
Edge-Computing-Based People-Counting System for Elevators Using MobileNet–Single-Stage Object Detection

Abstract
:1. Introduction
Our Contributions
2. Related Work
2.1. People Counting Using the ROI
2.2. People Counting Using the LOI
2.3. Counting High-Density Crowd
3. System Design Requirements and Challenges
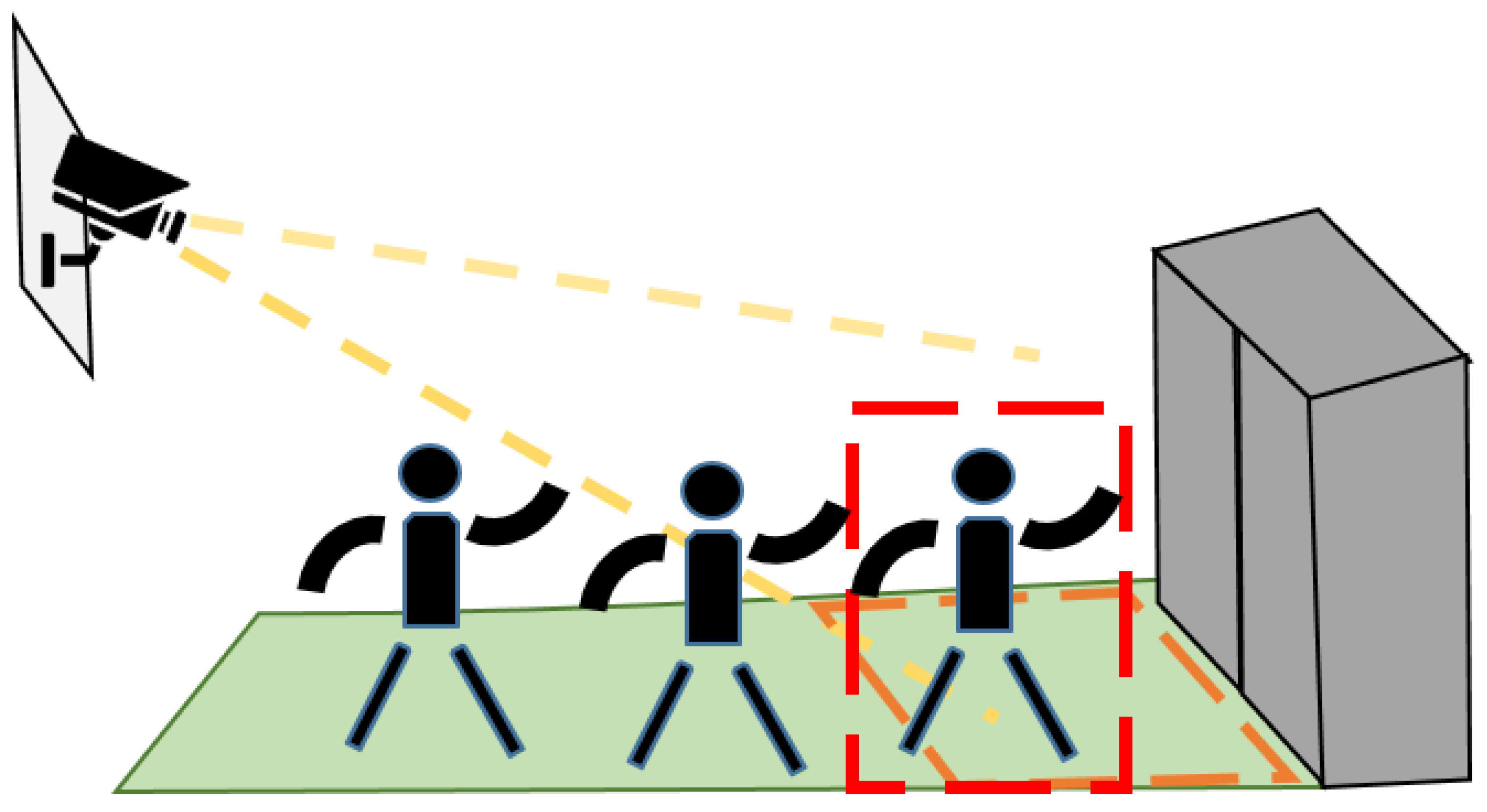
3.1. Recognizing the Elevator Hall Occupancy
3.2. Counting Elevator Occupants
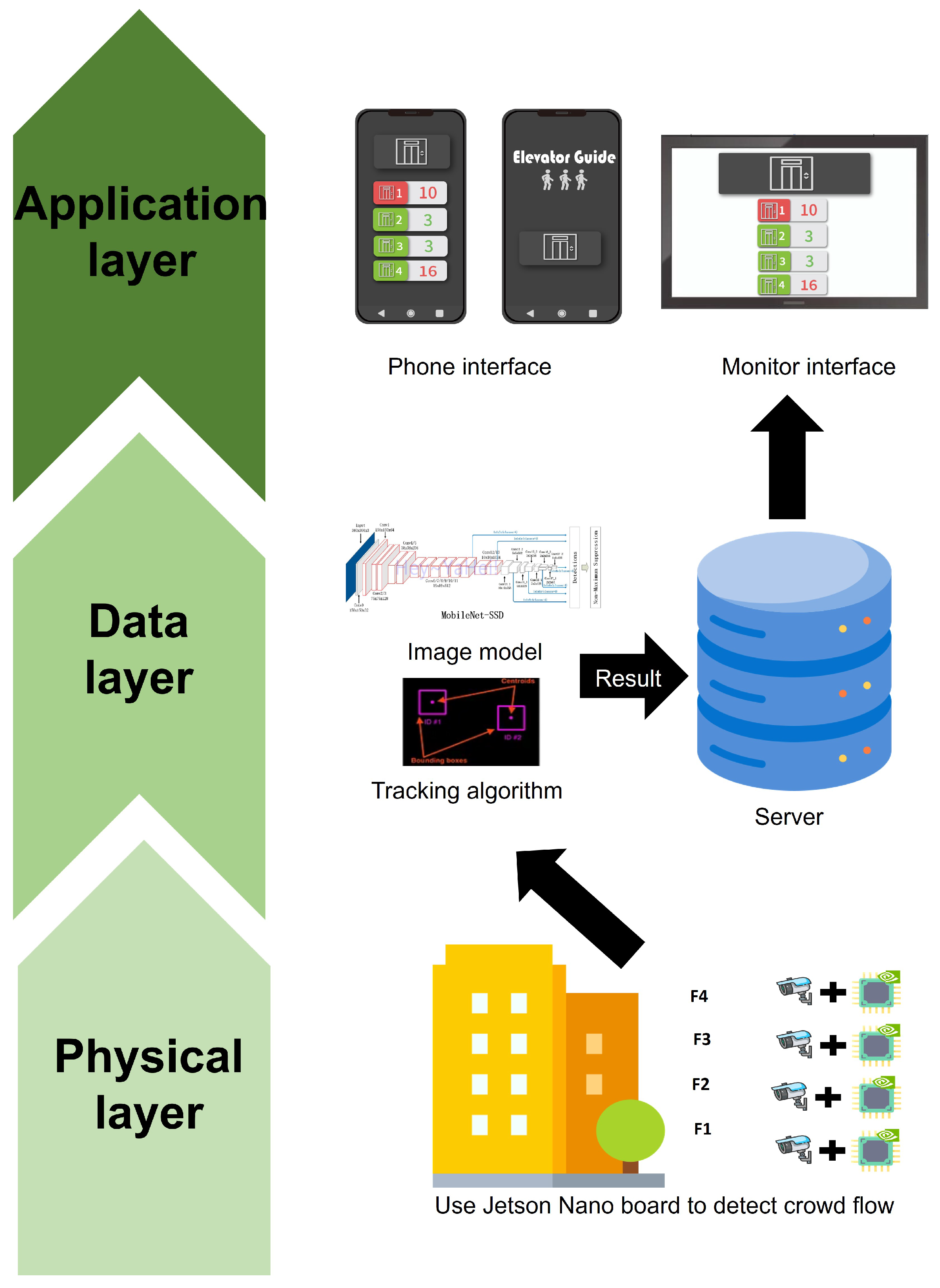
4. Elevator People-Counting System
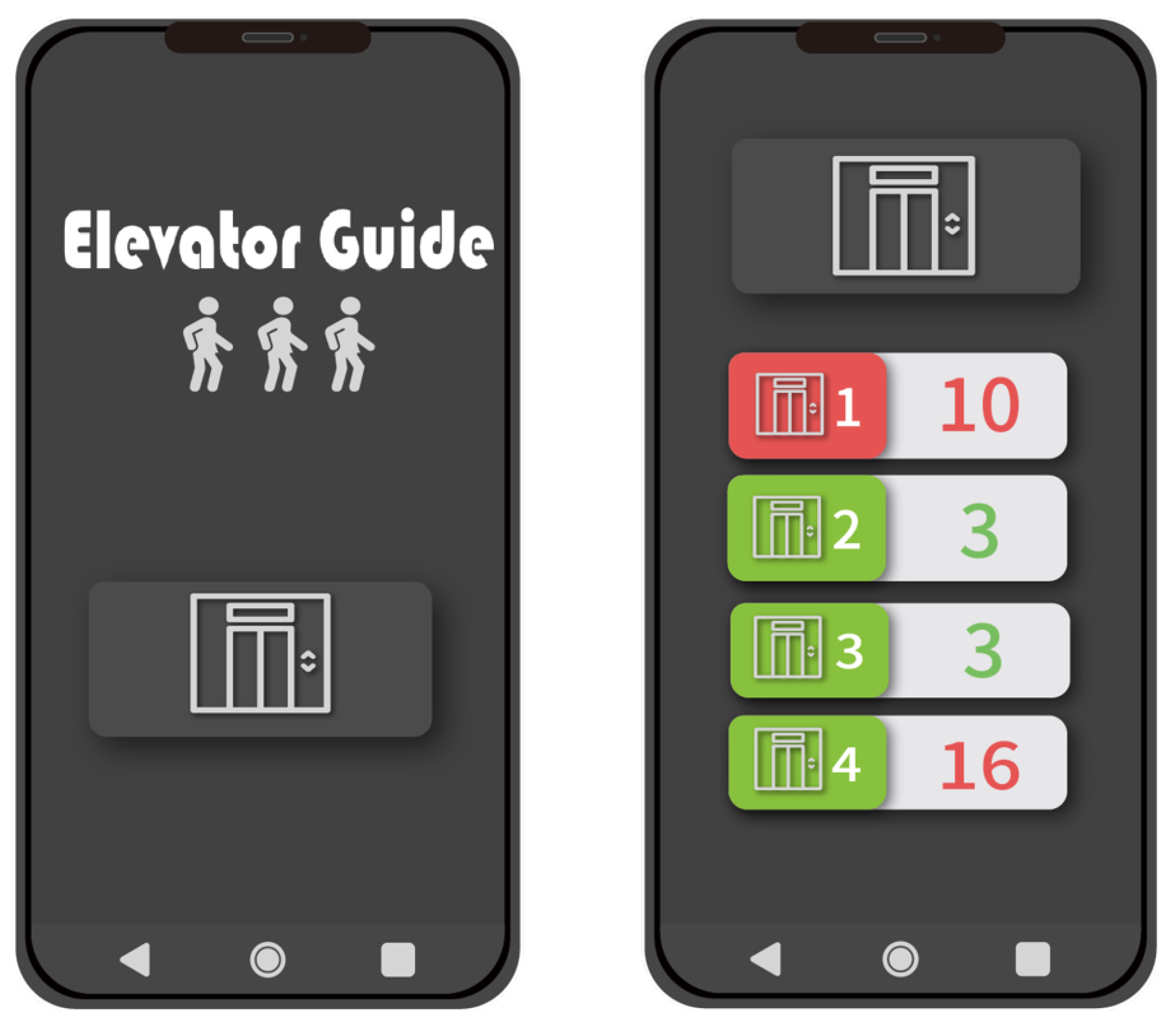
4.1. System Functions and User Interface
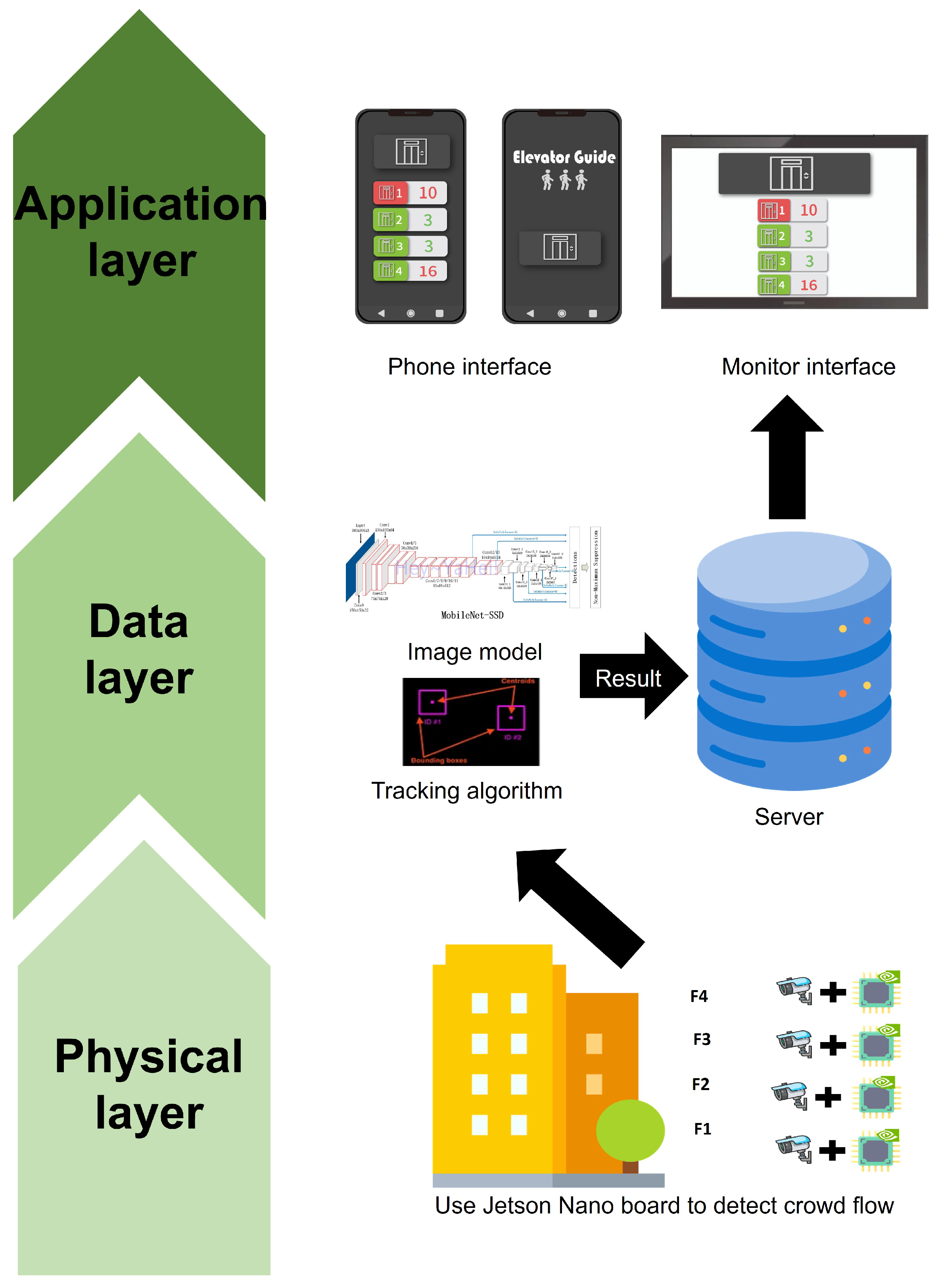
4.2. System Architecture and Usage Scenarios
4.3. People-Counting Method
4.4. Recognition Frequency
4.5. Confidence Threshold
4.6. Crowd Detection Module Porting
5. Experiment
5.1. Experiment Design
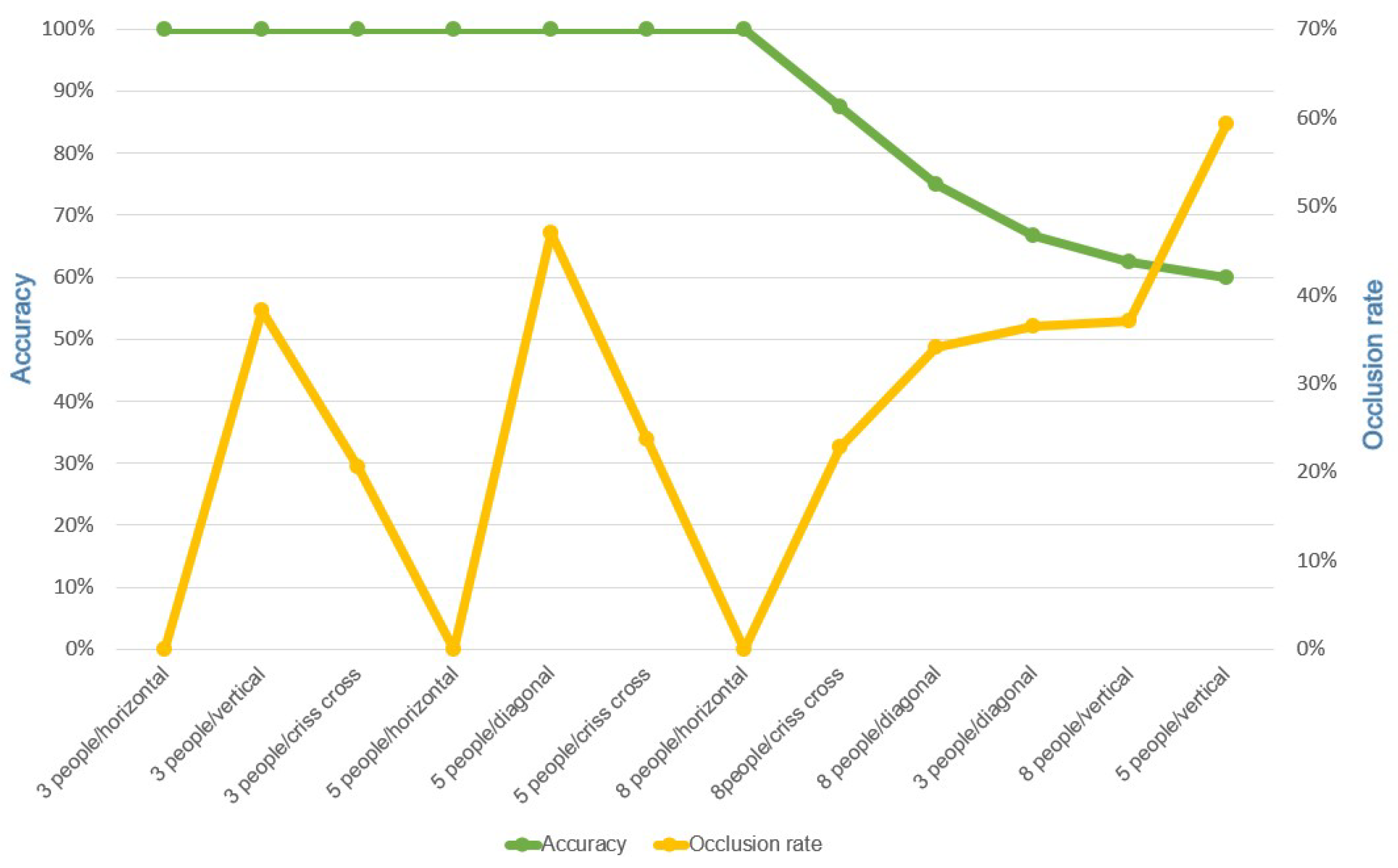
5.2. Accuracy of Cloud Computing
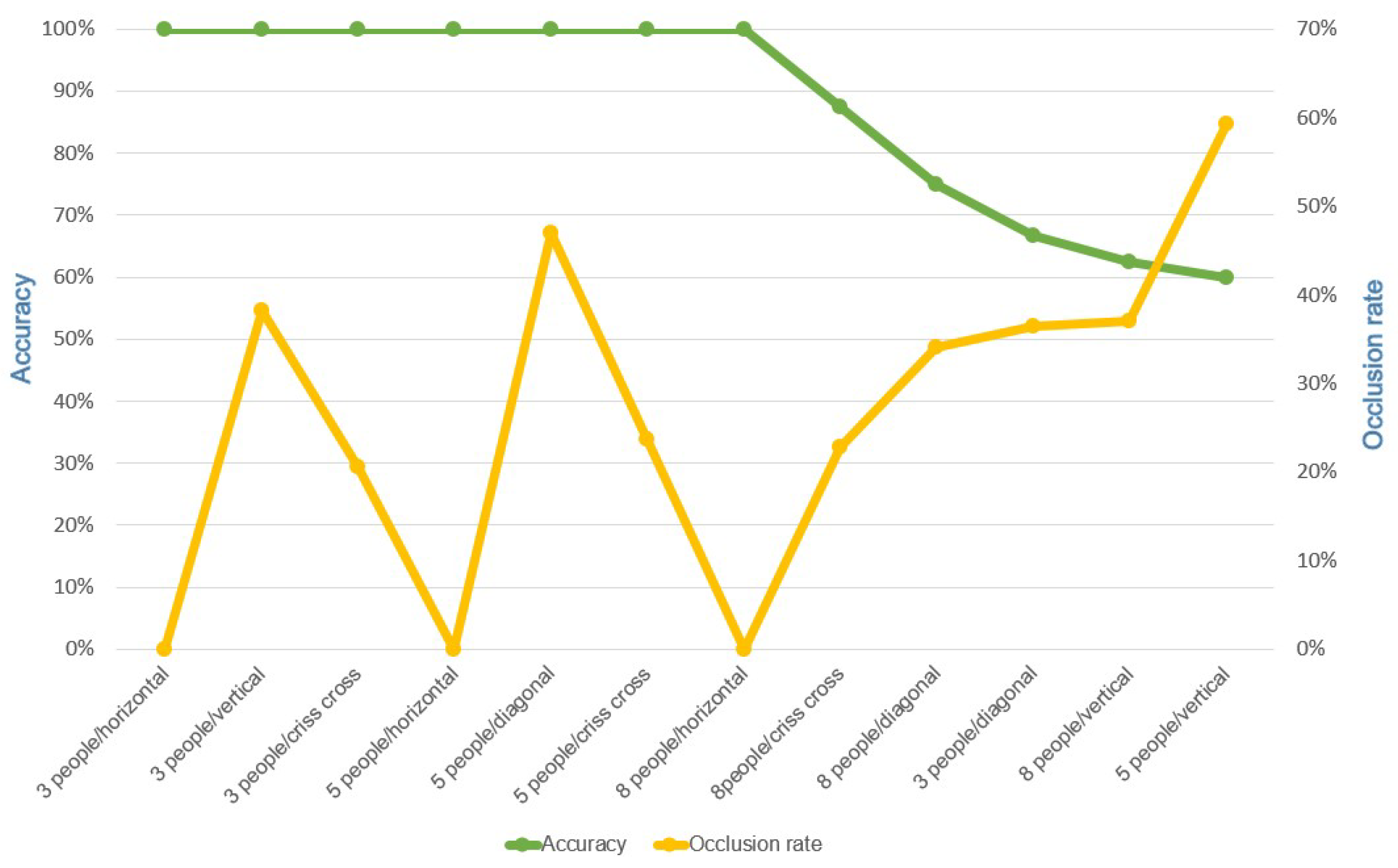
5.2.1. Effect of People Formations on the Accuracy
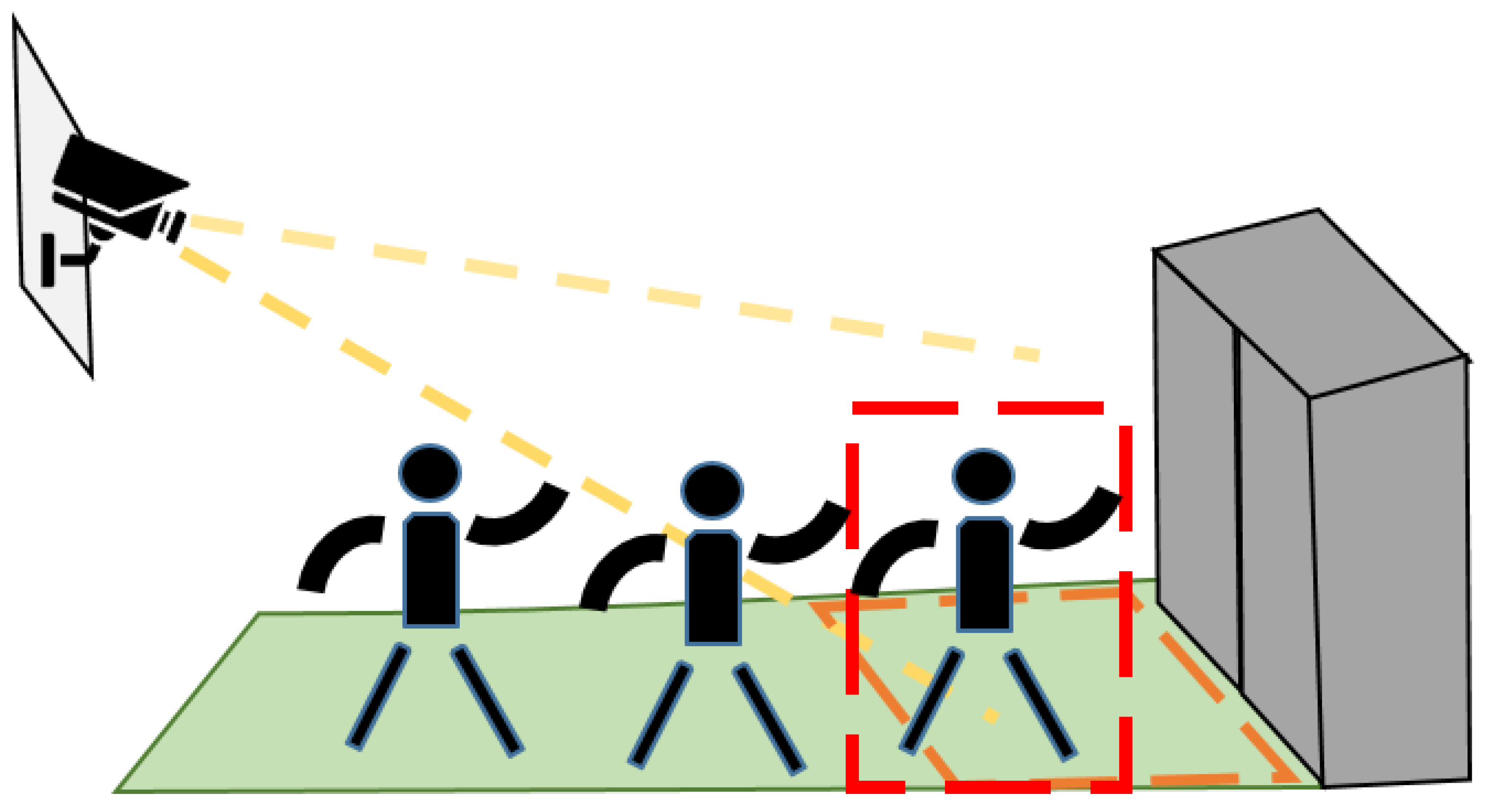
5.2.2. Effect of Occlusion on the Accuracy
5.2.3. Response Time
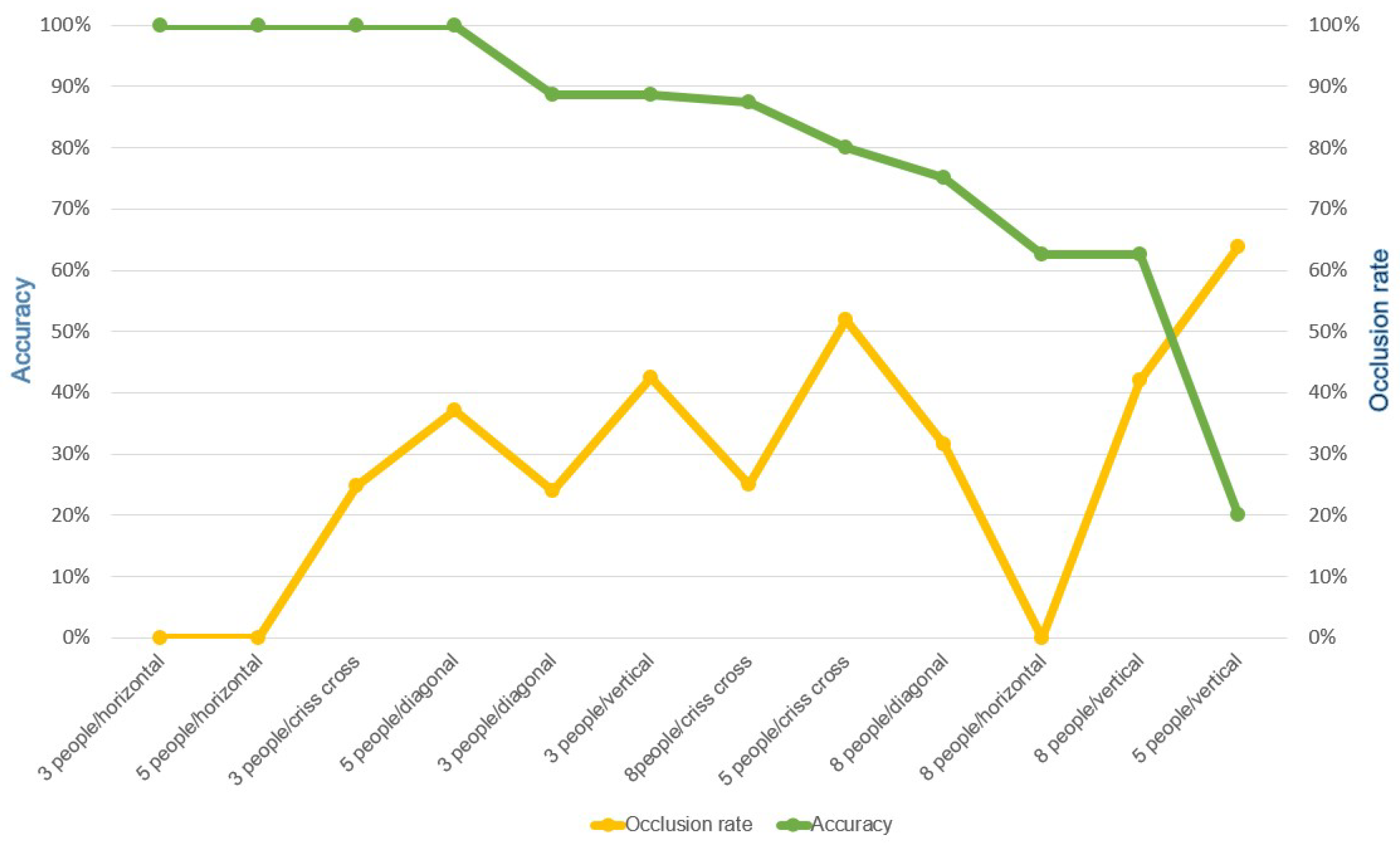
5.3. Accuracy of Edge Computing
5.3.1. Effect of People Formations on the Accuracy
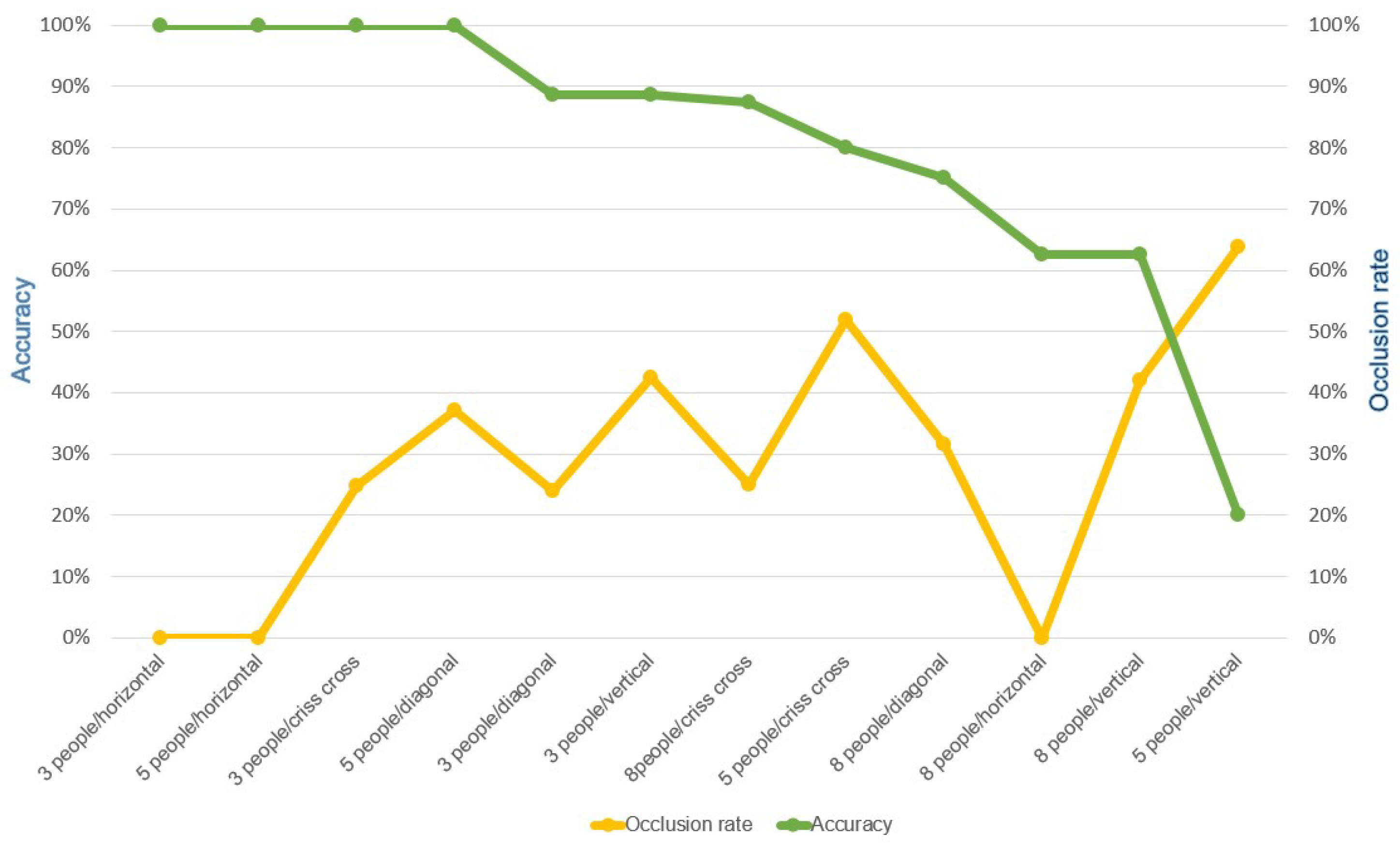
5.3.2. Effect of Occlusion on the Accuracy
5.3.3. Response Time
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fujino, A.; Tobita, T.; Segawa, K.; Yoneda, K.; Togawa, A. An elevator group control system with floor-attribute control method and system optimization using genetic algorithms. IEEE Trans. Ind. Electron. 1997, 44, 546–552. [Google Scholar] [CrossRef]
- Vodopija, A.; Stork, J. Thomas Bartz-Beielstein, and Bogdan Filipič. Elevator group control as a constrained multiobjective optimization problem. Appl. Soft Comput. 2022, 115, 108277. [Google Scholar] [CrossRef]
- Yamauchi, T.; Ide, R.; Sugawara, T. Fair and effective elevator car dispatching method in elevator group control system using cameras. Procedia Comput. Sci. 2019, 159, 455–464. [Google Scholar] [CrossRef]
- Yang, Z.; Qi, G.; Bao, R. Indoor regional people counting method based on bi-motion-model-framework using uwb radar. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Hashimoto, M.; Tsuji, A.; Nishio, A.; Takahashi, K. Laser-based tracking of groups of people with sudden changes in motion. In Proceedings of the 2015 IEEE International Conference on Industrial Technology (ICIT), Seville, Spain, 17–19 March 2015; pp. 315–320. [Google Scholar]
- Kouyoumdjieva, S.T.; Danielis, P.; Karlsson, G. Survey of non-image-based approaches for counting people. IEEE Commun. Surv. Tutor. 2020, 22, 1305–1336. [Google Scholar] [CrossRef]
- Cao, K.; Liu, Y.; Meng, G.; Sun, Q. An overview on edge computing research. IEEE Access 2020, 8, 85714–85728. [Google Scholar] [CrossRef]
- Mansouri, Y.; Babar, M.A. A review of edge computing: Features and resource virtualization. J. Parallel Distrib. Comput. 2021, 150, 155–183. [Google Scholar] [CrossRef]
- Li, X.; Yang, Y.; Xu, Y.; Wang, C.; Li, L. Crowd Abnormal Behavior Detection Combining Movement and Emotion Descriptors; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar]
- Li, M.; Zhang, Z.; Huang, K.; Tan, T. Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Akbar, N.; Djamal, E.C. Crowd counting using region convolutional neural networks. In Proceedings of the 2021 8th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Semarang, Indonesia, 20–21 October 2021; pp. 359–364. [Google Scholar]
- Ali, I.; Dailey, M.N. Multiple human tracking in high-density crowds. Image Vis. Comput. 2012, 30, 966–977. [Google Scholar] [CrossRef]
- Pham, N.T.; Leman, K.; Zhang, J.; Pek, I. Two-stage unattended object detection method with proposals. In Proceedings of the 2017 IEEE 2nd International Conference on Signal and Image Processing (ICSIP), Singapore, 4–6 August 2017; pp. 1–4. [Google Scholar]
- Le, M.C.; Le, M.; Duong, M. Vision-based people counting for attendance monitoring system. In Proceedings of the 2020 5th International Conference on Green Technology and Sustainable Development (GTSD), Ho Chi Minh City, Vietnam, 27–28 November 2020; pp. 349–352. [Google Scholar]
- Ma, Z.; Chan, A.B. Crossing the line: Crowd counting by integer programming with local features. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2539–2546. [Google Scholar]
- Cho, S.I.; Kang, S. Real-time people counting system for customer movement analysis. IEEE Access 2018, 6, 55264–55272. [Google Scholar] [CrossRef]
- Barandiaran, J.; Murguia, B.; Boto, F. Real-time people counting using multiple lines. In Proceedings of the 2008 Ninth International Workshop on Image Analysis for Multimedia Interactive Services, Klagenfurt, Austria, 7–9 May 2008; pp. 159–162. [Google Scholar]
- Liu, W.; Salzmann, M.; Fua, P. Counting people by estimating people flows. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 8151–8166. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhang, W.; Liu, Y.; Zhu, J. Multi-density map fusion network for crowd counting. Neurocomputing 2020, 397, 31–38. [Google Scholar] [CrossRef]
- Chen, J.; Xiu, S.; Chen, X.; Guo, H.; Xie, X. Flounder-net: An efficient cnn for crowd counting by aerial photography. Neurocomputing 2021, 420, 82–89. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, H.; Yang, L.; Liu, S.; Cao, X. Deep People Counting in Extremely Dense Crowds; Association for Computing Machinery: New York, NY, USA, 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single shot MultiBox detector. In Computer Vision—ECCV 2016; Springer International Publishing: Berlin, Germany, 2016; pp. 21–37. [Google Scholar]
- Magalhães, S.A.; Castro, L.; Moreira, G.; Santos, F.N.d.; Cunha, M.; Dias, J.; Moreira, A.P. Evaluating the single-shot multibox detector and yolo deep learning models for the detection of tomatoes in a greenhouse. Sensors 2021, 21, 3569. [Google Scholar] [CrossRef] [PubMed]
- Mockuphone. Available online: https://mockuphone.com/ (accessed on 25 August 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Main Objectives | Methods | |||
|---|---|---|---|---|---|
| Accuracy | Real-Time | Low Computation | Object Tracking | Feature Extraction | |
| Xiao Li et al. [9] | V | V | |||
| Min Li et al. [10] | V | V | V | ||
| Naufal Akbar et al. [11] | V | V | V | ||
| Irshad Ali et al. [12] | V | V | |||
| Nam Trung Pham. et al. [13] | V | V | V | V | |
| Zheng Ma et al. [15] | V | V | V | ||
| Sung In Cho. et al. [17] | V | V | V | V | |
| Javier Barandiaran et al. [19] | V | V | V | ||
| Yongjie Wang et al. [20] | V | V | |||
| Jingyu Chen et al. [21] | V | V | V | ||
| Ours | V | V | V | V | V |
| Formation | Horizontal | Vertical | Diagonal | Criss-Cross | |
|---|---|---|---|---|---|
| Number of People in Waiting Area | |||||
| 1 | 100% | 100% | 100% | 100% | |
| 2 | 100% | 100% | 100% | 100% | |
| 3 | 100% | 100% | 67% | 100% | |
| Formation | Horizontal | Vertical | Diagonal | Criss-Cross | |
|---|---|---|---|---|---|
| Number of People in Waiting Area | |||||
| 1 | 100% | 100% | 100% | 100% | |
| 2 | 100% | 100% | 100% | 100% | |
| 3 | 100% | 89% | 100% | 100% | |
| 4 | 100% | 75% | 100% | 100% | |
| 5 | 100% | 60% | 100% | 100% | |
| Formation | Horizontal | Vertical | Diagonal | Criss-Cross | |
|---|---|---|---|---|---|
| Number of People in Waiting Area | |||||
| 1 | 100% | 100% | 100% | 100% | |
| 2 | 100% | 100% | 100% | 100% | |
| 3 | 67% | 89% | 100% | 100% | |
| 4 | 75% | 75% | 100% | 75% | |
| 5 | 80% | 60% | 80% | 60% | |
| 6 | 83% | 67% | 83% | 67% | |
| 7 | 86% | 71% | 86% | 71% | |
| 8 | 75% | 75% | 75% | 75% | |
| Number of People | Formation | FPS |
|---|---|---|
| 3 | Horizontal | 15.91 |
| 3 | Vertical | 24.90 |
| 3 | Diagonal | 16.75 |
| 3 | Criss-Cross | 24.15 |
| 5 | Horizontal | 15.45 |
| 5 | Vertical | 24.98 |
| 5 | Diagonal | 17.24 |
| 5 | Criss-Cross | 16.91 |
| 8 | Horizontal | 19.69 |
| 8 | Vertical | 22.33 |
| 8 | Diagonal | 18.72 |
| 8 | Criss-Cross | 26.60 |
| Formation | Horizontal | Vertical | Diagonal | Criss-Cross | |
|---|---|---|---|---|---|
| Number of People in Waiting Area | |||||
| 1 | 100% | 100% | 100% | 100% | |
| 2 | 100% | 100% | 100% | 100% | |
| 3 | 100% | 89% | 89% | 100% | |
| Formation | Horizontal | Vertical | Diagonal | Criss-Cross | |
|---|---|---|---|---|---|
| Number of People in Waiting Area | |||||
| 1 | 100% | 100% | 100% | 100% | |
| 2 | 100% | 50% | 100% | 100% | |
| 3 | 100% | 33% | 100% | 100% | |
| 4 | 100% | 25% | 100% | 100% | |
| 5 | 100% | 20% | 100% | 80% | |
| Formation | Horizontal | Vertical | Diagonal | Criss-Cross | |
|---|---|---|---|---|---|
| Number of People in Waiting Area | |||||
| 1 | 100% | 100% | 100% | 100% | |
| 2 | 100% | 100% | 100% | 100% | |
| 3 | 100% | 100% | 100% | 100% | |
| 4 | 50% | 100% | 100% | 100% | |
| 5 | 40% | 80% | 100% | 80% | |
| 6 | 67% | 67% | 83% | 83% | |
| 7 | 57% | 71% | 86% | 86% | |
| 8 | 63% | 63% | 75% | 88% | |
| Number of People | Formation | FPS |
|---|---|---|
| 3 | Horizontal | 5.98 |
| 3 | Vertical | 6.85 |
| 3 | Diagonal | 6.57 |
| 3 | Criss-Cross | 6.58 |
| 5 | Horizontal | 4.11 |
| 5 | Vertical | 5.70 |
| 5 | Diagonal | 5.18 |
| 5 | Criss-Cross | 5.16 |
| 8 | Horizontal | 4.65 |
| 8 | Vertical | 5.93 |
| 8 | Diagonal | 4.26 |
| 8 | Criss-Cross | 5.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, T.-C.; Chu, E.T.-H. Edge-Computing-Based People-Counting System for Elevators Using MobileNet–Single-Stage Object Detection. Future Internet 2023, 15, 337. https://doi.org/10.3390/fi15100337
Shen T-C, Chu ET-H. Edge-Computing-Based People-Counting System for Elevators Using MobileNet–Single-Stage Object Detection. Future Internet. 2023; 15(10):337. https://doi.org/10.3390/fi15100337
Chicago/Turabian StyleShen, Tsu-Chuan, and Edward T.-H. Chu. 2023. "Edge-Computing-Based People-Counting System for Elevators Using MobileNet–Single-Stage Object Detection" Future Internet 15, no. 10: 337. https://doi.org/10.3390/fi15100337
APA StyleShen, T.-C., & Chu, E. T.-H. (2023). Edge-Computing-Based People-Counting System for Elevators Using MobileNet–Single-Stage Object Detection. Future Internet, 15(10), 337. https://doi.org/10.3390/fi15100337