1. Introduction
In the context of academic bibliography, the tools and methods of Machine and Deep Learning constitute an alternative approach to statistical methods for time series forecasting. However, the available data with regard to their relative performance in terms of accuracy and computational demands is limited [
1]. Artificial Intelligence, which is a superset of machine and deep learning, has expanded during the last decade in multiple fields of entrepreneurial and academic activity, with applications regarding the financial sector, medical care, industry, retail, supply chain, utilities, and networks [
2]. Nevertheless, the classical approach with respect to the analysis and forecasting of time series is mostly based on integrated autoregressive moving average (ARIMA) models, and their various versions [
3]. Moreover, a core issue of the existing academic literature in the field of machine learning forecasting techniques is the fact that the majority of publications point to adequate accuracy values, without a proper foundation, meaning without a preestablished comparison with the results of simple statistical methods and prediction models [
1].
In the present study, we will attempt a review of ARIMA, Machine Learning, and Deep Learning techniques with regard to their relative performance in time series forecasting. The strategy behind our review is to present a selection of academic papers in which the performance of machine learning, deep learning, and hybrid prediction models is compared with the performance of the ARIMA or SARIMA (Seasonal ARIMA) algorithms based on a variety of metrics. The results of these studies are presented in
Table 2,
Table 3,
Table 4 and
Table 5. The scientific works presented in this review consist of research in the financial sector (with a special focus on the application of bitcoin price prediction), in the health sector (with a special focus on the applications of predicting parameters and variables related to the disease of COVID-19), in the field of weather forecasting (wind speed, drought, solar energy production, etc.), in the field of utility parameters forecasting (offer and demand of energy, water consumption, oil production, etc.), and in network parameters prediction (both transportation and web network traffic prediction).
1.1. Data Driven Networks
The title of the present work refers to “data driven networks”, from the point of view of data and models used in time series forecasting. Big data collection is of utmost importance to modern forecasting applications, especially for the training of efficient machine learning predictive models, due to the fact that the problem of forecasting increases in complexity as the volume and dimensionality of available data sources increase. In recent applications and study fields regarding time series forecasting, the collection of data relies on large-scale networks of sensors and data collection points due to the distributed nature of the target applications. The analysis and forecasts based on these datasets are also fed to large-scale network applications (e.g., large-scale weather forecasts, health strategy planning on a national and global level, sales management on a global scale, etc.).
On the other hand, the term “data driven networks” also refers to the training and efficient deployment of the models proposed for time series forecasting by the scientific community. Especially in the case of machine learning models, whose application is mostly data- and problem-agnostic, data availability in sufficient quantity is crucial to successful forecasting.
1.2. Scientific Contributions
The present work attempts to address the existing gap in the scientific literature, regarding an extensive summary/review of the studies comparing the application of ARIMA and machine learning techniques in time series forecasting applications. This is the only such review, according to the authors’ best knowledge.
Our work compares time series forecasting studies across multiple applications and data sources, and it consists of mostly recent comparative studies published after 2018 (with the exception of the works of Zhang et al. [
4] and Nie et al. [
5]). Due to the multitude of different data sources and forecasting challenges, we attempt a multilateral, sampled view of the existing literature, presenting studies from five basic data categories (financial, medical, weather, utilities, and network characteristics). For the above reasons, our work constitutes a contemporary, multifaced, review of the existing literature comparing the ARIMA statistical approach with its machine learning counterparts. Our study also summarizes the main performance metrics of the algorithms presented in each study, thus enabling an intuitive review and comparison of the methods in each forecasting application. A practical evaluation (
Section 5) of the studies in which the ARIMA models outperform their machine learning counterparts results in an enumeration of the application, dataset, and model-dependent characteristics that drive the choice of the optimal forecasting model in any particular application.
1.3. Rationale and Structure
The rationale behind the structure of our review is based on organizing the collected scientific literature first in relation to the machine learning model being compared with ARIMA and second in relation to the field of forecasting applications. In that scope, the first model category to be presented in detail is ARIMA, which is the center of our review, and then we organize the machine learning approaches by model category. For each of the categories, we present the theoretical background, and then we demonstrate the relevant scientific literature organized by application category. The same principle applies to the category of hybrid forecasting models, meaning the combination of ARIMA and machine learning algorithms. Finally, we evaluate the reviewed scientific literature in total, and based on the finding that machine learning models outperform the ARIMA approach in the majority of forecasting applications, we aim to uncover the conditions under which we have a superior ARIMA forecasting result.
At this point, it is important to note that our work does not propose a new time series forecasting model, but rather constitutes an organized review of the published scientific literature comparing the ARIMA approach to different machine learning, and hybrid prediction models. We consider this aspect of our work crucial to the feasibility of our study because we aim to compare the optimized ARIMA and machine learning models on the same datasets. Therefore, although the scientific literature applying individual ARIMA or machine learning models to forecasting problems is extensive, we base our study only on the explicit comparisons of the three categories of models (ARIMA, machine learning, and hybrid).
The present work is organized as follows: The problem of time series forecasting, which—along with the ARIMA technique—constitutes the center of our work, is presented in
Section 2, along with the morphological characteristics of the time series that affect the choice of the forecasting algorithm and their respective results. A review is also carried out regarding the time series data sources and their inherent characteristics that predetermine the format of the data to be analyzed and, consequently, the choice of the forecasting algorithms. In
Section 3 and
Section 4, we perform a theoretical review of the algorithms and machine learning models that will be presented in the context of the attempted comparisons, and subsequently, we present the relevant scientific literature, organized by field of research (financial sector, medical care, etc.). Specifically, in
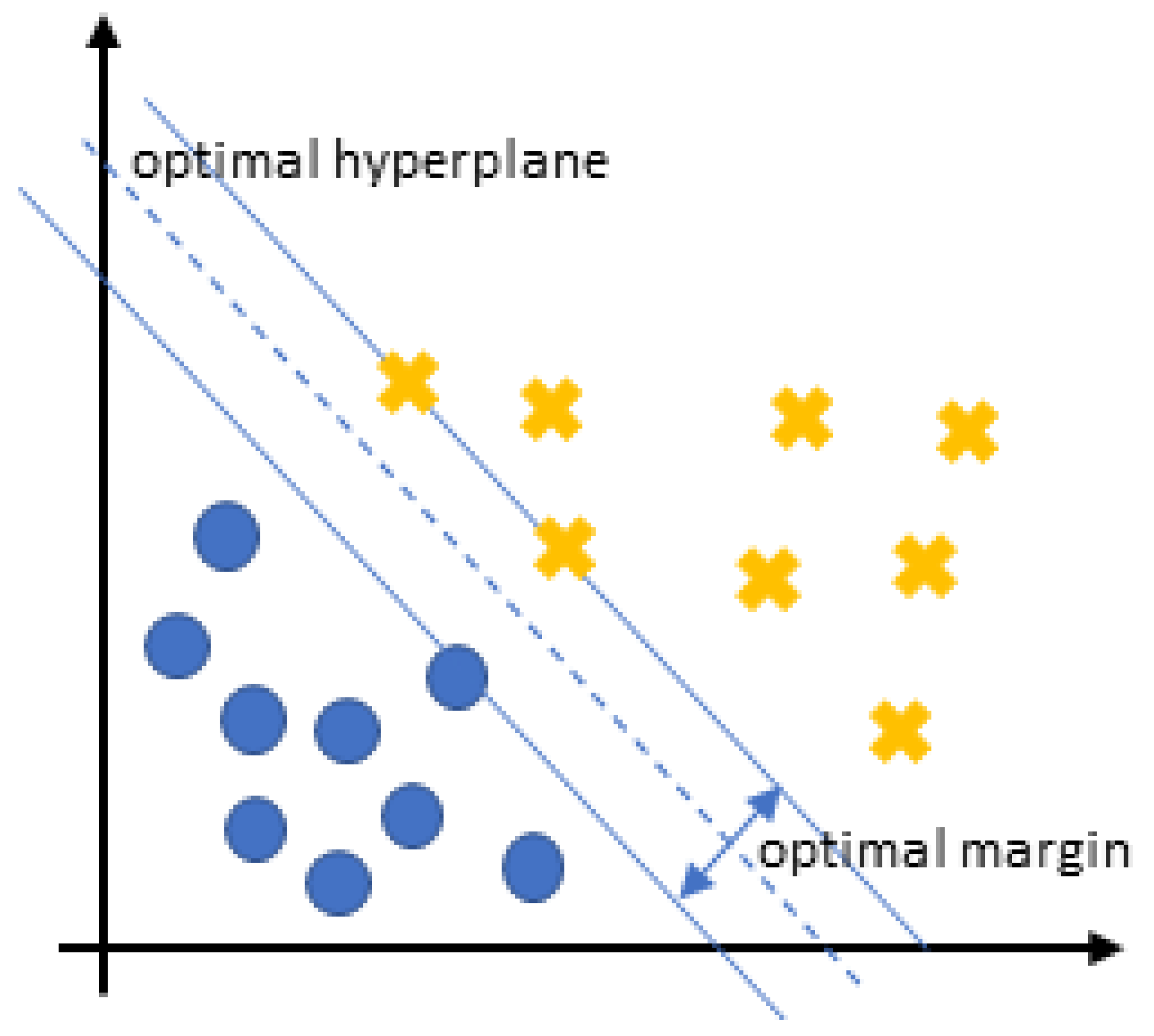
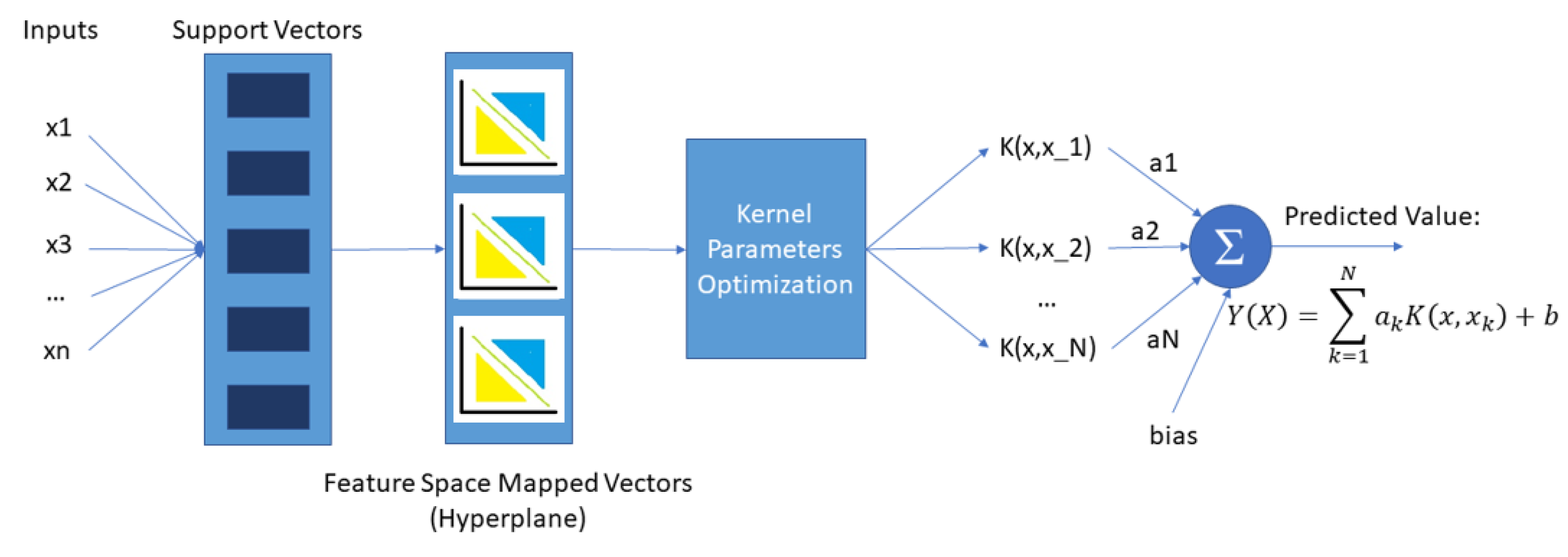
Section 3.1, we refer to the comparison of the SVM model with the classic ARIMA statistical technique, while in
Section 3.2, the theory and applications of decision tree-based models are analyzed.
Section 4 presents the rationale behind the development of hybrid forecasting models with a review of the indicative scientific literature. In any case, the hybrid models chosen for presentation and analysis are a combination of the ARIMA technique with a specific machine learning model.
Section 5 constitutes a practical evaluation of the reviewed literature, with a focus on extracting the conditions under which the ARIMA approach exhibits superior predictive performance compared with the machine learning models. Finally,
Section 6 covers the conclusions of our review.
2. Background: Data and Autoregressive Models
2.1. Time Series Data: Forecasting
Time is the central characteristic that distinguishes time series from other types of data. This property of theirs is both a limitation and a structural element of the data collection, as well as a source of additional information for their analysis [
6]. Essentially, time series data is any type of information presented as an ordered sequence and can be defined as a collection of observations of some variable, organized into equally spaced time intervals [
7].
The question of forecasting is one of the most difficult and essential problems that time series analysis must deal with. The performance and accuracy of the analysis results vary depending on the type of data and its assumptions. In addition to these parameters, the analysis is also affected by factors inherent to the respective field of research, such as the periodicity of the time series, unforeseen events, changes in the structure of the organizations or structures from which the data are collected, etc. [
8]. The “No-Free-Lunch” theorem proves that it is not possible to have a forecasting method that gives optimal performance for all possible time series [
9]. There is a significant amount of research literature on predictive models, and the results of these studies indicate the existence of two macro-categories of methods: statistical methods and machine learning methods. In the continuation of our paper, we will refer to the following categories of time series forecasting models: (a) statistical models, (b) machine and deep learning and (c) hybrid models [
10].
The comparison of the forecasting results of the aforementioned models in the context of the studies presented in the present work is based on various metrics, figure of merits, whose mathematical formulas are expressed below, where is the real value of the series at the time point t, is the corresponding forecasted value given by the model, and N is the time period of the forecast:
The popular error metric RMSE is used in the scientific literature in place of MSE (same scale of the variable), and it is the square root of the MSE metric.
It is a statistical measure to indicate the proportion of the dependent variable variation in a model that can be predicted from the variation in the independent model variables, and it is a metric used to determine how well our model fits a set of observations.
where
is the mean value of the forecasted values for the specific time range.
It is a metric used to assess the predictive capacity of hydrological models. It is computed using the following mathematical formula:
where
is the mean of observed discharges,
is the modeled discharge and
is the observed discharge at time
t.
The Kolmogorov–Smirnov test quantifies a distance metric between the distribution of our model outputs and a reference distribution defined by the null hypothesis of our study.
This metric is used specifically in the energy forecasting domain, being able to generalize under different upper bounding conditions.
where C is the capacity of the power plant.
2.2. Time Series Data: Characteristics
Data derived from time series may have the following characteristics [
6]:
Trend: This characteristic is associated with the presence of an upward, downward, or stable course of the series, with respect to the time dimension.
Seasonality: This characteristic indicates the existence of periodic patterns in the behavior of the time series, which repeat with a fixed frequency.
Stationarity: Stationary is a time series whose statistical properties (average, variance, dispersion of values, etc.) are stable over time. A stationary time series with no trend implies that its fluctuations around its mean have a constant width. Furthermore, the autocorrelation of static time series remains constant over time. Based on these assumptions, a time series of this form can be thought of as a combination of signal and noise [
11].
In addition to these basic characteristics, some of the more common patterns seen in time series data are the following [
7]:
-Cyclic behavior: In contrast to seasonal patterns, cyclical patterns appear when the factors influencing the data of each time series are not distinguished by a fixed or known frequency. This particular pattern mainly concerns studies related to financial data, where cyclical behavior is observed according to the cycles of the economy and the business environment. The average duration of these cycles is usually longer than the duration of seasonal patterns, of the order of two years.
-Diurnality: Refers to the inherent patterns observed in time series originating from a particular application that have a daily or monthly repeat cycle. Data related to solar, or weather observations are some examples indicating this property.
-Outliers: Regarding the detection of anomalies and outliers in time series data, the analysis focuses on identifying abnormal changes, both desirable and undesirable, in the data set.
-White noise: This characteristic refers to the cases where the data does not follow a specific pattern.
2.3. Time Series Data Sources
Time series data can come from a multitude of sources and systems with different classes of characteristics, complexity, volume, and frequency of acquisition. Some categories of sources of this kind of data are industrial production, the financial sector, the consumer electronics industry, health system structures, retail trade, meteorology, and generally any measurable and quantifiable manifestation of human life and its environment. Especially in recent years, through the exponential growth of data sources, time series analysis and forecasting systems have been required to approach models of ever-increasing dimension and complexity.
Time series from complex systems capture the dynamic behavior and causes of the underlying processes and provide a practical means of predicting and monitoring the evolution of the system state. However, the non-linearity and non-stationarity that often characterize the underlying processes of these systems pose a strong challenge to the process of accurate prediction. For most real-world systems, their dynamical state vector field is a nonlinear function of the state variables, meaning that the relationship connecting the system’s intrinsic state variables to their autoregressive terms and exogenous variables is nonlinear. The time series resulting from such complex systems show aperiodic (chaotic) patterns even in steady states. Furthermore, since real-world systems often evolve under transient conditions, the signals obtained from them tend to exhibit various forms of non-stationarity. However, the methods that dominate the literature on the analysis and forecasting of time series derived from such systems focus mainly on the forecasting of linear and static processes. According to the work of Cheng et al. [
12], conventional forecasting approaches, such as ARIMA techniques, cannot adequately capture the evolution of these systems from the perspectives of forecasting accuracy, computational workload, and sensitivity to the quantity and quality of a priori input information. This finding prompts us to assume that the success of the used prediction method, both in the category of classical algorithms and in the category of machine learning and deep learning techniques, depends to a large extent on the complexity of the system described by the data. From this point of view, artificial intelligence has an advantage over ARIMA techniques, as will be seen from the results of the studies presented later in the paper. At this point, it must be mentioned that a number of non-linear transformations exist for optimizing the ARIMA models in non-linear forecasting applications, which we will refer to in the ARIMA theoretical background of our study. On this note, there are a few notable exceptions where the performance of classical techniques exceeds that of artificial intelligence methods. These results will be commented on in the conclusions of our research.
2.4. AutoRegressive Integrated Moving Average (ARIMA) Models
The ARIMA model is a generalization of the ARMA model (AutoRegressive Moving Average model), suitable for handling non-stationary time series. As the classical ARMA model takes for granted the stationarity of the time series it is asked to analyze, the management of inherently non-stationary time series requires their transformation into a static data series by eliminating seasonality and trends, through a finite-point differentiation [
3]. As mentioned earlier, a stationary time series can be thought of as a combination of signal and noise. The ARIMA model handles the time signal, after first separating it from the noise, and outputs its prediction for a subsequent time point [
11]. As indicated by the method’s acronym, its structural components are the following [
13]:
AR: Autoregression. A regression model that uses the dependence relationship between an observation and a number of lagged observations (model parameter p).
I: Integration. Calculating the differences between observations at different time points (model parameter d), aiming to make the time series stationary.
MA: Moving Average. This approach considers the dependence that may exist between observations and the error terms created when a moving average model is used on observations that have a time lag (model parameter q).
The AR model of order p, AR(p), can be written as a linear process as follows:
where
the static variable,
c a constant, the terms
are autocorrelation coefficients at the time delay steps
and
are the samples of the Gaussian white noise series, with zero mean and
variance.
A simple moving average model of order q, MA(q), can be given as:
where
, is the expected value of
(it mostly equals to 0),
the weights applied to the current and past values of the stochastic term of the time series, and
. We consider
to be a Gaussian white noise series, with zero mean and
variance.
By combining these two models, autoregression and moving average, we create the ARMA model of class (p,q):
where
The parameters p, q constitute the order of the AR and MA models respectively.
The general form of an ARIMA model is written as ARIMA(p, d, q), including the integration term that guarantees the stationarity of the time series [
13], and it can be expressed as:
where
is a differential factor, introducing a difference of order
d, aiming to remove the nonstationarity of the time series
[
14].
Table 1 displays the basic parameter combinations for the nonseasonal ARIMA models.
2.4.1. ARIMA Parameter Determination
The optimal selection of the ARIMA p, d, and q parameters is crucial to the success of the forecasting procedure. The combination of the p and q parameters is based on the examination of the autocorrelation function (ACF) and partial autocorrelation function (PACF) plots for the specific dataset, while the d parameter is chosen in order to stationarize the time series.
In most of the scientific literature presented in the rest of this work, it is often needed to identify the best-performing ARIMA model among a number of different ARIMA (p,d,q) models for a specific forecasting application. In these cases, the selection criteria include the Akaike (AIC) and Bayesian (BIC) information criteria. The AIC measures the quality of a forecasting model, keeping a balance between overfitting and model complexity. In the case of BIC, the same rule applies, but with a higher penalty for complex models. In both criteria, lower values signify a better model.
There have been many attempts to automate the selection of the ARIMA model parameters over the years, using different tests in order to determine the optimal values for both seasonal and non-seasonal models. The auto.arima function in R [
15] constitutes a popular heuristic method for parameter selection in an ARIMA application, and it is based on a simple step-wise algorithm:
1. Start with a small number of basic ARIMA models and select the one with the minimum AIC value.
2. Consider up to a number of variations of the selected model and calculate the AIC value for each one. Whenever a model with a lower AIC is found, it replaces the reference model, and the procedure is repeated. The algorithm finishes when we cannot find a model close to the reference model with a lower AIC value.
A valid ARIMA model is always returned by the above algorithm due to the fact that the model space is finite and that at least one of the starting models will be accepted as a solution [
16].
2.4.2. ARIMA Variants
In cases of seasonal time series, it is possible, during the analysis, for the forecasting model to be partially shaped by non-seasonal, short-duration features of the data. Consequently, the formulation of a seasonal ARIMA model is required, which incorporates seasonal and non-seasonal factors into a combined model. The general form of a seasonal ARIMA model is represented by the formula: where p is the non-seasonal AR order, d is the non-seasonal differencing order, q is the non-seasonal MA order, P is the seasonal AR order, D is the seasonal differencing order, Q is the seasonal MA order and S is the recurrence time range of the seasonal pattern. The most important step in calculating a seasonal ARIMA model is determining the values of the parameters (p, d, q) and (P, D, Q).
The ARIMA technique has evolved over the years, resulting in the development of many variants of this model, such as the SARIMA (Seasonal ARIMA) and ARIMAX (ARIMA with Explanatory Variable) techniques. These models perform well in terms of short-term forecasts, but their performance is severely degraded for long-term predictions [
8].
2.4.3. Advantages and Disadvantages
The ARIMA technique presents several advantages, among which are the use of an online learning environment, the independence between sample size and storage costs, as well as the fact that parameter estimation can be performed online, in an efficient and scalable way. The disadvantages of this technique are the subjectivity of its progress evaluation, the fact that the reliability of the selected model may depend on the skill and experience of the specific forecaster, and the existence of several limitations to the parameters and classes of possible models. A consequence of all these limitations is the fact that the final choice of the prediction model can be a difficult task [
17].
Another important aspect of the application of the ARIMA to time series forecasting is the linearity of the dataset it aims to predict. The basic form of the ARIMA algorithms is designed to handle linear data relationships. However, their scope of successful application in forecasting can be significantly extended, considering the various transformations available, which extend the method’s capability to handle non-linear time series. A widely used family of such transformations, including both logarithmic and power transformations, is the Box-Cox toolset [
18], depending on the
parameter and defined as:
Based on the value of , the new time series can be transformed in order to improve the forecasting model.
4. Hybrid Models
Attempting to combine the best modeling features of both classical statistical algorithms and machine learning models, a large part of the time series forecasting scientific literature is concerned with the development of combinations of forecasting models. We will initially refer to the motivations behind the development of hybrid models and, indicatively, emphasize some applications from various fields of research while focusing on the characteristics of the given problem and how these are modeled by the trained prediction models.
Hybrid time series forecasting models are developed in the scientific literature based on three main factors:
First, because of the practical difficulty in determining whether the time series under consideration has been produced by linear or non-linear underlying processes, as well as the difficulty in choosing one forecasting method over the others for a particular task and forecasting environment. The usual practice to deal with this particular problem is essentially to develop, train (in the case of machine learning algorithms), and test more than one predictive model, while factors such as sampling uncertainty and the dispersion of the sampling process make it difficult to generalize the chosen model. Consequently, combining several algorithms to create a complex prediction model can facilitate the selection process.
The second reason for developing hybrid models is the fact that time series produced by real processes, in the majority of cases, do not have a purely linear or non-linear profile but contain a combination of linear and non-linear patterns. In these cases, single statistical or neural models are not sufficient for time series modeling and forecasting since the simple version of the ARIMA model cannot deal with non-linear relationships, while the neural network model alone is not able to handle linear and non-linear patterns equally well. Therefore, by combining ARIMA models with machine learning models, the complex autocorrelation structures in the data can be modeled more accurately.
The third factor to consider is the fact that in the scientific literature on time series forecasting, it is almost universally accepted that there is no one forecasting method that is better than all others for every forecasting situation. This is largely due to the fact that a real problem is often complex in nature, and any single model may not be able to capture the different patterns equally well. Therefore, the combination of different models can increase the probability of detecting different patterns in the data and improve the prediction performance. In addition, the combinatorial model is more robust to a possible structural change in the data [
4].
Regarding the combination of different forecasting algorithms in building an efficient hybrid model, various workflows are proposed, according to the forecasting problem at hand as well as its scientific approach.
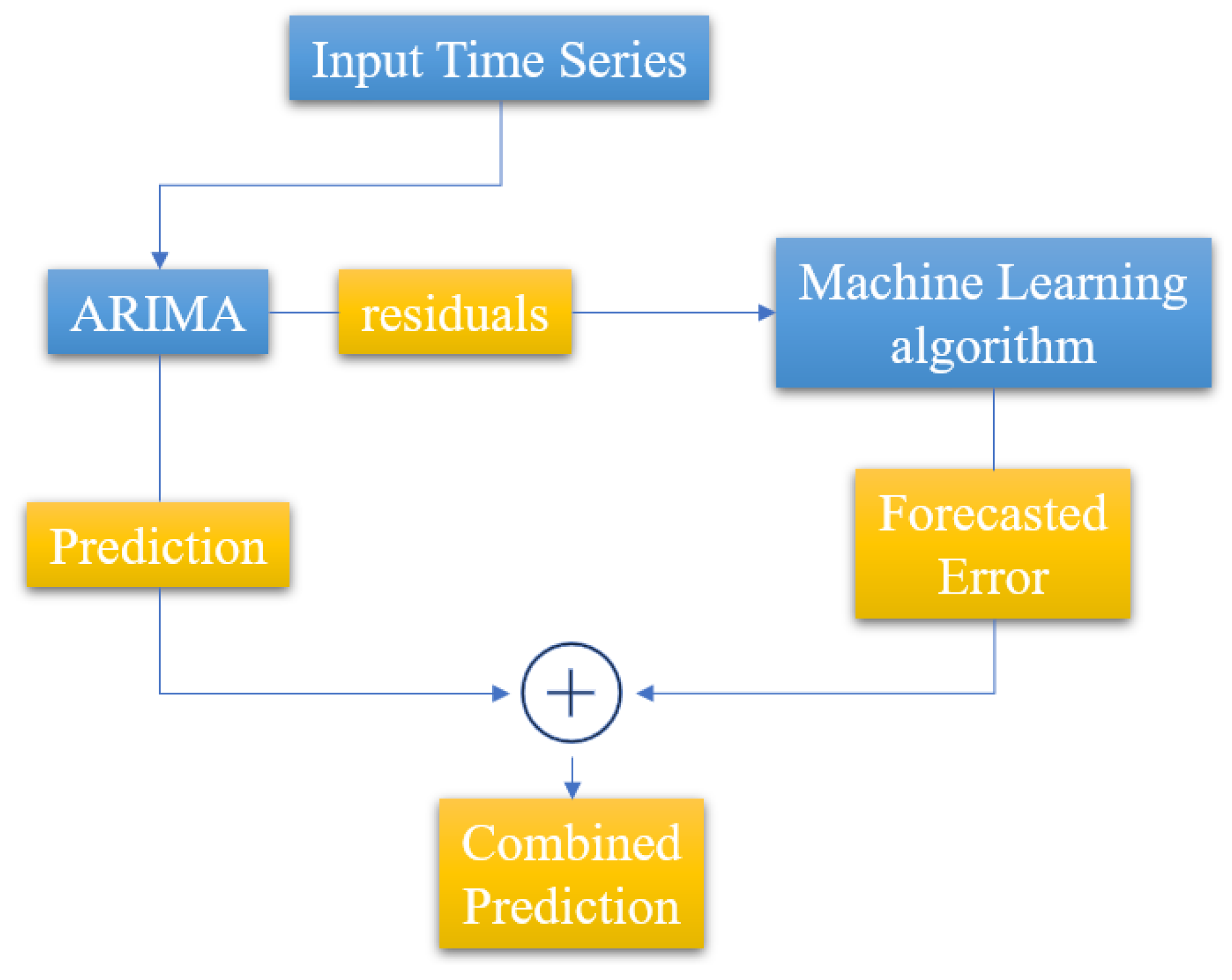
In the classic work by Zhang et al. [
4], a hybrid model combining ARIMA and neural networks is proposed, aiming to exploit the capabilities of each model in terms of linear and non-linear modeling, respectively. The proposed methodology consists of two steps: In the first step, the ARIMA model is used to analyze the linear part of the problem, while in the second step, a neural network is developed to model the residuals of the ARIMA model. Since the classical ARIMA model cannot capture the non-linear structure of the data, the residuals of the linear model will contain information about the non-linearity. The outputs of the neural network can be used as predictors for the error terms of the ARIMA model. The results of this research showed that the hybrid model improves the prediction accuracy of both individual models. The proposed hybrid approach is presented graphically in
Figure 6. A similar approach is used by Biswas et al. [
57], Prajapati et al. [
58], and Nie et al. [
5] in different research fields and with a different selection of machine learning algorithms, combined with the ARIMA model.
4.1. Financial Data
In the field of bitcoin price prediction research, which we have encountered in numerous works ([
6,
44,
45]) the development of hybrid forecasting models is a widely used practice. The work of Nguyen et al. [
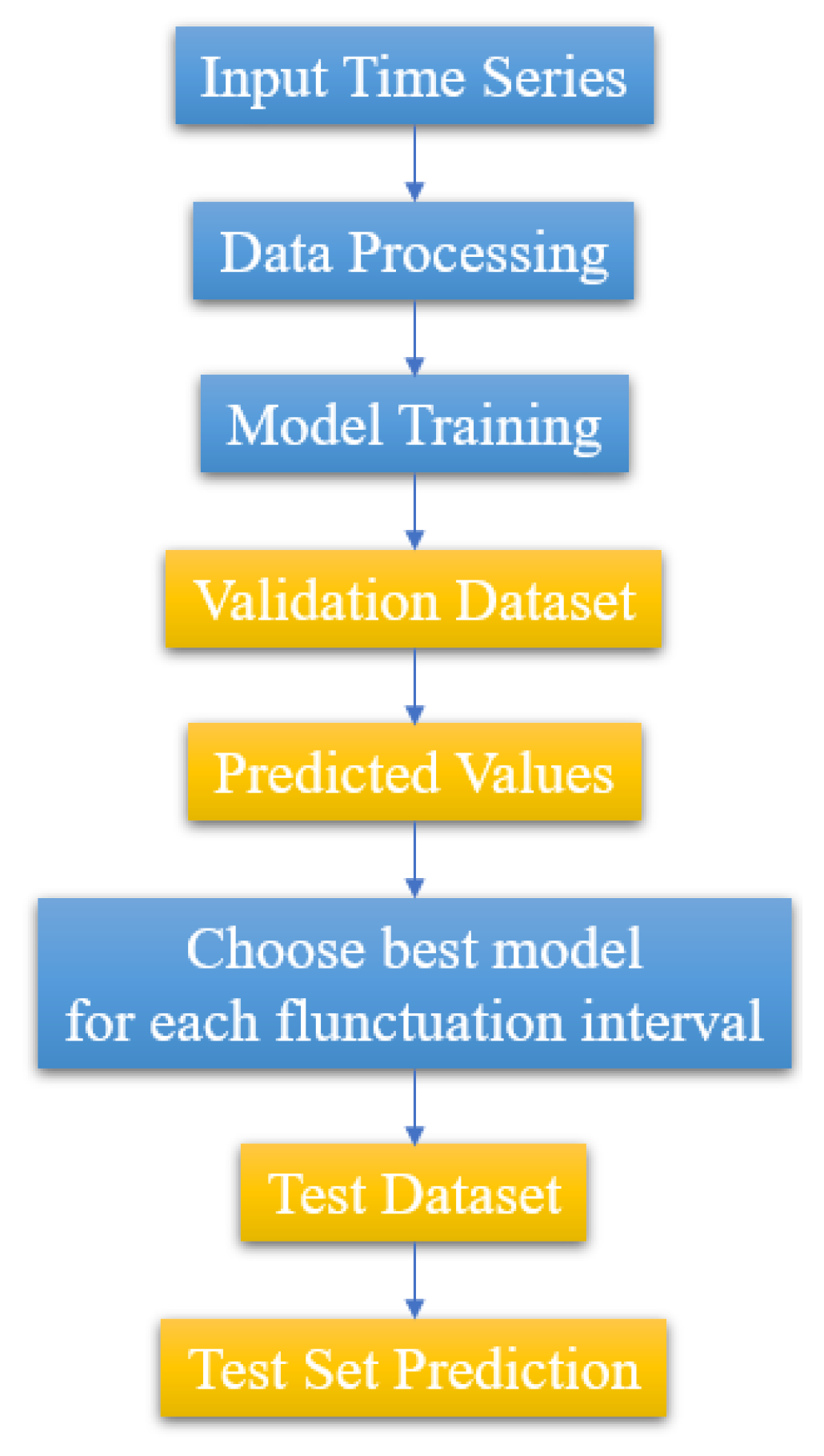
44] which we already mentioned in the deep learning models paragraph, uses combinations of ARIMA with FFNN, CNN, LSTM, and SVR models to make bitcoin price time series predictions, as well as to compare these hybrid models. This particular work uses a different hybrid strategy than the one presented in
Figure 6, namely, it utilizes each algorithm (ARIMA and ML-based) with respect to the fluctuation level observed for different time series intervals. The flowchart of this approach is depicted in
Figure 7. The results of the work based on the RMSE and MAPE metrics, show that the performances of the four hybrid models are very close, with the best being given by the combination of ARIMA with the CNN model. Another example of a hybrid model application in the financial domain is the work by Zheng et al.
4.2. Weather
In terms of weather forecasting, research by Biswas et al. [
57] suggests using a combination of regression and machine learning models to predict wind energy production over one, two, and seven day time horizons. The forecast is based on weather data such as wind speed and direction, air temperature and pressure, and density at the height of the measurement node. The preliminary results of this study indicate that the combination of ARIMA with Random Forest algorithms (ARIMA-RF) as well as the combination of ARIMA with Bayesian Regression and Classification Trees (BCART) help to improve the forecasting accuracy compared with the classical forecasting algorithm of ARIMA.
4.3. Healthcare Data
In the field of medical care and specifically regarding the prediction of COVID-19 cases, the work of Prajapati et al. [
58] moves on three levels: Modeling the overall trend in the number of cases over time, short-term forecasting on the order of ten days in countries with extremely high population density such as India, and determining which algorithm presents the best metrics performance in accurately modeling the linear and non-linear characteristics of the case count time series. Various individual prediction models based on the Prophet, Holt-Winters, LSTM, and ARIMA algorithms were used, as well as the ARIMA-NARNN (Nonlinear Autoregressive Neural Network) hybrid model. The simple ARIMA algorithm performed better than other individual models; however, the hybrid combination of ARIMA and NARNN had the best overall performance, with RMSE values almost 35.3% better than ARIMA.
4.4. Utilities
In relation to the applications of SVMs in time series forecasting, the work of Nie et al. [
5] deals with short-term load forecasting in energy transmission systems. Short-term load is a variable that is affected by many factors, and for this reason, it is difficult to make an accurate prediction with a single model. Utilizing the ARIMA algorithm to forecast the basic linear part of the load and the SVM algorithm to forecast the sensitive, non-linear part of the load, the paper presents a forecasting method based on a hybrid ARIMA and SVM model. ARIMA is used to forecast the daily load, and then the SVM model is used, aiming to correct the deviations from the previous forecasts. Due to their generalization ability and fast computation, SVMs show excellent performance in extracting the nonlinear part of the load and can be used to achieve the correction of the data deviation. The ARIMA-SVM hybrid model effectively combines the advantages of ARIMA and SVMs and through the simulation of a large sample of data, the results show that this hybrid model is much better than the two forecasting models applied separately.
4.5. Network Traffic
Finally, in the field of network parameter forecasting, we present the work of Ma et al. [
59], where the ARIMA algorithm is combined with the Multi Layer Perceptron and the Multidimensional Support Vector Regression models in a hybrid approach to the network-wide traffic state forecasting problem. An increased predictive performance is observed in relation to the statistical forecasting method in cases where the network traffic is considered both at a local and global scale with the incorporation of the hybrid prediction model. An interesting change in the hybrid model workflow with respect to the previously mentioned studies is the fact that in this case the ARIMA algorithm is used after the neural network in order to post-process the ML model residuals. This is also, according to the authors, “necessary and a warrant at least for the situation where the time series data are not sufficiently long”.
The specific work aims to predict the traffic state for a small city area based on the measurement and prediction of three macroscopic traffic variables: traffic volume, speed, and occupancy. The dataset is comprised of time series collected from a network of detectors along the Highway Ayalon in Tel Aviv, Israel. The proposed approach can not only capture the network-wide co-movement pattern of traffic flows in the transportation system but also seize location-specific traffic characteristics as well as the sharp nonlinearity of macroscopic traffic variables. The case study indicates that the accuracy of prediction can be significantly improved when both network-scale traffic features and location-specific characteristics are taken into account.
5. Discussion and Practical Evaluation
In this paper, a series of works on different areas of time series analysis and forecasting were selectively presented, with the aim of comparing the classic ARIMA forecasting algorithms with machine learning and deep learning models. As we see in the consolidated representation of these tasks in
Table 2,
Table 3,
Table 4 and
Table 5 the used metrics, based on which the comparison of each algorithm with the ARIMA technique was performed, are similar for the majority of the tasks.
Table 5.
Summary of studies comparing ARIMA and Hybrid Models in time series forecasting.
Table 5.
Summary of studies comparing ARIMA and Hybrid Models in time series forecasting.
| Article | Algorithms | Metrics | Dataset |
|---|
| Zhang et al. [4] | ARIMA/ANN | MSE | variety |
| | MAD | |
| Nguyen et al. [44] | ARIMA/FFNN | RMSE | bitcoin price |
| ARIMA/CNN | MAPE | |
| ARIMA/LSTM | | |
| ARIMA/SVR | | |
| Biswas et al. [57] | ARIMA/RF | NMAE | wind power |
| ARIMA/BCART | | |
| Prajapati et al. [58] | ARIMA/NARNN | RMSE | COVID-19 cases |
| Nie et al. [5] | ARIMA/SVM | MAPE | short-term load forecasting |
| | RMSE | |
| Ma et al. [59] | NN/ARIMA | MSE | network-wide |
| MSVR/ARIMA | MAPE | traffic |
In the comparisons of the individual machine learning models with the ARIMA algorithm, a large part of the applications indicate the superiority of the former based on the metrics used. However, there were a subset of studies in which ARIMA demonstrated higher predictive accuracy. We will refer to these studies in the rest of the present chapter in order to practically evaluate the performance of the ARIMA against the machine learning models and to uncover the circumstances (either dataset or model-dependent) under which the statistical approach exhibits superior performance in the task of time-series forecasting.
In the case of SVM algorithms, in the work of Zhang et al. [
24] on drought prediction, the ARIMA algorithm had clearly better prediction performance based on various metrics, compared with the selected WNN and SVM models (
Section 3.1.4). According to the authors of this paper, WNN and SVM machine learning models are not always superior to traditional ARIMA models in drought prediction. Different forecasting methods can be used for different geographic regions, and it would be subsequently advised for the data characteristics to be investigated in order to select the appropriate forecasting model.
This conclusion is consistent with the result of the work of Al Amin et al. [
25], in which ARIMA performed better than SVM networks in load prediction when the load was linear (
Section 3.1.5). As ARIMA is much more robust and efficient at analyzing linear time series, its choice over machine learning algorithms should primarily depend on the linearity of the data. In a different application field, the work by Priyadarshini et al. [
38] indicated the superiority of ARIMA, and SARIMA forecasting over multiple deep learning and tree-based forecasting models regarding anomaly detection in an IoT setting. However, this particular publication is focused on the application at hand rather than on the model comparison.
In the case of individual deep learning models vs. ARIMA, by introducing LSTM networks and the property of memory in the forecasting process, these models gain a great advantage over classical statistical forecasting methods, and this is shown by their dominance over ARIMA in the relevant literature. However, there are exceptions to this rule, which we will refer to below.
In the work of Paliari et al. [
32] on stock index forecasting, the LSTM and XGBoost algorithms gave better forecasting results than ARIMA for all but two data sets, whose data values were significantly lower than the rest (Paragraph “Financial Data”). This fact probably indicates an advantage of statistical methods when the data is characterized by a limited range of values.
ARIMA methods prevail over deep learning algorithms in bitcoin price prediction applications in the works of Nguyen et al. [
44] and Yamak et al. [
6], and this result may be due to several factors, as the chosen values of the model parameters and the total amount of data can affect the results of the analysis. The volume of data in the work of Yamak et al. is relatively small, and RNN models usually perform well on more voluminous datasets, as previous studies have shown (Paragraph “Financial Data”). Regarding this particular observation, it is worth mentioning the related work of Cerqueira et al. [
60], according to which machine learning methods improve their relative predictive performance over classical prediction algorithms as the data sample size grows.
In the work of Hua et al. [
45], ARIMA is quite effective relative to LSTMs in making bitcoin price predictions in the short term, but as time goes on, it shows a decreasing rate of accuracy (Paragraph “Financial Data”).
In the work of ArunKumar et al. [
51], the authors attempt to predict the rates of confirmed cases, recovered patients, and deaths from the COVID-19 disease in different countries of the world. For most cross-country time series data, the deep learning-based models (LSTM and GRU) outperform the statistical ARIMA and SARIMA models, with RMSE values 40 times smaller than those of the ARIMA models. However, in some countries, statistical models outperformed deep learning models (Paragraph “Healthcare Data”). Due to the highly dynamic nature of disease-specific data, the information they contain depends on the country of origin as well as the time at which they were generated. The shape of the data coming from some countries is non-linear, while ARIMA models are shown to perform better in modeling data that follows linear relationships. On the other hand, RNN models performed better in countries whose data were non-linear. These results once again confirm the conclusion made above, namely that since ARIMA is much more robust and efficient in linear time series analysis, its choice over machine learning algorithms should primarily depend on the linearity of the data. In this work, it is also interesting that while ARIMA is, according to the results, an ideal choice for modeling the rates of confirmed cases and recovered patients for some countries whose data have the appropriate profile, its performance is nevertheless very poor for modeling the number of deaths from COVID-19 in all countries, which is likely related to the increasing complexity of the data and the conditions that lead to the death of patients in general.
In the work of Liu et al. [
54], which concerns the prediction of time series consisting of the measured wind speed in coastal areas, the SARIMA approach outperformed deep learning-based algorithms in prediction performance (Paragraph “Weather and Environmental Parameter Studies”). The authors of this paper argue that the SARIMA approach is more suitable for dealing with offshore wind speed forecasting because of its ability to directly support making predictions of seasonal elements on univariate datasets.
Finally, in the work of Spyrou et al. [
17], ARIMA again outperforms LSTM models in predicting harbor area CO2 levels, which is likely related to the nature of the forecast data (Paragraph “Weather and Environmental Parameter Studies”).
On the other hand, as far as the hybrid forecasting models are concerned, in any case and in the context of this work, they result in better forecasting performance compared with the single ARIMA model, as they combine modeling features both from the point of view of classical statistical algorithms and on the part of machine learning models, making them capable of dealing with predictive data at multiple levels of analysis.
There are various conclusions derived from the scientific literature cited in the previous paragraphs.
At first, we observe that the optimal choice of a forecasting algorithm can be different, for different versions of a dataset (e.g., different geographic regions in drought forecasting [
24], different countries in modeling rates of confirmed and recovered cases of COVID-19 [
50]) within the same forecasting task. The particular differences in the datasets’ nature, also inferred from the optimal model choice, can be of great value in a multitude of forecasting and modeling tasks and can be an important source of information for region characterization.
On the other hand, in some applications, it is the dataset characteristics inherent to the specific data driven network that drive the modeling choice. The seasonality of the data collected (e.g., wind speed forecasting [
54]), the number of target variables, as well as a multitude of underlying causes and features (e.g., forecasting the number of COVID-19 deaths [
50]) can shape the nature of a forecasting application. In our opinion, the systematic characterization of applications and datasets would be of great value to modeling applications in order to fully exploit the capabilities of big data and data-driven networks.
The ARIMA also exhibits better predictive performance than its machine learning counterparts, in cases where the available dataset is characterized by a limited range of values or a limited time-span ([
6,
32,
45]). This observation can be attributed to the fact that machine learning, and especially deep learning models, require a large amount of data to train effectively. As a result, their performance can be inferior to statistical approaches for small datasets or for short-term forecasting.
The algorithmic nature of the ARIMA models provides some insight into their implementation value in the problem of time series forecasting. In comparison to complex machine learning models, ARIMA is a relatively explainable and intuitive approach that is widely used due to its flexibility and reliability. However, its focus on linear time dependencies in the data as well as its univariate modeling approach render it unsuitable for standalone application in forecasting complex real-world problems.
Apart from the details of the time series data, which can be a determining factor in the choice between ARIMA and machine learning models, an important aspect of the problem regards the computational and time complexity of the two approaches. In the case of machine learning forecasting models, a wider range of resources is needed, regarding the storage of the network architecture and weights, the training time, and the network optimization procedure, all of which are not necessary in the application of classical statistical algorithms. Furthermore, as the forecasting problem at hand becomes more complex and acquires longer time dependencies, so does its artificial intelligence modeling approach.
In
Table 6, we present some aggregated results and observations based on the practical evaluation of the ARIMA versus the machine learning approach to the problem of time series forecasting.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






