
Im2Graph: A Weakly Supervised Approach for Generating Holistic Scene Graphs from Regional Dependencies



Abstract
:1. Introduction
1.1. Objective
- 1.
- Proposing an explainable rule-based graph generation algorithm from image captions using dependency parsing;
- 2.
- Proposing an efficient graph merging technique based on the approximate maximum common subgraph based on visual features without using any graph-based supervision;
- 3.
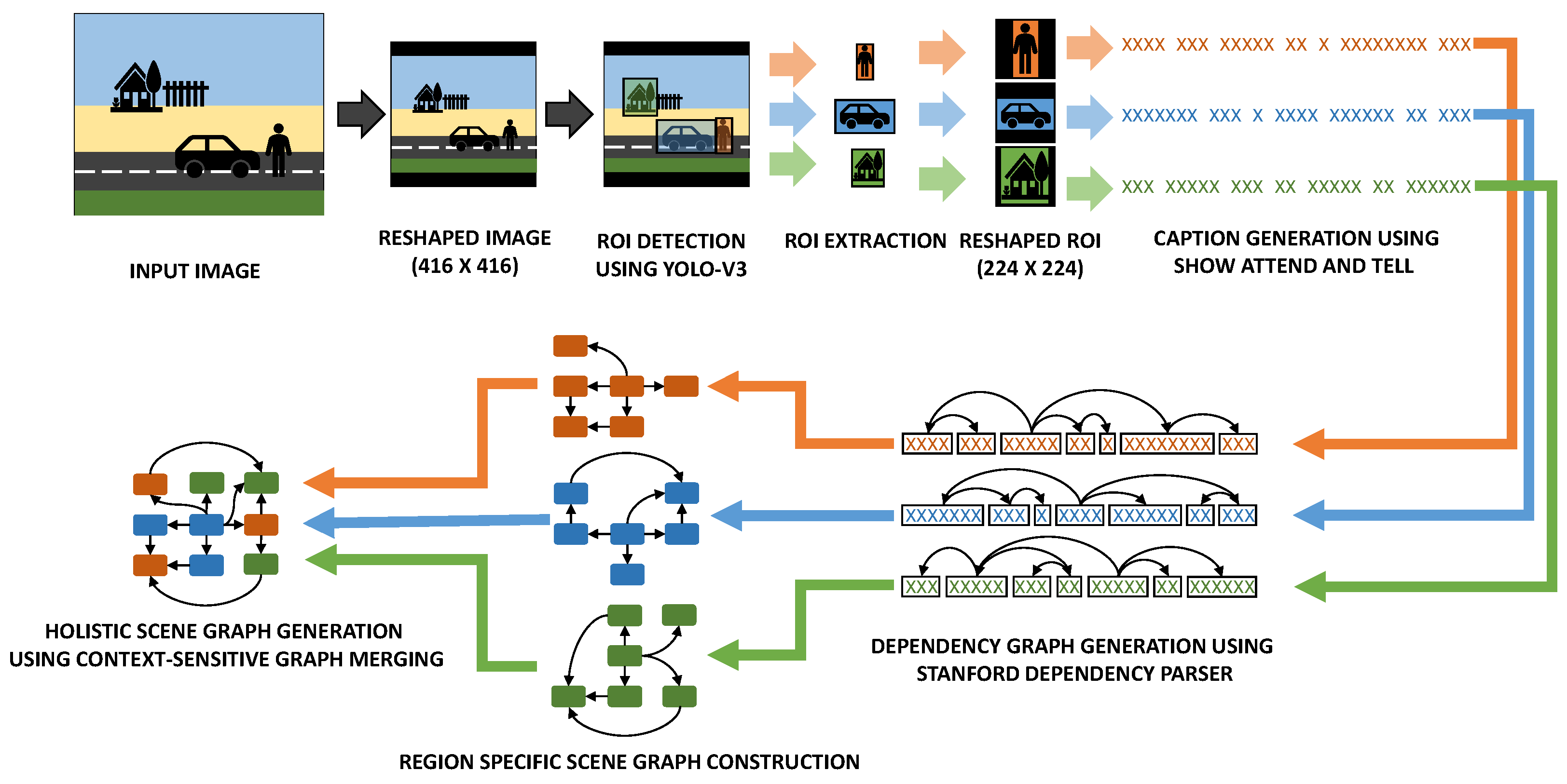
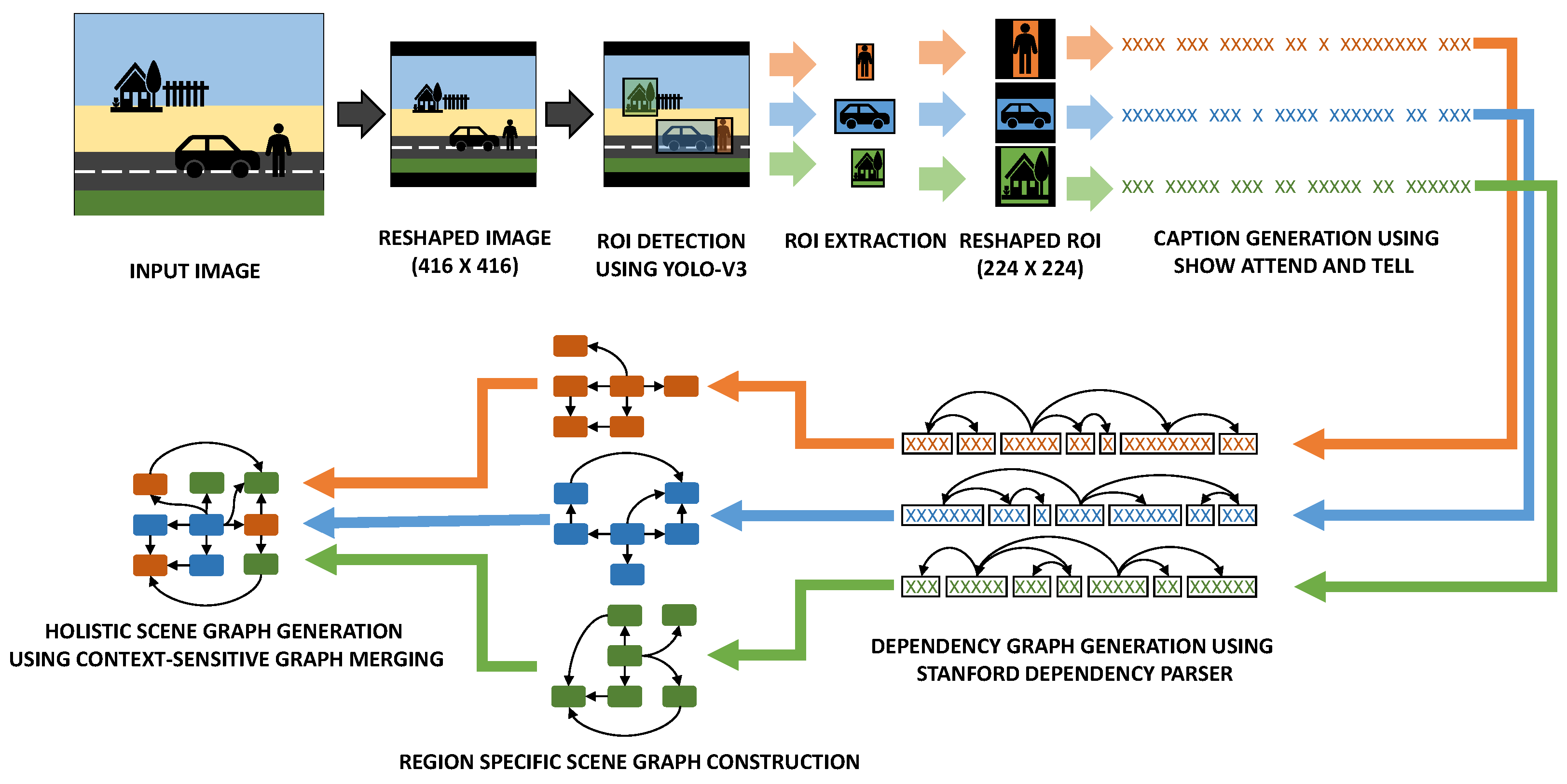
- An end-to-end framework that uses a third-party detection and caption generation framework to create holistic scene graphs by combining graphs generated from captions corresponding to various regions of interest extracted from images.
1.2. Motivation
2. Literature Survey
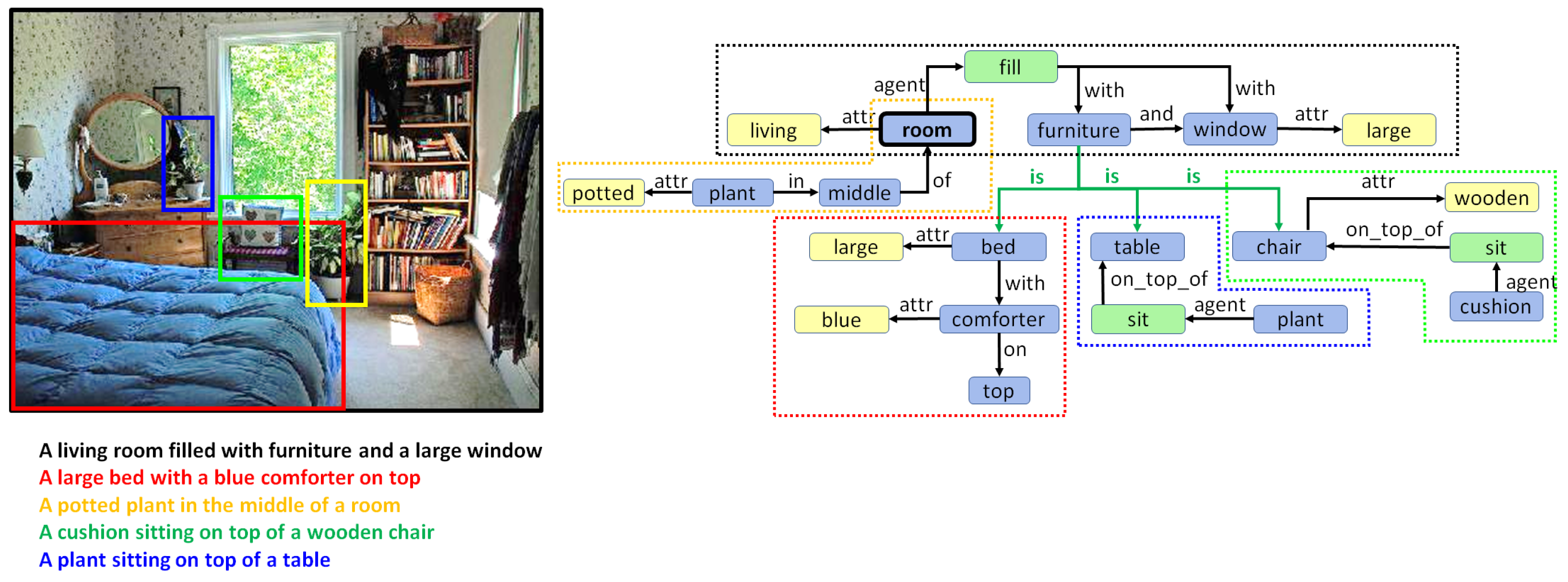
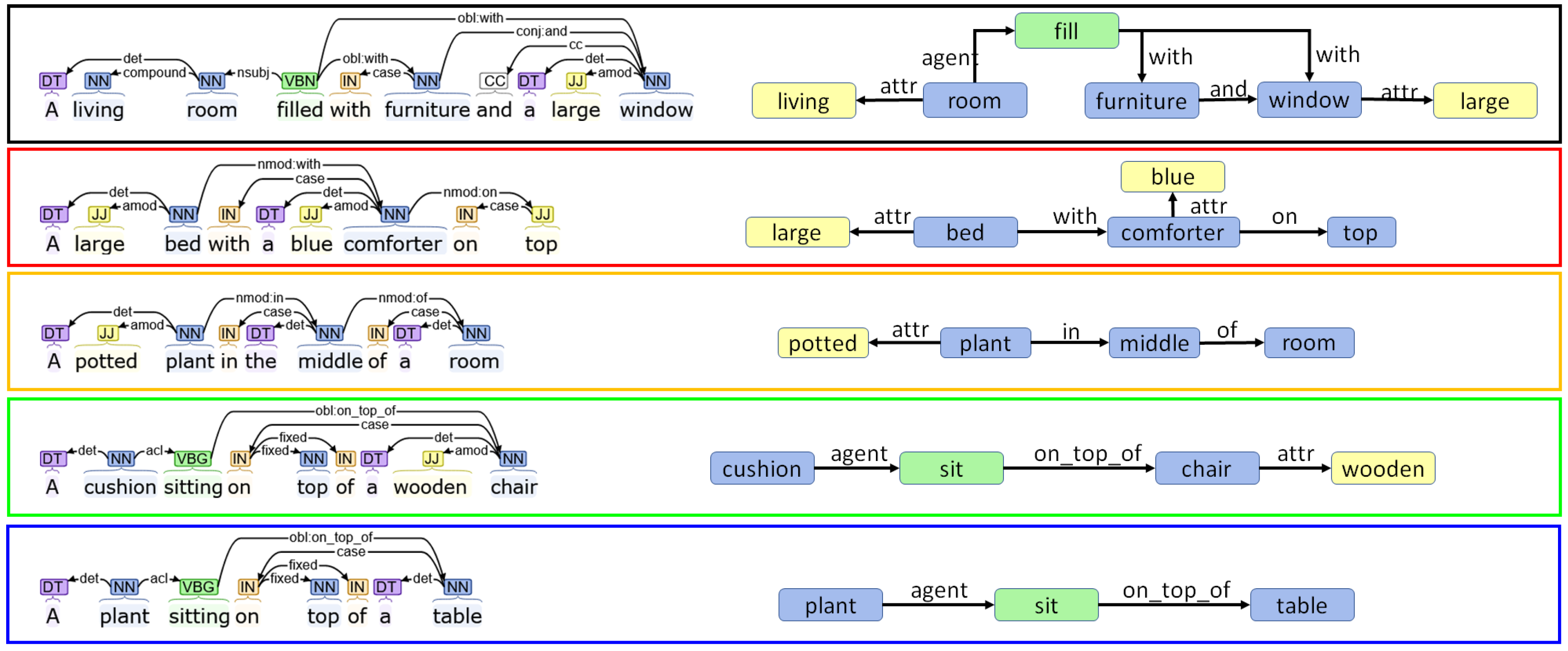
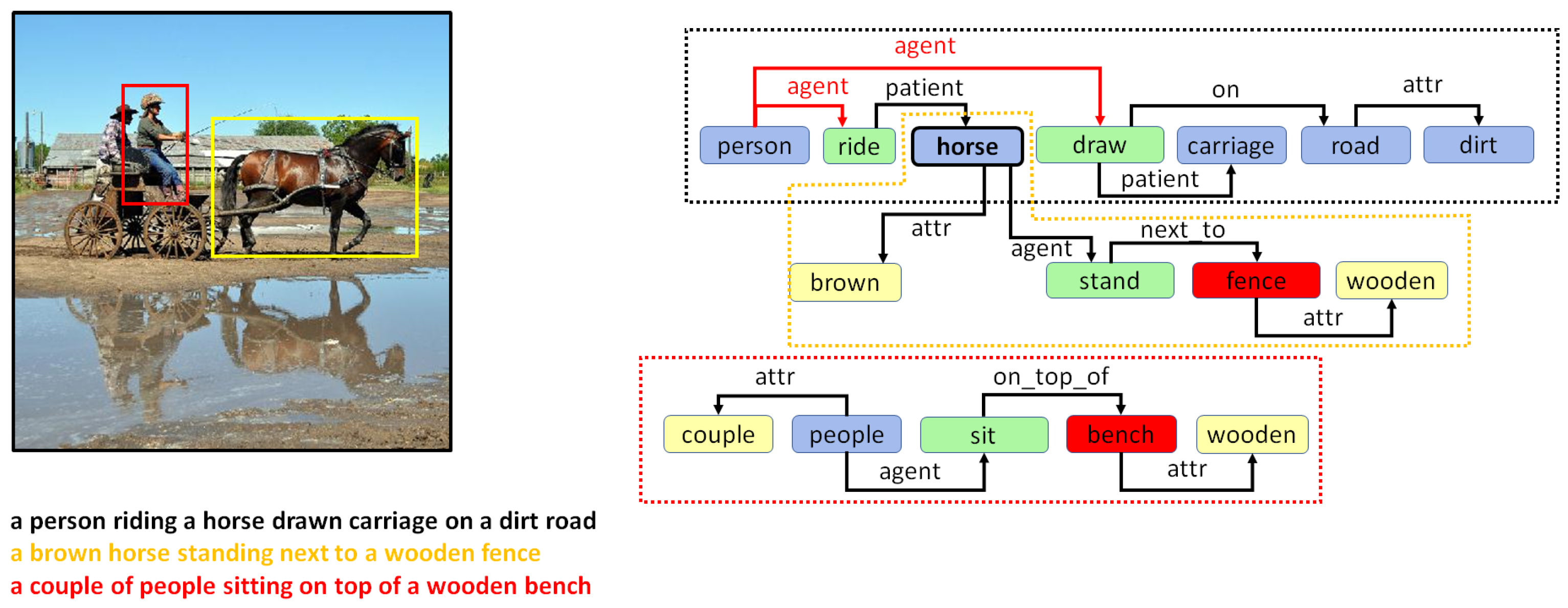
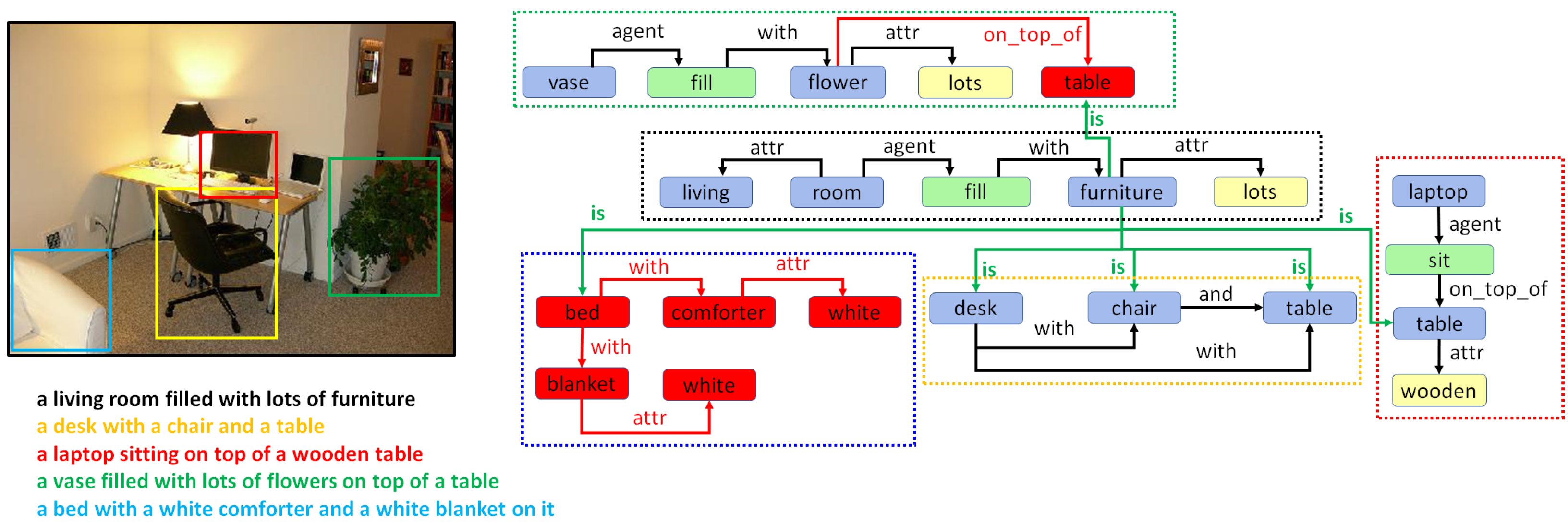
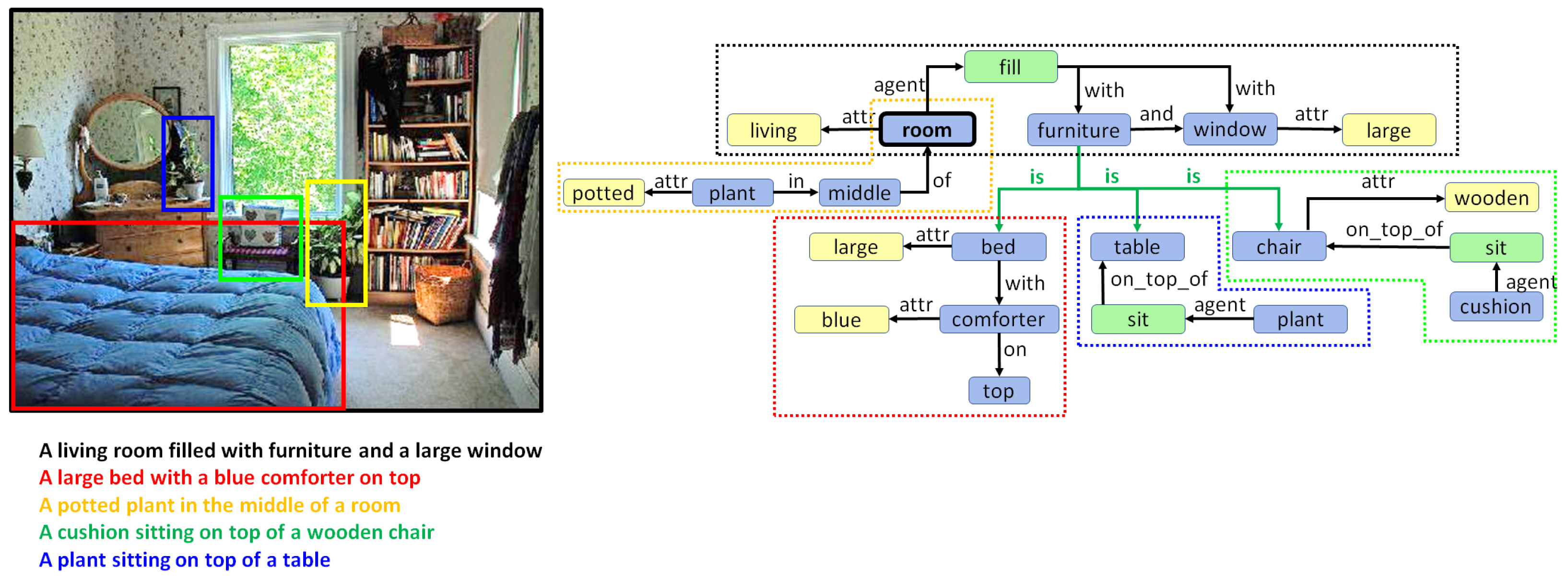
3. Holistic Scene Graphs
3.1. Nodes
- Entity node: Entities refer to subjects of interests in the scene. An entity in the scene can be any tangible living or non-living matter that contributes to the overall concept of the scene. For example, entities in a street scene can be “building”, “car”, “person”, “traffic light”, “sidewalk”, “road”, and so on.
- Action node: Actions refer to the activities related to the entities. An action can either be performed by an entity or it can be performed on an entity. Depending on that, the entity would be the agent or patient of the scene. Some common actions of a street scene would be “walking”, “parked”, “driving”, or “standing”.
- Attribute node: The third type of node is the attribute node, which acts as a modifier for the entities or actions. Attributes can refer to any qualitative or quantitative measure for entities or actions that further adds conceptual value to the scene. Examples of attributes in a street scene can be “red”, “tall”, “leafy”, “dry”, “slowly”, “two”, and so on.
3.2. Edges
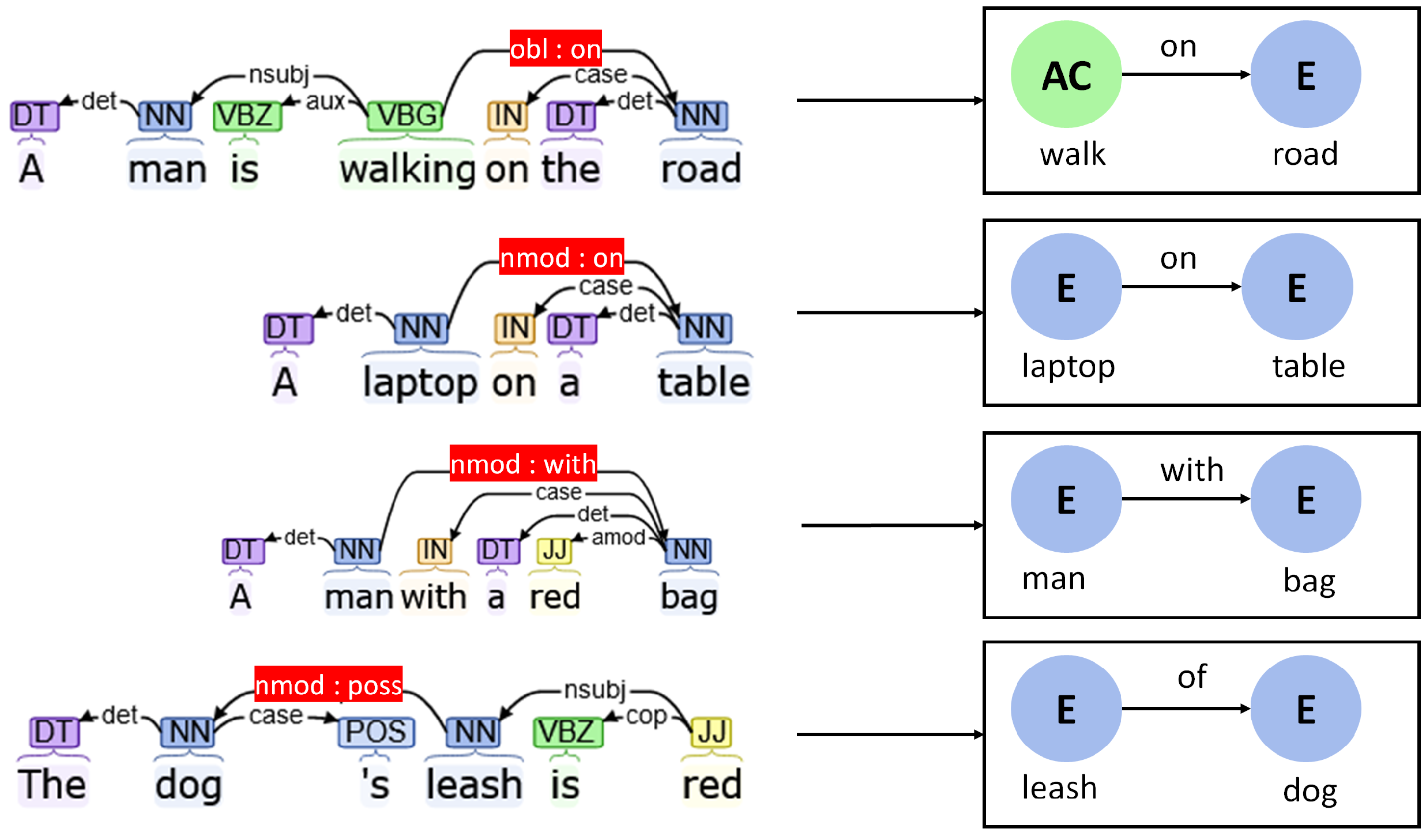
- Entity–entity: Relations among entities can be broadly categories into two types. Firstly, spatial relations signify the position and orientation of one entity with respect to another entity. These can be directly extracted from the scene itself. Some examples of such relations are “car on road” or “dog beside person”. Secondly, meronymic relations highlight part–whole connections between various objects. Examples of such relations can be “bike with wheels” or “trees have leaves”.
- Entity–attribute: Relations such as these serve as entity descriptors and mostly correspond to the qualitative or quantitative attributes of the entities such as “red car” or “tall building”.
- Action–attribute: Attributes can not only describe entities, but also various actions. Examples of such attributes are “rashly driving” or “jumping high”.
- Entity–action: One of the most-important factors when it comes to scene description is to associate various entities with related actions. This kind of relation is one of the hardest to predict because of various complications and dimensional constraints. Entity–action relations can also be of various types:
- –
- Agent–action relation: This kind of relation connects the action with the entity that is performing the action. For the sentence “The boy is playing”, “boy” is the subject or agent who is performing the action of “playing”. In most general cases, actions are always associated with some implicitly or explicitly defined subject.
- –
- Action–patient relations: It is often seen that various objects are directly affected as a result of an action. This object or patient of an action can be represented using this kind of relation. However, the presence of a patient of an action may not always occur in a scene. A simple example for this can be the sentence: “He is driving a car”. In this sentence, the person referred to by the pronoun “He” is the agent causing the action “driving”. However, “car” is the object that is being affected by the said action. Hence, “car” is the patient of the the action “driving”.
- –
- Spatial relations: Not all entities will directly be associated with an action, but can still be present in the context. An action can be carried out in a specific location that also reveals important information about the scene. For example, “driving on a highway” and “driving on a street” correspond to slightly different visual stimuli, which can be significantly important for a specific task. In each of these cases, entities such as “highway” and “street” are not directly involved in the action of driving, but their spatial context is informative nonetheless.
4. Graph Conversion from Dependency Tree
4.1. Graph Construction
4.1.1. Creating Nodes
- Entities: Entities refer to the objects that physically occupy space in a scene, e.g., “car”, “person”, “dog”.
- Actions: Actions refer to the various events or activities connected to the entities, e.g., “drive”, “stand”, “play”;
- Attributes: Attributes generally refer to the various properties that further define the entities or actions. Attribute nodes are generally connected to either entity or action nodes via an “attr” edge, e.g., “red”, “tall”, “two”.
- Primary nodes: These nodes are created by only observing the POS tags of the words. The node is defined typically by the actual token and lemma.
- Secondary nodes: These nodes are created by observing a combination of POS tags along with other factors such as the lemma or the named entity recognition tags. In these cases, the lemma of the created node is assigned a generic keyword.
- Tertiary nodes: These nodes are created when edges are created by reading the dependency relations. It may happen that an incoming dependency is coming from a word for which no primary or secondary node exists.
Creation of Primary Nodes
- Entity ← NN, NNS;
- Action ← VB, VBD, VBG, VBN, VBP, VBZ;
- Attribute ← JJ, JJR, JJS, RB, RBR, RBS.
Creating Secondary Nodes
- Pronouns: Since pronouns are representative of nouns, they can be used to create different types of entities as mentioned below. The distinction in this case is made on the basis of the lemma of the word: it can be used to detect whether the entity is a person or an object. It can also detect the singular or plural nature of the entity. Additionally, it can also reflect the gender, which is added as an attribute node named “masculine” or “feminine”. The type of entity or attribute generated by the lemma of each pronoun is:
- –
- Object: it, its, itself;
- –
- Person: I, you, my;
- –
- Masculine person: he, him, his, himself;
- –
- Feminine person: she, her, herself;
- –
- People: we, they, them, ’em, themselves.
- Determiners: Some determiners can signify the presence of an object, e.g., “this”, “that”, “these”, “those”.
- Proper nouns (NNP, NNPS): Proper nouns are also added as entities similar to common nouns. However, the lemma is updated according to the named entity recognition tag of the word, e.g., “location”, “person”, “organization”, and so on.
- Auxiliary verbs: Though auxiliary verbs are tagged as VB, they are not added as action tags.
- In some rare cases, action nodes can exist without a proper subject or entity. In that case, a dummy entity is created and connected using an “agent” relation.
Creation of Tertiary Nodes
- Action nodes: VB, VBD, VBG, VBN, VBP, VBZ, TO, CC.
- Attribute nodes:
- IN (prepositions).
- CD (lemma = “number”).
- Entity nodes:
- EX, RP (lemma = “location”).
4.1.2. Creating Edges
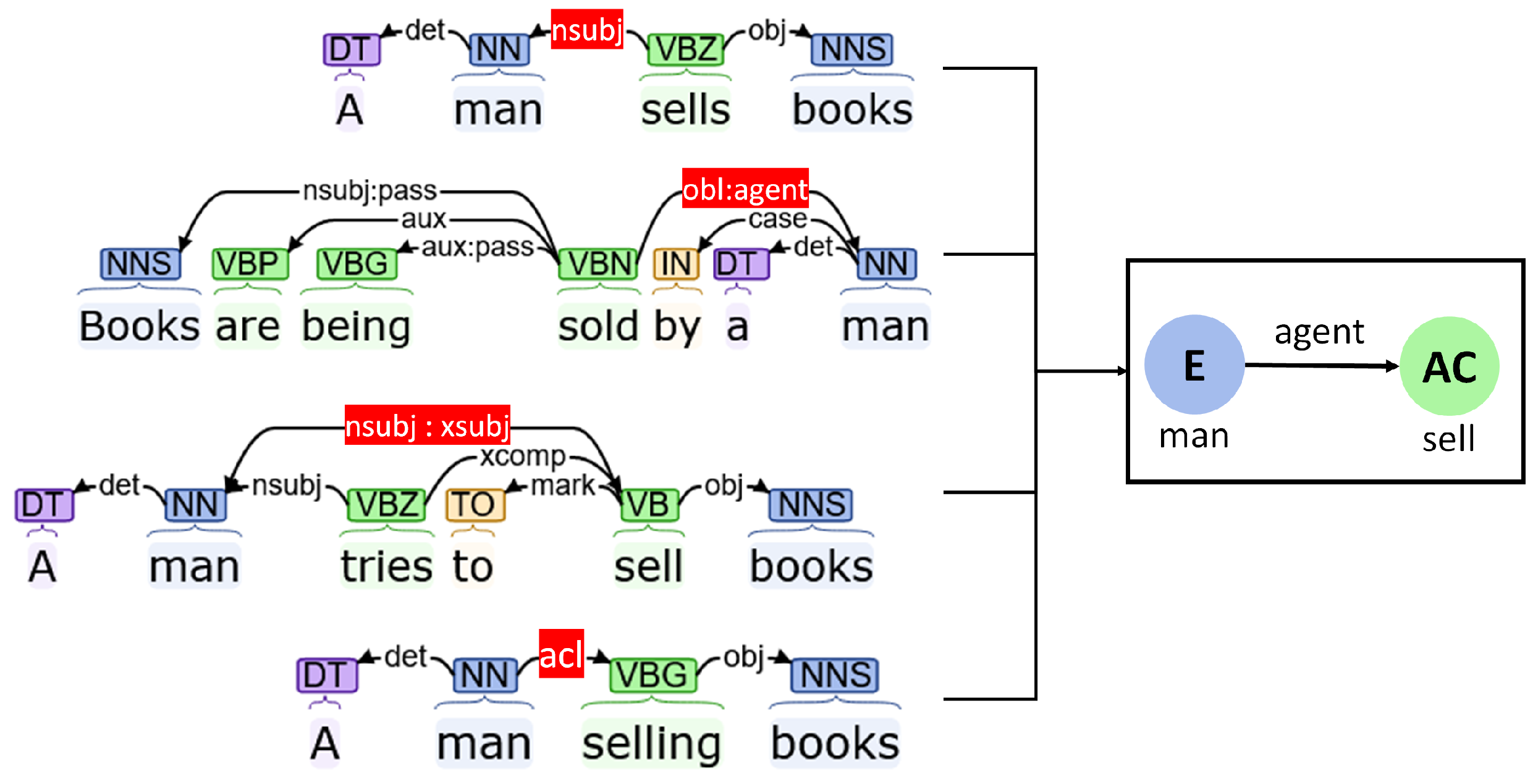
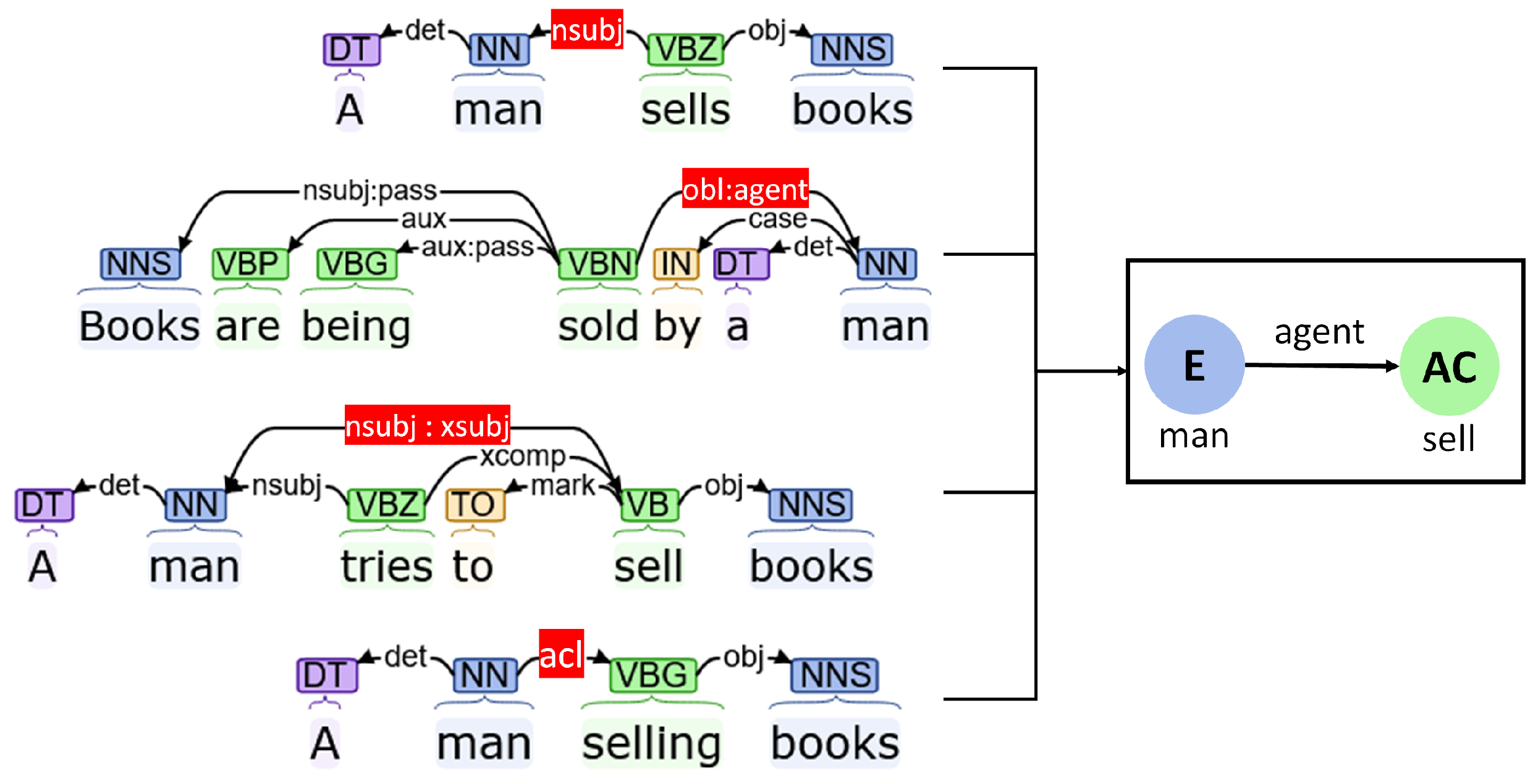
Agents
- Nominal subjects (“nsubj”): Nominal subjects primarily refer to the action causing proto-agents of a phrase. These dependencies can define which entities are responsible for which actions.
- Oblique agents (“obl:agent”): This type of relation highlights nominal subjects of passive verbs. The effect is similar to the “nsubj” node.
- Subjects of embedded actions (“nsubj:xsubj”): It is often seen that the scope of one verb is embedded and controlled by another verb. While the first verb exists as an open clausal complement (that is, without a direct subject), the controlling verb is associated with the subject. The “nsubj:xsubj” dependency connects those kinds of subjects with embedded actions.
- Adnominal clause (“acl”): This type of dependency connects verbs with nominals that modify the properties or state of the nominal. “acl” dependencies can thus be used to assign such actions to corresponding entities.
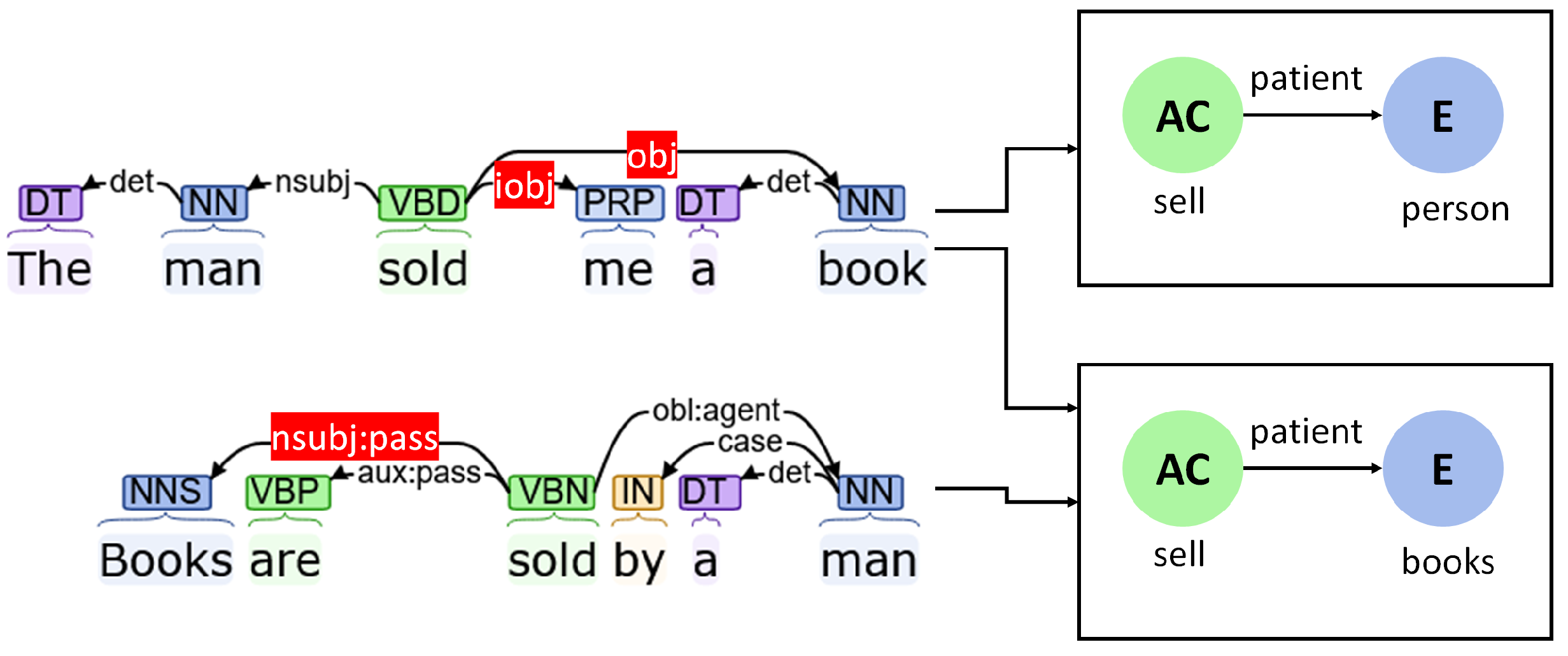
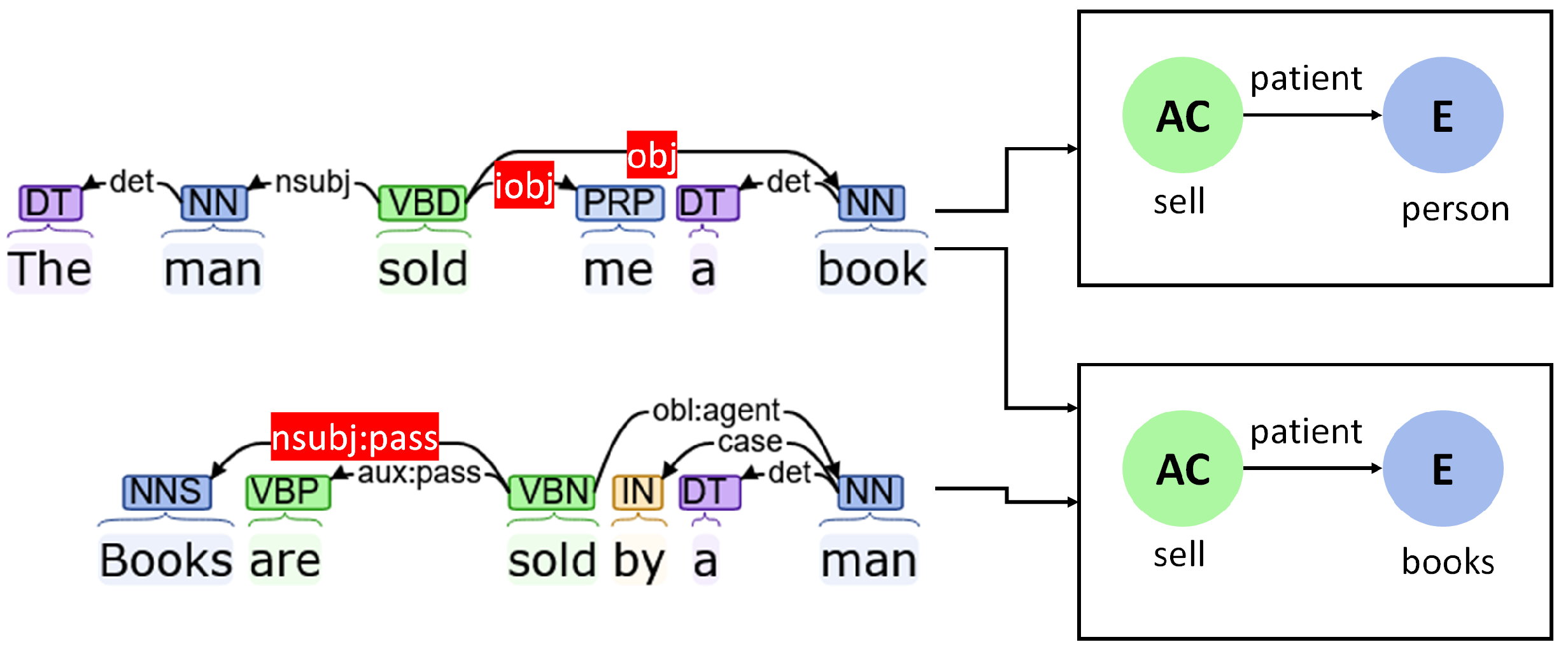
Patients
- (Direct) Objects (“obj”): Direct objects refer to entities who are the direct objects upon which the actions are performed. The edges in the graph corresponding to such dependencies are tagged as “patient”.
- Indirect objects (“iobj”): Indirect objects are secondary objects that also are affected by the action along with the direct object. The corresponding edges also mark the entity as the “patient” of the action.
- Passive object (“nsubj:pass”): When a verb is used in the passive tense, the subject in the sentence is actually the object upon which the action is performed. The effect is similar to previous situations.
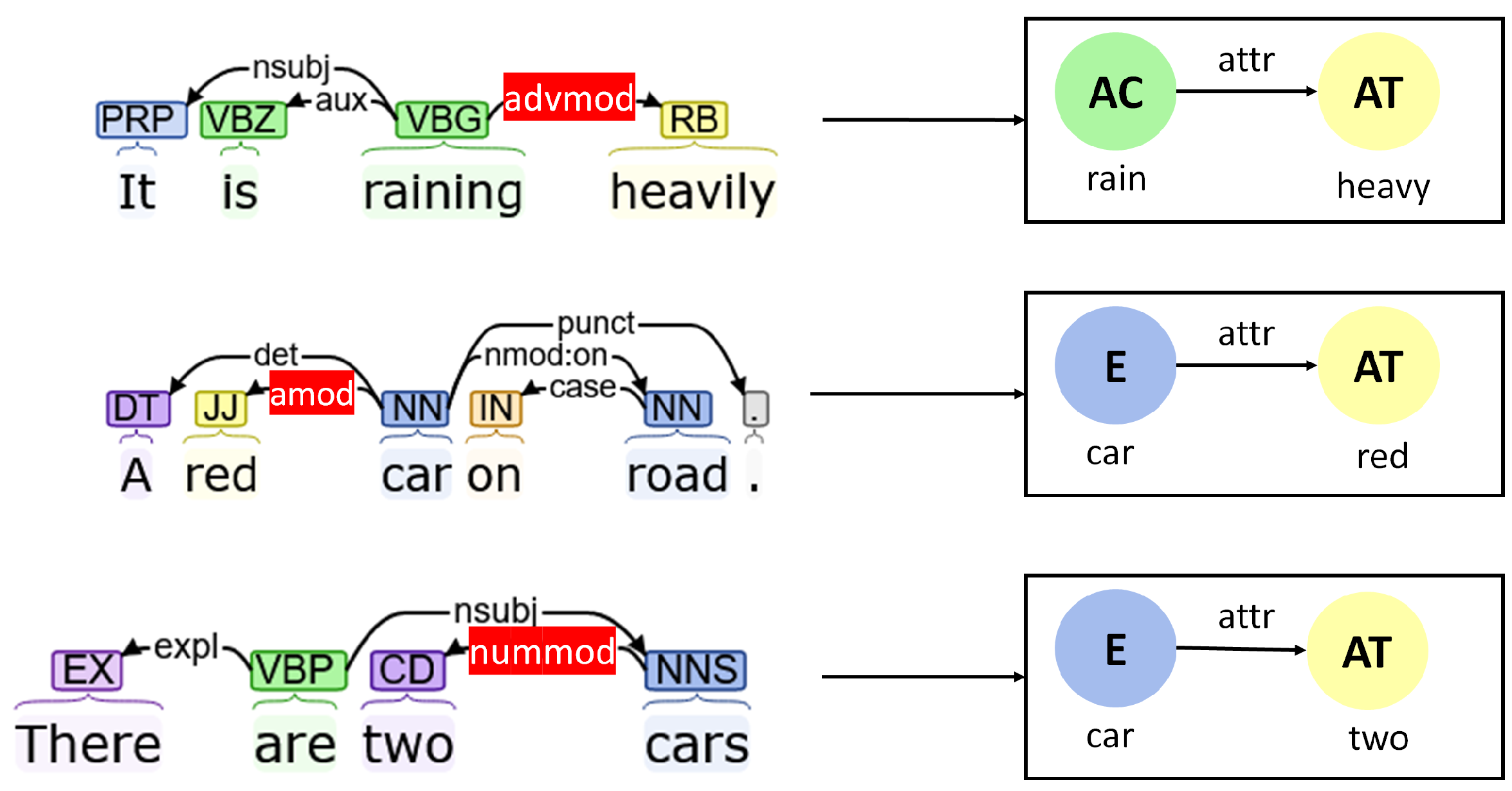
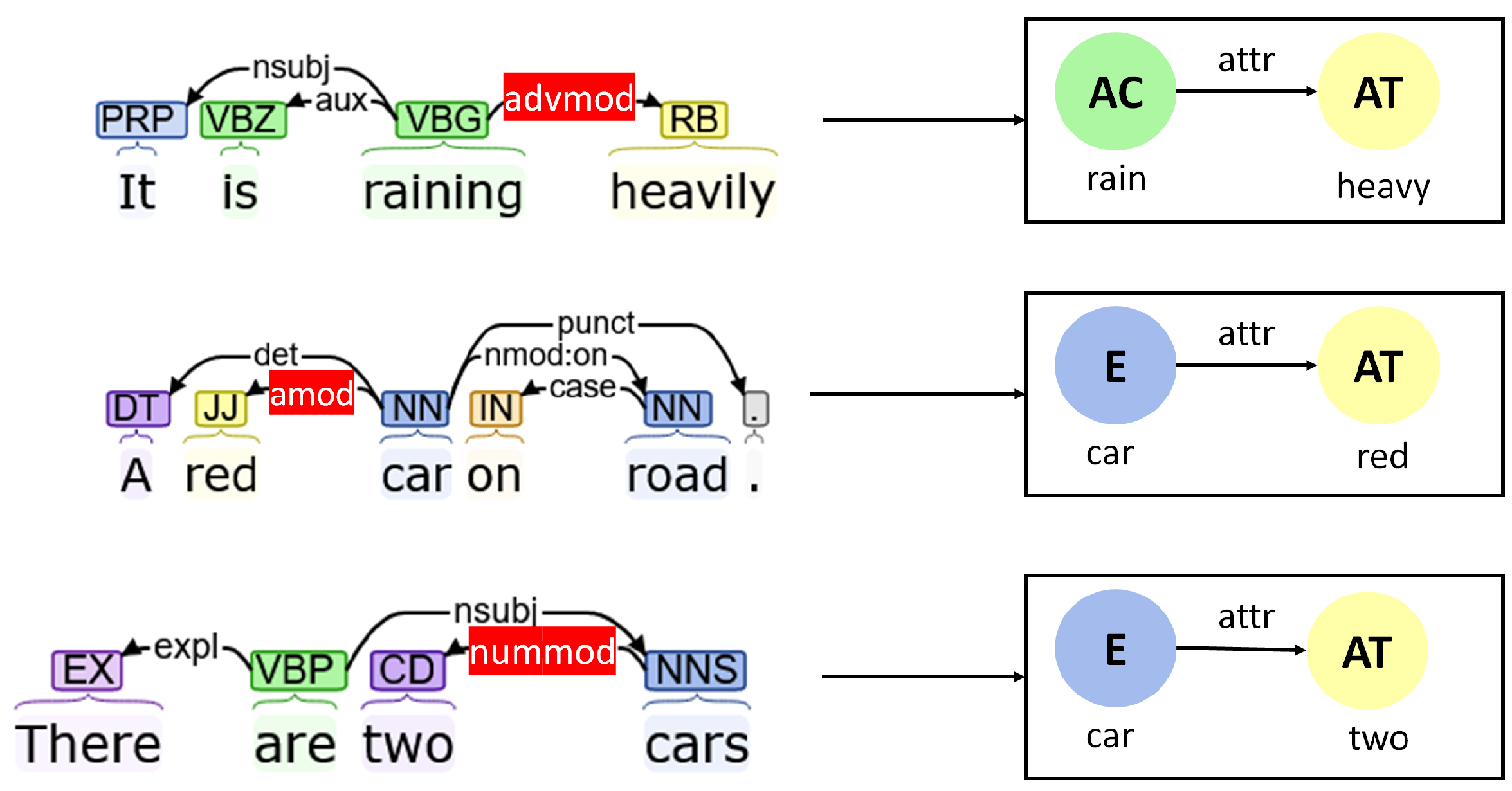
Attributes
- Adverbial modifier (“advmod”): Adverbial modifiers are generally used to modify other verbs or other modifiers. They can be used to generate “attr” edges, which provide qualitative insights about other actions and attributes.
- Adjectival modifier (“amod”): Adjectival modifiers are used to modify nouns and pronouns. In the context graph, they are used to define the attributes of entities.
- Numeric modifier (“nummod”): While adjectival modifiers describe an entity qualitatively, numeric modifiers define them quantitatively. Numeric modifiers are thus used to define the attributes corresponding to the number of entities.
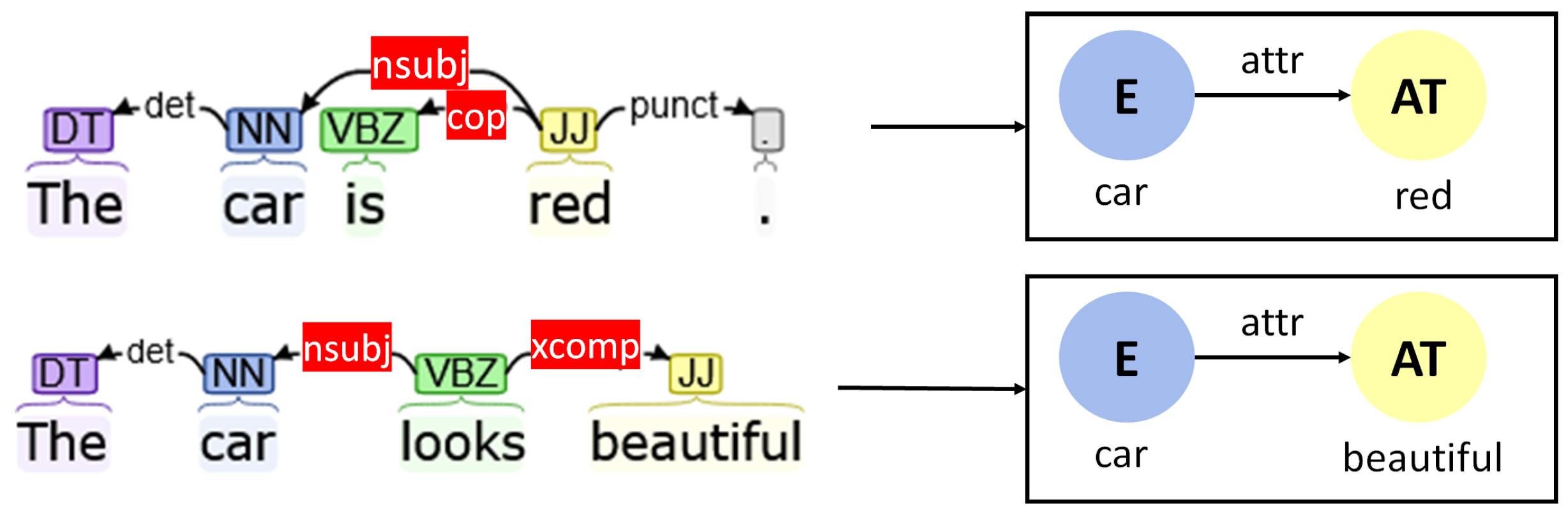
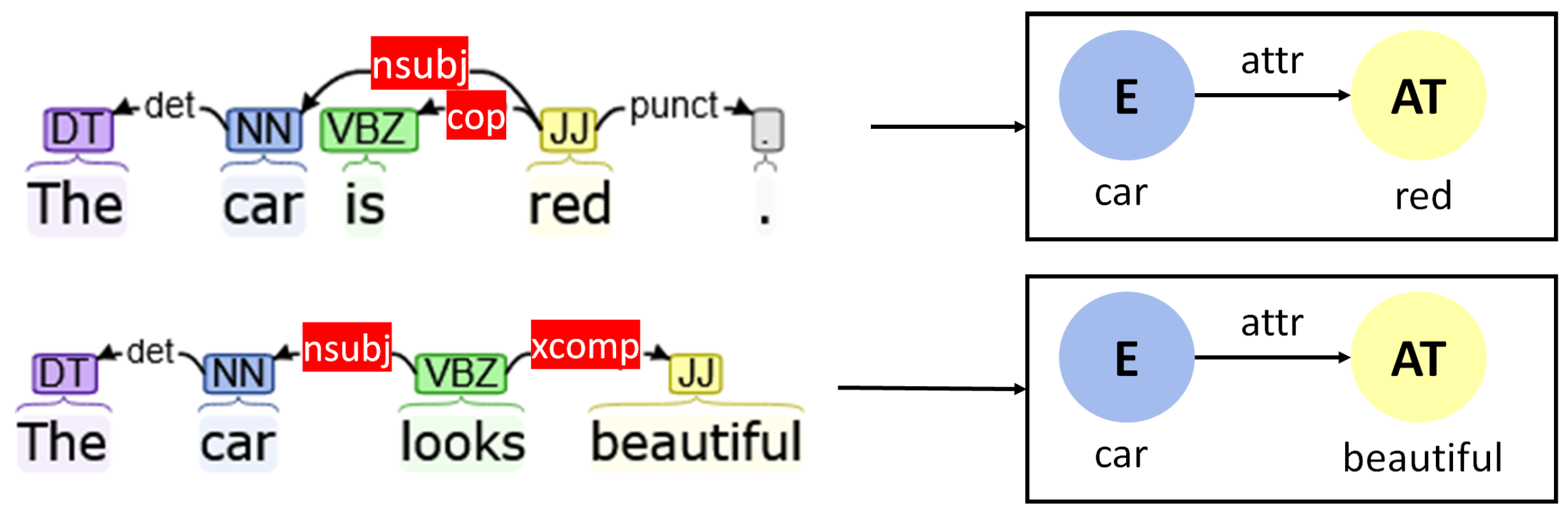
- Copula (“cop”): Copulas are used in those cases where entities are connected to an attribute using an auxiliary such as “is”. In the case of copulas, the auxiliary is connected to the attributes, which are in turn connected to the entity using a “nsubj” dependency.
- Open clausal complement (“xcomp”): Open clausal complements define the properties of an object through a verb that corresponds to a sensory action such as “looks beautiful” or “feels soft”.
Spatial Relations
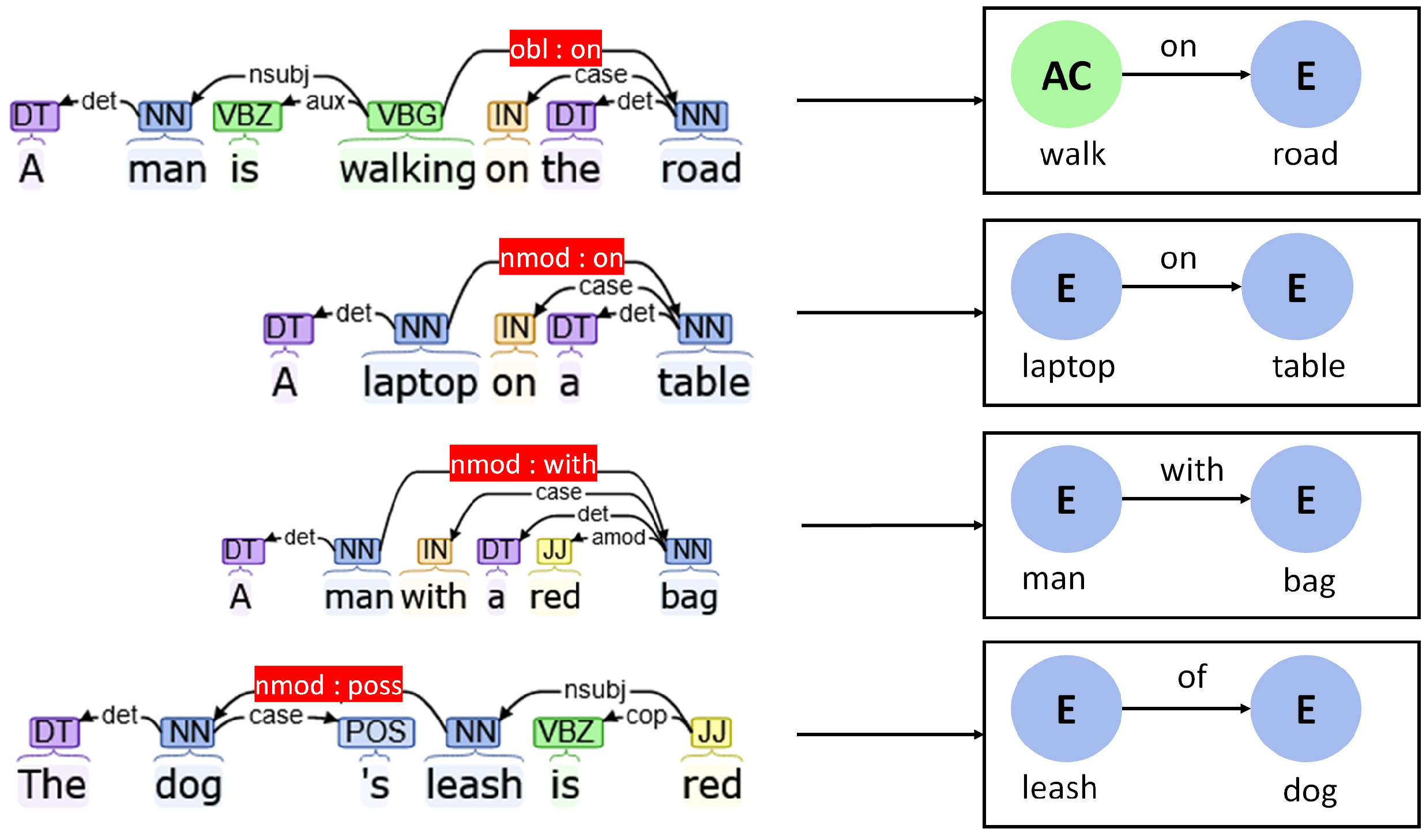
- Oblique dependencies with preposition (“obl:preposition”): In this case, a verb is connected to a preposition using an oblique relationship. This type of dependency can be used to establish the location of an action in a scene.
- Noun modifiers with preposition (“nmod:preposition”): Noun modifiers can also be used to connect two nouns with a preposition, which reflects the relative spatial interaction between them. In the concept graph, this dependency can be used to interpret similar relations among entities.
Special Relations
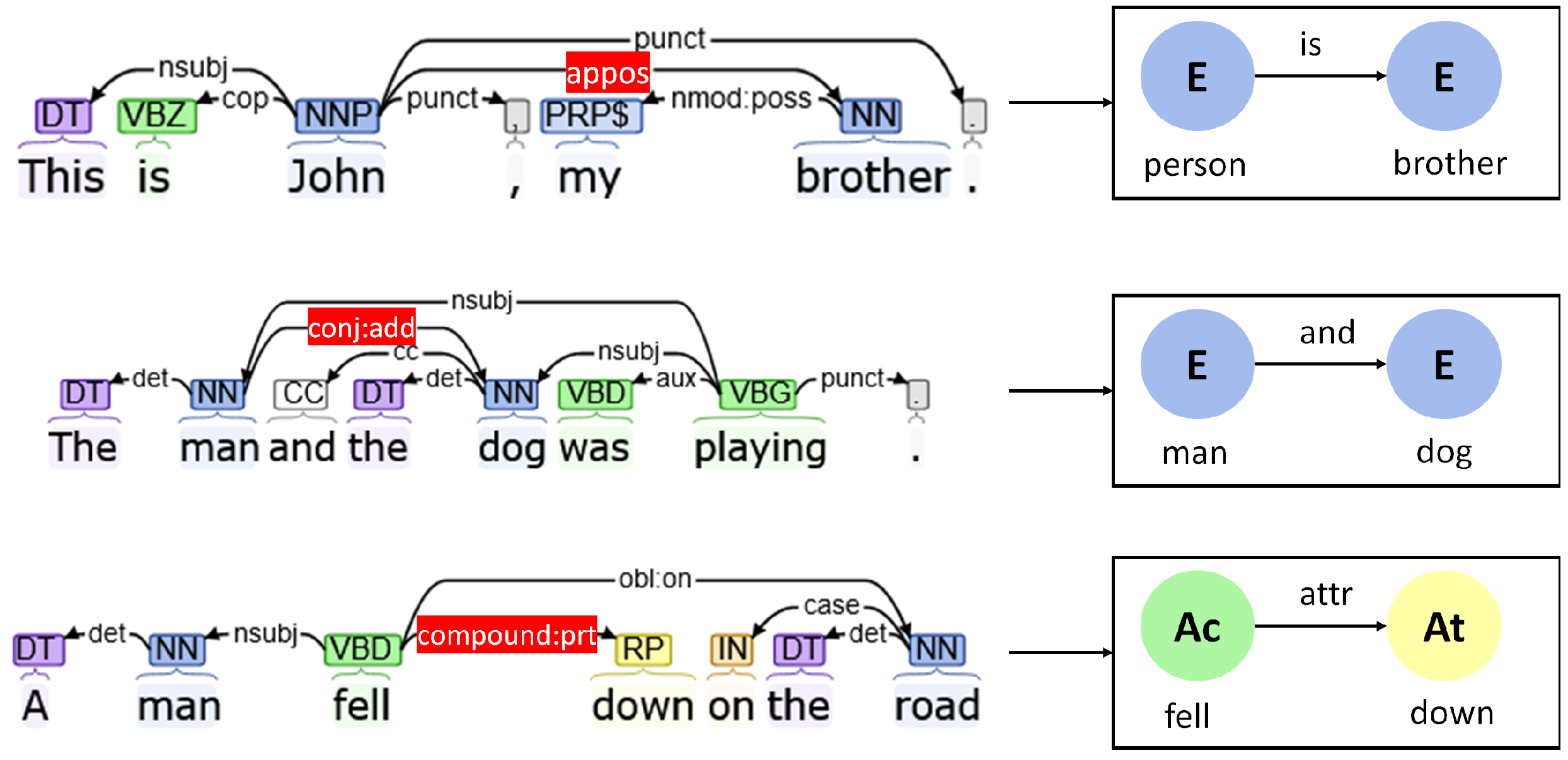
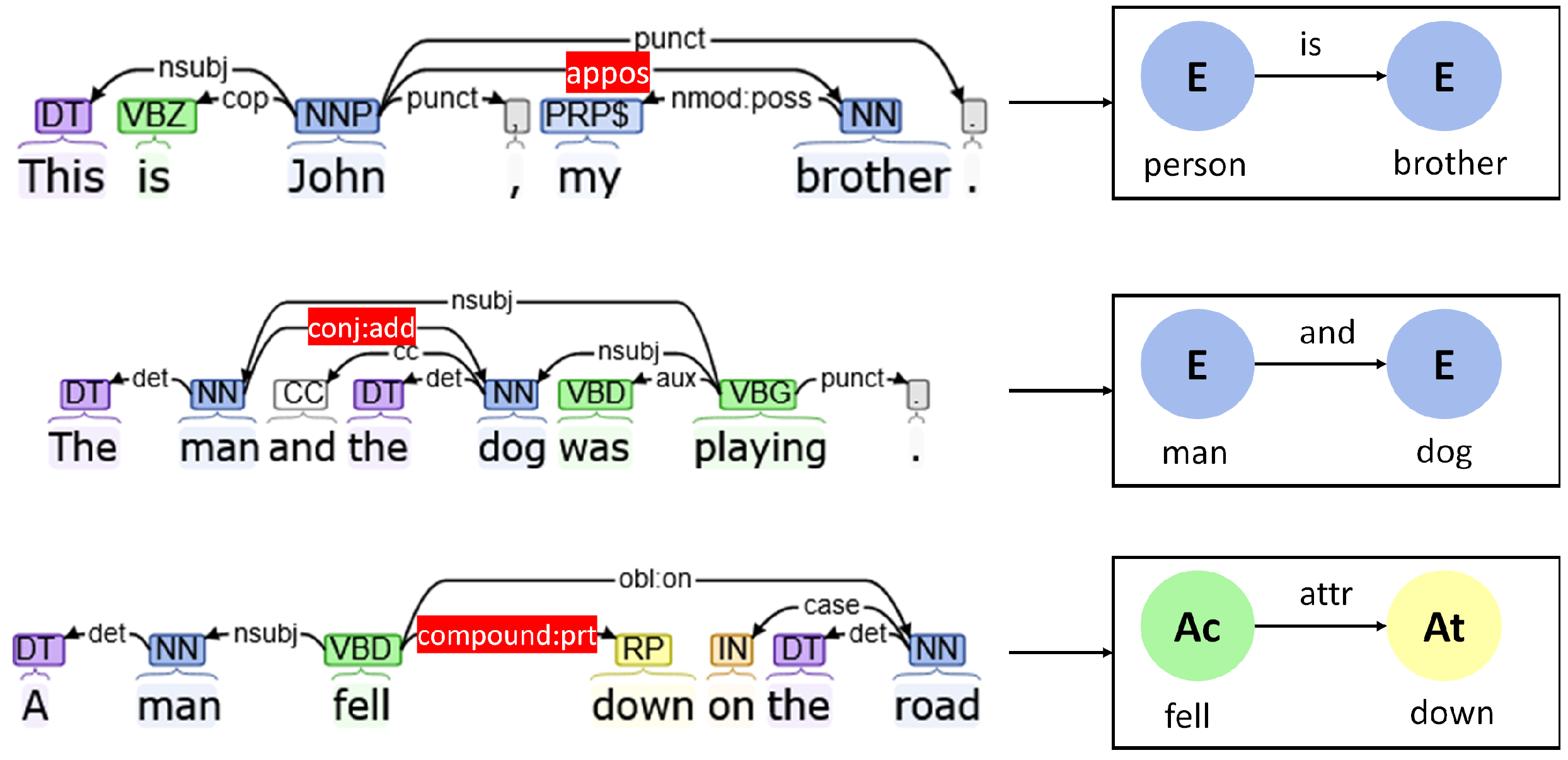
- Appositional modifiers (“appos”): Appositional modifiers of nouns are used when one noun acts as a descriptor for another noun. They are used in several situations such as “President Kalam” or “My brother, Rishi” or an abbreviation of a name of an entity. This is reflected by an “is” edge in the concept graph to illustrate that one entity acts as an alias of the other entity.
- Conjunction (“conj”): Conjunctions are used to group together multiple entities, attributes, or actions that exist in a similar environment. Enhanced++ dependencies automatically share the subjects’ attributes and actions with all members of the conjuncture. This can be used to group together several entities, attributes, and actions in an image as well.
- Compound participle (“compound:prt”): Compound participles modify the behaviors of verbs that emphasize the corresponding action such as “fell down”
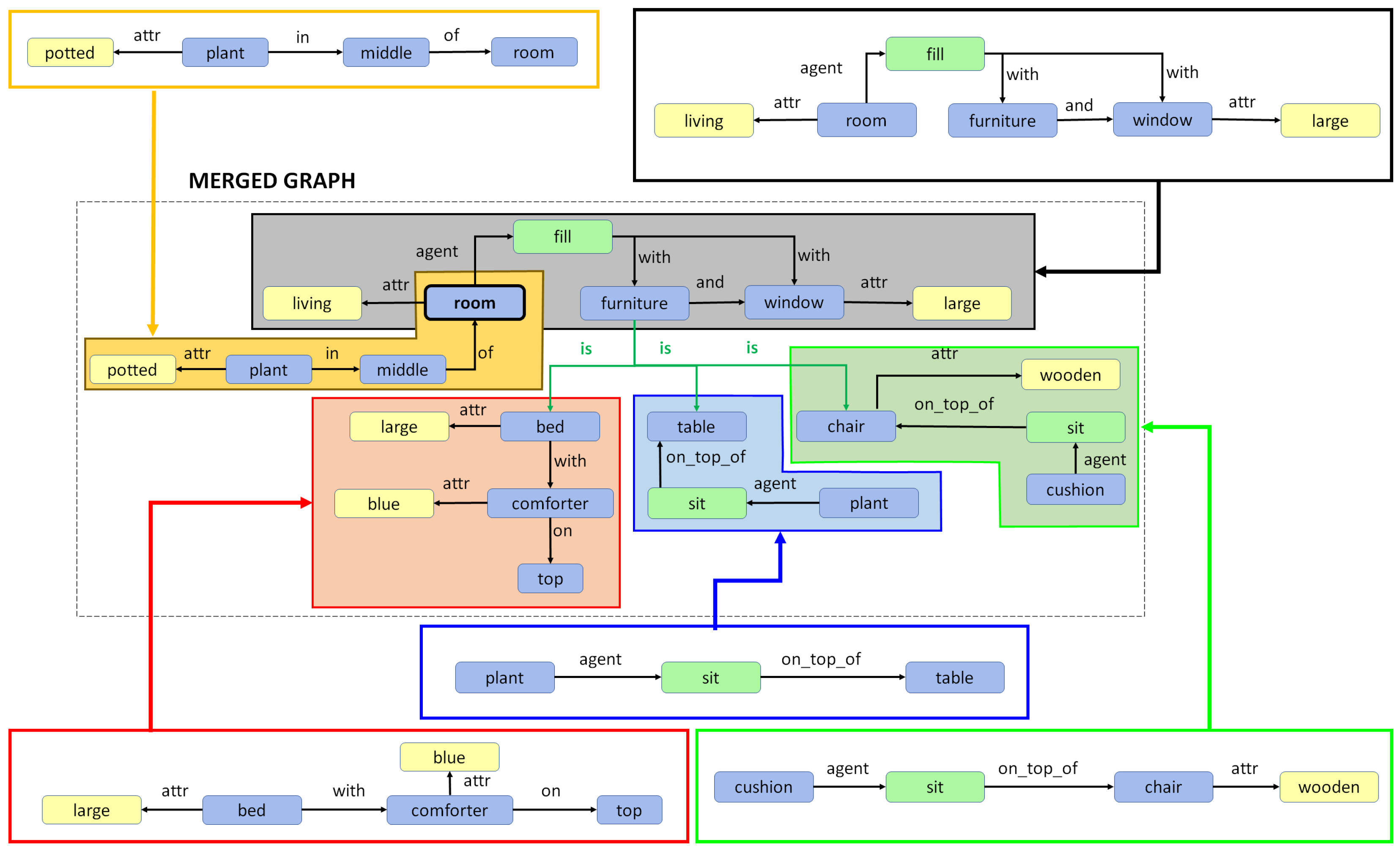
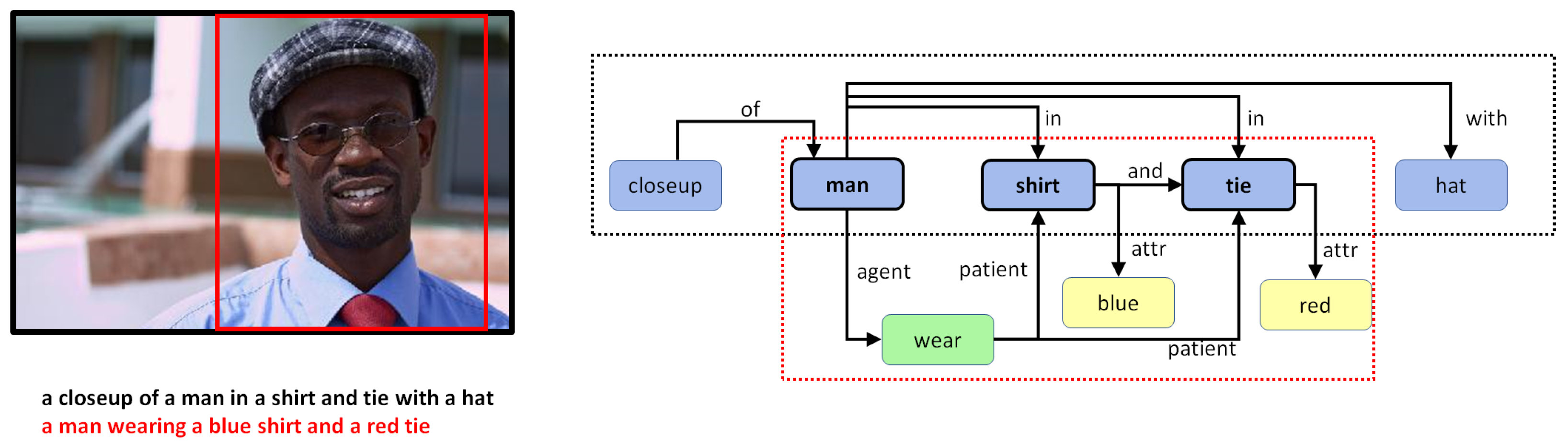
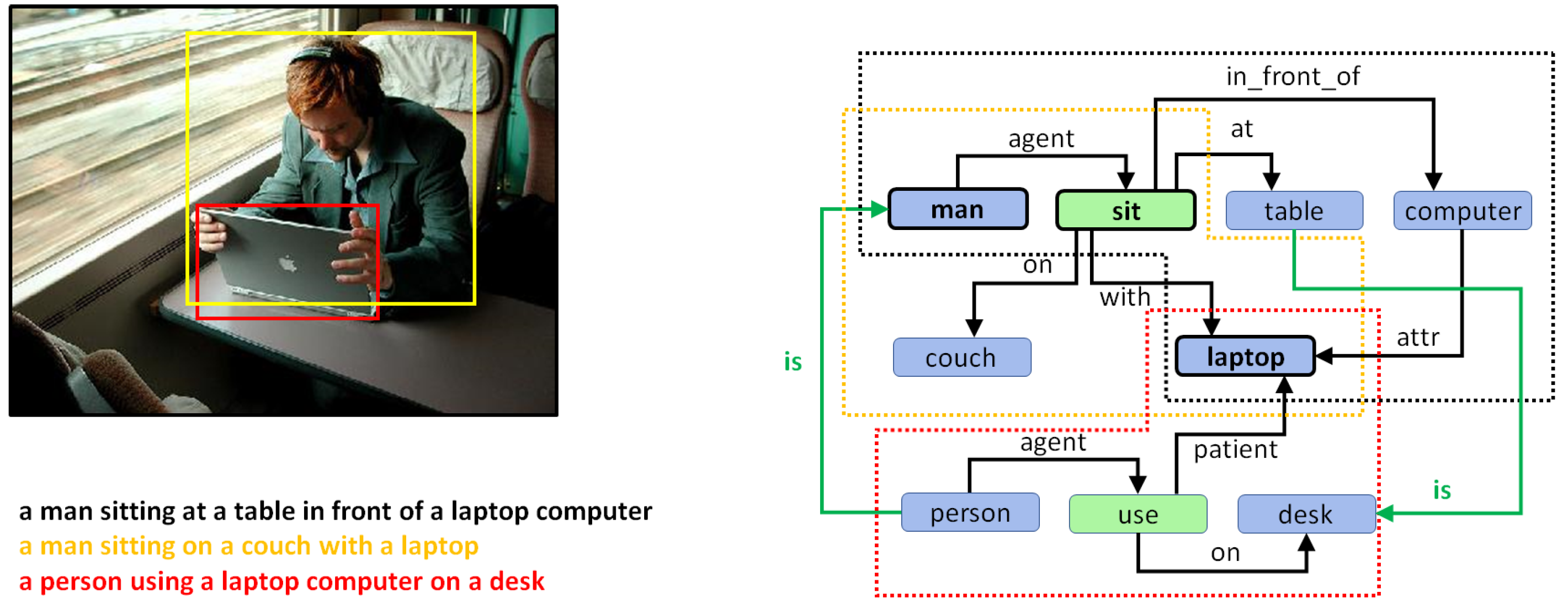
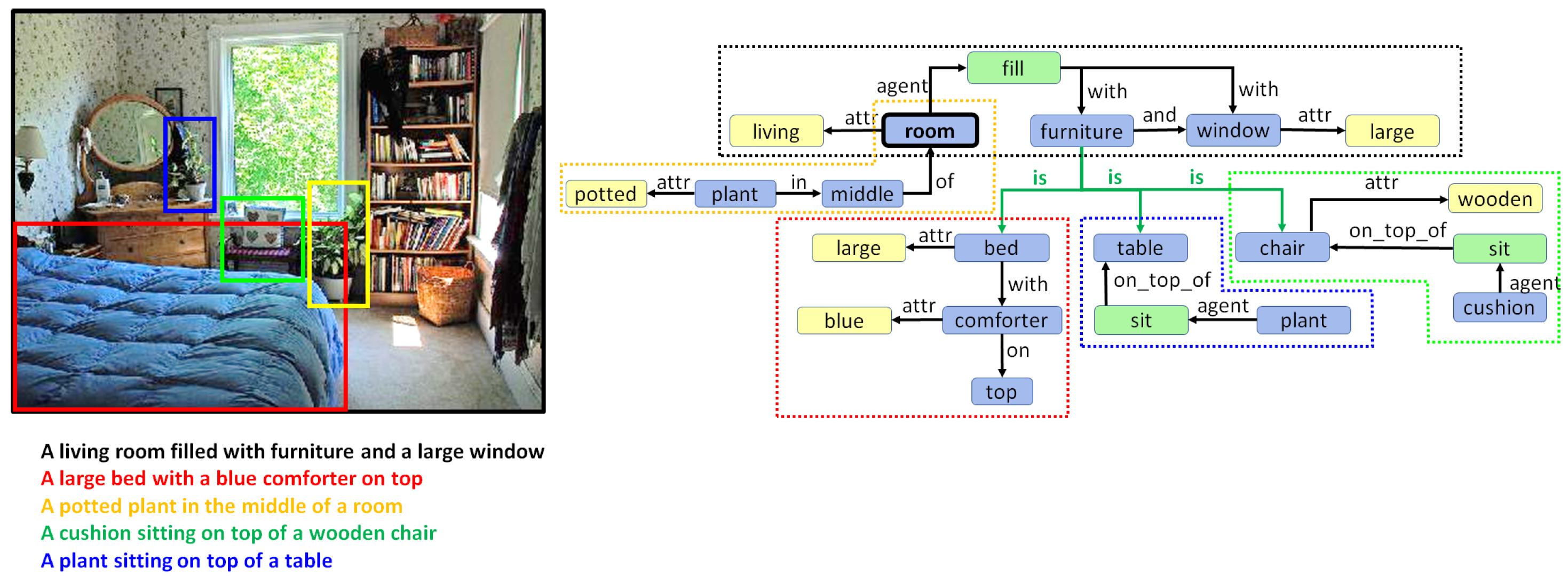
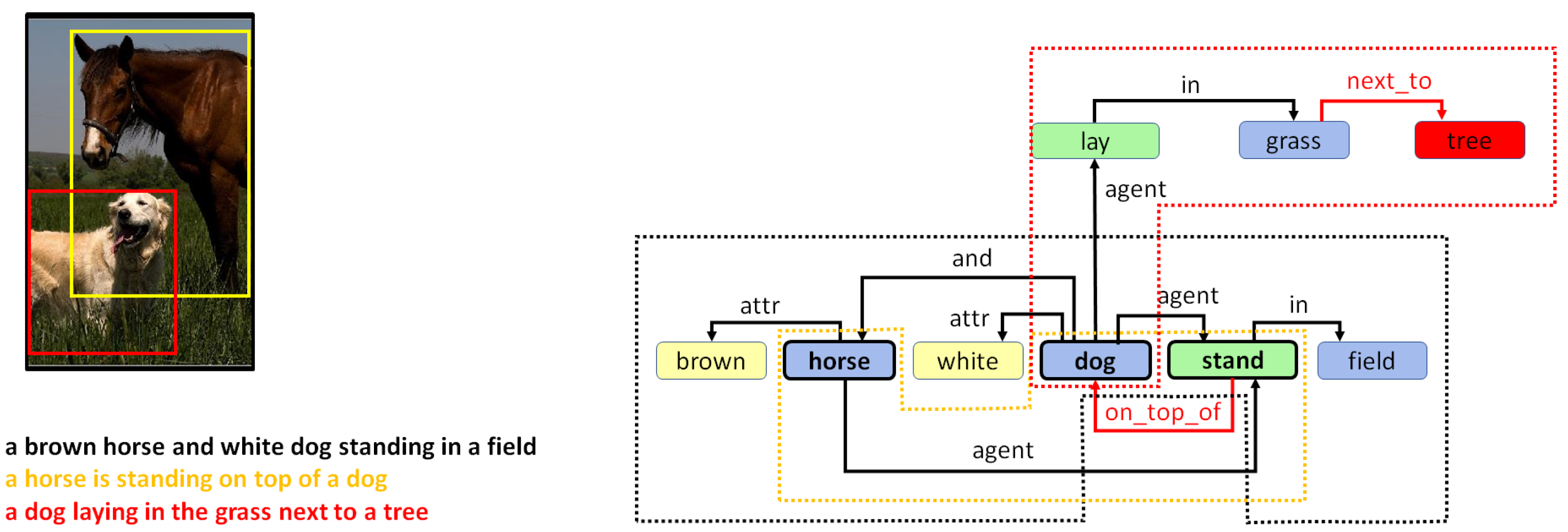
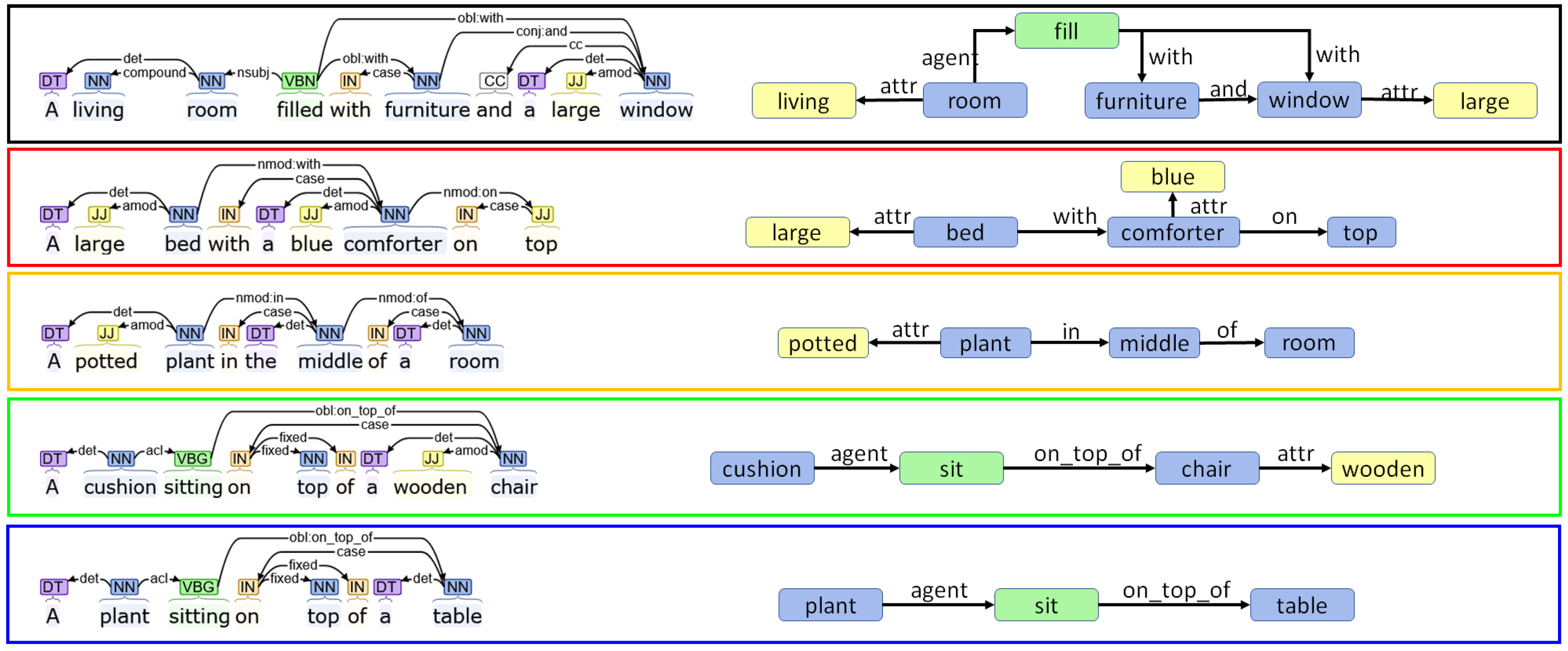
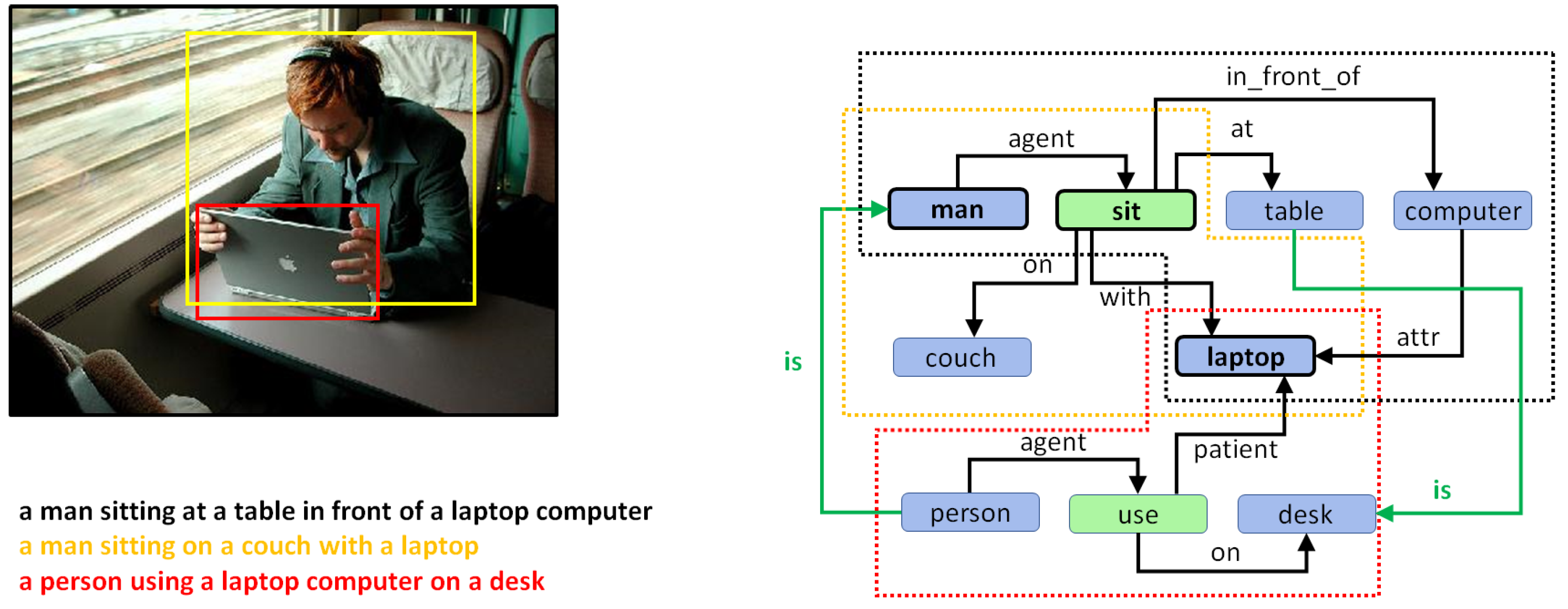
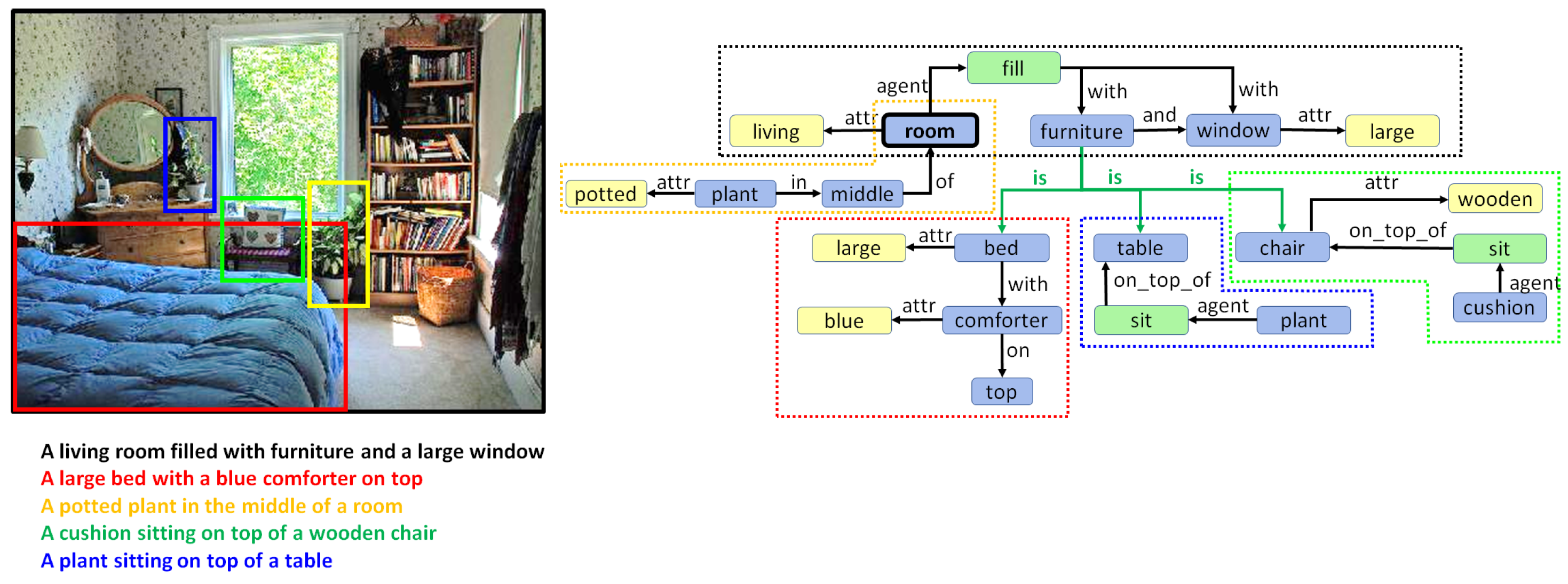
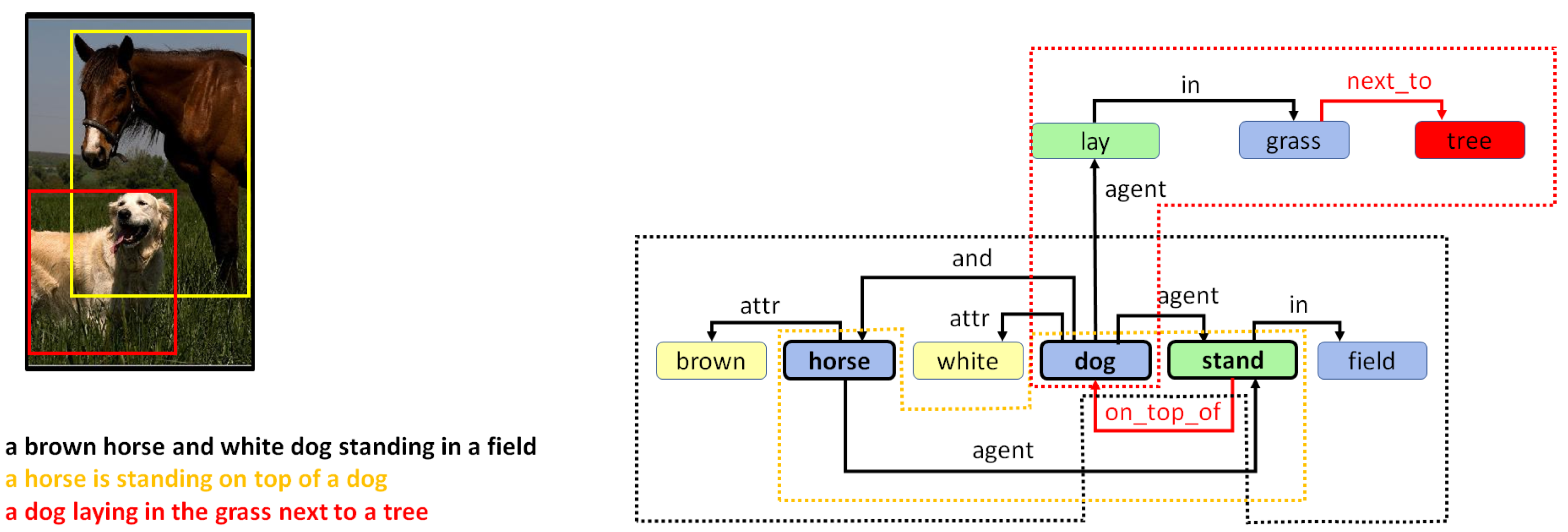
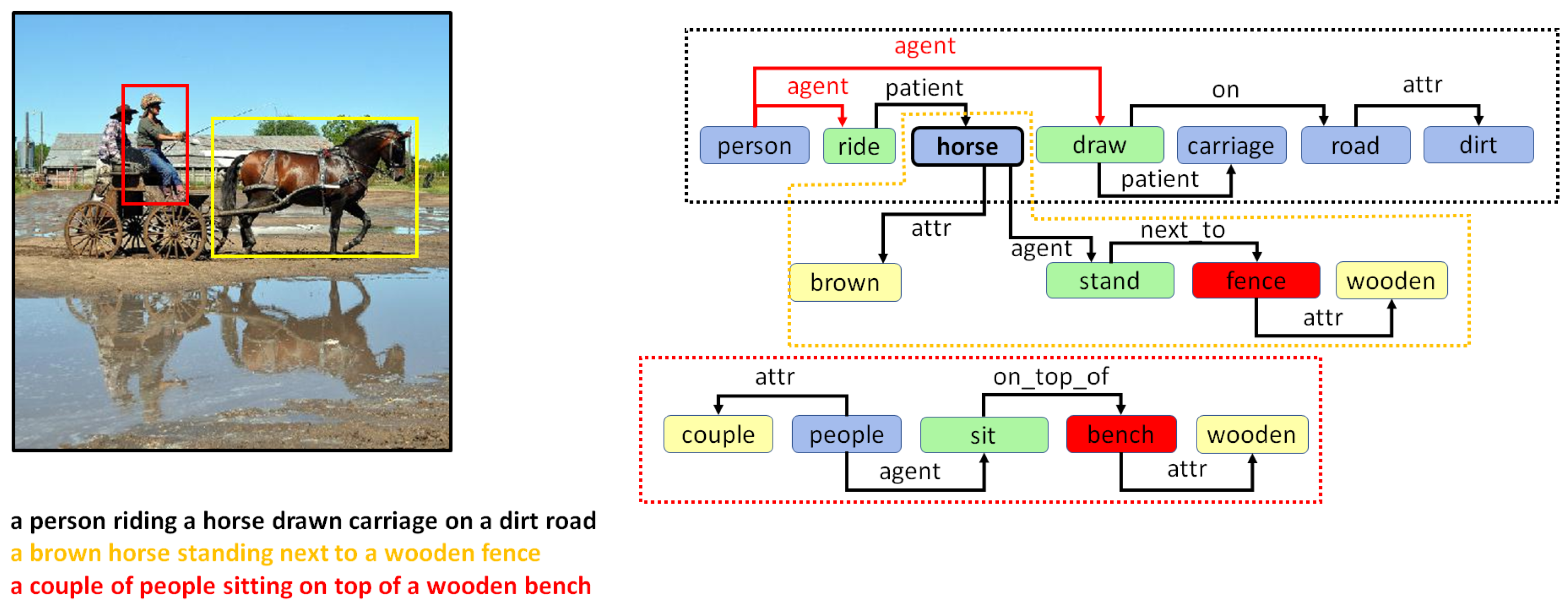
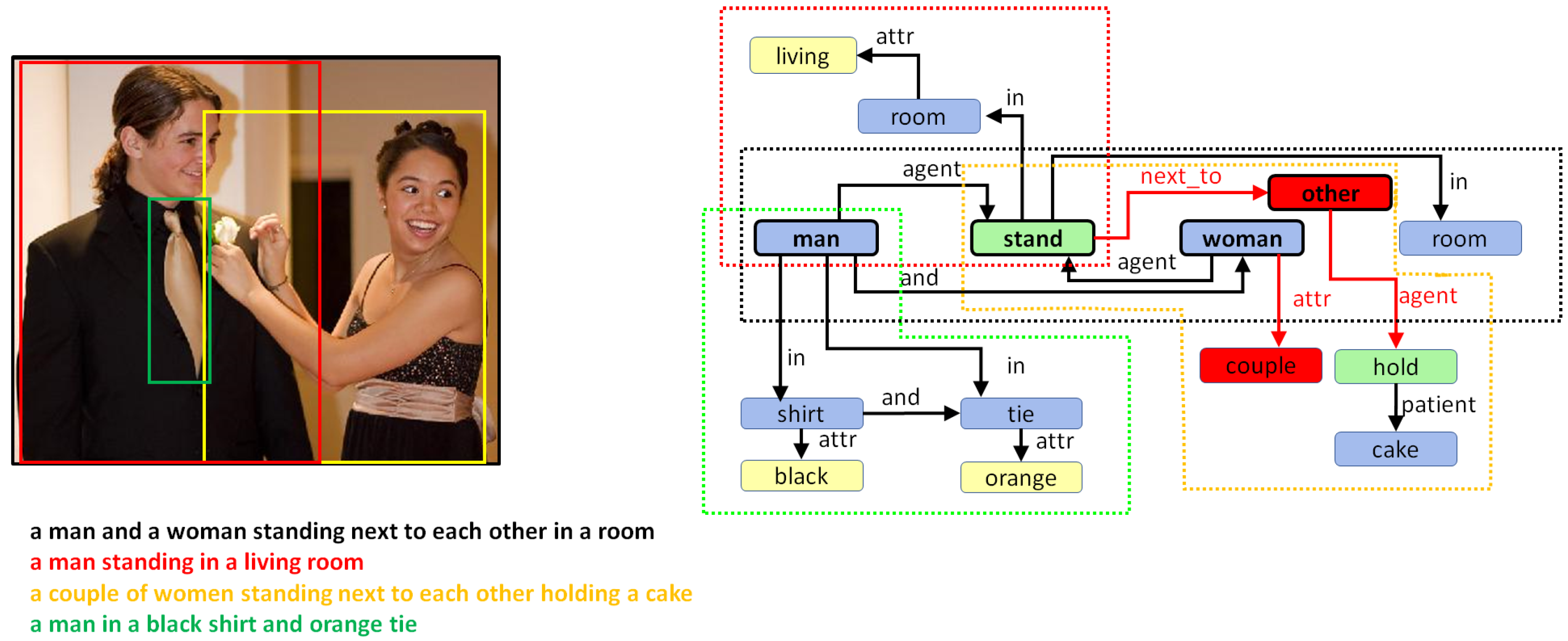
5. Combining Regional Graphs to Generate Concept Graphs
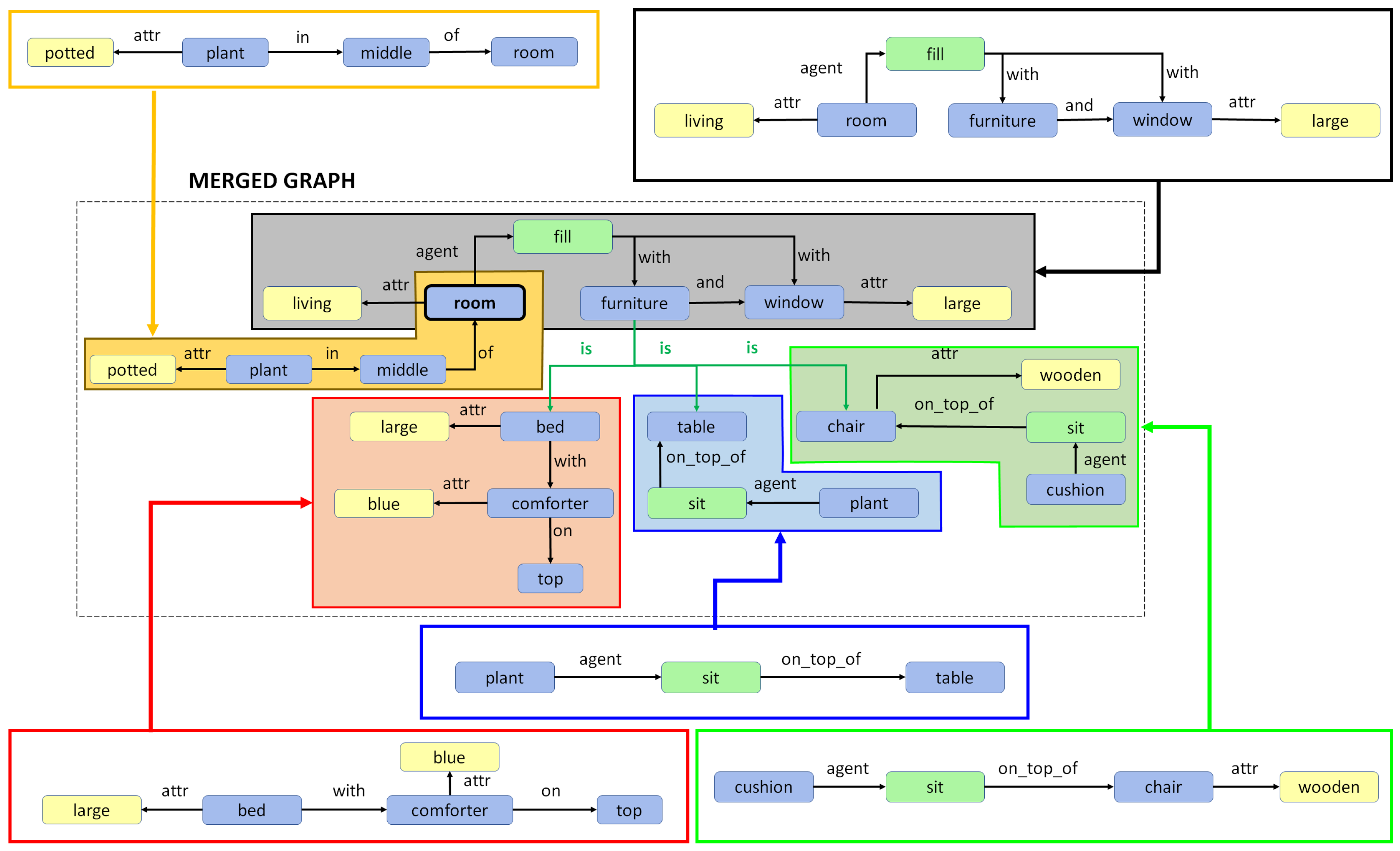
Combination of Region Graphs
- Phase I:
- Merging entities. The first phase aims to find out which entity nodes from the different region graphs can be merged. This is performed on the basis of the following rules:
- Same lemma. If two nodes have the same lemma and have an intersection-over-min (IOM) ratio above 0.5, they can be merged. The IOM ratio for two bounding boxes A and B is given by
- Different lemma. Entities with different lemmas may also be merged if they belong to the same synset in the WordNet hypernym chain. This can be detected when the Wu–Palmer similarity [60] is 1.0. For example, pairs such as or belong to the same synset and, hence, can be merged.
- Phase II:
- Merging actions and attributes. Once we have a pair of entities, one from each of two different region graphs that can be merged, the matching set of actions and entities connected to that entity in both regions graphs can also be merged.
- Phase III:
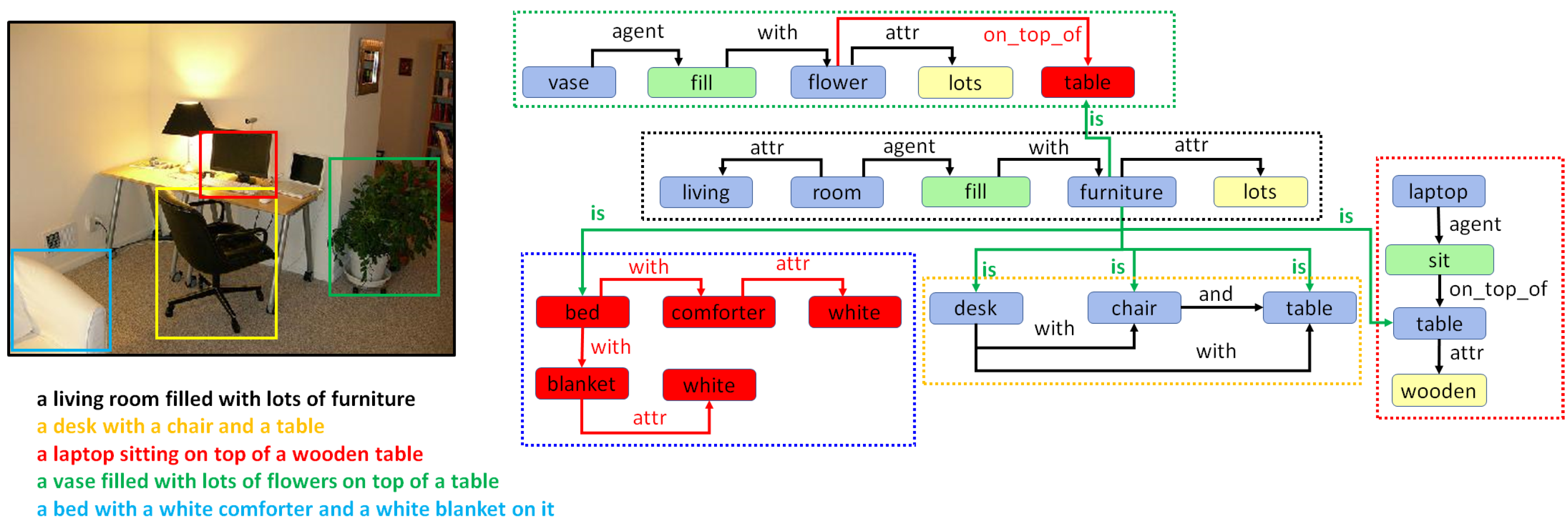
- Drawing special edges. Finally, some entities demonstrate more detail in a specific region graph. In cases where two regions have an IOM ratio over 0.5 and the lemma of the two corresponding entities belongs to different generations in the same WordNet hypernym chain, they can be connected using a special edge. For example, if we have two entities in two regions such as “furniture” and “table”, then an edge may be added that states “furniture is table”.
6. Results and Analysis
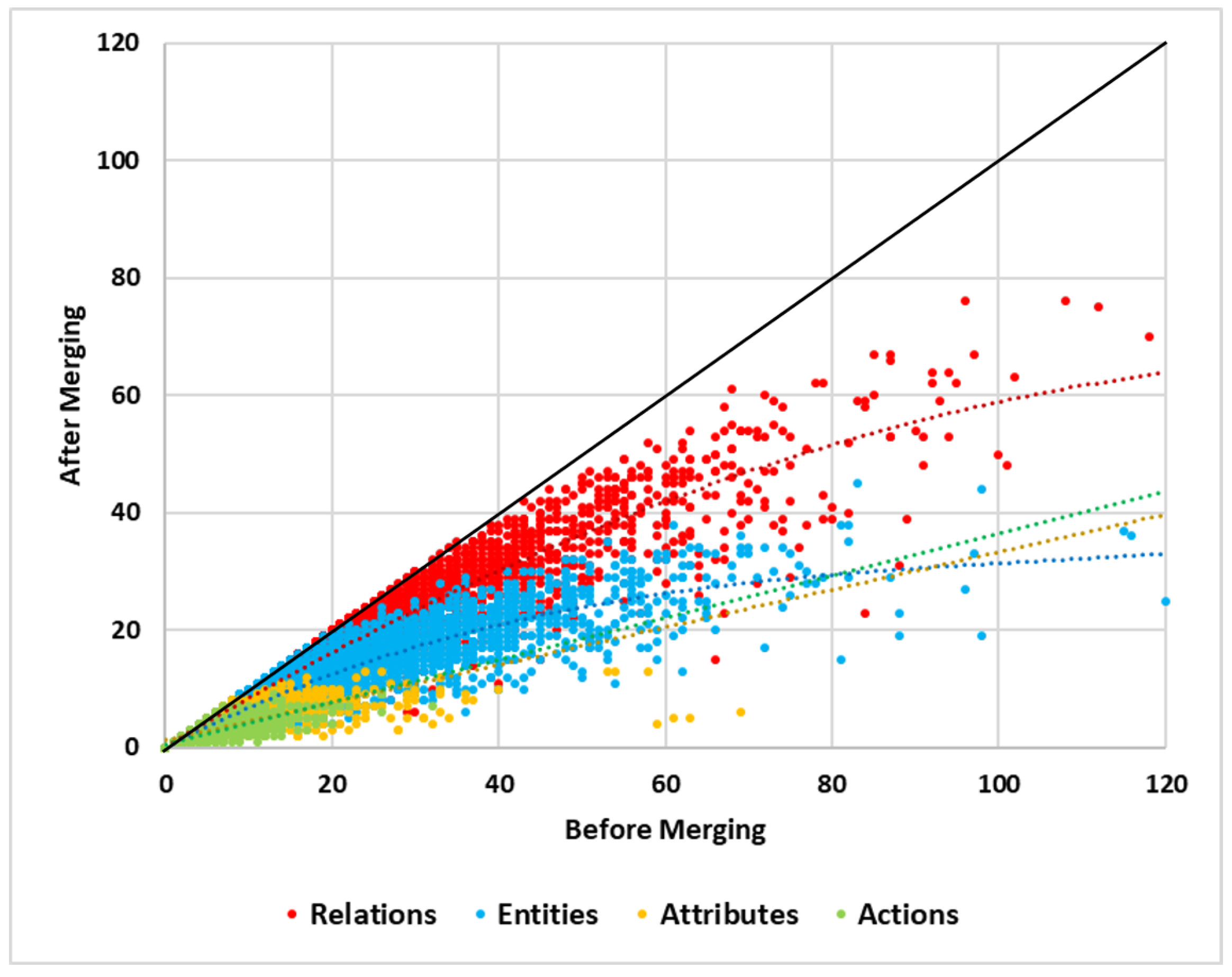
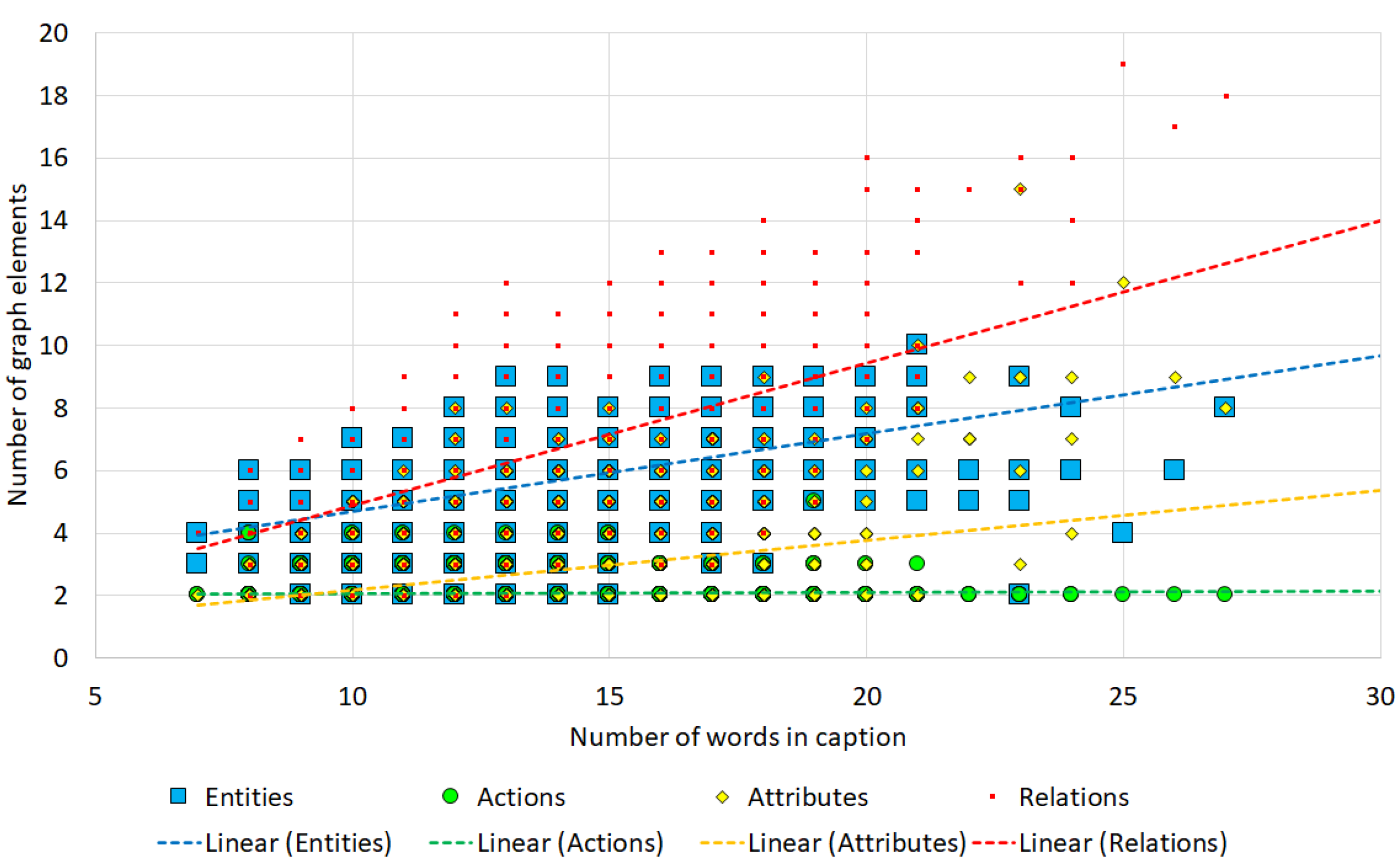
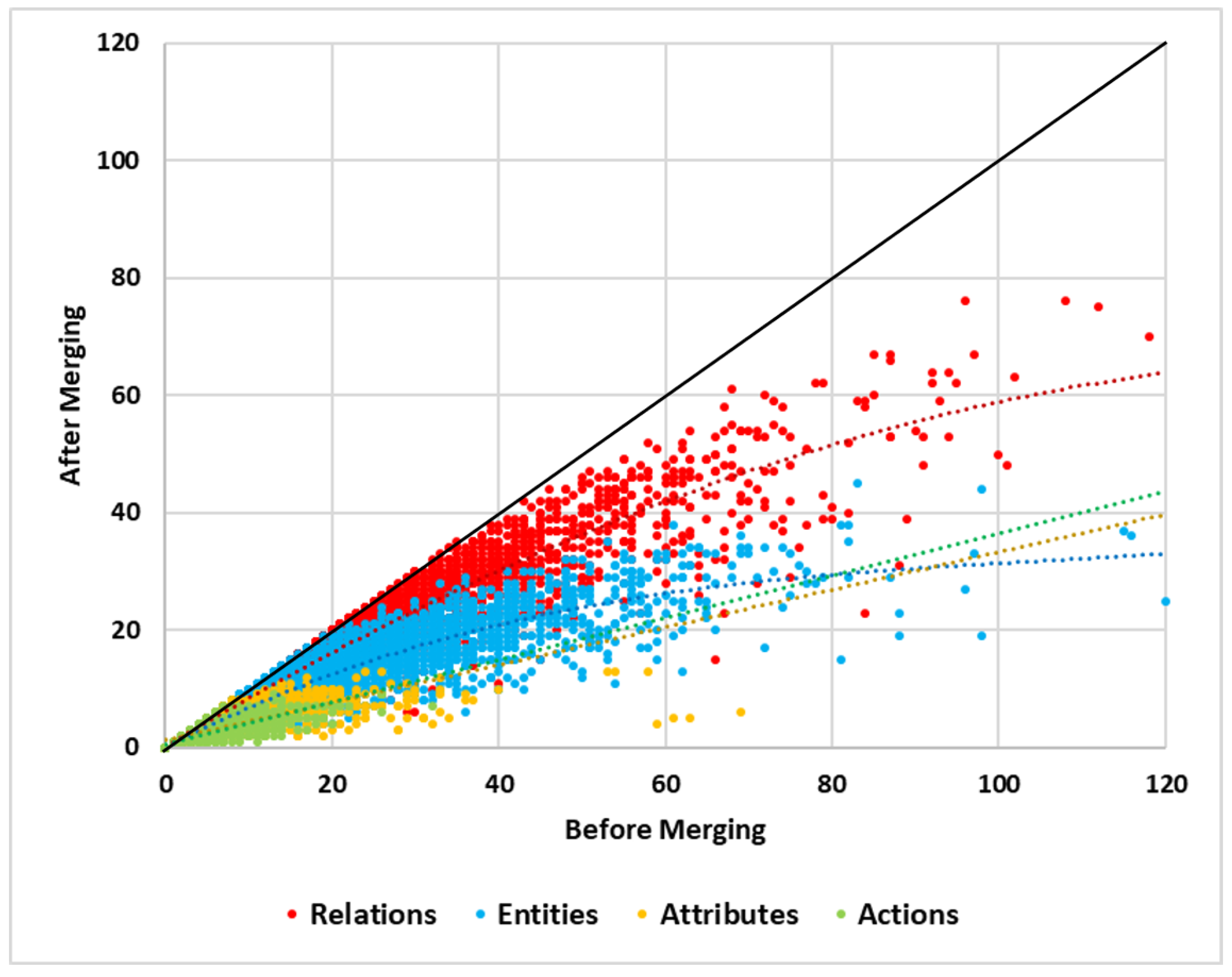
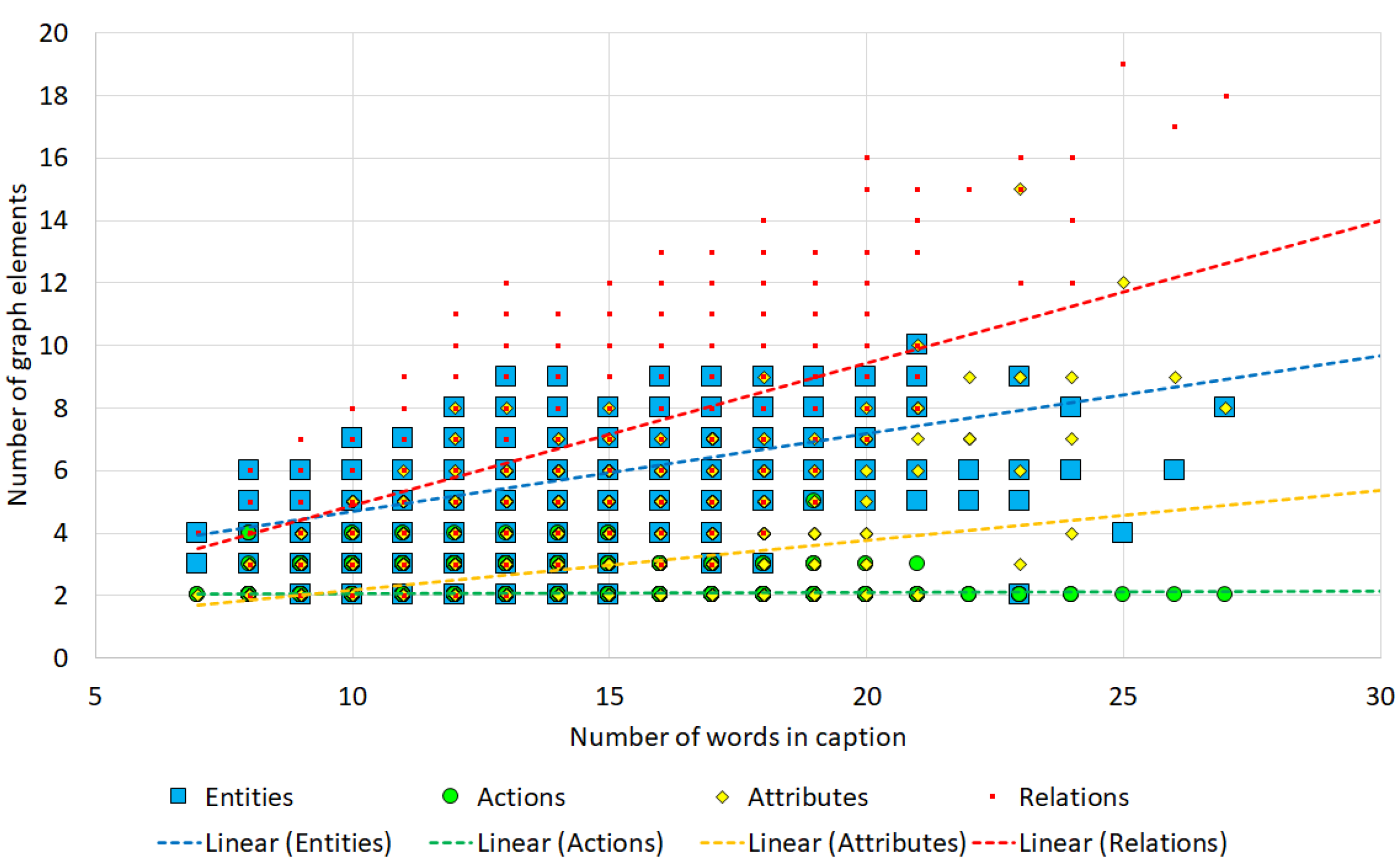
6.1. Statistical Analysis of Generated Graphs
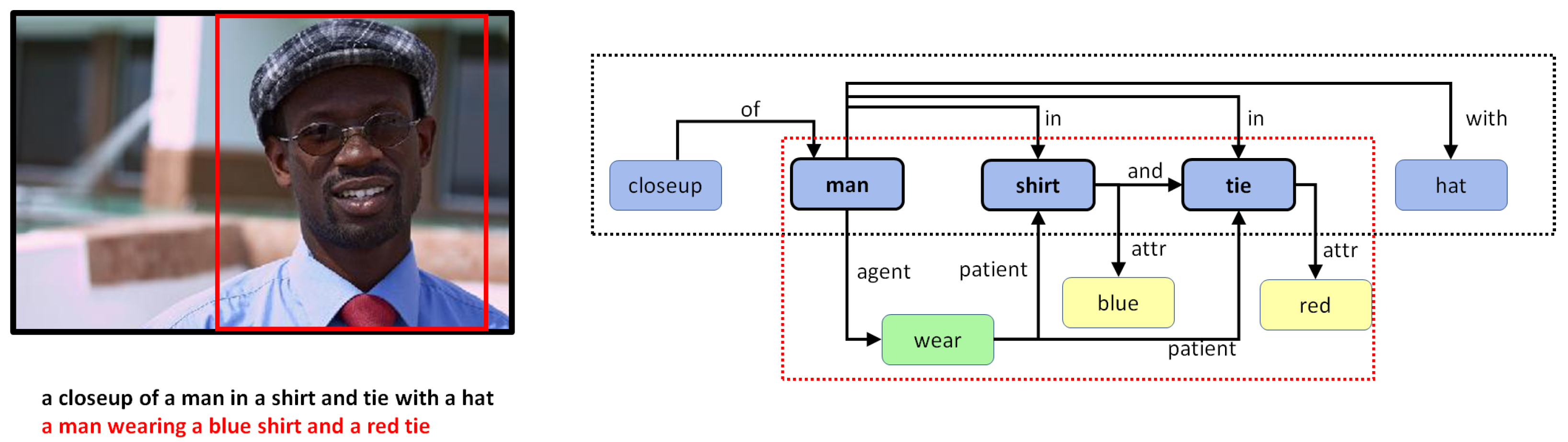
6.2. Qualitative Analysis
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Ghosh, S.; Das, N.; Gonçalves, T.; Quaresma, P. Representing image captions as concept graphs using semantic information. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 162–167. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Xu, D.; Zhu, Y.; Choy, C.B.; Li, F.-F. Scene graph generation by iterative message passing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5410–5419. [Google Scholar]
- Chen, M.; Wu, J.; Liu, L.; Zhao, W.; Tian, F.; Shen, Q.; Zhao, B.; Du, R. DR-Net: An improved network for building extraction from high resolution remote sensing image. Remote Sens. 2021, 13, 294. [Google Scholar] [CrossRef]
- Zellers, R.; Yatskar, M.; Thomson, S.; Choi, Y. Neural motifs: Scene graph parsing with global context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5831–5840. [Google Scholar]
- Johnson, J.; Krishna, R.; Stark, M.; Li, L.J.; Shamma, D.; Bernstein, M.; Li, F.-F. Image retrieval using scene graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3668–3678. [Google Scholar]
- Schuster, S.; Krishna, R.; Chang, A.; Li, F.-F.; Manning, C.D. Generating semantically precise scene graphs from textual descriptions for improved image retrieval. In Proceedings of the fourth Workshop on Vision and Language, Lisbon, Portugal, 18 September 2015; pp. 70–80. [Google Scholar]
- Andriyanov, N.; Dementiev, V.; Tashlinskii, A. Detection of objects in the images: From likelihood relationships towards scalable and efficient neural networks. Comput. Opt. 2022, 46, 139–159. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 202; pp. 213–229.
- Cong, W.; Wang, W.; Lee, W.C. Scene graph generation via conditional random fields. arXiv 2018, arXiv:1811.08075. [Google Scholar]
- Zhang, H.; Kyaw, Z.; Chang, S.F.; Chua, T.S. Visual translation embedding network for visual relation detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5532–5540. [Google Scholar]
- Gkanatsios, N.; Pitsikalis, V.; Koutras, P.; Zlatintsi, A.; Maragos, P. Deeply supervised multimodal attentional translation embeddings for visual relationship detection. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1840–1844. [Google Scholar]
- Hung, Z.S.; Mallya, A.; Lazebnik, S. Contextual translation embedding for visual relationship detection and scene graph generation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3820–3832. [Google Scholar] [CrossRef] [PubMed]
- Wan, H.; Luo, Y.; Peng, B.; Zheng, W.S. Representation Learning for Scene Graph Completion via Jointly Structural and Visual Embedding. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 949–956. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Woo, S.; Kim, D.; Cho, D.; Kweon, I.S. Linknet: Relational embedding for scene graph. arXiv 2018, arXiv:1811.06410. [Google Scholar]
- Li, Y.; Ouyang, W.; Wang, X.; Tang, X. Vip-cnn: Visual phrase guided convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1347–1356. [Google Scholar]
- Zhang, J.; Shih, K.; Tao, A.; Catanzaro, B.; Elgammal, A. An interpretable model for scene graph generation. arXiv 2018, arXiv:1811.09543. [Google Scholar]
- Kolesnikov, A.; Kuznetsova, A.; Lampert, C.; Ferrari, V. Detecting visual relationships using box attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 1749–1753. [Google Scholar]
- Yin, G.; Sheng, L.; Liu, B.; Yu, N.; Wang, X.; Shao, J.; Loy, C.C. Zoom-net: Mining deep feature interactions for visual relationship recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 322–338. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B.; Wang, K.; Wang, X. Scene graph generation from objects, phrases and region captions. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1261–1270. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1263–1272. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated graph sequence neural networks. arXiv 2015, arXiv:1511.05493. [Google Scholar]
- Goller, C.; Kuchler, A. Learning task-dependent distributed representations by backpropagation through structure. In Proceedings of the International Conference on Neural Networks (ICNN’96), Washington, DC, USA, 3–6 June 1996; Volume 1, pp. 347–352. [Google Scholar]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 2, pp. 729–734. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Santoro, A.; Raposo, D.; Barrett, D.G.; Malinowski, M.; Pascanu, R.; Battaglia, P.; Lillicrap, T. A simple neural network module for relational reasoning. arXiv 2017, arXiv:1706.01427. [Google Scholar]
- Bruna, J.; Mallat, S. Invariant scattering convolution networks. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1872–1886. [Google Scholar] [CrossRef]
- Dai, H.; Dai, B.; Song, L. Discriminative embeddings of latent variable models for structured data. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2702–2711. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning convolutional neural networks for graphs. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2014–2023. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Herzig, R.; Raboh, M.; Chechik, G.; Berant, J.; Globerson, A. Mapping images to scene graphs with permutation-invariant structured prediction. Adv. Neural Inf. Process. Syst. 2018, 31, 7211–7221. [Google Scholar]
- Herzig, R.; Levi, E.; Xu, H.; Gao, H.; Brosh, E.; Wang, X.; Globerson, A.; Darrell, T. Spatio-temporal action graph networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 2347–2356. [Google Scholar]
- Wang, X.; Gupta, A. Videos as space-time region graphs. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 399–417. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B.; Shi, J.; Zhang, C.; Wang, X. Factorizable net: An efficient subgraph-based framework for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 335–351. [Google Scholar]
- Yang, J.; Lu, J.; Lee, S.; Batra, D.; Parikh, D. Graph r-cnn for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 670–685. [Google Scholar]
- Qi, M.; Li, W.; Yang, Z.; Wang, Y.; Luo, J. Attentive relational networks for mapping images to scene graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3957–3966. [Google Scholar]
- Dornadula, A.; Narcomey, A.; Krishna, R.; Bernstein, M.; Li, F.F. Visual relationships as functions: Enabling few-shot scene graph prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 1730–1739. [Google Scholar]
- Zhang, J.; Shih, K.J.; Elgammal, A.; Tao, A.; Catanzaro, B. Graphical contrastive losses for scene graph parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11535–11543. [Google Scholar]
- Jung, T.W.; Jeong, C.S.; Kim, I.S.; Yu, M.S.; Kwon, S.C.; Jung, K.D. Graph Convolutional Network for 3D Object Pose Estimation in a Point Cloud. Sensors 2022, 22, 8166. [Google Scholar] [CrossRef] [PubMed]
- Andriyanov, N. Application of Graph Structures in Computer Vision Tasks. Mathematics 2022, 10, 4021. [Google Scholar] [CrossRef]
- Jayatilaka, G.; Hassan, J.; Sritharan, S.; Senanayaka, J.B.; Weligampola, H.; Godaliyadda, R.; Ekanayake, P.; Herath, V.; Ekanayake, J.; Dharmaratne, S. Holistic interpretation of public scenes using computer vision and temporal graphs to identify social distancing violations. Appl. Sci. 2022, 12, 8428. [Google Scholar] [CrossRef]
- Lu, C.; Krishna, R.; Bernstein, M.; Fei-Fei, L. Visual relationship detection with language priors. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 852–869. [Google Scholar]
- Liang, X.; Lee, L.; Xing, E.P. Deep variation-structured reinforcement learning for visual relationship and attribute detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 848–857. [Google Scholar]
- Cui, Z.; Xu, C.; Zheng, W.; Yang, J. Context-dependent diffusion network for visual relationship detection. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1475–1482. [Google Scholar]
- Yu, R.; Li, A.; Morariu, V.I.; Davis, L.S. Visual relationship detection with internal and external linguistic knowledge distillation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1974–1982. [Google Scholar]
- Dai, B.; Zhang, Y.; Lin, D. Detecting visual relationships with deep relational networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3076–3086. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef] [Green Version]
- Zareian, A.; Karaman, S.; Chang, S.F. Bridging knowledge graphs to generate scene graphs. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 606–623. [Google Scholar]
- Gu, J.; Zhao, H.; Lin, Z.; Li, S.; Cai, J.; Ling, M. Scene graph generation with external knowledge and image reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1969–1978. [Google Scholar]
- Lee, C.W.; Fang, W.; Yeh, C.K.; Wang, Y.C.F. Multi-label zero-shot learning with structured knowledge graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1576–1585. [Google Scholar]
- Speer, R.; Chin, J.; Havasi, C. Conceptnet 5.5: An open multilingual graph of general knowledge. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017.
- Johnson, J.; Karpathy, A.; Li, F.-F. Densecap: Fully convolutional localization networks for dense captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4565–4574. [Google Scholar]
- Ghosh, S.; Das, N.; Nasipuri, M. Reshaping inputs for convolutional neural network: Some common and uncommon methods. Pattern Recognit. 2019, 93, 79–94. [Google Scholar] [CrossRef]
- De Marneffe, M.C.; Dozat, T.; Silveira, N.; Haverinen, K.; Ginter, F.; Nivre, J.; Manning, C.D. Universal Stanford dependencies: A cross-linguistic typology. In Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC’14); 2014; pp. 4585–4592. [Google Scholar]
- Wu, Z.; Palmer, M. Verb semantics and lexical selection. arXiv 1994, arXiv:cmp-lg/9406033v3. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node Type | Type of Node | Description | Node Lemma | Criterion |
|---|---|---|---|---|
| Entity | Primary Nodes | Objects that physically occupy space | Word Lemma | POS Tags: NN, NNS |
| Secondary Nodes | Pronouns | Object | POS Tags: PRP, Lemma: it, its, itself | |
| Person | POS Tags: PRP, PRP$, Lemma: I, you, my | |||
| Masculine Person | POS Tags: PRP, PRP$, Lemma: he, him, his, himself | |||
| Feminine Person | POS Tags: PRP, PRP$, Lemma: she, her, herself | |||
| People | POS Tags: PRP, PRP$, Lemma: we, they, them, ’em, themselves | |||
| Determiners | Object | POS Tags: DT, Lemma: this, that, these, those | ||
| Proper Nouns | Location | POS Tags: NNP, NNPS, NER Tag: LOCATION | ||
| Person | POS Tags: NNP, NNPS, NER Tag: PERSON | |||
| Organization | POS Tags: NNP, NNPS, NER Tag: ORGANIZATION | |||
| Actions without Subjects | Subject | NA | ||
| Tertiary Nodes | Created during edge creation to account for missing nodes | Location | POS Tags: EX | |
| Location | POS Tags: RP, Lemma = location | |||
| Action | Primary Nodes | Events or activities connected with the entities | Word Lemma | POS Tags: VB, VBD, VBG, VBN, VBP, VBZ |
| Secondary Nodes | Action nodes are NOT created for auxiliary verbs | Not Created | POS Tags: VB | |
| Tertiary Nodes | Created during edge creation to account for missing nodes | Word Lemma | POS Tags: VB, VBD, VBG, VBN, VBP, VBZ, TO, CC | |
| Attributes | Primary Nodes | Properties that further define the entities or actions. | Word Lemma | POS Tags: JJ, JJR, JJS, RB, RBR, RBS |
| Tertiary Nodes | Created during edge creation to account for missing nodes | Word Lemma | POS Tags: IN (Prepositions) | |
| Lemma | POS Tags: CD, Word Lemma: “number” (Cardinals) |
| Edge Type | Dependency | Description | Edge |
|---|---|---|---|
| Agent | A → nsubj → B | Nominal Subject | B → agent → A |
| A → obl:agent → B | Oblique Agents | B → agent → A | |
| A → nsubj:xsubj → B | Subjects of Embedded Actions | B → agent → A | |
| A → acl → B | Adnominal Clause | B → agent → A | |
| Patient | A → obj → B | Direct Object | A → patient → B |
| A → iobj → B | Indirect Object | B → patient → A | |
| A → nsubj:pass → B | Passive Object | A → patient → B | |
| Attributes | A → advmod → B | Adverbial Modifier | A → attr → B |
| A → amod → B | Adjectival Modifier | A → attr → B | |
| A → numeric → B | Number Modifier | A → attr → B | |
| A → cop → B and A → nsubj → C | Copula | A → attr → C | |
| A → nsubj → B and A → xcomp → C | Open Clausal Complement | B → attr → C | |
| Spatial Relations | A → obl:preposition → B | Oblique Dependencies with prepositions | A → preposition → C |
| A → nmod:preposition → B | Noun Modifiers with prepositions | A → preposition → C | |
| Special relations | A → appos → B | Appositional Modifier | A → is → B |
| A → conj → B | Conjunction | A → and → B | |
| A → compound:prt → B | Compound Participles | A → attr → B |
| No. of Words | No. of Captions | No. of Entities | No. of Actions | No. of Attributes | No. of Relations |
|---|---|---|---|---|---|
| 7 | 3 | 3.33 ± 0.58 | 2.00 ± 0.00 | 2.00 ± 0.00 | 4.00 ± 0.00 |
| 8 | 339 | 3.91 ± 0.59 | 2.02 ± 1.04 | 2.07 ± 0.96 | 4.03 ± 1.10 |
| 9 | 1732 | 4.34 ± 0.76 | 2.03 ± 0.16 | 2.26 ± 0.59 | 4.78 ± 0.89 |
| 10 | 3418 | 4.67 ± 0.74 | 2.06 ± 0.23 | 2.31 ± 0.55 | 5.19 ± 1.07 |
| 11 | 4437 | 5.02 ± 0.73 | 2.05 ± 0.22 | 2.28 ± 0.59 | 5.25 ± 1.11 |
| 12 | 4344 | 5.17 ± 0.88 | 2.07 ± 0.26 | 2.49 ± 0.70 | 5.59 ± 1.12 |
| 13 | 3197 | 5.57 ± 0.91 | 2.10 ± 0.30 | 2.54 ± 0.83 | 6.03 ± 1.24 |
| 14 | 1745 | 5.79 ± 0.95 | 2.06 ± 0.25 | 2.68 ± 0.99 | 6.61 ± 1.38 |
| 15 | 959 | 5.84 ± 1.11 | 2.05 ± 0.23 | 3.05 ± 1.32 | 7.25 ± 1.58 |
| 16 | 553 | 6.18 ± 1.00 | 2.04 ± 0.19 | 3.20 ± 1.28 | 7.95 ± 1.88 |
| 17 | 257 | 6.00 ± 1.26 | 2.05 ± 0.23 | 3.88 ± 1.68 | 8.76 ± 2.02 |
| 18 | 118 | 6.79 ± 1.25 | 2.03 ± 0.18 | 3.53 ± 1.51 | 8.57 ± 1.81 |
| 19 | 49 | 7.37 ± 1.18 | 2.16 ± 0.51 | 3.24 ± 1.36 | 9.02 ± 1.73 |
| 20 | 21 | 6.62 ± 1.28 | 2.10 ± 0.30 | 4.52 ± 1.97 | 10.81 ± 2.71 |
| 21 | 12 | 6.50 ± 2.11 | 2.08 ± 0.29 | 5.92 ± 3.03 | 12.25 ± 2.49 |
| 22 | 5 | 5.80 ± 0.45 | 2.00 ± 0.00 | 7.40 ± 0.89 | 15.00 ± 0.00 |
| 23 | 5 | 5.40 ± 2.51 | 2.00 ± 0.00 | 8.40 ± 4.45 | 16.20 ± 3.63 |
| 24 | 3 | 6.67 ± 1.15 | 2.00 ± 0.00 | 6.67 ± 2.52 | 14.00 ± 2.00 |
| 25 | 1 | 4.00 ± 0.00 | 2.00 ± 0.00 | 12.00 ± 0.00 | 19.00 ± 0.00 |
| 26 | 1 | 6.00 ± 0.00 | 2.00 ± 0.00 | 9.00 ± 0.00 | 17.00 ± 0.00 |
| 27 | 1 | 8.00 ± 0.00 | 2.00 ± 0.00 | 8.00 ± 0.00 | 18.00 ± 0.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghosh, S.; Gonçalves, T.; Das, N. Im2Graph: A Weakly Supervised Approach for Generating Holistic Scene Graphs from Regional Dependencies. Future Internet 2023, 15, 70. https://doi.org/10.3390/fi15020070
Ghosh S, Gonçalves T, Das N. Im2Graph: A Weakly Supervised Approach for Generating Holistic Scene Graphs from Regional Dependencies. Future Internet. 2023; 15(2):70. https://doi.org/10.3390/fi15020070
Chicago/Turabian StyleGhosh, Swarnendu, Teresa Gonçalves, and Nibaran Das. 2023. "Im2Graph: A Weakly Supervised Approach for Generating Holistic Scene Graphs from Regional Dependencies" Future Internet 15, no. 2: 70. https://doi.org/10.3390/fi15020070
APA StyleGhosh, S., Gonçalves, T., & Das, N. (2023). Im2Graph: A Weakly Supervised Approach for Generating Holistic Scene Graphs from Regional Dependencies. Future Internet, 15(2), 70. https://doi.org/10.3390/fi15020070