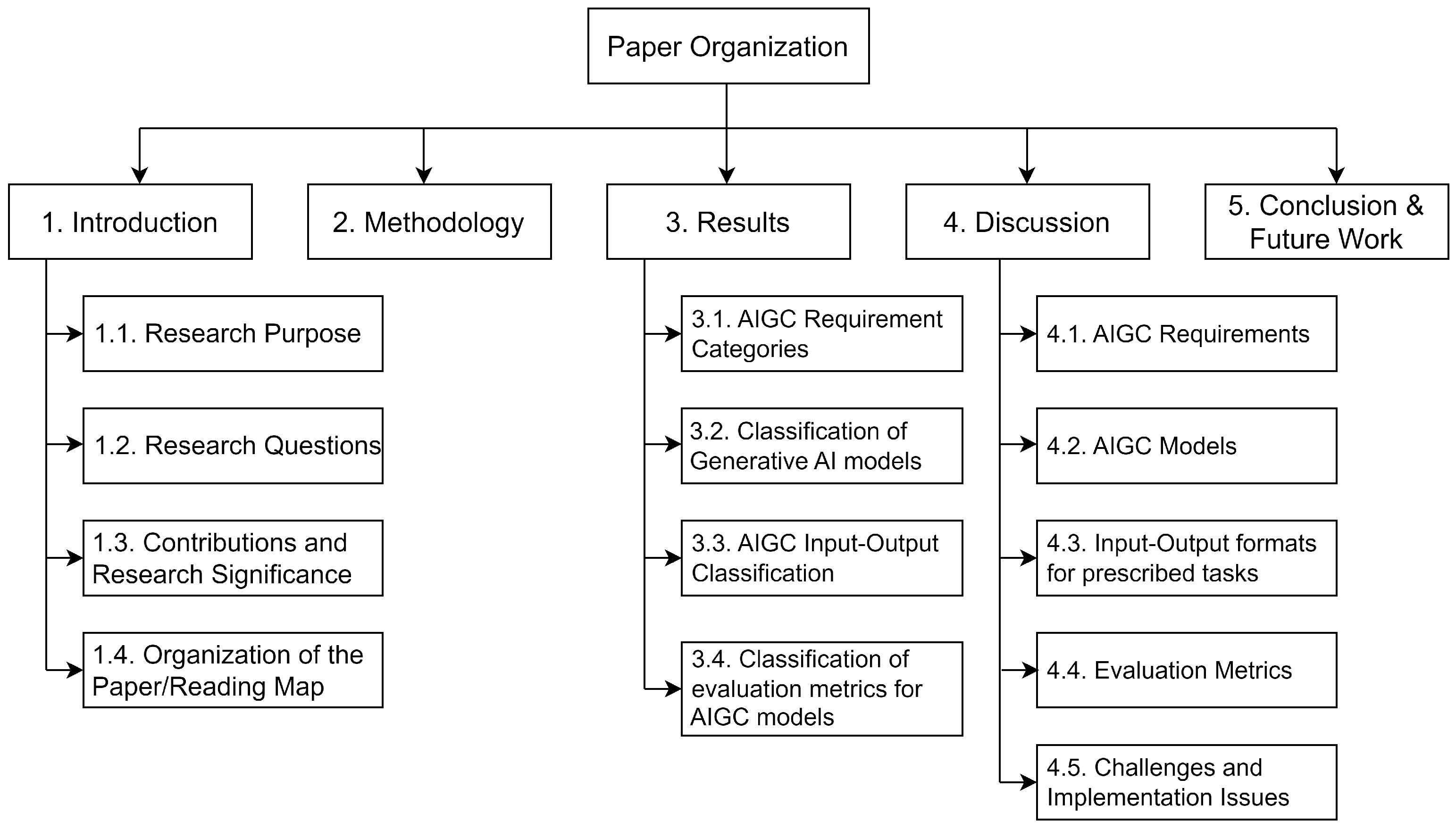
1.4. Organization of the Paper/Reading Map
2. Methodology
3. Results
3.1. AIGC Requirement Categories
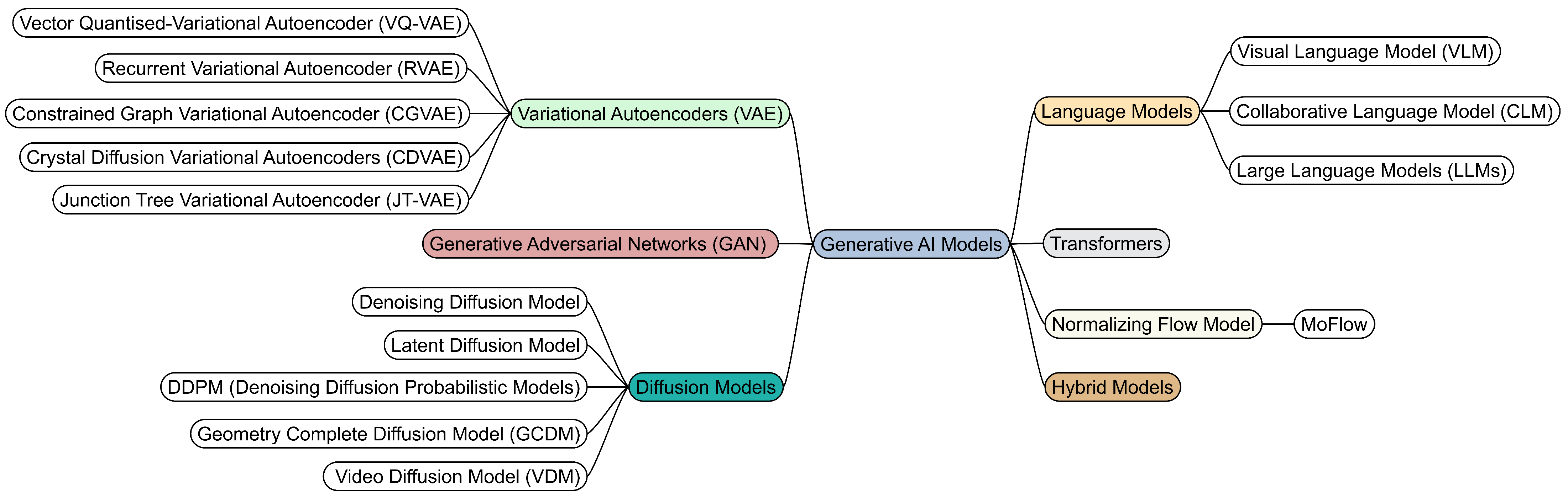
3.2. Classification of Generative AI Models
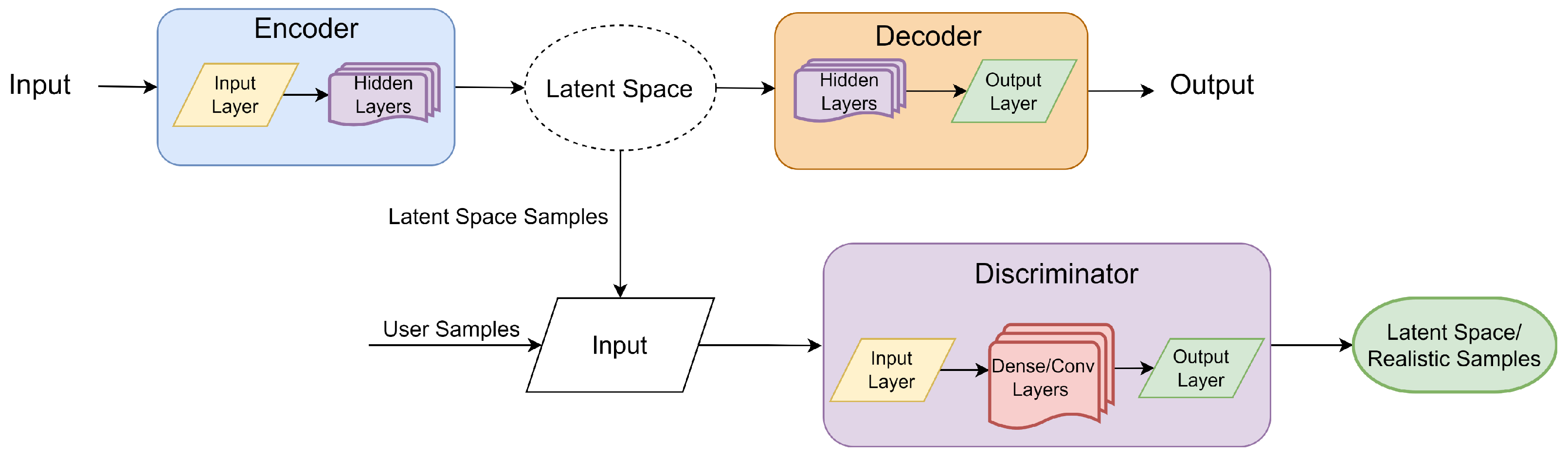
3.2.1. Variational Autoencoders (VAE)
3.2.2. Normalizing Flow Models
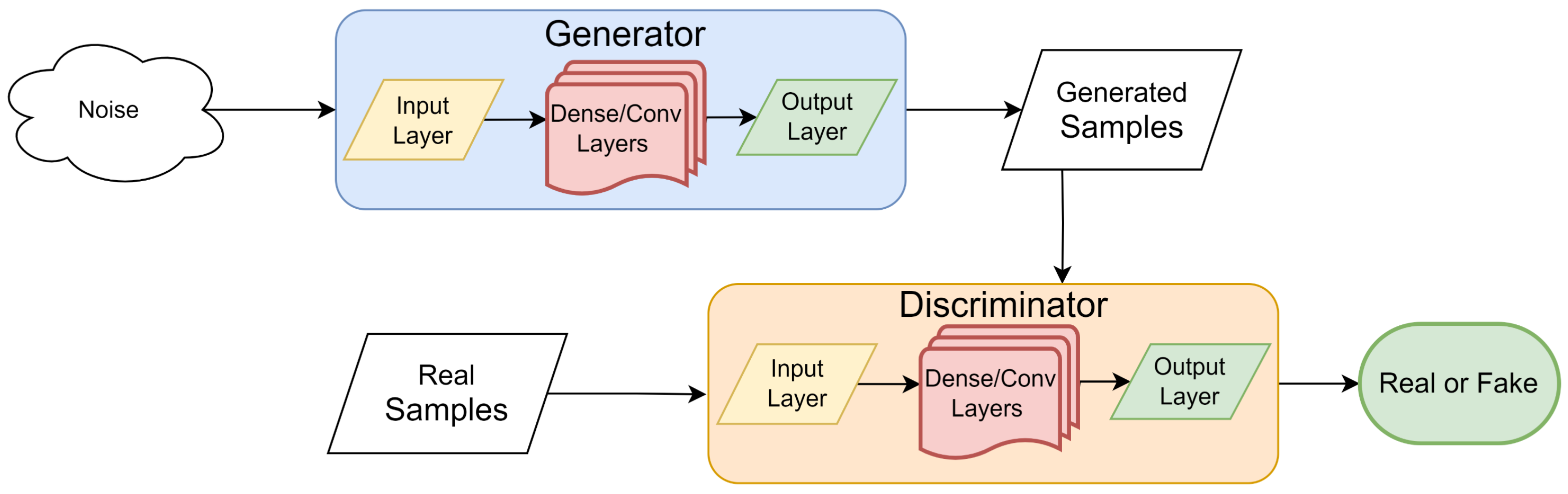
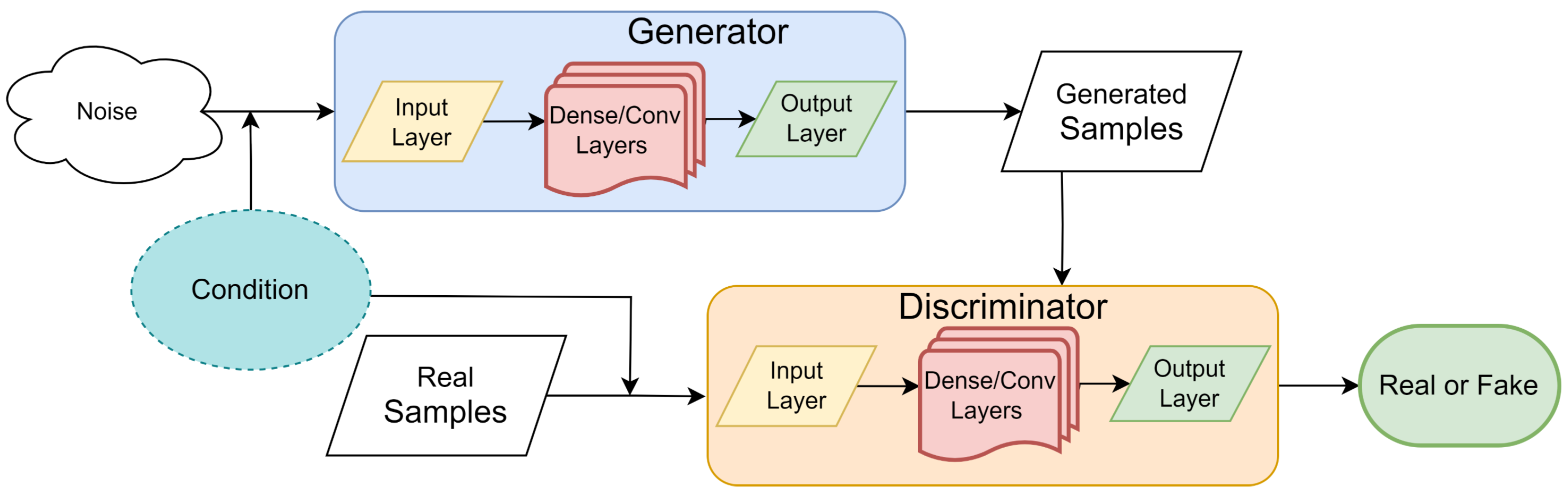
3.2.3. Generative Adversarial Networks (GAN)
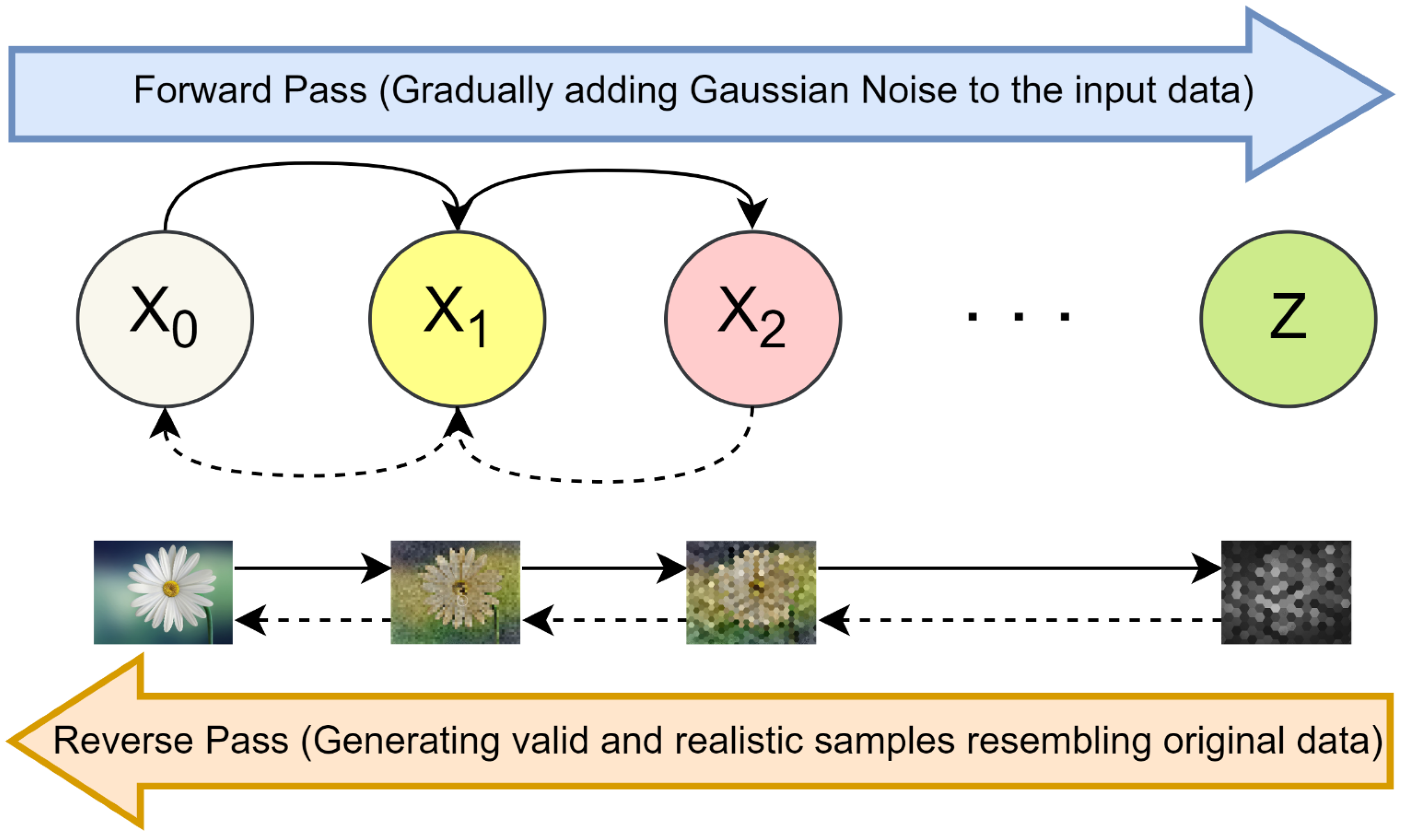
3.2.4. Diffusion Models
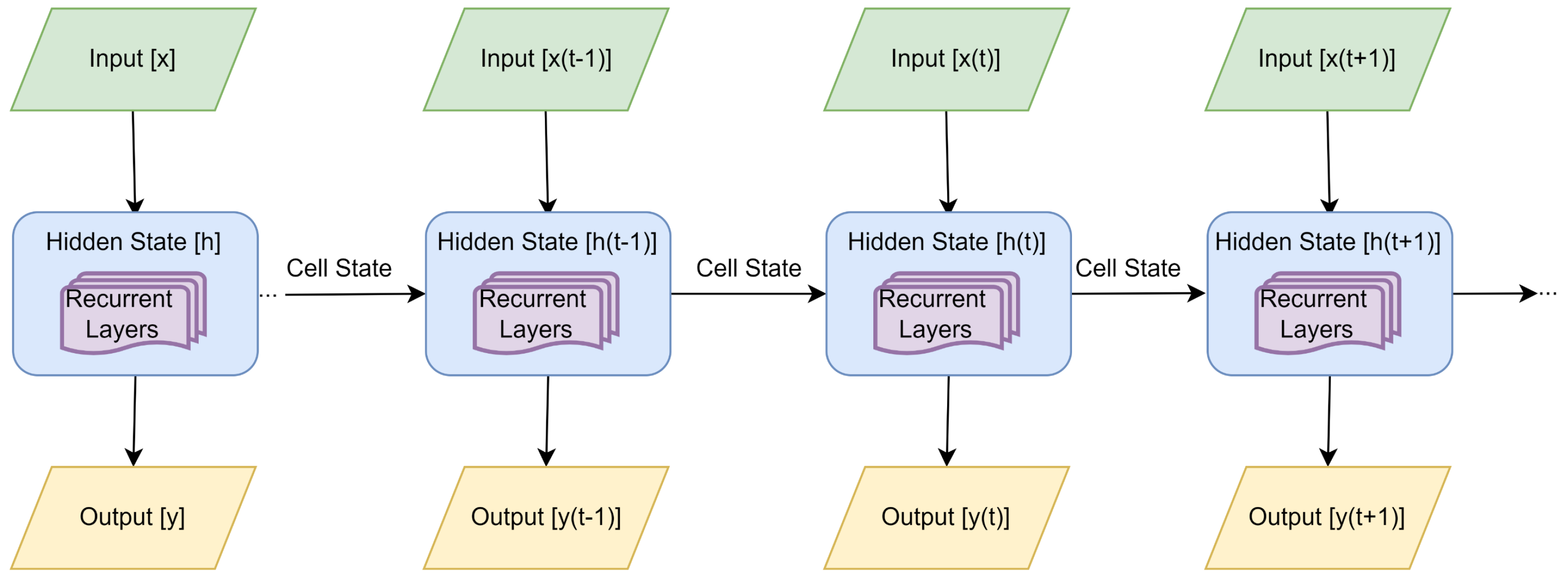
3.2.5. Language Models
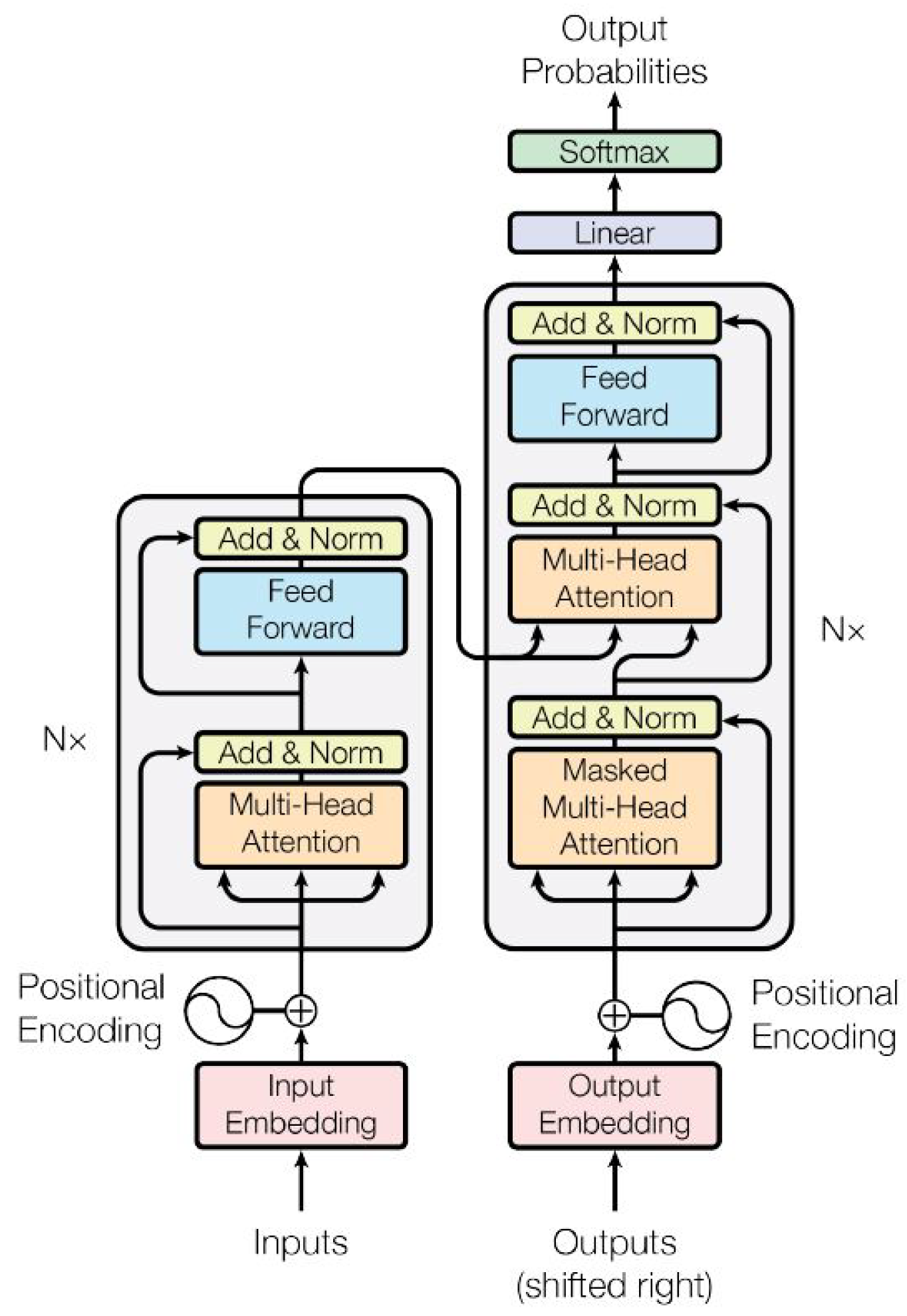
3.2.6. Transformers
3.2.7. Hybrid Models
3.3. AIGC Input–Output Classification
3.3.1. Text to Text
3.3.2. Text to Image
3.3.3. Text to Audio/Speech
3.3.4. Text to Code and Code to Text
3.3.5. Image to Text
3.3.6. Approaches for Visual Content Generation
Image to Image
Text-to-Video
Text+Video to Video
Video to Video
Image+Text to Image
3.3.7. Text-Driven 3D Content Generation
Text to 3D Image
Text to 3D Animation
3.3.8. Text to Molecule or Molecular Structure
3.3.9. Tabular Data to Tabular Data
3.3.10. Text to Knowledge Graph and Knowledge Graph to Text
3.3.11. Road Network to Road Network
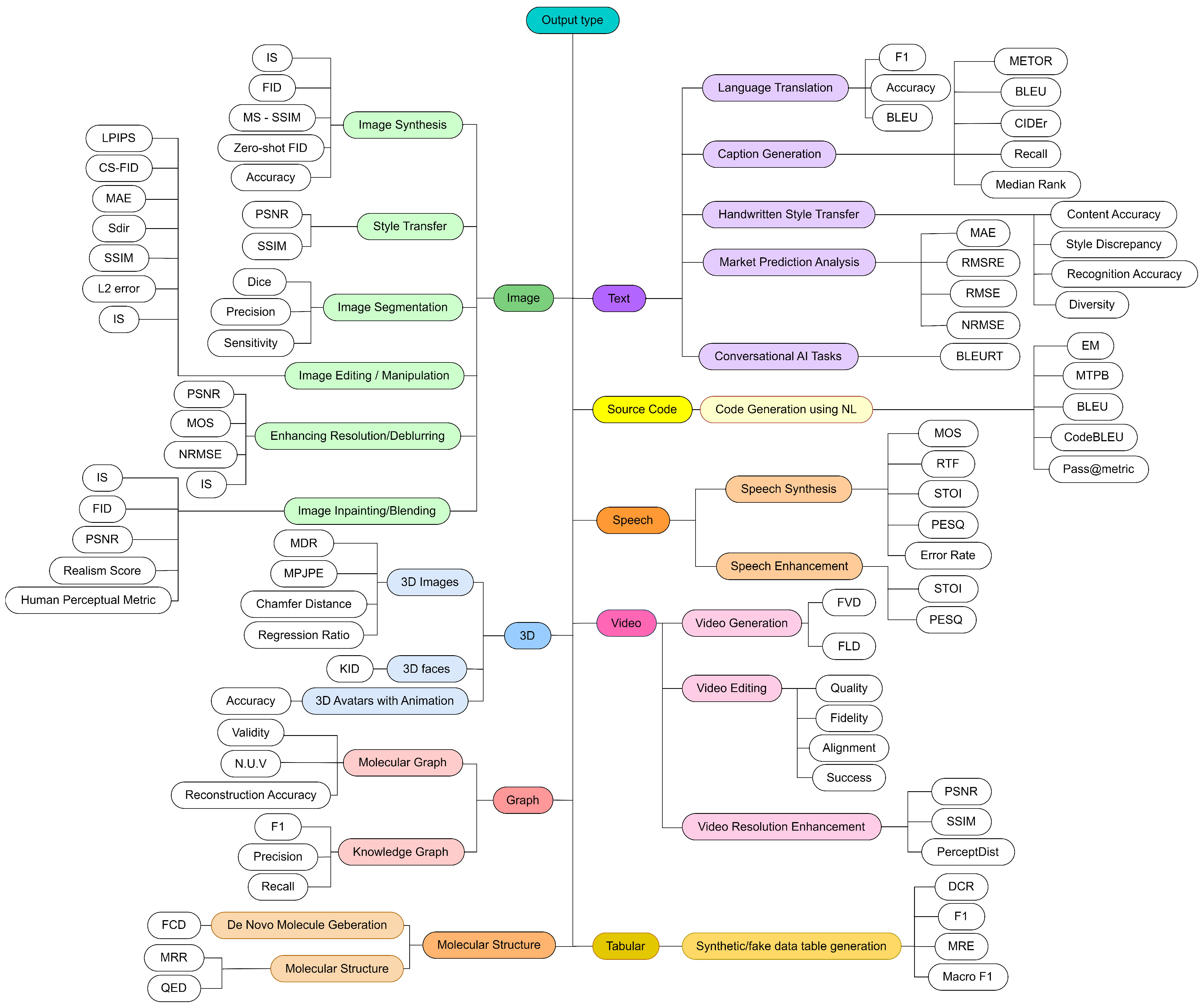
3.4. Classification of Evaluation Metrics for AIGC Models
3.4.1. Evaluation Metrics for Image Processing:
3.4.2. Evaluation Metrics for NLP Tasks
3.4.3. Performance Metrics for Code Generation Models
3.4.4. Evaluation Metrics for Various Graph Generation Models
3.4.5. Evaluation Metrics in Molecular Structure Generation
3.4.6. Evaluation Metrics for 3D Generation and Animation Techniques
3.4.7. Evaluation Metrics for Synthetic Data Generation in Tabular Datasets
3.4.8. Evaluation Metrics for Speech and Audio Generation Techniques
4. Discussion
4.1. AIGC Requirements
4.2. AIGC Models
4.3. Input–Output Formats for Prescribed Tasks
4.4. Evaluation Metrics
4.5. Challenges and Implementation Issues
- Training data requirements: Generative AI models require large and diverse datasets to learn the underlying patterns and generate meaningful outputs. However, acquiring and curating such datasets can be challenging. It may involve manually collecting or generating a vast amount of data that accurately represent the target domain. The quality of the data is crucial, as the model’s performance heavily relies on the richness and diversity of the training data [32].
- Computational resources: Training and deploying generative AI models can be computationally intensive. Large-scale models with millions or billions of parameters and complex tasks may require significant computational power, specialized hardware like GPUs or TPUs, and ample storage resources. The high computational requirements can limit the accessibility and affordability of generative AI for individuals or organizations with limited resources. Developing more efficient model architectures and optimization techniques, as well as leveraging cloud computing resources, can help address this challenge [30].
- Mode collapse: Mode collapse occurs when a generative model fails to capture the full diversity of the training data and instead generates repetitive or limited variations. For example, an image generation model may consistently produce images of a specific object, ignoring other possible objects in the training data [32]. Overcoming mode collapse is a significant challenge in generative AI research. Techniques such as improving model architectures, optimizing loss functions, or using ensemble methods are explored to encourage the model to generate a broader range of outputs.
- Interpretability and transparency: Many generative AI models, particularly deep neural networks, are often considered black boxes, meaning their decision-making processes are not easily interpretable by humans. This lack of interpretability and transparency can hinder trust, especially in critical domains where explanations and justifications are required [69]. Researchers are actively exploring techniques to enhance the interpretability of generative models, such as visualization methods, attention mechanisms, or generating explanations alongside the outputs, to provide insights into the model’s inner workings.
- Evaluation and feedback: Evaluating the quality and creativity of generative outputs is a complex task. Traditional evaluation metrics may not fully capture the desired characteristics of generated content, such as novelty, coherence, or semantic relevance. Developing reliable evaluation metrics specific to generative AI is an ongoing research area. Additionally, obtaining meaningful feedback from users or experts is crucial to improve the models iteratively [69]. Collecting feedback at scale and effectively incorporating it into the training process is challenging but necessary for model refinement.
- Generalization and adaptation: Generative models may struggle to generalize well to unseen or domain-shifted data. They may be sensitive to changes in input distribution or fail to capture the underlying patterns in new contexts. Adapting generative models to new domains or ensuring their reliable performance across different datasets and scenarios is an ongoing challenge. Techniques such as transfer learning, domain adaptation, or fine-tuning on specific target data are explored to improve generalization and adaptation capabilities.
- Ethical considerations: Generative AI technologies raise ethical concerns, particularly when they can be misused for malicious purposes. For instance, deepfake technology can create highly realistic but fabricated content, leading to potential misinformation or harm. Ensuring responsible and ethical use of generative models requires establishing guidelines, regulations, and safeguards. This includes implementing techniques for detecting and mitigating the misuse of generative AI, promoting transparency and accountability, and addressing potential biases in the generated outputs [23,173].
5. Conclusions and Future Work
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year Published | Number of Papers |
|---|---|
| 2014 | 2 |
| 2015 | 1 |
| 2016 | 7 |
| 2017 | 19 |
| 2018 | 22 |
| 2019 | 13 |
| 2020 | 12 |
| 2021 | 12 |
| 2022 | 26 |
| 2023 | 8 |
| Total | 122 |
| Paper Type | Number of Papers |
|---|---|
| Conferences | 60 |
| Journals | 14 |
| Archives | 48 |
| Total | 122 |
| Publication Venue | Number of Papers | Reference Code |
|---|---|---|
| arXiv | 48 | [33,34,43,49,50,55,58,63,69,78,80,82,84,89,94,102,104,105,106,111,112,113,114,115,116,117,119,120,121,123,124,126,128,133,139,142,143,145,147,150,153,157,159,160,162,164,165,167] |
| IEEE/CVF Conference on Computer Vision and Pattern Recognition | 15 | [4,59,61,64,65,81,90,92,99,103,122,127,131,136,151] |
| International Conference on Machine Learning | 10 | [45,57,70,86,88,110,130,132,149,152] |
| Advances in Neural Information Processing Systems | 8 | [42,67,77,79,83,101,109,148] |
| IEEE/CVF International Conference on Computer Vision | 7 | [56,62,87,93,98,138,163] |
| European Conference on Computer Vision | 4 | [118,140,141,144] |
| International Conference on Multimedia | 2 | [53,134] |
| Conference on Empirical Methods in Natural Language Processing | 1 | [60] |
| International Conference on Learning Representations | 1 | [95] |
| International Conference on Neural Information Processing Systems | 1 | [108] |
| International Conference on Image Processing | 1 | [135] |
| Winter Conference on Applications of Computer Vision | 1 | [54] |
| ACM Transactions on Graphics | 1 | [66] |
| International Conference on Acoustics, Speech and Signal Processing | 1 | [47] |
| IEEE Access | 1 | [36] |
| Mathematical Problems in Engineering | 1 | [156] |
| Neural Computing and Applications | 1 | [51] |
| Knowledge-Based Systems | 1 | [154] |
| Annual Meeting of the Association for Computational Linguistics | 1 | [129] |
| Sensors | 1 | [85] |
| International Conference on Knowledge Discovery & Data Mining | 1 | [76] |
| Journal of Cheminformatics | 1 | [125] |
| Medical Image Computing and Computer Assisted Intervention | 1 | [137] |
| Information | 1 | [158] |
| International Joint Conference on Neural Networks | 1 | [48] |
| Applied Cryptography and Network Security | 1 | [155] |
| Neurocomputing | 1 | [161] |
| American Association for the Advancement of Science | 1 | [35] |
| Advances in Multimedia Information Processing | 1 | [96] |
| Neuroinformatics | 1 | [100] |
| International Conference on Machine Vision | 1 | [146] |
| International Conference in Central Europe on Computer Graphics, Visualization and Computer Vision | 1 | [97] |
| International Conference on Very Large Data Bases | 1 | [52] |
| The Journal of Machine Learning Research | 1 | [39] |
| IEEE Transactions on Image Processing | 1 | [91] |
Appendix B
| Metric | Abbreviation |
| IS | Inception Score |
| FID | Fréchet Inception Distance |
| MS-SSIM | Multi-Scale Structural Similarity Index Measure |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity Index |
| LPIPS | Learned Perceptual Image Patch Similarity |
| CS-FID | Class-Conditional Fréchet Inception Distance |
| MAE | Mean Absolute Error |
| Sdir | Directional CLIP Similarity |
| MOS | Mean Opinion Score |
| NRMSE | Normalized Root Mean Square Error |
| BLEU | Bilingual Evaluation Understudy |
| METOR | Metric for Evaluation of Translation with Explicit Ordering |
| CIDEr | Consensus-based Image Description Evaluation |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Square Error |
| RMSRE | Root Mean Squared Relative Error |
| BLEURT | Bilingual Evaluation Understudy for Natural Language Understanding in Translation |
| EM | Exact Match |
| MTPB | Multi-Turn Programming Benchmark |
| MDR | Matching Distance Ratio |
| MPJPE | Mean per Joint Positioning Error |
| KID | Kernel Inception Distance |
| RTF | Real-Time Factor |
| STOI | Short-Time Objective Intelligibility |
| PESQ | Perceptual Evaluation of Speech Quality |
| N.U.V | Novel, Unique, and Valid Molecules |
| FVD | Fréchet Video Distance |
| FCD | Fréchet ChemNet Distance |
| MRR | Mean Reciprocal Rank |
| QED | Quantitative Estimate of Drug-Likeness |
| DCR | Distance to the Closest Record |
| MRE | Mean Relative Error |
References
- Cao, Y.; Li, S.; Liu, Y.; Yan, Z.; Dai, Y.; Yu, P.S.; Sun, L. A comprehensive survey of ai-generated content (aigc): A history of generative ai from gan to chatgpt. arXiv 2023, arXiv:2303.04226. [Google Scholar]
- Zhang, C.; Zhang, C.; Zheng, S.; Qiao, Y.; Li, C.; Zhang, M.; Dam, S.; Myaet Thwal, C.; Tun, Y.L.; Huy, L.; et al. A Complete Survey on Generative AI (AIGC): Is ChatGPT from GPT-4 to GPT-5 All You Need? arXiv 2023, arXiv:2303.11717. [Google Scholar] [CrossRef]
- Generative AI Market Size to Hit around USD 118.06 Bn by 2032. 2023. Available online: https://www.globenewswire.com/en/news-release/2023/05/15/2668369/0/en/Generative-AI-Market-Size-to-Hit-Around-USD-118-06-Bn-By-2032.html/ (accessed on 29 June 2023).
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Wang, K.; Gou, C.; Duan, Y.; Lin, Y.; Zheng, X.; Wang, F.Y. Generative adversarial networks: Introduction and outlook. IEEE/CAA J. Autom. Sin. 2017, 4, 588–598. [Google Scholar] [CrossRef]
- Pan, Z.; Yu, W.; Yi, X.; Khan, A.; Yuan, F.; Zheng, Y. Recent progress on generative adversarial networks (GANs): A survey. IEEE Access 2019, 7, 36322–36333. [Google Scholar] [CrossRef]
- Cao, Y.J.; Jia, L.L.; Chen, Y.X.; Lin, N.; Yang, C.; Zhang, B.; Liu, Z.; Li, X.X.; Dai, H.H. Recent Advances of Generative Adversarial Networks in Computer Vision. IEEE Access 2019, 7, 14985–15006. [Google Scholar] [CrossRef]
- Cheng, J.; Yang, Y.; Tang, X.; Xiong, N.; Zhang, Y.; Lei, F. Generative Adversarial Networks: A Literature Review. KSII Trans. Internet Inf. Syst. 2020, 14, 4625–4647. [Google Scholar]
- Dutta, I.K.; Ghosh, B.; Carlson, A.; Totaro, M.; Bayoumi, M. Generative adversarial networks in security: A survey. In Proceedings of the 2020 11th IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 28–31 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 0399–0405. [Google Scholar]
- Harshvardhan, G.; Gourisaria, M.K.; Pandey, M.; Rautaray, S.S. A comprehensive survey and analysis of generative models in machine learning. Comput. Sci. Rev. 2020, 38, 100285. [Google Scholar]
- Miao, Y.; Koenig, R.; Knecht, K. The Development of Optimization Methods in Generative Urban Design: A Review. In Proceedings of the 11th Annual Symposium on Simulation for Architecture and Urban Design (SimAUD 2020), Vienna, Austria, 25–27 May 2020. [Google Scholar]
- Jin, L.; Tan, F.; Jiang, S.; Köker, R. Generative Adversarial Network Technologies and Applications in Computer Vision. Intell. Neurosci. 2020, 2020, 1459107. [Google Scholar] [CrossRef]
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative adversarial network: An overview of theory and applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004. [Google Scholar] [CrossRef]
- Eckerli, F.; Osterrieder, J. Generative adversarial networks in finance: An overview. arXiv 2021, arXiv:2106.06364. [Google Scholar] [CrossRef]
- Jabbar, A.; Li, X.; Omar, B. A survey on generative adversarial networks: Variants, applications, and training. ACM Comput. Surv. (CSUR) 2021, 54, 157. [Google Scholar] [CrossRef]
- Jose, L.; Liu, S.; Russo, C.; Nadort, A.; Ieva, A.D. Generative Adversarial Networks in Digital Pathology and Histopathological Image Processing: A Review. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8609288/ (accessed on 25 July 2023).
- De Rosa, G.H.; Papa, J.P. A survey on text generation using generative adversarial networks. Pattern Recognit. 2021, 119, 108098. [Google Scholar] [CrossRef]
- Tong, X.; Liu, X.; Tan, X.; Li, X.; Jiang, J.; Xiong, Z.; Xu, T.; Jiang, H.; Qiao, N.; Zheng, M. Generative models for De Novo drug design. J. Med. Chem. 2021, 64, 14011–14027. [Google Scholar] [CrossRef] [PubMed]
- Aldausari, N.; Sowmya, A.; Marcus, N.; Mohammadi, G. Video generative adversarial networks: A review. ACM Comput. Surv. (CSUR) 2022, 55, 30. [Google Scholar] [CrossRef]
- Zeng, X.; Wang, F.; Luo, Y.; Kang, S.-g.; Tang, J.; Lightstone, F.C.; Fang, E.F.; Cornell, W.; Nussinov, R.; Feixiong, C. Deep generative molecular design reshapes drug discovery. Cell Rep. Med. 2022, 3, 100794. [Google Scholar] [CrossRef]
- Li, C.; Zhang, C.; Waghwase, A.; Lee, L.H.; Rameau, F.; Yang, Y.; Bae, S.H.; Hong, C.S. Generative AI meets 3D: A Survey on Text-to-3D in AIGC Era. arXiv 2023, arXiv:2305.06131. [Google Scholar]
- Dwivedi, Y.K.; Kshetri, N.; Hughes, L.; Slade, E.L.; Jeyaraj, A.; Kar, A.K.; Baabdullah, A.M.; Koohang, A.; Raghavan, V.; Ahuja, M.; et al. “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy. Int. J. Inf. Manag. 2023, 71, 102642. [Google Scholar] [CrossRef]
- Danel, T.; Łęski, J.; Podlewska, S.; Podolak, I.T. Docking-based generative approaches in the search for new drug candidates. Drug Discov. Today 2023, 28, 103439. [Google Scholar] [CrossRef]
- Gozalo-Brizuela, R.; Garrido-Merchán, E.C. A survey of Generative AI Applications. arXiv 2023, arXiv:2306.02781. [Google Scholar]
- Gozalo-Brizuela, R.; Garrido-Merchan, E.C. ChatGPT is not all you need. A State of the Art Review of large Generative AI models. arXiv 2023, arXiv:2301.04655. [Google Scholar]
- Liu, Y.; Yang, Z.; Yu, Z.; Liu, Z.; Liu, D.; Lin, H.; Li, M.; Ma, S.; Avdeev, M.; Shi, S. Generative artificial intelligence and its applications in materials science: Current situation and future perspectives. J. Mater. 2023, 9, 798–816. [Google Scholar] [CrossRef]
- Roumeliotis, K.I.; Tselikas, N.D. ChatGPT and Open-AI Models: A Preliminary Review. Future Internet 2023, 15, 192. [Google Scholar] [CrossRef]
- Zhang, M.; Qamar, M.; Kang, T.; Jung, Y.; Zhang, C.; Bae, S.H.; Zhang, C. A survey on graph diffusion models: Generative ai in science for molecule, protein and material. arXiv 2023, arXiv:2304.01565. [Google Scholar]
- Zhang, C.; Zhang, C.; Li, C.; Qiao, Y.; Zheng, S.; Dam, S.K.; Zhang, M.; Kim, J.U.; Kim, S.T.; Choi, J.; et al. One small step for generative ai, one giant leap for agi: A complete survey on chatgpt in aigc era. arXiv 2023, arXiv:2304.06488. [Google Scholar]
- Zhang, C.; Zhang, C.; Zheng, S.; Zhang, M.; Qamar, M.; Bae, S.H.; Kweon, I.S. A Survey on Audio Diffusion Models: Text To Speech Synthesis and Enhancement in Generative AI. arXiv 2023, arXiv:2303.13336. [Google Scholar]
- Zhang, C.; Zhang, C.; Zhang, M.; Kweon, I.S. Text-to-image Diffusion Models in Generative AI: A Survey. arXiv 2023, arXiv:2303.07909. [Google Scholar]
- Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. Lamda: Language models for dialog applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- Schick, T.; Dwivedi-Yu, J.; Jiang, Z.; Petroni, F.; Lewis, P.; Izacard, G.; You, Q.; Nalmpantis, C.; Grave, E.; Riedel, S. PEER: A Collaborative Language Model. arXiv 2022, arXiv:2208.11663. [Google Scholar]
- Li, Y.; Choi, D.; Chung, J.; Kushman, N.; Schrittwieser, J.; Leblond, R.; Eccles, T.; Keeling, J.; Gimeno, F.; Dal Lago, A.; et al. Competition-level code generation with alphacode. Science 2022, 378, 1092–1097. [Google Scholar] [CrossRef]
- Fang, W.; Ding, Y.; Zhang, F.; Sheng, J. Gesture Recognition Based on CNN and DCGAN for Calculation and Text Output. IEEE Access 2019, 7, 28230–28237. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Fonseca, E.; Favory, X.; Pons, J.; Font, F.; Serra, X. Fsd50k: An open dataset of human-labeled sound events. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 30, 829–852. [Google Scholar] [CrossRef]
- Kim, C.D.; Kim, B.; Lee, H.; Kim, G. Audiocaps: Generating captions for audios in the wild. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 119–132. [Google Scholar]
- Ren, Y.; Ruan, Y.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.Y. Fastspeech: Fast, robust and controllable text to speech. arXiv 2019, arXiv:1905.09263. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Berabi, B.; He, J.; Raychev, V.; Vechev, M. Tfix: Learning to fix coding errors with a text-to-text transformer. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 780–791. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Elizalde, B.; Deshmukh, S.; Al Ismail, M.; Wang, H. Clap learning audio concepts from natural language supervision. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Manco, I.; Benetos, E.; Quinton, E.; Fazekas, G. MusCaps: Generating Captions for Music Audio. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Chandramouli, P.; Gandikota, K.V. LDEdit: Towards Generalized Text Guided Image Manipulation via Latent Diffusion Models. arXiv 2022, arXiv:2210.02249. [Google Scholar]
- Nijkamp, E.; Pang, B.; Hayashi, H.; Tu, L.; Wang, H.; Zhou, Y.; Savarese, S.; Xiong, C. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis. arXiv 2022, arXiv:2203.13474. [Google Scholar]
- Jain, D.K.; Zareapoor, M.; Jain, R.; Kathuria, A.; Bachhety, S. GAN-Poser: An improvised bidirectional GAN model for human motion prediction. Neural Comput. Appl. 2020, 32, 14579–14591. [Google Scholar] [CrossRef]
- Park, N.; Mohammadi, M.; Gorde, K.; Jajodia, S.; Park, H.; Kim, Y. Data Synthesis Based on Generative Adversarial Networks. Proc. VLDB Endow. 2018, 11, 1071–1083. [Google Scholar] [CrossRef]
- Huang, R.; Zhao, Z.; Liu, H.; Liu, J.; Cui, C.; Ren, Y. Prodiff: Progressive fast diffusion model for high-quality text-to-speech. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 2595–2605. [Google Scholar]
- Chang, B.; Zhang, Q.; Pan, S.; Meng, L. Generating handwritten chinese characters using cyclegan. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 199–207. [Google Scholar]
- Jiang, R.; Wang, C.; Zhang, J.; Chai, M.; He, M.; Chen, D.; Liao, J. AvatarCraft: Transforming Text into Neural Human Avatars with Parameterized Shape and Pose Control. arXiv 2023, arXiv:2303.17606. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar]
- Jin, W.; Barzilay, R.; Jaakkola, T. Junction tree variational autoencoder for molecular graph generation. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2323–2332. [Google Scholar]
- Edwards, C.; Lai, T.; Ros, K.; Honke, G.; Ji, H. Translation between molecules and natural language. arXiv 2022, arXiv:2204.11817. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Edwards, C.; Zhai, C.; Ji, H. Text2mol: Cross-modal molecule retrieval with natural language queries. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, online, 18–24 July 2021; pp. 595–607. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Liang, X.; Hu, Z.; Zhang, H.; Gan, C.; Xing, E.P. Recurrent topic-transition gan for visual paragraph generation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3362–3371. [Google Scholar]
- Jeong, M.; Kim, H.; Cheon, S.J.; Choi, B.J.; Kim, N.S. Diff-tts: A denoising diffusion model for text-to-speech. arXiv 2021, arXiv:2104.01409. [Google Scholar]
- Chen, B.C.; Kae, A. Toward realistic image compositing with adversarial learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8415–8424. [Google Scholar]
- Chen, J.; Guo, H.; Yi, K.; Li, B.; Elhoseiny, M. Visualgpt: Data-efficient adaptation of pretrained language models for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18030–18040. [Google Scholar]
- Hong, F.; Zhang, M.; Pan, L.; Cai, Z.; Yang, L.; Liu, Z. AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars. ACM Trans. Graph. (TOG) 2022, 41, 1–19. [Google Scholar] [CrossRef]
- Nam, S.; Kim, Y.; Kim, S.J. Text-Adaptive Generative Adversarial Networks: Manipulating Images with Natural Language. Available online: https://dl.acm.org/doi/pdf/10.5555/3326943.3326948 (accessed on 25 July 2023).
- Zhang, H.; Li, Y.; Ma, F.; Gao, J.; Su, L. Texttruth: An unsupervised approach to discover trustworthy information from multi-sourced text data. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2729–2737. [Google Scholar]
- Evans, O.; Cotton-Barratt, O.; Finnveden, L.; Bales, A.; Balwit, A.; Wills, P.; Righetti, L.; Saunders, W. Truthful AI: Developing and governing AI that does not lie. arXiv 2021, arXiv:2110.06674. [Google Scholar]
- Liang, P.P.; Wu, C.; Morency, L.P.; Salakhutdinov, R. Towards understanding and mitigating social biases in language models. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 6565–6576. [Google Scholar]
- Marchandot, B.; Matsushita, K.; Carmona, A.; Trimaille, A.; Morel, O. ChatGPT: The next frontier in academic writing for cardiologists or a pandora’s box of ethical dilemmas. Eur. Heart J. Open 2023, 3, oead007. [Google Scholar] [CrossRef]
- Wu, Y.; Yu, N.; Li, Z.; Backes, M.; Zhang, Y. Membership Inference Attacks Against Text-to-image Generation Models. arXiv 2022, arXiv:2210.00968. [Google Scholar]
- Carlini, N.; Tramer, F.; Wallace, E.; Jagielski, M.; Herbert-Voss, A.; Lee, K.; Roberts, A.; Brown, T.B.; Song, D.; Erlingsson, U.; et al. Extracting Training Data from Large Language Models. In Proceedings of the USENIX Security Symposium, Virtual, 11–13 August 2021; Volume 6. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 25 July 2023).
- Jiang, Z.; Xu, F.F.; Araki, J.; Neubig, G. How can we know what language models know? Trans. Assoc. Comput. Linguist. 2020, 8, 423–438. [Google Scholar] [CrossRef]
- Zang, C.; Wang, F. MoFlow: An invertible flow model for generating molecular graphs. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery &Data Mining, Virtual Event, 6–10 July 2020; pp. 617–626. [Google Scholar]
- Ding, M.; Yang, Z.; Hong, W.; Zheng, W.; Zhou, C.; Yin, D.; Lin, J.; Zou, X.; Shao, Z.; Yang, H.; et al. Cogview: Mastering text-to-image generation via transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 19822–19835. [Google Scholar]
- Mansimov, E.; Parisotto, E.; Ba, J.L.; Salakhutdinov, R. Generating images from captions with attention. arXiv 2015, arXiv:1511.02793. [Google Scholar]
- Liu, Q.; Allamanis, M.; Brockschmidt, M.; Gaunt, A. Constrained Graph Variational Autoencoders for Molecule Design. Adv. Neural Inf. Process. Syst. Available online: https://proceedings.neurips.cc/paper_files/paper/2018/file/b8a03c5c15fcfa8dae0b03351eb1742f-Paper.pdf (accessed on 25 July 2023).
- Xie, T.; Fu, X.; Ganea, O.E.; Barzilay, R.; Jaakkola, T. Crystal diffusion variational autoencoder for periodic material generation. arXiv 2021, arXiv:2110.06197. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Michelsanti, D.; Tan, Z.H. Conditional generative adversarial networks for speech enhancement and noise-robust speaker verification. arXiv 2017, arXiv:1709.01703. [Google Scholar]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling Tabular Data Using Conditional Gan. Adv. Neural Inf. Process. Syst. Available online: https://proceedings.neurips.cc/paper_files/paper/2019/file/254ed7d2de3b23ab10936522dd547b78-Paper.pdf (accessed on 25 July 2023).
- Dash, A.; Gamboa, J.C.B.; Ahmed, S.; Liwicki, M.; Afzal, M.Z. Tac-gan-text conditioned auxiliary classifier generative adversarial network. arXiv 2017, arXiv:1703.06412. [Google Scholar]
- Nam, S.; Jeon, S.; Kim, H.; Moon, J. Recurrent gans password cracker for iot password security enhancement. Sensors 2020, 20, 3106. [Google Scholar] [CrossRef] [PubMed]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 1060–1069. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6 August–11 August 2017; pp. 1857–1865. [Google Scholar]
- Taigman, Y.; Polyak, A.; Wolf, L. Unsupervised cross-domain image generation. arXiv 2016, arXiv:1611.02200. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Lucas, A.; Lopez-Tapia, S.; Molina, R.; Katsaggelos, A.K. Generative adversarial networks and perceptual losses for video super-resolution. IEEE Trans. Image Process. 2019, 28, 3312–3327. [Google Scholar] [CrossRef]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake, UT, USA, 18–23 June 2018; IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 1316–1324. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Xu, L.; Veeramachaneni, K. Synthesizing tabular data using generative adversarial networks. arXiv 2018, arXiv:1811.11264. [Google Scholar]
- Samangouei, P.; Kabkab, M.; Chellappa, R. Defense-GAN: Protecting classifiers against adversarial attacks using generative models. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Shi, H.; Dong, J.; Wang, W.; Qian, Y.; Zhang, X. SSGAN: Secure steganography based on generative adversarial networks. In Proceedings of the Advances in Multimedia Information Processing–PCM 2017: 18th Pacific-Rim Conference on Multimedia, Harbin, China, 28–29 September 2017; Revised Selected Papers, Part I 18. Springer: Berlin/Heidelberg, Germany, 2018; pp. 534–544. [Google Scholar]
- Hartmann, S.; Weinmann, M.; Wessel, R.; Klein, R. Streetgan: Towards Road Network Synthesis with Generative Adversarial Networks. Available online: https://otik.uk.zcu.cz/bitstream/11025/29554/1/Hartmann.pdf (accessed on 25 July 2023).
- Patashnik, O.; Wu, Z.; Shechtman, E.; Cohen-Or, D.; Lischinski, D. Styleclip: Text-driven manipulation of stylegan imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2085–2094. [Google Scholar]
- Dolhansky, B.; Ferrer, C.C. Eye in-painting with exemplar generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7902–7911. [Google Scholar]
- Xue, Y.; Xu, T.; Zhang, H.; Long, L.R.; Huang, X. Segan: Adversarial network with multi-scale l 1 loss for medical image segmentation. Neuroinformatics 2018, 16, 383–392. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models; Curran Associates Inc.: Red Hook, NY, USA, 2020; NIPS’20. [Google Scholar]
- Zhang, L.; Qiu, Q.; Lin, H.; Zhang, Q.; Shi, C.; Yang, W.; Shi, Y.; Yang, S.; Xu, L.; Yu, J. DreamFace: Progressive Generation of Animatable 3D Faces under Text Guidance. arXiv 2023, arXiv:2304.03117. [Google Scholar] [CrossRef]
- Lin, C.H.; Gao, J.; Tang, L.; Takikawa, T.; Zeng, X.; Huang, X.; Kreis, K.; Fidler, S.; Liu, M.Y.; Lin, T.Y. Magic3d: High-resolution text-to-3d content creation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 18–22 June 2023; pp. 300–309. [Google Scholar]
- Wu, J.Z.; Ge, Y.; Wang, X.; Lei, W.; Gu, Y.; Hsu, W.; Shan, Y.; Qie, X.; Shou, M.Z. Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation. arXiv 2022, arXiv:2212.11565. [Google Scholar]
- Morehead, A.; Cheng, J. Geometry-complete diffusion for 3d molecule generation. arXiv 2023, arXiv:2302.04313. [Google Scholar]
- Molad, E.; Horwitz, E.; Valevski, D.; Acha, A.R.; Matias, Y.; Pritch, Y.; Leviathan, Y.; Hoshen, Y. Dreamix: Video diffusion models are general video editors. arXiv 2023, arXiv:2302.01329. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems–Volume 2; MIT Press: Cambridge, MA, USA, 2014; NIPS’14; pp. 3104–3112. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A visual language model for few-shot learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Kanade, A.; Maniatis, P.; Balakrishnan, G.; Shi, K. Learning and evaluating contextual embedding of source code. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 5110–5121. [Google Scholar]
- Bhavya, B.; Xiong, J.; Zhai, C. Analogy Generation by Prompting Large Language Models: A Case Study of InstructGPT. arXiv 2022, arXiv:2210.04186. [Google Scholar]
- Kale, M.; Rastogi, A. Text-to-text pre-training for data-to-text tasks. arXiv 2020, arXiv:2005.10433. [Google Scholar]
- Chen, M.; Tan, X.; Li, B.; Liu, Y.; Qin, T.; Zhao, S.; Liu, T.Y. Adaspeech: Adaptive text to speech for custom voice. arXiv 2021, arXiv:2103.00993. [Google Scholar]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. Codebert: A pre-trained model for programming and natural languages. arXiv 2020, arXiv:2002.08155. [Google Scholar]
- Wang, Y.; Wang, W.; Joty, S.; Hoi, S.C. Codet5: Identifier-aware unified pre-trained encoder–decoder models for code understanding and generation. arXiv 2021, arXiv:2109.00859. [Google Scholar]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.d.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating large language models trained on code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Melnyk, I.; Dognin, P.; Das, P. Knowledge Graph Generation From Text. arXiv 2022, arXiv:2211.10511. [Google Scholar]
- Tevet, G.; Gordon, B.; Hertz, A.; Bermano, A.H.; Cohen-Or, D. Motionclip: Exposing human motion generation to clip space. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXII. Springer: Berlin/Heidelberg, Germany, 2022; pp. 358–374. [Google Scholar]
- Villegas, R.; Babaeizadeh, M.; Kindermans, P.J.; Moraldo, H.; Zhang, H.; Saffar, M.T.; Castro, S.; Kunze, J.; Erhan, D. Phenaki: Variable length video generation from open domain textual description. arXiv 2022, arXiv:2210.02399. [Google Scholar]
- Borsos, Z.; Marinier, R.; Vincent, D.; Kharitonov, E.; Pietquin, O.; Sharifi, M.; Teboul, O.; Grangier, D.; Tagliasacchi, M.; Zeghidour, N. Audiolm: A language modeling approach to audio generation. arXiv 2022, arXiv:2209.03143. [Google Scholar] [CrossRef]
- Narang, S.; Raffel, C.; Lee, K.; Roberts, A.; Fiedel, N.; Malkan, K. Wt5?! training text-to-text models to explain their predictions. arXiv 2020, arXiv:2004.14546. [Google Scholar]
- Zhang, Z.; Song, Y.; Qi, H. Age progression/regression by conditional adversarial autoencoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5810–5818. [Google Scholar]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. Neural photo editing with introspective adversarial networks. arXiv 2016, arXiv:1609.07093. [Google Scholar]
- Maziarka, Ł.; Pocha, A.; Kaczmarczyk, J.; Rataj, K.; Danel, T.; Warchoł, M. Mol-CycleGAN: A generative model for molecular optimization. J. Cheminform. 2020, 12, 1–18. [Google Scholar] [CrossRef]
- Demir, U.; Unal, G. Patch-based image inpainting with generative adversarial networks. arXiv 2018, arXiv:1803.07422. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Liu, S.; Su, D.; Yu, D. Diffgan-tts: High-fidelity and efficient text-to-speech with denoising diffusion gans. arXiv 2022, arXiv:2201.11972. [Google Scholar]
- Distiawan, B.; Qi, J.; Zhang, R.; Wang, W. GTR-LSTM: A triple encoder for sentence generation from RDF data. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1627–1637. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Kim, G.; Kwon, T.; Ye, J.C. Diffusionclip: Text-guided diffusion models for robust image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 2426–2435. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6 August–11 August 2017; pp. 1243–1252. [Google Scholar]
- Poole, B.; Jain, A.; Barron, J.T.; Mildenhall, B. Dreamfusion: Text-to-3d using 2d diffusion. arXiv 2022, arXiv:2209.14988. [Google Scholar]
- Wu, H.; Zheng, S.; Zhang, J.; Huang, K. Gp-gan: Towards realistic high-resolution image blending. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2487–2495. [Google Scholar]
- Antipov, G.; Baccouche, M.; Dugelay, J.L. Face aging with conditional generative adversarial networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2089–2093. [Google Scholar]
- Tang, X.; Wang, Z.; Luo, W.; Gao, S. Face Aging with Identity-Preserved Conditional Generative Adversarial Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7939–7947. [Google Scholar] [CrossRef]
- Chen, Y.; Shi, F.; Christodoulou, A.G.; Xie, Y.; Zhou, Z.; Li, D. Efficient and accurate MRI super-resolution using a generative adversarial network and 3D multi-level densely connected network. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2018: 21st International Conference, Granada, Spain, 16–20 September 2018; Proceedings, Part I. Springer: Berlin/Heidelberg, Germany, 2018; pp. 91–99. [Google Scholar]
- Huang, R.; Zhang, S.; Li, T.; He, R. Beyond face rotation: Global and local perception gan for photorealistic and identity preserving frontal view synthesis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2439–2448. [Google Scholar]
- Berthelot, D.; Schumm, T.; Metz, L. Began: Boundary equilibrium generative adversarial networks. arXiv 2017, arXiv:1703.10717. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 702–716. [Google Scholar]
- Jetchev, N.; Bergmann, U.; Vollgraf, R. Texture synthesis with spatial generative adversarial networks. arXiv 2016, arXiv:1611.08207. [Google Scholar]
- Bergmann, U.; Jetchev, N.; Vollgraf, R. Learning texture manifolds with the periodic spatial GAN. arXiv 2017, arXiv:1705.06566. [Google Scholar]
- Hamada, K.; Tachibana, K.; Li, T.; Honda, H.; Uchida, Y. Full-Body High-Resolution Anime Generation with Progressive Structure-Conditional Generative Adversarial Networks. In Proceedings of the Computer Vision—ECCV 2018 Workshops, Munich, Germany, 8–14 September 2018; Leal-Taixé, L., Roth, S., Eds.; Springer International Publishing: Cham, Swizerland, 2019; pp. 67–74. [Google Scholar]
- Dhariwal, P.; Jun, H.; Payne, C.; Kim, J.W.; Radford, A.; Sutskever, I. Jukebox: A generative model for music. arXiv 2020, arXiv:2005.00341. [Google Scholar]
- Volkhonskiy, D.; Nazarov, I.; Burnaev, E. Steganographic generative adversarial networks. In Proceedings of the Twelfth International Conference on Machine Vision (ICMV 2019). SPIE, Amsterdam, Netherlands, 16–18 November 2020; Volume 11433, pp. 991–1005. [Google Scholar]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Sutskever, I.; Chen, M. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv 2021, arXiv:2112.10741. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; et al. Photorealistic text-to-image diffusion models with deep language understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36479–36494. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6 August–11 August 2017; pp. 2642–2651. [Google Scholar]
- Chang, H.; Zhang, H.; Barber, J.; Maschinot, A.; Lezama, J.; Jiang, L.; Yang, M.H.; Murphy, K.; Freeman, W.T.; Rubinstein, M.; et al. Muse: Text-To-Image Generation via Masked Generative Transformers. arXiv 2023, arXiv:2301.00704. [Google Scholar]
- Tao, M.; Bao, B.K.; Tang, H.; Xu, C. GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis. arXiv 2023, arXiv:2301.12959. [Google Scholar]
- Popov, V.; Vovk, I.; Gogoryan, V.; Sadekova, T.; Kudinov, M. Grad-tts: A diffusion probabilistic model for text-to-speech. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 8599–8608. [Google Scholar]
- Engel, J.; Agrawal, K.K.; Chen, S.; Gulrajani, I.; Donahue, C.; Roberts, A. Gansynth: Adversarial neural audio synthesis. arXiv 2019, arXiv:1902.08710. [Google Scholar]
- Hayashi, H.; Abe, K.; Uchida, S. GlyphGAN: Style-consistent font generation based on generative adversarial networks. Knowl.-Based Syst. 2019, 186, 104927. [Google Scholar] [CrossRef]
- Hitaj, B.; Gasti, P.; Ateniese, G.; Perez-Cruz, F. Passgan: A deep learning approach for password guessing. In Proceedings of the Applied Cryptography and Network Security: 17th International Conference, ACNS 2019, Bogota, Colombia, 5–7 June 2019; Proceedings 17. Springer: Berlin/Heidelberg, Germany, 2019; pp. 217–237. [Google Scholar]
- Zhou, X.; Pan, Z.; Hu, G.; Tang, S.; Zhao, C. Stock market prediction on high-frequency data using generative adversarial nets. Math. Probl. Eng. 2018, 2018, 4907423. [Google Scholar] [CrossRef]
- Muthukumar, P.; Zhong, J. A stochastic time series model for predicting financial trends using nlp. arXiv 2021, arXiv:2102.01290. [Google Scholar]
- Wu, W.; Huang, F.; Kao, Y.; Chen, Z.; Wu, Q. Prediction method of multiple related time series based on generative adversarial networks. Information 2021, 12, 55. [Google Scholar] [CrossRef]
- Singer, U.; Polyak, A.; Hayes, T.; Yin, X.; An, J.; Zhang, S.; Hu, Q.; Yang, H.; Ashual, O.; Gafni, O.; et al. Make-a-video: Text-to-video generation without text-video data. arXiv 2022, arXiv:2209.14792. [Google Scholar]
- Ho, J.; Chan, W.; Saharia, C.; Whang, J.; Gao, R.; Gritsenko, A.; Kingma, D.P.; Poole, B.; Norouzi, M.; Fleet, D.J.; et al. Imagen video: High definition video generation with diffusion models. arXiv 2022, arXiv:2210.02303. [Google Scholar]
- Yu, Y.; Huang, Z.; Li, F.; Zhang, H.; Le, X. Point Encoder GAN: A deep learning model for 3D point cloud inpainting. Neurocomputing 2020, 384, 192–199. [Google Scholar] [CrossRef]
- Zhang, K.A.; Cuesta-Infante, A.; Xu, L.; Veeramachaneni, K. SteganoGAN: High capacity image steganography with GANs. arXiv 2019, arXiv:1901.03892. [Google Scholar]
- Dong, H.; Yu, S.; Wu, C.; Guo, Y. Semantic image synthesis via adversarial learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5706–5714. [Google Scholar]
- Couairon, G.; Verbeek, J.; Schwenk, H.; Cord, M. Diffedit: Diffusion-based semantic image editing with mask guidance. arXiv 2022, arXiv:2210.11427. [Google Scholar]
- Cao, Y.; Cao, Y.P.; Han, K.; Shan, Y.; Wong, K.Y.K. Dreamavatar: Text-and-shape guided 3d human avatar generation via diffusion models. arXiv 2023, arXiv:2304.00916. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-Shot Text-to-Image Generation. In Proceedings of the 38th International Conference on Machine Learning, PMLR, online, 18–24 July 2021; Meila, M., Zhang, T., Eds.; Proceedings of Machine Learning Research. MIT Press: Cambridge, MA, USA, 2021; Volume 139, pp. 8821–8831. [Google Scholar]
- Li, Z.; Lu, S.; Guo, D.; Duan, N.; Jannu, S.; Jenks, G.; Majumder, D.; Green, J.; Svyatkovskiy, A.; Fu, S.; et al. CodeReviewer: Pre-Training for Automating Code Review Activities. arXiv 2022, arXiv:2203.09095. [Google Scholar]
- Liu, C.; Lu, S.; Chen, W.; Jiang, D.; Svyatkovskiy, A.; Fu, S.; Sundaresan, N.; Duan, N. Code Execution with Pre-trained Language Models. arXiv 2023, arXiv:2305.05383. [Google Scholar]
- Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Yin, J.; Jiang, D.; et al. GraphCodeBERT: Pre-training Code Representations with Data Flow. arXiv 2020, arXiv:2009.08366. [Google Scholar]
- Guo, D.; Lu, S.; Duan, N.; Wang, Y.; Zhou, M.; Yin, J. UniXcoder: Unified Cross-Modal Pre-Training for Code Representation. Available online: https://aclanthology.org/2022.acl-long.499/ (accessed on 25 July 2023).
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Pan, Y.; Qiu, Z.; Yao, T.; Li, H.; Mei, T. To create what you tell: Generating videos from captions. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA USA, 23–27 October 2017; pp. 1789–1798. [Google Scholar]
- Samuelson, P. Legal Challenges to Generative AI, Part I. Commun. ACM 2023, 66, 20–23. [Google Scholar] [CrossRef]


















| Attribute | Web 1.0 | Web 2.0 | Web 3.0 |
|---|---|---|---|
| Time line | 1990s to 2002 | 2002 to 2022 | 2022 to 2042 |
| User Interaction | Static websites with limited user interactivity. | Dynamic websites with enhanced user interactivity. | Intelligent and personalized user experiences. |
| Content Creation | Professional generated content (PGC), mainly generated by developers and content creators in the static websites. | User-generated content (UGC) became prominent in dynamic and interactive websites (blogging, social media). | Context-aware and intelligent content creation. User-generated and machine-generated content (AI-generated content (AIGC), smart devices). |
| Technology | Server-side processing using HTML, basic scripting, limited multimedia. | Client-side scripting with rich internet applications (JavaScript, Flash, AJAX). | Advanced technologies (AI, ML, NLP, blockchain, IoT). |
| Data Management | Centralized data storage and limited data sharing. | Decentralized data sharing and collaboration. | Distributed and interoperable data storage and sharing. |
| Communication | Basic email and discussion forums. | Social media platforms and instant messaging. | Advanced semantic communication and real-time collaboration. Seamless communication across platforms and devices. |
| Innovation | Limited innovation, focus on information. | Rapid innovation and collaboration. | Emphasis on AI, automation, and emerging technologies. |
| Computation resources | Limited computational and processing power on user devices. Focus on server-side computation. | Increased computational power on user devices. Focus on client-side computing. | Distributed computation and edge computing. |
| Storage capacity | Limited storage capacity on servers. | Increased cloud storage and scalable data storage solutions. | Expanded storage capacity. Distributed and scalable storage solutions. |
| Data access | Passive data consumption. | Active participation and data sharing. | Intelligent data access and personalized recommendations. |
| Examples | Early websites, static informational pages. | Social media platforms (Facebook, Twitter), blogging platforms. | Virtual collaborative assistants, AI-powered applications, blockchain platforms. |
| Reference | Year Published | AIGC Requirements Taxonomy | AIGC Models | AIGC Input–Output Classification | AIGC Evaluation Metric Classification | Remarks |
|---|---|---|---|---|---|---|
| [6] | 2017 | L | M | M | NA | A review of generative adversarial networks (GANs) and their applications across various domains. |
| [7] | 2019 | L | M | M | M | This highlights the background, evaluation metrics, and training processes of GANs. |
| [8] | 2019 | NA | M | M | L | A review of GANs, including comparisons, performance evaluations, and their applications in computer vision (CV). |
| [9] | 2020 | NA | M | M | L | A review of GANs, their training processes, evaluation indices, and applications in CV and NLP. |
| [10] | 2020 | NA | L | L | NA | Overview of GAN architecture, along with the state of the art in the security domain. |
| [11] | 2020 | L | H | L | M | Presented overview of generative AI model classifications. |
| [12] | 2020 | NA | L | L | NA | Focuses on the application of GANs in architecture and urban design. |
| [13] | 2020 | L | M | M | NA | A review of the progress made with GANs and their applications in computer vision (CV). |
| [14] | 2021 | L | L | M | NA | This highlights the various applications of GANs and their impact across different domains. |
| [15] | 2021 | L | M | L | L | Focusing on the application of GANs in finance research. |
| [16] | 2021 | L | H | H | L | A survey of GANs and their variants across various research fields. |
| [17] | 2021 | L | L | L | L | An overview of GANs in the field of digital pathology. |
| [18] | 2021 | L | L | L | M | A survey on GANs for NLP tasks, including available datasets and evaluation metrics. |
| [19] | 2021 | L | H | L | M | Focuses on AIGC models for drug discovery. |
| [20] | 2022 | L | M | L | M | An overview of the main enhancements, variations of GAN models, and their evaluation metrics. |
| [21] | 2022 | L | M | L | NA | A survey on generative AI models used in drug discovery. |
| [22] | 2023 | L | L | L | NA | A comprehensive survey on the underlying technology and applications of text-to-3D conversion. |
| [1] | 2023 | H | H | H | L | An overview of the history, components, recent advances, and challenges in AI-guided combinatorial chemistry. |
| [23] | 2023 | NA | NA | NA | NA | Focuses on the opportunities that AIGC presents in business, education, and society. |
| [24] | 2023 | NA | L | NA | L | Generative AI models in the domain of computer-aided drug design. |
| [25] | 2023 | L | M | H | NA | Focusing on applications that involve input–output classification. |
| [26] | 2023 | L | M | H | L | Focusing on applications that involve input–output classification. |
| [27] | 2023 | L | H | L | L | Progress of AIGC models, their challenges, and applications in material science. |
| [28] | 2023 | L | L | L | NA | A review of ChatGPT’s role across various research fields. |
| [29] | 2023 | L | M | M | M | Focuses on AIGC models in molecule, protein, and material science. |
| [30] | 2023 | L | M | L | NA | Focuses on ChatGPT, its underlying architecture, and its applications across various domains. |
| [31] | 2023 | L | L | M | M | A survey on recent progress of AIGC models in speech synthesis. |
| [32] | 2023 | M | L | M | M | A review of text-to-image diffusion models. |
| [2] | 2023 | M | H | M | L | A review of AIGC models across various research fields. |
| This paper | 2023 | H | H | H | H | Our paper focuses on all four areas and contributes significant results such as AIGC requirements categorization, AIGC models, input–output classification, and evaluation metrics. |
| Category | Description |
|---|---|
| Hardware requirements | Data can be collected using cameras [36], microphones, sensors and can use datasets that are released by researchers for specific tasks [37,38,39]. To train, fine-tune and optimize hyperparameters—Tesla V100 16 GB [47], RTX 2080Ti [48], NVIDIA RTX 2080Ti, NVIDIA GeForce RTX 3090 with 24 GB [49], TPU [50], etc., are generally used, while GTX 1060 6 GB of DDR5 [51] can also be used to train a small-scale model. Sample generation can be performed on basic configuration like CPU—i7 3.4 GHz and GPU—GTX970 [52] or the configuration required by the generative model. |
| Software requirements | For data collection and preprocessing, tools such as Web scraping frameworks [33,34,35], Pandas [48,52,53], Numpy [53,54,55], scikit-image [48,55,56], torch-audio, torchtext [48], RDKit [57], data acquisition tools, audio recording software, motion capture software. To train the models, deep learning frameworks like TensorFlow [52,58,59], PyTorch [60,61,62], scikit-learn [52,60,63], SciPy [53,63] are used, which provide support for various generative model architectures and optimization algorithms. PyTorch [64], TensorFlow [65], scikit-learn [60]: these libraries are also used to evaluate and validate the model. For post-processing and refinement of models, libraries like opencv_python [55,66], NLTK [59,67] are used. |
| User-experience requirements | Key considerations for user aspects are high quality, accuracy [68] and realistic outputs [69], customization and control, diversity [70] and novelty, performance and efficiency, interactivity and responsiveness to user input, ethics [71] and data privacy [72,73], and seamless integration with existing systems. |
| Model | Architecture Components | Training Method |
|---|---|---|
| Variational Autoencoders | Encoder–Decoder | Variational Inference [19] |
| Generative Adversarial Networks | Generator–Discriminator | Adversarial [44] |
| Diffusion Models | Noising (Forward)–Denoising | Iterative Refinement [31] |
| Transformers | Encoder–Decoder | Supervised [74] |
| Language Models | Recurrent Neural Networks | Supervised [75] |
| Normalizing Flow Models | Coupling Layers | Maximum-Likelihood Estimation [76] |
| Hybrid Models | Combination of Different Models | Varied |
| Input | Output | Prescribed Task | Technique/Technology/Model | Ref. |
|---|---|---|---|---|
| Image | 3D Image | Text-guided 3D object generation: generating 3D objects based on textual descriptions | DREAMFUSION | [133] |
| Image | Blind motion deblurring of a single photograph | DeblurGAN | [61] | |
| DeblurGAN-v2 | [56] | |||
| Image | Generate highly realistic and diverse synthetic images | StyleGAN | [4] | |
| Image | Blending two Images | Gaussian-Poisson Generative Adversarial Network (GP-GAN) | [134] | |
| Image | Image compositing or image blending | Geometrically and Color Consistent GANs (GCC-GANs) | [64] | |
| Image | Filling absent pixels in an image or image inpainting | Exemplar GANs (ExGANs) | [99] | |
| Contextual Attention Generative Adversarial Networks (CA-Generative Adversarial Networks (GAN)) | [127] | |||
| PGGAN | [126] | |||
| Image | Face aging: generating images that depict a hypothetical future appearance of a person. | Age-cGAN | [135] | |
| Conditional Adversarial Autoencoder (CAAE) | [122] | |||
| Identity-Preserved Conditional Generative Adversarial Networks (IPCGANs) | [136] | |||
| Image | Image editing | Introspective Adversarial Network (IAN) | [124] | |
| Image | Medical image analysis: segmenting objects or regions in an image | SegAN | [100] | |
| Image | Converting low-resolution images to high resolution | Multi-Level Densely Connected Super-Resolution Network (mDCSRN) | [137] | |
| Image | Synthesizing a photorealistic frontal view from a single face image | Two-Pathway Generative Adversarial Network | [138] | |
| Image | To increase the resolution of an image | Super Resolution GAN (SRGAN) | [90] | |
| Image | Generates high-quality face samples at a resolution of 128 × 128 pixels | Boundary Equilibrium GAN (BEGAN) | [139] | |
| Image | To increase the resolution of an image better than SRGAN | Enhanced Super Resolution GAN (SRGAN) | [140] | |
| Image | To convert the image content from one domain to another | Conditional Generative Adversarial Networks (CGAN) | [81] | |
| Image | Style transfer, image-to-image translation, domain adaptation, data augmentation | cycle generative adversarial networks (CycleGAN) | [87] | |
| Image | Style transfer, image synthesis, image-to-image translation, and domain adaptation | Discover Cross-Domain Relations with Generative Adversarial Networks (DiscoGAN) | [88] | |
| Image | Method for training generative neural networks for efficient texture synthesis | Markovian Generative Adversarial Networks (MGANs) | [141] | |
| Image | Specifically designed for spatial data and related tasks such as image generation, editing, manipulation, data augmentation, and style transfer | Spatial Generative Adversarial Networks (Spatial GAN) | [142] | |
| Image | Creating tileable textures for 3D models, generating repeating backgrounds or surfaces for digital art or design, or synthesizing periodic visual elements for games or virtual environments | Periodic Spatial Generative Adversarial Networks (Spatial GAN) | [143] | |
| Image | To generate high-quality, high-resolution, and diverse synthetic images that resemble real-world images | Big Generative Adversarial Networks (BigGAN) | [43] | |
| Image | Cyber intrusion and malware detection | Defense-Generative Adversarial Networks | [95] | |
| Image | Generating images in a target domain from a different source domain | Domain Transfer Network (DTN) | [89] | |
| Text | Generate textual descriptions for given images | Recurrent Topic-Transition Generative Adversarial Network (RTT-Generative Adversarial Networks (GAN)) | [62] | |
| Text | Image-to-text generation or image captioning | Show and Tell: Neural Image Captioning | [59] | |
| Text | Generating handwritten characters in a target font style or creating new fonts or handwritten font generation | DenseNet Cycle Generative Adversarial Networks (GAN) | [54] | |
| Text | Answers questions based on image input | Visual Language Model - Flamingo | [109] | |
| Text | 3D Image | Generate 3D images using textual descriptions | Magic3D | [103] |
| 3D Animated Avatar | Generate text-driven 3D avatar with animations | AvatarCLIP | [66] | |
| 3D Faces | Generate personalized, animatable 3D faces using text guidance | DreamFace | [102] | |
| 3D Human Avatar | Generate 3D human avatars with identities and artistic styles using a text prompt | AvatarCraft | [55] | |
| 3D Human Motion | Generate 3D motion using text descriptions | MotionCLIP | [118] | |
| Animated Character | Generate animated characters from text | Progressive Structure-conditional GANs (PSGAN) | [144] | |
| Audio | Generate audio using text | w2v-BERT (Word2Vec and BERT) | [120] | |
| Music | Generate music from lyrics | Jukebox | [145] | |
| Code | Generate valid programming code using natural language descriptions | CodeBERT | [114] | |
| CODEGEN | [50] | |||
| CodeT5 | [115] | |||
| Codex | [116] | |||
| It assists in code completion, bug detection, and code summarization | Code Understanding BERT (CuBERT) | [110] | ||
| Generate competition-level code | Pre-trained Transformer-Based Language Model - Alphacode | [35] | ||
| Knowledge graph | Generate a knowledge graph (KG) using textual inputs | Grapher | [117] | |
| Image | Generate images using text | Text Conditioned Auxiliary Classifier Generative Adversarial Network (TAC-GAN) | [84] | |
| Generate Steganographic images to hide secret information | Steganographic Generative Adversarial Networks model (SGAN) | [146] | ||
| Secure Steganography Based on Generative Adversarial Networks (SSGAN) | [96] | |||
| Manipulate/edit images using textual descriptions | Text-Adaptive Generative Adversarial Network (TAGAN) | [67] | ||
| Generate images based on textual instructions | Denoising Diffusion Probabilistic Models (DDPM) | [101] | ||
| Guided Language to Image Diffusion for Generation (GLIDE) | [147] | |||
| Imagen | [148] | |||
| Attentional Generative Adversarial Networks (AttnGAN) | [92] | |||
| CogView | [77] | |||
| Auxiliary Classifier GANs (AC-GAN) | [149] | |||
| Stacked Generative Adversarial Networks (StackGAN) | [93] | |||
| alignDRAW (Deep Recurrent Attention Writer) | [78] | |||
| Deep Convolutional Generative Adversarial Networks (DCGAN) | [86] | |||
| Muse | [150] | |||
| Text Conditioned Auxiliary Classifier GAN (TAC-GAN) | [67] | |||
| Image | Generate more complex images using captions | Generative Adversarial CLIPs (GALIP) | [151] | |
| Image | Generate original, realistic images and art using a text prompt | Contrastive Language Image Pre-training (CLIP) | [130] | |
| Molecule | Text-based de novo molecule generation, molecule captioning | MolT5 (Molecular T5) | [58] | |
| Molecule Structure | Generate or retrieve molecular structures using textual description | Text2Mol | [60] | |
| Speech | Synthesize custom voice speech using text | Adaptive Text to Speech (AdaSpeech) | [113] | |
| Convert text to human-like speech | Denoising Diffusion Model for Text-to-Speech (Diff-TTS) | [63] | ||
| Grad-TTS | [152] | |||
| ProDiff | [53] | |||
| DiffGenerative Adversarial Networks (GAN)-TTS | [128] | |||
| Pixel Convolutional Neural Network - Wavenet | [123] | |||
| Generate speech using text | Feed-Forward Transformer (FFT) | [42] | ||
| Generate high-quality, synthetic musical audio clips | Generative Adversarial Networks Synth (GANSynth) | [153] | ||
| Text | To translate text from one language to another | Text-to-Text Transfer Transformer (T5) | [39] | |
| Convolutional Sequence to Sequence Learning (ConvS2S) | [132] | |||
| Sequence to Sequence (Seq2Seq) | [108] | |||
| Text | Generate handwritten characters in a target/new font style using text | GlyphGAN | [154] | |
| Text | Generate accurate and meaningful corrections for code issues | TFix | [45] | |
| Text | Explains the given input statements | WT5 (Why, T5?) | [121] | |
| Text | Perform tasks like translation, question answering, classification, and summarization using input texts | Text-To-Text Transformer (T5) | [39] | |
| Text | Generate or crack passwords | PassGAN | [155] | |
| Text | Chat with users, answer follow-up questions, challenge incorrect premises, and reject inappropriate requests | InstructGPT (GPT-3) | [111] | |
| Text | Operate as a conversational AI system to chat with users and answer follow-up questions | Language Models for Dialog Applications (LaMDA) | [33] | |
| Text | Write drafts, add suggestions, propose edits and provide explanations for its actions | PEER (Plan, Edit, Explain, Repeat) | [34] | |
| Text | Password cracking | Improved Wasserstein GAN (IWGAN) | [85] | |
| Text | Predict future markets using historical data | GAN-FD | [156] | |
| Stochastic Time-series Generative Adversarial Network (ST-GAN) | [157] | |||
| Multiple Time-series Generative Adversarial Networks (MTSGAN) | [158] | |||
| Video | Generate text-guided videos | MAKE-A-VIDEO | [159] | |
| IMAGEN VIDEO | [160] | |||
| Tune-A-Video | [104] | |||
| 2D Structure Molecule | 3D Structure Molecule | Generating 3D molecular structure | Geometry Complete Diffusion Model (GCDM) | [105] |
| 3D Image | 3D Image | Performing inpainting on 3D images | Point Encoder GAN | [161] |
| Generation of realistic human poses | GAN-Poser | [51] | ||
| Audio | Text | Generating captions for audio | Contrastive Language-Audio Pretraining (CLAP) | [47] |
| Chemical Properties | Molecule | Designing molecules/drugs with desired properties | Mol-Cycle Generative Adversarial Networks (GAN) | [125] |
| Molecular Graphs | Creating molecular graphs or designing molecule graphs | Junction Tree Variational Autoencoder (JT-VAE) | [57] | |
| Molecular Graphs | Designing molecule graphs from chemical properties | MoFlow | [76] | |
| Data | Text | Generating natural language from structured data | Text-To-Text Transformer (T5) | [112] |
| Gesture | Text | Gesture recognition | DCGAN (Deep Convolutional Generative Adversarial Network) with CNN (Convolutional Neural Network) | [36] |
| Graphs | Molecule Structure | Molecule generation | Constrained Graph Variational Autoencoder (CGVAE) | [79] |
| Graph | Generates the periodic structure of materials | Crystal Diffusion Variational Autoencoders (CDVAE) | [80] | |
| Image+Text | Image | A text-guided image manipulation method | LDEdit | [49] |
| Generating steganographic images (hiding messages in an image) | SteganoGAN | [162] | ||
| Performing text-driven image manipulation/editing | Style Contrastive Language-Image Pre-training (StyleCLIP) | [98] | ||
| Describing and editing the given image based on the text prompt | Pre-trained Language Model (PLM) - Visual GPT | [65] | ||
| Knowledge Graph | Text | Converting knowledge graph-based RDF triples to text | GTR-Long Short-Term Memory (LSTM) | [129] |
| Music | Text | Generating captions for music audio | MusCaps | [48] |
| Road Network | Road Network | Synthesizing road networks | StreetGAN | [97] |
| Speech | Speech | Speech enhancement | SEcGAN | [82] |
| Tabular Data | Tabular Data | Synthesize fake tables that are statistically similar to the original table | Table-GAN | [52] |
| Generate a synthetic dataset that is statistically similar to the original data | Tabular GAN (TGAN) | [94] | ||
| Generate synthetic data for tabular datasets | Conditional Tabular GAN (CTGAN) | [83] | ||
| Text+Image | Image | Performing text-based realistic image synthesis/generation | Semantic Image Synthesis via Adversarial Learning (SISGAN) | [163] |
| Text-based image manipulation | DIFFEDIT | [164] | ||
| DiffusionCLIP | [131] | |||
| Video | Generating video from text prompt and input image | PHENAKI | [119] | |
| Text+Shape | 3D Avatar | Generating 3D avatars guided by text and shape | DreamAvatar | [165] |
| Video | Video | Converting low-resolution videos to higher-resolution videos | VSRResFeatGAN | [91] |
| Video+Text | Video | Editing videos based on text input and animating images based on input (image+text) | Video Diffusion Model (VDM) - Dreamix | [106] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bandi, A.; Adapa, P.V.S.R.; Kuchi, Y.E.V.P.K. The Power of Generative AI: A Review of Requirements, Models, Input–Output Formats, Evaluation Metrics, and Challenges. Future Internet 2023, 15, 260. https://doi.org/10.3390/fi15080260
Bandi A, Adapa PVSR, Kuchi YEVPK. The Power of Generative AI: A Review of Requirements, Models, Input–Output Formats, Evaluation Metrics, and Challenges. Future Internet. 2023; 15(8):260. https://doi.org/10.3390/fi15080260
Chicago/Turabian StyleBandi, Ajay, Pydi Venkata Satya Ramesh Adapa, and Yudu Eswar Vinay Pratap Kumar Kuchi. 2023. "The Power of Generative AI: A Review of Requirements, Models, Input–Output Formats, Evaluation Metrics, and Challenges" Future Internet 15, no. 8: 260. https://doi.org/10.3390/fi15080260
APA StyleBandi, A., Adapa, P. V. S. R., & Kuchi, Y. E. V. P. K. (2023). The Power of Generative AI: A Review of Requirements, Models, Input–Output Formats, Evaluation Metrics, and Challenges. Future Internet, 15(8), 260. https://doi.org/10.3390/fi15080260