1. Introduction
In recent years, the Internet has witnessed significant growth in data volume due to the increase in data communication between Internet-connected devices worldwide. In addition, the rapid internet of things (IoT) development brings many new devices into the global Internet; this number is predicted to rise to 25 billion devices in 2030 [
1]. These devices often collect users’ data and store it on the network, and, most importantly, many manufacturers are approaching the IoT device market, rushing to release new products continuously. This aspect has led to poor product design with open security vulnerabilities. This phenomenon creates challenges for network administrators to protect the system from hackers, who could examine the system with malicious emails, DoS/DDoS attacks and other malicious worms or Trojans.
Intrusion detection systems (IDS) can be built based on signature-based or anomaly-based approaches [
2]. The signature-based IDS scans each incoming network packet using stored rules in the system’s database; thus, it can prevent known attacks with a high accuracy rate. In the signature-based IDS, the vendor has to update the signature database regularly [
3]. These systems require not only additional storage resources, when new rules are added over time, but also introduce extra overhead [
4] while querying the ever-growing database. Furthermore, signature-based IDS cannot detect new attacks, which can potentially crash the system. Therefore, state-of-the-art IDS are applying anomaly-based approaches [
5] to be able to detect unknown attacks. In addition, anomaly-based approaches can be implemented using lightweight mathematical models, which rely primarily on computational resources rather than massive storage, compared to signature-based techniques.
In the meantime, the development of Artificial Intelligence (AI) has dramatically impacted many areas, including IDS implementations. AI applications have become a prominent topic because this technology can train machines to mimic human cognitive functions. It has achieved success in solving many practical problems, such as speech-recognition [
6], encryption [
7], biosignal monitoring [
8], etc. Besides, machine learning (ML) [
9] is renowned as an application of AI that can improve itself based on experience. ML has shown high efficiency and applicable results in predicting attacks in anomaly-based IDS, which is one of the classification problems. Many ML classification techniques [
10] such as linear classifiers, logistic regression, support vector machines (SVM), decision trees (DT) and artificial neural networks (ANN) have been used to predict the category to which the data belongs.
From the IoT network point of view, anomaly-based IDS have to be carefully designed and implemented due to the device’s limitations. On the one hand, IoT devices come from different manufacturers, requiring additional hardware configurations and connections. In other words, there has yet to be a consensus regarding protocols and standards between IoT devices; as a result, deploying and establishing communications for these devices is time-consuming. On the other hand, many devices need continuous power to function correctly; integrating ML applications into IoT devices has to consider both power consumption and computational capability. Additionally, anomaly-based IDS run real-time applications that heavily depend on hardware platforms. Thus, it is important to choose suitable hardware for prototyping and deploying IoT applications.
Hardware accelerators such as Graphics Processing Units (GPUs), low-power microprocessors and Field-Programmable Gate Arrays (FPGAs) have a high potential use for IoT devices running ML applications. This paper introduces an anomaly-based IDS framework on heterogeneous hardware for IoT devices. The framework aims to generate high-efficiency and low-power consumption ANN models for deploying on hardware accelerators.
1.1. Contribution
This research is extended from our existing FPGA Hardware Acceleration Framework [
11]. This paper introduces HH-NIDS—a heterogeneous hardware-based network intrusion detection framework for IoT security. HH-NIDS applies anomaly-based IDS approaches for IoT devices using hardware accelerators. The first prototype system utilises the supervised-learning method on the IoT-23 [
12] and UNSW-NB15 [
13] datasets to generate lightweight ANN models. We implement the proposed framework on a heterogeneous platform, including a microcontroller, an SoC FPGA and GPU platforms under the handling of host processors. The training phase is conducted on GPU, while the inference phase is accelerated on two hardware platforms:
Finally, the first prototype system is deployed on the MAX78000 evaluation kit [
15] (MAX78000EVKIT) and PYNQ-Z2 SoC FPGA board [
16]. The implemented systems are evaluated using a number of testing scenarios on the two public datasets: IoT-23 and UNSW-NB15. Hardware resource usage and power consumption are also discussed and compared to relevant works.
1.2. Organisation
The rest of this work is organised as follows.
Section 2 introduces modern anomaly-based IDS for IoT networks. In
Section 3, we present the materials and methods used here for framework design.
Section 4 shows our first prototype system based on the proposed hardware-based architecture. We evaluate and analyse our implemented system in
Section 5. Next, we discuss the advantages and disadvantages of HH-NIDS in
Section 6. Finally, the conclusions and future work suggestions are stated in
Section 7.
2. Related Works
Machine learning and deep learning (DL) have been widely adopted in anomaly-based IDS to detect unseen attacks [
17,
18,
19]. The authors in [
20,
21] have experimented with various machine learning algorithms on an IoT-based open-source dataset. They have achieved up to 99% accuracy by applying the random forest (RF) classifier; however, the dataset used in this research was small (357,952 records) compared to other practical datasets. RF has also been claimed, in [
22], as the best algorithm for detecting anomalies. Meanwhile, DL has shown better performance when dealing with large datasets. For instance, researchers in [
23] have trained deep neuron network (DNN) models on six different datasets with the best training accuracy in the range 95% to 99% on the KDDCup-99 and NSL-KDD datasets. On the same datasets, the system in [
24] has achieved similar results (up to 99% detection rate) by using a deep network model with an automatic feature extraction method. Even though ML and DL are prominent techniques for anomaly-based IDS with high detection rates, the trained DL models usually require heavy computational resources, which are limited on standard IoT devices.
Table 1 shows a summary of anomaly-based IDS for IoT networks. The paper [
25] has introduced a federated self-learning anomaly detection in IoT networks on a self-generated dataset. Similarly, authors in [
26] have proposed a decentralised federated-learning approach with an ensembler, which combines long short-term memory (LSTM) and gated recurrent units to enable anomaly detection. Researchers in [
27] have tested various ML algorithms on a generated dataset, called MQTT, for IoT network attack detection and achieved an accuracy of 98%. DL algorithms have also been used to generate detection models from various IoT datasets. For instance, authors in [
28] have built deep belief network models from the CICIDS 2017 dataset to classify normal records from six different attack types, with an average accuracy of 97.46%. In [
29], the Yahoo webscope s5 dataset has been used as input for convolutional neuron network (CNN) and recurrent autoencoder algorithms. Authors in [
30] have generated lightweight detection models based on a deep autoencoder from the Bot-IoT dataset. The best setup has reached 97.61% F1-score; however, the hardware platform for experimenting with the system is not mentioned. The self-generated dataset is collected in [
31]; the data are fed into a graph neural network, which has produced up to 97% accuracy in the literature.
The IoT-23 dataset has been trained with supervised-learning methods.
Table 2 presents the summary of anomaly-based IDS on the IoT-23 dataset. The authors in [
32,
33] have applied an ensemble strategy, which combines DNN and LSTM. The paper [
34] has proposed a universal feature set to detect botnet attacks on the IoT-23 dataset. However, the proposed feature extraction module is tool-based, which can cause dependency and add extra overhead [
35]. Malware and botnet analysis on the IoT-23 dataset has been examined in [
36,
37]. Authors in [
38] have reported 99.9% accuracy by applying hyper-parameter optimisation on the deep ensemble model (CNN and RF). Meanwhile, ML algorithms have been used in [
39,
40] to generate lightweight detection models, resulting in 99.62% and 99.98% accuracy, respectively. However, there are limitations in current works. On the one hand, most of the anomaly-based IDS for IoT networks are designed at the system’s high-level view that is usually deployable at the IoT gateway level. Anomaly behaviours can be detected earlier at the edge devices. On the other hand, they have focused on software-based metrics only, while hardware-based metrics, such as power consumption, performance and network throughput, are not mentioned.
Hardware accelerators, including specialised AI microcontrollers and SoC FPGA, are promising platforms for securing IoT devices [
41,
42]. IoT security monitoring systems [
43,
44] have implemented accelerating semantic caching on FPGA. Researchers in [
45] have introduced a mapping methodology to bring neuron network-based models to hardware. The proposed method has achieved a latency of 210 ns on a Xilinx Zynq UltraScale+ MPSoC FPGA running mapped LSTM models. FPGA acceleration for time series similarity prediction [
46] has been proposed for IoT edge devices. The implemented system can reach a throughput of 453.5G operations per second with a 10.7x faster inference rate on a Xilinx Ultra96-V2 FPGA compared to the Raspberry Pi. Lightweight ANN models for intrusion detection systems are proposed on an SoC FPGA platform in [
47]. They have achieved a speedup of 161.7 times faster than software-based methods on the NSL-KDD dataset. Overall, anomaly-based IDS for IoT devices on hardware accelerators is a promising approach. This paper introduces an ultra-low power consumption and low-latency heterogeneous hardware-based IDS framework. The prototype system is tested with the IoT-23 and UNSW-NB15 datasets on the MAX78000 microcontroller and SoC FPGA platforms.
4. Implementation
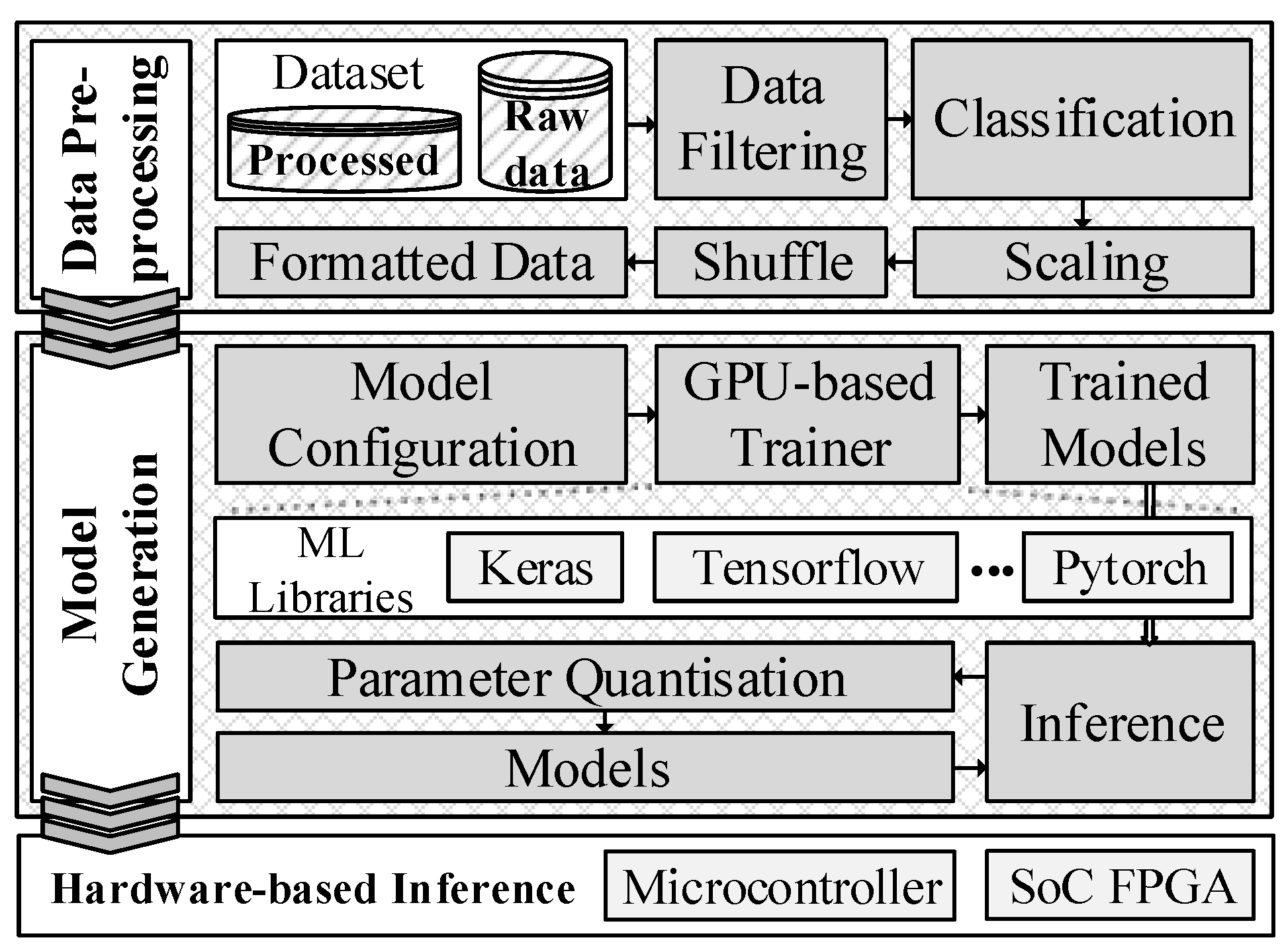
In this section, we introduce HH-NIDS’s prototype system implementation. The prototype system uses heterogeneous hardware, including GPU, Microcontroller, SoC FPGA and host processors for experimenting with the IoT-23 and UNSW-NB15 datasets. The implementation is explained as follows.
4.1. Data Pre-Processing
The HH-NIDS utilises static features for training the NN models.
Table 5 shows the static features definitions from the two datasets; the source/destination IP address is represented as four 8-bit inputs, while other fields are normalised/scaled to fit into the neurons’ inputs.
4.2. Model Generation
As described in the previous section, the pre-processing data phase extracts eleven flow features as inputs for our NN models. The hidden layer in a NN model is configured with 32 or 48 neurons, each followed by a hardware-efficient ReLU (Rectified Linear Unit) activation function; the softmax activation function is used in the output layer. The processed data are allocated at the rate of 50% for training, 25% for validation, and 25% for inference. The NN models were trained using the cross-entropy loss function and Adam optimiser with a batch size of 512, and the learning rate is set equal to 0.0005, 0.001, or 0.01.
4.3. Microcontroller
The inference phase has been deployed on the Maxim MAX78000EVKIT, which has an artificial intelligence microcontroller with ultralow-power neural network acceleration processors. Maxim provides sample projects, which generate NN models using the PyTorch library. The NN processors on the MAX78000EVKIT can only support a maximum of 8-bit registers for storing parameters (weights and bias). As a result, the training process is configured as quantisation-aware.
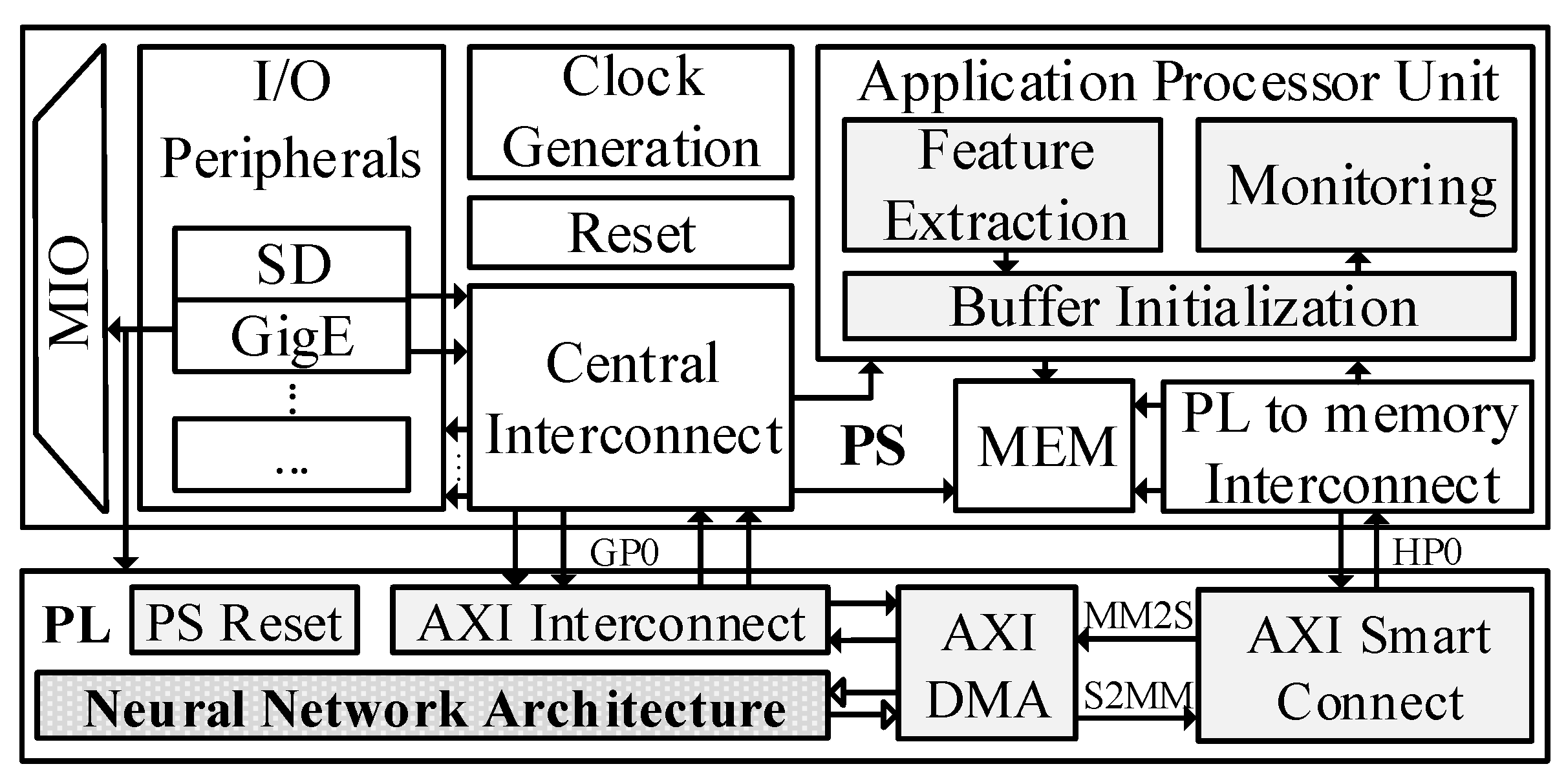
4.4. SoC FPGA
Figure 3 illustrates the inference phase block diagram on the Zynq-7000 SoC architecture, which includes two main domains: namely, the Processing System (PS) and the Programmable Logic (PL/FPGA). The PS has basic modules for a computer system: Multiplexer Input/Output (MIO), I/O Peripherals, Memory (MEM), Interconnects and an Application Processor Unit (APU). The SoC FPGA board is booted from an SD card, and the programmed application is loaded into the APU. Here, network packets will be sent to the APU for extracting input features in the
Feature Extraction module. Then, the extracted features are grouped together in the
Buffer Initialization module, before being sent to the PL. This buffer helps reduce overhead in data exchanges between the PS and the PL. Processed results from the PL are delivered back to the
Monitoring module for analysis. The PL domain has five main blocks, which are:
The PS Reset block: receives the reset control signals from the PS to reset the PL to the initial state.
The AXI Interconnect block: assigns user’s input values to registers in PL through General-Purpose Ports (GP0), which is configured as a 32-bit AXI-lite interface. There are two registers to be configured in the NN block: namely, the RESET register for resetting the module and the NUM_OF_INPUT register to indicate the number of records to be sent from PS each time.
AXI Smart Connect block: receives grouped input features, which are buffered in the PS, using High-Performance Ports (HP0). Then, data are sent to the AXI DMA block by a Memory-Mapped to Stream (MM2S) channel. In addition, the scanned data are transferred back from AXI DMA to this block by a Stream to Memory-Mapped (S2MM) channel. These data are intrusion detection results that are ready to be sent back to PS for analysis.
The AXI DMA block: this is connected to the NN block through an AXI Stream interface for sending/receiving data to/from the NN block.
The Neuron Network Architecture block: this contains the NN model on FPGA. This block is implemented in two approaches: namely, high-level synthesis (HLS) and Verilog implementation.
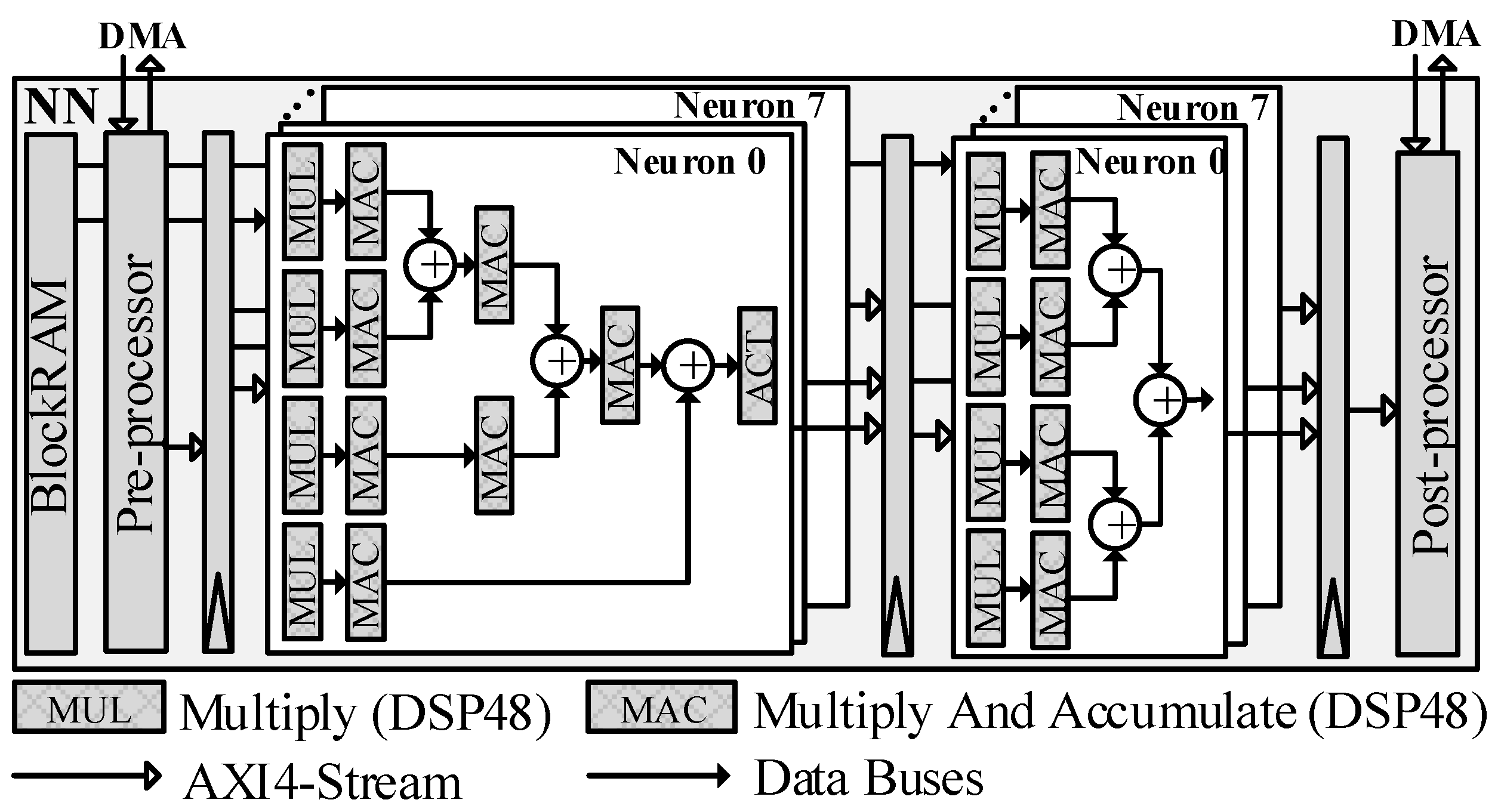
4.4.1. HLS Approach
The HLS approach builds the NN block from a C implementation.
Figure 4 describes the NN block’s architecture on FPGA. The trained parameters are loaded into BlockRAMs memory, and the input for neurons is extracted from the input stream by the
Pre-processor module. The hidden and output layers are configured using a pipeline strategy and resource-sharing techniques in which there are only eight neurons in each layer. Additionally, DSP48 blocks are used to implement both MUL and MAC operands. Finally, the
Post-processor module produces the output stream, which connects to the
AXI DMA block.
The NN block on FPGA is implemented by Vivado HLS 2018.2. Parameter quantisation and HLS Pragmas techniques are taken into account for implementation, in particular:
Parameter Quantisation: this transforms each trained parameter of an NN model to integer values. For instance, for a layer with weight values in the range of
, a quantised value,
, from
, is calculated by
where
n is the number of bits for storing a weight value in the FPGA. This number is set to 32 in the case of HLS implementation.
HLS Pragmas are applied for optimising our implementation in C++ into the RTL. For instance, HLS Dataflow is used for pipelining calculations between layers, HLS Pipeline and HLS Unroll are used for parallel computation of neurons in each layer.
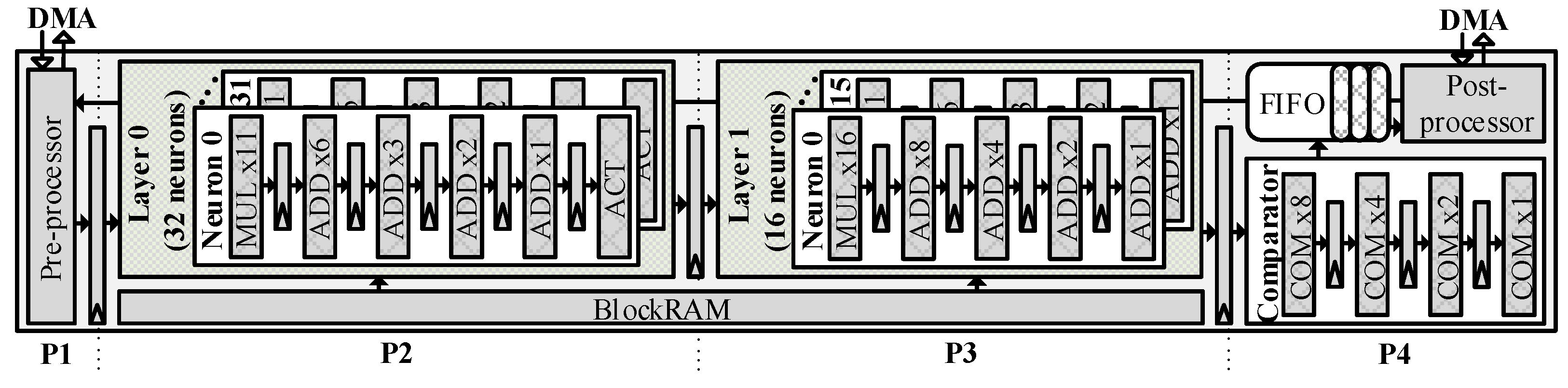
4.4.2. Verilog Implementation Approach
This approach uses a hardware description language to implement the
Neuron Network Architecture block.
Figure 5 shows the prototype implementation on an FPGA-based architecture. The data flow is similar to the
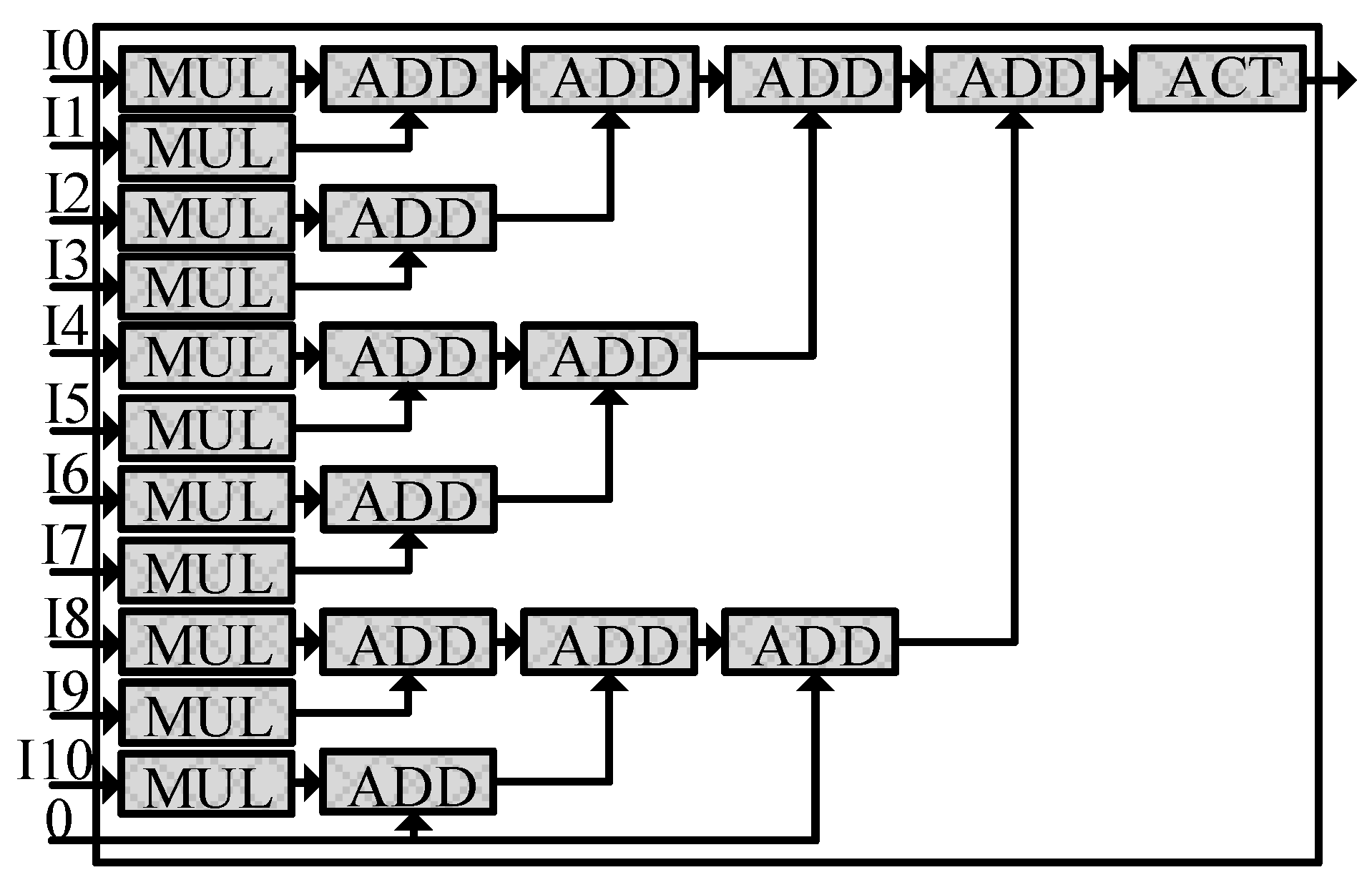
HLS implementation approach; however, the number of neurons in the hidden and output layers is maximised for the designed neuron network architecture (11 inputs, 32 hidden neurons, 16 output neurons).
By using Verilog, the processing performance is optimised manually with a pipeline strategy, in which buffers are placed between each calculation step. The pipelined NN architecture could be described as having four phases:
Input buffering (P1): contains the Pre-processor block to receive the eleven input features from DMA through the AXI4-Stream interface.
Layer_0 calculation (P2): has 32 neurons running simultaneously. These neurons have the same architecture, which has six calculation stages: multiplication, four additions, and an activation.
Figure 6 illustrates a single neuron architecture on FPGA. From the P1 phase, the 11-input features are fed into the corresponding eleven 2-input multipliers (
MULx 11 block). Next, these results are accumulated by the next four addition stages, represented as
ADD x6,
ADD x3,
ADD x2, and
ADD x1 blocks. The final summed result is passed to the
ACT block, which is implemented as a hardware-efficient ReLU (Rectified Linear Unit) activation function.
Layer_1 calculation (P3): receives buffered results from the P2 phase; then, these data are distributed to sixteen neurons in this block. Each neuron shares the same calculation architecture with Layer_0 neurons; except that each neuron in Layer_1 has five calculation stages: a multiplication (MUL x16 block) and four additions (ADD x8, ADD x4, ADD x2, and ADD x1 blocks). The final results are buffered and will be read in the next clock cycle.
Output buffering (P4): includes the Comparator, the FIFO buffer, and the Post-processor blocks. The Comparator block returns the maximum index from sixteen inputs, corresponding to sixteen output neurons in the P3 phase. These indices are stored in a FIFO (First in, first out) buffer. The Post-processor block reads data from the buffer and sends it to DMA; this block also sends a signal to the Pre-processor block to indicate if the buffer can store all the results.
5. Results
In this section, the prototype HH-NIDS implementation is evaluated. Firstly, we discuss the hardware resource usage on two platforms: microcontroller (MAX78000EVKIT) and SoC FPGA (PYNQ-Z2). Secondly, the accuracy results are discussed and compared to relevant works. Finally, the hardware performance is measured.
5.1. Implemented Result
On the MAX78000 microcontroller, the NN models have two parameter layers with a total of 1360 parameters, which corresponds to 1360 bytes. With respect to the total hardware resources on the board, 1360 bytes out of 442,368 bytes (0.3%) weight memory were used. Six bytes out of 2048 bytes of total bias memory were utilised (the bias was not used). The records were sent, one after another, repeatedly. Utilising the power monitor built into the MAX78000EVKIT, the power drawn was between 17 mW (loading weights etc.) and 18mW (when the NN model is inferring).
As introduced in
Section 4, our NN models on FPGA are implemented using two different approaches: namely, HLS and Verilog. These implementations on Vivado version 2018.2 were deployed on a PYNQ-Z2 board, which includes Dual ARM Cortex-A9 MPCore and a Xilinx Zynq xc7z020-1clg400c SoC (containing a total of 53,200 LUTs, 106,400 FFs, 140 BRAMs, and 220 DSP slices).
Table 6 shows the hardware resource usage, timing and power consumption estimation of the implemented NN for the IoT-23 dataset. In terms of FPGA resource usage, the HLS implementation approach consumed 24.60% LUTs, 15.25% FFs; while the Verilog implementation approach used nearly double these resources, which are 41.97% LUTs and 26.60% FFs on the PYNQ-Z2 board. Although the Verilog implementation approach used fewer BRAMs (14.29% compared to 30.36%), this approach required 220 DSP slices, which is 100% of the on-chip DSP slices on the PYNQ-Z2 board. The maximum frequency is approximately 101MHz in both implemented strategies. The power synthesised in the Verilog implementation is 0.3W less than the HLS implementation (1.53 W compared to 1.83 W).
Similarly,
Table 7 represents the hardware resource usage, timing and power consumption estimation of the implemented NN models on the UNSW-NB15 dataset. The used LUTs and FFs are 22.15% and 15.26% in the HLS implementation approach; these numbers are 52.64% and 31.93% in the Verilog implementation approach, respectively. The BRAMs and DSP resources used are approximately equal to those of the IoT-23 dataset implementations. The maximum frequency is approximately 102.4 MHz in both approaches, while the power consumption in the Verilog implementation is 0.23 W less than in the HLS implementation approach.
5.2. Accuracy
The training, validation and inference accuracy will be discussed in this section. There are two training schemes corresponding to the targeted hardware: MAX78000EVKIT and PYNQ-Z2. The training processes were run in each scenario with three different learning rates (LR): 0.0005, 0.001, and 0.01 on the UNSW-NB15 and IoT-23 datasets.
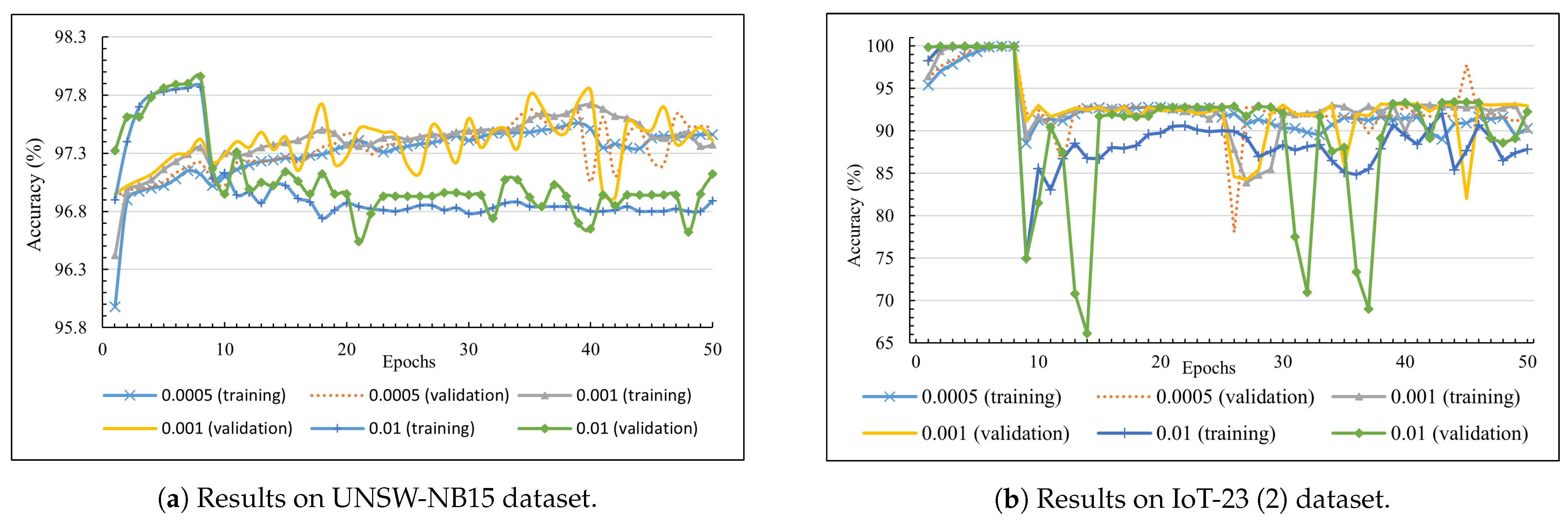
Figure 7 depicts the training and validation accuracy in the first scheme, which was aimed at the MAX78000EVKIT. In detail, the line chart in
Figure 7a shows trained results on the UNSW-NB15 dataset. The highest LR (0.01) returned the best score at 97.96% accuracy (epoch 8). However, this number dropped significantly, to approximately 96.82%, in the rest of the training process, after the quantisation-aware training was activated. The training processes with lower LR reported better results, which drew increasing trends in validation accuracy, from 97.12% to the peak at 97.84% from epoch 9 to epoch 40 (with LR at 0.001).
Figure 7b illustrates the training and validation accuracy on the IoT-23 dataset. The accuracy can reach up to 99.98% before dropping dramatically to 89.38% (0.001 LR) and 74.94% (0.01 LR) due to the activation of quantisation-aware training. The 0.0005 and 0.001 LR training processes showed a slight improvement over time, with training accuracy around 92.85%. The lower LR values (0.0005 and 0.001) produced better models in the quantisation-aware training processes. The accuracy fluctuated if LR was 0.01 on both datasets.
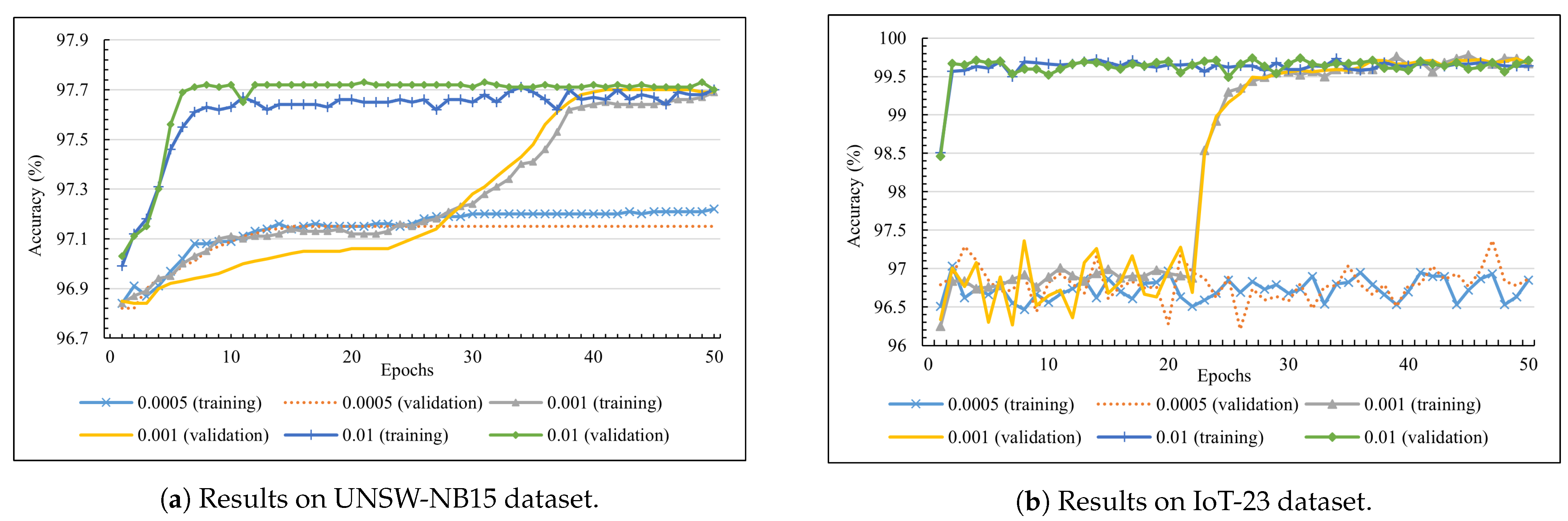
In the second scheme, the training processes were aimed at the PYNQ-Z2 board.
Figure 8 represents two charts showing accuracy results on the two datasets. The line chart in
Figure 8a shows trained results on the UNSW-NB15 dataset. The 0.01 LR reported 96.84% accuracy in training and validation at epoch one, before increasing to 97.71% in the subsequent seven epochs; this number fluctuated slightly in the rest of the training process. The 0.001 LR also reported the same results, with the best validation accuracy being 97.70% from epoch 40, while the smallest LR (0.0005) can only reach 97.15% accuracy at epoch 50. The second line chart, which are trained results on the IoT-23 dataset, shows similar training patterns to the first line chart. In detail, the higher LR (0.001 and 0.01) reported the highest validation accuracy at around 99.71%, while the 0.0005 LR training process achieved the best accuracy of 96.37% at epoch 47.
The four best models, in terms of validation accuracy, were collected from the trained results above. Evaluation metrics were calculated, including accuracy, precision, recall and F1-score on test data.
Table 8 shows inference results on the MAX78000EVKIT on two models, which are denoted as (1) and (2). Model (1) on the UNSW-NB15 dataset achieves 98.57% accuracy and a 93.47% F1-score. The precision is 6.98% lower than the recall value (90.11% compared to 97.09%), which means that the model is more sensitive to attack records than normal records. In addition, model (2) on the IoT-23 dataset reports 92.69% accuracy and, 95.13% F1-score.
Accordingly,
Table 9 represents inference results on the PYNQ-Z2 board from two models, which are denoted as (3) and (4). Model (3) reproduces similar results to model (1) on the UNSW-NB15 dataset, with 98.43% accuracy and 92.71% F1-score. The highest accuracy and F1-score (99.66% and 99.81%) are achieved by the model (4) on the IoT-23 dataset.
We have compared both our trained NN model on the IoT-23 dataset to related works in
Table 10. The authors in [
32] have achieved 99.70% accuracy by using DNN. They have improved this result to 99.99% by applying LSTM in [
49]; however, F1-score is not mentioned in this research. Authors in [
22,
34] have reported RF as the best algorithm for detecting attacks with 100% and 99.50% accuracy, respectively. Authors in [
37] have achieved accuracy with only 0.14% greater than our NN model. However, their experiments have not applied to the full IoT-23 dataset [
34,
37].
5.3. Performance
Inference time is one of the most critical metrics for evaluating the HH-NIDS framework. In this section, performance measurements will be performed on the four hardware platforms, including Intel® CoreTM i7-9750H 2.6 GHz CPU, NVIDIA GeForce GTX 1650 GPU, MAX78000EVKIT and PYNQ-Z2 SoC FPGA boards.
5.3.1. Inference Time
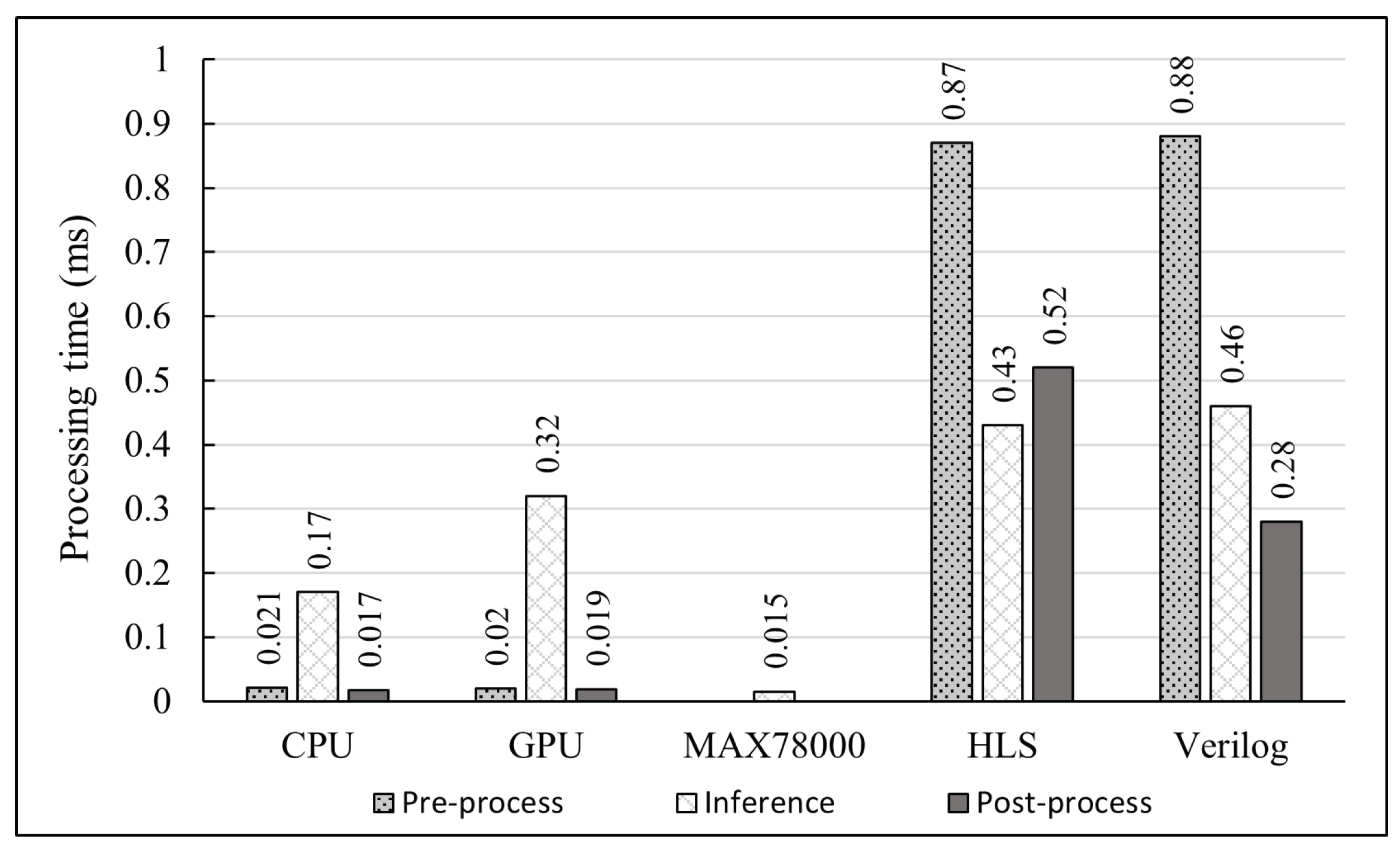
The first test measured pre-process time (allocates input buffers), inference time, and post-process time (for receiving results) of each implementation when only one input is sent.
Figure 9 illustrates the five implementations’ results. The bar chart shows that the inference time on the MAX78000EVKIT is only 15 μs, which is 11.3 and 21.3 times faster than CPU and GPU approaches, respectively. This number outperformed all other platforms in inference time; however, the pre-process and post-process times are not measured due to unsupported library issues. Besides, CPU and GPU implementations report the lowest pre-process and post-process time; these numbers are approximately 0.02 ms, thanks to high-frequency host processors. The inference time on CPU is 0.17 ms, while these times are 0.32 ms and 0.43 ms on GPU and FPGA, respectively. The FPGA implementations (HLS and Verilog) have higher inference times (between 0.45 ms and 0.46 ms) because of the overhead in data transfer time from the PS to the PL.
5.3.2. FPGA Performance
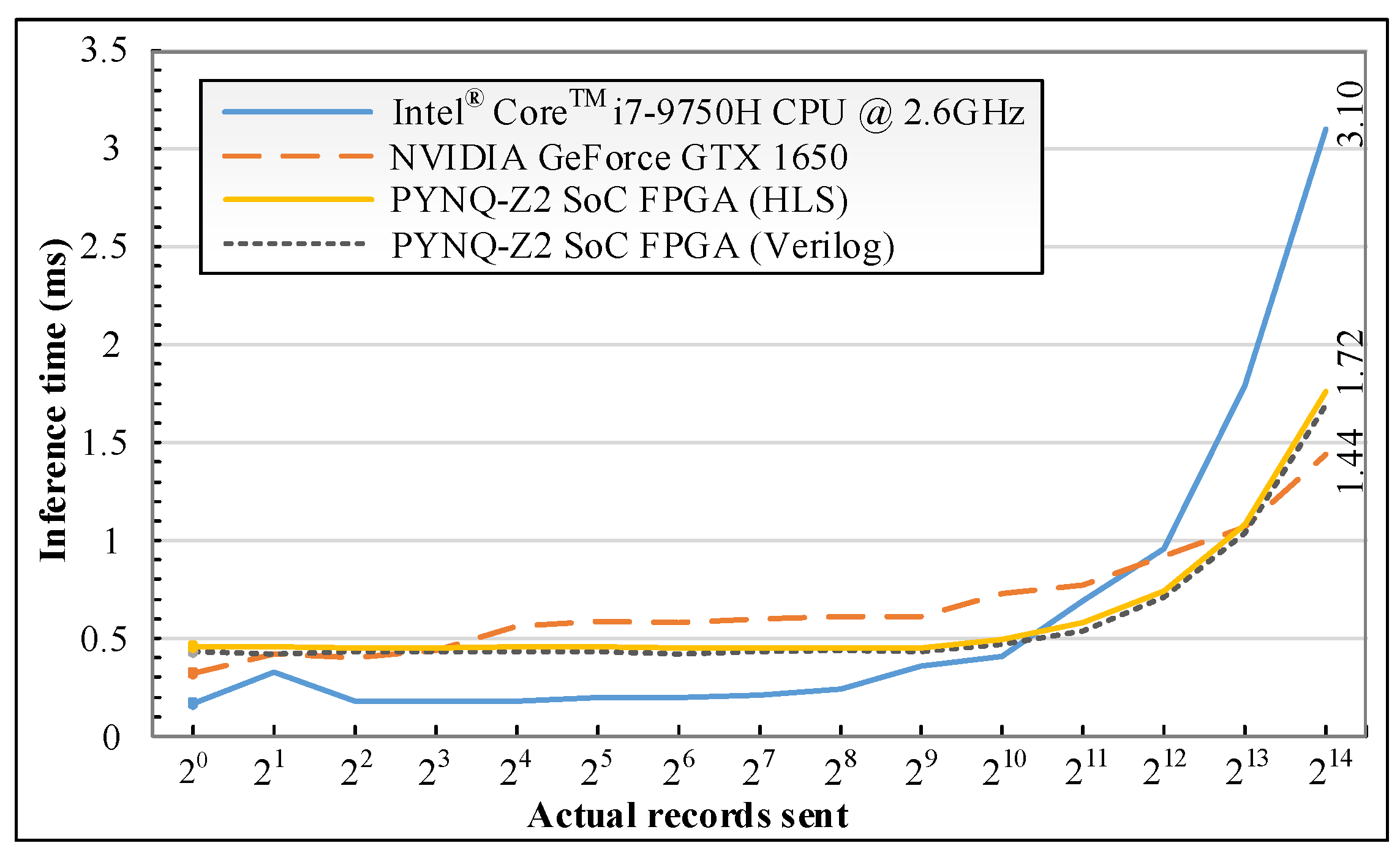
The PL configuration time is 340 ms on average, including the time for loading NN parameters into BlockRAM. The line graph in
Figure 10 shows the differences in inference times between CPU, GPU and FPGA. The horizontal and vertical axes present the number of records per test (input buffer size) and the processing time, respectively. By doubling the number of records sent each time, the CPU and GPU inference times increase gradually to approximately 0.92 ms, for both platforms, at the buffer size of
(4096 records). The CPU inference time rises exponentially to 3.01 ms, while the GPU starts to perform better, with only 1.44 ms, at the end of the test. HLS and Verilog implementation approaches on the PYNQ-Z2 SoC FPGA return a similar inference time, which starts at approximately 0.44 ms in the beginning and then increases slightly to 0.48 ms at the buffer size of 1024. This time is approximately 1.72 ms when the buffer size is 16,384 (
), which is equal to 9,525,581 records per second.
Next, a timer is placed in the inference code after DMA has sent data from the PS to the PL to measure the data transfer time. The timer reported that it takes 0.067 ms, on average, for an input on the PYNQ-Z2 Soc FPGA to be inferred and transferred back to the PS. In addition, the data transfer time from the PS to the PL is close to 0.42 ms. Therefore, the NN block on PYNQ-Z2 SoC, with a Xilinx xc7z020-1clg400c device, is 2.5 and 4.8 times (0.067 ms compared to 0.17 ms and 0.32 ms) faster than Intel
® Core
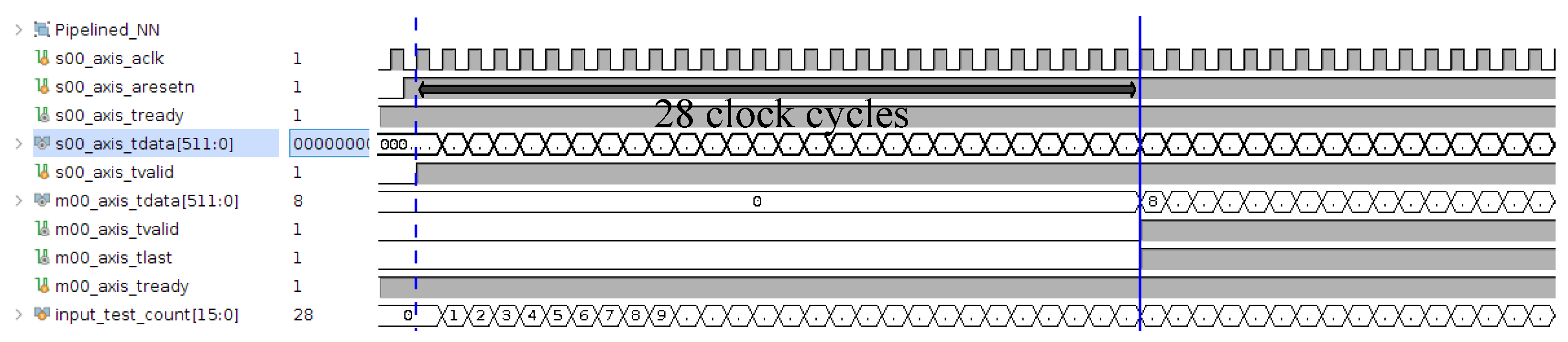
TM i7-9750H 2.6 GHz CPU and NVIDIA GeForce GTX 1650 GPU in inference time, respectively. The processing speed of the pipelined design on FPGA can be calculated through the waveform simulation result in
Figure 11.
The waveform displays the primary input and output AXI4-STREAM interfaces in the NN block. The testbench sends a new input at each clock cycle to demonstrate a network input flow. Each record takes 28 clock cycles to be processed (between the s00_axis_tvalid and m00_axis_tvalid signals). In this pipeline design, the input flow can go through the system continuously without waiting for other processing inputs in the system to be finished; thus, the system overhead for processing one flow is 28 clock cycles, which is equal to 0.28 μs on the PYNQ-Z2 (operating at 100 MHz). This means that the pipelined NN block on the FPGA accelerator at 100 MHz is 53.5 times faster than the max78000EVKIT in simulation. Some factors affected the inference time, in practice, and will be discussed in
Section 6.
Finally, the average inference times after ten trials are shown in
Table 11. To ensure a fair comparison with the work in [
47], the number of records for sending in DMA buffer size was made equal to the number in these works (22,544 records). The authors in [
47,
50] used the same NSL-KDD dataset for experimenting with their NN models. Our FPGA implementation is 4.15 times faster than the same platform in [
47] and 110.1 times faster than the CPU implementation in [
50].
6. Discussion
The HH-NIDS framework has trained lightweight NN models on the UNSW-NB15 and IoT-23 datasets using different schemes aimed at two hardware acceleration platforms. Although the eleven inputs used in this prototype are static features, the trained models have achieved high accuracy compared to the related works. To improve the results (higher accuracy and lower the false alarm rate), the Data Pre-processing block in the HH-NIDS framework needs to be upgraded to extract a more comprehensive input feature set.
In
Section 5.3.1, CPU and GPU implementations have an advantage in pre-process and post-process times thanks to high operating frequencies and rich memories for buffering input data; the data transfer buses in these platforms are also optimised for a broader range of applications. The GPU also has extra overhead for loading data into its on-chip memory, which explains why it starts to perform better with a greater input buffer size setup.
The MAX78000 microcontroller with NN accelerate processors performs well, requiring only 15
s to infer an input. The power consumption is ultra-low at 18 mW, while it draws from 15 W to 17 W on the NVIDIA GeForce GTX 1650 GPU to infer inputs. Besides, the NN models on FPGA have shown high overhead in data transferring between the PS and the PL; the actual inference time was explained in the waveform simulation results in
Section 5.3.2.
While the HLS implementation is more flexible in changing the NN architecture, the Verilog implementation with pipelining is optimised for the best processing performance. Even though the pipelined design on the PL has no bottle-neck points that possibly operate at the on-chip frequency with a fixed 28 clock cycles overhead, the pre-process and post-process blocks on the PYNQ-Z2 SoC FPGA are run on the PS (ARM-based) with limited speed.
7. Conclusions
This paper presents the HH-NIDS framework for a heterogeneous hardware-based implementation of anomaly detection in IoT networks. The framework includes dataset pre-processing, model generation and hardware-based inference on hardware accelerators. The proposed framework is tested with the UNSW-NB15 and IoT-23 datasets using NN models and achieves the highest accuracy of 99.66%. The inference phase is implemented using different approaches on the microcontroller and SoC FPGA. Firstly, the inference phase is implemented on the MAX780000EVKIT, which is 11.3 and 21.3 times faster than Intel® CoreTM i7-9750H 2.6GHz CPU and NVIDIA GeForce GTX 1650 GPU, respectively; the power drawn was between 17mW and 18mW when the NN model is inferring. In addition, the inference phase on SoC FPGA is implemented using HLS and Verilog approaches, achieving the same practical processing speed. However, the pipelined design on the PYNQ-Z2 board with the Xilinx Zynq xc7z020-1clg400c device has been optimised to run at the on-chip frequency with a fixed 28 clock cycles overhead. The simulation results have reported a speedup of 53.5 times compared to the MAX78000EVKIT. Future work will consider using FPGA network specialised hardware (e.g., NetFPGA-SUME) for studying high-performance intrusion detection systems.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}