4.1. Model Assessment
The PLS-SEM path analysis algorithm estimates standardized partial regression coefficients in the structural model after approximating the measurement model parameters [
61]. Thus, a two-stage evaluation of the psychometric features of the introduced conceptual model was undertaken. The quality of the measurement model was tested by examining the indicator reliability, internal consistency, convergent validity, and discriminant validity.
Indicator reliability was assessed by exploring the standardized loadings of items with their respective construct. According to Hulland’s purification guidelines [
62], items should be retained in the measurement model only if their standardized loadings are equal to or greater than 0.708. Since loadings of items USE3, EFF2, EFF4, and EASE1 were below the recommended threshold value, they were removed from the measurement model and further analysis. The outcome of the confirmatory factor analysis (CFA) shown in
Table 1 indicates that standardized loadings of all remaining items in the measurement model were above the acceptable cut-off level. Standardized loadings of items that constitute the measurement model are in the range from 0.708 to 0.937, which means that constructs accounted for between 50.13% and 87.80% of their items’ variance.
Internal consistency of constructs was tested using three indices: Cronbach’s alpha, the composite reliability (rho_C), and the consistent reliability coefficient (rho_A). Cronbach’s alpha [
63] is a lower bound estimate of construct reliability based on equal weightings of items. By considering the actual item loadings, composite reliability [
64] offers a more accurate estimate of internal consistency than Cronbach’s alpha. The consistent reliability coefficient proposed by Dijkstra and Henseler [
65] is an approximately exact measure of construct reliability and, as such, represents a compromise between Cronbach’s alpha and composite reliability [
66]. For all three indices, values between 0.60 and 0.70 are acceptable in exploratory studies, values between 0.70 and 0.95 represent good internal consistency, while values above 0.95 indicate item redundancy that plagues content validity [
67]. Considering that item SEC3 was poorly worded, it was removed from the measurement model, which resulted in values that were in the acceptable range for all three internal consistency indices of the associated security of personal data construct. As shown in
Table 2, estimated values for all three set forth indices were in a range from 0.740 to 0.949, thus implying good internal consistency of all eight constructs in the research framework.
Convergent validity was examined with average variance extracted (AVE). An AVE value of 0.50 and higher is considered acceptable because it indicates that the shared variance between a construct and its items exceeds the variance of the measurement error [
66]. Study findings presented in
Table 2 imply that all constructs in the research model have met the requirements of this criterion.
Discriminant validity refers to the degree to which a particular construct is unique when compared with the remaining ones in the model. It was examined with three measures: the cross-loadings, the Fornell–Larcker criterion, and the Heterotrait–Monotrait ratio of correlations (HTMT).
The cross-loadings measure suggests that the outer loading of each item on the associated construct should be greater than its loadings on the remaining constructs in the model. As shown in
Table 1, this appeared to be true for all items in the measurement model of the proposed research framework, which suggests that the requirements of the first measure of discriminant validity have been met. The Fornell–Larcker criterion [
68] states that the square root of the AVE of each construct should be greater than its highest correlation with any other construct in the model. Results presented in
Table 3 indicate that each construct shares more variance with items that are allocated to it (bold values on the diagonal) than with remaining constructs in the model, thus confirming that the requirements of the second measure of discriminant validity are met.
The Fornell–Larcker criterion is less effective when item loadings on a construct differ by a small amount [
66], so Henseler et al. [
69] proposed the Heterotrait–Monotrait ratio (HTMT) of the correlations as an alternative measure of discriminant validity. HTMT represents the ratio of the mean value of all correlations of indicators that measure different constructs and the mean value of correlations of indicators that measure the same construct. If there are related constructs in the model, then values above 0.90 imply the absence of discriminant validity, while in the case of conceptually different constructs in the model, the threshold value is set to 0.85 [
67]. As presented in
Table 4, the HTMT of all constructs in the research framework is below the cut-off value, which indicates that the requirements of the third and last measure of discriminant validity have been met and that constructs are sufficiently different. All of the above confirms that the measurement model is quite reliable and valid.
As soon as the measurement model was determined to be adequate, the appropriateness of the structural model was examined by testing collinearity, path significance, coefficient of determination, effect size, relative measure of predictive relevance, and prediction-oriented results assessment.
The evaluation of the structural model includes the estimation of many regression equations which represent the relationships between constructs. If two or more constructs in the structural model capture similar concepts, they will exhibit too much collinearity, and as a result, estimated partial regression coefficients could potentially be biased. Variance Inflation Factor (VIF) is a commonly used indicator for determining if collinearity among predictor constructs in the structural model exists. Although VIF values of 5 or higher suggest collinearity issues among exogenous constructs, they can easily occur even at VIF values of 3 [
66]. Therefore, VIF values should be close to 3 or lower. As shown in
Table 5, VIF values for predictor constructs are in a range from 1.000 to 1.721 thus confirming the lack of collinearity in the structural model.
The model’s explanatory power is examined with the coefficient of determination (
), which represents the proportion of endogenous constructs’ variance explained by the set of its predictors. The particularities of the research discipline and study being carried out play an important role in determining the acceptable values of
[
70]. According to Orehovački [
71], in empirical studies on software quality evaluation
values of 0.15, 0.34, and 0.46 suggest weak, moderate, and substantial explanatory power of exogenous constructs in the research model, respectively. It is a common practice to interpret adjusted
since it tailors the value of
concerning the size of the model [
67]. Study results presented in
Table 6 indicate that 39.5% variance in behavioral intention was explained by customer satisfaction, 40.3% of the variance in ease of use was accounted for by responsiveness and feedback quality, 20.3% of the variance in efficiency was explained by responsiveness, 60.9% of the variance in customer satisfaction was accounted for by the ease of use, usefulness, and security of personal data while 45.2% of the variance in usefulness was accounted for by efficiency and ease of use. Considering the aforementioned, determinants of customer satisfaction and usefulness have substantial explanatory power, predictors of behavioral intention and ease of use have moderate explanatory power, while the antecedent of responsiveness has weak explanatory power.
The hypothesized interplay among constructs in the research framework was examined by evaluating the goodness of path coefficients. Through bootstrapping resampling procedure, asymptotic two-tailed t-statistics were used to test the significance of path coefficients. While the number of cases was the same as the sample size, the number of bootstrap samples was 5.000. The outcome of testing the hypotheses is presented in
Table 7. It was discovered that ease of use (β = 0.277,
p < 0.05), usefulness (β = 0.465,
p < 0.0001), and security of personal data (β = 0.228,
p < 0.05) significantly contribute to customer satisfaction, thus providing support for H6, H7, and H8, respectively. Data analysis also uncovered that responsiveness (β = 0.459,
p < 0.0001) and feedback quality (β = 0.282,
p < 0.0001) significantly affect the ease of use, thereby supporting hypotheses H2 and H4. Furthermore, efficiency (β = 0.380,
p < 0.0001) and ease of use (β = 0.369,
p < 0.0001) were found to have a significant impact on usefulness, thus demonstrating support for H3 and H5, respectively. Study findings also indicate that responsiveness (β = 0.460,
p < 0.0001) is a significant determinant of efficiency and that customer satisfaction (β = 0.634,
p < 0.0001) is a significant antecedent of behavioral intention, which provides support for H1 and H9, respectively.
The effect size (
) refers to the change in the coefficient of determination of endogenous construct. Values for
of 0.02, 0.15, or 0.35 indicate that the exogenous construct has a small, medium, or large impact on the endogenous construct, respectively [
72]. Considering the values presented in
Table 8, customer satisfaction (
= 0.671) has a large influence on behavioral intention. Customer satisfaction is strongly affected by usefulness (
= 0.348), and modestly by both ease of use (
= 0.119) and security of private data (
= 0.115). Responsiveness (
= 0.277) has a medium impact on the ease of use which in turn is affected by feedback quality (
= 0.104) to a small extent. Finally, it appeared that responsiveness is medium in size (
= 0.268) predecessors of efficiency while both efficiency (
= 0.157) and ease of use (
= 0.148) have a medium impact on usefulness.
The nonparametric Stone’s [
73] and Geisser’s [
74] cross-validated redundancy measure
that drawing on the blindfolding reuse technique predicts the endogenous construct’s items is commonly applied for testing the predictive validity of exogenous constructs. However, since
combines aspects of out-of-sample prediction and in-sample explanatory power [
75], it does not represent a measure of out-of-sample prediction [
66]. To address the set forth, Shmueli et al. [
75,
76] developed a PLSpredict algorithm as an alternative approach for evaluating the predictive relevance of a model. PLSpredict employs k-fold cross-validation (where a fold is a subgroup of the total sample, and k is the number of subgroups) to determine whether the model outperforms the most naïve linear regression benchmark (referred to as
and defined as the indicator means from the analysis sample) [
66,
67,
76]. PLS path models with
values above 0 have lower prediction errors than those given by the most naïve benchmark. Given that
can be interpreted similarly as
, its values greater than 0, 0.25, and 0.5 point to small, medium, and large predictive relevance of the PLS path model [
66]. The predictive power of a model is usually examined with the root mean squared error (RMSE), but in the case of highly non-symmetric distribution of prediction errors, the mean absolute error (MAE) should be used as an alternative [
76]. The evaluation procedure represents a comparison of the RMSE (or MAE) values with a naïve benchmark that generates predictions for items by using a linear regression model (LM). The outcome of the comparison can be one of the following [
76]: (a) if prediction errors in terms of RMSE (or MAE) values are higher than those of the naïve LM benchmark for all items, the model lacks predictive power; (b) if the majority of endogenous construct items have higher prediction errors when compared to the naïve LM benchmark, this indicates that model has a low predictive power; (c) if the minority (or the same number) of construct items have higher prediction errors when compared to the naïve LM benchmark, this suggests that model has a medium predictive power; (d) if none of the items has higher RMSE (or MAE) values compared to the naïve LM benchmark, the model has high predictive power.
Visual inspection of error histograms uncovered that the distribution of prediction errors is highly non-symmetric. Hence, we based predictive power evaluation on MAE. As shown in the fourth column of
Table 9, the majority of endogenous construct items have higher PLS-SEM_MAE values when compared to the naïve LM_MAE benchmark, which suggests that the proposed model has low predictive power.
Changes in
reflect the relative impact (
) of exogenous constructs in predicting the observed measures of endogenous construct in the structural model. According to [
53],
values of 0.02, 0.15, or 0.35 signify that a particular exogenous construct has weak, moderate, or substantial relevance in predicting an endogenous construct, respectively. Values of
are calculated as follows [
72]:
refers to the
value of an endogenous construct when the observed exogenous construct is included in the model estimation while
refers to the
value of an endogenous construct when the observed exogenous construct is excluded from the model estimation. Study results provided in
Table 10 suggest that customer satisfaction (
= 0.227) has moderate relevance in predicting behavioral intention related to continued interaction with mobile banking applications. While responsiveness (
= 0.252) is a moderate predictor, feedback quality (
= 0.075) appeared to be a weak predictor of ease of use in the context of mobile banking applications. Responsiveness (
= 0.224) was also found to have moderate relevance in predicting the efficiency of mobile banking applications. While ease of use (
= 0.242) has moderate relevance and security of personal data (
= 0.062) has weak relevance, usefulness (
= 0.013) does not have sufficient relevance in predicting customer satisfaction with mobile banking applications. Finally, ease of use appeared to have weak relevance (
= 0.119) in predicting the usefulness of mobile banking applications while efficiency is not relevant enough (
= 0.005) in that respect.
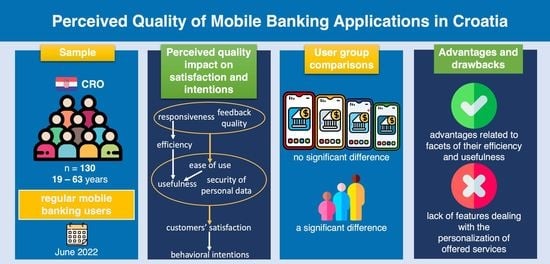
4.2. User Groups Comparisons
For the first comparison, study participants were divided into four independent groups of mobile banking application users. To determine if a significant difference in the perceived quality among mobile banking applications exists, and thus to test the H10 hypothesis, data that were collected with questionnaire items designed for measuring diverse dimensions of quality constructs were combined into a single-score indicator of perceived quality. More specifically, the composite measure of perceived quality represents the arithmetic mean of all responses of each study participant to the aforementioned questionnaire items. Since we only considered users of the four most commonly used mobile banking applications (PBZ mobile banking, Erste George, m-zaba, and OTP m-banking), out of 130 study participants, responses of 116 of them were used in this analysis. Results of the Kruskal–Wallis H test showed that there is no statistically significant difference in the perceived quality among four mobile banking applications that were examined in our study (χ2(3) = 0.648,
p = 0.885), thus providing support for the H10 hypothesis. The box plot, which illustrates item means per four commonly used mobile banking applications in Croatia, is shown in
Figure 3. Note that dots in the box plot indicate mild outliers.
Results of analyzing the composite measure revealed that the highest level of perceived quality among examined mobile banking applications belongs to m-zaba (M = 4.63, SD = 0.305), followed by PBZ mobile banking (M = 4.59, SD = 0.369), Erste George (M = 4.54, SD = 0.469), and OTP m-banking (M = 4.49, SD = 0.459) that appeared to have the lowest level of perceived quality.
For the second comparison, study respondents were split into three age groups: 19–24 years, 25–49 years, and 50–65 years. Group 1 (age 19–24) consisted of 85 subjects, group 2 (age 25–49) was composed of 25 participants, and group 3 (age 50–65) comprised 19 respondents. The composite measure of perceived quality was used here in the same manner as in the first user group comparison. The outcome of the Kruskal–Wallis H test suggests that there is a statistically significant difference in the perceived quality of mobile banking applications among three age groups of users (χ2(2) = 8.685,
p = 0.13), thus rejecting the H11 hypothesis. To follow up on this finding, post hoc analysis with a Bonferroni pairwise comparison in which the significance level was set at
p < 0.0167 was applied. We, in particular, discovered that a significant difference in perceived quality (Z = −2.705,
p = 0.007) exists between study participants who belong to the first (19–24 years) and the third (50–65 years) age groups of mobile banking applications users while differences in remaining pairwise comparisons were not significant. The box plot, which depicts composite perceived quality per three age groups of mobile banking application users, is shown in
Figure 4. Note that dots in the box plot represent mild outliers while the extreme outlier is marked with an asterisk.
The analysis of the composite measure uncovered that the third (50–65 years) age group of users is the least demanding (M = 4.74, SD = 0.335) when the quality of mobile banking applications is considered since they gave them the highest scores, followed by the second (25–49 years) group of study participants (M = 4.64, SD = 0.429), while the evaluated mobile banking applications received the lowest ratings (M = 4.52, SD = 0.392) from users belonging to the first (19–24 years) age group of respondents.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}