



A Replica-Selection Algorithm Based on Transmission Completion Time Estimation in ICN


Abstract
1. Introduction
- To solve the problem of replica node selection in ICN network, we propose the replica-selection algorithm based on the transmission completion time estimation. The transmission completion time of NDC is related to the size of NDC, the expected transmission rate, and the round-trip time (RTT). Therefore, we designed a method to obtain the expected transmission rate, RTT, and NDC size.
- To solve the problem that the replica nodes may not be selected again due to bad performance in a short time, we design an “activation” mechanism.
- We conducted experiments on the proposed algorithm. Experiments show that TCTE not only effectively improves the user’s download rate and edge node throughput, reduces download rate fluctuations, reduces user download delay, and improves fairness, but also has universal applicability.
2. Related Works

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application Scenarios | Approaches | Characteristics |
|---|---|---|
| NBR-based ICN architecture | Shortest-path routing | Only replicas on the path can be selected. |
| Cluster-based method | Cluster head node decision. | |
| iNRR | Select the nearest replica by flooding. | |
| SEARCH-CNG | Avoid selecting replicas on congested paths. | |
| INFORM | Use flooding to discover replicas, and complete replica selection based on indicators such as RTT. | |
| Stateful forwarding | Calculate the ranking value of the link and select the replica on the better link. | |
| SCAN | The information exchange of the cache node can select the neighbor replica of the node on the path. | |
| RFW | Applicable to a hierarchical ICN architecture, the lower-level replica is selected by random walk. | |
| NRS-based ICN architecture | MF | Select the closest replica based on a routing table. |
| ERS | Based on weighted values of congestion, RTT, and hops. | |
| NetInf TP | Based on latency and network distance. (No approach details provided by author.) | |
| Traditional network | Reference [30] | Proactively detects the network and selects the replica with the lowest flow completion time. |
| Ping-random | Randomly selects one of the five smallest replicas of RTT. | |
| 2RC | Randomly takes two replica nodes and chooses the one with the smaller load. |
3. NDC Transmission and NRS Overview
3.1. Overview of the NDC Transmission Process
3.2. Name Resolution System
4. Algorithm Description
4.1. Motivation
4.2. Overview of TCTE Algorithm
| Algorithm 1: Operation of the TCTE algorithm when receiving an REQ packet |
| Input: |
| Output: |
| 1: |
| 2: if then |
| 3: return |
| 4: else |
| 5: |
| 6: |
| 7: if then |
| 8: |
| 9: |
| 10: |
| 11: else |
| 12: |
| 13: if then |
| 14: |
| 15: end if |
| 16: |
| 17: end if |
| 18: end if |
| 19: return |
| Algorithm 2: Operation of the TCTE algorithm when receiving a DATA packet |
| Input: |
| Output: |
| 1: if then |
| 2: |
| 3: |
| 4: |
| 5: for in then |
| 6: |
| 7: if then |
| 8: |
| 9: |
| 10: end if |
| 11: end for |
| 12: |
| 13: end if |
| 14: return |
4.3. Estimated Transmission Rate of Replica Nodes
4.4. Overhead Analysis
5. Performance Evaluation
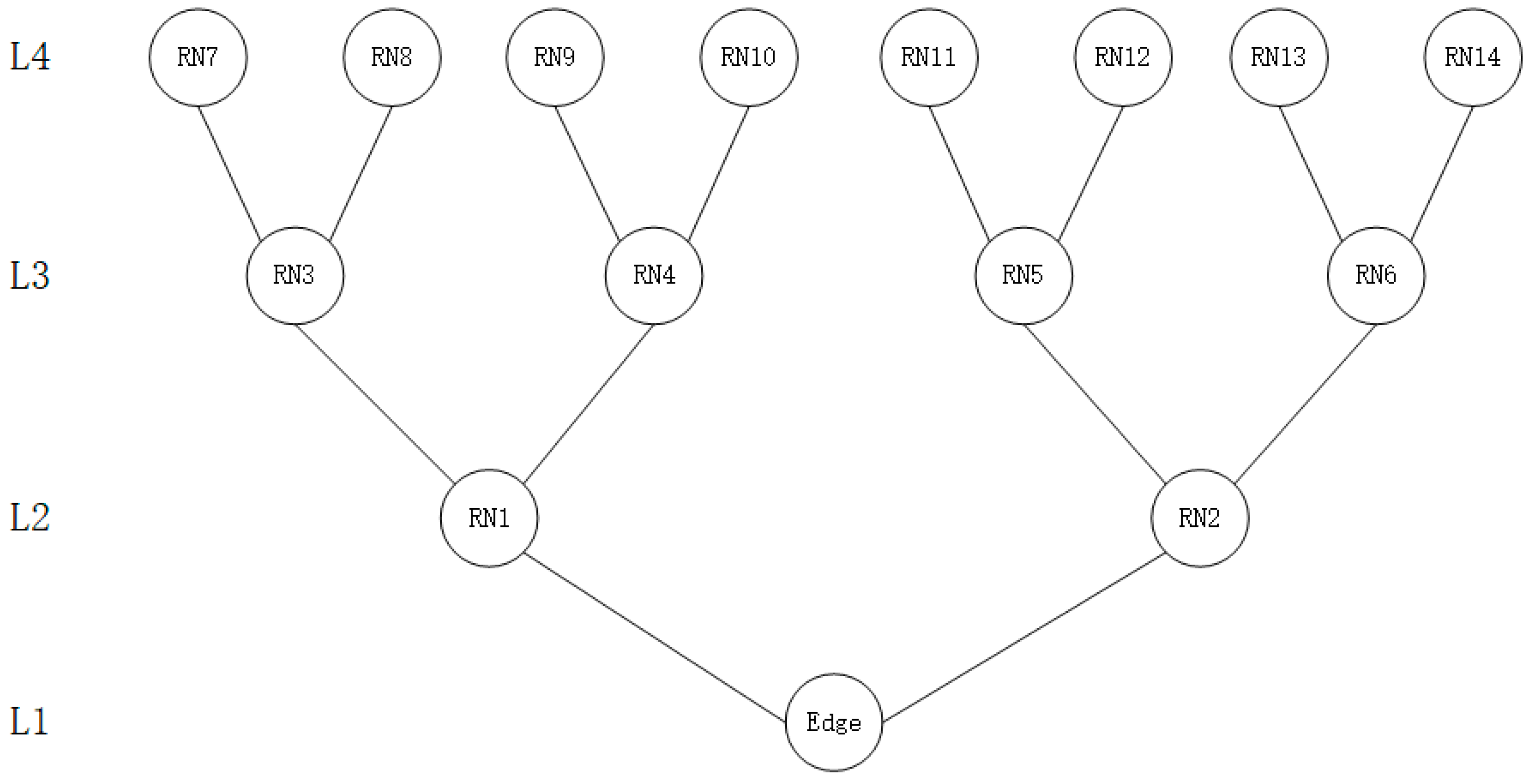
5.1. Experimental Setup
5.2. Performance Comparison
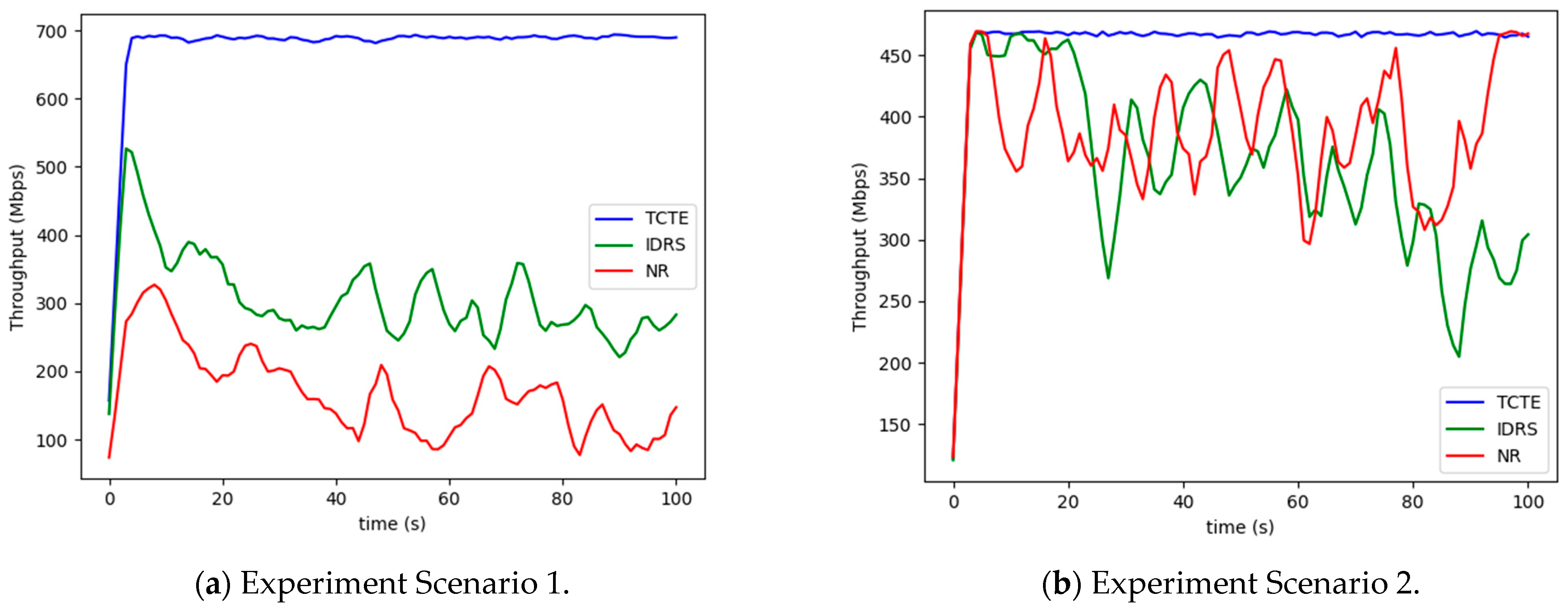
5.2.1. User’s Download Rate
5.2.2. Edge Node Throughput
5.2.3. Fairness
5.2.4. NDC Download Delay
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nour, B.; Sharif, K.; Li, F.; Yang, S.; Moungla, H.; Wang, Y. ICN publisher-subscriber models: Challenges and group-based communication. IEEE Netw. 2019, 33, 156–163. [Google Scholar] [CrossRef]
- Jacobson, V.; Smetters, D.K.; Thornton, J.D.; Plass, M.F.; Briggs, N.H.; Braynard, R.L. Networking named content. In Proceedings of the 5th International Conference on Emerging Networking Experiments and Technologies, Rome, Italy, 1–4 December 2009; pp. 1–12. [Google Scholar]
- NDN. The Named Data Networking Project. Available online: http://www.named-data.net/ (accessed on 9 January 2023).
- Raychaudhuri, D.; Nagaraja, K.; Venkataramani, A. Mobilityfirst: A robust and trustworthy mobility-centric architecture for the future internet. ACM Sigmob. Mob. Comput. Commun. Rev. 2012, 16, 2–13. [Google Scholar] [CrossRef]
- Dannewitz, C.; Kutscher, D.; Ohlman, B.; Farrell, S.; Ahlgren, B.; Karl, H. Network of information (netinf)–an information-centric networking architecture. Comput. Commun. 2013, 36, 721–735. [Google Scholar] [CrossRef]
- Koponen, T.; Chawla, M.; Chun, B.-G.; Ermolinskiy, A.; Kim, K.H.; Shenker, S.; Stoica, I. A data-oriented (and beyond) network architecture. In Proceedings of the 2007 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Kyoto, Japan, 27–31 August 2007; pp. 181–192. [Google Scholar]
- Wang, J.; Chen, G.; You, J.; Sun, P. SEANet: Architecture and Technologies of an On-site, Elastic, Autonomous Network. J. Netw. New Media 2020, 6, 1–8. [Google Scholar]
- Saadeh, H.; Almobaideen, W.; Sabri, K.E.; Saadeh, M. Hybrid SDN-ICN architecture design for the internet of things. In Proceedings of the 2019 Sixth International Conference on Software Defined Systems (SDS), Rome, Italy, 10–13 June 2019; pp. 96–101. [Google Scholar]
- Mehmood, K.; Kralevska, K.; Palma, D.J. Intent-driven autonomous network and service management in future networks: A structured literature review. arXiv 2021, arXiv:2108.04560. [Google Scholar] [CrossRef]
- Xylomenos, G.; Ververidis, C.N.; Siris, V.A.; Fotiou, N.; Tsilopoulos, C.; Vasilakos, X.; Katsaros, K.V.; Polyzos, G.C. A survey of information-centric networking research. IEEE Commun. Surv. Tutor. 2013, 16, 1024–1049. [Google Scholar] [CrossRef]
- Ioannou, A.; Weber, S. A Survey of Caching Policies and Forwarding Mechanisms in Information-Centric Networking. IEEE Commun. Surv. Tutor. 2016, 18, 2847–2886. [Google Scholar] [CrossRef]
- Song, Y.; Ni, H.; Zhu, X. An Enhanced Replica Selection Approach Based on Distance Constraint in ICN. Electronics 2021, 10, 490. [Google Scholar] [CrossRef]
- Liao, Y.; Sheng, Y.; Wang, J. A deterministic latency name resolution framework using network partitioning for 5G-ICN integration. Int. J. Innov. Comput. Inf. Control 2019, 15, 1865–1880. [Google Scholar]
- Dong, L.; Wang, G. A Hybrid Approach for Name Resolution and Producer Selection in Information Centric Network. In Proceedings of the 2018 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018; pp. 574–580. [Google Scholar]
- Wang, L.; Hoque, A.; Yi, C.; Alyyan, A.; Zhang, B. OSPFN: An OSPF Based Routing Protocol for Named Data Networking. Available online: https://named-data.net/techreport/TR003-OSPFN.pdf (accessed on 5 February 2023).
- Hoque, A.M.; Amin, S.O.; Alyyan, A.; Zhang, B.; Zhang, L.; Wang, L. NLSR: Named-data link state routing protocol. In Proceedings of the 3rd ACM SIGCOMM Workshop on Information-Centric Networking, Kyoto, Japan, 26–28 September 2016; pp. 15–20. [Google Scholar]
- Yan, H.; Gao, D.; Su, W.; Foh, C.H.; Zhang, H.; Vasilakos, A.V. Caching Strategy Based on Hierarchical Cluster for Named Data Networking. IEEE Access 2017, 5, 8433–8443. [Google Scholar] [CrossRef]
- Hasan, K.; Jeong, S.H. Efficient Caching for Delivery of Multimedia Information with Low Latency in ICN. In Proceedings of the 2019 Eleventh International Conference on Ubiquitous and Future Networks (ICUFN), Split, Croatia, 2–5 July 2019; pp. 745–747. [Google Scholar]
- Rossini, G.; Rossi, D. Coupling caching and forwarding: Benefits, analysis, and implementation. In Proceedings of the 1st ACM Conference on Information-Centric Networking, Osaka, Japan, 19–21 September 2022; pp. 127–136. [Google Scholar]
- Badov, M.; Seetharam, A.; Kurose, J.; Firoiu, V.; Nanda, S. Congestion-aware caching and search in information-centric networks. In Proceedings of the 1st ACM Conference on Information-Centric Networking, Osaka, Japan, 19–21 September 2022; pp. 37–46. [Google Scholar]
- Chiocchetti, R.; Perino, D.; Carofiglio, G.; Rossi, D.; Rossini, G. Inform: A dynamic interest forwarding mechanism for information centric networking. In Proceedings of the 3rd ACM SIGCOMM Workshop on Information-Centric Networking, Kyoto, Japan, 26–28 September 2016; pp. 9–14. [Google Scholar]
- Watkins, C.J.; Daya, P. Technical Note: Q-Learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Yi, C.; Afanasyev, A.; Moiseenko, I.; Wang, L.; Zhang, B.; Zhang, L. A case for stateful forwarding plane. Comput. Commun. 2013, 36, 779–791. [Google Scholar] [CrossRef]
- Lee, M.; Cho, K.; Park, K.; Kwon, T.; Choi, Y. SCAN: Scalable content routing for content-aware networking. In Proceedings of the 2011 IEEE International Conference on Communications (ICC), Kyoto, Japan, 5–9 June 2011; pp. 1–5. [Google Scholar]
- Bloom, B.H. Space/time trade-offs in hash coding with allowable errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Domingues, G.d.M.B.; Leão, R.M.M.; Menasché, D.S. Enabling information centric networks through opportunistic search, routing and caching. arXiv 2013, arXiv:1310.8258. [Google Scholar]
- Sevilla, S.; Mahadevan, P.; Garcia-Luna-Aceves, J. iDNS: Enabling information centric networking through The DNS. In Proceedings of the 2014 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 27 April–2 May 2014; pp. 476–481. [Google Scholar]
- Fuller, V.; Farinacci, D. RFC 6833: Locator/ID Separation Protocol (LISP) Map-Server Interface; RFC, Ed.; ACM Digital Library: New York City, NY, USA, 2013. [Google Scholar]
- Bogdanov, K.; Peón-Quirós, M.; Maguire, G.Q., Jr.; Kostić, D. The nearest replica can be farther than you think. In Proceedings of the Sixth ACM Symposium on Cloud Computing, Kohala Coast, HI, USA, 27–29 August 2015; pp. 16–29. [Google Scholar]
- Carter, R.L.; Crovella, M.E. Server selection using dynamic path characterization in wide-area networks. In Proceedings of the INFOCOM’97, Kobe, Japan, 7–12 April 1997; pp. 1014–1021. [Google Scholar]
- Hanna, K.M.; Natarajan, N.; Levine, B.N. Evaluation of a novel two-step server selection metric. In Proceedings of the Ninth International Conference on Network Protocols ICNP 2001, Riverside, CA, USA, 11–14 November 2001; pp. 290–300. [Google Scholar]
- Mitzenmacher, M. The power of two choices in randomized load balancing. IEEE Trans. Parallel Distrib. Syst. 2001, 12, 1094–1104. [Google Scholar] [CrossRef]
- Zeng, L.; Ni, H.; Han, R. An incrementally deployable IP-compatible-information-centric networking hierarchical cache system. Appl. Sci. 2020, 10, 6228. [Google Scholar] [CrossRef]
- Salsano, S.; Detti, A.; Cancellieri, M.; Pomposini, M.; Blefari-Melazzi, N. Transport-layer issues in information centric networks. In Proceedings of the Second Edition of the ICN Workshop on Information-Centric Networking, Helsinki, Finland, 17 August 2012; pp. 19–24. [Google Scholar]
- Song, Y.; Ni, H.; Zhu, X. Analytical Modeling of Optimal Chunk Size for Efficient Transmission in Information-Centric Networking. J Int. J. Innov. Comput. Inf. Control 2020, 16, 1511–1525. [Google Scholar]
- Wang, Z.; Ni, H.; Han, R. Copa-ICN: Improving Copa as a Congestion Control Algorithm in Information-Centric Networking. Electronics 2022, 11, 1710. [Google Scholar] [CrossRef]
- Saino, L.; Psaras, I.; Pavlou, G. Hash-routing schemes for information centric networking. In Proceedings of the 3rd ACM SIGCOMM Workshop on Information-Centric Networking, Kyoto, Japan, 26–28 September 2016; pp. 27–32. [Google Scholar]
- NS-3 Project. Available online: https://www.nsnam.org (accessed on 9 January 2023).
- Breslau, L.; Cao, P.; Fan, L.; Phillips, G.; Shenker, S. Web caching and Zipf-like distributions: Evidence and implications. In The Future Is Now (Cat. No. 99CH36320), Proceedings of the IEEE INFOCOM’99 Conference on Computer Communications, Eighteenth Annual Joint Conference of the IEEE Computer and Communications Societies, New York, NY, USA, 21–25 March 1999; IEEE: Piscataway, NJ, USA, 1999; pp. 126–134. [Google Scholar]
- Chiu, D.-M.; Jain, R. Analysis of the increase and decrease algorithms for congestion avoidance in computer networks. Comput. Netw. ISDN Syst. 1989, 17, 1–14. [Google Scholar] [CrossRef]













| Link | Bandwidth (Mbps) |
|---|---|
| Between L1 and L2 | Random values (20 to 100) |
| Between L2 and L3 | Random values (100 to 200) |
| Between L3 and L4 | Random values (200 to 300) |
| Experimental Scenario | TCTE-IDRS | IDRS-NR | NR-TCTE |
|---|---|---|---|
| Experimental Scenario 1 | |||
| Experimental Scenario 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Ni, H.; Han, R. A Replica-Selection Algorithm Based on Transmission Completion Time Estimation in ICN. Future Internet 2023, 15, 120. https://doi.org/10.3390/fi15040120
Wang Z, Ni H, Han R. A Replica-Selection Algorithm Based on Transmission Completion Time Estimation in ICN. Future Internet. 2023; 15(4):120. https://doi.org/10.3390/fi15040120
Chicago/Turabian StyleWang, Zhiyuan, Hong Ni, and Rui Han. 2023. "A Replica-Selection Algorithm Based on Transmission Completion Time Estimation in ICN" Future Internet 15, no. 4: 120. https://doi.org/10.3390/fi15040120
APA StyleWang, Z., Ni, H., & Han, R. (2023). A Replica-Selection Algorithm Based on Transmission Completion Time Estimation in ICN. Future Internet, 15(4), 120. https://doi.org/10.3390/fi15040120