
Data Is the New Oil–Sort of: A View on Why This Comparison Is Misleading and Its Implications for Modern Data Administration


Abstract
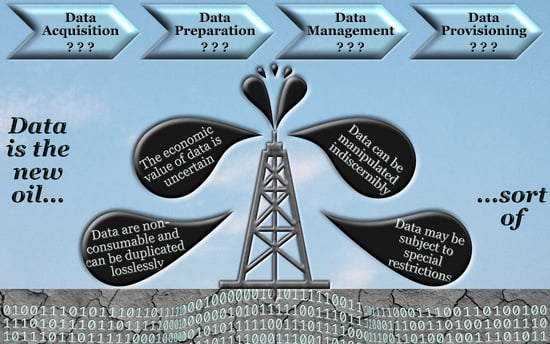
1. Introduction
- (a)
- We discuss the key differences between data and oil. For that purpose, we identify ten specific characteristics of data that need to be taken into account in data administration. In the context of this work, we focus on inherent challenges that arise due to technical characteristics of big data, often referred to as Big Vs [22]. Ethical social aspects, e.g., data liberation and fair distribution [23], or green processing, e.g., energy-efficient data acquisition and storage [24], are out of scope since such factors must also be considered for any other commodity.
- (b)
- For each identified special characteristic, we derive the resulting implications for data administration. In the context of this work, we take an end-to-end look at the data management process, i.e., we deal with data acquisition, data refinement, data storage, and data provision.
- (c)
- We present a concept for a novel reliable information retrieval and delivery platform, called REFINERY Platform, which addresses the data administration challenges, we have identified. In this context, ‘reliable’ refers to both the data producers—in those terms, it is ensured that sensitive data are handled in a trustworthy manner—and the data consumers—in those terms, it is ensured that data have the promised quality.
2. Characteristics of Data and Resulting Consequences for Data Administration
- I.
- Data are nonconsumable: When tangible commodities are transformed into value-added products, they are consumed in the process. This is completely different for the intangible commodity ‘data’. Even after data have been fully analyzed and a value-added data product has been generated (e.g., information or knowledge), the raw data are still available. They do not lose their meaning in the process, since they can be processed again, in another way, in order to derive new information or knowledge from it. Therefore, the volume of the data to be administered increases constantly, since processed data are neither consumed nor become worthless. For this reason, data management systems are needed that store these volumes of raw data in a resource-efficient manner as well as concepts that enable efficient access to the data. Without such concepts, data can no longer be retrieved as needed, resulting in an economic loss of value.
- II.
- Data can be duplicated losslessly: The supply of tangible commodities is finite. For instance, every single drop of oil is unique and can only be consumed once. Tangible commodities can be thinned down to a certain degree, but this reduces their quality and thus their value. Data, on the other hand, can be duplicated indefinitely and even without any loss. This initially sounds promising to data producers and data providers since it means that their product can never run out. However, this fact also means that the value of data is measured differently than that of oil. While the price of oil is determined primarily by supply and demand, the value of data is determined by how original and unique their content is. If previously unknown correlations can be determined with them, they represent a clear competitive advantage and thus a particularly high value. Whereas the more the data are reproduced—i.e., their content becomes common knowledge—the lower their value becomes. Concepts are therefore needed to ensure that the contents of the data remain as confidential as possible and that only certain data consumers gain insight.
- III.
- Data are generated at high velocity: Tangible commodities are available wherever they arise naturally. For instance, crude oil remains in the Earth’s crust until it is extracted. This can be done based on demand and free capacities in the refineries. Data, on the other hand, are generated at any point in time. A processable data object is obtained only if they are captured at exactly this point in time. If they are not captured, they are lost. However, since many IoT devices have limited memory resources, they cannot store the captured data indefinitely but rely on a stream-based processing concept, i.e., they process the data on the fly. Therefore, while oil requires a pull model (i.e., it is acquired from the source when needed), data require a push model (i.e., the source transmits the data when captured). Since data currently accumulate at a high velocity, data storage systems must either have large input buffers to temporarily store new data until screening and further processing or have the necessary capacities to handle voluminous data streams.
- IV.
- Data are volatile: Oil has no expiration date, which is why processing is not time critical. Yet, data are volatile. Although a data object can be stored indefinitely, its content is sometimes only relevant for a very short time. For instance, if a sensor in a driverless car detects that there is an obstacle in the lane, this information must be processed immediately, since it is only relevant until the collision occurs. In other cases, data also become invalid. For instance, if the driverless car detects that a traffic light is green, this information is rendered invalid as soon as the light changes to red. Data storage systems must therefore be able to cope with this limited lifespan and have the capability to process data in (near) real time. While some tangible commodities also have a limited shelf life, the volatility of data dynamically differs from data object to data object, and it is often not possible to specify its expiration date in advance, i.e., how quickly the data must be processed.
- V.
- Data are heterogeneous: Tangible commodities are usually homogeneous. Although each drop of oil is unique (i.e., it exists only once), all drops from one source are identical in terms of properties such as purity and quality. Therefore, all extracted oil can be stored in a common container and refined similarly. Data, meanwhile, are heterogeneous. For instance, they can have different data formats or schemata and have different levels of completeness and accuracy. Furthermore, the contents of the data differ. Therefore, data cannot be stored in a common storage. Either all data must initially be transformed into a common structure or data stores that support heterogeneous structures are required. Metadata management is also required to track the properties of the data so that they can be handled appropriately.
- VI.
- Data refinement has to be in accordance with the data source and intended use: There are established refinement processes for tangible commodities in order to convert them into certain value-added products. Even though these processes may be adapted over time due to new findings or technical innovations, they can be seen as static processes. With data, this is completely different. On the one hand, new and improved cleansing and preparation techniques are constantly developed, which require adjustments to the data refinement process. On the other hand, due to the heterogeneity of the data, a variety of processing steps geared to the raw data are required. This is aggravated by the fact that there is no one-size-fits-all data refinement process. Rather, adjustments must be made to the steps of the data refinement process depending on the intended use of the data. Only if the process is tailored to both the raw data and the intended use can an optimal result can be achieved. Therefore, data refinement requires flexible adjustments to dynamically respond to changes in sources (i.e., the raw data) and sinks (i.e., the intended use).
- VII.
- The economic value of data is uncertain: The value of tangible commodities is generally known. There are some fluctuations due to supply and demand, and over time, commodities can gain or lose value. However, these fluctuations tend to be rather small, while substantial changes are extremely rare. With data, this is completely different. Here, the economic value is initially completely unknown. Data that appear to be worthless today may prove to be needle-movers tomorrow. The reason for this is on the one hand that the derivable knowledge cannot be identified in advance but only when the data have been processed. On the other hand, in such a highly dynamic environment, new use cases for data are constantly emerging, which subsequently define the need and thus the value of the data. Since it is almost impossible to anticipate this need in advance, data administration must be able to manage and process data as cost-effectively as possible, since it is not feasible to distinguish between worthless and valuable data.
- VIII.
- Data can be manipulated indiscernibly: Tangible commodities are usually relatively resilient to manipulation. For instance, crude oil could be deliberately contaminated, but this can be detected and subsequently purified. In the worst case, sources can be corrupted to such an extent that they become unusable. However, this problem is far worse in the case of intangible commodities and, in particular, data. Data can be manipulated indiscernibly and, above all, in a targeted manner. Malicious parties can falsify data either in their favor or to harm the data consumers, blend fake data with real data, or withhold data. This can happen both when transferring data from the sources and while storing the data. Since the manipulation generally goes unnoticed, it is also almost impossible to undo the contamination. To make matters worse, besides third parties, data producers themselves may have an interest in falsifying the data they provide. Measures must therefore be taken to verify the authenticity and genuineness of data and to prevent subsequent manipulation.
- IX.
- Data may be subject to special restrictions: Tangible commodities such as oil are primarily subject to rights related to ownership. Whoever owns the oil well may extract, refine, and sell the oil. With regard to the last two issues, there may be further restrictions, e.g., regarding the environmental friendliness of the refining process or regarding sanctions that affect exports to certain customers. However, these restrictions always relate to the product as a whole. With data, the situation is much more complex. In particular, when it comes to personal data, the data subject (which is not necessarily the data producer) has far-reaching rights when it comes to data processing. For instance, the consent of the data subject is required for the processing of such data. This consent can be withdrawn at any time. However, even with the consent of the data subject, there are further restrictions to be observed when processing personal data, such as a purpose limitation or data minimization. Furthermore, the data subject has the right to request that all data about him or her be erased. Yet, this applies not only to the raw data themselves, but also to all data products in which the raw data in question have been incorporated. Data administration must therefore take measures to implement such privacy rights. These include, e.g., the use of privacy filters that either anonymize data or reduce the amount of contained information to a required minimum, or provenance mechanisms that make it possible to trace which raw data has been incorporated into which data products.
- X.
- Data require new trading concepts and infrastructures: When trading tangible commodities, the main problem is to build distribution infrastructures that bring the goods to international trading partners in time. This is not the case with data. Thanks to the Internet, data can be made available in an instant anywhere in the world. Explicit distribution channels therefore do not need to be established. With data, however, three novel trade problems arise: First, due to the large amount of constantly emerging data, there is an elevated risk of losing track of the available data. However, potential customers must be able to find data that are relevant to them. Second, customers must be able to rely on the provided data. This means that they must be able to use the data for their purposes and that there are no conflicting confidentiality or privacy restrictions. For instance, if privacy filters have to be applied to the data in advance, this contaminates the data and reduces the quality of the data. Data administration must therefore ensure that a customer can rely on the authenticity and quality of the data despite the use of such privacy techniques. Third, the privacy requirements of data subjects as well as the quality requirements of data consumers change dynamically. Therefore, it is not possible to offer static data products, but the data refinement must be constantly adapted to offer tailored data products. A trading platform for data must therefore establish concepts to cope with these three problems.
3. Related Work
3.1. Data Administration
- Data Acquisition. In the context of this work, data acquisition refers to the process of selecting relevant data from a wide variety of sources and then gathering them in a central data management architecture [31]. This represents the first step in the big data value chain and thus enables data to become an asset in the first place [32]. Due to the prevailing heterogeneity among data sources and schemas in which the raw data are available, a systematic approach is required for data acquisition. The so-called ETL process (ETL stands for extraction, transformation, loading) represents a well-established three-step process in which adapter technologies are used to first gather the selected data from the sources, then sanitize them, and finally store them in a structured form [33]. However, this process assumes that there is a central data management architecture with a uniform data schema and that the data in the sources are at rest, i.e., can be retrieved at any point in time [34]. However, due to the IoT, such a conception is outdated. Here, data have a high variety of features even within a single source. Therefore, a rigid target schema is not practicable, since information would be lost in the merger [35]. Moreover, the data are in motion, i.e., they are sent out as a data stream immediately after they are captured by the source, and they accrue in a large volume and at a high velocity, which requires adjustments to the ETL process [36]. Thus, modern-day data acquisition approaches must offer a combination of near real-time processing for streaming data (e.g., via Kafka [37]) and traditional batch-based processing for data at rest [38]. To store the collected raw data, modern data management systems such as Apache Hive (see https://hive.apache.org/; accessed on 6 February 2023) are suitable, as they are not only able to store large volumes of data efficiently, but also cope with heterogeneity within the data [39]. This way, an acquisition infrastructure for big data can be implemented based on the lambda architecture [40]. In the lambda architecture principle, a batch processing layer and a stream processing layer acquire and preprocess data independently of each other and then make them available via a merging layer [41]. A fundamental problem with this architecture is that two separate implementations of the same preprocessing logic need to be maintained for the batch processing layer and the stream processing layer, respectively. In the kappa architecture, all data are therefore gathered and preprocessed as micro-batches by a single stream processing system and made available in a schemaless mass storage system [42]. However, the composition of the micro-batches results in either latency (if the batches are too big which results in long waiting times until sufficient data are available) or a high overhead (if the batches are too small and therefore a lot of batches have to be processed). So, there are sacrifices to be made with both approaches. Therefore, approaches such as the delta architecture aim to combine these two architectures to achieve real-time processing with the ability to handle bulk data efficiently [43]. Nevertheless, more comprehensive preprocessing operations should be performed detached from data acquisition as part of subsequent data preparation [44].
- Data Preparation. Once data acquisition has been completed, the collected raw data must be converted into a machine-processable form via data cleansing, transforming, adding metadata, and harmonizing the schemas. These activities are collectively referred to as data preparation [45]. To carry out data preparation effectively, both data knowledge and domain knowledge are urgently needed [46]. The term ‘human in the loop’ encompasses approaches that empower experts without IT knowledge to actively participate in the data preparation process and contribute their expertise [47]. Research approaches therefore aim to cluster thematically related data sources and thereby represent the sources as a knowledge network so that users can easily identify further relevant sources [48]. Alternative approaches aim to group sources based on the features of their data, as they may need similar data preparation steps [49] or to suggest which data transforming operations are appropriate for such data [50]. Furthermore, the knowledge of the experts can be persisted in the form of a knowledge base that users can leverage in data preparation [51]. Sampling approaches aim directly at facilitating the work of experts by presenting them with only a representative sample of the complete base data. On this manageable sample, the expert defines cleansing and transforming steps, which are subsequently applied to the entire dataset [52]. Here, efficiency and effectiveness can be significantly increased if the data are initially divided into semantically related blocks, which are then taken into account for sampling [53]. Such defined cleansing and transforming steps can be converted into data preparation rules, which can be applied semi-automatically also to new datasets in the future [54]. These rules describe how to obtain processable data from raw data. For reasons of transparency, however, the backward direction must also be provided in order to be able to disclose later on which base data a result was obtained [55]. Why- and how-provenance can be used for this purpose [56]. In addition to human-in-the-loop approaches, however, there is also the countertrend, namely AI-assisted fully automated data preparation [57]. However, this results in a chicken-and-egg problem, since good and reliable training data are required to train the AI—this training data, however, also requires sound data preparation [58].
- Data Management. For the management of the processed data, data warehouses were state-of-the-art technology for a long time. Here, the data from multiple data sources are organized in a unified structure that is optimized for tailorable but predefined analysis purposes [59]. However, due to the IoT, the heterogeneity of data sources as well as the amount of semistructured or outright unstructured data increased drastically. Moreover, as data became an essential asset, there is a need for comprehensive and flexible data analysis. The rigid structure of data warehouses is not designed for either [60]. Although there are approaches to describe the semantics of inherently unstructured data to make them processable in a data warehouse [61], they are always limited to specific types of data. Since a rigid data structure is an inherent property of a data warehouse, such approaches do not solve the fundamental issues when dealing with IoT data. Data lakes are intended to overcome these challenges. The basic idea is that all raw data are stored (almost) untouched and data preparation takes place dynamically depending on the respective use case [62]. Thus, a data lake pursues a schema-on-read philosophy, i.e., only when data are processed, a schema that is appropriate for the data and the intended usage is defined and applied [63]. To reduce the resulting overhead that occurs with every data access and to facilitate data governance in general, a zone architecture for the data lake is highly recommended. Each zone provides data at a certain processing stage [64]. However, data lakes are rather concepts than clearly specified architectures [65]. Research approaches therefore attempt to create a reference model for a data lake in which, besides the raw data, harmonized data (i.e., data with a consolidated schema) and distilled data (i.e., aggregated data) are also kept in dedicated zones. In a sandbox zone, data scientists can play around with the data at will, in order to enable exploratory data analytics and provide the full flexibility of a data lake [66]. While this unlimited freedom initially sounds appealing, this might flood the data lake with too much irrelevant data—the data lake increasingly degenerates into a data swamp in which no useful data can be found. This can be prevented on the one hand by a systematic metadata management to keep an overview of all collected data [67] and on the other hand by sanitizing the raw data in terms of detecting integrity violations in the data and dealing with them to maintain the quality [68]. In practice, however, such monolithic data stores are prone to be exceedingly difficult to manage in terms of governance and operation. Research therefore aims to develop a data mesh in which the central data lake is split into distributed, independently managed data silos [69]. Other approaches focus on achieving an optimal trade-off between the flexibility of data lakes (i.e., support for all current and future use cases) and the structured organization of a data warehouses (i.e., efficient data processing and effective information retrieval) [70]. To this end, the data lakehouse architecture supports both classic BI and exploratory data analytics by means of a transaction layer that provides a logical ETL process on top of a data lake [71].
- Data Provisioning. In recent years, self-service BI has become increasingly relevant, i.e., users should be able to conduct customized analytics autonomously for their individual use cases [72]. However, a basic requirement to this end is that there is simple access to the relevant data of the required quality [73]. Due to the large amount of data required for today’s analyses, the data available internally in a corporation is often not sufficient. Therefore, data from external providers are required as well. As a consequence, data is not only a commodity but has also become a tradable good. To address this new strategic role of data, infrastructures for data marketplaces are being developed to allow customers to find and obtain data products [74]. However, a data marketplace is not a traditional warehouse, but because of the intangible nature of data, rather, a storefront for the available data products. Customers can select the data they want from a data catalog and the marketplace then acts as an interface to the respective data store [75]. From a data provider perspective, one of the most important functionalities that a data marketplace has to offer for this purpose is a comprehensive metadata management system that allows them to describe their data. This includes descriptive information about the data themselves (e.g., their data model or content descriptions) as well as information about the conditions under which they are permitted to be accessed (e.g., their price or their permitted usage) [76]. Since a marketplace usually represents the storefront for multiple third-party data providers, the metadata of all these providers must be merged to assemble a holistic data catalog [77]. From a customer perspective, the data marketplace must facilitate data retrieval. To this end, two main functionalities must be supported: On the one hand, it must be possible to find relevant data from all available sources (e.g., content- or quality-wise), and on the other hand, data acquisition has to be simple [78]. Comprehensive metadata management is required to this end as well [79]. One of the most important aspects of a data marketplace for both sides, however, is trust. Only if data providers can assume that confidentiality and privacy are guaranteed with regard to their data and customers can rely on the authenticity and quality of the offered data, they will use a data marketplace [80]. Therefore, data security and data privacy are central issues in the context of data provisioning.
3.2. Data Security
- Confidentiality. To protect against the disclosure of sensitive information, cryptography approaches are typically used. That is, data are available in encrypted form and can only be decrypted (and thus read) with the appropriate key. Both symmetric encryption—in which the same key is used for encryption and decryption—and asymmetric encryption—in which a key pair with different keys for encryption and decryption is used—can be applied to this end. While symmetric encryption approaches generally require less encryption time, asymmetric encryption approaches facilitate key distribution, since the private key always remains with the key owner, while the corresponding public key is shared with anybody without compromising confidentiality [84]. Combinations of these two techniques are also found, particularly in IoT environments, in order to reconcile simple key management with reduced hardware requirements [85]. To reduce the overall decryption effort required for each data access, homomorphic encryption can be used. Here, encrypted data are also unreadable without a corresponding key, but certain predefined operators can still be applied to them, such as aggregation functions, for statistical surveys [86] or search queries [87]. That is, the data can be preprocessed and even analyzed without being fully exposed [88]. An access control policy can be used to specify who has access to which data and for what purpose [89]. However, since the IoT is a dynamic environment, this must also be reflected in an access control system [90]. Thus, policy rules also have to consider the current context in which data are accessed (e.g., a spatiotemporal context in which the access takes place or a role-based context of the accessor) [91]. As a result, such a policy becomes highly complex, which is why access control systems in practice have to solve problems regarding conflicting policy rules [92] and scalable access management [93].
- Integrity. Currently, data integrity is often ensured by the use of blockchain technologies. A blockchain can be regarded as an immutable and tamper-resistant data store. By organizing the data in blocks that are inseparably linked to each other via cryptographic hashing, it can be ensured that neither individual data items within a block nor entire blocks can be manipulated. As this chain of blocks is managed in a distributed manner, i.e., multiple parties manage an equivalent copy of the chain, manipulations can be easily detected and reversed [94]. In addition to providing a secure storage for IoT data [95], however, blockchain technologies also facilitate the trustworthy sharing of sensitive data in inherently semi-trusted or unreliable environments [96]. Yet, inherent problems of blockchain-based data stores are their low throughput due to their serial operating principle in terms of query processing [97] and their limited data access support which results in minimalistic query capabilities [98]. Therefore, there are a variety of research approaches to improve the query performance as well as the query capabilities of blockchain-based data stores. For instance, SQL-based query languages are being developed for blockchain systems to improve usability [99]. In addition, there are query extensions for specific application domains that exceed the SQL standard, such as spatiotemporal queries [100] or top-k queries [101]. Other approaches aim to create schemata for the data in the blocks [102] or cross-block index structures, in order to improve the performance of query processing [103]. However, as blockchain systems not only have low throughput but also high storage costs [104], it is necessary to keep the volume of stored data as low as possible. Therefore, an off-chain strategy is often applied. In this case, the actual payload data are stored in an external data store. The blockchain itself only stores references to the payload data and digital fingerprints in the form of hash codes that can be used to verify the integrity of the data [105]. This way, even traditional relational databases can be extended by the integrity properties of blockchain storages by means of a lightweight blockchain-based verification layer on top of the database [106]. While such an approach can ensure the integrity of the payload data, the same cannot be said for the queries and the query results [107]. For this reason, there are also approaches aimed at deeper integration of blockchain technologies in a relational database system to enable more holistic integrity assurances [108].
- Availability. IoT devices generally do not have the capability to permanently store the vast amounts of data they collect, let alone the computing power to adequately process them. As a result, IoT applications rely on cloud providers to store, manage, and analyze their data [109]. Despite the undeniable advantages that cloud services offer in this context, the nontransparent nature of cloud computing requires blind trust on the part of the data owner in the cloud provider [110]. A key concern for data owners is that they have to hand over control of their data to the provider. This also includes where the provider stores the data and whether there are enough replicas of the data to ensure permanent availability [111]. In general, a semihonest provider is assumed in the cloud environment, i.e., a basic level of trust is appropriate, but a provider will always act to maximize its own benefit [112]. For instance, a provider could keep significantly fewer replicas of the data than promised in order to cut storage costs. Initially, there is no noticeable disadvantage for the data owner, but protection against data loss deteriorates considerably as a result [113]. Data owners therefore need tools to enable them to verify whether a cloud provider is storing their data reliably. So-called Proofs of Ownership and Retrievability (PoOR) are one option for this purpose [114]. Here, digital fingerprints of the data managed in the cloud are stored in the form of homomorphic verifiable tags [115] in a Merkle tree [116]. A data owner can pose challenges to the cloud provider, which the provider can only solve if it is in possession of the data. The user can verify the provider’s answers using the homomorphic verifiable tags. If this is successful, proof is provided that the data are available without having to download the full data. However, this does not ensure that there is also the promised number of replicas available. Proof of Retrievability and Reliability (PoRR) approaches can be applied to verify this as well [117]. Here, a verifiable delay function (VDF) is applied to the data, which is slow to compute but easy to verify [118]. Therefore, if a data owner poses challenges to instances of the cloud provider that are supposed to hold the data in question that relate to this function, the provider can only answer them if the data are actually at rest here. If the response takes too long, this is proof that there is no replica on the instance and the cloud provider needs to compute the VFD on the fly. In addition to unreliable cloud providers, a central server always represents a bottleneck and thus an inherent weak point with regard to the availability of data in traditional client-server structures. If such a server is flooded with requests, e.g., due to a distributed denial of service attack (DDoS), and thus becomes unavailable, all data managed by it are also no longer available to the clients. IoT environments in particular are severely vulnerable to such attacks [119]. In order to ensure data availability, it is therefore necessary to replace such centralized structures with highly distributed models that store the data in multiple replicas on different nodes to be resilient in the event of a single node failure [120]. Consequently, the use of blockchain technologies is also suitable for ensuring data availability as the blockchain is based on the distributed ledger technology [121]. This refers to technologies that enable data to be stored and shared over distributed computer networks. In simplified terms, a distributed ledger is a data storage system that manages data on multiple computer nodes with equal rights [122]. Due to the decentralized nature, no central authority has control and interpretational sovereignty over the data. Moreover, the collective of nodes can decide which data should be available and thus keep false or harmful data out of the data store [123]. As blockchain-based database systems typically require each node to manage the entire blockchain, this incurs excessive storage costs. Therefore, there are approaches in which only a few server nodes need to store the entire blockchain, while clients can still verify the authenticity of the data by means of authenticated data structures (ADS) [124]. Since this constrains the data distribution, which can endanger availability if the number of expected malicious or compromised nodes is remarkably high, other approaches rely on data partitioning. In sharding, the complete data stock of a blockchain is divided into several parts and distributed to the available nodes according to well-defined rules [125].
- Authenticity. In order to identify users, i.e., to verify their authenticity, passwords are commonly used. These can either be real words or PIN codes or lock patterns that have to be entered for authentication [126]. The IoT also offers other authentication options based on biometrics features such as voice, fingerprints, or facial expressions [127]. All of these methods have in common, however, that they can be easily exploited by shoulder surfing during input [128] or replay attacks [129]. To reduce the number of authentications required and thus mitigate some of these threats, there are OAuth-based approaches for the IoT. Here, an authentication service issues a token that authorizes the use of devices or services for a certain period of time [130]. However, this only shifts the problem of illegally acquired authentication data to the OAuth service. To address this, the ownership model relies on using a technical device for authentication that has a unique hardwired fingerprint [131], e.g., by means of physical unclonable functions (PUF) [132]. Yet, the loss of such a device inevitably enables another person to gain possession of the authentication data. In the IoT, this issue is further exacerbated as devices are not linked to specific users but are used by several people. Moreover, IoT devices have limited input capabilities, which means that users cannot enter their credentials like on a traditional computer [133]. For these reasons, there are trends away from ‘what you know’ (e.g., password-based approaches) or ‘what you have’ (token-based approaches) authentication toward ‘what you are’ authentication [134]. In attribute-based approaches, an entity is authenticated based on certain properties it has in the current situation. Especially in dynamic and rapidly changing environments, such a context-based description is advantageous [135]. Due to the high flexibility of attribute-based approaches, they are particularly suitable for IoT applications [136] or cloud-based applications [137]. In addition to users, however, it must also be ensured that data are authentic, in terms of, they come from the specified sources and have not been falsified [138]. For digital media, such as image, sound, or video data, digital watermarking can be used for this purpose. That is, an identification tag is inseparably burned into the carrier medium. If it can be ensured that no unauthorized third parties have access to the identification tag, authenticity can be verified by the presence of the digital watermark [139]. Similar techniques can also be applied to data in relational databases. Here, individual marker bits are inserted into the payload data [140]. While the origin of the data can be proven in this way, watermarking approaches inevitably contaminate the actual data with the inserted identification tags. Digital signatures represent a noise-free approach to ensure the authenticity of data [141]. Here, methods of asymmetric cryptography are used. While asymmetric cryptography uses the public key of a recipient for encryption—thereby ensuring that the message can only be decrypted with the corresponding private key, i.e., only by the recipient—the sender uses his or her own private key for signing. Since the sender’s public key is freely available, anyone can decrypt the message. However, this verifies that the sender has used the corresponding private key, which proves the origin of the data beyond doubt [142]. In the IoT, attribute-based signatures are suitable. Here, the attributes of a data source are stored in the signature (e.g., technical specifications of a sensor) and the receiver can verify whether these attributes are sufficient for the data to be authentic (e.g., does the sender have the capabilities to capture the data in the required quality) [143]. Yet, attribute-based signatures are computationally expensive, which is a particular problem in the context of lightweight IoT devices. Thus, research approaches aim to outsource part of the heavy workload to the cloud [144]. Other approaches deal with the problem that the attributes in the signature might contain sensitive information. To this end, a trusted intermediary is installed that preverifies the signatures and removes the sensitive attributes from it [145]. For areas like social media, where such an authentication of sources is not possible, the authenticity of data can be verified based on their content [146]. Then, fake news can either be blocked [147] or overridden by authentic data [148].
3.3. Data Privacy
- Right to be Informed. Data protection regulations give data subjects the right to be informed about the processing of their data. Three main research directions can be identified in this context. First, techniques are being developed to explain what knowledge can be derived from certain types of data. For instance, IoT data sources are described with the help of ontologies. Thus, it can be disclosed which data is collected by a sensor (including, e.g., the accuracy and frequency) and which information is derived from the respective data [164]. Based on such ontologies, reasoning can be done about what knowledge can be derived from this information [165]. These ontologies can be regarded as persisted knowledge of technical experts and domain experts. By involving privacy experts, the ontology can be extended in order to identify potential privacy threats and thereby make data subjects aware of critical issues. From this information, abnormal and questionable data usage patterns can be detected [166]. Second, in addition to informing about correlations between data and knowledge, research approaches also aim to describe the actual data processing. For this purpose, a holistic view of data-driven applications and processes is provided in order to identify inherent privacy threats. In the field of system safety, the STAMP framework (STAMPS stands for System-Theoretic Accident Model and Processes) provides such a top-down approach. Here, causal relationships between hazards and actions are initially modeled. Based on this model, the System-Theoretic Process Analysis (STPA) can be performed to identify problems in the design of the system that lead to or facilitate these hazardous actions [167]. This approach can be adapted to the field of privacy threats. Here, potential privacy threats posed by a data-processing application have to be identified initially, e.g., using the ontologies described earlier. The components of the application are then analyzed to determine whether they are sufficiently protected against these privacy threats [168]. Such a top-down analysis is ideal for modeling and analyzing complex data-driven systems and informing data subjects about inherent privacy-related vulnerabilities with respect to the data sources involved [169]. Third, data subjects also have a right to be informed about the data products for which their data was used as input. Machine learning models represent a prime example. Although these models can be processed by machines easily, they are usually a black box for humans. When applying such a model, it is generally nontransparent why it came to a certain result (e.g., a prediction or a suggestion). Since the models may be flawed or unfair due to an insufficient amount of appropriate training data, it is crucial that the results (and thus the models themselves) are comprehensible to data subjects [170]. To this end, there are three research areas: In the field of interpretable models, methods are developed which generate explainable models. In the field of model induction, models, which represent a black box, are transformed into an explainable model. Yet, both approaches have limitations when it comes to deep learning, as models in this context are far more complex. In deep explanation, deep learning algorithms are therefore adapted in such a way that not the model but at least the relevance of individual input factors are identified across the layers of the model, in order to determine what eventually led to a decision [171]. Yet, there are still many open questions to be solved, especially in the area of deep learning, before full transparency is achieved [172].
- Right to Restriction of Processing. However, all this information is of little use to a data subject in exercising his or her digital self-determination if s/he cannot also object to the data processing and enforce this technically. To this end, however, a binary consent system is far too restrictive. Here, a rejection leads to a massive reduction in service quality, which tempts data subjects to agree to all requests. Therefore, this is not an actual informed consent [173]. Instead, privacy-enhancing technologies (PET) should be used to minimize the data—or rather the amount of information they contain—in a target-oriented manner in accordance with the privacy requirements of the data subjects. Three fundamentally different types of PET can be identified: obfuscation techniques for users, statistical disclosure control for mass data providers, and distribution of data across multiple trusted third parties [174]. The obfuscation techniques for users apply privacy filters to the data. Very simple filters allow horizontal filtering [175]—which corresponds to the selection operator in relational algebra, i.e., filtering out specific data items from a dataset—or vertical filtering [176]—which corresponds to the projection operator in relational algebra, i.e., filtering out specific features of a data item. Also, an aggregation, i.e., condensing many data items to a single representative data item (e.g., the mean), can be used as a privacy filter [177]. However, such generic privacy filters are rather coarse-grained and therefore severely impair the data quality. Privacy filters that are tailored to a specific type of data are therefore more appropriate, as they are fine-grained and thus less invasive [178]. For instance, there are privacy filters that are tailored to location data and can optionally obfuscate individual locations or entire trajectories [179], privacy filters for health data that enable certain types of examinations only, while rendering the data unusable for all other analyses [180], or privacy filters that mask the voice or remove revealing background noise in speech data [181]. Other approaches focus on complex events that represent a specific sequence of data items instead of individual data items. Privacy-critical events are concealed, e.g., by reordering the data items or dropping or inserting data items. This preserves privacy without reducing the data quality of the data themselves [182]. Statistical disclosure controls for mass data providers include methods in which individual data subjects are hidden in the faceless masses formed by all users [183]. For instance, k-anonymity approaches ensure that a data item can only be mapped to a group of k users. With a sufficiently large k, no private information can be derived from the data about each of the k individuals [184]. Differential privacy is intended to protect an individual even more extensively. It ensures, e.g., by adding noise, that statistical analyses cannot determine whether the data of an individual data subject contributed (significantly) to the outcome [185]. While this sounds tempting in theory, differential privacy often turns out to be complex to implement and very costly to compute in practice [186]. If parameterized inappropriately, it even offers little protection and therefore leads to a false sense of security [187]. Federated learning can be regarded as an approach in the field of distribution of data across multiple trusted third parties. Here, the data with which a machine learning model is to be trained is distributed among several parties. Each party calculates its own local model, which is then incorporated into a global model. By partitioning the data appropriately, it can be ensured that no party gains a comprehensive insight into the data [188]. By using privacy filters when creating the local models, it can also be ensured that no unintended conclusions can be drawn from the global model [189].
- Right to be Forgotten. The right to be informed and the right to restriction of processing are, however, not sufficient to provide all-round protection. As data can become outdated, the privacy requirements of data subjects can change, or data may have been unlawfully transferred to data providers in the first place, there is also a need for a right to have all personal data erased. This also includes all related metadata as well as all data products in which these data have been integrated. In addition, personal data also have an inherent lifespan, after which they must also be completely deleted, as they may not be stored longer than required for the intended purpose. In terms of today’s data protection regulations, data erasure has to ensure that the data cannot be restored in any way or form [190]. From a technical point of view, therefore, measures are needed to enable secure deletion of all the data concerned. In the context of providers of big data, the large volume of data from a vast number of users means that, from an economic point of view, it is not feasible to apply deletion methods that destroy the data carriers. To this end, there are nondestructive approaches for both hard disk drives and solid-state drives. While overwriting-based approaches are effective for hard disk drives, where the sectors containing the data in question are overwritten several times with other data, erasure-based approaches for solid-state drives ensure that the flash block that provides access to the flash page containing the data is erased. As a result, the data can no longer be accessed and is finally dumped by the garbage collection [191]. So, while in theory, there are approaches to enable secure deletion for those physical data carriers, these approaches have limitations in terms of logical data storage. For instance, in the case of databases, such an approach is not possible as abstraction layers prevent a direct mapping of data to sectors or flash pages [192]. Blockchain-based data stores represent another example where this type of secure erasure is unsuccessful, as here the data are immutable, i.e., a deletion renders the blockchain invalid [193]. Cloud-based data stores also require other approaches, since only the cloud provider has control over the physical storages and the knowledge of how many replicas are held on which nodes [194]. In these cases, encryption-based approaches can be used. Here, the data are stored fully encrypted. This way, it is sufficient to delete the decryption key, which renders the encrypted data unreadable in the process. Hierarchical key management enables fine-grained deletion of individual data items, clusters of related data, or all data of a data subject at once [195]. Provenance analyses can be used to identify all data products that have been created based on a specific data item [196]. These data products must also be erased if a data subject requests to have their base data (or any part of it) deleted. It is evident that such a provenance analysis also generates a lot of additional data that potentially disclose private information [197]. To this end, when answering this kind of provenance queries, it is therefore necessary to rely on special privacy-aware approaches, such as intensional provenance answers [198].
3.4. Lessons Learned
4. The REFINERY Platform
4.1. Data Acquisition
4.2. Data Preparation
4.3. Data Management
4.4. Data Provisioning
5. Assessment
5.1. Security and Privacy Assessment
5.2. Feature Discussion
5.3. Case Study
- Privacy Control Capabilities. In our first case study, we focus on data acquisition of health applications for smartphones. Since it is evident that such applications are particularly beneficial, there is a mobile health application for literally all aspects of life [224]. One of the main drivers for these applications is the fact that the built-in sensors in standard smartphones can capture many health-related factors without a great deal of user input. For instance, the stress level [225] or the mood [226] can be determined passively (i.e., without explicit user interaction) by recording and analyzing the user’s voice via the microphone. Or image analysis techniques can be used to analyze pictures of a food product on a smartphone in order to determine its ingredients, such as bread units [227]. Furthermore, there is a large variety of IoT-enabled medical metering devices that can be connected to a smartphone and thus provide these applications with more specific health data [228].
- Specification of Tailored Data Products. Our second case study focuses on how effectively domain experts can specify tailored data products with our approach. For this purpose, we collaborated with food chemists. The number of people suffering from food allergies is constantly increasing. These allergies are in some cases life-threatening, which is why it is crucial that all ingredients are correctly indicated on a food product. Furthermore, control authorities are required to check the food products on a regular basis. Even the smallest particles of an allergen must be reliably detected even at the molecular level [233]. In our specific use case, we want to identify nut seeds in chocolate samples, since nut seeds are among the most prevalent food allergens which can trigger severe allergic shocks [234].
| Listing 1. Ontology Excerpt to Specify a Data Preparation Process in the Food Chemistry Domain. |
 |
5.4. Performance Evaluation
6. Conclusions
- (a)
- Our investigation of the commodity ‘data’ revealed that ten unique characteristics have to be taken into account when handling this intangible resource. For instance, data are not only nonconsumable but can also be duplicated losslessly, which means that their volume is constantly growing. Furthermore, data accumulate at high velocity and have to be processed quickly, as they are partially volatile. Their heterogeneous nature and the need to apply individual refinement techniques to the data further complicate this endeavor. Since the economic value of data cannot be estimated in advance, and indiscernibly data manipulations can impair the quality of the data, it is essential to avoid unreasonably high handling costs. Finally, data products can be subject to special restrictions in terms of processing and provisioning. Therefore, there is a fundamental need for new trading concepts and infrastructures for the commodity ‘data’.
- (b)
- Based on this knowledge base, our review of state-of-the-art techniques related to data administration indicated that there are four aspects in particular where these characteristics need to be taken into account in order to enable effective and efficient data handling. First, data have to be acquired appropriately (in terms of, e.g., quality and quantity) from heterogeneous sources. These data must then be cleansed and made processable by means of data preparation and transformed into custom-made data products. The data products, together with all the high-volume data artifacts generated during manufacturing, must be managed and made retrievable. Only then can they be offered to data consumers in a digital storefront as part of data provisioning. In addition to these data administration tasks, security and privacy aspects also have to be taken into account in each of these work steps.
- (c)
- Our review of related work revealed that there are many island solutions to individual aspects of these data administration problems. However, there is no holistic end-to-end solution addressing all data characteristics at once. This is necessary in order to achieve synergy effects and thus exploit the full potential of the commodity ‘data’. To this end, we presented our own concept toward a reliable information retrieval and delivery platform called REFINERY Platform. Our REFINERY Platform not only addresses all the challenges we identified in the area of data administration but also provides both data producers and data consumers with assertions regarding data security and privacy on the one hand and data quality on the other hand. An in-depth assessment confirms that our approach is effective (in terms of provided functionality), practicable (in terms of operability), and efficient (in terms of data throughput) in this respect.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADS | Authenticated Data Structures |
| AI | Artificial Intelligence |
| App | (Mobile) Application |
| BI | Business Intelligence |
| CPU | Central Processing Unit |
| DB | Database |
| DDoS | Distributed Denial of Service Attack |
| DDR | Double Data Rate |
| ETL | Extraction, Transformation, Loading |
| GB | Gigabyte |
| GDPR | General Data Protection Regulation |
| IoT | Internet of Things |
| IT | Information Technology |
| MB | Megabyte |
| NoSQL | Not only SQL |
| OAuth | Open Authorization |
| OS | Operating System |
| PET | Privacy-Enhancing Technologies |
| PIN | Personal Identification Number |
| PMP | Privacy Management Platform |
| PoOR | Proofs of Ownership and Retrievability |
| PoRR | Proofs of Retrievability and Reliability |
| PUF | Physical Unclonable Function |
| RDF | Resource Description Framework |
| REFINERY Platform | Reliable Information Retrieval and Delivery Platform |
| SQL | Structured Query Language |
| STAMP | System-Theoretic Accident Model and Processes |
| STPA | System-Theoretic Process Analysis |
| TB | Terabyte |
| VDF | Verifiable Delay Function |
| XML | Extensible Markup Language |
References
- Schwab, K.; Marcus, A.; Oyola, J.R.; Hoffman, W.; Luzi, M. Personal Data: The Emergence of a New Asset Class. An Initiative of the World Economic Forum. 2011, pp. 1–40. Available online: https://www.weforum.org/reports/personal-data-emergence-new-asset-class/ (accessed on 6 February 2023).
- Javornik, M.; Nadoh, N.; Lange, D. Data Is the New Oil. In Towards User-Centric Transport in Europe: Challenges, Solutions and Collaborations; Müller, B., Meyer, G., Eds.; Springer: Cham, Switzerland, 2019; pp. 295–308. [Google Scholar]
- Klingenberg, C.O.; Borges, M.A.V.; Antunes, J.A.V., Jr. Industry 4.0 as a data-driven paradigm: A systematic literature review on technologies. J. Manuf. Technol. Manag. 2021, 32, 570–592. [Google Scholar] [CrossRef]
- Sisinni, E.; Saifullah, A.; Han, S.; Jennehag, U.; Gidlund, M. Industrial Internet of Things: Challenges, Opportunities, and Directions. IEEE Trans. Ind. Inform. 2018, 14, 4724–4734. [Google Scholar] [CrossRef]
- Singh, M.; Fuenmayor, E.; Hinchy, E.P.; Qiao, Y.; Murray, N.; Devine, D. Digital Twin: Origin to Future. Appl. Syst. Innov. 2021, 4, 36. [Google Scholar] [CrossRef]
- Philbeck, T.; Davis, N. The Fourth Industrial Revolution: Shaping a New Era. J. Int. Aff. 2018, 72, 17–22. [Google Scholar]
- Schwab, K. (Ed.) The Fourth Industrial Revolution, illustrated ed.; Crown Business: New York, NY, USA, 2017. [Google Scholar]
- Lasi, H.; Fettke, P.; Kemper, H.G.; Feld, T.; Hoffmann, M. Industry 4.0. Bus. Inf. Syst. Eng. 2014, 6, 239–242. [Google Scholar] [CrossRef]
- Leelaarporn, P.; Wachiraphan, P.; Kaewlee, T.; Udsa, T.; Chaisaen, R.; Choksatchawathi, T.; Laosirirat, R.; Lakhan, P.; Natnithikarat, P.; Thanontip, K.; et al. Sensor-Driven Achieving of Smart Living: A Review. IEEE Sens. J. 2021, 21, 10369–10391. [Google Scholar] [CrossRef]
- Paiva, S.; Ahad, M.A.; Tripathi, G.; Feroz, N.; Casalino, G. Enabling Technologies for Urban Smart Mobility: Recent Trends, Opportunities and Challenges. Sensors 2021, 21, 2143. [Google Scholar] [CrossRef]
- Al-rawashdeh, M.; Keikhosrokiani, P.; Belaton, B.; Alawida, M.; Zwiri, A. IoT Adoption and Application for Smart Healthcare: A Systematic Review. Sensors 2022, 22, 5377. [Google Scholar] [CrossRef]
- Yar, H.; Imran, A.S.; Khan, Z.A.; Sajjad, M.; Kastrati, Z. Towards Smart Home Automation Using IoT-Enabled Edge-Computing Paradigm. Sensors 2021, 21, 4932. [Google Scholar] [CrossRef]
- Taffel, S. Data and oil: Metaphor, materiality and metabolic rifts. New Media Soc. 2021. [Google Scholar] [CrossRef]
- Urbach, N.; Ahlemann, F. IT Management in the Digital Age: A Roadmap for the IT Department of the Future; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Possler, D.; Bruns, S.; Niemann-Lenz, J. Data Is the New Oil–But How Do We Drill It? Pathways to Access and Acquire Large Data Sets in Communication Science. Int. J. Commun. 2019, 13, 3894–3911. [Google Scholar]
- Liew, A. Understanding Data, Information, Knowledge And Their Inter-Relationships. J. Knowl. Manag. Pract. 2007, 8, 1–10. [Google Scholar]
- Sarker, I.H. Data Science and Analytics: An Overview from Data-Driven Smart Computing, Decision-Making and Applications Perspective. SN Comput. Sci. 2021, 2, 377. [Google Scholar] [CrossRef]
- Arfat, Y.; Usman, S.; Mehmood, R.; Katib, I. Big Data Tools, Technologies, and Applications: A Survey. In Smart Infrastructure and Applications: Foundations for Smarter Cities and Societies; Mehmood, R., See, S., Katib, I., Chlamtac, I., Eds.; Springer: Cham, Switzerland, 2020; Chapter 19; pp. 453–490. [Google Scholar]
- Rowley, J. The wisdom hierarchy: Representations of the DIKW hierarchy. J. Inf. Sci. 2007, 33, 163–180. [Google Scholar] [CrossRef]
- Mandel, M. The Economic Impact of Data: Why Data Is Not Like Oil; ppi Radically Pragmatic: London, UK, 2017; pp. 1–20. Available online: https://www.progressivepolicy.org/publication/economic-impact-data-data-not-like-oil/ (accessed on 6 February 2023).
- Nolin, J.M. Data as oil, infrastructure or asset? Three metaphors of data as economic value. J. Inf. Commun. Ethics Soc. 2020, 18, 28–43. [Google Scholar] [CrossRef]
- Katal, A.; Wazid, M.; Goudar, R.H. Big data: Issues, challenges, tools and Good practices. In Proceedings of the 2013 Sixth International Conference on Contemporary Computing (IC3), Noida, India, 8–10 August 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 404–409. [Google Scholar]
- Mladenović, M.N. Data is not the new oil, but could be water or sunlight? From ethical to moral pathways for urban data management. In Proceedings of the 17th International Conference on Computational Urban Planning and Urban Management (CUPUM), Espoo, Finland, 9–11 June 2021; pp. 9–11. [Google Scholar]
- Hirsch, D.D. The Glass House Effect: Big Data, the New Oil, and the Power of Analogy. Maine Law Rev. 2014, 66, 373–395. [Google Scholar]
- van der Aalst, W.M.P. Data Scientist: The Engineer of the Future. In Proceedings of the 7th International Conference on Interoperability for Enterprises Systems and Applications (I-ESA), Albi, France, 24–28 March 2014; Springer: Cham, Switzerland, 2014; pp. 13–26. [Google Scholar]
- Siddiqa, A.; Hashem, I.A.T.; Yaqoob, I.; Marjani, M.; Shamshirband, S.; Gani, A.; Nasaruddin, F. A survey of big data management: Taxonomy and state-of-the-art. J. Netw. Comput. Appl. 2016, 71, 151–166. [Google Scholar] [CrossRef]
- Moreno, J.; Serrano, M.A.; Fernández-Medina, E. Main Issues in Big Data Security. Future Internet 2016, 8, 44. [Google Scholar] [CrossRef]
- Binjubeir, M.; Ahmed, A.A.; Ismail, M.A.B.; Sadiq, A.S.; Khurram Khan, M. Comprehensive Survey on Big Data Privacy Protection. IEEE Access 2020, 8, 20067–20079. [Google Scholar] [CrossRef]
- Löcklin, A.; Vietz, H.; White, D.; Ruppert, T.; Jazdi, N.; Weyrich, M. Data administration shell for data-science-driven development. Procedia CIRP 2021, 100, 115–120. [Google Scholar] [CrossRef]
- Jeyaprakash, T.; Padmaveni, K. Introduction to Data Science—An Overview. Int. J. Sci. Manag. Stud. 2021, 4, 407–410. [Google Scholar] [CrossRef]
- Lyko, K.; Nitzschke, M.; Ngonga Ngomo, A.C. Big Data Acquisition. In New Horizons for a Data-Driven Economy: A Roadmap for Usage and Exploitation of Big Data in Europe; Cavanillas, J.M., Curry, E., Wahlster, W., Eds.; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Curry, E. The Big Data Value Chain: Definitions, Concepts, and Theoretical Approaches. In New Horizons for a Data-Driven Economy: A Roadmap for Usage and Exploitation of Big Data in Europe; Cavanillas, J.M., Curry, E., Wahlster, W., Eds.; Springer: Cham, Switzerland, 2016; Chapter 3; pp. 29–37. [Google Scholar]
- Vassiliadis, P.; Simitsis, A.; Skiadopoulos, S. Conceptual Modeling for ETL Processes. In Proceedings of the 5th ACM International Workshop on Data Warehousing and OLAP (DOLAP), McLean, VA, USA, 8 November 2002; ACM: New York, NY, USA, 2002; pp. 14–21. [Google Scholar]
- Simitsis, A. Modeling and managing ETL processes. In Proceedings of the VLDB 2003 PhD Workshop co-located with the 29th International Conference on Very Large Databases (VLDB), Berlin, Germany, 9–12 September 2003; CEUR-WS.org: Aachen, Germany, 2003; pp. 1–5. [Google Scholar]
- Lau, B.P.L.; Marakkalage, S.H.; Zhou, Y.; Hassan, N.U.; Yuen, C.; Zhang, M.; Tan, U.X. A survey of data fusion in smart city applications. Inf. Fusion 2019, 52, 357–374. [Google Scholar] [CrossRef]
- Diouf, P.S.; Boly, A.; Ndiaye, S. Variety of data in the ETL processes in the cloud: State of the art. In Proceedings of the 2018 IEEE International Conference on Innovative Research and Development (ICIRD), Bangkok, Thailand, 11–12 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- D’silva, G.M.; Khan, A.; Gaurav.; Bari, S. Real-time processing of IoT events with historic data using Apache Kafka and Apache Spark with dashing framework. In Proceedings of the 2017 2nd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 19–20 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1804–1809. [Google Scholar]
- Geng, D.; Zhang, C.; Xia, C.; Xia, X.; Liu, Q.; Fu, X. Big Data-Based Improved Data Acquisition and Storage System for Designing Industrial Data Platform. IEEE Access 2019, 7, 44574–44582. [Google Scholar] [CrossRef]
- Huai, Y.; Chauhan, A.; Gates, A.; Hagleitner, G.; Hanson, E.N.; O’Malley, O.; Pandey, J.; Yuan, Y.; Lee, R.; Zhang, X. Major Technical Advancements in Apache Hive. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (SIGMOD), Snowbird, UT, USA, 22–27 June 2014; ACM: New York, NY, USA, 2014; pp. 1235–1246. [Google Scholar]
- Lee, G.; Lin, J.; Liu, C.; Lorek, A.; Ryaboy, D. The Unified Logging Infrastructure for Data Analytics at Twitter. Proc. VLDB Endow. 2012, 5, 1771–1780. [Google Scholar] [CrossRef]
- Marz, N. How to Beat the CAP Theorem. Thoughts from the Red Planet. 2011. Available online: http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html (accessed on 6 February 2023).
- Kreps, J. Questioning the Lambda Architecture. O’Reilly, 2 July 2014. Available online: https://www.oreilly.com/radar/questioning-the-lambda-architecture/ (accessed on 6 February 2023).
- Kraetz, D.; Morawski, M. Architecture Patterns—Batch and Real-Time Capabilities. In The Digital Journey of Banking and Insurance, Volume III: Data Storage, Data Processing and Data Analysis; Liermann, V., Stegmann, C., Eds.; Palgrave Macmillan: Cham, Switzerland, 2021; pp. 89–104. [Google Scholar]
- Lin, J. The Lambda and the Kappa. IEEE Internet Comput. 2017, 21, 60–66. [Google Scholar] [CrossRef]
- Terrizzano, I.; Schwarz, P.; Roth, M.; Colino, J.E. Data Wrangling: The Challenging Journey from the Wild to the Lake. In Proceedings of the 7th Biennial Conference on Innovative Data Systems Research (CIDR), Asilomar, CA, USA, 4–7 January 2015; pp. 1–9. [Google Scholar]
- Ding, X.; Wang, H.; Su, J.; Li, Z.; Li, J.; Gao, H. Cleanits: A Data Cleaning System for Industrial Time Series. Proc. VLDB Endow. 2019, 12, 1786–1789. [Google Scholar] [CrossRef]
- Behringer, M.; Hirmer, P.; Mitschang, B. A Human-Centered Approach for Interactive Data Processing and Analytics. In Proceedings of the 19th International Conference on Enterprise Information Systems (ICEIS), Porto, Portugal, 26–29 April 2017; Springer: Cham, Switzerland, 2018; pp. 498–514. [Google Scholar]
- Diamantini, C.; Lo Giudice, P.; Potena, D.; Storti, E.; Ursino, D. An Approach to Extracting Topic-guided Views from the Sources of a Data Lake. Inf. Syst. Front. 2021, 23, 243–262. [Google Scholar] [CrossRef]
- Bogatu, A.; Fernandes, A.A.A.; Paton, N.W.; Konstantinou, N. Dataset Discovery in Data Lakes. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 709–720. [Google Scholar]
- Megdiche, I.; Ravat, F.; Zhao, Y. Metadata Management on Data Processing in Data Lakes. In Proceedings of the 47th International Conference on Current Trends in Theory and Practice of Computer Science (SOFSEM), Bolzano-Bozen, Italy, 25–29 January 2021; Springer: Cham, Switzerland, 2021; pp. 553–562. [Google Scholar]
- Castro Fernandez, R.; Abedjan, Z.; Koko, F.; Yuan, G.; Madden, S.; Stonebraker, M. Aurum: A Data Discovery System. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1001–1012. [Google Scholar]
- Behringer, M.; Hirmer, P.; Fritz, M.; Mitschang, B. Empowering Domain Experts to Preprocess Massive Distributed Datasets. In Proceedings of the 23rd International Conference on Business Information Systems (BIS), Colorado Springs, CO, USA, 8–10 June 2020; Springer: Cham, Switzerland, 2020; pp. 61–75. [Google Scholar]
- Behringer, M.; Fritz, M.; Schwarz, H.; Mitschang, B. DATA-IMP: An Interactive Approach to Specify Data Imputation Transformations on Large Datasets. In Proceedings of the 27th International Conference on Cooperative Information Systems (CoopIS), Bozen-Bolzano, Italy, 4–7 October 2022; Springer: Cham, Switzerland, 2022; pp. 55–74. [Google Scholar]
- Mahdavi, M.; Abedjan, Z. Semi-Supervised Data Cleaning with Raha and Baran. In Proceedings of the 11th Annual Conference on Innovative Data Systems Research (CIDR), Chaminade, CA, USA, 11–15 January 2021; pp. 1–7. [Google Scholar]
- Wulf, A.J.; Seizov, O. “Please understand we cannot provide further information”: Evaluating content and transparency of GDPR-mandated AI disclosures. AI & Soc. 2022, 1–22. [Google Scholar] [CrossRef]
- Auge, T.; Heuer, A. ProSA—Using the CHASE for Provenance Management. In Proceedings of the 23rd European Conference on Advances in Databases and Information Systems (ADBIS), Bled, Slovenia, 8–11 September 2019; Springer: Cham, Switzerland, 2019; pp. 357–372. [Google Scholar]
- Lam, H.T.; Buesser, B.; Min, H.; Minh, T.N.; Wistuba, M.; Khurana, U.; Bramble, G.; Salonidis, T.; Wang, D.; Samulowitz, H. Automated Data Science for Relational Data. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2689–2692. [Google Scholar]
- Ilyas, I.F.; Rekatsinas, T. Machine Learning and Data Cleaning: Which Serves the Other? J. Data Inf. Qual. 2022, 14, 1–11. [Google Scholar] [CrossRef]
- Devlin, B.; Cote, L.D. Data Warehouse: From Architecture to Implementation; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1996. [Google Scholar]
- Aftab, U.; Siddiqui, G.F. Big Data Augmentation with Data Warehouse: A Survey. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2785–2794. [Google Scholar]
- Wongthongtham, P.; Abu-Salih, B. Ontology and trust based data warehouse in new generation of business intelligence: State-of-the-art, challenges, and opportunities. In Proceedings of the 2015 IEEE 13th International Conference on Industrial Informatics (INDIN), Cambridge, UK, 22–24 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 476–483. [Google Scholar]
- Mathis, C. Data Lakes. Datenbank-Spektrum 2017, 17, 289–293. [Google Scholar] [CrossRef]
- Taniar, D.; Rahayu, W. Data Lake Architecture. In Proceedings of the 9th International Conference on Emerging Internet, Data & Web Technologies (EIDWT), Chiang Mai, Thailand, 25–27 February 2021; Springer: Cham, Switzerland, 2021; pp. 344–357. [Google Scholar]
- Ravat, F.; Zhao, Y. Data Lakes: Trends and Perspectives. In Proceedings of the 30th International Conference on Database and Expert Systems Applications (DEXA), Linz, Austria, 26–29 August 2019; Springer: Cham, Switzerland, 2019; pp. 304–313. [Google Scholar]
- Giebler, C.; Gröger, C.; Hoos, E.; Schwarz, H.; Mitschang, B. Leveraging the Data Lake: Current State and Challenges. In Proceedings of the 21st International Conference on Big Data Analytics and Knowledge Discovery (DaWaK), Linz, Austria, 26–29 August 2019; Springer: Cham, Switzerland, 2019; pp. 179–188. [Google Scholar]
- Giebler, C.; Gröger, C.; Hoos, E.; Schwarz, H.; Mitschang, B. A Zone Reference Model for Enterprise-Grade Data Lake Management. In Proceedings of the 2020 IEEE 24th International Enterprise Distributed Object Computing Conference (EDOC), Eindhoven, The Netherlands, 5–8 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 57–66. [Google Scholar]
- Hai, R.; Geisler, S.; Quix, C. Constance: An Intelligent Data Lake System. In Proceedings of the 2016 International Conference on Management of Data (SIGMOD), San Francisco, CA, USA, 26 June–1 July 2016; ACM: New York, NY, USA, 2016; pp. 2097–2100. [Google Scholar]
- Farid, M.; Roatis, A.; Ilyas, I.F.; Hoffmann, H.F.; Chu, X. CLAMS: Bringing Quality to Data Lakes. In Proceedings of the 2016 International Conference on Management of Data (SIGMOD), San Francisco, CA, USA, 26 June–1 July 2016; ACM: New York, NY, USA, 2016; pp. 2089–2092. [Google Scholar]
- Machado, I.A.; Costa, C.; Santos, M.Y. Data Mesh: Concepts and Principles of a Paradigm Shift in Data Architectures. Procedia Comput. Sci. 2022, 196, 263–271. [Google Scholar] [CrossRef]
- Oreščanin, D.; Hlupić, T. Data Lakehouse—A Novel Step in Analytics Architecture. In Proceedings of the 2021 44th International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 9–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1242–1246. [Google Scholar]
- Armbrust, M.; Ghodsi1, A.; Xin, R.; Zaharia, M. Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. In Proceedings of the 11th Annual Conference on Innovative Data Systems Research (CIDR), Chaminade, CA, USA, 11–15 January 2021; pp. 1–8. [Google Scholar]
- Alpar, P.; Schulz, M. Self-Service Business Intelligence. Bus. Inf. Syst. Eng. 2016, 58, 151–155. [Google Scholar] [CrossRef]
- Lennerholt, C.; van Laere, J. Data access and data quality challenges of self-service business intelligence. In Proceedings of the 27th European Conference on Information Systems (ECIS), Stockholm and Uppsala, Sweden, 8–14 June 2019; AIS: Atlanta, GA, USA, 2019; pp. 1–13. [Google Scholar]
- Huang, L.; Dou, Y.; Liu, Y.; Wang, J.; Chen, G.; Zhang, X.; Wang, R. Toward a research framework to conceptualize data as a factor of production: The data marketplace perspective. Fundam. Res. 2021, 1, 586–594. [Google Scholar] [CrossRef]
- Gröger, C. There is No AI without Data. Commun. ACM 2021, 64, 98–108. [Google Scholar] [CrossRef]
- Eichler, R.; Gröger, C.; Hoos, E.; Schwarz, H.; Mitschang, B. From Data Asset to Data Product – The Role of the Data Provider in the Enterprise Data Marketplace. In Proceedings of the 17th Symposium and Summer School On Service-Oriented Computing (SummerSOC), Heraklion, Greece, 3–9 July 2022; Springer: Cham, Switzerland, 2022; pp. 119–138. [Google Scholar]
- Eichler, R.; Giebler, C.; Gröger, C.; Hoos, E.; Schwarz, H.; Mitschang, B. Enterprise-Wide Metadata Management: An Industry Case on the Current State and Challenges. In Proceedings of the 24th International Conference on Business Information Systems (BIS), Hannover, Germany, 14–17 June 2021; pp. 269–279. [Google Scholar]
- Eichler, R.; Gröger, C.; Hoos, E.; Schwarz, H.; Mitschang, B. Data Shopping—How an Enterprise Data Marketplace Supports Data Democratization in Companies. In Proceedings of the 34th International Conference on Advanced Information Systems Engineering (CAiSE), Leuven, Belgium, 6–10 June 2022; Springer: Cham, Switzerland, 2022; pp. 19–26. [Google Scholar]
- Eichler, R.; Giebler, C.; Gröger, C.; Schwarz, H.; Mitschang, B. Modeling metadata in data lakes—A generic model. Data Knowl. Eng. 2021, 136, 101931. [Google Scholar] [CrossRef]
- Driessen, S.W.; Monsieur, G.; Van Den Heuvel, W.J. Data Market Design: A Systematic Literature Review. IEEE Access 2022, 10, 33123–33153. [Google Scholar] [CrossRef]
- Chanal, P.M.; Kakkasageri, M.S. Security and Privacy in IoT: A Survey. Wirel. Pers. Commun. 2020, 115, 1667–1693. [Google Scholar] [CrossRef]
- Samonas, S.; Coss, D. The CIA Strikes Back: Redefining Confidentiality, Integrity and Availability in Security. J. Inf. Syst. Secur. 2014, 10, 21–45. [Google Scholar]
- ISO/IEC 27000:2018(en); Information Technology—Security Techniques—Information Security Management Systems—Overview and Vocabulary. International Organization for Standardization: Geneva, Switzerland, 2018.
- Maqsood, F.; Ali, M.M.; Ahmed, M.; Shah, M.A. Cryptography: A Comparative Analysis for Modern Techniques. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 442–448. [Google Scholar] [CrossRef]
- Henriques, M.S.; Vernekar, N.K. Using symmetric and asymmetric cryptography to secure communication between devices in IoT. In Proceedings of the 2017 International Conference on IoT and Application (ICIOT), Nagapattinam, India, 19–20 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Shafagh, H.; Hithnawi, A.; Burkhalter, L.; Fischli, P.; Duquennoy, S. Secure Sharing of Partially Homomorphic Encrypted IoT Data. In Proceedings of the 15th ACM Conference on Embedded Network Sensor Systems (SenSys), Delft, The Netherlands, 6–8 November 2017; ACM: New York, NY, USA, 2017; pp. 1–14. [Google Scholar]
- Do, H.G.; Ng, W.K. Blockchain-Based System for Secure Data Storage with Private Keyword Search. In Proceedings of the 2017 IEEE World Congress on Services (SERVICES), Honolulu, HI, USA, 25–30 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 90–93. [Google Scholar]
- Sun, X.; Zhang, P.; Liu, J.K.; Yu, J.; Xie, W. Private Machine Learning Classification Based on Fully Homomorphic Encryption. IEEE Trans. Emerg. Top. Comput. 2020, 8, 352–364. [Google Scholar] [CrossRef]
- Ouaddah, A.; Mousannif, H.; Abou Elkalam, A.; Ait Ouahman, A. Access control in the Internet of Things: Big challenges and new opportunities. Comput. Netw. 2017, 112, 237–262. [Google Scholar] [CrossRef]
- Qiu, J.; Tian, Z.; Du, C.; Zuo, Q.; Su, S.; Fang, B. A Survey on Access Control in the Age of Internet of Things. IEEE Internet Things J. 2020, 7, 4682–4696. [Google Scholar] [CrossRef]
- Alagar, V.; Alsaig, A.; Ormandjiva, O.; Wan, K. Context-Based Security and Privacy for Healthcare IoT. In Proceedings of the 2018 IEEE International Conference on Smart Internet of Things (SmartIoT), Xi’an, China, 17–19 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 122–128. [Google Scholar]
- Alkhresheh, A.; Elgazzar, K.; Hassanein, H.S. Context-aware Automatic Access Policy Specification for IoT Environments. In Proceedings of the 2018 14th International Wireless Communications & Mobile Computing Conference (IWCMC), Limassol, Cyprus, 25–29 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 793–799. [Google Scholar]
- Novo, O. Blockchain Meets IoT: An Architecture for Scalable Access Management in IoT. IEEE Internet Things J. 2018, 5, 1184–1195. [Google Scholar] [CrossRef]
- Raikwar, M.; Gligoroski, D.; Velinov, G. Trends in Development of Databases and Blockchain. In Proceedings of the 2020 Seventh International Conference on Software Defined Systems (SDS), Paris, France, 20–23 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 177–182. [Google Scholar]
- Li, R.; Song, T.; Mei, B.; Li, H.; Cheng, X.; Sun, L. Blockchain for Large-Scale Internet of Things Data Storage and Protection. IEEE Trans. Serv. Comput. 2019, 12, 762–771. [Google Scholar] [CrossRef]
- Chowdhury, M.J.M.; Colman, A.; Kabir, M.A.; Han, J.; Sarda, P. Blockchain as a Notarization Service for Data Sharing with Personal Data Store. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security And Privacy In Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1330–1335. [Google Scholar]
- Gupta, S.; Hellings, J.; Rahnama, S.; Sadoghi, M. Building High Throughput Permissioned Blockchain Fabrics: Challenges and Opportunities. Proc. VLDB Endow. 2020, 13, 3441–3444. [Google Scholar] [CrossRef]
- Li, Y.; Zheng, K.; Yan, Y.; Liu, Q.; Zhou, X. EtherQL: A Query Layer for Blockchain System. In Proceedings of the 22nd International Conference on Database Systems for Advanced Applications (DASFAA), Suzhou, China, 27–30 March 2017; Springer: Cham, Switzerland, 2017; pp. 556–567. [Google Scholar]
- Bragagnolo, S.; Rocha, H.; Denker, M.; Ducasse, S. Ethereum Query Language. In Proceedings of the 1st International Workshop on Emerging Trends in Software Engineering for Blockchain (WETSEB), Gothenburg, Sweden, 27 May 2018; ACM: New York, NY, USA, 2018; pp. 1–8. [Google Scholar]
- Qu, Q.; Nurgaliev, I.; Muzammal, M.; Jensen, C.S.; Fan, J. On spatio-temporal blockchain query processing. Future Gener. Comput. Syst. 2019, 98, 208–218. [Google Scholar] [CrossRef]
- Hao, K.; Xin, J.; Wang, Z.; Yao, Z.; Wang, G. On efficient top-k transaction path query processing in blockchain database. Data Knowl. Eng. 2022, 141, 102079. [Google Scholar] [CrossRef]
- Han, J.; Kim, H.; Eom, H.; Coignard, J.; Wu, K.; Son, Y. Enabling SQL-Query Processing for Ethereum-Based Blockchain Systems. In Proceedings of the 9th International Conference on Web Intelligence, Mining and Semantics (WIMS), Seoul, Republic of Korea, 26–28 June 2019; ACM: New York, NY, USA, 2019; pp. 1–7. [Google Scholar]
- Przytarski, D. Using Triples as the Data Model for Blockchain Systems. In Proceedings of the Blockchain enabled Semantic Web Workshop and Contextualized Knowledge Graphs Workshop Co-Located with the 18th International Semantic Web Conference (BlockSW/CKG@ISWC), Auckland, New Zealand, 26–30 October 2019; pp. 1–2. [Google Scholar]
- Kurt Peker, Y.; Rodriguez, X.; Ericsson, J.; Lee, S.J.; Perez, A.J. A Cost Analysis of Internet of Things Sensor Data Storage on Blockchain via Smart Contracts. Electronics 2020, 9, 244. [Google Scholar] [CrossRef]
- Hepp, T.; Sharinghousen, M.; Ehret, P.; Schoenhals, A.; Gipp, B. On-chain vs. off-chain storage for supply- and blockchain integration. IT Inf. Technol. 2018, 60, 283–291. [Google Scholar] [CrossRef]
- Schuhknecht, F.; Sharma, A.; Dittrich, J.; Agrawal, D. chainifyDB: How to get rid of your Blockchain and use your DBMS instead. In Proceedings of the 11th Annual Conference on Innovative Data Systems Research (CIDR), Chaminade, CA, USA, 11–15 January 2021; pp. 1–10. [Google Scholar]
- Wang, H.; Xu, C.; Zhang, C.; Xu, J. vChain: A Blockchain System Ensuring Query Integrity. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (SIGMOD), Portland, OR, USA, 14–19 June 2020; ACM: New York, NY, USA, 2020; pp. 2693–2696. [Google Scholar]
- Nathan, S.; Govindarajan, C.; Saraf, A.; Sethi, M.; Jayachandran, P. Blockchain Meets Database: Design and Implementation of a Blockchain Relational Database. Proc. VLDB Endow. 2019, 12, 1539–1552. [Google Scholar] [CrossRef]
- Cai, H.; Xu, B.; Jiang, L.; Vasilakos, A.V. IoT-Based Big Data Storage Systems in Cloud Computing: Perspectives and Challenges. IEEE Internet Things J. 2017, 4, 75–87. [Google Scholar] [CrossRef]
- Habib, S.M.; Hauke, S.; Ries, S.; Mühlhäuser, M. Trust as a facilitator in cloud computing: A survey. J. Cloud Comput. Adv. Syst. Appl. 2012, 1, 19. [Google Scholar] [CrossRef]
- Khan, K.M.; Malluhi, Q. Establishing Trust in Cloud Computing. IT Prof. 2010, 12, 20–27. [Google Scholar] [CrossRef]
- Gilad-Bachrach, R.; Laine, K.; Lauter, K.; Rindal, P.; Rosulek, M. Secure Data Exchange: A Marketplace in the Cloud. In Proceedings of the 2019 ACM SIGSAC Conference on Cloud Computing Security Workshop (CCSW), London, UK, 11 November 2019; ACM: New York, NY, USA, 2019; pp. 117–128. [Google Scholar]
- Gritti, C.; Chen, R.; Susilo, W.; Plantard, T. Dynamic Provable Data Possession Protocols with Public Verifiability and Data Privacy. In Proceedings of the 13th International Conference on Information Security Practice and Experience (ISPEC), Melbourne, Australia, 13–15 December 2017; Springer: Cham, Switzerland, 2017; pp. 485–505. [Google Scholar]
- Du, R.; Deng, L.; Chen, J.; He, K.; Zheng, M. Proofs of Ownership and Retrievability in Cloud Storage. In Proceedings of the 2014 IEEE 13th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Beijing, China, 24–26 September 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 328–335. [Google Scholar]
- Erway, C.C.; Küpçü, A.; Papamanthou, C.; Tamassia, R. Dynamic Provable Data Possession. ACM Trans. Inf. Syst. Secur. 2015, 17, 1–29. [Google Scholar] [CrossRef]
- Merkle, R.C. A Digital Signature Based on a Conventional Encryption Function. In Proceedings of the Conference on the Theory and Applications of Cryptographic Techniques (CRYPTO), Santa Barbara, CA, USA, 16–20 August 1987; Springer: Berlin/Heidelberg, Germany, 1988; pp. 369–378. [Google Scholar]
- Gritti, C.; Li, H. Efficient Publicly Verifiable Proofs of Data Replication and Retrievability Applicable for Cloud Storage. Adv. Sci. Technol. Eng. Syst. J. 2022, 7, 107–124. [Google Scholar] [CrossRef]
- Boneh, D.; Bonneau, J.; Bünz, B.; Fisch, B. Verifiable Delay Functions. In Proceedings of the 38th International Cryptology Conference (Crypto), Santa Barbara, CA, USA, 17–19 August 2018; Springer: Cham, Switzerland, 2018; pp. 757–788. [Google Scholar]
- Salim, M.M.; Rathore, S.; Park, J.H. Distributed denial of service attacks and its defenses in IoT: A survey. J. Supercomput. 2020, 76, 5320–5363. [Google Scholar] [CrossRef]
- Zhang, H.; Wen, Y.; Xie, H.; Yu, N. Distributed Hash Table: Theory, Platforms and Applications; Springer: New York, NY, USA, 2013. [Google Scholar]
- Singh, R.; Tanwar, S.; Sharma, T.P. Utilization of blockchain for mitigating the distributed denial of service attacks. Secur. Priv. 2020, 3, e96. [Google Scholar] [CrossRef]
- Liu, X.; Farahani, B.; Firouzi, F. Distributed Ledger Technology. In Intelligent Internet of Things: From Device to Fog and Cloud; Firouzi, F., Chakrabarty, K., Nassif, S., Eds.; Springer: Cham, Switzerland, 2020; Chapter 8; pp. 393–431. [Google Scholar]
- Zhu, Q.; Loke, S.W.; Trujillo-Rasua, R.; Jiang, F.; Xiang, Y. Applications of Distributed Ledger Technologies to the Internet of Things: A Survey. ACM Comput. Surv. 2019, 52, 1–34. [Google Scholar] [CrossRef]
- Peng, Y.; Du, M.; Li, F.; Cheng, R.; Song, D. FalconDB: Blockchain-Based Collaborative Database. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (SIGMOD), Portland, OR, USA, 14–19 June 2020; ACM: New York, NY, USA, 2020; pp. 637–652. [Google Scholar]
- El-Hindi, M.; Binnig, C.; Arasu, A.; Kossmann, D.; Ramamurthy, R. BlockchainDB: A Shared Database on Blockchains. Proc. VLDB Endow. 2019, 12, 1597–1609. [Google Scholar] [CrossRef]
- Barkadehi, M.H.; Nilashi, M.; Ibrahim, O.; Zakeri Fardi, A.; Samad, S. Authentication systems: A literature review and classification. Telemat. Inform. 2018, 35, 1491–1511. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Maglaras, L.; Derhab, A. Authentication and Authorization for Mobile IoT Devices Using Biofeatures: Recent Advances and Future Trends. Secur. Commun. Netw. 2019, 2019, 5452870. [Google Scholar] [CrossRef]
- Cheong, S.N.; Ling, H.C.; Teh, P.L. Secure Encrypted Steganography Graphical Password scheme for Near Field Communication smartphone access control system. Expert Syst. Appl. 2014, 41, 3561–3568. [Google Scholar] [CrossRef]
- Baig, A.F.; Eskeland, S. Security, Privacy, and Usability in Continuous Authentication: A Survey. Sensors 2021, 35, 5967. [Google Scholar] [CrossRef] [PubMed]
- Sciancalepore, S.; Piro, G.; Caldarola, D.; Boggia, G.; Bianchi, G. OAuth-IoT: An access control framework for the Internet of Things based on open standards. In Proceedings of the 2017 IEEE Symposium on Computers and Communications (ISCC), Heraklion, Crete, Greece, 3–6 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 676–681. [Google Scholar]
- Kulseng, L.; Yu, Z.; Wei, Y.; Guan, Y. Lightweight Mutual Authentication and Ownership Transfer for RFID Systems. In Proceedings of the 2010 30th IEEE International Conference on Computer Communications (INFOCOM), San Diego, CA, USA, 14–19 March 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1–5. [Google Scholar]
- Maes, R. Physically Unclonable Functions; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- He, W.; Golla, M.; Padhi, R.; Ofek, J.; Dürmuth, M.; Fernandes, E.; Ur, B. Rethinking Access Control and Authentication for the Home Internet of Things (IoT). In Proceedings of the 27th USENIX Security Symposium (USENIX Security), Baltimore, MD, USA, 15–17 August 2018; USENIX Association: Berkeley, CA, USA, 2018; pp. 255–272. [Google Scholar]
- Almuairfi, S.; Veeraraghavan, P.; Chilamkurti, N. A novel image-based implicit password authentication system (IPAS) for mobile and non-mobile devices. Math. Comput. Model. 2013, 58, 108–116. [Google Scholar] [CrossRef]
- Hu, V.C.; Kuhn, D.R.; Ferraiolo, D.F.; Voas, J. Attribute-Based Access Control. Computer 2015, 48, 85–88. [Google Scholar] [CrossRef]
- Hemdi, M.; Deters, R. Using REST based protocol to enable ABAC within IoT systems. In Proceedings of the 2016 IEEE 7th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 13–15 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–7. [Google Scholar]
- Hüffmeyer, M.; Schreier, U. Formal Comparison of an Attribute Based Access Control Language for RESTful Services with XACML. In Proceedings of the 21st ACM on Symposium on Access Control Models and Technologies (SACMAT), Shanghai, China, 6–8 June 2016; ACM: New York, NY, USA, 2016; pp. 171–178. [Google Scholar]
- Liu, S.; You, S.; Yin, H.; Lin, Z.; Liu, Y.; Yao, W.; Sundaresh, L. Model-Free Data Authentication for Cyber Security in Power Systems. IEEE Trans. Smart Grid 2020, 11, 4565–4568. [Google Scholar] [CrossRef]
- Arnold, M.; Schmucker, M.; Wolthusen, S.D. Techniques and Applications of Digital Watermarking and Content Protection; Artech House, Inc.: Norwood, MA, USA, 2003. [Google Scholar]
- Agrawal, R.; Haas, P.J.; Kiernan, J. Watermarking relational data: Framework, algorithms and analysis. VLDB J. 2003, 12, 157–169. [Google Scholar]
- Subramanya, S.; Yi, B.K. Digital signatures. IEEE Potentials 2006, 25, 5–8. [Google Scholar] [CrossRef]
- Kaur, R.; Kaur, A. Digital Signature. In Proceedings of the 2012 International Conference on Computing Sciences (ICCS), Phagwara, India, 14–15 September 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 295–301. [Google Scholar]
- Gritti, C.; Molva, R.; Önen, M. Lightweight Secure Bootstrap and Message Attestation in the Internet of Things. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing (SAC), Pau, France, 9–13 April 2018; ACM: New York, NY, USA, 2018; pp. 775–782. [Google Scholar]
- Gritti, C.; Önen, M.; Molva, R. CHARIOT: Cloud-Assisted Access Control for the Internet of Things. In Proceedings of the 2018 16th Annual Conference on Privacy, Security and Trust (PST), Belfast, Ireland, 28–30 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Gritti, C.; Önen, M.; Molva, R. Privacy-Preserving Delegable Authentication in the Internet of Things. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing (SAC), Limassol, Cyprus, 8–12 April 2019; ACM: New York, NY, USA, 2019; pp. 861–869. [Google Scholar]
- Antoniadis, S.; Litou, I.; Kalogeraki, V. A Model for Identifying Misinformation in Online Social Networks. In Proceedings of the 2015 Confederated International Conferences on the Move to Meaningful Internet Systems: CoopIS, ODBASE, and C&TC (OTM), Rhodes, Greece, 26–30 October 2015; Springer: Cham, Switzerland, 2015; pp. 473–482. [Google Scholar]
- Litou, I.; Kalogeraki, V.; Katakis, I.; Gunopulos, D. Efficient and timely misinformation blocking under varying cost constraints. Online Soc. Netw. Media 2017, 2, 19–31. [Google Scholar] [CrossRef]
- Litou, I.; Kalogeraki, V. Influence Maximization in Evolving Multi-Campaign Environments. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 448–457. [Google Scholar]
- Lupton, D. The Quantified Self; Polity: Cambridge, UK; Malden, MA, USA, 2016. [Google Scholar]
- Jiang, B.; Li, J.; Yue, G.; Song, H. Differential Privacy for Industrial Internet of Things: Opportunities, Applications, and Challenges. IEEE Internet Things J. 2021, 8, 10430–10451. [Google Scholar] [CrossRef]
- Perr, I.N. Privilege, confidentiality, and patient privacy: Status 1980. J. Forensic Sci. 1981, 26, 109–115. [Google Scholar] [CrossRef] [PubMed]
- Read, G. The Seal of Confession. Law Justice Christ. Law Rev. 2022, 188, 28–37. [Google Scholar]
- Roba, R.M. The legal protection of the secrecy of correspondence. Curentul Jurid. Jurid. Curr. Le Courant Juridique 2009, 36, 135–154. [Google Scholar]
- Bok, S. The Limits of Confidentiality. Hastings Cent. Rep. 1983, 13, 24–31. [Google Scholar] [CrossRef]
- Hirshleifer, J. Privacy: Its Origin, Function, and Future. J. Leg. Stud. 1980, 9, 649–664. [Google Scholar] [CrossRef]
- Westin, A.F. Privacy and Freedom; Atheneum Books: New York City, NY, USA, 1967. [Google Scholar]
- Margulis, S.T. On the Status and Contribution of Westin’s and Altman’s Theories of Privacy. J. Soc. Issues 2003, 59, 411–429. [Google Scholar] [CrossRef]
- Diamantopoulou, V.; Lambrinoudakis, C.; King, J.; Gritzalis, S. EU GDPR: Toward a Regulatory Initiative for Deploying a Private Digital Era. In Modern Socio-Technical Perspectives on Privacy; Knijnenburg, B.P., Page, X., Wisniewski, P., Lipford, H.R., Proferes, N., Romano, J., Eds.; Springer: Cham, Switzerland, 2022; Chapter 18; pp. 427–448. [Google Scholar]
- European Parliament and Council of the European Union. Regulation on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (Data Protection Directive). Legislative Acts L119. Off. J. Eur. Union 2016. Available online: https://eur-lex.europa.eu/eli/reg/2016/679/oj (accessed on 6 February 2023).
- Williams, M.; Nurse, J.R.C.; Creese, S. The Perfect Storm: The Privacy Paradox and the Internet-of-Things. In Proceedings of the 2016 11th International Conference on Availability, Reliability and Security (ARES), Salzburg, Austria, 31 August–2 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 644–652. [Google Scholar]
- Jung, F.; von Holdt, K.; Krüger, R.; Meyer, J.; Heuten, W. I Do. Do I?—Understanding User Perspectives on the Privacy Paradox. In Proceedings of the 25th International Academic Mindtrek Conference (Academic Mindtrek), Tampere, Finland, 16–18 November 2022; ACM: New York, NY, USA, 2022; pp. 268–277. [Google Scholar]
- Rubinstein, I.S.; Good, N. The trouble with Article 25 (and how to fix it): The future of data protection by design and default. Int. Data Priv. Law 2020, 10, 37–56. [Google Scholar] [CrossRef]
- Georgiopoulou, Z.; Makri, E.L.; Lambrinoudakis, C. GDPR compliance: Proposed technical and organizational measures for cloud provider. Inf. Comput. Secur. 2020, 28, 665–680. [Google Scholar] [CrossRef]
- Gyrard, A.; Zimmermann, A.; Sheth, A. Building IoT-Based Applications for Smart Cities: How Can Ontology Catalogs Help? IEEE Internet Things J. 2018, 5, 3978–3990. [Google Scholar] [CrossRef]
- Chen, G.; Jiang, T.; Wang, M.; Tang, X.; Ji, W. Modeling and reasoning of IoT architecture in semantic ontology dimension. Comput. Commun. 2020, 153, 580–594. [Google Scholar] [CrossRef]
- Gheisari, M.; Najafabadi, H.E.; Alzubi, J.A.; Gao, J.; Wang, G.; Abbasi, A.A.; Castiglione, A. OBPP: An ontology-based framework for privacy-preserving in IoT-based smart city. Future Gener. Comput. Syst. 2021, 123, 1–13. [Google Scholar] [CrossRef]
- Leveson, N.G. Engineering a Safer World: Systems Thinking Applied to Safety; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Shapiro, S.S. Privacy Risk Analysis Based on System Control Structures: Adapting System-Theoretic Process Analysis for Privacy Engineering. In Proceedings of the 2016 IEEE Security and Privacy Workshops (SPW), San Jose, CA, USA, 22–26 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 17–24. [Google Scholar]
- Renganathan, V.; Yurtsever, E.; Ahmed, Q.; Yener, A. Valet attack on privacy: A cybersecurity threat in automotive Bluetooth infotainment systems. Cybersecurity 2022, 5, 30. [Google Scholar] [CrossRef]
- Angerschmid, A.; Zhou, J.; Theuermann, K.; Chen, F.; Holzinger, A. Fairness and Explanation in AI-Informed Decision Making. Mach. Learn. Knowl. Extr. 2022, 4, 556–579. [Google Scholar] [CrossRef]
- Hagras, H. Toward Human-Understandable, Explainable AI. Computer 2018, 51, 28–36. [Google Scholar] [CrossRef]
- Holzinger, A.; Saranti, A.; Molnar, C.; Biecek, P.; Samek, W. Explainable AI Methods—A Brief Overview. In Proceedings of the International Workshop on Extending Explainable AI Beyond Deep Models and Classifiers Held in Conjunction with ICML 2020 (xxAI), Vienna, Austria, 18 July 2020; Springer: Cham, Switzerland, 2022; pp. 13–38. [Google Scholar]
- Utz, C.; Degeling, M.; Fahl, S.; Schaub, F.; Holz, T. (Un)Informed Consent: Studying GDPR Consent Notices in the Field. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security (CCS), London, UK, 11–15 November 2019; ACM: New York, NY, USA, 2019; pp. 973–990. [Google Scholar]
- Kaaniche, N.; Laurent, M.; Belguith, S. Privacy enhancing technologies for solving the privacy-personalization paradox: Taxonomy and survey. J. Netw. Comput. Appl. 2020, 171, 102807. [Google Scholar] [CrossRef]
- Li, N.; Qardaji, W.; Su, D. On Sampling, Anonymization, and Differential Privacy or, k-Anonymization Meets Differential Privacy. In Proceedings of the 7th ACM Symposium on Information, Computer and Communications Security (ASIACCS), Seoul, Republic of Korea, 2–4 May 2012; ACM: New York, NY, USA, 2012; pp. 32–33. [Google Scholar]
- Pattuk, E.; Kantarcioglu, M.; Ulusoy, H.; Malin, B. Privacy-aware dynamic feature selection. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering (ICDE), Seoul, Republic of Korea, 13–17 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 78–88. [Google Scholar]
- Dou, H.; Chen, Y.; Yang, Y.; Long, Y. A secure and efficient privacy-preserving data aggregation algorithm. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 1495–1503. [Google Scholar] [CrossRef]
- Alpers, S.; Oberweis, A.; Pieper, M.; Betz, S.; Fritsch, A.; Schiefer, G.; Wagner, M. PRIVACY-AVARE: An approach to manage and distribute privacy settings. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1460–1468. [Google Scholar]
- Jiang, H.; Li, J.; Zhao, P.; Zeng, F.; Xiao, Z.; Iyengar, A. Location Privacy-Preserving Mechanisms in Location-Based Services: A Comprehensive Survey. ACM Comput. Surv. 2021, 54, 4. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, B.; Srivastava, M. Protecting User Data Privacy with Adversarial Perturbations: Poster Abstract. In Proceedings of the 20th International Conference on Information Processing in Sensor Networks Co-Located with CPS-IoT Week 2021 (IPSN), Nashville, TN, USA, 18–21 May 2021; ACM: New York, NY, USA, 2021; pp. 386–387. [Google Scholar]
- Hernández Acosta, L.; Reinhardt, D. A Survey on Privacy Issues and Solutions for Voice-Controlled Digital Assistants. Pervasive Mob. Comput. 2022, 80, 101523. [Google Scholar] [CrossRef]
- Palanisamy, S.M.; Dürr, F.; Tariq, M.A.; Rothermel, K. Preserving Privacy and Quality of Service in Complex Event Processing through Event Reordering. In Proceedings of the 12th ACM International Conference on Distributed and Event-Based Systems (DEBS), Hamilton, New Zealand, 25–29 June 2018; ACM: New York, NY, USA, 2018; pp. 40–51. [Google Scholar]
- Kwecka, Z.; Buchanan, W.; Schafer, B.; Rauhofer, J. “I am Spartacus”: Privacy enhancing technologies, collaborative obfuscation and privacy as a public good. Artif. Intell. Law 2014, 22, 113–139. [Google Scholar] [CrossRef]
- Slijepčević, D.; Henzl, M.; Klausner, L.D.; Dam, T.; Kieseberg, P.; Zeppelzauer, M. k-Anonymity in practice: How generalisation and suppression affect machine learning classifiers. Comput. Secur. 2021, 111, 102488. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating Noise to Sensitivity in Private Data Analysis. J. Priv. Confidentiality 2017, 7, 17–51. [Google Scholar] [CrossRef]
- Machanavajjhala, A.; He, X.; Hay, M. Differential Privacy in the Wild: A Tutorial on Current Practices & Open Challenges. In Proceedings of the 2017 ACM International Conference on Management of Data (SIGMOD); Chicago, IL, USA, 14–19 May 2017; ACM: New York, NY, USA, 2017; pp. 1727–1730. [Google Scholar]
- Dwork, C.; Kohli, N.; Mulligan, D. Differential Privacy in Practice: Expose your Epsilons! J. Privacy Confid. 2019, 9, 1–22. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Cheng, Y.; Kang, Y.; Chen, T.; Yu, H. Federated Learning; Morgan & Claypool: San Rafael, CA, USA, 2019. [Google Scholar]
- Wu, X.; Zhang, Y.; Shi, M.; Li, P.; Li, R.; Xiong, N.N. An adaptive federated learning scheme with differential privacy preserving. Future Gener. Comput. Syst. 2022, 127, 362–372. [Google Scholar] [CrossRef]
- István, Z.; Ponnapalli, S.; Chidambaram, V. Software-Defined Data Protection: Low Overhead Policy Compliance at the Storage Layer is within Reach! Proc. VLDB Endow. 2021, 14, 1167–1174. [Google Scholar] [CrossRef]
- Wang, W.C.; Ho, C.C.; Chang, Y.M.; Chang, Y.H. Challenges and Designs for Secure Deletion in Storage Systems. In Proceedings of the 2020 Indo—Taiwan 2nd International Conference on Computing, Analytics and Networks (Indo-Taiwan ICAN), Rajpura, India, 7–15 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 181–189. [Google Scholar]
- Zhang, Q.; Jia, S.; Chang, B.; Chen, B. Ensuring data confidentiality via plausibly deniable encryption and secure deletion—A survey. Cybersecurity 2018, 1, 1. [Google Scholar] [CrossRef]
- Politou, E.; Alepis, E.; Virvou, M.; Patsakis, C. Privacy in Blockchain. In Privacy and Data Protection Challenges in the Distributed Era; Springer: Cham, Switzerland, 2022; Chapter 7; pp. 133–149. [Google Scholar]
- Meng, W.; Ge, J.; Jiang, T. Secure Data Deduplication with Reliable Data Deletion in Cloud. Int. J. Found. Comput. Sci. 2019, 30, 551–570. [Google Scholar] [CrossRef]
- Waizenegger, T.; Wagner, F.; Mega, C. SDOS: Using Trusted Platform Modules for Secure Cryptographic Deletion in the Swift Object Store. In Proceedings of the 20th International Conference on Extending Database Technology (EDBT), Venice, Italy, 21–24 March 2017; OpenProceedings.org: Konstanz, Germany, 2017; pp. 550–553. [Google Scholar]
- Auge, T. Extended Provenance Management for Data Science Applications. In Proceedings of the VLDB 2020 PhD Workshop co-located with the 46th International Conference on Very Large Databases (VLDB), Tokyo, Japan, 31 August–4 September 2020; CEUR-WS.org: Aachen, Germany, 2020; pp. 1–4. [Google Scholar]
- Davidson, S.B.; Khanna, S.; Roy, S.; Stoyanovich, J.; Tannen, V.; Chen, Y. On Provenance and Privacy. In Proceedings of the 14th International Conference on Database Theory (ICDT), Uppsala, Sweden, 21–24 March 2011; ACM: New York, NY, USA, 2011; pp. 3–10. [Google Scholar]
- Auge, T.; Scharlau, N.; Heuer, A. Privacy Aspects of Provenance Queries. In Proceedings of the 8th and 9th International Provenance and Annotation Workshop (IPAW), Virtual Event, 19–22 July 2021; Springer: Cham, Switzerland, 2021; pp. 218–221. [Google Scholar]
- Stach, C.; Alpers, S.; Betz, S.; Dürr, F.; Fritsch, A.; Mindermann, K.; Palanisamy, S.M.; Schiefer, G.; Wagner, M.; Mitschang, B.; et al. The AVARE PATRON—A Holistic Privacy Approach for the Internet of Things. In Proceedings of the 15th International Joint Conference on e-Business and Telecommunications (SECRYPT), Porto, Portugal, 26–28 July 2018; SciTePress: Setúbal, Portugal, 2018; pp. 372–379. [Google Scholar]
- Stach, C. How to Deal with Third Party Apps in a Privacy System—The PMP Gatekeeper. In Proceedings of the 2015 16th IEEE International Conference on Mobile Data Management (MDM), Pittsburgh, PA, USA, 15–18 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 167–172. [Google Scholar]
- Stach, C. VAULT: A Privacy Approach towards High-Utility Time Series Data. In Proceedings of the Thirteenth International Conference on Emerging Security Information, Systems and Technologies (SECURWARE), Nice, France, 27–31 October 2019; IARIA: Wilmington, DE, USA, 2019; pp. 41–46. [Google Scholar]
- Stach, C.; Mitschang, B. Privacy Management for Mobile Platforms—A Review of Concepts and Approaches. In Proceedings of the 2013 IEEE 14th International Conference on Mobile Data Management (MDM), Milan, Italy, 3–6 June 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 305–313. [Google Scholar]
- Stach, C.; Mitschang, B. Design and Implementation of the Privacy Management Platform. In Proceedings of the 2014 IEEE 15th International Conference on Mobile Data Management (MDM), Brisbane, Australia, 14–18 July 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 69–72. [Google Scholar]
- Stach, C.; Steimle, F.; Franco da Silva, A.C. TIROL: The Extensible Interconnectivity Layer for mHealth Applications. In Proceedings of the 23rd International Conference on Information and Software Technologies (ICIST), Druskininkai, Lithuania, 12–14 October 2017; Springer: Cham, Switzerland, 2017; pp. 190–202. [Google Scholar]
- Stach, C.; Mitschang, B. The Secure Data Container: An Approach to Harmonize Data Sharing with Information Security. In Proceedings of the 2016 17th IEEE International Conference on Mobile Data Management (MDM), Porto, Portugal, 13–16 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 292–297. [Google Scholar]
- Stach, C.; Mitschang, B. Curator—A Secure Shared Object Store: Design, Implementation, and Evaluation of a Manageable, Secure, and Performant Data Exchange Mechanism for Smart Devices. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing (SAC), Pau, France, 9–13 April 2018; ACM: New York, NY, USA, 2018; pp. 533–540. [Google Scholar]
- Stach, C.; Mitschang, B. ECHOES: A Fail-Safe, Conflict Handling, and Scalable Data Management Mechanism for the Internet of Things. In Proceedings of the 23rd European Conference on Advances in Databases and Information Systems (ADBIS), Bled, Slovenia, 8–11 September 2019; Springer: Cham, Switzerland, 2019; pp. 373–389. [Google Scholar]
- Stach, C.; Gritti, C.; Mitschang, B. Bringing Privacy Control Back to Citizens: DISPEL—A Distributed Privacy Management Platform for the Internet of Things. In Proceedings of the 35th Annual ACM Symposium on Applied Computing (SAC), Brno, Czech Republic, 30 March–3 April 2020; ACM: New York, NY, USA, 2020; pp. 1272–1279. [Google Scholar]
- Stach, C.; Behringer, M.; Bräcker, J.; Gritti, C.; Mitschang, B. SMARTEN—A Sample-Based Approach towards Privacy-Friendly Data Refinement. J. Cybersecur. Priv. 2022, 2, 606–628. [Google Scholar] [CrossRef]
- Stach, C.; Bräcker, J.; Eichler, R.; Giebler, C.; Mitschang, B. Demand-Driven Data Provisioning in Data Lakes: BARENTS—A Tailorable Data Preparation Zone. In Proceedings of the 23rd International Conference on Information Integration and Web Intelligence (iiWAS), Linz, Austria, 29 November–1 December 2021; ACM: New York, NY, USA, 2021; pp. 187–198. [Google Scholar]
- Weber, C.; Hirmer, P.; Reimann, P.; Schwarz, H. A New Process Model for the Comprehensive Management of Machine Learning Models. In Proceedings of the 21st International Conference on Enterprise Information Systems (ICEIS), Heraklion, Crete, Greece, 3–5 May 2019; SciTePress: Setúbal, Portugal, 2019; pp. 415–422. [Google Scholar]
- Weber, C.; Hirmer, P.; Reimann, P. A Model Management Platform for Industry 4.0 – Enabling Management of Machine Learning Models in Manufacturing Environments. In Proceedings of the 23rd International Conference on Business Information Systems (BIS), Colorado Springs, CO, USA, 8–10 June 2020; Springer: Cham, Switzerland, 2020; pp. 403–417. [Google Scholar]
- Stach, C.; Giebler, C.; Wagner, M.; Weber, C.; Mitschang, B. AMNESIA: A Technical Solution towards GDPR-compliant Machine Learning. In Proceedings of the 6th International Conference on Information Systems Security and Privacy (ICISSP), Valletta, Malta, 25–27 February 2020; SciTePress: Setúbal, Portugal, 2020; pp. 21–32. [Google Scholar]
- Weber, C.; Reimann, P. MMP—A Platform to Manage Machine Learning Models in Industry 4.0 Environments. In Proceedings of the 2020 IEEE 24th International Enterprise Distributed Object Computing Workshop (EDOCW), Eindhoven, The Netherlands, 5 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 91–94. [Google Scholar]
- Stach, C.; Gritti, C.; Przytarski, D.; Mitschang, B. Trustworthy, Secure, and Privacy-aware Food Monitoring Enabled by Blockchains and the IoT. In Proceedings of the 2020 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Austin, TX, USA, 23–27 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Stach, C.; Gritti, C.; Przytarski, D.; Mitschang, B. Assessment and Treatment of Privacy Issues in Blockchain Systems. ACM SIGAPP Appl. Comput. Rev. 2022, 22, 5–24. [Google Scholar] [CrossRef]
- Przytarski, D.; Stach, C.; Gritti, C.; Mitschang, B. Query Processing in Blockchain Systems: Current State and Future Challenges. Future Internet 2022, 14, 1. [Google Scholar] [CrossRef]
- Giebler, C.; Stach, C.; Schwarz, H.; Mitschang, B. BRAID—A Hybrid Processing Architecture for Big Data. In Proceedings of the 7th International Conference on Data Science, Technology and Applications (DATA), Lisbon, Portugal, 26–28 July 2018; SciTePress: Setúbal, Portugal, 2018; pp. 294–301. [Google Scholar]
- Stach, C.; Bräcker, J.; Eichler, R.; Giebler, C.; Gritti, C. How to Provide High-Utility Time Series Data in a Privacy-Aware Manner: A VAULT to Manage Time Series Data. Int. J. Adv. Secur. 2020, 13, 88–108. [Google Scholar]
- Mindermann, K.; Riedel, F.; Abdulkhaleq, A.; Stach, C.; Wagner, S. Exploratory Study of the Privacy Extension for System Theoretic Process Analysis (STPA-Priv) to Elicit Privacy Risks in eHealth. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference Workshops (REW), Lisbon, Portugal, 4–8 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 90–96. [Google Scholar]
- Stach, C.; Steimle, F. Recommender-Based Privacy Requirements Elicitation—EPICUREAN: An Approach to Simplify Privacy Settings in IoT Applications with Respect to the GDPR. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing (SAC), Limassol, Cyprus, 8–12 April 2019; ACM: New York, NY, USA, 2019; pp. 1500–1507. [Google Scholar]
- Stach, C.; Gritti, C.; Bräcker, J.; Behringer, M.; Mitschang, B. Protecting Sensitive Data in the Information Age: State of the Art and Future Prospects. Future Internet 2022, 14, 302. [Google Scholar] [CrossRef]
- Stach, C.; Mitschang, B. ACCESSORS—A Data-Centric Permission Model for the Internet of Things. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP), Funchal, Madeira, Portugal, 22–24 January 2018; SciTePress: Setúbal, Portugal, 2018; pp. 30–40. [Google Scholar]
- Siewiorek, D. Generation smartphone. IEEE Spectrum 2012, 49, 54–58. [Google Scholar] [CrossRef]
- Lu, H.; Frauendorfer, D.; Rabbi, M.; Mast, M.S.; Chittaranjan, G.T.; Campbell, A.T.; Gatica-Perez, D.; Choudhury, T. StressSense: Detecting Stress in Unconstrained Acoustic Environments Using Smartphones. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing (UbiComp), Pittsburgh, PA, USA, 5–8 September 2012; ACM: New York, NY, USA, 2012; pp. 351–360. [Google Scholar]
- Spathis, D.; Servia-Rodriguez, S.; Farrahi, K.; Mascolo, C.; Rentfrow, J. Passive Mobile Sensing and Psychological Traits for Large Scale Mood Prediction. In Proceedings of the 13th EAI International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), Trento, Italy, 20–23 May 2019; ACM: New York, NY, USA, 2019; pp. 272–281. [Google Scholar]
- Christ, P.F.; Schlecht, S.; Ettlinger, F.; Grün, F.; Heinle, C.; Tatavatry, S.; Ahmadi, S.A.; Diepold, K.; Menze, B.H. Diabetes60—Inferring Bread Units From Food Images Using Fully Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1526–1535. [Google Scholar]
- Madrid, R.E.; Ashur Ramallo, F.; Barraza, D.E.; Chaile, R.E. Smartphone-Based Biosensor Devices for Healthcare: Technologies, Trends, and Adoption by End-Users. Bioengineering 2022, 9, 101. [Google Scholar] [CrossRef] [PubMed]
- Knöll, M.; Neuheuser, K.; Cleff, T.; Rudolph-Cleff, A. A tool to predict perceived urban stress in open public spaces. Environ. Plan. B Urban Anal. City Sci. 2018, 45, 797–813. [Google Scholar] [CrossRef]
- Moosa, A.M.; Al-Maadeed, N.; Saleh, M.; Al-Maadeed, S.A.; Aljaam, J.M. Designing a Mobile Serious Game for Raising Awareness of Diabetic Children. IEEE Access 2020, 8, 222876–222889. [Google Scholar] [CrossRef]
- Stach, C. Secure Candy Castle—A Prototype for Privacy-Aware mHealth Apps. In Proceedings of the 2016 17th IEEE International Conference on Mobile Data Management (MDM), Porto, Portugal, 13–16 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 361–364. [Google Scholar]
- Shan, R.; Sarkar, S.; Martin, S.S. Digital health technology and mobile devices for the management of diabetes mellitus: State of the art. Diabetologia 2019, 62, 877–887. [Google Scholar] [CrossRef]
- Wangorsch, A.; Kulkarni, A.; Jamin, A.; Spiric, J.; Bräcker, J.; Brockmeyer, J.; Mahler, V.; Blanca-López, N.; Ferrer, M.; Blanca, M.; et al. Identification and Characterization of IgE-Reactive Proteins and a New Allergen (Cic a 1.01) from Chickpea (Cicer arietinum). Mol. Nutr. Food Res. 2020, 64, 2000560. [Google Scholar] [CrossRef]
- Bräcker, J.; Brockmeyer, J. Characterization and Detection of Food Allergens Using High-Resolution Mass Spectrometry: Current Status and Future Perspective. J. Agric. Food Chem. 2018, 66, 8935–8940. [Google Scholar] [CrossRef]
- Korte, R.; Bräcker, J.; Brockmeyer, J. Gastrointestinal digestion of hazelnut allergens on molecular level: Elucidation of degradation kinetics and resistant immunoactive peptides using mass spectrometry. Mol. Nutr. Food Res. 2017, 61, 1700130. [Google Scholar] [CrossRef]
- Lee, S.; Cui, B.; Bhandari, M.; Luo, N.; Im, P. VizBrick: A GUI-based Interactive Tool for Authoring Semantic Metadata for Building Datasets. In Proceedings of the 21st International Semantic Web Conference (ISWC), Hangzhou, China, 23–27 October 2022; CEUR-WS.org: Aachen, Germany, 2022; pp. 1–5. [Google Scholar]
- Molin, S. Hands-On Data Analysis with Pandas: A Python Data Science Handbook for Data Collection, Wrangling, Analysis, and Visualization, 2nd ed.; Packt Publishing: Birmingham, UK; Mumbai, India, 2021. [Google Scholar]
- McKinney, W. Apache Arrow and the “10 Things I Hate about Pandas”. Archives for Wes McKinney. 2017. Available online: https://wesmckinney.com/blog/apache-arrow-pandas-internals/ (accessed on 6 February 2023).
- Petersohn, D.; Macke, S.; Xin, D.; Ma, W.; Lee, D.; Mo, X.; Gonzalez, J.E.; Hellerstein, J.M.; Joseph, A.D.; Parameswaran, A. Towards Scalable Dataframe Systems. Proc. VLDB Endow. 2020, 13, 2033–2046. [Google Scholar] [CrossRef]
- Petersohn, D.; Tang, D.; Durrani, R.; Melik-Adamyan, A.; Gonzalez, J.E.; Joseph, A.D.; Parameswaran, A.G. Flexible Rule-Based Decomposition and Metadata Independence in Modin: A Parallel Dataframe System. Proc. VLDB Endow. 2022, 15, 739–751. [Google Scholar] [CrossRef]
- Rocklin, M. Dask: Parallel Computation with Blocked algorithms and Task Scheduling. In Proceedings of the 14th Python in Science Conference (SciPy), Austin, TX, USA, 6–12 July 2015; pp. 126–132. [Google Scholar]
- Moritz, P.; Nishihara, R.; Wang, S.; Tumanov, A.; Liaw, R.; Liang, E.; Elibol, M.; Yang, Z.; Paul, W.; Jordan, M.I.; et al. Ray: A Distributed Framework for Emerging AI Applications. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Carlsbad, CA, USA, 8–10 October 2018; USENIX Association: Berkeley, CA, USA, 2018; pp. 561–577. [Google Scholar]
- Sarkar, T. Parallelized Data Science. In Productive and Efficient Data Science with Python: With Modularizing, Memory Profiles, and Parallel/GPU Processing; Apress: Berkeley, CA, USA, 2022; Chapter 10; pp. 257–298. [Google Scholar]
- Kläbe, S.; Hagedorn, S. Applying Machine Learning Models to Scalable DataFrames with Grizzly. In Proceedings of the 19. Fachtagung für Datenbanksysteme für Business, Technologie und Web (BTW), Dresden, Germany, 19 April–21 June 2021; GI: Bonn, Germany, 2021; pp. 195–214. [Google Scholar]
- Hagedorn, S.; Kläbe, S.; Sattler, K.U. Putting Pandas in a Box. In Proceedings of the 11th Annual Conference on Innovative Data Systems Research (CIDR), Chaminade, CA, USA, 11–15 January 2021; pp. 1–6. [Google Scholar]











{kind=link}
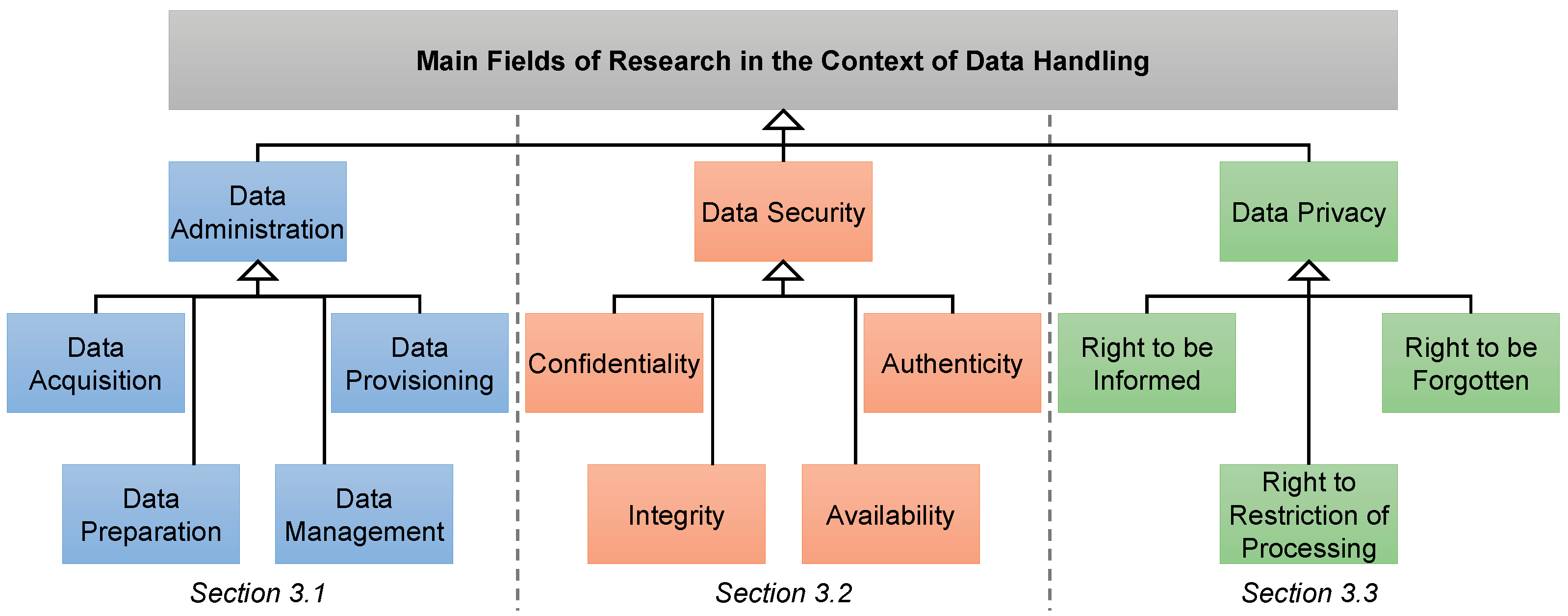{kind=link}
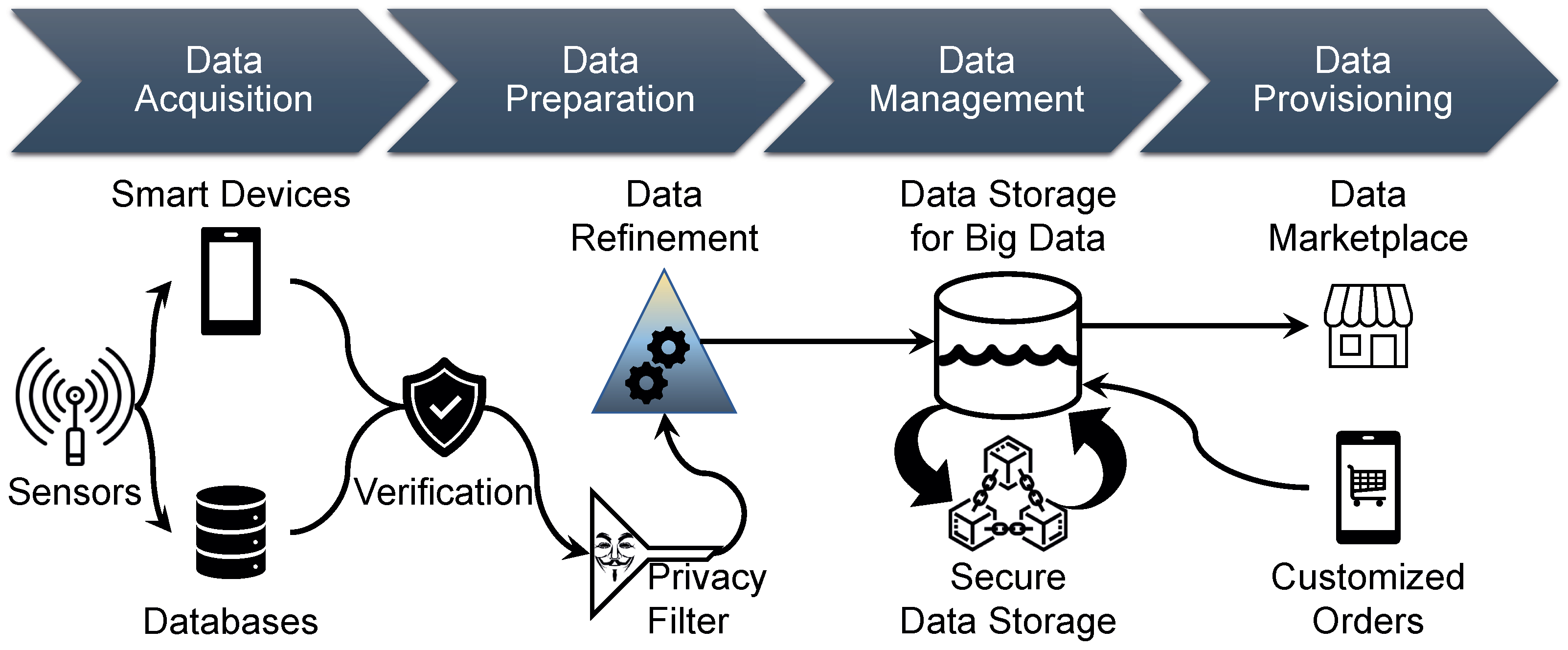{kind=link}
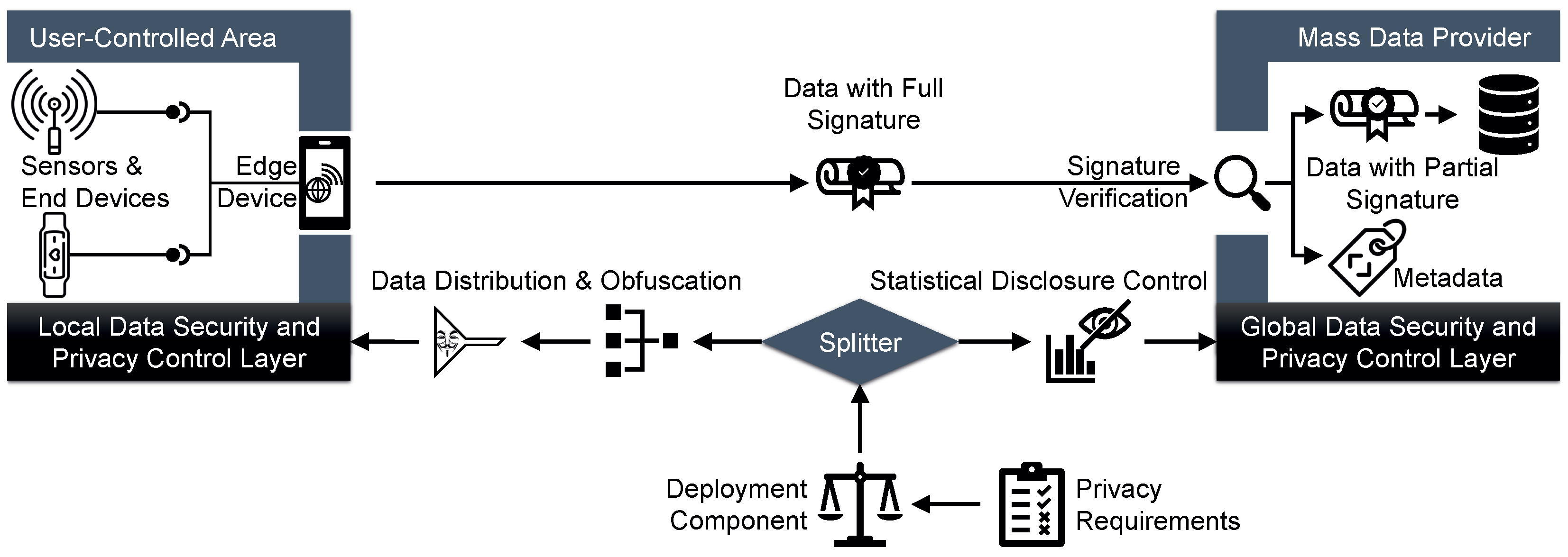{kind=link}
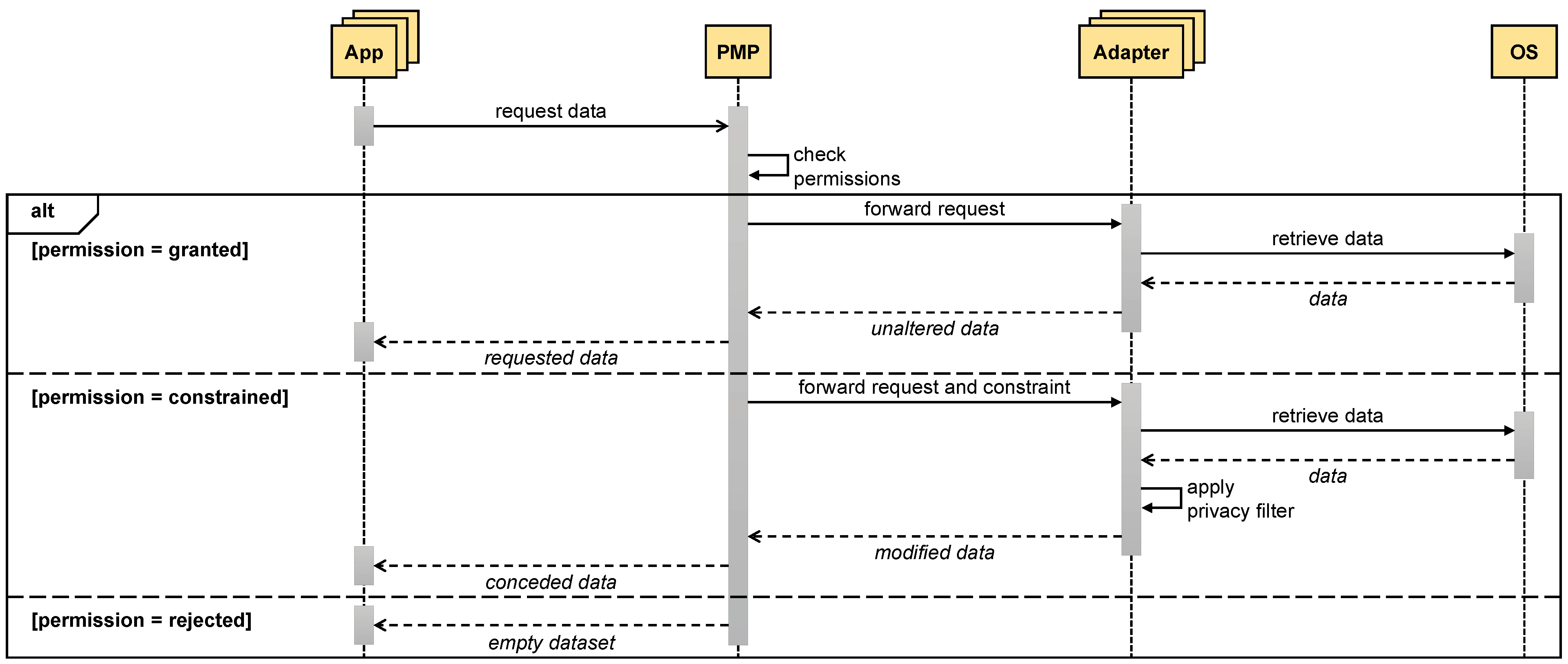{kind=link}
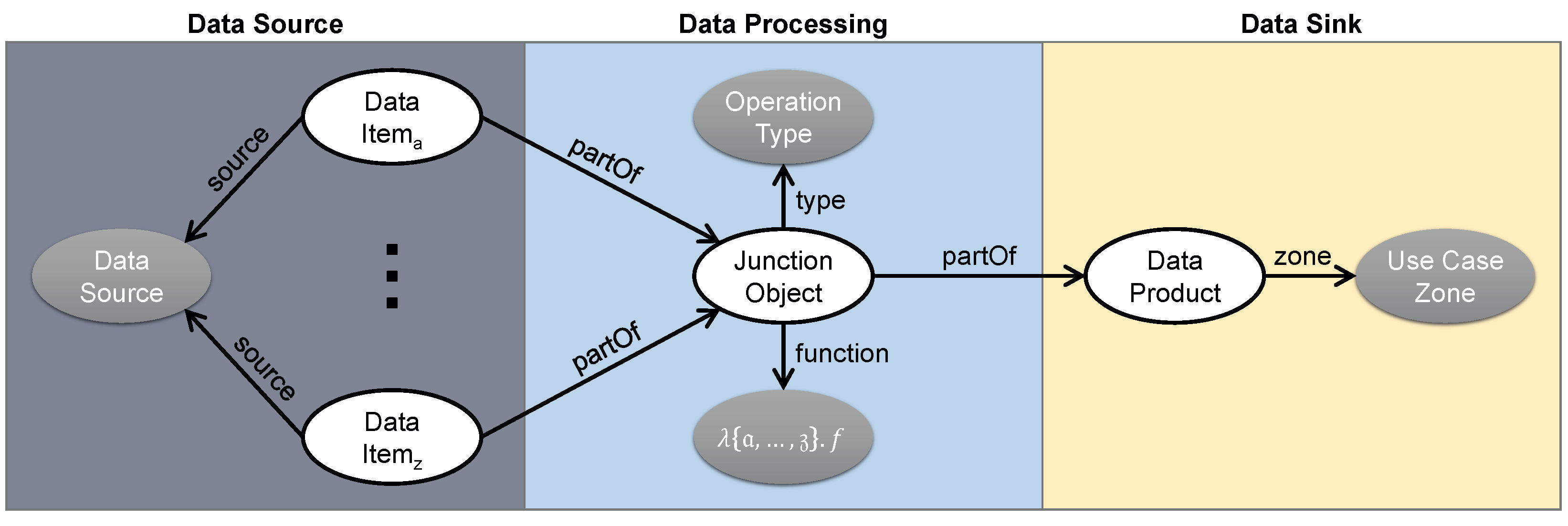{kind=link}
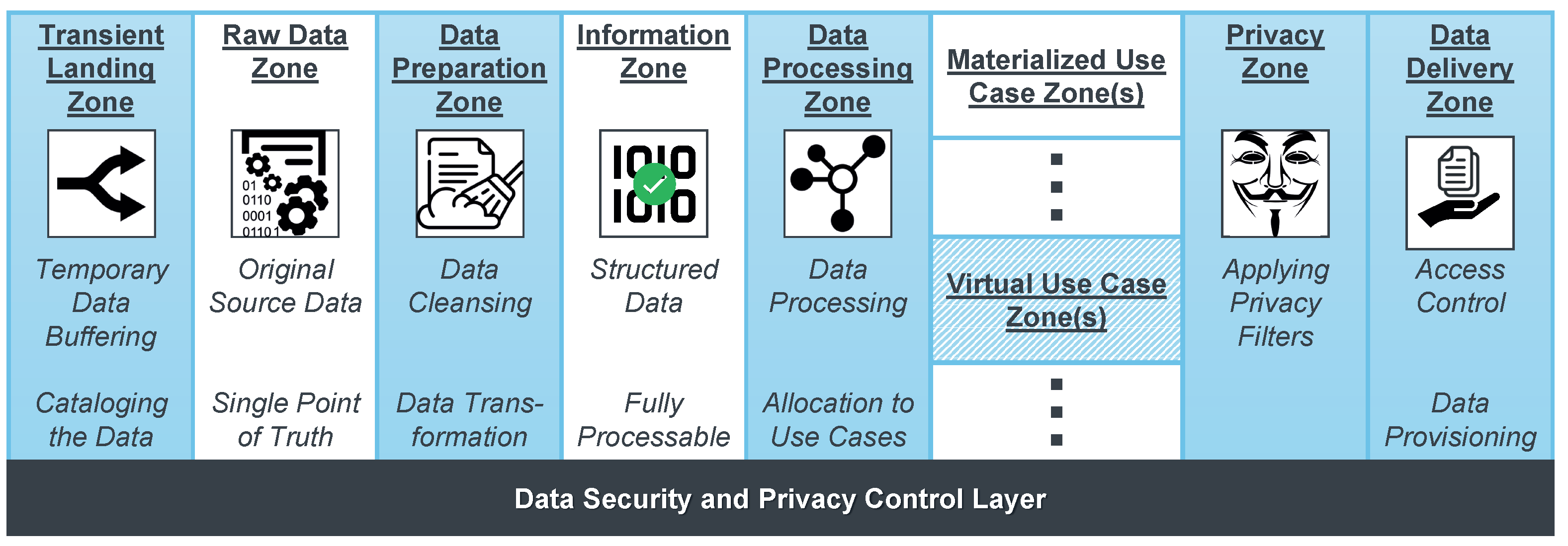{kind=link}
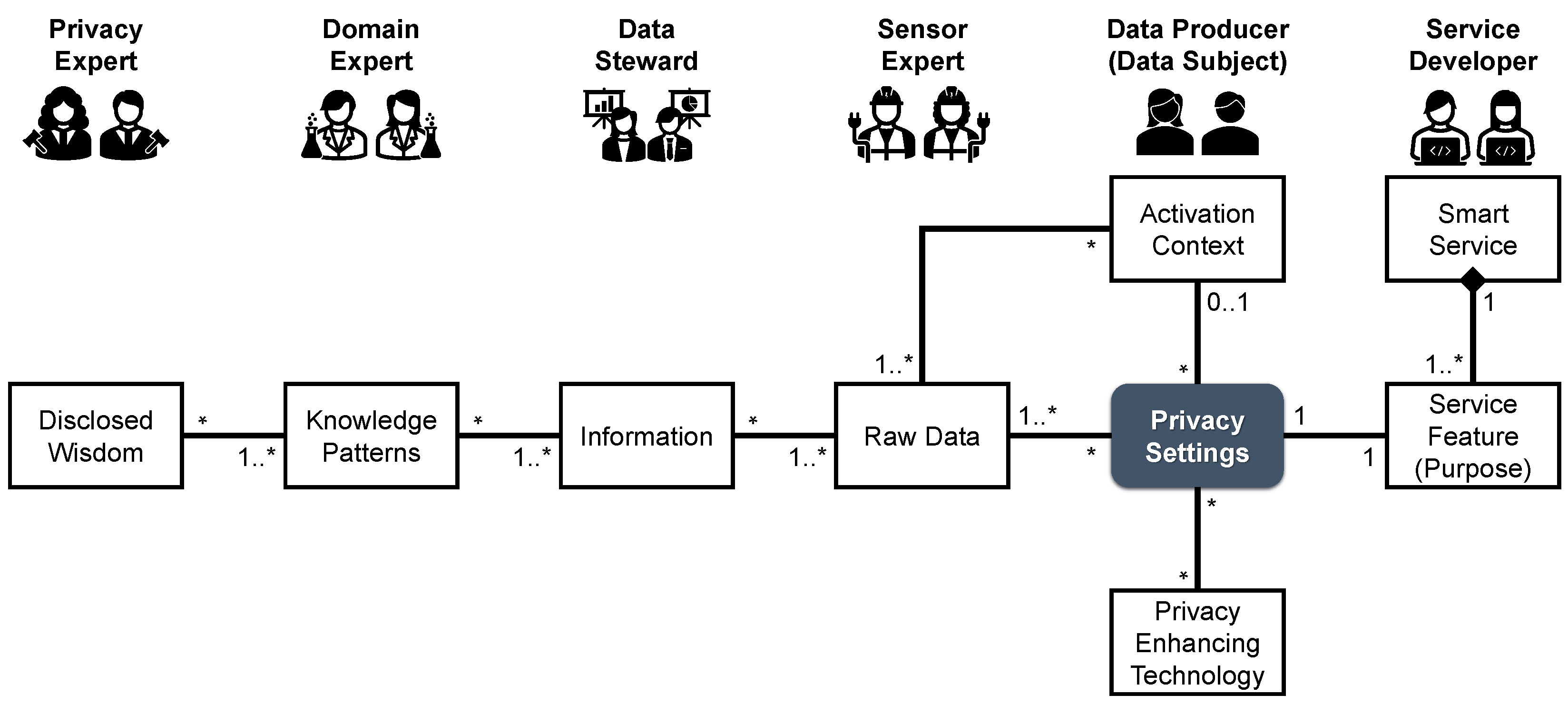{kind=link}
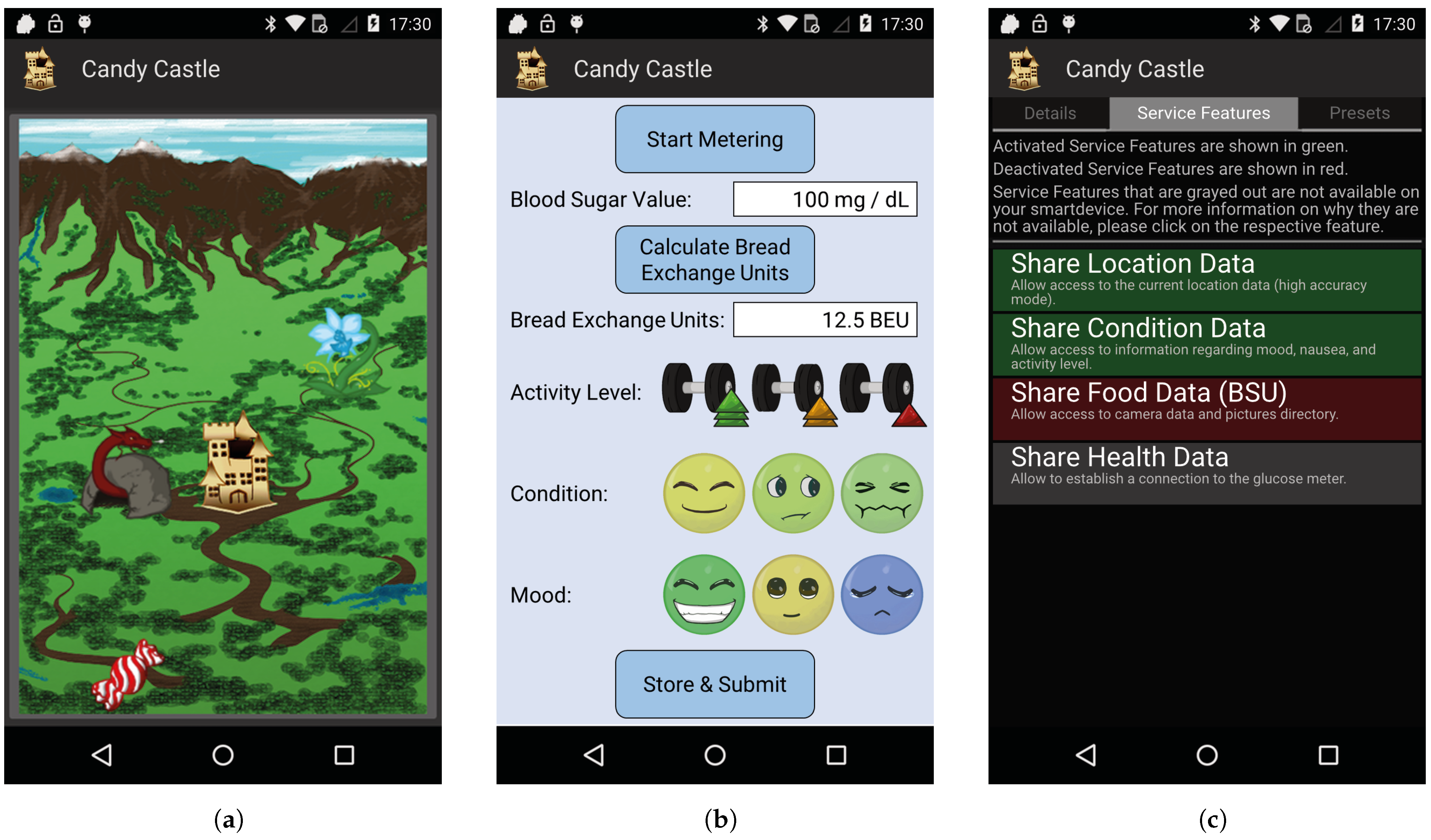{kind=link}
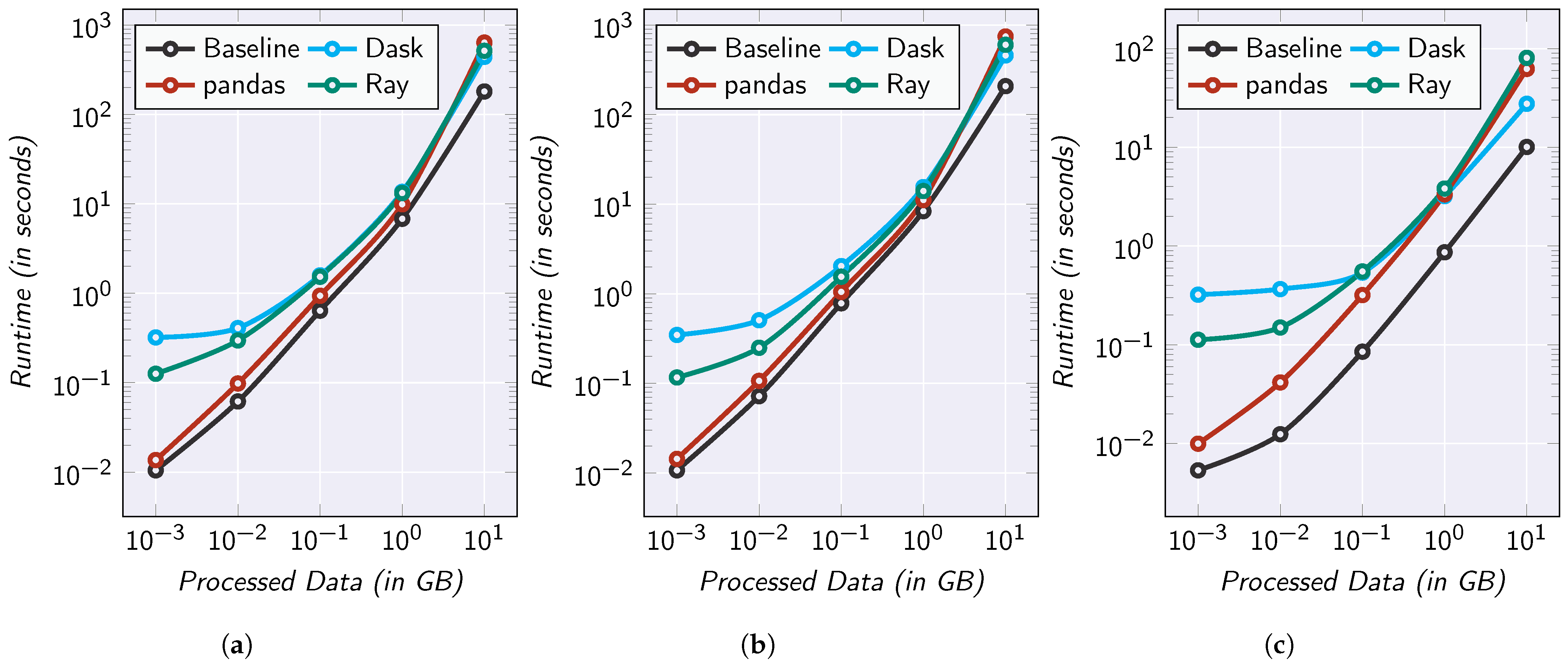{kind=link}
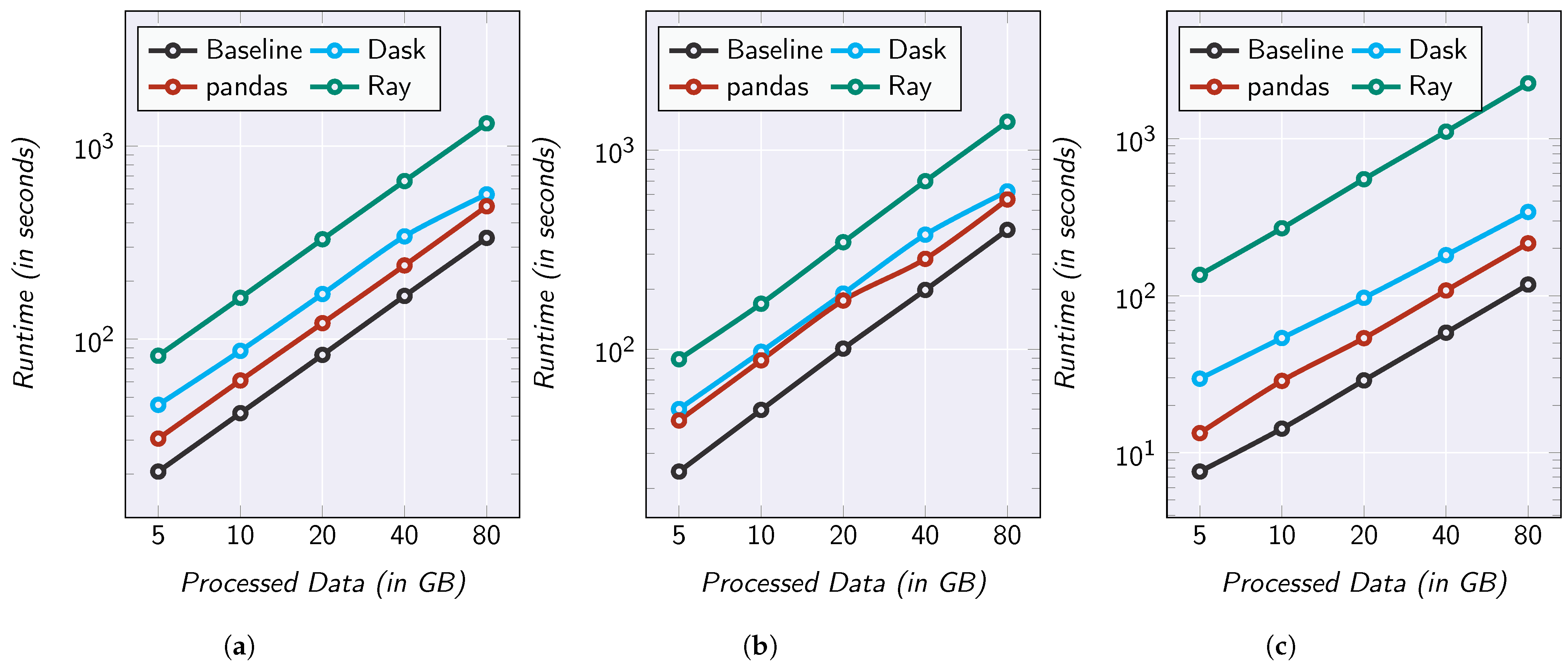{kind=link}
| Data Administration Task | Key Contributions to Data Security | Key Contributions to Data Privacy |
|---|---|---|
| Data Acquisition | On edge devices, data are fully encrypted. The data producers stipulate which data are transmitted. Digital signatures secure the transmission. | Data subjects specify privacy requirements that are applied by means of PET (e.g., privacy filters) on edge devices and in the REFINERY Platform. |
| Data Preparation | The applied sample-based data preparation ensures that no unauthorized insights into the data can be gained. | Data subjects specify a privacy threshold that is respected when selecting the data samples for the data stewards. |
| Data Management | Blockchain technologies ensure the integrity of the transmitted data via digital fingerprints. | Additional PET can be applied to a data product before it is distributed. |
| Data Provisioning | Our access control model enables to define who is allowed to access which data. Data access may be subject to additional privacy restrictions. | Since our model maps retrieved data to revealed knowledge patterns, this approach allows for truly informed consent. |
| Data Characteristic | Concept in the REFINERY Platform to Handle this Characteristic |
|---|---|
| I. Data are nonconsumable. | All incoming data are stored in the Raw Data Zone in an expandable big data storage. Data products that are not permanently demanded can be made available temporarily via a Virtual Use Case Zone and reproduced when needed. |
| II. Data can be duplicated losslessly. | Third parties such as data consumers only have access to data products, not the underlying raw data or the refined information. |
| III. Data are generated at high velocity. | Data are buffered on edge devices in our secure data store and updates are synchronized with the mass data storage automatically. |
| IV. Data are volatile. | Data products that are based on volatile data can be stored in Virtual Use Case Zones to ensure automatic sanitization of the provided products. |
| V. Data are heterogeneous. | The data storage in the Raw Data Zone is schemaless. Data preparation is based on a human-in-the-loop approach, i.e., no strict data schema is required here either. |
| VI. Data refinement has to be in accordance with the data source and intended use. | Data products are generated by means of an ontology, which can be extended if needed. Besides generic privacy filters, specialized filters tailored to specific types of data can be applied in order to preserve the data quality for the intended usage. |
| VII. The economic value of data is uncertain. | Virtually unlimited amounts of data can be stored in the Raw Data Zone at almost no cost. Therefore, their potential value does not need to be known in advance. |
| VIII. Data can be manipulated indiscernibly. | Digital signatures assure the integrity of the data in transit and the data in use while blockchain technologies enable to verify the integrity of the data at rest. |
| IX. Data may be subject to special restrictions. | The access policy model enables data subjects to define who can access which data and for what purpose. Access can be further constrained, e.g., via privacy filters. |
| X. Data require new trading concepts and infrastructures. | The information available in the Delivery Zone (e.g., metadata on raw data, specification of data products, and access policy) provide the foundation for a data marketplace. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stach, C. Data Is the New Oil–Sort of: A View on Why This Comparison Is Misleading and Its Implications for Modern Data Administration. Future Internet 2023, 15, 71. https://doi.org/10.3390/fi15020071
Stach C. Data Is the New Oil–Sort of: A View on Why This Comparison Is Misleading and Its Implications for Modern Data Administration. Future Internet. 2023; 15(2):71. https://doi.org/10.3390/fi15020071
Chicago/Turabian StyleStach, Christoph. 2023. "Data Is the New Oil–Sort of: A View on Why This Comparison Is Misleading and Its Implications for Modern Data Administration" Future Internet 15, no. 2: 71. https://doi.org/10.3390/fi15020071
APA StyleStach, C. (2023). Data Is the New Oil–Sort of: A View on Why This Comparison Is Misleading and Its Implications for Modern Data Administration. Future Internet, 15(2), 71. https://doi.org/10.3390/fi15020071